Kap. 5 Spatial (räumliches) Data Mining
|
|
|
- Lieselotte Glöckner
- vor 6 Jahren
- Abrufe
Transkript


1 Kap. 5 Spatial (räumliches) Data Mining Univ.-Prof. Dr.-Ing. Wolfgang Reinhardt AGIS / Inst. Für Angewandte Informatik (INF4) Universität der Bundeswehr München Wolfgang.Reinhardt@unibw.de
2 Überblick / Ziele Einführung Data Mining / Spatial Data Mining (sp. DM) Clusteranalyse als wesentliche Methode des sp. DM Anwendungsbeispiel Kennen der Methoden / Einschätzung der Anwendbarkeit 2 / 50
3 Data Mining Unter Data Mining ( Daten-Bergbau, Daten- Schürfen ), sinngemäß in einem Datenberg nach wertvollem Wissen suchen, versteht man die systematische Anwendung statistischer (u.a.) Methoden auf einen Datenbestand mit dem Ziel, neue Muster zu erkennen. Hierbei geht es auch um die Verarbeitung sehr großer Datenbestände, wofür effiziente Methoden benötigt werden (Abgeändert nach wikipedia) 3 / 52
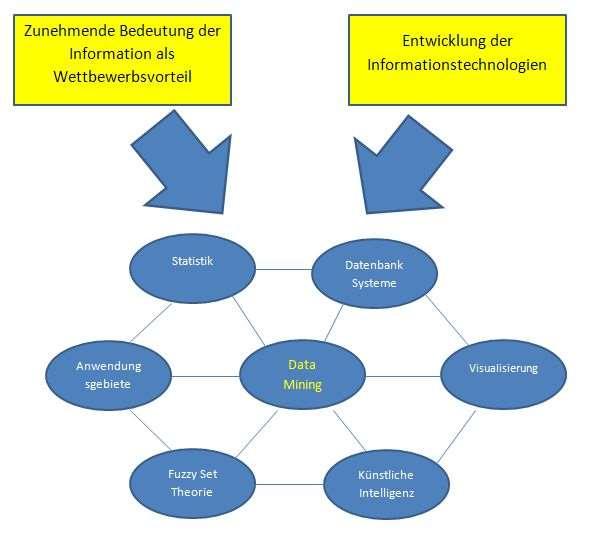
4 Data Mining SRC.: 4 / 52
5 Spatial Data Mining Spatial data mining (auch: KDD - knowledge discovery in spatial databases) Bezieht sich darauf implizit vorhandene Informationen, Beziehungen, räumliche Strukturen etc. in raumbezogenen Datenbeständen zu ermitteln (die nicht explizit gespeichert sind) 5 / 52

6 Spatial Data Mining Das klassische Beispiel Infizierte Wasserpumpe? Dr. John Snow, Untersuchung der Ursachen einer Choleraepidemie London, September 1854 Krankheitshäufung 6 / 52

 Räumliche Beziehung zu")
 Es ist")

7 Lösung durch Räumliche Analyse Räumliche Beziehungen von Objekten einer Art sind dargestellt (Todesfälle) Räumliche Beziehung zu Objekten anderer Arten sind dargestellt (Wasserpumpen) Es ist nicht nur wichtig wo ein Cluster ist sondern auch was sonst dort ist (z.b. Wasserpumpen)! 7 / 52
8 Ziele des Spatial Data Mining Räumliche Cluster erkennen Objekte erkennen, die solche Cluster möglicherweise verursachen Information extrahieren, die für die Erklärung der Cluster relevant ist (und irrelvante Information wegfiltern) Information so präsentieren, daß der Nutzer sein Anwendungswissen in die Analyse einbringen kann 8 / 52

9 Ansatz für Spatial Data Mining Data Mining Geoinformation / Methoden Spatial Data Mining 9 / 52

10 Besonderheiten des Spatial Data Mining Raumbezogene Daten (Raumbezug / weitere Attribute) Räumliche (u.a.) Beziehungen zw. Objekten Geometrische Topologische (vgl. Kap. 3 und 4) Konsequenz: spatial data mining deutlich komplexer als data mining 10 / 52
11 Kurze Einführung, spatial data mining CLUSTERANALYSEN 11 / 52
12 Data Mining Typische Aufgabenstellungen Klassifizierungsanalysen Segmentierungsanalysen Prognoseanalysen (-> Zeit) Abhängigkeitsanalysen Abweichungsanalysen 12 / 52
13 Data Mining Klassifizierung Objekte werden einer vorher bestimmten Klasse zugeordnet Zuordnung findet aufgrund der Parameter und der Klasseneigenschaften statt Anzahl an Klassen i.d.r. bekannt Informationen sind vorab bekannt Segmentierung Objekte werden in Gruppen zusammengefasst, welche vorher nicht bekannt sind Anzahl an Gruppen zu Beginn i.d.r. unbekannt Datenabhängige Einteilung objektiv nachvollziehbar und reproduzierbar 13 / 52
14 Data Mining Das am Häufigsten verwendete Verfahren der Segmentierung ist die Clusteranalyse Definition (Steinhausen und Langer, 1977): Clusteranalyse steht für eine Reihe unterschiedlicher mathematisch-statistischer und heuristischer Verfahren, deren Ziel darin besteht, eine meist umfangreiche Menge von Elementen durch Konstruktion homogener Klassen, Gruppen oder Cluster optimal zu strukturieren. 14 / 52
 oder verstreut")
15 Spatial data mining Bei räumlichen Daten spielt deren Lage zueinander eine große Rolle. -> Clusteranalyse Aber auch die Untersuchung der räumlichen Verteilung - sind Objekte gebündelt (clustered) oder verstreut (dispersed)- ist von Interesse: 15 / 52

16 Räumliche Verteilung von Objekten Einbeziehen des Nutzers Visualisierung Kontext! 16 / 52
17 Räumliche Verteilung von Objekten Frage: Sind die Standorte zufällig verteilt? Kriterium? 17 / 52
18 Räumliche Verteilung von Objekten Frage: Sind die Standorte zufällig verteilt? Abstand / Distanz zum nächsten Nachbarn (und deren Verteilung) Siehe Literatur 18 / 52
19 Räumliche Verteilung von Objekten Weitere Verfahren zur Ermittlung des Grades der räumlichen Verteilung: Verschiedene auf räumliche Autokorrelation beruhende Maße kommen zum Einsatz. Beispiel: Ripley k-function K(t), wird benutzt für: Beschreibung des Musters eines Punkthaufens Hypothesen über die Verteilung des Punkthaufens zu testen Beispiel: Test ob ein Punkthaufen rein zufällig verteilt ist (CSR: Complete spatial randomness), durch K(t) für einen homogenen Poisson Prozess: t Distanz zwischen Punkten 19 / 52
20 Räumliches Verteilung von Objekten Beispiel: Standorte verschiedener Spezies gegeben, sind diese zufällig verteilt? Src.: Answers: and 20 / 52
21 Räumliche Verteilung von Objekten Test der räumlichen Verteilung: Abweichung! K function Abstand t 21 / 52
22 Räumliche Verteilung von Objekten Cluster? Auffinden räumlicher Strukturen -> Clusteranalyse 22 / 52
23 Clusteranalyse Grundidee: Eine heterogene Gesamtheit von Fällen (Personen/Objekte) soll in homogene Gruppen oder Cluster aufgeteilt werden Dabei wird die Ähnlichkeit der Fälle auf allen relevanten Variablen berücksichtigt Zentrale Fragen: Wie wird die Ähnlichkeit von Fällen bestimmt? Welche Parameter werden ausgewählt? Wie wird die Gruppenaufteilung vorgenommen, wenn die Ähnlichkeit zwischen Fällen bekannt ist? 23 / 52
24 Clusteranalyse Objekte innerhalb eines Clusters sollen möglichst ähnlich sein (Homogenität in den Clustern) räumlich: möglichst geringer Abstand der Objekte und ggfs. weiterer Parameter Cluster zueinander sollen möglichst unähnlich sein (Heterogenität zwischen den Clustern), räumlich: möglichst großer Abstand der Cluster) 24 / 52
25 Bestimmung der Ähnlichkeit Quantifizierung der Ähnlichkeiten zwischen den in der Clusteranalyse berücksichtigten Objekten durch eine statistische Maßzahl Ähnlichkeitsmaße Drücken die Ähnlichkeit zwischen zwei Objekten aus Ein großer Wert beschreibt eine hohe Ähnlichkeit Distanzmaße Drücken die Unähnlichkeit zwischen zwei Objekten aus Ein großer Wert beschreibt eine niedrige Ähnlichkeit Bei identischen Objekten ist die Distanz Null Maße: abhängig von Skalen (binär, ordinal, metrisch ) 25 / 52
26 Bestimmung der Ähnlichkeit Hinweis: Clusteranalyse erfordert kein spezielles Skalenniveau (nominal, metrisch ) Thema dieser Vorlesung ist Geoinformatik, daher Konzentration auf metrische Skalen 26 / 52
