Clusteranalyse. Johann Bacher. Almo Statistik-System
|
|
|
- Robert Beutel
- vor 5 Jahren
- Abrufe
Transkript

1 Clusteranalyse Johann Bacher Almo Statistik-System
2 Das vorliegende Dokument ist eine gekürzte Version des Almo-Handbuchs zur Clusteranalyse. Herausgenommen wurden lediglich die in der Almo-Programmiersprache geschriebenen Syntax-Programme. Auch das Kapitel P0 Arbeiten mit Almo-Maskenprogrammen wurde herausgenommen. Es kann (überarbeitet) als Almo-Handbuch separat unter heruntergeladen werden. Nachfolgend wird häufig auf das Dokument P0 Bezug genommen. Dabei handelt es sich um das Almo-Dokument "Arbeiten mit Almo.PDF". Es kann in Almo heruntergeladen werden Weitere Almo-Dokumente Die folgenden Dokumente können alle von der Handbuchseite in heruntergeladen werden 0. Arbeiten_mit_Almo.PDF (1 MB) 1a. Eindimensionale Tabellierung.PDF (1.8 MB) 1b. Zwei- und drei-dimensionale Tabellierung.PDF (1.1 MB) 2. Beliebig-dimensionale Tabellierung.PDF (1.7 MB) 3. Nicht-parametrische Verfahren.PDF (0.9 MB) 4. Kanonische Analysen.PDF (1.8 MB) Diskriminanzanalyse.PDF (1.8 MB) enthält: Kanonische Korrelation, Diskriminanzanalyse, bivariate Korrespondenzanalyse, optimale Skalierung 5. Korrelation.PDF (1.4 MB) 6. Allgemeine multiple Korrespondenzanalyse.PDF (1.5 MB) 7. Allgemeines ordinales Rasch-Modell.PDF (0.6 MB) 7a. Wie man mit Almo ein Rasch-Modell rechnet.pdf (0.2 MB) 8. Tests auf Mittelwertsdifferenz, t-test.pdf (1,6 MB) 9. Logitanalyse.pdf (1,2MB) enthält Logit- und Probitanalyse 10. Koeffizienten der Logitanalyse.PDF (0,06 MB) 11. Daten-Fusion.PDF (1,1 MB) 12. Daten-Imputation.PDF (1,3 MB) 13. ALM Allgemeines Lineares Modell.PDF (2.3 MB) 13a. ALM Allgemeines Lineares Modell II.PDF (2.7 MB) 14. Ereignisanalyse: Sterbetafel-Methode, Kaplan-Meier-Schätzer, Cox-Regression.PDF (1,5 MB) 15. Faktorenanalyse.PDF (1,6 MB) 16. Konfirmatorische Faktorenanalyse.PDF (0,3 MB) 17. Clusteranalyse.PDF (3 MB) 18. Pisa 2012 Almo-Daten und Analyse-Programme.PDF (17 KB) 19. Guttman- und Mokken-Skalierung.PFD (0.8 MB) 20. Latent Structure Analysis.PDF (1 MB) 21. Statistische Algorithmen in C (80 KB) 22. Conjoint-Analyse (PDF 0,8 MB) 23. Ausreisser entdecken (PDF 170 KB) 24. Statistische Datenanalyse Teil I, Data Mining I 25. Statistische Datenanalyse Teil II, Data Mining II 26. Statistische Datenanalyse Teil III, Arbeiten mit Almo- Datenanalyse-System 27. Mehrfachantworten, Tabellierung von Fragen mit Mehrfachantworten (0.8 MB) 28. Metrische multidimensionale Skalierung (MDS) (0,4 MB) 29. Metrisches multidimensionales Unfolding (MDU) (0,6 MB) 30. Nicht-metrische multidimensionale Skalierung (MDS) (0,5 MB) 31. Pfadanalyse.PDF (0,7 MB) 32. Datei-Operationen mit Almo (1,1 MB) 33. Wählerstromanalyse und Wahlhochrechnung (1,6 MB) 2
3 Inhaltsverzeichnis Clusteranalyse...1 P36 Hierarchische Clusteranalyse...5 P36.0 Übersicht und Modelle... 5 P36.1 Eingabe einer Ähnlichkeits- oder Unähnlichkeitsmatrix P Eingabe mit Programm-Maske Prog36mf Das nachfolgende Programm findet der Benutzer unter dem Namen Prog36mf.Msk durch Klick auf den Knopf Verfahren dann Clusteranalyse/Prog36mf P Erläuterungen zu den Boxen P Ausgabe aus Programm Prog36mf P36.2 Auswahl eines Unähnlichkeits- oder Ähnlichkeitsmaßes P36.3 Eingabe von Individualdaten P Eingabe in Programm-Maske Prog36md P Eingabe als selbst geschriebenes ALMO-Syntax-Programm P Ausgabe der Ergebnisse P36.4 Reproduktion einer empirischen Ähnlichkeits- bzw. Unähnlichkeitsmatrix P36.5 Literatur P37 Clusteranalyse nach dem K-Means-Verfahren...58 P37.0 Übersicht P Kurzcharakteristika der Verfahren P Unterschiede und Gemeinsamkeiten der drei Verfahren P Anwendung der Verfahren (Vorgehensweise) P37.1 Transformation der Klassifikationsvariablen zur Lösung der Nichtvergleichbarkeit P Theoretische Gewichtung P Theoretische Gewichtung bei unterschiedlichen Maßeinheiten P Theoretische Gewichtung bei Über- bzw. Unterrepräsentativität von Klassifikationsmerkmale P Theoretische Gewichtung zur Steuerung des Klassifikationsprozesses P Theoretische oder empirische Gewichtung? P Gewichtungen mit Programm P P37.2 K-Means-Verfahren P Eingabe über Maskenprogramm P Maskenprogramm Prog37m P Erläuterung zu den Boxen von Prog37m P Ausgabe der Ergebnisse Maskenprogramm Prog37m P Die Grundlogik der K-Means-Verfahren P Der Algorithmus P Ein Beispiel zur Illustration des Algorithmus P Modifikationen des Algorithmus P "Quick-Clustering" P Die Auswahl des Startwertverfahrens P Das Austauschverfahren P Gewichtung der quadrierten euklidischen Distanzen P Ein Anwendungsbeispiel für eine explorative Analyse P Konfirmatorische K-Means-Analyse P Programm-Maske zur konfirmatiorischen Clusteranalyse Prog37mc P37.3 Analyse latenter Klassen (probabilistische Clusteranalyse, Modell=7) P Modellansatz und Submodelle P Latente Profilanalyse P Explorative Analyse
4 P Konfirmatorische latente Profilanalyse P Analyse latenter Klassen für nominalskalierte Variablen P Analysen latenter Klassen für ordinalskalierte Variablen P Analyse latenter Klassen für gemischte Variablen P37.4 Repräsentanten-Verfahren P Modellansatz P Beispiel zur Clusterbildung P37.5 Mehrschritt-Verfahren P Einführung P Eingabe mit Maskenprogramm Prog37m P Erläuterungen zu den Boxen P Ausgabe P Verwendung von Startwerten aus der hierarchisch agglomerativen Analyse P37.6 Literatur Index Schlagwortverzeichnis
5 P36 Hierarchische Clusteranalyse P36.0 Übersicht und Modelle Bei der Clusteranalyse (CA) werden in der Regel die Analyseeinheiten (Klassifikationsobjekte) hinsichtlich ihrer Ähnlichkeit bezüglich bestimmter Merkmale (Klassifikationsvariablen) 1 zu homogenen Gruppen zusammengefasst. Die gesuchte Klassifikation soll zwei Eigenschaften erfüllen: Die Cluster sollen in sich homogen (Homogenität in den Clustern) und voneinander gut getrennt (Heterogenität zwischen den Clustern) sein. ALMO enthält zwei Verfahrensgruppen zur Bestimmung von Clustern. hierachische Verfahren (Programm 36) k-means-verfahren (Verfahren zur Verbesserung einer Ausgangspartition, (Programm 37) Die Schritte zur Lösung einer Klassifikationsaufgabe werden in Abschnitt P37.0 dargestellt. Programm P36 enthält folgende Modelle, die ausführlich in Bacher (1996 und 2010) beschrieben sind: 1. Nächste-Nachbarn-Verfahren: Die Cluster werden so gebildet, dass (a) jedes Klassifikationsobjekt eine bestimmte Anzahl von nächsten Nachbarn in dem Cluster hat, dem es angehört, oder dass (b) jedes Klassifikationsobjekt in dem Cluster zumindest einen B-ten nächsten Nachbarn (z.b. einen dritt nächsten Nachbarn) besitzt. Nach dem Modellansatz (a) gehen vor (in Klammern geben wir die Bezeichnung in den Almo-Programm-Masken an) Complete-Linkage (COMPLETE_LINKAGE;) Single-Linkage (SINGLE_LINKAGE;) Complete-Linkage für überlappende Cluster (UEBERLAPP_ LINKAGE;) Nach dem Modell (b) geht das gegenseitige Nächste-Nachbarn-Verfahren vor (ALMO-Spezifikation: GEGEN_NACHBARN;) 2. Mittelwert-Verfahren: Die Cluster werden durch die durchschnittliche paarweise Ähnlichkeit oder Unähnlichkeit der Klassifikationsobjekte innerhalb der Cluster und/oder zwischen den Clustern charakterisiert. Dieser Gruppe von Modellen gehören an: Average-, Weighted-Average- und Within-Average-Linkage. Die ALMO- Spezifikationen für diese Verfahren sind: Average-Linkage (AVERAGE_LINKAGE;) Weighted-Average-Linkage (W_AVERAGE_LINKAGE;) Within-Average-Linkage (WITHIN_LINKAGE;) 1 Die Bezeichnungen "Merkmal(e)" bzw. "Variable(n)" werden synonym verwendet. 5
6 3. Clusterzentren als Repräsentanten (Verfahren zur Konstruktion von Clusterzentren): Hier wird angenommen, dass ein Cluster durch seine Clusterzentren (Mittelwerte des Clusters in den in die Clusterbildung einbezogenen Variablen) charakterisiert werden kann. Von diesem Modellansatz gehen das Median-, Zentroid- und Ward-Verfahren sowie die K-Means-Verfahren (siehe Programm P37) aus. Die Cluster werden so bestimmt, dass (a) die Clusterzentren maximal voneinander entfernt sind (Median- und Zentroid-Verfahren) oder dass (b) die Streuung zwischen den Clusterzentren maximiert wird (Ward-Verfahren, K- Means-Verfahren). Die ALMO-Spezifikation für die in Programm P36 enthaltenen Verfahren sind: Median-Verfahren (MEDIAN_LINKAGE;) Zentroid-Verfahren (CENTROID_LINKAGE;) Ward-Verfahren (WARD_LINKAGE;) Der Complete- und Single-Linkage, die Mittelwert-Verfahren und die Verfahren zur Konstruktion von Clusterzentren (mit Ausnahme der K-Means-Verfahren) werden als hierachisch agglomerative Verfahren bezeichnet. Diese Verfahren können auch zur Bestimmung der Struktur einer Ähnlichkeits- oder Unähnlichkeitsmatrix eingesetzt werden. Die untersuchte Fragestellung lautet dann: Lässt sich die in der Ähnlichkeitsoder Unähnlichkeitsmatrix enthaltene Struktur durch eine hierachische Struktur beschreiben? (siehe dazu Abschnitt P36.9). Anzumerken ist: Das Auffinden einer hierarchischen Ähnlichkeits- oder Unähnlichkeitsbeziehung ist nur sinnvoll, wenn die analysierten Einheiten eine inhaltliche Bedeutung haben. Dies ist immer der Fall, wenn Variablen untersucht werden. Werden dagegen Objekte (=Zeilen der Datenmatrix) untersucht, trifft dies allgemein nicht zu. So z.b. besitzen zwar politische Parteien oder Nationen eine inhaltliche Bedeutung, nicht aber die in einer Umfrage befragten Personen. Deshalb macht es wenig Sinn, eine hierarchische Ähnlichkeitsbeziehung zwischen den Befragten einer Umfrage zu bestimmen. Die Eigenschaften der Verfahren des Programms P36 sind in Bacher (1996) beschrieben. Sie können als Hilfskriterium für die Auswahl eines Verfahrens verwendet werden. Den Text zur Auswahl eines hierarchischen Verfahrens habe ich geändert, da die Regeln einen methodisch weniger geschulten Anwender wahrscheinlich verwirren. Es werden Eigenschaften, wie invariant gegenüber monotonen Transformationen usw., verwendet, die unbekannt sind. Der typische Fall wird als letzter behandelt. Hier der neue Textvorschlag: Zunächst ist zu beachten, dass sich nicht alle Verfahren für alle Aufgabenstellungen eignen. Für den typischen Anwendungsfall einer Clusterung von Objekten bzw. Fällen (objektorientierte Clusteranalyse) eignen sich alle in P36 enthaltenen Verfahren. Bei einer großen Objektzahl (abhängig von der Hardware Ihres PCs 200, 300, 500 oder mehr Fälle) müssen aber K-Means-Verfahren verwendet werden, da es zu Speicherplatz- und Berechnungsproblemen kommen kann. Welches Verfahren man konkret auswählen wird, hängt von weiteren Kriterien ab (siehe dazu unten). 6
7 Für eine variablenorientierte Clusteranalyse (Clusterung von Variablen) ist der Einsatz des Median-, Zentroid- und Ward-Verfahrens sowie des K-Means-Verfahrens nicht sinnvoll, da Clusterzentren gefunden werden sollen. Soll eine Ähnlichkeits- oder Unähnlichkeitsmatrix (siehe Abschnitt P36.9) untersucht werden, scheiden das Median-, Zentroid- und Ward-Verfahren sowie das K-Means-Verfahren ebenfalls aus. Für den typischen Anwendungsfall empfehlen wir die Anwendung des Average- Linkage, des Weighted-Average-Linkage oder des Ward-Verfahrens. Von diesen drei Verfahren scheidet das Ward-Verfahren aus, wenn bestimmte Gründe gegen die Verwendung von quadrierten euklidischen Distanzen bestehen. Das Ward-Verfahren erforderlich nämlich wie das Zentroid- und das Median-Verfahren quadrierte euklidische Distanzen als Unähnlichkeitsmaß. Liegt keine Datenmatrix vor, sondern eine Un- oder Ähnlichkeitsmatrix scheidet das Ward-Verfahren ebenfalls aus (siehe oben). Die Anwendung des Median- und Zentroid-Verfahrens sowie des Within-Average- Linkage ist für die typische Anwendungskonstellation nicht zu empfehlen, da bei diesen Verfahren beim Verschmelzungsvorgang Inversionen (das Verschmelzungsniveau nimmt nicht kontinuierlich zu oder ab) auftreten können. Gegen die Anwendung des Complete- und Single-Linkage spricht, dass sie von zu strengen bzw. zu schwachen Homogenitätsvorstellungen ausgehen. Beim Complete- Linkage kann es zu Dilatationen (ein relativ homogenes Cluster wird in Subcluster aufgespaltet) kommen. Der Single-Linkage kann zu Verkettungen (relativ gut getrennte Cluster werden verschmolzen) führen. Unter bestimmten Bedingungen kann es sinnvoll sein, von dieser Empfehlung abzuweichen: Die gefundene Klassifikation soll invariant gegenüber monotonen Transformationen der Un- oder Ähnlichkeiten sein. D.h., dass sich die Klassifikationsergebnisse nicht ändern sollen, wenn alle Ähnlichkeiten oder Unähnlichkeiten zwischen den Objekten bzw. Variablen quadriert oder logarithmiert werden. Ist Invarianz gegenüber monotonen Transformationen erwünscht, muss der Single- oder der Complete-Linkage verwendet werden. Soll die gesuchte Klassifikation einem sehr strengen Homogenitätskriterium genügen, wird man den Complete-Linkage anwenden. Soll diese strenge Homogenitätsvorstellung abgeschwächt werden, kann das gegenseitige Nächste- Nachbarn-Verfahren eingesetzt werden, wenn Invarianz gegenüber monotonen Transformationen erwünscht ist. Andernfalls wird man Mittelwertverfahren einsetzen. Soll die gesuchte Klassifikationen umgekehrt nur sehr schwache Homogenitätsvorstellungen erfüllen, wird man mit dem Single-Linkage rechnen. Dadurch können Ausreißer aufgefunden werden. Der Single-Linkage eignet sich also zur Ermittlung von Ausreißern. Ausreißer sind jene Objekte, die ein selbständiges Cluster bilden. Sollen schließlich auch Überlappungen erlaubt sein, steht der Complete-Linkage für Überlappungen zur Verfügung. Alle in Programm P36 enthaltenen Verfahren setzen voraus, dass eine Unähnlichkeitsoder Ähnlichkeitsmatrix zwischen den Klassifikationsobjekten vorliegt oder aus den Daten berechnet wird. Klassifikationsobjekte können sein: (a) Variablen (Spalten der 7
8 Datenmatrix) oder (b) Objekte (Zeilen der Datenmatrix). Werden Variablen geclustert, wird von einer variablenorientierten Clusteranalyse gesprochen. Bei der Clusteranalyse von Objekten wird von einer objektorientierten Clusteranalyse gesprochen. Die Un- oder Ähnlichkeitsmatrix kann (1) aus den Daten berechnet werden (siehe Abschnitt P36.2) oder (2) direkt eingegeben werden (siehe Abschnitt P36.5). Auf der Basis der eingegebenen oder berechneten Un- oder Ähnlichkeitsmatrix werden die Klassifikationsobjekte zu Clustern verschmolzen. Der Algorithmus der hierachisch agglomerativen Verfahren sieht folgendermaßen aus: Schritt 1: Zu Beginn wird angenommen, dass jedes Klassifikationsobjekt ein selbständiges Cluster bildet. Schritt 2: Die beiden Cluster mit der größten Ähnlichkeit bzw. mit der geringsten Unähnlichkeit werden zu einem Cluster verschmolzen. Schritt 3: Die Ähnlichkeiten oder Unähnlichkeiten zwischen diesem neuen Cluster und den verbleibenden Clustern werden neu berechnet. Schritt 2 und 3 werden solange wiederholt, bis nur mehr ein (großes) Cluster vorliegt. Der Algorithmus soll anhand eines Beispiels verdeutlicht werden. Gegeben sei folgende Unähnlichkeitsmatrix zwischen den sechs Objekten A, B,..., F. A B C D E F A B C D E F Die Unähnlichkeitsmatrix ist allgemein eine symmetrische Matrix. Das bedeutet: Die Unähnlichkeit zwischen A und B ist gleich der Unähnlichkeit zwischen B und A. Ein höherer Zahlenwert drückt eine größere Unähnlichkeit aus. In dem Beispiel sind also die Objekte A und B untereinander ähnlicher als die Objekte A und C. Nach dieser allgemeinen Ausführung können wir den Algorithmus auf unser Beispiel anwenden. Jedes Objekt bildet zunächst ein Cluster. Es liegen somit sechs Cluster C1, C2,... C6 vor mit den Elementen C1 = {A}, C2 = {B}, C3 = {C},..., C6 = {F}. Die beiden Cluster mit der größten Ähnlichkeit bzw. mit der geringsten Unähnlichkeit werden zu einem neuen Cluster verschmolzen. In dem Beispiel sind das die Cluster C1 und C2 (Unähnlichkeitswert = 0.1). Es liegt somit folgende neue Konfigurationen vor: C1' = {C1,C2}, C2' = {C3}, C3' = {C4}, C4' = {C5}, C5' = {C6}. Entsprechend Schritt 3 sind die Unähnlichkeiten zwischen dem neuen Cluster C1' und den verbleibenden Clustern C2',...C5' neu zu berechnen. Die Unähnlichkeiten sollen so gebildet werden, dass die Ähnlichkeit innerhalb der Cluster maximal wird. Betrachten wir dazu die Unähnlichkeiten zwischen den Objekten der Cluster C1' und C2'. C1' C2' A B C A C1' B C2' C
9 Es stehen zwei Werte zur Auswahl: oder neuer Unähnlichkeitswert zwischen C1' und C2' = 0.15 neuer Unähnlichkeitswert zwischen C1' und C2' = 0.20 Wenn wir als neuen Unähnlichkeitswert zwischen dem Cluster C1' und C2' den Wert 0.20 wählen, ist gewährleistet, dass bei einer späteren Verschmelzung der Cluster C1' und C2' die maximale Unähnlichkeit zwischen allen Objekten dieses Clusters gleich 0.20 ist. Anwendung dieser Überlegung auf die verbleibenden zu berechnenden Unähnlichkeiten ergibt folgende neue Unähnlichkeitsmatrix. C1' C2' C3' C4' C5' C1' = {C1,C2} = {A,B} C2' = {C3} = {C} C3' = {C4} = {D} C4' = {C5} = {E} C5' = {C6} = {F} Wiederholung der Schritte 2 und 3 bis nur mehr ein einziges Cluster vorliegt. Da nach dem ersten Durchlauf fünf Cluster C1', C2',..., C5' vorliegen sind die Schritte 2 und 3 viermal zu wiederholen. Die Ergebnisse der Wiederholung sind in Form eines Rechenschemas nachfolgend zusammengefasst. Verschmelzung von Niveau Ergebnis und neue Unähnlichkeitsmatrix 1 C1' und C2' 0.20 C1'' C2'' C3'' C4'' C1''={C1',C2'}={A,B,C} C2''={C3'}={D} C3''={C4'}={E} C4''={C5'}={F} C1'' und C2'' 0.30 C1''' C2''' C3''' C1'''={C1'',C2''}={A,B,C,D} C2'''={C3''}={E} C3'''={C4''}={F} C1''' und C2''' 0.40 C1''' C2''' C1''''={C1''',C2'''}={A,B,C,D,E} C2''''={C3'''}={F} C1'''' und C2'''' 1.40 C1'''''={C1'''',C2''''}={A,B,C,D,E,F} Das hier durchgerechnete Verfahren wird als "Complete-Linkage" bezeichnet. Es führt zu maximal homogenen Clustern. Der Complete-Linkage hat den Nachteil, dass er zu Dilatationen (ein relativ homogenes Cluster wird in Subcluster getrennt) führen kann. Bei den hierachischen agglomerativen Verfahren kann der schrittweise Verschmelzungsprozeß in Form eines Agglomerations- oder Verschmelzungsschemas protokolliert werden. Für das zuvor durchgerechnete Beispiel ergibt sich folgendes Verschmelzungsschema: Clusterverknüpfung Clusterzahl Distanzniveau Zuwachs des Distanzniveaus A B A C A D
10 A E A F Objekt im ersten der Cluster, die verschmolzen werden 1.Objekt im zweiten der Cluster, die verschmolzen werden Zahl der Cluster nach Verschmelzung Distanzniveau, zu dem verschmolzen wird Zuwachs = Differenz des neuen Distanzniveaus zum alten Aufgrund des Verschmelzungsschemas kann ähnlich wie beim Kriterium des Eigenwertabfalls der Faktorenanalyse die Bestimmung der Zahl der Cluster vorgenommen werden. Das Vorgehen soll an einem Beispiel verdeutlicht werden: Anzahl der Fall I Fall II Fall III Cluster DN ddn DN ddn DN ddn DN = Distanzniveau, ddn = Zunahme im Distanzniveau Fall I (= Rechenbeispiel) : Die "richtige" Clusterzahl ist 2, da bei der Verschmelzung von 2 zu einem Cluster das Distanzniveau um 1.00 zunimmt (=ddn) und vor 2 Clustern keine große Zunahme vorliegt. Graphisch dargestellt, ergibt sich bei zwei Clustern ein deutlicher Knickpunkt: Distanzniveau in Abhängigkeit von der Clusterzahl (Fall A) Distanzniveau Fall II: Es liegen keine trennbaren Cluster vor, da das Distanzniveau kontinuierlich um.10 wächst. Fall III: Es liegt ein großes Cluster vor, da das absolute Distanzniveau niedrig ist und keine Zunahme erfolgt. Würde das absolute Distanzniveau groß sein und keine Zunahme erfolgen, dann würde jede Analyseeinheit ein eigenständiges Cluster bilden. 10
11 Das Verschmelzungsschema kann auch graphisch in Form eines sogenannten Dendrogramms dargestellt werden. Für den Fall I ergibt sich folgendes Dendrogramm. Dendrogramm: E 5 D 4 C 3 B 2 A 1 F 6 In der graphischen Darstellungen lassen sich sehr leicht die beiden Cluster (C1={A, B, C, D, E} und C2={F}) des Falls A bestimmen. Weitere Kriterien zur Bestimmung der Clusterzahl werden in Abschnitt P36.7 dargestellt. Das hier behandelte Rechenbeispiel kann mit nachfolgender Programm-Maske Prog36mf nachgerechnet werden. P36.1 Eingabe einer Ähnlichkeits- oder Unähnlichkeitsmatrix P Eingabe mit Programm-Maske Prog36mf Das nachfolgende Programm findet der Benutzer unter dem Namen Prog36mf.Msk durch Klick auf den Knopf Verfahren dann Clusteranalyse/Prog36mf 11


12

13

14 P Erläuterungen zu den Boxen Die Boxen von Prog36mf sind weitgehend identisch mit denen von Pro36md aus Abschnitt P Box 1: Siehe P0.1 Box 2: Namen für zu clusternde Objekte Sollen keine Objektnamen verwendet werden, dann bleiben die Eingabefelder im oberen Teil der Box leer. Im unteren Teil wird in das 1. Eingabefeld 0 geschrieben. Das 2. Eingabefeld wird leer gemacht. Es gibt keine Namensvariable. Möchte man den Objekten Namen geben (die Almo dann im Output verwendet), dann besteht folgende Möglichkeit: Im oberen Teil der Box werden die Namen - an einem Beispiel gezeigt - in folgender Weise geschrieben: Name 7=:A, B, C, D, E, F; Beachte: 1. Die Objektname können über beliebig viele Eingabefelder hinweg geschrieben werden. 2. Als Nummer für die Namensvariable muss eine freie, nicht benutzte Nummer verwendet werden. In unserem Beispiel verwendet die eingelesene Matrix die Variable V1 bis V6. Die Variable V7 ist also frei. 3. Beachte die Schreibweise Name 7=:... ; Hinter dem Gleichheitszeichen folgt unmittelbar ein Doppelpunkt 4. Zum Schluss muss ein Semikolon geschrieben werden. 5. Die Namen werden den Objekten in der Reihenfolge zugeordnet, wie diese in der Matrix aufeinander folgen. Beispiel: Das 3. Objekt muss also C sein. 6. Sie können einen Namen auch durch ein Blank zwischen 2 Kommas schreiben. Das betreffende Objekt ist dann namenlos. Im unteren Teil der Box müssen Sie dann noch in das 1. Eingabefeld 1 schreiben und in das 2. Eingabefeld V7. V7 ist die Namensvariable. Box 3: Matrix aus Datei oder "selbst geschrieben" 14

15 Das Programm erlaubt es dem Benutzer, die Matrix am Programmende selbst zu schreiben oder die Matrix aus einer Datei einzulesen. 1. Möglichkeit: Benutzer will die Matrix selbst schreiben Klicken Sie auf den 3. Knopf. Es wird dann in das Eingabefeld das Wort "Eingabe" eingesetzt. Almo erwartet dann die Daten der Matrix am Programmende. Schalten Sie am Programmende in der Box "Schreiben der Matrixwerte" die Schreibsperre aus und schreiben Sie die Matrix-Daten hinter dem Programm. Die Matrix-Daten müssen in folgender Form geschrieben werden. Siehe dazu auch Almo-Handbuch, Teil 2 Almo-Programmiersprache, Abschnitt 43 6 Grösse der Matrix 487 Zahl der Fälle, aus der die Matrix, z.b. als Korrelationsmatrix gebildet wurde Variablennummern. V1 ist nominal mit den beiden Dummies 1.01 und 1.02 V2,3,4,12 sind quantitativ oder ordinal untere Dreiecksmatrix (mit Diagonale) Mittelwerte Stand.abweichungen Beachte: Jede Zeile, ausser der Dreiecksmatrix, kann durch '*', d.h. einen Stern bzw. das Multiplikationszeichen ersetzt werden. Die Matrix kann also auch so geschrieben werden: 15
16 * * * * * 2. Möglichkeit: Die Matrix soll aus einer Datei eingelesen werden. Klicken Sie auf den 2. Knopf. Almo präsentiert die Datei-Auswahl-Box. Selektieren Sie die Datei, die die Matrix enthält. Die Matrix muss die oben dargestellte Form besitzen!! Das ist automatisch der Fall, wenn sie mit einem Almo-Programm gespeichert wurde, beispielsweise mit dem Korrelationsprogramm Prog19bm (Optionsbox: Schreibe errechnete Matrix in Datei). Schalten Sie am Programmende in der Box "Schreiben der Matrixwerte" die Schreibsperre aus und löschen Sie die Daten hinter dem Programm. Mit der Tastenkombination Strg+Y löschen Sie jeweils die ganze Zeile, in der sich der Cursor befindet. Wenn Sie vergessen zu löschen, dann rechnet Almo trotzdem richtig, bringt jedoch zum Ende der Ergebnisausgabe die Fehlermeldung, dass mit der Programmstruktur etwas nicht stimmen könnte. Diesen Hinweis können Sie negieren. Box 4: Klassifikations-Variable für die Clusterung Siehe Erläuterungen zu Prog36md in Abschnitt P , Box 8. Box 5: Clusterzahl Siehe Erläuterungen zu Prog36md in Abschnitt P , Box 14. Box 6: Option: Verfahren (Voreinstellung: weigthed avarage) Siehe Erläuterungen zu Prog36md in Abschnitt P , Box 15. Box 7: Option: Distanzmaß (Voreinstellung: city_block) Siehe Erläuterungen zu Prog36md in Abschnitt P , Box 16. Box 8: Option: Teststatistiken Siehe Erläuterungen zu Prog36md in Abschnitt P , Box 17. Box 9: Grafik-Optionen Siehe Erläuterungen zu Prog36md in Abschnitt P , Box 21. Box 10: Schreiben der Matrixwerte Siehe oben Erläuterung zu Box 3. Das Programm liest eine Unähnlichkeitsmatrix ein und errechnet aus ihr eine Clusterlösung. 16
17 P Ausgabe aus Programm Prog36mf Das Programm liefert folgende Ergebnisse, die hier nur auszugsweise wiedergegeben sind: Ergebnisse aus ALMO Anzahl der nominalen Deskriptionsvariablen = 0 Anzahl der ordinalen Deskriptionsvariablen = 0 Anzahl der quantitativen Deskriptionsvariablen = 0 Anzahl der nominalen Klassifikationsvariablen = 0 Anzahl der ordinalen Klassifikationsvariablen = 0 Anzahl der quantitativen Klassifikationsvariablen= 0 Anzahl der Klassifikationsvariablen insgesamt = 0 Anzahl der Klassifikationsobjekte = 6 Gewichtungsvariable = keine Ausgewaehlte Verfahren: Complete-Linkage Ausgewaehlte (Un-)Aehnlichkeitsmasse: KW-Behandlung = Paarweises Ausscheiden Transponierung der Datenmatrix = nein (Zeilen werden geclustert) ************************************************************************ Unaehnlichkeitsmatrix (Distanzmatrix) ************************************************************************ A B C D E V7-1 V7-2 V7-3 V7-4 V7-5 A V B V C V D V E V F V F V7-6 A V B V C V D V E V F V7-6 0 Masszahlen zur Interpretation der Un- oder Aehnlichkeitsmatrix: Mittelwert = 0.59 Standardabw. = 0.46 Schiefe =
18 Die eingelesene Unähnlichkeitsmatrix wird ausgegebenen. Die durchschnittlichen Unähnlichkeiten sind Die Unähnlichkeiten zwischen den Objekten A, B, C, D und E liegen unterhalb dieses Wertes, während jene von A, B, C, D, E mit F über ihm liegen. ************************************************************************ Modell = Complete-Linkage fuer ************************************************************************ Clusterverknuepfung Clusterzahl Distanzniveau Zuwachs Minimum= 0.1, Maximum= 1.4 Dendrogramm: E D C B A F P36.2 Auswahl eines Unähnlichkeits- oder Ähnlichkeitsmaßes Wird keine Un- oder Ähnlichkeitsmatrix direkt eingelesen, muss der Anwender zur Berechnung einer Un- oder Ähnlichkeitsmatrix aus den Daten ein Un- oder Ähnlichkeitsmaß spezifizieren. Programm 36 enthält eine Reihe von Ähnlichkeits- bzw. Unähnlichkeitsmaßen, die der nachfolgenden Übersicht entnommen werden können. Meßniveau Ähnlichkeitsmaß Unähnlichkeitsmaß nominal - 1 City-Block-Metrik (city_block) dichotom 11 Jaccard I (jaccard1) 1 City-Block-Metrik (city_block) 12 Dice (dice) 13 Sokal & Sneath I (sokal_sneath1) 14 Russel & Rao (russel_rao) 15 Matching-Koeffizient (matching_koeff) 16 Sokal & Sneath II (sokal_sneath2) 17 Rogers & Tanimoto (rogers_tanimoto) 18 Phi-Koeffizient (phi_koeff) ordinal 1 City-Block-Metrik (city_block) 19 Canberra-Metrik (canberra) 20 modifizierte Canberra-Metrik 18
19 (modif_canberra) 21 Jaccard II (jaccard2) quantitativ 23 Pearson-Korrelation (pearson_korr) 1 City-Block-Metrik (city_block) 3-9 Minkowski-Metrik (minkowski3 - minkowski9) 2 Euklidische Distanz (euklid) 10 Chebychev-Metrik (chebychev) 22 quadrierte euklidische Distanz (quad_euklid) gemischt 1 City-Block-Metrik (city_block) Bezeichnungen in Klammer = Almo-Befehlswort Zahl vor dem Un- und Ähnlichkeitswert = Almo-Kurzschreibweise für Befehlswort Die für dichtome Variablen angegebenen Ähnlichkeitsmaße unterscheiden sich durch eine unterschiedliche Gewichtung des Besitzes bzw. Nichtbesitzes der Merkmalsausprägungen. Betrachten wir zur Verdeutlichung die beiden ersten Objekte A und B des obigen Beispiels. Die beiden Klassifikationsobjekte A und B besitzen folgende Merkmalsvektoren A [ ] B [ ] Eine "1" bedeutet, dass das Merkmal auftritt, eine "0", dass das Merkmal nicht vorkommt. Aus den Merkmalsvektoren kann für die beiden Objekte eine Vierfeldertafen gebildet werden. bzw. allgemein B 1 0 A B 1 0 A 1 a b 0 c e Bei den einzelnen Koeffizienten gehen die vier Zellen in unterschiedlicher Weise in die Berechnung ein (vgl. Steinhausen/Langer 1977: 55). Name Beispiel Ähnlichkeitsfunktio n allgemein 11 Jaccard I 3 a = (1+ 0) a + b + c Bemerkungen Eigenschaften Relativer Anteil gemeinsam vorhandener Eigenschaften bezogen auf die Variablen mit 19
20 12 Dice 13 Sokal &Sneath 14 Russel & Rao 15 Matching-Koeff. 16 Sokal & Sneath II 2*3 2a = *3 + (1+ 0) 2a + b + c 2 a = * (1 + 0) a + 2 (b + c) 2 a = m = a + e m 2*(2 + 3) 2 (a + e) = *(2 + 3)*(1 + 0) 2 (a + e) + b + c 17 Rogers & Tanimoto 18 Phi-Koffizient = *(1 + 0) 3* 2-0*0 (3*3*4*2) = mindestens einer 1. Doppelte Gewichtung gemeinsam vorhandener Eigenschaften Doppelte Gewichtung nichtübereinstimmender Positionen im Nenner Relativer Anteil gemeinsam vorhandener Positionen bezogen auf die Gesamtzahl der Variablen Relativer Anteil übereinstimmender Positionen bezogen auf die Gesamtzahl der Variablen Doppelte Gewichtung übereinstimmender Positionen a + e Doppelte Gewichtung nichtübereinstimmender Positionen a + e + 2 (b + c) im Nenner a e - b c ((a + c) (b + e) (a + b) (c + e)) 1 2 Korrelationskoeffizient Phi, Testgröße zum X 2 - Test auf Unabhängigkeit der 2x2 Kontingenztafel. m = Anzahl der in die Vierfeldertafel einbezogenen Klassifikationsmerkmale Zu beachten ist, dass die dargestellten Maßzahlen Ähnlichkeitsmaße sind: ein größerer Wert bedeutet eine größere Ähnlichkeit. Die City-Block-Metrik ist dagegen ein Unähnlichkeitsmaß. Für dichotome Merkmale ist sie gleich der Zahl der nichtübereinstimmenden Merkmalsausprägungen. CITY(A,B) = c + b = 1 (= Beispiel) Die City-Block-Metrik kann aus dem Matching-Koeffizienten berechnet werden mit: CITY(A,B) = m (1 - MATCHING-KOEFF(A,B)) Bei nominalen Merkmalen mit mehr als zwei Ausprägungen ist die City-Block-Metrik ebenfalls gleich der Zahl nichtübereinstimmender Merkmalsausprägungen. Formal ausgedrückt gilt: 20
21 mit CITY(A, B) g(x Ai x Bi = i 1 ) = 0 g(x wenn sonst Ai, x Bi ) x Ai x Bi xai = Merkmalsausprägung des Klassifikationsobjektes A im Merkmal i xbi = Merkmalsausprägung des Klassifikationsobjektes B im Merkmal i Bei ordinalen Merkmalen ist die City-Block-Metrik gleich der Zahl der Ausprägungskategorien (plus 1) zwischen den Ausprägungen der Objekte in den Klassifikationsmerkmalen. Betrachten wir ein Beispiel. Die ordinalen Merkmalsvektoren für die Klassifikationsobjekte A und B betragen: A [ ] B [ ] Die City-Block-Metrik ist allgemein definiert als CITY(A, B) = x Ai x Bi i und beträgt somit für das Beispiel: CITY(A,B) = = = 6 Zur Berechnung der anderen im Programm enthaltenen ordinalen Ähnlichkeitsmaße siehe Steinhausen/Langer (1977: 57). Für quantitative Merkmale steht als Unähnlichkeitsmaß die Minkowski-Metrik zur Verfügung. Diese ist definiert als: MINKOWSKI( A, B) = ( x Ai x i Bi p ) 1 p mit x Ai = Merkmalsausprägung des Klassifikationsobjektes A im Merkmal i x Bi = Merkmalsausprägung des Klassifikationsobjektes B im Merkmal i p = Metrikparameter Für p=1 ergibt sich die City-Block-Metrik, für p=2 die euklidische Distanz und für p= die Chebychev-Metrik. Die quadrierte euklidische Distanz stellt ein weiteres Unähnlichkeitsmaß für quantitative Merkmale dar. Sie ergibt sich dadurch, dass aus den quadratischen Abweichungen keine Wurzel berechnet wird: QEUKLID(A, B) = (x 2 Ai x Bi ) Die quadrierte euklidische Distanz muss für das Ward-, Median- und Centroidverfahren verwendet werden. Als Ähnlichkeitsmaß für quantitative Klassifikationsmerkmale steht ferner der Pearsons-Korrelationskoeffizient zur Verfügung: 21
22 PEARSON(A, B) = i (x (x Ai Ai x x A ) A 2 ) (x Bi (x x Bi B ) x B ) 2 Liegen Klassifikationsmerkmale mit unterschiedlichem (gemischtem) Meßniveau vor (gemischte Klassifikationsmerkmale) kann die City-Block-Metrik verwendet werden. Betrachten wir dazu ein Beispiel: nominale Klassifikationsmerkmale ordinale Klassifikationsmerkmale quantitative Klassifikationsmerkmale V2 V3 V4 V5 V6 V7 V8 V9 V10 A [1 1 3] [1 2 5] [ ] 0 B [2 1 4] [2 4 5] [ ] 0 V2 bis V4 sind nominale, V5 bis V7 sind ordinale und V8 bis V10 quantitative Merkmale. Die ordinalen Variablen V5 bis V7 besitzen eine Untergrenze von 1 und eine Obergrenze von 5. Die quantitativen Variablen V7 bis V9 haben eine Untergrenze von 0 und eine Obergrenze von 10. Wir können zunächst für jedes Klassifikationsmerkmal die City-Block-Metrik berechnen. CITY(A,B) [ ] [ ] [ ] Würden die einzelnen Distanzen aufaddiert werden, würde die Bedingung der Vergleichbarkeit (Bacher 1996: 173ff) verletzt sein, da die City-Block-Metrik bei den einzelnen Klassifikationsmerkmalen unterschiedliche Variationsbereiche besitzt. Die Variationsbereiche der City-Block-Metrik für die einzelnen Klassifikationsmerkmale sind. Klassifikationsmerkmale minimaler Wert d. City-Block Metrik maximaler Wert d. City-Block Metrik nominale Klassifikationsmerkmale V2(Maturatyp) 0 1 V3(1. Studienricht.) 0 1 V4(2. Studienricht.) 0 1 ordinale Klassifikationsmerkmale V5(Interesse f. Mathem.) 0 4 V6(Interesse f. Soziologie) 0 4 V7(Interesse f. Jus) 0 4 quantitative Klassifikationsmerkmale V8(Punkte in Mathem.) 0 10 V9(Punkte in Soziologie) 0 10 V10(Punkte in Jus) 0 10 (a) Der maximale Wert ist gleich der Spannweite = Obergrenze Untergrenze Bei nominalen Klassifikationsmerkmalen beträgt der maximale Wert der City-Block- Metrik immer 1.0, bei ordinalen und quantitativen Klassifikationsmerkmalen ist er gleich der Spannweite (Obergrenze minus Untergrenze) des Merkmals. 22
23 Vergleichbarkeit kann dadurch erreicht werden, dass die ordinalen und quantitativen Klassifikationsmerkmale mit dem Kehrwert der Spannweite, also mit "1/Spannweite" gewichtet werden. Für unser Beispiel sieht die Programm-Maske Prog36md folgendermaßen aus: Die von ALMO ausgegebene gewichtete City-Block-Metrik zwischen zwei Objekten A und B ist gleich gi gi CITY gew ( A, B) = gi x Ai xbi = gi CITYi ( A, B). giab giab Für jedes Variablenpaar (A, B) wird in der Variablen i die City-Block-Metrik xai xbi bzw. CITY i ( A, B) berechnet und mit dem Gewicht giab multipliziert. giab ist gleich dem Gewicht g i der Variablen i, wenn die Variable i in die Berechnung der City-Block- Metrik des Objektpaares (A, B) einbezogen wurde, d.h., wenn sowohl A und B in der Variablen i nicht KEIN_WERT sind. Bei KEIN_WERT einer oder beider Variablen wird g iab gleich 0 gesetzt. P36.3 Eingabe von Individualdaten P Eingabe in Programm-Maske Prog36md In der Programm-Maske wird ein Beispiel aus Nohlen (1984, 630ff) verwendet, das längst nicht mehr aktuell ist. Da es jedoch in vorausgehenden Publikation eingesetzt wurde, soll es hier beibehalten werden. Die Staaten Süd- und Mittelamerikas werden hinsichtlich ihrer sozialen Indikatoren klassifiziert. Das Klassifikationsziel besteht darin, die ausgewählten Länder nach ihrem sozialen Entwicklungsstand zu klassifizieren. 23

24


25

26

27 P Erläuterungen zu den Boxen Box 1 bis 4: Siehe P0.1 bis P0.3. Box 5: Namen für zu clusternde Objekte In unserem Beispiel werden die Objektnamen, also die Namen der südamerikanischen Länder als Variable V2 aus der Daten-Datei eingelesen. Doppelklicken Sie in der Box "Datei aus der gelesen wird" auf den Dateinamen. Die Datei wird in ein separates Fenster geladen. Sie sehen, dass V2 die Objektnamen enthält. 1 ARGENTINIEN BOLIVIEN BRASILIEN CHILE 'COSTA RICA' In diesem Fall bleiben die Eingabefelder im oberen Teil der Box leer. Im unteren Teil wird in das 1. Eingabefeld 2 geschrieben. In das 2. Eingabefeld wird V2 geschrieben. V2 ist die Namensvariable. Sollen überhaupt keine Objektnamen verwendet werden, dann bleiben die Eingabefelder im oberen Teil der Box leer. Im unteren Teil wird in das 1. Eingabefeld 0 geschrieben. Das 2. Eingabefeld wird leer gemacht. Es gibt keine Namensvariable. Sind die Objektnamen nicht als Variable in der Daten-Datei enthalten, möchte man aber trotzdem den Objekten Namen geben (die Almo dann im Output verwendet), dann besteht folgende Möglichkeit: Im oberen Teil der Box werden die Namen - an einem Beispiel gezeigt - in folgender Weise geschrieben: Name 21=:ARGENTINIEN,BOLIVIEN,BRASILIEN,CHILE,COSTA RICA,DOM.REP., ECUADOR,EHSALVADOR,GUATEMALA,HAITI,HONDURAS,JAMAICA, KOLUMBIEN,KUBA,MEXICO,NICARAGUA,PANAMA,PARAGUAY,PERU, TRINIDAD,URUGUAY,VENEZUELA ; Beachte: 27


28 1. Die Objektname können über beliebig viele Eingabefelder hinweg geschrieben werden. 2. Als Nummer für die Namensvariable muss eine freie, nicht benutzte Nummer verwendet werden. In unserem Beispiel umfasst ein eingelesener Datensatz 20 Variable. Die Variable 21 ist also frei. 3. Beachte die Schreibweise Name 21=:... Hinter dem Gleichheitszeichen folgt unmittelbar ein Doppelpunkt. 4. Zum Schluss muss ein Semikolon geschrieben werden. 5. Die Namen werden den Datensätzen in der Reihenfolge zugeordnet, wie diese eingelesen werden. Beispiel: Der 3. eingelesene Datensatz muss also BRASILIEN sein. 6. Sie können einen Namen auch durch ein Blank zwischen 2 Kommas schreiben. Das betreffende Objekt ist dann namenlos. Im unteren Teil der Box müssen Sie dann noch in das 1. Eingabefeld 1 schreiben und in das 2. Eingabefeld V21. V21 ist die Namensvariable. Box 6: Datei aus der gelesen wird Siehe P0.4. Box 7: Wenn Dateiformat FIX oder nicht Standard-FREI Wir zeigen nur den oberen Teil dieser Box. Die Variablennamen sind in unserem Beispiel in der 2. Variablen des Datensatzes enthalten. Box 8: Klassifikations-Variable für die Clusterung Klassifikationsvariable sind jene Variable, die zur Clusterbildung verwendet werden. 28
29 Es können Klassifikationsvariable aller 3 Messniveaus gleichzeitig angegeben werden. Beachte: Die nominalen Variable müssen ganzzahlig sein und mit Schrittweite 1 fortlaufend kodiert sein. Ihre Werte-Untergrenze muss aber nicht notwendigerweise bei 1 beginnen. Betrachten wir als Beispiel die Variable Beruf. Beruf Kodierung a Kodierung b Kodierung c Kodierung d Arbeiter Angestellter Beamter Bauer Kodierung a: Wurde die Variable nach der Kodierungsweise a kodiert, dann ist alles in Ordnung. Kodierung b: Auch die Kodierungsmethode b ist korrekt. Die Untergrenze muss nicht notwendigerweise bei 1 liegen. Kodierung c: Die Kodierungsmethode c ist nicht korrekt. Die Schrittweite ist nicht immer 1. Die Codeziffern springen von 2 auf 4. Der Wert 3 existiert nicht. In diesem Fall muss die Variable auf fortlaufende Schrittweite 1 umkodiert werden - in folgender Weise. Beruf ( 4=3; 5=4 ) Aus 4 wird 3 und aus 5 wird 4. Kodierung d: Bei der Kodierungsmethode d wurde die Variable nicht ganzzahlig kodiert. Almo rundet automatisch. Es macht aus 1.1 die Zahl 1 und aus 5.9 die Zahl 6. Dadurch würde die Bedingung, dass die Schrittweite fortlaufend 1 sein muss, verletzt. Die Ziffer 5 kommt nicht mehr vor. Der Benutzer sollte auf Ganzzahligkeit und Schrittweite 1 umkodieren - in folgender Weise Beruf( 1.1=1; 5.9=5 ) Wenn die Codeziffern nicht bekannt sind, dann kann man in folgender Weise umkodieren: Beruf ( 0 Schritt 1 bis 6 = I ) Der Buchstabe 'I' hinter dem Gleichheitszeichen bedeutet 'Intervallkodierung'. Von 0 bis 1 wird 1 Von 1 bis 2 wird 2 Von 2 bis 3 wird


30 Liegt eine Person genau auf der Intervallgrenze, dann fällt Sie in das untere Intervall. Box 9: Deskriptions-Variable Die Deskriptions-Variablen haben keinen Einfluss auf die Gewinnung der Cluster. Sie können weggelassen werden - ohne dass dadurch die Clusteranalyse beeinflusst würde. Ihr Sinn ist folgender: Almo ermittelt zuerst aus den Klassifikations-Variablen die Cluster. Nehmen wir an, es würden 3 Cluster gefunden. Dann errechnet Almo für die quantitativen Deskriptions-Variablen den Mittelwert für jedes der 3 Cluster und für die Ausprägungen der nominalen Deskriptions-Variable die Anteilswerte je Cluster ebenfalls für jedes der 3 Cluster. Die Deskriptionsvariablen dienen der Beschreibung der Cluster. Box 10: Option: Ein- und Ausschliessen von Untersuchungseinheiten Siehe P0.7. Box 11: Option: Umkodierungen und Kein-Wert-Angaben Siehe P0.5. Box 12: Option: Kein-Wert-Behandlung Optionsbox geöffnet: 30

