Technische Informatik 1
|
|
|
- Elly Pfaff
- vor 6 Jahren
- Abrufe
Transkript
1 Technische Informatik 1 5 Prozessor Pipelineimplementierung Lothar Thiele Computer Engineering and Networks Laboratory
2 Pipelining Definition 5 2
3 Definition Pipelining (Fliessbandverarbeitung) ist eine Architekturtechnik, bei der mehrere Instruktionen überlappend ausgeführt werden. Zerlegung der Abarbeitung einer Instruktion in 5 Phasen: IF (Instruction Fetch): Lesen der Instruktion. ID (Instruction Decode) oder RF (Register Fetch): Dekodieren der Instruktion und Lesen von Registerinhalten. EX (Execute): Ausführen der Instruktion oder Berechnung einer Adresse. MEM (Memory): Zugriff auf den Datenspeicher. WB (Write Back): Speichern der Resultate im Registerfeld. 5 3
4 Prinzpieller Ablauf Änderung des Programmzählers IF: Instruction Fetch RF: Register Fetch EX: Execute MEM: Memory Access WB: Write Back Register 5 4
5 Ablauf einer Instruktionsausführung 5 5
6 Vergleich verschiedener Architekturen T1 T2 Einzyklenverarb. LW SW T1 T2 T3 T4 T5 T6 T7 T8 T9 LW SW Mehrzyklenverarb. IF RF EX MEM WB IF RF EX MEM Pipelineverarb. IF RF EX MEM WB LW IF RF EX MEM WB SW 5 6
7 Berechnung der Effizienz Homogene Rechenzeiten pro Stufe: k Pipelinestufen IF RF EX MEM WB IF RF EX MEM WB IF RF EX MEM WB IF RF EX MEM WB IF RF EX MEM WB n Instruktionen n k Speedup k n 1 Speedup Effizienz k k n n 1 n 1 5 7
8 5 8 Berechnung der Effizienz Inhomogene Rechenzeiten: 1 2 k 3 i k i k i i n k i i i k i i k i k i i k n k k n Effizienz n k n Speedup max 1) ( max max 1) (
9 Beispiel Annahme über die Verzögerungszeiten im Datenpfad: 100ps für Register Schreiben oder Lesen 200ps für alle anderen Bausteine (ALU, Hauptspeicher) Instruktion Instr. Fetch Register Read ALU Op Memory Access Register Write Gesamt Zeit lw 200ps 100 ps 200ps 200ps 100 ps 800ps sw 200ps 100 ps 200ps 200ps 700ps R format 200ps 100 ps 200ps 100 ps 600ps beq 200ps 100 ps 200ps 500ps Effizienz = 800ps (5 200ps) = 80% Einzeltakt: 1 800ps = Instruktionen/s Pipelining: 1 200ps = Instruktionen/s 5 9
10 Pipelinearchitektur Einzyklenimplementierung 5 10
11 Entwurf einer Pipeline Architektur Strategie: Ausgangspunkt ist eine Architektur, bei der in jedem Takt eine neue Instruktion ausgeführt wird ( Single Cycle ). Der Kontrollpfad besitzt keinen internen Zustand und kann demzufolge durch eine kombinatorische Schaltung realisiert werden. Es sind folgende Instruktionen (beispielhaft) realisiert: lw, sw, beq, add, sub, and, or, slt (set on less than). Es gibt keinen Branch Delay und keine Latenz. Die Register Register Instruktionen add, sub, and, or und slt heissen auch R Instruktionen ( R type ). 5 11
12 Datenpfad und Kontrollpfad PCSrc ALUControl 5 12
13 Pipelinearchitektur Datenpfad 5 13
14 Anpassung des Einzeltakt Datenpfades Trennung aller Stufen (IF, ID, EX, MEM, WB) durch Register. Dadurch werden die Ergebnisse bei der Abarbeitung einer Instruktion nach jeder Phase gespeichert. Aufteilung der Komponenten des Datenpfades auf die einzelnen Phasen. Ausnahme: Das Registerfeld wird sowohl in der ID Phase als auch in der WB Phase genutzt. Innerhalb eines Taktes kann sowohl lesend als auch schreibend zugegriffen werden. Wird also ein neues Datum geschrieben, kann es gleichzeitig (also nicht erst nach dem nächsten Taktsignal) gelesen werden. Die Schreibadresse wird durch die Stufen ID, EX, MEM geführt. 5 14
15 Datenpfad einer Pipeline Architektur 5 15
: Pipeline Diagramm")
16 Beispiel eines Verarbeitungsablaufs Pipeline Diagramm (Kurzform): Pipeline Diagramm (Architektur): 5 16
17 Detaillierter Ablauf 5 17
18 Detaillierter Ablauf 5 18
19 Detaillierter Ablauf 5 19
20 Detaillierter Ablauf 5 20
21 Detaillierter Ablauf 5 21
22 Detaillierter Ablauf 5 22
23 Pipelinearchitektur Steuerung 5 23

24 Entwurf des Kontrollpfades Ausgangspunkt ist die Steuerung des Einzyklen Datenpfades. Die Steuerungsinformationen müssen zusammen mit der jeweiligen Instruktion transportiert werden. Damit ergibt sich auch ein Pipelining des Kontrollpfades. 5 24


25 Logik des Kontrollpfades Komponente ALU Control Komponente Control 5 25
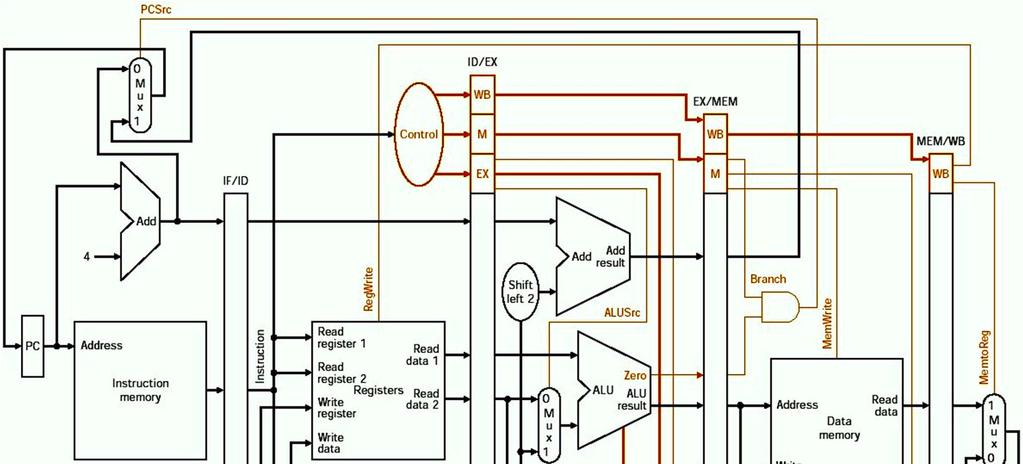

26 5 26
27 Hazards Klassifikation 5 27
28 Hazards Unter einem Hazard versteht man eine Situation in der Rechnerarchitektur, bei der eine Phase einer Instruktion nicht direkt im Anschluss an die vorherige Phase ausgeführt werden kann. Man unterscheidet drei Arten von Hazards: Struktureller Hazard, Ablauf Hazard und Daten Hazard. Struktureller Hazard Die Rechnerarchitektur kann die Kombination von Instruktionen, die derzeit ausgeführt werden soll, nicht unterstützen. Beispiel: Falls Daten und Instruktionsspeicher nicht getrennt wären, könnten zwei Instruktionen nicht gleichzeitig in der IF und MEM Phase sein, da beide lesend zugreifen. 5 28
29 Hazards Ablauf Hazard Das Ergebnis einer Instruktionsausführung wird benötigt, um zu entscheiden, welche Instruktionen anschliessend ausgeführt werden. Das Beispiel (siehe nächste Folie) zeigt eine Situation, bei der keine besonderen Massnahmen zur Vermeidung des Ablauf Hazard getroffen wurden. Die Instruktionen werden fälschlicherweise ausgeführt. Falls wir einen Branch Delay Slot annehmen, werden immerhin noch die Instruktionen 48 und 52 fälschlicherweise ausgeführt. Daten Hazard Ein Operand einer Instruktion hängt vom Ergebnis einer vorherigen Instruktion ab. Das Beispiel (siehe übernächste Folie) zeigt eine Situation, bei der keine besonderen Massnahmen zur Vermeidung des Daten Hazard getroffen wurden. Die von der Instruktion sub erzeugten Daten liegen für die Instruktionen and und or noch nicht vor. 5 29
30 Beispiel Ablauf Hazards 5 30
31 Beispiel Daten Hazard 5 31
32 Hazards Vermeidung von Datenhazards 5 32
33 Vermeidung von Daten Hazards Vermeidung von Daten Hazards durch Compiler Der Compiler kann versuchen, die Instruktionen so zu ordnen, dass das Ergebnis der Programmausführung nicht verändert wird und Hazards vermieden werden. Beispiel: lw $2, 20($1) and $4, $2, $5 or $8, $2, $6 slt $1, $6, $7 lw $2, 20($1) slt $1, $6, $7 nop and $4, $2, $5 or $8, $2, $6 Falls der Compiler keine sinnvolle Instruktion einfügen kann, so verwendet er die Instruktion nop. Sie verändert Daten nicht und wandert wie jede andere Instruktion durch die Pipeline. 5 33
34 Vermeidung von Daten Hazards Vermeidung von Daten Hazards durch Forwarding Die fehlenden Daten werden vorzeitig, das heisst vor ihrer Speicherung im Registerfeld, von den Komponenten des Datenpfades zur anfordernden Instruktion geleitet. Prinzip: 5 34
35 Vermeidung von Daten Hazards Beschreibung der Forwarding Funktion Notation: MEM/WB.RegisterRd Pipeline Register MEM/WB Feld mit dem Namen RegisterRd Weiterleiten eines Datums aus dem EX/MEM Register, das heisst eines vorherigen ALU Operanden (Beispiel der Forwarding Funktion für R Instruktionen): if ( EX/MEM.RegWrite = 1 and EX/MEM.RegisterRd!= 0 and EX/MEM.RegisterRd = ID/EX.RegisterRs) {ForwardA = 10 ;} if ( EX/MEM.RegWrite = 1 and EX/MEM.RegisterRd!= 0 and EX/MEM.RegisterRd = ID/EX.RegisterRt) {ForwardB = 10 ;} 5 35
36 Vermeidung von Daten Hazards Beschreibung der Forwarding Funktion Weiterleiten eines Datums aus dem MEM/WB Register, das heisst eines vergangenen ALU Operanden (Beispiel der Forwarding Funktion für R Instruktionen): if ( MEM/WB.RegWrite = 1 and MEM/WB.RegisterRd!= 0 and EX/MEM.RegisterRd!= ID/EX.RegisterRs and MEM/WB.RegisterRd = ID/EX.RegisterRs) {ForwardA = 01 ;} if ( MEM/WB.RegWrite = 1 and MEM/WB.RegisterRd!= 0 and EX/MEM.RegisterRd!= ID/EX.RegisterRt and MEM/WB.RegisterRd = ID/EX.RegisterRt) {ForwardB = 01 ;} 5 36
37 Vermeidung von Daten Hazards ForwardA ForwardB 5 37

