CLARIN-D. Einführung, Metadaten & CMDI, OAI-PMH, Repositorysysteme & Fedora. Volker Boehlke
|
|
|
- Marielies Biermann
- vor 5 Jahren
- Abrufe
Transkript
1 CLARIN-D Einführung, Metadaten & CMDI, OAI-PMH, Repositorysysteme & Fedora Volker Boehlke Abt. Automatische Sprachverarbeitung Institut für Informatik, Universität Leipzig Institut für Informatik 1
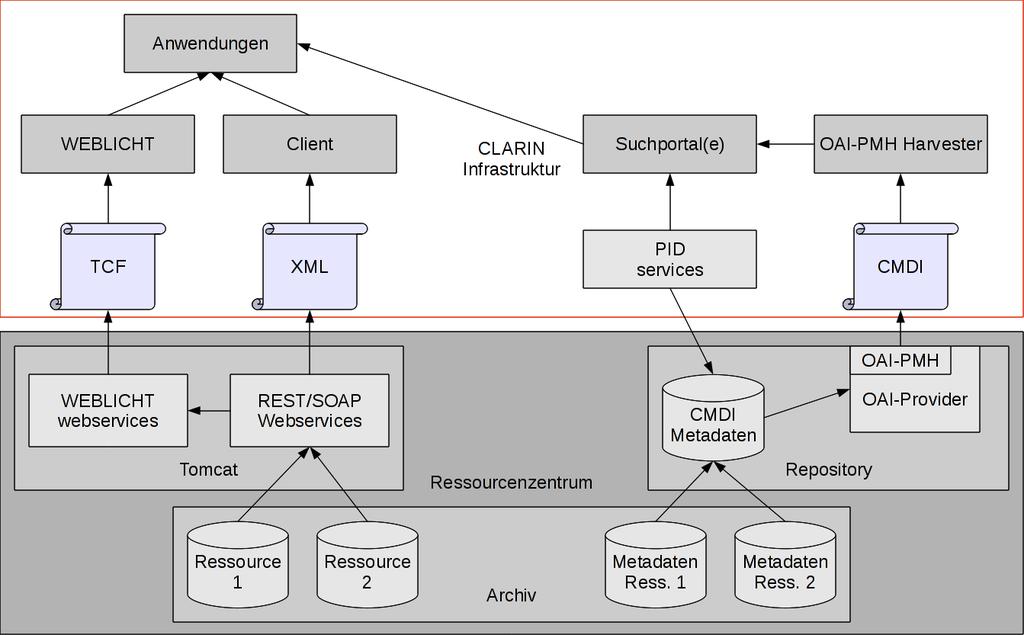
2 Motivation Warum CLARIN-D in der Vorlesung Wissens- und Contentmanagement? Content in CLARIN-D sind (zumeist) Daten in Form von Texten Ton- & Videoaufnahmen aber auch Verfahren => (zumeist) bereitgestellt in Form von Webservices CLARIN ist eine verteilte Forschungsinfrastruktur: Institutions- und Länderübegreifend nationale Initiativen zusammengefasst unter einem gemeinsamen europäischen Dach 2
3 Motivation Fragen: Auf welcher Basis können Services in einer verteilten Infrastruktur angeboten werden? => Standardisierung & Verzeichnisdienste Wie kann der unberechtigte Zugriff verhindert werden (Copyright, )? Wie können diese Inhalte durch die Nutzer effizient gefunden werden? => Metadaten + geeignete Tools Wo/Wie werden diese Inhalte archiviert (Langzeitarchivierung)? => Repository-Systeme Dies lässt sich auch auf Szenarien außerhalb von Forschungsinfrastrukturen übertragen! 3
4 Agenda Kurzvorstellung CLARIN-D Ziele Technik Metadaten Einführung CLARIN-D (CMDI & ISOcat) OAI-PMH Repository-Systeme Einführung Fedora (Fedora Digital Object Model) Zusammenfassung 4
5 Kurzvorstellung CLARIN-D 5
6 CLARIN-D CLARIN-D Eine web- und zentrenbasierte Forschungsinfrastruktur für die Geistes- und Sozialwissenschaften Linguistische Daten, Werkzeuge und Dienste sollen... in einer integrierten, interoperablen und skalierbaren Infrastruktur für die Fachdisziplinen der Geistes- und Sozialwissenschaften bereitgestellt werden gefördert durch das Bundesministerium für Bildung und Forschung Laufzeit: (ggf. 2016) im Web: 6
7 CLARIN-D Zielstellung Ziel: Mehrwert für die eigene Forschung durch Nutzung einer Infrastruktur Metadaten & föderierte Suche sicheres Zitieren mittels PIDs SimpleStore, Workspaces, Zugriff auf eine größere Menge von Ressourcen und Werkzeugen einfache, webbasierte Anwendung ohne Installationen einfache Verbreitung eigener Ressourcen und Werkzeuge in der Fachdisziplin 7
8 CLARIN-D Zentren BAS, Universität München (Florian Schiel) BBAW, Berlin (Wolfgang Klein) IDS, Mannheim (Ludwig Eichinger) MPI, Nijmegen (Peter Wittenburg) Universität Tübingen (Erhard Hinrichs) Universität des Saarlandes (Elke Teich) Universität Hamburg (Kristin Bührig) Universität Leipzig (Gerhard Heyer) Universität Stuttgart (Jonas Kuhn) 8
9 Aufgaben der CLARIN-D Zentren stellen Ressourcen zur Verfügung Zugriff auf Daten/Tools via Webservices einheitlicher Zugriff auf Metadaten (Langzeit) Archivierung von Daten/Tools Absicherung des Zugriffs über CLARIN-D AAI* Spezifizieren, Implementieren und Hosten Infrastrukturdienste * Authentication and Authorization Infrastructure 9
10 Was bedeutet Infrastruktur? 10
11 CLARIN-D Infrastruktur 11
12 CLARIN-D Infrastruktur Fragestellungen z.b. Projekt Postdemokratie und Neoliberalismus. Zur Nutzung neoliberaler Argumentationen in der bundesdeutschen Politik z.b. Frage: Hat Ernst Jünger schon zu seiner Zeit ein eher nationalistisch geprägtes Vokabular verwendet oder entsprach sein Vokabular dem Zeitgeist? 12
13 CLARIN-D Infrastruktur Fragestellung Projekt: Postdemokratie und Neoliberalismus. Zur Nutzung neoliberaler Argumentationen in der bundesdeutschen Politik. Frage: Hat Ernst Jünger schon zu seiner Zeit ein eher nationalistisch geprägtes Vokabular verwendet oder entsprach sein Vokabular dem Zeitgeist? 13
14 CLARIN-D Infrastruktur Operationalisierung Daten: Textsammlungen zur jeweiligen Fragestellung + geeignete Referenzkorpora Verfahren: Differenzanalyse (Satzsegmentierung, Tokenisierung, ) => Kombination zu einer konkreten Anwendung Fragestellung Projekt: Postdemokratie und Neoliberalismus. Zur Nutzung neoliberaler Argumentationen in der bundesdeutschen Politik. Ergebnisse: Format, Umfang, Recherchierbarkeit (Belegstellen),... Frage: Hat Ernst Jünger schon zu seiner Zeit ein eher nationalistisch geprägtes Vokabular verwendet oder entsprach sein Vokabular dem Zeitgeist? Visualisierung 14
15 CLARIN-D Infrastruktur Operationalisierung Fragestellung Projekt: Postdemokratie und Neoliberalismus. Zur Nutzung neoliberaler Argumentationen in der bundesdeutschen Politik. Frage: Hat Ernst Jünger schon zu seiner Zeit ein eher nationalistisch geprägtes Vokabular verwendet oder entsprach sein Vokabular dem Zeitgeist? Verfahren: Differenzanalyse (Satzsegmentierung, Tokenisierung, ) => Kombination zu einer konkreten Anwendung Daten: Textsammlungen zur jeweiligen Fragestellung + geeignete Referenzkorpora Ergebnisse: Format, Umfang, Recherchierbarkeit (Belegstellen),... Visualisierung 15

 => Kombination zu einer konkreten Anwendung Daten: Textsammlungen zur jeweiligen")
16 CLARIN-D Infrastruktur Operationalisierung Fragestellung Projekt: Postdemokratie und Neoliberalismus. Zur Nutzung neoliberaler Argumentationen in der bundesdeutschen Politik. Frage: Hat Ernst Jünger schon zu seiner Zeit ein eher nationalistisch geprägtes Vokabular verwendet oder entsprach sein Vokabular dem Zeitgeist? Verfahren: Differenzanalyse (Satzsegmentierung, Tokenisierung, ) => Kombination zu einer konkreten Anwendung Daten: Textsammlungen zur jeweiligen Fragestellung + geeignete Referenzkorpora Ergebnisse: Format, Umfang, Recherchierbarkeit (Belegstellen),... Visualisierung 16
17 CLARIN-D Infrastruktur - PIDs PIDs Persistent Identifiers eindeutige Identifikatoren für digitale Objekte genau eine PID für genau eine Ressource (in genau einer Version) standortunabhängig über (sehr) lange Zeiträume verfügbar Ziel: einfaches, eindeutiges und sicheres Zitieren auf Teile einer Ressource kann mit Hilfe von PartIdentifiern verwiesen werden 17

18 CLARIN-D Infrastruktur - PIDs PIDs Persistent Identifiers auf Teile einer Ressource kann mit Hilfe von PartIdentifiern verwiesen werden 18
19 CLARIN-D Infrastruktur - FCS FCS Federated Content Search Grundlage: SRU / CQL (Search/Retrieve via URL + Context Query Language) Abfrage von Inhalten aus verschiedenen Quellen mittels standardisierter Schnittstelle 19
20 CLARIN-D Infrastruktur - FCS 20
21 CLARIN-D Infrastruktur - FCS 21
.")
22 CLARIN-D Infrastruktur Shibboleth dient der Authentifizierung/Authorisierung in verteilten Umgebungen Grundprinzip: Authentifizierung gegenüber Heimateinrichtung; Externe Stellen vertrauen dieser Authentifizierung und Authorisieren auf dieser Grundlage den Zugriff (Vertrauensnetzwerk). Identity Provider (IdP): Authentifiziert Nutzer der Heimateinrichtung Service Provider (SP): schützt einen Dienst vor unberechtigtem Zugriff bzw. erzwingt die Authorisierung über einen IdP 22
23 CLARIN-D Infrastruktur Shibboleth Nutzersicht: Nutzer ruft Webseite auf 23

24 CLARIN-D Infrastruktur Shibboleth Nutzersicht: Nutzer ruft Webseite auf 24
25 CLARIN-D Infrastruktur Shibboleth Nutzersicht: Nutzer ruft Webseite auf Discovery-Service 25

26 CLARIN-D Infrastruktur Shibboleth Nutzersicht: Nutzer ruft Webseite auf Discovery-Service 26
27 CLARIN-D Infrastruktur Shibboleth Nutzersicht: Nutzer ruft Webseite auf Discovery-Service Authentifizierung bei der Heimateinrichtung 27
28 CLARIN-D Infrastruktur Shibboleth Authentifizierung Nutzer ruft Webseite bei der auf Heimateinrichtung Discovery-Service Authentifizierung bei der Heimateinrichtung 28
29 CLARIN-D Infrastruktur Shibboleth Nutzersicht: Nutzer ruft Webseite auf Discovery-Service Authentifizierung bei der Heimateinrichtung Weiterleitung zur Webanwendung 29

30 CLARIN-D Infrastruktur Shibboleth Nutzersicht: Nutzer ruft Webseite auf Discovery-Service Authentifizierung bei der Heimateinrichtung Weiterleitung zur Webanwendung 30
31 CLARIN-D Infrastruktur Shibboleth Weitergabe/Freigabe von Attributen wie: edupersontargetedid (Identifier; eindeutig für Nutzer/Service) edupersonscopedaffiliation (Art d. Zugehörigkeit zu einer Institution => student, staff, alum,... ) geschieht im Hintergrund => Datenschutz? 31
")

32 CLARIN-D Infrastruktur Shibboleth Weitergabe/Freigabe von Attributen wie: edupersontargetedid (Identifier; eindeutig für Nutzer/Service) edupersonscopedaffiliation (Art d. Zugehörigkeit zu einer Institution => student, staff, alum,... ) geschieht im Hintergrund => Datenschutz? 32
33 Metadaten - Einführung 33
34 Metadaten kurze Definition: (Metadaten sind) Daten über Daten. Wikipedia: Metadaten oder Metainformationen sind Daten, die Informationen über Merkmale anderer Daten enthalten, aber nicht diese Daten selbst. Durell (1985): Metadaten sind strukturierte, kodierte Daten, die Charakteristika informationstragender Entitäten beschreiben, zum Zweck der Identifikation, Recherche, Beurteilung und der Verwaltung der damit beschriebenen Entitäten. W3C: Metadaten sind maschinenlesbare Informationen über elektronische Ressourcen oder andere Dinge 34

35 Metadaten vs. Daten klassisches Beispiel: Daten: Inhalt eines Buches (z.b. Text oder Scan/Bild) Im Anfang schuf Gott den Himmel und die Erde. Und die Erde war wüst und leer, und es lag Finsternis auf der Tiefe, und der Geist Gottes schwebte über den Wassern. Und Gott sprach: Es werde Licht! Und es ward Licht. Und Gott sah, daß das Licht gut war; da schied Gott das Licht von der Finsternis; und Gott nannte das Licht Tag, und die Finsternis Nacht. Und es ward Abend, und es ward Morgen: der erste Tag. Quelle: 35

