Stochastik Praktikum Nichtparametrische Dichteschätzung
|
|
|
- Andrea Bieber
- vor 5 Jahren
- Abrufe
Transkript

1 Stochastik Praktikum Nichtparametrische Dichteschätzung Humboldt-Universität zu Berlin
2 Einleitung Zunächst: X 1,..., X n reellwertige i. i. d. Zufallsvariablen, deren Verteilung die Dichte f bezüglich des Lebesgue Maßes besitzt. Datenbeispiel: 272 beobachtete Ausbrüche des Old Faithful Geysirs im Yellowstone National Park mit Eruptionsdauer sowie der Wartezeit bis zum nächsten Ausbruch > data ( f a i t h f u l ) > er< f a i t h f u l $ e r u p t i o n s
3 Übersicht 1 Histogramm Schätzer und empirische Verteilungsfunktion 2 Univariate Kerndichteschätzung 3 Bandweitenwahl für Kernschätzer 4 Multivariate Kerndichteschätzung
4 Histogramm Schätzer Intervalle ( bins ) I s : I s = (a s 1, a s ], s {1,..., d} n s := #{x i I s, i {1,..., n}} ˆfhist (x) = n s n Im Falle gleicher Intervalllängen mit a s a s 1 h s {1,..., d}: 1 a s a s 1 1 {Is}(x) ˆfhist (x) = n s nh 1 {I s}(x)
5 > hist (er, freq=false,col="grey")

6 Nachteil des Histogramm Schätzers: Schätzer hängt von der Wahl der bin Längen und des Startwertes ab!
7 Empirische Verteilungsfunktion F n (x) = #{x i x i x, i {1,..., n} n = n i=1 1 n 1 (,x](x i ). Satz von Glivenko Cantelli liefert fast sichere gleichmäßige Konvergenz: lim sup F n (x) F(x) = 0 P f f.s. n x R > ecdf ( er ) E m p i r i c a l CDF C a l l : ecdf ( er ) x [ 1 : ] = 1.6, 1.667, 1.7,..., 5.067, 5.1 > summary ( ecdf ( er ) ) E m p i r i c a l CDF: 126 unique values with summary Min. 1 s t Qu. Median Mean 3 rd Qu. Max
8
9 Gleitendes Histogramm Durch den gleitenden Histogramm Schätzer ˆfGH (x) := #{x i x i (x h, x + h]} = F n(x + h) F n (x h) 2hn 2h = 1 n ( ) x xi K R mit K R (t) = (1/2)1 nh h [ 1,1] (t), i=1 bei dem jede Beobachtung Mittelpunkt eines bins ist, lässt sich das Startwertproblem lösen.
10
11 Übersicht 1 Histogramm Schätzer und empirische Verteilungsfunktion 2 Univariate Kerndichteschätzung 3 Bandweitenwahl für Kernschätzer 4 Multivariate Kerndichteschätzung
12 Kernfunktionen Definition Eine Funktion K : R R heißt Kern, falls gilt: 1 K(x)dx = 1, K(x) 0 x R, K(x) = K( x) Regularitätsbedingungen: 2 sup x R K(x) = M < 3 x K(x) 0 für x 0, x 2 K(x)dx =: k 2 <.
13 Beispiele für Kernfunktionen: Rechteckskern Dreieckskern K(x) = [ 1,1](x), K(x) = (1 x )1 [ 1,1] (x), Gaußkern K(x) = 1 2π exp( x 2 /2), Bisquarekern K(x) = (1 x 2 ) 2 1 [ 1,1] (x), Epanechnikovkern K(x) = 3 4 (1 x 2 )1 [ 1,1] (x).
14 Grafische Darstellung der Kernfunktionen
15 Univariater Kerndichteschätzer Definition Sei K : R R ein Kern. ˆfn (t) = 1 nh n ( ) t xi K = h i=1 1 h K ( t x h ) F n (dx) heißt (univariater) Kerndichteschätzer mit Bandweite h und Kern K. Mit K(t) := t K(x)dx lässt sich auch F schätzen durch: n ( t x ˆF n (t) = 1 n i=1 ( ) t xi K = h K h ) F n (dx).
16 Gauß Kernschätzer (fünf Moden)
17 Gauß Kernschätzer (neun Moden)
18 Gauß Kernschätzer (50 Moden)
19
20 Entscheidende Schwierigkeit: Wahl der Bandweite! h zu groß oversmoothing lokale Extrema werden nicht erkannt, zu glatt h zu klein undersmoothing lokale Moden, Schätzer ist hairy
21 Übersicht 1 Histogramm Schätzer und empirische Verteilungsfunktion 2 Univariate Kerndichteschätzung 3 Bandweitenwahl für Kernschätzer 4 Multivariate Kerndichteschätzung
22 Bias Satz Wenn K : R R ein Kern ist, der die oben genannten Regularitätsbedingungen erfüllt, und f C 2 (R), so gilt: E f [ˆf n (x)] f (x) = h2 2 f (x) x 2 K(x)dx + O(h 2 ).
23 Bias Beweis über Taylor Entwicklung von f : f (x ht) = f (x) htf (x) + h2 t 2 2 f (x) + O(h 2 t 2 ) ( ) 1 x y E f [ˆf n (x)] f (x) = h K f (y)dy f (x) h = hf (x) yk(y)dy + }{{} h 2 f (x) 2 =0 = h2 f (x) k 2 + O(h 2 t 2 ). 2 y 2 K(y)dy +O(h 2 t 2 ) } {{ } =k 2
24 Varianz Satz Wenn K : R R ein Kern ist, der die oben genannten Regularitätsbedingungen erfüllt, und f C(R), so gilt: ) Var f (ˆfn (x) = 1 nh f (x) ( K 2 (y)dy + O n 1 h 1).
25 Varianz Beweis: ) Var (ˆfn (x) = 1 n 2 h 2 = 1 nh 2 = 1 nh n i=1 = 1 nh f (x) ( ( x xi Var K K 2 ( x y h )) h ) f (y)dy 1 n ( ) 2 E[ˆf n (x)] ( K 2 (y)f (x yh)dy n 1 E[ˆf n (x)] ( K 2 (y)dy + O n 1 h 1). ) 2
26 Mean Squared Error: Bias Varianz Zerlegung [ ) ] 2 E f (ˆfn (x) f (x) = Bias(ˆf n (x h)) 2 + Var(ˆf n (x h)) ( ) f = h k nh f (x) Trade Off zwischen Bias und Varianz Anmerkung: ( K 2 (y)dy + O h 4 + n 1 h 1). Bias hängt nicht explizit vom Stichprobenumfang n ab.
27 Optimaler Kern Minimierung des MISE bezüglich h ergibt optimale Bandweite: ( K 2 (y)dy )1 /5 h opt = ( n 1 /5 k 1 /5 2 (f (y)) dy) 2 1/5. (1) Setzt man h opt in den MISE ein, erhält man ( MISE 5 ( 4/5 ) ( k 2 /5 (f 4 2 K (y)dy) 2 (y) ) ) 1/5 2 dy. Minimal für Epanechnikov Kern: K e (x) = 3 (1 4 x 2 ) [ 5,5] (x).
28 Optimaler Kern Setzt man h opt in den MISE ein, erhält man ( MISE 5 ( 4/5 ) ( k 2 /5 (f 4 2 K (y)dy) 2 (y) ) ) 1/5 2 dy. Minimal für Epanechnikov Kern: K e (x) = (1 x 2 5 ) 1 [ 5,5] (x). Effizienz eff (K) für K K e und n gegeben: Zahl eff (K) löst Gleichung MISE(n, K) = MISE(n eff (K), K e ). Gauß Kern: Effizienz von ca. 0.95, Rechteck Kern: Effizienz von ca
29 Andere Methoden zur Bandweitenwahl Methoden der ersten Generation: Silverman s rule of thumb biased und unbiased cross validation Methoden der zweiten Generation: Plug-in Methode von Sheather and Jones smoothed Cross Validation Kontrastmethoden Bootstrap/Jackknife Methoden
30 Andere Methoden zur Bandweitenwahl Methoden der ersten Generation: Silverman s rule of thumb biased und unbiased cross validation Methoden der zweiten Generation: Plug-in Methode von Sheather and Jones smoothed Cross Validation Kontrastmethoden Bootstrap/Jackknife Methoden
31 Andere Methoden zur Bandweitenwahl Methoden der ersten Generation: Silverman s rule of thumb biased und unbiased cross validation Methoden der zweiten Generation: Plug-in Methode von Sheather and Jones smoothed Cross Validation Kontrastmethoden Bootstrap/Jackknife Methoden
32 Andere Methoden zur Bandweitenwahl Methoden der ersten Generation: Silverman s rule of thumb biased und unbiased cross validation Methoden der zweiten Generation: Plug-in Methode von Sheather and Jones smoothed Cross Validation Kontrastmethoden Bootstrap/Jackknife Methoden
33 Andere Methoden zur Bandweitenwahl Methoden der ersten Generation: Silverman s rule of thumb biased und unbiased cross validation Methoden der zweiten Generation: Plug-in Methode von Sheather and Jones smoothed Cross Validation Kontrastmethoden Bootstrap/Jackknife Methoden
34 Andere Methoden zur Bandweitenwahl Methoden der ersten Generation: Silverman s rule of thumb biased und unbiased cross validation Methoden der zweiten Generation: Plug-in Methode von Sheather and Jones smoothed Cross Validation Kontrastmethoden Bootstrap/Jackknife Methoden
35 Silverman s rule of thumb Unter Normalverteilungsannahme (f = ϕ) kann man die optimale Bandweite (1) in Abhängigkeit von σ berechnen: (f (x) ) 2 dx = σ 5 (ϕ(x)) 2 dx = 3 8 π σ σ 5, h opt = ( ) 1/5 4 σn 1/5 1.06σn 1/5. 3 Schätzt man σ aus den Daten, lässt sich damit auch h opt schätzen.