38 Vermeidung von Daten Hazards 5 38
39 Vermeidung von Daten Hazards Vermeidung von Daten Hazards durch Stalls Forwarding kann nicht alle Hazards verhindern. Abhilfe durch das Einfügen einer Blase im Ablauf. Dies entspricht dem Einfügen einer nop Instruktion. Diese Blase wird aber nicht in der IF Phase sondern in einer späteren Phase eingefügt. Die Instruktionen in den nachfolgenden Stufen wandern wie üblich durch die Pipeline. Die Instruktionen in den Stufen vorher bleiben dort stehen. 5 39


40 Load Use Daten Hazard Instruktion muss für einen Zyklus anhalten (stall). Auch dann ist noch forwarding notwendig. 5 40
41 Load Use Hazard Erkennung Überprüfen, ob die benutzende Instruktion in der ID Phase ist (im Beispiel and $4, $2, $5). Die Registernummern der ALU Operanden der benutzenden Instruktion in der ID Phase: IF/ID.RegisterRs, IF/ID.RegisterRt Ein Load Use Hazard tritt auf, falls (ID/EX.MemRead = 1) and ((ID/EX.RegisterRt = IF/ID.RegisterRs) or (ID/EX.RegisterRt = IF/ID.RegisterRt)) Falls ein Hazard erkannt wurde, muss die Pipeline angehalten und eine Blase eingefügt werden. 5 41
42 Wie wird die Pipeline angehalten? Einfügen einer Blase zwischen der lw Instruktion (EX Phase) und der benutzenden Instruktion (ID Phase). Die Steuerungssignale am ID/EX Register werden auf 0 gesetzt: EX, MEM und WB führen in den folgenden Takten eine nop Instruktion aus (no operation). Verhindern, dass der Programmzähler (PC) und das IF/ID Register geschrieben werden: Die nachfolgende Instruktion wird nochmals gelesen (IF). Anhalten für einen Zyklus erlaubt MEM, die Daten für die lw Instruktionzu lesen. Sie können anschliessend zur EX Phase mittels forwarding weitergeleitet werden. 5 42

 wird hier")
43 Stall/Blase in der Pipeline detection forwarding Stall (Anhalten) wird hier ausgeführt. 5 43

44 Stall/Blase in der Pipeline detection Etwas genauer


45 Datenpfad mit Hazard Erkennung 5 45
46 Hazards Vermeidung von Ablaufhazards 5 46
47 Vermeidung von Ablauf Hazards Vermeidung von Ablauf Hazards durch Stalls : Einfügen von Blasen wie bei Daten Hazards. Beispiel: Verzweigungsentscheidung nach der MEM Phase bekannt. Jede Verzweigung führt zu 3 Stall Zyklen: Verzweigung IF ID EX MEM WB Instr. i+1/k IF 0 0 IF ID EX Instr. i+2/k+1 IF ID Instr. i+3/k+2 IF Berechnung der mittleren Zahl der Zyklen pro Instruktion: Annahmen: 5 stufiger Pipeline, 1 Taktperiode pro Stufe, nur Stalls durch Verzweigungen, das Programm weist 30% Verzweigungen auf. CPI = 0.3* = 1.9 (CPI = cycles per instruction) 5 47
48 Vermeidung von Ablauf Hazards Vermeidung von Ablauf Hazards durch statische Vorhersage: Der Prozessor nimmt an, dass der Programmfluss nicht verzweigt. Falls diese Vorhersage eintrifft, wird das Programm wie vorgesehen ausgeführt. Andernfalls werden die laufenden, fälschlicherweise begonnenen Instruktionen abgebrochen und die korrekte Instruktion geladen. Beispiel einer falschen Vorhersage, Verzweigungsentscheidung ist nach der MEM Phase bekannt: Verzweigung IF ID EX MEM WB Instr. i+1/k IF ID EX IF ID EX Instr. i+2/k+1 IF ID O IF ID Instr. k+2 IF O O IF 5 48
49 Vermeidung von Ablauf Hazards Berechung der mittleren Zahl der Zyklen pro Instruktion: Annahmen: 5 stufiger Pipeline, 1 Taktperiode pro Stufe, nur Stalls durch Verzweigungen, das Programm weist 30% Verzweigungen auf, in der Hälfte der Fälle wird die Verzweigung ausgeführt. CPI = 0.5*0.3* * = 1.45 Vermeidung von Ablauf Hazards durch dynamische Vorhersage: Der Prozessor trifft die Vorhersage nicht statisch sondern auf der Grundlage der vergangenen Verzweigungsentscheidungen. Falls das letzte Mal an dieser Instruktion verzweigt wurde, dann auch dieses Mal. Je nach Vorhersage wird dann im Programmfluss verzweigt oder auch nicht. Dieses Schema kann erweitert werden, in dem auch Entscheidungen in der weiteren Vergangenheit berücksichtigt werden. 5 49
50 Vermeidung von Ablauf Hazards Problem bei dynamischer Vorhersage: Bei Programmschleifen gelten oft sehr ungleiche Verzweigungswahrscheinlichkeiten (z.b. 99% ja, 1% nein). Bei einer falschen Prädiktion wird dann auch der nächste Durchlauf falsch vorhergesagt: Aktion Prädiktion Keine Verzw. Verzweigung Keine Verzw. Verzweigung 2 Bit Prädiktion Keine Verzw. Verzweigung 5 50
51 Vermeidung von Ablauf Hazards Lösung des Problems bei der dynamischen Vorhersage durch eine 2 Bit Prädiktion: Die Vorhersage wird nur bei zwei aufeinanderfolgenden falschen Vorhersagen geändert. Modellierung durch einen endlichen Automaten: not taken not taken not taken strongly taken likely taken likely not taken strongly not taken taken taken taken taken not taken 5 51
52 Vermeidung von Ablauf Hazards Verminderung von Ablauf Hazards durch frühzeitige Entscheidung: Verminderung der Zahl der Wartezyklen durch Vorverlegen des Zeitpunktes, zu dem die Entscheidung bekannt wird. Es kann zum Beispiel in der ID Stufe eine zusätzliche Vergleichskomponente eingesetzt und die Berechnung der Verzweigungsadresse ebenfalls in dieser Stufe durchgeführt werden. Berechnung Verzweigungsadresse frühzeitiger Vergleich 5 52

53 Vermeidung von Ablauf Hazards Beispiel für Kombination aus frühzeitiger Entscheidung und Stall. Assemblerprogramm: 36 sub $10,$4,$8 40 beq $1,$3,7 44 and $12,$2,$ lw $4,50($7) Taktzyklus der Entscheidung: 5 53
54 Vermeidung von Ablauf Hazards Beispiel für Kombination aus frühzeitiger Entscheidung und Stall. Assemblerprogramm: 36 sub $10,$4,$8 40 beq $1,$3,7 44 and $12,$2,$ lw $4,50($7) Taktzyklus nach der Entscheidung: 5 54
55 Vermeidung von Ablauf Hazards Verminderung von Ablauf Hazards durch Branch Delay Slot: Die Semantik der Verzweigungsinstruktion wird verändert. Die Instruktion nach der Verzweigungsinstruktion wird in jedem Fall ausgeführt. Es ist die Aufgabe des Compilers oder Assemblers, den freien Platz mit einer sinnvollen Instruktion zu füllen und dafür zu sorgen, dass die Semantik des Programms nicht verändert wird. 5 55
56 Vermeidung von Ablauf Hazards Berechung der mittleren Zahl der Zyklen pro Instruktion: Annahmen: 5 stufiger Pipeline, 1 Taktperiode pro Stufe, ein Branch Delay Slot, keine weiteren Stalls aufgrund einer Verzweigungsinstruktion, das Programm weist 30% Verzweigungen auf (Branch Delay Slots sind nicht mitgezählt), der Compiler kann den Slot so füllen, dass sich die Ausführung im Mittel um 0.6 Instruktionen verkürzt. CPI = 0.3*2 0.3* =
57 Instruktions Parallelität 5 57
58 Instruktionsparallelität (instruction level parallelism ILP) Ziel: Erhöhter Durchsatz an ausgeführten Instruktionen Architekturprinzipien zur Vergrösserung der Instruktionsparallelität: Spekulation: Vorhersage über das Ergebnis zukünftiger Instruktionen Mehr Pipelinestufen, tiefere Pipeline: weniger Rechenzeit pro Stufe und daher kürzere Taktperiode Parallele Ausführungseinheiten: Mehrere Instruktionen können in der Ausführungsstufe (EX) gleichzeitig bearbeitet werden. Mehrere Instruktionen pro Takt laden (multiple issue): Vervielfältigung der Pipelinestufen Gleichzeitiger Start mehrerer Instruktionen in einem Takt Im Prinzip: CPI<1, aber Abhängigkeiten zwischen Instruktionen vergrössern den CPI Wert 5 58
59 Spekulation Schätzen, was mit einer Instruktion geschehen soll: Starte die zugehörige Operation so bald wie möglich, auch wenn nicht alle Informationen vorliegen. Prüfe, ob die Entscheidung ( Schätzung ) korrekt war: Falls ja, fahre mit der Programmabarbeitung fort. Falls nein, stelle den vorherigen Systemzustand wieder her. Wird sowohl bei statischer als auch bei dynamischer Parallelität benutzt. Beispiele: Spekuliere auf das Ergebnis einer bedingten Verzweigung. Damit kann die Verarbeitung vor dem Vorliegen des Ergebnisses der Verzweigung fortgesetzt werden. Spekuliere darauf, dass ein sw und ein darauf folgendes lw nicht die gleiche Adresse referenzieren. Damit können die beiden Instruktionen umgeordnet werden. 5 59
60 Spekulation Compiler kann Instruktionen umordnen (z.b. lw Instruktion vor eine bedingte Verzweigung bewegen): Eventuell müssen dann Instruktionen eingefügt werden, die bei einer falschen Vorhersage das Resultat wieder korrigieren. Hardware kann Instruktionen vorziehen: Resultate werden zwischengespeichert, bis sie tatsächlich benötigt werden und die richtige Schätzung bestätigt wurde. Erst dann werden sie in das Registerfeld eingespeichert ( Commit Unit ). Bei einer falschen Vorhersage werden die Zwischenergebnisse gelöscht. 5 60
61 Instruktions Parallelität Superpipelining 5 61
62 Superpipelining Verwendung paralleler Ausführungseinheiten in der EX Stufe. Einführung vieler Pipelinestufen, vor allem bei den arithmetischen Einheiten. 5 62
63 Superpipelining Konsequenzen: Höhere Taktfrequenz durch geringere Laufzeit zwischen Pipelinestufen. Die Zahl der Stufen ist je nach Instruktion unterschiedlich lang. Daher werden sie zu unterschiedlichen Zeiten beendet ( out of order completion ). Der Einfluss von Hazards auf die Ausführungszeit von Programmen wird grösser. Zusätzlich sind strukturelle Hazards möglich. Operanden für ADDD werden spätestens benötigt Daten stehen frühestens zur Verfügung «out of order completion» 5 63
64 Instruktions Parallelität Multiple Issue 5 64
65 Multiple Issue Statische Parallelität (Static Multiple Issue) Compiler gruppiert Instruktionen (kombiniert Instruktionen in einer einzigen langen Instruktion), die gleichzeitig geladen werden sollen (VLIW very long instruction word). Der Compiler detektiert und verhindert Hazards. Dynamische Parallelität (Dynamic Multiple Issue) CPU lädt aufeinanderfolgende Instruktionen und bestimmt, welche davon als nächstes ausgeführt werden sollen. Compiler kann hierbei Vorarbeit leisten, in dem er Instruktionen global umsortiert. CPU löst Hazards durch erweiterte Techniken zur Laufzeit auf. 5 65

