Bayes sche Netze: Konstruktion, Inferenz, Lernen und Kausalität. Volker Tresp
|
|
|
- Emilia Bergmann
- vor 7 Jahren
- Abrufe
Transkript
1 Bayes sche Netze: Konstruktion, Inferenz, Lernen und Kausalität Volker Tresp 1
2 Einführung Bisher haben wir uns fast ausschließich mit überwachtem Lernen beschäftigt: Ziel war es, eine (oder mehr als eine) Zielgröße basierend auf Informationen über die Eingangsgrößen abzuschätzen Wenn anwendbar, ist überwachtes Lernen auch oft die beste Lösung und es stehen mächige Werkzeuge wie Neuronale Netze oder die SVM zur Verfügung Es gibt jedoch auch Problemstellungen, bei denen überwachtes Lernen nicht anwendbar ist, insbesondere wenn man mit fehlenden Daten oder unsicherer Information umgehen muss und wenn man nicht nur an einer Zielgrösse sondern an einer Vielzahl von Zielgrößen interessiert ist Ein Beispiel ist eine medizinisch diagnostische Domäne, die aus einer Vielzahl von Krankheiten, Symptomen und Kontextinformationen bestehen kann: Über einen gegebenen Patienten sind nur wenige Informationen bekannt und man interessiert sich für die Vorhersage der Wahrscheinlichkeit einer Vielzahl von Krankheiten Dies sind einige der Gründe, weshalb Bayes sche Netze in den letzten Jahren viel Aufmerksamkeit erfahren haben 2
3 Bayes sche Netze Bayes sche Netze konstruieren eine hochdimensionale W.-Verteilung basierend auf lokalen probabilistischen Regeln Sie sind eng verknüpft mit einer kausalen Modellierung der Welt Regelbasierte Systeme wahren der dominierende Ansatz zu Wissensmodellierung zu den Hochzeiten der Künstlichen Intelligenz (KI); die Fokussierung auf Logik in regelbasierten Systemen war den Problemen der Realwelt jedoch nicht angemessen: In der Mehrzahl der Anwendungen ist der Umgang mit Unsicherheit und mit fehlenden Informationen essentiell; eben dafür sind logikbasierte regelbasierte Systeme nur unzureichend ausgelegt Bayes sche Netze begannen als ein kleines Randgebiet und haben sich in den 90er Jahren zu einem der wichtigsten Ansätze in der KI entwickelt Sie stellen ebenso flexible und mächtige Modelle zur Realisierung lernender Systeme dar 3
4
5 Definition Bayes scher Netze Die Variablen einer Domäne werden zu Knoten in einer entsprechenden graphischen Repräsentation Gerichtete Kanten (Pfeile) repräsentieren direkte kausale Abhängigkeiten von Elternknoten zu Kindernoten Quantitative Spezifikation der Abhängigkeiten: Für Knoten ohne Eltern müssen a prior Wahrscheinlichkeiten definiert werden P (A = i) i Für Knoten mit Eltern müssen bedingte Wahrscheinlichkeiten spezifiziert werden P (A = i B = j, C = k) i, j, k 4
6 Gemeinsame W.-Verteilung Ein Bayes sches Netz spezifiziert eine W-Verteilung in der Form M P (X 1,... X M ) = P (X i par(x i )) i=1 wobei par(x i ) die Menge der Elternknoten angibt (diese Menge kann leer sein) 5
7 Definition eines Bayes schen Netzes aus der Produktzerlegung von W.-Verteilungen Wir beginnen mit der Produktzerlegung einer W.-Verteilung (siehe Review über W.- Theorie) P (X 1,... X M ) = M i=1 P (X i X 1,..., X i 1 ) Diese Zerlegung ist immer in jeder beliebigen Reihenfolge der Variablen möglich; jeder Term enthält die bedingte W.-Verteilung eines Knoten bedingt auf alle Vorgänger des Knotens Die Abhängigkeiten reduzieren sich, wenn eine Variable nicht von allen Vorgängerknoten abhängt mit P (X i X 1,..., X i 1 ) = P (X i par(x i )) par(x i ) X 1,..., X i 1 6
8 Wenn die Ordnung der Variablen der kausalen Ordnung entspricht, erhalten wir die kausale Zerlegung wie zuvor Eine Zerlegung ist jedoch in jeder beliebigen Reihenfolge der Variablen möglich; allerdings liefert eine Zerlegung, die die kausale Ordnung berücksichtigt, die am leichtesten interpretierbare und die sparsamste Repräsentation mit den wenigsten Kanten.
9 Inferenz Die wichtigste Operation in Bayes schen Netzen ist die Inferenz: gegeben, dass eine Menge von Variablen bekannt ist, so ist man an der Verteilung einer (oder mehrerer) der unbekannten Variablen interessiert Seien X m die Menge der bekannten (gemessenen) Variablen und sei X q die Variable, an deren a posteriori Verteilung wir interessiert sind. Die restlichen Variablen seien X r. Im einfachen Inferenzansatz geht man folgendermaßen vor: Marginalisierung: die restlichen Variablen sind ohne Interesse und müssen herausintegriert werden P (X q, X m ) = X r P (X 1,... X M ) Berechnung der Normalisierung: P (X m ) = X q P (X q, X m ) 7
10 Berechnung der bedingten Wahrscheinlichkeit P (X q X m ) = P (Xq, X m ) P (X m ) Für die Inferenz ist die Berechnung der Normalisierung in vielen Fällen nicht notwendig; Im Lernen von Bayes Netzen spielt sie allerdings eine wichtige Rolle
11
12
13
14
15

16
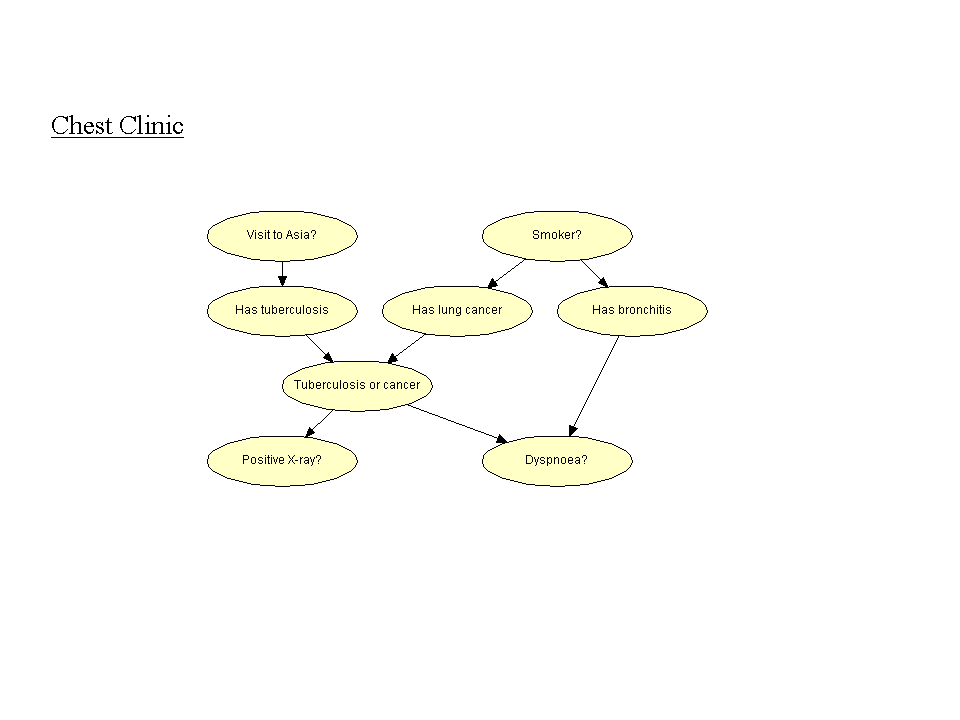
17
18
19 Inferenz in BNs ohne Zyklen Durch Konstruktion gibt es keine Zyklen im gerichteten Bayes Netz; die Struktur der Bayes Netze wird deshalb auch als directed acyclic graph (DAG) bezeichnet Es kann jedoch Zyklen geben, wenn man die Pfeilrichtungen ignoriert Wir betrachten zunächst nur Bayes Netze, die auch keine Zyklen enthalten, wenn man die Pfeilrichtungen wegläßt; die Struktur des Bayes Netzes ist dann ein Poly-tree: es gibt höchstens einen gerichteten Weg zwischen zwei Knoten 8
20 Die teure Operation in der Inferenz ist die Marginalisierung, denn sie Summe enthält exponentiell viele Terme Ziel ist es nun, die Struktur des Netzes auszunützen, um eine effiziente Marginalisiserung zu erreichen
21 Beispiel: betrachte die Markov Kette P (X 1 )P (X 2 X 1 )... P (X M X M 1 ) Dann ist P (X 1 ) bekannt und muss schon einmal nicht berechnet werden. Weiterhin ist = X M 1 P (X M ) = P (X 1 )P (X 2 X 1 )... P (X M X M 1 ) X 1,...,X M 1 P (X M X M 1 ) P (X M 1 X M 2 )... P (X 2 X 1 )P (X 1 ) X M 2 X 1 Oben muss man 2 M 1 Terme summieren, unten nur noch 2(M 1). Im allgemeinen kann Inferenz in Form eines Message Passing Algorithmus effizient implementiert werden
22 Belief Propagation (Sum-Product-Rule) Update für Knoten X mit Eltern U 1,..., U n und Kindern Y 1,..., Y m und lokaler Verteilung P (x u 1,..., u n ) (Notation nach Pearl: Probabilistic Reasoning) Im Netzwerk werden Botschaften (messages) in Pfeilrichtung (Top-down) und entgegen der Pfeilrichtung (Bottom-up) propagiert π Yj (x) ist die Top-down message von Knoten x zu seinem Kindknoten Y j λ X (u i ) ist die Bottom-up message von Knoten x zu seinem Elternknoten u i 9
23 Propagationsregeln In Gleichungen berechnen sich diese Botschaften für Knoten X lokal zu Top-down propagation (für alle Zustände x): π Yj (x) = λ Yk (x) P (x u 1,..., u n ) π X (u i ) k j u 1,...,u n Bottom-up propagation (für alle Zustände x): λ X (u i ) = λ(x) P (x u 1,..., u n ) π X (u k ) x u k :k i k i Mit λ(x) = j λ Y j (x) i 10
24
25
26 Berechnung des Beliefs Es reichen zwei Passagen durch das Netz aus, um alle Knoten zu berechnen Mit π(x) = P (x u 1,..., u n ) π X (u i ) u 1,...,u n i Ist (Z normalisiert die Verteilung) Bel(x) = P (x Evidence) = 1 Z λ(x)π(x) 11