27 Distanzmaße Werden hauptsächlich bei quantitativen Parametern verwendet (metrische Skalen) Die am häufigsten verwendeten basieren auf der Minkowski-Metrik r = 1 City-Block-Metrik r = 2 Euklidische Distanz 27 / 52
28 Ablauf der Clusteranalyse Analyse und Präzisierung der Fragestellung Auswahl der Parameter, Aufstellen der Matrix Modifikation, Korrektur Bestimmung der Ähnlichkeit Bestimmung der Clusteranzahl Auswahl des Algorithmus Durchführung Analyse/Bewertung der Ergebnisse 28 / 52
29 Auswahl der Parameter Clusteranalyse erfordert kein spezielles Skalenniveau (nominal, metrisch ) Wahl der Parameter muss dem Ziel der Analyse gerecht werden, beachten: Wahl von zu vielen Parametern viele Cluster, die sich weiter zusammenfassen ließen Wahl von zu wenigen Parametern wenige Cluster, die sich weiter ausdifferenzieren ließen Gute Auswahl der Parameter = einfaches und leicht verständliches Clusterergebnis Schlechte Auswahl der Parameter = komplexes Clusterergebnis, dessen wahre Struktur oft schwierig oder unmöglich zu erkennen ist 29 / 52
30 Auswahl der Parameter 2 räumliche Beispiele Beispiel 1, gegeben n Standorte (Punkte) Gesucht (Fragestellung): K Cluster von benachbarten Standorten -> univariate Clusteranalyse (u CA) Beispiel 2, gegeben n Vektoren Gesucht (Fragestellung): Cluster von Vektoren mit ähnlicher Richtung und Länge, die benachbart sind -> multivariate Clusteranalyse (m CA) U CA rel. einfach, Betrachtung m CA im weiteren 30 / 52
31 Aufstellen der Rohdatenmatrix (m CA) Parameter Aufstellen der Rohdatenmatrix (Beispiel) Objekte Parameter Vektor Vektor 1 Vektor 1 Vektor 2 Vektor 2 Vektor Vektor Vektor n n X [m] 1, ,7211, ,0351,673245, ,098 1,604 Geeignete Normierung der Werte! Z ij X ij S i X i Y [m] 0, ,2720, ,2721,923562, ,249-0,065 Länge [m] 1,499 20,883 1,499 20,883 1,49920, ,8040,315 Richtung [ ] -2, ,137-2, ,137-2, , ,832-0, / 52
32 Normierung 32 / 52
33 Gruppenbildung: Methoden der Clusteranalyse Cluster-Algorithmen Partitionierend Hierarchisch K-means Minimal Spanning Tree Single Linkage Complete Linkage s. z.b. Malczewski, J., 2006: GIS-based multicriteria decision analysis: a survey of the literature, IJGIS (20), S / 52
34 Partitionierende Clustermethoden Gehen von einer gegebenen Startgruppierung aus Die Startgruppierung muss vom Nutzer geschätzt werden Alle Objekte werden zu Beginn einem Cluster zugeordnet Prominentes Beispiel: K-Means 1. Festlegung von K Cluster-Mittelpunkten. 2. Zuordnen der Werte zu dem am nächsten liegenden Mittelpunkt. 3. Neuberechnung der Cluster-Mittelpunkte. 4. Prüfen, ob das Konvergenz-Kriterium, welches zu Beginn festgelegt wurde, erfüllt ist. 34 / 52
35 Methoden der Clusteranalyse k-means Festzulegende Parameter: Anzahl Cluster = 3 Gewählte Mittelpunke: P9, P84, P106 (aus den geg. Punkten) 35 / 52
36 Methoden der Clusteranalyse k-means P7 P8 P9 P81 P82 P84 P106 P107 M1= K106 34,85 21,36 28,58 13,67 8,06 24,36 0 6,77 M2 = K9 32,89 0,85 0 3,17 12,05 1,62 28,52 19,17 M3 = K84 42,57 2,66 1,62 1,81 6, ,36 21,07 Berechnete Distanzwerte der Punkte zu den Anfangs gewählten Mittelpunkten Hinweis: Die Distanzwerte der Punkte (Ki) sind aus den versch. Parametern (s. Folie 29) berechnet 36 / 52
37 Methoden der Clusteranalyse k-means Iterative Berechnung neuer Mittelpunkte Neue Zuordnung der Punkte zu clustern 37 / 52
38 Methoden der Clusteranalyse k-means Ergebnis hängt sehr stark von der Wahl der Anfangs- Cluster-Mittelpunkte ab Ergebnis bei Wahl von anderen Anfangsmittelpunkten! Quelle: M. Reus (2010), Diplomarbeit (unveröffentlicht) Weiteres und Anwendungsbeispiel: Nuhn, Eva; Kropat, E.; Reinhardt, Wolfgang; Pickl, S. (2012): Preparation of Complex Landslide Simulation Results with Clustering Approaches for Decision Support and Early Warning. hicss, pp , th Hawaii International Conference on System 38 / 52 Sciences.
39 Methoden der Clusteranalyse - hierarchisch Hierarchisches Vorgehen, keine Vorabwahl der Anzahl der Cluster Erstellen einer Ähnlichkeits-Matrix mit den Abständen der einzelnen Cluster zueinander (zu Beginn ist jeder Punkt ein cluster) Zusammenfassen der Cluster nach geg. Kriterien (s.u) Update der Ähnlichkeits-Matrix Iteration bis Abbruch-Kriterium erfüllt ist A B C D A 0 B 1 0 C D Geringster Abstand A/B C D A/B 0 C 5 0 D Ähnlichkeitsmatrix zu Beginn (li) und nach 1.Fusion (re) 39 / 52
 / Complete Linkage (CL) http://de.wikipedia.")


40 Methoden der Clusteranalyse - hierarchisch Single Linkage (SL) / Complete Linkage (CL) Dendrogramm für single-linkage Kriterium für Fusionen: Sl: Minimaler Abstand aller Elementpaare aus den beiden Clustern Cl: Maximaler Abstand aller Elementpaare aus den beiden Clustern 40 / 52
41 Methoden der Clusteranalyse - hierarchisch Vorteil für Single Linkage / complete linkage: - keine Vorabwahl der Anzahl der Cluster Single Linkage kann zu Längliche, kettenförmige Cluster führen Vorteil für complete linkage: Eher kompakte Cluster 41 / 52
42 Kurze Einführung, spatial data mining ANWENDUNGSBEISPIEL 42 / 52

43 Forschungsprojekt EGIFF Motivation Verbundprojekt EGIFF ( Geotechnologien, BMBF/DFG) Testgebiet Teilprojekt: Entwicklung eines gekoppelten Simulations- und Informationssystems Aufbereitung, Analyse und Visualisierung der komplexen Simulationsergebnisse mit Hilfe von Spatial Data Mining Methoden 43 / 52


44 Bruchentwicklung im SIMS 44 / 52
45 Ergebnis: Verschiebungen der Knoten 45 / 52



46 Simulationsergebnisse FE-Netz Clusterbildung Verschiebungsvektoren (Sehr große Datenmenge, Millionen von Vektoren) 46 / 52
47 Aufbereitung der Simulationsergebnisse Segmentierung der Verformungsbereiche: Methoden der Clusteranalyse Bestimmung des Rutschkörpers Simulationsergebnisse für den Rutschkörper 47 / 52
48 Methoden der Clusteranalyse Analyse und Präzisierung der Fragestellung Auswahl der Elemente und Variablen Wahl eines Proximitätsmaßes Bestimmung des Algorithmus Bestimmung der Clusteranzahl Technische Durchführung Analyse der Ergebnisse 2D: - Lage - Richtung - Länge 3D: - Ähnlichkeitsmaße - Lage - Distanzmaße - Azimuth, Inklination - Länge Z ij SF / CF Standardisierung: X ij S i X i d ( a 1 b )² ( a 1 2 b )²... ( a 2 n b n )² ( X 1 X 2 )² ( Y 1 Y )² ( L 2 1 L )² ( R 2 1 R 2 )² 48 / 52
49 Anwendung Clusteranalyse Analyse und Präzisierung der Fragestellung Auswahl der Elemente und Variablen Wahl eines Proximitätsmaßes Bestimmung des Algorithmus Bestimmung der Clusteranzahl Technische Durchführung Analyse der Ergebnisse - Subjektive Methoden - Objektive Methoden Stopping Rule von Mojena 49 / 52
 Einfluss der Lage zu groß!")
