Tutorium empirische Auswertung. Tobias Röding, M.Sc.
|
|
|
- Sophia Maier
- vor 5 Jahren
- Abrufe
Transkript

1 Tutorium empirische Auswertung Tobias Röding, M.Sc.
2 Agenda Einführung: Warum diese Veranstaltung? Der Fragebogen Methoden der statistischen Auswertung Schriftliche Aufbereitung der Ergebnisse Einblick in SPSS t-test Varianzanalyse (ANOVA) Regressionsanalyse Rückfragen
3 Quelle: Mau 2014 Einführung: Wo befinden wir uns?
4 Statistik allgemein: Literatur Backhaus, K.; Erichson, B.; Plinke, W.; Weiber, R. (2016): Multivariate Analysmethoden, (14. Aufl.), Berlin. Sedelmeier, P.; Renkewitz, F. (2008): Forschungsmethoden und Statistik in der Psychologie, München. Bortz, J. (2010): Statistik: Für Human- und Sozialwissenschaftler, 7. Aufl., Berlin. TU Dresden (Web): SPSS: Bühl, A. (2012): SPSS 20, (13. Aufl.), München. Janssen, J.; Laatz, W. (2010): Statistische Datenanalyse mit SPSS, Heidelberg.
5 Die Methoden und Kennzahlen Statistische Auswertung
6 In die quantitative Forschung Bearbeitung der Fragestellung durch einen standardisierten Fragebogen Erstellung des Fragebogens ausgehend von einer marketingrelevanten Theorie 1. Unabhängige Variable 1. Item:...? 2. Item:...? 3. Item:...? 2. Unabhängige Variable Abhängige Variable 1. Item:...? 2. Item:...? 3. Item:...? 1. Item:...? 2. Item:...? 3. Item:...?

7 Der fliegende Einkaufswagen

8 Status-Quo ebsco scholar research literatur

9 Find the gap and close it!

10 Forschungsfrage Wird von Seiten der Konsumenten ein (Mehr)-Wert mit Blick auf den Einsatz von fliegenden Einkaufswagen wahrgenommen?

11
12 Das Forschungsmodel Trust in Flying Shopping Carts H1 (+) Shopping Value hedonisch utilitaristisch Task- Technology-Fit H2 (+) H1: Je höher das Vertrauen in FSC, desto höher der Shopping Value. H2: Je höher der Technology-Task-Fit, desto höher der Shopping Value.

13 Wie messen wir das denn nun?
14 EXKURS1: Daten und Skalenniveaus Nicht-metrische Skalen WAS genau Nominalskala Klassifizierung qualitativer Eigenschaftsausprägungen Ordinalskala Ordnen von Objekten eines Gegenstandsbereiches Eigenschaften Häufigkeit Häufigkeit, Reihenfolge Berechnung keine arithmetischen Rechenoperationen Rangordnung von Objekten (keine Abstände) Modus Median, Quartile etc. Beispiel Geschlecht, Farbe,... Notenskala, Windstärken,
15 EXKURS1: Daten und Skalenniveaus metrische Skalen WAS genau Intervallskala Skala mit gleichgroßen Abschnitten ohne natürlichem Nullpunkt Ratioskala (Verhältnisskala) Skala mit gleichgroßen Abschnitten mit natürlichem Nullpunkt Eigenschaften Berechnung Häufigkeit, Reihenfolge, Abstand erlauben die Anwendung aller arithmetischen Rechenoperationen Häufigkeit, Reihenfolge, Abstand, natürlicher Nullpunkt erlauben die Anwendung aller arithmetischen Rechenoperationen (Multiplikation, Division etc.) Beispiel Datum,... Länge, Gewicht,...

16 EXKURS1: Daten und Skalenniveaus Nicht-metrische & metrische Skalen Quelle:

17 Vom Itemkatalog

18 ( über UniPark oder Pen & Paper )

19 zum Fragebogen

20 Von den Items zu den Konstrukten
21 Das Forschungsmodel (Mediator-Effekt) Teilweise Mediation Trust in Flying Shopping Carts H1 (+) Shopping Value hedonisch utilitaristisch H2 (+) Technology- Task-Fit H3 (+) H1: Je höher das Vertrauen in FSC, desto höher der Shopping Value. H2: Je höher das Vertrauen in FSC, desto höher der Technology-Task-Fit. H3: Je höher der Technology-Task-Fit, desto höher der Shopping Value.
22 Das Forschungsmodel (Mediator-Effekt) Vollständige Mediation Trust in Flying Shopping Carts Technology- Task-Fit H1 (+) H2 (+) Shopping Value hedonisch utilitaristisch H1: Je höher das Vertrauen in FSC, desto höher der Shopping Value. H2: Je höher das Vertrauen in FSC, desto höher der Technology-Task-Fit. H3: Je höher der Technology-Task-Fit, desto höher der Shopping Value.
23 Das Forschungsmodel (Moderator-Effekt) Trust in Flying Shopping Carts H1 (+) Shopping Value hedonisch utilitaristisch H2 (+) etwaige Prädispositionen, z.b.: persönliche, soziale oder kulturelle Determinanten H1: Je höher das Vertrauen in FSC, desto höher der Shopping Value. H2: Die Prädisposition erhöht den Einfluss des Vertrauens auf den Shopping Value.
24 EXKURS2: Lage- und Streuungsparameter Lage- und Streuungsparameter (stets bezogen auf eine Variable/Merkmal) sind Kennzahlen zur Beschreibung empirischer Merkmalsverteilungen Sie müssen folgende Kriterien erfüllen: große Aussagekraft bei möglichst geringem Informationsverlust Sachverhalt muss angemessen repräsentiert werden
25 Lageparameter typischen Eigenschaft der betrachteten Häufigkeitsverteilung Auskunft über den Schwerpunkt des Datenbündels Modus (Modalwert) nominal Median (Zentralwert) ordinal Arithmetischer Mittelwert metrisch Definition Der am häufigsten genannte Wert einer/s Stichprobe/Datensatzes (mehrere Modalwerte möglich) Teilt eine Stichprobe/Datensatz in die prozentuale Hälfte (50/50) (zwischenwerte sind möglich) (vgl. Armutsgrenze) Berechnung als Quotient aus der Summe aller in der/m Stichprobe/Datensatz vorkommenden Werte Beispiel: 1;2;2;2;5;5;6;37;39 1;2;2;2;5;5;6;37;39 1;2;2;2;5;5;6;37;39 ( )/9 = 11
26 Streuungsparameter Weite/Enge der Verteilung der einzelnen Merkmalswerte über den Bereich der Merkmalsskala Charakterisierung einer Verteilung durch einen Lageparameter Spannweite Standardabweichung Varianz Definition Größter Wert einer/s Stichprobe/Datensatzes minus dem kleinsten Wert Streuung der/s Stichprobe/Datensatzes um den arithmtischen Mittelwert Quadratsumme der Standardabweichung Beispiel: 1;2;2;2;5;5;6;37;39 =38 =15,4 =237,5 Per Definition: kein Streuungsmaß bei nominalem Skalenniveau

27 Einführung in SPSS Umgang und Aufbereitung



28 Der Datensatz x x x x
29 Nr. 1. Item 2. Item 3. Item 1. UV 1. Item 2. Item 3. Item 2. UV 1. Item 2. Item 3. Item AV , , , , , , Datensatz bereinigen und Variablen Definition 1. Unabhängige Variable Abhängige Variable 2. Unabhängige Variable Nachweis bestimmter Merkmalsausprägungen und ihrer Wirkungszusammenhänge


30 0. Datensatz bereinigen und Variablen Definition


31 1. Deskriptive Statistik

32 1. Deskriptive Statistik
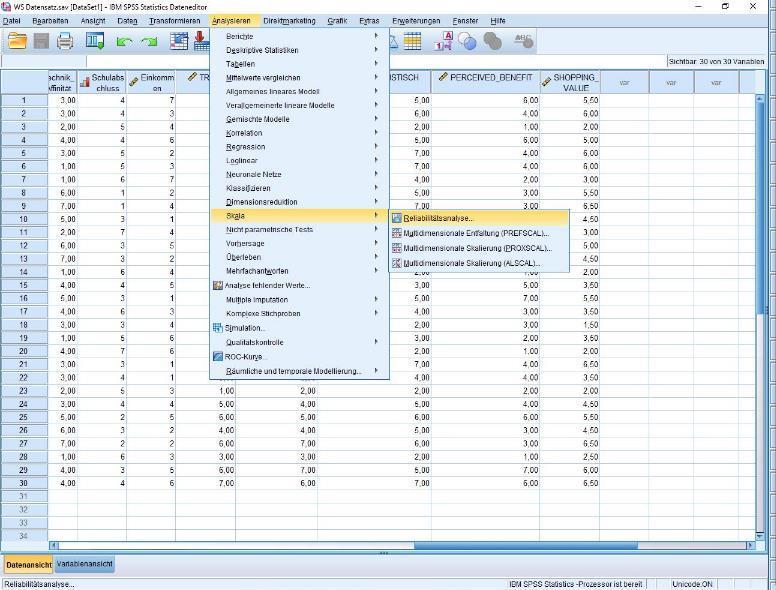

33 1. Reliabilitätscheck Cronbachs Alpha
34 2. Reliabilitätscheck Cronbachs Alpha Maß für die interne Konsistenz einer Skala (Beziehung untereinander) Cronbach's alpha Internal consistency 0.9 α Excellent 0.8 α < 0.9 Good 0.7 α < 0.8 Acceptable 0.6 α < 0.7 Questionable 0.5 α < 0.6 Poor α < 0.5 Unacceptable Quelle: George & Mallery (2002) Cronbachs Alpha Trust Cronbachs Alpha TTF Cronbachs Alpha SV

35 2. WÄHLT EURE WAFFEN WEISE


36 3.1 Korrellationsanalyse
 & auf MULTIKOLLINEARITÄT achten!")
37 3.1 Korrellationsanalyse VORSICHT: STATISTISCH UNSAUBERT (AUF SKALENNIVEAUS ACHTEN) & auf MULTIKOLLINEARITÄT achten!!!
38 3.1 Korrellationsanalyse Paarung NOMINAL ORDINAL METRISCH NOMINAL Kontingenzkoeffizient Phi/Cramer-V ORDINAL Chi² Kendalls Tau Spearman Gamma METRISCH Eta-Koeffizient Kendalls Tau Spearman Gamma Bravais/ Pearson
39 be aware of SCHEINKORRELATIONEN
40 4. Gruppenvergleiche (Mittelwertvergleich) Grobe Faustregel zur Identifikation des Testverfahrens (parametrisch): Unabhängige Variable Abhängige Variable Test nominal nominal Kreuztabelle metrisch nominal logaritmische Regression nominal metrisch t-test, Varianzanalyse ordinal metrisch t-test, Varianzanalyse metrisch metrisch Regressionsanalyse
41 4. Gruppenvergleiche (Mittelwertvergleich) Mittelwertvergleich zwischen 2 oder mehr Gruppen: Es wird getestet, ob es eine signifikante Änderung des Mittelwertes der metrischen abhängigen Variable zwischen den Gruppen existiert (z.b.: Kaufabsicht in einem Onlineshop, gemessen auf einer 7er Skala zwischen Männern und Frauen) H0: kein signifikanter Unterschied der abhängigen Variablen zwischen den Gruppen Es gibt drei Kriterien, die bei Tests auf signifikante Unterschiede relevant sind: Abhängigkeit der Stichproben Anzahl der Stichproben Skalierung und Normalverteilung der Stichproben