36 Kleinste Quadrate Kreuzvalidierung Betrachte integrierten quadratischen Fehler (ˆf f ) 2 = ˆf 2 2 ˆf f + f 2. Entscheidend: Mittleren Term schätzen. (Leave one out) Least Squares Cross Validation (LSCV): 1 ( ) x Xj ˆf i (x) = K. (n 1)h h Da der Bias nur von h und K abhängt, aber nicht von n, gilt: [ ] 1 ] ] E f ˆf i (X i ) = E n f [ˆfn (X n ) = E f [ˆf (X). i j i
37 Vergleich von Bandweiten
38 Übersicht 1 Histogramm Schätzer und empirische Verteilungsfunktion 2 Univariate Kerndichteschätzung 3 Bandweitenwahl für Kernschätzer 4 Multivariate Kerndichteschätzung
39 mehrdimensionale Kernfunktionen Modell: X 1,..., X n R p i. i. d. f. Definition (p-dimensionaler Kern) Eine Funktion K : R p R mit Regularitätsbedingungen: R p K(y)dy = 1 und K ist radialsymmetrische Wahrscheinlichkeitsdichte Beschränkter Träger oder zumindest x K(x) 0 für x 0
40 Mehrdimensionale Kernfunktionen Beispiele: uniformer Kern K(x) = 1 v p für x T x 1, Gaußkern K(x) = 1 (2π) p /2 exp ( 1 2 xt x ), Epanechnikovkern K(x) = 1+p/2 v p (1 x T x), x T x 1.
41 Multivariater Kernschätzer Definition Sei K : R p R ein Kern. ˆfn (x) = 1 nh p n ( x Xi K h i=1 ), x R p heißt multivariater Kerndichteschätzer mit Bandweite h und Kern K.
42 Multivariater Kernschätzer Definition Sei K : R p R ein Kern. ˆfn (x) = 1 nh p n ( x Xi K h i=1 ), x R p heißt multivariater Kerndichteschätzer mit Bandweite h und Kern K. Bias und Varianz: ) Bias h (ˆfn (x) = h2 2 ) Var h (ˆfn (x) = 1 nh p f (x) y 2 1 K(y)dy + O(h2 ), ( K 2 (y)dy + O n 1 h p).
43 Multivariater Kernschätzer Definition Sei K : R p R ein Kern. ˆfn (x) = 1 nh p n ( x Xi K h i=1 ), x R p heißt multivariater Kerndichteschätzer mit Bandweite h und Kern K. Minimierung des MISE: h p+4 opt = p n K 2 ( (y)dy ( y 2 1 K(y)dy ) 2 ) ( f (y)) 2 dy.

44 Darstellung zweidimensionaler Kernfunktionen Gaußkern und Epanechnikovkern mit p = 2
45 Verschiedene Bandweiten in unterschiedliche Richtungen Allgemeiner als in obiger Definition kann man den multivariaten Kerndichteschätzer mit einer Bandweitenmatrix H definieren: ˆfn (x) = 1 ( ) n H K H 1/2 (x X 1 /2 i ), x R p. Zuvor: H = h1 p, wobei 1 p die p dimensionale Einheitsmatrix bezeichnet In R: Diagonalmatrix H angebbar.
46 R Code: Zweidimensionale Kerndichteschätzung > l i b r a r y (MASS) > l i b r a r y ( KernSmooth ) > data ( f a i t h f u l ) > x< f a i t h f u l $ e r u p t i o n s > y< f a i t h f u l $ w a i t i n g > par ( mfrow=c ( 2, 2 ), pty ="m" ) > p l o t ( y, x, ylab =" e r u p t i o n ", xlab =" w a i t i n g " ) > z< kde2d ( x, y, lims=c (0,6,35,100)) > zz< bkde2d ( f a i t h f u l, range. x= l i s t ( c ( 0, 6 ), c ( 3 5, ) ), + bandwidth=c (bw. SJ ( x ),bw. SJ ( y ) ) ) > image ( z, xlab =" e r u p t i o n ", ylab =" w a i t i n g " ) > image ( zz$fhat, xlab =" e r u p t i o n ", ylab =" w a i t i n g " ) > persp ( z, c o l =" s l a t e g r e y ", t h e t a =35, x lim=c ( 0, 6 ), y lim=c (35,100), + t i c k t y p e =" d e t a i l e d ", xlab =" e r u p t i o n ", ylab =" w a i t i n g ", zlab = " " )
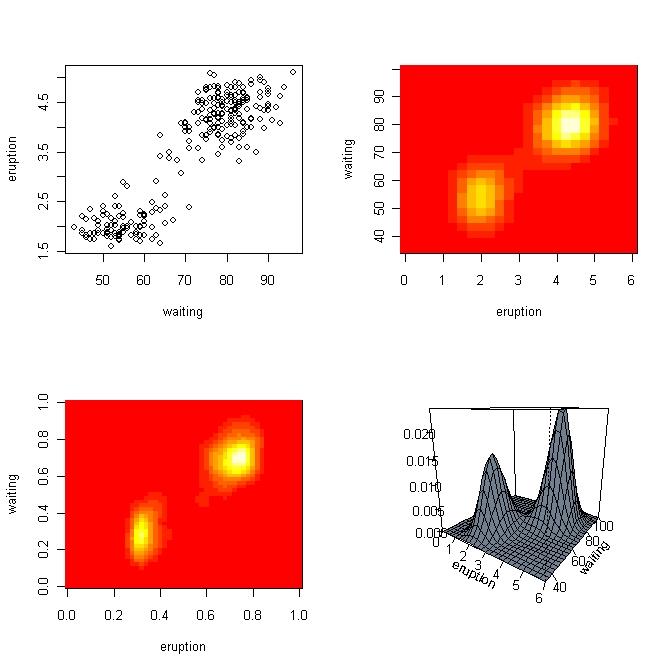
47 Zweidimensionale Kerndichteschätzung
 > contour ( zz$x1, zz$x2, zz$fhat")
48 > persp ( zz$x1, zz$x2, zz$fhat, c o l =" s l a t e g r e y ", + t h e t a =35, xlim=c ( 0, 6 ), ylim=c (35,100), + ticktype =" detailed ", xlab =" eruption ", + ylab =" w a i t i n g ", zlab = " " ) > contour ( zz$x1, zz$x2, zz$fhat )
49 Literatur Bernard W. Silverman Density estimation for statistics and data analysis. Chapman and Hall/CRC, Simon J. Sheather and M.C. Jones A Reliable Data-Based Bandwidth Selection Method for Kernel Density Estimation. Journal of the Royal Statistical Society, 53(3): , David W. Scott Multivariate Density Estimation: Theory, Practice and Visualization. New York: Wiley, 1992.
50 Literatur J. Steven Marron and Peter Hall and Byeong U. Park Smoothed Cross Validation. Probability Theory and Related Fields, 92:1-20, A. R. Mugdadi and Ibrahim A. Ahmad A Bandwidth Selection for Kernel Density Estimation of Functions of Random Variables. Computational Statistics and Data Analysis, 47(1):49-62, 1992.
