Recommender-Systeme Teil 2. Kollaboratives Filtern & inhaltsbasierte Empfehlungen
|
|
|
- Christa Waldfogel
- vor 6 Jahren
- Abrufe
Transkript
1 Recommender-Systeme Teil 2 Kollaboratives Filtern & inhaltsbasierte Empfehlungen 1
2 LIBRA Learning Intelligent Book Recommending Agent Inhaltsbasierender Recommender für Bücher, der Informationen über Titel verwendet, die von Amazon extrahiert wurden. Verwendet Informations-Exktration aus dem Web, um Text in Feldern zu organisieren: Autor Titel Redaktionnelle Reviews Stellungnahmen von Kunden Themenbezeichnungen Zugehörige Autoren Zugehörige Titel 2
3 LIBRA System Amazon Seiten Informations- Extraktion LIBRA Datenbank bewertete Beispiele Machinelles Lernen Lerner Empfehlungen 1.~~~~~~ 2.~~~~~~~ 3.~~~~~ : : : Prädiktor Anwenderprofil 3
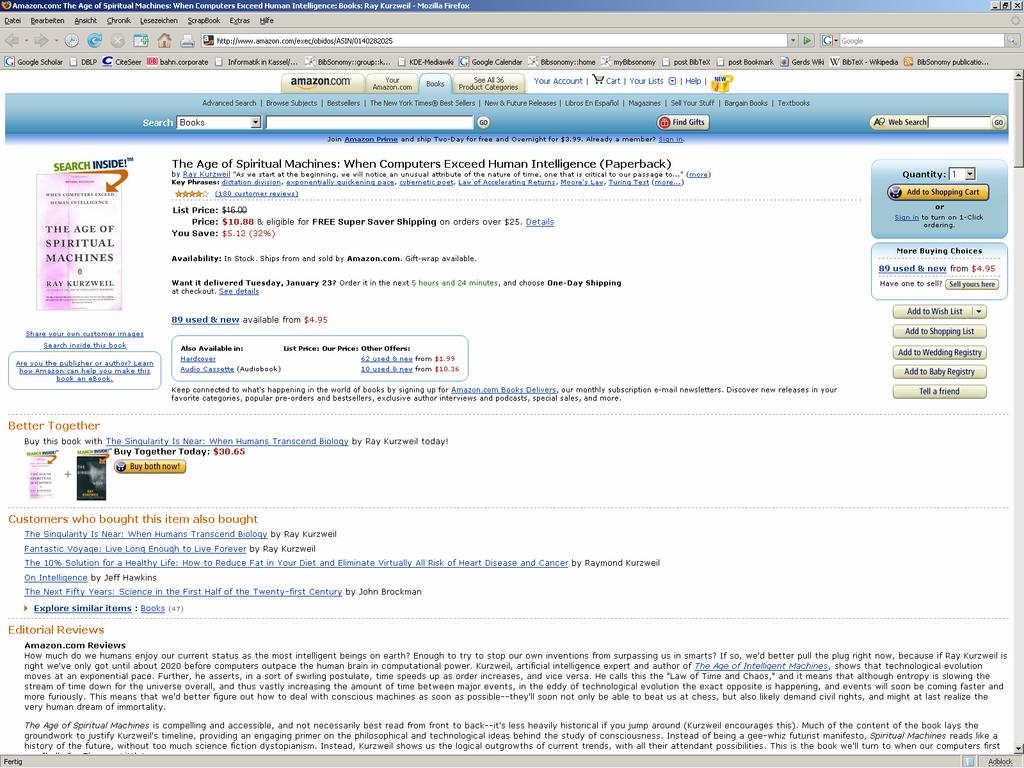
4 4
5 Bsp.: von Amazon extrahierte Informationen Titel: <The Age of Spiritual Machines: When Computers Exceed Human Intelligence> Autor: <Ray Kurzweil> Preis: <11.96> Datum der Veröffentlichung: <Januar 2000> ISBN: < > zugehörige Titel: <Titel: <Robot: Mere Machine or Transcendent Mind> Autor: <Hans Moravec> > Reviews: <Autor: <Amazon.com Reviews> Text: <How much do we humans > > Stellungnahmen: <Stars: <4> Autor: <Stephen A. Haines> Text:<Kurzweil has > > zugehörige Autoren: <Hans P. Moravec> <K. Eric Drexler> Betreffs: <Science/Mathematics> <Computers> <Artificial Intelligence> 5
6 Libra: Inhaltsinformationen Libra verwendet diese Information, um die folgenden Slots mit bags of words zu füllen: Autor Titel Beschreibung (Stellungnahmen und Kommentare) Betreffs verwandte Titel verwandte Autoren 6
7 Libra: Übersicht Anwender bewertet ausgewählte Titel auf einer Skala von 1 bis 10. Libra verwendet einen Naiven-Bayes-Text-Kategorisierungs- Algorithmus, um daraus ein Profil zu erlernen. Bewertung 6 10: positiv Bewertung 1 5: negativ Von den anderen Büchern werden diejenigen als Empfehlungen klassifiziert, bei denen die errechnete Wahrscheinlichkeit für eine positive Einschätzung groß genug ist. Der Anwender kann auch explizite positive/negative Schlüsselwörter liefern, die dann höher gewichtet werden. 7
8 Bayesian Kategorisierung in LIBRA Das Model ist verallgemeinert, um einen Vektor von bags of words zu erzeugen (ein bag für jeden Slot). Instanzen desselben Worts in verschiedenen Slots werden als separate Merkmale behandelt: Chrichton bei Autor Chrichton in der Beschreibung Trainingsbeispiele werden als positiv oder negativ gewichtete Beispiele bei der Schätzung der bedingten Wahrscheinlichkeitsparameter behandelt: Gegeben ist ein Beispiel mit Bewertung 1 r 10: positive Wahrscheinlichkeit: (r 1)/9 negative Wahrscheinlichkeit: (10 r)/9 8
9 Implementierung Stopwörter wurden von allen bags of words entfernt. Buchtitel und Autoren werden auch zu den Slots verwandte Titel bzw. verwandte Autoren hinzugefügt. Alle Wahrscheinlichkeiten werden wegen der kleinen Datenbasis mit der Laplace-Schätzung geglättet. Lisp-Implementierung ist ziemlich effizient: Training: 20 Datensätze in 0.4 s, 840 in 11.5 s Test: 200 Bücher pro Sekunde 9
10 Erläuterung von Profilen und Empfehlungen Stärke des Auftretens von Wort w k in Slot s j : strength( w, s ) = k j log P( w P( w k k positive, s negative,s j j ) ) 10
11 Experimentelle Daten Bücher aus verschiedenen Genres von Amazon. Titel, die zumindest eine Stellungnahme oder einen Kommentar haben, wurden ausgewählt. Datensätze: Literaturfiktion: 3,061 titles Mysterium: 7,285 titles Wissenschaft: 3,813 titles Science Fiction: 3,813 titles 11
12 Bewertete Daten Vier Anwender bewerteten zufällige Beispiele innerhalb eines Genres, indem sie die Amazon-Seiten hinsichtlich der Titel durchsahen: LIT1 936 titles LIT2 935 titles MYST 500 titles SCI 500 titles SF 500 titles 12
13 Experimentelle Methode 10-fache Kreuz-Validierung, um Lernkurven zu erzeugen. Auf unabhängigen Testdaten wurde gemessen: Präzision der Top 3: % der besten 3, die positiv sind Bewertung der Top 3: Durchschnittsbewertung, die den besten 3 zugeordnet ist Klassifizierungs-Korrelation: Spearman s, r s, zwischen vollständigen Klassifizierungen von System und Anwender. Test ohne die Slots verwandter Autor und verwandter Titel (LIBRA-NR). Testet den Einfluss von Informationen, die durch den kollaborativen Ansatz von Amazon erzeugt wurden. 13
14 Experimentelle Ergebnisse: Zusammenfassung Präzision der Top 3 ist nach nur 20 Beispielen mit um die 90 % ziemlich konsistent. Bewertung der Top 3 ist nach nur 20 Beispielen mit über 8 ziemlich konsistent. Alle Ergebnisse sind nach nur 5 Beispielen immer bedeutend besser als eine zufällige Auswahl. Klassifizierungs-Korrelation liegt nach nur 10 Beispielen generell über 0.3 (gemäßigt). Klassifizierungs-Korrelation liegt nach nur 40 Beispielen generell über 0.6 (hoch). 14
15 Präzision der Top 3 für Science 15
16 Bewertung der Top 3 für Science 16
17 Klassifizierungs-Korrelation für Science 17
18 Anwenderstudie Nutzer wurden gebeten, Libra zu verwenden und Empfehlungen anzufragen. wurden zu mehreren Feedback-Runden ermutigt. bewerteten alle Bücher der endgültigen Empfehlungs-Liste. wählten zwei Bücher zum Kauf. schickten nach Lesen der Auswahl Stellungnahmen zurück. vervollständigten Fragebogen über das System. 18
19 Verbinden von Inhalt und Kollaboration Inhaltsbasierte und kollaborative Methoden haben komplementäre Stärken und Schwächen. Kombiniere Methoden, um das Beste von beiden zu erhalten. Es gibt verschiedene hybride Ansätze: Wende beide Methoden an und verknüpfe die Empfehlungen. Verwende kollaborative Daten als Inhalt. Verwende inhaltsbasierte Empfehlungen als weiteren Nutzer, dessen Verhalten in weitere Vorhersagen einfliesst. Verwende einen inhaltsbasierten Empfehler, um kollaborative Daten zu vervollständigen. 19
20 Anwendung: Movies EachMovie Datensatz [Compaq Research Labs] enthält Anwenderbewertungen für Filme auf einer Skala von 0bis5. 72,916 Anwender (mit durchschn. 39 Bewertungen). 1,628 Filme. Spärliche besetzte Anwender-Bewertungsmatrix (zu 2.6% besetzt). Internet Movie Database (IMDb) Wurde für die Titel aus EachMovie gecrawlt. Wesentliche Filminformationen: Titel, Direktor, Rollenbesetzung, Genre, etc. Populäre Meinungen: Nutzerkommentare, Zeitungs- und Newsgroup-Berichte, etc. 20
21 Content-Boosted kollaboratives Filtern EachMovie Web Crawler IMDb User Ratings Matrix (Sparse) Movie Content Database Content-based Predictor Full User Ratings Matrix Active User Ratings Collaborative Filtering Recommendations 21
22 Content-Boosted CF - I User-ratings Vector Content-Based Predictor Training Examples User-rated Items Unrated Items Items with Predicted Ratings Pseudo User-ratings Vector 22

23 Content-Boosted CF - II User Ratings Matrix Content-Based Predictor Pseudo User Ratings Matrix Berechne Pseudo-Anwenderbewertungsmatrix Volle Matrix approximiert die konkreten Nutzerbewertungen Führe CF aus Unter Verwendung von Pearson-Korr.-Koeeffizient zwischen den Pseudo-Anwender-Bewertungsvektoren 23
