INSTITUT FÜR INFORMATIK Fachbereich Informatik und Mathematik
|
|
|
- Willi Fischer
- vor 8 Jahren
- Abrufe
Transkript
1 INSTITUT FÜR INFORMATIK Fachbereich Informatik und Mathematik Diplomarbeit Transformation zwischen Geschäftsdokumenten - am Beispiel der e-invoicing Dokumente von UNIFI (ISO 20022) und UBL Marcel Trawny Abgabe am 11. Dezember 2012 eingereicht bei Prof. Dott.-Ing. Roberto V. Zicari Datenbanken und Informationssysteme

2 II

3 Erklärung gemäß DPO 11 ABS.11 Hiermit versichere ich, dass ich die vorliegende Diplomarbeit selbstständig verfasst habe und keine anderen als die angegebenen Hilfsmittel verwendet habe. Frankfurt am Main, den 11. Dezember 2012 Marcel Trawny III

4 IV

5 Abstrakt Diese Arbeit beschäftigt sich mit dem Problem der Interoperabilität von elektronischen Geschäftsnachrichten mit Fokus auf Universal Financial Industry Message Scheme (UNIFI, spezifiziert als ISO 20022, daher im Nachfolgenden ISO 20022) und Universal Business Language (UBL). Beide sind im europäischen Raum verbreitet. ISO findet Anwendung in der Finanzwelt, UBL hingegen im geschäftlichen Umfeld. Dabei ist das Rechnungsdokument jedoch ein gemeinsamer Schnittpunkt beider Standards. Dieses steht im Mittelpunkt dieser Arbeit. Es werden Methoden vorgestellt, welche die verschiedenen Arten von Heterogenität lösen oder entschärfen. Neben der direkte Methode der Übersetzung, die jedem Quellelement ein Pendant im Zielelement zuweist, existiert eine weitere Methode, die auf einer Ontologie basiert. Es werden beide Methoden angewendet und gegenübergestellt. Aufgrund des Umfangs des Rechnungsdokumentes liegt der Fokus der Arbeit auf der Übersetzung von ISO zu UBL, wobei jedoch auch für die entgegengesetzte Richtung theoretische Lösungen präsentiert werden. Allerdings ist zu beachten, dass die Dokumente nicht deckungsgleich sind. Die Informationen, welche nicht durch das originäre UBL-Dokument abgedeckt werden, müssen mittels Customizing erstellt werden. Des weiteren wird ebenfalls die Ontologie erstellt, die als gemeinsame Repräsentation der Daten dient. Für die ontologie-basierende Methode wird zudem ein Programm erstellt, welches die Informationen in die Ontologie integriert sowie anschließend extrahiert. Im Zuge diese Arbeit werden alle notwendigen Grundlagen vermittelt die benötigt werden, um die die Problematik zu erfassen, zu verstehen und zu lösen. V

6 VI

7 Zusammenfassung Das Ziel dieser Arbeit ist eine Transformation zwischen Geschäftsdokumenten - am Beispiel der e-invoicing Dokumente von UNIFI (ISO 20022) und UBL. ISO ist ein Standard der Internationalen Organisation für Normung und findet Anwendung in der Domäne der Finanzwelt. UBL als eine Spezifikation der Organisation for the Advancement of Structured Information Standard (OASIS), ist eine Sammlung von standardisierten Dokumenten und deckt den Bereich der Geschäftsprozesse eines Unternehmens ab. Beide Standards verfügen unter anderem über die Rechnung (E-Invoice) als eigenständiges und separates Dokument. Obwohl das Problem der Interoperabilität der verschiedenen Nachrichtenstandards schon seit den 1960er Jahren bekannt ist, ist es 50 Jahre später immer noch hoch aktuell. Im Rahmen dieser Arbeit werden zunächst beide Standards vorgestellt sowie die nötigen Grundlagen. Es werden anschließend Methoden erarbeitet, mit Hilfe derer diese Standards ineinander überführt werden können, wobei der Fokus nur auf den jeweiligen Rechnungsdokumenten liegt. Durch die Komplexität und den Zeitaufwand der Transformation liegt der Schwerpunkt der Untersuchung auf die Richtung ISO zu UBL, wobei jedoch auch für die entgegengesetzte Richtung theoretische Lösungen präsentiert werden. Die Transformation wird auf zwei verschiedene Vorgehensweisen verfolgt. Die erste Methode ist eine direkte Übersetzung des ISO Rechnungsdokumentes in ein UBL-Rechnungsdokument mittels einer proprietären Anwendung sowie eines manuell erstellten Mappings und einem daraus folgendes XSLT-Skriptes. Die zweite Methode basiert auf einer Domänen-Ontologie als zentrale Repräsentation für die Informationen. Dies geschieht mittels zwei Transformationen, wobei die erste Transformation ein XML-Dokument in die Domänen-Ontologie integriert. Anschließend wird diese Informationseinheit in das Ziel-Dokument überführt. Für die zweite Methode wird ein Anwendung in der Programmiersprache Java erstellt, welche die Transformationen verwirklicht. VII
 als eigenständiges und separates Dokument.")
8 VIII
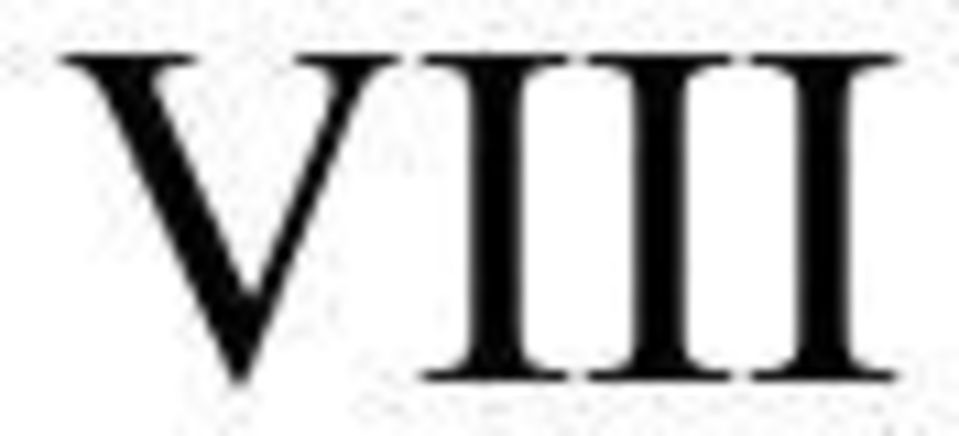
9 Danksagung Hiermit möchte ich meiner Mutter danken, die sowohl mein Studium als auch diese Arbeit durch ihre motivierende und finanzielle Unterstützung überhaupt erst ermöglicht hat. Ihr widme ich daher diese Arbeit. Es gilt: Meine Mutter ist die Beste. IX

10 X
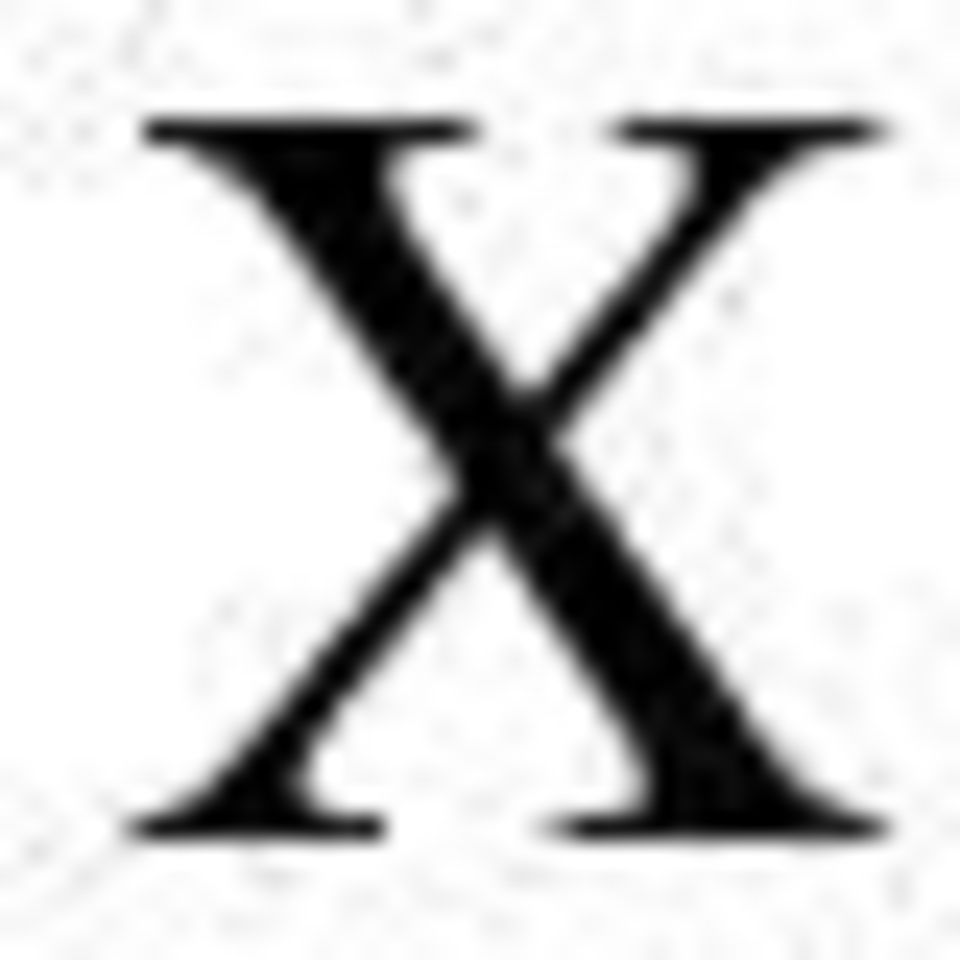
11 Inhaltsverzeichnis I Die Grundlagen 1 1 Einleitung Motiviation Ziel Aufbau Anmerkung Rechnung Gesetzliche Vorgaben in der BRD Kennzahlen Nachrichtenstandards mit E-Rechnungen Der elektronische Datenaustausch Entstehung des elektronischen Datenaustausches Prozessanforderungen für EDI Universal Business Language Einführung: Pan-European Public Procurement Online ebxml Core Components Technical Specification (CCTS) als Grundlage von UBL Die Schlüsselkonzept Core Components Das Schlüsselkonzept Business Information Entity Der Standard Das Support Package Die Dokumenttypen UBL Customization Codelist Beurteilung XI

