High Performance Computing
|
|
|
- Arthur Boer
- vor 5 Jahren
- Abrufe
Transkript
1 High Performance Computing SS 2002 PD Dr. A. Strey Abteilung Neuroinformatik, Universität Ulm Inhalt Einführung hohe Leistung durch Parallelität! kurze Historie des High Performance Computing (HPC) Top 500 Architekturen für HPC Exkurs: SIMD-Parallelrechner und Vektorrechner Hochleistungsprozessoren Parallelrechner mit gemeinsamem Speicher (SMP = Symmetric Multiprocessor ) Parallelrechner mit verteiltem Speicher (DMC = Distributed Memory Computer ) Parallelrechner mit virtuellem gemeinsamem Speicher (ccnuma = cache-coherent Non-Uniform Memory Access ) Cluster aus PCs/Workstations 2 1
2 Inhalt (Forts.) Programmierumgebungen für HPC High Performance Fortran PVM ( Parallel Virtual Machine ) MPI ( Message Passing Interface ) Threads OpenMP automatische Parallelisierung Leistungsbewertung von HPC-Systemen Typische HPC Anwendungen, z.b.: Lösen großer Gleichungssysteme Simulation neuronaler Netze Sequenzanalyse in Bioinformatik Ausblick: Trends und Perspektiven 3 Literatur D.E. Culler, J.P. Singh, Parallel Computer Architecture: A Hardware/Software Approach, Morgan Kaufmann, 1999 Ch. Märtin, Rechnerarchitekturen: CPUs, Systeme, Software- Schnittstellen, Carl Hanser Verlag, K. Dowd, Ch. Severance, High Performance Computing, O Reilly, 1998 G.C. Fox, R.D. Williams, Parallel Computing Works, Morgan Kaufmann, 1994 (Online-Version unter I. Foster, Designing and Building Parallel Programs, Addison- Wesley, 1995 (Online-Version unter www-unix.mcs.anl.gov/dbpp) 4 2
3 Organisatorisches Vorlesung: Mi., 12-14, Raum O27/122 (!?) voraussichtliche Vorlesungstermine: (Fr), , (Fr), , , , , , , , , Übung: Fr., , Raum O27/122 voraussichtliche Übungstermine: 1. Rechnerarchitekturen für HPC MPI, Teil MPI, Teil OpenMP, Teil OpenMP, Teil Leistungsbewertung Warum HPC? zur Reduktion der Rechenzeit bei der Lösung eines Problems zur Berechnung größerer Probleme bei gleicher Rechenzeit (Problemgröße wächst permanent., weil Wunsch nach Realitätsnähe bei Modellierung ständig zunimmt) zur Ermöglichung von Simulationen in Echtzeit typische heutige HPC Anwendungen: Wettervorhersage, Vorhersage von Molekülstrukturen, Proteinanalyse, Simulation von Autos, Schiffen und Flugzeugen, Visualisierung zur Lösung von zukünftigen noch bedeutend komplexeren Aufgaben ( Grand Challenge Problems ) mit ggf. neuen Algorithmen : Globale Klima-Simulation, Molekulardynamik, Erdbebenvorhersage, Simulation der Ozeanströmungen, Analyse des menschlichen Genoms 6 3
4 Parallelität hohe Leistung überwiegend durch hohe Taktraten und durch Ausnutzung von Parallelität in der Rechnerarchitektur Verteilung von Arbeit und Daten auf viele gleichzeitig arbeitende Rechenknoten Arten der Organisation von Parallelität (Flynn s Taxonomie) SISD ( Single Instruction, Single Data, keine Parallelität!) SIMD ( Single Instruction, Multiple Data ) MIMD ( Multiple Instruction, Multiple Data ) SPMD ( Same Program, Multiple Data ) Arten der Organisation des Speichers Gemeinsamer Speicher ( Shared Memory ) Verteilter Speicher ( Distributeted Memory ) 7 Parallelität (Forts.) Vor-/Nachteile paralleler Verarbeitung: + kürzere Ausführungszeit aufwendige Programmierung (hohe Kosten für Entwicklung und Pflege) effiziente Parallelisierung oft nicht trivial Schlüsselprobleme: Partitionierung eines Problems und ggf. Lastverteilung (Ziele: hohe Lokalität, maximale Auslastung, minimale Kommunikation) Skalierbarkeit (d.h. Erhöhung der Leistung bei Erhöhung der Prozessoranzahl) Portabilität der Anwendungen (d.h. rechnerunabhängige parallele Programmierung) Koordination und Synchronisation bei der parallelen Verarbeitung Kopplung sehr vieler Prozessoren 8 4
5 SIMD-Parallelrechner Kontrolleinheit broadcastet Instruktionen an viele einfache Prozessorelemente (PEs) Alle PEs führen taktsynchron die gleiche Instruktion auf unterschiedlichen Daten aus datenparallele Programmierung einzige Ausnahme: Maskierung durch paralleles if-konstrukt gut für Operationen auf Vektoren und Matrizen Beispiele: Connection Machine CM1 und CM2, ILLIAC IV, ICL DAP, MasPar MP1 und MP2 9 MIMD-Parallelrechner mehrere komplexe und unabhängig arbeitende Prozessoren prozeßparallele Programmierung gemeinsamer Speicher (mit globalem Adreßraum) oder verteilter Speicher größere Flexibilität als bei SIMD preiswerter dank Standardkomponenten weites Spektrum an Architekturen, z.b.: Symmetrische Multiprozessoren (SMP) Parallelrechner mit verteiltem Speicher (DMC = Distributed Memory Computer ) Cluster aus PCs/Workstations Beispiele: Intel ipsc und Paragon, Cray T3D und T3E, SP2, Sun HPC 10 5
 1986: erster SMP: Sequent Balance")
 11 Historie HPC : Meilensteine (Forts.")
6 Historie HPC : Meilensteine 1972: Slotnick entwickelt Illiac IV (erster SIMD-Computer mit Bit PEs in Gitter-Topologie) 1976: Cray installiert ersten Vektorrechner Cray-1 mit einer Leistung von 100 MFlop/s 1982: Fujitsu installiertvp-200 Vektorrechner mit 500 MFlop/s 1985: Thinking Machines stellt Connection Machine CM1 vor (SIMD-Computer mit 64k 1-Bit PEs) 1986: erster SMP: Sequent Balance 8000, 8 CPUs 1988: Intel stellt ipsc/2 vor (MIMD-Rechner mit bis zu 128 in einem Hyperkubus angeordneten 386-Prozessoren) 1992: MasPar liefert MP2 aus (SIMD-Computer mit 16k 32-Bit Prozessorelementen) 11 Historie HPC : Meilensteine (Forts.) 1993: Cray baut MIMD-Rechner Cray T3D (bis zu 2048 DEC Alpha-Prozessoren verbunden in 3DTorus-Topologie) 1994: SP2: Kopplung vieler RISCSystem/6000 Workstations über ein schnelles, skalierbares Netzwerk 1995: DEC Alpha Prozessor mit 4-facher Superskalarität 1996: SGI Origin (erster Parallelrechner mit virtuellem gemeinsamem Speicher) 1997: System Deep Blue schlägt Weltschachmeister Kasparov 1997: ASCI Red mit 4536 Pentium Pro Prozessoren erreicht eine Leistung von mehr als 1 TFlop/s : ASCI White aus 512 SMPs erreicht mehr als 10 TFlop/s (Details:
7 Leistung von HPC Systemen (für LINPACK) 13 Leistung von Prozessoren 14 7
8 Technologie für Prozessoren Taktrate bei Mikroprozessoren erhöhte sich von 1 MHz (1980) auf 1 GHz () Mooresches Gesetz: Verdopplung von Geschwindigkeit des Prozessors und Kapazität der Speicherbausteine alle 1,5 Jahre! gibt es physikalische Grenzen? Lichtgeschwindigkeit: 30 cm/ns Geschwindigkeit der Signalausbreitung in Kupfer: 9 cm/ns (1 GHz entspricht einer Taktbreite von 1ns) Energieverbrauch (und somit Wärmeentwicklung) wachsen linear mit Taktfrequenz (Reduktion der Betriebsspannung, kann nicht beliebig klein werden!) weitere Leistungssteigerungen langfristig hauptsächlich nur durch Ausnutzung von Parallelität! 15 TOP 500 seit 1993 wird jährlich eine Liste der weltweit 500 schnellsten HPC-Systeme erstellt Bewertungsmaßstab ist die Leistung bei der Lösung eines großen Systems linearer Gleichungen (LINPACK Benchmark): R max gibt die Leistung eines Systems in GigaFlop/s bei einer individuell gewählten optimalen Problemgröße N max an Details unter