42 4. Gruppenvergleiche (Mittelwertvergleich) Intervallskalierte und normalverteilte Variablen: Anzahl der Stichproben Art der Abhängigkeit Test 2 unabhängig t-test >2 unabhängig einfaktorielle Varianzanalyse 2 abhängig t-test für abhängige Stichproben Ordinalskalierte oder nicht normalverteilte Variablen: Anzahl der Stichproben Art der Abhängigkeit Test 2 unabhängig U-Test von Mann und Whitney >2 unabhängig H-Test nach Kruskal und Wallis 2 abhängig Wilcoxon-Test
43 4. Gruppenvergleiche (Mittelwertvergleich) Intervallskalierte und normalverteilte Variablen: t-test (unabhängig, 2 Stichproben) Innerhalb von zwei unabhängigen Gruppen (eine Experimental- & eine Kontrollgruppe, z.b.: Kindern & Erwachsenen; Untrainierte & Trainierte etc. (welche Ausprägung welcher Gruppe zugehört liegt am Tester)) soll beispielsweise der Unterschied in der Shopping Value bei der Nutzung fliegender Einkaufswagen ermittelt werden H0: kein signifikanter Unterschied im Mittelwert der abhängigen Variable zwischen den Gruppen Optimal: Verwerfung von H0 t-test (abhängige, 2 Stichproben) Innerhalb von zwei abhängigen Gruppen (z.b.: nach einer Woche & nach einem Jahr) soll der Unterschied in der Shopping Value bei der Nutzung fliegender Einkaufswagen ermittelt werden H0: kein signifikanter Unterschied im Mittelwert der abhängigen Variable zwischen den Gruppen Optimal: Verwerfung von H0 ACHTUNG: ein schrittweise paarweise Vergleich via t-test erhöht mit zunehmender Testdauer die Wahrscheinlichkeit einen Fehler der 1. Art zu begehen, daher ist an dieser Stelle eine einfaktoriellen Varianzanalyse zu empfehlen einfaktorielle Varianzanalyse (unabhängig & abhängigen, >2 Stichproben) Innerhalb von mehr als zwei unabhängigen(, aber auch abhängigen) Gruppen (z.b.: Kindern, Erwachsenen & Senioren; Untrainierte, Trainierte & Professionelle (einfaktoriell) (,zweifaktoriell: Einbezug eines weiteren Faktor wie beispielsweise der Technikaffinität) soll ermittelt werden, ob es einen sig. Unterschied in der Shopping Value (abhängige Variable) bei der Nutzung fliegender Einkaufswagen gibt H0: kein signifikanter Unterschied im Mittelwert der abhängigen Variablen zwischen den Gruppen Optimal: Verwerfung von H0
44 4.1 t-test (unabhängige Stichproben) H0: kein signifikanter Unterschied zwischen den Mittelwerten der ordinalen/metrischen AV (Shopping Value) Voraussetzungen: Abhängige Variable sollte Intervallskaliert sein Normalverteilung in den Gruppen (mindesten 30 Teilnehmer pro Gruppe) Stichproben stammen aus der selben Population Homogenität der Varianzen



45 4.1 t-test (Normalverteilung)


 H0: Normalverteilung liegt vor Da beide Tests über 0,05")
46 4.1 t-test (Normalverteilung) 1. Histogramm: 2. Schiefe und Kurtosis 3. Kolmogorov-Smirnov/Shapiro-Wilk Analysieren Deskriptive Statistiken Explorative Datenanalyse Je näher 0, desto optimaler (sollte nicht größer/kleiner 1 bzw. -1 sein) H0: Normalverteilung liegt vor Da beide Tests über 0,05 liegen, kann die H0 Hypothese hier nicht verworfen werden, sprich Normalverteilung liegt tendenziell vor
47 4.1 t-test (unabhängige Stichproben) H0: kein signifikanter Unterschied zwischen den Mittelwerten der ordinalen/metrischen AV (Shopping Value) Voraussetzungen: Abhängige Variable sollte Intervallskaliert sein Normalverteilung in den Gruppen (mindesten 30 Teilnehmer pro Gruppe) Stichproben stammen aus der selben Population Homogenität der Varianzen

 mit Blick auf das")
48 4.1 t-test (unabhängige Stichproben) H0: kein signifikanter Unterschied zwischen den Mittelwerten der ordinalen/metrischen AV (Shopping Value) mit Blick auf das Geschlecht
49 4.1 t-test (unabhängige Stichproben) H0: kein signifikanter Unterschied zwischen den Mittelwerten der ordinalen/metrischen AV (Shopping Value) mit Blick auf das Geschlecht Ergebnis: H0 (Varianzhomogenität gegeben) kann auf einem Signifikanzniveau von über 90% (94,8%) verworfen werden. Sprich, es liegt keine Homogenität in den Varianzen vor (ansonsten ist ein robustes Testverfahren zu wählen (Welch-Test)) Ergebnis: H0 kann auf einem Signifikanzniveau von 99,9% verworfen werden. Sprich, es gibt einen sig. Unterschied
50 4.1 t-test (unabhängige Stichproben) H0: kein signifikanter Unterschied zwischen den Mittelwerten der ordinalen/metrischen AV (Shopping Value) mit Blick auf das Geschlecht Ergebnis: H0 (Varianzhomogenität gegeben) kann auf einem Signifikanzniveau von über 90% (94,8%) verworfen werden. Sprich, es liegt keine Homogenität in den Varianzen vor (ansonsten ist ein robustes Testverfahren zu wählen (Welch-Test)) Ergebnis: H0 kann auf einem Signifikanzniveau von 99,9% verworfen werden. Sprich, es gibt einen sig. Unterschied
51 4.1 Cohen s d (Effektstärke) H0: kein signifikanter Unterschied zwischen den Mittelwerten der ordinalen/metrischen AV (Shopping Value) mit Blick auf das Geschlecht Effektstärke: d = M1-M2/((s1+s2)/2) = 2,73/0,82 = 3,35 Einteilung nach Cohen: Schwacher Effekt: d = 0.2 Mittlerer Effekt: d = 0.5 Starker Effekt: d = 0.8 Durch die geringen Stichprobenumfänge ergibt sich hier ein sehr hohes Cohen s d
52 Wie schreibt man...?
53 In den Abschnitt 4 (Ergebnisse) gehört: 1. (Datensatz prüfen und bereinigen (wenn auffällig!!)) 2. Deskriptive Auswertung 3. Reliabilitätscheck 4. Welche Varianzhomogenität klärt den Test 5. Variablen-/Gruppenvergleiche sind signifikant (p < 0,05) wie groß ist der Unterschied (Effektstärke?) 6. Welche Hypothesen bestätigen sich dadurch (nicht) Um die Hypothese Es liegt ein Unterschied zwischen den Geschlechtern vor zu überprüfen, wurde ein t-test für unabhängige Stichproben durchgeführt. Die Relevanz dieser Methodik ergibt sich aus den zwei unterschiedlichen und unabhängigen Gruppen, die es in diesem Zusammenhang zu untersuchen gilt. Eine Varianzhomogenität kann auf einem Niveau von 0,1 ausgeschlossen werden. Insgesamt zeigt sich ein signifikanter Unterschied mit Blick auf die Mittelwerte zwischen Frauen und Männern (p <,001), was zu einer Verwerfung der Nullhypothese führt. Des Weiteren ergibt sich mit 3,35 eine sehr hohe Effektstärke. Die in dieser Arbeit aufgestellte Hypothese ACHTUNG: Dieser Absatz dient rein zur Orientierung und ist daher in dieser Form innerhalb einer Seminar- oder Abschlussarbeit nicht eins zu eins umzusetzen!

 mit Blick auf die")
54 4.2 einfaktorielle Varianzanalyse H0: kein signifikanter Unterschied zwischen den Mittelwerten der ordinalen/metrischen AV (Shopping Value) mit Blick auf die Faktoren/Gruppen der Technikaffinität
55 4.2 einfaktorielle Varianzanalyse Ergebnis: H0 (Varianzhomogenität gegeben) kann auf einem Signifikanzniveau von über 95% (95,5%) verworfen werden. Sprich, es liegt keine Homogenität in den Varianzen vor (vgl. t-test ansonsten ist ein robustes Testverfahren zu wählen (Welch-Test)) Ergebnis: H0 kann auf einem Signifikanzniveau von 99,5% verworfen werden. Sprich, es gibt einen sig. Unterschied
56 4.2 einfaktorielle Varianzanalyse Ergebnis: H0 (Varianzhomogenität gegeben) kann auf einem Signifikanzniveau von über 95% (95,5%) verworfen werden. Sprich, es liegt keine Homogenität in den Varianzen vor (vgl. t-test ansonsten ist ein robustes Testverfahren zu wählen (Welch-Test)) Ergebnis: H0 kann auf einem Signifikanzniveau von 99,5% verworfen werden. Sprich, es gibt einen sig. Unterschied


57 4.2 zweifaktorielle Varianzanalyse H0: kein signifikanter Unterschied zwischen den Mittelwerten der ordinalen/metrischen AV (Shopping Value) mit Blick auf die Faktoren/Gruppen der Technikaffinität & Geschlecht

 kann auf einem Signifikanzniveau von über 90% nicht verworfen werden.")
58 4.2 zweifaktorielle Varianzanalyse Ergebnis: H0 für den Unterschied der Geschlechter, als auch Geschlechter*Technikaffinität kann auf einem Signifikanzniveau von 99,9% verworfen werden. Allerdings nicht H0 für den Unterschied bei der Technikaffinität Ergebnis: H0 (Varianzhomogenität gegeben) kann auf einem Signifikanzniveau von über 90% nicht verworfen werden. Sprich, es liegt eine Homogenität in den Varianzen vor
 Hochbergs GT2 (große Differenzen) Bonferroni Games-Howell Ergebnis: Auf einem Signifikanzniveau von 99,9% gibt es weitestgehend einen signifikanten")
59 4.2 zweifaktorielle Varianzanalyse Paarung GLEICHE VARIANZEN (VARIANZHOMOGENITÄT) UNGLEICHE VARIANZEN (KEINE VARIANZHOMOGENITÄT) GLEICHER STICHPROBENUMFANG R-E-G-W-Q Tukey Duncan S-N-K UNGLEICHER STICHPOBENUMFANG Gabriel (kleine Differenz) Hochbergs GT2 (große Differenzen) Bonferroni Games-Howell Ergebnis: Auf einem Signifikanzniveau von 99,9% gibt es weitestgehend einen signifikanten Unterschied unter den Gruppen der Technikaffinität.