Methoden der Statistik Kapitel 2: Deskriptive Statistik
 Methoden der Statistik Kapitel 2: Deskriptive Statistik Thorsten Dickhaus Humboldt-Universität zu Berlin Wintersemester 2011/2012 Übersicht Univariate Merkmale 1 Abschnitt 2.1: Univariate Merkmale 2 Abschnitt
Methoden der Statistik Kapitel 2: Deskriptive Statistik Thorsten Dickhaus Humboldt-Universität zu Berlin Wintersemester 2011/2012 Übersicht Univariate Merkmale 1 Abschnitt 2.1: Univariate Merkmale 2 Abschnitt
Grafische Darstellung bivariater Daten: Handwerkszeug der deskriptiven Statistik
 Grafische Darstellung bivariater Daten: Handwerkszeug der deskriptiven Statistik Beuth Hochschule für Technik 31. Oktober 2012 Multivariate Daten: Mietspiegel Daten > miete < read. table ( f i l e = "
Grafische Darstellung bivariater Daten: Handwerkszeug der deskriptiven Statistik Beuth Hochschule für Technik 31. Oktober 2012 Multivariate Daten: Mietspiegel Daten > miete < read. table ( f i l e = "
Übungen zur Vorlesung. Statistik 2
 Institut für Stochastik WS 2007/2008 Universität Karlsruhe JProf. Dr. H. Holzmann Blatt 11 Dipl.-Math. oec. D. Engel Übungen zur Vorlesung Statistik 2 Aufgabe 40 (R-Aufgabe, keine Abgabe) In dieser Aufgabe
Institut für Stochastik WS 2007/2008 Universität Karlsruhe JProf. Dr. H. Holzmann Blatt 11 Dipl.-Math. oec. D. Engel Übungen zur Vorlesung Statistik 2 Aufgabe 40 (R-Aufgabe, keine Abgabe) In dieser Aufgabe
4 Absolutstetige Verteilungen und Zufallsvariablen 215/1
 4 Absolutstetige Verteilungen und Zufallsvariablen 215/1 23. Bemerkung Integralbegriffe für Funktionen f : R d R (i) Lebesgue-Integral (Vorlesung Analysis IV). Spezialfall: (ii) Uneigentliches Riemann-Integral
4 Absolutstetige Verteilungen und Zufallsvariablen 215/1 23. Bemerkung Integralbegriffe für Funktionen f : R d R (i) Lebesgue-Integral (Vorlesung Analysis IV). Spezialfall: (ii) Uneigentliches Riemann-Integral
Nichtparametrische Verfahren
 Nictparametrisce Verfaren Dictescätzung Nacfolgend bezeicnen X 1,..., X n reellwertige i. i. d. Zufallsvariablen (unabängig und identisc verteilt), deren Verteilung eine Dicte f bezüglic des LebesgueMaÿes
Nictparametrisce Verfaren Dictescätzung Nacfolgend bezeicnen X 1,..., X n reellwertige i. i. d. Zufallsvariablen (unabängig und identisc verteilt), deren Verteilung eine Dicte f bezüglic des LebesgueMaÿes
1. Übungsblatt. Zeige: Falls für jedes ε > 0 endlich viele ε-klammern existieren, die F überdecken, so gilt die Glivenko-Cantelli-Eigenschaft
 Vorlesung Nichtparametrische Statistik Wintersemester 2010/11 Humboldt-Universität zu Berlin Prof. Dr. Markus Reiß Dipl. Math. Johanna Kappus 1. Übungsblatt 1. Es seien X 1,, X n unabhängig identisch verteilte
Vorlesung Nichtparametrische Statistik Wintersemester 2010/11 Humboldt-Universität zu Berlin Prof. Dr. Markus Reiß Dipl. Math. Johanna Kappus 1. Übungsblatt 1. Es seien X 1,, X n unabhängig identisch verteilte
Teil IV Deskriptive Statistik
 Woche 5: Deskriptive Statistik Teil IV Deskriptive Statistik WBL 15/17, 18.05.2015 Alain Hauser Berner Fachhochschule, Technik und Informatik Berner Fachhochschule Haute école spécialisée
Woche 5: Deskriptive Statistik Teil IV Deskriptive Statistik WBL 15/17, 18.05.2015 Alain Hauser Berner Fachhochschule, Technik und Informatik Berner Fachhochschule Haute école spécialisée
Von Daten zu Funktionen
 Funktionale Datenanalyse (Wintersemester 2014/2015) 27. Oktober 2014 Inhaltsverzeichnis 1 Einleitung 2 Basisvektoren Auswahl des Vektors c Lineare Glättung der Daten Freiheitsgrade 3 Kompromiss zwischen
Funktionale Datenanalyse (Wintersemester 2014/2015) 27. Oktober 2014 Inhaltsverzeichnis 1 Einleitung 2 Basisvektoren Auswahl des Vektors c Lineare Glättung der Daten Freiheitsgrade 3 Kompromiss zwischen
Teil VII. Deskriptive Statistik. Woche 5: Deskriptive Statistik. Arbeitsschritte der Datenanalyse. Lernziele
 Woche 5: Deskriptive Statistik Teil VII Patric Müller Deskriptive Statistik ETHZ WBL 17/19, 22.05.2017 Wahrscheinlichkeit und Statistik Patric Müller WBL 2017 Wahrscheinlichkeit
Woche 5: Deskriptive Statistik Teil VII Patric Müller Deskriptive Statistik ETHZ WBL 17/19, 22.05.2017 Wahrscheinlichkeit und Statistik Patric Müller WBL 2017 Wahrscheinlichkeit
Fakultät Verkehrswissenschaften Friedrich List Professur für Ökonometrie und Statistik, insb. im Verkehrswesen. Statistik II
 Statistik II 1. Ergänzungen zur Wahrscheinlichkeitstheorie Fakultät Verkehrswissenschaften Friedrich List Professur für Ökonometrie und Statistik, insb. im Verkehrswesen Statistik II 1. Ergänzungen zur
Statistik II 1. Ergänzungen zur Wahrscheinlichkeitstheorie Fakultät Verkehrswissenschaften Friedrich List Professur für Ökonometrie und Statistik, insb. im Verkehrswesen Statistik II 1. Ergänzungen zur
Klausur zur Vorlesung Stochastik II
 Institut für Mathematische Stochastik WS 003/004 Universität Karlsruhe 05. 04. 004 Prof. Dr. G. Last Klausur zur Vorlesung Stochastik II Dauer: 90 Minuten Name: Vorname: Matrikelnummer: Diese Klausur hat
Institut für Mathematische Stochastik WS 003/004 Universität Karlsruhe 05. 04. 004 Prof. Dr. G. Last Klausur zur Vorlesung Stochastik II Dauer: 90 Minuten Name: Vorname: Matrikelnummer: Diese Klausur hat
Deskriptive Statistik
 Deskriptive Statistik Deskriptive Statistik: Ziele Daten zusammenfassen durch numerische Kennzahlen. Grafische Darstellung der Daten. Quelle: Ursus Wehrli, Kunst aufräumen 1 Modell vs. Daten Bis jetzt
Deskriptive Statistik Deskriptive Statistik: Ziele Daten zusammenfassen durch numerische Kennzahlen. Grafische Darstellung der Daten. Quelle: Ursus Wehrli, Kunst aufräumen 1 Modell vs. Daten Bis jetzt
Deskriptive Statistik. (basierend auf Slides von Lukas Meier)
") Deskriptive Statistik (basierend auf Slides von Lukas Meier) Deskriptive Statistik: Ziele Daten zusammenfassen durch numerische Kennzahlen. Grafische Darstellung der Daten. Quelle: Ursus Wehrli, Kunst
Deskriptive Statistik (basierend auf Slides von Lukas Meier) Deskriptive Statistik: Ziele Daten zusammenfassen durch numerische Kennzahlen. Grafische Darstellung der Daten. Quelle: Ursus Wehrli, Kunst
Statistics, Data Analysis, and Simulation SS 2017
 Statistics, Data Analysis, and Simulation SS 2017 08.128.730 Statistik, Datenanalyse und Simulation Dr. Michael O. Distler Mainz, May 29, 2017 Dr. Michael O. Distler
Statistics, Data Analysis, and Simulation SS 2017 08.128.730 Statistik, Datenanalyse und Simulation Dr. Michael O. Distler Mainz, May 29, 2017 Dr. Michael O. Distler
Eine Einführung in R: Dichten und Verteilungsfunktionen
 Eine Einführung in R: Dichten und Verteilungsfunktionen Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig 25. November 2009 Bernd
Eine Einführung in R: Dichten und Verteilungsfunktionen Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig 25. November 2009 Bernd
I Grundbegriffe 1 1 Wahrscheinlichkeitsräume Bedingte Wahrscheinlichkeiten und Unabhängigkeit Reellwertige Zufallsvariablen...
 Inhaltsverzeichnis I Grundbegriffe 1 1 Wahrscheinlichkeitsräume......................... 1 2 Bedingte Wahrscheinlichkeiten und Unabhängigkeit........... 7 3 Reellwertige Zufallsvariablen........................
Inhaltsverzeichnis I Grundbegriffe 1 1 Wahrscheinlichkeitsräume......................... 1 2 Bedingte Wahrscheinlichkeiten und Unabhängigkeit........... 7 3 Reellwertige Zufallsvariablen........................
Eine Einführung in R: Dichten und Verteilungsfunktionen
 Eine Einführung in R: Dichten und Verteilungsfunktionen Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.uni-leipzig.de/
Eine Einführung in R: Dichten und Verteilungsfunktionen Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.uni-leipzig.de/
Theorie Parameterschätzung Ausblick. Schätzung. Raimar Sandner. Studentenseminar "Statistische Methoden in der Physik"
 Studentenseminar "Statistische Methoden in der Physik" Gliederung 1 2 3 Worum geht es hier? Gliederung 1 2 3 Stichproben Gegeben eine Beobachtungsreihe x = (x 1, x 2,..., x n ): Realisierung der n-dimensionalen
Studentenseminar "Statistische Methoden in der Physik" Gliederung 1 2 3 Worum geht es hier? Gliederung 1 2 3 Stichproben Gegeben eine Beobachtungsreihe x = (x 1, x 2,..., x n ): Realisierung der n-dimensionalen
13 Mehrdimensionale Zufallsvariablen Zufallsvektoren
 3 Mehrdimensionale Zufallsvariablen Zufallsvektoren Bisher haben wir uns ausschließlich mit Zufallsexperimenten beschäftigt, bei denen die Beobachtung eines einzigen Merkmals im Vordergrund stand. In diesem
3 Mehrdimensionale Zufallsvariablen Zufallsvektoren Bisher haben wir uns ausschließlich mit Zufallsexperimenten beschäftigt, bei denen die Beobachtung eines einzigen Merkmals im Vordergrund stand. In diesem
Stochastik-Praktikum
 Stochastik-Praktikum Zufallszahlen und Monte Carlo Peter Frentrup Humboldt-Universität zu Berlin 17. Oktober 2017 (Humboldt-Universität zu Berlin) Zufallszahlen und Monte Carlo 17. Oktober 2017 1 / 23
Stochastik-Praktikum Zufallszahlen und Monte Carlo Peter Frentrup Humboldt-Universität zu Berlin 17. Oktober 2017 (Humboldt-Universität zu Berlin) Zufallszahlen und Monte Carlo 17. Oktober 2017 1 / 23
70 Wichtige kontinuierliche Verteilungen
 70 Wichtige kontinuierliche Verteilungen 70. Motivation Zufallsvariablen sind nicht immer diskret, sie können oft auch jede beliebige reelle Zahl in einem Intervall [c, d] einnehmen. Beispiele für solche
70 Wichtige kontinuierliche Verteilungen 70. Motivation Zufallsvariablen sind nicht immer diskret, sie können oft auch jede beliebige reelle Zahl in einem Intervall [c, d] einnehmen. Beispiele für solche
Der Mittelwert (arithmetisches Mittel)
") Der Mittelwert (arithmetisches Mittel) x = 1 n n x i bekanntestes Lagemaß instabil gegen extreme Werte geeignet für intervallskalierte Daten Deskriptive Statistik WiSe 2015/2016 Helmut Küchenhoff (Institut
Der Mittelwert (arithmetisches Mittel) x = 1 n n x i bekanntestes Lagemaß instabil gegen extreme Werte geeignet für intervallskalierte Daten Deskriptive Statistik WiSe 2015/2016 Helmut Küchenhoff (Institut
Fakultät Verkehrswissenschaften Friedrich List Professur für Ökonometrie und Statistik, insb. im Verkehrswesen. Statistik II. Prof. Dr.