9 Top 500 Auszug (Top 20, international) Rank Manufact. Computer R max (GFlops) Installation Site Country Year #Proc 1 ASCI White, Lawrence Livermore National Laboratory Compaq AlphaServer SC ES45/1 GHz Pittsburgh Supercomputing Center way NERSC/LBNL Intel ASCI Red Sandia National Labs ASCI Blue-Pacific, SP 604e Lawrence Livermore National Laboratory Compaq AlphaServer SC ES45/1 GHz Los Alamos National Laboratory Hitachi SR8000/MPP University of Tokyo Japan SGI ASCI Blue Mountain Los Alamos National Laboratory Naval Oceanographic Office way Deutscher Wetterdienst Germany way Center for Atmospheric NEC SX-5/128M8 3.2ns Osaka University Japan Center for Environmental Prediction Center for Environmental Prediction T3E Government way Lawrence Livermore National Laboratory Hitachi SR8000-F1/ Leibniz Rechenzentrum Germany way UCSD/San Diego Supercomputer Center Hitachi SR8000-F1/ High Energy Accelerator Org. Japan T3E US Army HPC Center at NCS Top 500 Auszug (Country = Germany) Rank Manufacturer Computer R max (GFlops) Installation Site Year Inst. Type #Proc way Deutscher Wetterdienst Hitachi SR8000-F1/ Leibniz Rechenzentrum Academic T3E Deutscher Wetterdienst Rottendorf Pharma GmbH T3E Forschungszentrum Juelich (FZJ) T3E Max-Planck-Gesellschaft MPI/IPP T3E HWW/Universitaet Stuttgart DeTeCSM T3E ZIB/Konrad Zuse-Zentrum fuer Informationstechnik 1999 Academic SP PC604e 332 MHz Bayer AG T3E Forschungszentrum Juelich (FZJ) GWDG Academic Self-made CLIC PIII 800 MHz Technische Universitaet Chemnitz Academic Bayer AG HP SuperDome/HyperPlex Braun GmbH HP SuperDome/HyperPlex Wirth Adolf GmBH way PIK HP SuperDome/HyperPlex DKFZ DeTeCSM
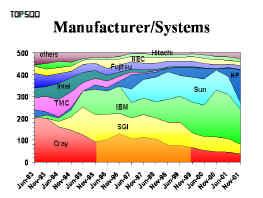



10 19 10
High Performance Computing
 High Performance Computing SS 2004 PD Dr. A. Strey Abteilung Neuroinformatik, Universität Ulm Email: strey@informatik.uni-ulm.de Inhalt Einführung hohe Leistung durch Parallelität! kurze Historie des High
High Performance Computing SS 2004 PD Dr. A. Strey Abteilung Neuroinformatik, Universität Ulm Email: strey@informatik.uni-ulm.de Inhalt Einführung hohe Leistung durch Parallelität! kurze Historie des High
Kapitel 5. Parallelverarbeitung. Formen der Parallelität
 Kapitel 5 Parallelverarbeitung é Formen der Parallelität é Klassifikation von parallelen Rechnerarchitekturen é Exkurs über Verbindungsstrukturen Bernd Becker Technische Informatik I Formen der Parallelität
Kapitel 5 Parallelverarbeitung é Formen der Parallelität é Klassifikation von parallelen Rechnerarchitekturen é Exkurs über Verbindungsstrukturen Bernd Becker Technische Informatik I Formen der Parallelität
2 Rechnerarchitekturen
 2 Rechnerarchitekturen Rechnerarchitekturen Flynns Klassifikation Flynnsche Klassifikation (Flynn sche Taxonomie) 1966 entwickelt, einfaches Modell, bis heute genutzt Beschränkung der Beschreibung auf
2 Rechnerarchitekturen Rechnerarchitekturen Flynns Klassifikation Flynnsche Klassifikation (Flynn sche Taxonomie) 1966 entwickelt, einfaches Modell, bis heute genutzt Beschränkung der Beschreibung auf
Distributed Memory Computer (DMC)
") Distributed Memory Computer (DMC) verteilter Speicher: jeder Prozessor kann nur auf seinen lokalen Speicher zugreifen Kopplung mehrerer Prozessoren über E/A-Schnittstellen und Verbindungsnetzwerk, nicht
Distributed Memory Computer (DMC) verteilter Speicher: jeder Prozessor kann nur auf seinen lokalen Speicher zugreifen Kopplung mehrerer Prozessoren über E/A-Schnittstellen und Verbindungsnetzwerk, nicht
Einleitung. Dr.-Ing. Volkmar Sieh WS 2005/2006. Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg
 Technologische Trends Historischer Rückblick Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2005/2006 Technologische Trends Historischer Rückblick Übersicht
Technologische Trends Historischer Rückblick Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2005/2006 Technologische Trends Historischer Rückblick Übersicht
Mehrprozessorarchitekturen
 Mehrprozessorarchitekturen (SMP, UMA/NUMA, Cluster) Arian Bär 12.07.2004 12.07.2004 Arian Bär 1 Gliederung 1. Einleitung 2. Symmetrische Multiprozessoren (SMP) Allgemeines Architektur 3. Speicherarchitekturen
Mehrprozessorarchitekturen (SMP, UMA/NUMA, Cluster) Arian Bär 12.07.2004 12.07.2004 Arian Bär 1 Gliederung 1. Einleitung 2. Symmetrische Multiprozessoren (SMP) Allgemeines Architektur 3. Speicherarchitekturen
Einleitung. Dr.-Ing. Volkmar Sieh. Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2006/2007
 Einleitung Dr.-Ing. Volkmar Sieh Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2006/2007 Einleitung 1/50 2006/10/09 Übersicht 1 Einleitung 2 Technologische
Einleitung Dr.-Ing. Volkmar Sieh Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2006/2007 Einleitung 1/50 2006/10/09 Übersicht 1 Einleitung 2 Technologische
Übersicht. Einleitung. Übersicht. Architektur. Dr.-Ing. Volkmar Sieh WS 2008/2009
 Übersicht Einleitung 1 Einleitung Dr.-Ing. Volkmar Sieh 2 Technologische Trends Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2008/2009 3 Historischer
Übersicht Einleitung 1 Einleitung Dr.-Ing. Volkmar Sieh 2 Technologische Trends Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2008/2009 3 Historischer
Architektur von Parallelrechnern 50
 Architektur von Parallelrechnern 50 Rechenintensive parallele Anwendungen können nicht sinnvoll ohne Kenntnis der zugrundeliegenden Architektur erstellt werden. Deswegen ist die Wahl einer geeigneten Architektur
Architektur von Parallelrechnern 50 Rechenintensive parallele Anwendungen können nicht sinnvoll ohne Kenntnis der zugrundeliegenden Architektur erstellt werden. Deswegen ist die Wahl einer geeigneten Architektur
Parallelrechner: Klassifikation. Parallelrechner: Motivation. Parallelrechner: Literatur. Parallelrechner: PC-Technologie SMP-Multiprozessorsysteme 69
 Parallelrechner: Motivation immer höhere Performance gefordert => schnellere Einzelprozessoren aber Takte oberhalb von 10 GHz unrealistisch => mehrere Prozessoren diverse Architekturkonzepte shared-memory
Parallelrechner: Motivation immer höhere Performance gefordert => schnellere Einzelprozessoren aber Takte oberhalb von 10 GHz unrealistisch => mehrere Prozessoren diverse Architekturkonzepte shared-memory
Architektur paralleler Plattformen
 Architektur paralleler Plattformen Freie Universität Berlin Fachbereich Informatik Wintersemester 2012/2013 Proseminar Parallele Programmierung Mirco Semper, Marco Gester Datum: 31.10.12 Inhalt I. Überblick
Architektur paralleler Plattformen Freie Universität Berlin Fachbereich Informatik Wintersemester 2012/2013 Proseminar Parallele Programmierung Mirco Semper, Marco Gester Datum: 31.10.12 Inhalt I. Überblick
Parallel Computing. Einsatzmöglichkeiten und Grenzen. Prof. Dr. Nikolaus Wulff
 Parallel Computing Einsatzmöglichkeiten und Grenzen Prof. Dr. Nikolaus Wulff Parallel Architekturen Flynn'sche Klassifizierung: SISD: single Instruction, single Data Klassisches von-neumann sequentielles
Parallel Computing Einsatzmöglichkeiten und Grenzen Prof. Dr. Nikolaus Wulff Parallel Architekturen Flynn'sche Klassifizierung: SISD: single Instruction, single Data Klassisches von-neumann sequentielles
Systeme 1: Architektur
 slide 1 Vorlesung Systeme 1: Architektur Prof. Dr. Ulrich Ultes-Nitsche Forschungsgruppe Departement für Informatik Universität Freiburg slide 2 Prüfung 18. Februar 2004 8h00-11h40 13h00-18h20 20 Minuten
slide 1 Vorlesung Systeme 1: Architektur Prof. Dr. Ulrich Ultes-Nitsche Forschungsgruppe Departement für Informatik Universität Freiburg slide 2 Prüfung 18. Februar 2004 8h00-11h40 13h00-18h20 20 Minuten
Proseminar Rechnerarchitekturen. Parallelcomputer: Multiprozessorsysteme
 wwwnet-texde Proseminar Rechnerarchitekturen Parallelcomputer: Multiprozessorsysteme Stefan Schumacher, , PGP Key http://wwwnet-texde/uni Id: mps-folientex,v
wwwnet-texde Proseminar Rechnerarchitekturen Parallelcomputer: Multiprozessorsysteme Stefan Schumacher, , PGP Key http://wwwnet-texde/uni Id: mps-folientex,v
Spielst du noch oder rechnest du schon?
