Molekulare Phylogenie II
|
|
|
- Christian Langenberg
- vor 6 Jahren
- Abrufe
Transkript

1 WS 2016/2017 Genomforschung und Sequenzanalyse - Einführung in Methoden der Bioinformatik- Thomas Hankeln Molekulare Phylogenie II 1
 Neighbor-joining Minimal Evolution (least squares) => Sequenzen in")
2 Stammbaumerstellung 1. Matrix-orientierte Methoden UPGM (Unweighted Pair-Group Method with rithmetric Means) Neighbor-joining Minimal Evolution (least squares) => Sequenzen in Distanzmatrix konvertiert 2. Charakter-orientierte Methoden Parsimony Maximum Likelihood, Bayes etc. => jede Position als informative Einheit 2


3 Datentypen Distanzen Sequenz 1 0,000 0,236 0,621 0,702 1,510 Sequenz 2 0,000 0,599 0,672 1,482 Sequenz 3 0,000 0,112 1,561 Sequenz 4 0,000 1,425 Sequenz 5 0,000 Charaktere Sequenz 1 TTGCTGCTGTGCTTGCT Sequenz 2 TT---CTGCTGGTCCTCCT Sequenz 3 TT---CTGCTGCGGCTTCTT Sequenz 4 TGTTGCCCGTTGCTCCTGCGT Sequenz 5 CGTGCTTGCCCGGGCCGCGT 3






4 Wo stehen wir? Sequenzen Multiples lignment * 20 * 40 YP QTK IYF PHF -DL SHG SQ IR HGK KVF L HE VNH ID : 39 YP QTK IYF PHF -DM SHN SQ IR HGK KVF SL HE VNH ID : 39 FP QTK TYF SHF -DV HHG STQ IRS HGK KVM LL GD VNH ID : 39 FP STK TYF SHF -DL GHN STQ VKG HGK KV DL TK VGH LD : 39 FP TTK TYF PHF -DL SHG SQ VKG HGK KV DL TN VH VD : 39 MP TTR IYF PK -DL SER SSY LHS HGK KVV GL TN VH ID : 39 YP QTK TYF SHW DL SPG SGP VKK HGK TIM GV GE ISK ID : 40 YP QTK TYF SHW DL SPG SP VKK HGG VIM GI GN VGL MD : 40 uswahl der Methode Distanz Charakter uswahl EvoModell % Evolutionsmodell und gamma shape Modeltest -> hlrt Stammbaumberechnung Ergebnisüberprüfung t WIE machen wir mit der korrigierten Distanzmatrix nun den Baum?
5 Distanzmatrix-Methoden Zwei Schritte: 1. Berechnen der korrigierten paarweisen bstände zwischen den Sequenzen => Evolutionsmodelle! DN: JC, K2P... Protein: PM, BLOSUM Erstellen eines Stammbaums anhand dieser bstandsdaten 5

6 Distanzmatrix Berechnen des paarweisen bstands Sequenz 1 0,000 0,236 0,621 0,702 1,510 Sequenz 2 0,000 0,599 0,672 1,482 Sequenz 3 0,000 0,112 1,561 Sequenz 4 0,000 1,425 Sequenz 5 0,000! usgedrückt i.d.r. als Mutationen pro Position! bstand kann > 1 werden! Bsp. Jukes-Cantor: p = 0.6 => K = 1.21 K 3 & 4 # = ln$ 1 p! 4 % 3 " 6
7 Vorgehensweise " lgorithmus berechnet aus den Distanzen den besten Stammbaum " Sequenzen selbst werden nicht mehr berücksichtigt 7

8 UPGM Unweighted Pair-Group Method with rithmetric Means 1. B C D OTU OTU B OTU C 0 19 OTU D 0 =3 3 3 B d C + d BC 2 d D + d BD 2 2. /B C D OTU /B OTU C 0 19 OTU D 0 =5, /B C 8
 ußengruppe wird")
9 UPGM 3. /B/C D Sequenz /B/C 0 19 Sequenz D B 5.5 C 9.5 D nimmt konstante Evolutionsraten an (= molecular clock) ußengruppe wird automatisch bestimmt 9






10 courtesy of Dan Graur
11 Molekulare Uhr bei Säuger-Proteinen K t
12 UPGM! dditive oder "Clustering"-Methode: OTUs werden durch sequenzielles Clustern nach absteigender Ähnlichkeit gruppiert. 12

13 UPGM usgangsmatrix B C D OTU OTU B OTU C 0 19 OTU D 0 rekonstruierte Matrix B C D OTU OTU B OTU C 0 19 OTU D B 5.5 C Problem: UPGM setzt absolute molekulare Uhr voraus, die es in Realität wohl nur selten gibt D 13

14 UPGM: Problem! ausgedachte Phylogenie = daraus abgeleitet... anhand der Matrix erstellt... UPGM liefert hier falsche Topologie!! 14
15 Neighbor-Joining (NJ) Saitou, Nei 1987 viel besser als UPGM: berücksichtigt unterschiedliche Evolutionsraten!! Baum-Topologie und stlängen werden getrennt ermittelt! Prinzip: Suche nach dem Baum mit der kleinsten Summe an stlängen ( Minimum Evolution tree ) Starte mit star-like-tree ; identifiziere sukzessive Nachbar-Taxa (= Clustering-lgorithmus)
/N-1 i j S 0 = Summe aller stlängen d ij = Distanzen zwischen allen OTUs N = nzahl der OTUs Welche Paare müssen kombiniert werden, damit man den")
16 Neighbor-joining (NJ) Ziel => Minimierung der Summe aller stlängen B Star-tree b c a d e E C D S 0 =78,5 B C D E OTU OTU B OTU C OTU D 10 OTU E 0 modified Star-tree B b c f a d e E C D S 0 =a+b+c+d+e S 0 = ( d ji )/N-1 i j S 0 = Summe aller stlängen d ij = Distanzen zwischen allen OTUs N = nzahl der OTUs Welche Paare müssen kombiniert werden, damit man den kürzesten Baum erhält? 16
17 Neighbor-joining (NJ) B modified Star-tree C Star tree -> Baumlänge berechnen Grouping -> Baumlängen berechnen -> kürzesten Baum identifizieren a b f e E d c D stlängen -> berechnen durch Fitch- Margoliash-Methode (FM) Neues Taxon (B) -> neue Matrix Topologie und stlängen separat bestimmt!
/N-2 B C D E Summe OTU 0 22 39 39 41 141 OTU B -74 0 41 41 43 147 OTU C -47,3-47 0 18 20 118 OTU D -46-44 -57,3 0 10 108 OTU E -44-44 -57,3-60,6 0 114 Grouping ( mit B) 18")
18 Neighbor-joining (NJ) Errechnen der Summe aller Einzel-Distanzen, dann der durchschnittlichen Distanzen einer Gruppe (z.b. hier +B) und zuletzt z.b. (S +S B )/N-2 B C D E Summe OTU OTU B OTU C OTU D OTU E Errechnen der Distanzunterschiede ( rate corrected distance ) z.b. D B =d B (S +S B )/N-2 B C D E Summe OTU OTU B OTU C -47, OTU D , OTU E ,3-60, Grouping ( mit B) 18
19 Neighbor-joining (NJ) B Der nächste Schritt: Errechnen der stlängen nach Fitch-Margoliash (FM) a b X C 19
 c c D C (2) stlängen nicht be")
20 Fitch-Margoliash-Methode 3 Taxa B D B (1) b a D BC (3) c c D C (2) stlängen nicht bekannt, Distanzen aber ja! => 2 Unbekannte (a, b); 1 Konstante (c) => z.b. aus der Differenz von (3) und (2) ist Unterschied der Äste errechenbar => uflösen nach b => Einsetzen in (1) C B C OTU OTU B 0 41 OTU C 0 OTU D Einzelabstände (1) D B = a+b = 22 (2) D C = a+c = 39 (3) D BC = b+c = 41 (2) - (3) a-b = = -2 -b = - 2-a b = 2+a a+a+2 = 22 2a = 22-2 a = 10 20
21 Fitch-Margoliash-Methode 3 Taxa B C OTU OTU B 0 41 OTU C 0 OTU D B (a): 10 (b): 12 (c): 29 b=12 c=29 C a=10 21
/2 <=> (39 10 + 41 12)/2 = 29 B C D E Summe OTU B 0 29 29 31 89 OTU C -49 0 18 20 67 OTU D -44-44 0 10 57 OTU E -44-44 -49 0 61 Berechnen der transformierten")
22 Neighbor-joining (NJ) usgangsmatrix B C D E Summe OTU OTU B OTU C OTU D OTU E Erstellen einer reduzierten Datenmatrix mit B als composite taxon d XC = (d C d X + d BC d BX )/2 <=> ( )/2 = 29 B C D E Summe OTU B OTU C OTU D OTU E Berechnen der transformierten Matrix, Identifizierung der nächsten Gruppierung, Berechnung der stlängen nach FM, usw... B 12 X 10 C D E 22

