Statistik. Inhaltsverzeichnis. Rade Kutil, Deskriptive Statistik 2. 2 Korrelation und Regression 8. 3 Ereignis- und Wahrscheinlichkeitsraum 11
|
|
|
- Petra Schuster
- vor 7 Jahren
- Abrufe
Transkript
1 Statistik Rade Kutil, 13 Inhaltsverzeichnis 1 Deskriptive Statistik Korrelation und Regression 8 3 Ereignis- und Wahrscheinlichkeitsraum 11 4 Kombinatorik 15 5 Bedingte Wahrscheinlichkeit 19 6 Zufallsvariablen 6.1 Diskrete Verteilungen Stetige Verteilungen Transformierte und unabhängige Zufallsvariablen Zentraler Grenzwertsatz 43 8 Schätzer 5 9 Konfidenzintervalle 5 1 Tests Simulation 64 1

2 Statistik beschäftigt sich damit, Daten, die aus natürlichen Prozessen (physikalischen, wirtschaftlichen,... ) entstehen bzw. dort gemessen werden, als Produkte von zufälligen Prozessen zu modellieren und daraus Rückschlüsse auf reale Zusammenhänge zu ziehen. Dabei gibt es drei Hauptkapitel. Das erste ist die deskriptive Statistik, bei der versucht wird, die Daten in Form von Histogrammen oder Kennwerten zusammenzufassen, die die Daten übersichtlicher beschreiben können. Das zweite ist die Wahrscheinlichkeitstheorie, in der der Begriff des zufälligen Ereignisses entwickelt wird, sowie Zufallsvariablen als Ereignissen zugeordnete Werte untersucht werden. Im dritten Kapitel, der schließenden Statistik, werden die ersten beiden Kapitel zusammengeführt. Das heißt, Stichproben werden als Realisierungen von Zufallsvariablen betrachtet und aus den Kennwerten der Stichprobe auf Kennwerte der Zufallsvariablen geschlossen. 1 Deskriptive Statistik Definition 1.1. Eine Stichprobe (sample) ist eine Menge von Merkmalsausprägungen einer Population (auch: Grundgesamtheit). Eine Stichprobe besteht in den meisten Fällen aus n Werten {x 1, x,..., x n } aus R oder N. n heißt Stichprobengröße. Beispiel 1.. Folgende Menge dient in der Folge als Beispiel für eine Stichprobe: {.14,.7,.43,.68,.81, 1.14, 1.45, 1.8,.36,.53,.9, 3.45, 4.51, 5.1, 5.68, 7.84}. Die Stichprobengröße ist n = 16. Zur Darstellung wird der Wertebereich einer Stichprobe in Klassen unterteilt. Definition 1.3. Eine Klasseneinteilung ist eine Folge {b,b 1,...b n } von aufsteigenden Klassengrenzen. Die Intervalle [b k 1,b k ) werden als Klassen bezeichnet. Definition 1.4. Die absolute Häufigkeit der k-ten Klasse [b k 1,b k ) ist die Anzahl der Stichprobenwerte, die in die Klasse fallen. Die relative Häufigkeit ist h k := H k n. H k := {i b k 1 x i < b k } Definition 1.5. Ein Histogramm ist eine graphische Darstellung einer Stichprobe, bei der Balken zwischen den Klassengrenzen b k 1,b k mit der Höhe der absoluten oder relativen Häufigkeit eingezeichnet werden.

3 (a) mit absoluten Häufigkeiten (b) mit relativen Häufigkeiten Abbildung 1: Histogramme der Beispielstichprobe (a) zu große Klassenbreite (b) zu kleine Klassenbreite Abbildung : Histogramme mit falsch gewählten Klassengrößen (a) ohne Skalierung (b) mit Skalierung Abbildung 3: Histogramme mit und ohne Skalierung 3
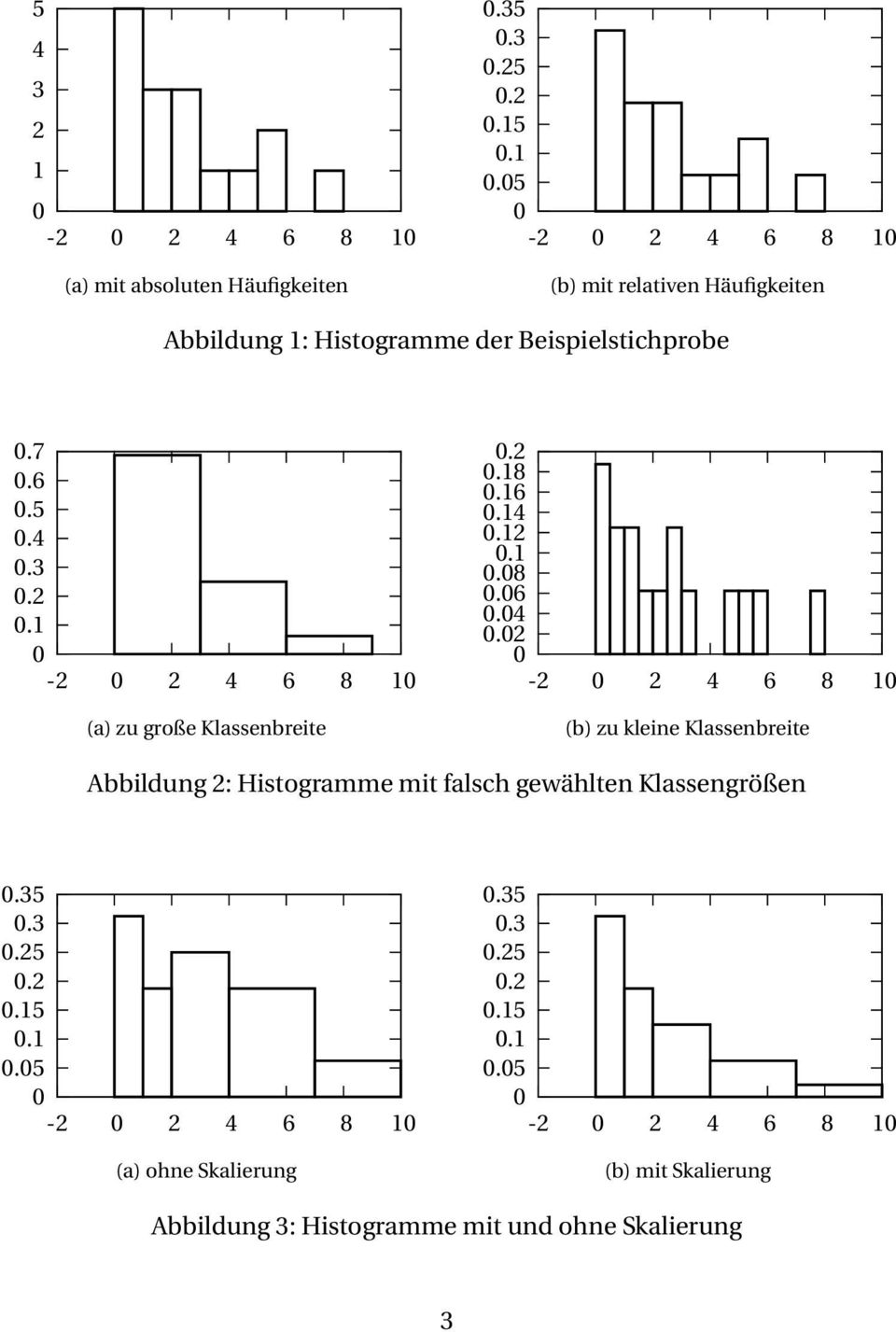
4 Beispiel 1.6. Wir wählen die gleichmäßig verteilten Klassengrenzen {, 1,,...} und berechnen zunächst die absoluten Häufigkeiten, z.b. H 3 = {i x i < 3} = {.36,.53,.9} = 3, und die relativen Häufigkeiten, z.b. h 3 = H 3 n = Dann zeichnen wir die Histogramme wie in Abbildung 1. Die Wahl der Klassenbreite ist wichtig, wie man in Abbildung sieht. Bei zu großer Klassenbreite zeigen zwar die Balkenhöhen aussagekräftige Werte an, aber die Auflösung des Wertebereichs ist zu gering. Bei zu kleiner Klassenbreite sind wiederum die Balkenhöhen zu gering aufgelöst. Vor allem wenn die Klassenbreiten nicht gleich sind, ist es sinnvoll, die Balkenhöhe umgekehrt proportional zur Klassenbreite zu skalieren. Definition 1.7. Die skalierte Balkenhöhe der k-ten Klassen ist die relative Häufigkeit dividiert durch die Klassenbreite: h k b k b k 1. Dadurch entspricht der Flächeninhalt des Balkens der Häufigkeit: A k = (b k h b k 1 ) k b k b k 1 = h k. Beispiel 1.8. Wir wählen die ungleichmäßig verteilten Klassengrenzen {, 1,, 4, 7,1} und berechnen die relativen Häufigkeiten, z.b. h 3 = 4 16 =.5 und die skalierten Balkenhöhen h 3 b 3 b =.5 4 =.15. Dann zeichnen wir die Histogramme wie in Abbildung 3. Definition 1.9. Die empirische Verteilungsfunktion F (x) gibt für jedes x R die relative Häufigkeit der Werte kleiner oder gleich x an: F (x) := 1 n {i x i x} Beispiel 1.1. Die Werte der Verteilungsfunktion können für jedes beliebige x ausgerechnet werden, z.b. F (.75) = 1 16 {.14,.7,.43,.68} = 4 16 =.5. Am besten rechnet man es aber für jeden Stichprobenwert x i aus und zeichnet zwischen den Punkten Plateaus ein. Das Ergebnis sieht man in Abbildung 4. Bei diskreten Merkmalen (x i N) ist es wahrscheinlich, dass gleiche Werte mehrmals auftreten. In diesem Fall ist es geschickter, die Werte in Form einer Häufigkeitstabelle anzugeben. Definition Eine Häufigkeitstabelle gibt eine diskrete Stichprobe als Liste von Paaren (x i, H i ) an. Das bedeutet, dass der Wert x i mit der Anzahl H i auftritt. 4

5 Abbildung 4: Empirische Verteilungsfunktion Beispiel 1.1. i = 1...m, m = 5, n = x i H i m H i = = 3 i=1 Für das Histogramm reicht es meist, eine Klasse pro Wert x i zu verwenden und die absolute (H i ) oder relative Häufigkeit (h i = H i n ) aufzutragen. Definition Die diskrete empirische Verteilungsfunktion ist dann F (x) = 1 n x i x H i. Beispiel Z.B.: x = 4, H = 5, h = F (4.6) = 1 3 x i 4.6 H i = = Eine Möglichkeit, die Verteilung bzw. die Eigenschaften der Verteilung einer Stichprobe zu beschreiben, ist die Analyse mittels Berechnung einer Reihe von Maßzahlen (Kennwerte, Lageparameter). Definition Das arithmetische Mittel (der Mittelwert) einer Stichprobe x ist x = 1 n n i=1 x i = x 1 + x x n n 5

6 s x s 5 1 Abbildung 5: Stichprobe, arithmetisches Mittel und Standardabweichung. Beispiel Wir verwenden in diesem und folgenden Beispielen die Stichprobe x = {5.1,7.7,5.9,3.9,9.5,7.1,6.3} x = 7 = = 6.5. Definition Die empirische Standardabweichung s und die empirische Varianz s sind Maße für die mittlere (quadratische) Abweichung der Stichprobenwerte vom Mittelwert. s := 1 n (x i x), s := s. n 1 Beispiel i=1 s = ( ) ( ) 6 = Siehe Abbildung 5 für eine Veranschaulichung. = 3.3, s = Bemerkung: Es gibt auch die analog zu Zufallsvariablen definierte Varianz σ = 1 n (xi x). Diese liefert jedoch im Mittel nicht das zu erwartende Ergebnis (siehe Kapitel Schätzer). Satz 1.19 (Verschiebungssatz). Auf folgende Weise kann die empirische Varianz oft einfacher berechnet werden. (( ) ) s = 1 n n x n 1 Beweis. x i i=1 1 n (x i x) = 1 n (x i n 1 i=1 n 1 x i x + x ) i=1 = 1 ( ( ) ( ) n n x i x i n 1 i=1 i=1 } {{ } =n x ) (( ) ) x + n x = 1 n x i n x n 1 i=1 6
 +... + (6.3 6.5) 6 = 19.9 6 Siehe Abbildung 5 für eine Veranschaulichung. = 3.3, s =.3 1.8. Bemerkung: Es gibt auch die analog zu Zufallsvariablen definierte Varianz σ = 1 n (xi x).")
7 Abbildung 6: Quantile als inverse Verteilungsfunktion. Beispiel 1.. s = = 3.3. Definition 1.1. Das Quantil x α ist der Wert, unter dem ein Anteil von α [,1] der Werte liegt. x 1 heißt Median, x 1 heißt erstes oder unteres Quartil, x 3 heißt 4 4 drittes oder oberes Quartil. Wenn die Werte x i sortiert sind, dann ist x α im Prinzip der Wert an der Stelle α n. Das kann man als die inverse empirische Verteilungsfunktion auffassen. Für < α < 1 gilt: { x αn αn N Beispiel 1.. x α := x αn +x αn+1 αn N x 1 = x = x = 5.1, x 1 = x 4 = 6.3, x 3 = x 6 = 7.7, x = x + x 3 = {3.9, { 5.1 }} { }{{},5.9, }{{} 6.3,7.1, }{{} 7.7,9.5} Abbildung 6 zeigt, wie die Quantile an der Verteilungsfunktion abgelesen werden können. Satz 1.3. Sind die Daten als Häufigkeitstabelle gegeben, so gilt: s = 1 m n 1 i=1 x = 1 n m H i x i, i=1 H i (x i x) = 1 n 1 (( m H i x i i=1 ) n x ) 7
 = 1 n 1 (( m H i x i i=1 ) n x ) 7")
8 Definition 1.4. Der Modus ist der am häufigsten auftretende Wert x i in der Stichprobe. Beispiel 1.5. Gegeben sei folgende Häufigkeitstabelle: x i 1 3 H i m = 4, n = 4 H i = 16 i=1 x = = = 7 4 s = ( Der Modus ist. (Und nicht 6!) Korrelation und Regression ) = = = 1 Definition.1. Bei mehrdimensionalen Stichproben werden mehrere Merkmale gleichzeitig gemessen. Eine zweidimensionale Stichproben besteht daher aus n Paaren von Werten {(x 1, y 1 ),(x, y ),...,(x n, y n )}, die man natürlich auch in Tabellenform angeben kann. Definition.. Die Kovarianz ist definiert durch (( ) ) s x,y := 1 n (x i x)(y i ȳ) = 1 n x i y i n xȳ n 1 n 1 i=1 Beispiel.3. i=1 x i y i x = s x = 1.87 ȳ = s y = s x,y = = Definition.4. Der Korrelationskoeffizient r x,y bzw. das Bestimmtheitsmaß rx,y geben die Stärke des linearen Zusammenhangs zwischen zwei Merkmalen an. Extremfälle sind: maximale (positive) Korrelation (r x,y = 1), keine Korrelation (r x,y = ), negative Korrelation (r x,y = 1). r x,y := s n x,y i=1 = x i y i n xȳ s x s ( y n i=1 x i n x)( n i=1 y nȳ ) i 8
,(x, y ),...,(x n, y n )}, die man natürlich auch in Tabellenform angeben kann. Definition.")