60 4.2 Cohen s partielles Eta-Quadrat (Effektstärke)


61 4.2 partielles Eta-Quadrat (Effektstärke) Die univariate Analyse gibt zusätzlich das partielles Eta- Quadrat mit an, welche letztendlich die Stärke eines signifikanten Effekts verdeutlicht Via Einfaktorieller Varianzanalyse ergibt sich außerdem: Ergebnis: 24,8 / 75,7 = 0,328 Einteilung: Schwacher Effekt: n = 0.01 Mittlerer Effekt: n = Starker Effekt: n = 0.138
62 Wie schreibt man...?
63 In den Abschnitt 4 (Ergebnisse) gehört: 1. (Datensatz prüfen und bereinigen (wenn auffällig!!)) 2. Deskriptive Auswertung 3. Reliabilitätscheck 4. Welche Varianzhomogenität klärt den Test 5. Variablen-/Gruppenvergleiche sind signifikant (p < 0,05) wie groß ist der Unterschied (Effektstärke?) 6. Welche Hypothesen bestätigen sich dadurch (nicht) Um die Hypothese Es liegt ein Unterschied zwischen den unterschiedlichen Ausprägungen der Technikaffinitäten vor zu überprüfen, wurde eine einfaktorielle Varianzanalyse durchgeführt. Die Relevanz dieser Methodik ergibt sich aus den drei unterschiedlichen und unabhängigen Gruppen, die es in diesem Zusammenhang zu untersuchen gilt. Eine Varianzhomogenität kann auf einem Niveau von 0,05 ausgeschlossen werden. Insgesamt zeigt sich ein signifikanter Unterschied mit Blick auf die Mittelwerte zwischen den drei Gruppen (p <=,005), was zu einer Verwerfung der Nullhypothese führt. Des Weiteren ergibt sich mit 0,328 eine sehr hohe Effektstärke. Die in dieser Arbeit aufgestellte Hypothese ACHTUNG: Dieser Absatz dient rein zur Orientierung und ist daher in dieser Form innerhalb einer Seminar- oder Abschlussarbeit nicht eins zu eins umzusetzen!
64 4.3 lineare Regressionsanalyse auf Basis der OLS (ordinary least squares) bzw. KQ-Methode (Methode der kleinste Quadreate) werden abhängige Modele geschätzt, die den Zusammenhang metrischer Variablen (AV) und metrischen/nominal Variablen (UV) (keine ordinalen, da diese in Form von Dummy Variablen (nominal) ergänzt werden müssten) erklären. H0: UV hat keinen signifikanten Einfluss auf AV, bzw. die Regressionsgleichung weist keine signifikante Steigung auf. Es gibt drei Kriterien, die bei Tests auf signifikante Unterschiede relevant sind: Abhängigkeit der Stichproben Anzahl der Stichproben Skalierung und Normalverteilung der Stichproben
65 4.3 Regressionsanalyse Untersuchung des Einflusses einer oder mehrerer unabhängiger metrisch skalierten Variable auf eine abhängige metrische Variable/n Aussage darüber, wie hoch der Einfluss ist Aussage darüber, ob der Einfluss positiv oder negativ ist Aussage darüber, ob der Einfluss zufällig oder signifikant (allgemeingültig) ist Aussage darüber, wie viel Prozent der Varianz der abhängigen Variable durch die unabhängigen Variablen erklärt werden können.

66 4.3 Regressionsanalyse Shopping Value (Kriterium) 4 3,5 3 2,5 2 Regressionsgerade 1,5 yˆ bo b1 x 1 0, ,5 1 1,5 2 2,5 3 Trust in FSC (Prädiktor)
 hat keinen signifikanten")

67 4.3 lineare Regressionsanalyse H0: UV (Trust/TTF) hat keinen signifikanten Einfluss auf AV (Shopping Value), bzw. die Regressionsgleichung weist keine signifikante Steigung auf.
68 4.3 lineare Regressionsanalyse H0: UV (Trust/TTF) hat keinen signifikanten Einfluss auf AV (Shopping Value), bzw. die Regressionsgleichung weist keine signifikante Steigung auf. Model 1: Model 2:
69 4.3 Regressionsanalyse Shopping Value (Kriterium) ŷ = 2, ,529x Regressionsgerade yˆ bo b1 x Trust in FSC (Prädiktor)
70 4.3 lineare Regressionsanalyse H0: UV (Trust/TTF) hat keinen signifikanten Einfluss auf AV (Shopping Value), bzw. die Regressionsgleichung weist keine signifikante Steigung auf. Wir konzentrieren uns hierbei auf die Frage nach dem Einfluss von Trust Model 3:

71 Wie schreibt man...?
72 In den Abschnitt 4 (Ergebnisse) gehört: 1. (Datensatz prüfen und bereinigen (wenn auffällig!!)) 2. Deskriptive Auswertung 3. Reliabilitätscheck (Cronbachs Alpha) 4. Korrigiertes R² (Bestimmtheitsmaß: Wie viel % der Varianz der abhängigen Variablen wird erklärt (Aussagekraft des Modells)) 5. F-Wert bzw. die Signifikanz der ANOVA (Varianzhomogenität) 6. Welche Variablen-/Gruppen sind signifikant (p < 0,05) 7. Wie sieht die Wirkungsrichtung der sig. Variablen aus (mit Blick auf den standardisierten Koeffizienten) 8. Welche Hypothesen bestätigen sich dadurch (nicht) Model 3: Zur Überprüfung der Hypothese 2A wurde eine lineare Regression durchgeführt. Hierbei zeigt sich, dass 93% der Varianz (korrigiertes R 2 =,933) des Shopping Values über Trust erklärt werden konnte. Außerdem liegt auf einer Irrtumswahrscheinlichkeit von 0,001% keine Varianzhomogenität vor. Der erhebliche signifikante Einfluss von Trust mit einem standarisierten Beta von β =,997 (p <,001) auf die Shopping Value im Gegensatz zu dem nicht signifikanten TTF zeigt, dass der Einfluss von Trust den Großteil der Varianz der abhängigen Variable erklärt. Die verbleibende Streuung der abhängigen Variable, welche nicht von Trust erklärt werden kann, lässt sich auch nicht durch die zweite unabhängige Variable (TTF) weiter erklären. Die aufgestellten Hypothesen ACHTUNG: Dieser Absatz dient rein zur Orientierung und ist daher in dieser Form innerhalb einer Seminar- oder Abschlussarbeit nicht eins zu eins umzusetzen!

73 4.4 Multiple Regressionsanalyse Shopping Value Regressionsgerade y = b 0 + b 1 x + b 2 z y = b 0 + b 1 x + b 2 z b n n TTF Trust in FSC


74 4.5 Multikollinearität Zwei oder mehr erklärende Variablen haben eine sehr starke Korrelation miteinander Problem: Verzerrung der Regressionskoeffizienten
75 4.5 Multikollinearität 1/Toleranz=VIF Nach O Brien (2007) ist ein VIF über 4 bereits bedenklich, kann aber bis 10 noch akzeptiert werden Im Optimalfall besteht eine hohe Korrelation zwischen den unabhängigen und der abhängigen Variable und eine geringe unter den unabhängigen Variablen Was macht hier überhaupt Sinn? Weniger ist häufig mehr um ein hohes R² zu generieren sinnvoll reduzieren!!!
76 Effektstärken Korrelation / standarisiertes Beta: Einteilung der Korrelationen: Schwacher Effekt: r = 0.1 Mittlerer Effekt: r = 0.3 Starker Effekt: r = 0.5 angepasstes R 2 Einteilung: Schwacher Effekt: R 2 = 0.02 Mittlerer Effekt: R 2 = 0.13 Starker Effekt: R 2 = 0.26 T-Test: Cohen s d Formel: d = M1 - M2 / ((s1+s2)/2) Einteilung: Schwacher Effekt: d = 0.2 Mittlerer Effekt: d = 0.5 Starker Effekt: d = 0.8 (M)AN(C)OVA: partielles Eta-Quadrat Formel: = Quadratsumme zwischen Gruppen Quadratsumme Gesamt Einteilung: Schwacher Effekt: n = 0.01 Mittlerer Effekt: n = Starker Effekt: n = 0.138