66 Statische Parallelität In jedem Takt werden mehrere Instruktionen dekodiert. Interne Komponenten werden dupliziert. Es gibt üblicherweise mehrere Arten von arithmetischen Einheiten, zum Beispiel Festkomma, Gleitkomma Einheiten, Multiplizierer, Dividierer. 5 66
67 Statische Parallelität: VLIW MIPS VLIW: Very Long Instruction Word MIPS Architektur mit einem doppelten Instruktionswort: 64 Bits ALU Op (R Format) oder Verzweigung (I Format) Load oder Store (I Format) Instruktionen werden immer paarweise geladen, dekodiert und ausgeführt. Die Rechnerarchitektur benötigt jetzt ein Registerfeld mit 4 Lese und 2 Schreibzugriffen sowie einen separaten Addierer für Speicheradressen. 5 67
68 5 68
69 Statische Parallelität: Compiler Techniken Programmbeispiel: lp: lw $t0,0($s1) # $t0=array element addu $t0,$t0,$s2 # add scalar ($s2) to $t0 sw $t0,0($s1) # store result addi $s1,$s1,-4 # decrement pointer bne $s1,$0,lp # branch if $s1!= 0 Compiler muss Instruktionen umsortieren: Instruktionen in einem Paket müssen unabhängig sein. Compiler muss Details der Rechnerarchitektur kennen. Hier: Separieren von Lade Instruktionen und der Benutzung der Daten um einen Takt zur Vermeidung von Hazards; im Beispiel nehmen wir an, dass Verzweigungen perfekt vorhergesagt werden; kein Branch Delay Slot; forwarding wird unterstützt 5 69
70 Statische Parallelität: Compiler Techniken ALU oder Verzweigung Datentransfer CC lp: lw $t0,0($s1) 1 addi $s1,$s1,-4 2 addu $t0,$t0,$s2 3 bne $s1,$0,lp sw $t0,4($s1) 4 4 Taktyzklen für 5 Instruktionen CPI = 0.8 (im besten Fall wäre CPI =0.5) Verbesserung durch Schleifenentfaltung (loop unrolling) Replizieren des Schleifenkörpers so dass Instruktionen von unterschiedlichen Iterationen kombiniert werden können. 5 70
71 Statische Parallelität: Compiler Techniken Schleife 4 mal entfalten (in unserem Beispiel): Register umbenennen um möglichst viele Abhängigkeiten zwischen Instruktionen zu entfernen. Nur ein Schleifentest anstelle von 4 Tests. lp: lw $t0,0($s1) # $t0=array element lw $t1,-4($s1) # $t1=array element lw $t2,-8($s1) # $t2=array element lw $t3,-12($s1) # $t3=array element addu $t0,$t0,$s2 # add scalar in $s2 addu $t1,$t1,$s2 # add scalar in $s2 addu $t2,$t2,$s2 # add scalar in $s2 addu $t3,$t3,$s2 # add scalar in $s2 sw $t0,0($s1) # store result sw $t1,-4($s1) # store result sw $t2,-8($s1) # store result sw $t3,-12($s1) # store result addi $s1,$s1,-16 # decrement pointer bne $s1,$0,lp # branch if $s1!=
72 Statische Parallelität: Compiler Techniken ALU oder Verzweigung Datentransfer CC lp: addi $s1,$s1,-16 lw $t0,0($s1) 1 lw $t1,12($s1) 2 addu $t0,$t0,$s2 lw $t2,8($s1) 3 addu $t1,$t1,$s2 lw $t3,4($s1) 4 addu $t2,$t2,$s2 sw $t0,16($s1) 5 addu $t3,$t3,$s2 sw $t1,12($s1) 6 sw $t2,8($s1) 7 bne $s1,$0,lp sw $t3,4($s1) 8 8 Taktzyklen um 14 Instruktionen auszuführen: CPI = 0.57 (gegenüber dem besten Fall CPI = 0.5) 5 72
73 Multiple Issue (Wiederholung) Statische Parallelität (Static Multiple Issue) Compiler gruppiert Instruktionen (kombiniert Instruktionen in einer einzigen langen Instruktion), die gleichzeitig geladen werden sollen (VLIW very long instruction word). Compiler detektiert und verhindert Hazards. Dynamische Parallelität (Dynamic Multiple Issue) CPU lädt aufeinanderfolgende Instruktionen und bestimmt, welche davon als nächstes ausgeführt werden sollen. Compiler kann hierbei Vorarbeit leisten, in dem er Instruktionen global umsortiert. CPU löst Hazards durch erweiterte Techniken zur Laufzeit auf. 5 73
74 Dynamische Parallelität Dynamic Multiple Issue : CPU entscheidet, wie viele Instruktionen begonnen werden. Dynamic Pipeline Scheduling : Die CPU vermeidet zur Laufzeit (dynamisch) strukturelle Hazards und Datenhazards und optimiert die Parallelität: Instruktionen werden nicht in der gegebenen Reihenfolge ausgeführt, aber die Ergebnisse werden in der richtigen Reihenfolge geschrieben. Compiler kann hierbei Vorarbeit leisten, in dem er Instruktionen global umsortiert. Weitere Techniken zur Verbesserung der Ausführungszeit: Spekulation Register Umbenennung (wird in der Vorlesung nicht behandelt) 5 74

 Kann auch Operanden beisteuern Resultate werden auch zu allen")
75 Dynamic Pipeline Scheduling Bestimmt Abhängigkeiten zwischen Instruktionen. Speichert die jeweils notwendigen Operanden. Schreibt Resultate in der richtigen Reihenfolge in die Prozessorregister (Registerfeld) Kann auch Operanden beisteuern Resultate werden auch zu allen darauf wartenden Reservation Stations gesendet. 5 75
76 Instruktions Parallelität Beispiele 5 76

77 Cortex A8 und Intel i7 5 77

78 ARM Cortex A8 Pipeline BP = branch predictor Adress Generation Unit 2 Instruktionen können gleichzeitig verarbeitet werden 5 78

