Cell Broadband Engine & CellSs: ein Programmiermodel für den Cell Prozessor
|
|
|
- Brigitte Amsel
- vor 6 Jahren
- Abrufe
Transkript
1 Cell Broadband Engine & CellSs: ein Programmiermodel für den Cell Prozessor Hardware-Software-Co-Design Universität Erlangen-Nürnberg 1
2 Cell Broadband Engine Übersicht Motivation Architektur Merkmale Power Processor Element Synergistic Processor Element Element Interconnect Bus 2

3 Cell Broadband Engine Motivation: Architekturen skalieren nicht sehr effektiv mit der Frequenz Trend zu immer mehr Kernen und Threads pro Prozessor - Intel Gulftown 6 Kerne mit je 2 Threads AMD Magny Cours mit bis zu 12 Kernen IBM Power7: bis zu 4 Kerne mit je 4 Threads Entwicklung von GPGPUs Heterogener Ansatz: CELL Broadband Engine : 3
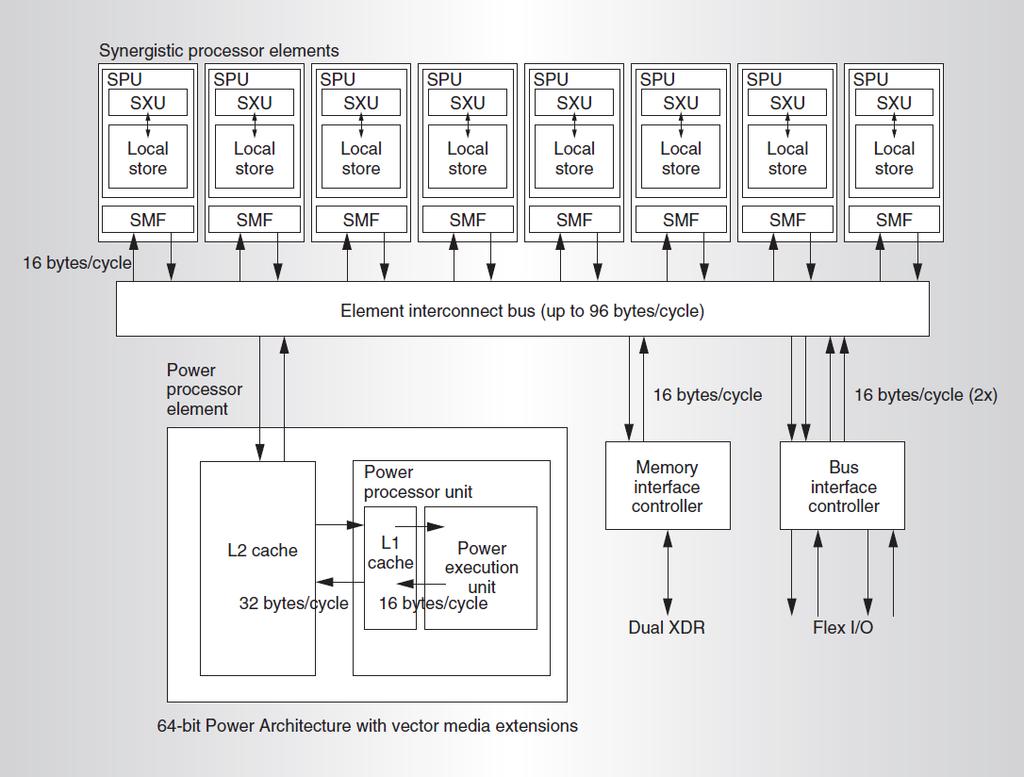
4 Cell Architektur 4
5 Merkmale der Cell Architektur 2 Unterschiedliche Processor Elemente: Power Processor Element (PPE) mit L2 Cache Synergistic Processor Element (SPE) mit Local Store Über DMA kann jedes Element auf den gesamten Adressraum (Local Store der SPEs und Hauptspeicher) zugreifen SPEs werden vom PPE gesteuert Alle Elemente verbunden durch einen Ringbus 5
 2-Fach Multithreaded L1 Cache 2x32KB L2 Cache 512KB VMX 3,2 Ghz + 6")
6 Power Processor Element (PPE) 64-bit RISC PowerPC Prozessor Kern (ähnlich Power5+ nach PowerPC ISA) 2-Fach Multithreaded L1 Cache 2x32KB L2 Cache 512KB VMX 3,2 Ghz + 6
 DMA Engine (Direct Memory Access) Berechnung und Kommunikation gleichzeitig")
7 Synergistic Processor Element (SPE) SPU 32-bit SIMD Local Store (256Kb SRAM) Synergistic Memory Flow Controller (SMF) DMA Engine (Direct Memory Access) Berechnung und Kommunikation gleichzeitig 7
8 Element Interconnect Bus (EIB) Ringbus der mit halber Prozessortaktrate läuft 4 Ringe die 16bit pro Takt Übertragen können Jeder Busteilnehmer verfügt über je 25,6GB/s für lesen und schreiben Der Gesamte Bus hat eine theoretische Bandbreite von 204,8GB/s 8
9 Referencen
10 Inhalt CellsS Einleitung Standard Cell Programmierung Struktur & Architektur Source-to-Source Compiler Laufzeit-Bibliothek Middleware Nutzung der lokalen Speicher Tracing Beispiele und Ergebnisse Ausblick & Zusammenfassung 10
11 Einleitung Hardware soll effizient genutzt werden Höheres Modell nötig, um parallele Abläufe besser nutzen zu können Modell nötig, um sequenziellen Programmcode zu parallelisieren Cell superscaler (CellSs): Einfach und Flexibel Anwender schreibt sequenziellen Code Framework nutzt Nebenläufigkeit im Programmablauf 11
12 Einleitung (Forts.) Verwendung: Über Annotations im Code werden Funktionen als parallel ausführbar deklariert Komponenten: Source-to-Source Compiler Laufzeit Bibliothek Locality aware task scheduling PPE & SPE Compiler Funktionsweise: Laufzeit Bibliothek erzeugt Graph aller Funktionen (Tasks) - Abhängigkeiten zwischen Tasks werden als Kanten repräsentiert Voneinander unabhängige Tasks werden parallel in den SPE's ausgeführt 12
13 Standard Cell Programmierung Grundlage: 'Linux-on-Cell' OS wird auf dem PPE ausgeführt SPU's werden nicht genutzt SPE's ohne OS Kein automatisches Speichermanagement Speichertransfers per DMA Quellcode für PPU und SPU getrennt Übersetzung mit verschiedenen Compilern nötig Threads müssen angelegt, parametrisiert und ausgeführt werden Umfangreiche API zur Kontrolle der SPU's 13
 Kommunikation via Mailbox System Alternative: IBM Octopiler Parallisierung zur Compilezeit Automatic")
14 Standard Cell Programmierung (Forts.) Kommunikation via Mailbox System Alternative: IBM Octopiler Parallisierung zur Compilezeit Automatic SIMDization - Single Instruction Multiple Data z.b. Vektoraddition c = a + b 14
15 Struktur & Architektur Source to Source Compiler erzeugt zwei C-Files: Haupt-Programm: Wird im PPE ausgeführt Mit PPE-Compiler übersetzt Task-Programm Eigenständiges Programm, wird in jedem SPE ausgeführt Mit SPE-Compiler übersetzt SPE-Programm muss ins Binary für das PPE integriert werden Beim Programmstart werden die Speicher der SPE's mit dem ausführbaren SPE-Binary geladen 15

16 Struktur & Architektur 16
17 Source-to-Source Compiler Funktionen & Verwendung: Funktionen werden als Task spezifiziert, die in den SPE's ausgeführt werden: - 2. Richtung der Parameter muss festgelegt werden - #pragma css task input; output; input/output 3. Übergabe von Arrays und ihrer Länge möglich Beispiel: #pragma css task input(a{}, b{}, index_i, index_j) output(c{}) void array_op(float a[n], float b[n], float c[n], float c[n], int index_i, int index_j); main(){ array_op(a, B, C, i, j); } 17
18 Source-to-Source Compiler (Forts.) Modifikation des Code: Aufrufe zur Initialisierung der Laufzeit Bibliothek Aufrufe zur Registrierung der Tasks und zur Erzeugung des Task-Graphen Task-Aufrufe werden durch Aufrufe zur entsprechenden Execute( ) Funktion ersetzt Für jeden Task wird ein Adapter erzeugt, der vom SPEHauptprogramm aufgerufen wird void css_array_op_adapter(int *params, char *data_buffer) { array_op_adapter(data_buffer[params[0]], data_buffer[params[2]], data_buffer[params[4]],...); } 18
19 Übersicht Teil 3 Runtime Library Cell SS runtime library Was passiert während der Programmausführung? Der Task-Graph Locality-Aware Scheduling Policy Beispiel Datenübertragung an SPEs Performance 19
20 Cell Superscalar Runtime Library Zwei Binärdateien: Hauptprogramm für PPEs Task-Programm für SPEs (wartet auf Anfragen des Hauptprogramms) Aufruf einer annotierten Funktion im Hauptprogramm (execute-aufruf): Task als Knoten in Ablaufgraph einfügen Datenabhängigkeitsanalyse Parameter Renaming (entfernt Write-Abhängigkeiten) Keine Abhängigkeiten: Ausführungsfreigabe (ready list) 20
21 Der Task-Graph Gerichteter, azyklischer Graph (DAG) Knoten entsprechen Tasks, Kanten sind Datenabh. Wird nach jedem Execute und jeder Task-Fertigstellung aktualisiert Knoten ohne unberechnete Vorgängerknoten bilden die ready list Verwendung des DAG: Nummerierung nach Zeitpunkt des Eintreffens Pro Scheduling-Schritt Subgraph mit max. Tiefe 2 Partitionierung Für jede SPE wird ein Task ausgewählt (ready list, Pfadlänge, Alphabetische Reihenfolge) Nach Ende des Tasks: - Knoten aus Graph entfernen Zeuweisung eines neuen Tasks 21