27 Initialisierung Für Knoten mit bekanntem Zustand: π(x) = 1, λ(x) = 1 Für Knoten mit unbekanntem Zustand:: π(x) = 0, λ(x) = 0 Ausnahmen: Für Knoten ohne Eltern: π(x) = p(x) Für Knoten ohne Kinder: λ(x) = 1 12
28 Reihenfolge Prinzipiell können Knoten in beliebiger Reihenfolge upgedated werden Effizient sind die Anwendung folgender Regeln: Wenn Messages von allen Eltern vorliegen, berechne π(x) Wenn Messages von allen Kindern vorliegen, berechne λ(x) Wenn Messages von allen Eltern vorliegen, und allen Kindern, außer möglicherweise Y i, berechne π Yi (x) Wenn Messages von allen Kindern vorliegen, und allen Eltern, außer möglicherweise U i, berechne λ Ui (x) 13
29
30 Max-Propagation Ähnlich effizient kann die maximal-wahrscheinliche Konfiguration berechnet werden (Max-product Rule) 14
31 Belief Propagation in anderer Form Hidden Markov Modelle (HMMs) sind die Basis moderner Spracherkennungssysteme; sie können als Bayes sches Modell verstanden werden Die Berechnung der wahrscheinlichsten Zustände, gegeben die akustische Messungen, wird mit dem Viterbi Algorithmus berechnet; dieser ist equivalent zum Max-Prop Algorithmus Der Kalman Filter ist equivalent zum HMM Modell, nur dass die Variablen stetig sind und die bedingten Wahrscheinlichkeiten Gaussverteilt sind; die Schätzung der versteckten Zustände wird mit einem Belief Propagation Algorithmus berechnet 15
32 Belief Propagation mit Schleifen Mit Schleifen im Graphen ohne Pfeilen ist der Algorithmus eigentlich so nicht anwendbar, denn die Informationen aus verschiedenen Richtungen kann korreliert sein Dennoch wird er oft angewandt und konvergiert zu guten Lösungen; hier müssen wiederholt message passing angewandt werden, bis eine Konvergenz erreicht wird (was nicht immer der Fall ist) Die Anwendung des Belief Propagation auf Netze mit Schleifen wird als Loopy Belief Propagation bezeichnet Eine korrekte Form der Implementierung ist der junction tree algorithm ; allerdings ist er nur effizient, wenn die Schleifen im BN nicht zu gross sind (in meisten Entwicklungsumgebungen ist der junction tree algorithm implementiert) Interessant ist, dass die Dekodierung im Turbocode und in Low-Density Parity-Check (LDPC) Codes über loopy Beliefpropagation geschieht; beide werden zur Kommunikation in NASA Projekten (Mars-Missionsn) und im Mobilfunk eingesetzt 16
33 Entwurf der Bayes schen Netze Der Experte muss die kausalen Abhängigkeiten definieren und quantifizieren, d.h. er muss die Tafeln der bedingten Wahrscheinlichkeit auffüllen Gerade, wenn eine Variable viele Eltern besitzt kann dies schwierig bis unmöglich sein; man bedient sich gewisser vereinfachender Strukturen; am bekanntesten ist das Noisy-Or 17
34 Noisy-Or Sei X {0, 1} eine binäre Variable mit Eltern U 1,..., U n Sei q i die Wahrscheinlichkeit, dass X = 0, wenn U i = 1 und alle anderen U j = 0; dies bedeutet, dass c i = 1 q i den Einfluss einer einzelnen Größe bewertet; Dann ist P (X = 0 U 1 = 1,..., U n = 1) = n i=1 q i Dies bedeutet, dass Ereignisse immer wahrscheinlicher werden, wenn mehrere der Bedingungen erfüllt sind Beispiel: Wenn Krankheit A Fieber mit Wahrscheinlichkeit c A = 1 q A erzeugt, und Krankheit B Fieber mit Wahrscheinlichkeit c B = 1 q B erzeugt, dann ist die Wahrscheinlichkeit von Fieber wenn beide Krankheiten vorliegen gleich 1 q A q B. Dieser Ausdruck ist größer als c A und c B 18
35 Lernen in BNs Wir nehmen an, dass Daten vollständig sind ML-Parameterlernen ist in diesen Systemen denkbar einfach: man zählt einfach ab Betrachten wir den Parameter θ i,j,k, der definiert ist als θ i,j,k = P (X i = k par(x i ) = j) Dies bedeutet, dass θ i,j,k gleich der Wahrscheinlichkeit ist, dass X i im Zustand k ist, wenn die Eltern in Zustand j sind (wir nehmen an, dass man die Zustände der Eltern in einer systematischen Art nummerieren kann). Dann ist die ML Schätzung θ ML i,j,k = N i,j,k k N i,j,k Hierbei ist N i,j,k die Anzahl der Trainingsdaten, bei denen X i = k, par(x i ) = j. 19
36 EM-Lernen Haben die Trainingsdaten fehlende Einträge oder versteckte Variablen, kann man die ML-Lösung mit dem EM Algorithmus finden Im E-Schritt (Expectation) wird mit den Inferenzverfahren (Belief Propagation, Junction tree algorithm,...) berechnet E(N i,j,k ) = N P (X i = k, par(x i ) = j d l, θ) l=1 d l ist der l-te möglicherweise unvollständige Datenpunkt und E steht für den Erwartungswert. Dies bedeutet, dass man im E-schritt die gemeinsame Verteilung eines Knotens und seiner Eltern berechnet, gegeben den aktuellen Datenpunkt und gegeben die aktuellen Parameterwerte θ Im M-Schritt (Maximization) benutzt man die Schätzungen θ ML i,j,k = E(N i,j,k) k E(N i,j,k) 20
37 E-schritt und M-schritt werden bis zur Konvergenz iteriert Der EM Algorithmus spielt allgemein (nicht nur bei Bayes Netzen) beim Lernen mit fehlenden Daten und latenten Variablen eine zentrale Rolle
38 EM-Lernen beim HMM und beim Kalman Filter HMMs werden mit dem Baum-Welch-Algorithmus trainiert; dies entspricht genau dem entsprechenden EM-Algorithmus Offline Versionen zum Training des Kalman Filters benutzen ebenfalls den EM-Algorithmus 21
39 Einbeziehen von Vorwissen Vorwissen kann leicht integriert werden Ich vergeben eine effektive Anzahl von Counts α i,j,k 0, die meinem a priori Glauben entsprechen Dann ist θ ML i,j,k = α i,j,k + N i,j,k k α i,j,k + N i,j,k Entsprechend im EM-Algorithmus i,j,k = α i,j,k + E(N i,j,k ) k α i,j,k + E(N i,j,k ) θ ML 22
40 Strukturlernen in Bayes schen Netzen Beim Strukturlernen muss man einige Dinge beachten So gibt es äquivalente Modelle, die sich basierend auf Daten nicht unterscheiden lassen, da sie die gleichen Unabhängigkeiten ausdrücken; A->B, B->A (independence equivalence) Man darf die Pfeilrichtungen nur unter sehr starken Annahmen kausal interpretieren; typische Annahmen, die man machen muss, ist dass die wahre Domäne kausal ist (kausales Weltmodell) und dass es keine wesentlichen Variablen gibt, die im Modell nicht enthalten sind (vollständiges Weltmodell); sogar dan können typischweise nicht alle kausalen Richtungen eindeutig identifiziert werden 23
41 Strukturlernen in Bayes schen Netzen (2) Die populärsten Ansätze definieren eine Kostenfunktion, die man in der Struktursuche mit einer Suchstrategie optimiert Außer in trivial kleinen Netzen kann man nicht alle möglichen Strukturen testen Greedy Search: Man beginnt mit einem Startnetz (vollvernetzt, leer,...), macht lokale Änderungen und akzeptiert eine Änderung, falls dadurch die Kostenfunktionsich verbessert wird Greedy search kann man mehrmals mit verschiedenen Startpunkten durchführen Alternativen: Simulated Annealing, Genetische Algorithmen 24
42 Kostenfunktionen Als Kostenfunktion kann man die Log-Likelihood auf einer Testmenge verwenden oder man wählt einen Kreuzvalisierungsansatz Beliebt is ebenfalls das BIC (Bayesian Information Criterion) Kriterium, maximiere: log L M 2 log N (M ist die Anzahl der Parameter und N ist die Anzahl der Datenpunkte) Für komplette Daten ohne fehlende oder latente Variablen kann man explizit P (D M) berechnen und eine saubere Bayes sche Modellselektion durchführen 25