12 XII INHALTSVERZEICHNIS 5 ISO Einführung: Single Euro Payments Area Der Standard ISO Begriffe innerhalb ISO Das Repository Die Geschäftsnachrichten Entwicklung einer Compliant Nachricht Codelisten Die Organisation Beurteilung Vergleich ISO zu UBL 53 7 Ontologien Ontologien Ontologie als Datenrepräsentation Eigenschaften einer Ontologie als gemeinsame Datenrepräsentation OWL als Ontologiesprache Die Entwicklung der Ontologie als konzeptuelles Datenmodell - Theorie Die Entwicklung der Ontologie als konzeptuelles Datenmodell - Praxis Fazit II Das Schemamanagment 73 8 Die Transformation und deren Herausforderung Die Transformation Heterogenität der Nachrichtenstandards Mapping Die Programmierung Die Mapping-Tools Die direkte Transformation Anforderungen der Transformation Phase 1 - Anforderungserhebung Phase 2 - Das Matching Phase 3 - Analyse des Mappings Die ontologie-basierenden Transformation Entwicklung der ontologie-basierenden Transformation Anforderungsanalyse XSLT oder Java als Technologie Die ontologie-basierende Applikation ISUT Die Technologien Das Interface Klassenaufbau von ISUT

13 INHALTSVERZEICHNIS XIII Die Mapping-Anweisung Vergleich zu der direkten Transformation Ausblick 103 Index 111 Abbildungsverzeichnis 113 Tabellenverzeichnis 115 Listingverzeichnis 117 Literaturverzeichnis 119

14 XIV INHALTSVERZEICHNIS

15 Teil I Die Grundlagen 1

16

17 KAPITEL 1 Einleitung 1.1 Motiviation Täglich wird weltweit eine unüberschaubare Menge an elektronischen Nachrichten versendet. Diese Nachrichten basieren auf einer Vielzahl unterschiedlicher Nachrichtenstandards, abhängig von thematischen Bereichen und teilweise von geographischen Grenzen. Dabei unterscheiden sich diese Standards auf verschiedenen Ebenen. So kann die technische Ebene (der Kommunikationskanal) oder auch die Struktur der Nachricht (die Syntax) differieren. Diese unterschiedlichen Ebenen führen dazu, dass die Nachrichten in der Regel nicht miteinander kompatibel sind und so ein Kommunikationsprozess zwischen Nachrichten, die auf verschieden Standards basieren, nicht ohne weiteres möglich ist. In Gegensatz zu den 1960er oder 1970er Jahren ist dabei das Problem eines unterschiedlichen Kommunikationskanals durch das Aufkommen des Internets bzw. der Kommunikationsprotokolle heutzutage nicht mehr so gravierend. Die Verständigung der verschieden Standards, beziehungsweise die wechselseitige Überführung von Nachrichten hingegen benötigt auch heute noch einen gewissen Aufwand, je nach dem wie unterschiedlich die Standards sind. Um diese Heterogenität der einzelnen Standards zu überwinden, ist eine Transformation der Quellnachricht in die Zielnachricht notwendig. Diese Punkt-zu-Punkt-Verbindung ist bei einer Kommunikation zwischen zwei Teilnehmern mit unterschiedlichen Standards vergleichsweise unproblematisch, da die Pflege dieser Verbindung überschaubar ist. Erweitert sich die Verbindung um weitere Gesprächspartner mit wiederum abweichenden Standards zu einem Netzwerk, wird die Pflege und Aufrechterhaltung dieses Netzwerkes für alle Teilnehmer kostspielig und ab einer bestimmten Größe schwer skalierbar. Je nach Größe und Aufstellung eines Teilnehmers sind die Faktoren unterschiedlich gewichtet. Das bedeutet, dass ein vollständiges Netzwerk aus n-teilnehmern ( n k) -Verbindungen besitzt und O(n 2 ) Übersetzungen benötigt. Die Nachrichtenstandards unterliegen zudem Einflüssen, die auf externen Faktoren wie Marktentwicklungen, politische Rahmenbedingungen oder auf technischen Veränderungen basieren. Um die Kosten der dadurch erforderlichen Anpassungen abzufedern, bietet sich die Kommunikation mittels einer zentralen Komponente an. Verändert sich der Standard, 3

18 4 KAPITEL 1. EINLEITUNG muss daher nur diese zentrale Komponente angepasst werden. Diese Komponente kann dabei unterschiedlicher Natur sein: Sie kann zu einem die Form eines zentralen Vermittlers im Sinne eines globalen Übersetzers haben oder auch die Form eines universellen Standards. Die Vergangenheit zeigt, dass diese zentralen Übersetzer (VANs) durch Ihre Kosten immer weniger Anklang finden. Der universelle Standard hingegen ersetzt die einzelnen Standards. Diese Vorgehensweise entschärft die Situation der vielen unterschiedlichen Standards zwar, löst diese aber nicht. Unterschiedliche Interessen kollidieren und verhindern so den Standard der Standards. Allerdings kristallisieren sich einige Standards hervor und die zu pflegende Heterogenität nimmt ab. Es besteht also nach wie vor ein Netzwerk unterschiedlicher Standards mit einer geminderten Anzahl von Nachrichtenstandards. Soll nun eine Nachricht von einem Standard in einem anderen Standard übersetzt werden, müssen verschiedene Übersetzungen (Mappings) gepflegt werden. Um diese Situation zu bewältigen bietet es sich an, die Informationen aus dem jeweiligen Standard heraus zu lösen und in einer gemeinsamen Modellierungssprache abzubilden. Verändert sich ein Standard müssen nur zwei Schnittstellen der zentralen Komponente überarbeitet werden, im Gegensatz zu n 1-Transformationen beim einem Netzwerk mit n-teilnehmern. Diese schwebenden Daten können anschließend in den Ziel-Standard übersetzt werden. Web Ontology Language (OWL) als Ontologie-Sprache kann diesen Platz einnehmen und bereichert zu dem diese Daten mit Inferenz- und Integritätsregeln. Zu dem ist auch eine Syntax unabhängige Datenrepräsentation gegeben, da die Daten auf einer abstrakten logischen Ebene existieren. Diese Methodik reduziert die nötigen Übersetzer von O(n 2 ) auf O(n). 1.2 Ziel Ziel dieser Arbeit ist die Transformation zwischen Geschäftsdokumenten - am Beispiel der e-invoicing Dokumente von UNIFI (ISO 20022) und UBL. Es sollen die notwendigen Grundlagen vermittelt werden, welche erforderlich sind, um die Problematik zu verstehen, zu erfassen und anschließend zu lösen. Bei den Grundlagen handelt es sich um das Rechnungsdokument, den elektronischen Nachrichtenaustausch, den UBL-Standard, den ISO Standard sowie die Ontologien. Hauptziel ist die Verwendung eine Ontologie als Basis für die Transformation. Dabei sollen Wege und Methoden erörtert werden, mittels derer dies realisiert werden kann. Neben diesem Hauptziel soll eine direkte Übersetzung verfolgt werden. Mit Blick auf diese Arbeit teilt sich das Hauptziel in vier Unterziele auf. Das erste Ziel ist das Customizing eines UBL-Dokumentes, gefolgt vom zweiten Ziel, der Erstellung einer Ontologie. Das dritte Ziel ist das direkte Übersetzen der ISO Nachricht in eine UBL-Nachricht inklusive des benötigten Mappings, gefolgt vom vierten Ziel, der Erstellung eines Programms mittels dessen die Transformation auf Basis der Ontologie ermöglicht werden kann. 1.3 Aufbau Die schriftliche Ausarbeitung ist in zwei Teile gegliedert. Der erste Teil präsentiert die Grundlagen, welche erforderlich sind, um die Transformation zu ermöglichen und ist in sieben Kapitel aufgeteilt. Dabei ist zu beachten, dass nicht nur theoretische Grundlagen,

19 1.3. AUFBAU 5 sondern auch praktische Arbeitsergebnisse mit einfließen, die ihren Ursprung im zweiten Teil der Arbeit haben. Die Kapitel sind wie folgt aufgebaut: Kapitel 2 - Rechnung Dieses Kapitel definiert das Rechnungsdokument innerhalb Deutschlands und spiegelt einige Fakten wie Volumina des Nachrichtenaustausches oder auch der Einsparungspotential wider. Kapitel 3 - Der elektronische Datenaustausch Diese Kapitel ist ein Rückblick auf die Entwicklung des elektronischen Datenaustausches sowie die Erläuterung der ebxml- Standards. Kapitel 4 - Universal Business Language Diese Kapitel stellt das europäische Projekt Pan- European Public Procurement OnLine (PEPPOL) vor, welches UBL verwendet. UBL als Bibliothek von Geschäftsdokumenten ist eine Spezifikation von OASIS. Dabei werden in diesem Kapitel nicht nur theoretische Grundlagen wie die Verbreitung, der Aufbau und die Codelisten erläutert, sondern auch praktische Elemente thematisiert. Beispielsweise wird das Customization beschrieben, welches als Ergebnis der Transformation entstand ist. Weiterhin findet auch eine Beurteilung der Spezifikation statt. Kapitel 5 - ISO Dieses Kapitel stellt das europäische Projekt SEPA vor, welches ISO als Nachrichtenstandard verwendet. Anschließend wird der Standard vorgestellt (Organisation, Repository, Nachrichten, Customizing sowie Codelisten). Dem folgt die Darstellung von praktischen Erfahrungen, welche durch den Prozess der Transformations-Entwicklung gesammelt wurden als Form einer Beurteilung. Kapitel 6 - Vergleich ISO UBL Dieses Kapitel vergleicht den Standard und die Spezifikation miteinander, zeigt Gemeinsamkeiten und erläutert Stärken und Schwächen. Kapitel 7 - Ontologien Dieses Kapitel stellt die Ontologie als Wissensrepräsentation vor, wobei ebenfalls Editoren und andere Faktoren Anklang finden. Es schließt dabei den ersten Teil der schriftlichen Ausarbeitung ab. Der zweite Teil dieser Arbeit behandelt den Prozess der Transformation und die daraus resultierenden Problemlösungen. Mittelpunkt ist dabei das Schemamanagment, welches die Techniken um die Vereinheitlichung heterogener Daten zusammenfasst. Dabei werden strukturelle und semantische Differenzen aufgelöst. Verwendung finden diese Techniken in der Informationsintegration sowie in der anschließenden Transformation. Der zweite Teil ist wie folgt aufgebaut: Kapitel 8 - Die Übersetzung Diese Kapitel erörtert die verschiedenen Probleme der Transformationen. Kapitel 9 - Die direkte Übersetzung Diese Kapitel behandelt die Wertkorrespondenzen sowie die Erstellung der direkten Transformation. Da beide im Prozess des Matching eine Rolle spielen, sind sie nur schwer trennbar. Kapitel 10 - Die ontologie-basierende Transformation Dieses Kapitel behandelt die Erstellung der Anwendung, welche benötigt wird um die Nachrichten mit Hilfe einer Ontologie zu übersetzen