9 Beispiel.5. r x,y = =.95 Bei der Regression versucht man, eine Funktion f (Modell) zu finden, mit der ein Merkmal y durch das andere Merkmal x mittels f (x) möglichst gut geschätzt werden kann (Modellanpassung). Dabei soll die gesamte Abweichung durch die Wahl der Parameter von f minimiert werden. Definition.6. Die Summe der Fehlerquadrate (sum of squared errors, SSE) ist S(f, x, y) := n (y i f (x i )). i=1 Definition.7. Die Regression nach der Methode der kleinsten Quadrate ist die Minimierung der Summe der Fehlerquadrate durch Variation der Parameter a 1, a,... des Modells f a1,a,... (â 1, â,...) = argmin a 1,a,... S(f a1,a,..., x, y) = argmin a 1,a,... n (y i f a1,a,...(x i )) Definition.8. Bei der linearen Regression setzt sich f aus einer Linearkombination f = a 1 f 1 + a f a m f m zusammen. Die f k können dabei beliebige Funktionen sein. Satz.9. Die Lösung einer linearen Regression ergibt sich aus der Lösung des linearen Gleichungssystems C a = b, wobei a der Vektor der m Parameter a 1, a,... ist, C eine m m Matrix und b ein m-vektor ist mit i=1 i=1 n n C k,l = f k (x i )f l (x i ), b k = y i f k (x i ). Beweis. Das Maximum von S(f, x, y) als Funktion der Parameter a k können wir durch partielles Ableiten nach den a k und Nullsetzen ermitteln. = S(f, x, y) = n (y i a 1 f 1 (x i ) a f (x i )... a m f m (x i )) a k a k i=1 n = (y i a 1 f 1 (x i ) a f (x i )...)f k (x i ). i=1 Durch Nullsetzen und Hineinziehen und Trennen der Summe bekommen wir n n n n a 1 f 1 (x i )f k (x i ) + a f (x i )f k (x i ) +... a m f m (x i )f k (x i ) = y i f k (x i ), i=1 i=1 was der Zeile k des obigen Gleichungssystems entspricht. i=1 i=1 i=1 9

10 Beispiel.1. Das Modell y = a 1 + a x + a 3 x soll an die Daten aus Beispiel.3 angepasst werden. D.h. f 1 (x) = 1, f (x) = x und f 3 (x) = x. Es ergibt sich das Gleichungssystem a 1 a a 3 = wobei z.b. C 1,3 = = oder C, = = 93.73, und b 3 = = Die Lösung des Gleichungssystems ergibt a 1 = 3.5, a =.1159, a 3 =.11. Definition.11. In einem linearen Regressionsmodell muss f eine lineare Funktion sein. Bei zweidimensionalen Stichproben heißt das: y f (x) = ax + b. f nennt man Regressionsgerade. Satz.1. Für das lineare Regressionsmodell ergibt sich a = s x,y s x, b = ȳ a x. Beweis. Mit f 1 = 1, f = x und a 1 = b, a = a lässt sich Satz.9 anwenden und man erhält ( )( ) ( ) n xi b yi xi x = a xi y i i Multipliziert man die erste Zeile mit 1 n xi und subtrahiert sie von der zweiten Zeile, erhält man b + a( x i 1 n ( x i ) ) = x i y i 1 xi yi n xi y i n xȳ a = x i n. x 1 Erweitert man oben und unten mit n 1, ergibt sich wie gewünscht a = s x,y. Dividiert man die erste Zeile des Gleichungssystems durch n, erhält man b 1+a x = ȳ sx und daraus b = ȳ a x. Beispiel.13. a = =.94, b = =.14. Definition.14. Die Stichprobe kann in einem Streudiagramm (Scatterplot) dargestellt werden, in das man jeden Punkt (x i, y i ) einzeichnet. In ein Streudiagramm können auch Regressionsgeraden und -kurven eingezeichnet werden., 1

11 Abbildung 7: Streudiagramm mit Regressions-Kurve und -Gerade. Beispiel.15. Abbildung 7 zeigt das Streudiagramm aus Beispiel.3, sowie die Regressionskurve aus Beispiel.1 und die Regressionsgerade aus Beispiel.13. Definition.16. Wie bei eindimensionalen diskreten Merkmalen gibt es auch hier ein Äquivalent zu Häufigkeitstabellen: Kontingenztabellen. Dabei stellt H i,j die absolute Häufigkeit der gemeinsamen Merkmalsausprägung (x i, y i ) dar. Die Randhäufigkeiten H i, und H,j sind die Häufigkeiten von x i bzw. y j. h i,j = H i,j h i, = H i, n, h,j = H,j n sind die zugehörigen relativen Häufigkeiten. y 1... y m x 1 H 1,1... H 1,m H 1, x l H l,1... H l,m H l, H,1... H,m n y 1... y m x 1 h 1,1... h 1,m h 1, x l h l,1... h l,m h l, h,1... h,m 1 Satz.17. Im Fall von Kontingenztabellen wird die Kovarianz berechnet durch: (( ) ) s x,y = 1 l m H i,j (x i x)(y j ȳ) = 1 l m H i,j x i y j n xȳ. n 1 n 1 i=1 j =1 i=1 j =1 3 Ereignis- und Wahrscheinlichkeitsraum Als Geburtsstunde der Wahrscheinlichkeitstheorie wird heute ein Briefwechsel zwischen Blaise Pascal und Pierre de Fermat aus dem Jahr 1654 gesehen, in dem es um eine spezielle Fragestellung zum Glücksspiel ging. Solche Fragestellungen waren damals noch schwer zu behandeln, weil die axiomatische Begründung n, 11

12 der Wahrscheinlichkeitstheorie fehlte, die erst Anfang des. Jahrhunderts entwickelt wurde. Ein Ereignis wie z.b. 5 gewürfelt ist eine Abstraktion, weil es viele Details wie etwa die Lage des Würfel ignoriert. Es fasst daher viele mögliche Ereignisse zusammen. Weiters gilt auch Zahl größer 4 gewürfelt als Ereignis, welches nochmals zwei Ereignisse zusammenfasst, nämlich 5 gewürfelt und 6 gewürfelt. Daher werden Ereignisse als Mengen abgebildet. Die Elemente, aus denen diese Mengen gebildet werden, nennt man Ergebnisse, weil sie die möglichen Ergebnisse eines Zufallsprozesses sind. Sie werden in der Ergebnismenge zusammengefasst. Definition 3.1. Der Ergebnisraum (oft auch Grundmenge) Ω ist die Menge aller möglichen Ergebnisse eines Zufallsprozesses. Definition 3.. Ein Ereignisraum (Ω, Σ) besteht aus einer Menge Σ von Ereignissen e aus dem Ergebnisraum Ω, e Σ, e Ω, und erfüllt folgende Axiome (σ- Algebra): Ω Σ, Σ e Σ Ω \ e Σ e 1,e,... Σ i e 1,e,... Σ i e i Σ e i Σ Das erste Axiom stellt sicher, dass Ω selbst, das sichere Ereignis, sowie die leere Menge, das unmögliche Ereignis, im Ereignisraum enthalten sind. Das zweite bewirkt, dass zu jedem Ereignis e auch das Gegenereignis ē = Ω \ e enthalten ist. Die letzten zwei Axiome stellen sicher, dass die Vereinigung und der Durchschnitt beliebiger Ereignisse enthalten sind. Man beachte, dass sowohl Ω als auch Σ unendlich groß sein können. Daher reicht es nicht, nur die Vereinigung zweier Ereignisse zu inkludieren, sondern es muss auch die Vereinigung abzählbarunendlich vieler Ereignisse inkludiert sein, was nicht automatisch folgen würde. Beispiel 3.3. Beim Werfen eines Würfels ist der Ergebnisraum Ω = {1,,3,4,5,6} und der Ereignisraum Σ = {{1},{},{1,},...,{1,,3,4,5,6}}. Das Elementarereignis Zahl 4 gewürfelt entspricht dem Element 4 bzw. der einelementigen Teilmenge {4}. Das Ereignis Zahl kleiner 3 gewürfelt entspricht der Menge e 1 = {1,} Ω, Zahl größer 4 entspricht e = {5,6} Ω. Die Vereinigung zweier Ereignisse interpretiert man als oder. e 1 e bedeutet also Zahl kleiner 3 oder größer 4 gewürfelt. Gleichermaßen interpretiert man 1

13 den Durchschnitt als und, das Gegenereignis als nicht. ē 1 bedeutet also Zahl größer-gleich 3 gewürfelt. Nun soll jedem Ereignis e eine Wahrscheinlichkeit P(e) [, 1] zugeordnet werden. P stellt dabei ein Maß dar im Sinne der Maßtheorie. Zusammen mit dem Ereignisraum bildet sie einen Maßraum, den Wahrscheinlichkeitsraum. Definition 3.4. Ein Wahrscheinlichkeitsraum (Ω, Σ, P) über einem Ereignisraum (Ω, Σ) enthält das Wahrscheinlichkeitsmaß P : Σ R und erfüllt folgende Axiome (nach Kolmogorov, 1933): e Σ : P(e) P(Ω) = 1 e 1,e,... Σ i j : e i e j = P ( i ) e i = P(e i ) i Die Wahrscheinlichkeit darf also nicht negativ sein, das sichere Ereignis Ω hat Wahrscheinlichkeit 1, und bei der Vereinigung disjunkter Ereignisse summieren sich die Wahrscheinlichkeiten. Daraus ergeben sich nun einige Folgerungen. Satz 3.5. Das Gegenereignis hat die Gegenwahrscheinlichkeit P(ē) = 1 P(e). Beweis. e ē = P(e) + P(ē) = P(e ē) = P(Ω) = 1. Satz 3.6. P( ) =. Beweis. P( ) = P( Ω) = 1 P(Ω) = 1 1 =. Satz 3.7. d e P(d) P(e). Beweis. P(e) = P(d (e \ d)) d (e\d)= ========= P(d) + P(e \ d) P(d). Wenn zwei disjunkte Ereignisse vereinigt werden, addieren sich laut Axiom ihre Wahrscheinlichkeiten. Was passiert, wenn sie nicht disjunkt sind, sehen wir hier: Satz 3.8 (Additionssatz). P(d e) = P(d) + P(e) P(d e). 13
 e i = P(e i ) i Die Wahrscheinlichkeit darf also nicht negativ sein, das sichere Ereignis Ω hat Wahrscheinlichkeit 1, und bei der Vereinigung disjunkter Ereignisse")
14 Beweis. P(d) = P(d \ e d e) = P(d \ e) + P(d e) P(d \ e) = P(d) P(d e), P(e) = P(e \ d e d) = P(e \ d) + P(e d) P(e \ d) = P(e) P(d e), P(d e) = P(d \ e e \ d d e) = P(d \ e) + P(e \ d) + P(d e) = P(d) P(d e) + P(e) P(d e) + P(d e). Sehr oft haben Ereignisse gleicher Größe (bezüglich der Ergebnisanzahl) auch die gleiche Wahrscheinlichkeit. Das muss nicht so sein, aber wenn es für den ganzen Wahrscheinlichkeitsraum zutrifft, dann gilt folgendes Modell: Definition 3.9. Im Laplace-Modell (oder nach der Laplace-Annahme) für endliche Wahrscheinlichkeitsräume haben alle Elementarereignisse die gleiche Wahrscheinlichkeit p. ω Ω : P({ω}) = p. Satz 3.1. Im Laplace-Modell kann die Wahrscheinlichkeit als relative Größe des Ereignisses berechnet werden: e Σ : P(e) = e Ω Das nennt man oft das Prinzip günstige durch mögliche Ergebnisse. Insbesondere gilt für Elementarereignisse Beweis. 1 = P(Ω) = P ( i {ω i } ) = i ω Ω : P({ω}) = 1 Ω. P({ω i }) = i p = Ω p p = 1 Ω. P(e) = P ( {ω} ) = P({ω}) = e p = e ω e ω e Ω. Beispiel Im Würfel-Beispiel gilt die Laplace-Annahme und daher für die Elementarereignisse P({1}) = P({}) =... = P({6}) =. Weiters gilt {1} {1,,3,4,5,6} = 1 6 {1,} P(e 1 ) = P( kleiner 3 ) = P({1,}) = {1,,3,4,5,6} = 6 = 1 3. Und da e 1 und e aus Beispiel 3.3 disjunkt sind, gilt P(e 1 e ) = P({1,,5,6}) = 3 = P(e 1) + P(e ) = Hingegen ist nach dem Additionssatz P( gerade oder kleiner 4 ) = P({,4,6} {1,,3}) = P({,4,6})+P({1,,3}) P({}) = = 5 6. Und für das Gegenereignis gilt P( nicht kleiner 3 ) = P(ē 1 ) = 1 P(e 1 ) = = 3. 14

15 Für unendliche Wahrscheinlichkeitsräume muss das Laplace-Modell anders formuliert werden, da die Elementarereignisse notgedrungen Wahrscheinlichkeit hätten. Definition 3.1. Im Laplace-Modell für unendliche Wahrscheinlichkeitsräume soll gelten P(e) = e Ω, wobei e ein Volumsmaß ist. Das erfüllt die Axiome des Wahrscheinlichkeitsraums, weil jedes Maß die Axiome 1 und 3 erfüllt und Axiom wegen P(Ω) = = 1 erfüllt ist. Ω Ω Wie gewünscht haben dann zwei gleich große Ereignisse die gleiche Wahrscheinlichkeit. Beispiel Die Wahrscheinlichkeit, dass der erste Regentropfen, der auf ein A4-Blatt fällt, in einen darauf gezeichneten Kreis mit Durchmesser 4 cm fällt, ist 4 Kombinatorik P( in Kreis ) = (cm) π 4 m %. Zur Berechnung von Wahrscheinlichkeiten in endlichen Wahrscheinlichkeiten sind folgende kombinatorische Formeln essentiell. Als Modell zur Veranschaulichung dient das Urnenmodell, bei dem n nummerierte (also unterscheidbare) Kugeln in einer Urne liegen und auf verschiedene Art daraus gezogen werden. Bei den Variationen ist die Reihenfolge wichtig, mit der die Kugeln gezogen werden; bei den Kombinationen zählt nur, welche Kugeln gezogen werden, nicht ihre Reihenfolge. Weiters gibt es die Möglichkeit, jede Kugel, nachdem sie gezogen wurde, wieder in die Urne zurück zu legen, so dass sich die Kugeln in der Ziehung wiederholen können. Über die Anzahl der Möglichkeiten, so eine Ziehung durchzuführen, kann man die Wahrscheinlichkeit einer bestimmten Ziehung ausrechnen. Definition 4.1. Als Permutation bezeichnet man die Menge der verschiedenen Anordnungen von n Elementen. {(a 1, a,..., a n ) a i {b 1,b,...,b n } i j : a i a j } Das entspricht der Ziehung aller n Kugeln aus einer Urne, wobei es auf die Reihenfolge ankommt, mit der die Kugeln gezogen werden. 15

16 Satz 4.. Die Anzahl der Permutationen ist n! = n (n 1) 1. Beweis. Es gibt n Möglichkeiten, das erste Element auszuwählen. Danach gibt es für jede Auswahl n 1 Möglichkeiten für die Auswahl des zweiten Elements. Und so weiter, bis nur noch eine Möglichkeit für das letzte Element übrigbleibt. Beispiel 4.3. {(a,b,c),(a,c,b),(b, a,c),(b,c, a),(c, a,b),(c,b, a)} = 3! = 3 = 6 Beispiel 4.4. Wenn sich fünf Kinder nebeneinander stellen, wie groß ist die Wahrscheinlichkeit, dass sie nach Größe geordnet stehen (aufsteigend oder absteigend)? Ω = 5!, G = {(a 1, a, a 3, a 4, a 5 ),(a 5, a 4, a 3, a, a 1 )}, P( geordnet ) = G Ω = 5! = %. Definition 4.5. Als Variation ohne Wiederholung bezeichnet man die Menge der Anordnungen von je k aus n Elementen. {(a 1, a,..., a k ) a i {b 1,b,...,b n } i j : a i a j } Das entspricht der Ziehung von k Kugeln aus n ohne Zurücklegen, wobei es auf die Reihenfolge ankommt, mit der die Kugeln gezogen werden. Satz 4.6. Die Anzahl der Variationen ohne Wiederholung ist n! (n k)!. Beweis. Wie bei den Permutationen gibt es n Möglichkeiten für das erste Element, n 1 für das zweite, und so weiter. Für das letzte, also das k-te Element gibt es dann noch n k +1 Möglichkeiten. Die gesamte Anzahl ist also n(n 1) (n k + 1) = n! (n k)!. Beispiel 4.7. {(a,b),(a,c),(b, a),(b,c),(c, a),(c,b)} = 3! (3 )! = 3! 1! = 3 1 = 6 Definition 4.8. Als Variation mit Wiederholung bezeichnet man die Menge der Anordnungen von je k aus n Elementen, wobei Elemente mehrfach vorkommen dürfen. {(a 1, a,..., a k ) a i {b 1,b,...,b n }} Das entspricht der Ziehung von k Kugeln aus n mit Zurücklegen der Kugeln, wobei es auf die Reihenfolge ankommt. 16
? Ω = 5!")