24 Experimentelle Evaluierung Teilmenge von EachMovie wurde verwandt: 7,893 Anwender; 299,997 Bewertungen Testmenge: 10% der Anwender wurden zufällig ausgewählt. Sie bewerteten je mindestens 40 Filme. Training auf der verbleibenden Menge. Hold-out -Menge: 25% der Objekte für jeden Testanwender. Vorhersage der Bewertung für jedes Objekt in der Hold-out -Menge. Vergleich CBCF mit anderen Ansätzen: Reines CF Rein inhaltsbasiert hybrider Naïve Bayes (Durchschnitts-CF und inhaltsbasierende Vorhersagen) 24
25 Maße Mittlerer absoluter Fehler (MAE) Vergleicht die Vorhersagen mit Anwenderbewertungen ROC Empfindlichkeit [Herlocker 99] Wie gut helfen die Vorhersagen den Anwendern, eine gute Auswahl zu treffen? Bewertungen 4 als gut betrachtet; < 4 als schlecht betrachtet Gepaarte T-test stellen die statistische Signifikanz fest. 25
26 Ergebnisse - I MAE MAE Algorithm CF Content Naïve CBCF CBCF ist bedeutend besser (4% über CF) bei (p < 0.001) 26
27 Ergebnis - II ROC Sensitivity ROC CF Content Naïve CBCF 0.58 Algorithm CBCF übertrifft Rest (5% Verbesserung über CF) 27
28 Aktives Lernen Wird verwendet, um die Anzahl der Trainingsbeispiele zu verringern. System fordert Bewertungen für spezifische Objekte, von denen es vermutet, am meisten zu lernen. Verschiedene existierende Methoden: Uncertainty Sampling Komitee-basiertes Sampling 28
29 Halbüberwachtes Lernen (weakly supervised, Bootstrapping) Verwende die große Anzahl ungekennzeichneter Beispiele, um das Lernen von einer kleinen Menge von gekennzeichneten Beispielen zu unterstützen. Einige neue Methoden: Halbüberwachtes EM (Erwartungsmaximierung) Ko-Training Transduktive SVM s 29
30 Schlussfolgerungen Empfehlungen und Personalisierung sind wichtige Ansätze zur Bekämpfung der Informations-Überfrachtung. Machinelles Lernen ist ein wichtiger Teil der Systeme für diese Aufgaben. Kollaboratives Filtern hat Probleme. Inhaltsbasierende Methoden sprechen diese Probleme an (haben aber eigene Probleme). Das beste ist, beides zu integrieren. 30
Recommender-Systeme. Kollaboratives Filtern & inhaltsbasierte Empfehlungen
 Recommender-Systeme Kollaboratives Filtern & inhaltsbasierte Empfehlungen 1 Empfehlungs-Systeme Systeme, um Nutzern Dinge zu empfehlen (z.b. Bücher, Filme, CDs, Webseiten, Newsgroup Nachrichten), die auf
Recommender-Systeme Kollaboratives Filtern & inhaltsbasierte Empfehlungen 1 Empfehlungs-Systeme Systeme, um Nutzern Dinge zu empfehlen (z.b. Bücher, Filme, CDs, Webseiten, Newsgroup Nachrichten), die auf
Recommender Systeme mit Collaborative Filtering
 Fakultät für Informatik Technische Universität München Email: rene.romen@tum.de 6. Juni 2017 Recommender Systeme Definition Ziel eines Recommender Systems ist es Benutzern Items vorzuschlagen die diesem
Fakultät für Informatik Technische Universität München Email: rene.romen@tum.de 6. Juni 2017 Recommender Systeme Definition Ziel eines Recommender Systems ist es Benutzern Items vorzuschlagen die diesem
Anwendung von Vektormodell und boolschem Modell in Kombination
 Anwendung von Vektormodell und boolschem Modell in Kombination Julia Kreutzer Seminar Information Retrieval Institut für Computerlinguistik Universität Heidelberg 12.01.2015 Motivation Welche Filme sind
Anwendung von Vektormodell und boolschem Modell in Kombination Julia Kreutzer Seminar Information Retrieval Institut für Computerlinguistik Universität Heidelberg 12.01.2015 Motivation Welche Filme sind
Seminar Datenbanksysteme
 Seminar Datenbanksysteme Recommender System mit Text Analysis für verbesserte Geo Discovery Eine Präsentation von Fabian Senn Inhaltsverzeichnis Geodaten Geometadaten Geo Discovery Recommendation System
Seminar Datenbanksysteme Recommender System mit Text Analysis für verbesserte Geo Discovery Eine Präsentation von Fabian Senn Inhaltsverzeichnis Geodaten Geometadaten Geo Discovery Recommendation System
Mining the Network Value of Customers
 Mining the Network Value of Customers Seminar in Datamining bei Prof. Fürnkranz Benjamin Herbert Technische Universität Darmstadt Sommersemester 2007 1 / 34 1 2 Werbung Netzwerkwert 3 Bezeichnungen Ansatz
Mining the Network Value of Customers Seminar in Datamining bei Prof. Fürnkranz Benjamin Herbert Technische Universität Darmstadt Sommersemester 2007 1 / 34 1 2 Werbung Netzwerkwert 3 Bezeichnungen Ansatz
Item-based Collaborative Filtering
 Item-based Collaborative Filtering Initial implementation Martin Krüger, Sebastian Kölle 12.05.2011 Seminar Collaborative Filtering Projektplan Implementierung Ideen Wdh.: Item-based Collaborative Filtering
Item-based Collaborative Filtering Initial implementation Martin Krüger, Sebastian Kölle 12.05.2011 Seminar Collaborative Filtering Projektplan Implementierung Ideen Wdh.: Item-based Collaborative Filtering
Ein meta-hybrides recommendation system für die webbasierte Filmplattform critic.de
 Dr. Krasen Max Dimitrov Mustermann Christian Wolff Lehrstuhl für Referat Medieninformatik Kommunikation Institut & Marketing für Information und Sprache und Kultur Fakultät für Sprach-, Literatur- Medien,
Dr. Krasen Max Dimitrov Mustermann Christian Wolff Lehrstuhl für Referat Medieninformatik Kommunikation Institut & Marketing für Information und Sprache und Kultur Fakultät für Sprach-, Literatur- Medien,
Vortrag zum Paper Results of the Active Learning Challenge von Guyon, et. al. Sören Schmidt Fachgebiet Knowledge Engineering
 Vortrag zum Paper Results of the Active Learning Challenge von Guyon, et. al. Sören Schmidt Fachgebiet Knowledge Engineering 11.12.2012 Vortrag zum Paper Results of the Active Learning Challenge von Isabelle
Vortrag zum Paper Results of the Active Learning Challenge von Guyon, et. al. Sören Schmidt Fachgebiet Knowledge Engineering 11.12.2012 Vortrag zum Paper Results of the Active Learning Challenge von Isabelle
Data Mining - Wiederholung
 Data Mining - Wiederholung Norbert Fuhr 18. Januar 2006 Problemstellungen Problemstellungen Daten vs. Information Def. Data Mining Arten von strukturellen Beschreibungen Regeln (Klassifikation, Assoziations-)
Data Mining - Wiederholung Norbert Fuhr 18. Januar 2006 Problemstellungen Problemstellungen Daten vs. Information Def. Data Mining Arten von strukturellen Beschreibungen Regeln (Klassifikation, Assoziations-)
Produkt-Benchmarking Analyseinstrument zunehmendem Wettbewerbsdruck Stärken und Schwächen aufdecken eigene Leistungsfähigkeit Dieses Tool
 Das Produkt-Benchmarking als Analyseinstrument ist für ein Unternehmen bei zunehmendem Wettbewerbsdruck nicht mehr wegzudenken! Denn nur durch systematischen Vergleich der eigenen Produkte mit der der
Das Produkt-Benchmarking als Analyseinstrument ist für ein Unternehmen bei zunehmendem Wettbewerbsdruck nicht mehr wegzudenken! Denn nur durch systematischen Vergleich der eigenen Produkte mit der der
Semestralklausur zur Vorlesung. Web Mining. Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2008 Termin: 4. 7.