² ( L 2 1 n b )² L )² ( R 2 n 1 R )² 2 ->")
50 Anwendung Clusteranalyse d Multivariate Clusteranalyse (X,Y,L,R) Einfluss der Lage zu groß! ( a ( X 1 1 b )² ( a 1 X )² ( Y b )²... ( a 2 Y )² ( L 2 1 n b )² L )² ( R 2 n 1 R )² 2 -> einige Tests erforderlich, -> Heuristik 50 / 52
² ( R 2 1 1 2 b )²... ( a 2 R )² 2 n b )² n Bivariate Clusteranalyse nach Länge und Richtung Nachbarschaftsbetrachtung 51 / 52")
51 Anwendung Clusteranalyse Bivariate Clusteranalyse mit Nachbarschaftsbetrachtung (nicht verbundene Clusterteile) d ( a ( L 1 1 b )² ( a L )² ( R b )²... ( a 2 R )² 2 n b )² n Bivariate Clusteranalyse nach Länge und Richtung Nachbarschaftsbetrachtung 51 / 52

52 Grundlage für Decision Support 52 / 52
53 Clusteranalysen Sehr gute Möglichkeit Daten aufzubereiten, verständlich zu machen, zusätzliche Information zu generieren etc. Allerdings erfordert der Einsatz viel Verständnis der Anwendung Lösung meist iterativ zu erarbeiten 53 / 52

54 Vielen Dank für die Aufmerksamkeit! Weitere Fragen? 54 / 52
Geoinformatik Kapitel 6 Ausgewählte GeoInf-Algorithmen
 Geoinformatik Kapitel 6 Ausgewählte GeoInf-Algorithmen Univ.-Prof. Dr.-Ing. Wolfgang Reinhardt AGIS / Inst. Für Angewandte Informatik (INF4) Universität der Bundeswehr München Wolfgang.Reinhardt@unibw.de
Geoinformatik Kapitel 6 Ausgewählte GeoInf-Algorithmen Univ.-Prof. Dr.-Ing. Wolfgang Reinhardt AGIS / Inst. Für Angewandte Informatik (INF4) Universität der Bundeswehr München Wolfgang.Reinhardt@unibw.de
4.Tutorium Multivariate Verfahren
 4.Tutorium Multivariate Verfahren - Clusteranalyse - Hannah Busen: 01.06.2015 und 08.06.2015 Nicole Schüller: 02.06.2015 und 09.06.2015 Institut für Statistik, LMU München 1 / 17 Gliederung 1 Idee der
4.Tutorium Multivariate Verfahren - Clusteranalyse - Hannah Busen: 01.06.2015 und 08.06.2015 Nicole Schüller: 02.06.2015 und 09.06.2015 Institut für Statistik, LMU München 1 / 17 Gliederung 1 Idee der
VII Unüberwachte Data-Mining-Verfahren
 VII Unüberwachte Data-Mining-Verfahren Clusteranalyse Assoziationsregeln Generalisierte Assoziationsregeln mit Taxonomien Formale Begriffsanalyse Self Organizing Maps Institut AIFB, 00. Alle Rechte vorbehalten.
VII Unüberwachte Data-Mining-Verfahren Clusteranalyse Assoziationsregeln Generalisierte Assoziationsregeln mit Taxonomien Formale Begriffsanalyse Self Organizing Maps Institut AIFB, 00. Alle Rechte vorbehalten.
Strukturerkennende Verfahren
 Strukturerkennende Verfahren Viele Verfahren der multivariaten Datenanalyse dienen dazu, die in den Daten vorliegenden Strukturen zu erkennen und zu beschreiben. Dabei kann es sich um Strukturen sehr allgemeiner
Strukturerkennende Verfahren Viele Verfahren der multivariaten Datenanalyse dienen dazu, die in den Daten vorliegenden Strukturen zu erkennen und zu beschreiben. Dabei kann es sich um Strukturen sehr allgemeiner
5. Clusteranalyse Vorbemerkungen. 5. Clusteranalyse. Grundlegende Algorithmen der Clusteranalyse kennen, ihre Eigenschaften
 5. Clusteranalyse Vorbemerkungen 5. Clusteranalyse Lernziele: Grundlegende Algorithmen der Clusteranalyse kennen, ihre Eigenschaften benennen und anwenden können, einen Test auf das Vorhandensein einer
5. Clusteranalyse Vorbemerkungen 5. Clusteranalyse Lernziele: Grundlegende Algorithmen der Clusteranalyse kennen, ihre Eigenschaften benennen und anwenden können, einen Test auf das Vorhandensein einer
5. Clusteranalyse. Lernziele: Grundlegende Algorithmen der Clusteranalyse kennen, ihre Eigenschaften
 5. Clusteranalyse Lernziele: Grundlegende Algorithmen der Clusteranalyse kennen, ihre Eigenschaften benennen und anwenden können, einen Test auf das Vorhandensein einer Clusterstruktur kennen, verschiedene
5. Clusteranalyse Lernziele: Grundlegende Algorithmen der Clusteranalyse kennen, ihre Eigenschaften benennen und anwenden können, einen Test auf das Vorhandensein einer Clusterstruktur kennen, verschiedene
Multivariate Verfahren
 Multivariate Verfahren Lineare Regression Zweck: Vorhersage x Dimensionsreduktion x x Klassifizierung x x Hauptkomponentenanalyse Korrespondenzanalyse Clusteranalyse Diskriminanzanalyse Eigenschaften:
Multivariate Verfahren Lineare Regression Zweck: Vorhersage x Dimensionsreduktion x x Klassifizierung x x Hauptkomponentenanalyse Korrespondenzanalyse Clusteranalyse Diskriminanzanalyse Eigenschaften:
Clusteranalyse. Anwendungsorientierte Einführung. R. Oldenbourg Verlag München Wien. Von Dr. Johann Bacher
 Clusteranalyse Anwendungsorientierte Einführung Von Dr. Johann Bacher R. Oldenbourg Verlag München Wien INHALTSVERZEICHNIS Vorwort XI 1 Einleitung 1 1.1 Primäre Zielsetzung clusteranalytischer Verfahren
Clusteranalyse Anwendungsorientierte Einführung Von Dr. Johann Bacher R. Oldenbourg Verlag München Wien INHALTSVERZEICHNIS Vorwort XI 1 Einleitung 1 1.1 Primäre Zielsetzung clusteranalytischer Verfahren
Clustering 2010/06/11 Sebastian Koch 1
 Clustering 2010/06/11 1 Motivation Quelle: http://www.ha-w.de/media/schulung01.jpg 2010/06/11 2 Was ist Clustering Idee: Gruppierung von Objekten so, dass: Innerhalb einer Gruppe sollen die Objekte möglichst
Clustering 2010/06/11 1 Motivation Quelle: http://www.ha-w.de/media/schulung01.jpg 2010/06/11 2 Was ist Clustering Idee: Gruppierung von Objekten so, dass: Innerhalb einer Gruppe sollen die Objekte möglichst
Dr. Ralf Gutfleisch, Stadt Frankfurt a.m.
 Zentrale Fragestellungen: Was Wie Wann ist eine Clusteranalyse? wird eine Clusteranalyse angewendet? wird eine Clusteranalyse angewendet? Clusteranalyse = Gruppenbildungsverfahren = eine Vielzahl von Objekten
Zentrale Fragestellungen: Was Wie Wann ist eine Clusteranalyse? wird eine Clusteranalyse angewendet? wird eine Clusteranalyse angewendet? Clusteranalyse = Gruppenbildungsverfahren = eine Vielzahl von Objekten
Mathematisch-Statistische Verfahren des Risiko-Managements - SS
 Clusteranalyse Mathematisch-Statistische Verfahren des Risiko-Managements - SS 2004 Allgemeine Beschreibung (I) Der Begriff Clusteranalyse wird vielfach als Sammelname für eine Reihe mathematisch-statistischer
Clusteranalyse Mathematisch-Statistische Verfahren des Risiko-Managements - SS 2004 Allgemeine Beschreibung (I) Der Begriff Clusteranalyse wird vielfach als Sammelname für eine Reihe mathematisch-statistischer
Ähnlichkeits- und Distanzmaße
 Ähnlichkeits- und Distanzmaße Jörg Rahnenführer, Multivariate Verfahren, WS89, TU Dortmund 11.1.8-1 - Ähnlichkeits- und Distanzmaße Jörg Rahnenführer, Multivariate Verfahren, WS89, TU Dortmund 11.1.8 -
Ähnlichkeits- und Distanzmaße Jörg Rahnenführer, Multivariate Verfahren, WS89, TU Dortmund 11.1.8-1 - Ähnlichkeits- und Distanzmaße Jörg Rahnenführer, Multivariate Verfahren, WS89, TU Dortmund 11.1.8 -
Inhalt. 1 Unvollständige Clusteranalyseverfahren 35
 Inhalt i Einleitung 15 1.1 Zielsetzung clusteranalytischer Verfahren 15 1.2 Homogenität als Grundprinzip der Bildung von Clustern 16 1.3 Clusteranalyseverfahren 18 1.4 Grundlage der Clusterbildung 20 1.5
Inhalt i Einleitung 15 1.1 Zielsetzung clusteranalytischer Verfahren 15 1.2 Homogenität als Grundprinzip der Bildung von Clustern 16 1.3 Clusteranalyseverfahren 18 1.4 Grundlage der Clusterbildung 20 1.5
Mathematische Grundlagen III
 Mathematische Grundlagen III Maschinelles Lernen III: Clustering Vera Demberg Universität des Saarlandes 7. Juli 202 Vera Demberg (UdS) Mathe III 7. Juli 202 / 35 Clustering vs. Klassifikation In den letzten
Mathematische Grundlagen III Maschinelles Lernen III: Clustering Vera Demberg Universität des Saarlandes 7. Juli 202 Vera Demberg (UdS) Mathe III 7. Juli 202 / 35 Clustering vs. Klassifikation In den letzten
Statistik IV für Studenten mit dem Nebenfach Statistik Lösungen zu Blatt 9 Gerhard Tutz, Jan Ulbricht SS 07
 Statistik IV für Studenten mit dem Nebenfach Statistik Lösungen zu Blatt 9 Gerhard Tutz, Jan Ulbricht SS 07 Ziel der Clusteranalyse: Bilde Gruppen (cluster) aus einer Menge multivariater Datenobjekte (stat