17 Satz 4.9. Die Anzahl der Variationen mit Zurücklegen ist n k. Beweis. Für jedes der k ausgewählten Elemente gibt es n Möglichkeiten. Die Gesamtanzahl ist daher n n n = n k. Beispiel 4.1. {a,b,c} = {(x 1, x ) x i {a,b,c}} = {(a, a),(a,b),(a,c),(b, a),...,(c,c)} = 3 = 9 Beispiel Wie groß ist die Wahrscheinlichkeit, dass in einer PS-Gruppe mit 3 Studenten mindestens zwei am selben Tag Geburtstag haben? Schaltjahre sind der Einfachheit halber zu ignorieren. Die Menge der möglichen Geburtstagslisten ist Ω = {1.1.,...,31.1.} 3, also eine Variation mit Wiederholung, und daher ist Ω = Mit G = mindestens zwei gleiche Geburtstage ist Ḡ = keine zwei gleichen Geburtstage eine Variation ohne Wiederholung. Daher ist P(G) = 1 P(Ḡ) = 1 365! (365 3)! = 7.6%. Definition 4.1. Als Kombination ohne Wiederholung bezeichnet man die Menge der Auswahlen von je k aus n Elementen. {A {b 1,b,...,b n } A = k} Das entspricht der Ziehung von k Kugeln aus n ohne Zurücklegen, wobei die Reihenfolge der Kugeln keine Rolle spielt. Satz Die Anzahl der Kombinationen ohne Wiederholung ist ( ) n n! = k k!(n k)!. Beweis. Die Variationen ohne Wiederholung sind gerade die Permutationen aller Kombinationen ohne Wiederholung, wobei man auf diese Weise keine Variation doppelt erzeugt. Die Anzahl der Kombinationen ist also die der Variationen dividiert durch die Permutationen der k Elemente, also dividiert durch k!, also n! (n k)!k!. Beispiel {x {a,b,c,d} x = } = {{a,b},{a,c},{a,d},{b,c},{b,d},{c,d}} ( ) 4 4! = =!(4 )! = 4!!! = 4 3 = 6 17

18 Beispiel Wie groß ist die Wahrscheinlichkeit, dass bei einer Lottoziehung (6 aus 45) die Zahl 13 vorkommt? ( ) 45 Ω = {x {1,...,45} x = 6}, Ω =. 6 P( 13 kommt vor ) = 1 P( 13 kommt nicht vor ) = 1 P(G) mit G := {x {1,...,1,14,...45} x = 6}. G = ( 44) 6. Es gilt die Laplace-Annahme (überlegen Sie warum). Daher ist P( 13 kommt vor ) = 1 G ( 44 ) Ω = 1 6 ) = 1 44! 6!39! = !38! 45! 45 = 6 45 = %. ( 45 6 Definition Als Kombination mit Wiederholung bezeichnet man die Menge der Auswahlen von je k aus n Elementen, wobei Elemente mehrfach ausgewählt werden dürfen. {(a 1, a,..., a k ) a i {b 1,b,...,b n } a 1 a... a k } Das entspricht der Ziehung von k Kugeln aus n mit Zurücklegen, wobei die Reihenfolge der Kugeln keine Rolle spielt. Satz Die Anzahl der Kombinationen mit Wiederholung ist ( ) n + k 1. k Beweis. Sowohl (b 1,b,...,b n ) als auch (a 1, a,..., a k ) seien aufsteigend sortiert. Jetzt fügt man Trennelemente # in die Kombination ein, und zwar zwischen a i = b k und a i+1 = b l genau l k Stück, wobei vorübergehend a = b 1 und a k+1 = b n gesetzt wird. So wird z.b. für n = 5 aus (1,,4,4) nun (1,#,,#,#,4,4,#). Die Kombination hat also jetzt n + k 1 Elemente und wird durch die Position der Trennelemente # eineindeutig beschrieben. Alternativ kann man auch die Position der Nicht-Trennelemente festlegen. Diese Positionen sind aber einfach eine Auswahl von k aus den n + k 1 Stellen, also eine Kombination ( n+k 1) k. Beispiel {(a, a),(a,b),(a,c),(a,d),(b,b),(b,c),(b,d),(c,c),(c,d),(d,d)} ( ) ( ) = = = 1 18
 a i {b 1,b,...,b n } a 1 a.")
19 Satz Werden zufällige Kombinationen mit Wiederholung als aufeinander folgende zufällige Auswahl von Elementen implementiert, z.b. als Ziehung aus der Urne mit Zurücklegen, dann ist die Laplace-Annahme im Allgemeinen nicht zu treffen, d.h. die Kombinationen sind nicht gleich wahrscheinlich. Aus diesem Grund haben Kombinationen mit Wiederholung in der Wahrscheinlichkeitsrechnung eigentlich keine allzu große Bedeutung. Beweis. Bei den Variationen mit Wiederholung gilt die Laplace-Annahme. Die Kombinationen mit Wiederholung sind nun eine Abstraktion der Variationen, also eine Zusammenfassung von Variationen mit gleicher Elementauswahl aber unterschiedlicher Reihenfolge. Jetzt gibt es zum Beispiel nur eine Variation für (1,1,1,1,1), aber fünf Variationen für (1,1,1,1,). Letztere Kombination ist also fünf mal so wahrscheinlich wie erstere. Bei anderen Kombinationen ist das Missverhältnis meist noch größer. 5 Bedingte Wahrscheinlichkeit Bei der bedingten Wahrscheinlichkeit wird ein zweites Ereignis B (die Bedingung) als neue Grundmenge betrachtet. Man kann das auch als zweistufiges Experiment betrachten: Zuerst tritt Ereignis B ein, dann wird ein Ereignis A unter dieser Voraussetzung untersucht. Jetzt hat A womöglich eine andere Wahrscheinlichkeit, da A von B vielleicht nicht unabhängig ist. Wir beschränken also den Ergebnisraum auf B und die Ereignisse auf jene, die in B liegen. Das Wahrscheinlichkeitsmaß P muss dann so normiert werden, dass P(B) eins wird. Satz 5.1. Sei (Ω,Σ,P) ein Wahrscheinlichkeitsraum und B Σ. Sei Σ B := {e Σ e B} und P B := P/P(B). Dann ist (B,Σ B,P B )) ein Wahrscheinlichkeitsraum. Beweis. (B,Σ B ) ist ein Ereignisraum, denn (1) B Σ B, weil B Σ und B B, () für e Σ B ist B \ e Σ B, weil B \ e = (Ω \ e) B und Ω \ e Σ und daher auch (Ω\e) B Σ und (Ω\e) B B, und (3,4) für e i Σ B gilt e i Σ B und e i Σ B, weil diese Σ sind aber auch B. P B ist ein zugehöriges Wahrscheinlichkeitsmaß, weil (1) P(e) P B (e) = P(e)/P(B), () P B (B) = P(B)/P(B) = 1, und (3) für e i Σ B e i e j ist P B ( e i ) = P( e i )/P(B) = P(e i )/P(B) = P B (e i ). Definition 5.. Die bedingte Wahrscheinlichkeit P(A B) ( Wahrscheinlichkeit von A unter der Bedingung B ) ist P(A B) P(A B) := P B (A B) =. P(B) 19

20 A Ā B B P(A B) = P(A B) P(B) Abbildung 8: Mengendiagramm zur bedingten Wahrscheinlichkeit. 1 P(A B) P(B) P(Ā B) P(A B) P( B) P(Ā B) P(A B) P(Ā B) P(A B) P(Ā B) Abbildung 9: Zweistufiger Entscheidungsbaum. In Abbildung 8 wird der Zusammenhang veranschaulicht. Die Wahrscheinlichkeit von A B ergibt sich also aus der Verkettung (Multiplikation) der Wahrscheinlichkeit von B in Bezug auf Ω (P(B)) und der Wahrscheinlichkeit von A B in Bezug auf B (P(A B)). Beispiel 5.3. Gegeben seien folgende Ereignisse: A = Auto hat nach Verkauf einen Defekt, B = Auto wurde an einem Montag produziert. P(B) = 1 5. Es sei P( Auto ist Montagsauto und hat Defekt ) = P(A B) = 5%. Dann ist P( Montagsauto hat Defekt ) = P(A B) = P(A B) P(B) = 5% 1 = 5%. 5 Definition 5.4. Ein Entscheidungsbaum ist ein Graph zur Darstellung von zweiund mehrstufigen Experimenten. Dabei steht an jeder Kante eine bedingte Wahrscheinlichkeit, am Anfang der Kante die Wahrscheinlichkeit der Bedingung und am Ende das Produkt der beiden. Abbildung 9 zeigt den zweistufigen Entscheidungsbaum. Abbildung 1(a) zeigt das Beispiel 5.3 als Entscheidungsbaum. Satz 5.5. Der Satz von der vollständigen Wahrscheinlichkeit bietet die Möglichkeit, ein Ereignis A in mehrere Bedingungen B 1,...,B n aufzuteilen. Die Bedingungen müssen vollständig sein (B 1... B n = Ω) und sich paarweise ausschließen ( i j : B i B j = ). Das gilt insbesondere für Bedingung und Gegenbedingung (B und B). Es gilt P(A) = P(A B 1 )P(B 1 ) P(A B n )P(B n ),
 = 1 5.")
21 1 5% 5 75% 1 4 1% 5 9% 5% 15% 8% 7% (a) B = Montag, A = Defekt 13% 38.5% 61.5% 1 87% 17.% 8.8% 5% 8% 15% 7% (b) A und B vertauscht. Abbildung 1: Beispiel für Entscheidungsbaum. bzw. für n = P(A) = P(A B)P(B) + P(A B)P( B). Beweis. P(A B 1 )P(B 1 ) P(A B n )P(B n ) = P(A B 1 ) P(A B n ) B i B j = ======== Bi =Ω P(A B 1... A B n ) = P(A (B 1... B n )) ======= P(A). Beispiel 5.6. P( Auto nicht am Montag produziert ) = P( B) = 4 5. Es sei P( Nichtmontagsauto hat Defekt ) = P(A B) = 1%. Dann ist P( Auto hat Defekt ) = P(A) = P(A B)P(B)+P(A B)P( B) = 5% % 4 5 = 5%+8% = 13%. Abbildung 1(b) zeigt den Zusammenhang im Entscheidungsbaum mit vertauschten Ereignissen A und B. Da man den Entscheidungsbaum quasi umdrehen kann, bietet es sich an, auch die bedingte Wahrscheinlichkeit umzudrehen, d.h. P(B i A) aus P(A B i ) zu berechnen. Satz 5.7 (Bayes). bzw. für n = P(B i A) = P(A B i )P(B i ) P(A) P(B A) = = P(A B i )P(B i ) P(A B 1 )P(B 1 ) P(A B n )P(B n ), P(A B)P(B) P(A B)P(B) + P(A B)P( B). Beweis. Aus der bedingten Wahrscheinlichkeit ergibt sich Umgeformt wird das zu P(A B i ) = P(A B i )P(B i ) = P(B i A)P(A). P(B i A) = P(A B i )P(B i ). P(A) 1
22 Setzt man nun für P(A) die vollständige Wahrscheinlichkeit, bekommt man die Aussage. Beispiel 5.8. P(A B)P(B) P( Defektes Auto ist Montagsauto ) = P(B A) = P(A B)P(B) + P(A B)P( B) 5% 1 5 = 5% % 4 5 = 5% 13% 38.5%. Abbildung 1(b) zeigt auch diese Wahrscheinlichkeit im Entscheidungsbaum mit vertauschten Ereignissen A und B. Zwei Ereignisse gelten als unabhängig, wenn man aus dem Wissen über das Eintreten des einen Ereignisses nichts über das Eintreten des anderen sagen kann, d.h. dass P(A B) = P(A) sein muss. Daraus folgt dann P(A B) = P(A B)P(B) = P(A)P(B). Deshalb definiert man: Definition 5.9. A,B unabhängig : P(A B) = P(A)P(B) Beispiel 5.1. P(A B) = 5% (siehe oben). P(A)P(B) = 13% 1 5 nicht unabhängig. =.6%. A,B 6 Zufallsvariablen Meist ist man nicht unmittelbar am genauen Ausgang eines Experiments (dem Ereignis) interessiert, sondern nur an einem Merkmal, das einem Wert aus Z oder R entspricht. Es wird also jedem Elementarereignis ω Ω ein Wert X (ω) zugewiesen. Definition 6.1. Eine Funktion X : Ω B heißt Zufallsvariable. B ist der Wertebereich der Zufallsvariable, also meist Z oder R. Definition 6.. Das Ereignis, dass die Zufallsvariable X einen bestimmten Wert x aus dem Wertebereich annimmt, wird X = x oder einfach X = x geschrieben. Es beinhaltet alle Elementarereignisse, denen der Wert x zugeordnet ist: X = x := {ω X (ω) = x} = X 1 (x). Analog werden die Ereignisse X < x, X x, X > x und X x definiert. Zum Beispiel ist X x := {ω X (ω) x} = X 1 ((, x]).