 Statistik II Fakultät Verkehrswissenschaften Friedrich List Professur für Ökonometrie und Statistik, insb. im Verkehrswesen Statistik II 2. Parameterschätzung: 2.1 Grundbegriffe; 2.2 Maximum-Likelihood-Methode;
Statistik II Fakultät Verkehrswissenschaften Friedrich List Professur für Ökonometrie und Statistik, insb. im Verkehrswesen Statistik II 2. Parameterschätzung: 2.1 Grundbegriffe; 2.2 Maximum-Likelihood-Methode;
Statistics, Data Analysis, and Simulation SS 2017
 Statistics, Data Analysis, and Simulation SS 2017 08.128.730 Statistik, Datenanalyse und Simulation Dr. Michael O. Distler Mainz, 4. Mai 2017 Dr. Michael O. Distler
Statistics, Data Analysis, and Simulation SS 2017 08.128.730 Statistik, Datenanalyse und Simulation Dr. Michael O. Distler Mainz, 4. Mai 2017 Dr. Michael O. Distler
13 Grenzwertsätze Das Gesetz der großen Zahlen
 13 Grenzwertsätze 13.1 Das Gesetz der großen Zahlen Der Erwartungswert einer zufälligen Variablen X ist in der Praxis meist nicht bekannt. Um ihn zu bestimmen, sammelt man Beobachtungen X 1,X 2,...,X n
13 Grenzwertsätze 13.1 Das Gesetz der großen Zahlen Der Erwartungswert einer zufälligen Variablen X ist in der Praxis meist nicht bekannt. Um ihn zu bestimmen, sammelt man Beobachtungen X 1,X 2,...,X n
Statistik für Informatiker, SS Grundlagen aus der Wahrscheinlichkeitstheorie
 Ereignisse, Zufallsvariablen und Wahrscheinlichkeiten 1/43 Statistik für Informatiker, SS 2018 1 Grundlagen aus der Wahrscheinlichkeitstheorie 1.1 Ereignisse, Zufallsvariablen und Wahrscheinlichkeiten
Ereignisse, Zufallsvariablen und Wahrscheinlichkeiten 1/43 Statistik für Informatiker, SS 2018 1 Grundlagen aus der Wahrscheinlichkeitstheorie 1.1 Ereignisse, Zufallsvariablen und Wahrscheinlichkeiten
Bootstrap: Punktschätzung
 Resampling Methoden Dortmund, 2005 (Jenő Reiczigel) 1 Bootstrap: Punktschätzung 1. Die Grundidee 2. Plug-in Schätzer 3. Schätzung des Standardfehlers 4. Schätzung und Korrektur der Verzerrung 5. Konsistenz
Resampling Methoden Dortmund, 2005 (Jenő Reiczigel) 1 Bootstrap: Punktschätzung 1. Die Grundidee 2. Plug-in Schätzer 3. Schätzung des Standardfehlers 4. Schätzung und Korrektur der Verzerrung 5. Konsistenz
x p 2 (x )dx, Hinweis: es ist nicht erforderlich, zu integrieren!
dx, Hinweis: es ist nicht erforderlich, zu integrieren!") Aufgabe T- Gegeben seien zwei normalverteilte Zufallsvariablen X N(µ, σ) 2 und X 2 N(µ 2, σ2) 2 mit pdf p (x) bzw. p 2 (x). Bestimmen Sie x (als Funktion der µ i, σ i, sodass x p (x )dx = + x p 2 (x )dx,
Aufgabe T- Gegeben seien zwei normalverteilte Zufallsvariablen X N(µ, σ) 2 und X 2 N(µ 2, σ2) 2 mit pdf p (x) bzw. p 2 (x). Bestimmen Sie x (als Funktion der µ i, σ i, sodass x p (x )dx = + x p 2 (x )dx,
Statistik für Informatiker, SS Verteilungen mit Dichte
 1/39 Statistik für Informatiker, SS 2017 1.1.6 Verteilungen mit Dichte Matthias Birkner http://www.staff.uni-mainz.de/birkner/statinfo17/ 17.5.2017 Zufallsvariablen mit Dichten sind ein kontinuierliches
1/39 Statistik für Informatiker, SS 2017 1.1.6 Verteilungen mit Dichte Matthias Birkner http://www.staff.uni-mainz.de/birkner/statinfo17/ 17.5.2017 Zufallsvariablen mit Dichten sind ein kontinuierliches
Multivariate Verteilungen. Gerhard Tutz LMU München
 Multivariate Verteilungen Gerhard Tutz LMU München INHALTSVERZEICHNIS 1 Inhaltsverzeichnis 1 Multivariate Normalverteilung 3 Wishart Verteilung 7 3 Hotellings T Verteilung 11 4 Wilks Λ 14 INHALTSVERZEICHNIS
Multivariate Verteilungen Gerhard Tutz LMU München INHALTSVERZEICHNIS 1 Inhaltsverzeichnis 1 Multivariate Normalverteilung 3 Wishart Verteilung 7 3 Hotellings T Verteilung 11 4 Wilks Λ 14 INHALTSVERZEICHNIS
Eine Einführung in R: Dichten und Verteilungsfunktionen
 Eine Einführung in R: Dichten und Verteilungsfunktionen Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.uni-leipzig.de/
Eine Einführung in R: Dichten und Verteilungsfunktionen Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.uni-leipzig.de/
Statistik für Informatiker, SS Grundlagen aus der Wahrscheinlichkeitstheorie
 1/19 Statistik für Informatiker, SS 2018 1 Grundlagen aus der Wahrscheinlichkeitstheorie 1.3 Bedingte Wahrscheinlichkeiten, Unabhängigkeit, gemeinsame Verteilung 1.3.4 Matthias Birkner http://www.staff.uni-mainz.de/birkner/statinfo18/
1/19 Statistik für Informatiker, SS 2018 1 Grundlagen aus der Wahrscheinlichkeitstheorie 1.3 Bedingte Wahrscheinlichkeiten, Unabhängigkeit, gemeinsame Verteilung 1.3.4 Matthias Birkner http://www.staff.uni-mainz.de/birkner/statinfo18/
EGRESSIONSANALYSE AVID BUCHATZ NIVERSITÄT ZU KÖLN
 1 EGRESSIONSANALYSE AVID BUCHATZ NIVERSITÄT ZU KÖLN UFBAU 1 Historie 2 Anwendungen / Ziele 3 Lineare Regression/ Beispiel KQ 4 Nichtlineare Regression 5 Eigenschaften der Schätzer istorie früheste Form
1 EGRESSIONSANALYSE AVID BUCHATZ NIVERSITÄT ZU KÖLN UFBAU 1 Historie 2 Anwendungen / Ziele 3 Lineare Regression/ Beispiel KQ 4 Nichtlineare Regression 5 Eigenschaften der Schätzer istorie früheste Form
Statistik I für Betriebswirte Vorlesung 13
 Statistik I für Betriebswirte Vorlesung 13 Dr. Andreas Wünsche TU Bergakademie Freiberg Institut für Stochastik 6. Juli 2017 Dr. Andreas Wünsche Statistik I für Betriebswirte Vorlesung 13 Version: 7. Juli
Statistik I für Betriebswirte Vorlesung 13 Dr. Andreas Wünsche TU Bergakademie Freiberg Institut für Stochastik 6. Juli 2017 Dr. Andreas Wünsche Statistik I für Betriebswirte Vorlesung 13 Version: 7. Juli
Wahrscheinlichkeit und Statistik: Zusammenfassung
 HSR Hochschule für Technik Rapperswil Wahrscheinlichkeit und Statistik: Zusammenfassung beinhaltet Teile des Skripts von Herrn Hardy von Lukas Wilhelm lwilhelm.net 12. Januar 2007 Inhaltsverzeichnis 1
HSR Hochschule für Technik Rapperswil Wahrscheinlichkeit und Statistik: Zusammenfassung beinhaltet Teile des Skripts von Herrn Hardy von Lukas Wilhelm lwilhelm.net 12. Januar 2007 Inhaltsverzeichnis 1
ÜBUNGSBLATT 11 LÖSUNGEN MAT121/MAT131 ANALYSIS II FRÜHJAHRSSEMESTER 2011 PROF. DR. CAMILLO DE LELLIS
 ÜBUNGSBLATT 11 LÖSUNGEN MAT121/MAT131 ANALYSIS II FRÜHJAHRSSEMESTER 2011 PROF. DR. CAMILLO DE LELLIS Aufgabe 1. a) Gegeben sei die Gleichung 2x 2 4xy +y 2 3x+4y = 0. Verifizieren Sie, dass diese Gleichung
ÜBUNGSBLATT 11 LÖSUNGEN MAT121/MAT131 ANALYSIS II FRÜHJAHRSSEMESTER 2011 PROF. DR. CAMILLO DE LELLIS Aufgabe 1. a) Gegeben sei die Gleichung 2x 2 4xy +y 2 3x+4y = 0. Verifizieren Sie, dass diese Gleichung
Hypothesenbewertungen: Übersicht
 Hypothesenbewertungen: Übersicht Wie kann man Fehler einer Hypothese abschätzen? Wie kann man einschätzen, ob ein Algorithmus besser ist als ein anderer? Trainingsfehler, wirklicher Fehler Kreuzvalidierung
Hypothesenbewertungen: Übersicht Wie kann man Fehler einer Hypothese abschätzen? Wie kann man einschätzen, ob ein Algorithmus besser ist als ein anderer? Trainingsfehler, wirklicher Fehler Kreuzvalidierung
Signalentdeckungstheorie, Dichteschätzung
 Signalentdeckungstheorie, Dichteschätzung Mustererkennung und Klassifikation, Vorlesung No. 6 1 M. O. Franz 15.11.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001.