Statistik IV für Studenten mit dem Nebenfach Statistik Lösungen zu Blatt 9 Gerhard Tutz, Jan Ulbricht SS 07 Ziel der Clusteranalyse: Bilde Gruppen (cluster) aus einer Menge multivariater Datenobjekte (stat
VII Unüberwachte Data-Mining-Verfahren. VII Unüberwachte Data-Mining-Verfahren
 VII Unüberwachte Data-Mg-Verfahren VII Unüberwachte Data-Mg-Verfahren Clusteranalyse Assoziationsregeln Generalisierte Assoziationsregeln mit Taxonomien Formale Begriffsanalyse Self Organizg Maps Institut
VII Unüberwachte Data-Mg-Verfahren VII Unüberwachte Data-Mg-Verfahren Clusteranalyse Assoziationsregeln Generalisierte Assoziationsregeln mit Taxonomien Formale Begriffsanalyse Self Organizg Maps Institut
Clusteranalyse. Florian Löwenstein. Clusteranalyse eoda GmbH
 Florian Löwenstein www.eoda.de 1 Übersicht Hypothesenfreies Verfahren Gehört zur Familie der Data-Mining-Techniken Ganze Verfahrensfamilie Ziel: Informationsreduktion und damit verbunden Abstraktion Typische
Florian Löwenstein www.eoda.de 1 Übersicht Hypothesenfreies Verfahren Gehört zur Familie der Data-Mining-Techniken Ganze Verfahrensfamilie Ziel: Informationsreduktion und damit verbunden Abstraktion Typische
4 Clusteranalyse 4.1 Einführung
 Clusteranalyse.0.0 - - Clusteranalyse. Einführung p Merkmale: X, X,..., X p (metrisch; auch ordinal möglich, falls geeignet nummeriert; nominalskaliert?!) Zu den Merkmalen werden n Datensätze bzw. Datenobjekte
Clusteranalyse.0.0 - - Clusteranalyse. Einführung p Merkmale: X, X,..., X p (metrisch; auch ordinal möglich, falls geeignet nummeriert; nominalskaliert?!) Zu den Merkmalen werden n Datensätze bzw. Datenobjekte
Lernmodul 2 Modelle des Raumes
 Folie 1 von 21 Lernmodul 2 Modelle des Raumes Bildnachweis: www. tagesschau.de Folie 2 von 21 Modelle des Raumes Übersicht Motivation Was ist Raum? Formalismus und Invarianz Metrischer Raum/Euklidischer
Folie 1 von 21 Lernmodul 2 Modelle des Raumes Bildnachweis: www. tagesschau.de Folie 2 von 21 Modelle des Raumes Übersicht Motivation Was ist Raum? Formalismus und Invarianz Metrischer Raum/Euklidischer
Lösungen zu den Aufgaben zur Multivariaten Statistik Teil 4: Aufgaben zur Clusteranalyse
 Prof. Dr. Reinhold Kosfeld Fachbereich Wirtschaftswissenschaften Universität Kassel Lösungen zu den Aufgaben zur Multivariaten Statistik Teil 4: Aufgaben zur Clusteranalyse 1. Erläutern Sie, wie das Konstrukt
Prof. Dr. Reinhold Kosfeld Fachbereich Wirtschaftswissenschaften Universität Kassel Lösungen zu den Aufgaben zur Multivariaten Statistik Teil 4: Aufgaben zur Clusteranalyse 1. Erläutern Sie, wie das Konstrukt
Ziel: Unterteilung beobachteter Objekte in homogene Gruppen. Vorab meist weder Anzahl noch Charakteristika der Gruppen bekannt.
 8 Clusteranalyse Ziel: Unterteilung beobachteter Objekte in homogene Gruppen. Vorab meist weder Anzahl noch Charakteristika der Gruppen bekannt. Anwendungsbeispiele: Mikrobiologie: Ermittlung der Verwandtschaft
8 Clusteranalyse Ziel: Unterteilung beobachteter Objekte in homogene Gruppen. Vorab meist weder Anzahl noch Charakteristika der Gruppen bekannt. Anwendungsbeispiele: Mikrobiologie: Ermittlung der Verwandtschaft
Entscheidungen bei der Durchführung einer Cluster-Analyse
 7712Clusterverfahren Entscheidungen bei der Durchführung einer Cluster-Analyse nach: Eckes, Thomas, und Helmut Roßbach, 1980: Clusteranalysen; Stuttgart:Kohlhammer A. Auswahl der Merkmale Festlegung des
7712Clusterverfahren Entscheidungen bei der Durchführung einer Cluster-Analyse nach: Eckes, Thomas, und Helmut Roßbach, 1980: Clusteranalysen; Stuttgart:Kohlhammer A. Auswahl der Merkmale Festlegung des
Kapitel ML: X (Fortsetzung)
") Kapitel ML: X (Fortsetzung) X. Clusteranalyse Einordnung Data Mining Einführung in die Clusteranalyse Hierarchische Verfahren Iterative Verfahren Dichtebasierte Verfahren Cluster-Evaluierung ML: X-31 Cluster
Kapitel ML: X (Fortsetzung) X. Clusteranalyse Einordnung Data Mining Einführung in die Clusteranalyse Hierarchische Verfahren Iterative Verfahren Dichtebasierte Verfahren Cluster-Evaluierung ML: X-31 Cluster
Clusteranalyse und Display-Methoden
 Ziel: Erkennen von Strukturen in Daten Vergleich der Algorithmen für die Clusteranalyse Beurteilung verschiedener Displaymethoden Stabilitätsdiagramme Betreuer: Dipl.-Chem. Stefan Hesse IAAC, Lehrbereich
Ziel: Erkennen von Strukturen in Daten Vergleich der Algorithmen für die Clusteranalyse Beurteilung verschiedener Displaymethoden Stabilitätsdiagramme Betreuer: Dipl.-Chem. Stefan Hesse IAAC, Lehrbereich
... Text Clustern. Clustern. Einführung Clustern. Einführung Clustern
 Clustern Tet Clustern Teile nicht kategorisierte Beispiele in disjunkte Untermengen, so genannte Cluster, ein, so daß: Beispiele innerhalb eines Clusters sich sehr ähnlich Beispiele in verschiedenen Clustern
Clustern Tet Clustern Teile nicht kategorisierte Beispiele in disjunkte Untermengen, so genannte Cluster, ein, so daß: Beispiele innerhalb eines Clusters sich sehr ähnlich Beispiele in verschiedenen Clustern
Konzepte II. Netzwerkanalyse für Politikwissenschaftler
 Konzepte II Netzwerkanalyse für Politikwissenschaftler Wiederholung Räumliche Distanzen und MDS Hauptkomponenten Neuere Entwicklungen Netzwerkanalyse für Politikwissenschaftler Konzepte II (1/20) Worum
Konzepte II Netzwerkanalyse für Politikwissenschaftler Wiederholung Räumliche Distanzen und MDS Hauptkomponenten Neuere Entwicklungen Netzwerkanalyse für Politikwissenschaftler Konzepte II (1/20) Worum
Projektgruppe. Clustering und Fingerprinting zur Erkennung von Ähnlichkeiten
 Projektgruppe Jennifer Post Clustering und Fingerprinting zur Erkennung von Ähnlichkeiten 2. Juni 2010 Motivation Immer mehr Internet-Seiten Immer mehr digitale Texte Viele Inhalte ähnlich oder gleich
Projektgruppe Jennifer Post Clustering und Fingerprinting zur Erkennung von Ähnlichkeiten 2. Juni 2010 Motivation Immer mehr Internet-Seiten Immer mehr digitale Texte Viele Inhalte ähnlich oder gleich
6. Multivariate Verfahren Zufallszahlen
 4. Zufallszahlen 6. Multivariate Verfahren Zufallszahlen - werden nach einem determinist. Algorithmus erzeugt Pseudozufallszahlen - wirken wie zufäll. Zahlen (sollen sie jedenfalls) Algorithmus: Startwert
4. Zufallszahlen 6. Multivariate Verfahren Zufallszahlen - werden nach einem determinist. Algorithmus erzeugt Pseudozufallszahlen - wirken wie zufäll. Zahlen (sollen sie jedenfalls) Algorithmus: Startwert
Clustern: Voraussetzungen
 Clustering Gruppen (Cluster) ähnlicher Elemente bilden Elemente in einem Cluster sollen sich möglichst ähnlich sein, u. den Elementen in anderen Clustern möglichst unähnlich im Gegensatz zu Kategorisierung
Clustering Gruppen (Cluster) ähnlicher Elemente bilden Elemente in einem Cluster sollen sich möglichst ähnlich sein, u. den Elementen in anderen Clustern möglichst unähnlich im Gegensatz zu Kategorisierung
Produktgruppen als mögliche Hilfe für die Auswahl zutreffender CE-Richtlinien
 Produktgruppen als mögliche Hilfe für die Auswahl zutreffender CE-Richtlinien Langenbach, J. Für jedes neue Produkt, welches in Europa auf den Markt gebracht wird, muss die CE-Zertifizierung beachtet werden.
Produktgruppen als mögliche Hilfe für die Auswahl zutreffender CE-Richtlinien Langenbach, J. Für jedes neue Produkt, welches in Europa auf den Markt gebracht wird, muss die CE-Zertifizierung beachtet werden.
Clusteranalyse. Gliederung. 1. Einführung 2. Vorgehensweise. 3. Anwendungshinweise 4. Abgrenzung zu Faktorenanalyse 5. Fallbeispiel & SPSS
 Clusteranalyse Seminar Multivariate Verfahren SS 2010 Seminarleiter: Dr. Thomas Schäfer Theresia Montag, Claudia Wendschuh & Anne Brantl Gliederung 1. Einführung 2. Vorgehensweise 1. Bestimmung der 2.
Clusteranalyse Seminar Multivariate Verfahren SS 2010 Seminarleiter: Dr. Thomas Schäfer Theresia Montag, Claudia Wendschuh & Anne Brantl Gliederung 1. Einführung 2. Vorgehensweise 1. Bestimmung der 2.