 Spielst du noch oder rechnest du schon? Mit Spielkonsole und Co. zum Supercomputer der Zukunft Fachbereich Elektrotechnik und Informationstechnik Fachhochschule Bielefeld University of Applied Sciences
Spielst du noch oder rechnest du schon? Mit Spielkonsole und Co. zum Supercomputer der Zukunft Fachbereich Elektrotechnik und Informationstechnik Fachhochschule Bielefeld University of Applied Sciences
Ein kleiner Einblick in die Welt der Supercomputer. Christian Krohn 07.12.2010 1
 Ein kleiner Einblick in die Welt der Supercomputer Christian Krohn 07.12.2010 1 Vorschub: FLOPS Entwicklung der Supercomputer Funktionsweisen von Supercomputern Zukunftsvisionen 2 Ein Top10 Supercomputer
Ein kleiner Einblick in die Welt der Supercomputer Christian Krohn 07.12.2010 1 Vorschub: FLOPS Entwicklung der Supercomputer Funktionsweisen von Supercomputern Zukunftsvisionen 2 Ein Top10 Supercomputer
Strukturelemente von Parallelrechnern
 Strukturelemente von Parallelrechnern Parallelrechner besteht aus einer Menge von Verarbeitungselementen, die in einer koordinierten Weise, teilweise zeitgleich, zusammenarbeiten, um eine Aufgabe zu lösen
Strukturelemente von Parallelrechnern Parallelrechner besteht aus einer Menge von Verarbeitungselementen, die in einer koordinierten Weise, teilweise zeitgleich, zusammenarbeiten, um eine Aufgabe zu lösen
Centre of Excellence for High Performance Computing Erlangen Kompetenzgruppe für Supercomputer und Technisch-Wissenschaftliche Simulation
 1 Centre of Excellence for High Performance Computing Erlangen Kompetenzgruppe für Supercomputer und Technisch-Wissenschaftliche Simulation Dr. G. Wellein, Regionales Rechenzentrum Erlangen Supercomputer
1 Centre of Excellence for High Performance Computing Erlangen Kompetenzgruppe für Supercomputer und Technisch-Wissenschaftliche Simulation Dr. G. Wellein, Regionales Rechenzentrum Erlangen Supercomputer
Überblick. Einleitung. Befehlsschnittstelle Mikroarchitektur Speicherarchitektur Ein-/Ausgabe Multiprozessorsysteme,...
 Überblick Einleitung Lit., Motivation, Geschichte, v.neumann- Modell, VHDL Befehlsschnittstelle Mikroarchitektur Speicherarchitektur Ein-/Ausgabe Multiprozessorsysteme,... Kap.6 Multiprozessorsysteme Einsatz
Überblick Einleitung Lit., Motivation, Geschichte, v.neumann- Modell, VHDL Befehlsschnittstelle Mikroarchitektur Speicherarchitektur Ein-/Ausgabe Multiprozessorsysteme,... Kap.6 Multiprozessorsysteme Einsatz
Verteilte Betriebssysteme
 Verteiltes System Eine Sammlung unabhängiger Rechner, die dem Benutzer den Eindruck vermitteln, es handle sich um ein einziges System. Verteiltes Betriebssystem Betriebssystem für verteilte Systeme Verwaltet
Verteiltes System Eine Sammlung unabhängiger Rechner, die dem Benutzer den Eindruck vermitteln, es handle sich um ein einziges System. Verteiltes Betriebssystem Betriebssystem für verteilte Systeme Verwaltet
Parallele und verteilte Programmierung
 Thomas Rauber Gudula Rünger Parallele und verteilte Programmierung Mit 165 Abbildungen und 17 Tabellen Jp Springer Inhaltsverzeichnis 1. Einleitung 1 Teil I. Architektur 2. Architektur von Parallelrechnern
Thomas Rauber Gudula Rünger Parallele und verteilte Programmierung Mit 165 Abbildungen und 17 Tabellen Jp Springer Inhaltsverzeichnis 1. Einleitung 1 Teil I. Architektur 2. Architektur von Parallelrechnern
Konzepte der parallelen Programmierung
 Fakultät Informatik, Institut für Technische Informatik, Professur Rechnerarchitektur Konzepte der parallelen Programmierung Parallele Programmiermodelle Nöthnitzer Straße 46 Raum 1029 Tel. +49 351-463
Fakultät Informatik, Institut für Technische Informatik, Professur Rechnerarchitektur Konzepte der parallelen Programmierung Parallele Programmiermodelle Nöthnitzer Straße 46 Raum 1029 Tel. +49 351-463
Computational Biology: Bioelektromagnetismus und Biomechanik
 Computational Biology: Bioelektromagnetismus und Biomechanik Implementierung Gliederung Wiederholung: Biomechanik III Statische Elastomechanik Finite Elemente Diskretisierung Finite Differenzen Diskretisierung
Computational Biology: Bioelektromagnetismus und Biomechanik Implementierung Gliederung Wiederholung: Biomechanik III Statische Elastomechanik Finite Elemente Diskretisierung Finite Differenzen Diskretisierung
Supercomputer Blue Gene/L
 FH Giessen Friedberg Supercomputer Blue Gene/L Sven Wagner Übersicht Einführung Supercomputer Begriffe Geschichte TOP500 Anwendung 2 Übersicht Blue Gene/L Historie Architektur & Packaging ASIC Netzwerk
FH Giessen Friedberg Supercomputer Blue Gene/L Sven Wagner Übersicht Einführung Supercomputer Begriffe Geschichte TOP500 Anwendung 2 Übersicht Blue Gene/L Historie Architektur & Packaging ASIC Netzwerk
Das HLRN-System. Peter Endebrock, RRZN Hannover
 Das HLRN-System Peter Endebrock, RRZN Hannover vorweg (1) Heute Vorträge im Dreierpack: Peter Endebrock: Das HLRN-System Gerd Brand: MPI Simone Knief: OpenMP Peter Endebrock, RRZN Hannover, Kolloquium,
Das HLRN-System Peter Endebrock, RRZN Hannover vorweg (1) Heute Vorträge im Dreierpack: Peter Endebrock: Das HLRN-System Gerd Brand: MPI Simone Knief: OpenMP Peter Endebrock, RRZN Hannover, Kolloquium,
Paradigmenwechsel: Von der Rechner-zentrierten zur Informationszentrierten DV Skalierbarkeit: Erweiterung von Ressourcen ohne Erhöhung der
 Sun: HPC mit Zukunft Wolfgang Kroj Vertriebsleiter Enterprise Business & Storage Sun Microsystems GmbH Tel.: +49-89-46008-589, Fax: +49-89-46008-590 Email: wolfgang.kroj@germany.sun.com Network Computing
Sun: HPC mit Zukunft Wolfgang Kroj Vertriebsleiter Enterprise Business & Storage Sun Microsystems GmbH Tel.: +49-89-46008-589, Fax: +49-89-46008-590 Email: wolfgang.kroj@germany.sun.com Network Computing
Technische Informatik I, SS 2001
 Technische Informatik I SS 2001 PD Dr. A. Strey Abteilung Neuroinformatik Universität Ulm Inhalt Einführung: Überblick über die historische Entwicklung der Rechnerhardware Teil 1: Digitale Logik kurzer
Technische Informatik I SS 2001 PD Dr. A. Strey Abteilung Neuroinformatik Universität Ulm Inhalt Einführung: Überblick über die historische Entwicklung der Rechnerhardware Teil 1: Digitale Logik kurzer
Eine kurze Einführung in Rechnerarchitektur und Programmierung von Hochleistungsrechnern als zentrales Werkzeug in der Simulation
 Eine kurze Einführung in Rechnerarchitektur und Programmierung von Hochleistungsrechnern als zentrales Werkzeug in der Simulation Dr. Jan Eitzinger Regionales Rechenzentrum (RRZE) der Universität Erlangen-Nürnberg
Eine kurze Einführung in Rechnerarchitektur und Programmierung von Hochleistungsrechnern als zentrales Werkzeug in der Simulation Dr. Jan Eitzinger Regionales Rechenzentrum (RRZE) der Universität Erlangen-Nürnberg
Kapitel 1 Parallele Modelle Wie rechnet man parallel?