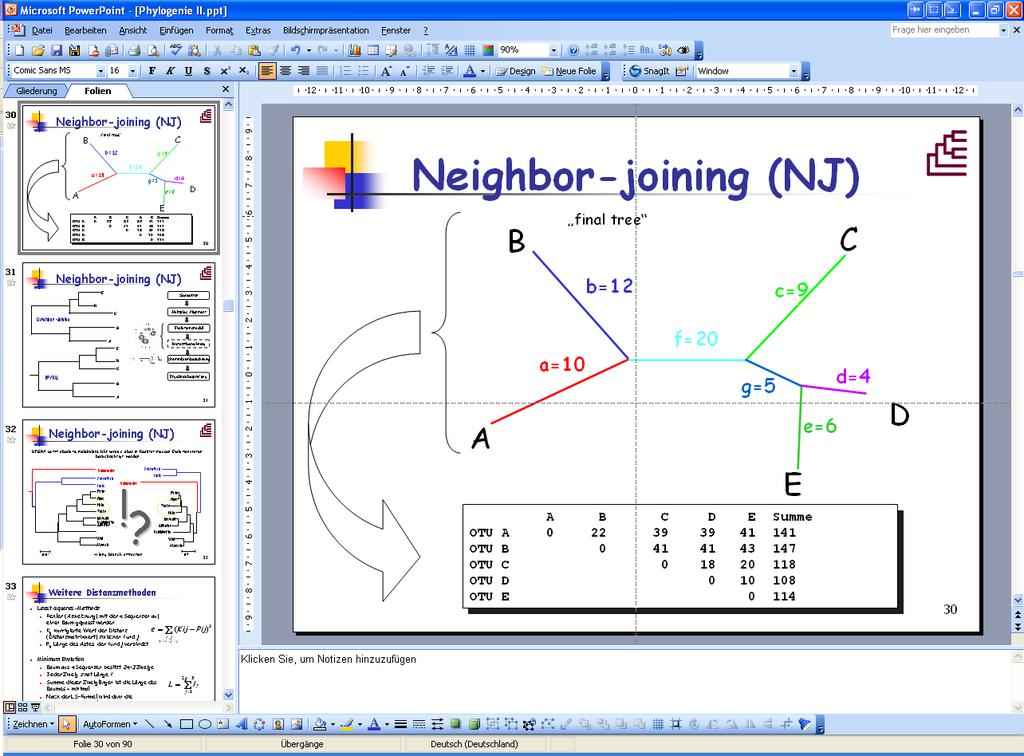
23 Neighbor-joining (NJ) B final tree C b=12 c=9 c a=10 f=20 g=5 E B C D E Summe OTU OTU B OTU C OTU D OTU E e=6 d=4 D 23
24 Distanzmethoden: UPGM vs. NJ B B C C D D E E UPGM F NJ F ußengruppe festgelegt konstante Evolutionsrate Verlust der realen stlängen Keine Matrixrekonstruktion möglich ußengruppe wählbar unterschiedliche Evolutionsraten Kein stlängenverlust Matrixrekonstruktion möglich
25 Weitere Distanzmethoden " Least-squares-Methode " Fehler (bweichung) mit der n Sequenzen auf einen Baum gepasst werden " K ij korrigierte Wert der Distanz (Distanzmatrixwert) zwischen i und j " P ij Länge des stes, der i und j verbindet e = i, j 1 i < j < ( Kij n Pij ) 2 " Minimum Evolution " Baum aus n Sequenzen besitzt 2n-3 Zweige " Jeder Zweig z hat Länge l " Summe dieser Zweiglängen ist die Länge des Baumes = minimal " Nach der LS-Formel wird dann die bweichung der stlängen von den Distanzen minimiert L = 2n 3 lz z = 1 25



26 Was bisher geschah... Daten MS Clustal Evolutionsmodelle (JC, K2P...) Distanzmatrix Stammbaum Clustering-lgorithmus z.b UPGM, NJ 26




27 Stammbaum-Rekonstruktion 1. Matrix-orientierte Methoden 2. Charakter-orientierte Methoden Maximum Parsimony (MP) Maximum Likelihood (ML) Bayes 27
28 Charakter-orientierte Methoden! rbeiten direkt mit dem lignment! Extrahieren mehr Information als Matrix-orientierte Methoden! rbeiten nicht mit Clustering, sondern durchsuchen den tree space nach dem optimalen Baum 28
29 29
30 Was sind Charaktere? kontinuierliche oder diskontinuierliche Eigenschaften. 1,2,3,4... = kontinuierliche Charaktere,T,G,C = diskontinuierliche Charaktere Nukleotide und minosäuren können als diskrete, diskontinuierliche Charaktere behandelt werden. Der phylogenetische Stammbaum wird anhand des Musters der Änderungen der Charaktere berechnet 30



31 Maximum Parsimony (MP) Methode des "maximalen Geizes" bzw. der "maximalen Sparsamkeit Entwickelt für morphologische Charaktere 1950 Grundzüge einer Theorie der phylogenetischen Systematik, Willi Hennig
")

32 Maximum Parsimony William of Ockham ( ) Ockham's razor : "Pluralitas non est ponenda sine neccesitate" ("Ohne Notwendigkeit soll keine Vielfältigkeit hinzugefügt werden") nnahme: Evolution ging den kürzesten Weg ( Ökonomie-Prinzip ) kürzester Stammbaum wird berechnet, d.h. der die wenigsten evolutiven Schritten benötigt Schritte = Änderungen von Charakteren 32
33 Maximum Parsimony Erklärung mit morphologischen Charakteren Gleiche Prinzipien sind für Sequenzen (Basenpaare, minosäuren) gültig 33
34 Maximum Parsimony pomorphie: bgeleiteter Charakter. Synapomorpie: bgeleiteter Charakter, welcher mehreren Taxa gemeinsam ist. Plesiomorphie: Primitiver Charakter. Symplesiomorphie:Primitiver Charakter, welcher mehreren Taxa gemeinsam ist. B C Synapomorphie B C Symplesiomorphie Nur Synapomorphien sind in MP zu verwerten! 34
35 Synapomorphie! Beispiel Haare: Haare sind in der Evolution nur einmal entstanden. D.h., der Besitz von Haaren ist ein synapomorphes Merkmal der Säugetiere. Eidechse Mensch Frosch Änderung Hund fehlt vorhanden Synapomorphie = "richtige" Information 35
36 Homoplasie " Homoplasie ist Übereinstimmung ohne Homologie (d.h., keine gemeinsame bstammung) " Homoplasie resultiert aus unabhängiger Evolution (Konvergenz, Reversion) " Homoplasie ist falsche Information, die zu falschen Stammbäumen führen kann " MP ist anfällig für Homoplasie 36
37 Homoplasie-Konvergenz Beispiel Schwanz: Schwanz ging unabhängig in den Fröschen und beim Menschen verloren. Eidechse Mensch Frosch Hund fehlt vorhanden 37
38 nwendung auf Sequenzen " Nukleotide und minosäuren sind diskrete, diskontinuierliche Charaktere " 4 (Nukleotide) bzw. 20 (minosäuren) Charaktere " Lücken ("gaps") können als 5. bzw. 21. Charakter behandelt werden 38
39 Maximum Parsimony Beispiel: Position Sequenz G G T G C B G C C G T G C G C G T T C C D G G T C C G 3 mögliche Stammbäume C B B B D C D D C ((,B),(C,D)) ((,C),(B,D)) ((,D),(B,C)) 39
40 Maximum Parsimony Welche Positionen sind informativ, bevorzugen also eine bestimmte Topologie? Position Sequenz G G T G C B G C C G T G C G C G T T C C D G G T C C G 3 Positionen invariabel => nicht informativ 40
41 Maximum Parsimony Position Sequenz G G T G C B G C C G T G C G C G T T C C D G G T C C G 6 Positionen sind variabel => aber auch informativ? 41
42 Maximum Parsimony Position Sequenz G G T G C B G C C G T G C G C G T T C C D G G T C C G 3 Positionen sind zwar variabel, aber nicht informativ 42
43 Maximum Parsimony Welche Positionen sind aber nun informativ? Position Sequenz G G T G C - B G C C G T G C G - G C G T T C C C G D G G T C C G C G * * * * => nur 3 von 9 Positionen sind informativ, d.h., favorisieren eine best. Topologie. => Indels sind Charaktere! 43
44 Maximum Parsimony Position Sequenz G G T G C B G C C G T G C G C G T T C C D G G T C C G ((,B),(C,D)) ((,C),(B,D)) ((,D),(B,C)) Position 3: Position 5: Position 9: G G G G C C C G G G G G G G G G G G G G G nicht informativ 44
45 Maximum Parsimony Position Sequenz G G T G C B G C C G T G C G C G T T C C D G G T C C G * * * 3 mögliche Stammbäume B C D C B D D B C 10 Mutationen 15 Mutationen 14 Mutationen 45
46 Maximum Parsimony durchsucht den tree space! Exhaustive = lle Stammbäume werden untersucht, der beste Stammbaum wird erhalten (garantiert). Branch-and-Bound = Einige Stammbäume werden berechnet, bester Stammbaum garantiert. Heuristic = Einige Stammbäume werden berechnet, bester Stammbaum nicht garantiert. 46

47 MP Exhaustive Search 47
48 MP Exhaustive Search Start: 3 beliebige Taxa (1) B C "Branch addition + 4. Taxon (D) in jeder möglichen Position -> 3 Bäume E B (2a) D C B (2b) D C E B C (2c) E E D E + 5. Taxon (E) in jeder der fünf möglichen Positionen => 15 Stammbäume etc. 48
49 MP Exhaustive Search Problem: nzahl der möglichen Stammbäume Number of OTUs Number of rooted trees Number of unrooted trees => bei > ~10 Sequenzen ausführliche Suche aller Stammbäume de facto unmöglich 49
50 MP tree search 1. Lösung "Branch and bound": Erster Stammbaum wird mit schneller Methode (z.b. NJ) berechnet > die nzahl der notwendigen Schritte (L) wird berechnet. => verwirft Gruppen von Bäumen, die nicht kürzer werden können als L. Kann für Problemlösungen mit ~ 20 Taxa verwendet werden. 50


51 MP branch & bound verzweigen und beenden 51
52 MP tree search 2. Lösung: Heuristische Verfahren " stepwise addition drei Taxa Baum schrittweise ddition auf allen nächsten Ebenen (großes Problem: lokale Maxima) " star decomposition : schrittweiser bbau von Taxa bzw. Zusammenführung und Evaluation (großes Problem: lokale Maxima) Kombination mit anderen lgorithmen " branch swapping (Zweige vertauschen): Nearest neighbor interchange (NNI) Subtree pruning and regrafting (SPR) Tree bisection and reconnection (TBR) 52
53 MP heuristic tree search " Nearest neighbor interchange (NNI) Nachbarschaftstausch C D E B F G D C E C D E B F G B F G 53
54 MP heuristic tree search " Subtree pruning and regrafting (SPR) stverpflanzung C D E B F G C E F G D B 54
")

55 MP heuristic tree search " Tree bisection and reconnection (TBR) Baumschnittwiederverknüpfung (effektiv) C D E B F E G B G F B C D F C D G Gutes Durchmischen, aber CPU-aufwändig E 55


56 Das Problem des blinden Bergsteigers...?! Lokale Maxima 56








57 Down? Don t go! go go go!!! No go!!! Back up!!! Lokales Maximum
58 long branch attraction OTUs mit hoher Evolutionsrate und vielen Veränderungen ( long branches ) enthalten notwendigerweise zahlreiche Homoplasien/Konvergenzen diese Homoplasien führen dazu, daß MP die long branch -OTUs im Baum fälschlicherweise zueinandergruppiert > u. U. Taxa mit long branches entfernen!