77 WAS GIBT ES SONST NOCH Zeitreihenanalyse Faktoranalyse Clusteranalayse Conjointanalyse Strukturgleichungsmodelle



78 FRAGEN & ANMERKUNGEN
Statistik. Jan Müller
 Statistik Jan Müller Skalenniveau Nominalskala: Diese Skala basiert auf einem Satz von qualitativen Attributen. Es existiert kein Kriterium, nach dem die Punkte einer nominal skalierten Variablen anzuordnen
Statistik Jan Müller Skalenniveau Nominalskala: Diese Skala basiert auf einem Satz von qualitativen Attributen. Es existiert kein Kriterium, nach dem die Punkte einer nominal skalierten Variablen anzuordnen
fh management, communication & it Constantin von Craushaar fh-management, communication & it Statistik Angewandte Statistik
 fh management, communication & it Folie 1 Überblick Grundlagen (Testvoraussetzungen) Mittelwertvergleiche (t-test,..) Nichtparametrische Tests Korrelationen Regressionsanalyse... Folie 2 Überblick... Varianzanalyse
fh management, communication & it Folie 1 Überblick Grundlagen (Testvoraussetzungen) Mittelwertvergleiche (t-test,..) Nichtparametrische Tests Korrelationen Regressionsanalyse... Folie 2 Überblick... Varianzanalyse
Stichwortverzeichnis. Ausgleichsgerade 177 Ausreißer 13, 40
 283 Stichwortverzeichnis a Alpha-Wert 76, 91 Alter 256 Alternativhypothese 68, 70 ANOVA siehe einfache Varianzanalyse, zweifache Varianzanalyse Anpassung 178 Anpassungstest siehe Chi-Quadrat-Anpassungstest
283 Stichwortverzeichnis a Alpha-Wert 76, 91 Alter 256 Alternativhypothese 68, 70 ANOVA siehe einfache Varianzanalyse, zweifache Varianzanalyse Anpassung 178 Anpassungstest siehe Chi-Quadrat-Anpassungstest
5. Lektion: Einfache Signifikanztests
 Seite 1 von 7 5. Lektion: Einfache Signifikanztests Ziel dieser Lektion: Du ordnest Deinen Fragestellungen und Hypothesen die passenden einfachen Signifikanztests zu. Inhalt: 5.1 Zwei kategoriale Variablen
Seite 1 von 7 5. Lektion: Einfache Signifikanztests Ziel dieser Lektion: Du ordnest Deinen Fragestellungen und Hypothesen die passenden einfachen Signifikanztests zu. Inhalt: 5.1 Zwei kategoriale Variablen
Angewandte Statistik 3. Semester
 Angewandte Statistik 3. Semester Übung 5 Grundlagen der Statistik Übersicht Semester 1 Einführung ins SPSS Auswertung im SPSS anhand eines Beispieles Häufigkeitsauswertungen Grafiken Statistische Grundlagen
Angewandte Statistik 3. Semester Übung 5 Grundlagen der Statistik Übersicht Semester 1 Einführung ins SPSS Auswertung im SPSS anhand eines Beispieles Häufigkeitsauswertungen Grafiken Statistische Grundlagen
Deskription, Statistische Testverfahren und Regression. Seminar: Planung und Auswertung klinischer und experimenteller Studien
 Deskription, Statistische Testverfahren und Regression Seminar: Planung und Auswertung klinischer und experimenteller Studien Deskriptive Statistik Deskriptive Statistik: beschreibende Statistik, empirische
Deskription, Statistische Testverfahren und Regression Seminar: Planung und Auswertung klinischer und experimenteller Studien Deskriptive Statistik Deskriptive Statistik: beschreibende Statistik, empirische
Parametrische vs. Non-Parametrische Testverfahren
 Parametrische vs. Non-Parametrische Testverfahren Parametrische Verfahren haben die Besonderheit, dass sie auf Annahmen zur Verteilung der Messwerte in der Population beruhen: die Messwerte sollten einer
Parametrische vs. Non-Parametrische Testverfahren Parametrische Verfahren haben die Besonderheit, dass sie auf Annahmen zur Verteilung der Messwerte in der Population beruhen: die Messwerte sollten einer
PRAXISORIENTIERTE EINFÜHRUNG
 GRUNDLAGEN DER STATISTIK PRAXISORIENTIERTE EINFÜHRUNG Rainer Gaupp Leiter Qualität & Prozesse 1 INHALTE DER EINFÜHRUNG Theoretische Grundlagen: Natur vs. Sozialwissenschaft. Skalentypen. Streu- und Lagemasse.
GRUNDLAGEN DER STATISTIK PRAXISORIENTIERTE EINFÜHRUNG Rainer Gaupp Leiter Qualität & Prozesse 1 INHALTE DER EINFÜHRUNG Theoretische Grundlagen: Natur vs. Sozialwissenschaft. Skalentypen. Streu- und Lagemasse.
Statistik II: Grundlagen und Definitionen der Statistik
 Medien Institut : Grundlagen und Definitionen der Statistik Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Hintergrund: Entstehung der Statistik 2. Grundlagen
Medien Institut : Grundlagen und Definitionen der Statistik Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Hintergrund: Entstehung der Statistik 2. Grundlagen
Statistik III Regressionsanalyse, Varianzanalyse und Verfahren bei Messwiederholung mit SPSS
 Statistik III Regressionsanalyse, Varianzanalyse und Verfahren bei Messwiederholung mit SPSS Verena Hofmann Dr. phil. des. Departement für Sonderpädagogik Universität Freiburg Petrus-Kanisius-Gasse 21
Statistik III Regressionsanalyse, Varianzanalyse und Verfahren bei Messwiederholung mit SPSS Verena Hofmann Dr. phil. des. Departement für Sonderpädagogik Universität Freiburg Petrus-Kanisius-Gasse 21
Hypothesentests mit SPSS
 Beispiel für eine einfache Regressionsanalyse (mit Überprüfung der Voraussetzungen) Daten: bedrohfb_v07.sav Hypothese: Die Skalenwerte auf der ATB-Skala (Skala zur Erfassung der Angst vor terroristischen
Beispiel für eine einfache Regressionsanalyse (mit Überprüfung der Voraussetzungen) Daten: bedrohfb_v07.sav Hypothese: Die Skalenwerte auf der ATB-Skala (Skala zur Erfassung der Angst vor terroristischen
Franz Kronthaler. Statistik angewandt. Datenanalyse ist (k)eine Kunst. mit dem R Commander. A Springer Spektrum
eine Kunst. mit dem R Commander. A Springer Spektrum") Franz Kronthaler Statistik angewandt Datenanalyse ist (k)eine Kunst mit dem R Commander A Springer Spektrum Inhaltsverzeichnis Teil I Basiswissen und Werkzeuge, um Statistik anzuwenden 1 Statistik ist
Franz Kronthaler Statistik angewandt Datenanalyse ist (k)eine Kunst mit dem R Commander A Springer Spektrum Inhaltsverzeichnis Teil I Basiswissen und Werkzeuge, um Statistik anzuwenden 1 Statistik ist
Inhaltsverzeichnis. Über die Autoren Einleitung... 21
 Inhaltsverzeichnis Über die Autoren.... 7 Einleitung... 21 Über dieses Buch... 21 Was Sie nicht lesen müssen... 22 Törichte Annahmen über den Leser... 22 Wie dieses Buch aufgebaut ist... 23 Symbole, die
Inhaltsverzeichnis Über die Autoren.... 7 Einleitung... 21 Über dieses Buch... 21 Was Sie nicht lesen müssen... 22 Törichte Annahmen über den Leser... 22 Wie dieses Buch aufgebaut ist... 23 Symbole, die
Statistik II Übung 3: Hypothesentests
 Statistik II Übung 3: Hypothesentests Diese Übung beschäftigt sich mit der Anwendung diverser Hypothesentests (zum Beispiel zum Vergleich der Mittelwerte und Verteilungen zweier Stichproben). Verwenden
Statistik II Übung 3: Hypothesentests Diese Übung beschäftigt sich mit der Anwendung diverser Hypothesentests (zum Beispiel zum Vergleich der Mittelwerte und Verteilungen zweier Stichproben). Verwenden
Inhaltsverzeichnis. 1 Über dieses Buch Zum Inhalt dieses Buches Danksagung Zur Relevanz der Statistik...
 Inhaltsverzeichnis 1 Über dieses Buch... 11 1.1 Zum Inhalt dieses Buches... 13 1.2 Danksagung... 15 2 Zur Relevanz der Statistik... 17 2.1 Beispiel 1: Die Wahrscheinlichkeit, krank zu sein, bei einer positiven
Inhaltsverzeichnis 1 Über dieses Buch... 11 1.1 Zum Inhalt dieses Buches... 13 1.2 Danksagung... 15 2 Zur Relevanz der Statistik... 17 2.1 Beispiel 1: Die Wahrscheinlichkeit, krank zu sein, bei einer positiven
Einführung in die Statistik für Politikwissenschaftler Sommersemester 2011
 Einführung in die Statistik für Politikwissenschaftler Sommersemester 2011 Es können von den Antworten alle, mehrere oder keine Antwort(en) richtig sein. Nur bei einer korrekten Antwort (ohne Auslassungen
Einführung in die Statistik für Politikwissenschaftler Sommersemester 2011 Es können von den Antworten alle, mehrere oder keine Antwort(en) richtig sein. Nur bei einer korrekten Antwort (ohne Auslassungen
Skalenniveaus =,!=, >, <, +, -
 ZUSAMMENHANGSMAßE Skalenniveaus Nominalskala Ordinalskala Intervallskala Verhältnisskala =,!= =,!=, >, < =,!=, >, ,
ZUSAMMENHANGSMAßE Skalenniveaus Nominalskala Ordinalskala Intervallskala Verhältnisskala =,!= =,!=, >, < =,!=, >, ,
FH- Management & IT. Constantin von Craushaar FH-Management & IT Statistik Angewandte Statistik (Übungen)
") FH- Management & IT Folie 1 Rückblick Häufigkeiten berechnen Mittelwerte berechnen Grafiken ausgeben Grafiken anpassen und als Vorlage abspeichern Variablenoperationen Fälle vergleichen Fälle auswählen
FH- Management & IT Folie 1 Rückblick Häufigkeiten berechnen Mittelwerte berechnen Grafiken ausgeben Grafiken anpassen und als Vorlage abspeichern Variablenoperationen Fälle vergleichen Fälle auswählen
Statistische Methoden in den Umweltwissenschaften
 Statistische Methoden in den Umweltwissenschaften Post Hoc Tests A priori Tests (Kontraste) Nicht-parametrischer Vergleich von Mittelwerten 50 Ergebnis der ANOVA Sprossdichte der Seegräser 40 30 20 10
Statistische Methoden in den Umweltwissenschaften Post Hoc Tests A priori Tests (Kontraste) Nicht-parametrischer Vergleich von Mittelwerten 50 Ergebnis der ANOVA Sprossdichte der Seegräser 40 30 20 10
Statistik II (Sozialwissenschaften)
") Dr. Hans-Otfried Müller Institut für Mathematische Stochastik Fachrichtung Mathematik Technische Universität Dresden http://www.math.tu-dresden.de/sto/mueller/ Statistik II (Sozialwissenschaften) 2. Konsultationsübung,