 Semestralklausur zur Vorlesung Web Mining Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2008 Termin: 4. 7. 2008 Name: Vorname: Matrikelnummer: Fachrichtung: Punkte: (1).... (2)....
Semestralklausur zur Vorlesung Web Mining Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2008 Termin: 4. 7. 2008 Name: Vorname: Matrikelnummer: Fachrichtung: Punkte: (1).... (2)....
Mathematische Grundlagen III
 Mathematische Grundlagen III Maschinelles Lernen III: Clustering Vera Demberg Universität des Saarlandes 7. Juli 202 Vera Demberg (UdS) Mathe III 7. Juli 202 / 35 Clustering vs. Klassifikation In den letzten
Mathematische Grundlagen III Maschinelles Lernen III: Clustering Vera Demberg Universität des Saarlandes 7. Juli 202 Vera Demberg (UdS) Mathe III 7. Juli 202 / 35 Clustering vs. Klassifikation In den letzten
Entscheidungsbäume. Minh-Khanh Do Erlangen,
 Entscheidungsbäume Minh-Khanh Do Erlangen, 11.07.2013 Übersicht Allgemeines Konzept Konstruktion Attributwahl Probleme Random forest E-Mail Filter Erlangen, 11.07.2013 Minh-Khanh Do Entscheidungsbäume
Entscheidungsbäume Minh-Khanh Do Erlangen, 11.07.2013 Übersicht Allgemeines Konzept Konstruktion Attributwahl Probleme Random forest E-Mail Filter Erlangen, 11.07.2013 Minh-Khanh Do Entscheidungsbäume
Recommender Systems. Stefan Beckers Praxisprojekt ASDL SS 2006 Universität Duisburg-Essen April 2006
 Recommender Systems Stefan Beckers Praxisprojekt ASDL SS 2006 Universität Duisburg-Essen April 2006 Inhalt 1 - Einführung 2 Arten von Recommender-Systemen 3 Beispiele für RCs 4 - Recommender-Systeme und
Recommender Systems Stefan Beckers Praxisprojekt ASDL SS 2006 Universität Duisburg-Essen April 2006 Inhalt 1 - Einführung 2 Arten von Recommender-Systemen 3 Beispiele für RCs 4 - Recommender-Systeme und
Nutzung maschinellen Lernens zur Extraktion von Paragraphen aus PDF-Dokumenten
 Nutzung maschinellen Lernens zur Extraktion von Paragraphen aus PDF-Dokumenten Albert-Ludwigs-Universität zu Freiburg 13.09.2016 Maximilian Dippel max.dippel@tf.uni-freiburg.de Überblick I Einführung Problemstellung
Nutzung maschinellen Lernens zur Extraktion von Paragraphen aus PDF-Dokumenten Albert-Ludwigs-Universität zu Freiburg 13.09.2016 Maximilian Dippel max.dippel@tf.uni-freiburg.de Überblick I Einführung Problemstellung
Semiüberwachte Paarweise Klassifikation
 Semiüberwachte Paarweise Klassifikation Andriy Nadolskyy Bachelor-Thesis Betreuer: Prof. Dr. Johannes Fürnkranz Dr. Eneldo Loza Mencía 1 Überblick Motivation Grundbegriffe Einleitung Übersicht der Verfahren
Semiüberwachte Paarweise Klassifikation Andriy Nadolskyy Bachelor-Thesis Betreuer: Prof. Dr. Johannes Fürnkranz Dr. Eneldo Loza Mencía 1 Überblick Motivation Grundbegriffe Einleitung Übersicht der Verfahren
4. Lernen von Entscheidungsbäumen
 4. Lernen von Entscheidungsbäumen Entscheidungsbäume 4. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
4. Lernen von Entscheidungsbäumen Entscheidungsbäume 4. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
Recommendation Engines im E Commerce
 Recommendation Engines im E Commerce Funktionsweise Einsatzgebiete Wirtschaftlichkeit Silvio Steiger, prudsys AG www.prudsys.de Ziele mehr Kunden die mehr kaufen Persönlich relevante: Angebote Inhalte
Recommendation Engines im E Commerce Funktionsweise Einsatzgebiete Wirtschaftlichkeit Silvio Steiger, prudsys AG www.prudsys.de Ziele mehr Kunden die mehr kaufen Persönlich relevante: Angebote Inhalte
, Data Mining, 2 VO Sommersemester 2008
 Evaluation 188.646, Data Mining, 2 VO Sommersemester 2008 Dieter Merkl e-commerce Arbeitsgruppe Institut für Softwaretechnik und Interaktive Systeme Technische Universität Wien www.ec.tuwien.ac.at/~dieter/
Evaluation 188.646, Data Mining, 2 VO Sommersemester 2008 Dieter Merkl e-commerce Arbeitsgruppe Institut für Softwaretechnik und Interaktive Systeme Technische Universität Wien www.ec.tuwien.ac.at/~dieter/
Data Mining und Statistik: Gemeinsamkeiten und Unterschiede. Daniel Meschenmoser
 Data Mining und Statistik: Gemeinsamkeiten und Unterschiede Daniel Meschenmoser Übersicht Gemeinsamkeiten von Data Mining und Statistik Unterschiede zwischen Data Mining und Statistik Assoziationsregeln
Data Mining und Statistik: Gemeinsamkeiten und Unterschiede Daniel Meschenmoser Übersicht Gemeinsamkeiten von Data Mining und Statistik Unterschiede zwischen Data Mining und Statistik Assoziationsregeln
Konzepte der AI: Maschinelles Lernen
 Konzepte der AI: Maschinelles Lernen Nysret Musliu, Wolfgang Slany Abteilung für Datenbanken und Artificial Intelligence Institut für Informationssysteme, TU-Wien Übersicht Was ist Lernen? Wozu maschinelles
Konzepte der AI: Maschinelles Lernen Nysret Musliu, Wolfgang Slany Abteilung für Datenbanken und Artificial Intelligence Institut für Informationssysteme, TU-Wien Übersicht Was ist Lernen? Wozu maschinelles
Lehrveranstaltungen im Wintersemester 2012/2013
 Lehrveranstaltungen im Wintersemester 2012/2013 Information Systems and Machine Learning Lab (ISMLL) Prof. Dr. Dr. Lars Schmidt-Thieme Hildesheim, Juli 2012 1 / 1 Übersicht Praktika Hildesheim, Juli 2012
Lehrveranstaltungen im Wintersemester 2012/2013 Information Systems and Machine Learning Lab (ISMLL) Prof. Dr. Dr. Lars Schmidt-Thieme Hildesheim, Juli 2012 1 / 1 Übersicht Praktika Hildesheim, Juli 2012
Splitting. Impurity. c 1. c 2. c 3. c 4
 Splitting Impurity Sei D(t) eine Menge von Lernbeispielen, in der X(t) auf die Klassen C = {c 1, c 2, c 3, c 4 } verteilt ist. Illustration von zwei möglichen Splits: c 1 c 2 c 3 c 4 ML: III-29 Decision
Splitting Impurity Sei D(t) eine Menge von Lernbeispielen, in der X(t) auf die Klassen C = {c 1, c 2, c 3, c 4 } verteilt ist. Illustration von zwei möglichen Splits: c 1 c 2 c 3 c 4 ML: III-29 Decision
Projekt Maschinelles Lernen WS 06/07
 Projekt Maschinelles Lernen WS 06/07 1. Auswahl der Daten 2. Evaluierung 3. Noise und Pruning 4. Regel-Lernen 5. ROC-Kurven 6. Pre-Processing 7. Entdecken von Assoziationsregeln 8. Ensemble-Lernen 9. Wettbewerb
Projekt Maschinelles Lernen WS 06/07 1. Auswahl der Daten 2. Evaluierung 3. Noise und Pruning 4. Regel-Lernen 5. ROC-Kurven 6. Pre-Processing 7. Entdecken von Assoziationsregeln 8. Ensemble-Lernen 9. Wettbewerb
Lernen von Assoziationsregeln
 Lernen von Assoziationsregeln Gegeben: R eine Menge von Objekten, die binäre Werte haben t eine Transaktion, t! R r eine Menge von Transaktionen S min " [0,] die minimale Unterstützung, Conf min " [0,]