Signalentdeckungstheorie, Dichteschätzung Mustererkennung und Klassifikation, Vorlesung No. 6 1 M. O. Franz 15.11.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001.
DWT 1.4 Rechnen mit kontinuierlichen Zufallsvariablen 234/467 Ernst W. Mayr
 1.4.2 Kontinuierliche Zufallsvariablen als Grenzwerte diskreter Zufallsvariablen Sei X eine kontinuierliche Zufallsvariable. Wir können aus X leicht eine diskrete Zufallsvariable konstruieren, indem wir
1.4.2 Kontinuierliche Zufallsvariablen als Grenzwerte diskreter Zufallsvariablen Sei X eine kontinuierliche Zufallsvariable. Wir können aus X leicht eine diskrete Zufallsvariable konstruieren, indem wir
Informationsverlust durch Anonymisierung am Beispiel der Berliner Einwohnerregisterdaten
 8 Zeitschrift für amtliche Statistik Berlin Brandenburg 3 1 Geheimhaltung Informationsverlust durch Anonymisierung am Beispiel der Berliner Einwohnerregisterdaten Anpassungsgüte nichtparametrischer Dichteschätzer
8 Zeitschrift für amtliche Statistik Berlin Brandenburg 3 1 Geheimhaltung Informationsverlust durch Anonymisierung am Beispiel der Berliner Einwohnerregisterdaten Anpassungsgüte nichtparametrischer Dichteschätzer
17 Nichtparametrische Schätzer
 17 Nichtparametrische Schätzer In diesem Paragraphen werden kurz einige Möglichkeiten skizziert, auch in nichtparametrischen Modellenzu Schätzern fürinteressierende statistische Größenzugelangen. a Empirische
17 Nichtparametrische Schätzer In diesem Paragraphen werden kurz einige Möglichkeiten skizziert, auch in nichtparametrischen Modellenzu Schätzern fürinteressierende statistische Größenzugelangen. a Empirische
Nichtparametrische Statistik Skript zur Vorlesung im Wintersemester 2012/13
 Nichtparametrische Statistik Skript zur Vorlesung im Wintersemester 2012/13 Markus Reiÿ Humboldt-Universität zu Berlin mreiss@mathematik.hu-berlin.de VORLÄUFIGE FASSUNG: 18. Oktober 2012 Inhaltsverzeichnis
Nichtparametrische Statistik Skript zur Vorlesung im Wintersemester 2012/13 Markus Reiÿ Humboldt-Universität zu Berlin mreiss@mathematik.hu-berlin.de VORLÄUFIGE FASSUNG: 18. Oktober 2012 Inhaltsverzeichnis
Stochastik Praktikum Markov Chain Monte Carlo Methoden
 Stochastik Praktikum Markov Chain Monte Carlo Methoden Humboldt-Universität zu Berlin 14.10.2010 Problemstellung Wie kann eine Zufallsstichprobe am Computer simuliert werden, deren Verteilung aus einem
Stochastik Praktikum Markov Chain Monte Carlo Methoden Humboldt-Universität zu Berlin 14.10.2010 Problemstellung Wie kann eine Zufallsstichprobe am Computer simuliert werden, deren Verteilung aus einem
Parameterschätzung. Kapitel 14. Modell Es sei {P θ θ Θ}, Θ R m eine Familie von Verteilungen auf χ (sog. Stichprobenraum),
,") Kapitel 14 Parameterschätzung Modell Es sei {P θ θ Θ}, Θ R m eine Familie von Verteilungen auf χ (sog. Stichprobenraum), = ( 1,..., n ) sei eine Realisierung der Zufallsstichprobe X = (X 1,..., X n ) zu
Kapitel 14 Parameterschätzung Modell Es sei {P θ θ Θ}, Θ R m eine Familie von Verteilungen auf χ (sog. Stichprobenraum), = ( 1,..., n ) sei eine Realisierung der Zufallsstichprobe X = (X 1,..., X n ) zu
Stochastik Praktikum Parametrische Schätztheorie
 Stochastik Praktikum Parametrische Schätztheorie Thorsten Dickhaus Humboldt-Universität zu Berlin 05.10.2010 Prolog Momentenmethode X : Ω 1 Ω Zufallsgröße, die Experiment beschreibt. Ein statistisches
Stochastik Praktikum Parametrische Schätztheorie Thorsten Dickhaus Humboldt-Universität zu Berlin 05.10.2010 Prolog Momentenmethode X : Ω 1 Ω Zufallsgröße, die Experiment beschreibt. Ein statistisches
Stochastik-Praktikum
 Stochastik-Praktikum Deskriptive Statistik Peter Frentrup Humboldt-Universität zu Berlin 7. November 2017 (Humboldt-Universität zu Berlin) Zufallszahlen und Monte Carlo 7. November 2017 1 / 27 Übersicht
Stochastik-Praktikum Deskriptive Statistik Peter Frentrup Humboldt-Universität zu Berlin 7. November 2017 (Humboldt-Universität zu Berlin) Zufallszahlen und Monte Carlo 7. November 2017 1 / 27 Übersicht
1.2 Summen von Zufallsvariablen aus einer Zufallsstichprobe
 1.2 Summen von Zufallsvariablen aus einer Zufallsstichprobe Nachdem eine Stichprobe X 1,..., X n gezogen wurde berechnen wir gewöhnlich irgendwelchen Wert damit. Sei dies T = T (X 1,..., X n, wobei T auch
1.2 Summen von Zufallsvariablen aus einer Zufallsstichprobe Nachdem eine Stichprobe X 1,..., X n gezogen wurde berechnen wir gewöhnlich irgendwelchen Wert damit. Sei dies T = T (X 1,..., X n, wobei T auch
Spezifische innere Volumina
 Spezifische innere Volumina Stochastische Geometrie und ihre en - Zufallsfelder Regina Poltnigg und Henrik Haßfeld Universität Ulm 13. Januar 2009 1 Regina Poltnigg und Henrik Haßfeld 1 2 Berechnung von
Spezifische innere Volumina Stochastische Geometrie und ihre en - Zufallsfelder Regina Poltnigg und Henrik Haßfeld Universität Ulm 13. Januar 2009 1 Regina Poltnigg und Henrik Haßfeld 1 2 Berechnung von
Statistics, Data Analysis, and Simulation SS 2015
 Mainz, May 12, 2015 Statistics, Data Analysis, and Simulation SS 2015 08.128.730 Statistik, Datenanalyse und Simulation Dr. Michael O. Distler Dr. Michael O. Distler
Mainz, May 12, 2015 Statistics, Data Analysis, and Simulation SS 2015 08.128.730 Statistik, Datenanalyse und Simulation Dr. Michael O. Distler Dr. Michael O. Distler
Korollar 116 (Grenzwertsatz von de Moivre)
") Ein wichtiger Spezialfall das Zentralen Grenzwertsatzes besteht darin, dass die auftretenden Zufallsgrößen Bernoulli-verteilt sind. Korollar 116 (Grenzwertsatz von de Moivre) X 1,..., X n seien unabhängige
Ein wichtiger Spezialfall das Zentralen Grenzwertsatzes besteht darin, dass die auftretenden Zufallsgrößen Bernoulli-verteilt sind. Korollar 116 (Grenzwertsatz von de Moivre) X 1,..., X n seien unabhängige