59 Größtes Problem bei MP: long branch attraction Homoplasie! Falsche Topologie! LB oder Felsenstein zone
60 Maximum Parsimony Vorteile:! einfach! ohne konkretes Evolutionsmodell! Errechnung anzestraler Positionen! funktioniert gut mit konsistenten Datensätzen Nachteile:! empfindlich gegen Homoplasien (Konvergenz)! empfindlich gegen "Long Branch ttraction"! stlängen werden unterschätzt! kein Evolutionsmodell möglich! 60
61 Methoden-Übersicht Rekonstruktionsmethode Clustering- lgorithmus Such- Strategie Distanzen UPGM Neighbor joining Minimum Evolution Datentyp Character Maximum Parsimony Maximum Likelihood Bayes
Fernstudium "Molekulare Evolution" Bernhard Lieb Michael Schaffeld. Institut für Zoologie Universität Mainz
 Fernstudium "Molekulare Evolution" ernhard Lieb Michael Schaffeld Institut für Zoologie Universität Mainz 1 Ziel des Kurses Wie erhalte ich aus meinen (Sequenz-) aten einen Stammbaum, und was sagt mir
Fernstudium "Molekulare Evolution" ernhard Lieb Michael Schaffeld Institut für Zoologie Universität Mainz 1 Ziel des Kurses Wie erhalte ich aus meinen (Sequenz-) aten einen Stammbaum, und was sagt mir
Fernstudium "Molekulare Phylogenie" Bernhard Lieb Michael Schaffeld. Institut für Zoologie Universität Mainz
 Fernstudium "Molekulare Phylogenie" Bernhard Lieb Michael Schaffeld Institut für Zoologie Universität Mainz 1 Ziel des Kurses Wie erhalte ich aus meinen (Sequenz-) Daten einen Stammbaum, und was sagt mir
Fernstudium "Molekulare Phylogenie" Bernhard Lieb Michael Schaffeld Institut für Zoologie Universität Mainz 1 Ziel des Kurses Wie erhalte ich aus meinen (Sequenz-) Daten einen Stammbaum, und was sagt mir
Wo waren wir stehen geblieben? Evolutions modelle
 Wo waren wir stehen geblieben? Evolutions modelle 1 Stammbaumerstellung 1. Distanz-orientierte Methoden UPGMA (Unweighted Pair-Group Method with Arithmetric Means) Neighbor-joining Minimal Evolution =>
Wo waren wir stehen geblieben? Evolutions modelle 1 Stammbaumerstellung 1. Distanz-orientierte Methoden UPGMA (Unweighted Pair-Group Method with Arithmetric Means) Neighbor-joining Minimal Evolution =>
Übungen zur Vorlesung Algorithmische Bioinformatik
 Übungen zur Vorlesung Algorithmische Bioinformatik Freie Universität Berlin, WS 2006/07 Utz J. Pape Johanna Ploog Hannes Luz Martin Vingron Blatt 6 Ausgabe am 27.11.2006 Abgabe am 4.12.2006 vor Beginn
Übungen zur Vorlesung Algorithmische Bioinformatik Freie Universität Berlin, WS 2006/07 Utz J. Pape Johanna Ploog Hannes Luz Martin Vingron Blatt 6 Ausgabe am 27.11.2006 Abgabe am 4.12.2006 vor Beginn
Rekonstruktion der Phylogenese
 Rekonstruktion der Phylogenese 15.12.2010 1 Outline Probleme bei der Rekonstruktion eines Stammbaumes: Welche Merkmale? Welche Methode zur Auswahl des wahrscheinlichsten Stammbaumes? Schulen der Klassifikation
Rekonstruktion der Phylogenese 15.12.2010 1 Outline Probleme bei der Rekonstruktion eines Stammbaumes: Welche Merkmale? Welche Methode zur Auswahl des wahrscheinlichsten Stammbaumes? Schulen der Klassifikation
Moderne Methoden der KI: Maschinelles Lernen
 Moderne Methoden der KI: Maschinelles Lernen Prof. Dr.Hans-Dieter Burkhard Vorlesung Entscheidungsbäume Darstellung durch Regeln ID3 / C4.5 Bevorzugung kleiner Hypothesen Overfitting Entscheidungsbäume
Moderne Methoden der KI: Maschinelles Lernen Prof. Dr.Hans-Dieter Burkhard Vorlesung Entscheidungsbäume Darstellung durch Regeln ID3 / C4.5 Bevorzugung kleiner Hypothesen Overfitting Entscheidungsbäume
Algorithmische Bioinformatik
 lgorithmische Bioinformatik Stringalignment Ulf Leser Wissensmanagement in der Bioinformatik Inhalt dieser Vorlesung pproximative Stringvergleiche Dotplots Edit-bstand und lignment Naiver lgorithmus Ulf
lgorithmische Bioinformatik Stringalignment Ulf Leser Wissensmanagement in der Bioinformatik Inhalt dieser Vorlesung pproximative Stringvergleiche Dotplots Edit-bstand und lignment Naiver lgorithmus Ulf
IQPNNI Moving fast through tree space and stopping in time. Unicyclic Networks: Compatibility and Enumeration
 IQPNNI Moving fast through tree space and stopping in time. : and Enumeration Aktuelle Themen der Bioinformatik SoSe 2006 Bärbel Lasitschka Motivation phylogenetic tree reconstruction basierend auf Sequenzdaten
IQPNNI Moving fast through tree space and stopping in time. : and Enumeration Aktuelle Themen der Bioinformatik SoSe 2006 Bärbel Lasitschka Motivation phylogenetic tree reconstruction basierend auf Sequenzdaten
Kapitel 15: Differentialgleichungen
 FernUNI Hagen WS 00/03 Kapitel 15: Differentialgleichungen Differentialgleichungen = Gleichungen die Beziehungen zwischen einer Funktion und mindestens einer ihrer Ableitungen herstellen. Kommen bei vielen
FernUNI Hagen WS 00/03 Kapitel 15: Differentialgleichungen Differentialgleichungen = Gleichungen die Beziehungen zwischen einer Funktion und mindestens einer ihrer Ableitungen herstellen. Kommen bei vielen
Die Laufzeit muss nun ebenfalls in Monaten gerechnet werden und beträgt 25 12 = 300 Monate. Damit liefert die Sparkassenformel (zweiter Teil):
:") Lösungen zur Mathematikklausur WS 2004/2005 (Versuch 1) 1.1. Hier ist die Rentenformel für gemischte Verzinsung (nachschüssig) zu verwenden: K n = r(12 + 5, 5i p ) qn 1 q 1 = 100(12 + 5, 5 0, 03)1, 0325
Lösungen zur Mathematikklausur WS 2004/2005 (Versuch 1) 1.1. Hier ist die Rentenformel für gemischte Verzinsung (nachschüssig) zu verwenden: K n = r(12 + 5, 5i p ) qn 1 q 1 = 100(12 + 5, 5 0, 03)1, 0325