 PRAM- PRAM- DAG- R UND R Coles und Kapitel 1 Wie rechnet man parallel? Vorlesung Theorie Paralleler und Verteilter Systeme vom 11. April 2008 der Das DAG- Das PRAM- Das werkmodell Institut für Theoretische
PRAM- PRAM- DAG- R UND R Coles und Kapitel 1 Wie rechnet man parallel? Vorlesung Theorie Paralleler und Verteilter Systeme vom 11. April 2008 der Das DAG- Das PRAM- Das werkmodell Institut für Theoretische
Beispiel Parallelisierung 2D Laplace. Lagrange Formulierung/Hyperelastisches Material. Finite Differenzen Diskretisierung
 Simulation von physikalischen Feldern im menschlichen Körper Implementierung Gliederung Gliederung Wiederholung: Biomechanik III Statische elastomechanische Probleme Finite Elemente Diskretisierung Finite
Simulation von physikalischen Feldern im menschlichen Körper Implementierung Gliederung Gliederung Wiederholung: Biomechanik III Statische elastomechanische Probleme Finite Elemente Diskretisierung Finite
Wissenschaftliches Rechen
 Wissenschaftliches Rechen Paralleles Höchstleistungsrechnen Christian Engwer Uni Münster April 5, 2011 Christian Engwer (Uni Münster) Wissenschaftliches Rechen April 5, 2011 1 / 20 Organisatorisches Vorlesung
Wissenschaftliches Rechen Paralleles Höchstleistungsrechnen Christian Engwer Uni Münster April 5, 2011 Christian Engwer (Uni Münster) Wissenschaftliches Rechen April 5, 2011 1 / 20 Organisatorisches Vorlesung
Symmetrischer Multiprozessor (SMP)
") Symmetrischer Multiprozessor (SMP) Motivation: ein globaler Adressraum für mehrere Prozesse P i Prozesse P i haben gemeinsame Daten ( shared variables ) private Daten ( private variables ) gemeinsamen
Symmetrischer Multiprozessor (SMP) Motivation: ein globaler Adressraum für mehrere Prozesse P i Prozesse P i haben gemeinsame Daten ( shared variables ) private Daten ( private variables ) gemeinsamen
Orientierungsveranstaltungen 2009 Informatikstudien der Universität Wien
 Orientierungsveranstaltungen 2009 Informatikstudien der Universität Wien Scientific Computing 07. Oktober 2009 Siegfried Benkner Wilfried Gansterer Fakultät für Informatik Universität Wien www.cs.univie.ac.at
Orientierungsveranstaltungen 2009 Informatikstudien der Universität Wien Scientific Computing 07. Oktober 2009 Siegfried Benkner Wilfried Gansterer Fakultät für Informatik Universität Wien www.cs.univie.ac.at
2.7. REALE PARALLELRECHNER UND DIE TOP500-LISTE
 Vorlesung 9 2.7. EALE PAALLELECHNE UND DIE TOP500-LISTE c 2010 BY SEGEI GOLATCH UNI MÜNSTE PAALLELE SYSTEME VOLESUNG 9 1 Vorlesung 9 2.7. EALE PAALLELECHNE UND DIE TOP500-LISTE Flynn sche Klassifikation
Vorlesung 9 2.7. EALE PAALLELECHNE UND DIE TOP500-LISTE c 2010 BY SEGEI GOLATCH UNI MÜNSTE PAALLELE SYSTEME VOLESUNG 9 1 Vorlesung 9 2.7. EALE PAALLELECHNE UND DIE TOP500-LISTE Flynn sche Klassifikation
1 Konzepte der Parallelverarbeitung
 Parallelverarbeitung Folie 1-1 1 Konzepte der Parallelverarbeitung Erhöhung der Rechenleistung verbesserte Prozessorarchitekturen mit immer höheren Taktraten Vektorrechner Multiprozessorsysteme (Rechner
Parallelverarbeitung Folie 1-1 1 Konzepte der Parallelverarbeitung Erhöhung der Rechenleistung verbesserte Prozessorarchitekturen mit immer höheren Taktraten Vektorrechner Multiprozessorsysteme (Rechner
Rechnerarchitektur SS 2012
 Rechnerarchitektur SS 2012 Parallele Rechnersysteme TU Dortmund, Fakultät für Informatik XII Literatur: Hennessy/Patterson: Computer Architecture, 3. Auflage, 2003, Kapitel 6, S. 527ff. Huang: Advanced
Rechnerarchitektur SS 2012 Parallele Rechnersysteme TU Dortmund, Fakultät für Informatik XII Literatur: Hennessy/Patterson: Computer Architecture, 3. Auflage, 2003, Kapitel 6, S. 527ff. Huang: Advanced
Computergrundlagen Moderne Rechnerarchitekturen
 Computergrundlagen Moderne Rechnerarchitekturen Axel Arnold Institut für Computerphysik Universität Stuttgart Wintersemester 2010/11 Aufbau eines modernen Computers DDR3- Speicher Prozessor Prozessor PEG
Computergrundlagen Moderne Rechnerarchitekturen Axel Arnold Institut für Computerphysik Universität Stuttgart Wintersemester 2010/11 Aufbau eines modernen Computers DDR3- Speicher Prozessor Prozessor PEG
ModProg 15-16, Vorl. 13
 ModProg 15-16, Vorl. 13 Richard Grzibovski Jan. 27, 2016 1 / 35 Übersicht Übersicht 1 Supercomputing FLOPS, Peak FLOPS Parallelismus Praktische Aspekte 2 Klausur von 2009 2 / 35 Supercomputing: HPC Modellierung
ModProg 15-16, Vorl. 13 Richard Grzibovski Jan. 27, 2016 1 / 35 Übersicht Übersicht 1 Supercomputing FLOPS, Peak FLOPS Parallelismus Praktische Aspekte 2 Klausur von 2009 2 / 35 Supercomputing: HPC Modellierung
Trend der letzten Jahre in der Parallelrechentechnik
 4.1 Einführung Trend der letzten 10-15 Jahre in der Parallelrechentechnik weg von den spezialisierten Superrechner-Plattformen hin zu kostengünstigeren Allzwecksystemen, die aus lose gekoppelten einzelnen
4.1 Einführung Trend der letzten 10-15 Jahre in der Parallelrechentechnik weg von den spezialisierten Superrechner-Plattformen hin zu kostengünstigeren Allzwecksystemen, die aus lose gekoppelten einzelnen
Hardware-Architekturen
 Kapitel 3 Hardware-Architekturen Hardware-Architekturen Architekturkategorien Mehrprozessorsysteme Begriffsbildungen g Verbindungsnetze Cluster, Constellation, Grid Abgrenzungen Beispiele 1 Fragestellungen
Kapitel 3 Hardware-Architekturen Hardware-Architekturen Architekturkategorien Mehrprozessorsysteme Begriffsbildungen g Verbindungsnetze Cluster, Constellation, Grid Abgrenzungen Beispiele 1 Fragestellungen
Computergrundlagen Moderne Rechnerarchitekturen
 Aufbau eines modernen Computers Computergrundlagen Moderne Rechnerarchitekturen Axel Arnold Institut für Computerphysik Universität Stuttgart DDR3- Speicher Prozessor Prozessor PEG Graphikkarte(n) weitere
Aufbau eines modernen Computers Computergrundlagen Moderne Rechnerarchitekturen Axel Arnold Institut für Computerphysik Universität Stuttgart DDR3- Speicher Prozessor Prozessor PEG Graphikkarte(n) weitere
Gregor Michalicek, Marcus Schüler. Multiprozessoren
 Gregor Michalicek, Marcus Schüler Gregor Michalicek Marcus Schüler Gregor Michalicek, Marcus Schüler Vorteile gegenüber Singleprozessoren ¾ sind zuverlässiger. Einige Multiprozessorsysteme können trotz
Gregor Michalicek, Marcus Schüler Gregor Michalicek Marcus Schüler Gregor Michalicek, Marcus Schüler Vorteile gegenüber Singleprozessoren ¾ sind zuverlässiger. Einige Multiprozessorsysteme können trotz
Wichtige Rechnerarchitekturen
 Wichtige Rechnerarchitekturen Teil 1 Überblick 1 Rechnergeschichte: Mechanische Rechenmaschinen Mechanische Rechenmaschinen (17.Jahrhundert) Rechenuhr von Schickard (1623) Pascaline von Blaise Pascal (1642)