79 ARM Cortex A8 Rechenleistung optimale Zyklen/Instruktion CPI=
80 Grenzen der Parallelität 5 80

")
81 Prozessor (Wiederholung) Intel Xeon Phi (5 Milliarden Transistoren, 22nm Technologie, 350mm 2 Fläche) Oracle Sparc T5 5 81
82 Gesetz von Amdahl Frage: Wo liegen die Grenzen der Parallelisierung? Annahme: Auszuführende Aufgabe hat einen seriellen Teil und einen parallelisierbaren Anteil. Amdahls «Gesetz»: Faktor =
83 Beispiel Aufgabe: Bilde Summe von 10 Skalaren sowie die Summe zweier 10x10 Matrizen. Die Last kann zwischen den Prozessoren gleichmässig aufgeteilt werden. Die Summe der Skalare wird naiv implementiert (sequentiell). Frage: Was ist die Beschleunigung bei 10 und 100 Prozessoren? Lösung: Einzelner Prozessor: Zeit = ( ) t add 10 Prozessoren: Zeit = 100/10 t add + 10 t add = 20 t add Beschleunigung = 110/20 = Prozessoren: Zeit = 100/100 t add + 10 t add = 11 t add Beschleunigung = 110/11 =
Das Prinzip an einem alltäglichen Beispiel
 3.2 Pipelining Ziel: Performanzsteigerung é Prinzip der Fließbandverarbeitung é Probleme bei Fließbandverarbeitung BB TI I 3.2/1 Das Prinzip an einem alltäglichen Beispiel é Sie kommen aus dem Urlaub und
3.2 Pipelining Ziel: Performanzsteigerung é Prinzip der Fließbandverarbeitung é Probleme bei Fließbandverarbeitung BB TI I 3.2/1 Das Prinzip an einem alltäglichen Beispiel é Sie kommen aus dem Urlaub und
Technische Informatik 1
 Technische Informatik 1 4 Prozessor Einzeltaktimplementierung Lothar Thiele Computer Engineering and Networks Laboratory Vorgehensweise 4 2 Prinzipieller Aufbau Datenpfad: Verarbeitung und Transport von
Technische Informatik 1 4 Prozessor Einzeltaktimplementierung Lothar Thiele Computer Engineering and Networks Laboratory Vorgehensweise 4 2 Prinzipieller Aufbau Datenpfad: Verarbeitung und Transport von
Leistung und Pipelining. Einführung in die Technische Informatik Falko Dressler, Stefan Podlipnig Universität Innsbruck
 Leistung und Pipelining Einführung in die Technische Informatik Falko Dressler, Stefan Podlipnig Universität Innsbruck Übersicht Leistung Leistungsmessung Leistungssteigerung Pipelining Einführung in die
Leistung und Pipelining Einführung in die Technische Informatik Falko Dressler, Stefan Podlipnig Universität Innsbruck Übersicht Leistung Leistungsmessung Leistungssteigerung Pipelining Einführung in die
Johann Wolfgang Goethe-Universität
 Flynn sche Klassifikation SISD (single instruction, single data stream): IS IS CU PU DS MM Mono (Mikro-)prozessoren CU: Control Unit SM: Shared Memory PU: Processor Unit IS: Instruction Stream MM: Memory
Flynn sche Klassifikation SISD (single instruction, single data stream): IS IS CU PU DS MM Mono (Mikro-)prozessoren CU: Control Unit SM: Shared Memory PU: Processor Unit IS: Instruction Stream MM: Memory
Technische Informatik 1
 Technische Informatik 1 2 Instruktionssatz Lothar Thiele Computer Engineering and Networks Laboratory Instruktionsverarbeitung 2 2 Übersetzung Das Kapitel 2 der Vorlesung setzt sich mit der Maschinensprache
Technische Informatik 1 2 Instruktionssatz Lothar Thiele Computer Engineering and Networks Laboratory Instruktionsverarbeitung 2 2 Übersetzung Das Kapitel 2 der Vorlesung setzt sich mit der Maschinensprache
Programmierung Paralleler Prozesse
 Vorlesung Programmierung Paralleler Prozesse Prof. Dr. Klaus Hering Sommersemester 2007 HTWK Leipzig, FB IMN Sortierproblem Gegeben: Menge M mit einer Ordnungsrelation (etwa Menge der reellen Zahlen) Folge
Vorlesung Programmierung Paralleler Prozesse Prof. Dr. Klaus Hering Sommersemester 2007 HTWK Leipzig, FB IMN Sortierproblem Gegeben: Menge M mit einer Ordnungsrelation (etwa Menge der reellen Zahlen) Folge
Einführung in die Systemprogrammierung
 Einführung in die Systemprogrammierung Speedup: Grundlagen der Performanz Prof. Dr. Christoph Reichenbach Fachbereich 12 / Institut für Informatik 30. April 2015 Eine Aufgabe aus der Praxis Gegeben ein
Einführung in die Systemprogrammierung Speedup: Grundlagen der Performanz Prof. Dr. Christoph Reichenbach Fachbereich 12 / Institut für Informatik 30. April 2015 Eine Aufgabe aus der Praxis Gegeben ein
Die Mikroprogrammebene eines Rechners
 Die Mikroprogrammebene eines Rechners Das Abarbeiten eines Arbeitszyklus eines einzelnen Befehls besteht selbst wieder aus verschiedenen Schritten, z.b. Befehl holen Befehl dekodieren Operanden holen etc.
Die Mikroprogrammebene eines Rechners Das Abarbeiten eines Arbeitszyklus eines einzelnen Befehls besteht selbst wieder aus verschiedenen Schritten, z.b. Befehl holen Befehl dekodieren Operanden holen etc.
Rechner Architektur. Martin Gülck
 Rechner Architektur Martin Gülck Grundlage Jeder Rechner wird aus einzelnen Komponenten zusammengesetzt Sie werden auf dem Mainboard zusammengefügt (dt.: Hauptplatine) Mainboard wird auch als Motherboard
Rechner Architektur Martin Gülck Grundlage Jeder Rechner wird aus einzelnen Komponenten zusammengesetzt Sie werden auf dem Mainboard zusammengefügt (dt.: Hauptplatine) Mainboard wird auch als Motherboard
2.2 Rechnerorganisation: Aufbau und Funktionsweise
 2.2 Rechnerorganisation: Aufbau und Funktionsweise é Hardware, Software und Firmware é grober Aufbau eines von-neumann-rechners é Arbeitsspeicher, Speicherzelle, Bit, Byte é Prozessor é grobe Arbeitsweise
2.2 Rechnerorganisation: Aufbau und Funktionsweise é Hardware, Software und Firmware é grober Aufbau eines von-neumann-rechners é Arbeitsspeicher, Speicherzelle, Bit, Byte é Prozessor é grobe Arbeitsweise
Lösungsvorschlag zur 4. Übung
 Prof. Frederik Armknecht Sascha Müller Daniel Mäurer Grundlagen der Informatik 3 Wintersemester 09/10 Lösungsvorschlag zur 4. Übung 1 Präsenzübungen 1.1 Schnelltest a) Welche Aussagen zu Bewertungskriterien
Prof. Frederik Armknecht Sascha Müller Daniel Mäurer Grundlagen der Informatik 3 Wintersemester 09/10 Lösungsvorschlag zur 4. Übung 1 Präsenzübungen 1.1 Schnelltest a) Welche Aussagen zu Bewertungskriterien
Einführung in die Systemprogrammierung 02
 Einführung in die Systemprogrammierung 02 Prof. Dr. Christoph Reichenbach Fachbereich 12 / Institut für Informatik 4. Mai 2014 Eine Aufgabe aus der Praxis Gegeben ein bestimmtes Programm: Machen Sie dieses
Einführung in die Systemprogrammierung 02 Prof. Dr. Christoph Reichenbach Fachbereich 12 / Institut für Informatik 4. Mai 2014 Eine Aufgabe aus der Praxis Gegeben ein bestimmtes Programm: Machen Sie dieses
Hardware/Software-Codesign
 Klausur zur Lehrveranstaltung Hardware/Software-Codesign Dr. Christian Plessl Paderborn Center for Parallel Computing Universität Paderborn 8.10.2009 Die Bearbeitungsdauer beträgt 75 Minuten. Es sind keine
Klausur zur Lehrveranstaltung Hardware/Software-Codesign Dr. Christian Plessl Paderborn Center for Parallel Computing Universität Paderborn 8.10.2009 Die Bearbeitungsdauer beträgt 75 Minuten. Es sind keine
Instruktionssatz-Architektur
 Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2005/2006 Übersicht 1 Einleitung 2 Bestandteile der ISA 3 CISC / RISC Übersicht 1 Einleitung 2 Bestandteile
Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2005/2006 Übersicht 1 Einleitung 2 Bestandteile der ISA 3 CISC / RISC Übersicht 1 Einleitung 2 Bestandteile
L3. Datenmanipulation
 L Datenmanipulation Aufbau eines Computers Prozessor, Arbeitsspeicher und system Maschinensprachen und Maschinenbefehle Beispiel einer vereinfachten Maschinensprache Ausführung des Programms und Befehlszyklus
L Datenmanipulation Aufbau eines Computers Prozessor, Arbeitsspeicher und system Maschinensprachen und Maschinenbefehle Beispiel einer vereinfachten Maschinensprache Ausführung des Programms und Befehlszyklus
Computer-Architektur Ein Überblick
 Computer-Architektur Ein Überblick Johann Blieberger Institut für Rechnergestützte Automation Computer-Architektur Ein Überblick p.1/27 Computer-Aufbau: Motherboard Computer-Architektur Ein Überblick p.2/27
Computer-Architektur Ein Überblick Johann Blieberger Institut für Rechnergestützte Automation Computer-Architektur Ein Überblick p.1/27 Computer-Aufbau: Motherboard Computer-Architektur Ein Überblick p.2/27
Kap 4. 4 Die Mikroprogrammebene eines Rechners
 4 Die Mikroprogrammebene eines Rechners Das Abarbeiten eines Arbeitszyklus eines einzelnen Befehls besteht selbst wieder aus verschiedenen Schritten (Befehl holen, Befehl dekodieren, Operanden holen etc.).
4 Die Mikroprogrammebene eines Rechners Das Abarbeiten eines Arbeitszyklus eines einzelnen Befehls besteht selbst wieder aus verschiedenen Schritten (Befehl holen, Befehl dekodieren, Operanden holen etc.).
Vorlesung: Technische Informatik 3
 Rechnerarchitektur und Betriebssysteme zhang@informatik.uni-hamburg.de Universität Hamburg AB Technische Aspekte Multimodaler Systeme zhang@informatik.uni-hamburg.de Inhaltsverzeichnis 4. Computerarchitektur........................235
Rechnerarchitektur und Betriebssysteme zhang@informatik.uni-hamburg.de Universität Hamburg AB Technische Aspekte Multimodaler Systeme zhang@informatik.uni-hamburg.de Inhaltsverzeichnis 4. Computerarchitektur........................235
11.0 Rechnerarchitekturen
 11.0 Rechnerarchitekturen Die Ziele dieses Kapitels sind: Kennen lernen der Rechnerklassifikation nach Flynn Betrachtung von Prozessorarchitekturen auf verschiedenen Abstraktionsebenen - Befehlsarchitektur
11.0 Rechnerarchitekturen Die Ziele dieses Kapitels sind: Kennen lernen der Rechnerklassifikation nach Flynn Betrachtung von Prozessorarchitekturen auf verschiedenen Abstraktionsebenen - Befehlsarchitektur
Aufgabe 1) Die folgenden Umwandlungen/Berechnungen beziehen sich auf das 32-Bit Single-Precision Format nach IEEE-754.