22 Locality-Aware Scheduling Policy Datenabhängigkeiten bei der Partitionierung: Abhängige Tasks möglichst in der selben SPE ausführen Dadurch weniger Speicherzugriffe und Datenaustausch zwischen SPEs Partitionen werden an SPEs geschickt Partitionierung kann sich zur Laufzeit dynamisch ändern, workload (un)balance 22
 23")


23 Beispiel (1) 23
24 Beispiel (2) 24
25 Datenübertragung in SPEs Tasks werden als ganze Partition an SPE übermittelt Benachrichtigung zum Start eines Tasks: Mailbox-System, ein Eintrag für jede SPE Enthält Anfrage und Adresse des task control buffer (TCB) Untätige SPEs pollen ihre Mailbox, bis Nachricht vorliegt Datentransfer TCB enthält Speicheradressen der benötigten Parameter Laden per DMA Nach Task-Ende: Daten entweder im lokalen Speicher halten oder zurückschreiben (laut TCB) 25
 Travelling Salesman Problem (TSP) Blockweise")
26 Performance Vergleich des Speedup bei verschiedenen Anwendungen Blockweise Matrix-Multiplikation (matmul) Travelling Salesman Problem (TSP) Blockweise Cholesky-Faktorisierung (cholesky) 26
Cell Broadband Engine
 Cell Broadband Engine 21.March 2006 Benjamin Keck Outline Why Cell?!? Application Areas Architectural Overview SPU Programming Model Programming on the PPE C/C++ Intrinsics The Cell Supercomputer on a
Cell Broadband Engine 21.March 2006 Benjamin Keck Outline Why Cell?!? Application Areas Architectural Overview SPU Programming Model Programming on the PPE C/C++ Intrinsics The Cell Supercomputer on a
Netgauge auf Cell BE
 TU Chemnitz 15. Oktober 2007 Inhaltsverzeichnis 1 Einführung Aufgabe Netgauge Cell BE 2 3 Aufgabe Einführung Aufgabe Netgauge Cell BE Netgauge + Cell = Messung Speichertransfers von Cell BE Aufgabe Einführung
TU Chemnitz 15. Oktober 2007 Inhaltsverzeichnis 1 Einführung Aufgabe Netgauge Cell BE 2 3 Aufgabe Einführung Aufgabe Netgauge Cell BE Netgauge + Cell = Messung Speichertransfers von Cell BE Aufgabe Einführung
Outline. Cell Broadband Engine. Application Areas. The Cell
 Outline 21.March 2006 Benjamin Keck Why Cell?!? Application Areas Architectural Overview Programming Model Programming on the PPE C/C++ Intrinsics 1 2 The Cell Supercomputer on a chip Multi-Core Microprocessor
Outline 21.March 2006 Benjamin Keck Why Cell?!? Application Areas Architectural Overview Programming Model Programming on the PPE C/C++ Intrinsics 1 2 The Cell Supercomputer on a chip Multi-Core Microprocessor
Über die Cell/B.E.-Architektur: Optionen zur Generierung von Programm-Traces
 Zentrum für Informationsdienste und Hochleistungsrechnen (ZIH) Über die Cell/B.E.-Architektur: Optionen zur Generierung von Programm-Traces Diplomverteidigung Nöthnitzer Straße 46 Informatik, Raum 1027
Zentrum für Informationsdienste und Hochleistungsrechnen (ZIH) Über die Cell/B.E.-Architektur: Optionen zur Generierung von Programm-Traces Diplomverteidigung Nöthnitzer Straße 46 Informatik, Raum 1027
Multicore-Architekturen
 Universität Erlangen- Nürnberg Technische Universität München Universität Stuttgart Multicore-Architekturen Vortrag im Rahmen der Ferienakademie 2009 Kurs 1: Programmierkonzepte für Multi-Core Rechner
Universität Erlangen- Nürnberg Technische Universität München Universität Stuttgart Multicore-Architekturen Vortrag im Rahmen der Ferienakademie 2009 Kurs 1: Programmierkonzepte für Multi-Core Rechner
General Purpose Computation on GPUs
 General Purpose Computation on GPUs Matthias Schneider, Robert Grimm Universität Erlangen-Nürnberg {matthias.schneider, robert.grimm}@informatik.stud.uni-erlangen.de M. Schneider, R. Grimm 1 Übersicht
General Purpose Computation on GPUs Matthias Schneider, Robert Grimm Universität Erlangen-Nürnberg {matthias.schneider, robert.grimm}@informatik.stud.uni-erlangen.de M. Schneider, R. Grimm 1 Übersicht
Compute Unified Device Architecture CUDA
 Compute Unified Device Architecture 06. Februar 2012 1 / 13 Gliederung 2 / 13 : Compute Unified Device Architecture entwickelt von Nvidia Corporation spezifiziert Software- und Hardwareeigenschaften Ziel:
Compute Unified Device Architecture 06. Februar 2012 1 / 13 Gliederung 2 / 13 : Compute Unified Device Architecture entwickelt von Nvidia Corporation spezifiziert Software- und Hardwareeigenschaften Ziel:
MAP CellSs Mapprakt3
 MAP CellSs Mapprakt3 Andreas Fall, Matthias Ziegler, Mark Duchon Hardware-Software-Co-Design Universität Erlangen-Nürnberg Andreas Fall, Matthias Ziegler, Mark Duchon 1 CellSs Cell CPU (1x PPU + 6x SPU)
MAP CellSs Mapprakt3 Andreas Fall, Matthias Ziegler, Mark Duchon Hardware-Software-Co-Design Universität Erlangen-Nürnberg Andreas Fall, Matthias Ziegler, Mark Duchon 1 CellSs Cell CPU (1x PPU + 6x SPU)
Zum Aufwärmen nocheinmal grundlegende Tatsachen zum Rechnen mit reelen Zahlen auf dem Computer. Das Rechnen mit Gleitkommazahlen wird durch den IEEE
 Zum Aufwärmen nocheinmal grundlegende Tatsachen zum Rechnen mit reelen Zahlen auf dem Computer. Das Rechnen mit Gleitkommazahlen wird durch den IEEE 754 Standard festgelegt. Es stehen sogenannte einfach
Zum Aufwärmen nocheinmal grundlegende Tatsachen zum Rechnen mit reelen Zahlen auf dem Computer. Das Rechnen mit Gleitkommazahlen wird durch den IEEE 754 Standard festgelegt. Es stehen sogenannte einfach
Praxiseinheit: Realisierung einer hardwarebeschleunigten Disparitätenberechnung zur automatischen Auswertung von Stereobildern
 Praxiseinheit: Realisierung einer hardwarebeschleunigten Disparitätenberechnung zur automatischen Auswertung von Stereobildern Institut für Betriebssysteme und Rechnerverbund TU Braunschweig 25.10., 26.10.
Praxiseinheit: Realisierung einer hardwarebeschleunigten Disparitätenberechnung zur automatischen Auswertung von Stereobildern Institut für Betriebssysteme und Rechnerverbund TU Braunschweig 25.10., 26.10.