43
44 Weitere Verfahren zur Strukturoptimierung Multiple-jump Markov Chain Monte Carlo (MCMC) Methoden; voll Bayes scher Ansatz Verfahren, die direkt Unabhängigkeiten abtesten (constraint-based methods) 26

45
46 Bemerkungen Markov Netze sind ähnlich zu Bayes Netzen, allerdings sind hier die Kanten ungerichtet und Markov Netze besitzen keine kausale Interpretation Bayes sche Netze und Markov Netze sind die wichtigsten Vertreter der Graphischen Modelle (graphical models) Neben diskreten Variablen gibt es Netze aus stetigen Gauss schen Variablen und weitere Varianten... 27
Bayesianische Netzwerke - Lernen und Inferenz
 Bayesianische Netzwerke - Lernen und Inferenz Manuela Hummel 9. Mai 2003 Gliederung 1. Allgemeines 2. Bayesianische Netzwerke zur Auswertung von Genexpressionsdaten 3. Automatische Modellselektion 4. Beispiel
Bayesianische Netzwerke - Lernen und Inferenz Manuela Hummel 9. Mai 2003 Gliederung 1. Allgemeines 2. Bayesianische Netzwerke zur Auswertung von Genexpressionsdaten 3. Automatische Modellselektion 4. Beispiel
Bayes-Netze (2) Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg
 Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg") Bayes-Netze (2) Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg (Lehrstuhl KI) Bayes-Netze (2) 1 / 23 Gliederung 1 Zusammenhang zwischen Graphenstruktur
Bayes-Netze (2) Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg (Lehrstuhl KI) Bayes-Netze (2) 1 / 23 Gliederung 1 Zusammenhang zwischen Graphenstruktur
Syntaktische und Statistische Mustererkennung. Bernhard Jung
 Syntaktische und Statistische Mustererkennung VO 1.0 840.040 (UE 1.0 840.041) Bernhard Jung bernhard@jung.name http://bernhard.jung.name/vussme/ 1 Rückblick Nicht lineare Entscheidungsfunktionen SVM, Kernel
Syntaktische und Statistische Mustererkennung VO 1.0 840.040 (UE 1.0 840.041) Bernhard Jung bernhard@jung.name http://bernhard.jung.name/vussme/ 1 Rückblick Nicht lineare Entscheidungsfunktionen SVM, Kernel
Semester-Fahrplan 1 / 17
 Semester-Fahrplan 1 / 17 Hydroinformatik I Einführung in die Hydrologische Modellierung Bayes sches Netz Olaf Kolditz *Helmholtz Centre for Environmental Research UFZ 1 Technische Universität Dresden TUDD
Semester-Fahrplan 1 / 17 Hydroinformatik I Einführung in die Hydrologische Modellierung Bayes sches Netz Olaf Kolditz *Helmholtz Centre for Environmental Research UFZ 1 Technische Universität Dresden TUDD
Bayes-Netze (1) Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg
 Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg") Bayes-Netze (1) Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg (Lehrstuhl KI) Bayes-Netze (1) 1 / 22 Gliederung 1 Unsicheres Wissen 2 Schließen
Bayes-Netze (1) Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg (Lehrstuhl KI) Bayes-Netze (1) 1 / 22 Gliederung 1 Unsicheres Wissen 2 Schließen
Methoden der KI in der Biomedizin Bayes Netze
 Methoden der KI in der Biomedizin Bayes Netze Karl D. Fritscher Bayes Netze Intuitiv: Graphische Repräsentation von Einfluss Mathematisch: Graphische Repräsentation von bedingter Unabhängigkeit Bayes Netze
Methoden der KI in der Biomedizin Bayes Netze Karl D. Fritscher Bayes Netze Intuitiv: Graphische Repräsentation von Einfluss Mathematisch: Graphische Repräsentation von bedingter Unabhängigkeit Bayes Netze
Der Metropolis-Hastings Algorithmus
 Der Algorithmus Michael Höhle Department of Statistics University of Munich Numerical Methods for Bayesian Inference WiSe2006/07 Course 30 October 2006 Markov-Chain Monte-Carlo Verfahren Übersicht 1 Einführung
Der Algorithmus Michael Höhle Department of Statistics University of Munich Numerical Methods for Bayesian Inference WiSe2006/07 Course 30 October 2006 Markov-Chain Monte-Carlo Verfahren Übersicht 1 Einführung
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Graphische Modelle. Niels Landwehr
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Graphische Modelle iels Landwehr Überblick: Graphische Modelle Graphische Modelle: Werkzeug zur Modellierung einer Domäne mit verschiedenen
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Graphische Modelle iels Landwehr Überblick: Graphische Modelle Graphische Modelle: Werkzeug zur Modellierung einer Domäne mit verschiedenen
Codes on Graphs: Normal Realizations
 Codes on Graphs: Normal Realizations Autor: G. David Forney, Jr. Seminarvortrag von Madeleine Leidheiser und Melanie Reuter Inhaltsverzeichnis Einführung Motivation Einleitung Graphendarstellungen Trellis
Codes on Graphs: Normal Realizations Autor: G. David Forney, Jr. Seminarvortrag von Madeleine Leidheiser und Melanie Reuter Inhaltsverzeichnis Einführung Motivation Einleitung Graphendarstellungen Trellis
Statistische Verfahren in der Künstlichen Intelligenz, Bayesische Netze
 Statistische Verfahren in der Künstlichen Intelligenz, Bayesische Netze Erich Schubert 6. Juli 2003 LMU München, Institut für Informatik, Erich Schubert Zitat von R. P. Feynman Richard P. Feynman (Nobelpreisträger
Statistische Verfahren in der Künstlichen Intelligenz, Bayesische Netze Erich Schubert 6. Juli 2003 LMU München, Institut für Informatik, Erich Schubert Zitat von R. P. Feynman Richard P. Feynman (Nobelpreisträger
Gibbs sampling. Sebastian Pado. October 30, Seien X die Trainingdaten, y ein Testdatenpunkt, π die Parameter des Modells
 Gibbs sampling Sebastian Pado October 30, 2012 1 Bayessche Vorhersage Seien X die Trainingdaten, y ein Testdatenpunkt, π die Parameter des Modells Uns interessiert P (y X), wobei wir über das Modell marginalisieren
Gibbs sampling Sebastian Pado October 30, 2012 1 Bayessche Vorhersage Seien X die Trainingdaten, y ein Testdatenpunkt, π die Parameter des Modells Uns interessiert P (y X), wobei wir über das Modell marginalisieren
Vorlesungsplan. Von Naïve Bayes zu Bayesischen Netzwerk- Klassifikatoren. Naïve Bayes. Bayesische Netzwerke
 Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Clusteranalyse. Tobias Scheffer Thomas Vanck
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Hidden-Markov-Modelle
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hidden-Markov-Modelle Tobias Scheffer Thomas Vanck Hidden-Markov-Modelle: Wozu? Spracherkennung: Akustisches Modell. Geschriebene
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hidden-Markov-Modelle Tobias Scheffer Thomas Vanck Hidden-Markov-Modelle: Wozu? Spracherkennung: Akustisches Modell. Geschriebene
5 BINÄRE ENTSCHEIDUNGS- DIAGRAMME (BDDS)
") 5 BINÄRE ENTSCHEIDUNGS- DIAGRAMME (BDDS) Sommersemester 2009 Dr. Carsten Sinz, Universität Karlsruhe Datenstruktur BDD 2 1986 von R. Bryant vorgeschlagen zur Darstellung von aussagenlogischen Formeln (genauer:
5 BINÄRE ENTSCHEIDUNGS- DIAGRAMME (BDDS) Sommersemester 2009 Dr. Carsten Sinz, Universität Karlsruhe Datenstruktur BDD 2 1986 von R. Bryant vorgeschlagen zur Darstellung von aussagenlogischen Formeln (genauer:
Clusteranalyse: Gauß sche Mischmodelle
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse: Gauß sche Mischmodelle iels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse: Gauß sche Mischmodelle iels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Bayesnetzmodelle (BNM) in der Kardiologie
 in der Kardiologie") Bayesnetzmodelle (BNM) in der Kardiologie Vorgehensmodell - Ergebnisse Claus Möbus - Heiko Seebold Jan-Ole Janssen, Andreas Lüdtke, Iris Najman, Heinz-Jürgen Thole Besonderen Dank an: Herrn Reinke (Münster)
Bayesnetzmodelle (BNM) in der Kardiologie Vorgehensmodell - Ergebnisse Claus Möbus - Heiko Seebold Jan-Ole Janssen, Andreas Lüdtke, Iris Najman, Heinz-Jürgen Thole Besonderen Dank an: Herrn Reinke (Münster)
Algebraische Statistik ein junges Forschungsgebiet. Dipl.-Math. Marcus Weber
 Algebraische Statistik ein junges Forschungsgebiet Dipl.-Math. Marcus Weber Disputationsvortrag 15. Februar 2006 Gliederung 1. Statistische Modelle 2. Algebraische Interpretation statistischer Probleme
Algebraische Statistik ein junges Forschungsgebiet Dipl.-Math. Marcus Weber Disputationsvortrag 15. Februar 2006 Gliederung 1. Statistische Modelle 2. Algebraische Interpretation statistischer Probleme
Schriftlicher Test Teilklausur 2
 Technische Universität Berlin Fakultät IV Elektrotechnik und Informatik Künstliche Intelligenz: Grundlagen und Anwendungen Wintersemester 2012 / 2013 Albayrak, Fricke (AOT) Opper, Ruttor (KI) Schriftlicher
Technische Universität Berlin Fakultät IV Elektrotechnik und Informatik Künstliche Intelligenz: Grundlagen und Anwendungen Wintersemester 2012 / 2013 Albayrak, Fricke (AOT) Opper, Ruttor (KI) Schriftlicher
Simulationsmethoden in der Bayes-Statistik
 Simulationsmethoden in der Bayes-Statistik Hansruedi Künsch Seminar für Statistik, ETH Zürich 6. Juni 2012 Inhalt Warum Simulation? Modellspezifikation Markovketten Monte Carlo Simulation im Raum der Sprungfunktionen
Simulationsmethoden in der Bayes-Statistik Hansruedi Künsch Seminar für Statistik, ETH Zürich 6. Juni 2012 Inhalt Warum Simulation? Modellspezifikation Markovketten Monte Carlo Simulation im Raum der Sprungfunktionen
Vorhersage von Protein-Funktionen. Patrick Pfeffer
 Vorhersage von Protein-Funktionen Patrick Pfeffer Überblick Motivation Einleitung Methode Markov Random Fields Der Gibbs Sampler Parameter-Schätzung Bayes sche Analyse Resultate Pfeffer 2 Motivation Es
Vorhersage von Protein-Funktionen Patrick Pfeffer Überblick Motivation Einleitung Methode Markov Random Fields Der Gibbs Sampler Parameter-Schätzung Bayes sche Analyse Resultate Pfeffer 2 Motivation Es
Stochastik Praktikum Markov Chain Monte Carlo Methoden
 Stochastik Praktikum Markov Chain Monte Carlo Methoden Humboldt-Universität zu Berlin 14.10.2010 Problemstellung Wie kann eine Zufallsstichprobe am Computer simuliert werden, deren Verteilung aus einem
Stochastik Praktikum Markov Chain Monte Carlo Methoden Humboldt-Universität zu Berlin 14.10.2010 Problemstellung Wie kann eine Zufallsstichprobe am Computer simuliert werden, deren Verteilung aus einem
Graphische Spiele. M i (p) M i (p[i : p i]) M i (p) + ε M i (p[i : p i])
![Graphische Spiele. M i (p) M i (p[i : p i]) M i (p) + ε M i (p[i : p i])](/thumbs/66/54745029.jpg "Graphische Spiele. M i (p) M i (p[i : p i]) M i (p) + ε M i (p[i : p i])") Seminar über Algorithmen 19. November 2013 Michael Brückner Graphische Spiele Wolfgang Mulzer, Yannik Stein 1 Einführung Da in Mehrspielerspielen mit einer hohen Anzahl n N an Spielern die Auszahlungsdarstellungen
Seminar über Algorithmen 19. November 2013 Michael Brückner Graphische Spiele Wolfgang Mulzer, Yannik Stein 1 Einführung Da in Mehrspielerspielen mit einer hohen Anzahl n N an Spielern die Auszahlungsdarstellungen
Einige Konzepte aus der Wahrscheinlichkeitstheorie (Review)
") Einige Konzepte aus der Wahrscheinlichkeitstheorie (Review) 1 Diskrete Zufallsvariablen (Random variables) Eine Zufallsvariable X(c) ist eine Variable (genauer eine Funktion), deren Wert vom Ergebnis c
Einige Konzepte aus der Wahrscheinlichkeitstheorie (Review) 1 Diskrete Zufallsvariablen (Random variables) Eine Zufallsvariable X(c) ist eine Variable (genauer eine Funktion), deren Wert vom Ergebnis c
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Graphische Modelle. Christoph Sawade/Niels Landwehr/Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Graphische Modelle Christoph Sawade/Niels Landwehr/Tobias Scheffer Graphische Modelle Werkzeug zur Modellierung einer Domäne mit
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Graphische Modelle Christoph Sawade/Niels Landwehr/Tobias Scheffer Graphische Modelle Werkzeug zur Modellierung einer Domäne mit
Bayes sche und probabilistische Netze
 Bayes sche und probabilistische Netze Gliederung Wahrscheinlichkeiten Bedingte Unabhängigkeit, Deduktion und Induktion Satz von Bayes Bayes sche Netze D-Separierung Probabilistische Inferenz Beispielanwendung
Bayes sche und probabilistische Netze Gliederung Wahrscheinlichkeiten Bedingte Unabhängigkeit, Deduktion und Induktion Satz von Bayes Bayes sche Netze D-Separierung Probabilistische Inferenz Beispielanwendung
Hidden Markov Models. Vorlesung Computerlinguistische Techniken Alexander Koller. 8. Dezember 2014
 idden Markov Models Vorlesung omputerlinguistische Techniken Alexander Koller 8. Dezember 04 n-gramm-modelle Ein n-gramm ist ein n-tupel von Wörtern. -Gramme heißen auch Unigramme; -Gramme Bigramme; -Gramme
idden Markov Models Vorlesung omputerlinguistische Techniken Alexander Koller 8. Dezember 04 n-gramm-modelle Ein n-gramm ist ein n-tupel von Wörtern. -Gramme heißen auch Unigramme; -Gramme Bigramme; -Gramme
Elektrotechnik und Informationstechnik
 Elektrotechnik und Informationstechnik Institut für Automatisierungstechnik, Professur Prozessleittechnik Bayes'sche Netze VL PLT2 Professur für Prozessleittechnik Prof. Leon Urbas, Dipl. Ing. Johannes
Elektrotechnik und Informationstechnik Institut für Automatisierungstechnik, Professur Prozessleittechnik Bayes'sche Netze VL PLT2 Professur für Prozessleittechnik Prof. Leon Urbas, Dipl. Ing. Johannes
Die Datenmatrix für Überwachtes Lernen
 Die Datenmatrix für Überwachtes Lernen X j j-te Eingangsvariable X = (X 0,..., X M 1 ) T Vektor von Eingangsvariablen M Anzahl der Eingangsvariablen N Anzahl der Datenpunkte Y Ausgangsvariable x i = (x
Die Datenmatrix für Überwachtes Lernen X j j-te Eingangsvariable X = (X 0,..., X M 1 ) T Vektor von Eingangsvariablen M Anzahl der Eingangsvariablen N Anzahl der Datenpunkte Y Ausgangsvariable x i = (x
2.7 Der Shannon-Fano-Elias Code
 2.7 Der Shannon-Fano-Elias Code Die Huffman-Codierung ist ein asymptotisch optimales Verfahren. Wir haben auch gesehen, dass sich die Huffman-Codierung gut berechnen und dann auch gut decodieren lassen.
2.7 Der Shannon-Fano-Elias Code Die Huffman-Codierung ist ein asymptotisch optimales Verfahren. Wir haben auch gesehen, dass sich die Huffman-Codierung gut berechnen und dann auch gut decodieren lassen.