Seminar in Statistik - FS Nonparametric Bayes. Handout verfasst von. Ivo Francioni und Philippe Muller
 Seminar in Statistik - FS 2008 Nonparametric Bayes Handout verfasst von Ivo Francioni und Philippe Muller Zürich, 17. März 2008 1 EINLEITUNG 1 1 Einleitung Bis jetzt haben wir in der Bayes schen Statistik
Seminar in Statistik - FS 2008 Nonparametric Bayes Handout verfasst von Ivo Francioni und Philippe Muller Zürich, 17. März 2008 1 EINLEITUNG 1 1 Einleitung Bis jetzt haben wir in der Bayes schen Statistik
Reelle Zufallsvariablen
 Kapitel 3 eelle Zufallsvariablen 3. Verteilungsfunktionen esultat aus der Maßtheorie: Zwischen der Menge aller W-Maße auf B, nennen wir sie W B ), und der Menge aller Verteilungsfunktionen auf, nennen
Kapitel 3 eelle Zufallsvariablen 3. Verteilungsfunktionen esultat aus der Maßtheorie: Zwischen der Menge aller W-Maße auf B, nennen wir sie W B ), und der Menge aller Verteilungsfunktionen auf, nennen
DWT 1.4 Rechnen mit kontinuierlichen Zufallsvariablen 240/476 c Ernst W. Mayr
 1.4.4 Laplace-Prinzip in kontinuierlichen Wahrscheinlichkeitsräumen Das folgende Beispiel zeigt, dass im kontinuierlichen Fall die Bedeutung von gleichwahrscheinlich nicht immer ganz klar sein muss. Bertrand
1.4.4 Laplace-Prinzip in kontinuierlichen Wahrscheinlichkeitsräumen Das folgende Beispiel zeigt, dass im kontinuierlichen Fall die Bedeutung von gleichwahrscheinlich nicht immer ganz klar sein muss. Bertrand
Unsupervised Kernel Regression
 9. Mai 26 Inhalt Nichtlineare Dimensionsreduktion mittels UKR (Unüberwachte KernRegression, 25) Anknüpfungspunkte Datamining I: PCA + Hauptkurven Benötigte Zutaten Klassische Kernregression Kerndichteschätzung
9. Mai 26 Inhalt Nichtlineare Dimensionsreduktion mittels UKR (Unüberwachte KernRegression, 25) Anknüpfungspunkte Datamining I: PCA + Hauptkurven Benötigte Zutaten Klassische Kernregression Kerndichteschätzung
3.5 Glattheit von Funktionen und asymptotisches Verhalten der Fourierkoeffizienten
 Folgerung 3.33 Es sei f : T C in einem Punkt x T Hölder stetig, d.h. es gibt ein C > und ein < α 1 so, dass f(x) f(x ) C x x α für alle x T. Dann gilt lim N S N f(x ) = f(x ). Folgerung 3.34 Es f : T C
Folgerung 3.33 Es sei f : T C in einem Punkt x T Hölder stetig, d.h. es gibt ein C > und ein < α 1 so, dass f(x) f(x ) C x x α für alle x T. Dann gilt lim N S N f(x ) = f(x ). Folgerung 3.34 Es f : T C
Dynamische Systeme und Zeitreihenanalyse // Multivariate Normalverteilung und ML Schätzung 11 p.2/38
 Dynamische Systeme und Zeitreihenanalyse Multivariate Normalverteilung und ML Schätzung Kapitel 11 Statistik und Mathematik WU Wien Michael Hauser Dynamische Systeme und Zeitreihenanalyse // Multivariate
Dynamische Systeme und Zeitreihenanalyse Multivariate Normalverteilung und ML Schätzung Kapitel 11 Statistik und Mathematik WU Wien Michael Hauser Dynamische Systeme und Zeitreihenanalyse // Multivariate
Stochastik Praktikum Testtheorie
 Stochastik Praktikum Testtheorie Thorsten Dickhaus Humboldt-Universität zu Berlin 11.10.2010 Definition X: Zufallsgröße mit Werten in Ω, (Ω, F, (P ϑ ) ϑ Θ ) statistisches Modell Problem: Teste H 0 : ϑ
Stochastik Praktikum Testtheorie Thorsten Dickhaus Humboldt-Universität zu Berlin 11.10.2010 Definition X: Zufallsgröße mit Werten in Ω, (Ω, F, (P ϑ ) ϑ Θ ) statistisches Modell Problem: Teste H 0 : ϑ
Teil VI. Gemeinsame Verteilungen. Lernziele. Beispiel: Zwei Würfel. Gemeinsame Verteilung
 Zusammenfassung: diskrete und stetige Verteilungen Woche 4: Verteilungen Patric Müller diskret Wahrscheinlichkeitsverteilung p() stetig Wahrscheinlichkeitsdichte f ()
Zusammenfassung: diskrete und stetige Verteilungen Woche 4: Verteilungen Patric Müller diskret Wahrscheinlichkeitsverteilung p() stetig Wahrscheinlichkeitsdichte f ()
5 Konfidenzschätzung. 5.1 Einige Grundbegriffe zur Konfidenzschätzung
 5 Konfidenzschätzung 5. Einige Grundbegriffe zur Konfidenzschätzung Diesem Kapitel liegt das parametrische Modell {X, B X, P } mit P {P Θ} zugrunde. {Θ, B Θ } sei ein Meßraum über Θ und µ ein σ-finites
5 Konfidenzschätzung 5. Einige Grundbegriffe zur Konfidenzschätzung Diesem Kapitel liegt das parametrische Modell {X, B X, P } mit P {P Θ} zugrunde. {Θ, B Θ } sei ein Meßraum über Θ und µ ein σ-finites
Wahrscheinlichkeitsrechnung und Statistik
 10. Vorlesung - 2018 Grundbegriffe der Statistik statistische Einheiten = Objekte an denen interessierende Größen erfaßt werden z.b. Bevölkerung einer Stadt; Schüler einer bestimmten Schule; Patienten
10. Vorlesung - 2018 Grundbegriffe der Statistik statistische Einheiten = Objekte an denen interessierende Größen erfaßt werden z.b. Bevölkerung einer Stadt; Schüler einer bestimmten Schule; Patienten
Numerische Verfahren und Grundlagen der Analysis
 Numerische Verfahren und Grundlagen der Analysis Rasa Steuding Hochschule RheinMain Wiesbaden Wintersemester 2011/12 R. Steuding (HS-RM) NumAna Wintersemester 2011/12 1 / 21 Quadraturverfahren R. Steuding
Numerische Verfahren und Grundlagen der Analysis Rasa Steuding Hochschule RheinMain Wiesbaden Wintersemester 2011/12 R. Steuding (HS-RM) NumAna Wintersemester 2011/12 1 / 21 Quadraturverfahren R. Steuding
Scheinklausur zur Vorlesung Stochastik II
 Institut für Mathematische Stochastik WS 2007/2008 Universität Karlsruhe 25. 02. 2008 Dr. B. Klar Scheinklausur zur Vorlesung Stochastik II Muster-Lösung Dauer: 90 Minuten Name: Vorname: Matrikelnummer:
Institut für Mathematische Stochastik WS 2007/2008 Universität Karlsruhe 25. 02. 2008 Dr. B. Klar Scheinklausur zur Vorlesung Stochastik II Muster-Lösung Dauer: 90 Minuten Name: Vorname: Matrikelnummer:
Bem. 6 Die charakterische Funktion existiert.