Computeranwendung in der Chemie Informatik für Chemiker(innen) 3. Software
 3. Software") Computeranwendung in der Chemie Informatik für Chemiker(innen) 3. Software Jens Döbler 2003 "Computer in der Chemie", WS 2003-04, Humboldt-Universität VL3 Folie 1 Grundlagen Software steuert Computersysteme
Computeranwendung in der Chemie Informatik für Chemiker(innen) 3. Software Jens Döbler 2003 "Computer in der Chemie", WS 2003-04, Humboldt-Universität VL3 Folie 1 Grundlagen Software steuert Computersysteme
Konzepte und Methoden der Systemsoftware. Aufgabe 1: Polling vs Interrupts. SoSe bis P
 SoSe 2014 Konzepte und Methoden der Systemsoftware Universität Paderborn Fachgebiet Rechnernetze Präsenzübung 3(Musterlösung) 2014-05-05 bis 2014-05-09 Aufgabe 1: Polling vs Interrupts (a) Erläutern Sie
SoSe 2014 Konzepte und Methoden der Systemsoftware Universität Paderborn Fachgebiet Rechnernetze Präsenzübung 3(Musterlösung) 2014-05-05 bis 2014-05-09 Aufgabe 1: Polling vs Interrupts (a) Erläutern Sie
Codesigned Virtual Machines
 Codesigned Virtual Machines Seminar Virtualisierung Philipp Kirchhofer philipp.kirchhofer@student.kit.edu Institut für Technische Informatik Lehrstuhl für Rechnerarchitektur Universität Karlsruhe (TH)
Codesigned Virtual Machines Seminar Virtualisierung Philipp Kirchhofer philipp.kirchhofer@student.kit.edu Institut für Technische Informatik Lehrstuhl für Rechnerarchitektur Universität Karlsruhe (TH)
2 Rechnerarchitekturen
 2 Rechnerarchitekturen Rechnerarchitekturen Flynns Klassifikation Flynnsche Klassifikation (Flynn sche Taxonomie) 1966 entwickelt, einfaches Modell, bis heute genutzt Beschränkung der Beschreibung auf
2 Rechnerarchitekturen Rechnerarchitekturen Flynns Klassifikation Flynnsche Klassifikation (Flynn sche Taxonomie) 1966 entwickelt, einfaches Modell, bis heute genutzt Beschränkung der Beschreibung auf
Systeme 1: Architektur
 slide 1 Vorlesung Systeme 1: Architektur Prof. Dr. Ulrich Ultes-Nitsche Forschungsgruppe Departement für Informatik Universität Freiburg slide 2 Prüfung 18. Februar 2004 8h00-11h40 13h00-18h20 20 Minuten
slide 1 Vorlesung Systeme 1: Architektur Prof. Dr. Ulrich Ultes-Nitsche Forschungsgruppe Departement für Informatik Universität Freiburg slide 2 Prüfung 18. Februar 2004 8h00-11h40 13h00-18h20 20 Minuten
Grafikkarten-Architektur
 > Grafikkarten-Architektur Parallele Strukturen in der GPU Name: Sebastian Albers E-Mail: s.albers@wwu.de 2 > Inhalt > CPU und GPU im Vergleich > Rendering-Pipeline > Shader > GPGPU > Nvidia Tesla-Architektur
> Grafikkarten-Architektur Parallele Strukturen in der GPU Name: Sebastian Albers E-Mail: s.albers@wwu.de 2 > Inhalt > CPU und GPU im Vergleich > Rendering-Pipeline > Shader > GPGPU > Nvidia Tesla-Architektur
Synthese Eingebetteter Systeme. 14 Abbildung von Anwendungen auf Multicore-Systeme
 12 Synthese Eingebetteter Systeme Wintersemester 2012/13 14 Abbildung von Anwendungen auf Multicore-Systeme Michael Engel Informatik 12 TU Dortmund 2012/12/19 Abbildung von Anwendungen auf Multicores Multicore-Architekturen
12 Synthese Eingebetteter Systeme Wintersemester 2012/13 14 Abbildung von Anwendungen auf Multicore-Systeme Michael Engel Informatik 12 TU Dortmund 2012/12/19 Abbildung von Anwendungen auf Multicores Multicore-Architekturen
Architektur paralleler Plattformen
 Architektur paralleler Plattformen Freie Universität Berlin Fachbereich Informatik Wintersemester 2012/2013 Proseminar Parallele Programmierung Mirco Semper, Marco Gester Datum: 31.10.12 Inhalt I. Überblick
Architektur paralleler Plattformen Freie Universität Berlin Fachbereich Informatik Wintersemester 2012/2013 Proseminar Parallele Programmierung Mirco Semper, Marco Gester Datum: 31.10.12 Inhalt I. Überblick
Technische Grundlagen der Informatik 2 SS Einleitung. R. Hoffmann FG Rechnerarchitektur Technische Universität Darmstadt E-1
 E-1 Technische Grundlagen der Informatik 2 SS 2009 Einleitung R. Hoffmann FG Rechnerarchitektur Technische Universität Darmstadt Lernziel E-2 Verstehen lernen, wie ein Rechner auf der Mikroarchitektur-Ebene
E-1 Technische Grundlagen der Informatik 2 SS 2009 Einleitung R. Hoffmann FG Rechnerarchitektur Technische Universität Darmstadt Lernziel E-2 Verstehen lernen, wie ein Rechner auf der Mikroarchitektur-Ebene
Multicore Architektur vs. Amdahl`s Gesetz
 Fakultätsname Informatik, Professur Technische Informatik Multicore Architektur vs. Amdahl`s Gesetz Dresden, 21.Juli.2010 Motivation Veröffentlichung von IEEE Computer 2008 von Mark D. Hill (University
Fakultätsname Informatik, Professur Technische Informatik Multicore Architektur vs. Amdahl`s Gesetz Dresden, 21.Juli.2010 Motivation Veröffentlichung von IEEE Computer 2008 von Mark D. Hill (University
Einführung in die Systemprogrammierung
 Einführung in die Systemprogrammierung Speedup: Grundlagen der Performanz Prof. Dr. Christoph Reichenbach Fachbereich 12 / Institut für Informatik 30. April 2015 Eine Aufgabe aus der Praxis Gegeben ein
Einführung in die Systemprogrammierung Speedup: Grundlagen der Performanz Prof. Dr. Christoph Reichenbach Fachbereich 12 / Institut für Informatik 30. April 2015 Eine Aufgabe aus der Praxis Gegeben ein
Grundlagen der Rechnerarchitektur
 Grundlagen der Rechnerarchitektur Speicher Übersicht Speicherhierarchie Cache Grundlagen Verbessern der Cache Performance Virtueller Speicher SS 2012 Grundlagen der Rechnerarchitektur Speicher 2 Speicherhierarchie
Grundlagen der Rechnerarchitektur Speicher Übersicht Speicherhierarchie Cache Grundlagen Verbessern der Cache Performance Virtueller Speicher SS 2012 Grundlagen der Rechnerarchitektur Speicher 2 Speicherhierarchie
- dynamisches Laden -
 - - Fachbereich Technik Department Elektrotechnik und Informatik 21. Juni 2012 1/23 2/23 s dynamisch Code kann von mehreren Programmen genutzt werden => kleinere Programme einzelne Teile eines Programms
- - Fachbereich Technik Department Elektrotechnik und Informatik 21. Juni 2012 1/23 2/23 s dynamisch Code kann von mehreren Programmen genutzt werden => kleinere Programme einzelne Teile eines Programms
moderne Prozessoren Jan Krüger jkrueger@techfak.uni-bielefeld.de
 moderne Prozessoren Jan Krüger jkrueger@techfak.uni-bielefeld.de Übersicht FachChinesisch SPARC - UltraSparc III/IV PowerPC - PowerPC 970(G5) X86 - Pentium4(Xeon), Itanium, (Pentium M) X86 - AthlonXP/MP,
moderne Prozessoren Jan Krüger jkrueger@techfak.uni-bielefeld.de Übersicht FachChinesisch SPARC - UltraSparc III/IV PowerPC - PowerPC 970(G5) X86 - Pentium4(Xeon), Itanium, (Pentium M) X86 - AthlonXP/MP,
Protected User-Level DMA in SCI Shared Memory Umgebungen
 Protected User-Level DMA in SCI Shared Memory Umgebungen Mario Trams University of Technology Chemnitz, Chair of Computer Architecture 6. Halle Chemnitz Seminar zu Parallelverarbeitung und Programmiersprachen
Protected User-Level DMA in SCI Shared Memory Umgebungen Mario Trams University of Technology Chemnitz, Chair of Computer Architecture 6. Halle Chemnitz Seminar zu Parallelverarbeitung und Programmiersprachen
Verteilte Systeme. Verteilte Systeme. 5 Prozeß-Management SS 2016
 Verteilte Systeme SS 2016 Universität Siegen rolanda.dwismuellera@duni-siegena.de Tel.: 0271/740-4050, Büro: H-B 8404 Stand: 31. Mai 2016 Betriebssysteme / verteilte Systeme Verteilte Systeme (1/14) i
Verteilte Systeme SS 2016 Universität Siegen rolanda.dwismuellera@duni-siegena.de Tel.: 0271/740-4050, Büro: H-B 8404 Stand: 31. Mai 2016 Betriebssysteme / verteilte Systeme Verteilte Systeme (1/14) i
Raytracing auf Desktop PCs Optimizing Cache Usage (Intel Corp.)