23 Es reicht nun, die Wahrscheinlichkeiten aller Ereignisse X = x oder besser X x zu kennen, um eine Zufallsvariable vollständig beschreiben zu können. Definition 6.3. Die Verteilungsfunktion F X : R [,1] ist F X (x) := P(X x). Ist der Wertebereich der Zufallsvariablen diskret (also z.b. N), dann spricht man von einer diskreten Verteilung. Die Verteilungsfunktion, als Funktion reeller x betrachtet, ist dann unstetig in den diskreten Werten und dazwischen konstant, also eine Treppenfunktion, die in mit dem Wert beginnt, in den diskreten Werten um P(X = x) springt, und in + mit dem Wert 1 endet. Ist die Verteilungsfunktion dagegen absolut stetig, spricht man von einer stetigen Verteilung. Es ist dann überall P(X = x) =. Die Verteilungsfunktion ist fast überall differenzierbar und kann als Integral einer Dichtefunktion dargestellt werden. Wir beschränken uns in der Folge auf diskrete und stetige Verteilungen mit Z und R als Wertebereiche. Definition 6.4. Auf dem Wahrscheinlichkeitsraum soll ein Integral definiert sein, das folgendermaßen geschrieben wird X (ω)dp(ω), A und den Inhalt unter der Funktion X : Ω R über der Teilmenge A Ω (A Σ) berechnet, wobei die Teilbereiche von A entsprechend P gewichtet werden sollen. Das Integral soll folgende Kriterien erfüllen. Erstens soll das Integral von 1 dem Wahrscheinlichkeitsmaß entsprechen: dp(ω) = P(A). Zweitens soll das Integral folgende Linearität besitzen: ax (ω) + by (ω)dp(ω) = a X (ω)dp(ω) + b A A A Y (ω)dp(ω), A wobei a,b konstant sind und X,Y : Ω R integrierbare Funktionen. Der Wertebereich von X,Y kann auch höherdimensional sein, also R n oder C. In dem Fall sollen die Koordinatenfunktionen die selben Kriterien erfüllen. Definition 6.5. Der Erwartungswert einer Zufallsvariable X ist definiert durch E(X ) := X (ω)dp(ω). Ω 3
24 Beachte, dass der Erwartungswert E keine einfache Funktion sondern ein sogenanntes Funktional ist, da es eine ganze Funktion, nämlich X, auf eine Zahl abbildet. Satz 6.6. Aufgrund der Definition leicht ersichtlich ist E(aX + by ) = a E(X ) + b E(Y ). Definition 6.7. Varianz V(X ) und Standardabweichung σ X := V(X ). V(X ) := E((X E(X )) ). Satz 6.8. Auch hier gibt es einen Verschiebungssatz. V(X ) = E(X ) (E(X )). Beweis. E((X E(X )) ) = E(X X E(X )+E(X ) ) = E(X ) E(X )E(X )+E(X ) = E(X ) E(X ). Beispiel 6.9. Für ein Bernoulli-Experiment mit X {,1} und P(X = 1) = p, P(X = ) = 1 p ist E(X ) = = X (ω)dp(ω) = dp(ω) + Ω X = X = X =1 X (ω)dp(ω) + 1dP(ω) = X =1 X = X (ω)dp(ω) dp(ω) + 1 X =1 dp(ω) = P(X = ) + 1 P(X = 1) = (1 p) + 1 p = p. V(X ) = X (ω)dp(ω) E(X ) = (1 p) + 1 p p = p(1 p). Ω Satz 6.1. Für a,b konstant gilt V(aX + b) = a V(X ). Beweis. V(aX +b) = E((aX +b E(aX +b)) ) = E((aX +b a E(X ) b) ) = E(a (X E(X )) ) = a V(X ). 6.1 Diskrete Verteilungen Definition Die Wahrscheinlichkeitsfunktion f X : Z [,1] einer diskreten Zufallsvariablen X gibt die Wahrscheinlichkeit des Werts k an und wird oft auch einfach p k geschrieben: f X (k) := p k := P(X = k). 4
25 (a) Wahrscheinlichkeitsfunktion f X (b) Verteilungsfunktion F X Abbildung 11: Augensumme zweier Würfel als Beispiel für eine diskrete Zufallsvariable. Satz 6.1. Die Verteilungsfunktion ist dann F X (x) = k x p k. Beispiel Wir betrachten die Augensumme bei zweimaligem Würfeln: Ω = {1,...,6} = {(a,b) a,b {1,...,6}}, X ((a,b)) := a + b. Dann erhalten wir z.b. p = P(X = ) = P({(1,1)}) = {(1,1)} Ω = 1 6 = 1 36, p 5 = P(X = 5) = P({(1,4),(,3),(3,),(4,1)}) = 4 6 = 1 9, p 1 = P(X = 1) = P({(6,6)}) = 1 36, p 13 = P(X = 13) = P( ) =, F X (4.3) = P(X 4.3) = P(X {,3,4}) = p + p 3 + p 4 = = 6 36 = 1 6. Abbildung 11 zeigt die Wahrscheinlichkeits- und Verteilungsfunktion. Der Erwartungswert E(X ) entspricht in etwa dem Mittelwert von Stichproben. Zur Erinnerung (für x k = k): x = 1 n k kh k = k kh k. Nun wird einfach h k durch p k ersetzt. 5
26 Satz E(X ) = V(X ) = k= k= Beweis. E(X ) = Ω X (ω)dp(ω) = k k P(X = k) = (k E(X )) p k = k= k= kp k, k p k E(X ). X =k k dp(ω) = k k P(X = k). V(X ) analog. Beispiel E(X ) = 1 k= kp k = = 5 36 = 7, V(X ) = ( 7) (3 7) (1 7) = 1 36 σ X , Definition Die Zufallsvariable X besitzt die diskrete Gleichverteilung innerhalb der Grenzen a und b, wenn gilt p k = { 1 b a+1 a k b sonst. Satz Ist X gleichverteilt zwischen a und b, dann gilt Beweis. E(X ) = b k=a E(X ) = a + b ( k b a + 1 = 1 b a b k + a, V(X ) = (b a + 1) 1. 1 Und mit n k= k = n(n + 1)(n + 1)/6 erhält man 1 V(X ) = V(X a) = b a + 1 b a k= (b a)(b a + 1)((b a) + 1) = 6(b a + 1) (b a)(4(b a) + 3(b a)) = 1 ) b a + b k = a k E(X a) 1 b a b a + b a = b a + 1 b a + 1 a + b. ( ) a + b (b a)((b a) + 1) (b a) a = 6 4 = (b a) + (b a) = (b a + 1)
27 (a) Wahrscheinlichkeitsfunktion f X (b) Verteilungsfunktion F X Abbildung 1: Binomialverteilung B,5%. Wird ein Bernoulli-Experiment mit zwei möglichen Ausgängen, erfolgreich bzw. nicht erfolgreich, n-mal wiederholt, wobei das Experiment mit Wahrscheinlichkeit p erfolgreich ist, dann stellt sich die Frage, wie oft das Experiment erfolgreich ist. Die Antwort gibt folgende Verteilung. Definition Eine Zufallsvariable X besitzt die Binomialverteilung, wenn gilt ( ) n f X (k) = p k (1 p) n k. k Man schreibt X B n,p. Satz Zur Plausibilität der Definition ist zu zeigen, dass k f X (k) = 1 ist. Beweis. 1 = 1 n = (p + (1 p)) n = n k= ( n k) p k (1 p) n k. Abbildung 1 zeigt Wahrscheinlichkeits- und Verteilungsfunktion einer Binomialverteilung. Satz 6.. Es werden n unabhängige Experimente mit Ausgang e i {,1} durchgeführt, wobei das Ereignis A i,ei = Experiment i ergibt e i für den erfolgreichen Ausgang e i = 1 die Wahrscheinlichkeit P(A i,1 ) = p hat. Es sei e = (e 1,...,e n ) ein Ausgang des Gesamtexperiments, A e = A 1,e1... A n,en das Ereignis, dass das Gesamtexperiment diesen Ausgang hat, und X (ω) := i e i für ω A e die Anzahl der erfolgreichen Ausgänge. Dann ist X binomialverteilt: X B n,p. Beweis. Die Wahrscheinlichkeit für Exp. nicht erfolgreich ist P(A i, ) = P(Ā i,1 ) = 1 p. Wegen der Unabhängigkeit der Experimente gilt P(A i,ei A j,e j ) = P(A i,ei ) 7
28 P(A j,e j ) für i j. Wenn nun e i = k ist, dann ist daher P(A e ) = p k (1 p) k. Die Anzahl der möglichen Gesamtexperimente mit k Erfolgen aus n Experimenten ist eine Kombination ohne Wiederholung. Ereignisse für verschiedene Ausgänge schließen sich gegenseitig aus. Daher ist schließlich P(X = k) = P ( ( ) ) n A e = P(A e ) = p k (1 p) n k. k Satz 6.1. Für X B n,p gilt ei =k ei =k E(X ) = np, V(X ) = np(1 p). Beweis. X kann als Zusammensetzung X = X X n von n einzelnen unabhängigen Experimenten X i dargestellt werden, mit X i {,1} und P(X i = 1) = p. Dann ist E(X ) = E(X X n ) = n E(X 1 ) = n(1 p + (1 p)) = np. V(X ) = E(X ) E(X ) = E((X X n ) ) (np) = E ( ) X i X j (np) = E(X i X j ) n p. i,j i,j Nun ist für i = j : E(X i ) = E(X i ) = p, weil = und 1 = 1. Für i j ist E(X i X j ) = (1 p) + 1 p(1 p) + 1 (1 p)p p = p. Es gibt n Fälle für i = j und n n Fälle für i j. Daher ist V(X ) = np + (n n)p n p = np np = np(1 p). Beispiel 6.. Ein Bauteil habe mit einer Wahrscheinlichkeit p =.3 einen Defekt. In einer Schachtel seien 1 Bauteile. P( genau 4 Bauteile defekt ) = P(X = 4) = ( 1) P( maximal 4 Bauteile defekt ) = p + p p In einer Schachtel sind durchschnittlich E(X ) = 1.3 = 3 Bauteile defekt mit einer Standardabweichung von σ X = Wenn man statt der Anzahl der erfolgreichen Versuche misst, wie viele Versuche man benötigt, bis Erfolg eintritt, wobei die Anzahl der gesamten Versuche nicht beschränkt ist, dann erhält man folgende Verteilung. Definition 6.3. Eine Zufallsvariable besitzt die geometrische Verteilung, wenn gilt f X (k) = p(1 p) k 1. Man schreibt X G p. 8
29 Satz 6.4. Zur Plausibilität zeigen wir wieder k f X (k) = 1. Beweis. S = k=1 p(1 p)k 1 = p+ k= p(1 p)k 1 = p+(1 p) k=1 p(1 p)k 1 = p + (1 p)s S(1 (1 p)) = p Sp = p S = 1. Satz 6.5. Seien e = (e 1,e,...) die Ausgänge von unendlich vielen Versuchen, A i,ei das Ereignis Versuch i ergibt e i, P(A i,1 ) := p, A e das Gesamtereignis für alle Ausgänge, und für ω A e sei X (ω) := k so dass e k = 1 und e j = für alle j < k. Dann ist X G p. Beweis. P(X = k) = P(A 1, A,... A k,1 ) = (1 p) k 1 p. Satz 6.6. X G p F X (m) = 1 (1 p) m. Beweis. F X (m) = m k=1 p(1 p)k 1 = 1 k=m+1 p(1 p)k 1 = 1 (1 p) m k=1 p(1 p) k 1 = 1 (1 p) m. Satz 6.7. X G p Beweis. E(X ) = E(X ) = 1 p, V(X ) = 1 p p. kp(1 p) k 1 = p + kp(1 p) k 1 = p +(1 p) (k +1)p(1 p) k 1 k=1 k=1 k= ( ) = p + (1 p) kp(1 p) k 1 + p(1 p) k 1 = p + (1 p)(e(x ) + 1) k=1 k=1 E(X )(1 (1 p)) = p + (1 p) = 1 E(X ) = 1 p. E(X ) = k p(1 p) k 1 = p + (1 p) (k + 1) p(1 p) k 1 k=1 ( ) = p + (1 p) k p(1 p) k 1 + kp(1 p) k 1 + p(1 p) k 1 k=1 k=1 k=1 k=1 = p + (1 p)(e(x ) + E(X ) + 1) ( ) E(X )(1 (1 p)) = p + (1 p) p + 1 = p 1 E(X ) = p 1 p V(X ) = E(X ) E(X ) = p 1 p 1 p = 1 p 1 p = 1 p p. 9
30 Wenn man den Parameter n der Binomialverteilung erhöht, dann wandert die ganze Verteilung, die sich ja um den Erwartungswert np konzentriert, nach rechts. Möchte man den Erwartungswert konstant auf λ = np halten, dann muss man p entsprechend kleiner machen. Dann kann man n sogar gegen unendlich gehen lassen und erhält folgende Verteilung. Definition 6.8. Eine Zufallsvariable X besitzt die Poisson-Verteilung, wenn gilt Man schreibt X P λ. Satz 6.9. Plausibilität: k f X (k) = 1. Beweis. k= λ k k! e λ = e λ e λ = 1. f X (k) = λk k! e λ. Satz 6.3. Wenn man in der Wahrscheinlichkeitsfunktion der Binomialverteilung p durch λ n ersetzt, dann konvergiert sie für n gegen die der Poisson- Verteilung. ( ) ( ) n λ k ( lim 1 λ ) n k = λk n k n n k! e λ Beweis. Der linke Ausdruck wird zu lim n n }{{} n =1 n 1 } {{ n } 1 n k + 1 λ k ( } {{ n } k! 1 was gegen die Poisson-Verteilung konvergiert. ) n 1 λ n } {{ } e λ ( 1 λ ) n } {{ } 1 Abbildung 13 zeigt den Vergleich zwischen Binomial- und Poisson-Verteilung. Die Approximation ist besser, je höher n und je kleiner p ist. k, Satz X P λ E(X ) = λ, V(X ) = λ. Beweis. E(X ) = k= k λk k! e λ = e λ k λk k=1 k! = λ k 1 e λ λ (k 1)! = λ k e λ λ k! = e λ λe λ = λ. k=1 k= 3
31 Binomial Poisson Abbildung 13: Vergleich von B, 1 und P 4 1 = P 5. 4 E(X ) = k λk k= k! e λ = e λ λ k λk 1 k=1 (k 1)! = e λ λ (k + 1) λk k= k! ( ) = e λ λ k λk k= k! + λ k = e λ λ(e λ λ + e λ ) = λ + λ. k= k! V(X ) = E(X ) E(X ) = λ + λ λ = λ. 6. Stetige Verteilungen Die Rolle der Wahrscheinlichkeitsfunktion übernimmt bei stetigen Verteilungen die Dichtefunktion. Definition 6.3. Die Dichtefunktion oder Dichte einer stetigen Zufallsvariable X ist eine Funktion f X : R R, deren Integral die Verteilungsfunktion ergibt: x f X (u)du = F X (x). Die Dichtefunktion ist nicht-negativ, weil sonst die Verteilungsfunktion nicht monoton steigend wäre und es negative Wahrscheinlichkeiten gäbe. Wo F differenzierbar ist, ist natürlich f X (x) = F X (x). Satz b P(a X b) = f X (x)dx = F X (b) F X (a). a 31
32 /R R (a) Dichtefunktion f X R (b) Verteilungsfunktion F X Abbildung 14: Mittelpunktsabstand als Beispiel für eine stetige Zufallsvariable. Satz = P( X + ) = + f X (x)dx = F X ( ) F X ( ) = 1 = 1. Beispiel Eine runde Schachtel mit Durchmesser R und einer kleinen Kugel drin wird geschüttelt. Danach befindet sich die Kugel an der Position (a, b) ((,) = Mitte). Ω = {(a,b) R a + b R }. Für eine exakte Position ist natürlich z.b. P({(.1,.)}) =. Aber: Die Wahrscheinlichkeit, dass die Kugel in einem bestimmten Bereich B mit Fläche I (B) liegt, ist P(B) = I (B) I (Ω) = I (B) R π (Laplace- Annahme). X sei nun der Abstand von der Mitte: X ((a,b)) := a + b. Auch die Wahrscheinlichkeit für einen exakten Abstand r ist P(X = r ) =. Das Ereignis X r entspricht der Kreisscheibe mit Radius r und Fläche r π. Daraus ergibt sich: r < r < r F X (r ) = π R π = r d r r R, f R X (r ) = dr = r r < R. R 1 r > R R r > R Abbildung 14 zeigt die Dichte- und Verteilungsfunktion. Satz Wenn eine Zufallsvariable X eine Dichtefunktion f X hat und g : R R eine integrierbare Funktion ist, dann gilt a X b g (X (ω))dp(ω) = b a g (x)f X (x)dx. 3
33 Das gilt auch mehrdimensional. Wenn X : Ω R eine zweidimensionale Zufallsvariable ist und eine Dichtefunktion f X : R R hat, das heißt a b f X (x 1, x )dx dx 1 = P(X 1 a X b), weiters g : R R integrierbar, dann gilt b d g (X (ω))dp(ω) = g (x 1, x )f X (x 1, x )dx dx 1. X [a,b] [c,d] Beweis. Das ist ein wichtiger Satz aus der Maßtheorie. Siehe also dort. a Satz Erwartungswert E(X ), Varianz V(X ) und Standardabweichung σ X = V(X ) werden hier über Integrale (statt Summen) berechnet. c E(X ) = + x f X (x)dx V(X ) = E((X E(X )) ) = = E(X ) (E(X )) = Beweis. Ergibt sich aus Satz Beispiel E(X ) = V(X ) = σ X = R R + + r r R dr = r 3 R R 3 = R 3, r r ( ) R R dr = r 4 3 R 4 R 18.36R. (x E(X )) f X (x)dx x f X (x)dx (E(X )). R 4R 9 = R 4R 9 = R 18, Definition Eine Zufallsvariable X besitzt die stetige Gleichverteilung zwischen a und b, wenn gilt f X (x) = { 1 b a a x b sonst. Satz 6.4. E(X ) = a + b (b a), V(X ) =. 1 33
34 1 µ-σ µ µ+σ µ-σ µ µ+σ (a) Dichtefunktion (b) Verteilungsfunktion Abbildung 15: Normalverteilung. Beweis. b x E(X ) = a b a dx = x (b a) b a = b a (b a) = a + b. Wir setzen g = b a, dann ist a E(X ) = g und b E(X ) = g und g x V(X ) = V(X E(X )) = g b a dx = x 3 3(b a) g g = g 3 ( g 3 ) 3(b a) (b a)3 = 8 3(b a) = g 3 3(b a) = (b a) 1 Definition Eine Zufallsvariable X besitzt die Normalverteilung mit Erwartungswert µ und Standardabweichung σ, wenn gilt Man schreibt X N µ,σ. f X (x) := 1 (x µ) e σ. πσ Diese Dichtefunktion ist leider nicht in geschlossener Form integrierbar, daher wird die Verteilungsfunktion meist in Tabellenform angegeben wie in Abbildung 5 oder über Näherungsformeln berechnet. Abbildung 15 zeigt beide Funktionen. Satz 6.4. Das Integral der Dichtefunktion über ganz R ist 1: f X (x)dx =