20 6 KAPITEL 1. EINLEITUNG Kapitel 11 - Ausblick Dieses Kapitel befasst sich mit dem Ausblick auf UBL und ISO sowie der Verwendung von Ontologie als Nachrichten. 1.4 Anmerkung Eine wichtige Komponente für Nachrichten ist die Extensible Markup Language (XML) als Auszeichnungssprache sowie die Extensible Stylesheet Language Transformations (XSLT) als Programmiersprache für Transformation von XML-Dokumenten. Diese Sprachen sind ebenfalls für die vorliegende Ausarbeitung von Bedeutung, da sie einen Teil der Grundlage darstellen. Da zu diesen Aspekten jedoch bereits eine Vielzahl an Werken existiert und die Thematik hinreichend bekannt ist, wird auf eine Erläuterung verzichtet und deren Kenntnis vorausgesetzt. Weiterhin sollte beachtet werden, dass der primäre Kontext dieser Arbeit im B2B und B2G-Bereich 1 liegt. Die Quellenangaben von Aussagen oder Referenzierung erfolgen in der Regel innerhalb des Fließtextes in Form von Fußnoten, unter Angabe der Seiten (S.) oder der Folien (F.). Im Kontext dieser Arbeit ist weiterhin die Fokussierung auf Straight Through Processing (STP) zu beachten. Dies hat zur Folge, dass bei Problemen keine menschliche Interaktion stattfindet in Form von Einzelfallunterscheidungen bei Unstimmigkeiten. 1 B2B Business-to-Business Beziehung zwischen Unternehmen B2C Business-to-Consumer Beziehung zwischen Konsument und Unternehmen B2A Business-to-Administration Beziehung zwischen Unternehmen und öffentlicher Verwaltung C2A Consumer-to-Administration Beziehung zwischen Konsument und öffentlicher Verwaltung
 als Auszeichnungssprache sowie die Extensible Stylesheet Language Transformations (XSLT) als")
21 KAPITEL 2 Rechnung Hauptgegenstand dieses Kapitels ist die Rechnung, auch bekannt als Faktura. Es ist davon auszugehen, dass Rechnungen zu den häufigst verwandten Dokumenten gehören. Der Dokumententyp Rechnung ist daher in allen Lebensbereichen präsent: Sowohl in Unternehmen, privaten Haushalten als auch innerhalb öffentlicher Institutionen. Sobald eine Leistung erbracht wird, welche die Grenze der Gefälligkeit überschreitet und somit steuerliche und rechtliche Relevanz auslöst, dient die Rechnung als Nachweis des Leistungsaustausches 1. Die Rechnung ist eine schriftliche Urkunde, mit welcher der Erbringer einer Leistung (Waren oder Dienstleistungen) gegenüber dem Empfänger diese Leistung dokumentiert und die finanzielle Gegenleistung abrechnet. Der Dokumententyp Rechnung ist in der Wirtschaft von erheblicher Bedeutung, da sie die Waren oder Dienstleistungen dokumentiert und so das Bindeglied zwischen dem Warenfluss (Physical Supply Chain) und dem Finanzfluss (Financial Supply Chain) darstellt. 2.1 Gesetzliche Vorgaben in der BRD Im deutschen Umsatzsteuergesetz (nachfolgend UStG) findet sich in 14 Absatz 1 eine Legaldefinition des Rechnungsbegriffes: Rechnung ist jedes Dokument, mit dem über eine Lieferung oder sonstige Leistung abgerechnet wird, gleichgültig, wie dieses Dokument im Geschäftsverkehr bezeichnet wird. Die Echtheit der Herkunft der Rechnung, die Unversehrtheit ihres Inhalts und ihre Lesbarkeit müssen gewährleistet werden. Echtheit der Herkunft bedeutet die Sicherheit der Identität des Rechnungsausstellers. Unversehrtheit des Inhalts bedeutet, dass die nach diesem Gesetz erforderlichen Angaben nicht geändert wurden. Jeder Unternehmer legt fest, in welcher Weise die Echtheit der Herkunft, die Unversehrtheit des Inhalts und die Lesbarkeit der Rechnung gewährleistet werden. Dies kann durch jegliche innerbetriebliche Kontrollverfahren erreicht werden, die einen verlässlichen Prüfpfad 1 Bei kleineren Beträgen reicht auch ein Quittung. 7
22 8 KAPITEL 2. RECHNUNG zwischen Rechnung und Leistung schaffen können. Rechnungen sind auf Papier oder vorbehaltlich der Zustimmung des Empfängers elektronisch zu übermitteln. Eine elektronische Rechnung ist eine Rechnung, die in einem elektronischen Format ausgestellt und empfangen wird. Aus Absatz 4 des 14 UStG ergeben sich zudem die zwingenden Bestandteile, die eine Rechnung zur Bezeichnung als solche aufweisen muss 2 : 1. den vollständigen Namen und die vollständige Anschrift des leistenden Unternehmers und des Leistungsempfängers, 2. die dem leistenden Unternehmer vom Finanzamt erteilte Steuernummer oder die ihm vom Bundeszentralamt für Steuern erteilte Umsatzsteuer- Identifikationsnummer, 3. das Ausstellungsdatum, 4. eine fortlaufende Nummer mit einer oder mehreren Zahlenreihen, die zur Identifizierung der Rechnung vom Rechnungsaussteller einmalig vergeben wird (Rechnungsnummer), 5. die Menge und die Art (handelsübliche Bezeichnung) der gelieferten Gegenstände oder den Umfang und die Art der sonstigen Leistung, 6. den Zeitpunkt der Lieferung oder sonstigen Leistung; in den Fällen des Absatzes 5 Satz 1 den Zeitpunkt der Vereinnahmung des Entgelts oder eines Teils des Entgelts, sofern der Zeitpunkt der Vereinnahmung feststeht und nicht mit dem Ausstellungsdatum der Rechnung übereinstimmt, 7. das nach und einzelnen Steuerbefreiungen aufgeschlüsselte Entgelt für die Lieferung oder sonstige Leistung ( 10) sowie jede im Voraus vereinbarte Minderung des Entgelts, sofern sie nicht bereits im Entgelt berücksichtigt ist, 8. den anzuwendenden Steuersatz sowie den auf das Entgelt entfallenden Steuerbetrag oder im Fall einer Steuerbefreiung einen Hinweis darauf, dass für die Lieferung oder sonstige Leistung eine Steuerbefreiung gilt und 9. in den Fällen des 14b Abs. 1 Satz 5 einen Hinweis auf die Aufbewahrungspflicht des Leistungsempfängers. Die elektronische Rechnung, auch bekannt unter E-Rechnungen, E-Billing 3 sowie E- Invoicing, ist eine besondere Form der Rechnung und wird durch den elektrischen Transport charakterisiert. Dabei ist zu beachten, dass E-Rechnungen wiederum durch Ihre Strukturiertheit und die daraus folgende Verarbeitung gekennzeichnet sind. Unstrukturierte Formate wie PDF-Dateien werden in der Regel teilautomatisiert bearbeitet und kommen verstärkt im Business-to-Consumer-Bereich vor. Strukturierte Formate wie XML-Dateien hingegen werden vollautomatisiert bearbeitet. E-Rechnungen unterliegen einer speziellen Reglementierung, um die Echtheit der Herkunft und die Unversehrtheit des Inhalts zu gewährleisten, 2 Originaler Gesetzeswortlaut, ergänzt um Hervorhebung einzelner Elemente. 3 Der Begriff E-Billing wird für Rechnungen an Verbrauchern verwendet, wobei E-Invoice zwischen Unternehmen und/oder dem öffentlichen Sektor verwendet wird (vgl. [Koc12] S. 9.).
23 2.2. KENNZAHLEN 9 da durch die Art der Übermittlung die elektronischen Daten einfacher und professioneller manipuliert werden können als innerhalb der klassischen Papierrechnung. Die Anforderungen an die E-Rechnung ergeben sich aus Absatz 3 des 14 UStG 4 : 1. eine qualifizierte elektronische Signatur oder eine qualifizierte elektronische Signatur mit Anbieter-Akkreditierung nach dem Signaturgesetz vom 16. Mai 2001 (BGBl. I S. 876), das zuletzt durch Artikel 4 des Gesetzes vom 17. Juli 2009 (BGBl. I S. 2091) geändert worden ist, in der jeweils geltenden Fassung oder 2. elektronischen Datenaustausch (EDI) nach Artikel 2 der Empfehlung 94/820/EG der Kommission vom 19. Oktober 1994 über die rechtlichen Aspekte des elektronischen Datenaustausches (ABl. L 338 vom , S. 98), wenn in der Vereinbarung über diesen Datenaustausch der Einsatz von Verfahren vorgesehen ist, die die Echtheit der Herkunft und die Unversehrtheit der Daten gewährleisten. 2.2 Kennzahlen Die klassischen Papierrechnungen stellen die häufigste Rechnungsart dar. Wie aus der Tabelle 2.1 ersichtlich, werden nur circa 10 Milliarden von mindestens 200 Milliarden Rechnungen weltweit in elektronischer Form versandt. Diese Zahlen sind umso bedeutender, da sich hinter diesen ein enormes Einsparpotenzial verbirgt. Abbildung 2.1 zeigt, dass ein Unternehmen mit 5000 Mitarbeitern bis zu 57 Prozent beim Versand sowie bis zu 62 Prozent beim Empfang pro Rechnung einsparen kann, wenn anstatt herkömmlichen Papierrechnungen ausschließlich E-Rechnungen verwendet werden. Zu beachten ist, dass dies theoretische Extremwerte sind, da höchstwahrscheinlich kein Unternehmen mit 5000 Mitarbeitern nur mit Papierrechnungen arbeitet. Geschätztes jährliches Geschätzter elek- Geschätztes jährlilumen Rechnungsvotronischer Anteil ches Wachstum der (mindestens) am Gesamtvolumen E-Rechnungen 2012 Empfänger Welt Europa Welt Europa Welt Europa Verbraucher 200 Milliardearden 17 Milli- 5 % 12 % 20 % 25 % Unternehmen 150 Milliardearden 16 Milli- 5 % 18 % 20 % 30 % & öffentlicher Sektor Tabelle 2.1: Menge der Rechnungen weltweit unterteilt in Rechnungen und E-Rechnungen - Quelle: [Koc12] S. 8. Aber nicht nur Unternehmen steht so ein deutliches Einsparungspotenzial offen, auch der öffentliche Sektor in Europa könnte durch die Verwendung der E-Rechnung jährlich (theoretisch) mindestens 40 Milliarden Euro einsparen. 5 Das entspricht 8 Prozent des Kre- 4 Originaler Gesetzeswortlaut, ergänzt um Hervorhebung einzelner Elemente. 5 vgl. [Koc12] S. 20
![10 KAPITEL 2. RECHNUNG Abbildung 2.1: Einsparungen bei Empfang und Senden elektronischer Rechnungen - Quelle: [HM10] S. 4. ditvolumens des Europäischer Stabilitätsmechanismus (ESM).](/docs-images/24/3309346/images/24-0.png "6 Trotz wachsender Globalisierung liegt das grenzüberschreitende Rechnungsvolumen bei nur circa 1 bis 5 Prozent. Wie in der nachfolgenden Abbildung 2.")