 4.4 Charakteristische Funktionen Def. 2.14 Sei X Zufallsvariable mit Verteilungsfunktion F X und Dichte f X (falls X stetig) oder Wkt.funktion p i (falls X diskret). Die Funktion φ X (t) := Ee itx = eitx
4.4 Charakteristische Funktionen Def. 2.14 Sei X Zufallsvariable mit Verteilungsfunktion F X und Dichte f X (falls X stetig) oder Wkt.funktion p i (falls X diskret). Die Funktion φ X (t) := Ee itx = eitx
ETWR Teil B. Spezielle Wahrscheinlichkeitsverteilungen (stetig)
") ETWR Teil B 2 Ziele Bisher (eindimensionale, mehrdimensionale) Zufallsvariablen besprochen Lageparameter von Zufallsvariablen besprochen Übertragung des gelernten auf diskrete Verteilungen Ziel des Kapitels
ETWR Teil B 2 Ziele Bisher (eindimensionale, mehrdimensionale) Zufallsvariablen besprochen Lageparameter von Zufallsvariablen besprochen Übertragung des gelernten auf diskrete Verteilungen Ziel des Kapitels
Übersicht Statistik-Funktionen. Statistische Software (R) Nützliche Funktionen. Nützliche Funktionen
 Nützliche Funktionen. Nützliche Funktionen") Übersicht Statistik-Funktionen Statistische Software (R) Paul Fink, M.Sc. Institut für Statistik Ludwig-Maximilians-Universität München Pseudo Zufallszahlen, Dichten, Verteilungsfunktionen, etc. Funktion
Übersicht Statistik-Funktionen Statistische Software (R) Paul Fink, M.Sc. Institut für Statistik Ludwig-Maximilians-Universität München Pseudo Zufallszahlen, Dichten, Verteilungsfunktionen, etc. Funktion
1 Multivariate Zufallsvariablen
 1 Multivariate Zufallsvariablen 1.1 Multivariate Verteilungen Definition 1.1. Zufallsvariable, Zufallsvektor (ZV) Sei Ω die Ergebnismenge eines Zufallsexperiments. Eine (univariate oder eindimensionale)
1 Multivariate Zufallsvariablen 1.1 Multivariate Verteilungen Definition 1.1. Zufallsvariable, Zufallsvektor (ZV) Sei Ω die Ergebnismenge eines Zufallsexperiments. Eine (univariate oder eindimensionale)
Vorlesung 5a. Zufallsvariable mit Dichten
 Vorlesung 5a 1 Vorlesung 5a Zufallsvariable mit Dichten Vorlesung 5a Zufallsvariable mit Dichten Teil 1 Uniforme Verteilung, Exponentialverteilung. Kontinuierlich uniform verteilte Zufallsvariable: 2 Kontinuierlich
Vorlesung 5a 1 Vorlesung 5a Zufallsvariable mit Dichten Vorlesung 5a Zufallsvariable mit Dichten Teil 1 Uniforme Verteilung, Exponentialverteilung. Kontinuierlich uniform verteilte Zufallsvariable: 2 Kontinuierlich
Kapitel 6. Verteilungsparameter. 6.1 Der Erwartungswert Diskrete Zufallsvariablen
 Kapitel 6 Verteilungsparameter Wie bei einem Merkmal wollen wir nun die Lage und die Streuung der Verteilung einer diskreten Zufallsvariablen durch geeignete Maßzahlen beschreiben. Beginnen wir mit Maßzahlen
Kapitel 6 Verteilungsparameter Wie bei einem Merkmal wollen wir nun die Lage und die Streuung der Verteilung einer diskreten Zufallsvariablen durch geeignete Maßzahlen beschreiben. Beginnen wir mit Maßzahlen
Box-Plots. Werkzeuge der empirischen Forschung. W. Kössler. Einleitung. Datenbehandlung. Wkt.rechnung. Beschreibende Statistik 174 / 258
 174 / 258 Box-Plots Ziel: übersichtliche Darstellung der Daten. Boxplot zu dem Eingangsbeispiel mit n=5: Descr_Boxplot0.sas Prozeduren: UNIVARIATE, GPLOT, BOXPLOT 174 / 258 Box-Plots Ziel: übersichtliche
174 / 258 Box-Plots Ziel: übersichtliche Darstellung der Daten. Boxplot zu dem Eingangsbeispiel mit n=5: Descr_Boxplot0.sas Prozeduren: UNIVARIATE, GPLOT, BOXPLOT 174 / 258 Box-Plots Ziel: übersichtliche
Mathematik II für Studierende der Informatik. Wirtschaftsinformatik (Analysis und lineare Algebra) im Sommersemester 2016
 im Sommersemester 2016") und Wirtschaftsinformatik (Analysis und lineare Algebra) im Sommersemester 2016 11. Juli 2016 Ableitungen im Höherdimensionalen Im Eindimensionalen war die Ableitung f (x 0 ) einer Funktion f : R R die
und Wirtschaftsinformatik (Analysis und lineare Algebra) im Sommersemester 2016 11. Juli 2016 Ableitungen im Höherdimensionalen Im Eindimensionalen war die Ableitung f (x 0 ) einer Funktion f : R R die
Erwartungswert und Varianz von Zufallsvariablen
 Kapitel 7 Erwartungswert und Varianz von Zufallsvariablen Im Folgenden sei (Ω, A, P ) ein Wahrscheinlichkeitsraum. Der Erwartungswert von X ist ein Lebesgue-Integral (allerdings allgemeiner als in Analysis
Kapitel 7 Erwartungswert und Varianz von Zufallsvariablen Im Folgenden sei (Ω, A, P ) ein Wahrscheinlichkeitsraum. Der Erwartungswert von X ist ein Lebesgue-Integral (allerdings allgemeiner als in Analysis
Theorem 9 Sei G eine Verteilungsfunktion in IR. 1. Quantil-Transformation: Wenn U U(0, 1) (standard Gleichverteilung), dann gilt P(G (U) x) = G(x).
 (standard Gleichverteilung), dann gilt P(G (U) x) = G(x).") Theorem 9 Sei G eine Verteilungsfunktion in IR. 1. Quantil-Transformation: Wenn U U(0, 1) (standard Gleichverteilung), dann gilt P(G (U) x) = G(x). 2. Wahrscheinlichkeit-Transformation: Sei Y eine Zufallsvariable
Theorem 9 Sei G eine Verteilungsfunktion in IR. 1. Quantil-Transformation: Wenn U U(0, 1) (standard Gleichverteilung), dann gilt P(G (U) x) = G(x). 2. Wahrscheinlichkeit-Transformation: Sei Y eine Zufallsvariable
Lineare Regression 2: Gute Vorhersagen
 Lineare Regression 2: Gute Vorhersagen Markus Kalisch 23.09.2014 1 Big Picture: Statistisches Lernen Supervised Learning (X,Y) Unsupervised Learning X VL 7, 11, 12 Regression Y kontinuierlich VL 1, 2,
Lineare Regression 2: Gute Vorhersagen Markus Kalisch 23.09.2014 1 Big Picture: Statistisches Lernen Supervised Learning (X,Y) Unsupervised Learning X VL 7, 11, 12 Regression Y kontinuierlich VL 1, 2,
Verfahren zur Datenanalyse gemessener Signale
 Verfahren zur Datenanalyse gemessener Signale Dr. rer. nat. Axel Hutt Vorlesung 4 zum Übungsblatt Aufgabe 1: sin( (f 3Hz)5s) sin( (f +3Hz)5s) X T (f) 1 i f 3Hz f +3Hz Nullstellen: T=5s: T=1s: f=3hz+2/5s,
Verfahren zur Datenanalyse gemessener Signale Dr. rer. nat. Axel Hutt Vorlesung 4 zum Übungsblatt Aufgabe 1: sin( (f 3Hz)5s) sin( (f +3Hz)5s) X T (f) 1 i f 3Hz f +3Hz Nullstellen: T=5s: T=1s: f=3hz+2/5s,
Statistics, Data Analysis, and Simulation SS 2017
 Mainz, 26. Juni 2017 Statistics, Data Analysis, and Simulation SS 2017 08.128.730 Statistik, Datenanalyse und Simulation Dr. Michael O. Distler Dr. Michael O. Distler
Mainz, 26. Juni 2017 Statistics, Data Analysis, and Simulation SS 2017 08.128.730 Statistik, Datenanalyse und Simulation Dr. Michael O. Distler Dr. Michael O. Distler
Regularisierung in Bildrekonstruktion und Bildrestaurierung
 Regularisierung in Bildrekonstruktion und Bildrestaurierung Ulli Wölfel 15. Februar 2002 1 Einleitung Gegeben seien Daten g(x, y), die Störungen enthalten. Gesucht ist das (unbekannte) Originalbild ohne
Regularisierung in Bildrekonstruktion und Bildrestaurierung Ulli Wölfel 15. Februar 2002 1 Einleitung Gegeben seien Daten g(x, y), die Störungen enthalten. Gesucht ist das (unbekannte) Originalbild ohne
Übungsklausur Höhere Mathematik I für die Fachrichtung Physik
 Karlsruher Institut für Technologie (KIT) Institut für Analysis Prof. Dr. Tobias Lamm Dr. Patrick Breuning WS /3 6..3 Übungsklausur Höhere Mathematik I für die Fachrichtung Physik Aufgabe ((3++5) Punkte)
Karlsruher Institut für Technologie (KIT) Institut für Analysis Prof. Dr. Tobias Lamm Dr. Patrick Breuning WS /3 6..3 Übungsklausur Höhere Mathematik I für die Fachrichtung Physik Aufgabe ((3++5) Punkte)
Statistics, Data Analysis, and Simulation SS 2015
 Mainz, 2. Juli 2015 Statistics, Data Analysis, and Simulation SS 2015 08.128.730 Statistik, Datenanalyse und Simulation Dr. Michael O. Distler Konjugierte Prior Konjugierte Prior
Mainz, 2. Juli 2015 Statistics, Data Analysis, and Simulation SS 2015 08.128.730 Statistik, Datenanalyse und Simulation Dr. Michael O. Distler Konjugierte Prior Konjugierte Prior
Gegenbeispiele in der Wahrscheinlichkeitstheorie
 VARIOUS KINDS OF CONVERGENCES OF SEQUENCES OF RANDOM VARIABLES 10 Dezember, 2012 1 Bekannte Konvergenzarten 2 3 1 Bekannte Konvergenzarten 2 3 Wahrscheinlichkeitsraum Im Folgenden betrachten wir immer
VARIOUS KINDS OF CONVERGENCES OF SEQUENCES OF RANDOM VARIABLES 10 Dezember, 2012 1 Bekannte Konvergenzarten 2 3 1 Bekannte Konvergenzarten 2 3 Wahrscheinlichkeitsraum Im Folgenden betrachten wir immer