31 Box 13: Option: Untersuchungseinheiten gewichten Siehe P0.8. Box 14: Clusterzahl Wenn Sie beispielsweise als minimale Clusterzahl 2 und als maximale Clusterzahl 4 angeben, dann rechnet Almo Clusterlösungen mit 2 Cluster, mit 3 Cluster und mit 4 Cluster. Der Benutzer kann dann entscheiden, welche Clusterzahl ihm als die plausibelste erscheint. Box 15: Option: Verfahren (Voreinstellung: weigthed avarage) Optionsbox geöffnet: Die einzelnen Verfahren werden in P36.0 dargestellt. Für das Beispiel mit den Daten von Nohlen wurde nicht die Voreinstellung "weigthed avarage" übernommen, sondern das Verfahren des "complete linkage" gewählt. Beachte: Im Prinzip ist es möglich, eine Analyse mit allen Verfahren und allen Distanzmaßen zu rechnen. Dabei kann aber ein so umfangreicher Output erzeugt werden, dass er im Extremfall von ALMO nicht mehr geladen werden kann. Abhilfe: Verwendung nur einiger Verfahren und nur einiger Distanzmaße. Beim Ward-, Median- und Zentroid-Verfahren muss in der folgenden Box "Distanzmaß" die quadrierte euklidische Distanz angegeben werden. Box 16: Option: Distanzmaß (Voreinstellung: city_block) 31

32 Optionsbox geöffnet: Die einzelnen Distanzmaße werden in P36.2 dargestellt. 32

33 Das Messniveau der Klassifikationsvariablen bestimmt die Wahl des Distanzmaßes. Die Tabelle in der Optionsbox informiert den Benutzer darüber. Beachte: Bei gemischtem Messniveau ist nur "city-block" zulässig. Beachte: Im Prinzip ist es möglich, eine Analyse mit allen Verfahren und allen Distanzmaßen, die gemäß obiger Tabelle zulässig sind, gleichzeitig zu rechnen. Dabei kann aber im Extremfall ein so umfangreicher Output erzeugt werden, dass er von ALMO nicht mehr geladen werden kann. Abhilfe: Verwendung nur einiger Verfahren und nur einiger Distanzmaße. Box 17: Option: Teststatistiken Optionsbox geöffnet: Zur kophenetischen und zur Gamma-Korrelation siehe P36.7 Abschnitt "Korrelationsmasse für eine bestimmte Clusterlösung" und Abschnitt "Signifikanztests für die Koeffizienten". Wurde im 1. Eingabefeld "3" oder "4" eingegeben, dann werden für den Signifikanztest Zufallsexperimente durchgeführt. Die Voreinstellung ist 20 Zufallsexperimente. Im 2. Eingabefeld kann die Zahl der Zufallsexperimente vom Benutzer frei bestimmt werden. Box 18: Option: Clusterzugehörigkeiten der Ojekte in Datei speichern Optionsbox geöffnet: 33

34 Wenn Sie einen Dateinamen in das Eingabefeld schreiben, dann 1. erzeugt Almo zwei Dateien mit diesem Namen einmal im Format FREI und einmal im Format DIREKT 2. und speichert in diese die Variablen aus der alten Datei 3. und speichert die Clusterzugehörigkeit der Objekte als letzte Variable hinter die Variablen aus der alten Datei 4. weiterhin erzeugt Almo eine Datei der Variablennamen. Diese enthält - die Variablennamen aus der alten Datei einschliesslich der in der Box "Freie Namensfelder" angegebenen (oder eventuell modifizierten) Namen - den Name "Cluster.." für die neue angeh ngte Variable der Clusterzugehörigkeit, wobei Almo anstelle der 2 Punkte die Variablennummer der Clustervariablen einsetzt. Siehe nachfolgendes BEACHTE. Sie können die Datei der Variablennamen in ein Fenster laden und Variablen- und Ausprägungsnamen beliebig verändern. Danach wieder speichern. Beachte: Almo hat beispielsweise folgenden Namen geschrieben. Name 21=Cluster21; Die Ziffer hinter "Cluster.." (im Beispiel '21') ist die Variablennummer der Clustervariablen. 34

35 Sie können diesen Variablenname beliebig verändern. Er muss jedoch eindeutig sein, d.h. er darf kein 2. Mal auftreten. Beachte: Das Speichern der Clusterzugehörigkeit hat nur dann einen Sinn, wenn Sie die endgültige Clusterlösung gefunden haben. Sie haben beispielsweise die Lösung mit 3 Clustern als die richtige entdeckt. Geben Sie dann in der Box "Clusterzahl" als minimale und als maximale Clusterzahl 3 an, also Minimale Zahl von Clustern 3 Maximale Zahl von Clustern 3 Bei der hierarchischen Clusteranalyse (Prog 36) dürfen Sie dann nur ein Verfahren und ein Distanzmaß angeben. Wenn Sie als minimale und als maximale Clusterzahl verschiedene Zahlen angeben, z.b. Minimale Zahl von Clustern 2 Maximale Zahl von Clustern 4 dann speichert Almo beim hierarchischen Verfahren die Clusterzugehörigkeit der minimalen Clusterlösung des zuletzt angegebenen Verfahrens und des zuletzt angebenen Distanzmaßes. Das ist verwirrend - sollte deswegen vermieden werden. Box 19: Option: Programm-Optionen lt. Handbuch Optionsbox geöffnet: In die beiden Eingabefelder können Sie Optionen einsetzen, die nicht über eine der Optionsboxen aktivierbar sind. Diese werden im folgenden angegeben. Sie können mehrere Angaben in ein Eingabefeld schreiben, beispieldweise so: Option 15=1; Option 23=0; Option 28=5; Für unser Beispiel mit den Daten von Nohlen wurde folgende Option eingesetzt: 35

36 Mit "Option 2=1;" werden die quantitativen Klassifikationsvariablen standardisiert. Achten Sie aber darauf, dass Sie nicht Optionen einsetzen, die bereits über eine der Optionsboxen des Programms aktiviert wurden oder im Widerspruch zu diesen stehen. Folgende Optionen können eingesetzt werden: Option 2 =..; Option2=0; Option2=1; Option2=2; Option2=3; Option2=4; Option2=5; Option 1 = 1; Mit dieser Anweisung können die Variablen und Objekte standardisiert werden: Option 2 steht nur bei quantitativen Klassifikationsvariablen zur Verfügung. (=Voreinstellung). Keine Standardisierung der Variablen und Objekte. Standardisierung der Variablen (=Spalten der Datenmatrix) Mittelwertzentrierung der Objekte (=Zeilen der Datenmatrix). Jedes Objekt (=Zeile der Datenmatrix) besitzt einen Mittelwert von 0 in den Klassifikationsvariablen. Standardisierung der Objekte (=Zeilen der Datenmatrix). Jedes Objekt besitzt einen Mittelwert von 0 und eine Standardabweichung von 1 in den Klassifikationsvariablen. Standardisierung der Variablen mit anschließender Mittelwertzentrierung der Objekte Standardisierung der Variablen mit anschließender Standardisierung der Objekte. Transponierung der Datenmatrix. Diese Option ist nur zulässig, wenn (a) keine Deskriptionsvariablen definiert sind (b) nur Klassifikationsvariablen mit einem Meßniveau vorhanden sind Die Datenmatrix wird transponiert, das heißt: Die Spalten und Zeilen werden vertauscht. Dadurch kann eine variablenorientierte Clusteranalyse durchgeführt werden, da nach der Transponierung die Variablen die neuen "Objekte" (=Zeilen der Datenmatrix) bilden. Die Voreinstellung ist Option 1=0; (keine Transponierung). Option 17 =..; Zufallstest des Verschmelzungsschemas Option 17 kann nur bei quantitativen 36
37 Klassifikationsvariablen angewendet werden. Durch diese Anweisung kann eine Zufallstestung des Verschmelzungsschemas durchgeführt werden. Es wird geprüft, ob sich das empirische Verschmelzungsschema von dem Verschmelzungsschema bei reinen normalverteilten Zufallsdaten ohne Clusterstruktur unterscheidet. Ist dies nicht der Fall, liegt keine Clusterstruktur vor. Durch beispielsweise die Anweisung "Option 17=20;" wird ALMO mitgeteilt, dass 20 Zufallsdatenmatrizen zur Testung berechnet werden sollen. Die Voreinstellung ist Option 17=0; Schreibe Ergebnismatrix in Datei 9 "C:\Almo\Progs\Unaehnl.mat"; Die berechnete bzw. eingelesene Unähnlichkeitsmatrix (Distanzmatrix) wird in eine Datei geschrieben. Selbstverständlich ist der Pfadund Dateiname beliebig. Option 20 bis Option 30 Hiermit kann der Benutzer die Form der auszugebenden Unähnlichkeitsmatrix (=Distanzmatrix) bestimmen. Siehe Handbuch, Teil 4, Anhang A3. Option 18 =...; Option 19 =...; Zwischergeb = 1; OPTION 37 =...; Durch diese Anweisung kann für das "gegenseitige Nächste-Nachbarn-Verfahren" (gegen_nachbarn) der b-te Nachbar definiert werden. Durch die Anweisung Option 18=2; wird ALMO mitgeteilt, dass jedes Objekt in einem Cluster mindestens der zweite Nachbar zu einem anderen Objekt desselben Clusters sein soll. Die Voreinstellung ist Option 18=2; Um so größer die Zahl gewählt wird, desto lang gestrecktere, aber inhomogenere Cluster werden berechnet. Diese Anweisung ist zum Speichern der Clusterzugehörigkeit bei den Modellen "gegen_nachbarn" und "ueberlapp_linkage" erforderlich. Nach dem Gleichheitszeichen muss die Nummer des Verschmelzungsschrittes angegeben werden, dessen Clusterlösung gespeichert werden soll. Mit dieser Anweisung können Zwischenergebnisse, z.b. Detailinformation über den Verschmelzungsvorgang oder über die Berechnung von Maßzahlen, ausgegeben werden. Die Voreinstellung ist ZWISCHERGEB=0; Mit dieser Anweisung kann festgelegt werden, wie viele Schritte des Verschmelzungsschemas ausgegeben und als Dendrogramm gezeichnet werden. Die Anweisung OPTION 37=30; bewirkt z.b., dass nur die letzten 30 Schritte ausgegeben und als Dendrogramm gezeichnet werden. Diese Option sollte verwendet werden, wenn viele Objekte (z.b. 100, 200 oder mehr) analysiert werden, um eine übersichtliche und gut interpretierbare Ausgabe zu erhalten. Die 37
 nicht nur bei einem Clusterpaar auftritt, sondern bei mehreren.")
38 Voreinstellung ist OPTION 37 = 0; und bewirkt die Ausgabe aller Schritte. Option 39 =...; Behandlung von Bindungen. ALMO protokolliert im Verschmelzungsschema das Auftreten von Bindungen. Bindungen liegen dann vor, wenn in einem Verschmelzungsschritt die größte Ähnlichkeit (geringste Unähnlichkeit) nicht nur bei einem Clusterpaar auftritt, sondern bei mehreren. Bindungen können die Ergebnisse beeinflussen. Daher sollte zur Kontrolle mit einer anderen Art der Bindungsbehandlung gerechnet werden. Dies ist mit Option 39 möglich. Bei "Option 39 = 1;" wird bei Bindungen das erste Clusterpaar ausgewählt (Voreinstellung), bei "Option 39 = 2;" das letzte Clusterpaar. Option 8 darf im Almo-Maskenprogramm Pro36md nicht verwendet werden, jedoch in "selbst geschriebenen" Almo-Programmen. Box 20: Option: Verzichte auf Ausgabe der Distanzmatrix Optionsbox geöffnet: Die Distanzmatrix ist eine symmetrische Matrix von der Ordnung Objekte * Objekte. Sie kann also sehr groß werden. Deswegen ermöglicht es Almo auf diese zu verzichten. Box 21: Grafik-Optionen Optionsbox geöffnet: Zum 2. Eingabefeld: Das Dendrogramm kann sehr groß werden (wenn viele Objekte vorhanden sind). Deswegen ermöglicht Almo, nur die x letzten Schritte des Verschmelzungsschemas zu zeigen. 38
39 P Eingabe als selbst geschriebenes ALMO-Syntax-Programm Das Syntax-Programm ist als Beispielprogramm unter dem Namen HierClus.Alm in Almo enthalten. Es kann geladen werden durch Öffnen des Menüs Almo, dann Liste aller Almo-Programme, dann HierClus.Alm. Die in diesem Programm verwendeten Parameter werden im ausführlichen Almo-Handbuch P36_37_Clusteranalyse erläutert P Ausgabe der Ergebnisse Für das Programm P36 erfolgt zunächst eine Kontrollausgabe der Programmparameter: Ergebnisse aus ALMO Anzahl der nominalen Deskriptionsvariablen = 0 Anzahl der ordinalen Deskriptionsvariablen = 0 Anzahl der quantitativen Deskriptionsvariablen = 0 Anzahl der nominalen Klassifikationsvariablen = 0 Anzahl der ordinalen Klassifikationsvariablen = 0 Anzahl der quantitativen Klassifikationsvariablen= 7 Anzahl der Klassifikationsvariablen insgesamt = 7 Anzahl der Klassifikationsobjekte = 22 Gewichtungsvariable = keine Ausgewaehlte Verfahren: Complete-Linkage Ausgewaehlte (Un-)Aehnlichkeitsmasse: City-Block-Metrik KW-Behandlung = Paarweises Ausscheiden Transponierung der Datenmatrix = nein (Zeilen werden geclustert) Fuer Analyse ausgewaehlte Deskriptionsvariablen nominale Deskriptionsvariablen: keine ordinale Deskriptionsvariablen: keine quantitative Deskriptionsvariablen: keine Fuer Analyse ausgewaehlte Klassifikationsvariablen nominale Klassifikationsvariable: keine ordinale Klassifikationsvariable: keine quantitative Klassifikationsvariable: 11 Kalorien Gewicht = LebErw Gewicht = Kindster Gewicht = Alpha80 Gewicht = Einschul Gewicht = ErwproAr Gewicht = BevZu80 Gewicht = 1.00 Es werden 22 Elemente analysiert 39
40 Daran anschließend wird die berechnete Unähnlichkeitsmatrix ausgegeben, die wir hier nur auszugsweise wiedergeben: Unaehnlichkeitsmatrix (Distanzmatrix) fuer City-Block-Metrik ************************************************************************ Land Land Land ARGENTINI BOLIVIEN BRASILIEN V1-1 V1-2 V1-3 Land ARGENTIN V Land BOLIVIEN V Land BRASILIE V Land CHILE V Land COSTA RI V Land DOM.REP. V Land ECUADOR V Land ELSALVAD V Land GUATEMAL V Land HAITI V Land HONDURAS V Land JAMAICA V Land KOLUMBIE V Land KUBA V Land MEXICO V Land NICARAGU V Land PANAMA V Land PARAGUAY V Land PERU V Land TRINIDAD V Land URUGUAY V Land VENEZUEL V Masszahlen zur Interpretation der Un- oder Aehnlichkeitsmatrix: Mittelwert = 7.76 Standardabw. = 4.07 Schiefe = 0.92 ************************************************************************ Distanzen größer 7.76 können als überdurchschnittlich hoch bezeichnet werden, Distanzen kleiner 7.76 als unterdurchschnittlich. Es folgt die Ausgabe des Verschmelzungsschemas: Modell = Complete-Linkage fuer City-Block-Metrik ************************************************************************ Clusterverknuepfung Clusterzahl Distanzniveau Zuwachs
41 Das Dendrogramm sieht folgendermaßen aus: PARAGUAY 18 VENEZUEL 22 MEXICO 15 KOLUMBIE 13 BRASILIE 3 PANAMA 17 COSTA RI 5 CHILE 4 URUGUAY 21 TRINIDAD 20 JAMAICA 12 KUBA 14 ARGENTIN 1 HAITI 10 GUATEMAL 9 NICARAGU 16 PERU 19 ECUADOR 7 HONDURAS 11 ELSALVAD 8 DOM.REP. 6 BOLIVIEN 2 In dem Dendrogramm lassen sich drei "Hügeln" (=Cluster) erkennen. Sieht man im Verschmelzungsprotokoll nach, so zeigt sich auch beim Übergang von zwei zu drei Clustern ein deutlicher Zuwachs von Man wird sich hier also vorläufig für eine 3-Clusterlösung entscheiden. Die Clusterzahl kann auch - wie bereits erwähnt - durch einen Scree-Test bestimmt werden. Dieser wird als inverser Scree-Test bezeichnet, da das Scree-Diagramm von rechts nach links solange gelesen wird, bis ein erster deutlicher Knickpunkt (in dem Beispiel bei 3 Clustern) erkennbar ist. Ein weiterer, schwächer ausgeprägter Knickpunkt liegt bei 6 Clustern vor. 41
42 Kriterium Knickpunkt Cluster 1 Cluster 2 Cluster 3 Cluster 4 Cluster 5 Cluster 6 Cluster 7 Cluster 8 Cluster 9 Cluster 10 Cluster 11 Cluster 12 Cluster 13 Cluster 14 Cluster 15 Cluster 16 Cluster 17 Cluster 18 Cluster 19 Cluster 20 Als weitere Hilfskriterien zur Bestimmung der Clusterzahl berechnet ALMO die Teststatististiken von Mojena (1977). Drei Teststatistiken werden ausgewiesen: Mojena I Mojena I modifiziert Mojena II modifiziert Die Teststatisitken gehen von folgenden Nullmodellen aus: Nullmodell 1: Die Verschmelzungsniveaus vi (i=1,2,..,n-1) sind bis zu einem bestimmten Schritt k normalverteilt mit dem Mittelwert v k = k i= 1 Vi k und der Standardabweichung s k = (1 k 1) (v i v k ) 2 Im Schritt k wird nun geprüft, ob das Verschmelzungsniveau v k+1 auf der Stufe k+1 noch dieser Normalverteilung angehört. Ist dies nicht der Fall, liegt ein "signifikanter" Zuwachs des Verschmelzungsniveaus vor und die Clusterzahl wird gleich k gesetzt. Die entsprechende Teststatistik lautet: 42
43 ( v v k+ 1 k ) / s k und sollte nach Mojena (1977) zwischen 2.75 und 3.50 liegen. Dies entspricht einem (einseitigen) Signifikanzniveau von mindestens 99.7 Prozent, wenn eine Normalverteilung angenommen wird. Nullmodell 2: Die Verschmelzungsniveaus v i (i=1,2,..,k) in einem Schritt k bilden eine Gerade mit: vˆ k = a k + b k k die mit Hilfe der einfachen linearen Regression geschätzt wird. Es wird geprüft, ob das k+1-te Verschmelzungsniveau v k+1 noch innerhalb des aufgrund der Regressionsgerade prognostizierten Wertes v k+1 = a k+ b k * (k+1) und dessen Vertrauensintervalls liegt. Die entsprechende Teststatistik lautet: ( v k+ 1 k+ 1 vˆ ) / s k Überschreitet die Testatistik den Wert von 2.75 zum erstenmal, liegt nach Mojena (1977) ein "signifikanter" Zuwachs vor und die Clusterzahl sollte gleich k gesetzt werden. Der Schwellenwert von 2.75 entspricht wiederum einem (einseitigen) Signifikanzniveau von 99.7 Prozent. Das Nullmodell 1 liegt dem modifiziertem Mojena-I Kriterium zugrunde. Das ursprüngliche Mojenakriterium verwendet an Stelle von v k und s k den Gesamtmittelwert v und die Gesamtstandardabweichung s. Das modifizierte Mojena-I Kriterium nimmt an, dass die Verschmelzungsniveaus bis zum Schritt k normalverteilt sind, das ursprüngliche Kriterium dagegen, dass alle Verschmelzungsniveaus normalverteilt sind. Dies führt dazu, dass die Testwerte i.d.r. kleiner sind. In unserem Beispiel signalisiert das ursprüngliche Mojena-I Kriterium erst beim Übergang von zwei zu einem Cluster eine signifikante Zunahme. Das ursprüngliche Kriterium ist auch in dem Statistikprogramm CLUSTAN (Wishart 1999) erhalten. Teststatstik zur Bestimmung der Clusterzahl nach MOJENA (Regel 1) - analog zu CLUSTAN Mittelwert = Standardabweichung = Freiheitsgrade = 20 Clusterzahl Teststatistik Freiheitsgrade Signifikanz
44 ******************************************************************* Teststatstik zur Bestimmung der Clusterzahl nach MOJENA (Regel 1) - modifiziert Clusterzahl Teststatistik Signifikanz Teststatstik zur Bestimmung der Clusterzahl nach MOJENA (Regel 2) - modifiziert 44
45 Clusterzahl Teststatistik Signifikanz nach MOJENA sollte Signifikanz groesser 99.7 sein! Der kritische Wert von 2.75 wird von der modifizierten Teststatistik I zum erstenmal bei 8-Clustern erreicht. Allerdings ist der Wert nicht signifikant. (ALMO ermittelt die exakte Signifikanz über die t-verteilung). Die Signifikanz von 99.7 wird bei der 4 Clusterlösung knapp überschritten, bei der 3 Cluster deutlich. Bei der modifizierten Teststatistik II erweist sich die 3 Clusterlösung als signifikant. Neben der 3-Clusterlösung wird somit noch eine feinere Struktur mit 8 und 4 Clustern als "signifikant" ausgewiesen. Welche der Lösungen "brauchbar" ist, muss letztlich der Anwender aufgrund inhaltlicher Kriterien entscheiden. Für weitere Analysen kann man sich aufgrund der bisherigen Ergebnisse entweder für eine 3-, 4- oder 8-Clusterösung entscheiden. Betrachten wir unter diesem Gesichtspunkt nochmals das Verschmelzungsschema, so erkennen wir, dass beim Übergang von 8 auf 7 Clustern und beim Übergang von 3 zu 2 Clustern ein deutlicher Zuwachs (von auf bzw. von auf 5.059) auftritt. Auch beim Übergang von 4 zu 3 Clustern ist ein Zuwachs (von auf 1.474) zu erkennen, der aber schwächer ausgeprägt ist. Die Ergebnisse der Teststatistiken bilden sich somit im Verschmelzungsschema ab. Ob überhaupt eine von reinen Zufallsdaten abweichende Clusterstruktur vorliegt, kann durch Verwendung einer Option geprüft werden. Beim Maskenprogramm Prog36md wird die Optionsbox Teststatistiken geöffnet. Siehe die ausführliche Erläuterung in Abschnitt P , Box 17. ALMO führt dann eine Zufallstestung des Verschmelzungsschemas durch. Dabei wird nach folgenden Schritten vorgegangen: 1. Berechne Mittelwerte und Standardabweichungen der untersuchten Variablen. 2. Erzeuge eine Zufallsdatenmatrix unter der Annahme einer homogenen, normalverteilten Population mit den empirischen Verteilungskennwerten. Es wird angenommen, dass sich die Objekte in den Variablen normalverteilen mit den empirischen Mittelwerten und Standardabweichungen und voneinander unabhängig sind. 45
46 3. Führe für die Zufallsdatenmatrix eine Clusteranalyse durch. 4. Speichere das Verschmelzungsschema. 5. Wiederhole die Schritte 2 bis 4 n-mal. Abhängig von der Größe der Datenmatrix wird man das Experiment 20 (bei großen Datenmatrizen), 50 (mittleren Datenmatrizen) oder 100 (bei kleinen Datenmatrizen) mal wiederholen. 6. Berechne die Durchschnittswerte, Standardabweichungen und Testatistiken aus den Verschmelzungsniveaus und stelle diese Werte den Verschmelzungswerten der ursprünglichen Datenmatrix gegenüber. 7. Liegen keine deutlichen Abweichungen zwischen dem Nullmodell einer homogenen normalverteilten Population und dem Verschmelzungsniveau der ursprünglichen Datenmatrix vor, ist keine Clusterstruktur zu erkennen. Das Verfahren setzt voraus, dass eine Datenmatrix untersucht wird. Die Ergebnisse sind: Zahl der Simulationen =20 Vi = emp. standard. Verschmelzungsniveau E(Vi) = Erwartungswert von Vi SA(Vi) = Standardabweichung von Vi E-2*SA = Erwartungswert minus 2*Standardabw. E+2*SA = Erwartungswert plus 2*Standardabw. Testst = Teststatistik (Vi-E(Vi))/SA(Vi) Schritt Vi E(Vi) SA(Vi) E-2*SA E+2*SA Testst Signifikante Abweichungen (z.b. Teststatistiken kleiner 2.75) treten zum erstenmal bei der 14-Clusterlösung auf. Man wird daher die Ergebnisse der Clusteranalyse als überzufällig betrachten. Das aufgrund der Daten berechnete Verschmelzungsschema weicht signifikant von einem bei homogenen Zufallsdaten erwarteten Verschmelzungsschema ab. Allgemein lässt sich zu den bisher behandelten Testgrößen anmerken: 46
47 1. Nach einer bestimmten Anwendungspraxis bereitet das Erkennen von Knick- Punkten im Verschmelzungsschema keine Probleme. Häufig liegen aber mehrere Knick-Punkte vor. 2. Besteht Unsicherheit dahingehend, ob überhaupt ein Knickpunkt vorliegt, wird man eine Zufallstestung durchführen. 3. Die Entscheidung für eine oder für mehrere Clusterlösung(en) wird man durch die Mojena-Kriterien absichern. Die Clusterlösungen sollten auch hohe Werte (Werte größer 2.75; Signifikanz 99.7 Prozent) in den Teststatistiken aufweisen. Bei der Verwendung von Signifikanztests ist allerdings Vorsicht angebracht. Unsere Erfahrungen zeigen, dass die Kriterien von Mojena bei großen Datensätzen oft bereits eine Zunahme bei einer sehr großen Clusterzahl (z.b. 30 Cluster) als signifikant ausweisen. Neben den hier behandelten Testgrößen wurden in der Literatur eine Reihe von weiteren Maßzahlen zur Bestimmung der Clusterzahl entwickelt. Einige dieser Maßzahlen werden nachfolgend behandelt, da sie sich auch zur Beschreibung der Homogenität in den Clustern eignen. Nach der Entscheidung für eine oder mehrere Clusterlösungen wird man in einem nächsten Schritt untersuchen, in welchem Ausmaß die gebildeten Cluster die Vorstellungen der Homogenität in den Clustern und jene der Heterogenität zwischen den Clustern erfüllen. Zur Beschreibung der Homogenität der Cluster wurden eine Reihe von Maßzahlen entwickelt, von denen hier nur folgende behandelt werden sollen: 1. Korrelationsmaße. 2. Homogenitätsindizes. Korrelationsmaße für eine bestimmte Clusterlösung: Für eine bestimmte Clusterlösung lässt sich nach folgender Regel eine theoretische Unähnlichkeitsmatrix bilden: û g,g * 0 = 1 * wenn Objekt g und g demselben Cluster angehören wenn sie unterschiedlichen Clustern angehören Zur Messung der Übereinstimmung zwischen der theoretischen und empirischen Unähnlichkeitsmatrix kann der Gamma-Korrelationskoeffizient berechnet werden. Bei den Mittelwertverfahren wird man anstelle des ordinalen Korrelationskoeffizienten Gamma den Produkt-Moment-Korrelationskoeffizienten (=kophenetische Korrelation) verwenden. Homogenitätsindizes für eine Clusterlösung: Bei den Homogenitätsindizes wird von folgender Überlegung ausgegangen: Sind die Cluster homogen, so sollten die Unähnlichkeiten in den Clustern kleiner den Unähnlichkeiten zwischen den Clustern sein. Berechnen wir für eine Clusterlösung die durchschnittliche paarweise Unähnlichkeit u in in den Clustern und die durchschnittliche paarweise Unähnlichkeit u zw zwischen den Clustern, so sollte u zw größer als u in sein. Zur Berechnung der durchschnittlichen oder mittleren Unähnlichkeiten sind mehrere Ansätze möglich. Wir 47
48 wollen hier nur eine Möglichkeit darstellen, bei der die durchschnittlichen Unähnlichkeiten wie folgt berechnet werden: u u in zw = k = k u(k) * k > k in / K u(k, k u (k) in = u g k * g1g g k * g > y u (k, k * ) zw = * ) * g k * * g k zw /(K * (K 1) / 2) /(nk * (nk 1) / 2) u * g1g /(n k * n * k ) wobei K die Zahl der Cluster und n k die Größe des Clusters k ist. Bei der Berechnung wird angenommen, dass alle Cluster unabhängig von ihrer Größe dasselbe Gewicht haben sollen. Zur Charakterisierung der Homogenität lässt sich die Differenz g = u zw u in verwenden. Signifikanztests für die Koeffizienten: Die Signifikanz des Homogenitätsindex g lässt sich wie folgt prüfen: Unter der Annahme, dass die Clustergrößen n k konstante Größen sind und die gefundene Clusterlösung rein zufällig ist, lässt sich der Erwartungswert und die Standardabweichung berechnen. Aus dem berechneten Erwartungswert und der Varianz lässt sich eine z-teststatistik konstruieren mit z=(g- E(g))/σ(g). Für diese kann geprüft werden, ob sie signifikant größer 0 ist, wenn eine Standardnormalverteilung angenommen wird. Anstelle der Annahme einer Normalverteilung kann die Signifikanz des Homogenitätsindex auch mit Hilfe der Chebychevschen Ungleichung bestimmt werden. Das Fehlerniveau berechnet sich mit 100/z 2, wobei z die Teststatistik ist. Eine andere Möglichkeit der Bestimmung von Signifikanzschwellen ist die Durchführung von Simulationsrechnungen. Dabei kann von folgendem Nullmodell ausgegangen werden: Jede andere K-Clusterlösung liefert gleich gute Ergebnisse. Ist dies der Fall, wird man die gefundene Clusterlösung als zufällig betrachten. Das Vorgehen besteht aus folgenden Schritten: 1. Ordne jedes Objekt zufällig einem der K-Cluster zu. 2. Berechne die entsprechende Maßzahl. 3. Wiederhole die Schritte 1 und 2 r-mal (z.b. r=100). Das Ergebnis der Simulationsrechnungen besteht darin, dass eine Wahrscheinlichkeitsverteilung für die verwendete Maßzahl berechnet wird. Aus dieser können zum einen Vertrauensintervalle und zum anderen eine z-teststatistik berechnet werden. Unsere Erfahrungen zeigen, dass zur Berechnung der z-teststatistik ein Zahl von 20 Simulationen ausreicht. Zur Berechnung von Signifikanzschwellen ist eine größere Zahl von Simulationen erforderlich. Die Zahl hängt hier von dem gewünschten Signifikanzniveau ab. Bei 100 Simulationen berechnet ALMO die Signifikanzschwelle 48
49 für 90 Prozent, bei 200 Simulationen für 95 Prozent usw. Das hier dargestellte Vorgehen wird in ALMO für die Signifikanztestung der Korrelationsmaße verwendet. Zur Berechnung der Korrelationsmaße muss im Maskenprogramm Prog36md die Optionsbox Teststatistiken geöffnet werden (siehe Abschnitt P , Box 17). ALMO berechnet folgende Testgrößen für die 3-Clusterlösung Clusterkennwerte fuer die 3-Loesung Unaehnlichkeiten in den Clustern: Cluster Paare Minimum Maximum arithm.m. Standardabw Unaehnlichkeiten zwischen den Clustern: Cluster Cluster Paare Minimum Maximum arithm.m. Standardabw W/B-Kriterium = C-Index = G1-Homogenitaetsmass = Erwartungswert = Varianz = z-wert = Signifikanz = Fehler (Chebychev) = Die Homogenität kann als überzufällig betrachtet werden. Der z-wert für den Homogenitätsindex beträgt und ist signifikant von Null verschieden (Signifikanz = ). Bei Verwendung der konservativen Chebychevschen Ungleichung ergibt sich ein Fehlerniveau von 3% für das Verwerfen der H 0-Hypothese, dass die Homogenität rein zufällig ist. Der Gamma-Korrelationskoeffizient ist in dem Beispiel Bei einer vollkommen homogenen Lösung (alle Unähnlichkeiten in den Clustern sind kleiner als die Unähnlichkeiten zwischen den Clustern) würde sich ein Wert von ergeben. Dies würde bedeuten, dass alle paarweisen Unähnlichkeiten in den Clustern kleinern als die paarweisen Unähnlichkeiten zwischen den Clustern sind. Der Gamma- Korrelationskoeffizient besitzt in unserem Beispiel eine Teststatistik von und kann somit unter der Verwendung eines kritischen Schwellenwertes von 2.0 (ca. 95%) als signifikant betrachtet werden. Der bei den Simulationen für eine Signifikanz von 95% ermittelte kritische Wert für Gamma beträgt Der empirische Wert von liegt deutlich über dieser Schwelle. 49
50 Gamma = Zahl der vorgeg. Simulationen = 200 Zahl der erfolgr. Simulationen = 200 Erwartungswert = Standardabweichung = 0.07 Teststatistik = Schwellwert fuer = 0.95 Prozent = 0.11 Gleiches trifft in dem Biespiel auf die kophenetische Korrelation zu: kophenetischer Korrelationskoeffizient = Zahl der vorgeg. Simulationen = 200 Zahl der erfolgr. Simulationen = 200 Erwartungswert = Standardabweichung = 0.06 Teststatistik = Schwellwert fuer = 0.95 Prozent = 0.10 Vor der inhaltlichen Beschreibung der Cluster kann eine Stabilitätsprüfung durchgeführt. (Sie kann auch nach der inhaltlichen Interpretation erfolgen) Eine gefundene Clusterlösung wird dann als stabil bezeichnet, wenn keine bzw. nur geringe Änderungen eintreten, wenn ein anderes Verfahren und/oder ein anderes Ähnlichkeits- oder Unähnlichkeitsmaß verwendet wird. Technisch wird die Stabilitätsprüfung wie folgt durchgeführt. Beim Maskenprogramm Prog36md in Abschnitt P bzw. P36.7.1: 1. Es wird die Optionsbox "Verfahren" geöffnet und folgende Verfahrten aktiviert: (Siehe auch Abschnitt P ) 50
51 2. Es wird die Optionsbox "Distanzmaß" geöffnet und folgende Verfahrten aktiviert: (Siehe auch Abschnitt P ) 3. In der Box "Clusterzahl" werden folgende Eingaben vorgenommen Beim "selbst geschriebenen" Syntaxprogramm "Clustan.ALM" in Abschnitt P Nach der Anweisung MODELL=...; werden alle jene Verfahren angeführt, die für die Lösung des Klassifikationsproblems geeignet sind. Also: Modell = complete_linkage, single_linkage, average_linkage; 51
52 2. Nach der Anweisung DISTANZ_MASS=...; werden alle jene Ähnlichkeits- und Unähnlichkeitsmaße angeführt, die für die Lösung des Klassifikationsproblems geeignet sind. Also: Distanz_mass = city_block, Euklid, Quad_euklid; 3. Es wird die minimale und maximale Clusterzahl angegeben. Also: Min_Clusterzahl = 2, Max_Clusterzahl = 8; In dem Beispiel wird untersucht, wie stabil die Clusterlösungen bei Verwendung des Complete-, Single- und Average-Linkage, sowie bei Verwendung der City-Block-Metrik, der euklidischen Distanz und der quadrierten euklidischen Distanz sind. Die Übereinstimmung zwischen den einzelnen Clusterlösungen wird durch den sogenannten Rand-Index (Rand 1971) gemessen. Der Index liegt zwischen 0 und 1. Ein Wert von 1 bedeutet perfekte Übereinstimmung, ein Wert von Null keine Übereinstimmung. Werte größer als 0.7 können als ausreichende Übereinstimmung interpretiert werden. Aggregierte Randindizes fuer (Un)Aehnlichkeitsmasse: (Un)Aehnlichkeitsmass Rand-Index City-Block-Metrik Euklidische Distanz quadrierte euklidische Distanz Aggregierte Randindizes fuer Modelle: Modell Rand-Index Complete-Linkage Single-Linkage Average-Linkage Aggregierte Randindizes fuer Clusterzahl: Clusterzahl Rand-Index Clusterzahl= Clusterzahl= Clusterzahl= Clusterzahl= Clusterzahl= Clusterzahl= Clusterzahl= ************************************************************************ Die Randindizes für die gewählten Unähnlichkeitsmaße liegen zwischen und und unterscheiden sich kaum. Die Wahl des Unähnlichkeitsmaßes hat somit keinen Einfluss auf die Stabilität: unabhängig vom gewählten Unähnlichkeitsmaß (City-Block-Metrik, euklidische Distanz, quadrierte euklidische Distanz) wird eine Stabilität von 77 % bis 81 % erzielt. Einen wesentlich deutlicheren Einfluss auf die Stabilität lässt sich hinsichtlich des gewählten Clusterverfahrens feststellen. Der "Single-Linkage" erbringt die geringste Stabilität, der "Average-Linkage" die höchste. Wenn aufgrund inhaltlicher Überlegungen keine eindeutige Entscheidung für ein bestimmtes Verfahren getroffen werden kann, wird man sich aufgrund dieser Ergebnisse für den "Average-Linkage" entscheiden. Er erbringt für die City-Block- Metrik folgendes Verschmelzungsschema: Beim Übergang von der 5-Clusterlösung zu 52
53 einer 4-Clusterlösung tritt - im Unterschied zu den Ergebnissen des Complete-Linkage (siehe Ergebnisse zu Beginn dieses Abschnitts) - ein erster deutlicher Zuwachs des Distanzniveaus von auf. Aber auch beim Übergang von 3 zu 2 Clustern lässt sich, wie beim Complete-Linkage, ein deutlicher Zuwachs beobachten. ************************************************************************ Modell = Average-Linkage fuer City-Block-Metrik ************************************************************************ Clusterverknuepfung Clusterzahl Distanzniveau Zuwachs Die 5-Clusterlösung erbringt folgende Zuordnung: ************************************************************************ Clusterzugehoerigkeit der Elemente bei 5 Clustern Cluster 1 (n= 13) 1 ARGENTIN 3 BRASILIE 4 CHILE 5 COSTA RI 12 JAMAICA 13 KOLUMBIE 14 KUBA 15 MEXICO 17 PANAMA 18 PARAGUAY 20 TRINIDAD 21 URUGUAY 22 VENEZUEL Cluster 2 (n= 1) Cluster 3 (n= 6) 2 BOLIVIEN 6 DOM.REP. 7 ECUADOR 8 ELSALVAD 11 HONDURAS 16 NICARAGU 19 PERU Cluster 4 (n= 1) 9 GUATEMAL Cluster 5 (n= 1) 10 HAITI ************************************************************************ 53