36 Metadaten vs. Daten klassisches Beispiel: Metadaten: Daten über das Buch Titel: Voyages et aventures du capitaine Hatteras Autor: Jules Verne Erscheinungsjahr: 1866 Quelle: 36
37 Metadaten strukturierte vs. unstrukturierte Metadaten Name-Wert Paarung: Autor: Jules Verne Erscheinungsjahr: 1866 typisiert Autor: Zeichenkette Erscheinungsjahr: Datum im Format YYYY standardisierte Semantik (für den jeweiligen Fall) Vorteil: einfach maschinell zu verarbeiten Nachteil: Erstellung (insb. bei hohem Detailgrad) aufwendig und mit unerwarteten Problemen behaftet. 37
38 Metadaten strukturierte vs. unstrukturierte Metadaten Name-Wert Paarung: Bill Gates (1981; angeblich): 640 kb sollten eigentlich genug für jeden sein. ( 640 ought to be enough for anybody. ) Autor: Jules kb Verne Erscheinungsjahr: => was tun im Jahr (oder )??? typisiert Erscheinungsjahr alter Dokumente (z.b. religiöse Schriften) oftmals unklar => es kann nur ein Zeitraum angeben werden. Autor: Zeichenkette Erscheinungsjahr: Datum im Format YYYY standardisierte Semantik (für den jeweiligen Fall) Vorteil: einfach maschinell zu verarbeiten Nachteil: Erstellung (insb. bei hohem Detailgrad) aufwendig und mit unerwarteten Problemen behaftet. 38
39 Metadaten strukturierte vs. unstrukturierte Metadaten textuelle Beschreibung (ohne Struktur/Semantik) Vorteil: ggf. einfach(er) zu Erstellen Nachteil: gar nicht / schwer (sehr ungenau) maschinell zu Verarbeiten 39
40 Metadaten - Dublin Core 1995: Konferenz in Dublin (Ohio) Einigung auf ein Kernset (Core) von 15 Elementen zur Beschreibung von Ressourcen (primär für Dokumente im Web) 40
41 Metadaten - Dublin Core Contributor: An entity responsible for making contributions to the resource. Coverage: The spatial or temporal topic of the resource, the spatial applicability of the resource, or the jurisdiction under which the resource is relevant. Creator: An entity primarily responsible for making the resource. Date: A point or period of time associated with an event in the lifecycle of the resource. Description: An account of the resource. Format: The file format, physical medium, or dimensions of the resource. Identifier: An unambiguous reference to the resource within a given context. Quelle: 41
42 Metadaten - Dublin Core Language: A language of the resource. Publisher: An entity responsible for making the resource available. Relation: A related resource. Rights: Information about rights held in and over the resource. Source: A related resource from which the described resource is derived. Subject: The topic of the resource. Title: A name given to the resource. Type: The nature or genre of the resource. Quelle: 42
43 Metadaten - Dublin Core (fiktives) Beispiel in XML: Quelle: 43
44 Metadaten - Dublin Core (fiktives) Beispiel in XML: Quelle: 44
45 Metadaten - CLARIN-D 45
46 CMDI CMDI Component MetaData Infrastructure Begriffe: Komponenten, Profile, Instanzen Tools: Component Registry, ISOcat 46
47 CMDI CMDI Component MetaData Infrastructure eine Komponente dient der Beschreibung einer bestimmten Gruppe von Metadaten Beispiele: Dublin Core (Titel, Autor, Sprache, ) Attribute zur Beschreibung eines Videos Komponenten sind wiederverwendbar 47
48 CMDI CMDI Component MetaData Infrastructure Profil: die Vereinigung (einer oder mehrerer) Komponenten dient der Beschreibung eines bestimmten Ressourcentyps ist selbst eine Komponente (mit der speziellen Eigenschaft ein Profil zu sein) Beispiel: Dublin Core (Titel, Autor, Sprache, ) + zusätzliche Attribute zur Beschreibung eines Videos 48
49 CMDI CMDI Component MetaData Infrastructure Basistechnologie ist XML Komponenten+Profil: XML-Schema Instanzen: Die Instanz einer Komponente / eines Profils ist ein XML Dokument, welches konform zum entsprechenden Schema ist. 49
50 CMDI CMDI Component MetaData Infrastructure Profile beschreiben eine bestimmte Klasse von Ressourcen (Bsp.: Wortschatz Korpora, Tools der ASV Toolbox, Webservices, ) Komponenten sind wiederverwendbare Bausteine zur Definition eines Profils bzw. von Komponenten (Rekursion) Aus einem Minimalschema werden alle weiteren Komponenten/Profile abgeleitet. Die folgenden Sektionen sind Pflicht: Header: Basisinformationen wie Profil, SelfLink/PID, Autor, Resources: Referenzierung externer Ressourcen Components: Enthält die eigentlichen, spezifischen Metadaten(komponenten) 50
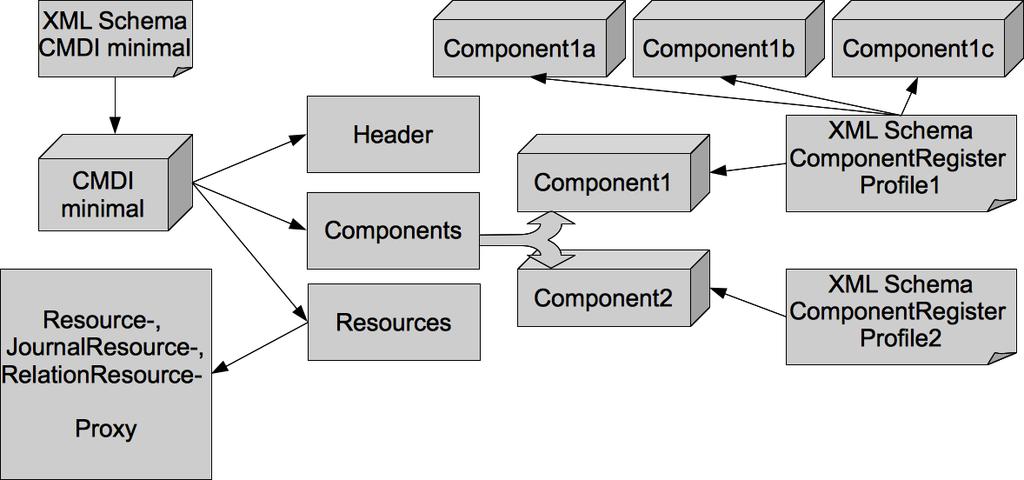
51 CMDI 51
52 CMDI CMDI Component MetaData Infrastructure minimales CMDI Dokument 52
53 CMDI CMDI Component MetaData Infrastructure minimales CMDI Dokument 53
54 CMDI CMDI Component MetaData Infrastructure minimales CMDI Dokument 54
55 CMDI CMDI Component MetaData Infrastructure minimales CMDI Dokument 55
56 CMDI CMDI Component MetaData Infrastructure minimales CMDI Dokument 56
57 CMDI Component Registry CMDI Component MetaData Infrastructure Component Registry: Webanwendung zur Verwaltung von CMDIKomponenten und -Profilen Suche/Abruf existierender Komponenten/Profile Registrierung eigener Komponenten/Profile Zugriff via Webservices 57

58 CMDI Component Registry Profile und Komponenten können in der CLARIN Component Registry hinterlegt und per PIDs referenziert werden 58

59 CMDI Component Registry Profile und Komponenten können in der CLARIN Component Registry hinterlegt und per PIDs referenziert werden 59

60 CMDI Component Registry Editieren der Komponente Corpus 60
")
61 CMDI Component Registry Registrierung eines Profils CorpusProfile (Wortschatz Korpus) 61
62 CMDI Component Registry maschinenlesbare Varianten der Profilspezifikation 62

63 CMDI Component Registry maschinenlesbare Varianten der Profilspezifikation 63

64 CMDI Component Registry maschinenlesbare Varianten der Profilspezifikation 64
Editor mit Unterstützung für CMDI (Nutzung existierender")
65 CMDI - Arbil CMDI Component MetaData Infrastructure Arbil: Metadaten-(XML)Editor mit Unterstützung für CMDI (Nutzung existierender CMDI-Profile) 65

66 CMDI - Arbil CMDI Component MetaData Infrastructure Anbindung an die Component Registry: 66
67 CMDI - Arbil CMDI Component MetaData Infrastructure CenterProfile: enthält Basisinformationen zu einem CLARIN Zentrum Name und Typ, Kontaktmöglichkeit, technische Zugriffspunkte (Typ und Adresse) Speicherung in der CenterRegistry => Zentrales Verzeichnis aller CLARIN Zentren (REST-WS) 67

68 CMDI - Arbil CMDI Component MetaData Infrastructure 68


69 CMDI - Arbil CMDI Component MetaData Infrastructure 69
70 CMDI - Arbil Eine (nicht vollständige) Instanz des CenterProfile -Profils Speicherung in der CenterRegistry => Zentrales Verzeichnis aller CLARIN Zentren (REST-WS) 70

71 CMDI - Arbil Eine (nicht vollständige) Instanz des CenterProfile -Profils Speicherung in der CenterRegistry => Zentrales Verzeichnis aller CLARIN Zentren (REST-WS) 71
72 CMDI - Center Registry CenterRegistry 72
73 CMDI - Center Registry Name und Typ 73
74 CMDI - Center Registry Zugriffspunkte 74
75 CMDI ISOcat Metadaten in CLARIN? XML-Dokumente welche einem bestimmten Profil entsprechen aber: Welche Bedeutung hat eine bestimmte Information? ISOcat - ISO 12620:2009 (ISO Standard Specification of data categories and management of a Data Category Registry for language resources ) data categories für CMDI: verschiedene Tags/Bezeichnungen aber gleiches Konzept (Autor vs. Author) hinter den (Meta)Daten stehende Konzepte, wie Corpus, Metadata, Name, werden über ISOcat identifiziert/beschrieben jedes Konzept wird geprüft und bekommt eine eindeutige ID eine Beschreibung in verschiedenen Sprachen 75
76 CMDI ISOcat ISOcat Metadaten zu einer data category resource name 76
77 CMDI ISOcat ISOcat Metadaten zu einer data category resource name 77


78 CMDI ISOcat ISOcat Metadaten zu einer data category resource name 78
79 CMDI ISOcat ISOcat Metadaten zu einer data category resource name 79

80 CMDI ISOcat ISOcat Metadaten zu einer data category resource name 80

81 CMDI ISOcat ISOcat Metadaten zu einer data category resource name 81
82 CMDI - Vorgehen Vorgehen bei der Erstellung und Veröffentlichung von Metadaten für CLARIN: Erzeugung von Komponentenbeschreibungen (ggf. Suche nach oder Anlegen von fehlenden ISOcat data categories) Erzeugung eines Profils aus diesen Komponenten Generierung des daraus resultierenden XML-Schemas Verlinkung des XML-Schemas in Metadaten-Beschreibungen Einfügen der Metadaten in ein Repository-System (wiederum registriert in CLARIN CenterRegistry) => muss per OAI-PMH abfragbar sein die ersten 4 Schritte werden durch CLARIN-D Infrastrukturkomponenten (component registry) unterstützt 82
83 CMDI - Zusammenfassung Zusammenfassung XML basiert minimales Schema beschreibt einige Grundfunktionen Meta-Meta -Sprache ist XML Schema durch Erweiterung werden individuelle Komponentenbeschreibungen definiert Komponentenbeschreibungen werden zu einem Profil kombiniert welches in einer Registry hinterlegt wird Komponenten sind wiederverwendbare Bausteine zur Definition eines Profils bzw. von Komponenten (Rekursion) Profile beschreiben eine bestimmte Klasse von Ressourcen (Bsp.: Wortschatz Korpora, Tools der ASV Toolbox, Webservices, ) 83
84 Metadaten - OAI-PMH 84
85 OAI-PMH OAI-PMH Open Archives Initiative Protocol for Metadata Harvesting dient dem einfachen Sammeln von Metadaten klassisch: Zugriff auf die bei data providern vorhandenen Datensätze (z.b.: Metadaten zu Büchern, ) CLARIN: ermöglicht den einfachen Zugriff auf die bei den Repositories hinterlegten Metadaten (im CMDI-Format) basiert auf HTTP/REST und XML Beispiel: Welche Datensätze im CMDI-Format wurden seit dem (Zeitpunkt des letzten Besuches) hinzugefügt? 85
86 OAI-PMH Liste alle Einträge im CMDI-Format auf (REST): 86
87 OAI-PMH Liste alle Einträge im CMDI-Format auf (REST): 87

88 OAI-PMH Liste alle Einträge im CMDI-Format auf (REST): 88
89 OAI-PMH Weitere Abfragemöglichkeiten: Liste alle Einträge im CMDI-Format auf, welche zum Set myset gehören: verb=listrecords&metadataprefix=cmdi&set=myset Liste alle Einträge im CMDI-Format auf, welche nach dem um 8:30 hinzugefügt/geändert wurden: verb=listrecords&metadataprefix=cmdi&from= t08:30:00z 89
90 OAI-PMH Liefert ein XML-Dokument mit Angaben zum Repository: 90

91 OAI-PMH Liefert ein XML-Dokument mit Angaben zum Repository: 91
92 OAI-PMH Liefert ein XML-Dokument mit Angaben zu den unterstützen Formaten (hier Dublin Core und CMDI): 92
93 OAI-PMH Liefert ein XML-Dokument mit Angaben zu den unterstützen Formaten (hier Dublin Core und CMDI): 93
: http://.../oaiprovider/?")
94 OAI-PMH Liefert ein XML-Dokument mit Angaben zu den unterstützen Formaten (hier Dublin Core und CMDI): 94

95 CLARIN-D Infrastruktur OAI-PMH Open Archives Initiative Protocol for Metadata Harvesting Was bietet CLARIN-D? dient dem einfachen Sammeln von Metadaten klassisch: Zugriff auf die bei data providern vorhandenen Datensätze (z.b.: Metadaten zufür Büchern, ) einheitliche Abfragemethode die Metadatenkataloge Zentrenermöglicht den einfachen Zugriff auf die bei in Repositories allerclarin: der Zentren hinterlegten Metadaten (im CMDI-Format) Centers Registry : Verzeichnis der CLARIN-D Zentren und basiert auf HTTP/REST und Endpoints XML der dortigen OAI-PMH => jeder kann die Metadaten aller CLARIN-D Zentren einsammeln & auswerten Angebot an Dritte: Bereitstellung von Metadaten über die Repositories / OAI-PMH Endpoints der Zentren 95
96 CLARIN-D Infrastruktur OAI-PMH Harvester Sammelt die dezentral in den Zentren hinterlegten Metadaten ein Beispiel: Welche Datensätze im CMDI-Format wurden seit dem (Zeitpunkt des letzten Besuches) hinzugefügt? 96