Der Beitrag der Genetik Kapitel 4
 Nichtrekombinierende DNS-Abschnitte, ob an der DNS der Mitochondrien, ob am X- oder Y-Chromosom, sind das geeignete Material, das es uns ermöglicht, Abstammungslinien in die Vergangenheit zurückzuverfolgen.
Nichtrekombinierende DNS-Abschnitte, ob an der DNS der Mitochondrien, ob am X- oder Y-Chromosom, sind das geeignete Material, das es uns ermöglicht, Abstammungslinien in die Vergangenheit zurückzuverfolgen.
Alignment von DNA- und Proteinsequenzen
 WS2012/2013 Genomforschung und Sequenzanalyse - Einführung in Methoden der Bioinformatik- Thomas Hankeln Alignment von DNA- und Proteinsequenzen das vielleicht wichtigste Werkzeug der Bioinformatik! 1
WS2012/2013 Genomforschung und Sequenzanalyse - Einführung in Methoden der Bioinformatik- Thomas Hankeln Alignment von DNA- und Proteinsequenzen das vielleicht wichtigste Werkzeug der Bioinformatik! 1
Clusteranalyse. Clusteranalyse. Fragestellung und Aufgaben. Abgrenzung Clusteranalyse - Diskriminanzanalyse. Rohdatenmatrix und Distanzmatrix
 TECHNISCHE UNIVERSITÄT MÜNCHEN-WEIHENSTEPHAN MATHEMATIK UND STATISTIK INFORMATIONS- UND DOKUMENTATIONSZENTRUM R. Biometrische und Ökonometrische Methoden II SS 00 Fragestellung und Aufgaben Abgrenzung
TECHNISCHE UNIVERSITÄT MÜNCHEN-WEIHENSTEPHAN MATHEMATIK UND STATISTIK INFORMATIONS- UND DOKUMENTATIONSZENTRUM R. Biometrische und Ökonometrische Methoden II SS 00 Fragestellung und Aufgaben Abgrenzung
Informationsmaterial Resistenz gegen HIV Recherche und Analyse molekularer Daten
 1 Informationsmaterial Resistenz gegen HIV Recherche und Analyse molekularer Daten (inkl. Anleitungen zur Recherche von Sequenzen mit GenBank und zur Analyse mit GeneDoc) In der Computer-basierten Version
1 Informationsmaterial Resistenz gegen HIV Recherche und Analyse molekularer Daten (inkl. Anleitungen zur Recherche von Sequenzen mit GenBank und zur Analyse mit GeneDoc) In der Computer-basierten Version
RNA Sekundärstruktur
 R Sekundärstruktur Dipl. Math. Isabelle Schneider niversität öttingen Institut für Mikrobiologie und enetik bteilung für Bioinformatik 12.12.2005 (niversität öttingen) 1 / 40 Themen der Vorlesung 1 R Motivation
R Sekundärstruktur Dipl. Math. Isabelle Schneider niversität öttingen Institut für Mikrobiologie und enetik bteilung für Bioinformatik 12.12.2005 (niversität öttingen) 1 / 40 Themen der Vorlesung 1 R Motivation
3. Einführung in die Theorie der Methoden
 3. Einführung in die Theorie der Methoden 3.1. Morphologische Daten Die Analyse morphologischer Merkmale bildet auch heute die Grundlage phylogenetischer Untersuchungen. Morphologische Merkmale sind der
3. Einführung in die Theorie der Methoden 3.1. Morphologische Daten Die Analyse morphologischer Merkmale bildet auch heute die Grundlage phylogenetischer Untersuchungen. Morphologische Merkmale sind der
Messen im psychologischen Kontext II: Reliabilitätsüberprüfung und explorative Faktorenanalyse
 Messen im psychologischen Kontext II: Reliabilitätsüberprüfung und explorative Faktorenanalyse Dominik Ernst 26.05.2009 Bachelor Seminar Dominik Ernst Reliabilität und explorative Faktorenanalyse 1/20
Messen im psychologischen Kontext II: Reliabilitätsüberprüfung und explorative Faktorenanalyse Dominik Ernst 26.05.2009 Bachelor Seminar Dominik Ernst Reliabilität und explorative Faktorenanalyse 1/20
Morphologie auf Binärbildern
 Morphologie auf Binärbildern WS07 5.1 Konen, Zielke WS07 5.2 Konen, Zielke Motivation Aufgabe: Objekte zählen Probleme: "Salt-&-Pepper"-Rauschen erzeugt falsche Objekte Verschmelzen richtiger Objekte durch
Morphologie auf Binärbildern WS07 5.1 Konen, Zielke WS07 5.2 Konen, Zielke Motivation Aufgabe: Objekte zählen Probleme: "Salt-&-Pepper"-Rauschen erzeugt falsche Objekte Verschmelzen richtiger Objekte durch
Rekonstruktion 3D-Datensätze
 Rekonstruktion 3D-Datensätze Messung von 2D Projektionsdaten von einer 3D Aktivitätsverteilung Bekannt sind: räumliche Anordnung der Detektoren/Projektionsflächen ->Ziel: Bestimmung der 3D-Aktivitätsverteilung
Rekonstruktion 3D-Datensätze Messung von 2D Projektionsdaten von einer 3D Aktivitätsverteilung Bekannt sind: räumliche Anordnung der Detektoren/Projektionsflächen ->Ziel: Bestimmung der 3D-Aktivitätsverteilung
6. Bayes-Klassifikation. (Schukat-Talamazzini 2002)
") 6. Bayes-Klassifikation (Schukat-Talamazzini 2002) (Böhm 2003) (Klawonn 2004) Der Satz von Bayes: Beweis: Klassifikation mittels des Satzes von Bayes (Klawonn 2004) Allgemeine Definition: Davon zu unterscheiden
6. Bayes-Klassifikation (Schukat-Talamazzini 2002) (Böhm 2003) (Klawonn 2004) Der Satz von Bayes: Beweis: Klassifikation mittels des Satzes von Bayes (Klawonn 2004) Allgemeine Definition: Davon zu unterscheiden
Evolution & Genetik (Beispiel Hämoglobin) Prof. Dr. Antje Krause FH Bingen 06721 / 409 253 akrause@fh-bingen.de
 Prof. Dr. Antje Krause FH Bingen 06721 / 409 253 akrause@fh-bingen.de") Evolution & Genetik (Beispiel Hämoglobin) Prof. Dr. Antje Krause FH Bingen 06721 / 409 253 akrause@fh-bingen.de DNA (Desoxyribonukleinsäure) 5 3 CGATGTACATCG GCTACATGTAGC 3 5 Doppelhelix Basen: Adenin,
Evolution & Genetik (Beispiel Hämoglobin) Prof. Dr. Antje Krause FH Bingen 06721 / 409 253 akrause@fh-bingen.de DNA (Desoxyribonukleinsäure) 5 3 CGATGTACATCG GCTACATGTAGC 3 5 Doppelhelix Basen: Adenin,
Kapitel ML: I. I. Einführung. Beispiele für Lernaufgaben Spezifikation von Lernproblemen
 Kapitel ML: I I. Einführung Beispiele für Lernaufgaben Spezifikation von Lernproblemen ML: I-8 Introduction c STEIN/LETTMANN 2005-2010 Beispiele für Lernaufgaben Autoeinkaufsberater Welche Kriterien liegen
Kapitel ML: I I. Einführung Beispiele für Lernaufgaben Spezifikation von Lernproblemen ML: I-8 Introduction c STEIN/LETTMANN 2005-2010 Beispiele für Lernaufgaben Autoeinkaufsberater Welche Kriterien liegen
Spezielle Eigenfunktionen des Transfer-Operators für Hecke Kongruenz Untergruppen
 Spezielle Eigenfunktionen des Transfer-Operators für Hecke Kongruenz Untergruppen Diplomarbeit 2005 Markus Fraczek Institut für Theoretische Physik Technische Universität Clausthal Abteilung Statistische
Spezielle Eigenfunktionen des Transfer-Operators für Hecke Kongruenz Untergruppen Diplomarbeit 2005 Markus Fraczek Institut für Theoretische Physik Technische Universität Clausthal Abteilung Statistische
!"#$%&"'()*'+,*-.*"&/$&*0"$.+ 12/+3"./+ + !"#$%&'("))*#"+#,$ -.$/.++$,0&'$1#(.+02#3$
*'+,*-.*&/$&*0$.+ 12/+3./+ + !#$%&'())*#+#,$ -.$/.++$,0&'$1#(.+02#3$") !"#$%&"'()*',*-.*"&/$&*0"$. 12/3"./!"#$%&'("))*#"#,$ -.$/.$,0&'$1#(.02#3$ [M*0'"()&,*-.*"&/$&*0"$. 43"./"5)$.&78//*5&$090*#"&' :;
!"#$%&"'()*',*-.*"&/$&*0"$. 12/3"./!"#$%&'("))*#"#,$ -.$/.$,0&'$1#(.02#3$ [M*0'"()&,*-.*"&/$&*0"$. 43"./"5)$.&78//*5&$090*#"&' :;
Vorlesung 3 MINIMALE SPANNBÄUME
 Vorlesung 3 MINIMALE SPANNBÄUME 72 Aufgabe! Szenario: Sie arbeiten für eine Firma, die ein Neubaugebiet ans Netz (Wasser, Strom oder Kabel oder...) anschließt! Ziel: Alle Haushalte ans Netz bringen, dabei
Vorlesung 3 MINIMALE SPANNBÄUME 72 Aufgabe! Szenario: Sie arbeiten für eine Firma, die ein Neubaugebiet ans Netz (Wasser, Strom oder Kabel oder...) anschließt! Ziel: Alle Haushalte ans Netz bringen, dabei
2. Lernen von Entscheidungsbäumen
 2. Lernen von Entscheidungsbäumen Entscheidungsbäume 2. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
2. Lernen von Entscheidungsbäumen Entscheidungsbäume 2. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
Datenanalyse und abstrakte Visualisierung
 Datenanalyse und abstrakte Visualisierung Patrick Auwärter Hauptseminar: Visualisierung großer Datensätze SS 2011 Inhalt Einleitung Anwendungsbeispiele Kondensationsvorgang Protein-Lösungsmittel System
Datenanalyse und abstrakte Visualisierung Patrick Auwärter Hauptseminar: Visualisierung großer Datensätze SS 2011 Inhalt Einleitung Anwendungsbeispiele Kondensationsvorgang Protein-Lösungsmittel System
MOL.504 Analyse von DNA- und Proteinsequenzen. Modul 2 BLAST-Sequenzsuche und Sequenzvergleiche
 MOL.504 Analyse von DNA- und Proteinsequenzen Modul 2 BLAST-Sequenzsuche und Sequenzvergleiche Summary Modul 1 - Datenbanken Wo finde ich die DNA Sequenz meines Zielgens? Wie erhalte ich Info aus der DNA-Datenbank
MOL.504 Analyse von DNA- und Proteinsequenzen Modul 2 BLAST-Sequenzsuche und Sequenzvergleiche Summary Modul 1 - Datenbanken Wo finde ich die DNA Sequenz meines Zielgens? Wie erhalte ich Info aus der DNA-Datenbank