54 Die Stabilität der 5-Clusterlösung beträgt 71% und ist etwas geringer als jene für die 3-Clusterlösung (77%). Neben einer 3- und 8-Clusterlösung kommt somit noch eine 5- Clusterlösung für die weitere Analyse in Frage. Beachte: Die aggregierten Randindizes ändern sich, wenn eine andere Clusterzahl definiert wird, ein Verfahren hinzugenommen oder entfernt wird oder mit anderen Distanzmaßen gerechnet wird. Nach der Entscheidung für eine bestimmte oder mehrere geeignete Clusterlösungen besteht die nächste Aufgabe der Lösung der Klassifikationsaufgabe darin, die gefundene(n) Clusterlösung(en) zu beschreiben. Als zusätzliche Hilfe können dazu sogenannte Deskriptionsvariablen in die Analyse einbezogen werden. Sie dienen der Beschreibung und Validitätsprüfung, werden aber nicht zur Clusterbildung verwendet. In unserem Beispiel können als Deskriptionsvariablen die Indikatoren der wirtschaftlichen Entwicklung aufgenommen werden. Im Maskenprogramm Prog36md in Abschnitt P wird in die Box Deskriptionsvariable eingetragen: Zur Beschreibung der Cluster berechnet ALMO für jede Klassifikations- und Deskriptionsvariable die kleinste und größte Ausprägung, den Mittelwert, die Standardabweichung und den z-wert in jedem Cluster. Der z-wert gibt an, wie stark der Clustermittelwert vom Gesamtmittelwert abweicht. Ein Absolutwert größer 2 kann als signifikant betrachtet. Die Ergebnisausgabe sieht folgendermaßen aus, wobei wir hier nur die Werte für das 1. Cluster wiedergeben: Masszahlen fuer Deskriptionsvariablen im Clustern 1: Variable n= Min. Max. MA SA z-wert BrSozPr Wachst Wachst Indust Indust Export Schulden Masszahlen fuer Klassifikationsvariablen im Clustern 1: Variable n= Min. Max. MA SA z-wert Kalorien LebErw
55 13 Kindster Alpha Einschul ErwproAr BevZu Das erste Cluster ist somit durch eine überdurchschnittliche Kalorienversorgung (z- Wert = 3.58) sowie durch eine überdurchschnittliche Lebenserwartung (Wert = 4.49) und Alphabetisierung (z-wert = 7.19) gekennzeichnet. Auch die Einschulungsquote liegt über den Gesamtdurchschnitt. Umkehrt liegt die Kindersterblichkeit unter dem Gesamtdurchschnitt. Auch die Versorgung mit Ärzten ist überdurchschnittlich, da das Verhältnis Einwohner pro Arzt unter dem Durchschnitt liegt. Hinsichtlich des Bevölkerungswachstums bestehen keine Unterscheide zum Gesamtmittelwert. Das Cluster 1 ist also insgesamt durch eine überdurchschnittliche soziale Entwicklung gekennzeichnet. Hinsichtlich der wirtschaftlichen Entwicklungsindikatoren, die als Deskriptionsvariablen in die Analyse einbezogen wurden, bestehen keine signifikanten Abweichungen vom Gesamtdurchschnitt. Nur das Brutto-Sozialprodukt pro Kopf (BrSozPr) liegt knapp unter dem kritischen Schwellenwert von 2.0. P36.4 Reproduktion einer empirischen Ähnlichkeits- bzw. Unähnlichkeitsmatrix durch eine hierachische Struktur. Die agglomerativ hierachischen Verfahren können auch dazu verwendet werden, eine empirische Ähnlichkeits- bzw. Unähnlichkeitsmatrix durch eine hierachische Struktur, wie sie im Dendrogramm abgebildet wird, zu reproduzieren. Die untersuchte Fragestellung lautet: Liegt der empirischen Ähnlichkeits- bzw. Unähnlichkeitsmatrix eine hierachische Struktur zugrunde? Zur Beantwortung dieser Fragestellung berechnet Almo - in Abhängigkeit von der Wahl von Option15 bzw. der Eingabe in die Optionsbox Teststatistiken - folgende Maßzahlen: Kophenetischer Korrelationskoeffizient. Dieser misst, wie stark die empirische Unbzw. Ähnlichkeiten mit den aufgrund des Dendrogramms reproduzierten Un- bzw. Ähnlichkeiten korreliert. Ein Wert von 1.0 bedeutet, dass die empirischen und reproduzierten Un- bzw. Ähnlichkeiten perfekt korrelieren. Ein Wert von 0 bedeutet, dass kein Zusammenhang vorliegt. Der Gamma-Korrelationskoeffizient. Dieser wird analog dem aus der Tabellenanalyse bekannten Gammakoeffizienten definiert. Er ist wie der kophenitische Korrelationskoeffizient ein Korrelationskoeffizient. Ein Wert von 1.0 drückt einen perfekten Zusammenhang aus, ein Wert von 0.0 Unabhängigkeit. Im Unterschied zum kophenitischen Korrelationskoeffizienten geht in Gamma nur die ordinale Information der empirischen und reproduzierten Un- bzw. Ähnlichkeiten ein. Ein Wert von 1.0 bzw. nahe von 1.0 bedeutet bei beiden Maßzahlen, dass die empirische Un- bzw. Ähnlichkeitsmatrix gut durch die hierachische Struktur reproduziert werden kann. Ein Wert von 0.0 bzw. nahe von 0.0 bedeutet, dass dies nicht der Fall ist. Schwellenwerte, ab denen eine Reproduktion noch als brauchbar akzeptiert werden kann, fehlen. Für das Beispiel des Abschnitts P36.7 ergeben sich folgende Werte, wenn in der Optionsbox Teststatistiken 4 eingegeben wird: 55
56 ************************************************************************ kophenetischer = Korrelationskoeffizient Zahl der vorgeg. Simulationen = 20 Zahl der erfolgr. Simulationen = 20 Erwartungswert = Standardabweichung = 0.05 Teststatistik = Schwellwert fuer = 0.50 Prozent = ************************************************************************ Gamma = Zahl der vorgeg. Simulationen = 20 Zahl der erfolgr. Simulationen = 20 Erwartungswert = Standardabweichung = 0.06 Teststatistik = Schwellwert fuer = 0.50 Prozent = Die Werte können wiederum als "signifikant" betrachtet werden, da die Teststatistiken mit bzw deutlich über einem Schwellenwert von 2 liegen. Die durch die hierarchisch agglomerativen Verfahren aufgefundene hierarchische Struktur, wie sie das Dendrogramm zum Ausdruck bringt, ist somit zur Reproduktion der empirischen Un- oder Ähnlichkeitsmatrix der untersuchten Objekte geeignet. Beachte: Die kophenetische Korrelation und der Korrelationskoeffizient Gamma können somit zur Beantwortung von zwei, vollkommen unterschiedlichen Fragestellungen angewendet werden. Erstens kann mit ihnen geprüft werden, wie homogen eine bestimmte Clusterlösung ist (siehe Abschnitt P36.7). Zum zweiten kann untersucht werden, wie gut die empirischen paarweisen Unähnlichkeits- bzw. Ähnlichkeitsbeziehungen zwischen den Objekten durch die Hierarchie der Verfahren insgesamt reproduziert werden. P36.5 Literatur J. Bacher / A. Pöge / K. Wenzig, 2010: Clusteranalyse. München-Wien Mojena, R., 1978: Hierachical Grouping Methods and Stopping Rules: An Evalution. Computer Journal, Vol.20, Nohlen, D.(Hg.), 1984: Lexikon Dritte Welt, Reinbek b. Hamburg Rand, W. M., 1971: Objektive Criteria for Evaluating Clustering Methods. Journal of 56
57 the American Statistical Association, Vol.66, Steinhausen, D./Langer, K., 1977: Clusteranalyse. Berlin/New York 57
58 P37 Clusteranalyse nach dem K-Means-Verfahren P37.0 Übersicht P Kurzcharakteristika der Verfahren Die im Programm 36 enthaltenen hierarchischen Verfahren haben den Nachteil, dass sie sehr speicherintensiv sind, da die Datenmatrix und die Unähnlichkeits- oder Ähnlichkeitsmatrix im Arbeitsspeicher des Programms gehalten wird. Dies bedeutet, dass abhängig von dem zur Verfügung stehenden Arbeitsspeicher nur eine bestimmte Anzahl von Klassifikationsobjekten "geclustert" werden kann. Mit Programm 37 kann dagegen eine im Prinzip beliebig große Anzahl von Klassifikationsobjekten untersucht werden, da die Verfahren des Programms P37 auf einen anderen Algorithmus basieren. Das Programm 37 enthält folgende Verfahren K-Means-Verfahren (Modell = 1 bis 6) Analyse latenter Klassen (Modell = 7) Repräsentanten-Verfahren (Modell = 8) Mehrstufiges Verfahren K-Means-Verfahren: Das Ziel der K-Means-Verfahren besteht darin, die Klassifikationsobjekte so zu Clustern zusammenzufassen, dass die Streuung innherhalb der Cluster ein Minimum wird. Die Streuung innerhalb eines Clusters k ist - ähnlich wie bei der einfachen Varianzanalyse - definiert als die Summe der quadratierten Abweichungen der Klassifikationsobjekte des Clusters k von dem Clusterzentrum des Clusters k in allen Klassifikationsvariablen. Unter dem Clusterzentrum eines Cluster k versteht man die Mittelwerte des Clusters k in den in die Analyse einbezogenen Klassifikationsmerkmalen. Die Aufgabe der "K-Means-Clustering"-Verfahren kann also auch folgendermaßen formuliert werden: Es sollen für K Cluster Clusterzentren (Mittelwerte; "Means") so bestimmt werden, dass die Streuung der Klassifikationsobjekte innerhalb der Cluster minimal ist. Die Berechnung der Clusterzentren erfolgt iterativ (siehe dazu Abschnitt P37.2.5). Mit den K-Means- Verfahren können sowohl quantitative als auch ordinale und nominale Variablen untersucht werden. Ordinale Variablen werden dabei wie quantitative Variablen behandelt. Die nominalen Variablen werden programmintern in ihre Dummies aufgelöst, die wie quantitative Variablen behandelt werden können. Die zur Clusterbildung verwendeten Variablen müssen vergleichbar sein, d.h., sie müssen in derselben Skaleneinheit gemessen sein (siehe Abschnitt P37.1). Analyse latenter Klassen (probabilistische Clusteranalyse): 58
59 Im Unterschied zu den K-Means-Verfahren werden bei der Analyse latenter Klassen die Cluster (= latenter Klassen) so gebildet, dass die Likelihood-Funktion maximiert wird. Das bedeutet: Die Modellparameter (die Klassengrößen, die Clusterzentren und bei quantitativen Variablen die Clusterstreuungen) werden so berechnet, dass die empirische Verteilung der untersuchten Objekte bestmöglich reproduziert wird. Durch diesen Modellansatz ergeben sich folgende Unterschiede zu den K-Means-Verfahren. 1. Die Analyse latenter Klassen führt zu einer probabilistischen Zuordnung der untersuchten Objekte. Jedes Objekt g gehört mit einer bestimmten Wahrscheinlichkeit jedem Cluster an. Beispiel: In einer 3-Cluster-Klassenlösung gehört das erste Objekt A dem Cluster 1 mit einer Wahrscheinlichkeit von 0.7 an, dem Cluster 2 mit einer Wahrscheinlichkeit von 0.2 und dem Cluster 3 mit einer Wahrscheinlichkeit von 0.1. Für das zweite Objekt B könnten sich folgende Zuordnungswahrscheinlichkeiten ergeben: 0.1 für Cluster 1, 0.5 für Cluster 2 und 0.4 für Cluster 3. Die K-Means-Verfahren führen dagegen zu einer deterministischen Zuordnung. Jedes Objekt gehört mit einer Wahrscheinlichkeit von 1 nur einem Cluster an. Beispiel: In einer 3-Clusterlösung gehört das erste Objekt A dem Cluster 1 an, das zweite Objekt B dem Cluster 2 usw. 2. Da bei der Analyse latenter Klassen mit Zuordnungswahrscheinlichkeiten gerechnet wird, müssen die zur Clusterbildung verwendeteten Variablen nicht vergleichbar sein. Wie bei den K-Means-Verfahren können Variablen unterschiedlichen Meßniveaus in die Analyse einbezogen werden. Die dabei entstehenden Submodelle enthält die nachfolgende Übersicht. Übersicht P37.0.1: Submodell der Analyse latenter Klassen Meßniveau der Klassifikationsvariablen nominal ordinal quantitativ gemischt Submodell der Analyse latenter Klassen Analyse latenter Klassen i. e. S. (bei dichotomen Variablen: klassischer Ansatz von Lasarsfeld/Henry (1968)), der in Programm P15 enthalten ist, im Unterschied zu Programm P15 wird eine ML-Lösung durchgeführt. Analyse latenter Klassen für ordinale Variablen nach Rost (1985) Analyse latenter Profile allgemeine Analyse latenter Klassen Repräsentanten-Verfahren: Beim Repräsentanten-Verfahren wird jedes Cluster durch ein typisches Objekt "repräsentiert". Im Unterschied zu den K-Means-Verfahren und der Analyse latenter Klassen werden nicht Clusterzentren (=Mittelwerte) berechnet, sondern es wird nach einem "typischen" Objekt für jedes Cluster gesucht. Überlappungen und Nichtklassifikationen sind erlaubt. Wie beim K-Means-Verfahren müssen die zur Clusterbildung verwendeten Variablen vergleichbar sein. In die Analyse können quantitative, ordinale und/oder nominale Variablen einbezogen werden. P Unterschiede und Gemeinsamkeiten der drei Verfahren Die nachfolgende Abbildung faßt die Unterschiede und Gemeinsamkeiten der drei Verfahren zusammen. 59
60 Übersicht P37.0.2: Unterschiede und Gemeinsamkeiten der Verfahren Merkmale zur Charakterisierung der Verfahren Meßniveau der Klassifikationsvariablen Vergleichbarkeit der Klassifikationsvariablen erforderlich Zuordnung der Objekte zu den den Clustern Überlappungen können auftreten Nichtklassifikationen von Objekte können auftreten konfimatorische Analyse möglich K-Means- Verfahren Analyse latenter Klassen Repräsentanten- Verfahren gemischt gemischt gemischt ja nein ja deterministisch probabilistisch deterministisch nein ja ja nein nein ja ja ja nein Die in der Übersicht verwendeten Begriffe bedeuten: Klassifikationsvariablen: Dies sind jene Variablen, die zur Clusterbildung verwendet werden. Sie sind von den sogenannten Deskriptionsvariablen zu unterscheiden, die der Beschreibung und Validitätsprüfung der Cluster dienen. Gemischtes Meßniveau: Die Variablen können quantitatives, ordinales und/oder nominales Meßniveau besitzen. Vergleichbarkeit der Klassifikationsvariablen: Vergleichbarkeit von Klassifikationsvariablen bedeutet, dass diese in derselben Skaleneinheit gemessen sind. Nichtvergleichbarkeit liegt in folgenden Situationen vor: 1. Die Variablen besitzen unterschiedliche Skaleneinheiten (Maßeinheiten). 2. Die Variablen besitzen gemischtes Meßniveau. 3. Die Variablen sind hierarchisch. Eine Variable kann nur auftreten, wenn in einer anderen Variablen eine bestimmte Ausprägung auftritt. Unterschiedliche Maßeinheiten: Als Indikatoren für die wirtschaftliche Entwicklung werden in einer Clusteranalyse das "Pro-Kopf-Bruttosozialprodukt" und das "jährliche Wirtschaftswachstum in den 80er-Jahren" verwendet. Diese beiden Variablen besitzen zwar das gleiche Meßniveau (=quantitativ), sind aber nicht vergleichbar, da das "Pro-Kopf-Bruttosozialprodukt" in einer bestimmten Währungseinheit (=Dollar) gemessen wird, das "jährliche Wirtschaftswachstum in den 80-Jahren" dagegen in Prozenten. Unterschiedliches (gemischtes) Meßniveau: In eine Clusteranalyse sollen die nominalen Variablen "Geschlecht" und "berufliche Tätigkeit", die ordinale Variable "abgeschlossene Schulbildung" und die quantitative Variable "Einkommen" einbezogen werden. In diesem Beispiel liegt Nichtvergleichbarkeit vor, da die Variablen unterschiedliches Meßniveau besitzen. Hierarchische oder bedingte Variablen: 60
61 Diese liegen dann vor, wenn das Auftreten einer Variablen von dem Auftreten der Ausprägung(en) einer oder mehrerer anderer Variablen abhängt. Die Variable "derzeitiger Beruf" tritt beispielsweise nur dann auf, wenn die vorausgehenden Variable "Berufstätigkeit" die Ausprägung "derzeit berufstätig" besitzt. Daneben können inhaltliche Überlegungen zu dem Urteil der Nichtvergleichbarkeit führen: Selbst wenn alle in die Analyse einbezogenen Variablen dieselbe Maßeinheit (z.b. Prozente) besitzen, wie z.b. "Industrialisierungsquote in den 80er Jahren", "jährliche Wirtschaftswachstum in den 80er Jahren", kann in Frage gestellt werden, ob beide Klassifikationsvariablen dieselbe "Maßeinheit" besitzen, ob also eine Differenz von 5 Prozent beim jährlichen Wirtschaftswachstum "dasselbe" bedeutet wie bei der Industrialisierungsquote. Weitere inhaltliche Überlegungen beziehen sich darauf, ob den Variablen gemeinsame Dimensionen zugrundeliegen, die durch eine unterschiedliche Anzahl von Indikatoren (=Variablen) repräsentiert sind (Problem der Über- bzw. Unterrepräsentativität). Das Problem der Nichtvergleichbarkeit muss bei allen Clusteranalyseverfahren der Programme P36 und P37 mit Ausnahme der probabilistischen Verfahren gelöst werden. Lösungsstrategien werden in Abschnitt P37.1 behandelt. Bei der Analyse latenter Klassen ist das Problem der Nichtvergleichbarkeit bedeutungslos, da mit Wahrscheinlichkeiten gerechnet wird. Deterministische Zuordnung der Objekte zu den Clustern: Die Objekte werden mit einer Wahrscheinlichkeit von 1.0 einem Cluster zugeordnet. Probabilistische Zuordnung der Objekte zu den Clustern: Die Objekte werden mit einer bestimmten Wahrscheinlichkeit jedem Cluster zugeordnet. Nachfolgende Tabelle veranschaulicht den Unterschied zwischen einer probabilistischen und deteministischen Zuordnung. Übersicht P37.0.3: Probabilistische und deterministische Zuordnung probabilistische Zuordnung deteministische Zuordnung Objekte C1 C2 C3 C1 C2 C3 A B C D Die Cluster wurden in der Übersicht mit C1, C2 und C3 bezeichnet, die Objekte mit A, B, C usw. Die Tabelle ist zeilenweise für jede Zuordnung zu lesen: Bei der probabilistischen Zuordnung wird das Objekt A dem Cluster C1 mit einer Wahrscheinlichkeit von 0.7 zugeordnet, dem Cluster C2 mit einer Wahrscheinlichkeit von 0.2 und dem Cluster C3 mit einer Wahrscheinlichkeit von 0.1. Bei der deterministischen Zuordnung gehört das Objekt A dem Cluster C1 an, usw. Überlappungen: Überlappungen liegen vor, wenn ein oder mehrere Objekte mehreren Clustern angehört (angehören). Probabilistische Clusteranalysen (latente Klassenanalysen) führen immer zu überlappenden Clustern, außer wenn jedes Objekt mit einer Wahrscheinlichkeit von 1 nur einem Cluster zugeordnet wird. Bei deterministischen Verfahren sind Überlappungen dadurch gekennzeichnet, dass ein oder mehrere 61
62 Objekte mit einer Wahrscheinlichkeit von 1.0 zwei oder mehreren Clustern angehört (angehören). Nachfolgende Tabelle verdeutlicht diesen Unterschied. Abbildung P37.0.4: Klassifikationen mit und ohne Überlappungen deterministische Zuordnung ohne Überlappung deterministische Zuordnung mit Überlappung Objekte C1 C2 C3 C1 C2 C3 A B C D Objekt B und C führen zu Überlappungen. Objekt B zu einer Überlappung von Cluster C2 und C3, Objekt C zu einer Überlappung der drei Cluster. Nichtklassifikationen: Nichtklassifikationen liegen vor, wenn ein oder mehrere Objekte keinen der gebildeten Cluster zugeordnet wird (werden), um beispielsweise Überlappungen zu vermeiden. Konfirmatorische Analyse: Der Anwender gibt bestimmte Merkmale der zu bildenden Cluster vor. Beispiel: Die Cluster C1 und C2 sollen in den Variablen V10 denselben Mittelwert haben. Cluster C1 soll in der Variablen V11 einen Mittelwert von 0.5 haben usw P Anwendung der Verfahren (Vorgehensweise) Bei allen drei Verfahren wird nach einer Klassifikation der Objekte einer Datenmatrix (=Zeilen der Datenmatrix) gesucht. Zur Lösung dieser Zielsetzung sind folgende Analyseschritte durchzuführen (siehe dazu ausführlich Bacher 1996): 1. Auswahl der Variablen (Spalten der Datenmatrix) 2. Auswahl der Objekte (Zeilen der Datenmatrix) 3. Spezifikation der Eigenschaften, die die Klassifikation erfüllen soll: Soll die gesuchte Klassifikation invariant gegenüber monotonen Transformationen sein? Soll die Klassifikation überlappungsfrei sein? usw. 4. Auswahl eines Verfahrens, das die spezifizierten Eigenschaften besitzt. 5. Transformation und Gewichtung der Variablen zur Beseitigung der Nichtvergleichbarkeit (Nur bei den K-Means-Verfahren und dem Repräsentanten- Verfahren erforderlich). 6. Auswahl eines Ähnlichkeits- oder Unähnlichkeitsmaßes, sofern das Verfahren nicht die Verwendung eines bestimmten Maßes voraussetzt. Eine Auswahl eines geeigneten Un- oder Ähnlichkeitsmaßes ist bei den hier behandelten Verfahren nur beim Repräsentanten-Verfahren erforderlich. 7. Durchführen der Clusteranalyse. 8. Bestimmung der Clusterzahl. 9. Prüfung der Modellanpassung. 10. Beschreibung und inhaltliche Interpretation der Cluster. 11. Stabilitäts- und Validitätstests für die gefundene Clusterlösung. 62
63 Die Stabilitätsprüfung kann auch vor dem Schritt 10 durchgeführt werden. Die Valitätsprüfung dagegen immer erst nach der inhaltlichen Interpretation. Die Schritte 1 bis 11 werden i.d.r. mehrmals durchlaufen, bis eine befriedigende Clusterlösung gefunden wurde. Das Ergebnis der Schritte 1 bis 6 ist ein ALMO-Programm zur Durchführung einer Clusteranalyse (= Schritt 7). Betrachten wir dazu ein Beispiel: 221 Jugendliche sollen aufgrund ihrer materialistischen und postmaterialistischen Wertorientierung geclustert werden. Es sollen also Werttypen bestimmt werden. Diese sollen durch sozialstrukturelle Variablen, wie dem besuchten Schultyp, dem Geschlecht usw. beschrieben werden. Für die Analyse wurden ausgewählt (Schritt 1 und Schritt 2): Die Gesamtpunktwerte für die postmaterialistische und materialistische Wertorientierung als quantitative Klassifikationsvariablen. Alle befragten Schüler als Objekte. Sozialstrukturelle Variable als Deskriptionsvariablen zur Beschreibung der Cluster. Als Clusteranalyseverfahren soll das K-Means-Verfahren ohne Gewichtung der Distanzen gewählt werden (= Schritt 3). Das bedeutet: Bei der Analyse wird angenommen, dass sich die Objekte zu überlappungsfreien Clustern deterministisch zuordnen lassen. Eine Transformation bzw. Gewichtung der Klassifikationsvariablen ist nicht erforderlich, da die beiden Klassifikationsvariablen vergleichbar sind (Schritt 4). Die Auswahl eines Ähnlichkeits- oder Unähnlichkeitsmaßes entfällt, da sie bei den Verfahren des Programms P37 nur beim Repräsentanten-Verfahren erforderlich ist. Der Benutzer rechne das Programm das wir später in Abschnitt P abbilden. Die Ergebisse dieses Programms werden dort ausführlich dargestellt und kommentiert. Wird das Programm gerechnet, so zeigt sich, dass mehrere Clusterlösungen zur Beschreibung der Daten geeignet sind. Diese Situation ist für die Clusteranalyse typisch. In diesem Fall müssen mehrere Lösungen weiter untersucht werden und jene Lösung(en) ausgewählt werden, die den Daten gut angepaßt, inhaltlich gut interpretierbar und stabil und valide ist (sind). Die inhaltliche Interpretierbarkeit kann durch konfirmatorische Analyse verbessert werden. In dem Beispiel kann man sich z.b. für eine erste weitere Analyse für die 4-Clusterlösung entscheiden. Maßzahlen zur Beurteilung der Modellanpassung für die inhaltliche Interpretierbarkeit sowie für eine formale Validitätsprüfung werden bei der Beschreibung der einzelnen Verfahren dargestellt. P37.1 Transformation der Klassifikationsvariablen zur Lösung der Nichtvergleichbarkeit Dieser Abschnitt kann von Anwendern, die nur an der Programmeingabe und - ausgabe interessiert sind, übersprungen werden. In der Forschungspraxis ist die Anwendungsvoraussetzung der Vergleichbarkeit der Klassifikationsvariablen oft nicht gegeben. In Abschnitt P37.0 wurden bereits Gründe für die Nichtvergleichbarkeit angeführt. Liegt Nichtvergleichbarkeit der Variablen vor, stehen u.a. folgende Strategien zur Verfügung: 63
64 1. Die Variablen werden vor der Analyse in der Lese-Schleife eines Almo-Syntax- Programms Umkodiert, bzw. transformiert, bzw. gewichtet. Einfacher ist es eine Programm-Maske zu verwenden, z.b. Prog45mh.Msk (Klick auf Knopf "Verfahren/Datei-Operationen") und dort in der Umkodierungs-Box die entsprechende Umkodierung vorzunehmen. 2. Die Variablen werden bei der Berechnung eines Ähnlichkeits- oder Unähnlichkeitsmaßes gewichtet. 3. Die Variablen werden in der Analyse gewichtet. 4. Es werden getrennte Analysen für jeweils jene Variablengruppen gerechnet, die vergleichbar sind. Beispiel: In einer Untersuchung wurden zwei Fragebatterien verwendet. Mit der ersten Fragebatterie wurden Erziehungsziele durch eine fünfstufige Antwortskala erfaßt, in einer zweiten gemeinsame familiäre Freizeitaktivitäten mit einer dichotomen Antwortskala. Um das Problem der Vergleichbarkeit zu umgehen, kann zunächst jede Fragebatterie getrennt untersucht werden. Diese Strategie ist am wenigsten geeignet, da nicht mehr die ursprüngliche Klassifikationsaufgabe gelöst wird. Allgemein sollte nach Möglichkeit bei der Datenerhebung das Problem der Nichtvergleichbarkeit vermieden werden, indem bedeutungsgleiche, der jeweiligen Fragestellung angepaßte Antwortskalen verwendet werden. Liegt dennoch Nichtvergleichbarkeit vor, kann eine der vier genannten Strategien eingesetzt werden, wobei die Strategien 1 bis 3 weitgehend identisch sind. Wir wollen nachfolgend zunächst die erstgenannte Strategie darstellen. Vergleichbarkeit von Klassifikationsvariablen kann durch eine Transformation der Klassifikationsvariablen erreicht werden. Eine häufig verwendete Transformation stellt die Standardisierung der Klassifikationsvariablen dar. Sie ist definiert als x x z = mit sx x = Mittelwert der Variablen x s = Standardabweichung der Variablen x x Wenn wir nun zwischen zwei Objekten g und g' die quadrierte euklidische Distanz berechenen, spielt die Mittelwertzentrierung keine Rolle: d (z g,z g' x g x x g' x ) = s x s x 2 x = s g x x s g' x 2 1 = 2 s x 2 1 ( ) ( ) x g x g' = d x g,x g' = d 1 x 1 2 g, x g' s x s x s x Die Standardisierung als Transformation der Klassifikationsvariablen x ist somit identisch mit einer Gewichtung des Klassifikationsvariablen mit 1 / sx oder mit einer 2 Gewichtung der quadrierten euklidischen Distanzen mit 1 / s x. Wir können also auch von einer Gewichtung der Klassifikationsvariablen oder der quadrierten euklidischen Distanzen sprechen. Der Begriff der Gewichtung ist allgemeiner als jener der Transformation von Klassifikationsvariablen. Er soll daher verwendet werden. Die Parameter, die zur Gewichtung verwendet werden, können aufgrund der theoretischen semantischen Beschaffenheit der Variablen bzw. deren Ausprägungen (theoretische Gewichtung) oder aufgrund der empirischen Verteilungen der Variablen (empirische Gewichtung) gewonnen werden. 64
65 P Theoretische Gewichtung Mit der theoretischen Gewichtung können folgende Probleme der Nichtvergleichbarkeit gelöst werden: unterschiedliche Maßeinheiten der Klassifikationsvariablen, Über- bzw. Unterrepräsentativität von Klassifikationsvariablen, hierarchische Klassifikationsvariablen, bewußte Steuerung des Klassifikationsprozesses. P Theoretische Gewichtung bei unterschiedlichen Maßeinheiten Vorausgesetzt werden quantitative Klassifikationsvariable, für die theoretische Unterund Obergrenzen sowie theoretische Skalenmittelwerte und -streuungen bekannt sind. Bei diesen Größen handelt es sich um a priori bekannte Maßzahlen der verwendeten Skalen, in denen die Klassifikationsvariablen gemessen werden. Sie können also ohne das Vorliegen empirischer Beobachtungen bestimmt werden. Zur Verdeutlichung des Unterschiedes zwischen diesen theoretischen Größen und ihren empirischen Pendants sei angenommen, dass eine Klassifikationsvariable ein Anteilswert sei. Die theoretische Untergrenze dieser Klassifikationsvariablen ist - unabhängig von den konkreten Beobachtungen - immer 0 bzw. 0%, die theoretische Obergrenze nimmt immer den Wert 1 bzw. 100% an. Der theoretische Skalenmittelwert liegt bei 0.5 und die theoretische Skalenstreuung bei 0.5 ( = 0.5*(1 0.5)) Die empirisch beobachteten Werte können davon abweichen, z.b. kann die empirische Untergrenze bei 0.15 liegen, die empirische Obergrenze bei 0.26, der empirische Mittelwert bei 0.18 und die empirische Standardabweichung bei Werden diese empirische Maßzahlen verwendet, wird von einer empirischen Gewichtung gesprochen. Wird dagegen auf die theoretischen Maßzahlen zurückgegriffen, liegt eine theoretische Gewichtung vor. Zur Beseitigung der Nichtvergleichbarkeit können vier Verfahren angewendet: Extremwertnormalisierung: Die Klassifikationsvariablen werden auf das Intervall (0,1) transformiert. z = x α β α mit α = theoret. Untergrenze, β = theoretische Obergrenze Spannweitennormalisierung: Die Klassifikationsmerkmale werden mit 1/Spannweite = ß - α gewichtet. 1 z = x β α mit α = theoret. Untergrenze, β = theoretische Obergrenze Bei der Anwendung der quadrierten euklidischen Distanzen und allgemein der Minkowski-Metrik führen die Spannweiten- und die Extremwertnormalisierung zu identischen Ergebnissen. Dies gilt auch für die beiden anderen Transformationsverfahren: Standardisierung: 65
66 x µ z = σ x x mit µ x = theoret. Skalenmittelwert, σ x= theoret. Skalenstreuung Varianznormalisierung: 1 z = x σ x Die eben genannten Anwendungsvoraussetzungen für das Vorliegen von theroetischen Skalenkennwerten ist i.d.r. nicht erfüllt, wenn die verwendeten Klassifikationsvariablen in absoluten Einheiten, wie z.b. Bruttosozialprodukt in 1000,- Euro je Einwohner, gemessen werden. Für diese absoluten Einheiten fehlen häufig eindeutige theoretische Obergrenzen, sodass eine theoretische Gewichtung nicht möglich ist und an Stelle dieser eine empirische Gewichtung bzw. Transformation erforderlich ist. P Theoretische Gewichtung bei Über- bzw. Unterrepräsentativität von Klassifikationsmerkmale Über- bzw. Unterrepräsentativität liegt dann vor, wenn die Klassifikationsvariablen gemeinsame, ihnen zugrundeliegende latente Dimensionen messen und jede dieser latenten Dimensionen durch eine unterschiedliche Anzahl von Indikatoren repräsentiert ist. Die Gewichte werden in diesem Fall im Verhältnis zur Anzahl der Indikatoren vergeben: Wird z.b. die latente Dimension 1 durch 2 Indikatoren gemessen, die latente Dimension 2 durch 4 und die latente Dimension 3 durch 3 Indikatoren, dann erhalten die Indikatoren der latenten Dimensionen 1 das größte Gewicht mit 1/2, da diese Dimension im Vergleich zu den beiden anderen unterrepräsentiert ist. Die Indikatoren der latenten Dimension 2 erhalten das kleinste Gewicht mit 1/4, da sie überrepräsentiert ist, und die der latenten Dimension 3 das Gewicht 1/3. Bei diesem Vorgehen wird nur die unterschiedliche Anzahl der Indikatoren, nicht aber deren Qualität berücksichtigt. Bei korrelierten Klassifikationsvariablen wird analog vorgegangen. Stark miteinander korrelierte Klassifikationsvariablen erhalten kleinere Gewichte als schwach korrelierte. Beachte: Beim Problem der Unter- und Überrepräsentation empfehlen wir zuerst eine Faktorenanalyse der untersuchten Fragebatterien durchzuführen und in die Clusteranalyse nicht die ursprünglichen Variablen, sondern abgeleitete Variablen, wie z.b. Gesamtpunktwerte oder Faktorwerte, einzubeziehen. Die Vorteile dieses Vorgehens bestehen darin, dass dabei zunächst überprüft wird, ob die verwendeten Indikatoren gemeinsame Dimensionen messen und dass die abgeleiteten Variablen meßfehlerfreier sind. Letzteres ist insofern wichtig, da die Ergebnisse der Clusteranalyse relativ sensibel gegenüber irrelevanten Variablen, wie zufälligen Meßfehlern, sind. P Theoretische Gewichtung zur Steuerung des Klassifikationsprozesses Oft ist eine explizite theoretische Steuerung des Klassifikationsprozesses erwünscht. Ein Beispiel dafür sind Klassifikationen von Verlaufskurven, bei denen bestimmten Zeitpunkten ein größeres Gewicht beigemessen werden soll (vgl. Blaschke/Liesegang 1977). 66
67 P Theoretische oder empirische Gewichtung? Bis auf die explizite Steuerung des Klassifikationsprozesses existiert zu jeder theoretischen Gewichtung ein empirisches Pendant, bei dem anstelle von theoretischen Gewichten empirische Gewichte verwendet werden. Anstelle der theoretischen Untergrenzen werden die empirischen Untergrenzen verwendet, anstelle der theoretischen Obergrenzen die empirischen Obergrenzen usw... Die technische Umsetzung in der Lese-Schleife unterscheidet sich nicht von jener der theoretischen Gewichtung. Der Unterschied besteht nur darin, ob die Größen auf der Grundlage der verwendeten Skala (theoretische Gewichtung) oder aus den erhobenen Daten (empirische Gewichtung) berechnet werden. Eine empirische Vorgehensweise hat allgemein zwei Nachteile, nämlich die Stichprobenabhängigkeit der Ergebnisse und die Abhängigkeit von Meßfehlern. Stichprobenabhängigkeit bedeutet, dass die empirischen Gewichte von der Verteilung der Untersuchungspopulation in den Klassifikationsvariablen abhängen. Dadurch entstehen Probleme beim Vergleich der Ergebnisse unterschiedlicher Untersuchungspopulationen, aber auch beim Vergleich innerhalb einer Untersuchungspopulation. Betrachten wir z.b. folgende Situation: In eine Clusteranalyse wurde als Klassifikationsvariable das Bruttosozialprodukt pro Kopf (BSP) einbezogen. Die Klassifikationsvariable wurde zu zwei Zeitpunkten t1 und t2 erhoben und für die Analyse empirisch standardisiert. Bei den Ergebnissen sind nun keine absoluten Aussagen, wie z.b. "in dem Cluster 3 hat sich das Bruttosozialprodukt in dem Zeitraum zwischen t1 und t2 erhöht" zulässig. Nur mehr relative Aussagen sind möglich, wie z.b.: "Die relativen Unterschiede der Cluster im Bruttosozialprodukt haben sich zwischen t1 und t2 verringert" oder "Im Vergleich zur Gesamtpopulation zu den beiden Zeiptunkten hat sich das Bruttosozialprodukt pro Kopf im Cluster 3 zwischen t1 und t2 erhöht.". In die empirische Gewichtung gehen darüber hinaus die Meßfehler der Klassifikationsvariablen ein. Das kann dazu führen, dass eine Klassifikationsvariable künstlich "aufgebläht" wird, obwohl diese Variable die Cluster nicht trennt (die Unterschiede sind rein zufällig) (vgl. dazu Schlosser 1976: 56-89). Umgekehrt kann eine empirische Standardisierung auch zu einer Reduktion von Meßfehlern führen. Dies ist dann der Fall, wenn eine hohe empirische Varianz nicht durch Unterschiede zwischen den Clustern entsteht sondern aufgrund von Meßfehlern. Allgemein empfehlen wir, eine theoretische Gewichtung durchzuführen, sofern die theoretischen Gewichte definiert und/oder inhaltlich begründet werden können und hohe empirische Varianzen nicht auf Meßfehler zurückzuführen sind. Ist dies nicht der Fall, muss auf eine empirische Gewichtung zurückgegriffen werden. Bei der Interpretation ist dann darauf zu achten, dass nur mehr relative Aussagen möglich sind. Insgesamt aber dürfte - so zeigen ertse Simulationsstudien - die Art der Standardisierung auf die Ergebnisse einen geringen Einfluss haben. P Gewichtungen mit Programm P37 In Programm P37 bestehen programmintern drei Möglichkeiten der Gewichtung: Definition von Variablengewichten durch die Anweisung: Gewicht4,5,6 = 0.2,0.3,06; Unterschiedliche Möglichkeiten der empirischen Transformation durch Verwendung von OPTION4 =...; Bei den K-Means-Verfahren durch Verwendung unterschiedlicher Modelle. 67
68 Die unterschiedlichen Modelle sind: Gewichtung der quadrierteten euklidischen Distanzen keine Varianzen der Klassifikationsvariablen Varianzen der Klassifikationsvariablen innerhalb der Cluster (gepoolte Varianzen der Klassifikationsvariablen) Kovarianzmatrix der Klassifikationsmerkmale Modellparameter Effekte der Gewichtung Modell=1; Modell=2; Modell=3; Unterschiedliche Skaleneinheiten werden durch Gewichtung mit emp. Standardabw. beseitigt. Modell=5; wie bei Modell = 3; Anstelle der Varianz der Klassifikationsvariablen wird dievarianz der Klassifikationsvariablen innerhalb der Cluster verwendet. Dadurch wird versucht, die Fehlervarianz zu beseitigen. Modell=4; Standardisierung und Orthogonalsierung der Klassifikationsvariablen. Stark korrelierende Variablen gehen mit einem geringeren Gewicht in die Berechnung der Distanzen ein. Durch die Orthogonalisierung wird ferner versucht, die Anwendungsvoraussetzung der Unabhängigkeit der Klassifikationsvariablen für den F-TEST nach BEALE zu erreichen. gepoolte Kovarianzmatrix Modell=6; wie Modell = 5; Die Begründung für die Verwendung der gepoolten Varianzen und Kovarianzen ist analog zur Begründung von Modell=5 und 4. Daneben können die Variablen in der Lese-Datenmanipulations-Schleife gewichtet werden. P37.2 K-Means-Verfahren P Eingabe über Maskenprogramm P Maskenprogramm Prog37m1 Zur Erläuterung der einzelnen Boxen des Maskenprogramms siehe auch P0. Im folgenden zeigen wir die allgemeine Eingabe in Programm 37. Diese Darstellung ist dem Almo-Handbuch P45 Almo-Data-Mining, Kapitel 10 entnommen. Daran anschließend wird das Maskenprogramm Prog 37m3 dargestellt, das viele Optionen anbietet. Betrachten wir folgendes Beispiel. Die Daten sind simuliert. Junge Menschen im Alter von 16 bis 32 wurden gefragt 68
69 1. wie viele Zigaretten sie am Tag rauchen 2. wie häufig sie Bier trinken 3. Wein 4. Schnaps 5. Aufputschgetränke 6. nicht-alkoholische Getränke 7. welche Art von Kleidung sie vorzugsweise tragen: a. konventionelle Kleidung b. unkonventionelle (schlampig, ausgeflippt) c. elegant, modisch Die Frage, die wir stellen wollen, lautet: Lassen sich die Jugendlichen über diese sieben Variablen in Typen untergliedern. Anders formuliert: Lassen sich die Jugendlichen in Cluster unterteilen. Um diese Frage zu beantworten rechnen wir eine Clusteranalyse mit Prog37m1. Wir werden drei Cluster unterscheiden können. Ein Cluster bilden beispielsweise die Jugendlichen, die sich modisch-elegant kleiden. Sie rauchen deutlich weniger als die anderen und trinken eher nicht-alkoholische Getränke und wenn schon Alkohol, dann eher Wein. Nun wird der Marktforscher noch eine zweite Frage stellen wollen: Lassen sich diese 3 Cluster mit demographischen und sozioökonomischen Variablen wie Geschlecht, Bildungsniveau, Lebensalter beschreiben. Unsere Daten umfassen deswegen noch folgende Variable. 8. Geschlecht 9. Bildungsgrad 10. Alter Einstellungen im Programm Prog37m1 Almo rechnet eine K-Means-Clusteranalyse. Die Parameter und Optionen sind so gewählt, dass mit jeder Datenkonstellation eine Clusteranalyse gerechnet werden kann. Die Eigenschaften von Prog37m1 sind folgende: 1. Es können beliebig viele quantitative und nominale Variable eingeführt werden. Ordinale Variable sollen entweder als quantitative oder als nominale deklariert werden. 2. Die Zahl der zu clusternden Untersuchungsobjekte ist nicht begrenzt. 3. Die nominalen Variablen werden intern in 0-1-kodierte Dummies aufgelöst. 4. Es wird ein Modell 3 gerechnet. Siehe Handbuch, Abschnitt P D.h. es wird ein Minimaldistanzverfahren mit gewichteten euklidischen Distanzen gerechnet. Als Gewichtungskriterium werden die Varianzen der Variablen verwendet. 5. Der Test auf die (richtige) Clusterzahl über das F-Max-Kriterium wird mit standardisierten Variablen gerechnet. 6. Die nominalen Variablen werden mit 0.5 gewichtet. Das in Almo enthaltene Programm zur K-Means-Clusteranalyse bietet eine Vielzahl von Optionen an. In Abschnitt P werden diese Optionen ausführlich dargestellt. Für den Benutzer kann diese Vielzahl verwirrend sein. Im Maskenprogramm Prog37m1 werden deshalb für die meisten Optionen die vorgesehenen Voreinstellungen verwendet - ohne dass dies der Benutzer sieht. In der später vorgestellten Programm-Maske Prog37m3 werden dann diese Optionen dem Benutzer explizit angeboten. 69
70 Folgende Einsetzungen werden in Prog37m1 automatisch voreingestellt: Option 4=0; 0=keine Standardisierung der Klassifikationsvariablen Option 11=0.05; Fehlerniveau für Detailanalyse der Cluster Option 12=1; 1=Standardisierte Clustermittelwerte bei Grafikausgabe verwenden Option 13=100; Zahl der Iterationen des K-Means-Verfahren Option 14=3; Startwertverfahren 3=Objekte werden zufällig zugeordnet Option 15=123123; Startzahl für Zufallsgenerator für Option 14=3 Option 16= ; Schwellenwert für Konvergenz (Option 43) Option 17=0; Simulationszahl für Zufallstestung der Clusterlösung Option 35=1; 1=Test auf Clusterzahl mit standardisierten Werten rechnen Option 42=5; Mindestfallzahl für Detailanalyse der Cluster Option 43=1; Konvergenz Option 44=0; Zwischeniteration Option 45=50; Zahl der Versuche je Clusterzahl, 50 = 50 Versuche Option 52=1; 1=Deterministische Zuordnung bei probabilistischer Analyse. 0=nein Objekte=0; 0=Objekte werden auf Platte zwischengespeichert Gewicht...= 0.5; Gewichtung für nominale Klassifik.variablen Siehe die ausfürliche Darstellung in Abschnitt P "Diverse Optionen in Programm-Maske P37m3 einfügen" Eingabe in Clusteranalyse-Programm Prog37m1 70

71


72
73 P Erläuterung zu den Boxen von Prog37m1 Box 1: Speicher für x Variable Siehe Anhang P0.1. Box 2: Option: Weitere Vereinbarungen Siehe Anhang P0.2. Box 3: Datei der Variablennamen Siehe Anhang P0.3. In unserem Beispiel umfaßt die Datei der Variablennamen folgende Namensgebungen: Name 1=Rauchen; Name 2=Bier; Name 3=Wein; Name 4=Schnaps; Name 5=Aufputschdrinks; Name 6=nichtalkoh.drinks; Name 2:6=:nie,selten,ca. 1x Monat,ca. 1x in 14 Tagen, ca. 1x in Woche,mehrmals in Woche,täglich; Name 7=Kleidung:konventionell,unkonventionell,elegant; Name 8=Geschlecht:männl,weibl; Name 9=Bildungsgrad; Name 10=Alter; Beachte: Die Variablen V2 bis V6, also "Bier" bis "nichtalkoh.drinks" besitzen alle dieselben Ausprägungsnamen. Almo erlaubt hier dem Benutzer folgende arbeitssparende Schreibweise. Name 2:6=:... Hinter dem Gleichheitszeichen folgt kein Variablennamen, sondern gleich ein Doppelpunkt. Damit wird signalisiert, dass jetzt Ausprägungnamen folgen. Box 4: Freie Namensfelder Siehe Anhang P0.3. Box 5 und 6: Datei aus der gelesen wird Siehe Anhang P
74 Box 7: Klassifikations-Variable für die Clusterung Die Klassifikationsvariable sind jene Variable, die verwendet werden, um Cluster zu identifizieren. Zu den 3 Begriffen quantitativ, ordinal, nominal, siehe Handbuch, Teil 3, Kap. P Eingabefeld: Quantitative Variable für die Clusterung Wir haben in unserem Beispiel als quantitative Variable eingesetzt: Rauchen,Bier,Wein,Schnaps,Aufputschdrinks,nichtalkoh.drinks 2. Eingabefeld: Ordinale Variable Diese werden (in der aktuellen Almo-Version) wie quantitative behandelt. 3. Eingabefeld: Nominale Variable für die Clusterung Wir haben als nominale Variable Kleidung mit den 3 Ausprägungen konventionell, unkonventionell, elegant eingesetzt. Die nominalen Variablen müssen ganzzahlig in 1-er Schritten kodiert sein. Sind sie das nicht, dann müssen sie in der Box "Kein-Wert-Angabe und Umkodierungen" entsprechend umkodiert werden. Beispiel: Die 3 Ausprägungen einer nominalen Variablen seien mit den Zahlen 2, 3.5, 7 kodiert worden. Die Variable muss in folgender Weise umkodiert werden: V10 ( 2=1; 3.5=2; 7=3) Die Codeziffern der nominalen Varibalen müssen nicht notwendigerweise bei 1 beginnen. Folgende Kodierung ist korrekt: 3, 4, 5. Die Variable ist ganzzahlig und mit 1-er Schritten kodiert. 74

75 Box 8: Deskriptions-Variable Die Deskriptions-Variablen haben keinen Einfluss auf die Gewinnung der Cluster. Sie können weggelassen werden. Ihr Sinn ist folgender: Almo ermittelt zuerst aus den Klassifikations-Variablen die Cluster. In unserem Beispiel werden 3 Cluster gefunden. Dann errechnet Almo für die quantitativen Deskriptions-Variablen den Mittelwert je Cluster und für die nominalen Deskriptions-Variable die Anteilswerte je Cluster. In unserem Beispiel gibt Almo folgendes aus: Zellenmittelwerte der Deskriptionsvariablen: (Mittelwerte bei quantitativen Variablen, Anteilswerte bei nominalen) Variable C1 C2 C3 V8 Geschlecht männl weibl V Bildungsgrad V Alter Betrachten wir Cluster C3. Das sind die modisch-elegant gekleideten Jugendlichen, die eher Wein und Limonade trinken etc. Der Anteil der Männer in diesem Cluster beträgt 0.43 (also 43 %), der der Frauen 0.57 (57 %). Die Frauen überwiegen also in C3 deutlich. Der Bildungsgrad ist mit einem Mittelwert von 3.56 in diesem Cluster höher als in den Clustern C1 und C2. Deskriptionsvariable dienen der Beschreibung und der inhaltlichen Validierung der Clusterlösung. Wir verwenden sie, um zu überprüfen, ob die gefundenen Cluster inhaltlich "stimmig" sind. Man könnte auch anders argumentieren: Deskriptionsvariable sind "ursächliche" Variable, mit deren Hilfe wir versuchen, die gefundenen Cluster zu erklären. Deskriptionsvariable können aber auch abhängige Variable (z.b. Wahlabsicht der drei gefundenen Lebensstilcluster) sein oder sie können mit der Klassifikation in korrelativer Beziehung (z.b. Musikgeschmack der gefundenen Lebensstilcluster) stehen. Box 9: Option: Ein- und Ausschliessen von Untersuchungseinheiten Siehe P0.7 75

76 Box 10: Option: Umkodierungen und Kein-Wert-Angaben Siehe P0.5 Box 11: Option: Untersuchungseinheiten gewichten Siehe P0.8 Box 12: Verfahren Möglich sind nachfolgende Verfahren. Empfehlenswert sind die Verfahren 3 und 5. Siehe auch Abschnitt P Modell = 1; Austauschverfahren mit quadrierten euklidischen Distanzen Modell = 2; Minimaldistanzverfahren mit quadrierten euklidischen Distanzen Modell = 3; Minimaldistanzverfahren mit gewichteten quadrierten euklidischen Distanzen (Gewichtungskriterium = Varianzen der Klassifikationsvariablen) Modell = 4; Minimaldistanzverfahren mit gewichteten quadrierten euklidischen Distanzen (Gewichtungskriterium = Kovarianzmatrix der Klassifikationsvariablen) Beachte: Das Verfahren kann nicht angewendet werden, wenn sich nominale Klassifikationsvariable im Modell befinden Modell = 5; Minimaldistanzverfahren mit gewichteten quadrierten euklidischen Distanzen (Gewichtungskriterium = gepoolte Varianzen der Klassifikationsvariablen innerhalb der Cluster) Modell = 6; Minimaldistanzverfahren mit gewichteten quadrierten euklidischen Distanzen (Gewichtungskriterium = gepoolte Kovarianzmatrix der Klassifikationsvariablen) Beachte: Das Verfahren kann nicht angewendet werden, wenn sich nominale Klassifikationsvariable im Modell befinden Modell = 7; probabilistische Clusteranalyse Analyse latenter Klassen mit den Submodellen: a. latente Klassen für nominal- und ordinalskalierte Klassifikationsvariable b. latente Profilanalyse für quantitative Klassifikationsvariablen Modell = 8; Repräsentanten-Verfahren Box 13: Clusterzahl 76
77 Ein unangenehmes Problem der Clusteranalyse ist es, dass sie es dem Benutzer weitgehend überläßt, die Zahl der Cluster, die in den Daten gefunden werden sollen, selbst zu bestimmen. Zwar gibt es einige formale Verfahren, die dem Benutzer eine bestimmte Clusterzahl vorschlagen - wir werden darauf zurück kommen - die beste Methode ist es jedoch, sich mehrere Clusterlösungen anzuschauen und sich dann für eine zu entscheiden, die inhaltlich sinnvoll ist. Ein weiteres Problem stellen lokale Minima bzw. Maxima dar. D.h., dass für eine bestimmte Clusterzahl nicht die beste Lösung gefunden wird. Dieses Problem kann umgangen werden, indem je Clusterzahl mit mehreren unterschiedlichen Startwerten gerechnet wird (Methode der multiplen zufälligen Startwerte). Mitunter sind mehr als 1000 Versuche je Clusterzahl erforderlich, wobei sich allerdings oft nur die Zuordnung von wenigen Objekten ändert, sodass die Clustermittelwerte relativ stabil sind. Wir empfehlen folgende Vorgehensweise: Der Benutzer rechnet mehrere Analysen. Bei der ersten Analyse werden in obiger Box als minimale Clusterzahl 1 eingegeben und als maximale Clusterzahl etwa 8. Almo rechnet dann in einer Analyse eine Lösung mit 1 Cluster, mit 2 Cluster, mit 3 Cluster,... bis 8 Cluster. Der Benutzer kann die 8 Clusterlösungen auf ihre Sinnhaftigkeit vergleichen und sich für eine entscheiden. Gleichzeitig macht Almo einen Vorschlag, welche Clusterzahl auf Grund eines formalen Kriteriums als entgültig betrachtet werden soll. Je Clusterzahl werden 50 Versuche (Voreinstellung) gerechnet. Diese Zahl kann zu klein sein und lokale Minima werden aufgefunden. Erkennbar sind diese u.a. daran, dass die zu maximierende oder minimierende Funktion mit der Clusterzahl nicht kontinuierlich steigt oder fällt. Almo gibt eine Fehlermeldung aus. In diesem Fall ist die Zahl der Versuche zu erhöhen. In einer weiteren Analyse wird man dann die Clusterzahl einschränken und beispielsweise sowohl als minimale wie auch als maximale Clusterzahl 3 angeben. Zur Reproduktion der gefundenen Lösung wird die Zahl der Versuche auf 1 gesetzt und der von ALMO ausgewiesene Startwert des Zufallszahlengenerators für die beste Lösung bei 3 Clustern eingegeben. Box 14: Option: Clusterzugehörigkeiten der Objekte in Datei speichern Nach Klick auf den Knopf mit dem nach unten weisenden Pfeil, wird dann die eigentliche Optionsbox geöffnet. 77

78 Nachdem der Benutzer sich für eine Clusterlösung entschieden hat, ist es sinnvoll, die Clusterzugehörigkeit in eine Variable einzuschreiben und diese an die schon vorhandenen Variablen anzufügen. Damit die Originaldatei nicht gefährdet wird, verlangt Almo, dass eine neue Datei angelegt wird. Wenn Sie einen Dateinamen in das Eingabefeld schreiben, dann 1. erzeugt Almo zwei Dateien mit diesem Namen einmal im Format FREI und einmal im Format DIREKT 2. und speichert in diese die Variablen aus der alten Datei 3. und speichert die Clusterzugehörigkeit der Objekte als letzte Variable hinter die Variablen aus der alten Datei 3. weiterhin erzeugt Almo eine Datei der Variablennamen. Diese enthält - die Variablennamen aus der alten Datei einschliesslich der in der Box "Freie Namensfelder" angegebenen (oder eventuell modifizierten) Namen - den Name "Cluster.." für die neue angehängte Variable der Clusterzugehörigkeit, wobei Almo anstelle der 2 Punkte die Variablennummer der Clustervariablen einsetzt. Siehe nachfolgendes BEACHTE. Sie können die neue Datei der Variablennamen durch Doppelklick in ein Fenster laden und Variablen- und Ausprägungsnamen beliebig verändern. Danach wieder speichern Beachte: Almo hat beispielsweise folgenden Namen geschrieben 78
79 Name 11=Cluster11; Die Ziffer hinter "Cluster.." (im Beispiel '11') ist die Variablennummer der Clustervariablen. Sie können diesen Variablenname beliebig verändern. Er muss jedoch eindeutig sein, d.h. er darf kein 2. Mal auftreten. Beachte: Das Speichern der Clusterzugehörigkeit hat nur dann einen Sinn, wenn Sie die entgültige Clusterlösung gefunden haben. Sie haben beispielsweise die Lösung mit 3 Clustern als die richtige entdeckt. Geben Sie dann in der Box "Clusterzahl" als minimale und als maximale Clusterzahl 3 an, also Minimale Zahl von Clustern 3 Maximale Zahl von Clustern 3 Almo erzeugt folgende neue Datei Clustneu.fre (und Clustneu.dir) V11: Clusterzugehörigkeit Mit dieser Datei kann man nun ein Prog20m0 (Allgemeines lineares Modell) bzw. Prog45mf "Ursachen für die Zielvariable" rechnen, wobei man V11 als Zielvariable angibt und die Deskriptionsvariablen V8 Geschlecht V9 Bildungsgrad V10 Alter als ursächliche Variable angibt. Mit dieser Analyse versucht man also die Determinanten der Clusterzugehörigkeit zu ermitteln. Wir zeigen dies im Almo-Data- Mining-Handbuch, in Abschnitt P45.20 und P Box 15: Option: Programm-Optionen lt. Handbuch Optionsbox geöffnet: 79