Dr. Hans-Otfried Müller Institut für Mathematische Stochastik Fachrichtung Mathematik Technische Universität Dresden http://www.math.tu-dresden.de/sto/mueller/ Statistik II (Sozialwissenschaften) 2. Konsultationsübung,
Statistik II Übung 4: Skalierung und asymptotische Eigenschaften
 Statistik II Übung 4: Skalierung und asymptotische Eigenschaften Diese Übung beschäftigt sich mit der Skalierung von Variablen in Regressionsanalysen und mit asymptotischen Eigenschaften von OLS. Verwenden
Statistik II Übung 4: Skalierung und asymptotische Eigenschaften Diese Übung beschäftigt sich mit der Skalierung von Variablen in Regressionsanalysen und mit asymptotischen Eigenschaften von OLS. Verwenden
'+4 Elisabeth Raab-Steiner / Michael Benesch. Der Fragebogen. Von der Forschungsidee zur SPSS-Auswertung. 4., aktualisierte und überarbeitete Auflage
 '+4 Elisabeth Raab-Steiner / Michael Benesch Der Fragebogen Von der Forschungsidee zur SPSS-Auswertung 4., aktualisierte und überarbeitete Auflage facultas «4 Inhaltsverzeichnis 1 Elementare Definitionen
'+4 Elisabeth Raab-Steiner / Michael Benesch Der Fragebogen Von der Forschungsidee zur SPSS-Auswertung 4., aktualisierte und überarbeitete Auflage facultas «4 Inhaltsverzeichnis 1 Elementare Definitionen
Arbeitsbuch zur deskriptiven und induktiven Statistik
 Helge Toutenburg Michael Schomaker Malte Wißmann Christian Heumann Arbeitsbuch zur deskriptiven und induktiven Statistik Zweite, aktualisierte und erweiterte Auflage 4ü Springer Inhaltsverzeichnis 1. Grundlagen
Helge Toutenburg Michael Schomaker Malte Wißmann Christian Heumann Arbeitsbuch zur deskriptiven und induktiven Statistik Zweite, aktualisierte und erweiterte Auflage 4ü Springer Inhaltsverzeichnis 1. Grundlagen
Klausur Statistik I Dr. Andreas Voß Wintersemester 2005/06
 Klausur Statistik I Dr. Andreas Voß Wintersemester 2005/06 Hiermit versichere ich, dass ich an der Universität Freiburg mit dem Hauptfach Psychologie eingeschrieben bin Name: Mat.Nr.: Unterschrift: Bearbeitungshinweise:
Klausur Statistik I Dr. Andreas Voß Wintersemester 2005/06 Hiermit versichere ich, dass ich an der Universität Freiburg mit dem Hauptfach Psychologie eingeschrieben bin Name: Mat.Nr.: Unterschrift: Bearbeitungshinweise:
Inhaltsverzeichnis. Teil 1 Basiswissen und Werkzeuge, um Statistik anzuwenden
 Inhaltsverzeichnis Teil 1 Basiswissen und Werkzeuge, um Statistik anzuwenden 1 Statistik ist Spaß 3 Warum Statistik? 3 Checkpoints 4 Daten 4 Checkpoints 7 Skalen - lebenslang wichtig bei der Datenanalyse
Inhaltsverzeichnis Teil 1 Basiswissen und Werkzeuge, um Statistik anzuwenden 1 Statistik ist Spaß 3 Warum Statistik? 3 Checkpoints 4 Daten 4 Checkpoints 7 Skalen - lebenslang wichtig bei der Datenanalyse
Ermitteln Sie auf 2 Dezimalstellen genau die folgenden Kenngrößen der bivariaten Verteilung der Merkmale Weite und Zeit:
 1. Welche der folgenden Kenngrößen, Statistiken bzw. Grafiken sind zur Beschreibung der Werteverteilung des Merkmals Konfessionszugehörigkeit sinnvoll einsetzbar? A. Der Modalwert. B. Der Median. C. Das
1. Welche der folgenden Kenngrößen, Statistiken bzw. Grafiken sind zur Beschreibung der Werteverteilung des Merkmals Konfessionszugehörigkeit sinnvoll einsetzbar? A. Der Modalwert. B. Der Median. C. Das
Einführung in die Statistik
 Elmar Klemm Einführung in die Statistik Für die Sozialwissenschaften Westdeutscher Verlag INHALTSVERZEICHNIS 1. Einleitung und Begrifflichkeiten 11 1.1 Grundgesamtheit, Stichprobe 12 1.2 Untersuchungseinheit,
Elmar Klemm Einführung in die Statistik Für die Sozialwissenschaften Westdeutscher Verlag INHALTSVERZEICHNIS 1. Einleitung und Begrifflichkeiten 11 1.1 Grundgesamtheit, Stichprobe 12 1.2 Untersuchungseinheit,
Sommersemester Marktforschung
 Dipl.-Kfm. Sascha Steinmann Universität Siegen Lehrstuhl für Marketing steinmann@marketing.uni-siegen.de Sommersemester 2010 Marktforschung Übungsaufgaben zu den Themen 3-6 mit Lösungsskizzen Aufgabe 1:
Dipl.-Kfm. Sascha Steinmann Universität Siegen Lehrstuhl für Marketing steinmann@marketing.uni-siegen.de Sommersemester 2010 Marktforschung Übungsaufgaben zu den Themen 3-6 mit Lösungsskizzen Aufgabe 1:
Statistische Datenanalyse
 Wolf-Michael Kahler Statistische Datenanalyse Verfahren verstehen und mit SPSS gekonnt einsetzen 6., verbesserte und erweiterte Auflage Mit 345 Abbildungen STUDIUM VIEWEG+ TEUBNER Inhaltsverzeichnis 1
Wolf-Michael Kahler Statistische Datenanalyse Verfahren verstehen und mit SPSS gekonnt einsetzen 6., verbesserte und erweiterte Auflage Mit 345 Abbildungen STUDIUM VIEWEG+ TEUBNER Inhaltsverzeichnis 1
Klausur Statistik I. Dr. Andreas Voß Wintersemester 2005/06
 Klausur Statistik I Dr. Andreas Voß Wintersemester 2005/06 Hiermit versichere ich, dass ich an der Universität Freiburg mit dem Hauptfach Psychologie eingeschrieben bin. Name: Mat.Nr.: Unterschrift: Bearbeitungshinweise:
Klausur Statistik I Dr. Andreas Voß Wintersemester 2005/06 Hiermit versichere ich, dass ich an der Universität Freiburg mit dem Hauptfach Psychologie eingeschrieben bin. Name: Mat.Nr.: Unterschrift: Bearbeitungshinweise:
Einführung in die Statistik für Politikwissenschaftler Sommersemester 2013
 Einführung in die Statistik für Politikwissenschaftler Sommersemester 2013 1. Welche Aussage zur Statistik (in den Sozialwissenschaften) sind richtig? (2 Punkte) ( ) Statistik ist die Lehre von Methoden
Einführung in die Statistik für Politikwissenschaftler Sommersemester 2013 1. Welche Aussage zur Statistik (in den Sozialwissenschaften) sind richtig? (2 Punkte) ( ) Statistik ist die Lehre von Methoden
Statistik II Übung 3: Hypothesentests Aktualisiert am
 Statistik II Übung 3: Hypothesentests Aktualisiert am 12.04.2017 Diese Übung beschäftigt sich mit der Anwendung diverser Hypothesentests (zum Beispiel zum Vergleich der Mittelwerte und Verteilungen zweier
Statistik II Übung 3: Hypothesentests Aktualisiert am 12.04.2017 Diese Übung beschäftigt sich mit der Anwendung diverser Hypothesentests (zum Beispiel zum Vergleich der Mittelwerte und Verteilungen zweier
Einführung in die Statistik
 Einführung in die Statistik 1. Deskriptive Statistik 2. Induktive Statistik 1. Deskriptive Statistik 1.0 Grundbegriffe 1.1 Skalenniveaus 1.2 Empirische Verteilungen 1.3 Mittelwerte 1.4 Streuungsmaße 1.0
Einführung in die Statistik 1. Deskriptive Statistik 2. Induktive Statistik 1. Deskriptive Statistik 1.0 Grundbegriffe 1.1 Skalenniveaus 1.2 Empirische Verteilungen 1.3 Mittelwerte 1.4 Streuungsmaße 1.0
Signifikanzprüfung. Peter Wilhelm Herbstsemester 2016
 Signifikanzprüfung Peter Wilhelm Herbstsemester 2016 1.) Auswahl des passenden Tests 2.) Begründete Festlegung des Alpha-Fehlers nach Abschätzung der Power 3.) Überprüfung der Voraussetzungen 4.) Durchführung
Signifikanzprüfung Peter Wilhelm Herbstsemester 2016 1.) Auswahl des passenden Tests 2.) Begründete Festlegung des Alpha-Fehlers nach Abschätzung der Power 3.) Überprüfung der Voraussetzungen 4.) Durchführung
Statistische Methoden
 Markus Pospeschill Statistische Methoden Strukturen, Grundlagen, Anwendungen in Psychologie und Sozialwissenschaften ELSEVIER SPEKTRUM AKADEMISCHER VERLAG Spektrum k_/l. AKADEMISCHER VERLAG VIII Inhaltsverzeichnis
Markus Pospeschill Statistische Methoden Strukturen, Grundlagen, Anwendungen in Psychologie und Sozialwissenschaften ELSEVIER SPEKTRUM AKADEMISCHER VERLAG Spektrum k_/l. AKADEMISCHER VERLAG VIII Inhaltsverzeichnis
Statistik K urs SS 2004
 Statistik K urs SS 2004 3.Tag Grundlegende statistische Maße Mittelwert (mean) Durchschnitt aller Werte Varianz (variance) s 2 Durchschnittliche quadrierte Abweichung aller Werte vom Mittelwert >> Die
Statistik K urs SS 2004 3.Tag Grundlegende statistische Maße Mittelwert (mean) Durchschnitt aller Werte Varianz (variance) s 2 Durchschnittliche quadrierte Abweichung aller Werte vom Mittelwert >> Die
Teil: lineare Regression
 Teil: lineare Regression 1 Einführung 2 Prüfung der Regressionsfunktion 3 Die Modellannahmen zur Durchführung einer linearen Regression 4 Dummyvariablen 1 Einführung o Eine statistische Methode um Zusammenhänge
Teil: lineare Regression 1 Einführung 2 Prüfung der Regressionsfunktion 3 Die Modellannahmen zur Durchführung einer linearen Regression 4 Dummyvariablen 1 Einführung o Eine statistische Methode um Zusammenhänge
htw saar 1 EINFÜHRUNG IN DIE STATISTIK: BESCHREIBENDE STATISTIK
 htw saar 1 EINFÜHRUNG IN DIE STATISTIK: BESCHREIBENDE STATISTIK htw saar 2 Grundbegriffe htw saar 3 Grundgesamtheit und Stichprobe Ziel: Über eine Grundgesamtheit (Population) soll eine Aussage über ein
htw saar 1 EINFÜHRUNG IN DIE STATISTIK: BESCHREIBENDE STATISTIK htw saar 2 Grundbegriffe htw saar 3 Grundgesamtheit und Stichprobe Ziel: Über eine Grundgesamtheit (Population) soll eine Aussage über ein
Zusammenhangsanalyse mit SPSS. Messung der Intensität und/oder der Richtung des Zusammenhangs zwischen 2 oder mehr Variablen
 - nominal, ordinal, metrisch In SPSS: - Einfache -> Mittelwerte vergleichen -> Einfaktorielle - Mehrfaktorielle -> Allgemeines lineares Modell -> Univariat In SPSS: -> Nichtparametrische Tests -> K unabhängige
- nominal, ordinal, metrisch In SPSS: - Einfache -> Mittelwerte vergleichen -> Einfaktorielle - Mehrfaktorielle -> Allgemeines lineares Modell -> Univariat In SPSS: -> Nichtparametrische Tests -> K unabhängige
Statistik im Klartext Für Psychologen, Wirtschaftsund Sozialwissenschaftler. Fabian Heimsch Rudolf Niederer Peter Zöfel