35 Beweis. Da das Integral nicht von µ abhängt, setzen wir µ =. Die Beweisstrategie geht auf Poisson zurück. Statt des einfachen Integrals wird das Quadrat berechnet: ( ) f X (x)dx = 1 ( πσ e x 1 σ dx 1 e x σ dx ) = 1 πσ e x+x 1 σ dx 1 dx. Jetzt geht man von kartesischen zu polaren Koordinaten über: x 1 = r cosϕ, x = r sinϕ. Dadurch verändert sich der Integrationsbereich auf (ϕ,r ) [,π] [, ) und der Integrand muss mit der Determinante der Jacobi-Matrix multipliziert werden. (x 1, x ) (r, ϕ) = cosϕ r sinϕ sinϕ r cosϕ = r (cos ϕ + sin ϕ) = r. Außerdem ist x 1 + x = r. Wenn wir nun noch sehen, dass d dr σ e r /σ = r e r /σ ist, dann ergibt sich = 1 πσ π Satz X N µ,σ e r σ r dϕdr = 1 σ Beweis. Zuerst differenzieren wir f X (x): f X (x) = d dx 1 x µ) e σ = πσ r e r σ dr = σ σ E(X ) = µ, V(X ) = σ. ( 1 (x µ) e σ πσ e ) (x µ) σ r σ = ( 1) = 1. = x µ σ f X (x). Daraus ergibt sich für x f X (x), welches wir in den Integralen brauchen werden: Und damit ist E(X ) = x f X (x) = µf X (x) σ f X (x). x f X (x)dx = µf X (x)dx σ f X (x) = µ ( ) = µ. Für die Varianz können wir wieder µ = setzen. Mit Hilfe der partiellen Integration ( uv = uv u v) und u = x und v = σ f X (x), erhalten wir V(X ) = }{{} x u x f X (x) } {{ } v dx = xσ f X (x) σ f X (x)dx = + σ 1 = σ. 35
36 Binomial Normal Stet.-korr Abbildung 16: Approximation der Binomialverteilung B,5% durch die Normalverteilung (Normalapproximation). Definition Die Standardnormalverteilung ist die Normalverteilung mit µ = und σ = 1, also N,1. Die Verteilungsfunktion der Standardnormalverteilung wird als Φ geschrieben. Satz Wenn X N µ,σ, dann ist X µ σ N,1. Es gilt daher b P(a X b) = f X (x)dx = F X (b) F X (a) = Φ a ( X µ Beweis. P(X x) = P σ ) x µ σ = Φ ( x µ ) σ. Aus Symmetriegründen ist Φ( x) = 1 Φ(x). ( b µ σ ) Φ ( a µ Satz X N µ,σ P( X µ σ) 68.%, P( X µ σ) 95.4%, P( X µ 3σ) 99.7%. Beispiel X sei die Füllmenge in einer Milchpackung in l. X N 1,.5. P(X.98) = Φ ( ) = Φ(.4) 34%. Die Umkehrfunktion Φ 1 ist wichtig, wenn Mindestwahrscheinlichkeiten gefragt sind. Satz P(X x) p Φ ( x µ ) x µ σ p σ Φ 1 (p) x σφ 1 (p) + µ. Beispiel Wie viel Milch ist mit Wahrscheinlichkeit p 99% in der Packung? P(X > x) p 1 Φ ( x µ ) x µ σ p σ Φ 1 (1 p) x σφ 1 (1 p) + µ =.5Φ 1 (.1) l. σ ). 36
37 Satz 6.5. Es ist möglich, die Binomialverteilung durch die Normalverteilung zu approximieren (Normalapproximation). Sei ( X B n,p und Y N E(X ),V(X ) = k np N np,np(1 p). Dann ist P(X k) P(Y k) = Φ ). Faustregel: es sollte np(1 p) np(1 p) 9 sein, sonst ist der Fehler zu groß. Da gerade für ganzzahlige Stellen k die Treppenfunktion der Binomial-Verteilung maximal von der Approximation abweicht, wählt man oft besser P(X k) P(Y k + 1 ) (Stetigkeitskorrektur). Der Grund für die Ähnlichkeit der Verteilungen ist der zentrale Grenzwertsatz (siehe Abschnitt 7). Abbildung 16 zeigt die Normalapproximationen. Beispiel Gegeben ist eine Packung mit 1 Bauteilen. Jedes Bauteil ist mit p =. defekt. P( max. 5 kaputt ) = P(X 5) = ( 5 1 ) k= k. k.98 1 k ( ) Φ 5 1. = Φ(1.19) 87% Definition 6.5. Eine Zufallsvariable besitzt die Exponentialverteilung mit Parameter λ >, wenn gilt { λe λx x f X (x) = x <. Satz Satz F X (x) = x λe λu du = e λu x E(X ) = 1 λ, V(X ) = 1 λ. = 1 e λx. Beweis. E(X ) = }{{} x u λe λx } {{ } v dx = x }{{} u } {{ } e λx v + }{{} 1 u e λx } {{ } v dx = + e λx λ = 1 λ. V(X ) = x }{{} u λe λx } {{ } v dx E(X ) = x e λx + xe λx dx 1 λ = + λ E(X ) 1 λ = λ 1 λ = 1 λ. Die folgenden Verteilungen sind für die schließende Statistik wichtig. Berechnet man zum Beispiel die Varianz einer Stichprobe und modelliert die einzelnen Stichprobenwerte als normalverteilte Zufallsvariablen, dann ergibt sich eine Summe von quadrierten normalverteilten Zufallsvariablen. Die folgende Verteilung modelliert diese Situation. 37
38 Abbildung 17: Dichtefunktion der χ -Verteilung für verschiedene Freiheitsgrade. Definition Seien Y 1,Y,...,Y n unabhängige, standardnormalverteilte Zufallsvariablen. Dann besitzt X = Y1 + Y Y n die χ -Verteilung ( Chi-Quadrat ) mit n Freiheitsgraden. Man schreibt X χ n. Satz f X (x) = n x n Γ( n 1 e x x ) x <, mit Γ(x) = t x 1 e t dt. Diese Funktionen sind schwer handhabbar, daher werden meistens Näherungsformeln oder Tabellen verwendet wie die in Abbildung 7. Die Verteilungsfunktion ist überhaupt nicht elementar darstellbar. Abbildung 17 zeigt die Dichtefunktion. Satz X χ n E(X ) = n, V(X ) = n. Betrachtet man den Mittelwert einer Stichprobe und modelliert die Stichprobenwerte als normalverteilte Zufallsvariablen, dann hängt die Verteilung des Mittelwerts von der Varianz der Zufallsvariablen ab. Ist diese aber nicht bekannt sondern muss aus der Stichprobe konstruiert werden, dann hat der Mittelwert eine leicht andere Verteilung. Definition Sei Y standardnormalverteilt und Z χ -verteilt mit n Freiheitsgraden, dann besitzt X = Y / Z /n die Student-t -Verteilung. Man schreibt X t n. Abbildung 18 zeigt die Dichtefunktion. Die t-verteilung konvergiert mit n gegen die Standardnormalverteilung und kann daher für größere n durch diese approximiert werden. 38
Statistik. Inhaltsverzeichnis. Rade Kutil, Deskriptive Statistik 2. 2 Korrelation und Regression 8. 3 Ereignis- und Wahrscheinlichkeitsraum 12
 Statistik Rade Kutil, 14 Inhaltsverzeichnis 1 Deskriptive Statistik Korrelation und Regression 8 3 Ereignis- und Wahrscheinlichkeitsraum 1 4 Kombinatorik 16 5 Bedingte Wahrscheinlichkeit 6 Zufallsvariablen
Statistik Rade Kutil, 14 Inhaltsverzeichnis 1 Deskriptive Statistik Korrelation und Regression 8 3 Ereignis- und Wahrscheinlichkeitsraum 1 4 Kombinatorik 16 5 Bedingte Wahrscheinlichkeit 6 Zufallsvariablen
Kapitel VI - Lage- und Streuungsparameter
 Universität Karlsruhe (TH) Institut für Statistik und Mathematische Wirtschaftstheorie Wahrscheinlichkeitstheorie Kapitel VI - Lage- und Streuungsparameter Markus Höchstötter Lehrstuhl für Statistik, Ökonometrie
Universität Karlsruhe (TH) Institut für Statistik und Mathematische Wirtschaftstheorie Wahrscheinlichkeitstheorie Kapitel VI - Lage- und Streuungsparameter Markus Höchstötter Lehrstuhl für Statistik, Ökonometrie
Wahrscheinlichkeitstheorie und Statistik
 Wahrscheinlichkeitstheorie und Statistik Definitionen und Sätze Prof. Dr. Christoph Karg Studiengang Informatik Hochschule Aalen Sommersemester 2018 2.5.2018 Diskrete Wahrscheinlichkeitsräume Diskreter
Wahrscheinlichkeitstheorie und Statistik Definitionen und Sätze Prof. Dr. Christoph Karg Studiengang Informatik Hochschule Aalen Sommersemester 2018 2.5.2018 Diskrete Wahrscheinlichkeitsräume Diskreter
Fit for Abi & Study Stochastik
 Fit for Abi & Study Stochastik Prof. Dr. Tilla Schade Hochschule Harz 15. und 16. April 2014 No. 1 Stochastik besteht aus: Wahrscheinlichkeitsrechnung Statistik No. 2 Gliederung Grundlagen Zufallsgrößen
Fit for Abi & Study Stochastik Prof. Dr. Tilla Schade Hochschule Harz 15. und 16. April 2014 No. 1 Stochastik besteht aus: Wahrscheinlichkeitsrechnung Statistik No. 2 Gliederung Grundlagen Zufallsgrößen
6. Stochastische Modelle II: Stetige Wahrscheinlichkeitsverteilungen, insbesondere Normalverteilungen
 6. Stochastische Modelle II: Stetige Wahrscheinlichkeitsverteilungen, insbesondere Normalverteilungen Dr. Antje Kiesel Institut für Angewandte Mathematik WS 2011/2012 Bisher: Diskrete Zufallsvariablen,
6. Stochastische Modelle II: Stetige Wahrscheinlichkeitsverteilungen, insbesondere Normalverteilungen Dr. Antje Kiesel Institut für Angewandte Mathematik WS 2011/2012 Bisher: Diskrete Zufallsvariablen,
Wichtige Begriffe und Sätze aus der Wahrscheinlichkeitsrechnung
 Wichtige Begriffe und Sätze aus der Wahrscheinlichkeitsrechnung Version: 22. September 2015 Evelina Erlacher 1 Mengen Es sei Ω eine Menge (die Universalmenge ) und A, B seien Teilmengen von Ω. Dann schreiben
Wichtige Begriffe und Sätze aus der Wahrscheinlichkeitsrechnung Version: 22. September 2015 Evelina Erlacher 1 Mengen Es sei Ω eine Menge (die Universalmenge ) und A, B seien Teilmengen von Ω. Dann schreiben
2.2 Binomialverteilung, Hypergeometrische Verteilung, Poissonverteilung
 2.2 Binomialverteilung, Hypergeometrische Verteilung, Poissonverteilung Die einfachste Verteilung ist die Gleichverteilung, bei der P(X = x i ) = 1/N gilt, wenn N die Anzahl möglicher Realisierungen von
2.2 Binomialverteilung, Hypergeometrische Verteilung, Poissonverteilung Die einfachste Verteilung ist die Gleichverteilung, bei der P(X = x i ) = 1/N gilt, wenn N die Anzahl möglicher Realisierungen von
Stetige Verteilungen. A: Beispiele Beispiel 1: a) In den folgenden Abbildungen sind die Dichtefunktionen von drei bekannten Verteilungen graphisch
 In den folgenden Abbildungen sind die Dichtefunktionen von drei bekannten Verteilungen graphisch") 6 Stetige Verteilungen 1 Kapitel 6: Stetige Verteilungen A: Beispiele Beispiel 1: a) In den folgenden Abbildungen sind die Dichtefunktionen von drei bekannten Verteilungen graphisch dargestellt. 0.2 6
6 Stetige Verteilungen 1 Kapitel 6: Stetige Verteilungen A: Beispiele Beispiel 1: a) In den folgenden Abbildungen sind die Dichtefunktionen von drei bekannten Verteilungen graphisch dargestellt. 0.2 6
Kenngrößen von Zufallsvariablen
 Kenngrößen von Zufallsvariablen Die Wahrscheinlichkeitsverteilung kann durch die sogenannten Kenngrößen beschrieben werden, sie charakterisieren sozusagen die Verteilung. Der Erwartungswert Der Erwartungswert
Kenngrößen von Zufallsvariablen Die Wahrscheinlichkeitsverteilung kann durch die sogenannten Kenngrößen beschrieben werden, sie charakterisieren sozusagen die Verteilung. Der Erwartungswert Der Erwartungswert
Grundbegriffe der Wahrscheinlichkeitstheorie
 KAPITEL 1 Grundbegriffe der Wahrscheinlichkeitstheorie 1. Zufallsexperimente, Ausgänge, Grundmenge In der Stochastik betrachten wir Zufallsexperimente. Die Ausgänge eines Zufallsexperiments fassen wir
KAPITEL 1 Grundbegriffe der Wahrscheinlichkeitstheorie 1. Zufallsexperimente, Ausgänge, Grundmenge In der Stochastik betrachten wir Zufallsexperimente. Die Ausgänge eines Zufallsexperiments fassen wir
Ü b u n g s b l a t t 15
 Einführung in die Stochastik Sommersemester 07 Dr. Walter Oevel 2. 7. 2007 Ü b u n g s b l a t t 15 Hier ist zusätzliches Übungsmaterial zur Klausurvorbereitung quer durch die Inhalte der Vorlesung. Eine
Einführung in die Stochastik Sommersemester 07 Dr. Walter Oevel 2. 7. 2007 Ü b u n g s b l a t t 15 Hier ist zusätzliches Übungsmaterial zur Klausurvorbereitung quer durch die Inhalte der Vorlesung. Eine
Philipp Sibbertsen Hartmut Lehne. Statistik. Einführung für Wirtschafts- und. Sozialwissenschaftler. 2., überarbeitete Auflage. 4^ Springer Gabler
 Philipp Sibbertsen Hartmut Lehne Statistik Einführung für Wirtschafts- und Sozialwissenschaftler 2., überarbeitete Auflage 4^ Springer Gabler Inhaltsverzeichnis Teil I Deskriptive Statistik 1 Einführung
Philipp Sibbertsen Hartmut Lehne Statistik Einführung für Wirtschafts- und Sozialwissenschaftler 2., überarbeitete Auflage 4^ Springer Gabler Inhaltsverzeichnis Teil I Deskriptive Statistik 1 Einführung
Wichtige Definitionen und Aussagen
 Wichtige Definitionen und Aussagen Zufallsexperiment, Ergebnis, Ereignis: Unter einem Zufallsexperiment verstehen wir einen Vorgang, dessen Ausgänge sich nicht vorhersagen lassen Die möglichen Ausgänge
Wichtige Definitionen und Aussagen Zufallsexperiment, Ergebnis, Ereignis: Unter einem Zufallsexperiment verstehen wir einen Vorgang, dessen Ausgänge sich nicht vorhersagen lassen Die möglichen Ausgänge
Stochastik. 1. Wahrscheinlichkeitsräume
 Stochastik 1. Wahrscheinlichkeitsräume Ein Zufallsexperiment ist ein beliebig oft und gleichartig wiederholbarer Vorgang mit mindestens zwei verschiedenen Ergebnissen, bei dem der Ausgang ungewiß ist.
Stochastik 1. Wahrscheinlichkeitsräume Ein Zufallsexperiment ist ein beliebig oft und gleichartig wiederholbarer Vorgang mit mindestens zwei verschiedenen Ergebnissen, bei dem der Ausgang ungewiß ist.
Wahrscheinlichkeit und Statistik: Zusammenfassung
 HSR Hochschule für Technik Rapperswil Wahrscheinlichkeit und Statistik: Zusammenfassung beinhaltet Teile des Skripts von Herrn Hardy von Lukas Wilhelm lwilhelm.net 12. Januar 2007 Inhaltsverzeichnis 1
HSR Hochschule für Technik Rapperswil Wahrscheinlichkeit und Statistik: Zusammenfassung beinhaltet Teile des Skripts von Herrn Hardy von Lukas Wilhelm lwilhelm.net 12. Januar 2007 Inhaltsverzeichnis 1
Kapitel 2 Wahrscheinlichkeitsrechnung
 Definition 2.77: Normalverteilung & Standardnormalverteilung Es sei µ R und 0 < σ 2 R. Besitzt eine stetige Zufallsvariable X die Dichte f(x) = 1 2 πσ 2 e 1 2 ( x µ σ ) 2, x R, so heißt X normalverteilt
Definition 2.77: Normalverteilung & Standardnormalverteilung Es sei µ R und 0 < σ 2 R. Besitzt eine stetige Zufallsvariable X die Dichte f(x) = 1 2 πσ 2 e 1 2 ( x µ σ ) 2, x R, so heißt X normalverteilt
Wirtschaftsmathematik
 Einführung in einige Teilbereiche der Wintersemester 206 Prof. Dr. Stefan Etschberger HSA Unabhängigkeit von Ereignissen A, B unabhängig: Eintreten von A liefert keine Information über P(B). Formal: P(A
Einführung in einige Teilbereiche der Wintersemester 206 Prof. Dr. Stefan Etschberger HSA Unabhängigkeit von Ereignissen A, B unabhängig: Eintreten von A liefert keine Information über P(B). Formal: P(A
1 Grundlagen der Wahrscheinlichkeitsrechnung Wahrscheinlichkeitsräume. Ein erster mathematischer Blick auf Zufallsexperimente...