80 In die beiden Eingabefelder können Sie Optionen einsetzen, die nicht über eine der Optionsboxen aktivierbar sind. Sie können mehrere Angaben in ein Eingabefeld schreiben, beispieldweise so: Option 11=0.05; Option 12=1; Option 13=100; Sie können auch über den rechten Boxenrand hinaus schreiben. Achten Sie aber darauf, dass Sie nicht Optionen einsetzen, die im Widerspruch zu einander stehen. Folgende Optionen werden in Prog37m1 mit folgenden Voreinstellungen verwendet. Diese können Sie in der Optionsbox mit veränderten Werten einsetzen. Lesen Sie aber zuerst die ausführliche Beschreibung der Optionen in Abschnitt P Option 4=0; 0=keine Standardisierung der Klassifikationsvariablen Option 11=0.05; Fehlerniveau für Detailanalyse der Cluster Option 12=1; 1=Standardisierte Clustermittelwerte bei Grafikausgabe verwenden Option 13=100; Zahl der Iterationen des K-Means-Verfahren Option 14=3; Startwertverfahren 3=Objekte werden zufällig zugeordnet Option 15=123123; Startzahl für Zufallsgenerator für Option 14=3 Option 16= ; Schwellenwert für Konvergenz (Option 43) Option 17=0; Simulationszahl für Zufallstestung der Clusterlösung Option 35=1; 1=Test auf Clusterzahl mit standardisierten Werten rechnen Option 42=5; Mindestfallzahl für Detailanalyse der Cluster Option 43=1; Konvergenz Option 44=0; Zwischeniteration Option 45=10; Zahl der Versuche je Clusterzahl Option 52=1; 1=Deterministische Zuordnung bei probabilistischer Analyse. 0=nein Objekte=0; 0=Objekte werden auf Platte zwischengespeichert Gewicht...= 0.5; Gewichtung für nominale Klassifik.variablen Box 16: Option: Grafik-Optionen Siehe Anhang P0.10. Box 17: Ausgabe der Ergebnisse Bei Eingabe von "3" werden die Ergebnisse in voller Länge ausgegeben. Siehe Abschnitt P und P Diese Option sollte nur gewählt werden, wenn die 80
81 beste bzw. die besten Lösungen untersucht werden und je Clusterzahl folglich nur eine Lösung berechnet wird. Andernfalls kann der Output mehrere tausend Zeilen umfassen und beim Laden kann es zu einem Programmabsturz kommen. P Ausgabe der Ergebnisse Siehe auch die sehr ausführliche Erläuterung der Ergebnisse eines anderen Beispielprogramms in Abschnitt P Ausgabe der Ergebisse Fuer Analyse ausgewaehlte Variable: Klassifikationsvariablen: V7 Kleidung nominal UG = 1 OG = 3 V1 Rauchen quantitativ V2 Bier quantitativ V3 Wein quantitativ V4 Schnaps quantitativ V5 Aufputschdrinks quantitativ V6 nichtalkoh.drinks quantitativ Deskriptionsvariablen: V8 Geschlecht nominal UG = 1 OG = 2 V9 Bildungsgrad quantitativ V10 Alter quantitativ Es wurden 589 Datensaetze eingelesen, davon werden 589 Datensaetze analysiert. ****************** Erläuterung: Um den Output kurz zu halten, haben wir im Kurzprogram Prog45mn in der Box 10 "Clusterzahl" als minimale Clusterzahl 2 und als maximale Clusterzahl 4 angegeben. Almo liefert nun im folgenden die Lösung für 2 Cluster, für 3 Cluster und für 4 Cluster. Ergebnisse fuer 2-Clusterloesung ======================================================================== Clustergroessen: C1 = 282 C2 = 307 ****************** Erläuterung: Cluster 1 umfasst 282 Personen Cluster 2 umfasst 307 Personen Zellenmittelwerte der Klassifikationsvariablen: (Mittelwerte bei quantitativen Variablen, Anteilswerte bei nominalen) 81
82 Variable C1 C2 V7 Kleidung konventionell unkonventionell elegant V Rauchen V Bier V Wein V Schnaps V Aufputschdrinks V nichtalkoh.drink ****************** Erläuterung: Dies ist nun die für uns wichtigste Tabelle. Wir werden diese Tabelle jedoch für die nachfolgende 3-Clusterlösung erläutern, da diese als die inhaltlich am besten interpretierbare erscheint. Ergebnisse fuer 3-Clusterloesung ======================================================================== Clustergroessen: C1 = 182 C2 = 217 C3 = 190 Zellenmittelwerte der Klassifikationsvariablen: (Mittelwerte bei quantitativen Variablen, Anteilswerte bei nominalen) Variable C1 C2 C3 V7 Kleidung konventionell unkonventionell elegant V Rauchen V Bier V Wein V Schnaps V Aufputschdrinks V nichtalkoh.drink ****************** Erläuterung: Almo teilt zunächst die Anteilswerte der nominalen Klassifikationsvariablen je Cluster mit. Betrachten wir zuerst Cluster C1. Von den 182 Personen, die Cluster 1 bilden, trägt ein Anteil von 0.07, also 7% konventionelle Kleidung. 73% tragen unkonventionelle ("ausgeflippte", schlampige) Kleidung und 21% tragen elegante Kleidung. Zusammen ergibt das 100%. Die Anteilswerte einer nominalen Variablen summieren sich für jedes Cluster zu 1.0. Cluster 1 enthält also vor allem die unkonventionell gekleideten Jugendlichen Betrachten wir nun Cluster C2. Von den 217 Personen, die Cluster 2 bilden, tragen 77% konventionelle Kleidung. In Cluster 3 tragen die meisten Jugendlichen elegante (modische) Kleidung. 82
83 Betrachten wir nun die Mittelwerte der quantitativen Klassifikationsvariablen je Cluster. Deutlich am wenigsten rauchen die Jugendlichen in Cluster 3. Das sind diejenigen, die wir bereits als die elegant gekleideten identifiziert haben. Die beiden anderen Cluster C1 und C2 unterscheiden sich nur wenig. Die Biertrinker finden wir vor allem in Cluster 2. Das sind die Jugendlichen, die wir als die konventionell gekleidet identifiziert haben. Die 3 Cluster können wir inhaltlich etwa so beschreiben: Cluster 1 Die Jugendlichen sind überwiegend unkonventionell ("ausgeflippt", schlampig) gekleidet. Sie rauchen und trinken (im Vergleich zu den anderen) häufiger Schnaps und Aufputschmittel. Cluster 2 Die Jugendlichen sind überwiegend konventionell gekleidet. Sie rauchen und trinken (im Vergleich zu den anderen) häufiger Bier. Cluster 3 Die Jugendlichen sind eher elegant (modisch) gekleidet. Sie rauchen wenig und trinken (im Vergleich zu den anderen) häufiger Wein und nicht-alkoholische Getränke. Allgemein gilt: Zur Interpretation der Cluster sollte man sich vor allem die maximalen und minimalen Werte je Zeile der Tabelle anschauen. In der weiter unten folgenden Tabelle "Signifikanz der z-werte" kann man dann nachschauen, ob der jeweilige Wert vom Mittelwert über alle Personen signifikant abweicht. Ergebnisse fuer 4-Clusterloesung ======================================================================== Clustergroessen: C1 = 149 C2 = 130 C3 = 190 C4 = 120 Zellenmittelwerte der Klassifikationsvariablen: (Mittelwerte bei quantitativen Variablen, Anteilswerte bei nominalen) Variable C1 C2 C3 C4 V7 Kleidung konventionell unkonventionell elegant V Rauchen V Bier V Wein V Schnaps V Aufputschdrinks V nichtalkoh.drink ======================================================================== Cluster- Streuungsquadratsummen F-Wert ETA**2 PRE zahl innerhalb zwischen KW
84 Beachte: Zur Berechnung der Streuungszerlegung wurden die Variablen standardisiert um Vergleichbarkeit zu erhalten. ****************** Erläuterung: Der höchste F-Wert (von ) entsteht bei der 3-Clusterlösung. Almo verwendet dies als formales Entscheidungskriterium für die richtige Zahl der Cluster und untersucht nun im folgenden die 3-Clusterlösung im Detail. In unserem Beispiel ist die 3-Clusterlösung auch jene, die am besten inhaltlich interpretierbar ist. Es muss aber ausdrücklich darauf hingewiesen werden, dass das nicht immer so ist. Unsere Empfehlung ist, jene Clusterlösung zu wählen, die inhaltlich gut interpretierbar ist, aber auch einen "ordentlichen" (nicht notwendigerweise den maximalen) F-Wert besitzt. ======================================================================== Die 3-Clusterloesung wird weiter untersucht ======================================================================== Clustergroessen: C1 182 ( %) C2 217 ( %) C3 190 ( %) KW-Faelle (ungewichtet)= 0 ======================================================================== Zellenmittelwerte der Klassifikationsvariablen (Mittelwerte bei quantitativen / ordinalen Variablen) (Anteilswerte bei nominalen Variablen) Variable C1 C2 C3 V7 Kleidung konventionell unkonventionell elegant V Rauchen V Bier V Wein V Schnaps V Aufputschdrinks V nichtalkoh.drink Standardabweichungen: Variable C1 C2 C3 V7 Kleidung konventionell unkonventionell elegant V Rauchen V Bier V Wein 84
85 V Schnaps V Aufputschdrinks V nichtalkoh.drink Z-Werte: Variable C1 C2 C3 V7 Kleidung konventionell unkonventionell elegant V Rauchen V Bier V Wein V Schnaps V Aufputschdrinks V nichtalkoh.drink Signifikanz der z-werte: Variable C1 C2 C3 V7 Kleidung konventionell unkonventionell elegant V Rauchen V Bier V Wein V Schnaps V Aufputschdrinks V nichtalkoh.drink ***************** Erläuterung: Die Tabelle gibt an, ob die Mittelwerte der Variablen je Cluster vom Gesamtmittelwert über alle Personen signifikant abweichen. Betrachten wir die Zeile V6 nichtalkoh.drinks. In der Tabelle der "Zellenmittelwerte der Klassifikationsvariablen" finden wir folgende Werte: C1 C2 C Für Cluster C2 finden wir einen Mittelwert von Dieser Mittelwert weicht nur mit einer Sicherheitswahrscheinlichkeit von 68.37% vom Gesamtmittelwert aus allen Personen ab. Umgekehrt betrachtet: Die Irrtumswahrscheinlichkeit beträgt %. Üblicherweise wird eine Mindestsicherheit von 95% bzw. eine maximale Irrtumswahrscheinlichkeit von 5% gefordert. Die Mittelwerte von C1 und C3 weichen mit 100%iger Sicherheit vom Gesamtmittelwert ab. Diese 100 % entstehen Almointern durch Aufrunden. Der richtige Wert ist % ======================================================================== Zellenmittelwerte der Deskriptionsvariablen: (Mittelwerte bei quantitativen Variablen, Anteilswerte bei nominalen) 85
86 Variable C1 C2 C3 V8 Geschlecht männl weibl V Bildungsgrad V Alter ***************** Erläuterung: Wie wir bereits bei der Erläuterung der Programm-Eingabe zu Box 7 "Deskriptionsvariable" ausgeführt haben, sind die Deskriptionsvariablen für die Clusteranalyse nicht notwendig. Sie haben keinen Einfluss auf die Clusterbildung. Almo liefert nun für die gefundenen 3 Cluster die Mittelwerte der quantitativen Deskriptionsvariablen bzw. die Anteilswerte der nominalen Deskriptionsvariablen. Cluster 1 (unkonventionell gekleidet, Raucher, Schnaps und Aufputschgetränke) weist keinen Unterschied der Geschlechter auf. Das Bildungsniveau liegt in der Mitte, weicht aber nicht signifikant vom Gesammittelwert ab (siehe nachfolgende Tabelle "Signifikanz der z-werte"). Das durchschnittliche Alter ist das niedrigste. Im Cluster 2 (konventionell gekleidet, Raucher, Biertrinker) sind die Männer deutlich überrepräsentiert. Das Bildungsniveau ist das niedrigste. Das durchschnittliche Alter ist das höchste. Im Cluster 3 (elegant-modisch gekleidet, Wenig-Raucher, Wein und Limonade) sind die Frauen überrepräsentiert. Das Bildungsniveau ist das höchste. Das durchschnittliche Alter weicht nicht signifikant vom Gesammittelwert ab. Wenn wir die Deskriptionsvariable wie ursächliche Variable (die die Clusterzugehörigkeit determinieren) betrachten, dann können wir sagen: Das Geschlecht bestimmt die Zugehörigkeit zu Cluster 2 und 3. Männer gehen eher in Cluster 2, Frauen eher in Cluster 3. Eine hohe Bildung determiniert eher die Zugegörigkeit zu Cluster 3. Die Jüngsten tendieren eher zu Cluster 1 und die Älteren eher zu Cluster 2 86
87 Standardabweichungen: Variable C1 C2 C3 V8 Geschlecht männl weibl V Bildungsgrad V Alter Z-Werte: Variable C1 C2 C3 V8 Geschlecht männl weibl V Bildungsgrad V Alter Signifikanz der z-werte: Variable C1 C2 C3 V8 Geschlecht männl weibl V Bildungsgrad V Alter ******************** Erläuterung: Die Tabelle gibt an, ob die Mittelwerte der Deskriptionsvariablen je Cluster vom Gesamtmittelwert über alle Peronen signifikant abweichen. Betrachten wir die Zeile V10 Alter. In der Tabelle der "Zellenmittelwerte der Deskriptionsvariablen" finden wir für die 3 Cluster folgende Mittelwert: C1 C2 C Diese Mittelwerte weichen nur mit der oben angegebenen Sicherheitswahrscheinlichkeit von vom Gesamtmittelwert des Alters aus allen Personen ab. Die Mittelwerte von C1 und C2 weichen mit einer Sicherheit von % bzw % vom Gesamtmittelwert ab. Wenn wir die Deskriptionsvariablen als Variable betrachten, die ursächlich für die Clusterzugehörigkeit sind, dann können wir folgen, dass das Lebensalter wesentlich die Zugehörigkeit zu Cluster 1 und 2 determiniert. Anders bei Cluster 3: Die Angehörigen dieses Clusters weichen in ihrem Alters-Mittelwert vom Gesamtmittelwert nicht signifikant ab. Es ist üblich, einen Wert von 95 % als Signifikanzgrenze zu betrachten. Das Alter ist keine Determinante für die Zugehörigkeit zu Cluster 3. 87
88 Gesamtstatistiken fuer Klassifikationsvariablen: F-Wert Signifikanz ETA**2 (1-p)*100 Name V7 Kleidung konventionell unkonventionell elegant V Rauchen V Bier V Wein V Schnaps V Aufputschdrinks V nichtalkoh.drinks ******************** Erläuterung: Die Tabelle gibt an, ob eine Variable insgesamt signifikant zur Trennung der Cluster beiträgt. In unserem Beispiel haben alle Klassifikationsvariable einen signifikanten Einfluss auf die Clusterbildung. Betrachten wir den ETA**2-Wert für Bier (=0.539). Er sagt aus, dass 53.9% der Streuung im Bierkonsum auf die Trennung in 3 Cluster zurückgeführt werden kann. Gesamtstatistiken fuer Deskriptionsvariablen: F-Wert Signifikanz ETA**2 (1-p)*100 Name V8 Geschlecht männl weibl V Bildungsgrad V Alter ******************** Erläuterung: Die Tabelle gibt an, welcher Teil der Streuung in den Deskriptionsvariablen auf die Trennung in 3 Cluster zurückgeführt werden kann und ob dieser signifikant von.0 verschieden ist. Das Alter z.b. hat einen ETA**2-Wert von D.h. 3.5% der Streuung des Alters können auf die Trennung in 3 Cluster zurückgeführt werden. Dieser Streuungsanteil ist mit %-iger Signifikanz von.0 verschieden. Almo zeichnet noch abschließend ein Liniendiagramm der Clustermittelwerte für alle Variable. Dabei sind die Variablen standardisiert, d.h. mit Standardabweichungen als Maßeinheiten gezeichnet. 88
89 Clustermittelwerte Cluster 2 Cluster 3 Cluster 1 Kleidung-konventionell Kleidung-unkonventionell Kleidung-elegant Rauchen Bier Wein Schnaps Aufputschdrinks nichtalkoh.drink Geschlecht-männl Geschlecht-w eibl Bildungsgrad Alter Die Linien in diesem Diagramm sind auf dem Bildschirm verschieden färbig. Hier im Druck sind sie als Grau-Abstufungen nicht gut voneinander zu trennen. In Abschnitt P wird mit einem anderen Beispiel nochmals eine ausführliche Progtamm-Ausgabe vorgestellt Maskenprogramm Prog37m3 Das nachfolgende Maskenprogramm ist weitgehend identisch mit dem bereits in Abschnitt P dargestellten Prog37m1. Es ist um die Möglichkeit erweitert, die Optionen, die für die K-Mean-Analyse in Almo angeboten werden, auch zu nutzen. 89


90

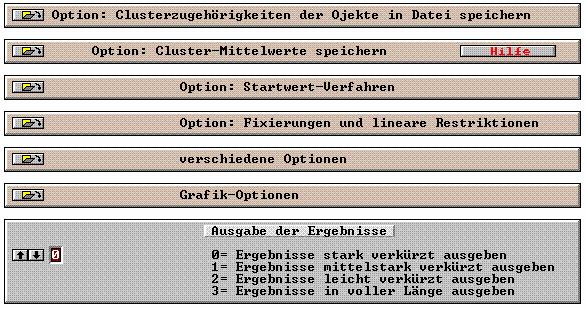
91

92 Erläuterung zu den Boxen von Prog37m3 Wie bereits gesagt, ist Prog37m3 weitgehend identisch mit dem in Abschnitt P dargestellten Prog37m1. Wir werden deswegen nur die Boxen erläutern, die zusätzlich in Prog37m3 enthalten sind. Box: Klassifikationsvariable gewichten: Box geöffnet: Durch z.b. die Anweisung: Gewicht 3:6 = 0.5, 1.0, 1.5, 2.0; können die in die Analyse einbezogenen Klassifikationsvariablen gewichtet werden. In dem Beispiel erhält die Variable V3 das Gewicht 0.5, die Variable V4 das Gewicht 1.0, die Variable V5 das Gewicht 1.5 und die Variable V6 das Gewicht 2.0. Die Gewichtung führt in dem Beispiel dazu, dass der Variablen V6 ein stärkeres Gewicht bei der Berechnung der Distanzen eines Objektes zu den Clustern zukommt als den anderen Variablen. Im Vergleich zu V3 kommt der Variablen V6 ein viermal so großes Gewicht zu, im Vergleich zu V4 ein zweimal so großes. Für die quadrierte euklidische Distanz (Modell = 1 und 2) lautet die Berechnungsformel: mit d (g, k) = j g j (x gj x kj) 2 g j x gj = Gewicht der Variablen j = Wert des Objekts g in der Variablen j x = Mittelwert des Clusters k in der Variablen j kj Bei den Modellen 3 bis 6 (Gewichtung der quadrierten euklidischen Distanzen) werden die Distanzen über die Mahalanobisdistanz berechnet mit mit d (g, k) = i j (gi g j) wij (x gj x kj) (x gi x ki ) 92

93 g j = Gewicht der Variablen j x gj = Wert des Objekts g in der Variablen j x = Mittelwert des Clusters k in der Variablen j kj g i = Gewicht der Variablen i x gi = Wert des Objekts g in der Variablen i x ki = Mittelwert des Clusters k in der Variablen i wij = Gewicht des Variablenpaares i,j Box Option: Cluster-Mittelwerte speichern Optionsbox geöffnet: Betrachten wir ein Beispiel mit 1 nominalen Klassifikationsvariablen V3 mit 3 Ausprägungen 6 ordinalen/quantitativen Klassifikationsvariablen V4, V5,...V9 wobei die Clusteranalyse 3 Cluster ausgegeben hat Folgende Daten werden in diesem Beispiel in die Datei gespeichert: Zahl der Cluster 9 Zahl der Variablen (nominale in Dummies aufgelöst) 435 Zahl d. Faelle Variablen-Nr Matrix der Clustermittelwerte Matrix der Cluster-Stand.abwg Bei der nominalen Variablen V3 lauten die Variablen-Nr. (der Dummies) 3.01, 3.02, 3.03 dabei ist 3 die Variablennummer, bezeichnen die 3 Dummies von V3 Bei der Matrix der Clustermittelwerte stehen in der Spalte 0 die Anteile, d.h. die relativen Haeufigkeiten je Cluster. Diese Matrix ist also folgendermassen zu verstehen: 93

94 Spalte: Cluster- Anteilswerte der Mittelwerte der ordinalen Anteil nominalen Klassi- danach quantitativen fikationsvariablen Klassifikationsvariablen V3.01 V3.02 V3.03 V4 V5 V6 V7 V8 V Cluster 1: Cluster 2: Cluster 2: Die Matrix der Cluster-Standardabweichungen enthält keine Spalte 0. Box "Option: Tabelle für Startwerte vereinbaren" Optionsbox geöffnet: Wenn Sie weiter unten im Maskenprogramm die Optionsbox "Option: Startwert-Verfahren" geöffnet haben und dort das Startwertverfahren 5 (Startwerte über Tabelle_A eingeben) gewählt haben, dann müssen Sie hier nun für die Tabelle_A Speicherplatz vereinbaren. Beachte: In der Box "Clusterzahl" müssen Sie für die minimale und die maximale Clusterzahl dieselbe Zahl angeben, d.h. es darf nur eine Clusterlösung gerechnet werden. Im Eingabefeld geben Sie als 1. Zahl die Zahl der Cluster an, dann ein Komma und dann die Zahl der Klassifikationsvariablen +1. Die Zahl der Klassifikationsvariablen setzt sich wie folgt zusammen: Zahl der Dummies (der Ausprägungen) der nominalen Variablen + Zahl der ordinalen Variablen + Zahl der qunatitativen Variablen Box "Option: Tabelle für Restriktionen vereinbaren" 94

95 Optionsbox geöffnet: Wenn Sie weiter unten im Maskenprogramm die Optionsbox "Option: Fixierungen und lineare Restriktionen" geöffnet haben, dann müssen Sie hier nun für die Tabelle_B Speicherplatz vereinbaren. Beachte: In der Box "Clusterzahl" müssen Sie für die minimale und die maximale Clusterzahl dieselbe Zahl angeben, d.h. es darf nur eine Clusterlösung gerechnet werden. Im Eingabefeld geben Sie als 1. Zahl die Zahl der Cluster an, dann ein Komma und dann die Zahl der Klassifikationsvariablen +1. Die Zahl der Klassifikationsvariablen setzt sich wie folgt zusammen: Zahl der Dummies (der Ausprägungen) der nominalen Variablen + Zahl der ordinalen Variablen + Zahl der qunatitativen Variablen Box "Option: Startwert-Verfahren" Optionsbox geöffnet: 95
 = 1; Die Daten (Klassifikationsobjekte) werden solange eingelesen, bis k-disjunkte, KEINWERT-freie")
96 Wenn Sie die Optionsbox nicht öffnen, dann wird das Startwertverfahren 3 gerechnet. Alle Klassifikationsobjekte werden zufällig einem Startcluster zugeordnet. 1. Eingabefeld: Folgende Startwertverfahren werden angeboten: Startwertverfahren (Option 14) = 1; Die Daten (Klassifikationsobjekte) werden solange eingelesen, bis k-disjunkte, KEINWERT-freie Startcluster berechnet werden können. Startwertverfahren (Option 14) = 2; Alle Daten (Klassifikationsobjekte) werden in der Reihenfolge ihres Auftretens einem Startcluster zugeordnet. Bei einer 3-Clusterlösung beispielsweise wird das 1. Objekt dem Cluster 1 zugeordnet, das 2. Objekt dem Cluster 2, das 3. Objekt dem Cluster 3, das 4. Objekt dem Cluster1 usw. Startwertverfahren (Option 14) = 3; Alle Daten (Klassifikationsobjekte) werden zufällig einem Startcluster zugeordnet. Dabei wird wie folgt vorgegangen: Für jedes Klassifikationsobjekt wird eine Zufallszahl zwischen 1 und k (k = Zahl der Cluster) erzeugt. Dies ist die Clusterzugehörigkeit. Startwertverfahren (Option 14) = 4; Die Starwerte werden aufgrund eines "Quick-Clustering" Verfahrens ermittelt (siehe dazu Abschnitt P ) Startwertverfahren (Option 14) = 5; Die Startwerte werden über eine Tabelle (Tabelle_A) eingegeben. Zusammengefasst: Option 14 = 1; Die Daten (Klassifikationsobjekte) werden solange eingelesen, bis 96
97 k-disjunkte, KEINWERT-freie Startcluster berechnet werden können. Option 14 = 2; Alle Daten (Klassifikationsobjekte) werden in der Reihenfolge ihres Auftretens einem Startcluster zugeordnet. Bei einer 3- Clusterlösung beispielsweise wird das 1. Objekt dem Cluster 1 zugeordnet, das 2. Objekt dem Cluster 2, das 3. Objekt dem Cluster 3, das 4. Objekt dem Cluster1 usw. Option 14 = 3; Alle Daten (Klassifikationsobjekte) werden zufällig einem Startcluster zugeordnet. Dabei wird wie folgt vorgegangen: Für jedes Klassifikationsobjekt wird eine Zufallszahl zwischen 1 und k (k = Zahl der Cluster) erzeugt. Dies ist die Clusterzugehörigkeit. Option 14 = 4; Die Starwerte werden aufgrund eines "Quick-Clustering" Verfahrens ermittelt (siehe dazu Abschnitt P ) Option 14 = 5; Die Startwerte werden über eine Tabelle (TabelleA) eingegeben. 2. Eingabefeld: Startzahl für Zufallsgenerator. Nur relevant, wenn das Startwertverfahren 3 (zufällige Zuordnung) gewählt wurde. Almo besitzt einen eingebauten Zufallsgenerator. Dieser Zufallsgenerator muss durch eine Startzahl (die dann in komplizierter Weise transformiert wird) in Betrieb gesetzt werden. Die Folge der Zufallszahlen, die Almo dann erzeugt, ist bei jeder Wiederholung des Programms dieselbe - es sei denn die Startzahl für den Zufallsgenerator wird verändert. Verwenden Sie eine ungerade 5- oder 6-stellige Zahl. Der 2. Teil der Optionsbox wird von Almo nur verwendet, wenn im 1. Eingabefeld das Startwertverfahren 5 (Eingabe der Startwerte über Tabelle_A) eingesetzt wurde. Ist dies der Fall, dann müssen Sie weiter oben im Programm die Optionsbox "Option: Tabelle für Startwerte vereinbaren" öffnen und Speicherplatz für die Tabelle_A vereinbaren 3. Eingabefeld: Dateiname für Startwerttabelle. Geben Sie den Namen der Datei an, in der sich die Tabelle der Startwerte befindet Löschen Sie den Dateinamen, wenn Sie nicht das Startwert-Verfahren 5 verwenden. Gehen Sie so vor: Erzeugen Sie ein leeres Fenster. Geben Sie diesem Fenster den von Ihnen gewählten Dateinamen. In dieses Fenster schreiben Sie die Startwerttabelle. Allgemeiner Aufbau der Tabellen Tabelle_A (und auch der anschliessend erläuterten Tabelle_B für die Fixierungen und Restriktionen) Siehe auch die ausführliche Darstellung in Abschnitt P Die Tabellen sind von der Ordnung c * (m+1) c = Zahl der Cluster m = Zahl der Klassifikationsvariablen Diese setzt sich wie folgt zusammen: Zahl der Dummies (der Ausprägungen) der nominalen Variablen 97
98 + Zahl der ordinalen Variablen + Zahl der qunatitativen Variablen m Zeile = 1. Cluster Zeile = 2. Cluster usw c. Zeile = c. Cluster quantitative Klassifikationsvariable, Reihenfolge entsprechend der Eingabe im Eingabefeld für quantitative Variable bzw hinter der Anweisung A_Quantitative_V=...; ordinale Klassifikationsvariable Reihenfolge entsprechend der Eingabe im Eingabefeld für ordinale Variable bzw. hinter der Anweisung A_Ordinale_V=...; usw. Dummies der 2. nominalen Klassifikationsvariablen Dummies der 1. nominalen Variablen 1. Spalte = Clustergrössen als Anteilswerte 4. Eingabefeld: Zahl aller Klassifikationsvariablen Diese setzt sich wie folgt zusammen: Zahl der Dummies (der Ausprägungen) der nominalen Variablen + Zahl der ordinalen Variablen + Zahl der qunatitativen Variablen Box "Option: Fixierungen und lineare Restriktionen" Fixierungen und lineare Restriktionen werden verwendet um eine konfirmatorische Clusteranalyse zu rechnen. 98

99 Optionsbox geöffnet: Sie müssen weiter oben im Programm die Optionsbox "Option: Tabelle für Restriktionen vereinbaren" öffnen und Speicherplatz für die Tabelle_B vereinbaren. Beachte: In der Box "Clusterzahl" müssen Sie für die minimale und die maximale Clusterzahl dieselbe Zahl angeben, d.h. es darf nur eine Clusterlösung gerechnet werden. Das 1. und 2. Eingabefeld ist in gleicher Weise auszufüllen wie oben bei der Box "Option: Startwert-Verfahren" die Eingabefelder 3 und Diverse Optionen in Programm-Maske P37m3 einfügen Box "verschiedene Optionen" Optionsbox geöffnet: 99
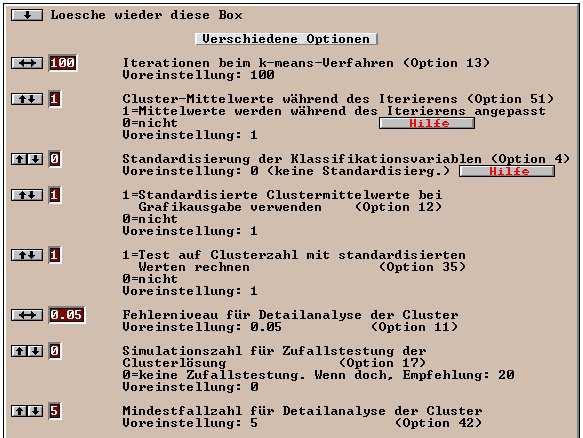

100 100

101 Die Optionsbox besteht aus 3 Teilen. Im 1. Teil sind die Optionen angeführt, die generell beim K-Means-Verfahren einsetzbar sind. Im 2. Teil sind die Optionen angeführt, die zusätzlich und nur bei der probalistischen K-Means-Clusteranalyse verwendet werden können. Im 3. Teil sind die Optionen angeführt, die zusätzlich und nur beim Repräsentanten- Verfahren der K-Means-Clusteranalyse verwendet werden können. Alle Optionen sind nachfolgend dargestellt. KEIN_WERT-Schwelle (Option 10): ALMO behandelt fehlende Werte in den Klassifikationsobjekten mit Hilfe der Methode des paarweisen Ausscheidens. Das bedeutet: Die Entfernung zwischen einem Klassifikationsobjekt und einem Cluster wird nur über die validen Werte berechnet. Beispiel: In eine Clusteranalye sollen die quantitiativen Variablen V3 bis V16 einbezogen werden. Besitzt beispielsweise ein Klassifikationsobjekt in den Variablen V3 und V5 keinen Wert, dann werden diese beiden Variablen aus der Berechnung der Entfernungen (Distanzen) des Objekts zu den Clusterzentren eliminiert. Um sicher zu stellen, dass für jedes Klassifikationsobjekt eine bestimmte Zahl valider Werte vorliegt, enthält das Programm eine KEIN_WERT-Schwelle. Die Voreinstellung für diesen Schwellenwert ist Das bedeutet, dass Klassifikationsobjekte mit einem Anteil fehlender Werte in allen Klassifikationsvariablen größer/gleich 0.33 aus der Analyse eliminiert werden. Fehlerniveau für die Detailanalyse der Cluster (OPTION 11): Das Programm führt in Anschluss an die Ausgabe der Clusterzentren, -streuungen und -besetzungszahlen für die ermittelte "beste" Clusterlösung eine Detailanalyse der berechneten Cluster durch. Diese ist als Hilfe zur Beschreibung der Clusterlösung gedacht. Zwei Fragestellungen werden dabei beantwortet: a) In welchen Klassifikationsvarialen unterscheidet sich das Cluster i signifikant von den anderen Clustern? b) Welche signifikanten Unterschiede zwischen den Klassifikationsvariablen gibt es innerhalb des Clusters i? Um diese beiden Analysen durchführen zu können, muss der Benutzer eine Schwelle für das Fehlerniveau und für die Mindestfallzahl eines Cluster, ab der eine Detailanalyse durchgeführt werden soll, eingeben. Das Fehlerniveau wird eingegeben mit Option 11 = 0.01; Durch diese Anweisung wird dem Programm mitgeteilt, dass nur Unterschiede als signifikant betrachtet werden, bei denen das "korrigierte" Fehlerniveau kleiner 1% 101
102 bzw. das Signifikanzniveau größer 99 % ist. Da mehrere statistische Tests durchgeführt werden, nimmt das Programm eine Bonferroni-Korrektur vor. Unterschiede werden als signifikant betrachtet, bei denen das berechnete Fehlerniveau alpha berechnet kleiner/gleich dem durch die Zahl der Vergleiche korrigierten Fehlerniveau alpha vorgegeben/ c (c=zahl der Vergleiche) ist. Die Voreinstellung ist Option 11=0.05; (=alphavorgegeben) Mindestfallzahl für die Detailanalyse der Cluster (OPTION 42): Mit der Anweisung Option42 = 10; kann die Mindestfallzahl für die Durchführung der Signifkanztests bei der Detailanalyse der Cluster festgelegt werden. Ist ein Cluster kleiner als die vorgegebene Mindestfallzahl, so wird es aus der Detailanalyse ausgeschlossen. Die Voreinstellung ist OPTION42=5; Konvergenz (OPTION 43): Mit dieser Option kann die Konvergenz gesteuert werden. OPTION 43=1; (=Voreinstellung) prüft nur eine "schwache" Konvergenzbedingung. Ist der Wert der zu minimierenden Funktion v(k) im k-ten Iterationsschritt kleiner dem Wert v(k-1) mal einem Schwellenwert, wird die Iteration abgebrochen. Der Schwellenwert kann durch die Anweisung OPTION 16 =...; definiert werden. Voreingestellt ist der Wert gleich Bei OPTION43=2; wird die "starke" Konvergenz geprüft. Schwache Konvergenz bedeutet, dass der Algorithmus mit der Iteration dann abbricht, wenn v(k) > v(k-1). (1-c) ist, wobei v(k) = Kriteriumswert der aktuellen Iteration k v(k-1) = Kriteriumswert der vorausgehenden Iteration k-1 c = der mit OPTION 16 definierte Schwellenwert. Durch die Wahl eines schwachen Konvergenzkriteriums kann bei grossen Datensätzen Rechenzeit gespart werden. Bei kleinen Datensätzen (n < 1000 oder 2000) empfehlen wir die starke Konvergenz. Zwischeniteration (OPTION 44): Um bei großen Datensätzen Rechenzeit einzusparen, kann bei MODELL=7; eine Zwischeniteration mit nur einer Stichprobe durchgeführt werden. Die Stichprobengröße wird bei OPTION 43 nach dem Ist-Gleichzeichen eingegeben. OPTION 43=100; führt dazu, dass im 1. Zwischeniterationsschritt zunächst die Parameter aus den ersten 100 Datensätzen berechnet werden, im 2. Zwischeniterationsschritt aus den ersten 200 Datensätzen usw. 102
103 Zahl der Iterationen (OPTION 13): Die Clusterbildung wird bei allen K-Means- Verfahren iterativ durchgeführt (siehe Abschnitt P37.2.3). Die Zahl der maximal möglichen Iterationen kann mit Option 13 = 1000; verändert werden. In dem Beispiel wird die Zahl maximal erlaubter Iterationen auf 1000 gesetzt. Die Voreinstellung ist OPTION 13 = 100; Das Programm führt mindestens 3 Iterationen durch. Soll nicht iteriert werden, dann muss gesetzt werden: OPTION13=0 und OPTION 51=0. Startzahl des Zufallsgenerators (Enthalten in Optionsbox Startwert-Verfahren ): Veränderung der Startzahl des Zufallszahlengenerators. Durch die Anweisung Option 15 = ; kann die Startzahl des Zufallszahlengenerators für das Startwertverfahren 3 (OPTION 14=3;) verändert werden. Die Voreinstellung ist OPTION 15 = ; Bei der Änderung der Startzahl ist zu beachten, dass die Startzahl zwischen 1 und und ungerade sein muss. Standardisierung der Klassifikationsvariablen und Objekte (OPTION 4): Mit OPTION 4 können folgende empirische Standardisierungen der Variablen und Objekte durchgeführt werden: Option 4 = 0; keine Standardisierung der Klassifikationsvariablen und Objekte (Voreinstellung) Option 4 = 1; Empirische Mittelwertzentrierung der Klassifikationsvariablen. Die Klassifikationsvariablen werden auf den Mittelwert 0 transformiert. Option 4 = 2; Empirische Standardisierung der Klassifikationsvariablen. Die Klassifikationsvariablen werden auf den Mittelwert 0 und auf eine Standardabweichung von 1 transformiert. Option 4 = 3; Empirische Mittelwertzentrierung der Objekte. Die Merkmalsausprägungen der Objekte in den Klassifikationsvariablen werden auf einen Mittelwert von 0 transformiert. Option 4 = 4; Empirische Standardisierung derobjekte. Die Merkmalsausprägung der Objekte in den Klassifikationsvariablen werden auf einen Mittelwert von 0 eine Standardabweichung von 1 transformiert. Option 4 = 5; Option 4 = 1 und Option 4 = 3; Option 4 = 6; Option 4 = 1 und Option 4 = 4; Option 4 = 7; Option 4 = 2 und Option 4 = 3; Option 4 = 8; Option 4 = 2 und Option 4 = 4; Beachte: Es werden alle Klassifikationsvariable standardisiert auch die Dummies der nominalen Variablen. Beachte: Bei Option 4 =6 und =7 und =8 werden zuerst die Variablen und dann die Objekte standardisiert. Daher sind Mittelwerte und Standardabweichungen der Variablen und der Objekte nicht gleich 0 bzw. 1. Zufallstestung einer Clusterlösung (OPTION 17): Durch die Anweisung Option 17 = 20; kann eine gefundene Clusterlösung auf "Zufälligkeit" geprüft werden. Es wird geprüft, ob die gefundene Clusterlösung auch bei reinen Zufallsdaten zu annähernd gleich 103
104 guten Ergebnissen führt. Ist dies der Fall, kann die berechnete Clusterlösung als Zufallsprodukt ("Artefakt") betrachtet werden. Wir empfehlen mindestens 20 Simulationen durchzuführen. Die Voreinstellung ist OPTION 17 = 0; Standardisierung der Clustermittelwerte bei der graphischen Ausgabe (OPTION 12=1;): Durch die Anweisung OPTION 12 = 1; können die Clustermittelwerte für die graphische Ausgabe standardisiert werden. Cluster-Mittelwerte während des Iterierens anpassen OPTION 51=1; die Startwerte, d.h. die Cluster-Mittelwerte der Klassifikationsvariablen werden während des Iterierens angepasst. OPTION 51=0; nicht, d.h. die Startwerte bleiben unverändert Voreinstellung: 1 Soll das K-Means-Verfahren ohne Iteration gerechnet werden, dann genügt es nicht, dass Option 13 auf 0 gesetzt wird, da Almo mindestens 3 Mal iteriert. Es muss zusätzlich noch Option 51=0 gesetzt werden. Unabhängig von Option 13 kann mit Option 51=0 auf einfache Art untersucht werden, wie gut theoretisch angenommene Startwerte sind. Zuordnung der Objekte bei probabilistischer Clusteranalyse OPTION 52 = 1; die Objekte werden deterministisch zugeordnet - entsprechend der maximalen Wahrscheinlichkeit für die jeweiligen Cluster OPTION 52 = 0; nicht Folgende Ausführungen gelten nur für Maskenprogramm Prog37m3 sofern als Verfahren 7 (die probabilistische Clusteranalyse) gewählt wurde. Wird die Optionsbox "Clusterzugehörigkeiten der Ojekte in Datei speichern" geöffnet, dann tritt beim probabilistischen Verfahren ein Problem auf, da dieses Verfahren für jedes Cluster eine bestimmte Wahrscheinlichkeit der Zugehörigkeit ermittelt hat. Setzt der Benutzer Option 52 auf 1, dann sucht Almo die maximale Wahrscheinlichkeit zu einem Cluster und gibt die Nummer dieses Clusters als Clusterzugehörigkeit in die neue Datei. Setzt der Benutzer Option 52 auf 0, dann verfährt Almo genau so, speichert aber zusätzlich die Wahrscheinlichkeiten der Zugehörigkeiten zu allen Clustern in die Datei "...Almo\Progs\Prob_Clust_Zugehoer.fre" - so dass der Benutzer, wenn er will, die einzelnen Wahrscheinlichkeiten nachsehen kann und auch die beiden Dateien verbinden kann. Siehe dazu Prog00me.Msk "2 parallele Dateien zusammenfügen". Klicken Sie dazu auf "Verfahren / Datei-Operationen". Ausgabe aus Prog37m3 Die Ergebnisse die die Programm-Maske Prog37m3 liefert, werden später in Abschnitt P an einem anderen Beispiel vorgetragen. 104
105 P Die Grundlogik der K-Means-Verfahren P Der Algorithmus Die Grundlogik der "K-Means-Clustering"-Verfahren besteht - wie bereits erwähnt - darin, die Klassifikationsobjekte iterativ so in Cluster zusammenzufassen, dass die Klassifikationsobjekte minimal um die Clusterzentren streuen. Die Clusterzentren werden nach folgendem Algorithmus iterativ bestimmt: Schritt 1: Festlegung der Zahl zu untersuchender Cluster. Es wird eine bestimmte Anzahl von Clustern vorgegeben, z.b. 1 bis 8 Cluster. Für jede Clusterzahl werden die nachfolgenden Schritte ausgeführt. Schritt 2: Berechnen von Startwerten für die Clusterzentren. Für eine bestimmte Clusterzahl (z.b.: drei) werden nach einem bestimmten Verfahren Startcluster (erste Schätzungen für die Clusterzentren) gebildet. Schritt 3: Zuordnung der Klassifikationsobjekte zu den Clusterzentren (beim ersten Durchlauf Clusterzentren = Startwerte). Jedes Klassifikationsobjekt wird jenem Cluster zugeordnet, zu dem es die geringste Entfernung besitzt. Das heißt: Die quadrierte euklidsche Distanz des Klassifikationsobjekts zu den Clustermittelwerten ist minimal. Schritt 4: Neuberechnung der Clusterzentren. Nach der (den) Zuordnung(en) werden die Clusterzentren neu berechnet. Schritt 5: Iteration (Wiederholung der Schritte 3 und 4). Schritt 3 und 4 werden solange wiederholt, bis sich die Zuordnung der Klassifikationsobjekte zu den Clustern nicht mehr ändert. P Ein Beispiel zur Illustration des Algorithmus Der Algorithmus soll anhand der in der Abbildung P dargestellten Datenmatrix verdeutlicht werden. Die Datenmatrix besteht aus den beiden Variablen (Klassifikationsvariablen) X und Y und aus den neun Objekten (Klassifikationsobjekten) a,b,c,...,i. Abbildung P37.2.1: Ein Datenbeispiel zur Illustration des Algorithmus Datenmatrix Objekte X Y a -2 1 b -1 2 c -1-2 d 0-1 e 1-1 f 2 2 g 3 2 h 4 2 i 4 3 a b c d y e i f g h x Wie der graphischen Darstellung der Datenmatrix entnommen werden kann, lassen sich die Klassifikationsobjekte zu drei Clustern zusammenfassen. Wir wollen nun prüfen, ob der dargestellte Algorithmus diese Clusterstruktur reproduziert. Schritt 1: Festlegung der Zahl zu untersuchender Cluster. 105
106 Die Clusterzahl soll zunächst auf drei festgelegt werden, d.h., dass eine Lösung mit drei Clustern ermittelt werden soll. Schritt 2: Berechnen von Startwerten für die Clusterzentren für eine bestimmte Clusterzahl. Zur Berechnung der Starwerte soll hier das einfachste Verfahren (siehe P37.2.2), bei dem die ersten k disjunkten Klassifikationsobjekte als Startcluster verwendet werden, eingesetzt werden. Die Objekte a, b und c bilden also die Startcluster (siehe Abbildung P37.3.2). Abbildung P37.2.2: Starwerte der 3-Clusterlösung für die Daten der Abbildung P Datenmatrix Objekte X Y a -2 1 b -1 2 c -1-2 d 0-1 e 1-1 f 2 2 g 3 2 h 4 2 i 4 3 Startwerte a b c d y e i f g h x Die Clusterzentren, mit denen Schritt 3 des Algorithmus zum erstenmal durchlaufen wird, sind: Tabelle P37.2.1: Startwerte für die Clusterzentren Cluster X Y Startcluster Startcluster Startcluster Schritt 3: Zuordnung der Klassifikationsobjekte zu den Clusterzentren. Die Klassifikationsobjekte werden jenem Cluster zugeordnet, von dem sie am geringsten entfernt sind. Unter Verwendung der quadrierten euklidischen Distanz ergibt sich folgendes Bild (siehe Tabelle P37.2.2). Tabelle P37.2.2: Zuordnung der Klassifikationsobjekte aufgrund der Startwerte i X Y Calt d(i,c1) d(i,c2) d(i,c3) Cneu a b c d e f g h i Calt = alte Clusterzugehörigkeit (-1 = nicht bekannt) Cneu = neue Clusterzugehörigkeit 106
107 d(i,c1) = quadrierte euklidische Distanz des Objekts i zum Cluster C1 d(i,c2) = quadrierte euklidische Distanz des Objekts i zum Cluster C2 d(i,c3) = quadrierte euklidische Distanz des Objekts i zum Cluster C3 unterstrichene Werte = kleinste quadrierte euklidische Distanz Da die ersten drei Objekte a, b und c die Startcluster bilden, ist die quadrierte euklidische Distanz zu dem jeweils dazugehörenden Cluster (für Objekt a Cluster 1, für Objekt b Cluster 2 und für Objekt c Cluster 3) gleich Null. Sie werden diesen Clustern zugeordnet. Die quadrierten euklidischen Distanzen des vierten Objekts d zu den drei Clustern nehmen folgende Werte an: d(4,c1)= (0-(-2)) 2 + (-1-(+1)) 2 =8.0 Differenzen zwischen Merkmalsausprägungen des Objekts 4(=0) und dem Mittelwert von C1 (=-2) in X zum Quadrat Differenz zwischen Merkmalsausprägungen des Objekts 4(=-1) und dem Mittelwert von C1 (=+1) in Y zum Quadrat d(4,c2)= (0 - (-1)) 2 + (-1 - (+2)) 2 =10.0 d(4,c3)= (0 - (-1)) 2 + (-1 - (+2)) 2 =2.0 Die geringste Entfernung für das Objekt 4 liegt für das dritte Cluster vor. Das Objekt wird deshalb diesem Cluster (Cneu) zugeordnet. Bei den verbleibenden Objekten e, f,.. wird analog verfahren. Schritt 4: Neuberechnung der "Startcluster" (Clusterzentren). Aufgrund der Zuordnung der Klassifikationsobjekte zu den Clustern ergeben sich folgende neue Clusterzentren: x c1 = 2.00 /1 = 2.00 y c 1 = 1.00 /1 = 1.00 x c 2 = ( ) / 5 = y c 2 = ( ) / 5 = x c 3 = ( ) / 3 = 0.00 y c3 = ( ) / 3 = 1.33 In Tabellenform dargestellt: Tabelle P37.2.3: Clusterzentren nach der 1. Iteration Cluster X Y C C C Schritt 5: Iteration (Wiederholung der Schritte 3 und 4). 107
108 Da die Klassifikationsobjekte zum ersten Mal den Clustern zugeordnet wurden, wurden neun Vertauschungen durchgeführt. Ein erneutes Durchlaufen der Schritte 3 und 4 ist erforderlich. Erneutes Durchlaufen des Schritts 3 ergibt folgendes Bild: Tabelle P37.2.4: Zuordnung der Klassifikationsobjekte aufgrund der im 1. Iterationsschritt berechneten Clusterzentren (Tab ) i X Y Calt d(i,c1) d(i,c2) d(i,c3) Cneu a b ** c d e f g h i Zur Bedeutung der Spaltenbezeichnungen siehe Tabelle P Bei der erneuten Durchführung des Schritts 3 ändert sich die Clusterzugehörigkeit des Objekts b. Es liegt somit eine Vertauschung vor und ein erneutes Durchlaufen der Schritte 3 und 4 ist erforderlich. In Schritt 3 werden folgende neu berechnete Clusterzentren einbezogen: Tabelle P37.2.5: Clusterzentren nach der 2. Iteration Cluster X Y C C C Schritt 3 führt zu folgendem Ergebnis: Tabelle P37.2.6: Zuordnung der Klassifikationsobjekte aufgrund der im 2. Iterationsschritt berechneten Clusterzentren (Tab. P37.2.5) i X Y Calt d(i,c1) d(i,c2) d(i,c3) Cneu a b c d e f g h i zur Bedeutung der Spaltenbezeichnungen siehe Tabelle P Es erfolgt keine Vertauschung der Klassifikationsobjekte mehr. Eine erneute Interation ist nicht erforderlich. Die Clusterzentren entsprechen den Werten der Tabelle P37.2.5: 108
109 Tabelle P37.2.7: Clusterzentren nach Abbruch der Iteration Cluster X Y C C C Graphisch dargestellt ergibt sich das Bild der Abbildung P Der Algorithmus hat also die drei vermuteten Cluster gefunden. Abbildung P37.2.3: Ergebnisse des "K-Means-Clustering" für das Beispiel der Abb. P Datenmatrix Cluster Objekte X Y a b c d e f g h i a b c d y e f g h i x P Modifikationen des Algorithmus In Abschnitt P wurden für den allgemeinen Algorithmus folgende Spezifikationen vorgenommen: 1) Dem Programm wurde die Berechnung einer 3-Clusterlösung aufgetragen. Die Parameter MIN_CLUSTERZAHL und MAX_CLUSTERZAHL wurden auf 3 gesetzt. 2) Als Startwerte für die Clusterzentren wurden die Merkmalsausprägungen der ersten 3 disjunkten Objekte verwendet. Option14 wird gleich 1 gesetzt. 3) Die Entfernungen der Klassifikationsobjekte zu den Clusterzentren wurden durch die quadrierte euklidische Distanzen berechnet. Dies kann durch Verwendung von Modell=2; erreicht werden. Das Beispiel kann somit mit dem ALMO-Syntax-Programm Prog37_2.ALM nachgerechnet werden (durch Öffnen des Menüs Almo, dann Liste aller Almo-Programme) 109
110 Das Programm befindet sich unter dem Namen Prog37_2.ALM im Verzeichnis der Beispiel-Programme. P "Quick-Clustering" Neben dem verwendeten Startwertverfahren stehen im Programm noch vier weitere Startwertverfahren zur Verfügung. Von diesen soll hier nur das "Quick-Clustering"- Verfahren (Option 14 = 4;) dargestellt werden, da es in der Literatur und in anderen Programmpaketen als eigenständiges Verfahren behandelt wird. y a b i f g h Quick-Cluster- Startwerte c d e x Bildlich gesprochen wählt QUICK-Clustering jene Objekte als Startcluster aus, die am weitesten voneinander entfernt sind. Die Ergebnisse sind abhängig von der Reihenfolge. In unserem Beispiel werden die Objekte b, c und i als Startcluster ausgewählt. P Die Auswahl des Startwertverfahrens Aufgrund derzeit vorliegender Simulationsstudien (Bacher/Pöge/Wenzig 2010, S ) ist die Methode der multiplen zufälligen Startwerte zu empfehlen, bei der je clusterzahl mehrere Versuche gerechnet werden. P Das Austauschverfahren Der in Abschnitt P wiedergegebene Algorithmus wird als Minimaldistanzverfahren bezeichnet. Er ist dadurch charakterisiert, dass die Clusterzentren erst nach der Zuordnung aller Klassifikationsobjekte neu berechnet werden. Folgende Modifikation ist denkbar: Nach der Zuordnung jedes Klassifikationsobjektes werden die Clusterzentren neu berechnet, sofern sich die Zuordnung ändert. Dies hat den Vorteil, dass die Datenmatrix nicht so häufig durchlaufen werden muss und Rechenzeit gespart werden kann. Der durch diese Modifikation entstehende Algorithmus wird als Austauschverfahren bezeichnet. Er ist als MODELL=1; in Programm P37 für die ungewichteteten quadrierten euklidischen Distanzen enthalten. P Gewichtung der quadrierten euklidischen Distanzen In den Modellen 1 und 2 wird mit der gewöhnlichen quadrierten euklidischen Distanz gerechnet. In jedem Iterationsschritt wird jedes Objekt dem Cluster zugeordnet, zu dem die quadrierte euklidische Distanz minimal ist (siehe Rechenbeispiel des Abschnitts P ). Die quadrierte euklidische Distanz zwischen einem Objekt g und einem Clusterzentrum k ist definiert als: 110
111 d(g,k) = g j (x gj x kj) mit j 2 g j = Gewicht der Variablen j x gj= Wert des Objekts g in der Variablen j x = Mittelwert des Clusters k in der Variablen j kj Bei den Modellen 3 bis 6 (Gewichtung der quadrierten euklidischen Distanzen) werden die Distanzen über die Mahalanobisdistanz berechnet mit d(g,k) = ( gi gi ) w ij (x gj x kj) (x gi x kj) mit i j g j = Gewicht der Variablen j x gj= Wert des Objekts g in der Variablen j x = Mittelwert des Clusters k in der Variablen j kj g i = Gewicht der Variablen i x gi= Wert des Objekts g in der Variablen i x ki = Mittelwert des Clusters k in der Variablen i w ij= Gewicht des Variablenpaares i,j Die Gewichte w ij der Mahalanobisdistanz sind für die einzelnen Modelle: w ii= 1/s i 2 w ij= 0 für Modell 3 (=1 dividiert durch die Varianz von i) w ii= 2 1 / s gep x w ij= 0 für Modell 4 (=1 dividiert durch die gepoolte Varianz von i) w ij= Inverse der Kovarianzmatrix der Variablen i, j für Modell 5 w ij= Inverse der gepoolten Kovarianzmatrix der Variablen i, j für Modell 6 Die Anweisung MODELL=3; entspricht - abgesehen von einer unterschiedlichen Normierung der Varianzen - einer empirischen Standardisierung in der Leseschleife oder der Verwendung von OPTION4=2;. Im Unterschied zu einer empirischen Standardisierung werden bei MODELL = 3; nichtstandardisierte Mittelwerte ausgegeben, bei einer empirischen Standardisierung in der Leseschleife oder bei OPTION 4 = 2; werden standardisierte Mittelwerte ausgegeben. P Ein Anwendungsbeispiel für eine explorative Analyse In Abschnitt P wurde ein Anwendungsbeispiel kurz vorgestellt. Wir wollen dieses Beispiel nun aufgreifen und die Ergebnisgrößen interpretieren. Aus Gründen der Vollständigkeit geben wir nochmals das entsprechende ALMO-Programm wieder. Die Programm-Maske Prog37m1 ist wie nachfolgend gezeigt auszufüllen. Programm befindet sich auch unter dem Namen Prog37_7 (als ausgefüllte Programm- Maske) und unter dem Namen Prog37_1.ALM (als Almo-Syntax-Programm) im 111