HEUTE. Datenstrukturen im Computer. Datenstrukturen. Rekursion. Feedback Evaluation. abstrakte Datenstrukturen
 9.2.5 HUT 9.2.5 3 atenstrukturen im omputer atenstrukturen ie beiden fundamentalen atenstrukturen in der Praxis sind rray und Liste Rekursion Feedback valuation rray Zugriff: schnell Umordnung: langsam
9.2.5 HUT 9.2.5 3 atenstrukturen im omputer atenstrukturen ie beiden fundamentalen atenstrukturen in der Praxis sind rray und Liste Rekursion Feedback valuation rray Zugriff: schnell Umordnung: langsam
Lösungen zu den Übungsaufgaben aus Kapitel 3
 Lösungen zu den Übungsaufgaben aus Kapitel 3 Ü3.1: a) Die Start-Buchungslimits betragen b 1 = 25, b 2 = 20 und b 3 = 10. In der folgenden Tabelle sind jeweils die Annahmen ( ) und Ablehnungen ( ) der Anfragen
Lösungen zu den Übungsaufgaben aus Kapitel 3 Ü3.1: a) Die Start-Buchungslimits betragen b 1 = 25, b 2 = 20 und b 3 = 10. In der folgenden Tabelle sind jeweils die Annahmen ( ) und Ablehnungen ( ) der Anfragen
Graphen: Einführung. Vorlesung Mathematische Strukturen. Sommersemester 2011
 Graphen: Einführung Vorlesung Mathematische Strukturen Zum Ende der Vorlesung beschäftigen wir uns mit Graphen. Graphen sind netzartige Strukturen, bestehend aus Knoten und Kanten. Sommersemester 20 Prof.
Graphen: Einführung Vorlesung Mathematische Strukturen Zum Ende der Vorlesung beschäftigen wir uns mit Graphen. Graphen sind netzartige Strukturen, bestehend aus Knoten und Kanten. Sommersemester 20 Prof.
Eine Einführung in R: Hochdimensionale Daten: n << p Teil II
 Eine Einführung in R: Hochdimensionale Daten: n
Eine Einführung in R: Hochdimensionale Daten: n
Data Mining und Text Mining Einführung. S2 Einfache Regellerner
 Data Mining und Text Mining Einführung S2 Einfache Regellerner Hans Hermann Weber Univ. Erlangen, Informatik 8 Wintersemester 2003 hans.hermann.weber@gmx.de Inhalt Einiges über Regeln und Bäume R1 ein
Data Mining und Text Mining Einführung S2 Einfache Regellerner Hans Hermann Weber Univ. Erlangen, Informatik 8 Wintersemester 2003 hans.hermann.weber@gmx.de Inhalt Einiges über Regeln und Bäume R1 ein
4. Lernen von Entscheidungsbäumen. Klassifikation mit Entscheidungsbäumen. Entscheidungsbaum
 4. Lernen von Entscheidungsbäumen Klassifikation mit Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch /Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden.
4. Lernen von Entscheidungsbäumen Klassifikation mit Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch /Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden.
Mathematikaufgaben zur Vorbereitung auf das Studium
 Hochschule für Technik und Wirtschaft Dresden (FH) Fachbereich Informatik/Mathematik Mathematikaufgaben zur Vorbereitung auf das Studium Studiengänge Informatik Medieninformatik Wirtschaftsinformatik Wirtschaftsingenieurwesen
Hochschule für Technik und Wirtschaft Dresden (FH) Fachbereich Informatik/Mathematik Mathematikaufgaben zur Vorbereitung auf das Studium Studiengänge Informatik Medieninformatik Wirtschaftsinformatik Wirtschaftsingenieurwesen
Alignment-Verfahren zum Vergleich biologischer Sequenzen
 zum Vergleich biologischer Sequenzen Hans-Joachim Böckenhauer Dennis Komm Volkshochschule Zürich. April Ein biologisches Problem Fragestellung Finde eine Methode zum Vergleich von DNA-Molekülen oder Proteinen
zum Vergleich biologischer Sequenzen Hans-Joachim Böckenhauer Dennis Komm Volkshochschule Zürich. April Ein biologisches Problem Fragestellung Finde eine Methode zum Vergleich von DNA-Molekülen oder Proteinen
Einführung in die Geostatistik (7) Fred Hattermann (Vorlesung), hattermann@pik-potsdam.de Michael Roers (Übung), roers@pik-potsdam.
 Fred Hattermann (Vorlesung), hattermann@pik-potsdam.de Michael Roers (Übung), roers@pik-potsdam.") Einführung in die Geostatistik (7) Fred Hattermann (Vorlesung), hattermann@pik-potsdam.de Michael Roers (Übung), roers@pik-potsdam.de 1 Gliederung 7 Weitere Krigingverfahren 7.1 Simple-Kriging 7.2 Indikator-Kriging
Einführung in die Geostatistik (7) Fred Hattermann (Vorlesung), hattermann@pik-potsdam.de Michael Roers (Übung), roers@pik-potsdam.de 1 Gliederung 7 Weitere Krigingverfahren 7.1 Simple-Kriging 7.2 Indikator-Kriging
Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut, keine vorgegebenen Klassen
 7. Clusteranalyse (= Häufungsanalyse; Clustering-Verfahren) wird der multivariaten Statistik zugeordnet Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut,
7. Clusteranalyse (= Häufungsanalyse; Clustering-Verfahren) wird der multivariaten Statistik zugeordnet Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut,
Datenbankanwendung. Prof. Dr.-Ing. Sebastian Michel TU Kaiserslautern. Wintersemester 2014/15. smichel@cs.uni-kl.de
 Datenbankanwendung Wintersemester 2014/15 Prof. Dr.-Ing. Sebastian Michel TU Kaiserslautern smichel@cs.uni-kl.de Wiederholung: Anfragegraph Anfragen dieses Typs können als Graph dargestellt werden: Der
Datenbankanwendung Wintersemester 2014/15 Prof. Dr.-Ing. Sebastian Michel TU Kaiserslautern smichel@cs.uni-kl.de Wiederholung: Anfragegraph Anfragen dieses Typs können als Graph dargestellt werden: Der
l2l (Frage 1): Die Hardy-Weinberg-Gleichung wird häufig in der
: Die Hardy-Weinberg-Gleichung wird häufig in der") Maikelnummer: Seite 1 Semesterklausur,,Evol utionsbiologie" SeruesrERKLAUsu R zur Vonlesu NG,, Evol utions biolog ie" ws 2014t2015 Wiederholungsklausur EnlAurenuruc: Die Zahlen in eckigen Klammern vor
Maikelnummer: Seite 1 Semesterklausur,,Evol utionsbiologie" SeruesrERKLAUsu R zur Vonlesu NG,, Evol utions biolog ie" ws 2014t2015 Wiederholungsklausur EnlAurenuruc: Die Zahlen in eckigen Klammern vor
Herzlich Willkommen ! " $' #$% (!)% " * +,'-. ! 0 12" 12'" " #$%"& /!' '- 2! 2' 3 45267 2-5267
% * +,'-. ! 0 12 12' #$%& /!' '- 2! 2' 3 45267 2-5267") Page 1/1 Herzlich Willkommen! " #$%"&! " $' #$% (!)% " * +,'-. /!' '-! 0 12" 12'" 2! 2' 3 45267 2-5267 -26 89 : 9; ;/!!' 0 '6'!!2' 2(' '' ' &! =>! = / 5,?//'6 20%! ' 6', 62 '! @ @! &> $'( #'/
Page 1/1 Herzlich Willkommen! " #$%"&! " $' #$% (!)% " * +,'-. /!' '-! 0 12" 12'" 2! 2' 3 45267 2-5267 -26 89 : 9; ;/!!' 0 '6'!!2' 2(' '' ' &! =>! = / 5,?//'6 20%! ' 6', 62 '! @ @! &> $'( #'/
Die Clusteranalyse 24.06.2009. Clusteranalyse. Grundidee Mögliche Anwendungsgebiete gg Vorgehensweise Beispiele. methodenlehre ll Clusteranalyse
 Clusteranalyse Thomas Schäfer SS 2009 1 Die Clusteranalyse Grundidee Mögliche Anwendungsgebiete gg Vorgehensweise Beispiele Thomas Schäfer SS 2009 2 1 Die Clusteranalyse Grundidee: Eine heterogene Gesamtheit
Clusteranalyse Thomas Schäfer SS 2009 1 Die Clusteranalyse Grundidee Mögliche Anwendungsgebiete gg Vorgehensweise Beispiele Thomas Schäfer SS 2009 2 1 Die Clusteranalyse Grundidee: Eine heterogene Gesamtheit
Evolution II. Molekulare Variabilität. Bachelorkurs Evolutionsbiolgie II WS 2013/14
 Evolution II Molekulare Variabilität Bachelorkurs Evolutionsbiolgie II WS 2013/14 Molekulare Variabilität 1) rten der molekularen Variabilität und ihre Entstehung (rten der Mutation) 2) Wie kann man molekulare
Evolution II Molekulare Variabilität Bachelorkurs Evolutionsbiolgie II WS 2013/14 Molekulare Variabilität 1) rten der molekularen Variabilität und ihre Entstehung (rten der Mutation) 2) Wie kann man molekulare
Lernende Suchmaschinen
 Lernende Suchmaschinen Qingchui Zhu PG 520 - Intelligence Service (WiSe 07 / SoSe 08) Verzeichnis 1 Einleitung Problemstellung und Zielsetzung 2 Was ist eine lernende Suchmaschine? Begriffsdefinition 3
Lernende Suchmaschinen Qingchui Zhu PG 520 - Intelligence Service (WiSe 07 / SoSe 08) Verzeichnis 1 Einleitung Problemstellung und Zielsetzung 2 Was ist eine lernende Suchmaschine? Begriffsdefinition 3
Korrigenda Handbuch der Bewertung
 Korrigenda Handbuch der Bewertung Kapitel 3 Abschnitt 3.5 Seite(n) 104-109 Titel Der Terminvertrag: Ein Beispiel für den Einsatz von Future Values Änderungen In den Beispielen 21 und 22 ist der Halbjahressatz
Korrigenda Handbuch der Bewertung Kapitel 3 Abschnitt 3.5 Seite(n) 104-109 Titel Der Terminvertrag: Ein Beispiel für den Einsatz von Future Values Änderungen In den Beispielen 21 und 22 ist der Halbjahressatz
Abschlussprüfung 2013 an den Realschulen in Bayern