 Inhaltsverzeichnis 1 Grundlagen der Wahrscheinlichkeitsrechnung 1 1.1 Wahrscheinlichkeitsräume Ein erster mathematischer Blick auf Zufallsexperimente.......... 1 1.1.1 Wahrscheinlichkeit, Ergebnisraum,
Inhaltsverzeichnis 1 Grundlagen der Wahrscheinlichkeitsrechnung 1 1.1 Wahrscheinlichkeitsräume Ein erster mathematischer Blick auf Zufallsexperimente.......... 1 1.1.1 Wahrscheinlichkeit, Ergebnisraum,
2. Rechnen mit Wahrscheinlichkeiten
 2. Rechnen mit Wahrscheinlichkeiten 2.1 Axiome der Wahrscheinlichkeitsrechnung Die Wahrscheinlichkeitsrechnung ist ein Teilgebiet der Mathematik. Es ist üblich, an den Anfang einer mathematischen Theorie
2. Rechnen mit Wahrscheinlichkeiten 2.1 Axiome der Wahrscheinlichkeitsrechnung Die Wahrscheinlichkeitsrechnung ist ein Teilgebiet der Mathematik. Es ist üblich, an den Anfang einer mathematischen Theorie
Zufallsvariablen. Diskret. Stetig. Verteilung der Stichprobenkennzahlen. Binomial Hypergeometrisch Poisson. Normal Lognormal Exponential
 Zufallsvariablen Diskret Binomial Hypergeometrisch Poisson Stetig Normal Lognormal Exponential Verteilung der Stichprobenkennzahlen Stetige Zufallsvariable Verteilungsfunktion: Dichtefunktion: Integralrechnung:
Zufallsvariablen Diskret Binomial Hypergeometrisch Poisson Stetig Normal Lognormal Exponential Verteilung der Stichprobenkennzahlen Stetige Zufallsvariable Verteilungsfunktion: Dichtefunktion: Integralrechnung:
Kapitel II Kontinuierliche Wahrscheinlichkeitsräume
 Kapitel II Kontinuierliche Wahrscheinlichkeitsräume 1. Einführung 1.1 Motivation Interpretation der Poisson-Verteilung als Grenzwert der Binomialverteilung. DWT 1.1 Motivation 211/476 Beispiel 85 Wir betrachten
Kapitel II Kontinuierliche Wahrscheinlichkeitsräume 1. Einführung 1.1 Motivation Interpretation der Poisson-Verteilung als Grenzwert der Binomialverteilung. DWT 1.1 Motivation 211/476 Beispiel 85 Wir betrachten
8. Formelsammlung. Pr[ ] = 0. 0 Pr[A] 1. Pr[Ā] = 1 Pr[A] A B = Pr[A] Pr[B] DWT 8.1 Gesetze zum Rechnen mit Ereignissen 203/467 Ernst W.
![8. Formelsammlung. Pr[ ] = 0. 0 Pr[A] 1. Pr[Ā] = 1 Pr[A] A B = Pr[A] Pr[B] DWT 8.1 Gesetze zum Rechnen mit Ereignissen 203/467 Ernst W.](/thumbs/69/59978031.jpg "8. Formelsammlung. Pr[ ] = 0. 0 Pr[A] 1. Pr[Ā] = 1 Pr[A] A B = Pr[A] Pr[B] DWT 8.1 Gesetze zum Rechnen mit Ereignissen 203/467 Ernst W.") 8. Formelsammlung 8.1 Gesetze zum Rechnen mit Ereignissen Im Folgenden seien A und B, sowie A 1,..., A n Ereignisse. Die Notation A B steht für A B und zugleich A B = (disjunkte Vereinigung). A 1... A
8. Formelsammlung 8.1 Gesetze zum Rechnen mit Ereignissen Im Folgenden seien A und B, sowie A 1,..., A n Ereignisse. Die Notation A B steht für A B und zugleich A B = (disjunkte Vereinigung). A 1... A
1 Elemente der Wahrscheinlichkeitstheorie
 H.-J. Starkloff Unendlichdimensionale Stochastik Kap. 01 11. Oktober 2010 1 1 Elemente der Wahrscheinlichkeitstheorie 1.1 Messbare Räume Gegeben seien eine nichtleere Menge Ω und eine Menge A von Teilmengen
H.-J. Starkloff Unendlichdimensionale Stochastik Kap. 01 11. Oktober 2010 1 1 Elemente der Wahrscheinlichkeitstheorie 1.1 Messbare Räume Gegeben seien eine nichtleere Menge Ω und eine Menge A von Teilmengen
Zufallsvariablen. Diskret. Stetig. Verteilung der Stichprobenkennzahlen. Binomial Hypergeometrisch Poisson. Normal Lognormal Exponential
 Zufallsvariablen Diskret Binomial Hypergeometrisch Poisson Stetig Normal Lognormal Exponential Verteilung der Stichprobenkennzahlen Zufallsvariable Erinnerung: Merkmal, Merkmalsausprägung Deskriptive Statistik:
Zufallsvariablen Diskret Binomial Hypergeometrisch Poisson Stetig Normal Lognormal Exponential Verteilung der Stichprobenkennzahlen Zufallsvariable Erinnerung: Merkmal, Merkmalsausprägung Deskriptive Statistik:
Wichtige Begriffe und Sätze aus der Wahrscheinlichkeitsrechnung
 Wichtige Begriffe und Sätze aus der Wahrscheinlichkeitsrechnung Version: 15. Jänner 2017 Evelina Erlacher Inhaltsverzeichnis 1 Mengen 2 2 Wahrscheinlichkeiten 3 3 Zufallsvariablen 5 3.1 Diskrete Zufallsvariablen............................
Wichtige Begriffe und Sätze aus der Wahrscheinlichkeitsrechnung Version: 15. Jänner 2017 Evelina Erlacher Inhaltsverzeichnis 1 Mengen 2 2 Wahrscheinlichkeiten 3 3 Zufallsvariablen 5 3.1 Diskrete Zufallsvariablen............................
Definition Sei X eine stetige Z.V. mit Verteilungsfunktion F und Dichte f. Dann heißt E(X) :=
 :=") Definition 2.34. Sei X eine stetige Z.V. mit Verteilungsfunktion F und Dichte f. Dann heißt E(X) := x f(x)dx der Erwartungswert von X, sofern dieses Integral existiert. Entsprechend wird die Varianz V(X)
Definition 2.34. Sei X eine stetige Z.V. mit Verteilungsfunktion F und Dichte f. Dann heißt E(X) := x f(x)dx der Erwartungswert von X, sofern dieses Integral existiert. Entsprechend wird die Varianz V(X)
Eine zweidimensionale Stichprobe
 Eine zweidimensionale Stichprobe liegt vor, wenn zwei qualitative Merkmale gleichzeitig betrachtet werden. Eine Urliste besteht dann aus Wertepaaren (x i, y i ) R 2 und hat die Form (x 1, y 1 ), (x 2,
Eine zweidimensionale Stichprobe liegt vor, wenn zwei qualitative Merkmale gleichzeitig betrachtet werden. Eine Urliste besteht dann aus Wertepaaren (x i, y i ) R 2 und hat die Form (x 1, y 1 ), (x 2,
Unterrichtsmaterialien in digitaler und in gedruckter Form. Auszug aus: Binomialverteilung und Bernoulli- Experiment
 Unterrichtsmaterialien in digitaler und in gedruckter Form Auszug aus: Binomialverteilung und Bernoulli- Experiment Das komplette Material finden Sie hier: Download bei School-Scout.de TOSSNET Der persönliche
Unterrichtsmaterialien in digitaler und in gedruckter Form Auszug aus: Binomialverteilung und Bernoulli- Experiment Das komplette Material finden Sie hier: Download bei School-Scout.de TOSSNET Der persönliche
12 Die Normalverteilung
 12 Die Normalverteilung Die Normalverteilung ist eine der wichtigsten Wahrscheinlichkeitsverteilungen in der Praxis, weil aufgrund des sogenannten zentralen Grenzwertsatzes in vielen Situationen angenommen
12 Die Normalverteilung Die Normalverteilung ist eine der wichtigsten Wahrscheinlichkeitsverteilungen in der Praxis, weil aufgrund des sogenannten zentralen Grenzwertsatzes in vielen Situationen angenommen
Stochastik Wiederholung von Teil 1
 Stochastik Wiederholung von Teil 1 Andrej Depperschmidt Sommersemester 2016 Wahrscheinlichkeitsraum Definition Das Tripple (Ω, A, P) heißt Wahrscheinlichkeitsraum, falls gilt: (i) A ist eine σ-algebra,
Stochastik Wiederholung von Teil 1 Andrej Depperschmidt Sommersemester 2016 Wahrscheinlichkeitsraum Definition Das Tripple (Ω, A, P) heißt Wahrscheinlichkeitsraum, falls gilt: (i) A ist eine σ-algebra,
2 Zufallsvariable und Verteilungsfunktionen
 8 2 Zufallsvariable und Verteilungsfunktionen Häufig ist es so, dass den Ausgängen eines Zufallexperiments, d.h. den Elementen der Ereignisalgebra, eine Zahl zugeordnet wird. Das wollen wir etwas mathematischer
8 2 Zufallsvariable und Verteilungsfunktionen Häufig ist es so, dass den Ausgängen eines Zufallexperiments, d.h. den Elementen der Ereignisalgebra, eine Zahl zugeordnet wird. Das wollen wir etwas mathematischer
Inferenzstatistik (=schließende Statistik)
") Inferenzstatistik (=schließende Statistik) Grundproblem der Inferenzstatistik: Wie kann man von einer Stichprobe einen gültigen Schluß auf di Grundgesamtheit ziehen Bzw.: Wie groß sind die Fehler, die
Inferenzstatistik (=schließende Statistik) Grundproblem der Inferenzstatistik: Wie kann man von einer Stichprobe einen gültigen Schluß auf di Grundgesamtheit ziehen Bzw.: Wie groß sind die Fehler, die
 Basiswissen Daten und Zufall Seite 1 von 8 1 Zufallsexperiment Ein Zufallsexperiment ist ein Versuchsaufbau mit zufälligem Ausgang, d. h. das Ergebnis kann nicht vorhergesagt werden. 2 Ergebnis (auch Ausgang)
Basiswissen Daten und Zufall Seite 1 von 8 1 Zufallsexperiment Ein Zufallsexperiment ist ein Versuchsaufbau mit zufälligem Ausgang, d. h. das Ergebnis kann nicht vorhergesagt werden. 2 Ergebnis (auch Ausgang)
1. Grundbegri e der Stochastik
 . Grundbegri e der Stochastik Raum der Ereignisse. Die einelementigen Teilmengen f!g heißen auch Elementarereignisse. Das Ereignis A tritt ein, wenn ein! A eintritt. A ist ein geeignetes System von Teilmengen
. Grundbegri e der Stochastik Raum der Ereignisse. Die einelementigen Teilmengen f!g heißen auch Elementarereignisse. Das Ereignis A tritt ein, wenn ein! A eintritt. A ist ein geeignetes System von Teilmengen
Zufallsvariablen: Die allgemeine Definition
 KAPITEL 8 Zufallsvariablen: Die allgemeine Definition 8.1. Zufallsvariablen Bis zu diesem Zeitpunkt haben wir ausschließlich Zufallsvariablen mit endlich oder abzählbar vielen Werten (also diskrete Zufallsvariablen)
KAPITEL 8 Zufallsvariablen: Die allgemeine Definition 8.1. Zufallsvariablen Bis zu diesem Zeitpunkt haben wir ausschließlich Zufallsvariablen mit endlich oder abzählbar vielen Werten (also diskrete Zufallsvariablen)
1. Grundbegri e der Stochastik
 Wiederholung von Grundwissen der Stochastik. Grundbegri e der Stochastik Menge der Ereignisse. Die Elemente! der Menge heißen Elementarereignisse und sind unzerlegbare Ereignisse. Das Ereignis A tritt
Wiederholung von Grundwissen der Stochastik. Grundbegri e der Stochastik Menge der Ereignisse. Die Elemente! der Menge heißen Elementarereignisse und sind unzerlegbare Ereignisse. Das Ereignis A tritt
Definition: Ein endlicher Ergebnisraum ist eine nichtleere Menge, deren. wird als Ereignis, jede einelementige Teilmenge als Elementarereignis
 Stochastische Prozesse: Grundlegende Begriffe bei zufälligen Prozessen In diesem Abschnitt beschäftigen wir uns mit den grundlegenden Begriffen und Definitionen von Zufallsexperimenten, also Prozessen,
Stochastische Prozesse: Grundlegende Begriffe bei zufälligen Prozessen In diesem Abschnitt beschäftigen wir uns mit den grundlegenden Begriffen und Definitionen von Zufallsexperimenten, also Prozessen,
1.5 Mehrdimensionale Verteilungen
 Poisson eine gute Näherung, da np = 0 und 500p = 5 00 = n. Wir erhalten somit als Näherung Exakte Rechnung ergibt P(2 X 0) = k=2 0 k=2 π (k) = 0,26424. 0 ( ) 00 P(2 X 0) = 0,0 k 0,99 00 k = 0,264238. k.4.2.4
Poisson eine gute Näherung, da np = 0 und 500p = 5 00 = n. Wir erhalten somit als Näherung Exakte Rechnung ergibt P(2 X 0) = k=2 0 k=2 π (k) = 0,26424. 0 ( ) 00 P(2 X 0) = 0,0 k 0,99 00 k = 0,264238. k.4.2.4
Kapitel II Kontinuierliche Wahrscheinlichkeitsraume
 Kapitel II Kontinuierliche Wahrscheinlichkeitsraume 1. Einfuhrung 1.1 Motivation Interpretation der Poisson-Verteilung als Grenzwert der Binomialverteilung. DWT 1.1 Motivation 195/460 Beispiel 78 Wir betrachten
Kapitel II Kontinuierliche Wahrscheinlichkeitsraume 1. Einfuhrung 1.1 Motivation Interpretation der Poisson-Verteilung als Grenzwert der Binomialverteilung. DWT 1.1 Motivation 195/460 Beispiel 78 Wir betrachten
Biometrieübung 5 Spezielle Verteilungen. 1. Anzahl von weiblichen Mäusen in Würfen von jeweils 4 Mäusen
 Biometrieübung 5 (Spezielle Verteilungen) - Aufgabe Biometrieübung 5 Spezielle Verteilungen Aufgabe 1. Anzahl von weiblichen Mäusen in Würfen von jeweils 4 Mäusen Anzahl weiblicher Mäuse (k) Anzahl Würfe
Biometrieübung 5 (Spezielle Verteilungen) - Aufgabe Biometrieübung 5 Spezielle Verteilungen Aufgabe 1. Anzahl von weiblichen Mäusen in Würfen von jeweils 4 Mäusen Anzahl weiblicher Mäuse (k) Anzahl Würfe
Beispiel: Zweidimensionale Normalverteilung I
 10 Mehrdimensionale Zufallsvariablen Bedingte Verteilungen 10.6 Beispiel: Zweidimensionale Normalverteilung I Wichtige mehrdimensionale stetige Verteilung: mehrdimensionale (multivariate) Normalverteilung
10 Mehrdimensionale Zufallsvariablen Bedingte Verteilungen 10.6 Beispiel: Zweidimensionale Normalverteilung I Wichtige mehrdimensionale stetige Verteilung: mehrdimensionale (multivariate) Normalverteilung
Wahrscheinlichkeitsverteilungen
 Wahrscheinlichkeitsverteilungen 1. Binomialverteilung 1.1 Abzählverfahren 1.2 Urnenmodell Ziehen mit Zurücklegen, Formel von Bernoulli 1.3 Berechnung von Werten 1.4 Erwartungswert und Standardabweichung
Wahrscheinlichkeitsverteilungen 1. Binomialverteilung 1.1 Abzählverfahren 1.2 Urnenmodell Ziehen mit Zurücklegen, Formel von Bernoulli 1.3 Berechnung von Werten 1.4 Erwartungswert und Standardabweichung
I Grundbegriffe 1 1 Wahrscheinlichkeitsräume Bedingte Wahrscheinlichkeiten und Unabhängigkeit Reellwertige Zufallsvariablen...
 Inhaltsverzeichnis I Grundbegriffe 1 1 Wahrscheinlichkeitsräume......................... 1 2 Bedingte Wahrscheinlichkeiten und Unabhängigkeit........... 7 3 Reellwertige Zufallsvariablen........................
Inhaltsverzeichnis I Grundbegriffe 1 1 Wahrscheinlichkeitsräume......................... 1 2 Bedingte Wahrscheinlichkeiten und Unabhängigkeit........... 7 3 Reellwertige Zufallsvariablen........................
P (X = 2) = 1/36, P (X = 3) = 2/36,...