112 Verzeichnis Almo_Bsp. Die beiden Programm werden geladen durch Öffnen des Menüs Almo, dann Liste aller Almo-Programme. Das Beispiel ist folgendes: 221 Schüler sollen aufgrund ihrer materialistischen und postmaterialistischen Wertorientierung geclustert werden. Es sollen also Werttypen bestimmt werden. Diese sollen durch sozialstrukturelle Variablen, wie dem besuchten Schultyp, dem Geschlecht usw. beschrieben werden. Für die Analyse wird also ausgewählt: Als quantitative Klassifikationsvariablen: Die materialistische und postmaterialistische Einstellung der Schüler (gemessen durch eine Batterie verschiedener Fragen) Als Deskriptionsvariablen zur Beschreibung der Cluster: Sozialstrukturelle Variable, wie Schultyp, Geschlecht der Schüler, Beruf und Berufsprestige des Vaters und der Mutter etc. 112


113 113

114 114

115 Erstes Ziel ist es die Clusterzahl zu bestimmen. Um den Output übersichtlich zu halten, hätte daher auch ohne Deskriptionsvariablen gerechnet werden können. Bei der Ausgabe wird zunächst die Spezifikation der Programmparameter protokolliert: Ergebnisse aus ALMO Modellspezifikation: Verfahren Minimaldistanzverfahren fuer Varianzkriterium Startwerte zufaellige Auswahl Startzahl Cluster von 1 bis 8 Gewichtung der Distanzen keine KEIN_WERT-Schwelle 0.33 Alpha_Niveau 0.05 Mindestfallzahl 5 Fuer Analyse ausgewaehlte Variable: 115
116 Klassifikationsvariablen: V33 GMAT quantitativ V34 GPMAT quantitativ Desktiptionsvariablen: V26 Sex nominal UG = 1 OG = 2 V25 Schultyp nominal UG = 1 OG = 3 V21 BerufV nominal UG = 1 OG = 7 V22 BerufM nominal UG = 1 OG = 8 V23 SchulV quantitativ V24 SchulM quantitativ V40 PrestV quantitativ V41 PrestM quantitativ Klassifikationsvariablen nach Dummy-Aufloesung = 2 Deskriptionsvariablen nach Dummy-Aufloesung = 25 Gewichte der Variablen in der Analyse: V33 GMAT Gewicht= 1.00 V34 GPMAT Gewicht= 1.00 lineare Restriktionen = nein Nach der Protokollierung der Modellspezifikation werden Gesamtstatistiken für die Klassifikations und Deskriptionsvariablen ausgegeben: Masszahlen fuer Klassifikationsvariablen Variable n= MA SA z-wert Name V GMAT V GPMAT Masszahlen fuer Deskriptionsvariablen Variable n= MA SA z-wert Name V26 Sex maennl weiblich V25 Schultyp BHS AHS BS V21 BerufV ungelarb angelarb Beamt Facharb VS-Lehr DiplIng Arzt Hausfr V22 BerufM ungelarb angelarb Beamt Facharb VS-Lehr DiplIng Arzt Hausfr V SchulV 116
117 V SchulM V PrestV V PrestM Gesamtstreuungsquadratsumme = Gesamtfallzahl = 442 Freiheitsgrade = 440 ======================================================================== H-0-Kriterium (1-Clustermodell) = Fallzahl = 221 Die Ergebnisse sind wie folgt zu lesen: Für die Klassifikationsvariable V33 liegen n = 221 gültige Angaben (KW-freie Angaben) vor. Der Mittelwert (= MA) von V33 ist gleich 2.07, die Standardabweichung (SA) beträgt Der z-wert misst die standardisierte Abweichung des Mittelwertes vom Gesamtmittelwert. Er ist daher für die Gesamtmittelwerte gleich 0. Die Variable V33 hat schließlich den Namen GMAT (= Gesamtpunktewert für materialistische Wertorientierung). Die für die anderen Variablen angeführten Maßzahlen sind analog zu interpretieren. Nominale Variablen werden bei der Ausgabe in Dummies aufgelöst. Die Mittelwerte der Dummies können als Anteilswerte interpretiert werden. Betrachten wir dazu ein Beispiel. Der Mittelwert der Ausprägung 1 (= BHS) der Variablen V25 (= Schultyp) beträgt Dieser Wert bedeutet: 37 % der befragten Jugendlichen besuchen eine BHS. Schließlich wird die Gesamtstreuungsquadratsumme und ihre Freiheitsgrade ausgegeben. In unserem Beispiel ist die Gesamtstreungsquadratsumme SQ Ges = Sie ist wie folgt definiert: SQ 2 Ges = (x gj x j) g j mit x gj = Wert des Objektes g in der Variable j x = Gesamtmittelwert des Objektes g j In die Berechnung gehen nur die Klassifikationsvariablen bzw. bei nominalen Klassifikationsvariablen die entsprechenden Dummies ein. Die Gesamtstreuungsquadratsumme kann aus den empirischen Standardabweichungen der Klassifikationsvariablen wie folgt berechnet werden: SQ Ges = n j s 2 j mit n j = Zahl der gültigen Angaben für die Variable s j = Standardabweichung der Variablen j Die Gesamtzahl n ist definiert als n = n j 117
118 und ist in unserem Beispiel gleich n = = 442. Die Zahl der Freiheitsgrade ist gleich df = (n j - 1) = (221-1) + (221-1) = 440. Die Gesamtstreuungsquadratsumme kann in zwei Komponenten zerlegt werden; in eine Streungsquadratsumme in den Clustern (SQ in(k)) und in eine zwischen den Clustern (SQzw(K)): SQ Ges = SQ in(k) + SQ zw(k) Bei den K-Means-Verfahren wird für eine gegebene Clusterzahl K eine Clusterlösung gesucht, die die Streuungsquadratsumme in den Clustern minimiert. Dies wird durch den in Abschnitt P dargestellten Algorithmus erreicht, der allerdings mitunter zu einem lokalen Minimum von SQ in(k) führen kann. Neben der Gesamtstreuungsquadratsumme wird noch das sogenannte H 0-Kriterium ausgegeben. Es ist der Wert der zu minimierenden bzw. zu maximierenden Funktion, bei Modell 1 bis 6 die (generalisierte) Varianz, bei Modell 7 der Wert der Log- Likelihood-Funktion und bei Modell 8 der Anteil der Nichtklassifikationen und Überlappungen. Der Wert von H 0 stimmt i.d.r. nicht mit der Gesamtstreuungsquadratsumme überein. Nur für Modell 1 und Modell 2 ist es gleich der Gesamtstreuungsquadratsumme, wenn keine fehlenden Werte vorliegen. Dies ist in unserem Beispiel der Fall. Der Wert des H 0-Kriteriums ist gleich der Gesamtstreuungsquadratsumme (= ). Liegen fehlende Werte vor, treten auch bei Modell 1 und Modell 2 Unterschiede zwischen den beiden Kriterien auf, da fehlende Werte bei der Berechnung des H 0-Kriteriums "hochgerechnet" werden. In der nächsten Ergebnisausgabe werden die Iterationsergebnisse berichtet. Ausgegeben wird der Wert der zu maximierenden oder zu minimierenden Funktion für die definierte Anzahl von Clustern. Der Wert für die 1-Clusterlösung ist gleich dem Wert des H 0-Kriteriums und in unserem Beispiel gleich der Gesamtstreuungsquardatsumme. 118
119 Ergebnisse der Iteration Cluster- Itera- Kriterium prozentuelle zahl tionen Verbesserung gegenueber H Bei Modellen 1 bis 6: Kriterium = Wert des Varianzkriteriums Bei Modell 7: : Kriterium = Wert der Log-Likelihood-Funktion Bei Modell 8: : Kriterium = Ueberlapp. + Nichtklass. Für die 1-Clusterlösung ist SQ in(1) gleich SQ Ges. Diese Streungsquadratsumme wird als H0-Modell betrachtet. Die 2-Clusterlösung führt nach 5 Iterationen zu einer Streuungsquadratsumme in den Clustern von Gegenüber der 1-Clusterlösung stellt dies eine prozentuelle Verbesserung von % dar (100*(1- (85.545/ )). Bei den Modellen 1 und 2 kann die prozentuelle Verbesserung gegenüber dem H0- Modell als erklärte Streuung (= ETA 2 ) interpretiert werden. Bei den anderen Modellen ist dies nicht der Fall. Die nachfolgende Tabelle basiert auf der oben angeführten Streuungszerlegung. Sind die Variablen nicht vergleichbar, sollte OPTION35=1; gesetzt werden. Die Variablen werden dann zur Berechnung der Streuungsquadratsumme und der nachfolgenden F- Werte programmintern "standardisiert". Auf die Ergebnisse hat diesen keinen Einfluss. Cluster- Streuungsquadratsummen F-Wert ETA**2 PRE zahl innerhalb zwischen KW Beachte: Die Interpretation dieser Testgroessen ist fuer die Modelle 3 bis 6 nur sinnvoll, wenn gleiche Skaleneinheiten der Variablen vorliegen. Dies gilt auch fuer die Bealschen F-Werte. Setze OPTION35=1; Bealsche F-Werte: (Spalte1..1-Clusterloesung, Spalte2..2-Clusterloesung usw.; unteres Dreieck = F-Werte; oberes Dreieck = Signifikanzen der F-Werte) 119
120 Spalte 1 Spalte 2 Spalte 3 Spalte 4 Spalte 5 Spalte 6 Spalte 7 Spalte Cluster- Streunngsquadratsummen F-Wert ETA**2 PRE zahl innerhalb zwischen KW Beachte: Die Interpretation dieser Testgroessen ist fuer die Modelle 3 bis 6 nur sinnvoll, wenn gleiche Skaleneinheiten der Variablen vorliegen. Dies gilt auch fuer die Bealschen F-Werte Bealsche F-Werte: (C1..1-Clusterloesung, C2..2-Clusterloesung usw.; unteres Dreieck = F-Werte; oberes Dreieck = Signifikanzen der F-Werte) Spalte 1 Spalte 2 Spalte 3 Spalte 4 Spalte 5 Spalte 6 Spalte 7 Spalte KW KW Die ausgegebenen Größen können zur Bestimmung der Clusterzahl verwendet werden. Sie sind wie folgt definiert: F Wert mit K SS = SS zw in (K) / K 1 (K) / n K F-WertK = F-Wert für eine bestimmte Clusterlösung mit K Clustern SSzw(K) = Streuungsquadratsumme zwischen den Clustern für die K-Clusterlösung SS in(k) = Streuungsquadratsumme innerhalb der Cluster für die K-Clusterlösung K = Zahl der Cluster n = Zahl der Klassifikationsobjekte Für die 2-Clusterlösung ergibt sich folgender Wert: 120
121 63.260/(2 1) F-Wert K = = /(221 2) Die F-Werte werden auch als F-MAX-Werte bezeichnet, da durch die Maximierung der Streuungsquadratsumme zwischen den Clustern bzw. durch die Minimierung der Streuungsquadratsumme innerhalb der Cluster der F-Wert maximiert wird. ETA 2 wird wie folgt berechnet: ETA 2 K = SS in SS zw (K) (K) + SS zw (K) Für die 2-Clusterlösung ergibt sich ein Wert von ETA 2 K = 2 = = 0.425( = 42.5%) Die 2-Clusterlösung erklärt somit 42.5% der Gesamtstreuung in den Klassifikationsvariablen. Der PRE-Koeffizient wird nach der allgemeinen Definition dieses Koeffizienten berechnet nach der Formel: PRE K = (Fehler _ ohne _ X) (Fehler (Fehler _ ohne _ X) _ mit _ X) SS = in (K 1 Cluster) SSin (K Cluster) SS (K 1 Cluster) in Für den Vergleich der 3 mit der 2-Clusterlösung ergibt sich in unserem Beispiel folgender Wert: ( ) PRE 3 = = 0.291( = 29.1%) Die 3-Clusterlösung verbessert die Lösung der 2-Clusterlösung um 29.1%. Bealsche F-Werte: Als weitere Teststatistiken werden vom Programm die F-WERTE nach BEALE (vgl. Kendall 1980: 41-42) ausgegeben. Sie werden nach folgender Formel berechnet: F-Wert K1,K2(BEALE)= mit SS in (K1) SSin (K SS (K ) in 2 ) n K / n K K * K / p 1 K 1 = Clusterlösung mit K 1-Clustern K 2 = Clusterlösung mit K 2-Clustern (K 1<K 2) n = Zahl der in die Analyse einbezogenen Klassifikationsobjekte p = Zahl der in die Analyse einbezogenen Klassifikationsmerkmale Für den Vergleich der 1-Clusterlösung mit der 2-Clusterlösung beispielsweise ergibt sich folgender F-WERT nach BEALE: 121
122 F-WERT 12(BEALE)= / * / 2 1 = / 1.009= Unter der Annahme, dass die Klassifikationsvariablen unabhängig und gleiche Standardabweichungen besitzen, weisen die F-WERTE nach BEALE eine F-Verteilung mit p(k2-k1) und p(n-k2) Freiheitsgraden auf. In unserem Beispiel nehmen die beiden Freiheitsgrade folgende Werte an: p(k2-k1)=2(2-1)=2 p(n-k 2)=2(221-1)=440 Das Signifikanzniveau des F-WERTES nach BEALE beträgt Die 2- Clusterlösung verbessert somit die 1-Clusterlösung nicht signifikant, wenn ein Schwellenwert von 95 % für die Signifikanz angenommen wird. Die Maßzahlen lassen sich nun wie folgt zur Bestimmung der Clusterzahl einsetzen: 1. Es wird (werden) jene Clusterlösung(en) ausgewählt, die zu einer deutlichen Reduktion der Fehlerstreuung führt (führen). 2. Es wird die Lösung mit dem maximalen Wert in der F-MAX-Statistik ausgewählt. 3. Es wird aufgrund der Bealschen F-Werte jene Lösung ausgewählt, die (a) im Vergleich zu vorausgehenden Clusterlösungen mit einer kleineren Clusterzahl zu einer signifikanten Reduktion der Fehlerstreuung führt, während (b) bei den nachfolgenden Clusterlösungen keine signifikante Reduktion des Fehlerstreuung mehr eintritt. Wir wollen diese Strategien am Beispiel der Wertedaten von Denz (1989) verdeutlichen. Bedeutsame Fehlerreduktion: Um eine bedeutsame Reduktion der Fehlerstreuung zu ermitteln, lesen wir die Ergebnisausgabe von oben nach unten. Eine erste deutliche Zunahme tritt beim Übergang von einem zu zwei Clustern auf. Die Fehlerstreuung (=Streuungsquadratsumme in den Clustern) reduziert sich von auf Diesen Zuwachs erkennen wir auch anhand des PRE- Koeffizienten. Er ist gleich und bei der 2-Clusterlösung immer gleich der erklärten Streuung (=ETA 2 ). Wenn wir von der 2-Clusterlösung zur 3-Clusterlösung übergehen, reduziert sich die Fehlerstreuung um 29.1 Prozent (PRE-Koeffizient) usw. Hohe PRE-Koeffizienten treten bei der 2-, 3-, 4- und 7-Clusterlösung auf. Man wird sich daher für eine der vier Lösungen entscheiden. Die Clusterlösungen 4 und 7 erfüllen ein weiteres Kriterium. Die anschließenden PRE-Werte sind klein. Man wird sie daher formal gegenüber gegeben der 2- und 3-Clusterlösung bevorzugen, da die nachfolgenden Lösungen eine geringer Erklärungskraft besitzen. Die Clusterzahl kann auch graphisch durch einen inversen Scree-Test bestimmt werden. Das Diagramm wird so lange von rechts nach links gelesen, bis ein deutlicher Knickpunkt auftritt. In der nachfolgenden Grafik ist dies bei 4 Clustern der Fall. 122
123 Kriterium Cluster 1 Cluster 2 Cluster 3 Cluster 4 Cluster 5 Cluster 6 Cluster 7 Cluster 8 Maximaler F-MAX-Wert (F-Werte der Ausgabe): Die Lösung mit dem maximalen F- MAX-Wert ist die 4-Clusterlösung. Allgemein ist zu dieser Strategie anzumerken: Tritt der maximale F-MAX-Wert bei der kleinsten bzw. der größten untersuchten Clusterzahl auf, ist eine erneute Analyse erforderlich, in der die kleinste bzw. größte Clusterzahl variiert wird. Bealsche F-Werte: Die Ausgabe enthält alle möglichen Bealschen F-Werte (unteres Dreieck). Der Bealsche F-Wert für die 2- und 6-Clusterlösung beispielsweise ist gleich F-WERT2,6(Beale) = (=6. Zeile und 2. Spalte). Die Signifikanzen der Bealschen F-Werte stehen im oberen Dreieck. Der Bealsche F-WERT 2,6(Beale) ist mit Prozent nicht signifikant (=2. Zeile und 6. Spalte). Das bedeutet, dass die erklärte Streuung der 6-Clusterlösung nicht signifikant größer ist als jene der 2-Clusterlösung. Die Bealschen F-Werte sind nur dann berechenbar, wenn die Clusterlösung mit der größeren Clusterzahl (K2 > K1) eine kleinere bzw. gleiche Streuungsquadratsumme in den Clustern (SS in(k2) > SS in(k1)) besitzt. Fassen wir unsere bisherige Analyse zusammen, so können wir festhalten: 1. Ein PRE-Koeffizient größer 0.14 tritt bei der 2-, 3-, 4- und 7-Clusterlösung auf. Formal zu bevorzugen sind die 4- und 7-Clusterlösungen. 2. Die 4-Clusterlösung ist die Lösung mit dem maximalen F-Wert. 3. Die Bealschen F-Werte legen die Vermutung nahe, dass keine sehr deutlich getrennten Cluster vorliegen. 4. Der inverse Scree-Test weist einen Knickpunkt bei 4 Clustern auf. 123
124 Das hier berichtete Ergebnisse ist für sozialwissenschaftliche Daten charakteristisch. Welche Lösung(en) den Daten angemessen ist (sind), kann erst nach deren Interpretation und Validitätsprüfung beurteilt werden. Inhaltlich kann man die Zahl möglicher Lösungen dadurch eingrenzen, dass zu Beginn erwartete Clusterstrukturen definiert und für diese konfirmatorische Analysen durchgeführt werden. Wir wollen nachfolgend die 4-Clusterlösung beschreiben. Die 4-Clusterlösung wurde ausgewählt, da sie - absolut betrachtet - um fast 10 Prozent mehr Varianz als die 3- Clusterlösung erklärt und eine 7-Clusterlösung für einen ersten Interpretationsdurchgang zu aufwendig erschien. Zufallstestung einer bestimmten Clusterlösung (Option17 = 20;) Mit Hilfe des Nullmodells einer homogenen, normalverteilten Population mit den empirischen Verteilungskennwerten kann für eine bestimmte Clusterlösung untersucht werden, ob die gefundene Lösung überzufällig ist. Für unser Beispiel sieht das Vorgehen folgendermaßen aus: Die beiden Variablen besitzen Mittelwerte von 2.07 (= Gesamtpunktwert für materialistische Items) bzw. von 1.60 (=Gesamtpunktwert für postmaterialistische Items) und Standardabweichungen von 0.67 bzw Da 221 Befragte (=Objekte) in die Analyse einbezogen wurden, werden in einer Simulation mehrere Zufallsdatenmatrizen für 221 fiktive Befragte und zwei normalverteilte Zufallsvariablen mit den entsprechenden Verteilungskennwerten erzeugt. Für diese Zufallsdatenmatrizen wird geprüft, wie gut sie durch die vorgegebene Clusterstruktur reproduziert werden können. Es wird also ein Nullmodell mit einer gegebenen Clusterstruktur verwendet. Ist die Reproduktion - gemessen durch die erklärte Streuung - annähernd gleich gut, wird man die Ergebnisse als Artefakt betrachten. In der oben abgebildeten Programm-Maske ist folgendes zu ändern 1. Die Deskriptionsvariablen werden gelöscht. 2. Die minimale und maximale Clusterzahl werden beide auf 4 gesetzt, da die 4- Cluster-Lösung untersucht werden soll 3. Die Optionsbox Programm-Optionen lt. Handbuch wird geöffnet und eingetragen: Option 17=20; Die 4-Clusterlösung soll durch eine Zufallstestung mit 20 Zufallsdaten-Matrizen überprüft werden Zur Verdeutlichung geben wir das entsprechende ALMO-Syntax-Programm an, wobei nur der Programmparameter-Block wiedergegeben ist, nicht jedoch der Daten- Leseblock. Vereinbare Variable = 500; Anfang Name33=GMAT; Name34=GPMAT; Programm=37; A_Quantitative_V=V33,34; Speicher für 500 Variable Beginn des ALMO-Programms Namensgebung der Variablen Definition der quantitativen Klassifikationsvariablen = Gesamtpunktwerte fuer 124
125 Modell=2; Option14=3; Objekte=221; Min_Clusterzahl=4; Max_Clusterzahl=4; Option17=20; Ende_Programmparameter Die Ergebnisausgabe für die Zufallstestung ist: materialistische und postmaterialistischen Wertorientierung Definition des K-Means-Verfahrens (Minimal-Distanz-Verfahren ohne Gewichtung der Distanzen) Defintion des Startwertverfahrens (= zufaellige Zuordnung der Objekte) Definition der Zahl der zu untersuchenden Objekte kleinste zu untersuchende Clusterzahl groesste zu untersuchende Clusterzahl Beide Groessen werden gleich 4 gesetzt, da die 4-Clusterloesung untersucht werden soll. Es wird eine Zufallstestung der 4-Clusterloesung durchgefuehrt. Dazu werden 20 Zufallsdatenmatrizen erzeugt. Zahl der Simulationen = 20 Simulationswerte: emp. Wert = Erwartungswert = Standardabw. = z-wert = Signifikanz = Alle Simulationswerte sind größer Das bedeutet: Die berechnete 4-Clusterlösung würde auch beim Vorliegen einer homogenen Population ohne Clusterstruktur 50 und mehr Prozent der Gesamtvarianz erklären. Der Mittelwert der Simulationsdaten ist gleich bzw Prozent und die Standardabweichung gleich bzw. 2.5 Prozent. Die 4-Clusterlösung erklärt somit im Durchschnitt 57.1 Prozent der Gesamtvarianz einer homogenen Population ohne Clusterstruktur. Konstruieren wir aus diesen beiden Kennwerten eine z-teststatistik mit t E(t) z = ; σ(t) so besitzt diese für t = (=empirischer Wert), E(t) = und σ(t) = einen Wert von ( )/0.025 = Der Wert liegt über einen kritischen Schwellenwert von 2, wenn wir eine Standardnormalverteilung für z und ein (einseitiges) Signifikanzniveau von 97.5 Prozent annehmen. Die für die empirischen Daten ermittelte erklärte Streuung von 69.3% kann somit als überzufällig betrachtet werden. Beschreibung und Interpretation der Cluster 125
126 Das Ziel des K-Means-Verfahren ist die Konstruktion von Clusterzentren. Das vorrangige Interpretationsziel richtet sich daher auf eine Interpretation der Clusterzentren. Da die Aussagekraft der Mittelwerte (Clusterzentren) von der Clustergröße und den Standardabweichungen in den Clustern abhängt, müssen diese Größen bei einer Interpretation mitberücksichtigt werden. Die entsprechenden Werte werden in ALMO wie folgt ausgegeben. Clustergroessen: C1 90 ( %) C2 27 ( %) C3 23 ( %) C4 81 ( %) KW-Faelle (ungewichtet)= 0 ======================================================================== Zellenmittelwerte der Klassifikationsvariablen (Mittelwerte bei quantitativen / ordinalen Variablen) (Anteilswerte bei nominalen Variablen) Variable C1 C2 C3 C4 V GMAT V GPMAT Standardabweichungen: Variable C1 C2 C3 C4 V GMAT V GPMAT Besetzungszahlen: Variable C1 C2 C3 C4 V GMAT V GPMAT Z-Werte: Variable C1 C2 C3 C4 V GMAT V GPMAT Signifikanz (1-p)*100 der z-werte: Variable C1 C2 C3 C4 V GMAT V GPMAT 126
127 Die Clustermittelwerte können in ALMO auch graphisch dargestellt werden. Clustermittelwerte Cluster 2 Cluster 1 Cluster 3 Cluster 4 GMAT GPMAT Die Variablen variieren zwischen 1 und 5. Ein Wert von 1 bedeutet "sehr wichtig", ein Wert von 2 "wichtig", ein Wert von 3 "eher unwichtig", ein Wert von 4 "unwichtig" und ein Wert von 5 "vollkommen unwichtig". Auf Grund der Mittelwerte und der Graphik lassen sich in einem ersten Interpretationsschritt den Clustern folgende Namen geben: gemäßigte Postmaterialisten (Cluster 1): Es besteht eine Präferenz für postmaterialistische Werte. Im Unterschied zum Cluster 2 werden die materialistischen Werte aber nicht so deutlich abgelehnt. extreme Postmaterialisten (Cluster 2): Es besteht eine sehr starke Präferenz für postmaterilistische Werte, da materialistische Werte klar abgelehnt werden. Nicht-Orientierte (Cluster 3): Kein Wert wird für sehr wichtig gehalten. Eine leichte Präferenz für materialistische Werte besteht. Mischtypus (Cluster 4): Beide Wertorientierungen sind ungefähr gleich wichtig. Die Interpretation der Standardabweichungen bereitet in der Forschungspraxis oft Probleme. Ist die Standardabweichung von 0.53 in der postmaterialistischen Wertorientierung für den Typus der Nicht-Orientierten (Cluster 3) hoch oder niedrig? Eine Möglichkeit zur Beurteilung der Standardabweichungen in den Clustern ist die Verwendung der theoretischen Skalenstandardabweichungen (siehe Abschnitt P ). Diese ist bei einer fünfstufige Skala entsprechend Übersicht P gleich Da der ±2σ-Wertebereich oft zur Charakterisierung einer Verteilung verwendet wird, kann man die Größe σ/4 als eine Art "Homogenitätsschwelle" betrachten. Ist die Standardabweichung in einem Cluster kleiner diesem Schwellenwert, kann das Cluster als homogom hinsichtlich der untersuchten Variablen definiert werden. Für unser Beispiel ergibt sich ein Schwellenwert von (=1.41/4). Alle 127
128 Standardabweichungen - mit Ausnahme von GMAT in Cluster C2 und GPMAT in der Cluster C3 - liegen unterhalb dieses Schwellenwertes. Sie können daher als homogen bezeichnet werden. Das hier dargestellte Vorgehen orientiert sich bei der Bewertung der empirischen Standardabweichung an einem theoretischen Modell, bei dem eine Gleichverteilung auf der untersuchten Skala angenommen wird. Ein anderes Nullmodell zur Bewertung der Standardabweichungen sind die empirischen Standardabweichungen der Variablen. Hier ist es sinnvoll zu fordern, dass die Standardabweichungen in den Clustern in den einzelnen Variablen kleiner sind als die entsprechenden empirischen Standardabweichungen der Variablen insgesamt. In unserem Beispiel ist die empirische Standardabweichung in der postmaterialistischen Wertorientierung gleich Im Cluster C3 (=Nicht-Orientierte) wird dieser Wert überschritten (Standardabweichung = 0.53). Ist die Homogenität innerhalb eines Clusters nicht erfüllt, sollte eine "Ausreißer"-Analyse durchgeführt werden. Dabei kann wie folgt vorgegangen werden: 1. Die mittlere Gesamtstreuungsquadratsumme (=SQges/n) wird als Bezugsgröße (Nullmodell) definiert. In unserem Beispiel ist diese Bezugsgröße gleich (= /221). Wir wollen diese Größe mit d 2 0 bezeichnen. 2. Die mittlere Gesamtstreuungsquadratsumme ist gleich der mittleren quadrierten euklidischen Distanz eines Objekts g in der 1-Clusterlösung. 3. Ist die gefundene Clusterlösung brauchbar, sollten die quadrierten euklidischen Distanzen d der Objekte g zu den Clusterzentren kleiner als die mittlere 2 g.k quadrierte euklidische Distanz des Nullmodells sein. 4. Anstelle der quadrierten euklidischen Distanzen kann man auch die euklidischen Distanzen verwenden, da diese in derselben Maßeinheit skaliert sind wie die Variablen. Die euklidischen Distanzen lassen sich als Entfernungen der Objekte zu ihren Clusterzentren interpretieren. Des weiteren lassen sich sogenannte standardisierte Entfernungen d = s tan d d 2 g,k / d 2 0 berechnen. In ALMO werden die standardisierten Entfernungen in fünf Intervalle eingeteilt. Werte kleiner 0.25 werden als Clusterrepräsentanten interpretiert. Die Entfernung des Objekts g beträgt nur ein Viertel der Entfernung des Nullmodells. Umgekehrt werden Werte größer 1.25 als Ausreißer interpretiert. Durch Verwendung von OPTION9 = 1; bzw. OPTION9 = 3; können die standardisierten Entfernungen und eine Klassifikation der Objekte ausgegeben werden. Bei OPTION9=2; werden nur Gesamtstatistiken ausgegeben, bei OPTION9=3; Detailstatistiken. Diese Optionen werden in der oben abgebildeten Programm-Maske Prog37m1 in die Optionsbox Programm-Optionen lt. Handbuch eingetragen Analyse der Klassifikationsobjekte: =================================== durchschnittl. Distanzen fuer H-0-Modell =
129 Die nachfolgenden Ergebnisse werden nur bei Verwendung von OPTION 9=3; ausgegeben. Objekt Charakeristik liegt im Ueberlappungsb. von C2 und C1 5 liegt im Ueberlappungsb. von C1 und C4 7 Repraesentant von Cluster C1 usw. 22 liegt im Ueberlappungsb. von C4 und C1 26 Repraesentant von Cluster C1 usw. 164 Ausreisser in Cluster C2 174 Ausreisser in Cluster C2 175 Repraesentant von Cluster C1 177 Repraesentant von Cluster C1 178 liegt im Ueberlappungsb. von C4 und C1 und C3 usw. 216 Ausreisser in Cluster C3 218 Ausreisser in Cluster C3 Objekt 1 liegt im Überlappungsbereich von C2 und C1, Objekt 5 im Überlappungsbereich von C1 und C4. Mit Objekt 7 wurde ein Repräsentant von Cluster C1 ermittelt. Er kann beispielsweise für eine Fallanalyse zur Verdeutlichung des Clusters verwendet werden. Die nachfolgenden Übersichtsstatistiken werden auch bereits bei Verwendung von OPTION 9=1; (=Voreinstellung) ausgegeben. Cluster C1 stand.distanz Faelle (in %) < ( %) 0.25 < ( %) 0.50 < ( %) 1.00 < ( 0.00 %) >= ( 0.00 %) usw. Cluster Repraesentanten Ausreisser Ueberlappungen C1 17 ( %) 0 ( 0.000%) 22 ( %) C2 1 ( 3.704%) 3 ( %) 2 ( 7.407%) C3 2 ( 8.696%) 2 ( 8.696%) 0 ( 0.000%) C4 18 ( %) 0 ( 0.000%) 7 ( 8.642%) Für jedes Cluster wird mindestens ein Repräsentant gefunden. Bei Cluster 2 (extreme Postmaterialisten) wird aber nur ein Repräsentant ermittelt, für Cluster 3 (Nicht- Orientierte) nur 2 Repräsentanten. Bei diesen beiden Clustern treten auch Ausreißer auf. C2 und C3 besitzen also eine geringere Homogenität. Cluster 1 (gemäßigte Postmaterialisten) ist durch relativ viele Fälle von Überlappungen gekennzeichnet. Es ist von den anderen Clustern nicht gut abgegrenzt. Clusterzugehoerigkeit der Objekte(Datensaetze): ( -1 = wegen Kein_Wert eliminiert) Objekt Clustererzu- quadrierte Distanz standardisierte. 129
130 gehoerigkeit zum Clusterzentrum mittlere Entfern Repräsentant usw Ausreißer usw Ausreißer Repräsentant usw Ausreißer Ausreißer Insgesamt gibt es nur wenige Ausreißer (n=5). Liegen mehrere Ausreißer vor, kann eine erneute Analyse ohne Ausreißer gerechnet werden, um den Einfluss der Ausreißer auf die Clusterlösung zu ermitteln. In unserem Beispiel ergeben sich dabei nur geringfügige Unterschiede, so dass die ursprüngliche Clusterlösung beibehalten werden kann. Bei einer Interpretation treten oft Fragestellungen der folgenden Art auf: 1. Unterscheiden sich die Mittelwerte x kj und x kj* der Variablen j und j* im Cluster k signifikant voneinander? 2. Sind mehrere Mittelwerte x kj, x kj* usw. in einem Cluster k gleich? 3. Unterscheiden sich die Mittelwerte x kj und x kj* in der Variablen j im Cluster k und k* signifikant voneinander? In unserem Beispiel kann z.b. für die 4-Clusterlösung gefragt werden: Ist der Unterschied im Cluster 3 zwischen dem Mittelwert in der materialistischen Wertorientierung (=2.15) und jenem für die postmaterialistische Wertorientierung (=2.60) statistisch signifikant, so dass auch von einer materialistischen Wertepräferenz oder von gemäßigten Materialisten gesprochen werden könnte? Sind die Mittelwerte in der materialistischen und postmaterialistischen Wertorientierung im Cluster C4 des Konsenstypus oder Mischtypus statistisch betrachtet gleich, wie wir bei der Interpretation angenommen haben? Unterscheiden sich die Mittelwerte in den materialistischen Wertorientierungen für die Cluster C1 bis C2, so dass die Postmaterialisten nach dem Grad ihrer Ablehnung materialistischer Items in gemäßigte Postmaterialisten und extreme Postmaterialisten unterteilt werden können? Fragestellungen dieser Art können durch den t-test behandelt werden. Der t-wert für den Vergleich von zwei Mittelwerten ist definiert mit: 130
131 t = ((n kj s 2 kj + n k*j* x kj s x 2 k*j* k*j* ) /(n kj + n k*j* 2)) 1/ 2 n n kj kj n + n k*j* k*j* 1/ 2 wobei 2 s kj die mit n kj normierte Varianz im Cluster k in der Variablen j ist. n kj ist die Zahl der Fälle im Cluster k in der Variablen j. s 2 k*j* und n k*j* sind analog für das Cluster k* und die Variable j* definiert. ALMO prüft automatisch die paarweisen Unterschiede zwischen den Clustern in allen Variablen. Das Ergebnis sieht folgendermaßen aus. Paarweise Clusterdifferenzen fuer Cluster=1 (n= 90) Klassifikationsvariablen: Variable C2 C3 C4 V33 < = > GMAT V34 = < = GPMAT Paarweise Clusterdifferenzen fuer Cluster=2 (n= 27) Klassifikationsvariablen: Variable C1 C3 C4 V33 > > > GMAT V34 = < < GPMAT usw. Dieses Vorgehen ermöglicht statistische Untersuchungen von Unterschieden zwischen Clustern. Ein "=" bedeutet, dass kein signifikanter Unterschied zu einem vorgegebenen Signifikanzniveau (z.b. 5 Prozent) vorliegt. Ein ">" bedeutet, dass das Bezugscluster einen signifikant größeren Wert hat, und "<" bedeutet, dass das Bezugscluster einen signifikant kleineren Wert hat. Bei der Berechnung des Signifikanzniveaus wird eine sogenannte Bonferroni-Korrektur (Bacher 1996) durchgeführt. Dadurch wird der Effekt beseitigt, dass bei einer mehrfachen Testung rein zufällige Unterschiede als signifikant erkannt werden können. Soll nun beispielsweise geprüft werden, ob sich die Cluster C1 bis C2 in der materialistischen Wertorientierung signifikant unterscheiden, kann C1 als Bezugscluster definiert werden. Sehen wir in der Tabelle nach, so ist der Mittelwert in der materialistischen Wertorientierung von C1 signifkant kleiner als jener von C2. Die bei der Namensgebung von C1 und C2 getroffene Unterscheidung nach dem Grad der Ablehnung materialisitscher Werte ist somit gerechtfertigt. Zur Analyse der Fragestellungen, ob innerhalb eines Clusters Mittelwerte in den Clustern gleich sind, bildet das Programm Variablengruppen nach folgendem hierarchischen Algorithmus: Schritt 1: Jede Variable bildet eine selbständige Variablengruppe. Schritt 2: Suche jenes Variablenpaar mit dem kleinsten t-wert. 131
132 Schritt 3: Prüfe, ob das entsprechende Fehlerniveau kleiner/gleich dem vorgegebenen Fehlerniveau nach einer Bonferroni-Korrektur ist. Bei nein, beende das Verfahren. Bei ja, gehe zu Schritt 4. Schritt 4: Verschmelze das Variablenpaar zu einer Gruppe und berechne den Mittelwert der Variablengruppe neu. Schritt 5: Gehe zu Schritt 2. Für das vierte Cluster (=Konsens- bzw. Mischtypus) beispielsweise führt der Algorithmus zu folgendem Ergebnis: Beziehung der Variablen im Cluster 4 ===================================== keine Verschmelzung bei vorgegebenen Alpha_Niveau moeglich Es wird keine Variablengruppe gefunden. Damit muss die Fragestellung, ob die beiden Mittelwerte gleich sind, negativ beantwortet werden. Die beiden Mittelwerte sind nicht gleich. Neben der paarweisen Prüfung von Unterschieden richtet sich die Interpretation oft noch auf allgemeinere Fragestellungen. Auch hier können formal drei Fragetypen unterschieden werden: 1. Weichen die Mittelwerte in den Clustern signifikant von den Gesamtmittelwerten ab? 2. Leisten alle Variablen einen signifikanten Beitrag zur Trennung der Cluster? 3. Erklärt die Clusterstruktur die Korrelationen zwischen den Variablen? Ist dies der Fall, hat man eine zu einem variablenorientierten Kausal- oder Korrelationsmodell alternative Erklärung für die Zusammenhänge gefunden. Signifikante Abweichungen von den Gesamtmittelwerten: Zur Beantwortung der Fragestellung, ob die Mittelwerte der Cluster signifikant von den jeweiligen Gesamtmittelwerten der Variablen abweichen, können die folgende z-werte verwendet werden: z kj x kj x j =, 1/ 2 (s /(n 1)) 2 kj kj 2 wobei s kj die Varianz der Variablen j im Cluster k und n kj die Zahl der gültigen Fälle (Werte) der Variablen j im Cluster k sind. x j ist der Gesamtmittelwert der Variablen j, x kj der Mittelwert des Clusters k in der Variablen j. Für das erste Cluster (k=1) und die materialistische Wertorientierung (j=1) ergibt sich ein z-wert von 4.27 (siehe nachfolgende Tabelle). Z-Werte: Variable C1 C2 C3 C4 V GMAT V GPMAT Signifikanz (1-p)*100 der z-werte: 132
133 Variable C1 C2 C3 C4 V GMAT V GPMAT Unter der Annahme eines kritischen Tabellenwertes von 2 weichen alle Mittelwerte bis auf zwei Ausnahmen vom jeweiligen Gesamtmittelwert ab. Die Ausnahmen sind: Cluster C3 weicht in V33 (GMAT) nicht signifikant vom Gesamtmittelwert ab, Cluster C4 in V34 (=G8MAT). Signifikanter Beitrag der Variablen: Zur Beantwortung der Frage, ob eine Variable insgesamt signifikant zur Trennung der Cluster beiträgt, kann für jede Variable die erklärte Streuung ETA 2 und ein F-Werte F-WERTjK berechnet werden. Der Index j / K "j/k" soll dabei symbolisieren, dass sich die erklärte Streuung oder der F-Wert auf die j-te Variable der untersuchten K-Clusterlösung bezieht. Die Größen sind wie folgt definiert: ETA 2 j/ K SQin ( j/ K) SQin ( j/ K) = 1 = 1 SQ ( j) n s ges SQ zw ( j/ K) / K 1 F WERT j/ K =, SQ ( j) / n K in j j 2 j wobei SQ in(j/k) die Streuungsquadratsumme in den Clustern in der Variablen j ist. n j ist die Zahl der in die Berechnung der Variablen j einbezogenen Fälle, s die Varianz der Variablen j. Für die beiden untersuchten Variablen ergibt sich folgendes Bild: Gesamtstatistiken fuer Klassifikationsvariablen: F-Wert Signifikanz ETA**2 (1-p)*100 Name V GMAT V GPMAT Die Variable V33 (Materialismus) leistet einen besseren Beitrag zur Trennung der Cluster als die Variable V34 (Postmaterialismus). Der F-Wert von V33 ist gleich Nimmt man als Nullmodell eine F-Verteilung mit 5 und 215 Freiheitsgraden an, besitzt der empirische Wert eine Signifikanz von 100 Prozent. Die Annahme einer F- Verteilung als Nullmodell ist strenggenommen nicht zulässig, da mit der Minimierung der Streuungsquadratsumme in den Clustern auch die Streuungsquadratsumme in jeder Variablen minimiert wird. Werden aber sehr viele Variablen in die Clusteranalyse einbezogen, hat jede Variable ein geringeres Gewicht. Die Annahme der F-Verteilung als Nullmodell ist dann annähernd erfüllt. Da wir nur zwei Variablen untersucht haben, trifft diese Argumentation nicht zu. Die Signifikanzen sind daher mit Vorsicht zu interpretieren. Leistet eine Variable keinen signifikanten Beitrag zur Trennung der Cluster, sollte sie zur Kontrolle als Klassifikationsvariable eliminiert und eine erneute Analyse gerechnet werden. 2 j 133
134 Erklärung des Zusammenhangs der Variablen durch die Clusterstruktur: Mitunter ist man bei einer Clusterananlyse an der Frage interessiert, ob die gefundene Clusterstruktur den Zusammenhang der untersuchten Klassifikationsvariablen erklären kann. Ist dies der Fall, stellen die Ergebnisse der Clusternanalyse eine zu einem variablenorientierten Kausal- oder Korrelationsmodell alternative Erklärung dar. Inwieferen eine berechnete Clusterstruktur die empirischen Zusammenhänge erklärt, kann dadurch geprüft werden, dass die Clusterzugehörigkeit als Kontrollvariable eingeführt wird. Bei einer perfekten Erklärung der Zusammenhangsstruktur der Variablen müßten die Korrelationen in jedem Cluster gleich Null sein. Die gepoolte Korrelationsmatrix, bei der die Korrelationen innerhalb der Cluster entsprechend den Clustergrößen gemittelt werden, gibt einen Gesamtüberblick, ob die Variablen innerhalb der Cluster unkorreliert sind. Für unser Beispiel berechnet ALMO folgende gepoolte Korrelationsmatrix: gepoolte Korrelationsmatrix W: Spalte 1 Spalte Determinante der Korrelationsmatrix = LR-Teststatistik fuer Unabhaengigkeit der Variablen = Freiheitsgrade = 1 Signifikanz = Zur Prüfung der H0-Hypothese, dass alle Korrelationen gleich Null sind, kann eine sogenannte Likelihood-Quotienten-Statistik (Bacher 1996) berechnet werden mit: LR = -n R ln(det(r)) wobei ln(..) der natürliche Logarithmus und Det(R) die Determinante der gepoolten Korrelationsmatrix ist. n R ist die Fallzahl, auf der die Berechnung der gepoolten Korrelationsmatrix basiert. In unserem Beispiel lässt sich die Determinante leicht berechnen, da nur zwei Variablen vorliegen. Die Determinante ist gleich = Die Berechnung basiert auf = 215 Fällen. Der Wert der LR-Statistik ist gleich Die LR-Statistik ist asymptotisch Chi-Quadrat-verteilt mit m (m-1)/2 Freiheitsgraden (m=zahl der Variablen). In unserem Beispiel ergibt sich ein Freiheitsgrad, da die Zahl der Variablen gleich 2 ist. Die Signifikanz der Teststatstik beträgt 100 Prozent. Die gepoolten Korrelationen sind also nicht gleich Null. Die Clusterstruktur erklärt nicht den Zusammenhang zwischen den Variablen. Sie führt in dem Beispiel dazu, dass die Variablen korreliert sind, während die nichtgepoolte Korrelation gleich ist. Beachte: An den Tatsachen, dass die gepoolte Korrelation von zwei Variablen gleich Null ist, kann nicht abgeleitet werden, dass die Variablen innerhalb jeden Clusters unkorreliert sind. Stabilitäts- und Validitätsprüfung: Die Validitätsprüfung besteht darin, dass bestimmte Hypothesen über die gefundenen Cluster aufgestellt werden. Da Wertorientierungen auf Sozialisationsprozesse zurückzuführen sind, in denen Bedürfnisse zu stabilen Wertemuster ausgeformt werden, wird man in einer Validitätsprüfung Einflüsse von Sozialisationsinstanzen annehmen. In der Untersuchung von Denz (1989) wurden zwei Sozialisationsinstanzen erfaßt, nämlich die Eltern und die Schule. Bezüglich des 134
135 Einflusses dieser Sozialisationsinstanzen lassen sich beispielsweise folgende Hypothesen für eine Validitätsprüfung formulieren: H1: Postmaterialisten (=Cluster 1 bis 2) kommen aus höheren sozialen Schichten. H2: Postmaterialisten besuchen häufiger die AHS als die anderen Wertetypen, da hier wegen der humanistischen Tradition und der Funktion der Allgemeinbildung postmaterialistische Werte in einem stärkeren Ausmaß vermittelt werden. Zur Überprüfung dieser Hypothesen werden die Variablen, die für die Sozialisationsinstanzen erfaßt wurden, als Deskriptionsvariablen in die Clusteranalyse einbezogen. In die nachfolgende Analyse wurden zusätzlich noch das Geschlecht aufgenommen. Die Ergebnisse sind: Zellenmittelwerte der Deskriptionsvariablen: (Mittelwerte bei quantitativen Variablen, Anteilswerte bei nominalen) Variable C1 C2 C3 C4 V26 Sex maennl weibl V25 Schultyp BHS AHS BS V21 BerufV ungelarb angelarb BeamtAng Facharb VS-Lehr DIPLIng Arzt Huasfr V22 BerufM ungelarb angelarb BeamtAng Facharb VS-Lehr DIPLIng Arzt Huasfr V SchulV V SchulM V PrestV V PrestM Standardabweichungen: (nicht abgedruckt) Besetzungszahlen: (nicht abgedruckt) Z-Werte: Variable C1 C2 C3 C4 V26 Sex maennl weibl 135
136 V25 Schultyp BHS AHS BS V21 BerufV ungelarb angelarb BeamtAng Facharb VS-Lehr DIPLIng Arzt Huasfr V22 BerufM ungelarb angelarb BeamtAng Facharb VS-Lehr DIPLIng Arzt Huasfr V SchulV V SchulM V PrestV V PrestM Signifikanz (1-p)*100 der z-werte: nur auszugsweise abgedruckt Variable C1 C2 C3 C4 V26 Sex maennl weibl V25 Schultyp BHS AHS BS V PrestV V PrestM Die vier Cluster unterscheiden sich hinsichtlich der sozialen Herkunft (Bildung Vater und Mutter, Beruf Vater und Mutter, Berufsprestige Vater und Mutter) kaum. Z-Werte mit einem Absolutbetrag größer 2 werden kaum berechnet. Nur bei Personen aus C2 (extreme Postmaterialisten) haben die Mütter ein höheres Berufsprestige. Bei Personen im Cluster C4 haben die Mütter eine geringe Bildung. Deutlichere Unterschiede gibt es beim Geschlecht und dem Schultyp. Extreme Postmaterialisten sind häufiger Burschen. Der Mischtypus setzt sich häufiger aus Mädchen zusammen. Im Cluster C2 dominiert die AHS, im Cluster C1 die BHS, im Cluster C4 die Berufsschule. 136
137 Zur exakteren Überprüfung der Hypothesen können die paarweisen Differenzen verwendet werden. Trifft Hypothese 1 zu, dann müsste C1 (=gemäßigte Postmaterialisten) und C2 (=extreme Postmaterialisten) im Vergleich zu C3 und C4 (Nichtorientierte und Mischtypus) bei den sozialen Herkunftsvariablen höhere Werte haben. Paarweise Clusterdifferenzen fuer Cluster=1 (n= 90) Deskriptionsvariablen: Variable C2 C3 C4 V23 = = = SchulV V24 = = = SchulM V40 = = = PrestV V41 = = = PrestM Paarweise Clusterdifferenzen fuer Cluster=2 (n= 27) Deskriptionsvariablen: V23 = = = SchulV V24 = = = SchulM V40 = = = PrestV V41 = = = PrestM Weder für C1 noch für C2 kann die Hypothese aufrecht erhalten werden. Bei der sozialen Herkunft gemessen durch die Schulbildung und das Berufsprestige der Eltern bestehen keine signifikanten Unterschiede. Auch Hypothese 2 kann nur partiell bestätigt werden. C1 (gemäßigte Postmaterialisten) unterscheidet sich beim AHS-Anteil nicht signifikant von Cluster C3 und C4. C2 (extreme Postmaterialisten) hat zwar einen signifikant höheren Anteil als C4 (und als C1, was für die Hypothese aber bedeutungslos ist). Zu C3 (Nicht- Orientierte) bestehen keine signifikanten Unterschiede. Bei der hier gewählten Vorgehensweise zur Prüfung von Validitätshypothesen ist zu beachten, dass das Vorgehen nicht ganz exakt ist. ALMO führt automatisch eine Bonferroni-Korrektur durch, um das Problem zufällig signifikanter Ergebnisse bei Mehrfachvergleichen zu beseitigen. Bei der Korrektur werden alle möglichen Paarvergleiche berücksichtigt. Dies führt zu einem sehr strengen Kriterium. Der Hypothesenstestung können weniger Vergleiche als bei der Korrektur angenommen zugrunde liegen, so dass hier mit einem zu strengen Signifikanzniveau gerechnet wird. Dieses Problem kann dadurch gelöst werden, dass die Clusterzugehörigkeit als Variable abgespeichert wird und die statistischen Tests mit anderen Programmen, z.b. mit P18 oder P20, durchgeführt werden. P Konfirmatorische K-Means-Analyse Bei der konfirmatorischen Clusteranalyse können analog zum Vorgehen bei den konfirmatorischen Strukturgleichungsmodellen (wie z.b.: in LISREL) bestimmte Clusterzentren gleich bestimmten Werten gesetzt werden, also fixiert werden. Die "gefixten" Werte werden in der Iteration nicht geändert. Daneben können lineare 137
138 Restriktionen hinsichtlich der Mittelwerte spezifiziert werden, wie z.b., dass der Mittelwert der Variablen j im Cluster k gleich dem Mittelwert der Variablen j* im Cluster k* sein soll. Es bestehen also folgende Möglichkeiten: Bestimmte Clusterzentren können gleich einem bestimmten Wert gesetzt (fixiert) werden. Es kann vorgegeben werden, dass zwei oder mehrere Clusterzentren denselben Wert haben sollen. Das Vorgehen soll für die Wertedaten von Denz (1989) verdeutlicht werden. Die angenommenen Clusterzentren sind Variable Cluster C1 C2 C3 C4 C5 materialistische Wertorientierung postmaterialistische Wertorientierung C1=Konsenstypus, C2=gemäßigte Materialisten, C3=gemäßigte Postmaterialisten, C4=Postmaterialisten, C5=Nicht-Orientierte Es sollen drei konfirmatorische Analysen durchgeführt werden: 1. Alle Clusterzentren werden fixiert. 2. Die kleinsten Mittelwerte in jedem Cluster werden fixiert. 3. Es werden lineare Restriktionen zwischen den Clustern spezifiziert. P Programm-Maske zur konfirmatiorischen Clusteranalyse Prog37mc In der ersten konfirmatorischen Analyse sind alle vorgegebenen Clusterzentren fixiert. Das heißt, es wird nur geprüft, wie gut die vorgegebene Clusterstruktur den Daten angepaßt ist. Eine Neuberechnung von Clusterzentren findet nicht statt. Die entsprechende Programm-Maske lautet: 138
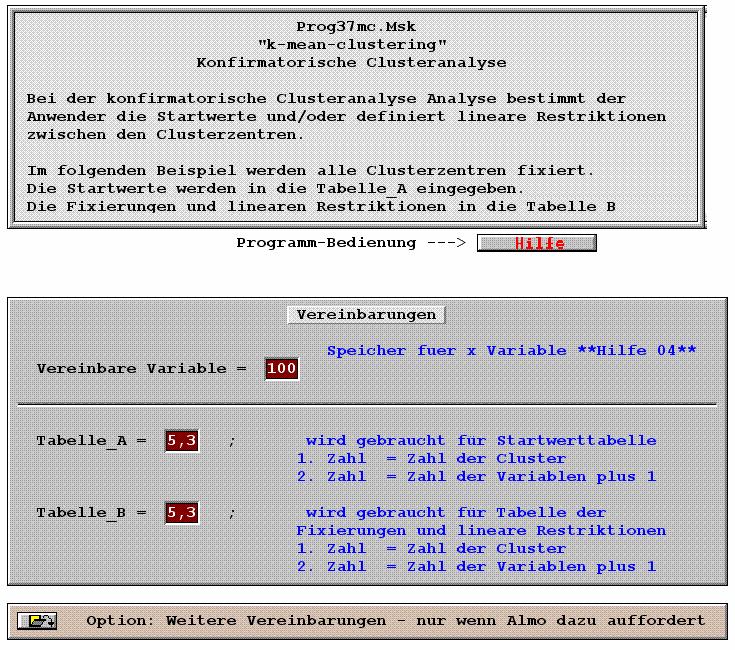
139 139