24 10 KAPITEL 2. RECHNUNG Abbildung 2.1: Einsparungen bei Empfang und Senden elektronischer Rechnungen - Quelle: [HM10] S. 4. ditvolumens des Europäischer Stabilitätsmechanismus (ESM). 6 Trotz wachsender Globalisierung liegt das grenzüberschreitende Rechnungsvolumen bei nur circa 1 bis 5 Prozent. Wie in der nachfolgenden Abbildung 2.2 ersichtlich, nutzen viele Unternehmen dieses Einsparpotential durch E-Rechnungen noch nicht. Aber nicht nur das Einsparpotential veranlasst Unternehmen zur Einführung von E-Rechnungen, sondern auch die Möglichkeiten, so neue Geschäftspartner zu gewinnen. So wird in Kapitel 3 dargestellt, dass einige Unternehmen ihre Geschäftsbeziehungen unter anderem davon abhängig machen, ob sie auf elektronischem Weg kommunizieren können. Abbildung 2.2 spiegelt den Anteil der Unternehmen wider, welche elektronische Rechnungen versenden und/oder empfangen. Abbildung 2.2: Unternehmen die E-Rechnungen verwenden (Senden oder Empfangen) - Quelle: [HM10] S vgl. [COU11] S. 32.
25 2.3. NACHRICHTENSTANDARDS MIT E-RECHNUNGEN Nachrichtenstandards mit E-Rechnungen Die Domäne E-Rechnung ist wie viele andere Domänen ebenfalls nicht vom der Vielfalt verschiedener Standards befreit. Allerdings zeigt folgende Auflistung, dass eine gewisse Konvergenz zur UBL existiert. Dabei werden die Standards nicht nur von geographischen Grenzen beeinflusst, sondern auch durch Branchen. Die nachfolgende Tabelle 2.2 gibt einen kurzen Überblick der Standards, deren Wirkungskreis und der Syntax. Durch diese Anzahl der verschiedenen Standards wird das Straight Through Processing (STP) 8 zum Teil schwer beeinträchtigt, je nachdem welche Standards miteinander kommunizieren. Wie die vorherige Tabelle 2.1 erkenntlich macht, wird das Aufkommen der E-Rechnungen von Jahr zu Jahr steigen. Zu beachten ist, dass die Tabelle 2.2 den Fokus auf die E-Rechnung legt, allgemeine elektronische Nachrichten sind nicht erfasst. Die E- Rechnung ist nur eine Zwischenstation in einem elektronischen Geschäftsprozess.So existiert je nach Prozess eine Vielzahl verschiedener Nachrichten, die im Kontext zur eigentlichen E-Rechnung ausgetauscht werden. Daraus ist ersichtlich, dass das Thema Nachrichtenstandards zunehmen wird und auch die Problematik deren Heterogenität, wobei in Kapitel 3 ersichtlich wird, dass das Problem der unterschiedlichen Standards seit 1960er Jahren existiert. 8 Im Deutschen Sprachraum auch bekannt als Durchgehende Datenverarbeitung (DDV). Dieses Konzept beschreibt den medienbruchlosen und möglichst interaktionsfreien Kommunikationsaustausch.
26 12 KAPITEL 2. RECHNUNG Standard UBL 2.0 Syntax proprietäres XML Webseite oasis-open.org/ committees/ubl/ Wirkungskreis (Land oder Branche) Branchenübergreifend ETIS Telefonrechnungen EDIFACT sowie ebxml (offizielle Aussage) GS1 Branchenübergreifend proprietäres XML ISO Finanzindustrie ISO MX (XML) org LITIG Anwaltskanzleien LEDES (XML) PIDIX Öl- und Gasindustrie PIDIX (XML) RosettaNet Autmobilindustrie RosettaNet (XML) rosettanet.org BMF Belgien EDIFACT OIOXML Dänemark UBL 2.0 Customization(XML) dk Finvoice Skandinavische ISO MX sowie Länder ebxml eu ebinterface Österreich ebinterface (XML) ebinterface.at Facturae Spanien UBL 2.0 Customization (XML) es Svefaktura Schweden UBL 2.0 Customization (XML) UBL NES 7 Skandinavische UBL 2.0 Customization Länder (XML) CEN BII Skandinavische UBL-UN/CEFACT Kon- Länder vergenz (UBL 2.0 überwiegt) Tabelle 2.2: Übersicht der verschiedenen Standards die auch e-invoice implementiert haben - Anlehnung an [Koc12] S. 63.
27 KAPITEL 3 Der elektronische Datenaustausch Diese Kapitel behandelt die Grundlagen des Versandes von elektronischen Nachrichten, allerdings ohne Vorstellung von XML und XSLT. 1 Dabei wird zunächst Electronic Data Interchange (EDI) vorgestellt und die Begründung geliefert, warum überhaupt elektronische Nachrichten existieren. Anschließend wird die Prozessanforderung für den elektronischen Nachrichtenaustausch vorgestellt. 3.1 Entstehung des elektronischen Datenaustausches Seit den späten 60er Jahren kam neben dem klassischen Datenaustausch der Geschäftsnachrichten per Papier oder Fax der elektronische Datenaustausch über Computersysteme hinzu. Dieser wurde durch Electronic Data Interchange (EDI) realisiert. Allerdings wurde diese Form des Datenaustausch meist nur durch große Unternehmen betrieben, da die Kosten für kleine und mittelständische Unternehmen (KMU) eine unnehmbare Hürde darstellten 2. KMU haben größtenteils EDI nur dann eingeführt, wenn es von den großen Geschäftspartner verlangt wurde 3. EDI wurde in der Regel über externe Dienstleister realisiert, sogenannte Value Added Networks (VAN) 4, welche mit hohen Kosten verbunden waren 5. EDI leistete im Bereich Datenaustausch Pionierarbeit - erst am Ende der 60er Jahren wurde das Internet entwickelt. Dies ist auch der Grund, warum es weder XML, noch HTTP-Protokolle oder Nachrichtenstandards gab 6. All diese Techniken, welche die heutige Kommunikation problemlos ermöglichen, existierten noch nicht. Durch die Automatisie- 1 Als Begründung Kapitel 1.4 beachten. 2 vgl. [Sch06] S Durch diesen Zwang entstand die Aussage EDI or die. 4 vgl. [Bux01] S. 8 5 Mitte der 90er Jahren kostete ein monatliches Nachrichten Kontingent mit ca EDI-Nachrichten zwischen und $. Abgerechnet wurden entweder Nachrichten- oder Zeichenanzahl. vgl. [Bux01] S. 8 6 vgl. [Tol06] F
28 14 KAPITEL 3. DER ELEKTRONISCHE DATENAUSTAUSCH rung der direkten Kommunikation der Geschäftspartner 7 erhofften sich die Early Adptor der EDI-Technologie durch die Verwendung nachfolgende Vorteile 8 : Reduzierung der Durchlaufzeiten der Geschäftsdaten, Reduzierung der Kommunikationskosten, Reduzierung der Erfassungsfehler- und Kosten durch medienbruchlose 9 Kommunikation, sofortige Verfügbarkeit von Informationen, die dadurch Just-in-Time-Produktionen ermöglichen. Dies ermöglicht wiederum kleinere Lagerbestände sowie Lager, den dadurch entstehende besserer Service sowie schnellere Reaktionsfähigkeit bei geänderten Wettbewerbsverhältnisse. Durch das Fehlen eines EDI-Standards entwickelten sich innerhalb der jeweiligen Domänen eigene proprietären Lösungen. Als Beispiele seien genannt: VDA in der Automobilindustrie, SWIFT in der Bankenbranche und DAKOSY in der Transportbranche. Diese einzelnen Standards haben den Vorteil, dass die betroffenen Unternehmen in ihrer Domäne problemlos kommunizieren und die Bedürfnisse der partizipierenden Akteure erfüllen können. Allerdings sind die Nachrichten der Standards außerhalb der betreffenden Domänen unverständlich, sodass jedes Unternehmen sich an den jeweiligen Geschäftspartner anpassen muss. Dadurch verändert sich die Granularität des Kommunikationsproblems, weg von einzelnen Firmen und deren proprietären Nachrichten hin zu ganzen Geschäftsbereichen. Um diesem Problem entgegen zu wirken wurde in den 80er Jahren die branchenübergreifenden Standards ANSI ASC X12 (American National Standards Institute Accredited Standards Committee X12) und UN/EDIFACT 10 (United Nations Electronic Data Interchange For Administration, Commerce and Transport) entwickelt 11. Zu erwähnen ist dabei, dass X12 älter ist als EDIFACT und so in EDIFACT einfloss. X12 wird verwaltet von ANSI ASC (American National Standards Institute Accredited Standards Committee), UN/EDIFACT steht unter der Schirmherrschaft von UN/CEFACT (United Nations Centre for Trade Facilitation and Electronic Business). EDIFACT besteht wiederum aus einzelnen Subsets für die jeweiligen Domänen, auf welche hier jedoch nicht eingegangen werden soll. Durch die Entstehung und die verstärkte Anwendung des Mediums Internet entwickelte sich 7 Hierbei hier zu erwähnen, dass EDI nicht ausschließlich zwischen zwei Unternehmen stattfindet. Der MAN-Konzern verwendet bereits in den 60er Jahren EDI für interne Kommunikation. vgl. [Bux01] S. 7 8 vgl. [Bux01] S. 7 9 Wird während einer Kommunikation das Medium des Übertragungsweges geändert, wird dies als Medienbruch bezeichnet. Als Beispiel sei hier genannt: Scannen eines Faxes oder Abtippen einer handschriftlichen Anmerkung. 10 ISO Meist wird EDIFACT anstatt UN/EDIFACT verwendet, ich schließe mich dieser Konvention an.