Konzepte II. Netzwerkanalyse für Politikwissenschaftler. Wiederholung
 Konzepte II Netzwerkanalyse für Politikwissenschaftler Netzwerkanalyse für Politikwissenschaftler Konzepte II (1/20) Worum geht es? Bisher: Eigenschaften einzelner Punkte bzw. des Netzwerkes Definiert
Konzepte II Netzwerkanalyse für Politikwissenschaftler Netzwerkanalyse für Politikwissenschaftler Konzepte II (1/20) Worum geht es? Bisher: Eigenschaften einzelner Punkte bzw. des Netzwerkes Definiert
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Clusteranalyse. Tobias Scheffer Thomas Vanck
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Data Mining auf Datenströmen Andreas M. Weiner
 Technische Universität Kaiserslautern Fachbereich Informatik Lehrgebiet Datenverwaltungssysteme Integriertes Seminar Datenbanken und Informationssysteme Sommersemester 2005 Thema: Data Streams Andreas
Technische Universität Kaiserslautern Fachbereich Informatik Lehrgebiet Datenverwaltungssysteme Integriertes Seminar Datenbanken und Informationssysteme Sommersemester 2005 Thema: Data Streams Andreas
Forschungsmethodik II, SS 2010
 Forschungsmethodik II, SS 2010 Michael Kickmeier-Rust Teil 5, 26. Mai 2010 Prinzipien statistischer Verfahren: Conclusio 1 Prinzipien statistischer Verfahren > χ 2 Beispiel: 4-Felder χ 2 Beobachtet: Erwartet:
Forschungsmethodik II, SS 2010 Michael Kickmeier-Rust Teil 5, 26. Mai 2010 Prinzipien statistischer Verfahren: Conclusio 1 Prinzipien statistischer Verfahren > χ 2 Beispiel: 4-Felder χ 2 Beobachtet: Erwartet:
Einführung Clusteranalyse PostgreSQL Geo Web Services OpenLayers
 Einführung Clusteranalyse PostgreSQL Geo Web Services OpenLayers Dipl.- Ing. Eva Nuhn Dipl.- Geogr. Stephan Schmid Dipl.- Ing (FH) Steffen Schwarz Arbeitsgemeinschaft GIS Universität der Bundeswehr München
Einführung Clusteranalyse PostgreSQL Geo Web Services OpenLayers Dipl.- Ing. Eva Nuhn Dipl.- Geogr. Stephan Schmid Dipl.- Ing (FH) Steffen Schwarz Arbeitsgemeinschaft GIS Universität der Bundeswehr München
x x x x Repräsentation von Lösungen (2) Repräsentation von Lösungen (1)
 Repräsentation von Lösungen (1)") Repräsentation von Lösungen () Repräsentation von Lösungen () Kontinuierliche Optimierung: x x x x n Binäre Optimierung: n = (,,, ) R x = ( x, x,, x ) {0,} n n Lokale Suche: x i = x i + ε Lokale Suche:
Repräsentation von Lösungen () Repräsentation von Lösungen () Kontinuierliche Optimierung: x x x x n Binäre Optimierung: n = (,,, ) R x = ( x, x,, x ) {0,} n n Lokale Suche: x i = x i + ε Lokale Suche:
Clustering. Clustering:
 Clustering Clustering: Gruppierung und Einteilung einer Datenmenge nach ähnlichen Merkmalen Unüberwachte Klassifizierung (Neuronale Netze- Terminologie) Distanzkriterium: Ein Datenvektor ist zu anderen
Clustering Clustering: Gruppierung und Einteilung einer Datenmenge nach ähnlichen Merkmalen Unüberwachte Klassifizierung (Neuronale Netze- Terminologie) Distanzkriterium: Ein Datenvektor ist zu anderen
GIS-Analysen - Analyseverfahren. Prof. Dr.-Ing. Wolfgang Reinhardt. Universität der Bundeswehr München
 GIS 3 Kapitel 2: GIS - Analysen Prof. Dr.-Ing. Wolfgang Reinhardt Arbeitsgemeinschaft GIS Universität der Bundeswehr München Wolfgang.Reinhardt@unibw.de www.agis.unibw.de GIS-Analysen - - Motivation -
GIS 3 Kapitel 2: GIS - Analysen Prof. Dr.-Ing. Wolfgang Reinhardt Arbeitsgemeinschaft GIS Universität der Bundeswehr München Wolfgang.Reinhardt@unibw.de www.agis.unibw.de GIS-Analysen - - Motivation -
4.4 Hierarchische Clusteranalyse-Verfahren
 Clusteranalyse 18.05.04-1 - 4.4 Hierarchische Clusteranalyse-Verfahren Ablauf von hierarchischen Clusteranalyse-Verfahren: (1) Start jedes Objekt sein eigenes Cluster, also Start mit n Clustern (2) Fusionierung
Clusteranalyse 18.05.04-1 - 4.4 Hierarchische Clusteranalyse-Verfahren Ablauf von hierarchischen Clusteranalyse-Verfahren: (1) Start jedes Objekt sein eigenes Cluster, also Start mit n Clustern (2) Fusionierung
Unüberwachtes Lernen: Clusteranalyse und Assoziationsregeln
 Unüberwachtes Lernen: Clusteranalyse und Assoziationsregeln Praktikum: Data Warehousing und Data Mining Clusteranalyse Clusteranalyse Idee Bestimmung von Gruppen ähnlicher Tupel in multidimensionalen Datensätzen.
Unüberwachtes Lernen: Clusteranalyse und Assoziationsregeln Praktikum: Data Warehousing und Data Mining Clusteranalyse Clusteranalyse Idee Bestimmung von Gruppen ähnlicher Tupel in multidimensionalen Datensätzen.
Repräsentation von Lösungen (1)
") Repräsentation von Lösungen (1) Kontinuierliche Optimierung: Binäre Optimierung: x x1 x2 x n n = (,,, ) R x = ( x1, x2,, x ) {0,1} n n Lokale Suche: x i = x i + ε Lokale Suche: x i = 1-x i 0.5 0.9 0.2
Repräsentation von Lösungen (1) Kontinuierliche Optimierung: Binäre Optimierung: x x1 x2 x n n = (,,, ) R x = ( x1, x2,, x ) {0,1} n n Lokale Suche: x i = x i + ε Lokale Suche: x i = 1-x i 0.5 0.9 0.2
Clusteranalyse. Mathematische Symbole Anzahl der Objekte, Versuchspersonen
 Clusteranalyse Ziel: Auffinden von Gruppen ( Cluster ) ähnlicher Obekte (bezogen auf die ausgewählten Variablen). Obekte i selben Cluster haben ähnliche Eigenschaften, Obekte in verschiedenen Clustern
Clusteranalyse Ziel: Auffinden von Gruppen ( Cluster ) ähnlicher Obekte (bezogen auf die ausgewählten Variablen). Obekte i selben Cluster haben ähnliche Eigenschaften, Obekte in verschiedenen Clustern
Multivariate Verfahren
 Multivariate Verfahren Oliver Muthmann 31. Mai 2007 Gliederung 1 Einführung 2 Varianzanalyse (MANOVA) 3 Regressionsanalyse 4 Faktorenanalyse Hauptkomponentenanalyse 5 Clusteranalyse 6 Zusammenfassung Komplexe
Multivariate Verfahren Oliver Muthmann 31. Mai 2007 Gliederung 1 Einführung 2 Varianzanalyse (MANOVA) 3 Regressionsanalyse 4 Faktorenanalyse Hauptkomponentenanalyse 5 Clusteranalyse 6 Zusammenfassung Komplexe
Inhalt. 6.1 Motivation. 6.2 Klassifikation. 6.3 Clusteranalyse. 6.4 Asszoziationsanalyse. Datenbanken & Informationssysteme / Kapitel 6: Data Mining
 6. Data Mining Inhalt 6.1 Motivation 6.2 Klassifikation 6.3 Clusteranalyse 6.4 Asszoziationsanalyse 2 6.1 Motivation Data Mining and Knowledge Discovery zielt darauf ab, verwertbare Erkenntnisse (actionable
6. Data Mining Inhalt 6.1 Motivation 6.2 Klassifikation 6.3 Clusteranalyse 6.4 Asszoziationsanalyse 2 6.1 Motivation Data Mining and Knowledge Discovery zielt darauf ab, verwertbare Erkenntnisse (actionable
Item-based Collaborative Filtering
 Item-based Collaborative Filtering Paper presentation Martin Krüger, Sebastian Kölle 28.04.2011 Seminar Collaborative Filtering KDD Cup 2011: Aufgabenbeschreibung Track 1 Item-based Collaborative Filtering
Item-based Collaborative Filtering Paper presentation Martin Krüger, Sebastian Kölle 28.04.2011 Seminar Collaborative Filtering KDD Cup 2011: Aufgabenbeschreibung Track 1 Item-based Collaborative Filtering
Mustererkennung. Übersicht. Unüberwachtes Lernen. (Un-) Überwachtes Lernen Clustering im Allgemeinen k-means-verfahren Gaussian-Mixture Modelle
 Überwachtes Lernen Clustering im Allgemeinen k-means-verfahren Gaussian-Mixture Modelle") Mustererkennung Unüberwachtes Lernen R. Neubecker, WS 01 / 01 Übersicht (Un-) Überwachtes Lernen Clustering im Allgemeinen k-means-verfahren 1 Lernen Überwachtes Lernen Zum Training des Klassifikators
Mustererkennung Unüberwachtes Lernen R. Neubecker, WS 01 / 01 Übersicht (Un-) Überwachtes Lernen Clustering im Allgemeinen k-means-verfahren 1 Lernen Überwachtes Lernen Zum Training des Klassifikators
Charakterisierung von 1D Daten
 Charakterisierung von D Daten Mittelwert: µ, Schätzung m x = x i / n Varianz σ2, Schätzung: s2 = (s: Standardabweichung) Höhere Momente s 2 = ( x i m x ) 2 n ( ) Eine Normalverteilung ist mit Mittelwert
Charakterisierung von D Daten Mittelwert: µ, Schätzung m x = x i / n Varianz σ2, Schätzung: s2 = (s: Standardabweichung) Höhere Momente s 2 = ( x i m x ) 2 n ( ) Eine Normalverteilung ist mit Mittelwert
Institut für angewandte Datenanalyse GmbH
 Institut für angewandte Datenanalyse GmbH Latent Class Cluster Analysen (LCCA) Was erwartet Sie nachfolgend? Einführung Klassifizierung der Segmentierungs-Verfahren Case Study Urlaubsreisen Das Prinzip
Institut für angewandte Datenanalyse GmbH Latent Class Cluster Analysen (LCCA) Was erwartet Sie nachfolgend? Einführung Klassifizierung der Segmentierungs-Verfahren Case Study Urlaubsreisen Das Prinzip
Statistische Methoden in der Geographie
 Statistische Methoden in der Geographie Band 2.; Multivariate Statistik Von Dr. rer. nat. Gerhard Bahrenberg Professor an der Universität Bremen Dr. rer. nat. Ernst Giese Professor an der Universität Gießen
Statistische Methoden in der Geographie Band 2.; Multivariate Statistik Von Dr. rer. nat. Gerhard Bahrenberg Professor an der Universität Bremen Dr. rer. nat. Ernst Giese Professor an der Universität Gießen
Data Mining im Einzelhandel Methoden und Werkzeuge
 Fakultät Informatik Institut für Angewandte Informatik Professur Technische Informationssysteme Proseminar Technische Informationssysteme Data Mining im Einzelhandel Methoden und Werkzeuge Betreuer: Dipl.-Ing.