 Die folgenden Umwandlungen/Berechnungen beziehen sich auf das 32-Bit Single-Precision Format nach IEEE-754.") Aufgabe 1) Die folgenden Umwandlungen/Berechnungen beziehen sich auf das 32-Bit Single-Precision Format nach IEEE-754. a) Stellen Sie die Zahl 7,625 in folgender Tabelle dar! b) Wie werden denormalisierte
Aufgabe 1) Die folgenden Umwandlungen/Berechnungen beziehen sich auf das 32-Bit Single-Precision Format nach IEEE-754. a) Stellen Sie die Zahl 7,625 in folgender Tabelle dar! b) Wie werden denormalisierte
Name: ES2 Klausur Thema: ARM 25.6.07. Name: Punkte: Note:
 Name: Punkte: Note: Hinweise für das Lösen der Aufgaben: Zeit: 95 min. Name nicht vergessen! Geben Sie alle Blätter ab. Die Reihenfolge der Aufgaben ist unabhängig vom Schwierigkeitsgrad. Erlaubte Hilfsmittel
Name: Punkte: Note: Hinweise für das Lösen der Aufgaben: Zeit: 95 min. Name nicht vergessen! Geben Sie alle Blätter ab. Die Reihenfolge der Aufgaben ist unabhängig vom Schwierigkeitsgrad. Erlaubte Hilfsmittel
Teil VIII Von Neumann Rechner 1
 Teil VIII Von Neumann Rechner 1 Grundlegende Architektur Zentraleinheit: Central Processing Unit (CPU) Ausführen von Befehlen und Ablaufsteuerung Speicher: Memory Ablage von Daten und Programmen Read Only
Teil VIII Von Neumann Rechner 1 Grundlegende Architektur Zentraleinheit: Central Processing Unit (CPU) Ausführen von Befehlen und Ablaufsteuerung Speicher: Memory Ablage von Daten und Programmen Read Only
HW/SW Codesign 5 - Performance
 HW/SW Codesign 5 - Performance Martin Lechner e1026059 Computer Technology /29 Inhalt Was bedeutet Performance? Methoden zur Steigerung der Performance Einfluss der Kommunikation Hardware vs. Software
HW/SW Codesign 5 - Performance Martin Lechner e1026059 Computer Technology /29 Inhalt Was bedeutet Performance? Methoden zur Steigerung der Performance Einfluss der Kommunikation Hardware vs. Software
Virtueller Speicher. SS 2012 Grundlagen der Rechnerarchitektur Speicher 44
 Virtueller Speicher SS 2012 Grundlagen der Rechnerarchitektur Speicher 44 Die Idee Virtuelle Adressen Prozess 1 Speicherblock 0 Speicherblock 1 Speicherblock 2 Speicherblock 3 Speicherblock 4 Speicherblock
Virtueller Speicher SS 2012 Grundlagen der Rechnerarchitektur Speicher 44 Die Idee Virtuelle Adressen Prozess 1 Speicherblock 0 Speicherblock 1 Speicherblock 2 Speicherblock 3 Speicherblock 4 Speicherblock
Technische Informatik 1
 Technische Informatik 1 1 Einleitung Lothar Thiele Computer Engineering and Networks Laboratory Technische Informatik 1 2 Was ist Technische Informatik? A. Ralston, E.D. Reilly: Encyclopedia of Computer
Technische Informatik 1 1 Einleitung Lothar Thiele Computer Engineering and Networks Laboratory Technische Informatik 1 2 Was ist Technische Informatik? A. Ralston, E.D. Reilly: Encyclopedia of Computer
Mikroprozessor als universeller digitaler Baustein
 2. Mikroprozessor 2.1 Allgemeines Mikroprozessor als universeller digitaler Baustein Die zunehmende Integrationsdichte von elektronischen Schaltkreisen führt zwangsläufige zur Entwicklung eines universellen
2. Mikroprozessor 2.1 Allgemeines Mikroprozessor als universeller digitaler Baustein Die zunehmende Integrationsdichte von elektronischen Schaltkreisen führt zwangsläufige zur Entwicklung eines universellen
Umsetzung in aktuellen Prozessoren
 Kapitel 8: Umsetzung in aktuellen Prozessoren 4 Realisierung elementarer Funktionen Reihenentwicklung Konvergenzverfahren 5 Unkonventionelle Zahlensysteme redundante Zahlensysteme Restklassen-Zahlensysteme
Kapitel 8: Umsetzung in aktuellen Prozessoren 4 Realisierung elementarer Funktionen Reihenentwicklung Konvergenzverfahren 5 Unkonventionelle Zahlensysteme redundante Zahlensysteme Restklassen-Zahlensysteme
Mikroprozessor bzw. CPU (Central Processing. - Steuerwerk (Control Unit) - Rechenwerk bzw. ALU (Arithmetic Logic Unit)
 - Rechenwerk bzw. ALU (Arithmetic Logic Unit)") Der Demo-Computer besitzt einen 4Bit-Mikroprozessor. Er kann entsprechend Wörter mit einer Breite von 4 Bits in einem Schritt verarbeiten. Die einzelnen Schritte der Abarbeitung werden durch Lampen visualisiert.
Der Demo-Computer besitzt einen 4Bit-Mikroprozessor. Er kann entsprechend Wörter mit einer Breite von 4 Bits in einem Schritt verarbeiten. Die einzelnen Schritte der Abarbeitung werden durch Lampen visualisiert.
Asynchrone Schaltungen
 Asynchrone Schaltungen Dr.-Ing. Volkmar Sieh Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg SS 2013 Asynchrone Schaltungen 1/25 2013/07/18 Asynchrone Schaltungen
Asynchrone Schaltungen Dr.-Ing. Volkmar Sieh Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg SS 2013 Asynchrone Schaltungen 1/25 2013/07/18 Asynchrone Schaltungen
Mikrocomputertechnik. Einadressmaschine
 technik Einadressmaschine Vorlesung 2. Mikroprozessoren Einführung Entwicklungsgeschichte Mikroprozessor als universeller Baustein Struktur Architektur mit Akku ( Nerdi) FH Augsburg, Fakultät für Elektrotechnik
technik Einadressmaschine Vorlesung 2. Mikroprozessoren Einführung Entwicklungsgeschichte Mikroprozessor als universeller Baustein Struktur Architektur mit Akku ( Nerdi) FH Augsburg, Fakultät für Elektrotechnik
Rechnerarchitektur und Betriebssysteme (CS201): Multiprogramming und -Tasking Flynn-Klassifikation, ILP, VLIW
: Multiprogramming und -Tasking Flynn-Klassifikation, ILP, VLIW") Rechnerarchitektur und Betriebssysteme (CS201): Multiprogramming und -Tasking Flynn-Klassifikation, ILP, VLIW 26. Oktober 2012 Prof. Dr. Christian Tschudin Departement Informatik, Universität Basel Uebersicht
Rechnerarchitektur und Betriebssysteme (CS201): Multiprogramming und -Tasking Flynn-Klassifikation, ILP, VLIW 26. Oktober 2012 Prof. Dr. Christian Tschudin Departement Informatik, Universität Basel Uebersicht
Mikroprozessortechnik. 03. April 2012
 Klausur 03. April 2012 Name:. Vorname Matr.-Nr:. Studiengang Hinweise: Bitte füllen Sie vor dem Bearbeiten der Aufgaben das Deckblatt sorgfältig aus. Die Klausur besteht aus 6 doppelseitig bedruckten Blättern.
Klausur 03. April 2012 Name:. Vorname Matr.-Nr:. Studiengang Hinweise: Bitte füllen Sie vor dem Bearbeiten der Aufgaben das Deckblatt sorgfältig aus. Die Klausur besteht aus 6 doppelseitig bedruckten Blättern.
Rechnerorganisation 2 TOY. Karl C. Posch. co1.ro_2003. Karl.Posch@iaik.tugraz.at 16.03.2011
 Technische Universität Graz Institut tfür Angewandte Informationsverarbeitung und Kommunikationstechnologie Rechnerorganisation 2 TOY Karl C. Posch Karl.Posch@iaik.tugraz.at co1.ro_2003. 1 Ausblick. Erste
Technische Universität Graz Institut tfür Angewandte Informationsverarbeitung und Kommunikationstechnologie Rechnerorganisation 2 TOY Karl C. Posch Karl.Posch@iaik.tugraz.at co1.ro_2003. 1 Ausblick. Erste
Technische Informatik 1 Übung 2 Assembler (Rechenübung) Georgia Giannopoulou (ggeorgia@tik.ee.ethz.ch) 22./23. Oktober 2015
 Georgia Giannopoulou (ggeorgia@tik.ee.ethz.ch) 22./23. Oktober 2015") Technische Informatik 1 Übung 2 Assembler (Rechenübung) Georgia Giannopoulou (ggeorgia@tik.ee.ethz.ch) 22./23. Oktober 2015 Ziele der Übung Aufgabe 1 Aufbau und Aufruf von Funktionen in Assembler Codeanalyse
Technische Informatik 1 Übung 2 Assembler (Rechenübung) Georgia Giannopoulou (ggeorgia@tik.ee.ethz.ch) 22./23. Oktober 2015 Ziele der Übung Aufgabe 1 Aufbau und Aufruf von Funktionen in Assembler Codeanalyse
Grundlagen der Parallelisierung
 Grundlagen der Parallelisierung Philipp Kegel, Sergei Gorlatch AG Parallele und Verteilte Systeme Institut für Informatik Westfälische Wilhelms-Universität Münster 3. Juli 2009 Inhaltsverzeichnis 1 Einführung
Grundlagen der Parallelisierung Philipp Kegel, Sergei Gorlatch AG Parallele und Verteilte Systeme Institut für Informatik Westfälische Wilhelms-Universität Münster 3. Juli 2009 Inhaltsverzeichnis 1 Einführung
Grundlagen der Rechnerarchitektur
 Grundlagen der Rechnerarchitektur Einführung Unsere erste Amtshandlung: Wir schrauben einen Rechner auf Grundlagen der Rechnerarchitektur Einführung 2 Vorlesungsinhalte Binäre Arithmetik MIPS Assembler
Grundlagen der Rechnerarchitektur Einführung Unsere erste Amtshandlung: Wir schrauben einen Rechner auf Grundlagen der Rechnerarchitektur Einführung 2 Vorlesungsinhalte Binäre Arithmetik MIPS Assembler
Systeme I: Betriebssysteme Kapitel 4 Prozesse. Maren Bennewitz
 Systeme I: Betriebssysteme Kapitel 4 Prozesse Maren Bennewitz Version 20.11.2013 1 Begrüßung Heute ist Tag der offenen Tür Willkommen allen Schülerinnen und Schülern! 2 Wdhlg.: Attributinformationen in
Systeme I: Betriebssysteme Kapitel 4 Prozesse Maren Bennewitz Version 20.11.2013 1 Begrüßung Heute ist Tag der offenen Tür Willkommen allen Schülerinnen und Schülern! 2 Wdhlg.: Attributinformationen in
Grundlagen der Rechnerarchitektur
 Grundlagen der Rechnerarchitektur Ein und Ausgabe Übersicht Grundbegriffe Hard Disks und Flash RAM Zugriff auf IO Geräte RAID Systeme SS 2012 Grundlagen der Rechnerarchitektur Ein und Ausgabe 2 Grundbegriffe
Grundlagen der Rechnerarchitektur Ein und Ausgabe Übersicht Grundbegriffe Hard Disks und Flash RAM Zugriff auf IO Geräte RAID Systeme SS 2012 Grundlagen der Rechnerarchitektur Ein und Ausgabe 2 Grundbegriffe
Einführung in die Systemprogrammierung 02
 Einführung in die Systemprogrammierung 02 Prof. Dr. Christoph Reichenbach Fachbereich 12 / Institut für Informatik 1. Mai 2013 Eine Aufgabe aus der Praxis Gegeben ein bestimmtes Programm: Machen Sie dieses
Einführung in die Systemprogrammierung 02 Prof. Dr. Christoph Reichenbach Fachbereich 12 / Institut für Informatik 1. Mai 2013 Eine Aufgabe aus der Praxis Gegeben ein bestimmtes Programm: Machen Sie dieses
Implementierung: Direkt abgebildeter Cache
 Implementierung: Direkt abgebildeter Cache Direkt-abgebildeter Cache von 64 KB mit 16-Byte-Linien (Adress- und Wortlänge 32 Bit, Byteadressierung) Address (showing bit positions) 31 30 29 28..... 19 18