Lernen von Assoziationsregeln Gegeben: R eine Menge von Objekten, die binäre Werte haben t eine Transaktion, t! R r eine Menge von Transaktionen S min " [0,] die minimale Unterstützung, Conf min " [0,]
Sentiment Analysis (SA) Robert Bärhold & Mario Sänger Text Analytics WS 2012/13 Prof. Leser
 Robert Bärhold & Mario Sänger Text Analytics WS 2012/13 Prof. Leser") Sentiment Analysis (SA) Robert Bärhold & Mario Sänger Text Analytics WS 2012/13 Prof. Leser Gliederung Einleitung Problemstellungen Ansätze & Herangehensweisen Anwendungsbeispiele Zusammenfassung 2 Gliederung
Sentiment Analysis (SA) Robert Bärhold & Mario Sänger Text Analytics WS 2012/13 Prof. Leser Gliederung Einleitung Problemstellungen Ansätze & Herangehensweisen Anwendungsbeispiele Zusammenfassung 2 Gliederung
Validation Model Selection Kreuz-Validierung Handlungsanweisungen. Validation. Oktober, von 20 Validation
 Validation Oktober, 2013 1 von 20 Validation Lernziele Konzepte des maschinellen Lernens Validierungsdaten Model Selection Kreuz-Validierung (Cross Validation) 2 von 20 Validation Outline 1 Validation
Validation Oktober, 2013 1 von 20 Validation Lernziele Konzepte des maschinellen Lernens Validierungsdaten Model Selection Kreuz-Validierung (Cross Validation) 2 von 20 Validation Outline 1 Validation
Häufige Item-Mengen: die Schlüssel-Idee. Vorlesungsplan. Apriori Algorithmus. Methoden zur Verbessung der Effizienz von Apriori
 Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
AI in Computer Games. Übersicht. Motivation. Vorteile der Spielumgebung. Techniken. Anforderungen
 Übersicht AI in Computer Games Motivation Vorteile der Spielumgebung Techniken Anwendungen Zusammenfassung Motivation Vorteile der Spielumgebung Modellierung glaubwürdiger Agenten Implementierung menschlicher
Übersicht AI in Computer Games Motivation Vorteile der Spielumgebung Techniken Anwendungen Zusammenfassung Motivation Vorteile der Spielumgebung Modellierung glaubwürdiger Agenten Implementierung menschlicher
Personalisierung elektronischer Märkte: Möglichkeiten und Techniken
 Personalisierung elektronischer Märkte: Möglichkeiten und Techniken Vortrag in der Lehrveranstaltung Unternehmen im internationalen Leistungswettbewerb von Stefan Marr Agenda 2 Motivation Nutzen für Kunden
Personalisierung elektronischer Märkte: Möglichkeiten und Techniken Vortrag in der Lehrveranstaltung Unternehmen im internationalen Leistungswettbewerb von Stefan Marr Agenda 2 Motivation Nutzen für Kunden
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz 1. Einführung: Was ist Künstliche Intelligenz? Malte Helmert Universität Basel 20. Februar 2015 Einführung: Überblick Kapitelüberblick Einführung: 1. Was ist Künstliche
Grundlagen der Künstlichen Intelligenz 1. Einführung: Was ist Künstliche Intelligenz? Malte Helmert Universität Basel 20. Februar 2015 Einführung: Überblick Kapitelüberblick Einführung: 1. Was ist Künstliche
1.1 Was ist KI? 1.1 Was ist KI? Grundlagen der Künstlichen Intelligenz. 1.2 Menschlich handeln. 1.3 Menschlich denken. 1.
 Grundlagen der Künstlichen Intelligenz 20. Februar 2015 1. Einführung: Was ist Künstliche Intelligenz? Grundlagen der Künstlichen Intelligenz 1. Einführung: Was ist Künstliche Intelligenz? Malte Helmert
Grundlagen der Künstlichen Intelligenz 20. Februar 2015 1. Einführung: Was ist Künstliche Intelligenz? Grundlagen der Künstlichen Intelligenz 1. Einführung: Was ist Künstliche Intelligenz? Malte Helmert
Einführung in das Maschinelle Lernen I
 Einführung in das Maschinelle Lernen I Vorlesung Computerlinguistische Techniken Alexander Koller 26. Januar 2015 Maschinelles Lernen Maschinelles Lernen (Machine Learning): äußerst aktiver und für CL
Einführung in das Maschinelle Lernen I Vorlesung Computerlinguistische Techniken Alexander Koller 26. Januar 2015 Maschinelles Lernen Maschinelles Lernen (Machine Learning): äußerst aktiver und für CL
Apache Lucene. Mach s wie Google! Bernd Fondermann freier Software Architekt bernd.fondermann@brainlounge.de berndf@apache.org
 Apache Lucene Mach s wie Google! Bernd Fondermann freier Software Architekt bernd.fondermann@brainlounge.de berndf@apache.org 1 Apache Apache Software Foundation Software free of charge Apache Software
Apache Lucene Mach s wie Google! Bernd Fondermann freier Software Architekt bernd.fondermann@brainlounge.de berndf@apache.org 1 Apache Apache Software Foundation Software free of charge Apache Software
Visual Analytics: Personalisierung im E- Commerce
 Visual Analytics: Personalisierung im E- Commerce Eduard Weigandt unsplash.com 2 Agenda 1. Motivation 2. Zielsetzung 3. Vorgehen 4. Chancen und Risiken otto.de 3 Warum? 1. persönlich: Bedürfnisse besser
Visual Analytics: Personalisierung im E- Commerce Eduard Weigandt unsplash.com 2 Agenda 1. Motivation 2. Zielsetzung 3. Vorgehen 4. Chancen und Risiken otto.de 3 Warum? 1. persönlich: Bedürfnisse besser
Bring your own Schufa!
 Bring your own Schufa! Jan Schweda Senior Softwareengineer Web & Cloud jan.schweda@conplement.de @jschweda Ziele des Vortrags Die Möglichkeiten von maschinellem Lernen aufzeigen. Azure Machine Learning
Bring your own Schufa! Jan Schweda Senior Softwareengineer Web & Cloud jan.schweda@conplement.de @jschweda Ziele des Vortrags Die Möglichkeiten von maschinellem Lernen aufzeigen. Azure Machine Learning
Prädiktion und Klassifikation mit
 Prädiktion und Klassifikation mit Random Forest Prof. Dr. T. Nouri Nouri@acm.org Technical University NW-Switzerland /35 Übersicht a. Probleme mit Decision Tree b. Der Random Forests RF c. Implementation
Prädiktion und Klassifikation mit Random Forest Prof. Dr. T. Nouri Nouri@acm.org Technical University NW-Switzerland /35 Übersicht a. Probleme mit Decision Tree b. Der Random Forests RF c. Implementation
4. Lernen von Entscheidungsbäumen. Klassifikation mit Entscheidungsbäumen. Entscheidungsbaum
 4. Lernen von Entscheidungsbäumen Klassifikation mit Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch /Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden.
4. Lernen von Entscheidungsbäumen Klassifikation mit Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch /Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden.
Modellierung mit künstlicher Intelligenz
 Samuel Kost kosts@mailbox.tu-freiberg.de Institut für Numerische Mathematik und Optimierung Modellierung mit künstlicher Intelligenz Ein Überblick über existierende Methoden des maschinellen Lernens 13.
Samuel Kost kosts@mailbox.tu-freiberg.de Institut für Numerische Mathematik und Optimierung Modellierung mit künstlicher Intelligenz Ein Überblick über existierende Methoden des maschinellen Lernens 13.