Fakultät Informatik Institut für Angewandte Informatik Professur Technische Informationssysteme Proseminar Technische Informationssysteme Data Mining im Einzelhandel Methoden und Werkzeuge Betreuer: Dipl.-Ing.
Methoden der Klassifikation und ihre mathematischen Grundlagen
 Methoden der Klassifikation und ihre mathematischen Grundlagen Mengenlehre und Logik A B "Unter einer 'Menge' verstehen wir jede Zusammenfassung M von bestimmten wohlunterschiedenen Objekten unserer Anschauung
Methoden der Klassifikation und ihre mathematischen Grundlagen Mengenlehre und Logik A B "Unter einer 'Menge' verstehen wir jede Zusammenfassung M von bestimmten wohlunterschiedenen Objekten unserer Anschauung
1 Beispiele multivariater Datensätze... 3
 Inhaltsverzeichnis Teil I Grundlagen 1 Beispiele multivariater Datensätze... 3 2 Elementare Behandlung der Daten... 15 2.1 Beschreibung und Darstellung univariater Datensätze... 15 2.1.1 Beschreibung und
Inhaltsverzeichnis Teil I Grundlagen 1 Beispiele multivariater Datensätze... 3 2 Elementare Behandlung der Daten... 15 2.1 Beschreibung und Darstellung univariater Datensätze... 15 2.1.1 Beschreibung und
Die Clusteranalyse 24.06.2009. Clusteranalyse. Grundidee Mögliche Anwendungsgebiete gg Vorgehensweise Beispiele. methodenlehre ll Clusteranalyse
 Clusteranalyse Thomas Schäfer SS 2009 1 Die Clusteranalyse Grundidee Mögliche Anwendungsgebiete gg Vorgehensweise Beispiele Thomas Schäfer SS 2009 2 1 Die Clusteranalyse Grundidee: Eine heterogene Gesamtheit
Clusteranalyse Thomas Schäfer SS 2009 1 Die Clusteranalyse Grundidee Mögliche Anwendungsgebiete gg Vorgehensweise Beispiele Thomas Schäfer SS 2009 2 1 Die Clusteranalyse Grundidee: Eine heterogene Gesamtheit
Modul Nr. 1608, M.Sc. Bau: Geodäsie und GIS Teil GIS Kapitel 3:
 Modul Nr. 1608, M.Sc. Bau: Geodäsie und GIS Teil GIS Kapitel 3: Univ.-Prof. Dr.-Ing. Wolfgang Reinhardt AGIS / Inst. Für Angewandte Informatik (INF4) Universität der Bundeswehr München Wolfgang.Reinhardt@unibw.de
Modul Nr. 1608, M.Sc. Bau: Geodäsie und GIS Teil GIS Kapitel 3: Univ.-Prof. Dr.-Ing. Wolfgang Reinhardt AGIS / Inst. Für Angewandte Informatik (INF4) Universität der Bundeswehr München Wolfgang.Reinhardt@unibw.de
Vergleich zwischen kmeans und DBScan
 Vergleich zwischen kmeans und DBScan Patrick Breithaupt und Christian Kromm Vorlesung/Seminar: Information Retrieval patrick.breithaupt@stud.uni-heidelberg.de kromm@stud.uni-heidelberg.de 11. Januar 2016
Vergleich zwischen kmeans und DBScan Patrick Breithaupt und Christian Kromm Vorlesung/Seminar: Information Retrieval patrick.breithaupt@stud.uni-heidelberg.de kromm@stud.uni-heidelberg.de 11. Januar 2016
Data Mining und Knowledge Discovery in Databases
 Data Mining und Knowledge Discovery in Databases Begriffsabgrenzungen... Phasen der KDD...3 3 Datenvorverarbeitung...4 3. Datenproblematik...4 3. Möglichkeiten der Datenvorverarbeitung...4 4 Data Mining
Data Mining und Knowledge Discovery in Databases Begriffsabgrenzungen... Phasen der KDD...3 3 Datenvorverarbeitung...4 3. Datenproblematik...4 3. Möglichkeiten der Datenvorverarbeitung...4 4 Data Mining
Geodatenbankunterstützung für die geotechnische Bewertung von Massenbewegungen mit Hilfe eines Web Geological Feature Server (WGFS)
") Geodatenbankunterstützung für die geotechnische Bewertung von Massenbewegungen mit Hilfe eines Web Geological Feature Server (WGFS) Björn Broscheit Universität Osnabrück Institut für Geoinformatik und
Geodatenbankunterstützung für die geotechnische Bewertung von Massenbewegungen mit Hilfe eines Web Geological Feature Server (WGFS) Björn Broscheit Universität Osnabrück Institut für Geoinformatik und
Using Sets of Feature Vectors for Similarity Search on Voxelized CAD Data
 Diplomarbeit Using Sets of Feature Vectors for Similarity Search on Voxelized CAD Data Stefan Brecheisen Aufgabensteller: Betreuer: Dank an: Prof. Dr. Hans-Peter Kriegel Martin Pfeifle Peer Kröger, Matthias
Diplomarbeit Using Sets of Feature Vectors for Similarity Search on Voxelized CAD Data Stefan Brecheisen Aufgabensteller: Betreuer: Dank an: Prof. Dr. Hans-Peter Kriegel Martin Pfeifle Peer Kröger, Matthias
Hauptseminar KDD SS 2002
 Hauptseminar KDD SS 2002 Prof. Dr. Hans-Peter Kriegel Eshref Januzaj Karin Kailing Peer Kröger Matthias Schubert Session: Clustering HS KDD, Ludwig-Maximilians-Universität München, SS 2002 1 Inhalt Einleitung
Hauptseminar KDD SS 2002 Prof. Dr. Hans-Peter Kriegel Eshref Januzaj Karin Kailing Peer Kröger Matthias Schubert Session: Clustering HS KDD, Ludwig-Maximilians-Universität München, SS 2002 1 Inhalt Einleitung
2. Datenvorverarbeitung
 Kurzreferat Das Ziel beim Clustering ist es möglichst gleich Datensätze zu finden und diese in Gruppen, sogenannte Cluster zu untergliedern. In dieser Dokumentation werden die Methoden k-means und Fuzzy
Kurzreferat Das Ziel beim Clustering ist es möglichst gleich Datensätze zu finden und diese in Gruppen, sogenannte Cluster zu untergliedern. In dieser Dokumentation werden die Methoden k-means und Fuzzy
Proseminar: Web-Performance
 Proseminar: Web-Performance Workload-Beschreibung (3) Skalierung, Clusteranalyse und algorithmen, Burstiness Skalierung Skalierungsmethoden zur Arbeitslastberechnung: unterschiedliche Einheiten können
Proseminar: Web-Performance Workload-Beschreibung (3) Skalierung, Clusteranalyse und algorithmen, Burstiness Skalierung Skalierungsmethoden zur Arbeitslastberechnung: unterschiedliche Einheiten können
VU mathematische methoden in der ökologie: räumliche verteilungsmuster 1/5 h.lettner /
 VU mathematische methoden in der ökologie: räumliche verteilungsmuster / h.lettner / Analyse räumlicher Muster und Verteilungen Die Analyse räumlicher Verteilungen ist ein zentrales Gebiet der ökologischen
VU mathematische methoden in der ökologie: räumliche verteilungsmuster / h.lettner / Analyse räumlicher Muster und Verteilungen Die Analyse räumlicher Verteilungen ist ein zentrales Gebiet der ökologischen
Nichtmetrische multidimensionale Skalierung (NMDS) Dr. Heike Culmsee Vegetationsanalyse & Phytodiversität
 Dr. Heike Culmsee Vegetationsanalyse & Phytodiversität") Nichtmetrische multidimensionale Skalierung (NMDS) Dr. Heike Culmsee Vegetationsanalyse & Phytodiversität Übersicht Ordinationsverfahren Linear methods Weighted averaging Multidimensional scaling Unconstrained
Nichtmetrische multidimensionale Skalierung (NMDS) Dr. Heike Culmsee Vegetationsanalyse & Phytodiversität Übersicht Ordinationsverfahren Linear methods Weighted averaging Multidimensional scaling Unconstrained
Routing A lgorithmen Algorithmen Begriffe, Definitionen Wegewahl Verkehrslenkung
 Begriffe, Definitionen Routing (aus der Informatik) Wegewahl oder Verkehrslenkung bezeichnet in der Telekommunikation das Festlegen von Wegen für Nachrichtenströme bei der Nachrichtenübermittlung über
Begriffe, Definitionen Routing (aus der Informatik) Wegewahl oder Verkehrslenkung bezeichnet in der Telekommunikation das Festlegen von Wegen für Nachrichtenströme bei der Nachrichtenübermittlung über