") Raytracing auf Desktop PCs Optimizing Cache Usage (Intel Corp.) von Martin Stöcker Motivation Geschwindigkeit der Prozessoren verdoppelt sich alle 18 Monate (Moore s Law) Geschwindigkeit des Speichers
Raytracing auf Desktop PCs Optimizing Cache Usage (Intel Corp.) von Martin Stöcker Motivation Geschwindigkeit der Prozessoren verdoppelt sich alle 18 Monate (Moore s Law) Geschwindigkeit des Speichers
Jürg Gutknecht, SI und ETH Zürich, April 2015
 Jürg Gutknecht, SI und ETH Zürich, April 2015 Der Staubsauger könnte ein Mikrofon eingebaut haben, welches sämtliche Geräusche im Raum aufnimmt und via Stromkabel an einen Geheimdienst weiterleitet Die
Jürg Gutknecht, SI und ETH Zürich, April 2015 Der Staubsauger könnte ein Mikrofon eingebaut haben, welches sämtliche Geräusche im Raum aufnimmt und via Stromkabel an einen Geheimdienst weiterleitet Die
Beispiele von Branch Delay Slot Schedules
 Beispiele von Branch Delay Slot Schedules Bildquelle: David A. Patterson und John L. Hennessy, Computer Organization and Design, Fourth Edition, 2012 Grundlagen der Rechnerarchitektur Prozessor 97 Weniger
Beispiele von Branch Delay Slot Schedules Bildquelle: David A. Patterson und John L. Hennessy, Computer Organization and Design, Fourth Edition, 2012 Grundlagen der Rechnerarchitektur Prozessor 97 Weniger
Systeme I: Betriebssysteme Kapitel 8 Speicherverwaltung
 Systeme I: Betriebssysteme Kapitel 8 Speicherverwaltung Version 21.12.2016 1 Inhalt Vorlesung Aufbau einfacher Rechner Überblick: Aufgabe, Historische Entwicklung, unterschiedliche Arten von Betriebssystemen
Systeme I: Betriebssysteme Kapitel 8 Speicherverwaltung Version 21.12.2016 1 Inhalt Vorlesung Aufbau einfacher Rechner Überblick: Aufgabe, Historische Entwicklung, unterschiedliche Arten von Betriebssystemen
Multicore Herausforderungen an das Software-Engineering. Prof. Dr.-Ing. Michael Uelschen Hochschule Osnabrück 15.09.2010
 Multicore Herausforderungen an das Software-Engineering Prof. Dr.-Ing. Michael Uelschen Hochschule Osnabrück 15.09.2010 Inhalt _ Motivation _ Herausforderung 1: Hardware _ Herausforderung 2: Software-Partitionierung
Multicore Herausforderungen an das Software-Engineering Prof. Dr.-Ing. Michael Uelschen Hochschule Osnabrück 15.09.2010 Inhalt _ Motivation _ Herausforderung 1: Hardware _ Herausforderung 2: Software-Partitionierung
Einführung. Übungen zur Vorlesung Virtuelle Maschinen. Stefan Potyra. SoSe 2009
 Einführung Übungen zur Vorlesung Virtuelle Maschinen Stefan Potyra Lehrstuhl für Informatik 3 (Rechnerarchitektur) Friedrich-Alexander-Universität Erlangen-Nürnberg SoSe 2009 Übungsaufgaben 1 Entwickeln
Einführung Übungen zur Vorlesung Virtuelle Maschinen Stefan Potyra Lehrstuhl für Informatik 3 (Rechnerarchitektur) Friedrich-Alexander-Universität Erlangen-Nürnberg SoSe 2009 Übungsaufgaben 1 Entwickeln
Echtzeitbetriebssysteme
 Speicherverwaltung (Memory Management) Aufgaben der Memory-Management-Unit ist l der Speicherschutz und l die Adressumsetzung Wird durch Hardware unterstützt l Memory Management Unit (MMU) l MMU wird vom
Speicherverwaltung (Memory Management) Aufgaben der Memory-Management-Unit ist l der Speicherschutz und l die Adressumsetzung Wird durch Hardware unterstützt l Memory Management Unit (MMU) l MMU wird vom
Johann Wolfgang Goethe-Universität
 Flynn sche Klassifikation SISD (single instruction, single data stream): IS IS CU PU DS MM Mono (Mikro-)prozessoren CU: Control Unit SM: Shared Memory PU: Processor Unit IS: Instruction Stream MM: Memory
Flynn sche Klassifikation SISD (single instruction, single data stream): IS IS CU PU DS MM Mono (Mikro-)prozessoren CU: Control Unit SM: Shared Memory PU: Processor Unit IS: Instruction Stream MM: Memory
Opteron und I/O. Toni Schmidbauer. 11. Mai Zusammenfassung. Eine kurze Beschreibung der AMD Opteron Architektur.
 Opteron und I/O Toni Schmidbauer 11. Mai 2005 Zusammenfassung Eine kurze Beschreibung der AMD Opteron Architektur Inhaltsverzeichnis 1 Allgemeines 2 2 Was ist ein Interconnect? 2 3 Traditionelles PC Chipset
Opteron und I/O Toni Schmidbauer 11. Mai 2005 Zusammenfassung Eine kurze Beschreibung der AMD Opteron Architektur Inhaltsverzeichnis 1 Allgemeines 2 2 Was ist ein Interconnect? 2 3 Traditionelles PC Chipset
Betriebssysteme Übung 2. Tutorium System Calls & Multiprogramming
 Betriebssysteme Übung 2. Tutorium System Calls & Multiprogramming Task Wiederholung 1 System SysCalls (1) Wozu? Sicherheit Stabilität Erfordert verschiedene modes of execution: user mode privileged mode
Betriebssysteme Übung 2. Tutorium System Calls & Multiprogramming Task Wiederholung 1 System SysCalls (1) Wozu? Sicherheit Stabilität Erfordert verschiedene modes of execution: user mode privileged mode
Simulink: Softwareentwurf für eingebettete Systeme ROS-Arduino-Interface. von Christian Schildwächter
 Simulink: Softwareentwurf für eingebettete Systeme ROS-Arduino-Interface von Christian Schildwächter Simulink Simulink S-Functions Softwareprojekt ROS-Arduino-Interface Simulink 3 LIVE DEMO 4 External
Simulink: Softwareentwurf für eingebettete Systeme ROS-Arduino-Interface von Christian Schildwächter Simulink Simulink S-Functions Softwareprojekt ROS-Arduino-Interface Simulink 3 LIVE DEMO 4 External
Grundlagen der Rechnerarchitektur. Ein und Ausgabe
 Grundlagen der Rechnerarchitektur Ein und Ausgabe Übersicht Grundbegriffe Hard Disks und Flash RAM Zugriff auf IO Geräte RAID Systeme SS 2012 Grundlagen der Rechnerarchitektur Ein und Ausgabe 2 Grundbegriffe
Grundlagen der Rechnerarchitektur Ein und Ausgabe Übersicht Grundbegriffe Hard Disks und Flash RAM Zugriff auf IO Geräte RAID Systeme SS 2012 Grundlagen der Rechnerarchitektur Ein und Ausgabe 2 Grundbegriffe
Intel 80x86 symmetrische Multiprozessorsysteme. Eine Präsentation im Rahmen des Seminars Parallele Rechnerarchitekturen von Bernhard Witte
 Intel 80x86 symmetrische Multiprozessorsysteme Eine Präsentation im Rahmen des Seminars Parallele Rechnerarchitekturen von Bernhard Witte Gliederung I. Parallel Computing Einführung II.SMP Grundlagen III.Speicherzugriff
Intel 80x86 symmetrische Multiprozessorsysteme Eine Präsentation im Rahmen des Seminars Parallele Rechnerarchitekturen von Bernhard Witte Gliederung I. Parallel Computing Einführung II.SMP Grundlagen III.Speicherzugriff
Praktikumsbericht. Jens Breitbart 01.08.2006-31.10.2006
 Praktikumsbericht Jens Breitbart 01.08.2006-31.10.2006 Inhaltsverzeichnis 1 IBM 4 1.1 Weltweit.................................... 4 1.2 IBM Deutschland GmbH........................... 4 1.2.1 Forschung
Praktikumsbericht Jens Breitbart 01.08.2006-31.10.2006 Inhaltsverzeichnis 1 IBM 4 1.1 Weltweit.................................... 4 1.2 IBM Deutschland GmbH........................... 4 1.2.1 Forschung