Wichtige Rechnerarchitekturen Teil 1 Überblick 1 Rechnergeschichte: Mechanische Rechenmaschinen Mechanische Rechenmaschinen (17.Jahrhundert) Rechenuhr von Schickard (1623) Pascaline von Blaise Pascal (1642)
Multiprozessor System on Chip
 Multiprozessor System on Chip INF-M1 AW1-Vortrag 25. November 2009 Übersicht 1. Einleitung und Motivation 2. Multiprozessor System on Chip (MPSoC) 3. Multiprozessoren mit Xilinx EDK 4. FAUST SoC Fahrzeug
Multiprozessor System on Chip INF-M1 AW1-Vortrag 25. November 2009 Übersicht 1. Einleitung und Motivation 2. Multiprozessor System on Chip (MPSoC) 3. Multiprozessoren mit Xilinx EDK 4. FAUST SoC Fahrzeug
Inhalt. Prozessoren. Curriculum Manfred Wilfling. 28. November HTBLA Kaindorf. M. Wilfling (HTBLA Kaindorf) CPUs 28. November / 9
 CPUs 28. November / 9") Inhalt Curriculum 1.4.2 Manfred Wilfling HTBLA Kaindorf 28. November 2011 M. Wilfling (HTBLA Kaindorf) CPUs 28. November 2011 1 / 9 Begriffe CPU Zentraleinheit (Central Processing Unit) bestehend aus Rechenwerk,
Inhalt Curriculum 1.4.2 Manfred Wilfling HTBLA Kaindorf 28. November 2011 M. Wilfling (HTBLA Kaindorf) CPUs 28. November 2011 1 / 9 Begriffe CPU Zentraleinheit (Central Processing Unit) bestehend aus Rechenwerk,
Maik Zemann. Flynn s Taxonomie. Parallele Rechnerarchitekturen SS 2004 Technische Fakultät Universität Bielefeld. 3. Mai 2004 Flynn's Taxonomie 1
 Maik Zemann Flynn s Taxonomie Parallele Rechnerarchitekturen SS 2004 Technische Fakultät Universität Bielefeld 3. Mai 2004 Flynn's Taxonomie 1 Gliederung Einleitung Gliederung Flynn s Taxonomie Das SISD-Modell
Maik Zemann Flynn s Taxonomie Parallele Rechnerarchitekturen SS 2004 Technische Fakultät Universität Bielefeld 3. Mai 2004 Flynn's Taxonomie 1 Gliederung Einleitung Gliederung Flynn s Taxonomie Das SISD-Modell
Seminarvortrag: Direktivenbasierte Programmierung von Beschleunigern mit OpenMP 4.5 und OpenACC 2.5 im Vergleich
 Seminarvortrag: Direktivenbasierte Programmierung von Beschleunigern mit Direktivenbasierte Programmierung von Beschleunigern mit Agenda Einführung / Motivation Überblick zu OpenMP und OpenACC Asynchronität
Seminarvortrag: Direktivenbasierte Programmierung von Beschleunigern mit Direktivenbasierte Programmierung von Beschleunigern mit Agenda Einführung / Motivation Überblick zu OpenMP und OpenACC Asynchronität
XSC. Reimar Bauer, Rebecca Breu. Dezember 2008. Forschungszentrum Jülich. Weihnachtsfeier, 10. Dezember 2008 1
 XSC Reimar Bauer, Rebecca Breu Forschungszentrum Jülich Dezember 2008 Weihnachtsfeier, 10. Dezember 2008 1 Supercomputing I I Forschungszentrum Ju lich mischt da mit Zweimal im Jahr gibt es eine Top 500-Liste
XSC Reimar Bauer, Rebecca Breu Forschungszentrum Jülich Dezember 2008 Weihnachtsfeier, 10. Dezember 2008 1 Supercomputing I I Forschungszentrum Ju lich mischt da mit Zweimal im Jahr gibt es eine Top 500-Liste
Multikern-Rechner und Rechnerbündel
 Multikern-Rechner und Rechnerbündel Dr. Victor Pankratius David J. Meder IPD Tichy Lehrstuhl für Programmiersysteme KIT die Kooperation von Forschungszentrum Karlsruhe GmbH und Universität Karlsruhe (TH)
Multikern-Rechner und Rechnerbündel Dr. Victor Pankratius David J. Meder IPD Tichy Lehrstuhl für Programmiersysteme KIT die Kooperation von Forschungszentrum Karlsruhe GmbH und Universität Karlsruhe (TH)
Rechneraufbau und Rechnerstrukturen
 Rechneraufbau und Rechnerstrukturen von Prof. Dr. em. Walter Oberschelp, RWTH Aachen und Prof. Dr. Gottfried Vossen, Universität Münster 9. Auflage Oldenbourg Verlag München Wien Inhaltsverzeichnis Vorwort
Rechneraufbau und Rechnerstrukturen von Prof. Dr. em. Walter Oberschelp, RWTH Aachen und Prof. Dr. Gottfried Vossen, Universität Münster 9. Auflage Oldenbourg Verlag München Wien Inhaltsverzeichnis Vorwort
Parallelrechner (1) Anwendungen: Simulation von komplexen physikalischen oder biochemischen Vorgängen Entwurfsunterstützung virtuelle Realität
 Anwendungen: Simulation von komplexen physikalischen oder biochemischen Vorgängen Entwurfsunterstützung virtuelle Realität") Parallelrechner (1) Motivation: Bedarf für immer leistungsfähigere Rechner Leistungssteigerung eines einzelnen Rechners hat physikalische Grenzen: Geschwindigkeit von Materie Wärmeableitung Transistorgröße
Parallelrechner (1) Motivation: Bedarf für immer leistungsfähigere Rechner Leistungssteigerung eines einzelnen Rechners hat physikalische Grenzen: Geschwindigkeit von Materie Wärmeableitung Transistorgröße
Paralleles Rechnen in der Physik
 Paralleles Rechnen in der Physik Georg Hager Regionales Rechenzentrum Erlangen HPC Services Universität Erlangen-Nürnberg 07.05. 2002 Überblick Motivation Parallelität verstehen Paralleles Rechnen in Beispielen
Paralleles Rechnen in der Physik Georg Hager Regionales Rechenzentrum Erlangen HPC Services Universität Erlangen-Nürnberg 07.05. 2002 Überblick Motivation Parallelität verstehen Paralleles Rechnen in Beispielen
Technische Informatik II
 Technische Informatik II WS 2003/2004 Prof. Dr. J. Kaiser Abteilung Rechnerstrukturen Universität Ulm PD Dr. A. Strey Abteilung Neuroinformatik Universität Ulm 1. Inhalt der Vorlesung Technische Informatik
Technische Informatik II WS 2003/2004 Prof. Dr. J. Kaiser Abteilung Rechnerstrukturen Universität Ulm PD Dr. A. Strey Abteilung Neuroinformatik Universität Ulm 1. Inhalt der Vorlesung Technische Informatik
Entwicklung einer FPGA-basierten asymmetrischen MPSoC Architektur
 Entwicklung einer FPGA-basierten asymmetrischen Architektur INF-M1 Seminar Vortrag 25. November 2010 Betreuer: Prof. Dr.-Ing. Bernd Schwarz Übersicht 1. Motivation 2. Zielsetzung & Vorarbeiten 3. Arbeitsschwerpunkte
Entwicklung einer FPGA-basierten asymmetrischen Architektur INF-M1 Seminar Vortrag 25. November 2010 Betreuer: Prof. Dr.-Ing. Bernd Schwarz Übersicht 1. Motivation 2. Zielsetzung & Vorarbeiten 3. Arbeitsschwerpunkte
Gliederung Seite 1. Gliederung
 Gliederung Seite 1 Gliederung 1. Klassifikationen...6 1.1. Klassifikation nach der Kopplung der rechnenden Einheiten...6 1.1.1. Enge Kopplung...6 1.1.2. Lose Kopplung...6 1.2. Klassifikation nach der Art
Gliederung Seite 1 Gliederung 1. Klassifikationen...6 1.1. Klassifikation nach der Kopplung der rechnenden Einheiten...6 1.1.1. Enge Kopplung...6 1.1.2. Lose Kopplung...6 1.2. Klassifikation nach der Art
Grundlagen der Parallelisierung
 Grundlagen der Parallelisierung Philipp Kegel, Sergei Gorlatch AG Parallele und Verteilte Systeme Institut für Informatik Westfälische Wilhelms-Universität Münster 3. Juli 2009 Inhaltsverzeichnis 1 Einführung