140 140

141 141
 Cluster von 5 bis 5 Maximale Zahl der Versuche je Clusterzahl 10 Gewichtung der Distanzen keine KEIN_WERT-Schwelle 0.33 Alpha_Niveau 0.")
142 Das Programm führt zu folgenden Ergebnissen (gekürzt): Ergebisse aus ALMO Modellspezifikation: Verfahren Minimaldistanzverfahren fuer Varianzkriterium Startwerte ueber Tabelle eingegeben (=5) Cluster von 5 bis 5 Maximale Zahl der Versuche je Clusterzahl 10 Gewichtung der Distanzen keine KEIN_WERT-Schwelle 0.33 Alpha_Niveau 0.05 Mindestfallzahl 5 Fuer Analyse ausgewaehlte Variable: 142
143 Klassifikationsvariablen: V33 materialist.einstellg V34 postmaterial.einstellg quantitativ quantitativ Deskriptionsvariablen: Klassifikationsvariablen nach Dummy-Aufloesung = 2 Deskriptionsvariablen nach Dummy-Aufloesung = 0 Gewichte der Distanzen in den Variablen in der Analyse: V33 materialist.einstellg Gewicht= 1.00 V34 postmaterial.einstellg Gewicht= 1.00 Die Distanzen in den Variablen werden wie folgt gewichtet: d(g,k)= w*sum_i(w(i)*(x(g,i)-x(k,i))**2 w = Reskalierungsfaktor w(i) = Gewicht der Variablen i x(g,i)= Wert des Objekts g in der Variablen i x(k,i)= Wert des Clustersk in der Variablen i ** = potenzieren Da die Gewichtung außerhalb der Klammer erfolgt, sind Dummies mit 0,5 zu gewichten. Restriktionen = ja lineare Restritkionen fuer Clustergroessen: C1 1 C2 2 C3 3 C4 4 C5 5 Matrix der linearen Restriktionen hinsichtlich der Clusterzentren: Variable C1 C2 C3 C4 C5 V materialist.eins V postmaterial.ein Aktualisierung der Clusterzentren = 1 (ja=voreinstellung) Deterministische Zuordnung bei probabilistischer Clusteranalyse = 0 (nein=voreinstellung) Es wurden 221 Datensaetze eingelesen, davon werden 221 Datensaetze analysiert. Masszahlen fuer Klassifikationsvariablen Variable n= MA SA z-wert Name V materialist. V postmaterial Gesamtstreuungsquadratsumme =
144 Gesamtfallzahl = 442 Freiheitsgrade = 440 ======================================================================== H-0-Kriterium (1-Clustermodell) = Fallzahl = 221 Ergebnisse der Iteration Cluster- Itera- Kriterium prozentuelle zahl tionen Verbesserung gegenueber H Bei Modellen 1 bis 6: Kriterium = Wert des Varianzkriteriums Bei Modell 7: : Kriterium = Wert der Log-Likelihood-Funktion Bei Modell 8: : Kriterium = Ueberlapp. + Nichtklass. Ergebnisse fuer Versuche je Cluster Cluster- Kriterium Versuche Startzahl Reproduktionen Rep.Index Reproduktionen= Anzahl der Versuche, bei denen Mimimum gefunden wurde. Rep.Index = Reproduktionen in Prozent Cluster- Streuungsquadratsummen F-Wert ETA**2 PRE PREzahl innerhalb zwischen Abfall KW KW BEACHTE: PRE fuer minimale Clusterzahl (=5) nicht berechenbar. PRE-Abfall ist definiert als: PRE-Abfall=PRE(K)/PRE(K+1). PRE(K) = PRE-Koeffizient der Lösung mit K Clustern PRE(K+1)= PRE-Koeffizient der nachfolgenden Lösung mit K+1 Clustern Ein starker Abfall ist ein Hinweis, dass K Cluster formal geeignet sind. Beachte: Die Interpretation dieser Testgroessen ist fuer die Modelle 3 bis 6 nur sinnvoll, wenn gleiche Skaleneinheiten der Variablen vorliegen. Dies gilt auch fuer die Bealschen F-Werte. Setze OPTION35=1; ======================================================================== Die 5-Clusterloesung wird weiter untersucht ======================================================================== modifiziertes ETA**2: SQ(gesamt) = df(gesamt) = SQ(innerhalb)= df(innerhalb)= mod. ETA**2 = Clustergroessen: C1 136 ( %) C2 14 ( %) C3 18 ( %) C4 49 ( %) C5 4 ( %) KW-Faelle (ungewichtet)= 0 144
145 ======================================================================== Zellenmittelwerte der Klassifikationsvariablen (Mittelwerte bei quantitativen / ordinalen Variablen) (Anteilswerte bei nominalen Variablen) Variable C1 C2 C3 C4 C5 V materialist.eins V postmaterial.ein Standardabweichungen: Variable C1 C2 C3 C4 C5 V materialist.eins V postmaterial.ein Homogenitaet in den Clustern: Variable C1 C2 C3 C4 C5 V materialist.eins V postmaterial.ein Besetzungszahlen: Variable C1 C2 C3 C4 C5 V materialist.eins V postmaterial.ein Z-Werte: Variable C1 C2 C3 C4 C5 V materialist.eins V postmaterial.ein Signifikanz (1-p)*100 der z-werte: Variable C1 C2 C3 C4 C5 V materialist.eins V postmaterial.ein Statistiken der Cluster: Cluster n= Streuung Homogenitaet innerhalb innerhalb C C C
146 C C Gesamt Das gerechnete Modell erklärt 54% der Gesamtvarianz. (Zum Vergleich erklärt das Modell ohne Restriktionen 72,6%!). Die meisten Fälle werden dem ersten Cluster zugeordnet. Dem letzten Cluster gehören nur 5 Fälle an. In einem nächsten Schritt wird man versuchen, dass Ausgangsmodell zu verbessern (siehe unten). P Der allgemeine Aufbau der Tabelle_A und Tabelle_B Die Almo-Worte Tabelle_A und Tabelle_B können durch TA und TB abgekürzt werden. Allgemein besitzt die Tabellen TA, in der die Startwerte für die Anteilswerte der Cluster und für die Clusterzentren stehen, folgenden Aufbau: 1. In den Zeilen stehen die Cluster. 2. In der ersten Spalte stehen die Anteilswerte der Cluster. 3. In den folgenden Spalten stehen die Werte für die Clustermittelwerte, wobei zunächst die Dummies der nominalen Klassifikationsvariablen eingegeben werden, daran anschließend folgen die ordinalen Klassifikationsvariablen und als letztes die quantitativen Klassifikationsvariablen. Die Deskriptionsvariablen werden nicht eingegeben. 4. Der allgemeine Aufbau von TA ist somit: 1. Spalte = Startwerte für die Anteilswerte der Cluster (Clustergröße). Diese haben beim K-Means-Verfahren keine Bedeutung, müssen aber aus Gründen der Vollständigkeit eingegeben werden. 2. Spalte = Die Startwerte für die Clustermittelwerte für die erste Dummy der ersten in der Anweisung "A_Nominale_V=..;" definierten Variablen. 3. Spalte = Die Startwerte für die Clustermittelwerte für die zweite Dummy der ersten in der Anweisung "A_Nominale_V=..;" definierten Variablen. usw. Die Startwerte für die Clustermittelwerte für die erste Dummy der zweite in der Anweisung "A_Nominale_V=..;" definierten Variablen. usw. 7. Spalte = Die Startwerte für die Clustermittelwerte für die erste in der An weisung "A_Ordinale_V=..;" definierten Variablen. 8. Spalte = Die Startwerte für die Clustermittelwerte für die zweite in der Anweisung "A_Ordinale_V=..;" definierten Variablen. usw. 12. Spalte = Die Startwerte für die Clustermittelwerte für die erste in der Anweisung "A_Quantative_V=..;" definierten Variablen. 13. Spalte = Die Startwerte für die Clustermittelwerte für die zweite in der Anweisung "A_Quantative_V=..;" definierten Variablen. usw. Betrachten wir dazu ein Beispiel: Es sollen die Startwerte für eine 3-Clusterlösung mit den quantitativen Klassifikationsvariablen V3 und V4, mit den ordinalen Klassifikationsvariablen V5, V6 und V10 und den nominalen Klassifikationsvariablen V20 (=3 Ausprägungen) und V26 (=2 Ausprägungen) gerechnet werden. Nach der Dummy-Auflösung der nominalen Variablen liegen somit 2 (=Zahl der quantitativen Variablen) + 3 (=Zahl der ordinalen Variablen) + 5 (=Zahl der Dummies, 3 Dummies 146
147 für V20 und 2 Dummies für V26) = 10 Variablen vor. Da in der ersten Spalte die Clustergrößen stehen, besteht die Tabelle TA aus 11 Spalten. Da 3 Cluster gesucht werden, besteht die Tabelle TA aus 3 Zeilen. Im Vereinbare-Teil der Programm-Maske Prog37mc ist daher zuschreiben: Tabelle_A = 3,11; ALMO erwartet folgenden Aufbau der Tabelle TA nach dem Ende der Programm-Maske 1. Zeile = Startwerte für das 1. Cluster 2. Zeile = Startwerte für das 2. Cluster 3. Zeile = Startwerte für das 3. Cluster 1. Spalte = Startwerte für die Clustergrößen 2. Spalte = Startwerte für 1. Dummy von Variable V20 3. Spalte = Startwerte für 2. Dummy von Variable V20 4. Spalte = Startwerte für 3. Dummy von Variable V20 5.Spalte = Startwerte für 1. Dummy von Variable V26 6.Spalte = Startwerte für 2. Dummy von Variable V26 7. Spalte = Startwerte für die Variable V5 8. Spalte = Startwerte für die Variable V6 9. Spalte = Startwerte für die Variable V Spalte = Startwerte für die Variable V3 11. Spalte = Startwerte für die Variable V4 In der Zelle TA(1,1) steht also der Startwert für die Clustergröße von Cluster 1, in der Tabelle TA(1,2) der Startwert für den Anteilswert des Clusters 1 in der 1. Dummy von Variable V20 usw. Die Matrix TB ist analog der Tabelle TA aufgebaut. Die Eintragungen bedeuten: a) 0 = Der entsprechende Wert ist gefixt. Er wird während der Iteration nicht geändert. b) >0 = Der entsprechende Wert wird geschätzt. c) >0 und gleicher Zahlenwert = Die Werte sollen gleich sein. Enthält die Tabelle TB ein oder mehrere gefixte Werte (=0), müssen die Startwerte über die Tabelle TA (= OPTION14=5; und Einlesen von TA) eingegeben werden. Sind alle Werte in TB größer 0, können die Startwerte auch in der Optionsbox Programm- Optionen lt. Handbuch über OPTION14=1 bis 4 geschätzt werden. Bei Verwendung von OPTION14=5; und/oder OPTION21=1; muss die minimale Clusterzahl gleich der maximalen Clusterzahl sein. Betrachten wir vor diesem Hintergrund das obige Beispiel, so besitzen die Tabellen TA und TB folgenden Aufbau: 1. Zeile = Startwerte für Cluster 1 2. Zeile = Startwerte für Cluster 2 usw. 1. Spalte = Startwerte für die Clustergrößen. Diese haben auf die Ergebnisse der K-Means-Verfahren keinen Einfluss. 2. Spalte = Startwerte für V33 147
148 3. Spalte = Startwerte für V34 Für das 1. Cluster (=1. Zeile) wurde also in V33 (=2. Spalte) ein Startwert von 1.50 und für V34 (=3. Spalte) ebenfalls ein Startwert von 1.50 angenommen. Tabelle TA: (1. Zeile = 1. Cluster) (2. Zeile = 2. Cluster) Die Eintragungen von 1 bis 5 in der 1. Spalte von TB bedeuten, dass die Clustergrößen geschätzt werden sollen. Alle anderen Werte in der 2. und 3. Spalte sind gleich 0. Die Clustermittelwerte in den Variablen V33 und V34 sind also fixiert. Sie werden nicht geschätzt, sondern gleich den Startwerten gesetzt. Tabelle TB: zweite in quant. Klassifikationsvariable definierte Variable (=V34) erste in quant. Klassifikationsvariable definierte Variable (=V33) Anteilswerte der Clustergrößen In einer zweiten konfirmatorischen Analyse soll nun untersucht werden, ob durch eine Abschwächung der Modellannahmen (Fixierung des kleinsten Wertes) eine deutlich höhere erklärte Streuung erzielt werden kann. Im Cluster 1 wurden beide Mittelwerte fixiert, da sie gleich sind. Im Cluster 2 wurde der Mittelwert der materialistischen Wertorientierung fixiert, da er kleiner der postmaterialistischen Wertorientierung ist. In den Clustern 3 und 4 wurde der Mittelwert für die postmaterialistische Wertorientierung fixiert und im Cluster 5 wiederum beide Mittelwerte. Das K-Means-Verfahren soll also folgende Mittelwerte schätzen: Den Mittelwert in der postmaterialistischen Wertorientierung im Cluster 2 (=gemäßigte Materialisten) und die Mittelwerte in der materialistischen Wertorientierungen für die Cluster 3 und 4. Tabelle_A und Tabelle_B würden also folgendermaßen Tabelle_A Tabelle_B 148
149 In einer dritten konfimatorischen Analyse werden folgende lineare Restriktionen der Clusterzentren untersucht: 1. Die Mittelwerte in der materialistischen und postmaterialistischen Wertorientierung im Cluster C1 sollen untereinander gleich und gleich dem Mittelwert in der materialistischen Wertorientierung des Cluters C2 sowie gleich dem Mittelwert in der postmaterialistischen Wertorientierung des Clusters C3 sein. Inhaltlich ausgedrückt besagt diese Annahme, dass für den Konsenstypus beide Wertorientierungen gleich wichtig sein sollen. Die materialistischen Werte sollen ferner gleich wichtig wie im Cluster C2 der gemäßigten Materialisten sein, die postmaterialistischen Werte sollen gleich wichtig wie im Cluster C3 der gemäßigten Materialisten sein. Wenn wir die Variablen mit 1 (=Materialismus) und 2 (=Postmaterialismus) numerieren, lässt sich diese lineare Restriktion anschreiben mit: x = x = x = bzw. TB(1,2) = TB(1,3) = TB(2,2) = TB(3,3), x 32 wobei der erste Index für das Cluster steht. 2. Die Ablehnung der postmaterialistischen Werte im Cluster C2 der gemäßigten Materialisten soll gleich der Ablehnung der materialistischen Werte im Cluster C3 der gemäßigten Postmaterialisten sein. Formal ausgedrückt, soll gelten: x = bzw. TB(2,3) = TB(3,2) 22 x Die Ablehnung der materialistischen Werte im Cluster C4 der Postmaterialisten soll gleich der Ablehnung der materialistischen und postmaterialistischen Werte im Cluster 5 der Nichtorientierten sein. Formal ausgedrückt: x = x = bzw. TB(4,2) = TB(5,2) = TB(5,3) x 52 Die linearen Restriktionen lassen sich durch folgende Tabelle_A und Tabelle_B reproduzieren: Tabelle_A Tabelle_B Durch die Ziffer 6 in der Tabelle_B wird in ALMO ausgedrückt, dass die Werte von TB(1,2), TB(1,3), TB(2,2), TB(3,3) gleich sein sollen (lineare Restriktion 1). 149
150 Die zweite lineare Restriktion TB(2,3) = TB(3,2) Kommt dadurch zum Ausdruck, dass den beiden Tabellen dieselbe Ziffer (= 7 ) zugeschoben wird. Analog wird für die 3. lineare Restriktion vorgegangen. P37.3 Analyse latenter Klassen (probabilistische Clusteranalyse, Modell=7) P Modellansatz und Submodelle Die Analyse latenter Klassen unterscheidet sich von den K-Means-Verfahren dadurch, dass Objekte jedem Cluster nur mit einer bestimmten Wahrscheinlichkeit p(k/g) zugeordnet werden. p(k/g) ist die Wahrscheinlichkeit, mit der Objekt g dem Cluster k angehört. Wir werden diese Wahrscheinlichkeit im folgenden als Zuordnungswahrscheinlichkeit bezeichnen. Auch die Bezeichnung Rekrutierungswahrscheinlichkeiten ("recruitment probabilities") ist üblich. ALMO enthält folgende Submodelle der Analyse latenter Klassen. Latente Profilanalyse (im Programmparameterblock werden nur quantitative Klassifikationsvariablen definiert.) Analyse latenter Klassen für nominalskalierte Variablen (im Programmparameterblock werden nur nominale Klassifikationsvariablen definiert.) Analyse latenter Klassen für ordinalskalierte Variablen (im Programmparameterblock werden nur ordinale Klassifikationsvariablen definiert.) Analyse latenter Klassen für gemischte Variablen (im Programmparameterblock werden qualitative ordinale und/oder nominale Klassifikationsvariablen definiert.) Alle Verfahren lassen sich als Verallgemeinerung des K-Means-Verfahren entwickeln. Technisch bestehen die Modifikationen im folgenden: 1. Der Schritt 3 des Algorithmus der K-Means-Verfahren (siehe Abschnitt P ), in dem jedes Objekt g dem Cluster zugeordnet wird, zu dem die quadrierte euklidische Distanz minimal ist, wird dahingehend geändert, dass die Zuordnungswahrscheinlichkeiten p(k/g) berechnet werden. Dazu sind in Abhängigkeit vom Meßniveau bestimmte Verteilungsannahmen erforderlich. Ferner geht in die Berechnung die Annahme der lokalen Unabhängigkeit ein (siehe dazu später). 2. Die Klassenmittelwerte x kj und Klassenanteilswerte p(k) (Schritt 4 des Algorithmus des K-Means-Verfahrens) werden als Maximum-Likelihood-Schätzer berechnet. Das heißt, sie werden so bestimmt, dass die empirische Verteilung der Objekte bestmöglich durch das Modell reproduziert wird. Mit Ausnahme dieser beiden Modifikationen erfolgt die Berechnung nach dem Algorithmus der K-Means-Verfahren. Dieser Algorithmus wird in der Literatur als EM- Algorithmus (=Expected-Maximum-Likelihood-Estimator) bezeichnet. Das Konzept der lokalen Unabhängigkeit ist für die in diesem Abschnitt behandelten Verfahren zentral. Es ist aus der Analyse latenter Strukturen von Lazarsfeld und Henry (1968) bekannt (siehe dazu auch z.b. Abschnitt P15) und geht von folgender Modellvorstellung aus: 150
151 1. Den Daten liegen K unbekannte (=nicht beobachtete) Klassen zugrunde. Diese werden als latente Klassen bezeichnet. 2. Sie erklären die Zusammenhänge zwischen den untersuchten beobachteten (=manifesten) Variablen. Werden die (latenten) Klassen also als Kontrollvariablen in die Analyse eingeführt, verschwinden die empirischen Zusammenhänge. Die manifesten Variablen sind innerhalb jeder Klasse unabhängig. Wegen der Beziehung zur Analyse latenter Klassen wird im folgenden anstelle von "Clustern" von "latenten Klassen" oder kurz von "Klassen" gesprochen, obwohl man sich selbstverständlich unter den "Klassen" "Cluster" vorstellen kann. Die Wahrscheinlichkeit des Auftretens der Variablenausprägungen eines Objektes g gegeben der latenten Klassen k ist entsprechend der Annahme der lokalen Unabhängigkeit gleich: p(g/k)= p(x g1 / k) p(x g2 /k)... p(x gm /k) wobei p(xgi/k) die Wahrscheinlichkeit des Auftretens der Ausprägung xgi des Objektes g in der Variablen i ist, wenn die latente Klasse k vorliegt. Die Wahrscheinlichkeiten p(x gi/k) werden in Abhängigkeit vom Meßniveau wie folgt berechnet: quantitative Klassifikationsvariablen: p(x gi / k) gi ki ki ki 2 1/ 2 ((x gi xki ) / ski ) = ϕ(x / x,s ) = (1/(s 2π)) e, wobei ϕ(..) die Dichte der Normalverteilung ist. x ki ist der Mittelwert der latenten Klassen k in der Variable i und s ki die Standardabweichung der latenten Klasse k in der Variablen i. ordinale Klassifikationsvariablen: mi xgi mi xgi p(x gi / k) = p(i / k) (1 p(i / h)) x, gi wobei mi die Zahl der Ausprägungen der ordinalen Variablen i minus 1 ist. p(i/k) ist die bedingte Zustimmungs- oder Ablehnungswahrscheinlichkeit der Variablen i in der latenten Klasse k. Die Interpretation von p(i/k) hängt von der Kodierung der untersuchten Variablen ab. Ist diese in Richtung einer Zustimmung kodiert (- ein größerer Zahlenwert bedeutet eine größere Zustimmung -) kann p(i/k) als Zustimmungswahrscheinlichkeit interpretiert werden. Bedeutet dagegen ein größerer Zahlwert eine stärkere Anlehnung, kann p(i/k) als Ablehnungswahrscheinlichkeit interpretiert werden. nominale Klassifikationsvariablen: p(x gi /k)= p(i(j)/k) für x gi = j, wobei p(i(j)/k) die Auftrittswahrscheinlichkeit der Ausprägung j in der Variable i für die latente Klasse k ist. Aufgrund der bedingten Auftrittswahrscheinlichkeiten p(x gi/k) bzw. p(g/k) und der Anteilswerte p(k) der latenten Klassen kann die Zuordnungswahrscheinlichkeit p(k/g) des Objektes g zur latenten Klasse k mit Hilfe des Satzes von Bayes berechnet werden mit 151
152 p(k / g) p(k) p(g / k) =, p(k) p(g / k) wobei p(g/k)= p(xg1/k) p(xg2/k)... p(xgm /k) ist. Die Modellparameter sind somit: Die Anteilswerte (Auftrittswahrscheinlichkeiten) der latenten Klassen k (k=1,2,...,k) Die Mittelwerte x ki und Standardabweichungen ski der quantitativen Variablen i für die latenten Klassen k (k=1,2,...,k) Die Zu- oder Ablehnungswahrscheinlichkeiten p(i/k) der ordinalen Variablen i. Diese sind formal strukturgleich den Mittelwerten x ki. Die Auftrittswahrscheinlichkeiten p(i(j)/k) der Ausprägungen j der nominalen Variablen i der latenten Klassen k. Diese sind formal gleich den Mittelwerten x ki( j) der Dummies der nominalen Variablen i. Da zur Berechnung der Zuordnungswahrscheinlichkeiten π(k/g) mit im Intervall [0,1] normierten Wahrscheinlichkeiten p(x gj /k) gerechnet wird, tritt das durch unterschiedliche Skaleneinheiten und Meßniveaus bedingte Problem der Nichtvergleichbarkeit nicht auf. P Latente Profilanalyse P Explorative Analyse Beispiel: Wir rechnen mit den Daten von Denz (1989) zur "materalistischen Wertorientierung" von Jugendlichen. Die Programm-Maske Prog37md.Msk wird entsprechend ausgefüllt. Die so ausgefüllte Programm-Maske ist als Beispielprogramm in Almo enthalten. Man findet es durch Öffnen des Menüs "Almo", dann Klick auf den Eintrag "Liste aller Almo-Programme", dann Prog37_9.Alm (die Liste ist alphabetisch sortiert). Das Programm steht auch als Almo-Syntax-Programm Prog37_4.ALM zur Verfügung. Maskenprogramm zur Profilanalyse Wir zeigen nur die relevanten Eingabeboxen aus der Programm-Maske Prog37_9.Alm. Die Programm-Maske Prog37_9.Alm ist die mit den Testdaten von Denz ausgefüllte Programm-Maske Prog37md. Prog37md wird durch Klick auf den Knopf Verfahren/Clusteranalyse geladen, Prog37_9 durch Klick auf das Menü Almo/Liste aller Programme/Prog39_9. 152

153 Die beiden Klassifiaktionsvariablen V33 und V34 erhalten einen Namen. 153
.")

154 Die Daten werden aus der Datei Denz3.fre gelesen. Sie befinden sich im freien Format (d.h. die Zahlen sind durch Blank voneinder getrennt). Ein Datensatz (ein Schüler) umfasst die Varieablen V1 bis V34. Die beiden Variblen V33,34 werden als Klassifikationsvariable deklariert. Deskriptionsvariable sind keine vorhanden. Sie sind für eine latente Profilanalyse irrelevant. Es sollen 1 bis 12 Cluster gebildet werden und 50 Lösungen versucht werden 154