ModProg 15-16, Vorl. 13
 ModProg 15-16, Vorl. 13 Richard Grzibovski Jan. 27, 2016 1 / 35 Übersicht Übersicht 1 Supercomputing FLOPS, Peak FLOPS Parallelismus Praktische Aspekte 2 Klausur von 2009 2 / 35 Supercomputing: HPC Modellierung
ModProg 15-16, Vorl. 13 Richard Grzibovski Jan. 27, 2016 1 / 35 Übersicht Übersicht 1 Supercomputing FLOPS, Peak FLOPS Parallelismus Praktische Aspekte 2 Klausur von 2009 2 / 35 Supercomputing: HPC Modellierung
CPU-Caches. Christian Duße. Seminar Effiziente Programmierung in C
 CPU-Caches Christian Duße Seminar Effiziente Programmierung in C Arbeitsbereich Wissenschaftliches Rechnen Fachbereich Informatik Fakultät für Mathematik, Informatik und Naturwissenschaften Universität
CPU-Caches Christian Duße Seminar Effiziente Programmierung in C Arbeitsbereich Wissenschaftliches Rechnen Fachbereich Informatik Fakultät für Mathematik, Informatik und Naturwissenschaften Universität
Maschinencode Dateiformat und Stackframes
 Maschinencode Dateiformat und Stackframes Proseminar C-Programmierung - Grundlagen und Konzepte Julian M. Kunkel julian.martin.kunkel@informatik.uni-hamburg.de Wissenschaftliches Rechnen Fachbereich Informatik
Maschinencode Dateiformat und Stackframes Proseminar C-Programmierung - Grundlagen und Konzepte Julian M. Kunkel julian.martin.kunkel@informatik.uni-hamburg.de Wissenschaftliches Rechnen Fachbereich Informatik
2. Der ParaNut-Prozessor "Parallel and more than just another CPU core"
 2. Der ParaNut-Prozessor "Parallel and more than just another CPU core" Neuer, konfigurierbarer Prozessor Parallelität auf Daten- (SIMD) und Thread-Ebene Hohe Skalierbarkeit mit einer Architektur neues
2. Der ParaNut-Prozessor "Parallel and more than just another CPU core" Neuer, konfigurierbarer Prozessor Parallelität auf Daten- (SIMD) und Thread-Ebene Hohe Skalierbarkeit mit einer Architektur neues
OpenMP. Viktor Styrbul
 OpenMP Viktor Styrbul Inhaltsverzeichnis Was ist OpenMP Warum Parallelisierung Geschichte Merkmale von OpenMP OpenMP-fähige Compiler OpenMP Ausführungsmodell Kernelemente von OpenMP Zusammenfassung Was
OpenMP Viktor Styrbul Inhaltsverzeichnis Was ist OpenMP Warum Parallelisierung Geschichte Merkmale von OpenMP OpenMP-fähige Compiler OpenMP Ausführungsmodell Kernelemente von OpenMP Zusammenfassung Was
C programmieren. Jürgen Wolf
 C programmieren Jürgen Wolf Vorwort 11 Kapitel 1: Schnelleinstieg 13 Was sollten Sie bereits können? 14 Was lernen Sie mit diesem Buch? 14 Was benötigen Sie noch? 14 Überblick zu den einzelnen Kapiteln
C programmieren Jürgen Wolf Vorwort 11 Kapitel 1: Schnelleinstieg 13 Was sollten Sie bereits können? 14 Was lernen Sie mit diesem Buch? 14 Was benötigen Sie noch? 14 Überblick zu den einzelnen Kapiteln
Einige Grundlagen zu OpenMP
 Einige Grundlagen zu OpenMP Stephanie Friedhoff, Martin Lanser Mathematisches Institut Universität zu Köln 22. Juni 2016 Überblick Was ist OpenMP? Basics Das OpenMP fork-join-modell Kompilieren und Ausführen
Einige Grundlagen zu OpenMP Stephanie Friedhoff, Martin Lanser Mathematisches Institut Universität zu Köln 22. Juni 2016 Überblick Was ist OpenMP? Basics Das OpenMP fork-join-modell Kompilieren und Ausführen
Neue Prozessor-Architekturen für Desktop-PC
 Neue Prozessor-Architekturen für Desktop-PC Bernd Däne Technische Universität Ilmenau Fakultät I/A - Institut TTI Postfach 100565, D-98684 Ilmenau Tel. 0-3677-69-1433 bdaene@theoinf.tu-ilmenau.de http://www.theoinf.tu-ilmenau.de/ra1/
Neue Prozessor-Architekturen für Desktop-PC Bernd Däne Technische Universität Ilmenau Fakultät I/A - Institut TTI Postfach 100565, D-98684 Ilmenau Tel. 0-3677-69-1433 bdaene@theoinf.tu-ilmenau.de http://www.theoinf.tu-ilmenau.de/ra1/
Übung 1 - Betriebssysteme I
 Prof. Dr. Th. Letschert FB MNI 13. März 2002 Aufgabe 0: Basiswissen Rechnerarchitektur: Übung 1 - Betriebssysteme I Aus welchen Komponenten besteht ein Rechner mit Von-Neumann Architektur? Was sind Bits
Prof. Dr. Th. Letschert FB MNI 13. März 2002 Aufgabe 0: Basiswissen Rechnerarchitektur: Übung 1 - Betriebssysteme I Aus welchen Komponenten besteht ein Rechner mit Von-Neumann Architektur? Was sind Bits
Power Grid Exist: A dynamic Cluster with Hierarchic Master Worker Architecture. Prof. Dipl.-Inform. Günther Bengel
 Power Grid Exist: A dynamic Cluster with Hierarchic Master Worker Architecture Prof. Dipl.-Inform. Günther Bengel Informatik-Berichte Hochschule Mannheim Fakultät für Informatik Computer Science Reports
Power Grid Exist: A dynamic Cluster with Hierarchic Master Worker Architecture Prof. Dipl.-Inform. Günther Bengel Informatik-Berichte Hochschule Mannheim Fakultät für Informatik Computer Science Reports
Freispeicherverwaltung Martin Wahl,
 Freispeicherverwaltung Martin Wahl, 17.11.03 Allgemeines zur Speicherverwaltung Der physikalische Speicher wird in zwei Teile unterteilt: -Teil für den Kernel -Dynamischer Speicher Die Verwaltung des dynamischen
Freispeicherverwaltung Martin Wahl, 17.11.03 Allgemeines zur Speicherverwaltung Der physikalische Speicher wird in zwei Teile unterteilt: -Teil für den Kernel -Dynamischer Speicher Die Verwaltung des dynamischen
Fachreferat. EFI -BIOS Nachfolger-
 Fachreferat EFI -BIOS Nachfolger- Kurzerläuterung Übersicht EFI - Geschichte Aufbau und Vorteile Grafische Veranschaulichung Was passiert beim direkten einschalten eines Computers? Wie kommt die Intelligenz
Fachreferat EFI -BIOS Nachfolger- Kurzerläuterung Übersicht EFI - Geschichte Aufbau und Vorteile Grafische Veranschaulichung Was passiert beim direkten einschalten eines Computers? Wie kommt die Intelligenz
Betriebssysteme G: Parallele Prozesse (Teil A: Grundlagen)
") Betriebssysteme G: Parallele Prozesse (Teil A: Grundlagen) 1 Prozesse Bei Betriebssystemen stoßen wir des öfteren auf den Begriff Prozess als wahrscheinlich am häufigsten verwendeter und am unklarsten
Betriebssysteme G: Parallele Prozesse (Teil A: Grundlagen) 1 Prozesse Bei Betriebssystemen stoßen wir des öfteren auf den Begriff Prozess als wahrscheinlich am häufigsten verwendeter und am unklarsten
Technische Informatik 1
 Technische Informatik 1 7 Prozesse und Threads Lothar Thiele Computer Engineering and Networks Laboratory Betriebssystem 7 2 7 3 Betriebssystem Anwendung Anwendung Anwendung Systemaufruf (syscall) Betriebssystem
Technische Informatik 1 7 Prozesse und Threads Lothar Thiele Computer Engineering and Networks Laboratory Betriebssystem 7 2 7 3 Betriebssystem Anwendung Anwendung Anwendung Systemaufruf (syscall) Betriebssystem
Name: Vorname: Matr.-Nr.: 4. a) RISC-Architekturen müssen zur Decodierung von Maschinenbefehlen stets ein mikroprogrammierbares Steuerwerk verwenden.