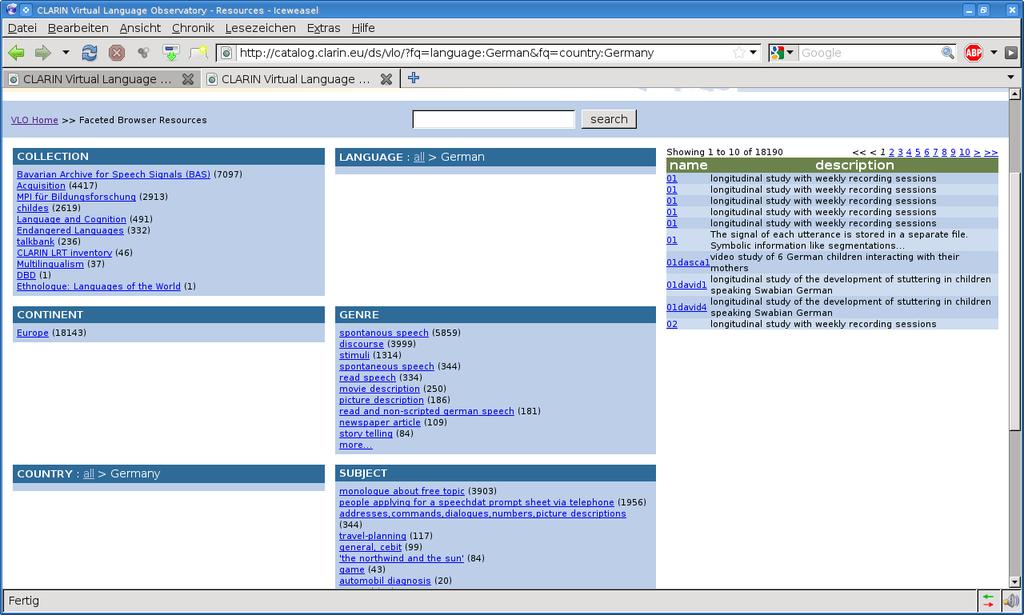
97 CLARIN-D Infrastruktur OAI-PMH Harvester Was bietet CLARIN-D? sammelt die dezentral in den Zentren hinterlegten Metadaten ein momentan existieren zwei Harvester in CLARIN-D Beispiel: Welche Datensätze im CMDI-Format wurden seit dem (Zeitpunkt des letzten Besuches) hinzugefügt? CMDI Metadaten für Ressourcen/Tools => automatische Integration in das Suchportal VLO Webservices => automatische Integration in die webbasierte Worflowengine Weblicht VLO (Virtual Language Observatory) Suche: Volltext (Metadaten), Katalog, faceted/geographical browsing Daten aus: CLARIN LRT inventory (manuell und OAI-PMH), MPI IMDI Portal (u.a. DobeS; Dokumentation bedrohter Sprachen), ELRA catalogue of language resources, WALS (World-Atlas of Languages) 97
98 VLO 98
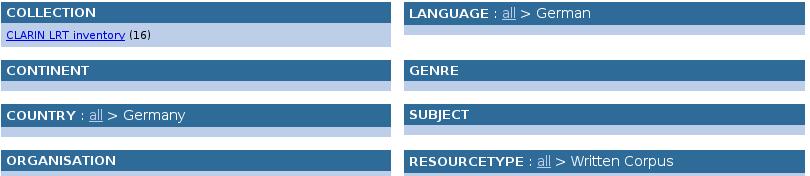
99 VLO Fragestellung Projekt Postdemokratie und Neoliberalismus. Zur Nutzung neoliberaler Argumentationen in der bundesdeutschen Politik => 1. Aufgabe: Suche nach geeigneten Daten => z.b. Nachrichtentexte aus den letzten x Jahren 99
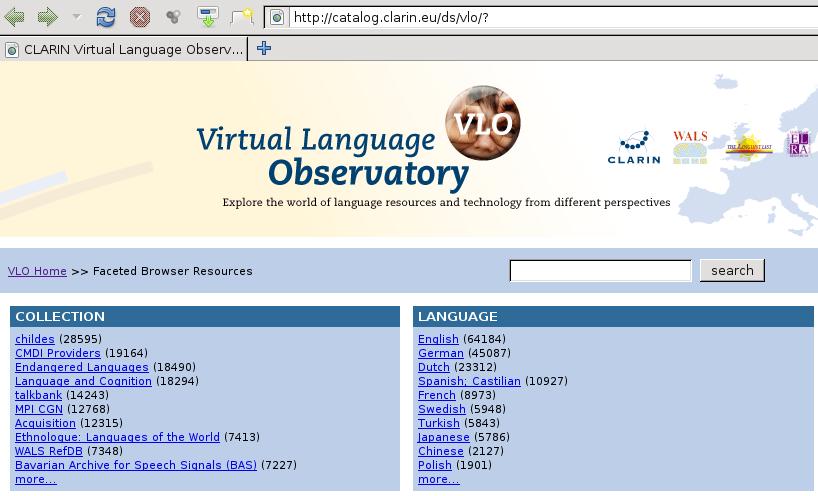
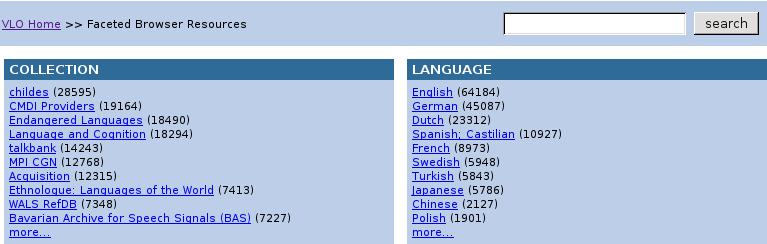
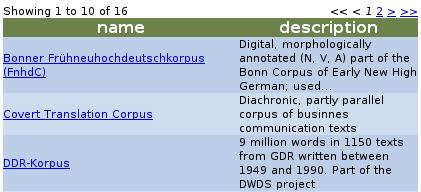
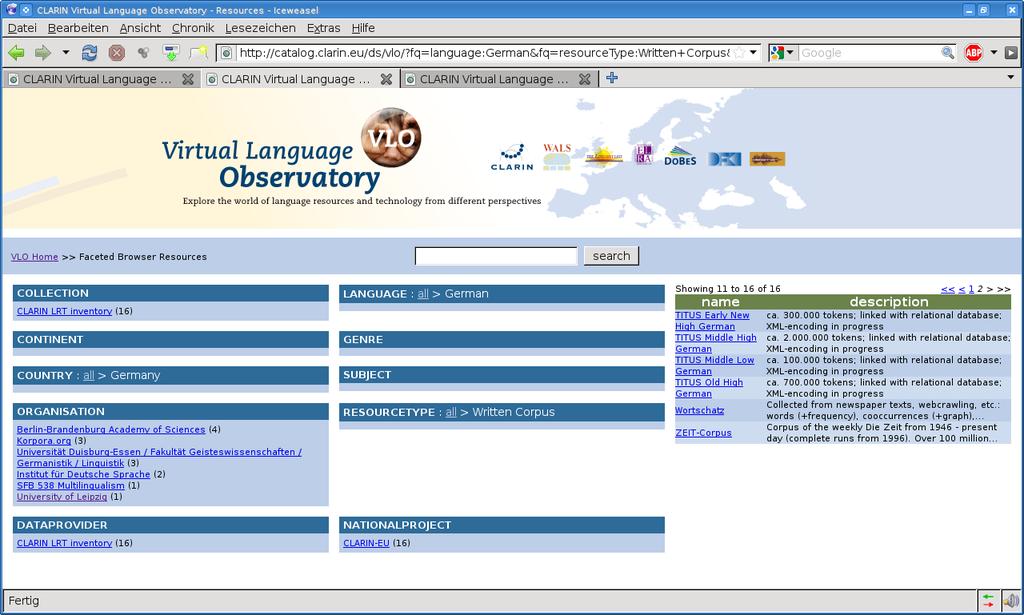
100 VLO ^ 100
101 VLO 101
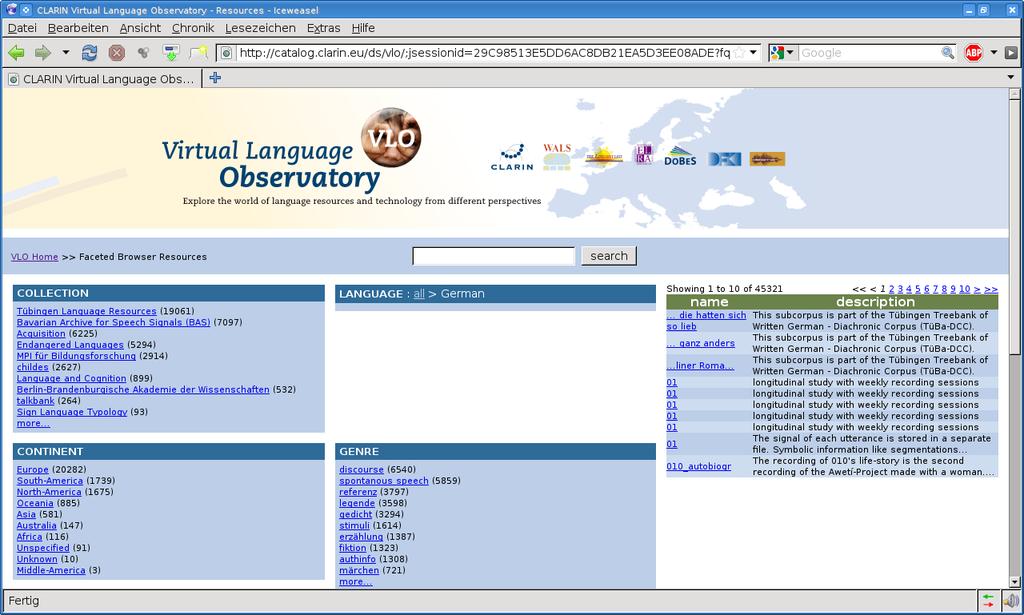

102 VLO 102

103 VLO 103
104 VLO 104
105 VLO 105

106 VLO 106
107 VLO 107
108 VLO 108

109 VLO 109

110 VLO Volltextsuche nach Wortschatz 110
111 VLO 111
112 Repositorysysteme - Einführung 112
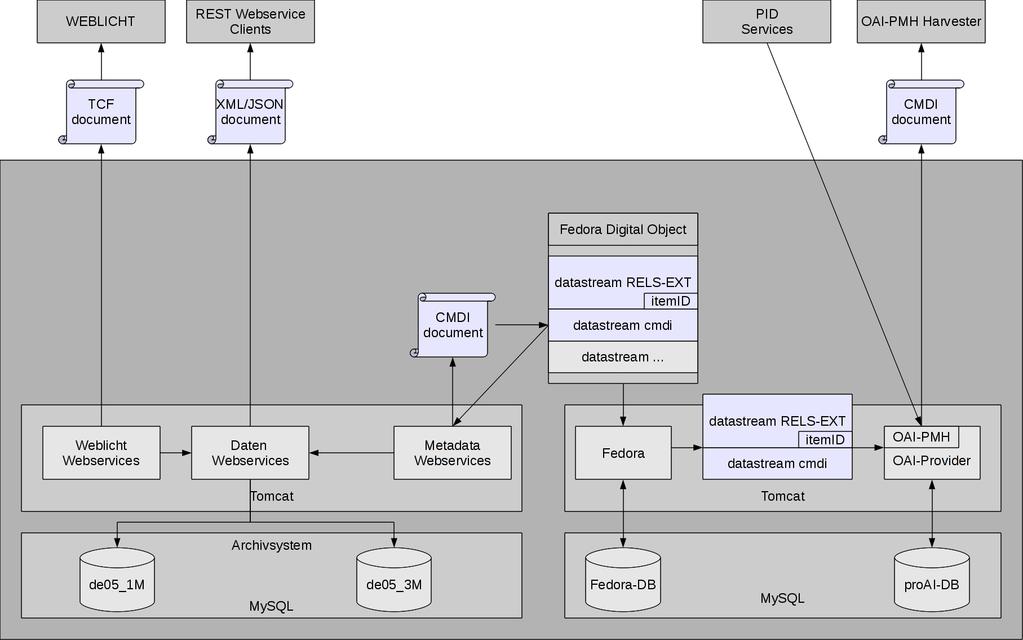
113 Repositorysysteme Metadaten in CLARIN sollen in Repositories (Langzeitarchivierung) verwaltet werden Repository: Verwaltung (digitaler) Objekte in einem (elektronischen) Archiv es existieren bereits zahlreiche verschiedene Systeme: DSpace, Fedora, MyCoRe, OPUS, EPrints,... DSpace: sehr einfach einzuführen (relativ) hoher Aufwand bei Abweichung vom Standardszenario Fedora: Fedora: komplexeres Setup sehr flexibel (REST-API) beide Systeme verschmelzen: 113
114 Repositorysysteme weitere Beispiele: Code Repositorien / Versionsverwaltung: (CVS), Subversion, Software Repositorien: Linux Distributionen, Artifact Repositorien: Maven Central, Archiva / Nexus,... Dokument Repositorien: Fedora, DSpace, (in der Regel Unterstützung für Dublin Core und OAI-PMH) OAI - Open Archives Initiative Zusammenschluss/Initiative der Entwickler/Betreiber von Dokument Repositorien Ziel: In den Repositories verwaltete Ressourcen besser auffindbar und nutzbar machen. Projekte: OAI-PMH (OAI Protocol for Metadata Harvesting) OAI-ORE (OAI Object Reuse and Exchange) 114
115 Repositorysysteme ROAR - Registry of Open Access Repositories Weltweit/Deutschland ( ): DSpace: / 15 EPrints: 481 / 21 OPUS: 50 / 44 Fedora: 48 / 1 MyCoRe: 6 / 6 Das Repository mit der höchsten Aktivität (Stand ) ist
 ist.")
116 Repositorysysteme Das Repository mit der höchsten Aktivität (Stand ) ist
117 Repositorysysteme - Fedora 117
 zugehörigen Metadaten und Relationen http://fedora-commons.")
118 Fedora Fedora: Flexible Extensible Digital Object Repository Architecture Flexible Verwaltung von: digitalen Objekten (Dokumente, Bilder, Videos) zugehörigen Metadaten und Relationen 118
119 Fedora Designziel: Einfache Integration in komplexere Anwendungssysteme, welche weitere Funktionalität (Suche, Workflow- und Rechtemanagement,) realisieren. Zugriff auf Daten und Funktionalität via Webservices Flexibles Datenmodel: Fedora Digital Object Model kann auch eigenständig eingesetzt werden => jedoch nicht sehr Nutzerfreundlich Einige weitere Funktionen: RDF Suche (SPARQL) Support für verschiedene Storage Systeme (Datenbanken und Filesystem) OAI-PMH, JMS (Java Message Service), Volltextsuche,
120 Fedora Warum Entscheidung für Fedora? Nutzerfreundliches Front-End für uns nicht zwingend nötig offenes, flexibles System (Webservices) Nachteil(e): hohe Einstiegshürde, viel Konfigurationsaufwand Skalierbarkeit: Objekte (Patente; ca Dokumente) => einige Tage (2-4) => Dauer der Einfügeoperation/Objekt blieb stabil Objekte mit Datenströmen => (super)lineares Verhalten 120