Intelligente Klassifizierung von technischen Inhalten. Automatisierung und Anwendungspotenziale
 Intelligente Klassifizierung von technischen Inhalten Automatisierung und Anwendungspotenziale Künstliche Intelligenz Machine Learning Deep Learning 1950 1980 2010 Abgeleitet von: https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/
Intelligente Klassifizierung von technischen Inhalten Automatisierung und Anwendungspotenziale Künstliche Intelligenz Machine Learning Deep Learning 1950 1980 2010 Abgeleitet von: https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/
Web Information Retrieval. Zwischendiskussion. Überblick. Meta-Suchmaschinen und Fusion (auch Rank Aggregation) Fusion
 Fusion") Web Information Retrieval Hauptseminar Sommersemester 2003 Thomas Mandl Überblick Mehrsprachigkeit Multimedialität Heterogenität Qualität, semantisch, technisch Struktur Links HTML Struktur Technologische
Web Information Retrieval Hauptseminar Sommersemester 2003 Thomas Mandl Überblick Mehrsprachigkeit Multimedialität Heterogenität Qualität, semantisch, technisch Struktur Links HTML Struktur Technologische
Seminarvortrag zum Thema maschinelles Lernen I - Entscheidungsbäume. von Lars-Peter Meyer. im Seminar Methoden wissensbasierter Systeme
 Seminarvortrag zum Thema maschinelles Lernen I - Entscheidungsbäume von Lars-Peter Meyer im Seminar Methoden wissensbasierter Systeme bei Prof. Brewka im WS 2007/08 Übersicht Überblick maschinelles Lernen
Seminarvortrag zum Thema maschinelles Lernen I - Entscheidungsbäume von Lars-Peter Meyer im Seminar Methoden wissensbasierter Systeme bei Prof. Brewka im WS 2007/08 Übersicht Überblick maschinelles Lernen
Bayes sches Lernen: Übersicht
 Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 10: Naive Bayes (V. 1.0)
Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 10: Naive Bayes (V. 1.0)
6. Bayes-Klassifikation. (Schukat-Talamazzini 2002)
") 6. Bayes-Klassifikation (Schukat-Talamazzini 2002) (Böhm 2003) (Klawonn 2004) Der Satz von Bayes: Beweis: Klassifikation mittels des Satzes von Bayes (Klawonn 2004) Allgemeine Definition: Davon zu unterscheiden
6. Bayes-Klassifikation (Schukat-Talamazzini 2002) (Böhm 2003) (Klawonn 2004) Der Satz von Bayes: Beweis: Klassifikation mittels des Satzes von Bayes (Klawonn 2004) Allgemeine Definition: Davon zu unterscheiden
RatSLAM. Torben Becker. 24. Mai HAW Hamburg
 HAW Hamburg 24. Mai 2012 Gliederung 1 Motivation 2 3 Aussicht 2 / 21 Motivation Warum SLAM? Navigation Umgebungskartografie Feststellung der Position innerhalb eines Geländes ohne Funksignale Keine vorherige
HAW Hamburg 24. Mai 2012 Gliederung 1 Motivation 2 3 Aussicht 2 / 21 Motivation Warum SLAM? Navigation Umgebungskartografie Feststellung der Position innerhalb eines Geländes ohne Funksignale Keine vorherige
Mash-Up Personal Learning Environments. Dr. Hendrik Drachsler
 Decision Support for Learners in Mash-Up Personal Learning Environments Dr. Hendrik Drachsler Personal Nowadays Environments Blog Reader More Information Providers Social Bookmarking Various Communities
Decision Support for Learners in Mash-Up Personal Learning Environments Dr. Hendrik Drachsler Personal Nowadays Environments Blog Reader More Information Providers Social Bookmarking Various Communities
Klassifikation im Bereich Musik
 Klassifikation im Bereich Musik Michael Günnewig 30. Mai 2006 Michael Günnewig 1 30. Mai 2006 Inhaltsverzeichnis 1 Was ist eine Klassifikation? 3 1.1 Arten und Aufbau von Klassifikationen.................
Klassifikation im Bereich Musik Michael Günnewig 30. Mai 2006 Michael Günnewig 1 30. Mai 2006 Inhaltsverzeichnis 1 Was ist eine Klassifikation? 3 1.1 Arten und Aufbau von Klassifikationen.................
Bitte an das Labor weiterleiten Wichtige Produktinformation. WICHTIGER PRODUKT-SICHERHEITS- UND KORREKTURHINWEIS VITEK MS System: Einschränkungen
 Customer Service Wichtige Information Genf, 10. Februar 2017 FSCA 1016267 - VTK MS Bitte an das Labor weiterleiten Wichtige Produktinformation WICHTIGER PRODUKT-SICHERHEITS- UND KORREKTURHINWEIS VITEK
Customer Service Wichtige Information Genf, 10. Februar 2017 FSCA 1016267 - VTK MS Bitte an das Labor weiterleiten Wichtige Produktinformation WICHTIGER PRODUKT-SICHERHEITS- UND KORREKTURHINWEIS VITEK
Ideen der Informatik. Maschinelles Lernen. Kurt Mehlhorn Adrian Neumann Max-Planck-Institut für Informatik
 Ideen der Informatik Maschinelles Lernen Kurt Mehlhorn Adrian Neumann Max-Planck-Institut für Informatik Übersicht Lernen: Begriff Beispiele für den Stand der Kunst Spamerkennung Handschriftenerkennung
Ideen der Informatik Maschinelles Lernen Kurt Mehlhorn Adrian Neumann Max-Planck-Institut für Informatik Übersicht Lernen: Begriff Beispiele für den Stand der Kunst Spamerkennung Handschriftenerkennung
Automatische Kategorisierung von Freitexten mittels Textanalyse am Beispiel von NPS Kundenzufriedenheitsumfragen
 Automatische Kategorisierung von Freitexten mittels Textanalyse am Beispiel von NPS Kundenzufriedenheitsumfragen ISR Information Products AG Robin Richter Aufgabenstellung Evaluationsstrategie Modellierung
Automatische Kategorisierung von Freitexten mittels Textanalyse am Beispiel von NPS Kundenzufriedenheitsumfragen ISR Information Products AG Robin Richter Aufgabenstellung Evaluationsstrategie Modellierung
Dokumentation des Filmdatensatzes
 Dokumentation des Filmdatensatzes 1 Datengrundlage Der Filmdatensatz (im Excel-Format.xlsx ) enthält eine Auswahl von dystopischen Spielfilmen, die der vorliegenden Arbeit zur Filmanalyse dienten. Die
Dokumentation des Filmdatensatzes 1 Datengrundlage Der Filmdatensatz (im Excel-Format.xlsx ) enthält eine Auswahl von dystopischen Spielfilmen, die der vorliegenden Arbeit zur Filmanalyse dienten. Die
Naive Bayes für Regressionsprobleme
 Naive Bayes für Regressionsprobleme Vorhersage numerischer Werte mit dem Naive Bayes Algorithmus Nils Knappmeier Fachgebiet Knowledge Engineering Fachbereich Informatik Technische Universität Darmstadt
Naive Bayes für Regressionsprobleme Vorhersage numerischer Werte mit dem Naive Bayes Algorithmus Nils Knappmeier Fachgebiet Knowledge Engineering Fachbereich Informatik Technische Universität Darmstadt
D1: Relationale Datenstrukturen (14)
") D1: Relationale Datenstrukturen (14) Die Schüler entwickeln ein Verständnis dafür, dass zum Verwalten größerer Datenmengen die bisherigen Werkzeuge nicht ausreichen. Dabei erlernen sie die Grundbegriffe
D1: Relationale Datenstrukturen (14) Die Schüler entwickeln ein Verständnis dafür, dass zum Verwalten größerer Datenmengen die bisherigen Werkzeuge nicht ausreichen. Dabei erlernen sie die Grundbegriffe
Anwendungen der Hauptkomponentenanalyse. Volker Tresp vertreten durch Florian Steinke
 Anwendungen der Hauptkomponentenanalyse Volker Tresp vertreten durch Florian Steinke 1 Dimensionsreduktion für Supervised Learning 2 Beispiel: Kaufentscheidung 3 Verbesserte Abstandsmaße durch Hauptkomponentenanalyse
Anwendungen der Hauptkomponentenanalyse Volker Tresp vertreten durch Florian Steinke 1 Dimensionsreduktion für Supervised Learning 2 Beispiel: Kaufentscheidung 3 Verbesserte Abstandsmaße durch Hauptkomponentenanalyse
SQL für Trolle. mag.e. Dienstag, 10.2.2009. Qt-Seminar
 Qt-Seminar Dienstag, 10.2.2009 SQL ist......die Abkürzung für Structured Query Language (früher sequel für Structured English Query Language )...ein ISO und ANSI Standard (aktuell SQL:2008)...eine Befehls-
Qt-Seminar Dienstag, 10.2.2009 SQL ist......die Abkürzung für Structured Query Language (früher sequel für Structured English Query Language )...ein ISO und ANSI Standard (aktuell SQL:2008)...eine Befehls-