Grundlagen der Parallelisierung Philipp Kegel, Sergei Gorlatch AG Parallele und Verteilte Systeme Institut für Informatik Westfälische Wilhelms-Universität Münster 3. Juli 2009 Inhaltsverzeichnis 1 Einführung
Georg Hager Regionales Rechenzentrum Erlangen (RRZE)
") Erfahrungen und Benchmarks mit Dual- -Prozessoren Georg Hager Regionales Rechenzentrum Erlangen (RRZE) ZKI AK Supercomputing Karlsruhe, 22./23.09.2005 Dual : Anbieter heute IBM Power4/Power5 (Power5 mit
Erfahrungen und Benchmarks mit Dual- -Prozessoren Georg Hager Regionales Rechenzentrum Erlangen (RRZE) ZKI AK Supercomputing Karlsruhe, 22./23.09.2005 Dual : Anbieter heute IBM Power4/Power5 (Power5 mit
Paralleles Rechnen. (Architektur verteilter Systeme) von Thomas Offermann Philipp Tommek Dominik Pich
 von Thomas Offermann Philipp Tommek Dominik Pich") Paralleles Rechnen (Architektur verteilter Systeme) von Thomas Offermann Philipp Tommek Dominik Pich Gliederung Motivation Anwendungsgebiete Warum paralleles Rechnen Flynn's Klassifikation Theorie: Parallel
Paralleles Rechnen (Architektur verteilter Systeme) von Thomas Offermann Philipp Tommek Dominik Pich Gliederung Motivation Anwendungsgebiete Warum paralleles Rechnen Flynn's Klassifikation Theorie: Parallel
The world we live in and Supercomputing in general
 The world we live in and Supercomputing in general Achim Streit aktuelle Prozessoren Desktop Intel Pentium 4 mit 3.2 GHz AMD Athlon XP 3200+ mit 2.2 GHz IBM PowerPC G5 mit 2.0 GHz (64-bit) Server & Workstation
The world we live in and Supercomputing in general Achim Streit aktuelle Prozessoren Desktop Intel Pentium 4 mit 3.2 GHz AMD Athlon XP 3200+ mit 2.2 GHz IBM PowerPC G5 mit 2.0 GHz (64-bit) Server & Workstation
Hochleistungsrechnen in Darmstadt: Der Lichtenberg- Hochleistungsrechner. Dr. Andreas Wolf. Gruppenleiter Hochleistungsrechnen Hochschulrechenzentrum
 Hochleistungsrechnen in Darmstadt: Der Lichtenberg- Hochleistungsrechner Dr. Andreas Wolf Gruppenleiter Hochleistungsrechnen Hochschulrechenzentrum Überblick Randbedingungen der HPC Beschaffung an der
Hochleistungsrechnen in Darmstadt: Der Lichtenberg- Hochleistungsrechner Dr. Andreas Wolf Gruppenleiter Hochleistungsrechnen Hochschulrechenzentrum Überblick Randbedingungen der HPC Beschaffung an der
Multi-threaded Programming with Cilk
 Multi-threaded Programming with Cilk Hobli Taffame Institut für Informatik Ruprecht-Karls Universität Heidelberg 3. Juli 2013 1 / 27 Inhaltsverzeichnis 1 Einleitung Warum Multithreading? Ziele 2 Was ist
Multi-threaded Programming with Cilk Hobli Taffame Institut für Informatik Ruprecht-Karls Universität Heidelberg 3. Juli 2013 1 / 27 Inhaltsverzeichnis 1 Einleitung Warum Multithreading? Ziele 2 Was ist
Intel 80x86 symmetrische Multiprozessorsysteme. Eine Präsentation im Rahmen des Seminars Parallele Rechnerarchitekturen von Bernhard Witte
 Intel 80x86 symmetrische Multiprozessorsysteme Eine Präsentation im Rahmen des Seminars Parallele Rechnerarchitekturen von Bernhard Witte Gliederung I. Parallel Computing Einführung II.SMP Grundlagen III.Speicherzugriff
Intel 80x86 symmetrische Multiprozessorsysteme Eine Präsentation im Rahmen des Seminars Parallele Rechnerarchitekturen von Bernhard Witte Gliederung I. Parallel Computing Einführung II.SMP Grundlagen III.Speicherzugriff
Übung 1. Letzte Änderung: 5. Mai 2017
 Übung 1 Letzte Änderung: 5. Mai 2017 Abhängigkeitsanalyse Synthese Mul prozessor Mul computer Compiler Parallelismustest Vektorrechner Rechenfelder Op mierung Flynns Schema Modelle Theorie Parallele Systeme
Übung 1 Letzte Änderung: 5. Mai 2017 Abhängigkeitsanalyse Synthese Mul prozessor Mul computer Compiler Parallelismustest Vektorrechner Rechenfelder Op mierung Flynns Schema Modelle Theorie Parallele Systeme
Ein Verteiltes System ist eine Ansammlung von unabhängigen Rechnern, die für seine Benutzer wie ein einzelnes Computersystem aussieht.
 Verteilte Systeme Verteilte etriebssysteme 2001-2004, F. Hauck, P. Schulthess, Vert. Sys., Univ. Ulm [2003w-VS--VS.fm, 2003-10-17 08.38] 1 1 Definition Definition nach Tanenbaum/van Steen Ein Verteiltes
Verteilte Systeme Verteilte etriebssysteme 2001-2004, F. Hauck, P. Schulthess, Vert. Sys., Univ. Ulm [2003w-VS--VS.fm, 2003-10-17 08.38] 1 1 Definition Definition nach Tanenbaum/van Steen Ein Verteiltes
Universität Karlsruhe (TH)
") Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Multikern-Rechner und Rechnerbündel Prof. Dr. Walter F. Tichy Dr. Victor Pankratius David Meder Ali Jannesari Inhalt der Vorlesung Rechnerbündel
Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Multikern-Rechner und Rechnerbündel Prof. Dr. Walter F. Tichy Dr. Victor Pankratius David Meder Ali Jannesari Inhalt der Vorlesung Rechnerbündel
Games with Cellular Automata auf Parallelen Rechnerarchitekturen
 Bachelor Games with Cellular Automata auf Parallelen en ( ) Dipl.-Inf. Marc Reichenbach Prof. Dietmar Fey Ziel des s Paralleles Rechnen Keine akademische Nische mehr Vielmehr Allgemeingut für den Beruf
Bachelor Games with Cellular Automata auf Parallelen en ( ) Dipl.-Inf. Marc Reichenbach Prof. Dietmar Fey Ziel des s Paralleles Rechnen Keine akademische Nische mehr Vielmehr Allgemeingut für den Beruf
3 Technikarchitekturen
 3 Technikarchitekturen 3.1 Rechnerarchitektur Definition Taxonomien Komponenten Rechnergrößentypologie 3.2 Kommunikationssystemarchitektur ISO-Referenzmodell TCP/IP Grundlagen der Telekommunikation 3.3
3 Technikarchitekturen 3.1 Rechnerarchitektur Definition Taxonomien Komponenten Rechnergrößentypologie 3.2 Kommunikationssystemarchitektur ISO-Referenzmodell TCP/IP Grundlagen der Telekommunikation 3.3
Seminar Parallele Rechnerarchitekturen SS04 \ SIMD Implementierung aktueller Prozessoren 2 (Dominik Tamm) \ Inhalt. Seite 1
 \ Inhalt. Seite 1") \ Inhalt Seite 1 \ Inhalt SIMD Kurze Rekapitulation 3Dnow! (AMD) AltiVec (PowerPC) Quellen Seite 2 \ Wir erinnern uns: Nach Flynn s Taxonomie kann man jeden Computer In eine von vier Kategorien einteilen:
\ Inhalt Seite 1 \ Inhalt SIMD Kurze Rekapitulation 3Dnow! (AMD) AltiVec (PowerPC) Quellen Seite 2 \ Wir erinnern uns: Nach Flynn s Taxonomie kann man jeden Computer In eine von vier Kategorien einteilen:
Parallele Programmierung. Prof. Dr. Rita Loogen Fachbereich Mathematik und Informatik WS 2008/09
 Parallele Programmierung Prof. Dr. Rita Loogen Fachbereich Mathematik und Informatik WS 2008/09 Vom Problem zum Programm Problem Algorithmus Programm Rechner 2 Sequentialität Sequenz: natürliches Konzept
Parallele Programmierung Prof. Dr. Rita Loogen Fachbereich Mathematik und Informatik WS 2008/09 Vom Problem zum Programm Problem Algorithmus Programm Rechner 2 Sequentialität Sequenz: natürliches Konzept