121 Fedora Fedora Digital Object Model Ein Fedora Digital Object (FDO) besteht aus: Grafik inspiriert von: 121

122 Fedora Fedora Digital Object Model Ein Fedora Digital Object (FDO) besteht aus: Grafik inspiriert von: 122
123 Fedora Fedora Datastreams Datastream Identifier, State (Active, Inactive, or Deleted) Created/Modified Date, Versionable (true/false) Label, MIME Type, Format Identifier, Alternate Identifiers Bytestream Content, Checksum Control Group: Internal XML Metadata: XML inline im XML des Digital Object Managed Content: in Fedora gespeichert (Verweis aus dem XML des Digital Object per internem Identifier) External Referenced Content: außerhalb von Fedora (Verweis; Stream/Redirect) 123
124 Fedora Fedora Datastreams Grafik inspiriert von: 124
125 Fedora direkte Repräsentation: Fedora Datastreams => Daten wird ohne Änderungen weitergereicht virtuelle Repräsentation => Daten werden zur Laufzeit erzeugt (z.b. aus existierenden Datastreams Grafik inspiriert von: 125

126 Fedora Fedora Datastreams Fedora info URI Schema Digital Object "info:fedora/" object-pid Beispiel: info:fedora/example:9876 Dissemination (Datastream) "info:fedora/" object-pid "/" dissem-name Beispiel: info:fedora/example:3/ds1 Grafik inspiriert von: 126
127 Fedora Fedora REST API API-A für lesenden Zugriff: findobjects: Suche nach Objekten listdatastreams: Auflisten von Datastreams getdatastreamdissemination: Zugriff auf Datastreams... API-M für schreibenden + low level Zugriff: ingest: Ein Objekt hinzufügen adddatastream: Einen Datastream anlegen addrelationship: Eine Relation anlegen
![Fedora Fedora REST API findobjects GET-Request: /objects? [terms query] [maxresults] [resultformat] [pid] [title] API-A für lesenden Zugriff: http://myhost:8080/fedora/objects?](/docs-images/93/114413228/images/128-3.jpg "findobjects: Suche nach Objekten pid=true&title=true&terms=&query=&maxresults=20&resultformat=xml listdatastreams: Auflisten von Datastreams getdatastreamdissemination: Zugriff auf Datastreams API-M")
128 Fedora Fedora REST API findobjects GET-Request: /objects? [terms query] [maxresults] [resultformat] [pid] [title] API-A für lesenden Zugriff: findobjects: Suche nach Objekten pid=true&title=true&terms=&query=&maxresults=20&resultformat=xml listdatastreams: Auflisten von Datastreams getdatastreamdissemination: Zugriff auf Datastreams API-M für schreibenden + low level Zugriff: ingest: Ein Objekt hinzufügen adddatastream: Einen Datastream anlegen addrelationship: Eine Relation anlegen 128
129 Fedora Fedora REST API API-A für lesenden Zugriff: listdatastreams findobjects: Suche nach Objekten GET-Request: /objects/{pid}/datastreams? [format] [asofdatetime] listdatastreams: Auflisten von Datastreams getdatastreamdissemination: Zugriff auf Datastreams format=xml API-M für schreibenden + low level Zugriff: ingest: Ein Objekt hinzufügen adddatastream: Einen Datastream anlegen addrelationship: Eine Relation anlegen 129
130 Fedora Fedora REST API API-A für lesenden Zugriff: getdatastreamdissemination findobjects: Suche nach Objekten GET-Request: /objects/{pid}/datastreams/{dsid}/content? [asofdatetime] [download] listdatastreams: Auflisten von Datastreams getdatastreamdissemination: Zugriff auf Datastreams DC/content API-M für schreibenden + low level Zugriff: ingest: Ein Objekt hinzufügen adddatastream: Einen Datastream anlegen addrelationship: Eine Relation anlegen 130
131 Fedora Fedora & OAI-PMH enthalten: Basic OAI-PMH Provider (nur Dublin Core) 131

132 Fedora Fedora & OAI-PMH enthalten: Basic OAI-PMH Provider (nur Dublin Core)
133 Fedora Proai repositoryunabhängige Implementierung des OAI-PMH Protokolls Quelle: 133
134 Fedora Proai repositoryunabhängige Implementierung des OAI-PMH Protokolls OAI-PMH 2.0 Interface (Meta)Daten liegen im XML Record Cache Cache Updater: regelmäßiger Abgleich mit dem Backend Driver: spezifischer Treiber zur Kommunikation mit dem Repository im Back End Quelle: 134
135 Fedora Proai repositoryunabhängige Implementierung des OAI-PMH Protokolls hohe Verfügbarkeit: OAI-PMH Interface unabhängig vom Repository ansprechbar Repository nicht als Performance-Flaschenhals Schema-Validierung: Daten können vor Aufnahme in den Cache validiert werden. Quelle: 135
136 Fedora Proai repositoryunabhängige Implementierung des OAI-PMH Protokolls Treiber / Anbindung Back End Implementierung eines Interface mit 8 Methoden: ListMetadataFormats() listrecords(date from, Date until, String mdprefix)... für Fedora bereits enthalten Quelle: 136
137 Fedora Proai Konfiguration für Fedora (proai.properties) proai.validateupdates = false proai.db.username = username proai.db.password = password driver.fedora.user = fedorauser driver.fedora.pass = fedorauserpass driver.fedora.itemid = driver.fedora.md.formats = oai_dc cmdi driver.fedora.md.format.cmdi.disstype = info:fedora/*/cmdi driver.fedora.md.format.cmdi.loc = 137
138 Fedora Proai Konfiguration für Fedora (proai.properties) proai.validateupdates = false Sollen nur valide Dokumente in den Cache aufgenommen proai.db.username = username werden? proai.db.password = password driver.fedora.user = fedorauser driver.fedora.pass = fedorauserpass driver.fedora.itemid = driver.fedora.md.formats = oai_dc cmdi driver.fedora.md.format.cmdi.disstype = info:fedora/*/cmdi 138
139 Fedora Proai Konfiguration für Fedora (proai.properties) proai.validateupdates = false proai.db.username = username proai.db.password = password driver.fedora.user = fedorauser driver.fedora.pass = fedorauserpass Nutzername/Passwort für Zugriff auf: driver.fedora.itemid = driver.fedora.md.formats DB Back End von/für Proai = oai_dc cmdi driver.fedora.md.format.cmdi.disstype Fedora = info:fedora/*/cmdi 139
140 Fedora Proai Konfiguration für Fedora (proai.properties) proai.validateupdates = false proai.db.username = username proai.db.password = password driver.fedora.user = fedorauser driver.fedora.pass = fedorauserpass driver.fedora.itemid = Der Fedora Treiber liefert=nur FDOs an Proai, welche im driver.fedora.md.formats oai_dc cmdi RELS_EXT Datenstrom durch die unter driver.fedora.itemid driver.fedora.md.format.cmdi.disstype spezifizierte ID gekennzeichnet sind = info:fedora/*/cmdi 140
141 Fedora Proai Konfiguration für Fedora (proai.properties) proai.validateupdates = false proai.db.username = username proai.db.password = password driver.fedora.user = fedorauser driver.fedora.pass = fedorauserpass driver.fedora.itemid = driver.fedora.md.formats = oai_dc cmdi Es existieren die Formate (Identifier): driver.fedora.md.format.cmdi.disstype = info:fedora/*/cmdi oai_dc (Dublin Core) cmdi (CMDI) 141
142 Fedora Proai Konfiguration für Fedora (proai.properties) proai.validateupdates = false proai.db.username = username proai.db.password = password driver.fedora.user = fedorauser driver.fedora.pass = fedorauserpass driver.fedora.itemid = driver.fedora.md.formats = oai_dc cmdi driver.fedora.md.format.cmdi.disstype = info:fedora/*/cmdi Die (Meta)Daten des Formats mit dem Identifier cmdi liegen im Datastream mit dem Identifier cmdi des jeweiligen FDOs 142

143 Fedora 143
144 CLARIN-D Infrastruktur 144
145 CLARIN-D Infrastruktur 145
146 Zusammenfassung 146
147 Zusammenfassung - CLARIN-D Eine web- und zentrenbasierte Forschungsinfrastruktur für die Geistes- und Sozialwissenschaften Infrastruktur: Metadaten, Webservices,... Technologien: PID Federated Content Search Shibboleth CMDI OAI-PMH 147
 Abfrage von Inhalten aus verschiedenen Quellen mittels standardisierter")
148 Zusammenfassung - CLARIN-D FCS Federated Content Search Grundlage: SRU / CQL (Search/Retrieve via URL + Context Query Language) Abfrage von Inhalten aus verschiedenen Quellen mittels standardisierter Schnittstelle 148
149 Zusammenfassung - Metadaten Metadaten: Daten über Daten. Daten vs. Metadaten strukturierte vs. unstrukturierte Metadaten Dublin Core CMDI 149
150 Zusammenfassung - CMDI Konzepte und Begriffe: Komponenten & Profile XML / XML-Schema Vorgehen bei der Erstellung von CMDI-Metadaten Werkzeuge: Component Registry Arbil ISOcat 150
151 Zusammenfassung - OAI-PMH Zweck: Einheitliche Schnittstelle für Metadata-Harvesting Interface: Identify ListMetadataFormats ListRecords 151
152 Zusammenfassung Reposit. Repository: Verwaltung (digitaler) Objekte in einem (elektronischen) Archiv Ziele: zentrale Speicherung & Bereitstellung von Daten + Metadaten Versionierung & (Langzeit)Archivierung... verschiedene Typen: Code Repositorien / Versionsverwaltung Software Repositorien / Artifact Repositorien Dokument Repositorien (Fedora, DSpace, ) 152
153 Zusammenfassung - Fedora Grundkonzept: Fedora Digital Objects (FDOs) (Meta)Daten wie Label, ID, Datastreams festverdrahtete wie RELS_EXT für Relationen zusätzlich freie Definition eigener Datenströme möglich Daten entweder direkt in Fedora oder nur Verweis mittels URI OAI-PMH nur für DC-Metadaten zusätzlicher OAI-Provider Service (basierend auf ProAI) erlaubt die Auslieferung von Metadaten in alternativen Formaten ein bestimmter Datenstrom dient dabei als Quelle für die Metadaten (in Format X) eines FDO's 153
154 Vielen Dank für Ihre Aufmerksamkeit! Institut für Informatik 154
155 CLARIN-D News Want to keep yourself informed on all things related to CLARIN-D? Visit the news section on: 155
156 CLARIN-D Newsletter Want to keep yourself informed on all things related to CLARIN-D? Check out the CLARIN-D newsletter on: 156
157 Website Interested in Learning more about CLARIN-D? Visit our Website at: 157