Data Mining und Maschinelles Lernen Lösungsvorschlag für das 7. Übungsblatt
 Data Mining und Maschinelles Lernen Lösungsvorschlag für das 7. Übungsblatt Knowledge Engineering Group Data Mining und Maschinelles Lernen Lösungsvorschlag 7. Übungsblatt 1 Aufgabe 1a) Auffüllen von Attributen
Data Mining und Maschinelles Lernen Lösungsvorschlag für das 7. Übungsblatt Knowledge Engineering Group Data Mining und Maschinelles Lernen Lösungsvorschlag 7. Übungsblatt 1 Aufgabe 1a) Auffüllen von Attributen
Theoretical Analysis of Protein-Protein Interactions. Proseminar SS 2004
 Theoretical Analysis of Protein-Protein Interactions Proseminar Virtual Screening: Predicting Pairs from Sequence Übersicht Einleitung 1.Modell: Vorhersage von Protein-Interfaces aus Sequenzprofilen und
Theoretical Analysis of Protein-Protein Interactions Proseminar Virtual Screening: Predicting Pairs from Sequence Übersicht Einleitung 1.Modell: Vorhersage von Protein-Interfaces aus Sequenzprofilen und
Einführung in Support Vector Machines (SVMs)
") Einführung in (SVM) Januar 31, 2011 Einführung in (SVMs) Table of contents Motivation Einführung in (SVMs) Outline Motivation Vektorrepräsentation Klassifikation Motivation Einführung in (SVMs) Vektorrepräsentation
Einführung in (SVM) Januar 31, 2011 Einführung in (SVMs) Table of contents Motivation Einführung in (SVMs) Outline Motivation Vektorrepräsentation Klassifikation Motivation Einführung in (SVMs) Vektorrepräsentation
Data Mining mit Rapidminer im Direktmarketing ein erster Versuch. Hasan Tercan und Hans-Peter Weih
 Data Mining mit Rapidminer im Direktmarketing ein erster Versuch Hasan Tercan und Hans-Peter Weih Motivation und Ziele des Projekts Anwendung von Data Mining im Versicherungssektor Unternehmen: Standard
Data Mining mit Rapidminer im Direktmarketing ein erster Versuch Hasan Tercan und Hans-Peter Weih Motivation und Ziele des Projekts Anwendung von Data Mining im Versicherungssektor Unternehmen: Standard
Entscheidungsbäume aus großen Datenbanken: SLIQ
 Entscheidungsbäume aus großen Datenbanken: SLIQ C4.5 iteriert häufig über die Trainingsmenge Wie häufig? Wenn die Trainingsmenge nicht in den Hauptspeicher passt, wird das Swapping unpraktikabel! SLIQ:
Entscheidungsbäume aus großen Datenbanken: SLIQ C4.5 iteriert häufig über die Trainingsmenge Wie häufig? Wenn die Trainingsmenge nicht in den Hauptspeicher passt, wird das Swapping unpraktikabel! SLIQ:
Vorlesungsplan. Von Naïve Bayes zu Bayesischen Netzwerk- Klassifikatoren. Naïve Bayes. Bayesische Netzwerke
 Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Recherchieren im Bibliothekskatalog
 Recherchieren im Bibliothekskatalog ZIM / Bibliothek Füllen Sie die Suchmaske mit einem oder mehreren Suchbegriffen aus. Wählen Sie dann einen Suchbereich für jeden Suchbegriff aus und fügen Sie einen
Recherchieren im Bibliothekskatalog ZIM / Bibliothek Füllen Sie die Suchmaske mit einem oder mehreren Suchbegriffen aus. Wählen Sie dann einen Suchbereich für jeden Suchbegriff aus und fügen Sie einen
Ground Truth ohne Datenqualität kein Machine Learning. Erfolgsfaktoren für Predictive Analytics, BI und Data Mining
 Ground Truth ohne Datenqualität kein Machine Learning. Erfolgsfaktoren für Predictive Analytics, BI und Data Mining Prof. Dr.-Ing. Peter Lehmann Hochschule der Medien Stuttgart GLIEDERUNG Etwas über Machine
Ground Truth ohne Datenqualität kein Machine Learning. Erfolgsfaktoren für Predictive Analytics, BI und Data Mining Prof. Dr.-Ing. Peter Lehmann Hochschule der Medien Stuttgart GLIEDERUNG Etwas über Machine
Big Data und künstliche Intelligenz
 Big Data und künstliche Intelligenz Wie Daten gewonnen und ausgewertet werden können. Mittwoch 15. März, 12:30 13:15 Uhr Marcel Bernet Weiterbildung wie ich sie will Definition Der aus dem englischen Sprachraum
Big Data und künstliche Intelligenz Wie Daten gewonnen und ausgewertet werden können. Mittwoch 15. März, 12:30 13:15 Uhr Marcel Bernet Weiterbildung wie ich sie will Definition Der aus dem englischen Sprachraum
Entwicklung einer KI für Skat. Hauptseminar Erwin Lang
 Entwicklung einer KI für Skat Hauptseminar Erwin Lang Inhalt Skat Forschung Eigene Arbeit Risikoanalyse Skat Entwickelte sich Anfang des 19. Jahrhunderts Kartenspiel mit Blatt aus 32 Karten 3 Spieler Trick-taking
Entwicklung einer KI für Skat Hauptseminar Erwin Lang Inhalt Skat Forschung Eigene Arbeit Risikoanalyse Skat Entwickelte sich Anfang des 19. Jahrhunderts Kartenspiel mit Blatt aus 32 Karten 3 Spieler Trick-taking
IR Seminar SoSe 2012 Martin Leinberger
 IR Seminar SoSe 2012 Martin Leinberger Suchmaschinen stellen Ergebnisse häppchenweise dar Google: 10 Ergebnisse auf der ersten Seite Mehr Ergebnisse gibt es nur auf Nachfrage Nutzer geht selten auf zweite
IR Seminar SoSe 2012 Martin Leinberger Suchmaschinen stellen Ergebnisse häppchenweise dar Google: 10 Ergebnisse auf der ersten Seite Mehr Ergebnisse gibt es nur auf Nachfrage Nutzer geht selten auf zweite
Domain-independent. independent Duplicate Detection. Vortrag von Marko Pilop & Jens Kleine. SE Data Cleansing
 SE Data Cleansing Domain-independent independent Duplicate Detection Vortrag von Marko Pilop & Jens Kleine http://www.informatik.hu-berlin.de/~pilop/didd.pdf {pilop jkleine}@informatik.hu-berlin.de 1.0
SE Data Cleansing Domain-independent independent Duplicate Detection Vortrag von Marko Pilop & Jens Kleine http://www.informatik.hu-berlin.de/~pilop/didd.pdf {pilop jkleine}@informatik.hu-berlin.de 1.0
Franz Kronthaler. Statistik angewandt. Datenanalyse ist (k)eine Kunst. mit dem R Commander. A Springer Spektrum
eine Kunst. mit dem R Commander. A Springer Spektrum") Franz Kronthaler Statistik angewandt Datenanalyse ist (k)eine Kunst mit dem R Commander A Springer Spektrum Inhaltsverzeichnis Teil I Basiswissen und Werkzeuge, um Statistik anzuwenden 1 Statistik ist
Franz Kronthaler Statistik angewandt Datenanalyse ist (k)eine Kunst mit dem R Commander A Springer Spektrum Inhaltsverzeichnis Teil I Basiswissen und Werkzeuge, um Statistik anzuwenden 1 Statistik ist
3.3 Nächste-Nachbarn-Klassifikatoren
 3.3 Nächste-Nachbarn-Klassifikatoren Schrauben Nägel Klammern Neues Objekt Instanzbasiertes Lernen (instance based learning) Einfachster Nächste-Nachbar-Klassifikator: Zuordnung zu der Klasse des nächsten
3.3 Nächste-Nachbarn-Klassifikatoren Schrauben Nägel Klammern Neues Objekt Instanzbasiertes Lernen (instance based learning) Einfachster Nächste-Nachbar-Klassifikator: Zuordnung zu der Klasse des nächsten
Inhalt. 4.1 Motivation. 4.2 Evaluation. 4.3 Logistische Regression. 4.4 k-nächste Nachbarn. 4.5 Naïve Bayes. 4.6 Entscheidungsbäume
 4. Klassifikation Inhalt 4.1 Motivation 4.2 Evaluation 4.3 Logistische Regression 4.4 k-nächste Nachbarn 4.5 Naïve Bayes 4.6 Entscheidungsbäume 4.7 Support Vector Machines 4.8 Neuronale Netze 4.9 Ensemble-Methoden
4. Klassifikation Inhalt 4.1 Motivation 4.2 Evaluation 4.3 Logistische Regression 4.4 k-nächste Nachbarn 4.5 Naïve Bayes 4.6 Entscheidungsbäume 4.7 Support Vector Machines 4.8 Neuronale Netze 4.9 Ensemble-Methoden
3. Entscheidungsbäume. Verfahren zum Begriffslernen (Klassifikation) Beispiel: weiteres Beispiel: (aus Böhm 2003) (aus Morik 2002)
 Beispiel: weiteres Beispiel: (aus Böhm 2003) (aus Morik 2002)") 3. Entscheidungsbäume Verfahren zum Begriffslernen (Klassifikation) Beispiel: weiteres Beispiel: (aus Böhm 2003) (aus Morik 2002) (aus Wilhelm 2001) Beispiel: (aus Böhm 2003) Wann sind Entscheidungsbäume