2 Reproduktion oder Verwendung dieser Unterlage bedarf in jedem Fall der Zustimmung des Autors.
 1 Definition Definition nach Tanenbaum/van Steen Ein Verteiltes System ist eine Ansammlung von unabhängigen Rechnern, die für seine enutzer wie ein einzelnes Computersystem aussieht. Verteilte Systeme
1 Definition Definition nach Tanenbaum/van Steen Ein Verteiltes System ist eine Ansammlung von unabhängigen Rechnern, die für seine enutzer wie ein einzelnes Computersystem aussieht. Verteilte Systeme
Technische Grundlagen der Informatik 2 SS Einleitung. R. Hoffmann FG Rechnerarchitektur Technische Universität Darmstadt E-1
 E-1 Technische Grundlagen der Informatik 2 SS 2009 Einleitung R. Hoffmann FG Rechnerarchitektur Technische Universität Darmstadt Lernziel E-2 Verstehen lernen, wie ein Rechner auf der Mikroarchitektur-Ebene
E-1 Technische Grundlagen der Informatik 2 SS 2009 Einleitung R. Hoffmann FG Rechnerarchitektur Technische Universität Darmstadt Lernziel E-2 Verstehen lernen, wie ein Rechner auf der Mikroarchitektur-Ebene
Neue Dual-CPU Server mit Intel Xeon Scalable Performance (Codename Purley/Skylake-SP)
") Neue Dual-CPU Server mit Intel Xeon Scalable Performance (Codename Purley/Skylake-SP) @wefinet Werner Fischer, Thomas-Krenn.AG Webinar, 17. Oktober 2017 Intel Xeon Scalable Performance _ Das ist NEU: Neue
Neue Dual-CPU Server mit Intel Xeon Scalable Performance (Codename Purley/Skylake-SP) @wefinet Werner Fischer, Thomas-Krenn.AG Webinar, 17. Oktober 2017 Intel Xeon Scalable Performance _ Das ist NEU: Neue
Rechnerarchitektur SS 2014
 Rechnerarchitektur SS 2014 Parallele Rechnersysteme Michael Engel TU Dortmund, Fakultät für Informatik Teilweise basierend auf Material von Gernot A. Fink und R. Yahyapour 3. Juni 2014 1/30 Mehrprozessorsysteme
Rechnerarchitektur SS 2014 Parallele Rechnersysteme Michael Engel TU Dortmund, Fakultät für Informatik Teilweise basierend auf Material von Gernot A. Fink und R. Yahyapour 3. Juni 2014 1/30 Mehrprozessorsysteme
Technische Informatik I
 Technische Informatik I SS 2001 PD Dr. A. Strey Abteilung Neuroinformatik Universität Ulm Inhalt Einführung: Überblick über die historische Entwicklung der Rechnerhardware Teil 1: Digitale Logik kurzer
Technische Informatik I SS 2001 PD Dr. A. Strey Abteilung Neuroinformatik Universität Ulm Inhalt Einführung: Überblick über die historische Entwicklung der Rechnerhardware Teil 1: Digitale Logik kurzer
Di 7.4. Herausforderung Mehrkern-Systeme. Walter Tichy. January 26-30, 2009, Munich, Germany ICM - International Congress Centre Munich
 Di 7.4 January 26-30, 2009, Munich, Germany ICM - International Congress Centre Munich Herausforderung Mehrkern-Systeme Walter Tichy Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Herausforderung
Di 7.4 January 26-30, 2009, Munich, Germany ICM - International Congress Centre Munich Herausforderung Mehrkern-Systeme Walter Tichy Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Herausforderung
Cell and Larrabee Microarchitecture
 Cell and Larrabee Microarchitecture Benjamin Grund Dominik Wolfert Universität Erlangen-Nürnberg 1 Übersicht Einleitung Herkömmliche Prozessorarchitekturen Motivation für Entwicklung neuer Architekturen
Cell and Larrabee Microarchitecture Benjamin Grund Dominik Wolfert Universität Erlangen-Nürnberg 1 Übersicht Einleitung Herkömmliche Prozessorarchitekturen Motivation für Entwicklung neuer Architekturen
Michael Stumpen Grid Computing. Prof. Dr. Fuhr SS04 Kommunikation. Wide-Area Implementation of the Message Passing Interface
 Michael Stumpen 740261 Grid Computing Prof. Dr. Fuhr SS04 Kommunikation Wide-Area Implementation of the Message Passing Interface 1. Einleitung Idee zu Grid Computing entstand Anfang der 70er Zunehmendes
Michael Stumpen 740261 Grid Computing Prof. Dr. Fuhr SS04 Kommunikation Wide-Area Implementation of the Message Passing Interface 1. Einleitung Idee zu Grid Computing entstand Anfang der 70er Zunehmendes
Generation 5: Invisible Computers (ab 1993)
") Generation 5: Invisible Computers (ab 1993) Jahr Name Gebaut von Kommentar 1993 PIC Microchip Technology Erster Mikrocontroller auf Basis von EEPROMs. Diese erlauben das Flashen ohne zusätzliche. Bemerkung:
Generation 5: Invisible Computers (ab 1993) Jahr Name Gebaut von Kommentar 1993 PIC Microchip Technology Erster Mikrocontroller auf Basis von EEPROMs. Diese erlauben das Flashen ohne zusätzliche. Bemerkung:
Grundlagen der Rechnerarchitektur. Einführung
 Grundlagen der Rechnerarchitektur Einführung Unsere erste Amtshandlung: Wir schrauben einen Rechner auf Grundlagen der Rechnerarchitektur Einführung 2 Vorlesungsinhalte Binäre Arithmetik MIPS Assembler
Grundlagen der Rechnerarchitektur Einführung Unsere erste Amtshandlung: Wir schrauben einen Rechner auf Grundlagen der Rechnerarchitektur Einführung 2 Vorlesungsinhalte Binäre Arithmetik MIPS Assembler
System-Architektur und -Software
 System-Architektur und -Software Sommersemester 2001 Lutz Richter Institut für Informatik Universität Zürich Obligatorische Veranstaltung des Kerngebietes System-Architektur und -Software Voraussetzungen
System-Architektur und -Software Sommersemester 2001 Lutz Richter Institut für Informatik Universität Zürich Obligatorische Veranstaltung des Kerngebietes System-Architektur und -Software Voraussetzungen
Paralleles Höchstleistungsrechnen Einführung
 1/40 Paralleles Höchstleistungsrechnen Einführung Peter Bastian Interdisziplinäres Zentrum für Wissenschaftliches Rechnen Universität Heidelberg Im Neuenheimer Feld 368 D-69120 Heidelberg email: Peter.Bastian@iwr.uni-heidelberg.de
1/40 Paralleles Höchstleistungsrechnen Einführung Peter Bastian Interdisziplinäres Zentrum für Wissenschaftliches Rechnen Universität Heidelberg Im Neuenheimer Feld 368 D-69120 Heidelberg email: Peter.Bastian@iwr.uni-heidelberg.de
B Einführung. 1 Historische Entwicklung. 1 Historische Entwicklung (3) 1 Historische Entwicklung (2)
 1 Historische Entwicklung (2)") 1 Historische Entwicklung 8500 v. Chr.: Zählsysteme in vielen Kulturen benutzt häufig 5 oder 10 als Basis 1. historische Entwicklung 2. Entwicklung der Mikroprozessoren 3. Entwicklung der Betriebssysteme
1 Historische Entwicklung 8500 v. Chr.: Zählsysteme in vielen Kulturen benutzt häufig 5 oder 10 als Basis 1. historische Entwicklung 2. Entwicklung der Mikroprozessoren 3. Entwicklung der Betriebssysteme
Rechnerstrukturen Winter EINFÜHRUNG. (c) Peter Sturm, University of Trier 1
 Peter Sturm, University of Trier 1") 1. EINFÜHRUNG (c) Peter Sturm, University of Trier 1 Teilnehmer Vorlesung für Bachelor- Informatik Vorlesungszeiten Montags, 12.30 14.00 Uhr, Hörsaal HS13 Übungen und Übungsblätter Wöchentlich Blog Asysob
1. EINFÜHRUNG (c) Peter Sturm, University of Trier 1 Teilnehmer Vorlesung für Bachelor- Informatik Vorlesungszeiten Montags, 12.30 14.00 Uhr, Hörsaal HS13 Übungen und Übungsblätter Wöchentlich Blog Asysob
Sun HPC Agenda
 Sun HPC 2005 - Agenda 10:00 Willkommen und Einleitung Klaus Brühl, RZ, 10:15 Neues vom Aachener Sun Fire SMP Cluster Dieter an Mey, RZ, 10:30 UltraSPARC - Today and Tomorrow Ruud van der Pas, Scalable
Sun HPC 2005 - Agenda 10:00 Willkommen und Einleitung Klaus Brühl, RZ, 10:15 Neues vom Aachener Sun Fire SMP Cluster Dieter an Mey, RZ, 10:30 UltraSPARC - Today and Tomorrow Ruud van der Pas, Scalable
(Software) Architektur der Dinge. Roland Graf / Simon Kranzer IKT-Forum 2016 I(o)T for Industry - Von IT zu IoT
 Architektur der Dinge. Roland Graf / Simon Kranzer IKT-Forum 2016 I(o)T for Industry - Von IT zu IoT") (Software) Architektur der Dinge Roland Graf / Simon Kranzer IKT-Forum 2016 I(o)T for Industry - Von IT zu IoT Hardware Mainframe Speichersysteme Rechner Kopplung Zentralisierung Anwendungsprogramme Software
(Software) Architektur der Dinge Roland Graf / Simon Kranzer IKT-Forum 2016 I(o)T for Industry - Von IT zu IoT Hardware Mainframe Speichersysteme Rechner Kopplung Zentralisierung Anwendungsprogramme Software
Teil Rechnerarchitekturen M07. Multiprogramming und Tasking, Flynn-Klassifikation, Parallelismus. Corinna Schmitt
 Teil Rechnerarchitekturen M07 Multiprogramming und Tasking, Flynn-Klassifikation, Parallelismus Corinna Schmitt corinna.schmitt@unibas.ch Multiprogrammierung und -Tasking 2015 Corinna Schmitt Teil Rechnerarchitekturen
Teil Rechnerarchitekturen M07 Multiprogramming und Tasking, Flynn-Klassifikation, Parallelismus Corinna Schmitt corinna.schmitt@unibas.ch Multiprogrammierung und -Tasking 2015 Corinna Schmitt Teil Rechnerarchitekturen
Datenparallelität. Bildverarbeitung Differentialgleichungen lösen Finite Element Methode in Entwurfssystemen
 Datenparallelität PPJ-38 Viele Prozesse bzw. Prozessoren führen zugleich die gleichen Operationen auf verschiedenen Daten aus; meist Datenelemente in regulären Datenstrukturen: Array, Folge Matrix, Liste.