Topicmodelle. Gerhard Heyer, Patrick Jähnichen Universität Leipzig. tik.uni-leipzig.de
 Topicmodelle Universität Leipzig heyer@informa tik.uni-leipzig.de jaehnichen@informatik.uni-leipzig.de Institut für Informatik Topicmodelle Problem: je mehr Informationen verfügbar sind, desto schwieriger
Topicmodelle Universität Leipzig heyer@informa tik.uni-leipzig.de jaehnichen@informatik.uni-leipzig.de Institut für Informatik Topicmodelle Problem: je mehr Informationen verfügbar sind, desto schwieriger
Künstliche Intelligenz Maschinelles Lernen
 Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
Reasoning and decision-making under uncertainty
 Reasoning and decision-making under uncertainty 9. Vorlesung Actions, interventions and complex decisions Sebastian Ptock AG Sociable Agents Rückblick: Decision-Making A decision leads to states with values,
Reasoning and decision-making under uncertainty 9. Vorlesung Actions, interventions and complex decisions Sebastian Ptock AG Sociable Agents Rückblick: Decision-Making A decision leads to states with values,
Lineare Regression. Volker Tresp
 Lineare Regression Volker Tresp 1 Die Lernmaschine: Das lineare Modell / ADALINE Wie beim Perzeptron wird zunächst die Aktivierungsfunktion gewichtete Summe der Eingangsgrößen x i berechnet zu h i = M
Lineare Regression Volker Tresp 1 Die Lernmaschine: Das lineare Modell / ADALINE Wie beim Perzeptron wird zunächst die Aktivierungsfunktion gewichtete Summe der Eingangsgrößen x i berechnet zu h i = M
Bayes sches Lernen: Übersicht
 Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 10: Naive Bayes (V. 1.0)
Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 10: Naive Bayes (V. 1.0)
Latente Dirichlet-Allokation
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Latente Dirichlet-Allokation Tobias Scheffer Peter Haider Paul Prasse Themenmodellierung Themenmodellierung (Topic modeling) liefert
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Latente Dirichlet-Allokation Tobias Scheffer Peter Haider Paul Prasse Themenmodellierung Themenmodellierung (Topic modeling) liefert
Entscheidungsverfahren für die Software-Verifikation. 4 - BDDs
 Entscheidungsverfahren für die Software-Verifikation 4 - BDDs Datenstruktur BDD 1986 von R. Bryant vorgeschlagen zur Darstellung von aussagenlogischen Formeln (genauer: Booleschen Funktionen) Boolesche
Entscheidungsverfahren für die Software-Verifikation 4 - BDDs Datenstruktur BDD 1986 von R. Bryant vorgeschlagen zur Darstellung von aussagenlogischen Formeln (genauer: Booleschen Funktionen) Boolesche
Datenstrukturen & Algorithmen
 Datenstrukturen & Algorithmen Matthias Zwicker Universität Bern Frühling 2010 Übersicht Dynamische Programmierung Einführung Ablaufkoordination von Montagebändern Längste gemeinsame Teilsequenz Optimale
Datenstrukturen & Algorithmen Matthias Zwicker Universität Bern Frühling 2010 Übersicht Dynamische Programmierung Einführung Ablaufkoordination von Montagebändern Längste gemeinsame Teilsequenz Optimale
Wichtige Definitionen und Aussagen
 Wichtige Definitionen und Aussagen Zufallsexperiment, Ergebnis, Ereignis: Unter einem Zufallsexperiment verstehen wir einen Vorgang, dessen Ausgänge sich nicht vorhersagen lassen Die möglichen Ausgänge
Wichtige Definitionen und Aussagen Zufallsexperiment, Ergebnis, Ereignis: Unter einem Zufallsexperiment verstehen wir einen Vorgang, dessen Ausgänge sich nicht vorhersagen lassen Die möglichen Ausgänge
Methoden der Statistik Markov Chain Monte Carlo Methoden
 Methoden der Statistik Markov Chain Monte Carlo Methoden Humboldt-Universität zu Berlin 08.02.2013 Problemstellung Wie kann eine Zufallsstichprobe am Computer simuliert werden, deren Verteilung aus einem
Methoden der Statistik Markov Chain Monte Carlo Methoden Humboldt-Universität zu Berlin 08.02.2013 Problemstellung Wie kann eine Zufallsstichprobe am Computer simuliert werden, deren Verteilung aus einem
Vorlesung Wissensentdeckung
 Vorlesung Wissensentdeckung Klassifikation und Regression: nächste Nachbarn Katharina Morik, Uwe Ligges 14.05.2013 1 von 24 Gliederung Funktionsapproximation 1 Funktionsapproximation Likelihood 2 Kreuzvalidierung
Vorlesung Wissensentdeckung Klassifikation und Regression: nächste Nachbarn Katharina Morik, Uwe Ligges 14.05.2013 1 von 24 Gliederung Funktionsapproximation 1 Funktionsapproximation Likelihood 2 Kreuzvalidierung
1.8 Shift-And-Algorithmus
 .8 Shift-And-Algorithmus nutzt durch Bitoperationen mögliche Parallelisierung Theoretischer Hintergrund: Nichtdeterministischer endlicher Automat Laufzeit: Θ(n), falls die Länge des Suchwortes nicht größer
.8 Shift-And-Algorithmus nutzt durch Bitoperationen mögliche Parallelisierung Theoretischer Hintergrund: Nichtdeterministischer endlicher Automat Laufzeit: Θ(n), falls die Länge des Suchwortes nicht größer
Dr. Johannes Bauer Institut für Soziologie, LMU München. Directed Acyclic Graphs (DAG)
") Dr. Institut für Soziologie, LMU München Directed Acyclic Graphs (DAG) Wie ist der Zusammenhang von und Z blockiert den Pfad Mediator 50% = 1 50% = 0 Z Z if =0: 20% if =1: 80% Gegenwsk if Z=0: 20% if Z=1:
Dr. Institut für Soziologie, LMU München Directed Acyclic Graphs (DAG) Wie ist der Zusammenhang von und Z blockiert den Pfad Mediator 50% = 1 50% = 0 Z Z if =0: 20% if =1: 80% Gegenwsk if Z=0: 20% if Z=1:
Numerische Methoden und Algorithmen in der Physik
 Numerische Methoden und Algorithmen in der Physik Hartmut Stadie, Christian Autermann 15.01.2009 Numerische Methoden und Algorithmen in der Physik Christian Autermann 1/ 47 Methode der kleinsten Quadrate
Numerische Methoden und Algorithmen in der Physik Hartmut Stadie, Christian Autermann 15.01.2009 Numerische Methoden und Algorithmen in der Physik Christian Autermann 1/ 47 Methode der kleinsten Quadrate
Vorlesung: Statistik II für Wirtschaftswissenschaft
 Vorlesung: Statistik II für Wirtschaftswissenschaft Prof. Dr. Helmut Küchenhoff Institut für Statistik, LMU München Sommersemester 2017 6 Genzwertsätze Einführung 1 Wahrscheinlichkeit: Definition und Interpretation
Vorlesung: Statistik II für Wirtschaftswissenschaft Prof. Dr. Helmut Küchenhoff Institut für Statistik, LMU München Sommersemester 2017 6 Genzwertsätze Einführung 1 Wahrscheinlichkeit: Definition und Interpretation
Statistik und Wahrscheinlichkeitsrechnung
 Statistik und Wahrscheinlichkeitsrechnung Dr. Jochen Köhler 1 Inhalt der heutigen Vorlesung Statistik und Wahrscheinlichkeitsrechnung Zusammenfassung der vorherigen Vorlesung Übersicht über Schätzung und
Statistik und Wahrscheinlichkeitsrechnung Dr. Jochen Köhler 1 Inhalt der heutigen Vorlesung Statistik und Wahrscheinlichkeitsrechnung Zusammenfassung der vorherigen Vorlesung Übersicht über Schätzung und
Bayesianische Netzwerke I
 Bayesianische Netzwerke I Christiane Belitz 2.5.2003 Überblick Der Vortrag basiert auf Using Bayesian Networks to Analyze Expression Data von Friedman et al. (2000) Definition: Bayesianisches Netzwerk
Bayesianische Netzwerke I Christiane Belitz 2.5.2003 Überblick Der Vortrag basiert auf Using Bayesian Networks to Analyze Expression Data von Friedman et al. (2000) Definition: Bayesianisches Netzwerk
8 Einführung in Expertensysteme
 8 Einführung in Expertensysteme 22. Vorlesung: Constraints; Probabilistisches Schließen Für die Programmierung von Expertensystemen werden verschiedene Grundtechniken der Wissensrepräsentation und spezielle
8 Einführung in Expertensysteme 22. Vorlesung: Constraints; Probabilistisches Schließen Für die Programmierung von Expertensystemen werden verschiedene Grundtechniken der Wissensrepräsentation und spezielle
Signalverarbeitung 2. Volker Stahl - 1 -
 - 1 - Hidden Markov Modelle - 2 - Idee Zu klassifizierende Merkmalvektorfolge wurde von einem (unbekannten) System erzeugt. Nutze Referenzmerkmalvektorfolgen um ein Modell Des erzeugenden Systems zu bauen
- 1 - Hidden Markov Modelle - 2 - Idee Zu klassifizierende Merkmalvektorfolge wurde von einem (unbekannten) System erzeugt. Nutze Referenzmerkmalvektorfolgen um ein Modell Des erzeugenden Systems zu bauen
Künstliche Intelligenz - Optimierungsprobleme - Suche in Spielbäumen
 Künstliche Intelligenz - Optimierungsprobleme - Suche in Spielbäumen Stephan Schwiebert WS 2009/2010 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Optimierungsprobleme
Künstliche Intelligenz - Optimierungsprobleme - Suche in Spielbäumen Stephan Schwiebert WS 2009/2010 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Optimierungsprobleme
8. A & D - Heapsort. Werden sehen, wie wir durch geschicktes Organsieren von Daten effiziente Algorithmen entwerfen können.
 8. A & D - Heapsort Werden sehen, wie wir durch geschicktes Organsieren von Daten effiziente Algorithmen entwerfen können. Genauer werden wir immer wieder benötigte Operationen durch Datenstrukturen unterstützen.
8. A & D - Heapsort Werden sehen, wie wir durch geschicktes Organsieren von Daten effiziente Algorithmen entwerfen können. Genauer werden wir immer wieder benötigte Operationen durch Datenstrukturen unterstützen.