3. Entscheidungsbäume Verfahren zum Begriffslernen (Klassifikation) Beispiel: weiteres Beispiel: (aus Böhm 2003) (aus Morik 2002) (aus Wilhelm 2001) Beispiel: (aus Böhm 2003) Wann sind Entscheidungsbäume
Softwareprojektpraktikum Maschinelle Übersetzung
 Softwareprojektpraktikum Maschinelle Übersetzung Jan-Thorsten Peter, Andreas Guta, Jan Rosendahl max.bleu@i6.informatik.rwth-aachen.de Vorbesprechung 5. Aufgabe 22. Juni 2017 Human Language Technology
Softwareprojektpraktikum Maschinelle Übersetzung Jan-Thorsten Peter, Andreas Guta, Jan Rosendahl max.bleu@i6.informatik.rwth-aachen.de Vorbesprechung 5. Aufgabe 22. Juni 2017 Human Language Technology
Klassifikation und Ähnlichkeitssuche
 Klassifikation und Ähnlichkeitssuche Vorlesung XIII Allgemeines Ziel Rationale Zusammenfassung von Molekülen in Gruppen auf der Basis bestimmter Eigenschaften Auswahl von repräsentativen Molekülen Strukturell
Klassifikation und Ähnlichkeitssuche Vorlesung XIII Allgemeines Ziel Rationale Zusammenfassung von Molekülen in Gruppen auf der Basis bestimmter Eigenschaften Auswahl von repräsentativen Molekülen Strukturell
Coaching Als Instrument Der Personalentwicklung (German Edition) By Silke Hundertmark
 By Silke Hundertmark") Coaching Als Instrument Der Personalentwicklung (German Edition) By Silke Hundertmark Coaching als Personalentwicklung hrtoday.ch - Genau da setzt Coaching an und wird zu einem immer wichtigeren Instrument
Coaching Als Instrument Der Personalentwicklung (German Edition) By Silke Hundertmark Coaching als Personalentwicklung hrtoday.ch - Genau da setzt Coaching an und wird zu einem immer wichtigeren Instrument
Bayes sches Lernen: Übersicht
 Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 5: Naive Bayes + IBL (V.
Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 5: Naive Bayes + IBL (V.
Wie Web 2.0 und Suche zusammenwachsen. Prof. Dr. Dirk Lewandowski dirk.lewandowski@haw-hamburg.de
 Wie Web 2.0 und Suche zusammenwachsen Prof. Dr. Dirk Lewandowski dirk.lewandowski@haw-hamburg.de Web search: Always different, always the same AltaVista 1996 1 http://web.archive.org/web/19961023234631/http://altavista.digital.com/
Wie Web 2.0 und Suche zusammenwachsen Prof. Dr. Dirk Lewandowski dirk.lewandowski@haw-hamburg.de Web search: Always different, always the same AltaVista 1996 1 http://web.archive.org/web/19961023234631/http://altavista.digital.com/
Vorlesung Maschinelles Lernen
 Vorlesung Maschinelles Lernen LACE Katharina Morik LS 8 Künstliche Intelligenz Fakultät für Informatik Technische Universität Dortmund 28.1.2014 1 von 71 Gliederung 1 Organisation von Sammlungen Web 2.0
Vorlesung Maschinelles Lernen LACE Katharina Morik LS 8 Künstliche Intelligenz Fakultät für Informatik Technische Universität Dortmund 28.1.2014 1 von 71 Gliederung 1 Organisation von Sammlungen Web 2.0
Methoden zur Cluster - Analyse
 Kapitel 4 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig Machine learning in bioinformatics
Kapitel 4 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig Machine learning in bioinformatics
Bayes Klassifikatoren M E T H O D E N D E S D A T A M I N I N G F A B I A N G R E U E L
 Bayes Klassifikatoren M E T H O D E N D E S D A T A M I N I N G F A B I A N G R E U E L Inhalt Grundlagen aus der Wahrscheinlichkeitsrechnung Hypothesenwahl Optimale Bayes Klassifikator Naiver Bayes Klassifikator
Bayes Klassifikatoren M E T H O D E N D E S D A T A M I N I N G F A B I A N G R E U E L Inhalt Grundlagen aus der Wahrscheinlichkeitsrechnung Hypothesenwahl Optimale Bayes Klassifikator Naiver Bayes Klassifikator
Lernende Suchmaschinen
 Lernende Suchmaschinen Qingchui Zhu PG 520 - Intelligence Service (WiSe 07 / SoSe 08) Verzeichnis 1 Einleitung Problemstellung und Zielsetzung 2 Was ist eine lernende Suchmaschine? Begriffsdefinition 3
Lernende Suchmaschinen Qingchui Zhu PG 520 - Intelligence Service (WiSe 07 / SoSe 08) Verzeichnis 1 Einleitung Problemstellung und Zielsetzung 2 Was ist eine lernende Suchmaschine? Begriffsdefinition 3
Automatische Rekonstruktion und Spezifizierung von Attributnamen in Webtabellen
 Automatische Rekonstruktion und Spezifizierung von Attributnamen in Webtabellen Mark Reinke Bachelorarbeit TU Dresden 17. Februar 2014 Webtabellen Warum sind Webtabellen von Bedeutung? Sie können relationale
Automatische Rekonstruktion und Spezifizierung von Attributnamen in Webtabellen Mark Reinke Bachelorarbeit TU Dresden 17. Februar 2014 Webtabellen Warum sind Webtabellen von Bedeutung? Sie können relationale
2. Lernen von Entscheidungsbäumen
 2. Lernen von Entscheidungsbäumen Entscheidungsbäume 2. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
2. Lernen von Entscheidungsbäumen Entscheidungsbäume 2. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
Semestralklausur zur Vorlesung. Web Mining. Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7.
 Semestralklausur zur Vorlesung Web Mining Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7. 2004 Name: Vorname: Matrikelnummer: Fachrichtung: Punkte: (1).... (2)....
Semestralklausur zur Vorlesung Web Mining Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7. 2004 Name: Vorname: Matrikelnummer: Fachrichtung: Punkte: (1).... (2)....
Supervised Learning Algorithmus für Stellenanzeigenklassifikation und Jobdeskriptoren Gewinnung
 Informatik Pawel Broda Supervised Learning Algorithmus für Stellenanzeigenklassifikation und Jobdeskriptoren Gewinnung Diplomarbeit Ludwig Maximilian Universität zu München Centrum für Informations- und
Informatik Pawel Broda Supervised Learning Algorithmus für Stellenanzeigenklassifikation und Jobdeskriptoren Gewinnung Diplomarbeit Ludwig Maximilian Universität zu München Centrum für Informations- und
Statistisches Data Mining (StDM) Woche 7. Aufgabe 1 Boston crime data (LDA vs logistische Regression)
 Woche 7. Aufgabe 1 Boston crime data (LDA vs logistische Regression)") Statistisches Data Mining (StDM) HS 2016 Woche 7 Aufgabe 1 Boston crime data (LDA vs logistische Regression) Verwenden Sie den Boston Datensatz (boston aus package MASS) um vorherzusagen, ob ein Stadtteil
Statistisches Data Mining (StDM) HS 2016 Woche 7 Aufgabe 1 Boston crime data (LDA vs logistische Regression) Verwenden Sie den Boston Datensatz (boston aus package MASS) um vorherzusagen, ob ein Stadtteil
3.3.1 Referenzwerte für Fruchtwasser-Schätzvolumina ( SSW)
") 50 3.3 Das Fruchtwasser-Schätzvolumen in der 21.-24.SSW und seine Bedeutung für das fetale Schätzgewicht in der 21.-24.SSW und für das Geburtsgewicht bei Geburt in der 36.-43.SSW 3.3.1 Referenzwerte für
50 3.3 Das Fruchtwasser-Schätzvolumen in der 21.-24.SSW und seine Bedeutung für das fetale Schätzgewicht in der 21.-24.SSW und für das Geburtsgewicht bei Geburt in der 36.-43.SSW 3.3.1 Referenzwerte für
Kapitel V. V. Ensemble Methods. Einführung Bagging Boosting Cascading
 Kapitel V V. Ensemble Methods Einführung Bagging Boosting Cascading V-1 Ensemble Methods c Lettmann 2005 Einführung Bewertung der Generalisierungsfähigkeit von Klassifikatoren R (c) wahre Missklassifikationsrate
Kapitel V V. Ensemble Methods Einführung Bagging Boosting Cascading V-1 Ensemble Methods c Lettmann 2005 Einführung Bewertung der Generalisierungsfähigkeit von Klassifikatoren R (c) wahre Missklassifikationsrate
5 Suchmaschinen Page Rank. Page Rank. Information Retrieval und Text Mining FH Bonn-Rhein-Sieg, SS Suchmaschinen Page Rank
 Page Rank Google versucht die Bedeutung von Seiten durch den sogenannten Page Rank zu ermitteln. A C Page Rank basiert auf der Verweisstruktur des Webs. Das Web wird als großer gerichteter Graph betrachtet.