Hauptseminar Technische Informationssysteme
 Fakultät Informatik Institut für Angewandte Informatik Hauptseminar Technische Informationssysteme - Platzierung von WLAN Access Points - Rene Ranft, Betreuer: Dipl.-Ing. Ralf Zenker Dresden, 24.06.2011
Fakultät Informatik Institut für Angewandte Informatik Hauptseminar Technische Informationssysteme - Platzierung von WLAN Access Points - Rene Ranft, Betreuer: Dipl.-Ing. Ralf Zenker Dresden, 24.06.2011
Unüberwachtes Lernen
 Unüberwachtes Lernen Mustererkennung und Klassifikation, Vorlesung No. 12 M. O. Franz 17.01.2008 Übersicht 1 Hauptkomponentenanalyse 2 Nichtlineare Hauptkomponentenanalyse 3 K-Means-Clustering Übersicht
Unüberwachtes Lernen Mustererkennung und Klassifikation, Vorlesung No. 12 M. O. Franz 17.01.2008 Übersicht 1 Hauptkomponentenanalyse 2 Nichtlineare Hauptkomponentenanalyse 3 K-Means-Clustering Übersicht
Aufgabenstellung Klausur
 Aufgabenstellung Klausur Methoden der Marktforschung 02.03.2004 Der Automobilhersteller People Car möchte nach erfolgreicher Markteinführung des neuen Modells Wolf in Deutschland dieses Modell auch auf
Aufgabenstellung Klausur Methoden der Marktforschung 02.03.2004 Der Automobilhersteller People Car möchte nach erfolgreicher Markteinführung des neuen Modells Wolf in Deutschland dieses Modell auch auf
Einführung in die Cluster-Analyse mit SPSS
 Einführung in die -Analyse mit SPSS SPSS-Benutzertreffen am URZ Carina Ortseifen. Juli 00 Inhalt. analyse im allgemeinen Definition, Distanzmaße, Gruppierung, Kriterien. analyse mit SPSS a) Hierarchische
Einführung in die -Analyse mit SPSS SPSS-Benutzertreffen am URZ Carina Ortseifen. Juli 00 Inhalt. analyse im allgemeinen Definition, Distanzmaße, Gruppierung, Kriterien. analyse mit SPSS a) Hierarchische
Winter 2011/ Projekt kd- Trees. achsenparallelen Farbwürfel angeordnet. Die beiden schwarz- weiß- Ecken verbindet eine Graulinie.
 Praktikum Algorithmik Prof. Dr. Heiner Klocke Winter 2011/2012 12.11.2011 1. Erläuterung des Umfeldes Projekt kd- Trees Bei der Bildanalyse sollen Farbpunkte eines Bildes klassifiziert werden. Die Farbe
Praktikum Algorithmik Prof. Dr. Heiner Klocke Winter 2011/2012 12.11.2011 1. Erläuterung des Umfeldes Projekt kd- Trees Bei der Bildanalyse sollen Farbpunkte eines Bildes klassifiziert werden. Die Farbe
Clustering. Hauptseminar Machine Learning WS 2003/2004. Referent: Can Önder Betreuer: Martin Wagner
 Clustering Hauptseminar Machine Learning WS 2003/2004 Referent: Can Önder Betreuer: Martin Wagner Gliederung Partitionierendes Clustering Hierarchisches Clustering Wahrscheinlichkeitsbasiertes Clustering
Clustering Hauptseminar Machine Learning WS 2003/2004 Referent: Can Önder Betreuer: Martin Wagner Gliederung Partitionierendes Clustering Hierarchisches Clustering Wahrscheinlichkeitsbasiertes Clustering
Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut, keine vorgegebenen Klassen
 7. Clusteranalyse (= Häufungsanalyse; Clustering-Verfahren) wird der multivariaten Statistik zugeordnet Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut,
7. Clusteranalyse (= Häufungsanalyse; Clustering-Verfahren) wird der multivariaten Statistik zugeordnet Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut,
Statistik II: Klassifikation und Segmentierung
 Medien Institut : Klassifikation und Segmentierung Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Faktorenanalyse 2. Clusteranalyse 3. Key Facts 2 I 14 Ziel
Medien Institut : Klassifikation und Segmentierung Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Faktorenanalyse 2. Clusteranalyse 3. Key Facts 2 I 14 Ziel
Whisky-Empfehlungen. Whisky-Empfehlungen - Joachim Schole
 Whisky-Empfehlungen 1 Agenda Motivation Einführung in die Domäne Whisky Einführung Empfehlungssysteme Einführung KDD, Data Mining, Clustering Aktueller Stand & Aufgaben 2 Motivation Problem Whisky-Empfehlung
Whisky-Empfehlungen 1 Agenda Motivation Einführung in die Domäne Whisky Einführung Empfehlungssysteme Einführung KDD, Data Mining, Clustering Aktueller Stand & Aufgaben 2 Motivation Problem Whisky-Empfehlung
Multivariate Statistik
 Multivariate Statistik von Univ.-Prof. Dr. Rainer Schlittgen Oldenbourg Verlag München I Daten und ihre Beschreibung 1 1 Einführung 3 1.1 Fragestellungen 3 1.2 Datensituation 8 1.3 Literatur und Software
Multivariate Statistik von Univ.-Prof. Dr. Rainer Schlittgen Oldenbourg Verlag München I Daten und ihre Beschreibung 1 1 Einführung 3 1.1 Fragestellungen 3 1.2 Datensituation 8 1.3 Literatur und Software
fh management, communication & it Constantin von Craushaar fh-management, communication & it Statistik Angewandte Statistik
 fh management, communication & it Folie 1 Überblick Grundlagen (Testvoraussetzungen) Mittelwertvergleiche (t-test,..) Nichtparametrische Tests Korrelationen Regressionsanalyse... Folie 2 Überblick... Varianzanalyse
fh management, communication & it Folie 1 Überblick Grundlagen (Testvoraussetzungen) Mittelwertvergleiche (t-test,..) Nichtparametrische Tests Korrelationen Regressionsanalyse... Folie 2 Überblick... Varianzanalyse
Analysis of Crash Simulation Data using Spectral Embedding with Histogram Distances
 Analysis of Crash Simulation Data using Spectral Embedding with Histogram Distances Luisa Schwartz Universität Bonn Institut für Numerische Simulation Fraunhofer SCAI 25. September 2014 Luisa Schwartz
Analysis of Crash Simulation Data using Spectral Embedding with Histogram Distances Luisa Schwartz Universität Bonn Institut für Numerische Simulation Fraunhofer SCAI 25. September 2014 Luisa Schwartz
Clusteranalyse: Gauß sche Mischmodelle
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse: Gauß sche Mischmodelle iels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse: Gauß sche Mischmodelle iels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Lineare Diskriminanzanalyse Ein sehr kurzer Einblick
 Ein sehr kurzer Einblick 1 Beispiele 2 Grundgedanken der DA 3 Diskriminanzkriterium 4 Schätzung der Diskriminanzfunktion 5 Teststatistiken 6 Klassifizierung 7 Schätzung der Klassifikationsfehler Literatur:
Ein sehr kurzer Einblick 1 Beispiele 2 Grundgedanken der DA 3 Diskriminanzkriterium 4 Schätzung der Diskriminanzfunktion 5 Teststatistiken 6 Klassifizierung 7 Schätzung der Klassifikationsfehler Literatur:
Übungen zu Multimedia-Datenbanken Aufgabenblatt 4 - Musterlösungen
 Übungen zu Multimedia-Datenbanken Aufgabenblatt 4 - Musterlösungen Übung: Dipl.-Inf. Tina Walber Vorlesung: Dr.-Ing. Marcin Grzegorzek Fachbereich Informatik, Universität Koblenz Landau Ausgabe: 31.0.2010
Übungen zu Multimedia-Datenbanken Aufgabenblatt 4 - Musterlösungen Übung: Dipl.-Inf. Tina Walber Vorlesung: Dr.-Ing. Marcin Grzegorzek Fachbereich Informatik, Universität Koblenz Landau Ausgabe: 31.0.2010
1 Einleitung Definitionen, Begriffe Grundsätzliche Vorgehensweise... 3
 Inhaltsverzeichnis 1 Einleitung 1 1.1 Definitionen, Begriffe........................... 1 1.2 Grundsätzliche Vorgehensweise.................... 3 2 Intuitive Klassifikation 6 2.1 Abstandsmessung zur Klassifikation..................