 RISC-Architekturen müssen zur Decodierung von Maschinenbefehlen stets ein mikroprogrammierbares Steuerwerk verwenden.") Name: Vorname: Matr.-Nr.: 4 Aufgabe 1 (8 Punkte) Entscheiden Sie, welche der folgenden Aussagen zum Thema CISC/RISC-Prinzipien korrekt sind. a) RISC-Architekturen müssen zur Decodierung von Maschinenbefehlen
Name: Vorname: Matr.-Nr.: 4 Aufgabe 1 (8 Punkte) Entscheiden Sie, welche der folgenden Aussagen zum Thema CISC/RISC-Prinzipien korrekt sind. a) RISC-Architekturen müssen zur Decodierung von Maschinenbefehlen
Smartphone Entwicklung mit Android und Java
 Smartphone Entwicklung mit Android und Java predic8 GmbH Moltkestr. 40 53173 Bonn Tel: (0228)5552576-0 www.predic8.de info@predic8.de Was ist Android Offene Plattform für mobile Geräte Software Kompletter
Smartphone Entwicklung mit Android und Java predic8 GmbH Moltkestr. 40 53173 Bonn Tel: (0228)5552576-0 www.predic8.de info@predic8.de Was ist Android Offene Plattform für mobile Geräte Software Kompletter
Systeme I: Betriebssysteme Kapitel 4 Prozesse. Maren Bennewitz
 Systeme I: Betriebssysteme Kapitel 4 Prozesse Maren Bennewitz Version 21.11.2012 1 Begrüßung Heute ist Tag der offenen Tür Willkommen allen Schülerinnen und Schülern! 2 Testat nach Weihnachten Mittwoch
Systeme I: Betriebssysteme Kapitel 4 Prozesse Maren Bennewitz Version 21.11.2012 1 Begrüßung Heute ist Tag der offenen Tür Willkommen allen Schülerinnen und Schülern! 2 Testat nach Weihnachten Mittwoch
 TECHNISCHE HOCHSCHULE NÜRNBERG GEORG SIMON OHM Die Mikroprogrammebene eines Rechners Das Abarbeiten eines Arbeitszyklus eines einzelnen Befehls besteht selbst wieder aus verschiedenen Schritten, z.b. Befehl
TECHNISCHE HOCHSCHULE NÜRNBERG GEORG SIMON OHM Die Mikroprogrammebene eines Rechners Das Abarbeiten eines Arbeitszyklus eines einzelnen Befehls besteht selbst wieder aus verschiedenen Schritten, z.b. Befehl
Programmierbeispiele und Implementierung. Name: Michel Steuwer E-Mail: michel.steuwer@wwu.de
 > Programmierbeispiele und Implementierung Name: Michel Steuwer E-Mail: michel.steuwer@wwu.de 2 > Übersicht > Matrix Vektor Multiplikation > Mandelbrotmenge / Apfelmännchen berechnen > Kantendetektion
> Programmierbeispiele und Implementierung Name: Michel Steuwer E-Mail: michel.steuwer@wwu.de 2 > Übersicht > Matrix Vektor Multiplikation > Mandelbrotmenge / Apfelmännchen berechnen > Kantendetektion
Instruktionssatz-Architektur
 Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2005/2006 Übersicht 1 Einleitung 2 Bestandteile der ISA 3 CISC / RISC Übersicht 1 Einleitung 2 Bestandteile
Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2005/2006 Übersicht 1 Einleitung 2 Bestandteile der ISA 3 CISC / RISC Übersicht 1 Einleitung 2 Bestandteile
Inhalt. Prozessoren. Curriculum Manfred Wilfling. 28. November HTBLA Kaindorf. M. Wilfling (HTBLA Kaindorf) CPUs 28. November / 9
 CPUs 28. November / 9") Inhalt Curriculum 1.4.2 Manfred Wilfling HTBLA Kaindorf 28. November 2011 M. Wilfling (HTBLA Kaindorf) CPUs 28. November 2011 1 / 9 Begriffe CPU Zentraleinheit (Central Processing Unit) bestehend aus Rechenwerk,
Inhalt Curriculum 1.4.2 Manfred Wilfling HTBLA Kaindorf 28. November 2011 M. Wilfling (HTBLA Kaindorf) CPUs 28. November 2011 1 / 9 Begriffe CPU Zentraleinheit (Central Processing Unit) bestehend aus Rechenwerk,
Wie groß ist die Page Table?
 Wie groß ist die Page Table? Im vorigen (typischen) Beispiel verwenden wir 20 Bits zum indizieren der Page Table. Typischerweise spendiert man 32 Bits pro Tabellen Zeile (im Vorigen Beispiel brauchten
Wie groß ist die Page Table? Im vorigen (typischen) Beispiel verwenden wir 20 Bits zum indizieren der Page Table. Typischerweise spendiert man 32 Bits pro Tabellen Zeile (im Vorigen Beispiel brauchten
Busse. Dr.-Ing. Volkmar Sieh. Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2008/2009
 Busse Dr.-Ing. Volkmar Sieh Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2008/2009 Busse 1/40 2008-10-13 Übersicht 1 Einleitung 2 Bus-Konfiguration
Busse Dr.-Ing. Volkmar Sieh Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2008/2009 Busse 1/40 2008-10-13 Übersicht 1 Einleitung 2 Bus-Konfiguration
Assembler - Einleitung
 Assembler - Einleitung Dr.-Ing. Volkmar Sieh Department Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg SS 2008 Assembler - Einleitung 1/19 2008-04-01 Teil 1: Hochsprache
Assembler - Einleitung Dr.-Ing. Volkmar Sieh Department Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg SS 2008 Assembler - Einleitung 1/19 2008-04-01 Teil 1: Hochsprache
Foliensatz. Theorie und Einsatz von Verbindungseinrichtungen in parallelen Rechnersystemen
 Foliensatz Center for Information Services and High Performance Computing (ZIH) Theorie und Einsatz von Verbindungseinrichtungen in parallelen Rechnersystemen Hochgeschwindigkeitskommunikationen 13. Juli
Foliensatz Center for Information Services and High Performance Computing (ZIH) Theorie und Einsatz von Verbindungseinrichtungen in parallelen Rechnersystemen Hochgeschwindigkeitskommunikationen 13. Juli
Bibliotheks-basierte Virtualisierung
 Dr.-Ing. Volkmar Sieh Department Informatik 4 Verteilte Systeme und Betriebssysteme Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2015/2016 V. Sieh Bibliotheks-basierte Virtualisierung (WS15/16)
Dr.-Ing. Volkmar Sieh Department Informatik 4 Verteilte Systeme und Betriebssysteme Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2015/2016 V. Sieh Bibliotheks-basierte Virtualisierung (WS15/16)
Convey, Hybrid-Core Computing
 Convey, Hybrid-Core Computing Vortrag im Rahmen des Seminars Ausgewählte Themen in Hardwareentwurf und Optik HWS 09 Universität Mannheim Markus Müller 1 Inhalt Hybrid-Core Computing? Convey HC-1 Überblick
Convey, Hybrid-Core Computing Vortrag im Rahmen des Seminars Ausgewählte Themen in Hardwareentwurf und Optik HWS 09 Universität Mannheim Markus Müller 1 Inhalt Hybrid-Core Computing? Convey HC-1 Überblick
(a) Wie unterscheiden sich synchrone und asynchrone Unterbrechungen? (b) In welchen drei Schritten wird auf Unterbrechungen reagiert?
 Wie unterscheiden sich synchrone und asynchrone Unterbrechungen? (b) In welchen drei Schritten wird auf Unterbrechungen reagiert?") SoSe 2014 Konzepte und Methoden der Systemsoftware Universität Paderborn Fachgebiet Rechnernetze Präsenzübung 2 2014-04-28 bis 2014-05-02 Aufgabe 1: Unterbrechungen (a) Wie unterscheiden sich synchrone
SoSe 2014 Konzepte und Methoden der Systemsoftware Universität Paderborn Fachgebiet Rechnernetze Präsenzübung 2 2014-04-28 bis 2014-05-02 Aufgabe 1: Unterbrechungen (a) Wie unterscheiden sich synchrone
Die Mikroprogrammebene eines Rechners
 Die Mikroprogrammebene eines Rechners Das Abarbeiten eines Arbeitszyklus eines einzelnen Befehls besteht selbst wieder aus verschiedenen Schritten, z.b. Befehl holen Befehl dekodieren Operanden holen etc.
Die Mikroprogrammebene eines Rechners Das Abarbeiten eines Arbeitszyklus eines einzelnen Befehls besteht selbst wieder aus verschiedenen Schritten, z.b. Befehl holen Befehl dekodieren Operanden holen etc.