29 3.2. PROZESSANFORDERUNGEN FÜR EDI 15 auch EDI weiter 12. Es gab nun die Möglichkeit EDI mit Hilfe das Internet zu erweitern. Anstatt der kostspieligen VANs konnten FTP-Server oder der -Verkehr für den Transport der Nachrichten verwenden werden, diese Methodik ist bekannt als Internet-EDI. Wie Internet-EDI verwendete auch Web-EDI das Medium Internet, allerdings mit der bewussten Verletzung des Gedanken des zweiseitigen elektronischen Datenaustausch. Denn hier erfolgte der Nachrichtenaustausch nur einseitig bedingt durch Formulareingaben in einen Browser. Dieses Verfahren bietet sich beispielsweise für Ein-Mann-Betriebe an, da kleine Unternehmen in der Regel keine oder nur sehr rudimentäre EDV besitzen. Das Auftauchen von XML hat auch EDI beeinflusst. So entstanden EDI-Sprachen, welche XML als Syntax verwendeten. Dabei war der Vorteil nicht nur die gemeinsame Syntax, sondern auch die damit verbundenen Möglichkeiten wie Transformation und Validierung mittels Schemata. EDI mit Verbindung von XML wird in drei verschiedenen Arten unterteilt 13 : EDI/XML-Schemata Durch Vorgaben einer Nachrichtenstruktur mittels einer Dokumenttypdefinition (DTD) oder später eines XML-Schemas (XSD) wurden einheitliche Nachrichten ermöglicht. So existiert ein standardisiertes Dokument für ein spezifische Nachricht. EDI/XML-Repositories Ein Repository ist eine Art Container und beinhaltet verschiedene Informationen zu einem jeweiligen Bereich und soll gleichzeitig den Zugang zu den Informationen ermöglichen. So besitzt ein EDI/XML-Repository eine Sammlung verschiedener XML-Technologien, wie Schemata, Stylesheets oder auch Codelisten. EDI/XML-Frameworks Ein Framework geht weiter als die anderen EDI/XML-Methoden, vereinnahmt diese aber auch. Hier werden ganze Prozessabläufe identifiziert und mittels elektronischen Nachrichten ermöglicht. So werden auch Abläufe und Regeln erstellt um unternehmensübergreifende Nachrichten zu gewährleisten. 3.2 Prozessanforderungen für EDI Allerdings hat die Verwendung von EDI nicht nur Vorteile 14. Durch die starre Struktur von EDI ist eine erhebliche Klärung notwendig. Alle semiotischen Ebenen (Syntax, Semantik und Pragmatik) müssen im Detail definiert werden, bevor die Nachrichten versendet werden können. Dadurch ist eine Ad-hoc Kommunikation nicht möglich. EDI wird meist in Routinenprozessen verwendet, diese Prozesse zeichnen sich durch folgende Merkmale aus: niedrige Komplexität und Variabilität der Kommunikationsstruktur, stabile Geschäftsbeziehungen, die hohe Strukturiertheit sowie ein großes Belegvolumen und hohe Performanzanforderungen. Diesen Prozessen stehen die Regelprozesse gegenüber. Dies sind Prozesse, die sich durch 12 vgl. [Sch06] S vgl. [Fro01] S. 48f 14 vgl. [Köh10] S. 7f
30 16 KAPITEL 3. DER ELEKTRONISCHE DATENAUSTAUSCH mittlere Komplexität und Variabilität, wechselnde Kommunikationspartner, geringe Wiederholungshäufigkeit, ad-hoc Kommunikation, eingeschränkt determinierbare Abläufe und Struktur sowie einer im Vergleich zu Routineprozessen höheren Interprozessverflechtung auszeichnen.
31 KAPITEL 4 Universal Business Language Dieses Kapitel behandelt die Geschäftsdokumente der Universal Business Language 2.0 (UBL 2.0) 1. Zuerst wird in Abschnitt 4.1 das europäische Projekt PEPPOL vorgestellt und die Verbindung zu UBL. Anschließend erfolgt die Darstellung von ebxml als Grundlage von UBL (Abschnitt 4.2. Dem folgt in Abschnitt 4.3 die Beleuchtung des UBL 2.0 Standards. Zuerst wird in Unterabschnitt die Veröffentlichung der Dateien durch das Support Package präsentiert, gefolgt von den verschiedenen Nachrichtentypen innerhalb UBL im Unterabschnitt Dabei steht das Dokument Rechnung in im Fokus. In wird das Customizing vorgestellt und die Unterscheidung zwischen UBL Compatibility und UBL Conformance. Danach folgt die Handhabung der Codelists in Abschließend wird in diesem Kapitel durch Abschnitt 4.4 der Standard beurteilt. 4.1 Einführung: Pan-European Public Procurement Online UBL wird in vielen Bereichen, Projekten oder Initiativen verwendet wie aus Tabelle 2.2 ersichtlich. Eine Projekt, welches UBL verwendet, ist das Pan-European Public Procurement Online (PEPPOL)-Projekt. Das PEPPOL-Projekt entstand im Rahmenprogramm für Wettbewerbsfähigkeit und Innovation (CIP) 2 und verfolgt das Ziel, die elektronische Kommunikation zwischen öffentlichen Auftraggebern und privatwirtschaftlichen Lieferanten grenzüberschreitend innerhalb Europas zu realisieren. Dies ermöglicht jedem Unternehmen innerhalb Europas, sich auf Ausschreibungen des öffentlichen Sektors zu bewerben. Der gesamte Beschaffungsprozess (Procurement) des öffentlichen Sektors soll so elektronisch abgewickelt werden können (E-Procurement). Obwohl der öffentliche Sektor in der Summe den größten Auftraggeber innerhalb der Europäischen Union darstellt, sind die Fähigkeiten für die elektronische Abwicklung im Gegensatz zur Privatwirtschaft weniger ent- 1 Abgekürzt in dieser Arbeit durch UBL 2 peppol 17
32 18 KAPITEL 4. UNIVERSAL BUSINESS LANGUAGE wickelt 3 4. So macht der Beschaffungsprozess im öffentlichen Sektor circa 19 Prozent des europäischen Bruttoinlandsprodukt aus, was eine Summe von mehr als 2200 Milliarden darstellt. Unterstellt, der komplette öffentliche Sektor in Europa würde nur E-Procurement verwenden, wäre eine geschätzte Einsparung von mindestens 50 Milliarden Euro möglich. Der Anteil von E-Procurement lag im Jahr 2010 bei weniger als 5 Prozent und nur 1,6 Prozent des Beschaffungsprozesses waren grenzüberschreitend 5. Diese Zahlen verdeutlichen die Bedeutung dieser Initiative, insbesondere, dass diese nicht nur von ideellen Werten geprägt ist. Zwischen 2008 und 2012 erarbeitet das Projekt acht Arbeitspakete, wobei die ersten fünf von elementarer Natur sind 6 : elektronische Signatur (E-Signature) elektronische Nachweise (Virtual Company Dossier) elektronischer Katalog (E-Catalogue) elektronische Bestellung (E-Ordering) elektronische Rechnung (E-Invoicing) Konsortium Management Öffentlichkeitsarbeit Lösungsarchitektur, Design und Analyse Unterstützt wird dies mit einem Budget von 20 Millionen Euro. Im Gegensatz zu SEPA ist PEPPOL keine gesetzliche Vorgabe, das bedeutet, dass Regierungen sich daran beteiligen können, aber nicht müssen. Wie bereits erwähnt verwendet PEPPOL UBL, dies geschieht dabei in Verbindung mit UBL 2.0 und CEN/BII-Profilen. Diese Profile spezifizieren dabei den Ablauf der Geschäftsprozesse. 4.2 ebxml 1999 startete UN/CEFACT und OASIS (Organization for the Advancement of Structured Information Standards) mit der Entwicklung des ebxml-standards (Electronic Business using extensible Markup Language). OASIS beschreibt sich selbst wie folgt 7 : OASIS (Organization for the Advancement of Structured Information Standards) is a not-for-profit consortium that drives the development, convergence 3 vgl. [Son12] F. 2 4 Allerdings sollte angemerkt werden, dass nicht alle öffentliche Bereiche davon betroffen sind. So akzeptieren öffentliche Institute in Dänemark seit dem Jahr 2005 nur Rechnungen, wenn sie im elektronischen Format vorliegen, welches auf UBL basiert. Dabei spielt es keine Rolle, ob in- oder ausländische Firmen als Rechnungsaussteller auftreten. In diesem Zuge wurde eine Institution geschaffen, welche alle Papierrechnungen entgegennimmt, umwandelt und anschließend weiterleitet (vgl. [Rei07] S. 61ff) 5 vgl. [Sch] F. 2 6 vgl. [Son12] F
33 4.2. EBXML 19 and adoption of open standards for the global information society. OASIS promotes industry consensus and produces worldwide standards for security, Cloud computing, SOA, Web services, the Smart Grid, electronic publishing, emergency management, and other areas. OASIS open standards offer the potential to lower cost, stimulate innovation, grow global markets, and protect the right of free choice of technology. (...) Dieser Standard ermöglicht mit seinen Spezifikationen Verfahren und Richtlinien zur Modell- Erzeugung für den Nachrichtenaustausch zwischen Geschäftspartnern. Dieses Rahmenwerk hat als Ziel den Entwurf von offenen technischen Spezifikationen, die einen einheitlichen, weltweiten, konsistenten Austausch elektronischer Geschäftsdaten mit XML als Syntax ermöglichen 8. Dieser Standard ermöglicht also die Entwicklung von Nachrichtenstandards. Daraus folgt, dass es selbst kein Nachrichtenstandard ist. Unternehmen können unabhängig von ihrer Größe, geographischen Lage oder Branche ebxml als eine gemeinsame Plattform für die Zusammenarbeit nutzen. Zudem bietet ebxml auch die Vorteile der lizenzfreien Verwendung sowie der Übertragung mittels Internet 9 an, kostspielige VANs werden also nicht benötigt. Der Standard wurde von ISO als Standard ISO normiert 10 und besteht aus fünf Hauptkomponenten, welche jedoch unabhängig voneinander verwendbar sind 11 : Business Processes Hier werden die Geschäftspraktiken erfasst, indem die Funktionen, die Parteien, die ausgetauschten Nachrichten, die Terminologie und die Datentypelemente abgebildet werden für den jeweiligen Geschäftsbereich. Core Components Identifizieren gemeinsame Informationseinheiten (Business Informations Entities (BIEs)) in den einzelnen Industrie-Domänen. Diese Bausteine sind wiederverwendbar und kommen in verschiedenen Sektoren vor. Collaboration Protocol Agreements Die Agreements stellen Regeln für den Datenversand auf. Messaging Dieses Paket ermöglicht den Transport der ebxml-nachrichten über das Internet, oder direkten Datentransfer. Es unterstützt dabei Recovery-Methoden und Sicherheitsmechanismen. Registries und Repositories Die verschiedenen Registries sind verantwortlich für die Aufnahme und Indexierung der Nachrichten im Repository, einer Art Nachrichtendepot. Einer der ersten Adaptoren der ebxml Core Components Technical Specification 2.01 ist UBL. Daher ist ebxml der Ausgangspunkt für UBL und verwendet die oben genannten BIEs ohne die CCs. 8 vgl. [Bux01] S vgl. [OAS06] P. Are there royalty fees for the use of ebxml? 10 Alle fünf Teile der Norm sind Technical Specification 11 vgl. [KW01] S. 31