D-MATH Numerische Methoden FS 2017 Dr. Vasile Gradinaru Luc Grosheintz. Serie 4. 1 f i (x)dx
dx") D-MATH Numerische Methoden FS 217 Dr. Vasile Gradinaru Luc Grosheintz Serie 4 Abgabedatum: Di./Mi. 2.3/21.3 in den Übungsgruppen oder im HG J68 Koordinatoren: Luc Grosheintz, HG J 46, luc.grosheintz@sam.ethz.ch
D-MATH Numerische Methoden FS 217 Dr. Vasile Gradinaru Luc Grosheintz Serie 4 Abgabedatum: Di./Mi. 2.3/21.3 in den Übungsgruppen oder im HG J68 Koordinatoren: Luc Grosheintz, HG J 46, luc.grosheintz@sam.ethz.ch
Zufällige stabile Prozesse und stabile stochastische Integrale. Stochastikseminar, Dezember 2011
 Zufällige stabile Prozesse und stabile stochastische Integrale Stochastikseminar, Dezember 2011 2 Stabile Prozesse Dezember 2011 Stabile stochastische Prozesse - Definition Stabile Integrale α-stabile
Zufällige stabile Prozesse und stabile stochastische Integrale Stochastikseminar, Dezember 2011 2 Stabile Prozesse Dezember 2011 Stabile stochastische Prozesse - Definition Stabile Integrale α-stabile
7.4 Charakteristische Funktionen
 7.4 Charakteristische Funktionen Def. 25 Sei X Zufallsvariable mit Verteilungsfunktion F X und Dichte f X (falls X stetig) oder Wkt.funktion p i (falls X diskret). Die Funktion φ X (t) := Ee itx = eitx
7.4 Charakteristische Funktionen Def. 25 Sei X Zufallsvariable mit Verteilungsfunktion F X und Dichte f X (falls X stetig) oder Wkt.funktion p i (falls X diskret). Die Funktion φ X (t) := Ee itx = eitx
Anpassungsrechnungen mit kleinsten Quadraten und Maximum Likelihood
 Anpassungsrechnungen mit kleinsten Quadraten und Maximum Likelihood KARLSRUHER INSTITUT FÜR TECHNOLOGIE (KIT) 0 KIT 06.01.2012 Universität des Fabian Landes Hoffmann Baden-Württemberg und nationales Forschungszentrum
Anpassungsrechnungen mit kleinsten Quadraten und Maximum Likelihood KARLSRUHER INSTITUT FÜR TECHNOLOGIE (KIT) 0 KIT 06.01.2012 Universität des Fabian Landes Hoffmann Baden-Württemberg und nationales Forschungszentrum
Einführung in die Induktive Statistik: Schätzen von Parametern und Verteilungen
 Einführung in die Induktive Statistik: Schätzen von Parametern und Verteilungen Jan Gertheiss LMU München Sommersemester 2011 Vielen Dank an Christian Heumann für das Überlassen von TEX-Code! Inhalt Stichproben
Einführung in die Induktive Statistik: Schätzen von Parametern und Verteilungen Jan Gertheiss LMU München Sommersemester 2011 Vielen Dank an Christian Heumann für das Überlassen von TEX-Code! Inhalt Stichproben
Wichtige Definitionen und Aussagen
 Wichtige Definitionen und Aussagen Zufallsexperiment, Ergebnis, Ereignis: Unter einem Zufallsexperiment verstehen wir einen Vorgang, dessen Ausgänge sich nicht vorhersagen lassen Die möglichen Ausgänge
Wichtige Definitionen und Aussagen Zufallsexperiment, Ergebnis, Ereignis: Unter einem Zufallsexperiment verstehen wir einen Vorgang, dessen Ausgänge sich nicht vorhersagen lassen Die möglichen Ausgänge
Zufallsvariablen. Diskret. Stetig. Verteilung der Stichprobenkennzahlen. Binomial Hypergeometrisch Poisson. Normal Lognormal Exponential
 Zufallsvariablen Diskret Binomial Hypergeometrisch Poisson Stetig Normal Lognormal Exponential Verteilung der Stichprobenkennzahlen Stetige Zufallsvariable Verteilungsfunktion: Dichtefunktion: Integralrechnung:
Zufallsvariablen Diskret Binomial Hypergeometrisch Poisson Stetig Normal Lognormal Exponential Verteilung der Stichprobenkennzahlen Stetige Zufallsvariable Verteilungsfunktion: Dichtefunktion: Integralrechnung:
Sammlung alter Klausuraufgaben zur Stochastik keine Abgabe keine Besprechung in den Tutorien
 Sammlung alter Klausuraufgaben zur Stochastik keine Abgabe keine Besprechung in den Tutorien Prof. F. Merkl 23. Mai 2016 Zu Ihrer Information und als zusätzliches Übungsmaterial sind hier die Aufgaben
Sammlung alter Klausuraufgaben zur Stochastik keine Abgabe keine Besprechung in den Tutorien Prof. F. Merkl 23. Mai 2016 Zu Ihrer Information und als zusätzliches Übungsmaterial sind hier die Aufgaben
Statistische Software (R)
") Statistische Software (R) Paul Fink, M.Sc. Institut für Statistik Ludwig-Maximilians-Universität München Verteilungen und Zufallszahlen Übersicht Statistik-Funktionen Funktion mean() median() exp(mean(log(
Statistische Software (R) Paul Fink, M.Sc. Institut für Statistik Ludwig-Maximilians-Universität München Verteilungen und Zufallszahlen Übersicht Statistik-Funktionen Funktion mean() median() exp(mean(log(
3. Gemeinsame und bedingte Verteilung, stochastische Unabhängigkeit
 3. Gemeinsame und bedingte Verteilung, stochastische Unabhängigkeit Lernziele dieses Kapitels: Mehrdimensionale Zufallsvariablen (Zufallsvektoren) (Verteilung, Kenngrößen) Abhängigkeitsstrukturen Multivariate
3. Gemeinsame und bedingte Verteilung, stochastische Unabhängigkeit Lernziele dieses Kapitels: Mehrdimensionale Zufallsvariablen (Zufallsvektoren) (Verteilung, Kenngrößen) Abhängigkeitsstrukturen Multivariate
Kapitel 2.9 Der zentrale Grenzwertsatz. Stochastik SS
 Kapitel.9 Der zentrale Grenzwertsatz Stochastik SS 07 Vom SGGZ zum ZGWS Satz.4 (Schwaches Gesetz großer Zahlen) Sei (X i ) i eine Folge unabhängiger, identisch verteilter Zufallsvariablen mit E[X ]
Kapitel.9 Der zentrale Grenzwertsatz Stochastik SS 07 Vom SGGZ zum ZGWS Satz.4 (Schwaches Gesetz großer Zahlen) Sei (X i ) i eine Folge unabhängiger, identisch verteilter Zufallsvariablen mit E[X ]
Empirische Wirtschaftsforschung
 Empirische Wirtschaftsforschung Prof. Dr. Bernd Süßmuth Universität Leipzig Institut für Empirische Wirtschaftsforschung Volkswirtschaftslehre, insbesondere Ökonometrie 1 3. Momentenschätzung auf Stichprobenbasis
Empirische Wirtschaftsforschung Prof. Dr. Bernd Süßmuth Universität Leipzig Institut für Empirische Wirtschaftsforschung Volkswirtschaftslehre, insbesondere Ökonometrie 1 3. Momentenschätzung auf Stichprobenbasis
Kapitel 8 Absolutstetige Verteilungen
 Kapitel 8 Absolutstetige Verteilungen Vorlesung Wahrscheinlichkeitsrechnung I vom 27. Mai 2009 Lehrstuhl für Angewandte Mathematik FAU 8. Absolutstetige Verteilungen Charakterisierung von Verteilungen
Kapitel 8 Absolutstetige Verteilungen Vorlesung Wahrscheinlichkeitsrechnung I vom 27. Mai 2009 Lehrstuhl für Angewandte Mathematik FAU 8. Absolutstetige Verteilungen Charakterisierung von Verteilungen
Statistische Software (R)
") Statistische Software (R) Paul Fink, M.Sc., Eva Endres, M.Sc. Institut für Statistik Ludwig-Maximilians-Universität München Verteilungen und Zufallszahlen Übersicht Statistik-Funktionen Funktion mean()
Statistische Software (R) Paul Fink, M.Sc., Eva Endres, M.Sc. Institut für Statistik Ludwig-Maximilians-Universität München Verteilungen und Zufallszahlen Übersicht Statistik-Funktionen Funktion mean()
Punktetabelle (wird von den Korrektoren beschriftet)
") Probability and Statistics FS 2018 Prüfung 13.08.2018 Dauer: 180 Minuten Name: Legi-Nummer: Diese Prüfung enthält 12 Seiten (zusammen mit dem Deckblatt) und 10 Aufgaben. Das Formelblatt wird separat verteilt.
Probability and Statistics FS 2018 Prüfung 13.08.2018 Dauer: 180 Minuten Name: Legi-Nummer: Diese Prüfung enthält 12 Seiten (zusammen mit dem Deckblatt) und 10 Aufgaben. Das Formelblatt wird separat verteilt.
3 Produktmaße und Unabhängigkeit
 3 Produktmaße und Unabhängigkeit 3.1 Der allgemeine Fall Im Folgenden sei I eine beliebige Indexmenge. i I sei (Ω i, A i ein messbarer Raum. Weiter sei Ω : i I Ω i ein neuer Ergebnisraum. Wir definieren
3 Produktmaße und Unabhängigkeit 3.1 Der allgemeine Fall Im Folgenden sei I eine beliebige Indexmenge. i I sei (Ω i, A i ein messbarer Raum. Weiter sei Ω : i I Ω i ein neuer Ergebnisraum. Wir definieren
Konvergenz im quadratischen Mittel und die Parsevelsche Gleichung
 Konvergenz im quadratischen Mittel und die Parsevelsche Gleichung Skript zum Vortrag im Proseminar Analysis bei Dr. Gerhard Mülich Christian Maaß 6.Mai 8 Im letzten Vortrag haben wir gesehen, dass das
Konvergenz im quadratischen Mittel und die Parsevelsche Gleichung Skript zum Vortrag im Proseminar Analysis bei Dr. Gerhard Mülich Christian Maaß 6.Mai 8 Im letzten Vortrag haben wir gesehen, dass das