CUDA. Jürgen Pröll. Multi-Core Architectures and Programming. Friedrich-Alexander-Universität Erlangen-Nürnberg Jürgen Pröll 1
 CUDA Jürgen Pröll Multi-Core Architectures and Programming Jürgen Pröll 1 Image-Resize: sequentiell resize() mit bilinearer Interpolation leicht zu parallelisieren, da einzelne Punkte voneinander unabhängig
CUDA Jürgen Pröll Multi-Core Architectures and Programming Jürgen Pröll 1 Image-Resize: sequentiell resize() mit bilinearer Interpolation leicht zu parallelisieren, da einzelne Punkte voneinander unabhängig
Dr. Monika Meiler. Inhalt
 Inhalt 15 Parallele Programmierung... 15-2 15.1 Die Klasse java.lang.thread... 15-2 15.2 Beispiel 0-1-Printer als Thread... 15-3 15.3 Das Interface java.lang.runnable... 15-4 15.4 Beispiel 0-1-Printer
Inhalt 15 Parallele Programmierung... 15-2 15.1 Die Klasse java.lang.thread... 15-2 15.2 Beispiel 0-1-Printer als Thread... 15-3 15.3 Das Interface java.lang.runnable... 15-4 15.4 Beispiel 0-1-Printer
PROGRAMMIEREN MIT C. }, wird kompiliert mit dem Befehl. (-o steht für output) und ausgeführt mit dem Befehl
 und ausgeführt mit dem Befehl") PROGRAMMIEREN MIT C Allgemeine hinweise Alles was hier beschrieben wird, soll auch ausprobiert werden. Warum C? Weil die coolen Dinge mit C am einfachsten gehen. Das werden wir in den folgenden Übungen
PROGRAMMIEREN MIT C Allgemeine hinweise Alles was hier beschrieben wird, soll auch ausprobiert werden. Warum C? Weil die coolen Dinge mit C am einfachsten gehen. Das werden wir in den folgenden Übungen
Die Sandy-Bridge Architektur
 Fakultät Informatik - Institut für Technische Informatik - Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Die Sandy-Bridge Architektur René Arnold Dresden, 12. Juli 2011 0. Gliederung 1.
Fakultät Informatik - Institut für Technische Informatik - Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Die Sandy-Bridge Architektur René Arnold Dresden, 12. Juli 2011 0. Gliederung 1.
White Paper. Embedded Treiberframework. Einführung
 Embedded Treiberframework Einführung White Paper Dieses White Paper beschreibt die Architektur einer Laufzeitumgebung für Gerätetreiber im embedded Umfeld. Dieses Treiberframework ist dabei auf jede embedded
Embedded Treiberframework Einführung White Paper Dieses White Paper beschreibt die Architektur einer Laufzeitumgebung für Gerätetreiber im embedded Umfeld. Dieses Treiberframework ist dabei auf jede embedded
Game Engine Architecture and Development. Platform Unabhängiger Code Multi Threading in Game Engines Profiling
 Game Engine Architecture and Development Platform Unabhängiger Code Multi Threading in Game Engines Profiling Folien Die Folien werden auf acagamics.de hochgeladen Das Passwort ist 60fps (ohne ) Rückblick:
Game Engine Architecture and Development Platform Unabhängiger Code Multi Threading in Game Engines Profiling Folien Die Folien werden auf acagamics.de hochgeladen Das Passwort ist 60fps (ohne ) Rückblick:
2.2 Rechnerorganisation: Aufbau und Funktionsweise
 2.2 Rechnerorganisation: Aufbau und Funktionsweise é Hardware, Software und Firmware é grober Aufbau eines von-neumann-rechners é Arbeitsspeicher, Speicherzelle, Bit, Byte é Prozessor é grobe Arbeitsweise
2.2 Rechnerorganisation: Aufbau und Funktionsweise é Hardware, Software und Firmware é grober Aufbau eines von-neumann-rechners é Arbeitsspeicher, Speicherzelle, Bit, Byte é Prozessor é grobe Arbeitsweise
Übersicht. Virtuelle Maschinen Erlaubnisse (Permission, Rechte) Ringe. AVS SS Teil 12/Protection
 Ringe. AVS SS Teil 12/Protection") Übersicht Virtuelle Maschinen Erlaubnisse (Permission, Rechte) Ringe 2 Behandelter Bereich: Virtualisierung Syscall-Schnittstelle Ports Server Apps Server Apps Betriebssystem Protokolle Betriebssystem
Übersicht Virtuelle Maschinen Erlaubnisse (Permission, Rechte) Ringe 2 Behandelter Bereich: Virtualisierung Syscall-Schnittstelle Ports Server Apps Server Apps Betriebssystem Protokolle Betriebssystem
1 Proseminar: Konzepte von Betriebssystem-Komponenten. Thema: Server OS AS/400 Referend: Sand Rainer. Server OS - AS/400
 1 Proseminar: Konzepte von Betriebssystem-Komponenten Server OS - AS/400 Gliederung Was ist eine AS/400? Wie ist OS/400 aufgebaut? Was kann eine AS/400? Bsp.: Logische Partitionierung 2 Proseminar: Konzepte
1 Proseminar: Konzepte von Betriebssystem-Komponenten Server OS - AS/400 Gliederung Was ist eine AS/400? Wie ist OS/400 aufgebaut? Was kann eine AS/400? Bsp.: Logische Partitionierung 2 Proseminar: Konzepte
Vertiefungsrichtung Rechnerarchitektur
 srichtung () ( für ) Prof. Dietmar Fey Ziele der srichtung RA Vertiefen des Verständnis vom Aufbau, Funktionsweise von Rechnern und Prozessoren Modellierung und Entwurf von Rechnern und Prozessoren ()
srichtung () ( für ) Prof. Dietmar Fey Ziele der srichtung RA Vertiefen des Verständnis vom Aufbau, Funktionsweise von Rechnern und Prozessoren Modellierung und Entwurf von Rechnern und Prozessoren ()
System Monitoring mit strace. Systemcall tracing
 System Monitoring mit strace Systemcall tracing 1 Gliederung Einleitung: Was ist strace Grundlagen zu strace Kernel Kernelspace vs. Userspace Systemcalls ptrace Simple strace (Demo) strace die wichtigsten
System Monitoring mit strace Systemcall tracing 1 Gliederung Einleitung: Was ist strace Grundlagen zu strace Kernel Kernelspace vs. Userspace Systemcalls ptrace Simple strace (Demo) strace die wichtigsten
Paralleles Rechnen. (Architektur verteilter Systeme) von Thomas Offermann Philipp Tommek Dominik Pich
 von Thomas Offermann Philipp Tommek Dominik Pich") Paralleles Rechnen (Architektur verteilter Systeme) von Thomas Offermann Philipp Tommek Dominik Pich Gliederung Motivation Anwendungsgebiete Warum paralleles Rechnen Flynn's Klassifikation Theorie: Parallel
Paralleles Rechnen (Architektur verteilter Systeme) von Thomas Offermann Philipp Tommek Dominik Pich Gliederung Motivation Anwendungsgebiete Warum paralleles Rechnen Flynn's Klassifikation Theorie: Parallel
Unterprogramme. Funktionen. Bedeutung von Funktionen in C++ Definition einer Funktion. Definition einer Prozedur
 Unterprogramme Unterprogramme sind abgekapselte Programmfragmente, welche es erlauben, bestimmte Aufgaben in wiederverwendbarer Art umzusetzen. Man unterscheidet zwischen Unterprogrammen mit Rückgabewert
Unterprogramme Unterprogramme sind abgekapselte Programmfragmente, welche es erlauben, bestimmte Aufgaben in wiederverwendbarer Art umzusetzen. Man unterscheidet zwischen Unterprogrammen mit Rückgabewert
Computergrundlagen Geschichte des Computers
 Computergrundlagen Geschichte des Computers Axel Arnold Institut für Computerphysik Universität Stuttgart Wintersemester 2010/11 1641: Rechenmaschine von B. Pascal B. Pascal, 1632-1662 mechanische Rechenmaschine
Computergrundlagen Geschichte des Computers Axel Arnold Institut für Computerphysik Universität Stuttgart Wintersemester 2010/11 1641: Rechenmaschine von B. Pascal B. Pascal, 1632-1662 mechanische Rechenmaschine
RST-Labor WS06/07 GPGPU. General Purpose Computation On Graphics Processing Units. (Grafikkarten-Programmierung) Von: Marc Blunck
 Von: Marc Blunck") RST-Labor WS06/07 GPGPU General Purpose Computation On Graphics Processing Units (Grafikkarten-Programmierung) Von: Marc Blunck Ablauf Einführung GPGPU Die GPU GPU Architektur Die Programmierung Programme
RST-Labor WS06/07 GPGPU General Purpose Computation On Graphics Processing Units (Grafikkarten-Programmierung) Von: Marc Blunck Ablauf Einführung GPGPU Die GPU GPU Architektur Die Programmierung Programme
Die L4-Mikrokern. Mikrokern-Familie. Hauptseminar Ansätze für Betriebssysteme der Zukunft. Michael Steil. Michael Steil 18.04.2002
 Die L4-Mikrokern Mikrokern-Familie Hauptseminar Ansätze für Betriebssysteme der Zukunft 18.04.2002 Folie 1 Aufbau des Vortrags 1. Mikrokerne: Idee und Geschichte 2. L4: ein schneller Mikrokern 3. L4Linux:
Die L4-Mikrokern Mikrokern-Familie Hauptseminar Ansätze für Betriebssysteme der Zukunft 18.04.2002 Folie 1 Aufbau des Vortrags 1. Mikrokerne: Idee und Geschichte 2. L4: ein schneller Mikrokern 3. L4Linux:
3. Klassen Statische Komponenten einer Klasse. Klassenvariablen
 Klassenvariablen Wir wollen die Zahl der instantiierten Studentenobjekte zählen. Dies ist jedoch keine Eigenschaft eines einzelnen Objektes. Vielmehr gehört die Eigenschaft zu der Gesamtheit aller Studentenobjekte.