 Statistik im Klartext Für Psychologen, Wirtschaftsund Sozialwissenschaftler 2., aktualisierte und erweiterte Aulage Fabian Heimsch Rudolf Niederer Peter Zöfel Statistik im Klartext - PDF Inhaltsverzeichnis
Statistik im Klartext Für Psychologen, Wirtschaftsund Sozialwissenschaftler 2., aktualisierte und erweiterte Aulage Fabian Heimsch Rudolf Niederer Peter Zöfel Statistik im Klartext - PDF Inhaltsverzeichnis
Korrelation Regression. Wenn Daten nicht ohne einander können Korrelation
 DAS THEMA: KORRELATION UND REGRESSION Korrelation Regression Wenn Daten nicht ohne einander können Korrelation Korrelation Kovarianz Pearson-Korrelation Voraussetzungen für die Berechnung die Höhe der
DAS THEMA: KORRELATION UND REGRESSION Korrelation Regression Wenn Daten nicht ohne einander können Korrelation Korrelation Kovarianz Pearson-Korrelation Voraussetzungen für die Berechnung die Höhe der
Inhalt. Vorwort Univariate Verteilungen Verteilungen Die Normalverteilung... 47
 Inhalt Vorwort... 9 1 Einleitung: Grundlagen der Statistik... 11 1.1 Die statistische Fragestellung im Forschungsprozess... 11 1.2 Grundbegriffe der Statistik... 13 1.3 Voraussetzung jeder Statistik: Die
Inhalt Vorwort... 9 1 Einleitung: Grundlagen der Statistik... 11 1.1 Die statistische Fragestellung im Forschungsprozess... 11 1.2 Grundbegriffe der Statistik... 13 1.3 Voraussetzung jeder Statistik: Die
Statistische Datenanalyse mit SPSS für Windows
 Jürgen Janssen Wilfried Laatz Statistische Datenanalyse mit SPSS für Windows Eine anwendungsorientierte Einführung in das Basissystem und das Modul Exakte Tests Zweite, neubearbeitete Auflage Mit 357 AbbOdungen
Jürgen Janssen Wilfried Laatz Statistische Datenanalyse mit SPSS für Windows Eine anwendungsorientierte Einführung in das Basissystem und das Modul Exakte Tests Zweite, neubearbeitete Auflage Mit 357 AbbOdungen
Inhaltsverzeichnis Grundlagen aufigkeitsverteilungen Maßzahlen und Grafiken f ur eindimensionale Merkmale
 1. Grundlagen... 1 1.1 Grundgesamtheit und Untersuchungseinheit................ 1 1.2 Merkmal oder statistische Variable........................ 2 1.3 Datenerhebung.........................................
1. Grundlagen... 1 1.1 Grundgesamtheit und Untersuchungseinheit................ 1 1.2 Merkmal oder statistische Variable........................ 2 1.3 Datenerhebung.........................................
Prüfungsliteratur: Rudolf & Müller S
 1 Beispiele zur univariaten Varianzanalyse Einfaktorielle Varianzanalyse (Wiederholung!) 3 Allgemeines lineares Modell 4 Zweifaktorielle Varianzanalyse 5 Multivariate Varianzanalyse 6 Varianzanalyse mit
1 Beispiele zur univariaten Varianzanalyse Einfaktorielle Varianzanalyse (Wiederholung!) 3 Allgemeines lineares Modell 4 Zweifaktorielle Varianzanalyse 5 Multivariate Varianzanalyse 6 Varianzanalyse mit
Glossar. den man als mindesten oder interessanten Effekt für die Population annimmt. Anpassungstest; 148 f., 151: Der Anpassungstest
 Literatur Aron, A., Aron, E. N., and Coups, E. J. (2009). Statistics for Psychology. Upper Saddle River: Prentice Hall. Backhaus, K.; Erichson, B.; Plinke, W. und Weiber, R. (2006). Multivariate Analysemethoden.
Literatur Aron, A., Aron, E. N., and Coups, E. J. (2009). Statistics for Psychology. Upper Saddle River: Prentice Hall. Backhaus, K.; Erichson, B.; Plinke, W. und Weiber, R. (2006). Multivariate Analysemethoden.
SigmaStat Nina Becker, Christoph. Rothenwöhrer. Copyright 2004 Systat Software, Inc.
 SigmaStat 3.11 Copyright 2004 Systat Software, Inc. http://www.systat.com Nina Becker, Christoph Rothenwöhrer Die Aufgabe der Statistik ist die Zusammenfassung von Daten, deren Darstellung, Analyse und
SigmaStat 3.11 Copyright 2004 Systat Software, Inc. http://www.systat.com Nina Becker, Christoph Rothenwöhrer Die Aufgabe der Statistik ist die Zusammenfassung von Daten, deren Darstellung, Analyse und
Kapitel 3 Schließende lineare Regression Einführung. induktiv. Fragestellungen. Modell. Matrixschreibweise. Annahmen.
 Kapitel 3 Schließende lineare Regression 3.1. Einführung induktiv Fragestellungen Modell Statistisch bewerten, der vorher beschriebenen Zusammenhänge auf der Basis vorliegender Daten, ob die ermittelte
Kapitel 3 Schließende lineare Regression 3.1. Einführung induktiv Fragestellungen Modell Statistisch bewerten, der vorher beschriebenen Zusammenhänge auf der Basis vorliegender Daten, ob die ermittelte
Bitte am PC mit Windows anmelden!
 Einführung in SPSS Plan für heute: Grundlagen/ Vorwissen für SPSS Vergleich der Übungsaufgaben Einführung in SPSS http://weknowmemes.com/generator/uploads/generated/g1374774654830726655.jpg Standardnormalverteilung
Einführung in SPSS Plan für heute: Grundlagen/ Vorwissen für SPSS Vergleich der Übungsaufgaben Einführung in SPSS http://weknowmemes.com/generator/uploads/generated/g1374774654830726655.jpg Standardnormalverteilung
Signifikanzprüfung. Peter Wilhelm Herbstsemester 2014
 Signifikanzprüfung Peter Wilhelm Herbstsemester 2014 1.) Auswahl des passenden Tests 2.) Begründete Festlegung des Alpha- Fehlers nach Abschätzung der Power 3.) Überprüfung der Voraussetzungen 4.) Durchführung
Signifikanzprüfung Peter Wilhelm Herbstsemester 2014 1.) Auswahl des passenden Tests 2.) Begründete Festlegung des Alpha- Fehlers nach Abschätzung der Power 3.) Überprüfung der Voraussetzungen 4.) Durchführung
Einfaktorielle Varianzanalyse Vergleich mehrerer Mittelwerte
 Einfaktorielle Varianzanalyse Vergleich mehrerer Mittelwerte Es wurden die anorganischen Phosphatwerte im Serum (mg/dl) eine Stunde nach einem Glukosetoleranztest bei übergewichtigen Personen mit Hyperinsulinämie,
Einfaktorielle Varianzanalyse Vergleich mehrerer Mittelwerte Es wurden die anorganischen Phosphatwerte im Serum (mg/dl) eine Stunde nach einem Glukosetoleranztest bei übergewichtigen Personen mit Hyperinsulinämie,
Einführung in die Statistik
 Einführung in die Statistik Analyse und Modellierung von Daten Von Prof. Dr. Rainer Schlittgen 4., überarbeitete und erweiterte Auflage Fachbereich Materialwissenschaft! der Techn. Hochschule Darmstadt
Einführung in die Statistik Analyse und Modellierung von Daten Von Prof. Dr. Rainer Schlittgen 4., überarbeitete und erweiterte Auflage Fachbereich Materialwissenschaft! der Techn. Hochschule Darmstadt
Einführung in die Varianzanalyse mit SPSS
 Einführung in die Varianzanalyse mit SPSS SPSS-Benutzertreffen am URZ Carina Ortseifen 6. Mai 00 Inhalt. Varianzanalyse. Prozedur ONEWAY. Vergleich von k Gruppen 4. Multiple Vergleiche 5. Modellvoraussetzungen
Einführung in die Varianzanalyse mit SPSS SPSS-Benutzertreffen am URZ Carina Ortseifen 6. Mai 00 Inhalt. Varianzanalyse. Prozedur ONEWAY. Vergleich von k Gruppen 4. Multiple Vergleiche 5. Modellvoraussetzungen
Deskriptive Statistik
 Helge Toutenburg Christian Heumann Deskriptive Statistik Eine Einführung in Methoden und Anwendungen mit R und SPSS Siebte, aktualisierte und erweiterte Auflage Mit Beiträgen von Michael Schomaker 4ü Springer
Helge Toutenburg Christian Heumann Deskriptive Statistik Eine Einführung in Methoden und Anwendungen mit R und SPSS Siebte, aktualisierte und erweiterte Auflage Mit Beiträgen von Michael Schomaker 4ü Springer
VS PLUS
 VS PLUS Zusatzinformationen zu Medien des VS Verlags Statistik II Inferenzstatistik 2010 Übungsaufgaben und Lösungen Inferenzstatistik 2 [Übungsaufgaben und Lösungenn - Inferenzstatistik 2] ÜBUNGSAUFGABEN
VS PLUS Zusatzinformationen zu Medien des VS Verlags Statistik II Inferenzstatistik 2010 Übungsaufgaben und Lösungen Inferenzstatistik 2 [Übungsaufgaben und Lösungenn - Inferenzstatistik 2] ÜBUNGSAUFGABEN
Es können keine oder mehrere Antworten richtig sein. Eine Frage ist NUR dann richtig beantwortet, wenn ALLE richtigen Antworten angekreuzt wurden.
 Teil III: Statistik Alle Fragen sind zu beantworten. Es können keine oder mehrere Antworten richtig sein. Eine Frage ist NUR dann richtig beantwortet, wenn ALLE richtigen Antworten angekreuzt wurden. Wird
Teil III: Statistik Alle Fragen sind zu beantworten. Es können keine oder mehrere Antworten richtig sein. Eine Frage ist NUR dann richtig beantwortet, wenn ALLE richtigen Antworten angekreuzt wurden. Wird
Mehrfaktorielle Varianzanalyse
 Professur E-Learning und Neue Medien Institut für Medienforschung Philosophische Fakultät Einführung in die Statistik Mehrfaktorielle Varianzanalyse Überblick Einführung Empirische F-Werte zu einer zweifaktoriellen
Professur E-Learning und Neue Medien Institut für Medienforschung Philosophische Fakultät Einführung in die Statistik Mehrfaktorielle Varianzanalyse Überblick Einführung Empirische F-Werte zu einer zweifaktoriellen
Statistik in der Praxis
 Peter Zöfel Statistik in der Praxis Zweite, überarbeitete Auflage 48 Abbildungen, 118 Tabellen und 22 Tafeln I Gustav Fischer Verlag Stuttgart Inhaltsverzeichnis Vorwort V 1. Allgemeine Grundlagen 1 1.1
Peter Zöfel Statistik in der Praxis Zweite, überarbeitete Auflage 48 Abbildungen, 118 Tabellen und 22 Tafeln I Gustav Fischer Verlag Stuttgart Inhaltsverzeichnis Vorwort V 1. Allgemeine Grundlagen 1 1.1
Einführung in die Statistik für Politikwissenschaftler Wintersemester 2011/2012
 Einführung in die Statistik für Politikwissenschaftler Wintersemester 2011/2012 Es können von den Antwortmöglichkeiten alle, mehrere, eine oder keine Antwort(en) richtig sein. Nur bei einer korrekten Antwort