155 Die Optionsbox verschiedene Optionen muss geöffnet werden. In folgenden Eingabefelder werden Änderungen gegenüber den Voreinstellungen vorgenommen werden. 1. Die maximale Iterationszahl (Option 13) wird auf 500 gesetzt. 155
156 2. Der Schwellenwert für die Konvergenz (Option 16) wird verkleinert auf 1 an der 7. Kommastelle 3. Die Konvergenz (Option 43) wird auf 2=stark gesetzt. Bestimmung der Klassenzahl Zur Bestimmung der Klassenzahl wird das Verfahren wiederum mit einer unterschiedlichen Anzahl von Klassen durchgerechnet. Nachfolgende Testgrößen werden von Almo berechnet. Prozentuelle Verbesserung PV0k gegenüber dem Nullmodell der 1-Klassenlösung: Diese wird analog zu ETA 2 berechnet mit L k PVO k = 1 bzw. PV0 k(in%) = 100*PV0 k, L 1 wobei L1 der Absolutbetrag der Log-Likelihood-Funktion für die 1-Klassenlösung und L k der Absolutbetrag der Log-Likelihood-Funktion der K-Klassenlösung ist. Für die 5-Klassenlösung beispielsweise beträgt die prozentuelle Verbesserung 15.5 Prozent. Ergebnisse der Iteration Cluster- Itera- Kriterium prozentuelle zahl tionen Verbesserung gegenueber H Bei Modellen 1 bis 6: Kriterium = Wert des Varianzkriteriums Bei Modell 7: : Kriterium = Wert der Log-Likelihood-Funktion Bei Modell 8: : Kriterium = Ueberlapp. + Nichtklass. Wie der Tabelle zu entnehmen ist, werden ab der 4 Klassenlösung mehr als 100 Iterationen benötigt. Wird die maximale Iterationszahl überschritten, bringt ALMO eine Warnung. Prozentuelle Verbesserung PV0 gegenüber der vorausgehenden Klassenlösung: Diese Maßzahl ist analog dem PRE-Koeffizienten beim K-Means-Verfahren definiert mit PV L k k = 1 bzw. PVk(in%) = 100*PVk L k 1 156
157 In unserem Beispiel ist der Wert für die 3-Klassenlösung gleich Aus der Tabelle ist zu entnehmen, dass relativ hohe Werte bei der 2-, 3- und 7-Klassenlösung auftreten. Die 3- und die 7-Klassenlösung erfüllen zusätzlich das Kriterium, dass anschließend die Koeffizientenwerte gering sind. Aus formalen Gründen könnte auch noch die 11-Klassenlösung ausgewählt werden: Sie verbessert die vorausgehenden Lösungen und die nachfolgend Lösung bringt keine Verbesserung mehr. Zu beachten ist hier aber, dass für die 12-Klassenlösugn wahrscheinlich ein lokales Minimum gefunden wurde, da der Wert von PV(k-1) negativ ist. Auch bei der 9-Klassenlösung tritt ein negativer Wert auf Clusterzahl Log(L) df PV(k-1) KW ******************** WARNUNG Moeglicherweise nur lokales Miminum/Maximum gefunden ******************** WARNUNG Moeglicherweise nur lokales Miminum/Maximum gefunden. Negative Werte bei der prozentuellen Verbesserung sind ein Hinweis, dass kein globales Maximum, sondern nur ein lokales Maximum gefunden wurde. Der Wert der Log-Likelihood-Funktion nimmt nicht ab, sondern wird größer. ALMO bringt daher eine entsprechende WARNUNG. In diesem Fall sollte die Zahl der Lösungsversuche erhöht werden. Informationsmaß von Akaike (Akaike 1974; Kaufmann und Pape 1984: 443). Dieses ist definiert als IA k = L k- m k, wobei m k die Zahl der zu schätzenden Parameter ist. Für die latente Profilanalyse ohne Restriktionen ist m gleich (K-1)+m K+m K, da (K-1) Klassenanteilswerte und jeweils m*k Klassenmittelwerte bzw. Klassenvarianzen zu schätzen sind (m= Zahl der Variablen). Für K=5 ergibt sich in unserem Beispiel eine Zahl zu schätzender Parameter von (5-1) + 2*5 + 2*5 = 24. Das Informationsmaß für 5-Klassen ist = Das Informationsmaß von Akaike berücksichtigt somit wie die F-MAX-Statistik die Tatsache, dass bei einer größeren Klassenzahl in der Tendenz "automatisch" eine bessere Modellanpassung erzielt wird. 157
158 Zusätzlich berechnet wird: Informationskriterium von Akaike nach Rost (1996: 443) = -2*AIK Von der Verwendung des Informationsmaßes von Akaike wird heute insbesondere für Modellvergleiche abgeraten, da es tendenziell die Klassenzahl überschätzt. Empfohlen werden: Best Information Criterion (BIC; Rost 1996: 443) und Consistent Akaikes Information Criterion (CAIC; Rost 1996: 443). ALMO berechnet daher auch diese Kriterien. AIK hat negative Werte, die Werte der anderen Koeffizienten sind positiv. Die beste Lösung ist jene mit dem kleinsten positiven oder negativen Wert. Für das Informationsmaß nach Akaike ist dies die 7-Klassenlösung. BIC und CAIC empfehlen dagegen die 3-Klassenlösung. Clusterzahl AIK -2*AIK BIC CAIC AIK=Informationskriterium von Akaike nach Bacher (1994: 366) -2*AIK=Informationskriterium von Akaike nach Rost (1996: 443) BIC=Best Information Criterion; Rost (1996: 443) CAIC=Consistent Akaikes Information Criterion ; Rost (1996: 443) beste Loesung = Loesung mit dem kleinsten Wert Bacher, J., 1994: Clusteranalyse. München Rost, J., 1996: Testtheorie. Testkonstruktion. Bern u.a. Chi-Quadrat-Test für die Likelihood-Quotienten-Teststatistik: Wegen der Maximum-Likelihood-Schätzung ist die Teststatistik -2*(L k-1 - L k ) approximativ Chi- Quadrat-verteilt mit df = mk - mm-1 Freiheitsgrade. Bei kleinen Stichproben ist diese Approximation schlecht, es sollte daher die modifizierte Likelihood-Quotienten- Teststatistik nach Wolfe verwendet werden (Bacher 1996): LQk (Wolfe) = -(2/n) (n-1-m-k/2) (Lk-1 - Lk) Diese Testgröße ist approximativ Chi-Quadrat-verteilt mit 2 m Freiheitsgraden. Mit dieser Teststatistik wird geprüft, ob die K-Klassenlösung eine signifikant bessere Modellanpassung erbringt als die K-1-Klassenlösung. Sie entspricht somit den Bealschen F-Werten. Sollen allerdings die Klassenlösungen mit K-h (h>1) Klassen mit der K-Klassenlösung vergleichen werden, muss die gewöhnliche Likelihood- 158
159 Quotienten-Statistik -2 (L k-h - L k ) verwendet werden. Für den Vergleich der 5- und 6- Klassenlösung ergibt sich ein Wert von LQ 5 (Wolfe) = = (siehe Spalte 5, unteres Dreieck). Dieser ist signifikant von 0 verschieden (Signifikanz = ; Spalte 6, oberes Dreieck). LR-Chi-Quadratwerte nach WOLFE: (Spalte1..1-Clusterloesung, Spalte2..2-Clusterloesung usw.; unteres Dreieck = LR-Wert; oberes Dreieck = Signifikanzen der LR-Werte) Spalte 1 Spalte 2 Spalte 3 Spalte 4 Spalte 5 Spalte 6 Spalte Spalte 8 Spalte 9 Spalte10 Spalte11 Spalte KW KW KW KW 0 Beachte: Die hier nicht wiedergegebene Tabelle der LR-Werte ist analog zu interpretieren. Die bereits erwähnte Analogie der Modellprüfgrößen zu den Modellprüfgrößen des K- Means-Verfahrens gilt auch für das Vorgehen bei der Bestimmung der Klassenzahl. Beziehung zwischen den Modellprüfgrößen der latenten Profilanlyse und jene des K- Means-Verfahren. 159
160 Modellprüfgrößen der latenten Profilanalyse Prozentuelle Verbesserung gegenüber 1-Klassenlösung (=PV0 k ) Prozentuelle Verbesserung gegenüber vorausgehender Lösungen (=PV k ) Informationsmaße Likelihood-Quotienten- Statistiken (gewöhnliche LQ- Statistiken und LQ k (Wolfe)) Modellprüfgrößen des K- Means-Verfahren 2 Erkärte Streuung ( = ETA ) Es werden nur jene k Anwendung zur Bestimmung der Klassenzahl Lösungen ausgewählt, wo PV0 k einen bestimmten Wert überschreitet. 2 PRE-Koeffizient ( = PRE ) Es wird (werden) jene Maximaler F-MAX- Wert (= F-MAX k ) Bealsche F-Werte k Lösung(en) ausgewählt, wo PV k im Vergleich zu der vorausgehenden Lösungen relativ groß ist, während die nachfolgenden Werte klein sind. Es wird jene Lösung mit dem maximalen Informationsmaß (=kleinster neg. Wert oder kleinster pos. Wert) ausgewählt. Es wird jene Lösung ausgewählt, die (a) im Vergleich zu allen vorausgehenden Lösungen signifikant und (b) im Vergleich zu allen nachfolgenden Lösungen nicht signifikant ist. Wendet man die bei den K-Means-Verfahren dargestellten Strategien an, würden wir uns für folgende Lösungen entscheiden: Prozentuelle Verbesserung PVk gegenüber vorausgehender Lösung: Für die 2-, 3- und 7-Klassenlösung, da hier die prozentuelle Verbesserung relativ groß sind (8.969%, 7.175% und 3.071%). Bei 3 und 7 Klassen tritt anschließend ein deutlicher Abfall aus. Formal sind daher die 3- und 7-Klassenlösungen der 2- Klassenlösung vorzuziehen. Absolut betrachtet sind die prozentuellen Verbesserungen aber gering (<10 Prozent). Informationsmaße: Für die 3- oder 7-Klassenlösung. Likelihood-Quotienten-Test: Für eine Analyse mit 7 Klassen, da die 7- Klassenlösung (=7. Spalte) gegenüber den vorausgehenden Klassenlösungen signifikant ist und die nachfolgenden mit Ausnahme der 11-Klassenlösung nicht signifikant sind. Prozentuelle Verbesserung gegenüber Nullmodell der 1. Klassenlösung: Mitunter würden wir uns hier für die 7-Klassenlösung entscheiden, da für sie - im Vergleich zur 2- und 3-Klassenlösung - die prozentuelle Verbesserung größer 20 Prozent ist. Das Programm wählt für die weitere Analyse eine Lösung aufgrund der LQ- Teststatistik von Wolfe aus. Es wird jene Lösung ausgewählt, die im Vergleich zu den vorausgehenden Lösungen signifikant ist, während die nachfolgenden Lösungen nicht signifikant sind. In unserem Beispiel ist dies die 7-Clusterlösung. 160
161 Wir wollen im Folgenden aber die formal ebenfalls zulässige 3- oder 5-Klassenlösung betrachten, da sie eine einfachere inhaltliche Interpretation besitzt. Um diese zu berechnen, muss im Programm Prog37_4.ALM die minimale und maximale Clusterzahl gleich 3 gesetzt werden. Modellprüfgrößen für eine bestimmte Klassenlösung: Für eine bestimmte Klassenlösung, z.b. für die 5-Klassenlösung, können zur Beschreibung die entsprechenden Modellprüfgrößen verwendet werden. Darüber hinaus können - wie beim K-Means-Verfahren - varianzanalytische Maßzahlen verwendet werden, insbesondere die erklärte Streuung, sofern die Variablen in denselben Skaleneinheiten gemessen sind. In unserem Beispiel ergibt sich eine erklärte Streuung von 31.9 Prozent für die 3-Klassenlösung. Die erklärte Streuung bei der latenten Profilanalyse ist i.d.r. kleiner als beim K-Means-Verfahren, da die Fehlerstreuung nicht minimiert wird. Cluster- Streuungsquadratsummen F-Wert ETA**2 PRE zahl innerhalb zwischen KW Zufallstestung einer Klassenlösung: Wie beim K-Means-Verfahren kann auch bei der latenten Profilanalyse mit Hilfe des Nullmodells einer homogen, normalverteilten Population geprüft werden, ob eine bestimmte Klassenlösung überzufällig ist. Dazu werden wiederum mit der Anweisung OPTION17=..; Zufallsdatenmatrizen für das homogene Nullmodell erzeugt. Für diese wird geprüft, wie gut sie durch die berechnete Klassenlösung reproduziert werden können. Ergibt sich eine annähernd gleich gute Reproduktion - gemessen durch den Wert der Log-Likelihood-Funktion - wird man die Lösung als Zufallsprodukt betrachten. Führt man 20 Simulationen (OPTION17=20;) durch, ergeben sich Simulationswerte, die deutlich kleiner dem empirischen Wert von Der Mittelwert der Simulationswerte ist gleich , die Standardabweichung hat einen Wert von Konstruieren wir eine z-teststatistik mit z=(t-e(t)/s(t), wobei t der Wert der empirischen Log-Likelihood-Funktion (t=lk), E(t) der Mittelwert der Log-Likelihood-Werte der simulierten Daten und s(t) deren Standardabweichung ist, ergibt sich ein Wert von Dieser ist größer einem kritischen Schwellenwert von 2. Wir können daher die 3-Klassenlösung als überzufällig betrachten. Beschreibung und Interpretation einer Klassenlösung: Bei der Beschreibung und Interpretation einer Klassenlösung wird analog wie beim K- Means-Verfahren vorgegangen. Das bedeutet u.a.: 1. Für jede Variable kann geprüft werden, ob sie signifikant zur Trennung der Klassen beiträgt. Dazu wird die durch eine Variable erklärte Streuung und ein entsprechender F-Wert berechnet. Da im Unterschied zum K-Means-Verfahren nicht die Streuungsquadratsumme in den Klassen minimiert wird, ist die Durchführung eines Signifikanztests für den F- Wert angemessener. 2. Es können die paarweisen Unterschiede zwischen den Klassen berechnet werden. 3. Die Variablen innerhalb einer Klasse können zu Variablengruppen zusammengefasst werden. 4. Es können z-werte zur Beantwortung der Frage, ob signifikante Abweichungen von den Gesamtmittelwerten vorliegen, berechnet werden. 161
162 5. Zur Beschreibung und Validitätsprüfung können Deskriptionsvariablen in die Analyse einbezogen werden. Zellenmittelwerte der Klassifikationsvariablen (Mittelwerte bei quantitativen / ordinalen Variablen) (Anteilswerte bei nominalen Variablen) Variable C1 C2 C3 V GMAT V GPMAT Standardabweichungen: nicht abgedruckt Besetzungszahlen: nicht abgedruckt Z-Werte: nicht abgedruckt Signifikanz (1-p)*100 der z-werte: nicht abgedruckt Die latente Klasse 1 können wir als Postmaterialisten interpretieren. Latente Klasse 2 bildet eine Gruppe von Nicht-Orientierten (beide Werte sind weniger wichtig, es besteht aber eine Tendenz in Richtung Postmaterialismus) ab, latente Klasse 3 stellt einen Mischtypus (Konsenstypus: beide Wertorientierungen sind wichtig) dar. Der Überlappungsanteil kann entscheidend die Konvergenz und Stabilität der Ergebnisse der latenten Profilanalyse beeinflussen. Eine Grobabschätzung des Überlappungsanteils kann dadurch durchgeführt werden, dass die Zuordnungswahrscheinlichkeiten dichotomisiert und alle Ausprägungskombinationen berechnet werden. Als Dichotomierungsschwelle kann man dabei 1/K wählen, also jenen Wert, der sich ergibt, wenn ein Objekt jeder Klasse mit der gleichen Wahrscheinlichkeit angehört. Insgesamt liegen bei 3 Klassen 28.5 Prozent der Befragten in einem Überlappungsbereich. Eine genauere Abschätzung des Überlappungsanteils kann durch folgende Maßzahlen gewonnen werden, die im Rahmen von Verfahren zum Fuzzy-Clustering (Jain und Dubes 1988: ; Kaufman und Rousseeuw 1990: 171) entwickelt wurden: 2 DUNN k = (1/ n p (k / g) 1/ K) /(1 (1/ K)) g BACKER = 1 ((1/ n) (2 / K 1)) k g k k* <> k min(p(k / g), p(k * / g)) Diese beiden Maßzahlen wurden von Dunn (1976; zitiert in Kaufmann und Rousseeuw 1990: 171) bzw. Backer (1978; zitiert in Jain und Dubes 1988: ) entwickelt und sind zwischen 0 und 1 normiert. Sie werden auch als Partitionsindexwerte bezeichnet. "1" bedeutet, dass keine Überlappungen vorliegen: Jedes Objekt gehört mit einer Wahrscheinlichkeit von 1 nur einer Klasse an. Die Klassen sind auf der empirischen Ebene gut getrennt. Der Wert "0" tritt dann auf, wenn alle Objekte mit einer Wahrscheinlichkeit von 1/K allen Klassen zugeordnet sind, wenn also keine erkennbare Klassenstruktur vorliegt. 162
163 Für unser Beispiel ergeben sich für die 3-Klassenlösung folgende Werte: DUNN = und BACKER = Clusterzahl Ueberlap. PK(Dunn) PSK(Baker) Allgemein lässt sich festhalten: Umso größer der Überlappungsanteil bzw. umso kleiner die Partitions-Indexwerte von Dunn und Backer sind, desto stärker weichen die Ergebnisse des K-Means-Verfahrens und der latenten Profilanalyse ab. Ab einem bestimmten Überlappungsanteil - genaue Grenzwerte lassen sich nicht angeben - besteht die Gefahr, dass die Ergebnisse der latenten Profilanalyse instabil sind. In diesem Fall sind auf jedem Fall Stabilitätsuntersuchungen durchzuführen. Bei großen Stichproben (z.b. n > 2000) kann man dabei so vorgehen, dass man Stichproben unterschiedlicher Größe (z.b. n = 500, n = 750, n = 1000 usw.) zieht und das Konvergenzverhalten empirisch untersucht. Die Stabilität kann ferner - wie bei den K- Means-Verfahren - durch eine Änderung der Startwerte überprüft werden. Neben der Inspektion des Überlappungsanteils sollte anhand der Ergebnisse auch geprüft werden, ob die Annahme der lokalen Unabhängigkeit erfüllen, ob also die Variablen innerhalb der Klassen unkorreliert sind. Das diesbezügliche Testverfahren haben wir bereits beim K-Means-Verfahren besprochen. Es besteht darin, dass für die gepoolte Korrelationsmatrix eine Likelihood-Quotienten-Statistik berechnet wird. Für das Beispiel ergeben sich folgende Werte: gepoolte Korrelationsmatrix W: Spalte 1 Spalte Determinante der Korrelationsmatrix = LR-Teststatistik fuer Unabhaengigkeit der Variablen = Freiheitsgrade = 1 Signifikanz = Wir können die Variablen innerhalb der Klassen als unkorreliert betrachten. Die Modellannahme der lokalen Unabhängigkeit ist somit erfüllt. Strenggenommen müsste der Test innerhalb jeder latenten Klasse durchgeführt werden, da durch das "Poolen" (=Aggregierungen) Zusammenhänge verschwinden können. So kann z.b. in einer latenten Klasse ein starker positiver Zusammenhang zwischen beiden Variablen bestehen, in einer anderen latenten Klasse dagegen ein starker negativer mit dem Ergebnis, dass die gepoolte Korrelation gleich 0 ist. 163
164 P Konfirmatorische latente Profilanalyse Wie bei den K-Means-Verfahren können bei der Analyse latenter Profile bestimmte Parameter fixiert oder gleich gesetzt werden. ALMO ermöglicht folgende Restriktionen: 1. Bestimmte Klassenanteilswerte können fixiert werden. 2. Bestimmte Klassenanteilswerte können gleich gesetzt werden (lineare Restriktionen zwischen den Klassenanteilswerten). 3. Bestimmte Klassenzentren können fixiert werden. 4. Bestimmte Klassenzentren können gleich gesetzt werden (lineare Restriktionen zwischen den Klassenzentren bzw. Klassenmittelwerten). Eine Fixierung von Klassenstreuungen sowie lineare Restriktionen bezüglich der Klassenstreuungen sind derzeit nicht möglich. Für die Eingabe gelten die bei den K-Means-Verfahren angeführten Regeln. Wir wollen an die bisherigen Ergebnisse anknüpfen und folgende Modelle konfimatorisch analysieren. Modell I Modell II Modell III Typus GM GP Typus GM GP Typus GM GP APMAT NO NO AMAT AMAT GMAT PMAT PMAT PMAT GPMAT GPMAT GPMAT KONS KONS KONS APMAT = Anti-Postmaterialisten AMAT = Anti-Materialisten PMAT = Postmaterialisten GPMAT = gemäßigte Postmaterialisten KONS = Konsestypus NO = Nicht-Orientierte GMAT = gemäßigte Materialisten GP = Postmaterialismus GM = Materialismus 164
165 Maskenprogramm zur konfirmatorischen latenten Profilanalyse Wir verwenden die Programm-Maske Prog37mc für die konfirmatorische Clusteranalyse. In ihr muss nur folgendes geändert werden 1. In der Eingabebox Verfahren wird die Zahl 7 eingesetzt. 7 steht für die probabilistische Clusteranalyse 2. Am Ende der Programm-Maske werden die Fixierungen eingetragen Für Modell I sind dies, wie oben angegeben, folgende: Tabelle_A Tabelle_B Die so ausgefüllte Programm_Maske ist zu finden unter Menü Almo/Liste aller Almo- Programme/Prog37_B.Alm. Ein entsprechendes ALMO-Syntax-Programm für das Modell I ist zu finden durch Öffnen des Menüs Almo, dann Liste aller Almo-Programme, dann Prog37_5.Alm Ergebnisse Fixiert man die Klassenzentren in allen drei Modellen, ergeben sich folgende Ergebnisse, von ein modifiziertes Informationsmaß. Clusterzahl AIK -2*AIK BIC CAIC I: II: III: Null: Zur Erzeugung dieser Tabellen müssen vier Analysen gerechnet. Das "Nullmodell" ist die Lösung ohne Restriktionen. Verwendet man für den Vergleich die dafür besonders geeigneten BIC und CAIC, so erweist sich Modell III als am besten geeignet. Für bestimmte Modellvergleiche kann auch eine Likelihood-Quotienten-Statistik verwendet werden. Dies ist dann der Fall, wenn zwischen den Modellen eine hierarchische Beziehung besteht. Ist das Modell M* ein Submodell von M, so kann mit der Teststatistik LQ = - 2 (L M* - L M ) 165
166 geprüft werden, ob das Submodell signifikant schlechter ist als das übergeordnete Modell. Die Likelihood-Quotienten-Statistik ist approximativ Chi-Quadratverteilt mit df M* - df M Freiheitsgraden. df M* sind die Freiheitsgrade des Submodells M*, df M jene des übergeordneten Modells M. Ein Modell M* ist dann Submodell eines Modells M, wenn bestimmte Modellparameter in M fixiert und/oder durch lineare Restriktionen verbunden werden. Die von uns untersuchten Modelle erfüllen nicht diese Bedingung. Sie sind gleichrangig. Sie können aber als Submodelle eines 5-Klassenmodells mit frei variierbaren Parametern aufgefaßt werden. P Analyse latenter Klassen für nominalskalierte Variablen Die Eingabe und Ergebnisinterpretation ist analog jener der latenten Profilanalyse. P Analysen latenter Klassen für ordinalskalierte Variablen Die Eingabe und Ausgabe ist analog jener der latenten Profilanalyse. P Analyse latenter Klassen für gemischte Variablen Werden im Programmparameterblock Klassifikationsvariablen mit einem unterschiedlichen Meßniveau definiert, wird eine Analyse latenter Klassen mit gemischten Variablen gerechnet. Wir wollen dazu ein Beispiel betrachten und für die Wertedaten von Denz (1989) folgende Analyse durchführen: 1. Als nominale Klassifikationsvariablen sollen das Geschlecht (=2 Ausprägungen) der befragten Schüler und der derzeit besuchte Schultyp (=3 Ausprägungen) einbezogen werden. 2. Als ordinale Variablen sollen die abgeschlossene Schulbildung des Vaters und jene der Mutter eingehen. 3. Als quantitative Variablen sollen das Berufsprestige des Vaters und jenes der Mutter eingehen. Die Ausprägung "Hausfrau" wurde dabei als fehlender Wert behandelt. Die Variable Berufsprestige ist dann strenggenommen eine ordinale Variable. Zu Demonstrationszwecken wurde sie wie eine quantitative behandelt. Das Ziel der Analyse ist somit eine Clusterung der befragten Schüler aufgrund von sozialstrukturellen Merkmalen. Zur Bestimmung der Klassenzahl wurde eine Analyse mit maximal 12 Klassen gerechnet. Die Programm-Maske Prog37md.Msk wird entsprechend ausgefüllt. Das (so ausgefüllte Maskenprogramm) wird gefunden durch Öffnen des Menüs Almo, dann Liste aller Almo-Programme, dann Prog37_C.Alm. Die Eingabebox für die Klassifikationsvariable sieht also folgendermaßen aus: 166
 df PV(k-1) ---------------------------------------------------- 1-1759.725 9.000 KW 2-1578.057 19.000 10.324 3-1546.703 29.000 1.987 4-1529.539 39.000 1.110 5-1519.")
167 Auch ein Almo-Syntax-Programm mit diesen Eingaben ist im Menü Almo/Liste aller Almo-Programme/Prog37_6.Alm zu finden. Ergebnisse Die Startwerte wurden durch eine zufällige Zuordnung berechnet. Die Modellprüfgrößen sind: Clusterzahl Log(L) df PV(k-1) KW ******************** WARNUNG Moeglicherweise nur lokales Miminum/Maximum gefunden. Aendere OPTION15 und rechne das Programm neu Clusterzahl AIK -2*AIK BIC CAIC
168 LR-Chi-Quadratwerte: (Spalte1..1-Clusterloesung, Spalte2..2-Clusterloesung usw.; unteres Dreieck = LR-Wert; oberes Dreieck = Signifikanzen der LR-Werte) Spalte 1 Spalte 2 Spalte 3 Spalte 4 Spalte 5 Spalte 6 Spalte Spalte 8 Spalte 9 Spalte10 Spalte11 Spalte KW KW Das Kriterium der prozentuellen Verbesserung legt eine 2-Klassenlösung nahe, die Informationsmaße eine 6-Klassenlösung (Akaike) oder eine 3-bzw. 2-Klassenslösung (BIC und CAIC), da das Informationsmaß nach Akaike bei 6-Klassen mit bzw ein Minimum ist, während BIC das Minimum bei 3 Klassen und CIAC das Minimum bei 2-Klassen erreicht. Die LR-Testwerte legen eine 7- oder 11- Klassenlösung nahe. Wir wollen im folgenden die 2-Klassenlösung betrachten. Die Modellprüfgrößen ermöglichen wiederum keine eindeutige Entscheidung. Clustergroessen: C1 56 ( %) C2 155 ( %) KW-Faelle (ungewichtet)= 10 ======================================================================== Zellenmittelwerte der Klassifikationsvariablen (Mittelwerte bei quantitativen / ordinalen Variablen) 168
169 (Anteilswerte bei nominalen Variablen) Variable C1 C2 V26 Sex maennl weibl V25 Schultyp BHS AHS BS V SchulV V SchulM V PrestV V PrestM Standardabweichungen: nicht abgedruckt Besetzungszahlen: nicht abgedruckt Z-Werte: Variable C1 C2 V26 Sex maennl weibl V25 Schultyp BHS AHS BS V SchulV V SchulM V PrestV V PrestM Signifikanz (1-p)*100 der z-werte: nicht abgedruckt Es lassen sich zwei soziale Schichten unterscheiden, eine höhere und eine untere. Der höheren sozialen Schicht gehören 26,5% an. Die Eltern der befragten Schüler haben eine höhere Schulbildung und ein höheres Berufsprestige. Die Schüler besuchen häufiger eine AHS. Umgekehrt haben die Eltern der unteren sozialen Schichten (73,5%) eine geringere Bildung und ein geringeres Berufsprestige. Die Schüler selbst besuchen häufiger eine Berufsschule (=BS). Interessant an den Befunden ist, dass es keine Unterschiede bei der BHS (berufsbildende höhere Schule) gibt. Die BHS trägt somit zum Abbau sozialer Unterschiede bei. Des weiteren bestehen zwischen den beiden Klassen keine geschlechtspezifischen Unterschiede. Dies bringt auch der paarweise Test auf Mittelwertunterschiede zum Ausdruck: Paarweise Clusterdifferenzen fuer Cluster=1 (n= 56) Klassifikationsvariablen: Variable C2 169
170 V26 Sex 1 = maennl 2 = weibl V25 Schultyp 1 = BHS 2 > AHS 3 < BS V23 > SchulV V24 > SchulM V40 > PrestV V41 > PrestM Konfirmatorische Analyse Wie bei allen in diesem Abschnitt behandelten Modellen können die Modellparameter (mit Ausnahme der Klassenvarianzen) fixiert und lineare Restriktionen definiert werden. P37.4 Repräsentanten-Verfahren P Modellansatz Das Ziel der Repräsentanten-Verfahren ist, K Cluster durch jeweils ein typisches (=repräsentatives) Objekt zu charakterisieren. Unser Verfahren geht von folgenden Modellannahmen aus. 1. Es gibt K Cluster, die der Größe nach geordnet sind: n1 > n2 >... (nk = Größe des Clusters k) 2. Ein Objekt g soll einem Cluster k angehören, wenn es zu dem Repräsentanten rk des Clusters k eine Unähnlichkeit kleiner/gleich bzw. eine Ähnlichkeit größer/gleich einem bestimmten Schwellenwert besitzt. Dieser Schwellenwert soll mit Uhomo für Unähnlichkeiten bzw. mit Ähomo für Ähnlichkeiten bezeichnet werden. Ein Objekt g muss somit folgende Bedingung erfüllen, damit es einem Cluster k angehört: 170
171 ug,rk < U homo bzw. äg,rk > Ähomo, Bedingung (A) mit ug,rk = Unähnlichkeit zwischen Objekt g und dem Repräsentanten rk des Clusters k bzw. äi,rk = Ähnlichkeit zwischen Objekt g und dem Repräsentanten r.k 3. Der Repräsentant rk eines Clusters k soll jenes Objekt mit den meisten nächsten Nachbarn sein. Ein nächster Nachbar soll dann vorliegen, wenn die Unähnlichkeit kleiner/gleich bzw. die Ähnlichkeit größer/gleich dem Schwellenwert für die Clusterhomogenität ist. Ferner wird gefordert, dass die Repräsentanten voneinander verschieden sind: Die Unähnlichkeit bzw. Ähnlichkeit zwischen den Repräsentanten soll größer bzw. kleiner einem weiteren Schwellenwert für die Clusterheterogenität sein. Bezeichnen wird diese Schwellenwerte mit U hetero (>Uhomo ) bzw. Ä hetero (<Ähomo ), so soll gelten: urk,rk* > Uhetero bzw. ärk,rk* > Ähetero für alle rk, rk* Bedingung (B) Die Schwellenwerte für die Clusterheterogenität haben die Funktion, die Zahl der Überlappungen zu steuern. Je geringer der Unterschied zwischen den Schwellenwerten Uhomo und Uhetero bzw. Ähomo und Ä hetero ist, desto größer ist der Anteil der Überlappungen. 4. Grundsätzlich sind aber Überlappungen und Nichtklassifikationen erlaubt. Der Algorithmus zum Auffinden der Repräsentanten ist: 1. Berechnung der Zahl nng nächster Nachbarn für jedes Objekt g: Zusätzlich wird für jedes Objekt g die durchschnittliche (=mittlere) Unähnlichkeit uug bzw. die durchschnittliche (=mittlere) Ähnlichkeit ääg der nächsten Nachbarn zum Objekt g berechnet. Die mittleren Ähnlichkeiten bzw. Unähnlichkeiten werden für die Größenanordnung benötigt, wenn zwei Objekte dieselbe Anzahl von nächsten Nachbarn haben. In die Berechnung beider Kennwerte wird auch die Ähnlichkeit bzw. Unähnlichkeit des Objekts zu sich selbst einbezogen. Dadurch können auch einzelne Objekte als Cluster identifiziert werden. Jedes Objekt besitzt somit immer mindestens einen nächsten Nachbarn, nämlich sich selbst. 2. Größenanordnung der Objekte: Die Objekte g werden entsprechend der Zahl nächster Nachbarn absteigend nng > nng* > nng** >... angeordnet. Sind zwei oder mehrere Cluster gleich groß, so werden sie aufgrund der durchschnittlichen Un- oder Ähnlichkeiten gereiht. Wenn also z.b. nng = nng* und uug < uug*, wird das Objekt g vor dem Objekt g* gereiht, da g als möglicher Repräsentant homogener ist. Die erwähnte Invarianzeingenschaft des Repräsentanten- Verfahrens (siehe Abschnitt P36.0) gegenüber monotonen Transformationen gilt also nur, wenn alle Objekte eine unterschiedliche Zahl von nächsten Nachbarn haben. 3. Berechnung der Repräsentanten. Die Berechnung der Repräsentanten erfolgt hierarchisch, wobei das erste Objekt in der geordneten Objektliste immer ein Repräsentant (für das Cluster 1) ist. Die weiteren Repräsentanten werden wie folgt bestimmt: Es wird geprüft, ob das zweite Objekt der geordneten Objektliste ein Repräsentant ist, ob also die Bedingung (B) erfüllt ist. Ist dies der Fall, wird 171
172 das zweite Objekt der Repräsentant eines neuen Clusters (=Cluster 2). Die Prüfung wird mit dem nächsten Objekt fortgesetzt. Ist das zweitgrößte Objekt kein Repräsentant, wird die Prüfung der Bedingung (B) unmittelbar mit dem nächsten Objekt fortgesetzt. Die Berechnung der Repräsentanten wird abgeschlossen, wenn alle Objekte geprüft sind. 4. Zuordnung der Objekte: Nach der Bildung der Repräsentanten werden die Objekte entsprechend der Bedingung (A) den Clustern zugeordnet. Dabei können drei Ergebnisse eintreten: Das Objekt g gehört (a) nur einem Cluster an, gehört (b) zwei oder mehreren Clustern an und (c) keinem Cluster an. Das Repräsentanten-Verfahren erfordert die Definition von zwei Schwellenwerten, nämlich von U homo und Uhetero. Diese werden über die Anweisung "OPTION32= UHOMO;" und "OPTION33= UHETERO;" definiert. Zusätzlich kann noch das verwendete Distanzmaß mit der Anweisung "OPTION31=..;" definiert werden. Folgende Distanzmaße stehen zur Verfügung: Option31= 1; mittlere City-Block-Metrik 2; mittlere euklidische Distanz 3; Chebychew-Metrik 4; Jaccard-I-Koeffizient für dichotome Variablen 5; mittlere quadrierte euklidische Distanz Die mittlere City-Block-Metrik zwischen zwei Objekten g und g' ist definiert als: d (g, g' ) x gi 1 = m x g' i wobei m die Zahl der Variablen ist. Die anderen Größen berechnen sich wie folgt: mittlere euklidische Distanz: d(g, g' ) = Chebychew-Metrik d(g, g' ) 2 1 [ ] 1/ 2 m x gi x g'i = max( x gi x g'i Jaccard-I-Koeffizient: siehe Abschnitt P36.2 mittlere quadrierte euklidische Distanz: d (g, g' ) = 1 m 2 (x gi x g'i ) Im Unterschied zu den anderen Verfahren des Programms P37 muss im Programmparameterblock die Zahl zu untersuchender Objekte mit der Anweisung "Objekte=Zahlenwert;" definiert werden. Konfirmatorische Analyse sind nicht möglich. 172
173 P Beispiel zur Clusterbildung Der dargestellte Algorithmus soll nun für das Beispiel des Abschnitts P36.7 veranschaulicht werden. Ziel der Analyse ist eine Clusterbildung für die 22 Länder Mittel- und Südamerikas aufgrund ihrer Faktorwerte in den vier bei einer Faktoranalyse berechneten Faktoren zu clustern. Die gefundenen Faktoren sind: Befriedigung existenzieller Grundbedürfnisse, Wirtschaftswachstum, Industrialisierung und Bildungsintervention. Als Unähnlichkeitsmaß soll die mittlere City-Block- Metrik verwendet werden. Für die Homogenität Uhomo in den Clustern wurde ein Schwellenwert von 0.5 angenommen, für die Heterogenität Uhetero zwischen den Clustern ein Wert von 0.7. Die Unähnlichkeiten der Objekte eines Clusters k zu dem Clusterrepräsentanten sollen also kleiner/gleich 0.5 und die Unähnlichkeit zwischen den Repräsentanten sollen größer 0.7 sein. # CLUSTERANALYSE # #- mehrere suedamerikanischer Laender werden mit Hilfe von Variablen, -# #- die ihren Entwicklungsstand charakterisieren, geclustert -# # Daten: NOHLEN,D.(Hg.) 1984: LEXIKON DRITTE WELT.S 630 ff # VEREINBARE # Es wird Speicherplatz fuer 32 Variablen # Variable=32; # reserviert # ANFANG N21=exGrundbed; # Den Faktorwerten werden Namen gegeben # N22=WirtWachst; N23=Indust; N24=Bildung; Programm=37; # Spezifikation des Programms # A_quantitative_V=v21:24;# Definition der quantitativen Klassifikations- # # variablen # Modell=8; # Das Repraesentantenverfahren soll gerechnet # # werden # Option31=1; # Die mittlere City-Block-Metrik soll als # # Distanzmass verwendet werden. # Option32=0.5; # Definition des Schwellenwertes fuer die # # Homogenitaet in den Clustern # Option33=0.7; # Definition des Schwellenwertes fuer die # # Heterogenitaet zwischen den Clustern # Objekte=22; # Zahl der Objekte # Min_clusterzahl=1; # Definition der kleinsten und groessten # Max_clusterzahl=22; # Clusterzahl # Option9=3; # Es sollen Detailergebnisse ausgegeben werden # Ende_Programmparameter Lese alle_v # Lesen der Faktorwerte feur die Laender # aus Datei 2 # aus der Datei ENTWFA.DIR # 'C:\ALMO\PROGS\ENTWFA.DIR' Format direkt leerzu Ende; Gehe_in_Programm Gehe_zu LESE # naechstes Land lesen# ENDE Maskenprogramm zum Repräsentanten-Verfahren Im Maskenprogramm Prog37m3 in Abschnitt P muss in der Box "Verfahren" auf "8" gestellt werden. 173

174 In der Box "Clusterzahl wird "2" und "12" in die beiden Eingabefelder eingetragen Sollen ebenfalls die Optionen 31, 32, 33 wie im vorausgegangenem "selbst geschriebenen" Syntaprogramm verwendet werden, dann muss die Optionsbox "Verschiedene Optionen" nicht geöffnet werden, da diese Optionswerte als Voreinstellungen im Maskenprogramm Prog37m3 eingesetzt sind. Wollen Sie jedoch andere Werte eingeben, dann öffnen Sie diese Optionsbox. Die 3 Optionen 31,32,33 sind im unteren Teil der Optionsbox enthalten. Der erste Schritt des Algorithmus besteht darin, für jedes Objekt g die Zahl nng nächster Nachbarn und die durchschnittliche Unähnlichkeit uug der nächsten Nachbarn zu dem Objekt g zu berechnen. Die diesbezüglichen Ergebnisse sind Kennwerte fuer Objekte: Nummer Objekt Nachbarn Distanz In der Tabelle wurde auch bereits die Größenanordnung der Objekte (=Schritt 2 des Algorithmus) durchgeführt. Die meisten nächsten Nachbarn (=8) hat das Objekt 17 (=Panama). Daran anschließend folgen zwei Objekte (=Kolumbien und Costa Rica), die jeweils sechs nächste Nachbarn haben. Kolumbien wird vor Costa Rica gereiht, da die mittlere Unähnlichkeit von Kolumbien kleiner ist als jene für Costa Rica (0.29 gegenüber 0.31). An unterster Stelle stehen die Länder, die außer sich selbst keinen weiteren nächsten Nachbarn haben. Dies sind: Objekt 7 (=Ecuador), Objekt 10 (=Haiti), Objekt 2 (=Bolivien), Objekt 20 (=Trinidad), Objekt 12 (=Jamaika) und Objekt 174
175 22 (=Venezuela). Im dritten Schritt des Algorithmus erfolgt die Bestimmung der Repräsentanten. Als erster Repräsentant wird immer das erstgrößte (erst gereihte) Objekt (Objekt 17=Panama) in der sortierten Liste ausgewählt, da es die meisten nächsten Nachbarn hat. Als nächster möglicher Repräsentant kommt das zweitgrößte Objekt (Objekt 13=Kolumbien) in Frage. Kolumbien hat eine Unähnlichkeit von zum ersten Repräsentanten (=Panama). Der Wert liegt unter dem vorgegebenen Schwellenwert von 0.7 für die Clusterheterogenität. Kolumbien scheidet somit als Repräsentant für ein zweites Cluster aus. Dies gilt auch für die nachfolgende Objekte bis zum zehntgrößten Objekt (Objekt 11=Honduras). Die Unähnlichkeit zwischen Honduras und Panama (=1. Repräsentant) ist gleich und liegt über dem Schwellenwert von 0.7 für die Clusterheterogenität. Honduras wird somit entsprechend dem Algorithmus als Repräsentant des zweiten Clusters ausgewählt. Die Repräsentantenssuche wird mit dem elftgrößten Objekt (Objekt 18=Paraguay) fortgesetzt usw. Insgesamt werden sechs Repräsentanten gefunden. Repraesentanten: Repraesentant = 1 = Objekt = 17 Zahl der gefundenen Repraesenten = 1 Anteil der Ueberlappungen = Anteil der Nichtklassifik.= Modellfehler = Distanz in Clustern = ======================================================================== Clustergroessen: C1 = 1 Auspraegungen der Repraesentanten: Variable C1 V exgrundbed V WirtWachst V Indust V Bildung Kennwerte fuer Objekte: Nummer Objekt Nachbarn Distanz Repraesentanten: 175
176 Repraesentant = 1 = Objekt = 17 Repraesentant = 2 = Objekt = 11 Zahl der gefundenen Repraesenten = 2 Anteil der Ueberlappungen = Anteil der Nichtklassifik. = Modellfehler = Distanz in Clustern = usw. ======================================================================== Clustergroessen: C1 = 1 C2 = 1 Auspraegungen der Repraesentanten: Variable C1 C2 V exgrundbed V WirtWachst V Indust V Bildung usw. H-0-Kriterium (1-Clustermodell) = Ergebnisse der Iteration Cluster- Itera- Kriterium prozentuelle zahl tionen Verbesserung gegenueber H Bei Modellen 1 bis 6: Kriterium = Wert des Varianzkriteriums Bei Modell 7: : Kriterium = Wert der Log-Likelihood-Funktion Bei Modell 8: : Kriterium = Ueberlapp. Nichtklass. Cluster- Ueber- Nichtklas- Modell- Distanz zahl lappungen sifikationen fehler in Cluster ======================================================================== Das erste Cluster wird durch Panama repräsentiert. Panama als Repräsentant ist durch ein mittleres wirtschaftliches Wachstum und eine mittlere Industrialisierung gekennzeichnet. Die Befriedigung existentieller Bedürfnisse und das erreichte Bildungsniveau ist im Vergleich zu den anderen Ländern leicht überdurchschnittlich. Honduras als Repräsentant des Clusters 2 unterscheidet sich von Panama, durch eine 176
177 unter dem Gesamtdurchschnitt liegende Befriedigung existentieller Grundbedürfnisse. Die erreichte Industrialisierung und Bildung liegt ebenfalls unter dem Gesamtdurchschnitt, während das Wirtschaftswachstum über dem Gesamtdurchschnitt liegt. Im letzten Schritt des Algorithmus wird jedes Objekt g dem oder den Clustern zugeordnet, zu dessen Repräsentant(en) die Unähnlichkeit(en) kleiner 0.5 ist (sind). Es ergibt sich das in der folgenden Tabelle dargestellte Bild. Dem ersten Cluster gehören somit neben dem Repräsentanten (=Panama) an: Argentinien (1), Brasilien (3), Chile (4), Costa Rica (5), Kolumbien (13), Kuba (14) und Mexiko (15), dem zweiten Cluster die Dominikanische Republik, El Salvador, Guatemala und Honduras. Die anderen Cluster werden jeweils nur von ihren Repräsentanten gebildet. Clusterzugehoerigkeit der Objekte(Datensaetze): ( -1 = wegen Kein_Wert eliminiert) Objekt Clustererzu- Distanz Zuordnungswahr-. gehoerigkeit zum Cluster- scheinlichkeiten. zentrum Insgesamt können 16 der 22 Länder (= 62.7 Prozent) geclustert werden. Die Nichtklassifikationen (=27.3 Prozent) entstehen dadurch, dass zum einen die nichtklassifizierten Objekte keinem Cluster zugeordnet werden können, da die Unähnlichkeit zu keinem Repräsentanten kleiner/gleich dem vorgegebenen Schwellenwert von 0.5 für die Clusterhomogenität ist. Auf der anderen Seite ist die Unähnlichkeit zu den Repräsentanten aber kleiner dem vorgegebenen Schwellenwert von 0.7 für die Clusterheterogenität, so dass diese Objekte auch kein eigenständiges Cluster bilden. Durch eine Änderung des Schwellenwertes für die Clusterheterogenität kann eine Zuordnung aller Objekte erreicht werden. Nichtzuordnungen sind dadurch erkennbar, dass alle Zuordnungswahrscheinlichkeiten gleich 0 sind, wie z.b. bei Objekt 18. ALMO gibt in diesem Fall als Clusterzugehörigkeit das Cluster 1 an, da Objekt 18 mit einer Unähnlichkeit von 0.59 zum Cluster 1 die geringste Unähnlichkeit aufweist. Diese liegt aber über den vorgegebenen Schwellenwert von 0.5. Maßzahlen der Modellanpassung: 177
178 Maßzahlen zur Beurteilung der Modellanpassung sind: 1. Mittlere Unähnlichkeit aller Objekte zu ihren jeweiligen Repräsentanten. Diese Maßzahl soll im folgenden mit u r bezeichnet werden. 2. Anteil der Nichtklassifikationen. Für diese Maßzahl soll im folgenden die Bezeichnung pnkl verwendet werden. 3. Anteil der Überlappungen. Diese Größe wird für die weiteren Ausführungen mit pülp bezeichnet. 4. Anteil der Nichtklassifikationen und Überlappungen als Gesamtmaß. Für diese Größe soll die Bezeichnung pges = pnkl + p ÜLP verwendet werden. Liegt eine gute Modellanpassung vor, sollte die mittlere Unähnlichkeit u r der Objekte zu ihren Repräsentanten gering und der Anteil der Nichtklassifikationen pnkl und jener der Überlappungen p ÜLP nahe bei Null sein. Für die letzten beiden Forderungen kann als Globalmaß der Gesamanteil p GES der Nichtklassifikationen und Überlappungen verwendet werden. Die bisher dargestellten Maßzahlen beziehen sich auf die berechnete Gesamtstruktur. Maßzahlen, die über die einzelnen Cluster Auskunft geben, sind: 1. mittlere Unähnlichkeiten u rkder Objekte zu ihren jeweiligen Repräsentanten für jedes Cluster k. Dieser Wert ist gleich der Größe uu g für den Repräsentanten des Clusters. 2. Unähnlichkeiten u rk,rk* zwischen den Repräsentanten rk und rk*. 3. paarweise mittlere Unähnlichkeiten u( k) in der Objekte in den Clustern k 4. paarweise mittlere Unähnlichkeiten u( k, k*) zw der Objekte zwischen den Clustern k und k*. Für die 6-Clusterlösung ergeben sich folgende Werte. mittlere Entfernungen der Clusterzentren bzw. Repraesentanten zueinander: Spalte 1 Spalte 2 Spalte 3 Spalte 4 Spalte 5 Spalte mittlere Entfernungen der Objekte zueinander: Spalte 1 Spalte 2 Spalte 3 Spalte 4 Spalte 5 Spalte In der Diagonalen stehen die paarweisen mittleren Unähnlichkeiten innerhalb der Cluster (= u( k) in ), außerhalb der Diagonalen jene zwischen den Clustern (= u( k, k*) zw ).Die Frage, ob die gefundene Clusterstruktur signifikant ist, kann durch die Berechnung des Homogenitätsindex g beantwortet werden (siehe Abschnitt P36.7). Für die 6- und 11-Clusterlösungen ergeben sich folgende Kennwerte. 178
179 G1-Homogenitaetsindex = Erwartungswert = Varianz = z-wert = Signifikanz = Fehler (Chebychev) = Die Lösungen kann zu einem Fehlerniveau von 10 Prozent als signifikant (=überzufällig) betrachtet werden, wenn als konservative Teststrategie die Ungleichung von Chebychev verwendet wird. Die Modellanpassung kann schließlich wiederum durch Simulationsstudien geprüft werden. Dabei kann von dem Nullmodell einer homogenen, normalverteilten Population mit gegebenen empirischen Verteilungskennwerten (Mittelwerte und Standardabweichungen) ausgegangen werden. Die Variablen sollen ferner voneinander unabhängig sein. Aufgrund dieses Nullmodells werden wiederum durch Verwendung von OPTION17=...; Zufallsdatenmatrizen (z.b. 20) erzeugt. Für jede Zufallsdatmatrix wird geprüft, wie gut sie sich durch die berechnete Clusterstruktur reproduzieren läßt. Die Wahl der Schwellenwerte: Die Ergebnisse des Repräsentanten-Verfahrens hängen von der Wahl der Schwellenwerte für die Homogenität in den Clustern (=U homo ) und der Heterogenität zwischen den Clustern (=U hetero ) ab. Allgemein gilt: Je größer der Schwellenwert Uhomo gewählt wird, desto weniger, aber dafür inhomogene Cluster werden berechnet. Umso größer der Schwellenwert U hetero im Vergleich zum Schwellenwert Uhomo ist, desto mehr Nichtklassifikationen, aber weniger Überlappungen treten auf. In der Forschungspraxis wird man daher Uhomo = Uhetero wählen, wenn alle Objekte klassifiziert werden sollen. Ist man dagegen an gut getrennten Clustern interessiert, wird man für den Schwellenwert für die Clusterheterogenität einen größeren Wert wählen, z.b. Uhetero = 1.5*Uhomo. I.d.R. wird man mehrere Konstellationen für die Schwellenwerte ausprobieren. Bei der Auswahl kann man sich an inhaltlichen und formalen Kriterien orientieren. So z.b. kann gefordert werden, dass die mittlere Unähnlichkeit der Objekte zu ihren Repräsentanten nicht größer einer halben Skaleneinheit sein soll. Ist die Skaleneinheit beispielsweise - wie in unserem Beispiel - gleich 1, wird man für U homo einen Wert von 0.5 wählen und abhängig davon, ob alle Objekte klassifiziert werden sollen, für den Schwellenwert Uhetero Werte von 0.5 (=alle Objekte werden klassifiziert), 0.7 und 1.0 (=Nichtklassifikationen, aber keine Überlappungen) wählen. Neben der Beschaffenheit der Skala der untersuchten Variablen können Signifikanzüberlegungen, sofern sie für das ausgewählte Unähnlichkeitsmaß möglich sind, verwendet werden. So z.b. wählen Lorr und Radhakrishnan (1967) die Schwellenwerte so, dass U homo gleich dem kritischen Wert für eine Signifikanz von 95 Prozent und U hetero gleich dem kritischen Wert für eine Signifikanz von 99 Prozent ist. 179
180 P37.5 Mehrschritt-Verfahren P Einführung Mehrschritt-Verfahren versuchen die Vorteile der in Programm 36 und 37 enthaltenen Verfahren zu nutzen und deren Nachteile zu vermeiden. Die Vorteile der agglomerativ hierarchischen Verfahren (Programm 36) sind: Für die Bestimmung der Clusterzahl stehen mehr Kriterien zur Bestimmung der Clusterzahl zur Verfügung. Häufig ist es auch aufgrund des Dendrogramms leichter, die Zahl der Cluster zu bestimmen. Zwischen den Clusterlösungen besteht eine Hierarchie. Die 2-Clusterlösung entsteht durch Verschmelzung von zwei Clustern der 3-Clusterlösung, die 3- Clusterlösung durch Verschmelzung von zwei Clustern der 4-Clusterlösung usw. Entscheidet man sich für eine bestimmte Clusterlösung mit K Clustern, so hat man die Garantie, dass K-1 Cluster dieser Lösung sowohl in der vorausgehenden als auch in der nachfolgenden Lösung ebenfalls vorhanden sind. Lösungen mit einer unterschiedlichen Clusterzahl weichen somit nicht stark voneinander ab. Einige Cluster werden immer identisch sein. Umgekehrt haben die agglomerativ hierarchischen Verfahren folgende Nachteile: Sie sind für große Datensätze ungeeignet. Für eine feste Clusterzahl K kann die Lösung suboptimal sein, da die Lösung von den vorausgehenden Clusterlösungen abhängt. K-Means-Verfahren sind dagegen für große Datensätze geeignet und bestimmen für eine gegebene Clusterzahl K eine optimale Partition. Umgekehrt bereitet hier die Bestimmung der Clusterzahl häufig größere Probleme und eine Hierarchie zwischen den Lösungen besteht nicht. Mehrschritt-Verfahren können zwar einige, aber nicht alle Nachteile beseitigen. Der Anwender muss sich entscheiden, ob der Schwerpunkt auf einer Hierarchie der Lösungen liegen soll oder ob er für ein feste Clusterzahl K eine optimale Lösung haben will. Die Mehrschritt-Verfahren bestehen aus folgenden Schritten: 1. Schritt 1: Im ersten Schritt wird ein K-Means-Verfahren durchgeführt. Ziel ist hier eine Datenreduktion auf eine Fallzahl, die für hierarchische Verfahren handbar ist. Es werden also z.b. 50, 100, 200, 300 oder 500 Cluster bestimmt. Die Cluster sollten möglichst homogen sein. Ziel dieses Schrittes ist es nicht, eine gut interpretierbare Clusterlösung mit wenigen Clustern (z.b. 3 oder 5) zu erhalten. 2. Schritt 2: Es wird eine hierarchische Clusteranalyse durchgeführt. Sie dient der Bestimmung der Clusterzahl. Geclustert werden nicht die Ausgangsdaten, sondern die Ergebnisse des K-Means-Verfahrens des ersten Schrittes. 3. Schritt 3: Es wird erneut eine K-Means-Analyse gerechnet. Die im Schritt 2 berechneten Clustermittelwerte gehen als Startwerte für die Clusterzentren in die Analyse ein. Es bestehen zwei Möglichkeiten: 180
181 a) Die Startwerte werden nicht geändert. D.h., die Fälle werden nur zugeordnet. Dadurch bleibt die Hierarchie bestehen. Diese Methode wird als Zwei-Schritt- Verfahren bezeichnet. b) Die Startwerte werden geändert. Die Hierarchie geht verloren, dafür wird eine optimale Partition gefunden. Diese Methode wird als Drei-Schritt-Verfahen bezeichnet. P Eingabe mit Maskenprogramm Prog37m2 181

182

183

184 P Erläuterungen zu den Boxen Die Boxen sind weitgehend identisch mit denen von Prog37m1 in Abschnitt P und denen von Prog37m3 in Abschnitt P Wir werden deswegen nur die Boxen erläutern, die zusätzlich in Prog37m2 enthalten sind. Box "Clusterzahl" Es darf nur eine Clusterzahl angegeben werden. Dies ist programmtechnisch erforderlich. Zur Bestimmung der Clusterzahl empfehlen wir folgendes Vorgehen: In einem ersten Programmdurchlauf wird eine beliebige Clusterzahl festgelegt. Das Programm wird gerechnet. Auf der Grundlage der Ausgabe des zweiten Schrittes (=Ausgabe der agglomerativ hierarchischen Verfahren) legt der Anwender die Clusterzahl fest. Es können dazu die in Abschnitt P erörterten Kriterien verwendet werden. Nach der Entscheidung für eine oder mehrere Clusterlösungen wird das Programm erneut gerechnet, wobei bei "Clusterzahl" die richtige Anzahl von Clustern eingetragen wird. Kommen mehr als eine Lösung in Frage, wird das Programm mehrfach gerechnet. Box "Mehrschritt-Verfahren" Eingabefeld 1: Wird "2" eingegeben, dann rechnet Almo eine 2-Schritt-Lösung. Es wird zuerst ein K-Means-Verfahren gerechnet, dessen Ergebnisse dann an die hierarchische Clusteranalyse übergeben werden. Siehe die ausführliche Darstellung in Abschnitt P Wird "3" eingegeben, dann wird zuerst eine 2-Schritt-Lösung gerechnet. Die Ergebnisse aus der hierarchischen Clusteranalyse werden dann (nochmals) an die K- Means-Analyse übergeben. Siehe die ausführliche Darstellung in Abschnitt P Eingabefeld 2: Überspringe Stufe 1 Fordert der Benutzer im Eingabefeld 1 ein 3-stufiges Verfahren an und verlangt er im Eingabefeld 2, dass Stufe 1 (das k-means-verfahren) übersprungen wird, dann führt Almo ein 2-stufiges Verfahren durch, bei dem in der 1. Stufe eine hierarchische Analyse gerechnet wird, deren Ergebnisse als Startwerte in das k-means-verfahren eingegeben werden, das somit die abschliessende 2. Stufe bildet. Beachte: Es ist möglich, aber nicht sinnvoll, im Eingabefeld 1 ein 2-stufiges Verfahren anzufordern und dann im Eingabefeld 2 das Überspringen der 1. Stufe zu verlangen. Es wird dann nur eine hierarchische Analyse mit einer stark reduzierten Ausgabe gerechnet, die besser mit Programm Prog36md gerechnet werden sollte. 184

185 Box "Optionen in Stufe 1 (K-Means-Verfahren)" Optionsbox geöffnet: Die Optionen werden ausführlich in Abschnitt P erläutert. Zu erläutern ist lediglich das Eingabefeld 2. In der 1. Stufe, dem k-means-verfahren setzt Almo unabhängig von der Eingabe des Benutzers in die Box "Clusterzahl" - die Clusterzahl auf 10 Prozent der eingelesenen Objekte. Dies ist die Voreinstellung. Im 2. Eingabefeld dieser Optionsbox kann der Benutzer diese Clusterzahl erhöhen oder verringern. Box "Optionen in Stufe 2 (hierarchisches Verfahren)" Optionsbox geöffnet: 185

186 Der Benutzer kann das Verfahren und das Distanzmaß für die 2. Stufe bestimmen. Siehe die ausführliche Darstellung in Abschnitt P Wird die Optionsbox nicht geöffnet, dann ist als Verfahren das Ward-Linkage und als Distanzmaß die quadrierte eunklidische Distanz voreingestellt. Box "Optionen in Stufe 3 (K-Means-Verfahren)" Diese Optionsbox darf nur geöffnet werden, wenn in der Box "Mehrschritt-Verfahren" "3" (also das 3-stufige Verfahren) eingegeben wurde. 186