Implementierung: Direkt abgebildeter Cache Direkt-abgebildeter Cache von 64 KB mit 16-Byte-Linien (Adress- und Wortlänge 32 Bit, Byteadressierung) Address (showing bit positions) 31 30 29 28..... 19 18
a. Flipflop (taktflankengesteuert) Wdh. Signalverläufe beim D-FF
 Wdh. Signalverläufe beim D-FF") ITS Teil 2: Rechnerarchitektur 1. Grundschaltungen der Digitaltechnik a. Flipflop (taktflankengesteuert) Wdh. Signalverläufe beim D-FF b. Zähler (Bsp. 4-Bit Zähler) - Eingang count wird zum Aktivieren
ITS Teil 2: Rechnerarchitektur 1. Grundschaltungen der Digitaltechnik a. Flipflop (taktflankengesteuert) Wdh. Signalverläufe beim D-FF b. Zähler (Bsp. 4-Bit Zähler) - Eingang count wird zum Aktivieren
B1 Stapelspeicher (stack)
") B1 Stapelspeicher (stack) Arbeitsweise des LIFO-Stapelspeichers Im Kapitel "Unterprogramme" wurde schon erwähnt, dass Unterprogramme einen so genannten Stapelspeicher (Kellerspeicher, Stapel, stack) benötigen
B1 Stapelspeicher (stack) Arbeitsweise des LIFO-Stapelspeichers Im Kapitel "Unterprogramme" wurde schon erwähnt, dass Unterprogramme einen so genannten Stapelspeicher (Kellerspeicher, Stapel, stack) benötigen
5.BMaschinensprache und Assembler
 Die Maschinenprogrammebene eines Rechners Jörg Roth 268 5.BMaschinensprache und Assembler Die vom Prozessor ausführbaren Befehle liegen im Binärformat vor. Nur solche Befehle sind direkt ausführbar. So
Die Maschinenprogrammebene eines Rechners Jörg Roth 268 5.BMaschinensprache und Assembler Die vom Prozessor ausführbaren Befehle liegen im Binärformat vor. Nur solche Befehle sind direkt ausführbar. So
Java-Prozessoren. Die Java Virtual Machine spezifiziert... Java Instruktions-Satz. Datentypen. Operanden-Stack. Konstanten-Pool.
 Die Java Virtual Machine spezifiziert... Java Instruktions-Satz Datentypen Operanden-Stack Konstanten-Pool Methoden-Area Heap für Laufzeit-Daten Class File Format 26 Die Java Virtual Machine Java Instruktions-Satz
Die Java Virtual Machine spezifiziert... Java Instruktions-Satz Datentypen Operanden-Stack Konstanten-Pool Methoden-Area Heap für Laufzeit-Daten Class File Format 26 Die Java Virtual Machine Java Instruktions-Satz
1 Einleitung zum RISC Prozessor
 1 Einleitung zum RISC Prozessor Wesentliche Entwicklungsschritte der Computer-Architekturen [2, 3]: Familienkonzept von IBM mit System/360 (1964) und DEC mit PDP-8 (1965) eingeführt: Gleiche Hardware-Architekturen
1 Einleitung zum RISC Prozessor Wesentliche Entwicklungsschritte der Computer-Architekturen [2, 3]: Familienkonzept von IBM mit System/360 (1964) und DEC mit PDP-8 (1965) eingeführt: Gleiche Hardware-Architekturen
Komplexpraktikum Prozessorentwurf SoSe 2015
 Fakultät Informatik Institut für Technische Informatik Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Komplexpraktikum Prozessorentwurf SoSe 2015 Ansprechpartner Martin Zabel, martin.zabel@tu-dresden.de,
Fakultät Informatik Institut für Technische Informatik Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Komplexpraktikum Prozessorentwurf SoSe 2015 Ansprechpartner Martin Zabel, martin.zabel@tu-dresden.de,
Grundlagen der Rechnerarchitektur
 Grundlagen der Rechnerarchitektur ARM, x86 und ISA Prinzipien Übersicht Rudimente des ARM Assemblers Rudimente des Intel Assemblers ISA Prinzipien Grundlagen der Rechnerarchitektur Assembler 2 Rudimente
Grundlagen der Rechnerarchitektur ARM, x86 und ISA Prinzipien Übersicht Rudimente des ARM Assemblers Rudimente des Intel Assemblers ISA Prinzipien Grundlagen der Rechnerarchitektur Assembler 2 Rudimente
Übungscomputer mit Prozessor 8085 - Bedienungsanleitung
 Seite 1 von 9 Pinbelegung der Steckerleisten im Übungsgerät Seite 2 von 9 Inbetriebnahme: Schalter S1, S2, und S3 in Stellung 1 (oben) schalten. Spannung 5 V anlegen. ACHTUNG auf Polarität achten. Taste
Seite 1 von 9 Pinbelegung der Steckerleisten im Übungsgerät Seite 2 von 9 Inbetriebnahme: Schalter S1, S2, und S3 in Stellung 1 (oben) schalten. Spannung 5 V anlegen. ACHTUNG auf Polarität achten. Taste
3.0 8051 Assembler und Hochsprachen
 3.0 8051 Assembler und Hochsprachen Eine kurze Übersicht zum Ablauf einer Programmierung eines 8051 Mikrocontrollers. 3.1 Der 8051 Maschinencode Grundsätzlich akzeptiert ein 8051 Mikrocontroller als Befehle
3.0 8051 Assembler und Hochsprachen Eine kurze Übersicht zum Ablauf einer Programmierung eines 8051 Mikrocontrollers. 3.1 Der 8051 Maschinencode Grundsätzlich akzeptiert ein 8051 Mikrocontroller als Befehle
3 Rechnen und Schaltnetze
 3 Rechnen und Schaltnetze Arithmetik, Logik, Register Taschenrechner rste Prozessoren (z.b. Intel 4004) waren für reine Rechenaufgaben ausgelegt 4 4-Bit Register 4-Bit Datenbus 4 Kbyte Speicher 60000 Befehle/s
3 Rechnen und Schaltnetze Arithmetik, Logik, Register Taschenrechner rste Prozessoren (z.b. Intel 4004) waren für reine Rechenaufgaben ausgelegt 4 4-Bit Register 4-Bit Datenbus 4 Kbyte Speicher 60000 Befehle/s
C. BABBAGE (1792 1871): Programmgesteuerter (mechanischer) Rechner
: Programmgesteuerter (mechanischer) Rechner") Von-Neumann-Rechner (John von Neumann : 1903-1957) C. BABBAGE (1792 1871): Programmgesteuerter (mechanischer) Rechner Quelle: http://www.cs.uakron.edu/~margush/465/01_intro.html Analytical Engine - Calculate
Von-Neumann-Rechner (John von Neumann : 1903-1957) C. BABBAGE (1792 1871): Programmgesteuerter (mechanischer) Rechner Quelle: http://www.cs.uakron.edu/~margush/465/01_intro.html Analytical Engine - Calculate
1. Übung - Einführung/Rechnerarchitektur
 1. Übung - Einführung/Rechnerarchitektur Informatik I für Verkehrsingenieure Aufgaben inkl. Beispiellösungen 1. Aufgabe: Was ist Hard- bzw. Software? a Computermaus b Betriebssystem c Drucker d Internetbrowser
1. Übung - Einführung/Rechnerarchitektur Informatik I für Verkehrsingenieure Aufgaben inkl. Beispiellösungen 1. Aufgabe: Was ist Hard- bzw. Software? a Computermaus b Betriebssystem c Drucker d Internetbrowser
Rechnerarithmetik. Vorlesung im Sommersemester 2008. Eberhard Zehendner. FSU Jena. Thema: Ripple-Carry- und Carry-Skip-Addierer
 Rechnerarithmetik Vorlesung im Sommersemester 2008 Eberhard Zehendner FSU Jena Thema: Ripple-Carry- und Carry-Skip-Addierer Eberhard Zehendner (FSU Jena) Rechnerarithmetik Ripple-Carry- und Carry-Skip-Addierer
Rechnerarithmetik Vorlesung im Sommersemester 2008 Eberhard Zehendner FSU Jena Thema: Ripple-Carry- und Carry-Skip-Addierer Eberhard Zehendner (FSU Jena) Rechnerarithmetik Ripple-Carry- und Carry-Skip-Addierer
IT-Infrastruktur, WS 2014/15, Hans-Georg Eßer
 ITIS-D'' IT-Infrastruktur WS 2014/15 Hans-Georg Eßer Dipl.-Math., Dipl.-Inform. Foliensatz D'': Rechnerstrukturen, Teil 3 v1.0, 2014/11/27 Folie D''-1 Dieser Foliensatz Vorlesungsübersicht Seminar Wiss.
ITIS-D'' IT-Infrastruktur WS 2014/15 Hans-Georg Eßer Dipl.-Math., Dipl.-Inform. Foliensatz D'': Rechnerstrukturen, Teil 3 v1.0, 2014/11/27 Folie D''-1 Dieser Foliensatz Vorlesungsübersicht Seminar Wiss.
Brückenkurs / Computer
 Brückenkurs / Computer Sebastian Stabinger IIS 23 September 2013 Sebastian Stabinger (IIS) Brückenkurs / Computer 23 September 2013 1 / 20 Content 1 Allgemeines zum Studium 2 Was ist ein Computer? 3 Geschichte
Brückenkurs / Computer Sebastian Stabinger IIS 23 September 2013 Sebastian Stabinger (IIS) Brückenkurs / Computer 23 September 2013 1 / 20 Content 1 Allgemeines zum Studium 2 Was ist ein Computer? 3 Geschichte
Rechnerarchitektur Atmega 32. 1 Vortrag Atmega 32. Von Urs Müller und Marion Knoth. Urs Müller Seite 1 von 7
 1 Vortrag Atmega 32 Von Urs Müller und Marion Knoth Urs Müller Seite 1 von 7 Inhaltsverzeichnis 1 Vortrag Atmega 32 1 1.1 Einleitung 3 1.1.1 Hersteller ATMEL 3 1.1.2 AVR - Mikrocontroller Familie 3 2 Übersicht
1 Vortrag Atmega 32 Von Urs Müller und Marion Knoth Urs Müller Seite 1 von 7 Inhaltsverzeichnis 1 Vortrag Atmega 32 1 1.1 Einleitung 3 1.1.1 Hersteller ATMEL 3 1.1.2 AVR - Mikrocontroller Familie 3 2 Übersicht
Rechnerarchitektur. M. Jakob. 1. Februar 2015. Gymnasium Pegnitz
 Rechnerarchitektur M. Jakob Gymnasium Pegnitz 1. Februar 2015 Inhaltsverzeichnis 1 Aufbau eines Computersystems Praktische Grundlagen Von-Neumann-Rechner 2 Darstellung und Speicherung von Zahlen 3 Registermaschinen
Rechnerarchitektur M. Jakob Gymnasium Pegnitz 1. Februar 2015 Inhaltsverzeichnis 1 Aufbau eines Computersystems Praktische Grundlagen Von-Neumann-Rechner 2 Darstellung und Speicherung von Zahlen 3 Registermaschinen
Gliederung. Tutorium zur Vorlesung. Gliederung. Gliederung. 1. Gliederung der Informatik. 1. Gliederung der Informatik. 1. Gliederung der Informatik
 Informatik I WS 2012/13 Tutorium zur Vorlesung 1. Alexander Zietlow zietlow@informatik.uni-tuebingen.de Wilhelm-Schickard-Institut für Informatik Eberhard Karls Universität Tübingen 11.02.2013 1. 2. 1.
Informatik I WS 2012/13 Tutorium zur Vorlesung 1. Alexander Zietlow zietlow@informatik.uni-tuebingen.de Wilhelm-Schickard-Institut für Informatik Eberhard Karls Universität Tübingen 11.02.2013 1. 2. 1.
Einführung (0) Erster funktionsfähiger programmgesteuerter Rechenautomat Z3, fertiggestellt 1941 Bild: Nachbau im Deutschen Museum München
 Erster funktionsfähiger programmgesteuerter Rechenautomat Z3, fertiggestellt 1941 Bild: Nachbau im Deutschen Museum München") Einführung (0) Erster funktionsfähiger programmgesteuerter Rechenautomat Z3, fertiggestellt 1941 Bild: Nachbau im Deutschen Museum München Einführung (1) Was ist ein Rechner? Maschine, die Probleme für
Einführung (0) Erster funktionsfähiger programmgesteuerter Rechenautomat Z3, fertiggestellt 1941 Bild: Nachbau im Deutschen Museum München Einführung (1) Was ist ein Rechner? Maschine, die Probleme für