 = 1/36, P (X = 3) = 2/36,...") 2.3 Zufallsvariablen 2.3 Zufallsvariablen Meist sind die Ereignisse eines Zufallseperiments bereits reelle Zahlen. Ist dies nicht der Fall, kann man Ereignissen eine reelle Zahl zuordnen. Zum Beispiel
2.3 Zufallsvariablen 2.3 Zufallsvariablen Meist sind die Ereignisse eines Zufallseperiments bereits reelle Zahlen. Ist dies nicht der Fall, kann man Ereignissen eine reelle Zahl zuordnen. Zum Beispiel
Sprechstunde zur Klausurvorbereitung
 htw saar 1 Sprechstunde zur Klausurvorbereitung Mittwoch, 15.02., 10 12 + 13.30 16.30 Uhr, Raum 2413 Bei Interesse in Liste eintragen: Max. 20 Minuten Einzeln oder Kleingruppen (z. B. bei gemeinsamer Klausurvorbereitung)
htw saar 1 Sprechstunde zur Klausurvorbereitung Mittwoch, 15.02., 10 12 + 13.30 16.30 Uhr, Raum 2413 Bei Interesse in Liste eintragen: Max. 20 Minuten Einzeln oder Kleingruppen (z. B. bei gemeinsamer Klausurvorbereitung)
Inhaltsverzeichnis. Dozent: Andreas Nestke Lehrfach: Mathe 3 Thema: Wahrscheinlichkeitstheorie Datum: Autor: René Pecher
 Dozent: Andreas Nestke Lehrfach: Mathe 3 Thema: Wahrscheinlichkeitstheorie Datum: 24.01.2011 Autor: René Pecher Inhaltsverzeichnis 1 Permutation 1 1.1 ohne Wiederholungen........................... 1 1.2
Dozent: Andreas Nestke Lehrfach: Mathe 3 Thema: Wahrscheinlichkeitstheorie Datum: 24.01.2011 Autor: René Pecher Inhaltsverzeichnis 1 Permutation 1 1.1 ohne Wiederholungen........................... 1 1.2
Statistik für NichtStatistiker
 Statistik für NichtStatistiker Zufall und Wahrscheinlichkeit von Prof. Dr. Karl Bosch 5., verbesserte Auflage R. Oldenbourg Verlag München Wien Inhaltsverzeichnis 1. ZufalLsexperimente und zufällige Ereignisse
Statistik für NichtStatistiker Zufall und Wahrscheinlichkeit von Prof. Dr. Karl Bosch 5., verbesserte Auflage R. Oldenbourg Verlag München Wien Inhaltsverzeichnis 1. ZufalLsexperimente und zufällige Ereignisse
Programm. Wiederholung. Gleichverteilung Diskrete Gleichverteilung Stetige Gleichverteilung. Binomialverteilung. Hypergeometrische Verteilung
 Programm Wiederholung Gleichverteilung Diskrete Gleichverteilung Stetige Gleichverteilung Binomialverteilung Hypergeometrische Verteilung Wiederholung verschiedene Mittelwerte für verschiedene Skalenniveaus
Programm Wiederholung Gleichverteilung Diskrete Gleichverteilung Stetige Gleichverteilung Binomialverteilung Hypergeometrische Verteilung Wiederholung verschiedene Mittelwerte für verschiedene Skalenniveaus
Inhaltsverzeichnis. Inhalt Teil I: Beschreibende (Deskriptive) Statistik Seite. 1.0 Erste Begriffsbildungen Merkmale und Skalen 5
 Statistik Seite. 1.0 Erste Begriffsbildungen Merkmale und Skalen 5") Inhaltsverzeichnis Inhalt Teil I: Beschreibende (Deskriptive) Statistik Seite 1.0 Erste Begriffsbildungen 1 1.1 Merkmale und Skalen 5 1.2 Von der Urliste zu Häufigkeitsverteilungen 9 1.2.0 Erste Ordnung
Inhaltsverzeichnis Inhalt Teil I: Beschreibende (Deskriptive) Statistik Seite 1.0 Erste Begriffsbildungen 1 1.1 Merkmale und Skalen 5 1.2 Von der Urliste zu Häufigkeitsverteilungen 9 1.2.0 Erste Ordnung
Universität Basel Wirtschaftswissenschaftliches Zentrum. Zufallsvariablen. Dr. Thomas Zehrt
 Universität Basel Wirtschaftswissenschaftliches Zentrum Zufallsvariablen Dr. Thomas Zehrt Inhalt: 1. Einführung 2. Zufallsvariablen 3. Diskrete Zufallsvariablen 4. Stetige Zufallsvariablen 5. Erwartungswert
Universität Basel Wirtschaftswissenschaftliches Zentrum Zufallsvariablen Dr. Thomas Zehrt Inhalt: 1. Einführung 2. Zufallsvariablen 3. Diskrete Zufallsvariablen 4. Stetige Zufallsvariablen 5. Erwartungswert
Statistik für Ingenieure Vorlesung 3
 Statistik für Ingenieure Vorlesung 3 Prof. Dr. Hans-Jörg Starkloff TU Bergakademie Freiberg Institut für Stochastik 14. November 2017 3. Zufallsgrößen 3.1 Zufallsgrößen und ihre Verteilung Häufig sind
Statistik für Ingenieure Vorlesung 3 Prof. Dr. Hans-Jörg Starkloff TU Bergakademie Freiberg Institut für Stochastik 14. November 2017 3. Zufallsgrößen 3.1 Zufallsgrößen und ihre Verteilung Häufig sind
Diskrete Strukturen und Logik WiSe 2007/08 in Trier. Henning Fernau Universität Trier
 Diskrete Strukturen und Logik WiSe 2007/08 in Trier Henning Fernau Universität Trier fernau@uni-trier.de 1 Diskrete Strukturen und Logik Gesamtübersicht Organisatorisches Einführung Logik & Mengenlehre
Diskrete Strukturen und Logik WiSe 2007/08 in Trier Henning Fernau Universität Trier fernau@uni-trier.de 1 Diskrete Strukturen und Logik Gesamtübersicht Organisatorisches Einführung Logik & Mengenlehre
13 Mehrdimensionale Zufallsvariablen Zufallsvektoren
 3 Mehrdimensionale Zufallsvariablen Zufallsvektoren Bisher haben wir uns ausschließlich mit Zufallsexperimenten beschäftigt, bei denen die Beobachtung eines einzigen Merkmals im Vordergrund stand. In diesem
3 Mehrdimensionale Zufallsvariablen Zufallsvektoren Bisher haben wir uns ausschließlich mit Zufallsexperimenten beschäftigt, bei denen die Beobachtung eines einzigen Merkmals im Vordergrund stand. In diesem
Klausur zur Wahrscheinlichkeitstheorie für Lehramtsstudierende
 Universität Duisburg-Essen Essen, den 0.0.009 Fachbereich Mathematik Prof. Dr. M. Winkler C. Stinner Klausur zur Wahrscheinlichkeitstheorie für Lehramtsstudierende Lösung Die Klausur gilt als bestanden,
Universität Duisburg-Essen Essen, den 0.0.009 Fachbereich Mathematik Prof. Dr. M. Winkler C. Stinner Klausur zur Wahrscheinlichkeitstheorie für Lehramtsstudierende Lösung Die Klausur gilt als bestanden,
Diskrete Zufallsvariablen (Forts.) I
 I") 9 Eindimensionale Zufallsvariablen Diskrete Zufallsvariablen 9.4 Diskrete Zufallsvariablen (Forts.) I T (X ) ist endlich oder abzählbar unendlich, die Elemente von T (X ) werden daher im Folgenden häufig
9 Eindimensionale Zufallsvariablen Diskrete Zufallsvariablen 9.4 Diskrete Zufallsvariablen (Forts.) I T (X ) ist endlich oder abzählbar unendlich, die Elemente von T (X ) werden daher im Folgenden häufig
Diskrete Zufallsvariablen (Forts.) I
 I") 9 Eindimensionale Zufallsvariablen Diskrete Zufallsvariablen 9.4 Diskrete Zufallsvariablen (Forts.) I T (X ) ist endlich oder abzählbar unendlich, die Elemente von T (X ) werden daher im Folgenden häufig
9 Eindimensionale Zufallsvariablen Diskrete Zufallsvariablen 9.4 Diskrete Zufallsvariablen (Forts.) I T (X ) ist endlich oder abzählbar unendlich, die Elemente von T (X ) werden daher im Folgenden häufig
Zusammenfassung Mathe II. Themenschwerpunkt 2: Stochastik (ean) 1. Ein- und mehrstufige Zufallsexperimente; Ergebnismengen
 1. Ein- und mehrstufige Zufallsexperimente; Ergebnismengen") Zusammenfassung Mathe II Themenschwerpunkt 2: Stochastik (ean) 1. Ein- und mehrstufige Zufallsexperimente; Ergebnismengen Zufallsexperiment: Ein Vorgang, bei dem mindestens zwei Ereignisse möglich sind
Zusammenfassung Mathe II Themenschwerpunkt 2: Stochastik (ean) 1. Ein- und mehrstufige Zufallsexperimente; Ergebnismengen Zufallsexperiment: Ein Vorgang, bei dem mindestens zwei Ereignisse möglich sind
5. Stochastische Modelle I: Diskrete Zufallsvariablen
 5. Stochastische Modelle I: Diskrete Zufallsvariablen Dr. Antje Kiesel Institut für Angewandte Mathematik WS 2011/2012 Zufallsgrößen Eine Zufallsgröße X ist eine Größe, deren Wert wir nicht exakt kennen
5. Stochastische Modelle I: Diskrete Zufallsvariablen Dr. Antje Kiesel Institut für Angewandte Mathematik WS 2011/2012 Zufallsgrößen Eine Zufallsgröße X ist eine Größe, deren Wert wir nicht exakt kennen
Statistik... formeln für Dummies
 Timm Si99 Statistik... formeln für Dummies Fachkorrektur tlon Christoph Maas und Joachim Gaukel WILEY WILEY-VCH Verlag GmbH & Co. KGaA lnhaftsllerzeichnis Einleitun9 17 Teil I Formeln aus der beschreibenden
Timm Si99 Statistik... formeln für Dummies Fachkorrektur tlon Christoph Maas und Joachim Gaukel WILEY WILEY-VCH Verlag GmbH & Co. KGaA lnhaftsllerzeichnis Einleitun9 17 Teil I Formeln aus der beschreibenden
Abiturvorbereitung Stochastik. neue friedländer gesamtschule Klasse 12 GB Holger Wuschke B.Sc.
 Abiturvorbereitung Stochastik neue friedländer gesamtschule Klasse 12 GB 24.02.2014 Holger Wuschke B.Sc. Siedler von Catan, Rühlow 2014 Organisatorisches 0. Begriffe in der Stochastik (1) Ein Zufallsexperiment
Abiturvorbereitung Stochastik neue friedländer gesamtschule Klasse 12 GB 24.02.2014 Holger Wuschke B.Sc. Siedler von Catan, Rühlow 2014 Organisatorisches 0. Begriffe in der Stochastik (1) Ein Zufallsexperiment
1. Grundbegri e. T n i=1 A i = A 1 \ A 2 \ : : : \ A n alle A i treten ein. na = A das zu A komplementäre Ereignis; tritt ein, wenn A nicht eintritt.
 . Grundbegri e Menge der Ereignisse. Die Elemente! der Menge heißen Elementarereignisse und sind unzerlegbare Ereignisse. Das Ereignis A tritt ein, wenn ein! A eintritt. ist auch das sichere Ereignis,
. Grundbegri e Menge der Ereignisse. Die Elemente! der Menge heißen Elementarereignisse und sind unzerlegbare Ereignisse. Das Ereignis A tritt ein, wenn ein! A eintritt. ist auch das sichere Ereignis,
Biostatistik, Sommer 2017
 1/51 Biostatistik, Sommer 2017 Wahrscheinlichkeitstheorie: Verteilungen, Kenngrößen Prof. Dr. Achim Klenke http://www.aklenke.de 8. Vorlesung: 09.06.2017 2/51 Inhalt 1 Verteilungen Normalverteilung Normalapproximation
1/51 Biostatistik, Sommer 2017 Wahrscheinlichkeitstheorie: Verteilungen, Kenngrößen Prof. Dr. Achim Klenke http://www.aklenke.de 8. Vorlesung: 09.06.2017 2/51 Inhalt 1 Verteilungen Normalverteilung Normalapproximation
Arbeitsbuch zur deskriptiven und induktiven Statistik
 Helge Toutenburg Michael Schomaker Malte Wißmann Christian Heumann Arbeitsbuch zur deskriptiven und induktiven Statistik Zweite, aktualisierte und erweiterte Auflage 4ü Springer Inhaltsverzeichnis 1. Grundlagen
Helge Toutenburg Michael Schomaker Malte Wißmann Christian Heumann Arbeitsbuch zur deskriptiven und induktiven Statistik Zweite, aktualisierte und erweiterte Auflage 4ü Springer Inhaltsverzeichnis 1. Grundlagen
Von der Normalverteilung zu z-werten und Konfidenzintervallen
 Von der Normalverteilung zu z-werten und Konfidenzintervallen Sven Garbade Fakultät für Angewandte Psychologie SRH Hochschule Heidelberg sven.garbade@hochschule-heidelberg.de Statistik 1 S. Garbade (SRH
Von der Normalverteilung zu z-werten und Konfidenzintervallen Sven Garbade Fakultät für Angewandte Psychologie SRH Hochschule Heidelberg sven.garbade@hochschule-heidelberg.de Statistik 1 S. Garbade (SRH
KAPITEL 5. Erwartungswert
 KAPITEL 5 Erwartungswert Wir betrachten einen diskreten Wahrscheinlichkeitsraum (Ω, P) und eine Zufallsvariable X : Ω R auf diesem Wahrscheinlichkeitsraum. Die Grundmenge Ω hat also nur endlich oder abzählbar
KAPITEL 5 Erwartungswert Wir betrachten einen diskreten Wahrscheinlichkeitsraum (Ω, P) und eine Zufallsvariable X : Ω R auf diesem Wahrscheinlichkeitsraum. Die Grundmenge Ω hat also nur endlich oder abzählbar
Sachrechnen/Größen WS 14/15-
 Kapitel Daten & Wahrscheinlichkeit 3.1 Kombinatorische Grundlagen 3.2 Kombinatorik & Wahrscheinlichkeit in der Grundschule 3.3 Daten Darstellen 3.1 Kombinatorische Grundlagen Verschiedene Bereiche der
Kapitel Daten & Wahrscheinlichkeit 3.1 Kombinatorische Grundlagen 3.2 Kombinatorik & Wahrscheinlichkeit in der Grundschule 3.3 Daten Darstellen 3.1 Kombinatorische Grundlagen Verschiedene Bereiche der
Folie zur Vorlesung Wahrscheinlichkeitsrechnung und Stoch. Prozesse
 Folie zur Vorlesung Wahrscheinlichkeitsrechnung und Stoch. Prozesse Die Gamma-Verteilung 13.12.212 Diese Verteilung dient häufig zur Modellierung der Lebensdauer von langlebigen Industriegüstern. Die Dichte
Folie zur Vorlesung Wahrscheinlichkeitsrechnung und Stoch. Prozesse Die Gamma-Verteilung 13.12.212 Diese Verteilung dient häufig zur Modellierung der Lebensdauer von langlebigen Industriegüstern. Die Dichte
Statistik I für Betriebswirte Vorlesung 4
 Statistik I für Betriebswirte Vorlesung 4 Prof. Dr. Hans-Jörg Starkloff TU Bergakademie Freiberg Institut für Stochastik 25. April 2016 Prof. Dr. Hans-Jörg Starkloff Statistik I für Betriebswirte Vorlesung
Statistik I für Betriebswirte Vorlesung 4 Prof. Dr. Hans-Jörg Starkloff TU Bergakademie Freiberg Institut für Stochastik 25. April 2016 Prof. Dr. Hans-Jörg Starkloff Statistik I für Betriebswirte Vorlesung
1 1 e x2 =2 d x 1. e (x2 +y 2 )=2 d x d y : Wir gehen nun zu Polarkoordinaten uber und setzen x := r cos und y := r sin.
=2 d x d y : Wir gehen nun zu Polarkoordinaten uber und setzen x := r cos und y := r sin.") Lemma 92 Beweis: Wir berechnen zunachst I 2 : I 2 = Z 1 I := e x2 =2 d x p = 2: 1 Z 1 1 Z 1 Z 1 = 1 1 Z 1 e x2 =2 d x 1 e (x2 +y 2 )=2 d x d y : e y2 =2 d y Wir gehen nun zu Polarkoordinaten uber und setzen
Lemma 92 Beweis: Wir berechnen zunachst I 2 : I 2 = Z 1 I := e x2 =2 d x p = 2: 1 Z 1 1 Z 1 Z 1 = 1 1 Z 1 e x2 =2 d x 1 e (x2 +y 2 )=2 d x d y : e y2 =2 d y Wir gehen nun zu Polarkoordinaten uber und setzen
Statistik I für Betriebswirte Vorlesung 3
 Statistik I für Betriebswirte Vorlesung 3 Dr. Andreas Wünsche TU Bergakademie Freiberg Institut für Stochastik 15. April 2019 Dr. Andreas Wünsche Statistik I für Betriebswirte Vorlesung 3 Version: 1. April
Statistik I für Betriebswirte Vorlesung 3 Dr. Andreas Wünsche TU Bergakademie Freiberg Institut für Stochastik 15. April 2019 Dr. Andreas Wünsche Statistik I für Betriebswirte Vorlesung 3 Version: 1. April
10. Vorlesung. Grundlagen in Statistik. Seite 291. Martin-Luther-Universität Halle/Wittenberg
 . Vorlesung Grundlagen in Statistik Seite 29 Beispiel Gegeben: Termhäufigkeiten von Dokumenten Problemstellung der Sprachmodellierung Was sagen die Termhäufigkeiten über die Wahrscheinlichkeit eines Dokuments
. Vorlesung Grundlagen in Statistik Seite 29 Beispiel Gegeben: Termhäufigkeiten von Dokumenten Problemstellung der Sprachmodellierung Was sagen die Termhäufigkeiten über die Wahrscheinlichkeit eines Dokuments
I. Deskriptive Statistik 1
 I. Deskriptive Statistik 1 1. Einführung 3 1.1. Grundgesamtheit und Stichprobe.................. 5 1.2. Merkmale und Verteilungen..................... 6 1.3. Tabellen und Grafiken........................