158 SHKs/WHKs gesucht Das Leipziger CLARIN-D Team sucht engagierte Mitstreiter nützliche Kenntnisse: Java Eclipse Maven Webservices MySQL XML Spring Vaadin Fedora, CMDI,
Metadaten in CLARIN-D
 Metadaten in CLARIN-D Zielstellung, PIDs, CMDI, OAI-PMH, Fedora Prof. Dr. Gerhard Heyer Torsten Compart Abt. Automatische Sprachverarbeitung Institut für Informatik, Universität Leipzig heyerasv@informatik.uni-leipzig.de
Metadaten in CLARIN-D Zielstellung, PIDs, CMDI, OAI-PMH, Fedora Prof. Dr. Gerhard Heyer Torsten Compart Abt. Automatische Sprachverarbeitung Institut für Informatik, Universität Leipzig heyerasv@informatik.uni-leipzig.de
CLARIN-D. Überblick, Metadaten, Demo. Christoph Kuras. Abt. Automatische Sprachverarbeitung Institut für Informatik, Universität Leipzig
 CLARIN-D Überblick, Metadaten, Demo Christoph Kuras Abt. Automatische Sprachverarbeitung Institut für Informatik, Universität Leipzig Institut für Informatik 1 CLARIN: Common Language Resource and Technology
CLARIN-D Überblick, Metadaten, Demo Christoph Kuras Abt. Automatische Sprachverarbeitung Institut für Informatik, Universität Leipzig Institut für Informatik 1 CLARIN: Common Language Resource and Technology
SICHTWEISE VON CLARIN ZUKÜNFTIGE AUFGABEN, KOMPONENTEN, HERAUSFORDERUNGEN THORSTEN TRIPPEL, UNIVERSITÄT TÜBINGEN.
 SICHTWEISE VON CLARIN ZUKÜNFTIGE AUFGABEN, KOMPONENTEN, HERAUSFORDERUNGEN THORSTEN TRIPPEL, UNIVERSITÄT TÜBINGEN CLARIN in Europa Zweites European Research Infrastructure Consortium (ERIC) Mitglieder:
SICHTWEISE VON CLARIN ZUKÜNFTIGE AUFGABEN, KOMPONENTEN, HERAUSFORDERUNGEN THORSTEN TRIPPEL, UNIVERSITÄT TÜBINGEN CLARIN in Europa Zweites European Research Infrastructure Consortium (ERIC) Mitglieder:
BAS Repository. Uwe Reichel Institute of Phonetics and Speech Processing University of Munich. 31. März CLARIN WORKSHOP 2014: BAS Repository
 BAS Repository Institute of Phonetics and Speech Processing University of Munich 31. März 2014 Inhalt Was ist ein Daten-Repository? Wie kommen die Daten ins Repository? Wie kann man auf die Daten zugreifen?
BAS Repository Institute of Phonetics and Speech Processing University of Munich 31. März 2014 Inhalt Was ist ein Daten-Repository? Wie kommen die Daten ins Repository? Wie kann man auf die Daten zugreifen?
PROBADO Systemarchitektur
 PROBADO Systemarchitektur Maximilian Scherer Interactive Graphics Systems Group TU Darmstadt, Germany maximilian.scherer@gris.tu-darmstadt.de March 8, 2011 Maximilian Scherer 1 Überblick PROBADO Core:
PROBADO Systemarchitektur Maximilian Scherer Interactive Graphics Systems Group TU Darmstadt, Germany maximilian.scherer@gris.tu-darmstadt.de March 8, 2011 Maximilian Scherer 1 Überblick PROBADO Core:
Open Archives. Gudrun Fischer Universität Duisburg-Essen
 Open Archives Gudrun Fischer Universität Duisburg-Essen Inhalt Harvesting-Protokoll Archive Services OAI für die Informatik Implementierung 2004-09-30 Gudrun Fischer: Open Archives 2 Open Archives Protocol
Open Archives Gudrun Fischer Universität Duisburg-Essen Inhalt Harvesting-Protokoll Archive Services OAI für die Informatik Implementierung 2004-09-30 Gudrun Fischer: Open Archives 2 Open Archives Protocol
Metadaten und Identifikatoren
 Planung des Forschungsdaten-Managements: Metadaten und Identifikatoren Timo Gnadt SUB Göttingen gnadt@sub.uni-goettingen.de 6. Dezember 2011, Göttingen Überblick Metadaten Motivation Planungsaspekte Dimensionen
Planung des Forschungsdaten-Managements: Metadaten und Identifikatoren Timo Gnadt SUB Göttingen gnadt@sub.uni-goettingen.de 6. Dezember 2011, Göttingen Überblick Metadaten Motivation Planungsaspekte Dimensionen
Vom digitalen Hausmeister zum international vernetzten Forschungsdatenzentrum. Die Entwicklung der digitalen Infrastruktur des
 Vom digitalen Hausmeister zum international vernetzten Forschungsdatenzentrum. Die Entwicklung der digitalen Infrastruktur des Daniel Jettka, Hanna Hedeland, Timm Lehmberg 16.09.2015 1 Struktur und Profil
Vom digitalen Hausmeister zum international vernetzten Forschungsdatenzentrum. Die Entwicklung der digitalen Infrastruktur des Daniel Jettka, Hanna Hedeland, Timm Lehmberg 16.09.2015 1 Struktur und Profil
CLARIN in Stuttgart: Metadaten, ehumanities und trainierbare Werkzeuge
 CLARIN in Stuttgart: Metadaten, ehumanities und trainierbare Werkzeuge Kerstin Eckart Universität Stuttgart Institut für Maschinelle Sprachverarbeitung Pfaffenwaldring 5b 70569 Stuttgart Berlin, 27.11.2013
CLARIN in Stuttgart: Metadaten, ehumanities und trainierbare Werkzeuge Kerstin Eckart Universität Stuttgart Institut für Maschinelle Sprachverarbeitung Pfaffenwaldring 5b 70569 Stuttgart Berlin, 27.11.2013
Forschungsdaten in den Geisteswissenschaften die germanistische Sprachwissenschaft
 Forschungsdaten in den Geisteswissenschaften die germanistische Sprachwissenschaft Andreas Witt Institut für Deutsche Sprache, Mannheim Workshop Forschungsdaten WGL Geschäftsstelle Berlin 2012-05-10 Institut
Forschungsdaten in den Geisteswissenschaften die germanistische Sprachwissenschaft Andreas Witt Institut für Deutsche Sprache, Mannheim Workshop Forschungsdaten WGL Geschäftsstelle Berlin 2012-05-10 Institut
Grundlagen der Web-Entwicklung INF3172
 Grundlagen der Web-Entwicklung INF3172 Web-Services Thomas Walter 16.01.2014 Version 1.0 aktuelles 2 Webservice weitere grundlegende Architektur im Web: Webservice (Web-Dienst) Zusammenarbeit verschiedener
Grundlagen der Web-Entwicklung INF3172 Web-Services Thomas Walter 16.01.2014 Version 1.0 aktuelles 2 Webservice weitere grundlegende Architektur im Web: Webservice (Web-Dienst) Zusammenarbeit verschiedener
Open Archives Initiative - Protocol for Metadata Harvesting (OAI-PMH)
") , XML LV BF23 (0F32) Open Archives Initiative - Protocol for Metadata Harvesting (OAI-PMH) Achim Oßwald FH Köln Institut für Informationswissenschaft Wintersemester 2010 (Stand: 3.12.10) 1/ 18 OAI-PMH
, XML LV BF23 (0F32) Open Archives Initiative - Protocol for Metadata Harvesting (OAI-PMH) Achim Oßwald FH Köln Institut für Informationswissenschaft Wintersemester 2010 (Stand: 3.12.10) 1/ 18 OAI-PMH
Marine Network for Integrated Data Access
 Marine Network for Integrated Data Access Workflows vom Schiff zum Portal Deutsche Meeresforschung Roland Koppe Überblick Gefördert durch die Helmholtz Gemeinschaft Laufzeit 02/2012 07/2014 (Phase 1) Koordination
Marine Network for Integrated Data Access Workflows vom Schiff zum Portal Deutsche Meeresforschung Roland Koppe Überblick Gefördert durch die Helmholtz Gemeinschaft Laufzeit 02/2012 07/2014 (Phase 1) Koordination
MyCoRe > V1.0: Technische Weiterentwicklung
 MyCoRe > V1.0: Technische Weiterentwicklung Frank Lützenkirchen, Kathleen Krebs Folie 1 Kontrollflüsse bisher Kontrollflüsse sind im MyCoRe Kern oder der darauf basierenden Applikation fix und explizit
MyCoRe > V1.0: Technische Weiterentwicklung Frank Lützenkirchen, Kathleen Krebs Folie 1 Kontrollflüsse bisher Kontrollflüsse sind im MyCoRe Kern oder der darauf basierenden Applikation fix und explizit
4. RADAR-WORKSHOP RADAR APPLICATION PROGRAMMING INTERFACE KARLSRUHE, 25./26. JUNI Matthias Razum, FIZ Karlsruhe
 4. RADAR-WORKSHOP KARLSRUHE, 25./26. JUNI 2018 RADAR APPLICATION PROGRAMMING INTERFACE Matthias Razum, FIZ Karlsruhe APPLICATION PROGRAMMING INTERFACE POTENZIAL ANWENDUNG Application Programming Interface
4. RADAR-WORKSHOP KARLSRUHE, 25./26. JUNI 2018 RADAR APPLICATION PROGRAMMING INTERFACE Matthias Razum, FIZ Karlsruhe APPLICATION PROGRAMMING INTERFACE POTENZIAL ANWENDUNG Application Programming Interface
Enterprise Content Management für Hochschulen
 Enterprise Content Management für Hochschulen Eine Infrastuktur zur Implementierung integrierter Archiv-, Dokumentenund Content-Managementservices für die Hochschulen des Landes Nordrhein Westfalen Management
Enterprise Content Management für Hochschulen Eine Infrastuktur zur Implementierung integrierter Archiv-, Dokumentenund Content-Managementservices für die Hochschulen des Landes Nordrhein Westfalen Management
Ressourcen in den GSHS... am Beispiel LEXUS
 > Digitale Ressourcen in den GSHS... am Beispiel LEXUS GSHS LIBRARY CONFERENCE Florenz 10.11.2006 < Marc Kemps-Snijders, Jaqcuelijn Ringersma, Peter Wittenburg MPI for Psycholinguistics, Netherlands
> Digitale Ressourcen in den GSHS... am Beispiel LEXUS GSHS LIBRARY CONFERENCE Florenz 10.11.2006 < Marc Kemps-Snijders, Jaqcuelijn Ringersma, Peter Wittenburg MPI for Psycholinguistics, Netherlands
DARIAH-DE Repositorium
 Förderkennzeichen 01UG1610A bis J DARIAH-DE Repositorium Lisa Klaffki, HAB Folien teilweise von Stefan Funk, SUB Berlin, 24./25. Oktober 2016 23/11/2016 de.dariah.eu DARIAH-DE Übersicht DARIAH-DE-Repositorium
Förderkennzeichen 01UG1610A bis J DARIAH-DE Repositorium Lisa Klaffki, HAB Folien teilweise von Stefan Funk, SUB Berlin, 24./25. Oktober 2016 23/11/2016 de.dariah.eu DARIAH-DE Übersicht DARIAH-DE-Repositorium
Strukturelle und linguistische Annotation in historischen Textkorpora am Beispiel des Deutschen Textarchivs
 Strukturelle und linguistische Annotation in historischen Textkorpora am Beispiel des Deutschen Textarchivs Susanne Haaf, Alexander Geyken, Bryan Jurish, Matthias Schulz, Christian Thomas, Frank Wiegand
Strukturelle und linguistische Annotation in historischen Textkorpora am Beispiel des Deutschen Textarchivs Susanne Haaf, Alexander Geyken, Bryan Jurish, Matthias Schulz, Christian Thomas, Frank Wiegand
Ja, Statistiken. Aber.
 OA-Statistik mit Dspace Ja, Statistiken. Aber. Marco Recke Dspace User Group Treffen * Tübingen 5. Oktober 2015 Ja Statistiken, aber welche stimmt? Sessions TOP Downloads Universität Ulm Volltextserver
OA-Statistik mit Dspace Ja, Statistiken. Aber. Marco Recke Dspace User Group Treffen * Tübingen 5. Oktober 2015 Ja Statistiken, aber welche stimmt? Sessions TOP Downloads Universität Ulm Volltextserver
Aspekte der Datenqualität, Adressierung und Auszeichnung von Dokumenten
 Aspekte der Datenqualität, Adressierung und Auszeichnung von Dokumenten Workshop: Technische Aspekte des DINI-Zertifikats 2007 Wolfram Horstmann / Friedrich Summann Hintergrund Datenqualität, Adressierung
Aspekte der Datenqualität, Adressierung und Auszeichnung von Dokumenten Workshop: Technische Aspekte des DINI-Zertifikats 2007 Wolfram Horstmann / Friedrich Summann Hintergrund Datenqualität, Adressierung
Metadaten für die Langzeitarchivierung
 1 22 Metadaten für die Langzeitarchivierung 18. April 2016 Stefan Hein Metadaten für die Langzeitarchivierung Konzepte, Standards, Erzeugung und Anwendungsszenarien 18. April 2016 2 22 Metadaten für die
1 22 Metadaten für die Langzeitarchivierung 18. April 2016 Stefan Hein Metadaten für die Langzeitarchivierung Konzepte, Standards, Erzeugung und Anwendungsszenarien 18. April 2016 2 22 Metadaten für die
Ein Java Repository für digitalen Content in Bibliotheken
 Ein Java Repository für digitalen Content in Bibliotheken 9. Sun Summit Bibliotheken 13.-14. November 2007, Deutsche Nationalbibliothek Christof Mainberger, BSZ Digitale Bibliotheken verwalten digitalen
Ein Java Repository für digitalen Content in Bibliotheken 9. Sun Summit Bibliotheken 13.-14. November 2007, Deutsche Nationalbibliothek Christof Mainberger, BSZ Digitale Bibliotheken verwalten digitalen
DOI-Desk der ETH Zürich: Ein Service für den Schweizer Hochschul- und Forschungsbereich
 DOI-Desk der ETH Zürich: Ein Service für den Schweizer Hochschul- und Forschungsbereich Workshop DOI für Forschungsergebnisse, Projekt e-infrastructures Austria Wien, Österreichische Akademie der Wissenschaften,
DOI-Desk der ETH Zürich: Ein Service für den Schweizer Hochschul- und Forschungsbereich Workshop DOI für Forschungsergebnisse, Projekt e-infrastructures Austria Wien, Österreichische Akademie der Wissenschaften,