Einführung in die technische Informatik
 Einführung in die technische Informatik Christopher Kruegel chris@auto.tuwien.ac.at http://www.auto.tuwien.ac.at/~chris Betriebssysteme Aufgaben Management von Ressourcen Präsentation einer einheitlichen
Einführung in die technische Informatik Christopher Kruegel chris@auto.tuwien.ac.at http://www.auto.tuwien.ac.at/~chris Betriebssysteme Aufgaben Management von Ressourcen Präsentation einer einheitlichen
Projekt-Planung Delphi Tage 2012
 Projekt-Planung Delphi Tage 2012 Daniela Sefzig (Delphi Praxis - Daniela.S) Version 1.0 Agenda Kommunikation mit dem Auftraggeber Prozesse kennen lernen - Ereignisgesteuerte Prozessketten Das System mit
Projekt-Planung Delphi Tage 2012 Daniela Sefzig (Delphi Praxis - Daniela.S) Version 1.0 Agenda Kommunikation mit dem Auftraggeber Prozesse kennen lernen - Ereignisgesteuerte Prozessketten Das System mit
1. Übung aus Digitaltechnik 2. 1. Aufgabe. Die folgende CMOS-Anordnung weist einen Fehler auf:
 Fachhochschule Regensburg Fachbereich Elektrotechnik 1. Übung aus Digitaltechnik 2 1. Aufgabe Die folgende CMOS-Anordnung weist einen Fehler auf: A B C p p p Y VDD a) Worin besteht der Fehler? b) Bei welcher
Fachhochschule Regensburg Fachbereich Elektrotechnik 1. Übung aus Digitaltechnik 2 1. Aufgabe Die folgende CMOS-Anordnung weist einen Fehler auf: A B C p p p Y VDD a) Worin besteht der Fehler? b) Bei welcher
Klausur zur Mikroprozessortechnik
 Prof. Dr. K. Wüst WS 2001 FH Gießen Friedberg, FB MNI Studiengang Informatik Klausur zur Mikroprozessortechnik Nachname: Vorname: Matrikelnummer: 7.3.2001 Punkteverteilung Aufgabe Punkte erreicht 1 3 2
Prof. Dr. K. Wüst WS 2001 FH Gießen Friedberg, FB MNI Studiengang Informatik Klausur zur Mikroprozessortechnik Nachname: Vorname: Matrikelnummer: 7.3.2001 Punkteverteilung Aufgabe Punkte erreicht 1 3 2
Assembler-Programmierung
 Assembler-Programmierung Dr.-Ing. Volkmar Sieh Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg SS 2011 Assembler-Programmierung 1/48 2012-02-29 Assembler-Programmierung
Assembler-Programmierung Dr.-Ing. Volkmar Sieh Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg SS 2011 Assembler-Programmierung 1/48 2012-02-29 Assembler-Programmierung
DLX Befehlsübersicht
 DLX sübersicht 1 Instruktionen für den Daten-Transfer Daten können mit folgenden en zwischen Registern und dem Speicher oder zwischen Integer- und Fließkomma-Registern ausgetauscht werden. Der einzige
DLX sübersicht 1 Instruktionen für den Daten-Transfer Daten können mit folgenden en zwischen Registern und dem Speicher oder zwischen Integer- und Fließkomma-Registern ausgetauscht werden. Der einzige
Binärcodierung elementarer Datentypen: Darstellung negativer Zahlen
 Binärcodierung elementarer Datentypen: Darstellung negativer Zahlen Statt positive Zahlen von 0 bis 2 n -1mit einem Bitmuster der Länge n darzustellen und arithmetische Operationen darauf auszuführen,
Binärcodierung elementarer Datentypen: Darstellung negativer Zahlen Statt positive Zahlen von 0 bis 2 n -1mit einem Bitmuster der Länge n darzustellen und arithmetische Operationen darauf auszuführen,
Grundlagen der Programmierung 2. Parallele Verarbeitung
 Grundlagen der Programmierung 2 Parallele Verarbeitung Prof. Dr. Manfred Schmidt-Schauÿ Künstliche Intelligenz und Softwaretechnologie 27. Mai 2009 Parallele Algorithmen und Ressourcenbedarf Themen: Nebenläufigkeit,
Grundlagen der Programmierung 2 Parallele Verarbeitung Prof. Dr. Manfred Schmidt-Schauÿ Künstliche Intelligenz und Softwaretechnologie 27. Mai 2009 Parallele Algorithmen und Ressourcenbedarf Themen: Nebenläufigkeit,
Static-Single-Assignment-Form
 Static-Single-Assignment-Form Compilerbau Static-Single-Assignment-Form 195 Static-Single-Assignment-Form besondere Darstellungsform des Programms (Zwischensprache) vereinfacht Datenflussanalyse und damit
Static-Single-Assignment-Form Compilerbau Static-Single-Assignment-Form 195 Static-Single-Assignment-Form besondere Darstellungsform des Programms (Zwischensprache) vereinfacht Datenflussanalyse und damit
Multicore Programming: Transactional Memory
 Software (STM) 07 Mai 2009 Software (STM) 1 Das Problem 2 Probleme mit 3 Definitionen Datenspeicherung Konflikterkennung Granularität Optimierungsmöglichkeiten Software (STM) 4 Software (STM) Beispielimplementation
Software (STM) 07 Mai 2009 Software (STM) 1 Das Problem 2 Probleme mit 3 Definitionen Datenspeicherung Konflikterkennung Granularität Optimierungsmöglichkeiten Software (STM) 4 Software (STM) Beispielimplementation
Parallelrechner (1) Anwendungen: Simulation von komplexen physikalischen oder biochemischen Vorgängen Entwurfsunterstützung virtuelle Realität
 Anwendungen: Simulation von komplexen physikalischen oder biochemischen Vorgängen Entwurfsunterstützung virtuelle Realität") Parallelrechner (1) Motivation: Bedarf für immer leistungsfähigere Rechner Leistungssteigerung eines einzelnen Rechners hat physikalische Grenzen: Geschwindigkeit von Materie Wärmeableitung Transistorgröße
Parallelrechner (1) Motivation: Bedarf für immer leistungsfähigere Rechner Leistungssteigerung eines einzelnen Rechners hat physikalische Grenzen: Geschwindigkeit von Materie Wärmeableitung Transistorgröße
Das Rechnermodell von John von Neumann
 Das Rechnermodell von John von Neumann Historisches Die ersten mechanischen Rechenmaschinen wurden im 17. Jahhundert entworfen. Zu den Pionieren dieser Entwichlung zählen Wilhelm Schickard, Blaise Pascal
Das Rechnermodell von John von Neumann Historisches Die ersten mechanischen Rechenmaschinen wurden im 17. Jahhundert entworfen. Zu den Pionieren dieser Entwichlung zählen Wilhelm Schickard, Blaise Pascal
Ergänzungen zum Manual OS V 2.05/2.06
 Ergänzungen zum Manual OS V 2.05/2.06 SYSTEMRESOURCEN - PROGRAMM DOWNLOAD - Ab der Betriebssystemversion 2.05 haben die C-Control Units M-2.0 und Station 2.0 die Möglichkeit das Anwenderprogramm von einem
Ergänzungen zum Manual OS V 2.05/2.06 SYSTEMRESOURCEN - PROGRAMM DOWNLOAD - Ab der Betriebssystemversion 2.05 haben die C-Control Units M-2.0 und Station 2.0 die Möglichkeit das Anwenderprogramm von einem
Theorie und Einsatz von Verbindungseinrichtungen in parallelen Rechnersystemen
 Center for Information Services and High Performance Computing (ZIH) Theorie und Einsatz von Verbindungseinrichtungen in parallelen Rechnersystemen Hochgeschwindigkeitskommunikationen 13. Juli 2012 Andy
Center for Information Services and High Performance Computing (ZIH) Theorie und Einsatz von Verbindungseinrichtungen in parallelen Rechnersystemen Hochgeschwindigkeitskommunikationen 13. Juli 2012 Andy
Algorithmen zur Integer-Multiplikation
 Algorithmen zur Integer-Multiplikation Multiplikation zweier n-bit Zahlen ist zurückführbar auf wiederholte bedingte Additionen und Schiebeoperationen (in einfachen Prozessoren wird daher oft auf Multiplizierwerke
Algorithmen zur Integer-Multiplikation Multiplikation zweier n-bit Zahlen ist zurückführbar auf wiederholte bedingte Additionen und Schiebeoperationen (in einfachen Prozessoren wird daher oft auf Multiplizierwerke
Ein Scan basierter Seitenangriff auf DES
 Ein Scan basierter Seitenangriff auf DES Seminar Codes & Kryptographie SS04 Tobias Witteler 29.06.2004 Struktur des Vortrags 1. Einführung / Motivation 2. Struktur von DES 3. Die Attacke Begriffsklärung:
Ein Scan basierter Seitenangriff auf DES Seminar Codes & Kryptographie SS04 Tobias Witteler 29.06.2004 Struktur des Vortrags 1. Einführung / Motivation 2. Struktur von DES 3. Die Attacke Begriffsklärung:
Synchronisierung von Transaktionen ohne Sperren. Annahme: Es gibt eine Methode, zu erkennen, wann eine Transaktion die serielle Ordnung verletzt.
 OPTIMISTIC CONCURRENCY CONTROL Synchronisierung von Transaktionen ohne Sperren. Annahme: Es gibt eine Methode, zu erkennen, wann eine Transaktion die serielle Ordnung verletzt. Abbruch einer Transaktion
OPTIMISTIC CONCURRENCY CONTROL Synchronisierung von Transaktionen ohne Sperren. Annahme: Es gibt eine Methode, zu erkennen, wann eine Transaktion die serielle Ordnung verletzt. Abbruch einer Transaktion
IT für Führungskräfte. Zentraleinheiten. 11.04.2002 Gruppe 2 - CPU 1
 IT für Führungskräfte Zentraleinheiten 11.04.2002 Gruppe 2 - CPU 1 CPU DAS TEAM CPU heißt Central Processing Unit! Björn Heppner (Folien 1-4, 15-20, Rollenspielpräsentation 1-4) Harald Grabner (Folien
IT für Führungskräfte Zentraleinheiten 11.04.2002 Gruppe 2 - CPU 1 CPU DAS TEAM CPU heißt Central Processing Unit! Björn Heppner (Folien 1-4, 15-20, Rollenspielpräsentation 1-4) Harald Grabner (Folien
Benchmarking Intel Pentium III-S vs. Intel Pentium 4
 Benchmarking Intel Pentium III-S vs. Intel Pentium 4 André Ceselski Raphael Rosendahl 30.01.2007 Gliederung Motivation Vorstellung der Architekturen Intel P6 Architektur Intel NetBurst TM Architektur Architektur-Unterschiede
Benchmarking Intel Pentium III-S vs. Intel Pentium 4 André Ceselski Raphael Rosendahl 30.01.2007 Gliederung Motivation Vorstellung der Architekturen Intel P6 Architektur Intel NetBurst TM Architektur Architektur-Unterschiede
Stephan Brumme, SST, 2.FS, Matrikelnr. 70 25 44
 Aufgabe 33 a) Der Pseudobefehl move $rd,$rs wird als addu $rd,$0,$rs übersetzt. Dabei macht sich SPIM zunutze, dass das Register $0 immer Null ist. Somit wird das Register $rd ersetzt durch $rd=0+$rs=$rs,
Aufgabe 33 a) Der Pseudobefehl move $rd,$rs wird als addu $rd,$0,$rs übersetzt. Dabei macht sich SPIM zunutze, dass das Register $0 immer Null ist. Somit wird das Register $rd ersetzt durch $rd=0+$rs=$rs,
Datensicherung. Beschreibung der Datensicherung
 Datensicherung Mit dem Datensicherungsprogramm können Sie Ihre persönlichen Daten problemlos Sichern. Es ist möglich eine komplette Datensicherung durchzuführen, aber auch nur die neuen und geänderten