187 Optionsbox geöffnet: 187
 ------------------------------------------------------- Fuer Analyse ausgewaehlte Variable: Klassifikationsvariablen: V7 Kleidung nominal UG = 1")
188 Die Optionen werden ausführlich in Abschnitt P erläutert. P Ausgabe Ergebisse aus ALMO Stufe der two-stage-clusteranalyse (K-Means-Analyse) Fuer Analyse ausgewaehlte Variable: Klassifikationsvariablen: V7 Kleidung nominal UG = 1 OG = 3 V1 Rauchen quantitativ V2 Bier quantitativ V3 Wein quantitativ V4 Schnaps quantitativ V5 Aufputschdrinks quantitativ V6 nichtalkoh.drinks quantitativ Deskriptionsvariablen: V8 Geschlecht nominal UG = 1 OG = 2 V9 Bildungsgrad quantitativ V10 Alter quantitativ Es wurden 589 Datensaetze eingelesen, 188
Clusteranalyse. Anwendungsorientierte Einführung. R. Oldenbourg Verlag München Wien. Von Dr. Johann Bacher
 Clusteranalyse Anwendungsorientierte Einführung Von Dr. Johann Bacher R. Oldenbourg Verlag München Wien INHALTSVERZEICHNIS Vorwort XI 1 Einleitung 1 1.1 Primäre Zielsetzung clusteranalytischer Verfahren
Clusteranalyse Anwendungsorientierte Einführung Von Dr. Johann Bacher R. Oldenbourg Verlag München Wien INHALTSVERZEICHNIS Vorwort XI 1 Einleitung 1 1.1 Primäre Zielsetzung clusteranalytischer Verfahren
Clusteranalyse Hierarchische Verfahren
 Workshop Clusteranalyse Clusteranalyse Hierarchische Verfahren Graz, 8. 9. Oktober 2009 Johann Bacher Johannes Kepler Universität Linz Linz 2009 Graz, 8.-9.10.2009 1 1. Programmsystem ALMO vollständiges
Workshop Clusteranalyse Clusteranalyse Hierarchische Verfahren Graz, 8. 9. Oktober 2009 Johann Bacher Johannes Kepler Universität Linz Linz 2009 Graz, 8.-9.10.2009 1 1. Programmsystem ALMO vollständiges
Arbeiten mit dem Almo-Datenanalyse-System
 Kurt Holm Arbeiten mit dem Almo-Datenanalyse-System Statistische Datenanalyse III Data-Mining III Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2014 Zum Begriff "Data-Mining"
Kurt Holm Arbeiten mit dem Almo-Datenanalyse-System Statistische Datenanalyse III Data-Mining III Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2014 Zum Begriff "Data-Mining"
Soziometrie. Hermann Denz. Auswertung soziometrischer Daten. Almo Statistik-System
 Soziometrie Auswertung soziometrischer Daten Hermann Denz Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2018 Das vorliegende Dokument ist ein Kapitel aus dem Almo-Handbuch
Soziometrie Auswertung soziometrischer Daten Hermann Denz Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2018 Das vorliegende Dokument ist ein Kapitel aus dem Almo-Handbuch
Lösungen zu den Aufgaben zur Multivariaten Statistik Teil 4: Aufgaben zur Clusteranalyse
 Prof. Dr. Reinhold Kosfeld Fachbereich Wirtschaftswissenschaften Universität Kassel Lösungen zu den Aufgaben zur Multivariaten Statistik Teil 4: Aufgaben zur Clusteranalyse 1. Erläutern Sie, wie das Konstrukt
Prof. Dr. Reinhold Kosfeld Fachbereich Wirtschaftswissenschaften Universität Kassel Lösungen zu den Aufgaben zur Multivariaten Statistik Teil 4: Aufgaben zur Clusteranalyse 1. Erläutern Sie, wie das Konstrukt
Diskriminanzanalyse. Sub-Modelle der Kanonischen Analyse. Kanonische Korrelation Diskriminanzanalyse Korrespondenzanalyse Optimale Skalierung
 Diskriminanzanalyse Sub-Modelle der Kanonischen Analyse Kanonische Korrelation Diskriminanzanalyse Korrespondenzanalyse Optimale Skalierung Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de
Diskriminanzanalyse Sub-Modelle der Kanonischen Analyse Kanonische Korrelation Diskriminanzanalyse Korrespondenzanalyse Optimale Skalierung Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de
Statistische Datenanalyse II Teil 2 (Almo-Data-Mining) Ein Standard-Auswertungssystem
 Ein Standard-Auswertungssystem") Kurt Holm Statistische Datenanalyse II Teil 2 (Almo-Data-Mining) Ein Standard-Auswertungssystem 2014 Zum Begriff "Data-Mining" Inzwischen sind wir mit dem Begriff "Data-Mining" nicht mehr sehr glücklich.
Kurt Holm Statistische Datenanalyse II Teil 2 (Almo-Data-Mining) Ein Standard-Auswertungssystem 2014 Zum Begriff "Data-Mining" Inzwischen sind wir mit dem Begriff "Data-Mining" nicht mehr sehr glücklich.
Clusteranalyse K-Means-Verfahren
 Workshop Clusteranalyse Clusteranalyse K-Means-Verfahren Graz, 8. 9. Oktober 2009 Johann Bacher Johannes Kepler Universität Linz Linz 2009 1 1. Fragestellung und Algorithmus Bestimmung von Wertetypen (Bacher
Workshop Clusteranalyse Clusteranalyse K-Means-Verfahren Graz, 8. 9. Oktober 2009 Johann Bacher Johannes Kepler Universität Linz Linz 2009 1 1. Fragestellung und Algorithmus Bestimmung von Wertetypen (Bacher
Multivariate Verfahren
 Multivariate Verfahren Lineare Regression Zweck: Vorhersage x Dimensionsreduktion x x Klassifizierung x x Hauptkomponentenanalyse Korrespondenzanalyse Clusteranalyse Diskriminanzanalyse Eigenschaften:
Multivariate Verfahren Lineare Regression Zweck: Vorhersage x Dimensionsreduktion x x Klassifizierung x x Hauptkomponentenanalyse Korrespondenzanalyse Clusteranalyse Diskriminanzanalyse Eigenschaften:
Pfadanalyse als wiederholte Regressionsanalyse P25
 Pfadanalyse als wiederholte Regressionsanalyse P25 Kurt Holm www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2015 Weitere Almo-Dokumente Die folgenden Dokumente können alle kostenlos von
Pfadanalyse als wiederholte Regressionsanalyse P25 Kurt Holm www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2015 Weitere Almo-Dokumente Die folgenden Dokumente können alle kostenlos von
Strukturerkennende Verfahren
 Strukturerkennende Verfahren Viele Verfahren der multivariaten Datenanalyse dienen dazu, die in den Daten vorliegenden Strukturen zu erkennen und zu beschreiben. Dabei kann es sich um Strukturen sehr allgemeiner
Strukturerkennende Verfahren Viele Verfahren der multivariaten Datenanalyse dienen dazu, die in den Daten vorliegenden Strukturen zu erkennen und zu beschreiben. Dabei kann es sich um Strukturen sehr allgemeiner
Test auf Mittelwert-Differenzen. t-test Median-Test Ridit-Test. Johann Bacher / Kurt Holm
 Test auf Mittelwert-Differenzen t-test Median-Test Ridit-Test Johann Bacher / Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2014 Der Programmteil, der die
Test auf Mittelwert-Differenzen t-test Median-Test Ridit-Test Johann Bacher / Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2014 Der Programmteil, der die
4.Tutorium Multivariate Verfahren
 4.Tutorium Multivariate Verfahren - Clusteranalyse - Hannah Busen: 01.06.2015 und 08.06.2015 Nicole Schüller: 02.06.2015 und 09.06.2015 Institut für Statistik, LMU München 1 / 17 Gliederung 1 Idee der
4.Tutorium Multivariate Verfahren - Clusteranalyse - Hannah Busen: 01.06.2015 und 08.06.2015 Nicole Schüller: 02.06.2015 und 09.06.2015 Institut für Statistik, LMU München 1 / 17 Gliederung 1 Idee der
Datei-Operationen mit Almo
 Datei-Operationen mit Almo Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2016 Im Text wird häufig auf das Dokument P0 Bezug genommen. Dabei handelt es sich
Datei-Operationen mit Almo Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2016 Im Text wird häufig auf das Dokument P0 Bezug genommen. Dabei handelt es sich
Statistik IV für Studenten mit dem Nebenfach Statistik Lösungen zu Blatt 9 Gerhard Tutz, Jan Ulbricht SS 07
 Statistik IV für Studenten mit dem Nebenfach Statistik Lösungen zu Blatt 9 Gerhard Tutz, Jan Ulbricht SS 07 Ziel der Clusteranalyse: Bilde Gruppen (cluster) aus einer Menge multivariater Datenobjekte (stat
Statistik IV für Studenten mit dem Nebenfach Statistik Lösungen zu Blatt 9 Gerhard Tutz, Jan Ulbricht SS 07 Ziel der Clusteranalyse: Bilde Gruppen (cluster) aus einer Menge multivariater Datenobjekte (stat
Ähnlichkeits- und Distanzmaße
 Einheit 1 Ähnlichkeits- und Distanzmaße IFAS JKU Linz c 2015 Multivariate Verfahren 1 0 / 41 Problemstellung Ziel: Bestimmung von Ähnlichkeit zwischen n Objekten, an denen p Merkmale erhoben wurden. Die
Einheit 1 Ähnlichkeits- und Distanzmaße IFAS JKU Linz c 2015 Multivariate Verfahren 1 0 / 41 Problemstellung Ziel: Bestimmung von Ähnlichkeit zwischen n Objekten, an denen p Merkmale erhoben wurden. Die
Nicht-metrische multidimensionale Skalierung Iterative MDS
 Nicht-metrische multidimensionale Skalierung Iterative MDS P34 Johann Bacher / Kurt Holm / Heinrich Potuschak www.almo-statistik.de holm@almo-statistik.de johann.bacher@jku.at kurt.holm@jku.at heinrich.potuschak@linzag.net
Nicht-metrische multidimensionale Skalierung Iterative MDS P34 Johann Bacher / Kurt Holm / Heinrich Potuschak www.almo-statistik.de holm@almo-statistik.de johann.bacher@jku.at kurt.holm@jku.at heinrich.potuschak@linzag.net
4.4 Hierarchische Clusteranalyse-Verfahren
 Clusteranalyse 18.05.04-1 - 4.4 Hierarchische Clusteranalyse-Verfahren Ablauf von hierarchischen Clusteranalyse-Verfahren: (1) Start jedes Objekt sein eigenes Cluster, also Start mit n Clustern (2) Fusionierung
Clusteranalyse 18.05.04-1 - 4.4 Hierarchische Clusteranalyse-Verfahren Ablauf von hierarchischen Clusteranalyse-Verfahren: (1) Start jedes Objekt sein eigenes Cluster, also Start mit n Clustern (2) Fusionierung
Multivariate Statistische Methoden
 Multivariate Statistische Methoden und ihre Anwendung in den Wirtschafts- und Sozialwissenschaften Von Prof. Dr. Hans Peter Litz Carl von Ossietzky Universität Oldenburg v..v.-'... ':,. -X V R.Oldenbourg
Multivariate Statistische Methoden und ihre Anwendung in den Wirtschafts- und Sozialwissenschaften Von Prof. Dr. Hans Peter Litz Carl von Ossietzky Universität Oldenburg v..v.-'... ':,. -X V R.Oldenbourg
5. Clusteranalyse Vorbemerkungen. 5. Clusteranalyse. Grundlegende Algorithmen der Clusteranalyse kennen, ihre Eigenschaften
 5. Clusteranalyse Vorbemerkungen 5. Clusteranalyse Lernziele: Grundlegende Algorithmen der Clusteranalyse kennen, ihre Eigenschaften benennen und anwenden können, einen Test auf das Vorhandensein einer
5. Clusteranalyse Vorbemerkungen 5. Clusteranalyse Lernziele: Grundlegende Algorithmen der Clusteranalyse kennen, ihre Eigenschaften benennen und anwenden können, einen Test auf das Vorhandensein einer
Clusteranalyse mit SPSS
 Autor: Thomas Nirschl, Amt für Stadtforschung und Statistik, Stadt Nürnberg Clusteranalyse mit SPSS Das Statistikpaket SPSS (aktuell in der Version 17 vorliegend) stellt dem Anwender eine große Vielfalt
Autor: Thomas Nirschl, Amt für Stadtforschung und Statistik, Stadt Nürnberg Clusteranalyse mit SPSS Das Statistikpaket SPSS (aktuell in der Version 17 vorliegend) stellt dem Anwender eine große Vielfalt
Multivariate Statistische Methoden und ihre Anwendung
 Multivariate Statistische Methoden und ihre Anwendung in den Wirtschafts- und Sozialwissenschaften Von Prof. Dr. Hans Peter Litz Carl von Ossietzky Universität Oldenburg R. Oldenbourg Verlag München Wien
Multivariate Statistische Methoden und ihre Anwendung in den Wirtschafts- und Sozialwissenschaften Von Prof. Dr. Hans Peter Litz Carl von Ossietzky Universität Oldenburg R. Oldenbourg Verlag München Wien
Statistik K urs SS 2004
 Statistik K urs SS 2004 3.Tag Grundlegende statistische Maße Mittelwert (mean) Durchschnitt aller Werte Varianz (variance) s 2 Durchschnittliche quadrierte Abweichung aller Werte vom Mittelwert >> Die
Statistik K urs SS 2004 3.Tag Grundlegende statistische Maße Mittelwert (mean) Durchschnitt aller Werte Varianz (variance) s 2 Durchschnittliche quadrierte Abweichung aller Werte vom Mittelwert >> Die
Pisa 2012 Almo-Daten und Analyse-Programme
 Pisa 2012 Almo-Daten und Analyse-Programme Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2013 Die Daten zur Pisa-Studie 2012 liegen nunmehr im Almo-Format
Pisa 2012 Almo-Daten und Analyse-Programme Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2013 Die Daten zur Pisa-Studie 2012 liegen nunmehr im Almo-Format
5. Clusteranalyse. Lernziele: Grundlegende Algorithmen der Clusteranalyse kennen, ihre Eigenschaften
 5. Clusteranalyse Lernziele: Grundlegende Algorithmen der Clusteranalyse kennen, ihre Eigenschaften benennen und anwenden können, einen Test auf das Vorhandensein einer Clusterstruktur kennen, verschiedene
5. Clusteranalyse Lernziele: Grundlegende Algorithmen der Clusteranalyse kennen, ihre Eigenschaften benennen und anwenden können, einen Test auf das Vorhandensein einer Clusterstruktur kennen, verschiedene
3. Lektion: Deskriptive Statistik
 Seite 1 von 5 3. Lektion: Deskriptive Statistik Ziel dieser Lektion: Du kennst die verschiedenen Methoden der deskriptiven Statistik und weißt, welche davon für Deine Daten passen. Inhalt: 3.1 Deskriptive
Seite 1 von 5 3. Lektion: Deskriptive Statistik Ziel dieser Lektion: Du kennst die verschiedenen Methoden der deskriptiven Statistik und weißt, welche davon für Deine Daten passen. Inhalt: 3.1 Deskriptive
1 Beispiele multivariater Datensätze... 3
 Inhaltsverzeichnis Teil I Grundlagen 1 Beispiele multivariater Datensätze... 3 2 Elementare Behandlung der Daten... 15 2.1 Beschreibung und Darstellung univariater Datensätze... 15 2.1.1 Beschreibung und
Inhaltsverzeichnis Teil I Grundlagen 1 Beispiele multivariater Datensätze... 3 2 Elementare Behandlung der Daten... 15 2.1 Beschreibung und Darstellung univariater Datensätze... 15 2.1.1 Beschreibung und
Conjoint-Analyse Analyse verbundener Messungen
 Conjoint-Analyse Analyse verbundener Messungen Johann Bacher Almo Statistik-System www.almo-statistik.de johann.bacher@jku.at 2013 1 Der vorliegende Text ist eine leicht überarbeitete und gekürzte Fassung
Conjoint-Analyse Analyse verbundener Messungen Johann Bacher Almo Statistik-System www.almo-statistik.de johann.bacher@jku.at 2013 1 Der vorliegende Text ist eine leicht überarbeitete und gekürzte Fassung
Multivariate Statistik
 Multivariate Statistik von Univ.-Prof. Dr. Rainer Schlittgen Oldenbourg Verlag München I Daten und ihre Beschreibung 1 1 Einführung 3 1.1 Fragestellungen 3 1.2 Datensituation 8 1.3 Literatur und Software
Multivariate Statistik von Univ.-Prof. Dr. Rainer Schlittgen Oldenbourg Verlag München I Daten und ihre Beschreibung 1 1 Einführung 3 1.1 Fragestellungen 3 1.2 Datensituation 8 1.3 Literatur und Software
Clustern: Voraussetzungen
 Clustering Gruppen (Cluster) ähnlicher Elemente bilden Elemente in einem Cluster sollen sich möglichst ähnlich sein, u. den Elementen in anderen Clustern möglichst unähnlich im Gegensatz zu Kategorisierung
Clustering Gruppen (Cluster) ähnlicher Elemente bilden Elemente in einem Cluster sollen sich möglichst ähnlich sein, u. den Elementen in anderen Clustern möglichst unähnlich im Gegensatz zu Kategorisierung
Clusteranalyse. Anwendungsorientierte Einführung in Klassifikationsverfahren. von. Universitätsprofessor Dr. Johann Bacher
 Clusteranalyse Anwendungsorientierte Einführung in Klassifikationsverfahren von Universitätsprofessor Dr. Johann Bacher Johannes-Kepler-Universität, Linz Akademischer Rat Dr. Andreas Pöge Universität Bielefeld
Clusteranalyse Anwendungsorientierte Einführung in Klassifikationsverfahren von Universitätsprofessor Dr. Johann Bacher Johannes-Kepler-Universität, Linz Akademischer Rat Dr. Andreas Pöge Universität Bielefeld
Ziel: Unterteilung beobachteter Objekte in homogene Gruppen. Vorab meist weder Anzahl noch Charakteristika der Gruppen bekannt.
 8 Clusteranalyse Ziel: Unterteilung beobachteter Objekte in homogene Gruppen. Vorab meist weder Anzahl noch Charakteristika der Gruppen bekannt. Anwendungsbeispiele: Mikrobiologie: Ermittlung der Verwandtschaft
8 Clusteranalyse Ziel: Unterteilung beobachteter Objekte in homogene Gruppen. Vorab meist weder Anzahl noch Charakteristika der Gruppen bekannt. Anwendungsbeispiele: Mikrobiologie: Ermittlung der Verwandtschaft
Gibt es einen Zusammenhang zwischen Merkmalen? Korrelationen
 Arbeitsblatt SPSS Kapitel 8 Seite Gibt es einen Zusammenhang zwischen Merkmalen? Korrelationen Wie in allen Kapiteln gehen wir im Folgenden davon aus, dass Sie die Datei elporiginal.sav geöffnet haben.
Arbeitsblatt SPSS Kapitel 8 Seite Gibt es einen Zusammenhang zwischen Merkmalen? Korrelationen Wie in allen Kapiteln gehen wir im Folgenden davon aus, dass Sie die Datei elporiginal.sav geöffnet haben.
Korrespondenzanalyse Nominale Faktorenanalyse
 Korrespondenzanalyse Nominale Faktorenanalyse P30.8 Kurt Holm Almo Statistik-System http://www.almo-statistik.de/ holm@almo-statistik.de kurt.holm@jku.at 2014 Im Text wird häufig auf das Dokument P0 Bezug
Korrespondenzanalyse Nominale Faktorenanalyse P30.8 Kurt Holm Almo Statistik-System http://www.almo-statistik.de/ holm@almo-statistik.de kurt.holm@jku.at 2014 Im Text wird häufig auf das Dokument P0 Bezug
Ähnlichkeits- und Distanzmaße
 Ähnlichkeits- und Distanzmaße Jörg Rahnenführer, Multivariate Verfahren, WS89, TU Dortmund 11.1.8-1 - Ähnlichkeits- und Distanzmaße Jörg Rahnenführer, Multivariate Verfahren, WS89, TU Dortmund 11.1.8 -
Ähnlichkeits- und Distanzmaße Jörg Rahnenführer, Multivariate Verfahren, WS89, TU Dortmund 11.1.8-1 - Ähnlichkeits- und Distanzmaße Jörg Rahnenführer, Multivariate Verfahren, WS89, TU Dortmund 11.1.8 -
Konfirmatorische Faktorenanalyse
 Konfirmatorische Faktorenanalyse P30.5 Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2014 Siehe auch die beiden PDF-Dokumente Nr.15 "Faktorenanalyse" und
Konfirmatorische Faktorenanalyse P30.5 Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2014 Siehe auch die beiden PDF-Dokumente Nr.15 "Faktorenanalyse" und
Eigene MC-Fragen SPSS. 1. Zutreffend auf die Datenerfassung und Datenaufbereitung in SPSS ist
 Eigene MC-Fragen SPSS 1. Zutreffend auf die Datenerfassung und Datenaufbereitung in SPSS ist [a] In der Variablenansicht werden für die betrachteten Merkmale SPSS Variablen definiert. [b] Das Daten-Editor-Fenster
Eigene MC-Fragen SPSS 1. Zutreffend auf die Datenerfassung und Datenaufbereitung in SPSS ist [a] In der Variablenansicht werden für die betrachteten Merkmale SPSS Variablen definiert. [b] Das Daten-Editor-Fenster
Deskription, Statistische Testverfahren und Regression. Seminar: Planung und Auswertung klinischer und experimenteller Studien
 Deskription, Statistische Testverfahren und Regression Seminar: Planung und Auswertung klinischer und experimenteller Studien Deskriptive Statistik Deskriptive Statistik: beschreibende Statistik, empirische
Deskription, Statistische Testverfahren und Regression Seminar: Planung und Auswertung klinischer und experimenteller Studien Deskriptive Statistik Deskriptive Statistik: beschreibende Statistik, empirische
Clusteranalyse. Gliederung. 1. Einführung 2. Vorgehensweise. 3. Anwendungshinweise 4. Abgrenzung zu Faktorenanalyse 5. Fallbeispiel & SPSS
 Clusteranalyse Seminar Multivariate Verfahren SS 2010 Seminarleiter: Dr. Thomas Schäfer Theresia Montag, Claudia Wendschuh & Anne Brantl Gliederung 1. Einführung 2. Vorgehensweise 1. Bestimmung der 2.
Clusteranalyse Seminar Multivariate Verfahren SS 2010 Seminarleiter: Dr. Thomas Schäfer Theresia Montag, Claudia Wendschuh & Anne Brantl Gliederung 1. Einführung 2. Vorgehensweise 1. Bestimmung der 2.
Latent Structure Analysis
 Latent Structure Analysis Hermann Denz Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2014 1 Das vorliegende Dokument ist ein Kapitel aus dem Almo-Handbuch "Sozialwissenschaftliche
Latent Structure Analysis Hermann Denz Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2014 1 Das vorliegende Dokument ist ein Kapitel aus dem Almo-Handbuch "Sozialwissenschaftliche
Ausreisser erkennen Daten von Ausreissern bereinigen
 Ausreisser erkennen Daten von Ausreissern bereinigen Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2014 Im Text wird häufig auf das Dokument P0 Bezug genommen.
Ausreisser erkennen Daten von Ausreissern bereinigen Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2014 Im Text wird häufig auf das Dokument P0 Bezug genommen.
Die Clusteranalyse 24.06.2009. Clusteranalyse. Grundidee Mögliche Anwendungsgebiete gg Vorgehensweise Beispiele. methodenlehre ll Clusteranalyse
 Clusteranalyse Thomas Schäfer SS 2009 1 Die Clusteranalyse Grundidee Mögliche Anwendungsgebiete gg Vorgehensweise Beispiele Thomas Schäfer SS 2009 2 1 Die Clusteranalyse Grundidee: Eine heterogene Gesamtheit
Clusteranalyse Thomas Schäfer SS 2009 1 Die Clusteranalyse Grundidee Mögliche Anwendungsgebiete gg Vorgehensweise Beispiele Thomas Schäfer SS 2009 2 1 Die Clusteranalyse Grundidee: Eine heterogene Gesamtheit
1 Univariate Statistiken
 1 Univariate Statistiken Im ersten Kapitel berechnen wir zunächst Kenngrößen einer einzelnen Stichprobe bzw. so genannte empirische Kenngrößen, wie beispielsweise den Mittelwert. Diese können, unter gewissen
1 Univariate Statistiken Im ersten Kapitel berechnen wir zunächst Kenngrößen einer einzelnen Stichprobe bzw. so genannte empirische Kenngrößen, wie beispielsweise den Mittelwert. Diese können, unter gewissen
Metrische multidimensionale Skalierung Metrische MDS
 Metrische multidimensionale Skalierung Metrische MDS P34.6 Kurt Holm www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2015 Weitere Almo-Dokumente Die folgenden Dokumente können alle kostenlos
Metrische multidimensionale Skalierung Metrische MDS P34.6 Kurt Holm www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2015 Weitere Almo-Dokumente Die folgenden Dokumente können alle kostenlos
Nichtmetrische multidimensionale Skalierung (NMDS) Dr. Heike Culmsee Vegetationsanalyse & Phytodiversität
 Dr. Heike Culmsee Vegetationsanalyse & Phytodiversität") Nichtmetrische multidimensionale Skalierung (NMDS) Dr. Heike Culmsee Vegetationsanalyse & Phytodiversität Übersicht Ordinationsverfahren Linear methods Weighted averaging Multidimensional scaling Unconstrained
Nichtmetrische multidimensionale Skalierung (NMDS) Dr. Heike Culmsee Vegetationsanalyse & Phytodiversität Übersicht Ordinationsverfahren Linear methods Weighted averaging Multidimensional scaling Unconstrained
Bivariate explorative Datenanalyse in R
 Bivariate explorative Datenanalyse in R Achim Zeileis, Regina Tüchler 2006-10-09 In der LV Statistik 1 haben wir auch den Zusammenhang von 2 Variablen untersucht. Hier werden die dazugehörenden R-Befehle
Bivariate explorative Datenanalyse in R Achim Zeileis, Regina Tüchler 2006-10-09 In der LV Statistik 1 haben wir auch den Zusammenhang von 2 Variablen untersucht. Hier werden die dazugehörenden R-Befehle
fh management, communication & it Constantin von Craushaar fh-management, communication & it Statistik Angewandte Statistik
 fh management, communication & it Folie 1 Überblick Grundlagen (Testvoraussetzungen) Mittelwertvergleiche (t-test,..) Nichtparametrische Tests Korrelationen Regressionsanalyse... Folie 2 Überblick... Varianzanalyse
fh management, communication & it Folie 1 Überblick Grundlagen (Testvoraussetzungen) Mittelwertvergleiche (t-test,..) Nichtparametrische Tests Korrelationen Regressionsanalyse... Folie 2 Überblick... Varianzanalyse
Lage- und Streuungsparameter
 Lage- und Streuungsparameter Beziehen sich auf die Verteilung der Ausprägungen von intervall- und ratio-skalierten Variablen Versuchen, diese Verteilung durch Zahlen zu beschreiben, statt sie graphisch
Lage- und Streuungsparameter Beziehen sich auf die Verteilung der Ausprägungen von intervall- und ratio-skalierten Variablen Versuchen, diese Verteilung durch Zahlen zu beschreiben, statt sie graphisch
Methoden der Klassifikation und ihre mathematischen Grundlagen
 Methoden der Klassifikation und ihre mathematischen Grundlagen Mengenlehre und Logik A B "Unter einer 'Menge' verstehen wir jede Zusammenfassung M von bestimmten wohlunterschiedenen Objekten unserer Anschauung
Methoden der Klassifikation und ihre mathematischen Grundlagen Mengenlehre und Logik A B "Unter einer 'Menge' verstehen wir jede Zusammenfassung M von bestimmten wohlunterschiedenen Objekten unserer Anschauung
Klassifikation und Ähnlichkeitssuche
 Klassifikation und Ähnlichkeitssuche Vorlesung XIII Allgemeines Ziel Rationale Zusammenfassung von Molekülen in Gruppen auf der Basis bestimmter Eigenschaften Auswahl von repräsentativen Molekülen Strukturell
Klassifikation und Ähnlichkeitssuche Vorlesung XIII Allgemeines Ziel Rationale Zusammenfassung von Molekülen in Gruppen auf der Basis bestimmter Eigenschaften Auswahl von repräsentativen Molekülen Strukturell
Clusteranalyse. Clusteranalyse. Fragestellung und Aufgaben. Abgrenzung Clusteranalyse - Diskriminanzanalyse. Rohdatenmatrix und Distanzmatrix
 TECHNISCHE UNIVERSITÄT MÜNCHEN-WEIHENSTEPHAN MATHEMATIK UND STATISTIK INFORMATIONS- UND DOKUMENTATIONSZENTRUM R. Biometrische und Ökonometrische Methoden II SS 00 Fragestellung und Aufgaben Abgrenzung
TECHNISCHE UNIVERSITÄT MÜNCHEN-WEIHENSTEPHAN MATHEMATIK UND STATISTIK INFORMATIONS- UND DOKUMENTATIONSZENTRUM R. Biometrische und Ökonometrische Methoden II SS 00 Fragestellung und Aufgaben Abgrenzung
Dr. Ralf Gutfleisch, Stadt Frankfurt a.m.
 Zentrale Fragestellungen: Was Wie Wann ist eine Clusteranalyse? wird eine Clusteranalyse angewendet? wird eine Clusteranalyse angewendet? Clusteranalyse = Gruppenbildungsverfahren = eine Vielzahl von Objekten
Zentrale Fragestellungen: Was Wie Wann ist eine Clusteranalyse? wird eine Clusteranalyse angewendet? wird eine Clusteranalyse angewendet? Clusteranalyse = Gruppenbildungsverfahren = eine Vielzahl von Objekten
1 x 1 y 1 2 x 2 y 2 3 x 3 y 3... n x n y n
 3.2. Bivariate Verteilungen zwei Variablen X, Y werden gemeinsam betrachtet (an jedem Objekt werden gleichzeitig zwei Merkmale beobachtet) Beobachtungswerte sind Paare von Merkmalsausprägungen (x, y) Beispiele:
3.2. Bivariate Verteilungen zwei Variablen X, Y werden gemeinsam betrachtet (an jedem Objekt werden gleichzeitig zwei Merkmale beobachtet) Beobachtungswerte sind Paare von Merkmalsausprägungen (x, y) Beispiele:
9 Faktorenanalyse. Wir gehen zunächst von dem folgenden Modell aus (Modell der Hauptkomponentenanalyse): Z = F L T
: Z = F L T") 9 Faktorenanalyse Ziel der Faktorenanalyse ist es, die Anzahl der Variablen auf wenige voneinander unabhängige Faktoren zu reduzieren und dabei möglichst viel an Information zu erhalten. Hier wird davon
9 Faktorenanalyse Ziel der Faktorenanalyse ist es, die Anzahl der Variablen auf wenige voneinander unabhängige Faktoren zu reduzieren und dabei möglichst viel an Information zu erhalten. Hier wird davon
Mathematisch-Statistische Verfahren des Risiko-Managements - SS
 Clusteranalyse Mathematisch-Statistische Verfahren des Risiko-Managements - SS 2004 Allgemeine Beschreibung (I) Der Begriff Clusteranalyse wird vielfach als Sammelname für eine Reihe mathematisch-statistischer
Clusteranalyse Mathematisch-Statistische Verfahren des Risiko-Managements - SS 2004 Allgemeine Beschreibung (I) Der Begriff Clusteranalyse wird vielfach als Sammelname für eine Reihe mathematisch-statistischer
Einführung in die Statistik für Politikwissenschaftler Sommersemester 2011
 Einführung in die Statistik für Politikwissenschaftler Sommersemester 2011 Es können von den Antworten alle, mehrere oder keine Antwort(en) richtig sein. Nur bei einer korrekten Antwort (ohne Auslassungen
Einführung in die Statistik für Politikwissenschaftler Sommersemester 2011 Es können von den Antworten alle, mehrere oder keine Antwort(en) richtig sein. Nur bei einer korrekten Antwort (ohne Auslassungen
Konzepte II. Netzwerkanalyse für Politikwissenschaftler
 Konzepte II Netzwerkanalyse für Politikwissenschaftler Wiederholung Räumliche Distanzen und MDS Hauptkomponenten Neuere Entwicklungen Netzwerkanalyse für Politikwissenschaftler Konzepte II (1/20) Worum
Konzepte II Netzwerkanalyse für Politikwissenschaftler Wiederholung Räumliche Distanzen und MDS Hauptkomponenten Neuere Entwicklungen Netzwerkanalyse für Politikwissenschaftler Konzepte II (1/20) Worum
Musterlösung. Modulklausur Multivariate Verfahren
 Musterlösung Modulklausur 31821 Multivariate Verfahren 27. März 2015 Aufgabe 1 Kennzeichnen Sie die folgenden Aussagen über die beiden Zufallsvektoren ([ ] [ ]) ([ ] [ ]) 2 1 0 1 25 2 x 1 N, x 3 0 1 2
Musterlösung Modulklausur 31821 Multivariate Verfahren 27. März 2015 Aufgabe 1 Kennzeichnen Sie die folgenden Aussagen über die beiden Zufallsvektoren ([ ] [ ]) ([ ] [ ]) 2 1 0 1 25 2 x 1 N, x 3 0 1 2
Statistisches Testen
 Statistisches Testen Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Differenzen Anteilswert Chi-Quadrat Tests Gleichheit von Varianzen Prinzip des Statistischen Tests Konfidenzintervall
Statistisches Testen Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Differenzen Anteilswert Chi-Quadrat Tests Gleichheit von Varianzen Prinzip des Statistischen Tests Konfidenzintervall
Bivariate Analyse: Gemeinsame (bivariate) Häufigkeitstabelle. Sie wird auch Kontingenz-, Assoziations- oder Korrelationstabelle (f b )genannt.
 Häufigkeitstabelle. Sie wird auch Kontingenz-, Assoziations- oder Korrelationstabelle (f b )genannt.") Bivariate Analyse: Tabellarische Darstellung: Gemeinsame (bivariate) Häufigkeitstabelle. Sie wird auch Kontingenz-, Assoziations- oder Korrelationstabelle (f b )genannt. Beispiel: Häufigkeitsverteilung
Bivariate Analyse: Tabellarische Darstellung: Gemeinsame (bivariate) Häufigkeitstabelle. Sie wird auch Kontingenz-, Assoziations- oder Korrelationstabelle (f b )genannt. Beispiel: Häufigkeitsverteilung
W-Seminar: Versuche mit und am Menschen 2017/2019 Skript
 3. Deskriptive Statistik Die deskriptive (auch: beschreibende) Statistik hat zum Ziel, [ ] Daten durch Tabellen, Kennzahlen [ ] und Grafiken übersichtlich darzustellen und zu ordnen. Dies ist vor allem
3. Deskriptive Statistik Die deskriptive (auch: beschreibende) Statistik hat zum Ziel, [ ] Daten durch Tabellen, Kennzahlen [ ] und Grafiken übersichtlich darzustellen und zu ordnen. Dies ist vor allem
Kapitel 2. Mittelwerte
 Kapitel 2. Mittelwerte Im Zusammenhang mit dem Begriff der Verteilung, der im ersten Kapitel eingeführt wurde, taucht häufig die Frage auf, wie man die vorliegenden Daten durch eine geeignete Größe repräsentieren
Kapitel 2. Mittelwerte Im Zusammenhang mit dem Begriff der Verteilung, der im ersten Kapitel eingeführt wurde, taucht häufig die Frage auf, wie man die vorliegenden Daten durch eine geeignete Größe repräsentieren
Bei näherer Betrachtung des Diagramms Nr. 3 fällt folgendes auf:
 18 3 Ergebnisse In diesem Kapitel werden nun zunächst die Ergebnisse der Korrelationen dargelegt und anschließend die Bedingungen der Gruppenbildung sowie die Ergebnisse der weiteren Analysen. 3.1 Ergebnisse
18 3 Ergebnisse In diesem Kapitel werden nun zunächst die Ergebnisse der Korrelationen dargelegt und anschließend die Bedingungen der Gruppenbildung sowie die Ergebnisse der weiteren Analysen. 3.1 Ergebnisse
Grundlagen der empirischen Sozialforschung
 Grundlagen der empirischen Sozialforschung Sitzung 11 - Datenanalyseverfahren Jan Finsel Lehrstuhl für empirische Sozialforschung Prof. Dr. Petra Stein 5. Januar 2009 1 / 22 Online-Materialien Die Materialien
Grundlagen der empirischen Sozialforschung Sitzung 11 - Datenanalyseverfahren Jan Finsel Lehrstuhl für empirische Sozialforschung Prof. Dr. Petra Stein 5. Januar 2009 1 / 22 Online-Materialien Die Materialien
PROC MEANS. zum Berechnen statistischer Maßzahlen (für quantitative Merkmale)
") PROC MEAS zum Berechnen statistischer Maßzahlen (für quantitative Merkmale) Allgemeine Form: PROC MEAS DATA=name Optionen ; VAR variablenliste ; CLASS vergleichsvariable ; Beispiel und Beschreibung der
PROC MEAS zum Berechnen statistischer Maßzahlen (für quantitative Merkmale) Allgemeine Form: PROC MEAS DATA=name Optionen ; VAR variablenliste ; CLASS vergleichsvariable ; Beispiel und Beschreibung der
Angewandte Statistik 3. Semester
 Angewandte Statistik 3. Semester Übung 5 Grundlagen der Statistik Übersicht Semester 1 Einführung ins SPSS Auswertung im SPSS anhand eines Beispieles Häufigkeitsauswertungen Grafiken Statistische Grundlagen
Angewandte Statistik 3. Semester Übung 5 Grundlagen der Statistik Übersicht Semester 1 Einführung ins SPSS Auswertung im SPSS anhand eines Beispieles Häufigkeitsauswertungen Grafiken Statistische Grundlagen
Konzepte II. Netzwerkanalyse für Politikwissenschaftler. Wiederholung
 Konzepte II Netzwerkanalyse für Politikwissenschaftler Netzwerkanalyse für Politikwissenschaftler Konzepte II (1/20) Worum geht es? Bisher: Eigenschaften einzelner Punkte bzw. des Netzwerkes Definiert
Konzepte II Netzwerkanalyse für Politikwissenschaftler Netzwerkanalyse für Politikwissenschaftler Konzepte II (1/20) Worum geht es? Bisher: Eigenschaften einzelner Punkte bzw. des Netzwerkes Definiert
Einführung in Quantitative Methoden
 Einführung in Quantitative Methoden Mag. Dipl.Ing. Dr. Pantelis Christodoulides & Mag. Dr. Karin Waldherr SS 2014 Christodoulides / Waldherr Einführung in Quantitative Methoden- 2.VO 1/57 Die Deskriptivstatistik
Einführung in Quantitative Methoden Mag. Dipl.Ing. Dr. Pantelis Christodoulides & Mag. Dr. Karin Waldherr SS 2014 Christodoulides / Waldherr Einführung in Quantitative Methoden- 2.VO 1/57 Die Deskriptivstatistik
Mathematische Grundlagen III
 Mathematische Grundlagen III Maschinelles Lernen III: Clustering Vera Demberg Universität des Saarlandes 7. Juli 202 Vera Demberg (UdS) Mathe III 7. Juli 202 / 35 Clustering vs. Klassifikation In den letzten
Mathematische Grundlagen III Maschinelles Lernen III: Clustering Vera Demberg Universität des Saarlandes 7. Juli 202 Vera Demberg (UdS) Mathe III 7. Juli 202 / 35 Clustering vs. Klassifikation In den letzten
Lineare Gleichungssystem
 Lineare Gleichungssystem 8. Juli 07 Inhaltsverzeichnis Einleitung Der Gauß-Algorithmus 4 3 Lösbarkeit von Gleichungssystemen 6 Einleitung Wir haben uns bisher hauptsächlich mit dem Finden von Nullstellen
Lineare Gleichungssystem 8. Juli 07 Inhaltsverzeichnis Einleitung Der Gauß-Algorithmus 4 3 Lösbarkeit von Gleichungssystemen 6 Einleitung Wir haben uns bisher hauptsächlich mit dem Finden von Nullstellen
Clustern von numerischen Wettervorhersagen
 Clustern von numerischen Wettervorhersagen Diplomarbeit in der Studienrichtung Technische Mathematik zur Erlangung des akademischen Grades Diplom-Ingenieurin eingereicht an der Fakultät für Mathematik,
Clustern von numerischen Wettervorhersagen Diplomarbeit in der Studienrichtung Technische Mathematik zur Erlangung des akademischen Grades Diplom-Ingenieurin eingereicht an der Fakultät für Mathematik,
TEIL 12: BIVARIATE ANALYSE FÜR METRISCH SKALIERTE VARIABLEN
 TEIL 12: BIVARIATE ANALYSE FÜR METRISCH SKALIERTE VARIABLEN Bivariate Analyse für metrisch skalierte Variablen Grundlagen Verfahren für metrische Daten nutzen den vollen mathematischen Informationsgehalt
TEIL 12: BIVARIATE ANALYSE FÜR METRISCH SKALIERTE VARIABLEN Bivariate Analyse für metrisch skalierte Variablen Grundlagen Verfahren für metrische Daten nutzen den vollen mathematischen Informationsgehalt
Statistische Methoden in den Umweltwissenschaften
 Statistische Methoden in den Umweltwissenschaften Korrelationsanalysen Kreuztabellen und χ²-test Themen Korrelation oder Lineare Regression? Korrelationsanalysen - Pearson, Spearman-Rang, Kendall s Tau
Statistische Methoden in den Umweltwissenschaften Korrelationsanalysen Kreuztabellen und χ²-test Themen Korrelation oder Lineare Regression? Korrelationsanalysen - Pearson, Spearman-Rang, Kendall s Tau
4 Clusteranalyse 4.1 Einführung
 Clusteranalyse.0.0 - - Clusteranalyse. Einführung p Merkmale: X, X,..., X p (metrisch; auch ordinal möglich, falls geeignet nummeriert; nominalskaliert?!) Zu den Merkmalen werden n Datensätze bzw. Datenobjekte
Clusteranalyse.0.0 - - Clusteranalyse. Einführung p Merkmale: X, X,..., X p (metrisch; auch ordinal möglich, falls geeignet nummeriert; nominalskaliert?!) Zu den Merkmalen werden n Datensätze bzw. Datenobjekte
Biometrisches Tutorial III
 Biometrisches Tutorial III Montag 16-18 Uhr Sitzung 3 07.05.2018 Dr. Christoph Borzikowsky Biometrisches Tutorial III 1. Anforderungen an Daten und Datenstrukturen 2. Einführung in SPSS (Grundlagen) 3.
Biometrisches Tutorial III Montag 16-18 Uhr Sitzung 3 07.05.2018 Dr. Christoph Borzikowsky Biometrisches Tutorial III 1. Anforderungen an Daten und Datenstrukturen 2. Einführung in SPSS (Grundlagen) 3.
z Partitionierende Klassifikationsverfahren
 4.4 Partitionierende Klassifikationsverfahren Partitionierenden Verfahren: - gegeben: eine Zerlegung der Objektmenge in G Cluster, die jedoch nicht als "optimal" angesehen wird; - Verbesserung der Ausgangspartition
4.4 Partitionierende Klassifikationsverfahren Partitionierenden Verfahren: - gegeben: eine Zerlegung der Objektmenge in G Cluster, die jedoch nicht als "optimal" angesehen wird; - Verbesserung der Ausgangspartition
Sommersemester Marktforschung
 Dipl.-Kfm. Sascha Steinmann Universität Siegen Lehrstuhl für Marketing steinmann@marketing.uni-siegen.de Sommersemester 2010 Marktforschung Übungsaufgaben zu den Themen 3-6 mit Lösungsskizzen Aufgabe 1:
Dipl.-Kfm. Sascha Steinmann Universität Siegen Lehrstuhl für Marketing steinmann@marketing.uni-siegen.de Sommersemester 2010 Marktforschung Übungsaufgaben zu den Themen 3-6 mit Lösungsskizzen Aufgabe 1:
Charakterisierung von 1D Daten
 Charakterisierung von D Daten Mittelwert: µ, Schätzung m x = x i / n Varianz σ2, Schätzung: s2 = (s: Standardabweichung) Höhere Momente s 2 = ( x i m x ) 2 n ( ) Eine Normalverteilung ist mit Mittelwert
Charakterisierung von D Daten Mittelwert: µ, Schätzung m x = x i / n Varianz σ2, Schätzung: s2 = (s: Standardabweichung) Höhere Momente s 2 = ( x i m x ) 2 n ( ) Eine Normalverteilung ist mit Mittelwert
Master: Quantitative Methoden
 Technische Hochschule Köln Fakultät für Wirtschafts- und Rechtswissenschaften Prof. Dr. Arrenberg Raum 221, Tel. 39 14 jutta.arrenberg@th-koeln.de Master: Quantitative Methoden Alte Klausuren Aufgabe (06.07.2016)
Technische Hochschule Köln Fakultät für Wirtschafts- und Rechtswissenschaften Prof. Dr. Arrenberg Raum 221, Tel. 39 14 jutta.arrenberg@th-koeln.de Master: Quantitative Methoden Alte Klausuren Aufgabe (06.07.2016)
Inhaltsverzeichnis Grundlagen aufigkeitsverteilungen Maßzahlen und Grafiken f ur eindimensionale Merkmale
 1. Grundlagen... 1 1.1 Grundgesamtheit und Untersuchungseinheit................ 1 1.2 Merkmal oder statistische Variable........................ 2 1.3 Datenerhebung.........................................
1. Grundlagen... 1 1.1 Grundgesamtheit und Untersuchungseinheit................ 1 1.2 Merkmal oder statistische Variable........................ 2 1.3 Datenerhebung.........................................
Kapitel VII - Konzentration von Merkmalswerten
 Institut für Volkswirtschaftslehre (ECON) Lehrstuhl für Ökonometrie und Statistik Kapitel VII - Konzentration von Merkmalswerten Deskriptive Statistik Prof. Dr. W.-D. Heller Hartwig Senska Carlo Siebenschuh
Institut für Volkswirtschaftslehre (ECON) Lehrstuhl für Ökonometrie und Statistik Kapitel VII - Konzentration von Merkmalswerten Deskriptive Statistik Prof. Dr. W.-D. Heller Hartwig Senska Carlo Siebenschuh
Was sind Zusammenhangsmaße?
 Was sind Zusammenhangsmaße? Zusammenhangsmaße beschreiben einen Zusammenhang zwischen zwei Variablen Beispiele für Zusammenhänge: Arbeiter wählen häufiger die SPD als andere Gruppen Hochgebildete vertreten
Was sind Zusammenhangsmaße? Zusammenhangsmaße beschreiben einen Zusammenhang zwischen zwei Variablen Beispiele für Zusammenhänge: Arbeiter wählen häufiger die SPD als andere Gruppen Hochgebildete vertreten
1.1 Graphische Darstellung von Messdaten und unterschiedliche Mittelwerte. D. Horstmann: Oktober
 1.1 Graphische Darstellung von Messdaten und unterschiedliche Mittelwerte D. Horstmann: Oktober 2014 4 Graphische Darstellung von Daten und unterschiedliche Mittelwerte Eine Umfrage nach der Körpergröße
1.1 Graphische Darstellung von Messdaten und unterschiedliche Mittelwerte D. Horstmann: Oktober 2014 4 Graphische Darstellung von Daten und unterschiedliche Mittelwerte Eine Umfrage nach der Körpergröße
TEIL 12: BIVARIATE ANALYSE FÜR METRISCH SKALIERTE VARIABLEN
 TEIL 12: BIVARIATE ANALYSE FÜR METRISCH SKALIERTE VARIABLEN GLIEDERUNG Bivariate Analyse für metrisch skalierte Variablen Grundlagen Streudiagramme und Visualisierungen von Zusammenhängen Positive lineare
TEIL 12: BIVARIATE ANALYSE FÜR METRISCH SKALIERTE VARIABLEN GLIEDERUNG Bivariate Analyse für metrisch skalierte Variablen Grundlagen Streudiagramme und Visualisierungen von Zusammenhängen Positive lineare
Deskriptive Statistik
 Helge Toutenburg Christian Heumann Deskriptive Statistik Eine Einführung in Methoden und Anwendungen mit R und SPSS Siebte, aktualisierte und erweiterte Auflage Mit Beiträgen von Michael Schomaker 4ü Springer
Helge Toutenburg Christian Heumann Deskriptive Statistik Eine Einführung in Methoden und Anwendungen mit R und SPSS Siebte, aktualisierte und erweiterte Auflage Mit Beiträgen von Michael Schomaker 4ü Springer
Mustererkennung. Übersicht. Unüberwachtes Lernen. (Un-) Überwachtes Lernen Clustering im Allgemeinen k-means-verfahren Gaussian-Mixture Modelle
 Überwachtes Lernen Clustering im Allgemeinen k-means-verfahren Gaussian-Mixture Modelle") Mustererkennung Unüberwachtes Lernen R. Neubecker, WS 01 / 01 Übersicht (Un-) Überwachtes Lernen Clustering im Allgemeinen k-means-verfahren 1 Lernen Überwachtes Lernen Zum Training des Klassifikators
Mustererkennung Unüberwachtes Lernen R. Neubecker, WS 01 / 01 Übersicht (Un-) Überwachtes Lernen Clustering im Allgemeinen k-means-verfahren 1 Lernen Überwachtes Lernen Zum Training des Klassifikators
Forschungsmethodik II, SS 2010
 Forschungsmethodik II, SS 2010 Michael Kickmeier-Rust Teil 5, 26. Mai 2010 Prinzipien statistischer Verfahren: Conclusio 1 Prinzipien statistischer Verfahren > χ 2 Beispiel: 4-Felder χ 2 Beobachtet: Erwartet:
Forschungsmethodik II, SS 2010 Michael Kickmeier-Rust Teil 5, 26. Mai 2010 Prinzipien statistischer Verfahren: Conclusio 1 Prinzipien statistischer Verfahren > χ 2 Beispiel: 4-Felder χ 2 Beobachtet: Erwartet:
Wählerstromanalyse und Wahlhochrechnung
 Wählerstromanalyse und Wahlhochrechnung Johann Bacher Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at johann. bacher@jku.at 2018 Im Text wird häufig auf das
Wählerstromanalyse und Wahlhochrechnung Johann Bacher Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at johann. bacher@jku.at 2018 Im Text wird häufig auf das
Test auf Mittelwert-Differenzen P18. Johann Bacher / Kurt Holm
 Test auf Mittelwert-Differenzen P18 Johann Bacher / Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at Inhaltsverzeichnis P18 PROGRAMM 18: Zellenmittelwerte und
Test auf Mittelwert-Differenzen P18 Johann Bacher / Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at Inhaltsverzeichnis P18 PROGRAMM 18: Zellenmittelwerte und
6. Vorlesung. Rechnen mit Matrizen.
 6. Vorlesung. Rechnen mit Matrizen. In dieser Vorlesung betrachten wir lineare Gleichungs System. Wir betrachten lineare Gleichungs Systeme wieder von zwei Gesichtspunkten her: dem angewandten Gesichtspunkt
6. Vorlesung. Rechnen mit Matrizen. In dieser Vorlesung betrachten wir lineare Gleichungs System. Wir betrachten lineare Gleichungs Systeme wieder von zwei Gesichtspunkten her: dem angewandten Gesichtspunkt
5.5 PRE-Maße (Fehlerreduktionsmaße) 6
 6") 359 5.5 PRE-Maße (Fehlerreduktionsmaße) 6 5.5.1 Die grundlegende Konstruktion Völlig andere, sehr allgemeine Grundidee zur Beschreibung von Zusammenhängen. Grundlegendes Prinzip vieler statistischer Konzepte.
359 5.5 PRE-Maße (Fehlerreduktionsmaße) 6 5.5.1 Die grundlegende Konstruktion Völlig andere, sehr allgemeine Grundidee zur Beschreibung von Zusammenhängen. Grundlegendes Prinzip vieler statistischer Konzepte.
Modulklausur Multivariate Verfahren
 Name, Vorname Matrikelnummer Modulklausur 31821 Multivariate Verfahren Datum Punkte Note Termin: 28. März 2014, 9.00-11.00 Uhr Erstprüfer: Univ.-Prof. Dr. H. Singer Hinweise zur Bearbeitung der Modulklausur
Name, Vorname Matrikelnummer Modulklausur 31821 Multivariate Verfahren Datum Punkte Note Termin: 28. März 2014, 9.00-11.00 Uhr Erstprüfer: Univ.-Prof. Dr. H. Singer Hinweise zur Bearbeitung der Modulklausur
Grundlagen der empirischen Sozialforschung
 Grundlagen der empirischen Sozialforschung Sitzung 10 - Datenanalyseverfahren Jan Finsel Lehrstuhl für empirische Sozialforschung Prof. Dr. Petra Stein 22. Dezember 2008 1 / 21 Online-Materialien Die Materialien
Grundlagen der empirischen Sozialforschung Sitzung 10 - Datenanalyseverfahren Jan Finsel Lehrstuhl für empirische Sozialforschung Prof. Dr. Petra Stein 22. Dezember 2008 1 / 21 Online-Materialien Die Materialien
Einführung in die Korrelationsrechnung
 Einführung in die Korrelationsrechnung Sven Garbade Fakultät für Angewandte Psychologie SRH Hochschule Heidelberg sven.garbade@hochschule-heidelberg.de Statistik 1 S. Garbade (SRH Heidelberg) Korrelationsrechnung
Einführung in die Korrelationsrechnung Sven Garbade Fakultät für Angewandte Psychologie SRH Hochschule Heidelberg sven.garbade@hochschule-heidelberg.de Statistik 1 S. Garbade (SRH Heidelberg) Korrelationsrechnung
Wie bekomme ich einen schnellen Überblick über die bereits eingegebenen Daten?
 Datenanalyse 1 Datenanalyse Wie bekomme ich einen schnellen Überblick über die bereits eingegebenen Daten? In SPSS: Die Variablenansicht sollte bereits ordentlich ausgefüllt sein! Daten öffnen: Doppelklick
Datenanalyse 1 Datenanalyse Wie bekomme ich einen schnellen Überblick über die bereits eingegebenen Daten? In SPSS: Die Variablenansicht sollte bereits ordentlich ausgefüllt sein! Daten öffnen: Doppelklick
Statistische Datenanalyse II Teil 2 (Almo-Data-Mining) Ein Standard-Auswertungssystem
 Ein Standard-Auswertungssystem") Kurt Holm Statistische Datenanalyse II Teil 2 (Almo-Data-Mining) Ein Standard-Auswertungssystem 2014 Zum Begriff "Data-Mining" Inzwischen sind wir mit dem Begriff "Data-Mining" nicht mehr sehr glücklich.
Kurt Holm Statistische Datenanalyse II Teil 2 (Almo-Data-Mining) Ein Standard-Auswertungssystem 2014 Zum Begriff "Data-Mining" Inzwischen sind wir mit dem Begriff "Data-Mining" nicht mehr sehr glücklich.