Quellen des Neuen Die Integration von Ressourcen zur schulischen und universitären Bildung in die CLARIN-D-Infrastruktur
 Quellen des Neuen Die Integration von Ressourcen zur schulischen und universitären Bildung in die CLARIN-D-Infrastruktur - Ein CLARIN-D Kurationsprojekt der F-AG Neuere Geschichte - Maret Keller, Christian
Quellen des Neuen Die Integration von Ressourcen zur schulischen und universitären Bildung in die CLARIN-D-Infrastruktur - Ein CLARIN-D Kurationsprojekt der F-AG Neuere Geschichte - Maret Keller, Christian
Langzeitarchivierungsmetadaten. in Rosetta
 Langzeitarchivierungsmetadaten in Rosetta Tobias Beinert, Bayerische Staatsbibliothek 06.06.2018 Langzeitarchivierung an der BSB Ab 2004: Aufbau des Bibliothekarischen Archivierungs- und Bereitstellungssystems
Langzeitarchivierungsmetadaten in Rosetta Tobias Beinert, Bayerische Staatsbibliothek 06.06.2018 Langzeitarchivierung an der BSB Ab 2004: Aufbau des Bibliothekarischen Archivierungs- und Bereitstellungssystems
Metadaten Nutzen und Nutzung
 Metadaten Nutzen und Nutzung Axel Herold Berlin-Brandenburgische Akademie der Wissenschaften 18. Februar 2013, DTA/CLARIN-D-Konferenz Übersicht 1. Was sind eigentlich Metadaten? 2. Wozu werden Metadaten
Metadaten Nutzen und Nutzung Axel Herold Berlin-Brandenburgische Akademie der Wissenschaften 18. Februar 2013, DTA/CLARIN-D-Konferenz Übersicht 1. Was sind eigentlich Metadaten? 2. Wozu werden Metadaten
Die Warenkorbfunktion (workbasket)
") Beschreibung der Komponente zur integration eines Warenkorbs in die Anwendung Table of contents 1 Allgemein...2 2 Körbe speichern und laden...3 3 Aufgelöstes XML oder beliebige weitere Metadaten im Korb...
Beschreibung der Komponente zur integration eines Warenkorbs in die Anwendung Table of contents 1 Allgemein...2 2 Körbe speichern und laden...3 3 Aufgelöstes XML oder beliebige weitere Metadaten im Korb...
RADAR. ABLAGE & NACHNUTZUNG von FORSCHUNGSDATEN. Dr. Angelina Kraft. Technische Informationsbibliothek (TIB), Hannover
, Hannover") RADAR ABLAGE & NACHNUTZUNG von FORSCHUNGSDATEN Dr. Angelina Kraft Technische Informationsbibliothek (TIB), Hannover 10.03.2016, Hamburg Agenda Übersicht Zielgruppen Geschäftsmodell Dienstleistungsmodell
RADAR ABLAGE & NACHNUTZUNG von FORSCHUNGSDATEN Dr. Angelina Kraft Technische Informationsbibliothek (TIB), Hannover 10.03.2016, Hamburg Agenda Übersicht Zielgruppen Geschäftsmodell Dienstleistungsmodell
//E-LIB Elektronische Bibliothek Bremen
 //E-LIB Elektronische Bibliothek Bremen Internet Publisher Elektronische Universitätsmedien E-LIB Bremen - Grundkonzeption Publikation elektronischer Universitätsdokumente Internet-Publisher / Open Archives
//E-LIB Elektronische Bibliothek Bremen Internet Publisher Elektronische Universitätsmedien E-LIB Bremen - Grundkonzeption Publikation elektronischer Universitätsdokumente Internet-Publisher / Open Archives
Sarah Hartmann. ORCID DE Förderung der ORCID in Deutschland
 1 Sarah Hartmann ORCID DE Förderung der ORCID in Deutschland 2 16 ORCID DE Normdatenanwendertreffen Bibliothekskongress Leipzig 15. März 2016 Was ist ORCID (Open Researcher and Contributor ID)? System
1 Sarah Hartmann ORCID DE Förderung der ORCID in Deutschland 2 16 ORCID DE Normdatenanwendertreffen Bibliothekskongress Leipzig 15. März 2016 Was ist ORCID (Open Researcher and Contributor ID)? System
 PDF/A Competence Center Webinars
PDF/A Competence Center Webinars Metadaten im Kontext intelligenter Information
 Metadaten im Kontext intelligenter Information DocMuc 2018 München, 2018-06-21 Dr. Stefan Bradenbrink, PANTOPIX GmbH & Co. KG Ziele des Vortrags Was sind Metadaten? Wofür werden Metadaten eingesetzt? Wie
Metadaten im Kontext intelligenter Information DocMuc 2018 München, 2018-06-21 Dr. Stefan Bradenbrink, PANTOPIX GmbH & Co. KG Ziele des Vortrags Was sind Metadaten? Wofür werden Metadaten eingesetzt? Wie
Entwicklung einer REST-API zur Erstellung und Konfiguration von Microsoft Teams. Jan Kruse, utilitas GmbH
 Entwicklung einer REST-API zur Erstellung und Konfiguration von Microsoft Teams Jan Kruse, utilitas GmbH 15.01.2018 Gliederung Einleitung Motivation Ziele Grundlagen ASP.Net Web API REST-API Microsoft
Entwicklung einer REST-API zur Erstellung und Konfiguration von Microsoft Teams Jan Kruse, utilitas GmbH 15.01.2018 Gliederung Einleitung Motivation Ziele Grundlagen ASP.Net Web API REST-API Microsoft
Ein XML Dokument zeichnet sich im Wesentlichen durch seine baumartige Struktur aus:
 RDF in wissenschaftlichen Bibliotheken 5HWULHYDODXI5') Momentan existiert noch keine standardisierte Anfragesprache für RDF Dokumente. Auf Grund der existierenden XML Repräsentation von RDF liegt es jedoch
RDF in wissenschaftlichen Bibliotheken 5HWULHYDODXI5') Momentan existiert noch keine standardisierte Anfragesprache für RDF Dokumente. Auf Grund der existierenden XML Repräsentation von RDF liegt es jedoch
Templatebasierter CDA-Generator mit ART-DECOR. Vortrag im Rahmen der HL7 Austria Jahrestagung 2017, Wien Dipl.-Inform. Med.
 Templatebasierter CDA-Generator mit ART-DECOR Vortrag im Rahmen der HL7 Austria Jahrestagung 2017, Wien Dipl.-Inform. Med. Markus Birkle Praktische Herausforderungen bei der CDA Implementierung Implementierungsaufwand
Templatebasierter CDA-Generator mit ART-DECOR Vortrag im Rahmen der HL7 Austria Jahrestagung 2017, Wien Dipl.-Inform. Med. Markus Birkle Praktische Herausforderungen bei der CDA Implementierung Implementierungsaufwand
Langzeitarchivierungsaspekte. im Dokumentenlebenszyklus
 Document Engineering Langzeitarchivierungsaspekte im enlebenszyklus Motivation Disziplin der Computer Wissenschaft, welche Systeme für e aller Formen und Medien erforscht. enlebenszyklus en Management
Document Engineering Langzeitarchivierungsaspekte im enlebenszyklus Motivation Disziplin der Computer Wissenschaft, welche Systeme für e aller Formen und Medien erforscht. enlebenszyklus en Management
Deutsche Übersetzung des Dublin-Core-Metadaten-Elemente-Sets. Version 1.1
 Deutsche Übersetzung des Dublin-Core-Metadaten-Elemente-Sets Version 1.1 Identifier: http://www.kim-forum.org/material/pdf/uebersetzung_dcmes_20070822.pdf Source: http://www.dublincore.org/documents/dces/
Deutsche Übersetzung des Dublin-Core-Metadaten-Elemente-Sets Version 1.1 Identifier: http://www.kim-forum.org/material/pdf/uebersetzung_dcmes_20070822.pdf Source: http://www.dublincore.org/documents/dces/
Federated Search: Integration von FAST DataSearch und Lucene
 Federated Search: Integration von FAST DataSearch und Lucene Christian Kohlschütter L3S Research Center BSZ/KOBV-Workshop, Stuttgart 24. Januar 2006 Christian Kohlschütter, 24. Januar 2006 p 1 Motivation
Federated Search: Integration von FAST DataSearch und Lucene Christian Kohlschütter L3S Research Center BSZ/KOBV-Workshop, Stuttgart 24. Januar 2006 Christian Kohlschütter, 24. Januar 2006 p 1 Motivation
CLARIN Europäische Netzwerke und Forschungsservices
 CLARIN Europäische Netzwerke und Forschungsservices Prof. Dr. Erhard Hinrichs und Dr. Thorsten Trippel Wissenschaftliche Koordination CLARIN-D Eberhard Karls Universität Tübingen CLARIN Common Language
CLARIN Europäische Netzwerke und Forschungsservices Prof. Dr. Erhard Hinrichs und Dr. Thorsten Trippel Wissenschaftliche Koordination CLARIN-D Eberhard Karls Universität Tübingen CLARIN Common Language
Persistenzschicht in Collaborative Workspace
 Persistenzschicht in Collaborative Workspace Mykhaylo Kabalkin 03.06.2006 Überblick Persistenz im Allgemeinen Collaborative Workspace Szenario Anforderungen Systemarchitektur Persistenzschicht Metadaten
Persistenzschicht in Collaborative Workspace Mykhaylo Kabalkin 03.06.2006 Überblick Persistenz im Allgemeinen Collaborative Workspace Szenario Anforderungen Systemarchitektur Persistenzschicht Metadaten
Web Services. Web Services in the News. Vision: Web of Services. Learning for Results. DECUS Symposium 2002, Vortrag 1K07,
 Web Services Vision: Web of Services Applikationen und Services Ralf Günther Compaq Computer GmbH, Köln Ralf.Guenther@compaq.com DECUS Symposium 2002, Vortrag 1K07, 16.04.2002 Web Services in the News
Web Services Vision: Web of Services Applikationen und Services Ralf Günther Compaq Computer GmbH, Köln Ralf.Guenther@compaq.com DECUS Symposium 2002, Vortrag 1K07, 16.04.2002 Web Services in the News
Topic Maps. Wissensmanagement in Bildungseinrichtungen. Seminar Web Engineering Lars Heuer,
 Topic Maps Wissensmanagement in Bildungseinrichtungen Seminar Web Engineering Lars Heuer, 14.01.2005 Inhalt Zielsetzung Problemstellung Was sind Topic Maps? Eigenschaften von Topic Maps Merging RDF Einsatz
Topic Maps Wissensmanagement in Bildungseinrichtungen Seminar Web Engineering Lars Heuer, 14.01.2005 Inhalt Zielsetzung Problemstellung Was sind Topic Maps? Eigenschaften von Topic Maps Merging RDF Einsatz
Metadaten für die Informationsversorgung von morgen: Kooperativ erstellen - gemeinsam nutzen
 Metadaten für die Informationsversorgung von morgen: Kooperativ erstellen - gemeinsam nutzen Was sind Metadaten? Metadaten sind strukturierte Daten über Daten. Sie dienen der Beschreibung von Informationsressourcen.
Metadaten für die Informationsversorgung von morgen: Kooperativ erstellen - gemeinsam nutzen Was sind Metadaten? Metadaten sind strukturierte Daten über Daten. Sie dienen der Beschreibung von Informationsressourcen.
Bausteine einer VRE für die Linguistik - Beispiel:
 HS: Virtuelle Forschungsumgebungen WS 2010-11 Leitung: Prof. Thaller Referentin: Katja Diederichs Bausteine einer VRE für die Linguistik - Beispiel: Dokumentation bedrohter Sprachen VRE für die Linguistik
HS: Virtuelle Forschungsumgebungen WS 2010-11 Leitung: Prof. Thaller Referentin: Katja Diederichs Bausteine einer VRE für die Linguistik - Beispiel: Dokumentation bedrohter Sprachen VRE für die Linguistik
IHR WEG ZUR DOI-REGISTRIERUNG
 // TIB DOI-SERVICE IHR WEG ZUR DOI-REGISTRIERUNG So werden Ihre Forschungsdaten im Internet auffindbar und zitierfähig. 10.3207/2959859860 10.1594/GFZ.GEOFON.gfz2009kciu 100 90 80 70 60 50 40 30 20 10
// TIB DOI-SERVICE IHR WEG ZUR DOI-REGISTRIERUNG So werden Ihre Forschungsdaten im Internet auffindbar und zitierfähig. 10.3207/2959859860 10.1594/GFZ.GEOFON.gfz2009kciu 100 90 80 70 60 50 40 30 20 10
Forschungsinfrastrukturen: Verfügbarkeit von Daten und deren Langzeitarchivierung
 SFB 833: Bedeutungskonstitution - Dynamik und Adaptivität sprachlicher Strukturen Forschungsinfrastrukturen: Verfügbarkeit von Daten und deren Langzeitarchivierung Erfahrungen und Verfahren in Tübingen
SFB 833: Bedeutungskonstitution - Dynamik und Adaptivität sprachlicher Strukturen Forschungsinfrastrukturen: Verfügbarkeit von Daten und deren Langzeitarchivierung Erfahrungen und Verfahren in Tübingen
Multimedia-Metadaten und ihre Anwendung
 Multimedia-Metadaten und ihre Anwendung 14.02.2006 MPEG-7: Überblick und Zusammenfassung Anneke Winter Inhalt der Präsentation 1. MPEG 2. Einordnung in die MPEG Familie 3. MPEG-7 Idee 4. MPEG-7 Hauptelemente
Multimedia-Metadaten und ihre Anwendung 14.02.2006 MPEG-7: Überblick und Zusammenfassung Anneke Winter Inhalt der Präsentation 1. MPEG 2. Einordnung in die MPEG Familie 3. MPEG-7 Idee 4. MPEG-7 Hauptelemente
ehealth Composite Plattform (ehc) FormsFramework Eine Schlüsseltechnologie zur Umsetzung semantischer Interoperabilität
 FormsFramework Eine Schlüsseltechnologie zur Umsetzung semantischer Interoperabilität") ehealth Composite Plattform (ehc) FormsFramework Eine Schlüsseltechnologie zur Umsetzung semantischer Interoperabilität Dipl.-Inform. Med. Markus Birkle TELEMED 2015 Berlin HL7 Clinical Document Architecture
ehealth Composite Plattform (ehc) FormsFramework Eine Schlüsseltechnologie zur Umsetzung semantischer Interoperabilität Dipl.-Inform. Med. Markus Birkle TELEMED 2015 Berlin HL7 Clinical Document Architecture