Datenparallelität PPJ-38 Viele Prozesse bzw. Prozessoren führen zugleich die gleichen Operationen auf verschiedenen Daten aus; meist Datenelemente in regulären Datenstrukturen: Array, Folge Matrix, Liste.
Parallele Programmiermodelle
 Parallele Programmiermodelle ProSeminar: Parallele Programmierung Semester: WS 2012/2013 Dozentin: Margarita Esponda Einleitung - Kurzer Rückblick Flynn'sche Klassifikationsschemata Unterteilung nach Speicherorganissation
Parallele Programmiermodelle ProSeminar: Parallele Programmierung Semester: WS 2012/2013 Dozentin: Margarita Esponda Einleitung - Kurzer Rückblick Flynn'sche Klassifikationsschemata Unterteilung nach Speicherorganissation
Automatische Parallelisierung
 MPI und OpenMP in HPC Anwendungen findet man immer häufiger auch den gemeinsamen Einsatz von MPI und OpenMP: OpenMP wird zur thread-parallelen Implementierung des Codes auf einem einzelnen Rechenknoten
MPI und OpenMP in HPC Anwendungen findet man immer häufiger auch den gemeinsamen Einsatz von MPI und OpenMP: OpenMP wird zur thread-parallelen Implementierung des Codes auf einem einzelnen Rechenknoten
HPC und paralleles Rechnen
 Prof. Dr. Dieter Kranzlmüller Dr. Nils gentschen Felde Dr. Karl Fürlinger Stephan Reiter Christian Straube HPC und paralleles Rechnen Workshop im Rahmen des Informatik-Probestudiums 2012 1 Überblick/Agenda
Prof. Dr. Dieter Kranzlmüller Dr. Nils gentschen Felde Dr. Karl Fürlinger Stephan Reiter Christian Straube HPC und paralleles Rechnen Workshop im Rahmen des Informatik-Probestudiums 2012 1 Überblick/Agenda
COMPUTERKLASSEN MULTICOMPUTER und SPEZIALANWENDUNGSSYSTEME
 D - CA - XIX - CC,M&SPC - 1 HUMBOLDT-UNIVERSITÄT ZU BERLIN INSTITUT FÜR INFORMATIK Vorlesung 19 COMPUTERKLASSEN MULTICOMPUTER und SPEZIALANWENDUNGSSYSTEME Sommersemester 2003 Leitung: Prof. Dr. Miroslaw
D - CA - XIX - CC,M&SPC - 1 HUMBOLDT-UNIVERSITÄT ZU BERLIN INSTITUT FÜR INFORMATIK Vorlesung 19 COMPUTERKLASSEN MULTICOMPUTER und SPEZIALANWENDUNGSSYSTEME Sommersemester 2003 Leitung: Prof. Dr. Miroslaw
Projektseminar Parallele Programmierung
 HTW Dresden WS 2014/2015 Organisatorisches Praktikum, 4 SWS Do. 15:00-18:20 Uhr, Z136c, 2 Doppelstunden o.g. Termin ist als Treffpunkt zu verstehen Labore Z 136c / Z 355 sind Montag und Donnerstag 15:00-18:20
HTW Dresden WS 2014/2015 Organisatorisches Praktikum, 4 SWS Do. 15:00-18:20 Uhr, Z136c, 2 Doppelstunden o.g. Termin ist als Treffpunkt zu verstehen Labore Z 136c / Z 355 sind Montag und Donnerstag 15:00-18:20
Erste Ergebnisse mit MPI auf der NEC SX-4
 PARALLELES RECHNEN Erste Ergebnisse mit MPI auf der NEC SX-4 Verwendung von MPI MPI/SX MPICH Kommunikationsleistung Leistung einer CFD-Applikation Literatur Message Passing-Anwendungen auf einer shared-memory
PARALLELES RECHNEN Erste Ergebnisse mit MPI auf der NEC SX-4 Verwendung von MPI MPI/SX MPICH Kommunikationsleistung Leistung einer CFD-Applikation Literatur Message Passing-Anwendungen auf einer shared-memory
Evaluation. Einleitung. Implementierung Integration. Zusammenfassung Ausblick
 Christopher Schleiden Bachelor Kolloquium 15.09.2009 Einleitung Evaluation Implementierung Integration Zusammenfassung Ausblick Einleitung laperf Lineare Algebra Bibliothek für C++ Möglichkeit zur Integration
Christopher Schleiden Bachelor Kolloquium 15.09.2009 Einleitung Evaluation Implementierung Integration Zusammenfassung Ausblick Einleitung laperf Lineare Algebra Bibliothek für C++ Möglichkeit zur Integration
Speicherarchitektur (23) Suchen einer Seite:
 Suchen einer Seite:") Speicherarchitektur (23) Suchen einer Seite: Vorlesung Rechnersysteme SS `09 E. Nett 7 Speicherarchitektur (24) Adressschema inklusive Seitenfehler: Vorlesung Rechnersysteme SS `09 E. Nett 8 Speicherarchitektur
Speicherarchitektur (23) Suchen einer Seite: Vorlesung Rechnersysteme SS `09 E. Nett 7 Speicherarchitektur (24) Adressschema inklusive Seitenfehler: Vorlesung Rechnersysteme SS `09 E. Nett 8 Speicherarchitektur
moderne Prozessoren Jan Krüger jkrueger@techfak.uni-bielefeld.de
 moderne Prozessoren Jan Krüger jkrueger@techfak.uni-bielefeld.de Übersicht FachChinesisch SPARC - UltraSparc III/IV PowerPC - PowerPC 970(G5) X86 - Pentium4(Xeon), Itanium, (Pentium M) X86 - AthlonXP/MP,
moderne Prozessoren Jan Krüger jkrueger@techfak.uni-bielefeld.de Übersicht FachChinesisch SPARC - UltraSparc III/IV PowerPC - PowerPC 970(G5) X86 - Pentium4(Xeon), Itanium, (Pentium M) X86 - AthlonXP/MP,
Parallele Algorithmen
 Parallele Algorithmen Dipl.-Inf., Dipl.-Ing. (FH) Michael Wilhelm Hochschule Harz FB Automatisierung und Informatik mwilhelm@hs-harz.de Raum 2.202 Tel. 03943 / 659 338 FB Automatisierung und Informatik:
Parallele Algorithmen Dipl.-Inf., Dipl.-Ing. (FH) Michael Wilhelm Hochschule Harz FB Automatisierung und Informatik mwilhelm@hs-harz.de Raum 2.202 Tel. 03943 / 659 338 FB Automatisierung und Informatik:
Parallele Algorithmen
 Parallele Algorithmen Dipl.-Inf., Dipl.-Ing. (FH) Michael Wilhelm Hochschule Harz FB Automatisierung und Informatik mwilhelm@hs-harz.de Raum 2.202 Tel. 03943 / 659 338 FB Automatisierung und Informatik:
Parallele Algorithmen Dipl.-Inf., Dipl.-Ing. (FH) Michael Wilhelm Hochschule Harz FB Automatisierung und Informatik mwilhelm@hs-harz.de Raum 2.202 Tel. 03943 / 659 338 FB Automatisierung und Informatik:
Ruprecht-Karls-Universität Heidelberg
 Ruprecht-Karls-Universität Heidelberg PS: Themen der technischen Informatik Sommersemester 2013 Referentin: Hanna Khoury Betreuer: Prof. Dr. Ulrich Brüning, Dr. Frank Lemke Datum: 10.06.2014 1) Einige
Ruprecht-Karls-Universität Heidelberg PS: Themen der technischen Informatik Sommersemester 2013 Referentin: Hanna Khoury Betreuer: Prof. Dr. Ulrich Brüning, Dr. Frank Lemke Datum: 10.06.2014 1) Einige