 Prüfugsdauer: 50 Miute Abschlussprüfug 03 a de Realschule i Bayer Mathematik II Name: Vorame: Klasse: Platzziffer: Pukte: Aufgabe A Haupttermi A 0 Die ebestehede kizze zeigt de Axialschitt eier massive
Prüfugsdauer: 50 Miute Abschlussprüfug 03 a de Realschule i Bayer Mathematik II Name: Vorame: Klasse: Platzziffer: Pukte: Aufgabe A Haupttermi A 0 Die ebestehede kizze zeigt de Axialschitt eier massive
Einführung in die Kodierungstheorie
 Einführung in die Kodierungstheorie Einführung Vorgehen Beispiele Definitionen (Code, Codewort, Alphabet, Länge) Hamming-Distanz Definitionen (Äquivalenz, Coderate, ) Singleton-Schranke Lineare Codes Hamming-Gewicht
Einführung in die Kodierungstheorie Einführung Vorgehen Beispiele Definitionen (Code, Codewort, Alphabet, Länge) Hamming-Distanz Definitionen (Äquivalenz, Coderate, ) Singleton-Schranke Lineare Codes Hamming-Gewicht
Die Varianzanalyse ohne Messwiederholung. Jonathan Harrington. Bi8e noch einmal datasets.zip laden
 Die Varianzanalyse ohne Messwiederholung Jonathan Harrington Bi8e noch einmal datasets.zip laden Variablen, Faktoren, Stufen Eine Varianzanalyse ist die Erweiterung von einem t- test t- test oder ANOVA
Die Varianzanalyse ohne Messwiederholung Jonathan Harrington Bi8e noch einmal datasets.zip laden Variablen, Faktoren, Stufen Eine Varianzanalyse ist die Erweiterung von einem t- test t- test oder ANOVA
 Preisliste w a r e A u f t r a g 8. V e r t r b 8. P C K a s s e 8. _ D a t a n o r m 8. _ F I B U 8. O P O S 8. _ K a s s a b u c h 8. L o h n 8. L e t u n g 8. _ w a r e D n s t l e t u n g e n S c h
Preisliste w a r e A u f t r a g 8. V e r t r b 8. P C K a s s e 8. _ D a t a n o r m 8. _ F I B U 8. O P O S 8. _ K a s s a b u c h 8. L o h n 8. L e t u n g 8. _ w a r e D n s t l e t u n g e n S c h
Modulabschlussklausur Analysis II
 Modulabschlussklausur Analysis II. Juli 015 Bearbeitungszeit: 150 min Aufgabe 1 [5/10 Punkte] Es sei a R und f a : R 3 R mit f a (x, y, z) = x cos(y) + z 3 sin(y) + a 3 + (z + ay a y) cos(x) a) Bestimmen
Modulabschlussklausur Analysis II. Juli 015 Bearbeitungszeit: 150 min Aufgabe 1 [5/10 Punkte] Es sei a R und f a : R 3 R mit f a (x, y, z) = x cos(y) + z 3 sin(y) + a 3 + (z + ay a y) cos(x) a) Bestimmen
Algorithmische Modelle als neues Paradigma
 Algorithmische Modelle als neues Paradigma Axel Schwer Seminar über Philosophische Grundlagen der Statistik, WS 2010/11 Betreuer: Prof. Dr. Thomas Augustin München, den 28. Januar 2011 1 / 29 LEO BREIMAN
Algorithmische Modelle als neues Paradigma Axel Schwer Seminar über Philosophische Grundlagen der Statistik, WS 2010/11 Betreuer: Prof. Dr. Thomas Augustin München, den 28. Januar 2011 1 / 29 LEO BREIMAN
2.12 Potenzreihen. 1. Definitionen. 2. Berechnung 2.12. POTENZREIHEN 207. Der wichtigste Spezialfall von Funktionenreihen sind Potenzreihen.
 2.2. POTENZREIHEN 207 2.2 Potenzreihen. Definitionen Der wichtigste Spezialfall von Funktionenreihen sind Potenzreihen. Eine Potenzreihe mit Entwicklungspunkt x 0 ist eine Reihe a n x x 0 n. Es gilt: es
2.2. POTENZREIHEN 207 2.2 Potenzreihen. Definitionen Der wichtigste Spezialfall von Funktionenreihen sind Potenzreihen. Eine Potenzreihe mit Entwicklungspunkt x 0 ist eine Reihe a n x x 0 n. Es gilt: es
StatStream : Statistical Monitoring of Thousands of Data Streams in Real Time Yunyue Zhu,Dennis Sasha. Vorgetragen von Matthias Altmann
 StatStream : Statistical Monitoring of Thousands of Data Streams in Real Time Yunyue Zhu,Dennis Sasha Vorgetragen von Matthias Altmann Mehrfache Datenströme Beispiel Luft und Raumfahrttechnik: Space Shuttle
StatStream : Statistical Monitoring of Thousands of Data Streams in Real Time Yunyue Zhu,Dennis Sasha Vorgetragen von Matthias Altmann Mehrfache Datenströme Beispiel Luft und Raumfahrttechnik: Space Shuttle
1. Man schreibe die folgenden Aussagen jeweils in einen normalen Satz um. Zum Beispiel kann man die Aussage:
 Zählen und Zahlbereiche Übungsblatt 1 1. Man schreibe die folgenden Aussagen jeweils in einen normalen Satz um. Zum Beispiel kann man die Aussage: Für alle m, n N gilt m + n = n + m. in den Satz umschreiben:
Zählen und Zahlbereiche Übungsblatt 1 1. Man schreibe die folgenden Aussagen jeweils in einen normalen Satz um. Zum Beispiel kann man die Aussage: Für alle m, n N gilt m + n = n + m. in den Satz umschreiben:
Ergänzungen zur Analysis I
 537. Ergänzungsstunde Logik, Mengen Ergänzungen zur Analysis I Die Behauptungen in Satz 0.2 über die Verknüpfung von Mengen werden auf die entsprechenden Regelnfür die Verknüpfung von Aussagen zurückgeführt.
537. Ergänzungsstunde Logik, Mengen Ergänzungen zur Analysis I Die Behauptungen in Satz 0.2 über die Verknüpfung von Mengen werden auf die entsprechenden Regelnfür die Verknüpfung von Aussagen zurückgeführt.
Clustering Seminar für Statistik
 Clustering Markus Kalisch 03.12.2014 1 Ziel von Clustering Finde Gruppen, sodas Elemente innerhalb der gleichen Gruppe möglichst ähnlich sind und Elemente von verschiedenen Gruppen möglichst verschieden
Clustering Markus Kalisch 03.12.2014 1 Ziel von Clustering Finde Gruppen, sodas Elemente innerhalb der gleichen Gruppe möglichst ähnlich sind und Elemente von verschiedenen Gruppen möglichst verschieden
16. All Pairs Shortest Path (ASPS)
") . All Pairs Shortest Path (ASPS) All Pairs Shortest Path (APSP): Eingabe: Gewichteter Graph G=(V,E) Ausgabe: Für jedes Paar von Knoten u,v V die Distanz von u nach v sowie einen kürzesten Weg a b c d e
. All Pairs Shortest Path (ASPS) All Pairs Shortest Path (APSP): Eingabe: Gewichteter Graph G=(V,E) Ausgabe: Für jedes Paar von Knoten u,v V die Distanz von u nach v sowie einen kürzesten Weg a b c d e
DIFFERENTIALGLEICHUNGEN
 DIFFERENTIALGLEICHUNGEN GRUNDBEGRIFFE Differentialgleichung Eine Gleichung, in der Ableitungen einer unbekannten Funktion y = y(x) bis zur n-ten Ordnung auftreten, heisst gewöhnliche Differentialgleichung
DIFFERENTIALGLEICHUNGEN GRUNDBEGRIFFE Differentialgleichung Eine Gleichung, in der Ableitungen einer unbekannten Funktion y = y(x) bis zur n-ten Ordnung auftreten, heisst gewöhnliche Differentialgleichung
Lernen von Entscheidungsbäumen. Volker Tresp Summer 2014
 Lernen von Entscheidungsbäumen Volker Tresp Summer 2014 1 Anforderungen an Methoden zum Datamining Schnelle Verarbeitung großer Datenmengen Leichter Umgang mit hochdimensionalen Daten Das Lernergebnis
Lernen von Entscheidungsbäumen Volker Tresp Summer 2014 1 Anforderungen an Methoden zum Datamining Schnelle Verarbeitung großer Datenmengen Leichter Umgang mit hochdimensionalen Daten Das Lernergebnis
Abschlussprüfung 2008 an den Realschulen in Bayern
 bschlussprüfung 008 an den Realschulen in Bayern Mathematik II Haupttermin ufgabe Lösungsmuster und Bewertung FUNKTIONEN. ( ) p und C(6 ) p: 0,5 ( ) + b( ) + c + + 0,5 6 b6 c b,c b IL(b c) {( )} c p: y
bschlussprüfung 008 an den Realschulen in Bayern Mathematik II Haupttermin ufgabe Lösungsmuster und Bewertung FUNKTIONEN. ( ) p und C(6 ) p: 0,5 ( ) + b( ) + c + + 0,5 6 b6 c b,c b IL(b c) {( )} c p: y
Kann man mit dem öffentlichen Beschaffungswesen Lehrstellen fördern?
 Working Paper No. 85 Kann man mit dem öffentlichen Beschaffungswesen Lehrstellen fördern? Mirjam Strupler Leiser und Stefan C. Wolter!#$%&'#()(*+,&#-.* /01*2*/'(#(3(*4,&*0%(&#%5'6#&('-.74('8%.&%* Leading
Working Paper No. 85 Kann man mit dem öffentlichen Beschaffungswesen Lehrstellen fördern? Mirjam Strupler Leiser und Stefan C. Wolter!#$%&'#()(*+,&#-.* /01*2*/'(#(3(*4,&*0%(&#%5'6#&('-.74('8%.&%* Leading
Grundlagen der Elektrotechnik I (GET I)
") Grundlagen der lektrotechnik (GT ) Vorlesung am 09.0.007 Fr. 08:30-0:00 Uhr; R. 603 (Hörsaal) Dr.-ng. René Marklein -Mail: marklein@uni-kassel.de kassel.de Tel.: 056 804 646; Fax: 056 804 6489 URL: http://www.tet.e-technik.uni
Grundlagen der lektrotechnik (GT ) Vorlesung am 09.0.007 Fr. 08:30-0:00 Uhr; R. 603 (Hörsaal) Dr.-ng. René Marklein -Mail: marklein@uni-kassel.de kassel.de Tel.: 056 804 646; Fax: 056 804 6489 URL: http://www.tet.e-technik.uni
Verwendung von LS-OPT zur Generierung von Materialkarten am Beispiel von Schaumwerkstoffen
 Verwendung von LS-OPT zur Generierung von Materialkarten am Beispiel von Schaumwerkstoffen Katharina Witowski (DYNAmore GmbH) Peter Reithofer (4a engineering GmbH) Übersicht Problemstellung Parameteridentifikation