I. Deskriptive Statistik 1 1. Einführung 3 1.1. Grundgesamtheit und Stichprobe.................. 5 1.2. Merkmale und Verteilungen..................... 6 1.3. Tabellen und Grafiken........................
Vorlesung Gesamtbanksteuerung Mathematische Grundlagen II Dr. Klaus Lukas Carsten Neundorf. Vorlesung 04 Mathematische Grundlagen II,
 Vorlesung Gesamtbanksteuerung Mathematische Grundlagen II Dr. Klaus Lukas Carsten Neundorf 1 Was sollen Sie heute lernen? 2 Agenda Wiederholung stetige Renditen deskriptive Statistik Verteilungsparameter
Vorlesung Gesamtbanksteuerung Mathematische Grundlagen II Dr. Klaus Lukas Carsten Neundorf 1 Was sollen Sie heute lernen? 2 Agenda Wiederholung stetige Renditen deskriptive Statistik Verteilungsparameter
Übungsrunde 9, Gruppe 2 LVA 107.369, Übungsrunde 8, Gruppe 2, 12.12. Markus Nemetz, TU Wien, 12/2006
 3.75. Angabe Übungsrunde 9, Gruppe 2 LVA 07.369, Übungsrunde 8, Gruppe 2, 2.2. Markus Nemetz, markus.nemetz@tuwien.ac.at, TU Wien, 2/2006 X sei eine stetige sg mit Dichte f(x), x R. Ermitteln Sie einen
3.75. Angabe Übungsrunde 9, Gruppe 2 LVA 07.369, Übungsrunde 8, Gruppe 2, 2.2. Markus Nemetz, markus.nemetz@tuwien.ac.at, TU Wien, 2/2006 X sei eine stetige sg mit Dichte f(x), x R. Ermitteln Sie einen
i =1 i =2 i =3 x i y i 4 0 1
 Aufgabe (5+5=0 Punkte) (a) Bei einem Minigolfturnier traten 6 Spieler gegeneinander an. Die Anzahlen der von ihnen über das gesamte Turnier hinweg benötigten Schläge betrugen x = 24, x 2 = 27, x = 2, x
Aufgabe (5+5=0 Punkte) (a) Bei einem Minigolfturnier traten 6 Spieler gegeneinander an. Die Anzahlen der von ihnen über das gesamte Turnier hinweg benötigten Schläge betrugen x = 24, x 2 = 27, x = 2, x
Einführung in die Statistik
 Einführung in die Statistik Analyse und Modellierung von Daten Von Prof. Dr. Rainer Schlittgen 4., überarbeitete und erweiterte Auflage Fachbereich Materialwissenschaft! der Techn. Hochschule Darmstadt
Einführung in die Statistik Analyse und Modellierung von Daten Von Prof. Dr. Rainer Schlittgen 4., überarbeitete und erweiterte Auflage Fachbereich Materialwissenschaft! der Techn. Hochschule Darmstadt
Prüfungsvorbereitungskurs Höhere Mathematik 3
 Prüfungsvorbereitungskurs Höhere Mathematik 3 Stochastik Marco Boßle Jörg Hörner Mathematik Online Frühjahr 2011 PV-Kurs HM 3 Stochastik 1-1 Zusammenfassung Wahrscheinlichkeitsraum (WR): Menge der Elementarereignisse
Prüfungsvorbereitungskurs Höhere Mathematik 3 Stochastik Marco Boßle Jörg Hörner Mathematik Online Frühjahr 2011 PV-Kurs HM 3 Stochastik 1-1 Zusammenfassung Wahrscheinlichkeitsraum (WR): Menge der Elementarereignisse
Deskriptive Statistik Kapitel IX - Kontingenzkoeffizient
 Deskriptive Statistik Kapitel IX - Kontingenzkoeffizient Georg Bol bol@statistik.uni-karlsruhe.de Markus Höchstötter hoechstoetter@statistik.uni-karlsruhe.de Agenda 1. Untersuchung der Abhängigkeit 2.
Deskriptive Statistik Kapitel IX - Kontingenzkoeffizient Georg Bol bol@statistik.uni-karlsruhe.de Markus Höchstötter hoechstoetter@statistik.uni-karlsruhe.de Agenda 1. Untersuchung der Abhängigkeit 2.
Vorwort zur 3. Auflage 15. Vorwort zur 2. Auflage 15. Vorwort 16 Kapitel 0 Einführung 19. Teil I Beschreibende Statistik 29
 Inhaltsübersicht Vorwort zur 3. Auflage 15 Vorwort zur 2. Auflage 15 Vorwort 16 Kapitel 0 Einführung 19 Teil I Beschreibende Statistik 29 Kapitel 1 Eindimensionale Häufigkeitsverteilungen 31 Kapitel 2
Inhaltsübersicht Vorwort zur 3. Auflage 15 Vorwort zur 2. Auflage 15 Vorwort 16 Kapitel 0 Einführung 19 Teil I Beschreibende Statistik 29 Kapitel 1 Eindimensionale Häufigkeitsverteilungen 31 Kapitel 2
SozialwissenschaftlerInnen II
 Statistik für SozialwissenschaftlerInnen II Henning Best best@wiso.uni-koeln.de Universität zu Köln Forschungsinstitut für Soziologie Statistik für SozialwissenschaftlerInnen II p.1 Wahrscheinlichkeitsfunktionen
Statistik für SozialwissenschaftlerInnen II Henning Best best@wiso.uni-koeln.de Universität zu Köln Forschungsinstitut für Soziologie Statistik für SozialwissenschaftlerInnen II p.1 Wahrscheinlichkeitsfunktionen
Über dieses Buch Die Anfänge Wichtige Begriffe... 21
 Inhalt Über dieses Buch... 12 TEIL I Deskriptive Statistik 1.1 Die Anfänge... 17 1.2 Wichtige Begriffe... 21 1.2.1 Das Linda-Problem... 22 1.2.2 Merkmale und Merkmalsausprägungen... 23 1.2.3 Klassifikation
Inhalt Über dieses Buch... 12 TEIL I Deskriptive Statistik 1.1 Die Anfänge... 17 1.2 Wichtige Begriffe... 21 1.2.1 Das Linda-Problem... 22 1.2.2 Merkmale und Merkmalsausprägungen... 23 1.2.3 Klassifikation
825 e 290 e 542 e 945 e 528 e 486 e 675 e 618 e 170 e 500 e 443 e 608 e. Zeichnen Sie das Box-Plot. Sind in dieser Stichprobe Ausreißer vorhanden?
 1. Aufgabe: Eine Bank will die jährliche Sparleistung eines bestimmten Kundenkreises untersuchen. Eine Stichprobe von 12 Kunden ergab folgende Werte: 825 e 290 e 542 e 945 e 528 e 486 e 675 e 618 e 170
1. Aufgabe: Eine Bank will die jährliche Sparleistung eines bestimmten Kundenkreises untersuchen. Eine Stichprobe von 12 Kunden ergab folgende Werte: 825 e 290 e 542 e 945 e 528 e 486 e 675 e 618 e 170
Prüfungsvorbereitungskurs Höhere Mathematik 3
 Prüfungsvorbereitungskurs Höhere Mathematik 3 Stochastik Marco Boßle Jörg Hörner Marcel Thoms Mathematik Online Herbst 211 PV-Kurs HM 3 Stochastik 1-1 Zusammenfassung Wahrscheinlichkeitsraum (WR): Menge
Prüfungsvorbereitungskurs Höhere Mathematik 3 Stochastik Marco Boßle Jörg Hörner Marcel Thoms Mathematik Online Herbst 211 PV-Kurs HM 3 Stochastik 1-1 Zusammenfassung Wahrscheinlichkeitsraum (WR): Menge
DWT 1.4 Rechnen mit kontinuierlichen Zufallsvariablen 234/467 Ernst W. Mayr
 1.4.2 Kontinuierliche Zufallsvariablen als Grenzwerte diskreter Zufallsvariablen Sei X eine kontinuierliche Zufallsvariable. Wir können aus X leicht eine diskrete Zufallsvariable konstruieren, indem wir
1.4.2 Kontinuierliche Zufallsvariablen als Grenzwerte diskreter Zufallsvariablen Sei X eine kontinuierliche Zufallsvariable. Wir können aus X leicht eine diskrete Zufallsvariable konstruieren, indem wir
Inhaltsverzeichnis Inhaltsverzeichnis VII Erst mal locker bleiben: Es f angt ganz einfach an! Keine Taten ohne Daten!
 Inhaltsverzeichnis Inhaltsverzeichnis VII 1 Erst mal locker bleiben: Es fängt ganz einfach an! 1 1.1 Subjektive Wahrscheinlichkeit - oder warum...?..... 4 1.2 Was Ethik mit Statistik zu tun hat - Pinocchio
Inhaltsverzeichnis Inhaltsverzeichnis VII 1 Erst mal locker bleiben: Es fängt ganz einfach an! 1 1.1 Subjektive Wahrscheinlichkeit - oder warum...?..... 4 1.2 Was Ethik mit Statistik zu tun hat - Pinocchio
Übung 1: Wiederholung Wahrscheinlichkeitstheorie
 Übung 1: Wiederholung Wahrscheinlichkeitstheorie Ü1.1 Zufallsvariablen Eine Zufallsvariable ist eine Variable, deren numerischer Wert solange unbekannt ist, bis er beobachtet wird. Der Wert einer Zufallsvariable
Übung 1: Wiederholung Wahrscheinlichkeitstheorie Ü1.1 Zufallsvariablen Eine Zufallsvariable ist eine Variable, deren numerischer Wert solange unbekannt ist, bis er beobachtet wird. Der Wert einer Zufallsvariable
Inhaltsverzeichnis (Ausschnitt)
") 8 Messbarkeit und Bildwahrscheinlichkeit Inhaltsverzeichnis (Ausschnitt) 8 Messbarkeit und Bildwahrscheinlichkeit Messbare Abbildungen Bildwahrscheinlichkeit Deskriptive Statistik und Wahrscheinlichkeitsrechnung
8 Messbarkeit und Bildwahrscheinlichkeit Inhaltsverzeichnis (Ausschnitt) 8 Messbarkeit und Bildwahrscheinlichkeit Messbare Abbildungen Bildwahrscheinlichkeit Deskriptive Statistik und Wahrscheinlichkeitsrechnung
Grundgesamtheit, Merkmale, Stichprobe. Eigenschaften der Stichprobe. Klasseneinteilung, Histogramm. Arithmetisches Mittel, empirische Varianz
 - 1 - Grundgesamtheit, Merkmale, Stichprobe Dimension, Umfang Skalierung Eigenschaften der Stichprobe kennzeichnende Größen Eigenschaften der Stichprobe kennzeichnende Größen Punktediagramm, Regressionsgerade,
- 1 - Grundgesamtheit, Merkmale, Stichprobe Dimension, Umfang Skalierung Eigenschaften der Stichprobe kennzeichnende Größen Eigenschaften der Stichprobe kennzeichnende Größen Punktediagramm, Regressionsgerade,
Zufallsgröße X : Ω R X : ω Anzahl der geworfenen K`s
 X. Zufallsgrößen ================================================================= 10.1 Zufallsgrößen und ihr Erwartungswert --------------------------------------------------------------------------------------------------------------
X. Zufallsgrößen ================================================================= 10.1 Zufallsgrößen und ihr Erwartungswert --------------------------------------------------------------------------------------------------------------
Zufallsvariablen [random variable]
![Zufallsvariablen [random variable]](/thumbs/52/29710821.jpg "Zufallsvariablen [random variable]") Zufallsvariablen [random variable] Eine Zufallsvariable (Zufallsgröße) X beschreibt (kodiert) die Versuchsausgänge ω Ω mit Hilfe von Zahlen, d.h. X ist eine Funktion X : Ω R ω X(ω) Zufallsvariablen werden
Zufallsvariablen [random variable] Eine Zufallsvariable (Zufallsgröße) X beschreibt (kodiert) die Versuchsausgänge ω Ω mit Hilfe von Zahlen, d.h. X ist eine Funktion X : Ω R ω X(ω) Zufallsvariablen werden
Über den Autor 7. Teil Beschreibende Statistik 29
 Inhaltsverzeichnis Über den Autor 7 Einführung Über dieses Buch - oder:»... für Dummies«verpflichtet! Wie man dieses Buch benutzt 22 Wie ich Sie mir vorstelle 22 Wie dieses Buch aufgebaut ist 23 Teil I:
Inhaltsverzeichnis Über den Autor 7 Einführung Über dieses Buch - oder:»... für Dummies«verpflichtet! Wie man dieses Buch benutzt 22 Wie ich Sie mir vorstelle 22 Wie dieses Buch aufgebaut ist 23 Teil I:
5 Binomial- und Poissonverteilung
 45 5 Binomial- und Poissonverteilung In diesem Kapitel untersuchen wir zwei wichtige diskrete Verteilungen d.h. Verteilungen von diskreten Zufallsvariablen): die Binomial- und die Poissonverteilung. 5.1
45 5 Binomial- und Poissonverteilung In diesem Kapitel untersuchen wir zwei wichtige diskrete Verteilungen d.h. Verteilungen von diskreten Zufallsvariablen): die Binomial- und die Poissonverteilung. 5.1
Varianz und Kovarianz
 KAPITEL 9 Varianz und Kovarianz 9.1. Varianz Definition 9.1.1. Sei (Ω, F, P) ein Wahrscheinlichkeitsraum und X : Ω eine Zufallsvariable. Wir benutzen die Notation (1) X L 1, falls E[ X ]
KAPITEL 9 Varianz und Kovarianz 9.1. Varianz Definition 9.1.1. Sei (Ω, F, P) ein Wahrscheinlichkeitsraum und X : Ω eine Zufallsvariable. Wir benutzen die Notation (1) X L 1, falls E[ X ]
JosefPuhani. Kleine Formelsammlung zur Statistik. 10. Auflage. averiag i
 JosefPuhani Kleine Formelsammlung zur Statistik 10. Auflage averiag i Inhalt- Vorwort 7 Beschreibende Statistik 1. Grundlagen 9 2. Mittelwerte 10 Arithmetisches Mittel 10 Zentral wert (Mediän) 10 Häufigster
JosefPuhani Kleine Formelsammlung zur Statistik 10. Auflage averiag i Inhalt- Vorwort 7 Beschreibende Statistik 1. Grundlagen 9 2. Mittelwerte 10 Arithmetisches Mittel 10 Zentral wert (Mediän) 10 Häufigster
Grundlagen der Mathematik, der Statistik und des Operations Research für Wirtschaftswissenschaftler
 Grundlagen der Mathematik, der Statistik und des Operations Research für Wirtschaftswissenschaftler Von Professor Dr. Gert Heinrich 3., durchgesehene Auflage R.Oldenbourg Verlag München Wien T Inhaltsverzeichnis
Grundlagen der Mathematik, der Statistik und des Operations Research für Wirtschaftswissenschaftler Von Professor Dr. Gert Heinrich 3., durchgesehene Auflage R.Oldenbourg Verlag München Wien T Inhaltsverzeichnis
Der Trainer einer Fußballmannschaft stellt die Spieler seiner Mannschaft auf. Insgesamt besteht der Kader seiner Mannschaft aus 23 Spielern.
 Aufgabe 1 (2 + 1 + 2 + 2 Punkte) Der Trainer einer Fußballmannschaft stellt die Spieler seiner Mannschaft auf. Insgesamt besteht der Kader seiner Mannschaft aus 23 Spielern. a) Wieviele Möglichkeiten hat
Aufgabe 1 (2 + 1 + 2 + 2 Punkte) Der Trainer einer Fußballmannschaft stellt die Spieler seiner Mannschaft auf. Insgesamt besteht der Kader seiner Mannschaft aus 23 Spielern. a) Wieviele Möglichkeiten hat