Verkettete Datenstrukturen: Bäume
 Verkettete Datenstrukturen: Bäume 1 Graphen Gerichteter Graph: Menge von Knoten (= Elementen) + Menge von Kanten. Kante: Verbindung zwischen zwei Knoten k 1 k 2 = Paar von Knoten (k 1, k 2 ). Menge aller
Verkettete Datenstrukturen: Bäume 1 Graphen Gerichteter Graph: Menge von Knoten (= Elementen) + Menge von Kanten. Kante: Verbindung zwischen zwei Knoten k 1 k 2 = Paar von Knoten (k 1, k 2 ). Menge aller
Boole sches Retrieval als frühes, aber immer noch verbreitetes IR-Modell mit zahlreichen Erweiterungen
 Rückblick Boole sches Retrieval als frühes, aber immer noch verbreitetes IR-Modell mit zahlreichen Erweiterungen Vektorraummodell stellt Anfrage und Dokumente als Vektoren in gemeinsamen Vektorraum dar
Rückblick Boole sches Retrieval als frühes, aber immer noch verbreitetes IR-Modell mit zahlreichen Erweiterungen Vektorraummodell stellt Anfrage und Dokumente als Vektoren in gemeinsamen Vektorraum dar
Bedingt unabhängige Zufallsvariablen
 7. Markov-Ketten 7. Definition und Eigenschaften von Markov-Ketten Benannt nach Andrei A. Markov [856-9] Einige Stichworte: Markov-Ketten Definition Eigenschaften Konvergenz Hidden Markov Modelle Sei X
7. Markov-Ketten 7. Definition und Eigenschaften von Markov-Ketten Benannt nach Andrei A. Markov [856-9] Einige Stichworte: Markov-Ketten Definition Eigenschaften Konvergenz Hidden Markov Modelle Sei X
Grundlagen der Objektmodellierung
 Grundlagen der Objektmodellierung Daniel Göhring 30.10.2006 Gliederung Grundlagen der Wahrscheinlichkeitsrechnung Begriffe zur Umweltmodellierung Bayesfilter Zusammenfassung Grundlagen der Wahrscheinlichkeitsrechnung
Grundlagen der Objektmodellierung Daniel Göhring 30.10.2006 Gliederung Grundlagen der Wahrscheinlichkeitsrechnung Begriffe zur Umweltmodellierung Bayesfilter Zusammenfassung Grundlagen der Wahrscheinlichkeitsrechnung
Reinforcement Learning
 Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Bayes sches Lernen. Niels Landwehr
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayes sches Lernen Niels Landwehr Überblick Grundkonzepte des Bayes schen Lernens Wahrscheinlichstes Modell gegeben Daten Münzwürfe
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayes sches Lernen Niels Landwehr Überblick Grundkonzepte des Bayes schen Lernens Wahrscheinlichstes Modell gegeben Daten Münzwürfe
Maschinelle Sprachverarbeitung: N-Gramm-Modelle
 HUMBOLD-UNIVERSIÄ ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: N-Gramm-Modelle obias Scheffer, Ulf Brefeld Statistische Sprachmodelle Welche Sätze sind
HUMBOLD-UNIVERSIÄ ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: N-Gramm-Modelle obias Scheffer, Ulf Brefeld Statistische Sprachmodelle Welche Sätze sind
KAPITEL 5. Erwartungswert
 KAPITEL 5 Erwartungswert Wir betrachten einen diskreten Wahrscheinlichkeitsraum (Ω, P) und eine Zufallsvariable X : Ω R auf diesem Wahrscheinlichkeitsraum. Die Grundmenge Ω hat also nur endlich oder abzählbar
KAPITEL 5 Erwartungswert Wir betrachten einen diskreten Wahrscheinlichkeitsraum (Ω, P) und eine Zufallsvariable X : Ω R auf diesem Wahrscheinlichkeitsraum. Die Grundmenge Ω hat also nur endlich oder abzählbar
Bayessche Netze. Kevin Klamt und Rona Erdem Künstliche Intelligenz II SoSe 2012 Dozent: Claes Neuefeind
 Bayessche Netze Kevin Klamt und Rona Erdem Künstliche Intelligenz II SoSe 2012 Dozent: Claes Neuefeind Einleitung Sicheres vs. Unsicheres Wissen Kausale Netzwerke Abhängigkeit Verbindungsarten Exkurs:
Bayessche Netze Kevin Klamt und Rona Erdem Künstliche Intelligenz II SoSe 2012 Dozent: Claes Neuefeind Einleitung Sicheres vs. Unsicheres Wissen Kausale Netzwerke Abhängigkeit Verbindungsarten Exkurs:
Hidden Markov Models
 Hidden Markov Models Kursfolien Karin Haenelt 09.05002 1 Letzte Änderung 18.07002 Hidden Markov Models Besondere Form eines probabilistischen endlichen Automaten Weit verbreitet in der statistischen Sprachverarbeitung
Hidden Markov Models Kursfolien Karin Haenelt 09.05002 1 Letzte Änderung 18.07002 Hidden Markov Models Besondere Form eines probabilistischen endlichen Automaten Weit verbreitet in der statistischen Sprachverarbeitung
Künstliche Intelligenz Unsicherheit. Stephan Schwiebert WS 2009/2010 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln
 Künstliche Intelligenz Unsicherheit Stephan Schwiebert WS 2009/2010 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Rückblick Agent in der Wumpuswelt konnte Entscheidungen
Künstliche Intelligenz Unsicherheit Stephan Schwiebert WS 2009/2010 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Rückblick Agent in der Wumpuswelt konnte Entscheidungen
Elektrotechnik und Informationstechnik
 Elektrotechnik und Informationstechnik Institut für utomatisierungstechnik, Professur Prozessleittechnik Bayessche Netze VL Prozessinformationsverarbeitung WS 2009/2010 Problemstellung Wie kann Wissen
Elektrotechnik und Informationstechnik Institut für utomatisierungstechnik, Professur Prozessleittechnik Bayessche Netze VL Prozessinformationsverarbeitung WS 2009/2010 Problemstellung Wie kann Wissen
Fortgeschrittene Netzwerk- und Graph-Algorithmen
 Fortgeschrittene Netzwerk- und Graph-Algorithmen Prof. Dr. Hanjo Täubig Lehrstuhl für Effiziente Algorithmen (Prof. Dr. Ernst W. Mayr) Institut für Informatik Technische Universität München Wintersemester
Fortgeschrittene Netzwerk- und Graph-Algorithmen Prof. Dr. Hanjo Täubig Lehrstuhl für Effiziente Algorithmen (Prof. Dr. Ernst W. Mayr) Institut für Informatik Technische Universität München Wintersemester
Einige Konzepte aus der Wahrscheinlichkeitstheorie (Wiederh.)
") Einige Konzepte aus der Wahrscheinlichkeitstheorie (Wiederh.) 1 Zusammenfassung Bedingte Verteilung: P (y x) = P (x, y) P (x) mit P (x) > 0 Produktsatz P (x, y) = P (x y)p (y) = P (y x)p (x) Kettenregel
Einige Konzepte aus der Wahrscheinlichkeitstheorie (Wiederh.) 1 Zusammenfassung Bedingte Verteilung: P (y x) = P (x, y) P (x) mit P (x) > 0 Produktsatz P (x, y) = P (x y)p (y) = P (y x)p (x) Kettenregel
Codes on Graphs: Normal Realizations
 Codes on Graphs: Normal Realizations Autor: G. David Forney Seminarvortrag von Madeleine Leidheiser und Melanie Reuter 1 Inhaltsverzeichnis: 1. Einführung 3 1.1 Motivation 3 1.2 Einleitung 3 2. Graphendarstellungen
Codes on Graphs: Normal Realizations Autor: G. David Forney Seminarvortrag von Madeleine Leidheiser und Melanie Reuter 1 Inhaltsverzeichnis: 1. Einführung 3 1.1 Motivation 3 1.2 Einleitung 3 2. Graphendarstellungen
Quantitative Methoden Wissensbasierter Systeme
 Quantitative Methoden Wissensbasierter Systeme Probabilistische Netze und ihre Anwendungen Robert Remus Universität Leipzig Fakultät für Mathematik und Informatik Abteilung für Intelligente Systeme 23.
Quantitative Methoden Wissensbasierter Systeme Probabilistische Netze und ihre Anwendungen Robert Remus Universität Leipzig Fakultät für Mathematik und Informatik Abteilung für Intelligente Systeme 23.