Verwendung von LS-OPT zur Generierung von Materialkarten am Beispiel von Schaumwerkstoffen Katharina Witowski (DYNAmore GmbH) Peter Reithofer (4a engineering GmbH) Übersicht Problemstellung Parameteridentifikation
Umgang mit und Ersetzen von fehlenden Werten bei multivariaten Analysen
 Umgang mit und Ersetzen von fehlenden Werten bei multivariaten Analysen Warum überhaupt Gedanken machen? Was fehlt, ist doch weg, oder? Allgegenwärtiges Problem in psychologischer Forschung Bringt Fehlerquellen
Umgang mit und Ersetzen von fehlenden Werten bei multivariaten Analysen Warum überhaupt Gedanken machen? Was fehlt, ist doch weg, oder? Allgegenwärtiges Problem in psychologischer Forschung Bringt Fehlerquellen
Abschlussprüfung 2010 an den Realschulen in Bayern
 Lösungsmuster und Bewertung 0 Minuten bschlussprüfung 00 an den Realschulen in Bayern Mathematik II ufgaben - Nachtermin RUMGEOMETRIE. EB B EB 8,9cm ES EB + BS ES 9,00cm α cm sin α 8,9 α ]0 ;80 [ 9,00cm
Lösungsmuster und Bewertung 0 Minuten bschlussprüfung 00 an den Realschulen in Bayern Mathematik II ufgaben - Nachtermin RUMGEOMETRIE. EB B EB 8,9cm ES EB + BS ES 9,00cm α cm sin α 8,9 α ]0 ;80 [ 9,00cm
Entscheidungsbäume. Definition Entscheidungsbaum. Frage: Gibt es einen Sortieralgorithmus mit o(n log n) Vergleichen?
 Vergleichen?") Entscheidungsbäume Frage: Gibt es einen Sortieralgorithmus mit o(n log n) Vergleichen? Definition Entscheidungsbaum Sei T ein Binärbaum und A = {a 1,..., a n } eine zu sortierenden Menge. T ist ein Entscheidungsbaum
Entscheidungsbäume Frage: Gibt es einen Sortieralgorithmus mit o(n log n) Vergleichen? Definition Entscheidungsbaum Sei T ein Binärbaum und A = {a 1,..., a n } eine zu sortierenden Menge. T ist ein Entscheidungsbaum
Marion Pucher Membrantechnik S26 Matthias Steiger. Membrantechnik. Betreuer: Univ. Prof. Dr. Anton Friedl. Durchgeführt von:
 Membrantechnik Betreuer: Univ. Prof. Dr. Anton Friedl Durchgeführt von: Marion Pucher Mtk.Nr.:0125440 Kennzahl: S26 Mtk.Nr.:0125435 Kennzahl: Datum der Übung: 17.3.2004 Seite 1/11 1. Ziel der Übung Mithilfe
Membrantechnik Betreuer: Univ. Prof. Dr. Anton Friedl Durchgeführt von: Marion Pucher Mtk.Nr.:0125440 Kennzahl: S26 Mtk.Nr.:0125435 Kennzahl: Datum der Übung: 17.3.2004 Seite 1/11 1. Ziel der Übung Mithilfe
Satz 2.8.3: Sei Q eine Intensitätsmatrix. Dann hat die
 Satz 2.8.3: Sei Q eine Intensitätsmatrix. Dann hat die Rückwärtsgleichung P (t) = QP (t), P (0) = E eine minimale nicht negative Lösung (P (t) : t 0). Die Lösung bildet eine Matrix Halbgruppe, d.h. P (s)p
Satz 2.8.3: Sei Q eine Intensitätsmatrix. Dann hat die Rückwärtsgleichung P (t) = QP (t), P (0) = E eine minimale nicht negative Lösung (P (t) : t 0). Die Lösung bildet eine Matrix Halbgruppe, d.h. P (s)p
Vorlesungsplan. Von Naïve Bayes zu Bayesischen Netzwerk- Klassifikatoren. Naïve Bayes. Bayesische Netzwerke
 Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
7 Die Determinante einer Matrix
 7 Die Determinante einer Matrix ( ) a11 a Die Determinante einer 2 2 Matrix A = 12 ist erklärt als a 21 a 22 det A := a 11 a 22 a 12 a 21 Es ist S 2 = { id, τ}, τ = (1, 2) und sign (id) = 1, sign (τ) =
7 Die Determinante einer Matrix ( ) a11 a Die Determinante einer 2 2 Matrix A = 12 ist erklärt als a 21 a 22 det A := a 11 a 22 a 12 a 21 Es ist S 2 = { id, τ}, τ = (1, 2) und sign (id) = 1, sign (τ) =
Vorlesung - Medizinische Biometrie
 Vorlesung - Medizinische Biometrie Stefan Wagenpfeil Institut für Medizinische Biometrie, Epidemiologie und Medizinische Informatik Universität des Saarlandes, Homburg / Saar Vorlesung - Medizinische Biometrie
Vorlesung - Medizinische Biometrie Stefan Wagenpfeil Institut für Medizinische Biometrie, Epidemiologie und Medizinische Informatik Universität des Saarlandes, Homburg / Saar Vorlesung - Medizinische Biometrie
BRUTTOPREISLISTE. Made in Austria AUSTRIA. 03 2009 zu Katalog 2009l10
 Connection to the future BRUTTOPREISLISTE Made in Austria AUSTRIA 03 2009 zu Katalog 2009l10 013-10 15 13,94 013-10TT 15 13,94 013-2 15 13,94 0132-10 15 25,25 0132-10TT 15 25,25 0132-2 15 25,25 0132-2TT
Connection to the future BRUTTOPREISLISTE Made in Austria AUSTRIA 03 2009 zu Katalog 2009l10 013-10 15 13,94 013-10TT 15 13,94 013-2 15 13,94 0132-10 15 25,25 0132-10TT 15 25,25 0132-2 15 25,25 0132-2TT
Künstliche Intelligenz Maschinelles Lernen
 Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
Diana Lange. Generative Gestaltung Operatoren
 Diana Lange Generative Gestaltung Operatoren Begriffserklärung Verknüpfungsvorschrift im Rahmen logischer Kalküle. Quelle: google Operatoren sind Zeichen, die mit einer bestimmten Bedeutung versehen sind.
Diana Lange Generative Gestaltung Operatoren Begriffserklärung Verknüpfungsvorschrift im Rahmen logischer Kalküle. Quelle: google Operatoren sind Zeichen, die mit einer bestimmten Bedeutung versehen sind.
Mathematik 1. Inhaltsverzeichnis. Prof. Dr. K. Melzer. karin.melzer@hs-esslingen.de http://www.hs-esslingen.de/de/mitarbeiter/karin-melzer.
 Mathematik 1 Prof Dr K Melzer karinmelzer@hs-esslingende http://wwwhs-esslingende/de/mitarbeiter/karin-melzerhtml Inhaltsverzeichnis 1 Matrizenrechnung 2 11 Matrixbegri 2 12 Spezielle Matrizen 3 13 Rechnen
Mathematik 1 Prof Dr K Melzer karinmelzer@hs-esslingende http://wwwhs-esslingende/de/mitarbeiter/karin-melzerhtml Inhaltsverzeichnis 1 Matrizenrechnung 2 11 Matrixbegri 2 12 Spezielle Matrizen 3 13 Rechnen
! " # $! %&' () * +, - +, *, $! %.' ()* +, (( / * +, * +, 0112
 * +, - +, *, $! %.' ()* +, (( / * +, * +, 0112") ! " # $! %&' () * +, - +, *, $! %.' ()* +, (( / * +, * +, 0112 + $ 3! " 4 5 6 78 12 0119 + ( $! %.' () * +, 5! ) + +":(: *" 4+ ' ; < 4 " : 3 %: +! %! " + ( =:6
! " # $! %&' () * +, - +, *, $! %.' ()* +, (( / * +, * +, 0112 + $ 3! " 4 5 6 78 12 0119 + ( $! %.' () * +, 5! ) + +":(: *" 4+ ' ; < 4 " : 3 %: +! %! " + ( =:6
Physik 1 für Ingenieure
 Physik 1 für Ingenieure Othmar Marti Experimentelle Physik Universität Ulm Othmar.Marti@Physik.Uni-Ulm.de Skript: http://wwwex.physik.uni-ulm.de/lehre/physing1 Übungsblätter und Lösungen: http://wwwex.physik.uni-ulm.de/lehre/physing1/ueb/ue#
Physik 1 für Ingenieure Othmar Marti Experimentelle Physik Universität Ulm Othmar.Marti@Physik.Uni-Ulm.de Skript: http://wwwex.physik.uni-ulm.de/lehre/physing1 Übungsblätter und Lösungen: http://wwwex.physik.uni-ulm.de/lehre/physing1/ueb/ue#
Effiziente Algorithmen und Datenstrukturen I. Kapitel 9: Minimale Spannbäume
 Effiziente Algorithmen und Datenstrukturen I Kapitel 9: Minimale Spannbäume Christian Scheideler WS 008 19.0.009 Kapitel 9 1 Minimaler Spannbaum Zentrale Frage: Welche Kanten muss ich nehmen, um mit minimalen
Effiziente Algorithmen und Datenstrukturen I Kapitel 9: Minimale Spannbäume Christian Scheideler WS 008 19.0.009 Kapitel 9 1 Minimaler Spannbaum Zentrale Frage: Welche Kanten muss ich nehmen, um mit minimalen
Auswertung und Darstellung wissenschaftlicher Daten (1)
") Auswertung und Darstellung wissenschaftlicher Daten () Mag. Dr. Andrea Payrhuber Zwei Schritte der Auswertung. Deskriptive Darstellung aller Daten 2. analytische Darstellung (Gruppenvergleiche) SPSS-Andrea
Auswertung und Darstellung wissenschaftlicher Daten () Mag. Dr. Andrea Payrhuber Zwei Schritte der Auswertung. Deskriptive Darstellung aller Daten 2. analytische Darstellung (Gruppenvergleiche) SPSS-Andrea
1.) Soll die gesamte Spalte oder Zeile ausgewählt werden, reicht es auf den Spalten-/Zeilenkopf (Ziffer bzw. Buchstabe) zu klicken
 Soll die gesamte Spalte oder Zeile ausgewählt werden, reicht es auf den Spalten-/Zeilenkopf (Ziffer bzw. Buchstabe) zu klicken") Leitfaden für Excel Inhaltsverzeichnis Grundsätzliches... 3 Nützliche Tastenkombinationen... 4 Die oberste Zeile einer Tabelle fixieren... 5 Eine Seite einrichten (für ein übersichtliches Layout beim Drucken)...
Leitfaden für Excel Inhaltsverzeichnis Grundsätzliches... 3 Nützliche Tastenkombinationen... 4 Die oberste Zeile einer Tabelle fixieren... 5 Eine Seite einrichten (für ein übersichtliches Layout beim Drucken)...
Bildgebende Systeme in der Medizin
 10/27/2011 Page 1 Hochschule Mannheim Bildgebende Systeme in der Medizin Computer-Tomographie Faculty of Medicine Mannheim University of Heidelberg Theodor-Kutzer-Ufer 1-3 D-68167 Mannheim, Germany Friedrich.Wetterling@MedMa.Uni-Heidelberg.de