34 20 KAPITEL 4. UNIVERSAL BUSINESS LANGUAGE Core Components Technical Specification (CCTS) als Grundlage von UBL Die Core Components 12 Technical Specification 13 beschreibt, wie Nachrichten erkannt, standardisiert und wiederverwendbar gemacht werden. Eines der Ziele der Spezifikation ist die Interoperabilität zu gewährleisten und das Straight Through Processing bestmöglich zu unterstützen. Allerdings wird neben der maschinellen Verarbeitbarkeit auch die Lesbarkeit für Menschen unterstützt. Da die Core Components eine feste semantische Bedeutung haben, ist die Syntax nicht fest vorgegeben. Dies hat zur Folge, dass zum Beispiel XML aber auch UN/EDIFACT als Syntax verwendet werden kann. Die Schlüsselkonzepte des CCTS lassen sich in zwei Bereiche fokussieren - die Core Components und die Business Information Entities Die Schlüsselkonzept Core Components Das erste Konzept der CCTS sind diecore Components (CC). Diese semantischen Bausteine stellen die Basis für die Konstruktion elektronischer Nachrichten dar sowie die Basis für die Business Information Entities. Es werden vier verschiedene Arten von Core Components unterschieden 14 : Basic Core Component (BCC) Association Core Component (ASCC) Core Component Type (CCT) Aggregate Core Component (ACC) Diese Bausteine werden je nach Zustand und Verbindung zueinander charakterisiert. Die Abbildung 4.1 zeigt dabei ein Beispiel der genannten Arten, wobei auf eine genaue Definition der Objekte verzichtet wird. 15 Die Objekte Person.Details und Address.Details sind vom Typ ACC. Die Verbindungen Person.Residence.Address und Person.Official.Address sind vom Typ ASCC. Die restlichen Objekte wie Person.Details.Text oder Address.Details.Town stellen BCC da. In diesem Beispiel fehlen die CCT, die CCT sind eine Art von Datentyp wie sie aus dem Welt der Programmierung bekannt sind und sind eine Verbund den anderen CC sowie Werte. So existiert Amount.Type oder auch Date.Type Das Schlüsselkonzept Business Information Entity Nun folgt der zweite wichtige Teil der CCTS, die sogenannten Business Information Entities (BIEs). Der Unterschied von den CC zu den BIEs ist der Besitz einer Semantik in einem Business Context. Der Business Context spezialisiert und qualifiziert die CC damit diese in 12 zu deutsch Kernkomponenten 13 Alle hier gemachten Aussagen stammen, wenn nicht anderes erwähnt, von der CCTS Spezifikation [UN/03] 14 Meistens ist in der Literatur nur von drei Arten die Rede. Obwohl CCT in der Spezifikation aufgezählt wird, wird es meist nicht als Core Component identifiziert 15 Für eine genaue Definition bitte die Spezifikation [UN/03] oder die inoffizielle Übersetzung [UN/02] beachten
35 4.2. EBXML 21 Abbildung 4.1: Beispiel der Core Components an Hand der Informationseinheit einer Adresse - Quelle: [UN/03] S. 12 den jeweiligen spezifizierten Geschäftsbereich Anwendung finden können. Die BIEs verwenden also für ihre Geschätsspezifschen Bedürfnisse die CC als Bautsteine. Die BIEs werden in drei verschiedene Kategorien unterschieden: Basic Business Information Entity (BBIE) Association Business Information Entity (ASBIE) Aggregate Business Information Entity (ABIE) Abbildung 4.2 verdeutliche mit Anlehnung an das Beispiel der CCs, die verschiedenen BIEs. Abbildung 4.2: Beispiel der Core Components an Hand der Informationseinheit einer Adresse - Quelle: [UN/03] S. 16 Die Objekte US_Person.Details und US_Address.Details sind vom Typ ASBIE. Objekte wie US_Person.Details.Name oder US_Address.Details.Street stellen BBIEs dar. US_Person.US_Residence.US_Address und US_Person.US_Official.US_Residence
36 22 KAPITEL 4. UNIVERSAL BUSINESS LANGUAGE sind vom Typ ASBIE. Abbildung 4.3 verdeutlicht den Unterschied zwischen beiden Schlüsselkonzepte. Dabei ist zu beachten, dass das Rechteck links oben BCC, ASCC oder ACC sein kann. Abbildung 4.3: Übersicht und Unterscheidung beider Schlüsselkonzepte - Quelle [UN/03] S Der Standard Die Universal Business Language (UBL) ist eine Sammlung oder auch Bibliothek von Geschäftsdokumenten und deren XML-Schemata. Diese Dokumente basieren auf einen konzeptuellem Modell von Informationskomponenten, bekannt als Business Information Entities (BIEs). Durch die Verwendung der BIEs sind die Dokumente modular, wiederverwendbar und erweiterbar. UBL ist die erste Adaption des ebxml Core Components Technical Specification Diese BIEs können unter der Beachtung der UBL-Designregeln als Bausteine für verschiedene Dokumente verwendet werden. Als Beispiele genannt seien Rechnungen, Frachtbriefe oder Bestellungen. Die Entwicklung von UBL ist durch eine Zusammenarbeit verschiedenster Teilnehmer entstanden mit dem Ziel, eine gebührenfreie Bibliothek verschiedenster XML-Geschäftsdokumente zu entwickeln, wobei diese Bibliothek als ein Standard fungieren soll. Dabei konnten verschiedenste Industriestandards Einfluss nehmen und ermöglichen so KMUs die Verwendung. UBL wird wie ebxml auch von OASIS betreut. Dies Konsortium hat 12. Dezember 2006 die zweite Version von UBL (UBL 2.0) veröffentlicht, diese ist eine Erweiterung von UBL 1.0, welche am 15. September 2004 veröffentlicht wurde. UBL 1.0 konzentrierte sich auf den typischen Order- To-Invoice-Procurement-Lebenszyklus und umfasste daher auch zunächst nur acht verschiedene Nachrichtentypen (Order, Order Response Simple, Order Response (detailed), Order Change, Order Cancellation, Despatch Advice, Receipt Advice, Invoice). Abbildung 16 vgl. [JB11] P. 1
37 4.3. DER STANDARD stellt eine typischen Beschaffungsprozess 17 da. Die Spalten sind die betroffenen Parteien und beinhalten die möglichen Aktionen. Dabei kommunizieren diese Parteien über die rechteckigen Objekte, diese sind die jeweiligen UBL-Nachrichten. So ist die Bestellung (Order) die Nachricht UBL-Order, die mögliche Stornierung (OrderCancellation) die Nachricht UBL-OrderResponse und die Rechnung (Invoice) die Nachricht UBL-Invoice. Abbildung 4.4: Order-to-Invoice Business Prozess - Quelle: [JB06] P. B1 UBL 2.0 unterstützt neben dem klassischen Order-To-Invoice-Procurement-Lebenszyklus nun auch folgende Prozesse Sourcing (Katalogartige Bereitstellung von Informationen) Fulfilment (Sicherstellung der zu erbingenden Leistung) Billing (Abrechnung) Payment (Bezahlung) Initiate Transport Services (Abwicklung der Transportes) sowie verschiedene Dokumententypen. Insgesamt wurde UBL auf 31 Nachrichten erweitert. Dabei wurden die Nachrichten von UBL 1.0 ebenfalls aktualisiert, auch der Umgang mit Codelisten wurde geändert. 18. Aktuell wird an UBL 2.1 gearbeitet, diese liegt bislang jedoch nur im Entwurf zur zweiten öffentlichen Review aus. Ziel der UBL-Bibliothek ist ein einheitlicher Nachrichtenstandard und die Beachtung des Paretoprinzips (bekannt auch als Regel). Dieses Prinzip besagt, dass 80 Prozent eines Zieles mit 20 Prozent Einsatz erreicht wird. Das heißt, dass die 31 UBL-Nachrichten nur 20 Prozent aller möglichen Nachrichtentypen abdecken, allerdings sind diese für 80 Prozent der Geschäftstransaktion verantwortlich 19. Dabei sind die Prozesse, die innerhalb der restlichen 20 Prozent liegen, jedoch nicht automatisch verloren. UBL ermöglicht durch Customizing eine Erweiterung oder Modifizierung bestehender Dokumente oder Erstellung vollkommen neuer Dokumente das Auffangen dieser 20 Prozent. 17 englisch: Procurement oder auch Purchasing. 18 Für detaillierte Information bitte [JB06] Abschnitt Appendix B. Upgrading from UBL 1.0 to UBL 2.0 (Informative) beachten 19 vgl. [Eve12] F. 32
38 24 KAPITEL 4. UNIVERSAL BUSINESS LANGUAGE UBL verwendet als Syntax XML und gibt zu jedem Dokument ein Schemata vor, wobei all diese Schemata nach dem gleichen Muster aufgebaut sind. Die Abbildung 4.5 erklärt die Abhängigkeiten und den Aufbau von Geschäftsnachrichten 20. Abbildung 4.5: Der Abhängigkeiten eines UBL Business Dokumentes - Quelle: [JB06] P. 5.3 Folgende Aufzählung definiert die einzelnen Elemente der Abbildung 4.5, wobei die Abkürzung in der Klammern den jeweiligen XML-Namespace darstellt: Document Schema Modul Dies ist die Geschäftsnachricht wie zum Beispiel die Rechnung oder auch Bestellung. UBL 2.0 besitzt unsgesamt 31 verschiedene Geschäftsnachrichten. Common Aggregate Components (cac:) Dieses Schema definiert die Aggregate Business Information Entities (ABIEs) und fungiert als eine Sammlung von Informationseinheiten mit einem stark definierten semantischen Sinn. So beherbergt dieses Schema semantische Einheiten wie eine Adresse (AddressType) oder auch Parteien mit bestimmten Rollen wie Verkäufer (SellerCostumerParty) oder Käufer (Buyer- CostumerParty). Diese ABIEs sind eine Komposition von Informationseinheiten mit einem allgemeineren semantischen Sinn, den BBIEs. Common Basic Components (cbc:) Dieses Schema stellt die Basic Business Information Entities (BBIEs) dar und liefert Informationseinheiten, welche wiederum die semanti- 20 vgl. [JB06], P. 5.2