Metadaten in Service Repositories
 AIFB Metadaten in Service Repositories Steffen Lamparter, Sudhir Agarwal Institut AIFB / KSRI, Universität Karlsruhe (TH) Bibliothekartag Mannheim, 4. Juni 2008 Agenda 1 Einführung Metadaten und Dienste
AIFB Metadaten in Service Repositories Steffen Lamparter, Sudhir Agarwal Institut AIFB / KSRI, Universität Karlsruhe (TH) Bibliothekartag Mannheim, 4. Juni 2008 Agenda 1 Einführung Metadaten und Dienste
Forschungsdatenmanagement
 Forschungsdatenmanagement Das institutionelle Forschungsdatenrepositorium FDAT mit Schwerpunkt Geistes- und Sozialwissenschaften an der Universität Tübingen 27.11.17 Steve Kaminski escience-center 27.11.17
Forschungsdatenmanagement Das institutionelle Forschungsdatenrepositorium FDAT mit Schwerpunkt Geistes- und Sozialwissenschaften an der Universität Tübingen 27.11.17 Steve Kaminski escience-center 27.11.17
Architektur von REST basierten Webservices
 28.11.2005 Architektur von REST basierten Webservices Referent MARK ALTHOFF REST was invented by ROY T. FIELDING and RICHARD N. TAYLOR Geschichtlicher Hintergrund von REST 1994-1995 taucht der Begriff
28.11.2005 Architektur von REST basierten Webservices Referent MARK ALTHOFF REST was invented by ROY T. FIELDING and RICHARD N. TAYLOR Geschichtlicher Hintergrund von REST 1994-1995 taucht der Begriff
Stand der Entwicklung von Shibboleth 2
 Stand der Entwicklung von Shibboleth 2 5. Shibboleth-Workshop Berlin, 17. Oktober 2007 Bernd Oberknapp Universitätsbibliothek Freiburg E-Mail: bo@ub.uni-freiburg.de Übersicht Offizieller Status Kommunikation
Stand der Entwicklung von Shibboleth 2 5. Shibboleth-Workshop Berlin, 17. Oktober 2007 Bernd Oberknapp Universitätsbibliothek Freiburg E-Mail: bo@ub.uni-freiburg.de Übersicht Offizieller Status Kommunikation
OAI in Deutschland eine Bestandsaufnahme. Silke Schomburg (HBZ)
") OAI in Deutschland eine Bestandsaufnahme Silke Schomburg (HBZ) Open Archives Initiative Bedeutung und Idee Mit der Entwicklung der OAI-Technologie ist eine einfache Schnittstelle zum Austausch von Metadaten
OAI in Deutschland eine Bestandsaufnahme Silke Schomburg (HBZ) Open Archives Initiative Bedeutung und Idee Mit der Entwicklung der OAI-Technologie ist eine einfache Schnittstelle zum Austausch von Metadaten
<Insert Picture Here> Einführung in SOA
 Einführung in SOA Markus Lohn Senior Principal Consultant SOA? - Ideen Selling Oracle To All SAP On ABAP Increasing Sales Of Applications 3 Agenda Motivation SOA-Definition SOA-Konzepte
Einführung in SOA Markus Lohn Senior Principal Consultant SOA? - Ideen Selling Oracle To All SAP On ABAP Increasing Sales Of Applications 3 Agenda Motivation SOA-Definition SOA-Konzepte
Projektgruppe. Thomas Kühne. Komponentenbasiertes Software Engineering mit OSGi
 Projektgruppe Thomas Kühne Komponentenbasiertes Software Engineering mit OSGi Anforderungen der PG IDSE an ein Komponenten- Client Nativer Client Web Client Alternativen IDSE Nutzer Szenario Pipe IDSE
Projektgruppe Thomas Kühne Komponentenbasiertes Software Engineering mit OSGi Anforderungen der PG IDSE an ein Komponenten- Client Nativer Client Web Client Alternativen IDSE Nutzer Szenario Pipe IDSE
Neue Welten: Externe Daten mit APEX nutzen
 Neue Welten: Externe Daten mit APEX nutzen Carsten Czarski Oracle Application Express Development-Team DOAG Regio München - 17. Mai 2018 Copyright 2017 Oracle and/or its affiliates. All rights reserved.
Neue Welten: Externe Daten mit APEX nutzen Carsten Czarski Oracle Application Express Development-Team DOAG Regio München - 17. Mai 2018 Copyright 2017 Oracle and/or its affiliates. All rights reserved.
e-infrastructures Austria
 e-infrastructures Austria Use Case aus der Klimaforschung Fortbildungsseminar für Forschungsdaten und e-infrastrukturen Universität Wien, 6.-9. Juni 2016 Chris Schubert, CCCA Data Centre Diese Unterlagen
e-infrastructures Austria Use Case aus der Klimaforschung Fortbildungsseminar für Forschungsdaten und e-infrastrukturen Universität Wien, 6.-9. Juni 2016 Chris Schubert, CCCA Data Centre Diese Unterlagen
Web Solutions for Livelink
 Web Solutions for Livelink Current Status and Roadmap (Stand: September 2007) 2007 RedDot Solutions Web Solutions für Open Text Livelink ES Integrate Nahtlose Integration mit dem Livelink Enterprise Server
Web Solutions for Livelink Current Status and Roadmap (Stand: September 2007) 2007 RedDot Solutions Web Solutions für Open Text Livelink ES Integrate Nahtlose Integration mit dem Livelink Enterprise Server
Software & Schnittstellen (1/28)
") Software & Schnittstellen Bachelor Informationsmanagement Modul Digitale Bibliothek (SS 2014) Dr Jakob Voß 2014-05-19 Software & Schnittstellen (1/28) CC-BY-SA / 2014-05-19 / Dr Jakob Voß Software Computerprogramm
Software & Schnittstellen Bachelor Informationsmanagement Modul Digitale Bibliothek (SS 2014) Dr Jakob Voß 2014-05-19 Software & Schnittstellen (1/28) CC-BY-SA / 2014-05-19 / Dr Jakob Voß Software Computerprogramm
Preservation Planning im Digitalen Archiv Österreich. Hannes Kulovits
 Preservation Planning im Digitalen Archiv Österreich Hannes Kulovits 11.3.2015 Agenda Preservation Planning/Operations Synchronisation mit AIS Showcase Agenda Preservation Planning/Operations Synchronisation
Preservation Planning im Digitalen Archiv Österreich Hannes Kulovits 11.3.2015 Agenda Preservation Planning/Operations Synchronisation mit AIS Showcase Agenda Preservation Planning/Operations Synchronisation
Neu bei der DOI-Registrierung?
 Neu bei der DOI-Registrierung? Ihr Weg zum DOI! Birte Lindstädt, Kerstin Helbig und Sven Vlaeminck 20. Januar 2015 Bessere Zitierbarkeit und Auffindbarkeit von Forschungsdaten durch DataCite-DOIs DataCite-Workshop
Neu bei der DOI-Registrierung? Ihr Weg zum DOI! Birte Lindstädt, Kerstin Helbig und Sven Vlaeminck 20. Januar 2015 Bessere Zitierbarkeit und Auffindbarkeit von Forschungsdaten durch DataCite-DOIs DataCite-Workshop
Ablieferung von Netzpublikationen an die Deutsche Nationalbibliothek. Maren Brodersen
 Ablieferung von Netzpublikationen an die Deutsche Nationalbibliothek Maren Brodersen Inhaltsverzeichnis Pflichtablieferung - Ablieferung von Netzpublikationen Schnittstellen zur Ablieferung - Problemstellung
Ablieferung von Netzpublikationen an die Deutsche Nationalbibliothek Maren Brodersen Inhaltsverzeichnis Pflichtablieferung - Ablieferung von Netzpublikationen Schnittstellen zur Ablieferung - Problemstellung
Archivierung mit PDF und XPS. Formate, Standards und Prozessabläufe
 Archivierung mit PDF und XPS Formate, Standards und Prozessabläufe Dr. Hans Bärfuss PDF Tools AG Winterthur, 8. Mai 2007 Copyright 2007 PDF Tools AG 1 Inhalt Formate Anforderungen an ein Archivformat Ordnung
Archivierung mit PDF und XPS Formate, Standards und Prozessabläufe Dr. Hans Bärfuss PDF Tools AG Winterthur, 8. Mai 2007 Copyright 2007 PDF Tools AG 1 Inhalt Formate Anforderungen an ein Archivformat Ordnung
Zusammenfassung. 1 Ansprechpartner und Adressen 1
 Zusammenfassung iii 1 Ansprechpartner und Adressen 1 2 Ziele und Nutzen von epub.oeaw 2 2.1 Was ist epub.oeaw?........................... 2 2.2 Nutzen für Autoren........................... 2 2.3 Nutzen
Zusammenfassung iii 1 Ansprechpartner und Adressen 1 2 Ziele und Nutzen von epub.oeaw 2 2.1 Was ist epub.oeaw?........................... 2 2.2 Nutzen für Autoren........................... 2 2.3 Nutzen
RADAR Archivierung und Publikation von Forschungsdaten als Baustein für die NFDI. Matthias Razum, 04. Oktober 2018
 RADAR Archivierung und Publikation von Forschungsdaten als Baustein für die NFDI Matthias Razum, 04. Oktober 2018 RADAR: Forschungsdatenrepositorium als Dienst Gehostete Lösung für: sichere und langfristige
RADAR Archivierung und Publikation von Forschungsdaten als Baustein für die NFDI Matthias Razum, 04. Oktober 2018 RADAR: Forschungsdatenrepositorium als Dienst Gehostete Lösung für: sichere und langfristige
KIM. www.kim-forum.org
 KIM www.kim-forum.org Interoperable Metadatenmodelle und Repositorien Stefanie Rühle Niedersächsische Staats- und Universitätsbibliothek Göttingen Mirjam Keßler Deutsche Nationalbibliothek KIM Ausgangslage
KIM www.kim-forum.org Interoperable Metadatenmodelle und Repositorien Stefanie Rühle Niedersächsische Staats- und Universitätsbibliothek Göttingen Mirjam Keßler Deutsche Nationalbibliothek KIM Ausgangslage
DIGITAL REPOSITORY NIJOLE UKELYTE CHRISTOPHER POLLIN KERSTIN HUMMELBRUNNER
 DIGITAL REPOSITORY NIJOLE UKELYTE CHRISTOPHER POLLIN KERSTIN HUMMELBRUNNER REPOSITORY INTRO Problem der Sichtbarkeit der Repositorien GRÜNDE LÖSUNGSVERSUCHE: OAI, ROAR, OperDOAR REPOSITORY PROBLEM DER
DIGITAL REPOSITORY NIJOLE UKELYTE CHRISTOPHER POLLIN KERSTIN HUMMELBRUNNER REPOSITORY INTRO Problem der Sichtbarkeit der Repositorien GRÜNDE LÖSUNGSVERSUCHE: OAI, ROAR, OperDOAR REPOSITORY PROBLEM DER
Anleitung zur Integration der /data.mill API in SAP Java Applikationen
 Anleitung zur Integration der /data.mill API in SAP Java Applikationen Inhalt 1. Anlage einer HTTP Destination 1 1.1. Anmelden an SAP Cloud Platform 1 1.2. Destination Konfiguration 3 1.3. Eintragen der
Anleitung zur Integration der /data.mill API in SAP Java Applikationen Inhalt 1. Anlage einer HTTP Destination 1 1.1. Anmelden an SAP Cloud Platform 1 1.2. Destination Konfiguration 3 1.3. Eintragen der
MIRACOLIX. Prof. Dr. Martin Sedlmayr MEDICAL INFORMATICS REUSABLE ECO-SYSTEM OF OPEN SOURCE LINKABLE AND INTEROPERABLE SOFTWARE TOOLS X
 MIRACOLIX MEDICAL INFORMATICS REUSABLE ECO-SYSTEM OF OPEN SOURCE LINKABLE AND INTEROPERABLE SOFTWARE TOOLS X Prof. Dr. Martin Sedlmayr Institut für Medizinische Informatik und Biometrie Zentrum für Medizinische
MIRACOLIX MEDICAL INFORMATICS REUSABLE ECO-SYSTEM OF OPEN SOURCE LINKABLE AND INTEROPERABLE SOFTWARE TOOLS X Prof. Dr. Martin Sedlmayr Institut für Medizinische Informatik und Biometrie Zentrum für Medizinische
DOORS Training IBM Rational DOORS StartUp Training - Modul 4
 DOORS Training IBM Rational DOORS StartUp Training - Modul 4 Historie und Baselines Inhalt Modul Historie Objekt Historie Baselines Baseline Sets Welche Möglichkeiten bietet DOORS, wenn Daten sich über
DOORS Training IBM Rational DOORS StartUp Training - Modul 4 Historie und Baselines Inhalt Modul Historie Objekt Historie Baselines Baseline Sets Welche Möglichkeiten bietet DOORS, wenn Daten sich über
Akademisches Lehrmaterial online
 Akademisches Lehrmaterial online Christian Weber cweber@akleon.de Entstanden im Rahmen des DFN-Projekts META-AKAD gefördert mit Mitteln des BMBF Mitwirkende an der TU Kaiserslautern Universitätsbibliothek
Akademisches Lehrmaterial online Christian Weber cweber@akleon.de Entstanden im Rahmen des DFN-Projekts META-AKAD gefördert mit Mitteln des BMBF Mitwirkende an der TU Kaiserslautern Universitätsbibliothek
Open Access Netzwerk
 Osnabrück, 2-4 März 2011 Open Access Netzwerk als Linked (Open) Data Linked Data Definition Standards für Linked Data Maximalziele im OA-Netzwerk Lösungsansätze D2R Server OA-Netzwerk als Linked Open Data:
Osnabrück, 2-4 März 2011 Open Access Netzwerk als Linked (Open) Data Linked Data Definition Standards für Linked Data Maximalziele im OA-Netzwerk Lösungsansätze D2R Server OA-Netzwerk als Linked Open Data:
Beschreibung von E-Learning Angeboten auf der Basis von Dublin Core Metadaten
 Beschreibung von E-Learning Angeboten auf der Basis von Dublin Core Metadaten Prof. Dr. Gerhard Heyer Abt. Automatische Sprachverarbeitung Institut für Informatik Universität Leipzig heyer@informatik.uni-leipzig.de
Beschreibung von E-Learning Angeboten auf der Basis von Dublin Core Metadaten Prof. Dr. Gerhard Heyer Abt. Automatische Sprachverarbeitung Institut für Informatik Universität Leipzig heyer@informatik.uni-leipzig.de
GRDDL, Microformats, RDF/A