Datensicherung Mit dem Datensicherungsprogramm können Sie Ihre persönlichen Daten problemlos Sichern. Es ist möglich eine komplette Datensicherung durchzuführen, aber auch nur die neuen und geänderten
Convey, Hybrid-Core Computing
 Convey, Hybrid-Core Computing Vortrag im Rahmen des Seminars Ausgewählte Themen in Hardwareentwurf und Optik HWS 09 Universität Mannheim Markus Müller 1 Inhalt Hybrid-Core Computing? Convey HC-1 Überblick
Convey, Hybrid-Core Computing Vortrag im Rahmen des Seminars Ausgewählte Themen in Hardwareentwurf und Optik HWS 09 Universität Mannheim Markus Müller 1 Inhalt Hybrid-Core Computing? Convey HC-1 Überblick
Klausur zur Vorlesung
 Prof. Dr. Franz J. Rammig Paderborn, 2..2001 C. Böke Klausur zur Vorlesung "Grundlagen der technischen Informatik" und "Grundlagen der Rechnerarchitektur" Sommersemester 2001 1. Teil: GTI Der erste Teil
Prof. Dr. Franz J. Rammig Paderborn, 2..2001 C. Böke Klausur zur Vorlesung "Grundlagen der technischen Informatik" und "Grundlagen der Rechnerarchitektur" Sommersemester 2001 1. Teil: GTI Der erste Teil
Überblick über COPYDISCOUNT.CH
 Überblick über COPYDISCOUNT.CH Pläne, Dokumente, Verrechnungsangaben usw. werden projektbezogen abgelegt und können von Ihnen rund um die Uhr verwaltet werden. Bestellungen können online zusammengestellt
Überblick über COPYDISCOUNT.CH Pläne, Dokumente, Verrechnungsangaben usw. werden projektbezogen abgelegt und können von Ihnen rund um die Uhr verwaltet werden. Bestellungen können online zusammengestellt
1 Vom Problem zum Programm
 1 Vom Problem zum Programm Ein Problem besteht darin, aus einer gegebenen Menge von Informationen eine weitere (bisher unbekannte) Information zu bestimmen. 1 Vom Problem zum Programm Ein Algorithmus ist
1 Vom Problem zum Programm Ein Problem besteht darin, aus einer gegebenen Menge von Informationen eine weitere (bisher unbekannte) Information zu bestimmen. 1 Vom Problem zum Programm Ein Algorithmus ist
Im Original veränderbare Word-Dateien
 Das Von-Neumann-Prinzip Prinzipien der Datenverarbeitung Fast alle modernen Computer funktionieren nach dem Von- Neumann-Prinzip. Der Erfinder dieses Konzeptes John von Neumann (1903-1957) war ein in den
Das Von-Neumann-Prinzip Prinzipien der Datenverarbeitung Fast alle modernen Computer funktionieren nach dem Von- Neumann-Prinzip. Der Erfinder dieses Konzeptes John von Neumann (1903-1957) war ein in den
Datentechnik. => Das Rechenergebnis ist nur dann sinnvoll, wenn es rechtzeitig vorliegt. Die Zeit muß daher beim Programmdesign berücksichtigt werden.
 5. Steuerung technischer Prozesse 5.1 Echtzeit (real time) Im Gegensatz zu Aufgabenstellungen aus der Büroumgebung, wo der Anwender mehr oder weniger geduldig wartet, bis der Computer ein Ergebnis liefert
5. Steuerung technischer Prozesse 5.1 Echtzeit (real time) Im Gegensatz zu Aufgabenstellungen aus der Büroumgebung, wo der Anwender mehr oder weniger geduldig wartet, bis der Computer ein Ergebnis liefert
Technischer Aufbau und allgemeine Funktionsweise eines Computers
 Technischer Aufbau und allgemeine Funktionsweise eines Computers Jannek Squar Proseminar CiS Physik 01.11.2011 Technischer Aufbau und allgemeine Funktionsweise eines Computers -Was ist ein Computer S.
Technischer Aufbau und allgemeine Funktionsweise eines Computers Jannek Squar Proseminar CiS Physik 01.11.2011 Technischer Aufbau und allgemeine Funktionsweise eines Computers -Was ist ein Computer S.
bereits in A,3 und A.4: Betrachtung von Addierschaltungen als Beispiele für Schaltnetze und Schaltwerke
 Rechnerarithmetik Rechnerarithmetik 22 Prof. Dr. Rainer Manthey Informatik II Übersicht bereits in A,3 und A.4: Betrachtung von Addierschaltungen als Beispiele für Schaltnetze und Schaltwerke in diesem
Rechnerarithmetik Rechnerarithmetik 22 Prof. Dr. Rainer Manthey Informatik II Übersicht bereits in A,3 und A.4: Betrachtung von Addierschaltungen als Beispiele für Schaltnetze und Schaltwerke in diesem
Grundlagen der Rechnerarchitektur. Einführung
 Grundlagen der Rechnerarchitektur Einführung Unsere erste Amtshandlung: Wir schrauben einen Rechner auf Grundlagen der Rechnerarchitektur Einführung 2 Vorlesungsinhalte Binäre Arithmetik MIPS Assembler
Grundlagen der Rechnerarchitektur Einführung Unsere erste Amtshandlung: Wir schrauben einen Rechner auf Grundlagen der Rechnerarchitektur Einführung 2 Vorlesungsinhalte Binäre Arithmetik MIPS Assembler
Datenübernahme easyjob 3.0 zu easyjob 4.0
 Datenübernahme easyjob 3.0 zu easyjob 4.0 Einführung...3 Systemanforderung easyjob 4.0...3 Vorgehensweise zur Umstellung zu easyjob 4.0...4 Installation easyjob 4.0 auf dem Server und Arbeitsstationen...4
Datenübernahme easyjob 3.0 zu easyjob 4.0 Einführung...3 Systemanforderung easyjob 4.0...3 Vorgehensweise zur Umstellung zu easyjob 4.0...4 Installation easyjob 4.0 auf dem Server und Arbeitsstationen...4
Assembler-Programme. Systemprogrammierung (37-023) Elementare Komponenten eines Assembler-Programmes
 Elementare Komponenten eines Assembler-Programmes") Systemprogrammierung (37-023) Assemblerprogrammierung Betriebssystemgrundlagen Maschinenmodelle Dozent: Prof. Thomas Stricker krankheitshalber vertreten durch: Felix Rauch WebSite: http://www.cs.inf.ethz.ch/37-023/
Systemprogrammierung (37-023) Assemblerprogrammierung Betriebssystemgrundlagen Maschinenmodelle Dozent: Prof. Thomas Stricker krankheitshalber vertreten durch: Felix Rauch WebSite: http://www.cs.inf.ethz.ch/37-023/
Lektion 3: Was ist und was kann ein Computer?
 Lektion 3: Was ist und was kann ein Computer? Helmar Burkhart Informatik burkhart@ifi.unibas.ch EINFÜHRUNG IN DIE INFORMATIK I 3-0 Übersicht Lektion 3 Hardware Software Aufbau eines Computers Rechnerkern
Lektion 3: Was ist und was kann ein Computer? Helmar Burkhart Informatik burkhart@ifi.unibas.ch EINFÜHRUNG IN DIE INFORMATIK I 3-0 Übersicht Lektion 3 Hardware Software Aufbau eines Computers Rechnerkern
Modul Computersysteme Prüfungsklausur SS 2011. Prof. Dr. J. Keller LG Parallelität und VLSI Prof. Dr.-Ing. W. Schiffmann LG Rechnerarchitektur
 Modul Computersysteme Prüfungsklausur SS 2011 Lösungsvorschläge Prof. Dr. J. Keller LG Parallelität und VLSI Prof. Dr.-Ing. W. Schiffmann LG Rechnerarchitektur 1 Aufgabe 1 (12 Punkte): a) Gegeben ist das
Modul Computersysteme Prüfungsklausur SS 2011 Lösungsvorschläge Prof. Dr. J. Keller LG Parallelität und VLSI Prof. Dr.-Ing. W. Schiffmann LG Rechnerarchitektur 1 Aufgabe 1 (12 Punkte): a) Gegeben ist das
Proseminar Rechnerarchitekturen. Parallelcomputer: Multiprozessorsysteme
 wwwnet-texde Proseminar Rechnerarchitekturen Parallelcomputer: Multiprozessorsysteme Stefan Schumacher, , PGP Key http://wwwnet-texde/uni Id: mps-folientex,v
wwwnet-texde Proseminar Rechnerarchitekturen Parallelcomputer: Multiprozessorsysteme Stefan Schumacher, , PGP Key http://wwwnet-texde/uni Id: mps-folientex,v
Eine Baumstruktur sei folgendermaßen definiert. Eine Baumstruktur mit Grundtyp Element ist entweder
 Programmieren in PASCAL Bäume 1 1. Baumstrukturen Eine Baumstruktur sei folgendermaßen definiert. Eine Baumstruktur mit Grundtyp Element ist entweder 1. die leere Struktur oder 2. ein Knoten vom Typ Element
Programmieren in PASCAL Bäume 1 1. Baumstrukturen Eine Baumstruktur sei folgendermaßen definiert. Eine Baumstruktur mit Grundtyp Element ist entweder 1. die leere Struktur oder 2. ein Knoten vom Typ Element
ARM Cortex-M Prozessoren. Referat von Peter Voser Embedded Development GmbH
 ARM Cortex-M Prozessoren Referat von Peter Voser Embedded Development GmbH SoC (System-on-Chip) www.embedded-development.ch 2 Instruction Sets ARM, Thumb, Thumb-2 32-bit ARM - verbesserte Rechenleistung
ARM Cortex-M Prozessoren Referat von Peter Voser Embedded Development GmbH SoC (System-on-Chip) www.embedded-development.ch 2 Instruction Sets ARM, Thumb, Thumb-2 32-bit ARM - verbesserte Rechenleistung
Vorlesung Programmieren
 Vorlesung Programmieren Funktionsweise von Computern Prof. Dr. Stefan Fischer Institut für Telematik, Universität zu Lübeck http://www.itm.uni-luebeck.de/people/fischer Inhalt 1. Ein Blick zurück 2. Stand
Vorlesung Programmieren Funktionsweise von Computern Prof. Dr. Stefan Fischer Institut für Telematik, Universität zu Lübeck http://www.itm.uni-luebeck.de/people/fischer Inhalt 1. Ein Blick zurück 2. Stand
Prozessor HC680 fiktiv
 Prozessor HC680 fiktiv Dokumentation der Simulation Die Simulation umfasst die Struktur und Funktionalität des Prozessors und wichtiger Baugruppen des Systems. Dabei werden in einem Simulationsfenster
Prozessor HC680 fiktiv Dokumentation der Simulation Die Simulation umfasst die Struktur und Funktionalität des Prozessors und wichtiger Baugruppen des Systems. Dabei werden in einem Simulationsfenster
Samsungs Exynos 5 Dual
 Fakultät Informatik, Institut für Technische Informatik, Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Samsungs Exynos 5 Dual Candy Lohse Dresden, 12.12.12 Gliederung 1. Motivation und
Fakultät Informatik, Institut für Technische Informatik, Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Samsungs Exynos 5 Dual Candy Lohse Dresden, 12.12.12 Gliederung 1. Motivation und
Technische Informatik. Der VON NEUMANN Computer
 Technische Informatik Der VON NEUMANN Computer Inhalt! Prinzipieller Aufbau! Schaltkreise! Schaltnetze und Schaltwerke! Rechenwerk! Arbeitsspeicher! Steuerwerk - Programmausführung! Periphere Geräte! Abstraktionsstufen
Technische Informatik Der VON NEUMANN Computer Inhalt! Prinzipieller Aufbau! Schaltkreise! Schaltnetze und Schaltwerke! Rechenwerk! Arbeitsspeicher! Steuerwerk - Programmausführung! Periphere Geräte! Abstraktionsstufen