39 4.3. DER STANDARD 25 schen Grundbausteine liefern. So werden elementare Objekte wie Name (Name), Menge (Amount), Abteilung (Department) und letztes Lieferdatum (LatestDelivery- Date) im Schema hinterlegt. Qualified Datatypes (qdt:) Dieses Schema ist eine Ableitung von den UDT (Unqualified Data Types) und definiert ebenfalls Datentypen diese allerdings mit Codelisten zusammenarbeiten. Im Gegensatz zu den UDT sind diese innerhalb von UBL entstanden und haben einen spezifischen Zweck für die verschiedenen Geschäftskontexte. Unqualified DataTypes (udt:) Dieses Schema definiert die UDT, welche von CCTS vorgegeben sind. Diese Daten bilden die generellen Grundbausteine, alle anderen Informationseinheiten bestehen aus diesen Objekten. So werden solche Informationen wie einen Mengenwert (AmountType), eine Videodatei (VideoType), ein Text (TextType) oder auch eine Identifikationsnummer (IdentifierType) hinterlegt. Dieses Schema wurde von UN/CEFACT definiert. Nur diese dürfen verwendet werden, elementare XML Datentypen wie STRING oder BOOLEAN dürfen nicht genutzt werden. Common Extension Components (ext:) Dieses Schema wird für UBL Compatibility-Dokumente (Siehe Punkt 4.3.3) verwendet und ermöglicht so eine Erweiterung von existierenden oder neuen Schemata. Dabei erhält dieses Schema nur indirekt neue Elemente, denn es inkludiert die eigenen definierten Objekte, welche sich in dem Extension Content Datatype-Schema befinden. Neben dieser Inklusion besitzt dieses Schema zudem die dazugehörigen Metadaten wie den Namen des Erstellers (Extension- AgencyNameType) oder auch die Version (ExtensionVersionIDType). Extension Content Datatype (ext:) Dieses Schema dient als Container aller eigenen Definitionen von Daten. Bei der Erstellung müssen die UBL-Designregeln beachtet werden Das Support Package UBL verwendet kein Repository wie einige andere Nachrichtenstandards, sondern verwendet ein Support Package. Diese Paket enthält alle nötigen Informationen um die UBL- Nachrichten zu verwenden, zu entwickeln, zu analysieren und zu validieren. Angeboten wird es auf der freizugänglichen OASIS UBL-Website 21 als zip-archiv, dabei gibt es zwei verschiedene Versionen. Ein kleineres Archiv (ca. 8,5 MB) mit den Neuerungen sowie ein Archiv (ca. 31,5 MB) mit der kompletten aktuellen Fassung. Diese Paket enthält unter anderem die Schemata und zugehörige Instanzen, Codelisten, die UBL-Spezifikation, die Spezifikationen der Schemata sowie UML-Diagramme (keine Modelle, sondern nur Bilder). Für UBL existieren keine Spiegelseiten Die Dokumenttypen Die verschiedenen Dokumenttypen sind im Support Package hinterlegt. Es handelt sich insgesamt um 31 Dokumenttypen, wobei der Fokus auf dem E-Rechnungsdokument liegt. 21
40 26 KAPITEL 4. UNIVERSAL BUSINESS LANGUAGE Das Schema des Invoice Dokumentes UBL beinhaltet den Nachrichten-Typ UBL-Invoice-2.0 im Support Package, um die Funktionalität einer Rechnung abzudecken. Dabei wird die Nachricht wie folgt definiert: A document claiming payment for goods or services supplied under conditions agreed between the supplier and the customer. In most cases this document describes the actual financial commitment of goods or services ordered from the supplier 22. Folgende Charakteristika können über das Schema konkretisiert werden.das XML Schema ist unkomprimiert Bytes groß, hat den eindeutigen Namen UBL-Invoice-2.0.xsd, verfügt über 856 Zeilen, verwendet XML in der Version 1.0, kodiert die Informationen mit UTF-8, importiert 5 weitere Schemata (siehe Aufbau einer UBL Nachricht 4.3), besitzt 12 simpletype sowie 630 complextype Elemente (inklusive Import der anderen Schemata), wurde nach dem Garden-of-Eden-Stil 2324 entwickelt, besitzt Namespace-Deklarationen (xmlns:xsd=" xmlns="urn:oasis:names:specification:ubl:schema:xsd:invoice-2", xmlns:cac="urn:oasis:names:specification:ubl:schema:xsd:commonaggregatecomponents-2", xmlns:cbc="urn:oasis:names:specification:ubl:schema:xsd:commonbasiccomponents-2", xmlns:udt="urn:un:unece:uncefact:data:specification:unqualifieddatatypesschemamodule:2", xmlns:ccts="urn:un:unece:uncefact:documentation:2", xmlns:ext="urn:oasis:names:specification:ubl:schema:xsd:commonextensioncomponents-2", xmlns:qdt="urn:oasis:names:specification:ubl:schema:xsd:qualifieddatatypes-2", die TargetNamespace-Deklaration (targetnamespace="urn:oasis:names:specification:ubl:schema:xsd:invoice-2") und definiert jedes einzelne XML-Element mit einem Dokumentationszweig. Das Dokument besitzt eine flache Struktur. So sind alle ASBIE wie Verkäufer, Käufer oder auch Zahlungsanweisung Geschwister in der Hierarchie. 22 vgl. [JB06] P vgl. [Mal02] F Es wird bei der XML-Schema-Entwicklung zwischen vier verschieden Typen unterschieden, je nachdem wie die Elemente global und lokal definiert wurden. Für Informationen bitte [Gre12] beachten
41 4.3. DER STANDARD UBL Customization UBL beschreibt mit Customization den Prozess der Modifizierung einer existenten Nachricht, im schlimmsten Fall die Erstellung einer komplett neuen Nachricht. Dieser Vorgang unterliegt bestimmten Bedingungen und Regeln. Wird festgestellt, dass ein Customizing nötig ist, muss zuerst entschieden werden, ob das Endprodukt UBL Conformant oder UBL Compatible sein soll, also UBL konform oder UBL kompatibel. Nachfolgende Informationen stammen alle aus [TC09]. Die verschieden Arten des Customizing unterscheiden sich dabei wie folgt: UBL Conformance: Conformant Instanzen und Conformant Schemata stellen eine Untermenge der regulären Nachrichten (wie in Abbildung 4.6 ersichtlich). Durch die Untermengenbildung sind die Instanzen oder Schemata UBL-konform, wenn diese valide gegen die originären Schemata sind. Dies bedeutet, dass eine UBL conformant Instanz gegen das originäre Schema valide ist, also zum Beispiel UBL-Catalogue, UBL-Invoice oder UBL-Order. Ein UBL Conformant Schema ist ein Schema, das nur UBL Conformant Instanzen validiert. Die Bildung eines UBL Conformant Schemas ist auf zwei unterschiedlichen Arten möglich. Subset UBL-Dokumente können viele Daten beherbergen. So kann alleine das Order-Dokument circa Elemente und Attribute beinhalten 25. Dabei müssen nicht alle Angaben für Anwender nötig sein, eine Untermenge der möglichen Informationen ist ausreichend. Die Untermenge, also eine Entfernung von BIEs unterliegt Regeln, welche die Kardinalität betreffen. So kann die Kardinalität 0..1 auf [0..0] oder [1..1] geändert werden. 0..n auf [0..1], [1..m], [1..n], [m..n] oder [0..0] mit 1<m<n. 1..n auf [1..1], [m..n] oder [1..m] mit 1<m<n nicht verändert werden. Codelists Mögliche Werte von Elementen können auf Codelisten fixiert werden. Beide Methoden können gleichzeitig angewendet werden. So ist zum Beispiel das Ändern der Kardinalität von [1..1] auf [1..n] des ASBIE Price im ABIE Invoice- Line nicht gestattet, um so noch andere Währungen anzugeben. UBL Compatibility: Im Gegensatz zu UBL Conformance ist Compatibility keine Teilmengenbildung der Nachrichtenstandards. UBL compatible bedeutet, dass die Dokumente konsistent mit UBL Information Entities sowie den Prinzipien, die hinter den UBL- Modellen und deren Entwicklung stehen, sind. Durch die Kreation neuer oder Erweiterung bestehender Dokumente ist eine Verletzung der Validität der UBL Standard Dokumente gegeben wie in Abbildung 4.7 ersichtlich. Dabei ist die Modifikation einer bestehenden Definition nicht gestattet, da Vertragspartner, die sich auf UBL- Dokumente geeinigt haben, sicher gehen müssen, dass die Informationen auf beiden Seiten konsistent sind. Alle neuen oder geänderten Daten müssen im Schema Extension Content Datatype definiert werden, diese Schema wird dann vom Schema Common Extension Components inkludiert. Neben diesem inkludierten Schema erfasst 25 vgl. [TC09] S. 16
42 28 KAPITEL 4. UNIVERSAL BUSINESS LANGUAGE das letztere Schema auch die Metadaten der neuen Informationen. Wird der Schluss gezogen, dass eine wichtige Information in einem BIE fehlt, darf diese ausschließlich im Extension Datatype-Schema hinzugefügt werden. Außerdem darf für das Definieren neuer Informationseinheiten ausschließlich Qualidied Datatypes oder Unqualified Datatypes verwendet werden, XML Datentypen wie STRING oder INTEGER sind nicht gestattet. Abbildung 4.6: Aufbau eines Conformant Schemas und Instanz. Dabei ist die echte Teilmengen-Beziehung ersichtlich - Quelle: [TC09] P Abbildung 4.7: Aufbau und Vergleich von Conformant- sowie Compatible-Dokumenten. Bei Conformant-Dokumenten existiert keine echte Teilmengen-Beziehung - Quelle: [TC09] P Für die Transformation von ISO zu UBL wurde im Zuge des Kapitel 9 ein UBL Compatibility-Dokument erstellt. Dabei wurden einige Regeln des [TC09] bewusst außer Acht gelassen, um das Mapping besser sowie die Erstellung der Extension Elementes und die Zusammengehörigkeit auf den ersten Blick zuerkennen Codelist UBL verwendet für die Beschränkung der möglichen Werte spezieller XML-Elemente externe Codelisten. Es existiert eine zentrale default-liste im Form eines Stylesheet, dieses Stylesheet prüft die Gültigkeit der verwendeten Werte für spezielle Elemente. Ist der