10/27/2011 Page 1 Hochschule Mannheim Bildgebende Systeme in der Medizin Computer-Tomographie Faculty of Medicine Mannheim University of Heidelberg Theodor-Kutzer-Ufer 1-3 D-68167 Mannheim, Germany Friedrich.Wetterling@MedMa.Uni-Heidelberg.de
Informationstechnologie in der Pflanzenzüchtung. Biocomputing in einem Züchtungsunternehmen. Andreas Menze KWS SAAT AG, Einbeck
 Informationstechnologie in der Pflanzenzüchtung Biocomputing in einem Züchtungsunternehmen Andreas Menze KWS SAAT AG, Einbeck Biocomputing in einem Züchtungsunternehmen Biocomputing Was ist das? Wozu wird
Informationstechnologie in der Pflanzenzüchtung Biocomputing in einem Züchtungsunternehmen Andreas Menze KWS SAAT AG, Einbeck Biocomputing in einem Züchtungsunternehmen Biocomputing Was ist das? Wozu wird
Matrizennorm. Definition 1. Sei A M r,s (R). Dann heißt A := sup die Matrixnorm. Wir wissen zunächst nicht, ob A eine reelle Zahl ist.
. Dann heißt A := sup die Matrixnorm. Wir wissen zunächst nicht, ob A eine reelle Zahl ist.") Matrizennorm Es seien r,s N Mit M r,s (R bezeichnen wir die Menge der reellen r s- Matrizen (also der linearen Abbildungen R s R r, und setze M s (R := M s,s (R (also die Menge der linearen Abbildungen
Matrizennorm Es seien r,s N Mit M r,s (R bezeichnen wir die Menge der reellen r s- Matrizen (also der linearen Abbildungen R s R r, und setze M s (R := M s,s (R (also die Menge der linearen Abbildungen
Bestimmung einer ersten
 Kapitel 6 Bestimmung einer ersten zulässigen Basislösung Ein Problem, was man für die Durchführung der Simplexmethode lösen muss, ist die Bestimmung einer ersten zulässigen Basislösung. Wie gut das geht,
Kapitel 6 Bestimmung einer ersten zulässigen Basislösung Ein Problem, was man für die Durchführung der Simplexmethode lösen muss, ist die Bestimmung einer ersten zulässigen Basislösung. Wie gut das geht,
Design Theorie für relationale Datenbanken
 Design Theorie für relationale Datenbanken Design von relationalen Datenbanken alternativen Datenabhängigkeiten Normalisierung Ziel: automatisches Datenbankdesign IX-1 Schlechtes Datenbank Design Frage:
Design Theorie für relationale Datenbanken Design von relationalen Datenbanken alternativen Datenabhängigkeiten Normalisierung Ziel: automatisches Datenbankdesign IX-1 Schlechtes Datenbank Design Frage:
34 5. FINANZMATHEMATIK
 34 5. FINANZMATHEMATIK 5. Finanzmathematik 5.1. Ein einführendes Beispiel Betrachten wir eine ganz einfache Situation. Wir haben einen Markt, wo es nur erlaubt ist, heute und in einem Monat zu handeln.
34 5. FINANZMATHEMATIK 5. Finanzmathematik 5.1. Ein einführendes Beispiel Betrachten wir eine ganz einfache Situation. Wir haben einen Markt, wo es nur erlaubt ist, heute und in einem Monat zu handeln.
Data Mining-Modelle und -Algorithmen
 Data Mining-Modelle und -Algorithmen Data Mining-Modelle und -Algorithmen Data Mining ist ein Prozess, bei dem mehrere Komponenten i n- teragieren. Sie greifen auf Datenquellen, um diese zum Training,
Data Mining-Modelle und -Algorithmen Data Mining-Modelle und -Algorithmen Data Mining ist ein Prozess, bei dem mehrere Komponenten i n- teragieren. Sie greifen auf Datenquellen, um diese zum Training,
Der Advanced Encryption Standard (AES)
") Der Advanced Encryption Standard (AES) Prof. Dr. Rüdiger Weis TFH Berlin Sommersemester 2008 Geschichte des AES Die Struktur des AES Angriffe auf den AES Aktuelle Ergebnisse DerAdvanced Encryption Standard
Der Advanced Encryption Standard (AES) Prof. Dr. Rüdiger Weis TFH Berlin Sommersemester 2008 Geschichte des AES Die Struktur des AES Angriffe auf den AES Aktuelle Ergebnisse DerAdvanced Encryption Standard
( ) als den Punkt mit der gleichen x-koordinate wie A und der
 als den Punkt mit der gleichen x-koordinate wie A und der") ETH-Aufnahmeprüfung Herbst 05 Mathematik I (Analysis) Aufgabe [6 Punkte] Bestimmen Sie den Schnittwinkel α zwischen den Graphen der Funktionen f(x) x 4x + x + 5 und g(x) x x + 5 im Schnittpunkt mit der
ETH-Aufnahmeprüfung Herbst 05 Mathematik I (Analysis) Aufgabe [6 Punkte] Bestimmen Sie den Schnittwinkel α zwischen den Graphen der Funktionen f(x) x 4x + x + 5 und g(x) x x + 5 im Schnittpunkt mit der
KLASSIFIZIERUNG VON SCHADSOFTWARE ANHAND VON SIMULIERTEM NETZWERKVERKEHR
 Retail KLASSIFIZIERUNG VON SCHADSOFTWARE ANHAND VON SIMULIERTEM NETZWERKVERKEHR Technology Life Sciences & Healthcare Florian Hockmann Ruhr-Universität Bochum florian.hockmann@rub.de Automotive Consumer
Retail KLASSIFIZIERUNG VON SCHADSOFTWARE ANHAND VON SIMULIERTEM NETZWERKVERKEHR Technology Life Sciences & Healthcare Florian Hockmann Ruhr-Universität Bochum florian.hockmann@rub.de Automotive Consumer
Einführung in die numerische Quantenchemie
 Einführung in die numerische Quantenchemie Michael Martins michael.martins@desy.de Characterisation of clusters and nano structures using XUV radiation p.1 Literatur A. Szabo, N.S. Ostlund, Modern Quantum
Einführung in die numerische Quantenchemie Michael Martins michael.martins@desy.de Characterisation of clusters and nano structures using XUV radiation p.1 Literatur A. Szabo, N.S. Ostlund, Modern Quantum
Multiuser Client/Server Systeme
 Multiuser /Server Systeme Christoph Nießner Seminar: 3D im Web Universität Paderborn Wintersemester 02/03 Übersicht Was sind /Server Systeme Wie sehen Architekturen aus Verteilung der Anwendung Protokolle
Multiuser /Server Systeme Christoph Nießner Seminar: 3D im Web Universität Paderborn Wintersemester 02/03 Übersicht Was sind /Server Systeme Wie sehen Architekturen aus Verteilung der Anwendung Protokolle
Kodierungsalgorithmen
 Kodierungsalgorithmen Komprimierung Verschlüsselung Komprimierung Zielsetzung: Reduktion der Speicherkapazität Schnellere Übertragung Prinzipien: Wiederholungen in den Eingabedaten kompakter speichern
Kodierungsalgorithmen Komprimierung Verschlüsselung Komprimierung Zielsetzung: Reduktion der Speicherkapazität Schnellere Übertragung Prinzipien: Wiederholungen in den Eingabedaten kompakter speichern
VERDAMPFUNGSGLEICHGEWICHTE: SIEDEDIAGRAMM EINER BINÄREN MISCHUNG
 VERDAMPFUNGSGLEICHGEWICHTE: RAMM EINER BINÄREN MISCHUNG 1. Lernziel Ziel des Versuchs ist es, ein zu bestimmen, um ein besseres Verständnis für Verdampfungsgleichgewichte und Mischeigenschaften flüssiger
VERDAMPFUNGSGLEICHGEWICHTE: RAMM EINER BINÄREN MISCHUNG 1. Lernziel Ziel des Versuchs ist es, ein zu bestimmen, um ein besseres Verständnis für Verdampfungsgleichgewichte und Mischeigenschaften flüssiger
Codierung, Codes (variabler Länge)
") Codierung, Codes (variabler Länge) A = {a, b, c,...} eine endliche Menge von Nachrichten (Quellalphabet) B = {0, 1} das Kanalalphabet Eine (binäre) Codierung ist eine injektive Abbildung Φ : A B +, falls
Codierung, Codes (variabler Länge) A = {a, b, c,...} eine endliche Menge von Nachrichten (Quellalphabet) B = {0, 1} das Kanalalphabet Eine (binäre) Codierung ist eine injektive Abbildung Φ : A B +, falls
Geometrische Optik. Beschreibung der Propagation durch Richtung der k-vektoren ( Lichtstrahlen )
") Geometrische Optik Beschreibung der Propagation durch Richtung der k-vektoren ( Lichtstrahlen ) k - Vektoren zeigen zu Wellenfronten für Ausdehnung D von Strukturen, die zu geometrischer Eingrenzung führen
Geometrische Optik Beschreibung der Propagation durch Richtung der k-vektoren ( Lichtstrahlen ) k - Vektoren zeigen zu Wellenfronten für Ausdehnung D von Strukturen, die zu geometrischer Eingrenzung führen
Seminar Text- und Datamining Datamining-Grundlagen
 Seminar Text- und Datamining Datamining-Grundlagen Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 23.05.2013 Gliederung 1 Klassifikationsprobleme 2 Evaluation
Seminar Text- und Datamining Datamining-Grundlagen Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 23.05.2013 Gliederung 1 Klassifikationsprobleme 2 Evaluation
Approximationsalgorithmen: Klassiker I. Kombinatorische Optimierung Absolute Gütegarantie Graph-Coloring Clique Relative Gütegarantie Scheduling
 Approximationsalgorithmen: Klassiker I Kombinatorische Optimierung Absolute Gütegarantie Graph-Coloring Clique Relative Gütegarantie Scheduling VO Approximationsalgorithmen WiSe 2011/12 Markus Chimani
Approximationsalgorithmen: Klassiker I Kombinatorische Optimierung Absolute Gütegarantie Graph-Coloring Clique Relative Gütegarantie Scheduling VO Approximationsalgorithmen WiSe 2011/12 Markus Chimani