Inhaltsverzeichnis 1 Einleitung 1 1.1 Definitionen, Begriffe........................... 1 1.2 Grundsätzliche Vorgehensweise.................... 3 2 Intuitive Klassifikation 6 2.1 Abstandsmessung zur Klassifikation..................
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Clusteranalyse. Niels Landwehr
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Niels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer Ansatz:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Niels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer Ansatz:
OPT Optimierende Clusteranalyse
 Universität Augsburg Fakultät für angewandte Informatik Lehrstuhl für Physische Geographie und Quantitative Methoden Übung zum Projektseminar: Wetterlagen und Feinstaub Leitung: Dr. Christoph Beck Referentin:
Universität Augsburg Fakultät für angewandte Informatik Lehrstuhl für Physische Geographie und Quantitative Methoden Übung zum Projektseminar: Wetterlagen und Feinstaub Leitung: Dr. Christoph Beck Referentin:
Methoden zur Cluster - Analyse
 Kapitel 4 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig Machine learning in bioinformatics
Kapitel 4 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig Machine learning in bioinformatics
Gliederung. 1. Einleitung (1) 1. Einleitung (2) On detecting differences between groups
 1. Einleitung (2) On detecting differences between groups") Seminar im Fach Informatik Sommersemester 2006 Sascha Rüger Gliederung 1. Einleitung 2. Data Mining Systeme 3. Auswertung 4. Weitere Untersuchungen 5. Fazit 1. Einleitung (1) wichtige Aufgabe der Datenanalyse:
Seminar im Fach Informatik Sommersemester 2006 Sascha Rüger Gliederung 1. Einleitung 2. Data Mining Systeme 3. Auswertung 4. Weitere Untersuchungen 5. Fazit 1. Einleitung (1) wichtige Aufgabe der Datenanalyse:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Tobias Scheffer Christoph Sawade
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Christoph Sawade Heute: Niels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Christoph Sawade Heute: Niels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz:
Distributed Algorithms. Image and Video Processing
 Chapter 6 Optical Character Recognition Distributed Algorithms for Übersicht Motivation Texterkennung in Bildern und Videos 1. Erkennung von Textregionen/Textzeilen 2. Segmentierung einzelner Buchstaben
Chapter 6 Optical Character Recognition Distributed Algorithms for Übersicht Motivation Texterkennung in Bildern und Videos 1. Erkennung von Textregionen/Textzeilen 2. Segmentierung einzelner Buchstaben
Textmining Clustering von Dokumenten
 Textmining Clustering von Dokumenten Dept. Informatik 8 (Künstliche Intelligenz) Friedrich-Alexander-Universität Erlangen-Nürnberg (Informatik 8) Clustering 1 / 25 Clustering Definition Clustering ist
Textmining Clustering von Dokumenten Dept. Informatik 8 (Künstliche Intelligenz) Friedrich-Alexander-Universität Erlangen-Nürnberg (Informatik 8) Clustering 1 / 25 Clustering Definition Clustering ist
Informationssysteme. Prof. Dr. Hans Czap. Lehrstuhl für Wirtschaftsinformatik I. Lehrstuhl für Wirtschaftsinformatik I - II - 1 -
 Vorlesung Grundlagen betrieblicher Informationssysteme Prof. Dr. Hans Czap Email: Hans.Czap@uni-trier.de - II - 1 - Inhalt Kap. 1 Ziele der Datenbanktheorie Kap. 2 Datenmodellierung und Datenbankentwurf
Vorlesung Grundlagen betrieblicher Informationssysteme Prof. Dr. Hans Czap Email: Hans.Czap@uni-trier.de - II - 1 - Inhalt Kap. 1 Ziele der Datenbanktheorie Kap. 2 Datenmodellierung und Datenbankentwurf
Reader Teil 5: Clusteranalyse
 r. Katharina est Sommersemester 2011 12. Mai 2011 Reader Teil 5: Clusteranalyse WiMa-raktikum ei der Clusteranalyse wollen wir Gruppen in aten auffinden. ie Aufgabe ist, in vorhandenen aten Klassen resp.
r. Katharina est Sommersemester 2011 12. Mai 2011 Reader Teil 5: Clusteranalyse WiMa-raktikum ei der Clusteranalyse wollen wir Gruppen in aten auffinden. ie Aufgabe ist, in vorhandenen aten Klassen resp.
Clustering. Herbert Stoyan Stefan Mandl. 18. Dezember 2003
 Clustering Herbert Stoyan Stefan Mandl 18. Dezember 2003 Einleitung Clustering ist eine wichtige nicht-überwachte Lernmethode Andwenungen Marketing: Finde Gruppen von Kunden mit gleichem Kaufverhalten,
Clustering Herbert Stoyan Stefan Mandl 18. Dezember 2003 Einleitung Clustering ist eine wichtige nicht-überwachte Lernmethode Andwenungen Marketing: Finde Gruppen von Kunden mit gleichem Kaufverhalten,
Clusteranalyse K-Means-Verfahren
 Workshop Clusteranalyse Clusteranalyse K-Means-Verfahren Graz, 8. 9. Oktober 2009 Johann Bacher Johannes Kepler Universität Linz Linz 2009 1 1. Fragestellung und Algorithmus Bestimmung von Wertetypen (Bacher
Workshop Clusteranalyse Clusteranalyse K-Means-Verfahren Graz, 8. 9. Oktober 2009 Johann Bacher Johannes Kepler Universität Linz Linz 2009 1 1. Fragestellung und Algorithmus Bestimmung von Wertetypen (Bacher
Bildverarbeitung Herbstsemester. Mustererkennung
 Bildverarbeitung Herbstsemester Herbstsemester 2009 2012 Mustererkennung 1 Inhalt Einführung Mustererkennung in Grauwertbildern Ähnlichkeitsmasse Normalisierte Korrelation Korrelationskoeffizient Mustererkennung
Bildverarbeitung Herbstsemester Herbstsemester 2009 2012 Mustererkennung 1 Inhalt Einführung Mustererkennung in Grauwertbildern Ähnlichkeitsmasse Normalisierte Korrelation Korrelationskoeffizient Mustererkennung
Kapitel 4: Data Mining
 LUDWIG- MAXIMILIANS- UNIVERSITY MUNICH DEPARTMENT INSTITUTE FOR INFORMATICS Skript zur Vorlesung: Einführung in die Informatik: Systeme und Anwendungen Sommersemester 2017 Kapitel 4: Data Mining Vorlesung:
LUDWIG- MAXIMILIANS- UNIVERSITY MUNICH DEPARTMENT INSTITUTE FOR INFORMATICS Skript zur Vorlesung: Einführung in die Informatik: Systeme und Anwendungen Sommersemester 2017 Kapitel 4: Data Mining Vorlesung:
Automatisiertes Auffinden von Präfix- und Suffix-Inklusionsabhängigkeiten in relationalen Datenbankmanagementsystemen
 Automatisiertes Auffinden von Präfix- und Suffix-Inklusionsabhängigkeiten in relationalen Datenbankmanagementsystemen Exposé für eine Diplomarbeit Jan Hegewald Betreut von Jana Bauckmann 7. März 2007 1
Automatisiertes Auffinden von Präfix- und Suffix-Inklusionsabhängigkeiten in relationalen Datenbankmanagementsystemen Exposé für eine Diplomarbeit Jan Hegewald Betreut von Jana Bauckmann 7. März 2007 1
Geoinformation I Datenmodellierung
 Seite 1 von 61 Geoinformation I Datenmodellierung Seite 2 von 61 Datenmodellierung Übersicht Datenverwaltung und Datenbanken objektorientierte Abbildung der Realität Grundlagen der Objektorientierung Darstellung
Seite 1 von 61 Geoinformation I Datenmodellierung Seite 2 von 61 Datenmodellierung Übersicht Datenverwaltung und Datenbanken objektorientierte Abbildung der Realität Grundlagen der Objektorientierung Darstellung
Entwicklung einer Entscheidungssystematik für Data- Mining-Verfahren zur Erhöhung der Planungsgüte in der Produktion
 Entwicklung einer Entscheidungssystematik für Data- Mining-Verfahren zur Erhöhung der Planungsgüte in der Produktion Vortrag Seminararbeit David Pogorzelski Aachen, 22.01.2015 Agenda 1 2 3 4 5 Ziel der
Entwicklung einer Entscheidungssystematik für Data- Mining-Verfahren zur Erhöhung der Planungsgüte in der Produktion Vortrag Seminararbeit David Pogorzelski Aachen, 22.01.2015 Agenda 1 2 3 4 5 Ziel der
1. Referenzpunkt Transformation
 2.3 Featurereduktion Idee: Anstatt Features einfach wegzulassen, generiere einen neuen niedrigdimensionalen Featureraum aus allen Features: Redundante Features können zusammengefasst werden Irrelevantere
2.3 Featurereduktion Idee: Anstatt Features einfach wegzulassen, generiere einen neuen niedrigdimensionalen Featureraum aus allen Features: Redundante Features können zusammengefasst werden Irrelevantere