Page Rank Google versucht die Bedeutung von Seiten durch den sogenannten Page Rank zu ermitteln. A C Page Rank basiert auf der Verweisstruktur des Webs. Das Web wird als großer gerichteter Graph betrachtet.
Semantische Bildsuche mittels kollaborativer Filterung und visueller Navigation
 Semantische Bildsuche mittels kollaborativer Filterung und visueller Navigation Prof. Dr. Kai Uwe Barthel HTW Berlin / pixolution GmbH Übersicht Probleme der gegenwärtigen Bildsuchsysteme Schlagwortbasierte
Semantische Bildsuche mittels kollaborativer Filterung und visueller Navigation Prof. Dr. Kai Uwe Barthel HTW Berlin / pixolution GmbH Übersicht Probleme der gegenwärtigen Bildsuchsysteme Schlagwortbasierte
Bayesianische Netzwerke - Lernen und Inferenz
 Bayesianische Netzwerke - Lernen und Inferenz Manuela Hummel 9. Mai 2003 Gliederung 1. Allgemeines 2. Bayesianische Netzwerke zur Auswertung von Genexpressionsdaten 3. Automatische Modellselektion 4. Beispiel
Bayesianische Netzwerke - Lernen und Inferenz Manuela Hummel 9. Mai 2003 Gliederung 1. Allgemeines 2. Bayesianische Netzwerke zur Auswertung von Genexpressionsdaten 3. Automatische Modellselektion 4. Beispiel
Semantische Klassifikation und Ähnlichkeit von Objekten (Produkten)
") Semantische Klassifikation und Ähnlichkeit von Objekten (Produkten) Berlin, 13.04.2007 Sven Schwarz Kurze Information Privates Hobby Neben eigentlicher Forschung / PhD / Freizeit Seit kurzem unterstützt
Semantische Klassifikation und Ähnlichkeit von Objekten (Produkten) Berlin, 13.04.2007 Sven Schwarz Kurze Information Privates Hobby Neben eigentlicher Forschung / PhD / Freizeit Seit kurzem unterstützt
Entwicklung einer Entscheidungssystematik für Data- Mining-Verfahren zur Erhöhung der Planungsgüte in der Produktion
 Entwicklung einer Entscheidungssystematik für Data- Mining-Verfahren zur Erhöhung der Planungsgüte in der Produktion Vortrag Seminararbeit David Pogorzelski Aachen, 22.01.2015 Agenda 1 2 3 4 5 Ziel der
Entwicklung einer Entscheidungssystematik für Data- Mining-Verfahren zur Erhöhung der Planungsgüte in der Produktion Vortrag Seminararbeit David Pogorzelski Aachen, 22.01.2015 Agenda 1 2 3 4 5 Ziel der
INTELLIGENTE DATENANALYSE IN MATLAB. Überwachtes Lernen: Entscheidungsbäume
 INTELLIGENTE DATENANALYSE IN MATLAB Überwachtes Lernen: Entscheidungsbäume Literatur Stuart Russell und Peter Norvig: Artificial Intelligence. Andrew W. Moore: http://www.autonlab.org/tutorials. 2 Überblick
INTELLIGENTE DATENANALYSE IN MATLAB Überwachtes Lernen: Entscheidungsbäume Literatur Stuart Russell und Peter Norvig: Artificial Intelligence. Andrew W. Moore: http://www.autonlab.org/tutorials. 2 Überblick
Dissertation. Doktoringenieur (Dr.-Ing.) vorgelegt an der Technischen Universität Dresden Fakultät Informatik
 vorgelegt an der Technischen Universität Dresden Fakultät Informatik") TECHNISCHE UNIVERSITÄT DRESDEN Fakultät Informatik, Institut für Angewandte Informatik, Privat-Dozentur für Angewandte Informatik NUTZUNG VON RECOMMENDER-SYSTEMEN UND KOLLEKTIVER INTELLIGENZ IN BUSINESS-ON-DEMAND
TECHNISCHE UNIVERSITÄT DRESDEN Fakultät Informatik, Institut für Angewandte Informatik, Privat-Dozentur für Angewandte Informatik NUTZUNG VON RECOMMENDER-SYSTEMEN UND KOLLEKTIVER INTELLIGENZ IN BUSINESS-ON-DEMAND
Bei näherer Betrachtung des Diagramms Nr. 3 fällt folgendes auf:
 18 3 Ergebnisse In diesem Kapitel werden nun zunächst die Ergebnisse der Korrelationen dargelegt und anschließend die Bedingungen der Gruppenbildung sowie die Ergebnisse der weiteren Analysen. 3.1 Ergebnisse
18 3 Ergebnisse In diesem Kapitel werden nun zunächst die Ergebnisse der Korrelationen dargelegt und anschließend die Bedingungen der Gruppenbildung sowie die Ergebnisse der weiteren Analysen. 3.1 Ergebnisse
Personalisierung. Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung. Data Mining.
 Personalisierung Personalisierung Thomas Mandl Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung Klassifikation Die Nutzer werden in vorab bestimmte Klassen/Nutzerprofilen
Personalisierung Personalisierung Thomas Mandl Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung Klassifikation Die Nutzer werden in vorab bestimmte Klassen/Nutzerprofilen
Strukturierte Extraktion von Text aus PDF. Präsentation der Masterarbeit von Fabian Schillinger
 Strukturierte Extraktion von Text aus PDF Präsentation der Masterarbeit von Fabian Schillinger Übersicht Motivation Probleme bei der Textextraktion Ablauf des entwickelten Systems Ergebnisse Präsentation
Strukturierte Extraktion von Text aus PDF Präsentation der Masterarbeit von Fabian Schillinger Übersicht Motivation Probleme bei der Textextraktion Ablauf des entwickelten Systems Ergebnisse Präsentation
Semantik auf Knopfdruck? Qualität von CMS-generierten semantischen Daten. Hannes Mühleisen, AG NBI / WBSG
 Semantik auf Knopfdruck? Qualität von CMS-generierten semantischen Daten Hannes Mühleisen, AG NBI / WBSG Xinnovations 2012 Fahrplan 2 Fahrplan Eingebette strukturierte Daten auf Webseiten 2 Fahrplan Eingebette
Semantik auf Knopfdruck? Qualität von CMS-generierten semantischen Daten Hannes Mühleisen, AG NBI / WBSG Xinnovations 2012 Fahrplan 2 Fahrplan Eingebette strukturierte Daten auf Webseiten 2 Fahrplan Eingebette
Space Usage Rules. Neele Halbur, Helge Spieker InformatiCup 2015 19. März 2015
 Space Usage Rules? InformatiCup 2015 1 Agenda 1. Vorstellung des Teams 2. Entwicklungsprozess und Umsetzung 3. Verbesserung der Strategien 4. Auswertung der Strategien 5. Ausblick 6. Fazit 2 Vorstellung
Space Usage Rules? InformatiCup 2015 1 Agenda 1. Vorstellung des Teams 2. Entwicklungsprozess und Umsetzung 3. Verbesserung der Strategien 4. Auswertung der Strategien 5. Ausblick 6. Fazit 2 Vorstellung
Elementare Begriffe der Wahrscheinlichkeitstheorie für die Sprachverarbeitung
 Elementare Begriffe der Wahrscheinlichkeitstheorie für die Sprachverarbeitung Kursfolien Karin Haenelt 1 Übersicht Wahrscheinlichkeitsfunktion P Wahrscheinlichkeit und bedingte Wahrscheinlichkeit Bayes-Formeln
Elementare Begriffe der Wahrscheinlichkeitstheorie für die Sprachverarbeitung Kursfolien Karin Haenelt 1 Übersicht Wahrscheinlichkeitsfunktion P Wahrscheinlichkeit und bedingte Wahrscheinlichkeit Bayes-Formeln