Einführung in die Theorie der Markov-Ketten. Jens Schomaker
 Einführung in die Theorie der Markov-Ketten Jens Schomaker Markov-Ketten Zur Motivation der Einführung von Markov-Ketten betrachte folgendes Beispiel: 1.1 Beispiel Wir wollen die folgende Situation mathematisch
Einführung in die Theorie der Markov-Ketten Jens Schomaker Markov-Ketten Zur Motivation der Einführung von Markov-Ketten betrachte folgendes Beispiel: 1.1 Beispiel Wir wollen die folgende Situation mathematisch
Inhaltsverzeichnis. 4 Statistik Einleitung Wahrscheinlichkeit Verteilungen Grundbegriffe 98
 Inhaltsverzeichnis 1 Datenbehandlung und Programmierung 11 1.1 Information 11 1.2 Codierung 13 1.3 Informationsübertragung 17 1.4 Analogsignale - Abtasttheorem 18 1.5 Repräsentation numerischer Daten 20
Inhaltsverzeichnis 1 Datenbehandlung und Programmierung 11 1.1 Information 11 1.2 Codierung 13 1.3 Informationsübertragung 17 1.4 Analogsignale - Abtasttheorem 18 1.5 Repräsentation numerischer Daten 20
Multiple Alignments. Vorlesung Einführung in die Angewandte Bioinformatik Prof. Dr. Sven Rahmann. Webseite zur Vorlesung
 Multiple Alignments Vorlesung Einführung in die Angewandte Bioinformatik Prof. Dr. Sven Rahmann Webseite zur Vorlesung http://bioinfo.wikidot.com/ Sprechstunde Mo 16-17 in OH14, R214 Sven.Rahmann -at-
Multiple Alignments Vorlesung Einführung in die Angewandte Bioinformatik Prof. Dr. Sven Rahmann Webseite zur Vorlesung http://bioinfo.wikidot.com/ Sprechstunde Mo 16-17 in OH14, R214 Sven.Rahmann -at-
Arbeit: Page, Brin, Motwani, Winograd (1998). Ziel: Maß für absolute
. Ziel: Maß für absolute") 3.4 PageRank Arbeit: Page, Brin, Motwani, Winograd (1998). Ziel: Maß für absolute Wichtigkeit von Webseiten; nicht Relevanz bezüglich Benutzeranfrage. Anfrageunabhängiges Ranking. Ausgangspunkt: Eingangsgrad.
3.4 PageRank Arbeit: Page, Brin, Motwani, Winograd (1998). Ziel: Maß für absolute Wichtigkeit von Webseiten; nicht Relevanz bezüglich Benutzeranfrage. Anfrageunabhängiges Ranking. Ausgangspunkt: Eingangsgrad.
Wie komme ich von hier zum Hauptbahnhof?
 NP-Vollständigkeit Wie komme ich von hier zum Hauptbahnhof? P Wie komme ich von hier zum Hauptbahnhof? kann ich verwende für reduzieren auf Finde jemand, der den Weg kennt! Alternativ: Finde eine Stadtkarte!
NP-Vollständigkeit Wie komme ich von hier zum Hauptbahnhof? P Wie komme ich von hier zum Hauptbahnhof? kann ich verwende für reduzieren auf Finde jemand, der den Weg kennt! Alternativ: Finde eine Stadtkarte!
BAYES SCHE STATISTIK
 BAES SCHE STATISTIK FELIX RUBIN EINFÜHRUNG IN DIE STATISTIK, A.D. BARBOUR, HS 2007 1. Einführung Die Bayes sche Statistik gibt eine weitere Methode, um einen unbekannten Parameter θ zu schätzen. Bisher
BAES SCHE STATISTIK FELIX RUBIN EINFÜHRUNG IN DIE STATISTIK, A.D. BARBOUR, HS 2007 1. Einführung Die Bayes sche Statistik gibt eine weitere Methode, um einen unbekannten Parameter θ zu schätzen. Bisher
INTELLIGENTE DATENANALYSE IN MATLAB. Überwachtes Lernen: Entscheidungsbäume
 INTELLIGENTE DATENANALYSE IN MATLAB Überwachtes Lernen: Entscheidungsbäume Literatur Stuart Russell und Peter Norvig: Artificial Intelligence. Andrew W. Moore: http://www.autonlab.org/tutorials. 2 Überblick
INTELLIGENTE DATENANALYSE IN MATLAB Überwachtes Lernen: Entscheidungsbäume Literatur Stuart Russell und Peter Norvig: Artificial Intelligence. Andrew W. Moore: http://www.autonlab.org/tutorials. 2 Überblick
Algorithmische Methoden zur Netzwerkanalyse
 Algorithmische Methoden zur Netzwerkanalyse Prof. Dr. Henning Meyerhenke Institut für Theoretische Informatik 1 KIT Henning Universität desmeyerhenke, Landes Baden-Württemberg Institutund für Theoretische
Algorithmische Methoden zur Netzwerkanalyse Prof. Dr. Henning Meyerhenke Institut für Theoretische Informatik 1 KIT Henning Universität desmeyerhenke, Landes Baden-Württemberg Institutund für Theoretische
Endliche Markov-Ketten - eine Übersicht
 Endliche Markov-Ketten - eine Übersicht Diese Übersicht über endliche Markov-Ketten basiert auf dem Buch Monte Carlo- Algorithmen von Müller-Gronbach et. al. und dient als Sammlung von Definitionen und
Endliche Markov-Ketten - eine Übersicht Diese Übersicht über endliche Markov-Ketten basiert auf dem Buch Monte Carlo- Algorithmen von Müller-Gronbach et. al. und dient als Sammlung von Definitionen und
Datenstrukturen und Algorithmen. Christian Sohler FG Algorithmen & Komplexität
 Datenstrukturen und Algorithmen Christian Sohler FG Algorithmen & Komplexität 1 Clustering: Partitioniere Objektmenge in Gruppen(Cluster), so dass sich Objekte in einer Gruppe ähnlich sind und Objekte
Datenstrukturen und Algorithmen Christian Sohler FG Algorithmen & Komplexität 1 Clustering: Partitioniere Objektmenge in Gruppen(Cluster), so dass sich Objekte in einer Gruppe ähnlich sind und Objekte
80 7 MARKOV-KETTEN. 7.1 Definition und Eigenschaften von Markov-Ketten
 80 7 MARKOV-KETTEN 7 Markov-Ketten 7. Definition und Eigenschaften von Markov-Ketten Sei X = (X 0, X, X 2,...) eine Folge von diskreten Zufallsvariablen, die alle Ausprägungen in einer endlichen bzw. abzählbaren
80 7 MARKOV-KETTEN 7 Markov-Ketten 7. Definition und Eigenschaften von Markov-Ketten Sei X = (X 0, X, X 2,...) eine Folge von diskreten Zufallsvariablen, die alle Ausprägungen in einer endlichen bzw. abzählbaren
Algorithmen & Komplexität
 Algorithmen & Komplexität Angelika Steger Institut für Theoretische Informatik steger@inf.ethz.ch Kürzeste Pfade Problem Gegeben Netzwerk: Graph G = (V, E), Gewichtsfunktion w: E N Zwei Knoten: s, t Kantenzug/Weg
Algorithmen & Komplexität Angelika Steger Institut für Theoretische Informatik steger@inf.ethz.ch Kürzeste Pfade Problem Gegeben Netzwerk: Graph G = (V, E), Gewichtsfunktion w: E N Zwei Knoten: s, t Kantenzug/Weg
Relationen und DAGs, starker Zusammenhang
 Relationen und DAGs, starker Zusammenhang Anmerkung: Sei D = (V, E). Dann ist A V V eine Relation auf V. Sei andererseits R S S eine Relation auf S. Dann definiert D = (S, R) einen DAG. D.h. DAGs sind
Relationen und DAGs, starker Zusammenhang Anmerkung: Sei D = (V, E). Dann ist A V V eine Relation auf V. Sei andererseits R S S eine Relation auf S. Dann definiert D = (S, R) einen DAG. D.h. DAGs sind
Einführung in die Computerlinguistik
 Einführung in die Computerlinguistik Spracherkennung und Hidden Markov Modelle Dozentin: Wiebke Petersen WS 2004/2005 Wiebke Petersen Einführung in die Computerlinguistik WS 04/05 Spracherkennung Merkmalsextraktion
Einführung in die Computerlinguistik Spracherkennung und Hidden Markov Modelle Dozentin: Wiebke Petersen WS 2004/2005 Wiebke Petersen Einführung in die Computerlinguistik WS 04/05 Spracherkennung Merkmalsextraktion
Theorie der Informatik Übersicht. Theorie der Informatik SAT Graphenprobleme Routing-Probleme. 21.
 Theorie der Informatik 19. Mai 2014 21. einige NP-vollständige Probleme Theorie der Informatik 21. einige NP-vollständige Probleme 21.1 Übersicht 21.2 Malte Helmert Gabriele Röger 21.3 Graphenprobleme
Theorie der Informatik 19. Mai 2014 21. einige NP-vollständige Probleme Theorie der Informatik 21. einige NP-vollständige Probleme 21.1 Übersicht 21.2 Malte Helmert Gabriele Röger 21.3 Graphenprobleme
Bayes sches Lernen: Übersicht
 Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 5: Naive Bayes + IBL (V.
Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 5: Naive Bayes + IBL (V.