Einführung in die Statistik für Politikwissenschaftler Wintersemester 2011/2012 Es können von den Antwortmöglichkeiten alle, mehrere, eine oder keine Antwort(en) richtig sein. Nur bei einer korrekten Antwort
Inhaltsverzeichnis. II. Statistische Modelle und sozialwissenschaftliche Meßniveaus 16
 Vorwort 1 1. Kapitel: Der Stellenwert der Statistik für die sozialwissenschaflliche Forschung 1 1. Zur Logik (sozial-)wissenschaftlicher Forschung 1 1. Alltagswissen und wissenschaftliches Wissen 1 2.
Vorwort 1 1. Kapitel: Der Stellenwert der Statistik für die sozialwissenschaflliche Forschung 1 1. Zur Logik (sozial-)wissenschaftlicher Forschung 1 1. Alltagswissen und wissenschaftliches Wissen 1 2.
Regression ein kleiner Rückblick. Methodenseminar Dozent: Uwe Altmann Alexandra Kuhn, Melanie Spate
 Regression ein kleiner Rückblick Methodenseminar Dozent: Uwe Altmann Alexandra Kuhn, Melanie Spate 05.11.2009 Gliederung 1. Stochastische Abhängigkeit 2. Definition Zufallsvariable 3. Kennwerte 3.1 für
Regression ein kleiner Rückblick Methodenseminar Dozent: Uwe Altmann Alexandra Kuhn, Melanie Spate 05.11.2009 Gliederung 1. Stochastische Abhängigkeit 2. Definition Zufallsvariable 3. Kennwerte 3.1 für
Methodenlehre. Vorlesung 12. Prof. Dr. Björn Rasch, Cognitive Biopsychology and Methods University of Fribourg
 Methodenlehre Vorlesung 12 Prof. Dr., Cognitive Biopsychology and Methods University of Fribourg 1 Methodenlehre II Woche Datum Thema 1 FQ Einführung, Verteilung der Termine 1 18.2.15 Psychologie als Wissenschaft
Methodenlehre Vorlesung 12 Prof. Dr., Cognitive Biopsychology and Methods University of Fribourg 1 Methodenlehre II Woche Datum Thema 1 FQ Einführung, Verteilung der Termine 1 18.2.15 Psychologie als Wissenschaft
Unterschiedshypothesen für maximal 2 Gruppen, wenn die Voraussetzungen für parametrische Verfahren nicht erfüllt sind
 Schäfer A & Schöttker-Königer T, Statistik und quantitative Methoden für (2015) Arbeitsblatt 1 SPSS Kapitel 6 Seite 1 Unterschiedshypothesen für maximal 2 Gruppen, wenn die Voraussetzungen für parametrische
Schäfer A & Schöttker-Königer T, Statistik und quantitative Methoden für (2015) Arbeitsblatt 1 SPSS Kapitel 6 Seite 1 Unterschiedshypothesen für maximal 2 Gruppen, wenn die Voraussetzungen für parametrische
Stichprobenumfangsplanung
 Professur E-Learning und Neue Medien Institut für Medienforschung Philosophische Fakultät Einführung in die Statistik Stichprobenumfangsplanung Überblick Einführung Signifikanzniveau Teststärke Effektgröße
Professur E-Learning und Neue Medien Institut für Medienforschung Philosophische Fakultät Einführung in die Statistik Stichprobenumfangsplanung Überblick Einführung Signifikanzniveau Teststärke Effektgröße
Statistische Messdatenauswertung
 Roland Looser Statistische Messdatenauswertung Praktische Einführung in die Auswertung von Messdaten mit Excel und spezifischer Statistik-Software für naturwissenschaftlich und technisch orientierte Anwender
Roland Looser Statistische Messdatenauswertung Praktische Einführung in die Auswertung von Messdaten mit Excel und spezifischer Statistik-Software für naturwissenschaftlich und technisch orientierte Anwender
Zusammenfassung. Einführung in die Statistik. Professur E-Learning und Neue Medien. Institut für Medienforschung Philosophische Fakultät
 Professur E-Learning und Neue Medien Institut für Medienforschung Philosophische Fakultät Einführung in die Statistik Zusammenfassung Überblick 2 Überblick Zentrale Tendenz, Streuung und Verteilung Tabellen
Professur E-Learning und Neue Medien Institut für Medienforschung Philosophische Fakultät Einführung in die Statistik Zusammenfassung Überblick 2 Überblick Zentrale Tendenz, Streuung und Verteilung Tabellen
Teil / Ein paar statistische Grundlagen 25. Kapitel 1 Was Statistik ist und Warum sie benötigt Wird 2 7
 Inhaltsverzeichnis Einführung 21 Über dieses Buch 21 Törichte Annahmen über den Leser 22 Wie dieses Buch aufgebaut ist 23 Teil I: Ein paar statistische Grundlagen 23 Teil II: Die beschreibende Statistik
Inhaltsverzeichnis Einführung 21 Über dieses Buch 21 Törichte Annahmen über den Leser 22 Wie dieses Buch aufgebaut ist 23 Teil I: Ein paar statistische Grundlagen 23 Teil II: Die beschreibende Statistik
Lehrinhalte Statistik (Sozialwissenschaften)
") Lehrinhalte Technische Universität Dresden Institut für Mathematische Stochastik Dresden, 13. November 2007 Seit 2004 Vorlesungen durch Klaus Th. Hess und Hans Otfried Müller. Statistik I: Beschreibende
Lehrinhalte Technische Universität Dresden Institut für Mathematische Stochastik Dresden, 13. November 2007 Seit 2004 Vorlesungen durch Klaus Th. Hess und Hans Otfried Müller. Statistik I: Beschreibende
UE Angewandte Statistik Termin 4 Gruppenvergleichstests
 UE Angewandte Statistik Termin 4 Gruppenvergleichstests Martina Koller Institut für Pflegewissenschaft SoSe 2015 INHALT 1 Allgemeiner Überblick... 1 2 Normalverteilung... 2 2.1 Explorative Datenanalyse...
UE Angewandte Statistik Termin 4 Gruppenvergleichstests Martina Koller Institut für Pflegewissenschaft SoSe 2015 INHALT 1 Allgemeiner Überblick... 1 2 Normalverteilung... 2 2.1 Explorative Datenanalyse...
Dr. Maike M. Burda. Welchen Einfluss hat die Körperhöhe auf das Körpergewicht? Eine Regressionsanalyse. HU Berlin, Econ Bootcamp
 Dr. Maike M. Burda Welchen Einfluss hat die Körperhöhe auf das Körpergewicht? Eine Regressionsanalyse. HU Berlin, Econ Bootcamp 8.-10. Januar 2010 BOOTDATA.GDT: 250 Beobachtungen für die Variablen... cm:
Dr. Maike M. Burda Welchen Einfluss hat die Körperhöhe auf das Körpergewicht? Eine Regressionsanalyse. HU Berlin, Econ Bootcamp 8.-10. Januar 2010 BOOTDATA.GDT: 250 Beobachtungen für die Variablen... cm:
4.1. Verteilungsannahmen des Fehlers. 4. Statistik im multiplen Regressionsmodell Verteilungsannahmen des Fehlers
 4. Statistik im multiplen Regressionsmodell In diesem Kapitel wird im Abschnitt 4.1 zusätzlich zu den schon bekannten Standardannahmen noch die Annahme von normalverteilten Residuen hinzugefügt. Auf Basis
4. Statistik im multiplen Regressionsmodell In diesem Kapitel wird im Abschnitt 4.1 zusätzlich zu den schon bekannten Standardannahmen noch die Annahme von normalverteilten Residuen hinzugefügt. Auf Basis
Einführung in die Statistik für Politikwissenschaftler Sommersemester 2013
 Einführung in die Statistik für Politikwissenschaftler Sommersemester 2013 Die folgende Klausur umfasst 24 Fragen. Bitte bearbeiten Sie ALLE Fragen. Bei den Multiple Choice Fragen können keine, eine, mehrere
Einführung in die Statistik für Politikwissenschaftler Sommersemester 2013 Die folgende Klausur umfasst 24 Fragen. Bitte bearbeiten Sie ALLE Fragen. Bei den Multiple Choice Fragen können keine, eine, mehrere
Eine computergestützte Einführung mit
 Thomas Cleff Deskriptive Statistik und Explorative Datenanalyse Eine computergestützte Einführung mit Excel, SPSS und STATA 3., überarbeitete und erweiterte Auflage ^ Springer Inhaltsverzeichnis 1 Statistik
Thomas Cleff Deskriptive Statistik und Explorative Datenanalyse Eine computergestützte Einführung mit Excel, SPSS und STATA 3., überarbeitete und erweiterte Auflage ^ Springer Inhaltsverzeichnis 1 Statistik
Einführung in die Statistik
 Einführung in die Statistik Analyse und Modellierung von Daten von Prof. Dr. Rainer Schlittgen Universität Hamburg 12., korrigierte Auflage Oldenbourg Verlag München Inhaltsverzeichnis 1 Statistische Daten
Einführung in die Statistik Analyse und Modellierung von Daten von Prof. Dr. Rainer Schlittgen Universität Hamburg 12., korrigierte Auflage Oldenbourg Verlag München Inhaltsverzeichnis 1 Statistische Daten
Häufigkeitsauszählungen, zentrale statistische Kennwerte und Mittelwertvergleiche
 Lehrveranstaltung Empirische Forschung und Politikberatung der Universität Bonn, WS 2007/2008 Häufigkeitsauszählungen, zentrale statistische Kennwerte und Mittelwertvergleiche 30. November 2007 Michael
Lehrveranstaltung Empirische Forschung und Politikberatung der Universität Bonn, WS 2007/2008 Häufigkeitsauszählungen, zentrale statistische Kennwerte und Mittelwertvergleiche 30. November 2007 Michael
Biomathematik für Mediziner
 Institut für Medizinische Biometrie, Informatik und Epidemiologie der Universität Bonn (Direktor: Prof. Dr. Max P. Baur) Biomathematik für Mediziner Klausur SS 2002 Aufgabe 1: Franz Beckenbauer will, dass
Institut für Medizinische Biometrie, Informatik und Epidemiologie der Universität Bonn (Direktor: Prof. Dr. Max P. Baur) Biomathematik für Mediziner Klausur SS 2002 Aufgabe 1: Franz Beckenbauer will, dass
Gibt es einen Zusammenhang zwischen Merkmalen? Korrelationen
 Arbeitsblatt SPSS Kapitel 8 Seite Gibt es einen Zusammenhang zwischen Merkmalen? Korrelationen Wie in allen Kapiteln gehen wir im Folgenden davon aus, dass Sie die Datei elporiginal.sav geöffnet haben.
Arbeitsblatt SPSS Kapitel 8 Seite Gibt es einen Zusammenhang zwischen Merkmalen? Korrelationen Wie in allen Kapiteln gehen wir im Folgenden davon aus, dass Sie die Datei elporiginal.sav geöffnet haben.
Einführung in die computergestützte Datenanalyse
 Karlheinz Zwerenz Statistik Einführung in die computergestützte Datenanalyse 6., überarbeitete Auflage DE GRUYTER OLDENBOURG Vorwort Hinweise zu EXCEL und SPSS Hinweise zum Master-Projekt XI XII XII TEIL