Klassenvariablen Wir wollen die Zahl der instantiierten Studentenobjekte zählen. Dies ist jedoch keine Eigenschaft eines einzelnen Objektes. Vielmehr gehört die Eigenschaft zu der Gesamtheit aller Studentenobjekte.
Software Engineering für moderne, parallele Plattformen
 Software Engineering für moderne, parallele Plattformen b. Ergänzungen zur Performanz Dr. Victor Pankratius Dr. Victor Pankratius IPD Lehrstuhl für Programmiersysteme-Tichy KIT die Kooperation von Forschungszentrum
Software Engineering für moderne, parallele Plattformen b. Ergänzungen zur Performanz Dr. Victor Pankratius Dr. Victor Pankratius IPD Lehrstuhl für Programmiersysteme-Tichy KIT die Kooperation von Forschungszentrum
Computational Biology: Bioelektromagnetismus und Biomechanik
 Computational Biology: Bioelektromagnetismus und Biomechanik Implementierung Gliederung Wiederholung: Biomechanik III Statische Elastomechanik Finite Elemente Diskretisierung Finite Differenzen Diskretisierung
Computational Biology: Bioelektromagnetismus und Biomechanik Implementierung Gliederung Wiederholung: Biomechanik III Statische Elastomechanik Finite Elemente Diskretisierung Finite Differenzen Diskretisierung
Computational Engineering I
 DEPARTMENT INFORMATIK Lehrstuhl für Informatik 3 (Rechnerarchitektur) Friedrich-Alexander-Universität Erlangen-Nürnberg Martensstraße 3, 91058 Erlangen 25.01.2016 Probeklausur zu Computational Engineering
DEPARTMENT INFORMATIK Lehrstuhl für Informatik 3 (Rechnerarchitektur) Friedrich-Alexander-Universität Erlangen-Nürnberg Martensstraße 3, 91058 Erlangen 25.01.2016 Probeklausur zu Computational Engineering
Leistungsanalyse von Rechnersystemen
 Zentrum für Informationsdienste und Hochleistungsrechnen (ZIH) Leistungsanalyse von Rechnersystemen Auf Ein-/Ausgabe spezialisierte Benchmarks Zellescher Weg 12 Willers-Bau A109 Tel. +49 351-463 - 32424
Zentrum für Informationsdienste und Hochleistungsrechnen (ZIH) Leistungsanalyse von Rechnersystemen Auf Ein-/Ausgabe spezialisierte Benchmarks Zellescher Weg 12 Willers-Bau A109 Tel. +49 351-463 - 32424
Grundlagen der Rechnerarchitektur
 Grundlagen der Rechnerarchitektur Ein und Ausgabe Übersicht Grundbegriffe Hard Disks und Flash RAM Zugriff auf IO Geräte RAID Systeme SS 2012 Grundlagen der Rechnerarchitektur Ein und Ausgabe 2 Grundbegriffe
Grundlagen der Rechnerarchitektur Ein und Ausgabe Übersicht Grundbegriffe Hard Disks und Flash RAM Zugriff auf IO Geräte RAID Systeme SS 2012 Grundlagen der Rechnerarchitektur Ein und Ausgabe 2 Grundbegriffe
Paralleles Rechnen: Multicores, Playstation 3, Rekonfigurierbare Hardware
 Paralleles Rechnen: Multicores, Playstation 3, Rekonfigurierbare Hardware Oliver Sinnen o.sinnen@auckland.ac.nz www.ece.auckland.ac.nz/~sinnen/ Von wo? Neuseeland Auckland Wirtschaftszentrum Größte Stadt
Paralleles Rechnen: Multicores, Playstation 3, Rekonfigurierbare Hardware Oliver Sinnen o.sinnen@auckland.ac.nz www.ece.auckland.ac.nz/~sinnen/ Von wo? Neuseeland Auckland Wirtschaftszentrum Größte Stadt
Current and Emerging Architectures Multi-core Architectures and Programming
 Current and Emerging Architectures Multi-core Architectures and Programming Adel El-Rayyes Hardware-Software-Co-Design, Friedrich-Alexander-Universität Erlangen-Nürnberg 9. Mai 2012 Inhalt Überblick über
Current and Emerging Architectures Multi-core Architectures and Programming Adel El-Rayyes Hardware-Software-Co-Design, Friedrich-Alexander-Universität Erlangen-Nürnberg 9. Mai 2012 Inhalt Überblick über
Optimierung der Code-Generierung virtualisierender Ausführungsumgebungen zur Erzielung deterministischer Ausführungszeiten
 Optimierung der Code-Generierung virtualisierender Ausführungsumgebungen zur Erzielung deterministischer Ausführungszeiten Martin Däumler Matthias Werner Lehrstuhl Betriebssysteme Fakultät für Informatik
Optimierung der Code-Generierung virtualisierender Ausführungsumgebungen zur Erzielung deterministischer Ausführungszeiten Martin Däumler Matthias Werner Lehrstuhl Betriebssysteme Fakultät für Informatik
Deklarationen in C. Prof. Dr. Margarita Esponda
 Deklarationen in C 1 Deklarationen Deklarationen spielen eine zentrale Rolle in der C-Programmiersprache. Deklarationen Variablen Funktionen Die Deklarationen von Variablen und Funktionen haben viele Gemeinsamkeiten.
Deklarationen in C 1 Deklarationen Deklarationen spielen eine zentrale Rolle in der C-Programmiersprache. Deklarationen Variablen Funktionen Die Deklarationen von Variablen und Funktionen haben viele Gemeinsamkeiten.
Prozesse und Scheduling
 Betriebssysteme für Wirtschaftsinformatiker SS04 KLAUSUR Vorbereitung mit Lösungen / Blatt 1 Prozesse und Scheduling Aufgabe 1 : Scheduling Gegeben seien die folgenden Prozesse und die Längen des jeweiligen
Betriebssysteme für Wirtschaftsinformatiker SS04 KLAUSUR Vorbereitung mit Lösungen / Blatt 1 Prozesse und Scheduling Aufgabe 1 : Scheduling Gegeben seien die folgenden Prozesse und die Längen des jeweiligen
Hugepages, NUMA or nothing on Linux?
 Hugepages, NUMA or nothing on Linux? Daniel Hillinger Value Transformation Services S.r.l. Zweigniederlassung Deutschland München Schlüsselworte Memory; Arbeitsspeicher; NUMA; Hugepages Einleitung Speicherarchitekturen
Hugepages, NUMA or nothing on Linux? Daniel Hillinger Value Transformation Services S.r.l. Zweigniederlassung Deutschland München Schlüsselworte Memory; Arbeitsspeicher; NUMA; Hugepages Einleitung Speicherarchitekturen
Parallelrechner (1) Anwendungen: Simulation von komplexen physikalischen oder biochemischen Vorgängen Entwurfsunterstützung virtuelle Realität
 Anwendungen: Simulation von komplexen physikalischen oder biochemischen Vorgängen Entwurfsunterstützung virtuelle Realität") Parallelrechner (1) Motivation: Bedarf für immer leistungsfähigere Rechner Leistungssteigerung eines einzelnen Rechners hat physikalische Grenzen: Geschwindigkeit von Materie Wärmeableitung Transistorgröße
Parallelrechner (1) Motivation: Bedarf für immer leistungsfähigere Rechner Leistungssteigerung eines einzelnen Rechners hat physikalische Grenzen: Geschwindigkeit von Materie Wärmeableitung Transistorgröße
Seminar aus Praktischer Informatik DI Dr. Hermann Hellwagner SS 2000 Ausarbeitung von: Marcus Hassler, Franz Kollmann
 Netzwerkprozessoren Seminar aus Praktischer Informatik DI Dr. Hermann Hellwagner SS 2000 Ausarbeitung von: Marcus Hassler, Franz Kollmann 1 Überblick Entwicklung von Netzwerkprodukten Status quo von Netzwerksystemen
Netzwerkprozessoren Seminar aus Praktischer Informatik DI Dr. Hermann Hellwagner SS 2000 Ausarbeitung von: Marcus Hassler, Franz Kollmann 1 Überblick Entwicklung von Netzwerkprodukten Status quo von Netzwerksystemen