 GRDDL, Microformats, RDF/A Daniel Schmitzer Daniel Schmitzer 1 Gliederung Einleitung GRDDL Funktionsweise Anwendungsbeispiel Anwendungen und Tools Microformats Was sind Microformate Beispiel RDF/A Was
GRDDL, Microformats, RDF/A Daniel Schmitzer Daniel Schmitzer 1 Gliederung Einleitung GRDDL Funktionsweise Anwendungsbeispiel Anwendungen und Tools Microformats Was sind Microformate Beispiel RDF/A Was
Namespaces, Application Profiles und Guidelines. Dr. Heike Neuroth Projekt-Management SUB Göttingen
 Niedersächsische Staats- und Universitätsbibliothek Göttingen (SUB) Metadaten: Namespaces, Application Profiles und Guidelines Dr. Heike Neuroth Projekt-Management SUB Göttingen neuroth@mail.sub.uni-goettingen.de
Niedersächsische Staats- und Universitätsbibliothek Göttingen (SUB) Metadaten: Namespaces, Application Profiles und Guidelines Dr. Heike Neuroth Projekt-Management SUB Göttingen neuroth@mail.sub.uni-goettingen.de
Content-Management-Systeme
 Wintersemester 2016/2017 Content-Management-Systeme Dipl.-Inform. Roman Jansen-Winkeln Vorlesung 2: Einführung in PLONE Through-the-Web Inhalt heute Kurzreferate Through the Web Freiwillige vor Nutzung
Wintersemester 2016/2017 Content-Management-Systeme Dipl.-Inform. Roman Jansen-Winkeln Vorlesung 2: Einführung in PLONE Through-the-Web Inhalt heute Kurzreferate Through the Web Freiwillige vor Nutzung
Semantic Technologies
 Semantic Technologies Proseminar Künstliche Intelligenz Universität Ulm Mario Volke 15. Juli 2008 1 / 32 Inhaltsverzeichnis 1 Einführung 2 3 Schlusswort 2 / 32 Einführung Motivation DEMO Who was president
Semantic Technologies Proseminar Künstliche Intelligenz Universität Ulm Mario Volke 15. Juli 2008 1 / 32 Inhaltsverzeichnis 1 Einführung 2 3 Schlusswort 2 / 32 Einführung Motivation DEMO Who was president
BASE ein kooperativer Service im wissenschaftlichen Informationsnetzwerk. Friedrich Summann Universitätsbibliothek Bielefeld
 BASE ein kooperativer Service im wissenschaftlichen Informationsnetzwerk Friedrich Summann Universitätsbibliothek Bielefeld BASE = Bielefeld Academic Search Engine www.base-search.net Spezialsuchmaschine
BASE ein kooperativer Service im wissenschaftlichen Informationsnetzwerk Friedrich Summann Universitätsbibliothek Bielefeld BASE = Bielefeld Academic Search Engine www.base-search.net Spezialsuchmaschine
Vernetzung Institutioneller Repositorien Universität Bielefeld
 Vernetzung Institutioneller Repositorien Universität Bielefeld Najko Jahn Universitätsbibliothek Bielefeld najkojahn@uni-bielefeldde Deutscher Bibliothekartag 24 05 2012 Agenda 1 Hintergrund 2 Vernetzung
Vernetzung Institutioneller Repositorien Universität Bielefeld Najko Jahn Universitätsbibliothek Bielefeld najkojahn@uni-bielefeldde Deutscher Bibliothekartag 24 05 2012 Agenda 1 Hintergrund 2 Vernetzung
Linked Data und Repositorien
 Linked Data und Repositorien Pascal-Nicolas Becker Technische Universität Berlin DINI Jahrestagung Frankfurt, 27.10.2015 If not indicated otherwise content is licensed under CC BY 4.0 Creative Commons
Linked Data und Repositorien Pascal-Nicolas Becker Technische Universität Berlin DINI Jahrestagung Frankfurt, 27.10.2015 If not indicated otherwise content is licensed under CC BY 4.0 Creative Commons
Stand und Planungen im Bereich der Schnittstellen in der VZG
 Stand und Planungen im Bereich der Schnittstellen in der VZG Jakob Voß 28. August 2013, 17. Verbundkonferenz des GBV Schnittstellen Allgemein Patrons Account Information API (PAIA) Strategie und Planungen
Stand und Planungen im Bereich der Schnittstellen in der VZG Jakob Voß 28. August 2013, 17. Verbundkonferenz des GBV Schnittstellen Allgemein Patrons Account Information API (PAIA) Strategie und Planungen
Persistent Identifier
 Archivierung sozial- und wirtschaftswissenschaftlicher Datenbestände Persistent Identifier Nicole von der Hude, Deutsche Nationalbibliothek 1 Gesetzlicher Auftrag der DNB ursprünglich Deutsche Publikationen
Archivierung sozial- und wirtschaftswissenschaftlicher Datenbestände Persistent Identifier Nicole von der Hude, Deutsche Nationalbibliothek 1 Gesetzlicher Auftrag der DNB ursprünglich Deutsche Publikationen
Dipl. Wirtsch.-Ing. Lars Geldner Nürnberg, 22.11.2007
 Dipl. Wirtsch.-Ing. Lars Geldner Nürnberg, 22.11.2007 Projektbericht Entwicklung eines Content Management Systems mit der Oracle 10g XML DB Agenda Projektbezug: EU-Projekt ENN-ICS Anforderungen wiederverwendbare
Dipl. Wirtsch.-Ing. Lars Geldner Nürnberg, 22.11.2007 Projektbericht Entwicklung eines Content Management Systems mit der Oracle 10g XML DB Agenda Projektbezug: EU-Projekt ENN-ICS Anforderungen wiederverwendbare
Raoul Borenius, DFN-AAI-Team
 Technische Übersicht zu Shibboleth 2.0 Funktionalität und Einsatzbereiche am Beispiel der Authentifizierungs- und Autorisierungs-Infrastruktur des Deutschen Forschungsnetzes (DFN-AAI) Raoul Borenius, DFN-AAI-Team
Technische Übersicht zu Shibboleth 2.0 Funktionalität und Einsatzbereiche am Beispiel der Authentifizierungs- und Autorisierungs-Infrastruktur des Deutschen Forschungsnetzes (DFN-AAI) Raoul Borenius, DFN-AAI-Team
DARIAH-DE Collection Registry und DARIAH Collection Description Data Model
 DARIAH-DE Collection Registry und DARIAH Collection Description Data Model Beata Mache, Niedersächsische Staats- und Universitätsbibliothek Göttingen Workshop Bestände zugänglich machen Anforderungen an
DARIAH-DE Collection Registry und DARIAH Collection Description Data Model Beata Mache, Niedersächsische Staats- und Universitätsbibliothek Göttingen Workshop Bestände zugänglich machen Anforderungen an
Archiving LEXUS 3 multimedia lexica
 2/6/202. Hintergrund 2. Lexus 3 SEBASTIAN DRUDE, ANDRÉ MOREIRA, MENZO WINDHOUWER, SHAKILA SHAYAN The Language Archive Max Planck Institute for Psycholinguistics Nijmegen, The Netherlands 202 23 Internetlexikographie
2/6/202. Hintergrund 2. Lexus 3 SEBASTIAN DRUDE, ANDRÉ MOREIRA, MENZO WINDHOUWER, SHAKILA SHAYAN The Language Archive Max Planck Institute for Psycholinguistics Nijmegen, The Netherlands 202 23 Internetlexikographie
Open Archives Initiative und Metadaten. Ting Li Universität Duisburg-Essen Standort Duisburg
 Open Archives Initiative und Metadaten Ting Li Universität Duisburg-ssen Standort Duisburg mailto:li@is.informatik.uni-duisburg.de 1.inleitung der OAI(1) 1.1 Gründe der ntstehung der OAI Bemühungen zum
Open Archives Initiative und Metadaten Ting Li Universität Duisburg-ssen Standort Duisburg mailto:li@is.informatik.uni-duisburg.de 1.inleitung der OAI(1) 1.1 Gründe der ntstehung der OAI Bemühungen zum
Linked Open Data in Musikbibliotheken. am Beispiel des RISM-OPAC. AIBM-Tagung bis in Nürnberg
 Linked Open Data in Musikbibliotheken am Beispiel des RISM-OPAC AIBM-Tagung 23.9. bis 26.9.2014 in Nürnberg Magda Gerritsen, Bayerische Staatsbibliothek Agenda 1. Was ist Linked Open Data (LOD)? 2. LOD
Linked Open Data in Musikbibliotheken am Beispiel des RISM-OPAC AIBM-Tagung 23.9. bis 26.9.2014 in Nürnberg Magda Gerritsen, Bayerische Staatsbibliothek Agenda 1. Was ist Linked Open Data (LOD)? 2. LOD
Persistenz. Ralf Gitzel
 Persistenz Ralf Gitzel ralf_gitzel@hotmail.de 1 Themenübersicht Ralf Gitzel ralf_gitzel@hotmail.de 2 Übersicht Grundkonzepte Entity Beans Meine erste Entity Entity-Manager Lernziele Übungsaufgabe 3 Grundkonzepte
Persistenz Ralf Gitzel ralf_gitzel@hotmail.de 1 Themenübersicht Ralf Gitzel ralf_gitzel@hotmail.de 2 Übersicht Grundkonzepte Entity Beans Meine erste Entity Entity-Manager Lernziele Übungsaufgabe 3 Grundkonzepte
Der DFG-Viewer als nationaler Standard im Spannungsfeld medientypologischer Diversität
 Der DFG-Viewer als nationaler Standard im Spannungsfeld medientypologischer Diversität Einer für alle, alle für einen? Mai 27, 2015 104. Bibliothekartag, Nürnberg Einführung Der DFG-Viewer ist ein Browser-Webdienst
Der DFG-Viewer als nationaler Standard im Spannungsfeld medientypologischer Diversität Einer für alle, alle für einen? Mai 27, 2015 104. Bibliothekartag, Nürnberg Einführung Der DFG-Viewer ist ein Browser-Webdienst
Linked Open Data & Bibliotheken Warum? Was? Wie? FIS Fachtagung, Frankfurt/Main 22. Mai 2012 Adrian Pohl
 Linked Open Data & Bibliotheken Warum? Was? Wie? FIS Fachtagung, Frankfurt/Main 22. Mai 2012 Adrian Pohl 2 3 4 5 Was steckt dahinter? 6 Agenda 1. Warum Linked Open Data? 2. Linked Data
Linked Open Data & Bibliotheken Warum? Was? Wie? FIS Fachtagung, Frankfurt/Main 22. Mai 2012 Adrian Pohl 2 3 4 5 Was steckt dahinter? 6 Agenda 1. Warum Linked Open Data? 2. Linked Data
Einführung in Shibboleth. Raoul Borenius, DFN-AAI-Team
 Einführung in Shibboleth Raoul Borenius, DFN-AAI-Team hotline@aai.dfn.de AAI: Übersicht Zugriff auf geschützte Web-Resourcen und die damit verbundenen Probleme die DFN-Föderation als mögliche Lösung prinzipielle
Einführung in Shibboleth Raoul Borenius, DFN-AAI-Team hotline@aai.dfn.de AAI: Übersicht Zugriff auf geschützte Web-Resourcen und die damit verbundenen Probleme die DFN-Föderation als mögliche Lösung prinzipielle
Einführung in Shibboleth. Raoul Borenius, DFN-AAI-Team
 Einführung in Shibboleth Raoul Borenius, DFN-AAI-Team hotline@aai.dfn.de AAI: Übersicht Zugriff auf geschützte Web-Resourcen und die damit verbundenen Probleme die DFN-Föderation als mögliche Lösung prinzipielle
Einführung in Shibboleth Raoul Borenius, DFN-AAI-Team hotline@aai.dfn.de AAI: Übersicht Zugriff auf geschützte Web-Resourcen und die damit verbundenen Probleme die DFN-Föderation als mögliche Lösung prinzipielle
Uta Ackermann / Dirk Weisbrod (DNB) URN-Service der DNB
 URN-Service der DNB") Uta Ackermann / Dirk Weisbrod (DNB) URN-Service der DNB Inhaltsverzeichnis 1. urn:nbn:de 1. Ursprung und Motivation 2. urn:nbn:de-service als kooperativer Dienst 3. URN an der DNB 4. Andere PI an der DNB
Uta Ackermann / Dirk Weisbrod (DNB) URN-Service der DNB Inhaltsverzeichnis 1. urn:nbn:de 1. Ursprung und Motivation 2. urn:nbn:de-service als kooperativer Dienst 3. URN an der DNB 4. Andere PI an der DNB
VO Sprachtechnologien, Informations- und Wissensmanagement
 , Informations- und Wissensmanagement Zentrum für Translationswissenschaft Rückblick: Definition Digital Humanities Hilfswissenschaft im Spannungsfeld zwischen geisteswissenschaftlichen Fragestellungen,
, Informations- und Wissensmanagement Zentrum für Translationswissenschaft Rückblick: Definition Digital Humanities Hilfswissenschaft im Spannungsfeld zwischen geisteswissenschaftlichen Fragestellungen,
Erläuterungen zu Darstellung des DLQ-Datenportals
 Erläuterungen zu Darstellung des DLQ-Datenportals Definition zum Datenportal Das DLQ-Datenportal (DP) definiert fachliche Schnittstellen für den Datenaustausch zwischen verschiedenen Kommunikationspartnern.
Erläuterungen zu Darstellung des DLQ-Datenportals Definition zum Datenportal Das DLQ-Datenportal (DP) definiert fachliche Schnittstellen für den Datenaustausch zwischen verschiedenen Kommunikationspartnern.
Big Data in den Digital Humanities?
 Big Data in den Digital Humanities? Prof. Dr. Gerhard Heyer Abteilung Automatische Sprachverarbeitung, Universität Leipzig www.scads.de FRAGEN Digital Humanities sind keine klassische Big Data Anwendung.
Big Data in den Digital Humanities? Prof. Dr. Gerhard Heyer Abteilung Automatische Sprachverarbeitung, Universität Leipzig www.scads.de FRAGEN Digital Humanities sind keine klassische Big Data Anwendung.
KRITERIEN FÜR DIE ZERTIFIZIERUNG VON METADATENPROFILEN
 KRITERIEN FÜR DIE ZERTIFIZIERUNG VON METADATENPROFILEN Identifier: http://www.kimforum.org/material/pdf/zertifizierungsrichtlinien_20101503.pdf Title: Kriterien für die Zertifizierung von Metadatenprofilen
KRITERIEN FÜR DIE ZERTIFIZIERUNG VON METADATENPROFILEN Identifier: http://www.kimforum.org/material/pdf/zertifizierungsrichtlinien_20101503.pdf Title: Kriterien für die Zertifizierung von Metadatenprofilen