Grundlagen digitaler Systeme WS12
 Grundlagen digitaler Systeme WS12 Binary Decision Diagrams Johann Blieberger 183.580, VU 2.0 Automation Systems Group E183-1 Institute of Computer Aided Automation Vienna University of Technology email:
Grundlagen digitaler Systeme WS12 Binary Decision Diagrams Johann Blieberger 183.580, VU 2.0 Automation Systems Group E183-1 Institute of Computer Aided Automation Vienna University of Technology email:
(d) das zu Grunde liegende Problem gut konditioniert ist.
 das zu Grunde liegende Problem gut konditioniert ist.") Aufgabe 0: (6 Punkte) Bitte kreuzen Sie die richtige Lösung an. Es ist jeweils genau eine Antwort korrekt. Für jede richtige Antwort erhalten Sie einen Punkt, für jede falsche Antwort wird Ihnen ein Punkt
Aufgabe 0: (6 Punkte) Bitte kreuzen Sie die richtige Lösung an. Es ist jeweils genau eine Antwort korrekt. Für jede richtige Antwort erhalten Sie einen Punkt, für jede falsche Antwort wird Ihnen ein Punkt
2. Woche Eindeutige Entschlüsselbarleit, Sätze von Kraft und McMillan, Huffmancodierung
 2 Woche Eindeutige Entschlüsselbarleit, Sätze von Kraft und McMillan, Huffmancodierung 2 Woche: Eindeutige Entschlüsselbarleit, Sätze von Kraft und McMillan, Huffmancodierung 24/ 44 Zwei Beispiele a 0
2 Woche Eindeutige Entschlüsselbarleit, Sätze von Kraft und McMillan, Huffmancodierung 2 Woche: Eindeutige Entschlüsselbarleit, Sätze von Kraft und McMillan, Huffmancodierung 24/ 44 Zwei Beispiele a 0
Statistik. Sommersemester Prof. Dr. Stefan Etschberger HSA. für Betriebswirtschaft und International Management
 Statistik für Betriebswirtschaft und International Management Sommersemester 2014 Prof. Dr. Stefan Etschberger HSA Streuungsparameter Varianz Var(X) bzw. σ 2 : [x i E(X)] 2 f(x i ), wenn X diskret Var(X)
Statistik für Betriebswirtschaft und International Management Sommersemester 2014 Prof. Dr. Stefan Etschberger HSA Streuungsparameter Varianz Var(X) bzw. σ 2 : [x i E(X)] 2 f(x i ), wenn X diskret Var(X)
1 DFS-Bäume in ungerichteten Graphen
 Praktikum Algorithmen-Entwurf (Teil 3) 06.11.2006 1 1 DFS-Bäume in ungerichteten Graphen Sei ein ungerichteter, zusammenhängender Graph G = (V, E) gegeben. Sei ferner ein Startknoten s V ausgewählt. Startet
Praktikum Algorithmen-Entwurf (Teil 3) 06.11.2006 1 1 DFS-Bäume in ungerichteten Graphen Sei ein ungerichteter, zusammenhängender Graph G = (V, E) gegeben. Sei ferner ein Startknoten s V ausgewählt. Startet
1 DFS-Bäume in ungerichteten Graphen
 Praktikum Algorithmen-Entwurf (Teil 3) 31.10.2005 1 1 DFS-Bäume in ungerichteten Graphen Sei ein ungerichteter, zusammenhängender Graph G = (V, E) gegeben. Sei ferner ein Startknoten s V ausgewählt. Startet
Praktikum Algorithmen-Entwurf (Teil 3) 31.10.2005 1 1 DFS-Bäume in ungerichteten Graphen Sei ein ungerichteter, zusammenhängender Graph G = (V, E) gegeben. Sei ferner ein Startknoten s V ausgewählt. Startet
Wahrscheinlichkeitsrechnung
 Statistik und Wahrscheinlichkeitsrechnung Prof. Dr. Michael Havbro Faber 28.05.2009 1 Korrektur zur letzten Vorlesung Bsp. Fehlerfortpflanzung in einer Messung c B a 2 2 E c Var c a b A b 2 2 2 n h( x)
Statistik und Wahrscheinlichkeitsrechnung Prof. Dr. Michael Havbro Faber 28.05.2009 1 Korrektur zur letzten Vorlesung Bsp. Fehlerfortpflanzung in einer Messung c B a 2 2 E c Var c a b A b 2 2 2 n h( x)
6. Bayes-Klassifikation. (Schukat-Talamazzini 2002)
") 6. Bayes-Klassifikation (Schukat-Talamazzini 2002) (Böhm 2003) (Klawonn 2004) Der Satz von Bayes: Beweis: Klassifikation mittels des Satzes von Bayes (Klawonn 2004) Allgemeine Definition: Davon zu unterscheiden
6. Bayes-Klassifikation (Schukat-Talamazzini 2002) (Böhm 2003) (Klawonn 2004) Der Satz von Bayes: Beweis: Klassifikation mittels des Satzes von Bayes (Klawonn 2004) Allgemeine Definition: Davon zu unterscheiden
Dynamische Systeme und Zeitreihenanalyse // Multivariate Normalverteilung und ML Schätzung 11 p.2/38
 Dynamische Systeme und Zeitreihenanalyse Multivariate Normalverteilung und ML Schätzung Kapitel 11 Statistik und Mathematik WU Wien Michael Hauser Dynamische Systeme und Zeitreihenanalyse // Multivariate
Dynamische Systeme und Zeitreihenanalyse Multivariate Normalverteilung und ML Schätzung Kapitel 11 Statistik und Mathematik WU Wien Michael Hauser Dynamische Systeme und Zeitreihenanalyse // Multivariate
5 Interpolation und Approximation
 5 Interpolation und Approximation Problemstellung: Es soll eine Funktion f(x) approximiert werden, von der die Funktionswerte nur an diskreten Stellen bekannt sind. 5. Das Interpolationspolynom y y = P(x)
5 Interpolation und Approximation Problemstellung: Es soll eine Funktion f(x) approximiert werden, von der die Funktionswerte nur an diskreten Stellen bekannt sind. 5. Das Interpolationspolynom y y = P(x)
Mehrdimensionale Zufallsvariablen
 Mehrdimensionale Zufallsvariablen Im Folgenden Beschränkung auf den diskreten Fall und zweidimensionale Zufallsvariablen. Vorstellung: Auswerten eines mehrdimensionalen Merkmals ( ) X Ỹ also z.b. ω Ω,
Mehrdimensionale Zufallsvariablen Im Folgenden Beschränkung auf den diskreten Fall und zweidimensionale Zufallsvariablen. Vorstellung: Auswerten eines mehrdimensionalen Merkmals ( ) X Ỹ also z.b. ω Ω,
Proseminar Kodierverfahren bei Dr. Ulrich Tamm Sommersemester 2003 Thema: Codierung von Bäumen (Prüfer Codes...)
") Proseminar Kodierverfahren bei Dr. Ulrich Tamm Sommersemester 2003 Thema: Codierung von Bäumen (Prüfer Codes...) Inhalt: Einleitung, Begriffe Baumtypen und deren Kodierung Binäre Bäume Mehrwegbäume Prüfer
Proseminar Kodierverfahren bei Dr. Ulrich Tamm Sommersemester 2003 Thema: Codierung von Bäumen (Prüfer Codes...) Inhalt: Einleitung, Begriffe Baumtypen und deren Kodierung Binäre Bäume Mehrwegbäume Prüfer
Übersicht. Datenstrukturen und Algorithmen. Übersicht. Heaps. Vorlesung 8: Heapsort (K6) Joost-Pieter Katoen. 7. Mai 2015
 Joost-Pieter Katoen. 7. Mai 2015") Datenstrukturen und Algorithmen Vorlesung 8: (K6) 1 Joost-Pieter Katoen Lehrstuhl für Informatik Software Modeling and Verification Group http://moves.rwth-aachen.de/teaching/ss-15/dsal/ 7. Mai 015 3 Joost-Pieter
Datenstrukturen und Algorithmen Vorlesung 8: (K6) 1 Joost-Pieter Katoen Lehrstuhl für Informatik Software Modeling and Verification Group http://moves.rwth-aachen.de/teaching/ss-15/dsal/ 7. Mai 015 3 Joost-Pieter
(a, b)-bäume / 1. Datenmenge ist so groß, dass sie auf der Festplatte abgespeichert werden muss.
-bäume / 1. Datenmenge ist so groß, dass sie auf der Festplatte abgespeichert werden muss.") (a, b)-bäume / 1. Szenario: Datenmenge ist so groß, dass sie auf der Festplatte abgespeichert werden muss. Konsequenz: Kommunikation zwischen Hauptspeicher und Festplatte - geschieht nicht Byte für Byte,
(a, b)-bäume / 1. Szenario: Datenmenge ist so groß, dass sie auf der Festplatte abgespeichert werden muss. Konsequenz: Kommunikation zwischen Hauptspeicher und Festplatte - geschieht nicht Byte für Byte,
(a)... ein Spieler eine Entscheidung treffen muss... (b)... der andere Spieler (Experte) über private...
... ein Spieler eine Entscheidung treffen muss... (b)... der andere Spieler (Experte) über private...") 1 KAP 19. Expertenberatung Wir betrachten eine Modell, in dem... (a)... ein Spieler eine Entscheidung treffen muss... (b)... der andere Spieler (Experte) über private...... entscheidungsrelevante Information
1 KAP 19. Expertenberatung Wir betrachten eine Modell, in dem... (a)... ein Spieler eine Entscheidung treffen muss... (b)... der andere Spieler (Experte) über private...... entscheidungsrelevante Information