Karlheinz Zwerenz Statistik Einführung in die computergestützte Datenanalyse 6., überarbeitete Auflage DE GRUYTER OLDENBOURG Vorwort Hinweise zu EXCEL und SPSS Hinweise zum Master-Projekt XI XII XII TEIL
Eigene MC-Fragen SPSS. 1. Zutreffend auf die Datenerfassung und Datenaufbereitung in SPSS ist
 Eigene MC-Fragen SPSS 1. Zutreffend auf die Datenerfassung und Datenaufbereitung in SPSS ist [a] In der Variablenansicht werden für die betrachteten Merkmale SPSS Variablen definiert. [b] Das Daten-Editor-Fenster
Eigene MC-Fragen SPSS 1. Zutreffend auf die Datenerfassung und Datenaufbereitung in SPSS ist [a] In der Variablenansicht werden für die betrachteten Merkmale SPSS Variablen definiert. [b] Das Daten-Editor-Fenster
Deskriptive Statistik
 Markus Wirtz, Christof Nachtigall Deskriptive Statistik 2008 AGI-Information Management Consultants May be used for personal purporses only or by libraries associated to dandelon.com network. Statistische
Markus Wirtz, Christof Nachtigall Deskriptive Statistik 2008 AGI-Information Management Consultants May be used for personal purporses only or by libraries associated to dandelon.com network. Statistische
Welche der folgenden Aussagen sind richtig? (x aus 5) A Ein metrisches Merkmal, das überabzählbar viele Ausprägungen besitzt heißt diskret.
 A Ein metrisches Merkmal, das überabzählbar viele Ausprägungen besitzt heißt diskret.") Grundlagen der Statistik 25.9.2014 7 Aufgabe 7 Welche der folgenden Aussagen sind richtig? (x aus 5) A Ein metrisches Merkmal, das überabzählbar viele Ausprägungen besitzt heißt diskret. B Ein Merkmal
Grundlagen der Statistik 25.9.2014 7 Aufgabe 7 Welche der folgenden Aussagen sind richtig? (x aus 5) A Ein metrisches Merkmal, das überabzählbar viele Ausprägungen besitzt heißt diskret. B Ein Merkmal
Anteile Häufigkeiten Verteilungen Lagemaße Streuungsmaße Merkmale von Verteilungen. Anteile Häufigkeiten Verteilungen
 DAS THEMA: VERTEILUNGEN LAGEMAßE - STREUUUNGSMAßE Anteile Häufigkeiten Verteilungen Lagemaße Streuungsmaße Merkmale von Verteilungen Anteile Häufigkeiten Verteilungen Anteile und Häufigkeiten Darstellung
DAS THEMA: VERTEILUNGEN LAGEMAßE - STREUUUNGSMAßE Anteile Häufigkeiten Verteilungen Lagemaße Streuungsmaße Merkmale von Verteilungen Anteile Häufigkeiten Verteilungen Anteile und Häufigkeiten Darstellung
Statistische Grundlagen I
 Statistische Grundlagen I Arten der Statistik Zusammenfassung und Darstellung von Daten Beschäftigt sich mit der Untersuchung u. Beschreibung von Gesamtheiten oder Teilmengen von Gesamtheiten durch z.b.
Statistische Grundlagen I Arten der Statistik Zusammenfassung und Darstellung von Daten Beschäftigt sich mit der Untersuchung u. Beschreibung von Gesamtheiten oder Teilmengen von Gesamtheiten durch z.b.
Statistik für Human- und Sozialwissenschaftler
 Jürgen Bortz Statistik für Human- und Sozialwissenschaftler Sechste, vollständig überarbeitete und aktualisierte Auflage mit 84 Abbildungen und 242 Tabellen 4y Springer Inhaltsverzeichnis* > Vorbemerkungen:
Jürgen Bortz Statistik für Human- und Sozialwissenschaftler Sechste, vollständig überarbeitete und aktualisierte Auflage mit 84 Abbildungen und 242 Tabellen 4y Springer Inhaltsverzeichnis* > Vorbemerkungen:
Einführung in SPSS. Sitzung 4: Bivariate Zusammenhänge. Knut Wenzig. 27. Januar 2005
 Sitzung 4: Bivariate Zusammenhänge 27. Januar 2005 Inhalt der letzten Sitzung Übung: ein Index Umgang mit missing values Berechnung eines Indexes Inhalt der letzten Sitzung Übung: ein Index Umgang mit
Sitzung 4: Bivariate Zusammenhänge 27. Januar 2005 Inhalt der letzten Sitzung Übung: ein Index Umgang mit missing values Berechnung eines Indexes Inhalt der letzten Sitzung Übung: ein Index Umgang mit
Gundlagen empirischer Forschung & deskriptive Statistik. Statistische Methoden in der Korpuslinguistik Heike Zinsmeister WS 2008/09
 Gundlagen empirischer Forschung & deskriptive Statistik Statistische Methoden in der Korpuslinguistik Heike Zinsmeister WS 2008/09 Grundlagen Vorbereitung einer empirischen Studie Allgemeine Beschreibung
Gundlagen empirischer Forschung & deskriptive Statistik Statistische Methoden in der Korpuslinguistik Heike Zinsmeister WS 2008/09 Grundlagen Vorbereitung einer empirischen Studie Allgemeine Beschreibung
absolute Häufigkeit h: Anzahl einer bestimmten Note relative Häufigkeit r: Anzahl einer bestimmten Note, gemessen an der Gesamtzahl der Noten
 Statistik Eine Aufgabe der Statistik ist es, Datenmengen zusammenzufassen und darzustellen. Man verwendet dazu bestimmte Kennzahlen und wertet Stichproben aus, um zu Aussagen bzw. Prognosen über die Gesamtheit
Statistik Eine Aufgabe der Statistik ist es, Datenmengen zusammenzufassen und darzustellen. Man verwendet dazu bestimmte Kennzahlen und wertet Stichproben aus, um zu Aussagen bzw. Prognosen über die Gesamtheit
Statistik II: Signifikanztests /2
 Medien Institut : Signifikanztests /2 Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Korrelation 2. Exkurs: Kausalität 3. Regressionsanalyse 4. Key Facts 2 I
Medien Institut : Signifikanztests /2 Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Korrelation 2. Exkurs: Kausalität 3. Regressionsanalyse 4. Key Facts 2 I
Statistik III. Einfaktorielle Varianzanalyse (ANOVA), Regressionsanalyse und Verfahren bei Messwiederholung mit SPSS.
, Regressionsanalyse und Verfahren bei Messwiederholung mit SPSS.") Statistik III Einfaktorielle Varianzanalyse (ANOVA), Regressionsanalyse und Verfahren bei Messwiederholung mit SPSS Verena Hofmann Dr. phil. Departement für Sonderpädagogik Universität Freiburg Petrus-Kanisius-Gasse
Statistik III Einfaktorielle Varianzanalyse (ANOVA), Regressionsanalyse und Verfahren bei Messwiederholung mit SPSS Verena Hofmann Dr. phil. Departement für Sonderpädagogik Universität Freiburg Petrus-Kanisius-Gasse
= = =0,2=20% 25 Plätze Zufallsübereinstimmung: 0.80 x x 0.20 = %
 allgemein Klassifizierung nach Persönlichkeitseigenschaften Messung von Persönlichkeitseigenschaften Zuordnung von Objekten zu Zahlen, so dass die Beziehungen zwischen den Zahlen den Beziehungen zwischen
allgemein Klassifizierung nach Persönlichkeitseigenschaften Messung von Persönlichkeitseigenschaften Zuordnung von Objekten zu Zahlen, so dass die Beziehungen zwischen den Zahlen den Beziehungen zwischen
Ziel: Vorhersage eines Kriteriums/Regressand Y durch einen Prädiktor/Regressor X.
 Lineare Regression Einfache Regression Beispieldatensatz: trinkgeld.sav Ziel: Vorhersage eines Kriteriums/Regressand Y durch einen Prädiktor/Regressor X. H0: Y lässt sich nicht durch X erklären, das heißt
Lineare Regression Einfache Regression Beispieldatensatz: trinkgeld.sav Ziel: Vorhersage eines Kriteriums/Regressand Y durch einen Prädiktor/Regressor X. H0: Y lässt sich nicht durch X erklären, das heißt
Inhalt. I Einführung. Kapitel 1 Konzept des Buches Kapitel 2 Messen in der Psychologie... 27
 Inhalt I Einführung Kapitel 1 Konzept des Buches........................................ 15 Kapitel 2 Messen in der Psychologie.................................. 27 2.1 Arten von psychologischen Messungen....................
Inhalt I Einführung Kapitel 1 Konzept des Buches........................................ 15 Kapitel 2 Messen in der Psychologie.................................. 27 2.1 Arten von psychologischen Messungen....................
Grundlagen der Statistik I
 NWB-Studienbücher Wirtschaftswissenschaften Grundlagen der Statistik I Beschreibende Verfahren Von Professor Dr. Jochen Schwarze 10. Auflage Verlag Neue Wirtschafts-Briefe Herne/Berlin Inhaltsverzeichnis
NWB-Studienbücher Wirtschaftswissenschaften Grundlagen der Statistik I Beschreibende Verfahren Von Professor Dr. Jochen Schwarze 10. Auflage Verlag Neue Wirtschafts-Briefe Herne/Berlin Inhaltsverzeichnis
Statistische Tests (Signifikanztests)
") Statistische Tests (Signifikanztests) [testing statistical hypothesis] Prüfen und Bewerten von Hypothesen (Annahmen, Vermutungen) über die Verteilungen von Merkmalen in einer Grundgesamtheit (Population)
Statistische Tests (Signifikanztests) [testing statistical hypothesis] Prüfen und Bewerten von Hypothesen (Annahmen, Vermutungen) über die Verteilungen von Merkmalen in einer Grundgesamtheit (Population)
Methodenlehre. Vorlesung 11. Prof. Dr. Björn Rasch, Cognitive Biopsychology and Methods University of Fribourg
 Methodenlehre Vorlesung 11 Prof. Dr., Cognitive Biopsychology and Methods University of Fribourg 1 03.12.13 Methodenlehre I Woche Datum Thema 1 FQ Einführung, Verteilung der Termine 1 25.9.13 Psychologie
Methodenlehre Vorlesung 11 Prof. Dr., Cognitive Biopsychology and Methods University of Fribourg 1 03.12.13 Methodenlehre I Woche Datum Thema 1 FQ Einführung, Verteilung der Termine 1 25.9.13 Psychologie
Statistik. Datenanalyse mit EXCEL und SPSS. R.01denbourg Verlag München Wien. Von Prof. Dr. Karlheinz Zwerenz. 3., überarbeitete Auflage
 Statistik Datenanalyse mit EXCEL und SPSS Von Prof. Dr. Karlheinz Zwerenz 3., überarbeitete Auflage R.01denbourg Verlag München Wien Inhalt Vorwort Hinweise zu EXCEL und SPSS Hinweise zum Master-Projekt
Statistik Datenanalyse mit EXCEL und SPSS Von Prof. Dr. Karlheinz Zwerenz 3., überarbeitete Auflage R.01denbourg Verlag München Wien Inhalt Vorwort Hinweise zu EXCEL und SPSS Hinweise zum Master-Projekt