43 4.4. BEURTEILUNG 29 Wert nicht korrekt für das in der Codeliste existierende Schema, erscheint eine begründete Textausgabe. So erscheint zum Beispiel bei einem falschen Wert für ein Währungscode die Ausgabe is unacceptable for codes identified by CurrencyCode in the Diese Liste beinhaltet aktuell Werte für 30 Elemente, allerdings ist diese default-liste aus den einzelnen Genericode 26 (Endung.gc) Listen zusammengestellt. Das UBL TC rät dabei dem Benutzer auf die einzelnen Codelisten zuzugreifen. Die Codelisten werden in drei Kategorien eingeteilt: default Diese Kategorie enthält Standard-Werte sowie Platzhalter für eigene Listen. So wird zum Beispiel die Means of Payment oder Werte für den Dokumentenstatus vorgegeben. Es exisitieren 15 Codeliste mit Standard-Werte sowie 73 Platzhalter-Listen, die keine Werte vorgeben. cefact Diese Kategorie enthält Listen, die von UN/CEFACT spezifiziert worden sind. Es sind vier verschiedene Listen, diese regeln MIME-Arten, Währungen, Sprachen sowie Maße. Im Gegensatz zu den Default-Werten sind diese Werte fest in die Schemen integriert, da die Unqualified Data Types von UN/CEFACT durch UBL adaptiert wurden. special-purpose Diese Kategorie enthält zwei Listen, die für spezielle Anwendungen von Relevanz sind. Durch die Größe sind sie nicht in der default-liste, jede Liste ist ca. 30 MB groß. Die erste Liste definiert Größen von (Schiffs-)Container und die zweite Häfen. Neben diesen Codeliste existieren noch XSL-Stylesheets, die allerdings nicht zum Standard gehören. Weiterhin decken die XSL-Dateien nur die default-listen und special-purpose- Listen ab. 4.4 Beurteilung Die Beurteilung ist subjektiver Natur und basiert auf den gesammelten Erfahrungen dieses Arbeitsprozesses. Bedingt durch die zahlreichen Fachbegriffe und den komplexen Aufbau der Schemata benötigt eine gewisse Zeit, um die Methode von Core Components Technical Specification zu erfassen. Das Lesen der Dokumentation der Schemata sowie der gemeinsamen BIE- Bibliothek ist zeitaufwendig. Die Abbildung 4.8 zeigt einen Teil der Definition des ABIE InvoiceLine. Abbildung 4.8: Teil Auszug der Common Libary-Dokumentation Wie hier ersichtlich ist, steht neben den ASBIEs keine Definition dieser, sondern nur der Vermerk, dass es eine Verbindung zu den jeweiligen ABIE ist. Erst in Zeile 34 befindet sich die Definition des ABIE AllowanceCharge Information about a charge or discount 26 Genericode Listen sind im Genericode-Projekt entwickelt worden. Genericode verfolgt das Ziel ein einheitliches Format für Codelisten zu etablieren.
44 30 KAPITEL 4. UNIVERSAL BUSINESS LANGUAGE price component. Wird ein BIE auf seine Komponenten untersucht, führt dies zu einem wiederholten Wechsel innerhalb der Definition. ABIEs bestehen immer aus BBIEs und /oder ASBIEs, dabei ist dies eine Vereinigung dieser Objekte. Es existiert keine Entweder-oder- Beziehung basierend auf dem XML-Schema-Element CHOICE 27. Das hat zu Folge, dass das ABIE Party Informationen beherbergt, die eine juristische Person und gleichzeitig eine natürliche Person beschreibt. Die Vorgabe, dass es entweder eine juristische oder natürliche Person sein muss, ist nicht möglich. Dies stellt eine Inkonsistenz in der Logik der Daten dar. Nachfolgend wird die Struktur eines UBL XML-Nachrichten-Schemas in Hauptkörper und Extension Element unterteilt. Das Erweitern bestehender Schemata über das Extension Element ermöglicht einen Überblick über alle Erweiterungen. Allerdings besteht keine Gefahr Elemente zu übersehen, falls diese im Hauptkörper hinterlegt sind aufgrund der Möglichkeit der XML-Schema-Validierung. Denn eine Validierung mit dem originären Schema würde Fehler melden. Ein Nachteil dieses Kapselung ist der Verlust eines Zusammenhangs. Abbildung 4.9 veranschaulicht dieses Problem. Abbildung 4.9: Der semantische ABIE Baustein InvoiceLineType. Zur Veranschaulichung wurden einige Elemente entfernt (UBL conformant). Soll nun die obere Schranke der Kardinalität des ABIE Price von 1 auf n erhöht werden, darf dies nicht im Hauptkörper geschehen, sondern nur im Extension Element. Es existiert auch kein Vermerk im Hauptkörper, dass dieses ABIE eine Erweiterung im Extension-Element besitzt, obwohl dies möglich wäre durch eine Attributes-Angabe. Des Weiteren verschachtelt UBL manche BIEs unnötigerweise. So besitzt das ABIE Party das ABIE PartyName, welches wiederum nur aus einem BBIE Name besteht. Dies ist auch beim ABIE PartyIdentification mit dem BIE ID der Fall. Die Dokumentation der einzelnen Typen in den Schemata unterliegt ebenfalls der CCTS, was dazu führt, dass jedes <xsd:annotation>-element mit einer Hülle an Informationen aufgebläht wird. Listing 4.1 zeigt die Dokumentation eines einzigen BBIE, in diesem Fall das BBIE IssueDate im Invoice-Dokument. 1 <xsd:element ref="cbc:issuedate" minoccurs="1" maxoccurs="1"> 2 <xsd:annotation> 3 <xsd:documentation> 4 <ccts:component> 5 <ccts:componenttype>bbie</ccts:componenttype> 6 <ccts:dictionaryentryname>invoice. Issue Date. Date</ccts: DictionaryEntryName> 7 <ccts:definition>the date assigned by the Creditor on which the Invoice was issued.</ccts:definition> 8 <ccts:cardinality>1</ccts:cardinality> 27 vgl. [TC09] P. 7.7
45 4.4. BEURTEILUNG 31 9 <ccts:objectclass>invoice</ccts:objectclass> 10 <ccts:propertyterm>issue Date</ccts:PropertyTerm> 11 <ccts:representationterm>date</ccts:representationterm> 12 <ccts:datatype>date. Type</ccts:DataType> 13 <ccts:alternativebusinessterms>invoice Date</ccts: AlternativeBusinessTerms> 14 </ccts:component> 15 </xsd:documentation> 16 </xsd:annotation> 17 </xsd:element> Listing 4.1: BBIE IssueDate im Invoice-Dokument von UBL. Der Auszug zeigt die Komplexität der Dokumentationspflicht von CCTS - Quelle: ISO Inovice Schema Werden nun diese Zeilen mit einem Texteditor betrachtet oder editiert, erschwert dieses Dokumentations-Konstrukt die Übersicht. Nicht nur einfache Texteditoren sind betroffen. Auch professionelle Anwendungen wie die Software MapForce 2013 von Altova zeigt diese Dokumentation nicht an, im Gegensatz zu XMLSpy von Altova. Hier wird die komplette Dokumentation angezeigt, was einen unübersichtlichen Baum erzeugt. Dabei stellt sich die Frage, ob dabei das Schema das Problem hervorruft oder die Software einfach ungenügend ist. Erschwert wird die Übersicht der Schemata durch die verschiedenen Import-Befehle. So importiert jedes der 31 UBL-Schemata 5 grundlegende Schemata. Diese Import-Anweisungen rufen ein Springen von Schemata zu Schemata hervor. Allerdings hat dies auch den Vorteil einer gemeinsamen Bibliothek. So werden die einzelnen Schemata schlank gehalten und die Administration hat einen geringeren Aufwand bei einer Aktualisierung einzelner BIEs. Dem gegenüber steht allerdings, das nicht jede Software mit dieser Import- Konstruktion zurecht kommt. So wurden im Zuge der noch folgenden Ontologie-Entwicklung Stylesheets und Programme ausprobiert, die die Schemata in Ontologien transformieren sollten. So sind die Stylesheets an den Import-Befehlen gescheitert. Alleine der TopBraid Composer von TopQuadrant kam mit diesem Umstand zurecht. Eine weiterer fragwürdiger Umstand ist das ABIE Contact. Dieses ist wie folgt aufgebaut: ID (BBIE), Name (BBIE), Telephone (BBIE), Telefax (BBIE), ElectronicMail(BBIE), Note (BBIE) und Other Communication (ABIE). Diese semantische Einheit soll die Kontaktdaten einer Person oder Firma beherbergen. Es existiert nur ein BBIE für den Namen, was problematisch bei der Kontaktaufnahme ist. Für den eigenen Sprachraum ist in der Regel ersichtlich, welches Geschlecht sich hinter dem Namen verbirgt, sowie die Erkennung des Vor- und Nachnamen. Allerdings ist dies
46 32 KAPITEL 4. UNIVERSAL BUSINESS LANGUAGE problematisch für fremde Sprachräume und eine höfliche und den Regeln entsprechende Ansprache ist nicht ohne Weiteres möglich. 28 Alle BIEs in Contact sind in ihrer Kardinalität auf maximal 1 beschränkt, dies kommt scheint ein wenig praxisfern, da Kontakte oftmals beispielsweise über mehrere Telefonnummern oder -Adressen verfügen. Das ASBIE OtherCommunication hebt hingegen diese Beschränkung auf, indem beispielsweise eine weitere Telefonnummer angegeben werden kann. Generell stellt sich hier die Frage, warum OASIS sich nicht an dem vcard 4.0-XML-Format orientiert hat. Erwähnenswert ist auch, dass UBL in seiner Spezifikation aussagt, dass die Incoterms 2000 anstatt Incoterms 2010 verwendet werden soll, die erforderliche Codeliste wird für diese Empfehlung jedoch nicht vorgegeben. Generell ist UBL sehr restriktiv bei der maximalen Kardinalität. So hat das ABIE Party maximal eine Kontaktperson sowie maximal nur eine Sprache, was auch wieder in Frage gestellt werden kann, da aufgrund der Globalisierung Unternehmen meist mehrsprachig aufgestellt sind. Weiterhin ist die sehr geringe Anzahl der Codelisten ein wenig unschön. Allerdings sind die eben bemängelten Aussagen nicht von großer Relevanz. UBL ist durch die Basierung auf CCTS sehr durchdacht und logisch aufgebaut. Sobald die Methode der BIEs verstanden ist, ist ein schnelles und einfaches Arbeiten möglich. Die Unterstützung des Support Packages ist sehr hilfreich und bietet alles, was für die Arbeit mit UBL notwendig ist. Die Möglichkeit UBL-Dokumente zu modifizieren, ist von Vor- und Nachteil zugleichen. Der Vorteil liegt darin, dass Benutzer dieses Standards durch Ergänzung der Nachrichten ihre Bedürfnisse vollständig befriedigen können. Allerdings entstehen so fremde Dokumente, die semantische Inkonsistenzen beherbergen können. Die Fixierung auf XML als Syntax verhindert eine Trennung von Semantik und Syntax. Dabei erschwert dies die Modellierung von Daten, da Definitionen direkt per XML erfolgen und nicht per syntaxneutraler Modellierungssprache. Ein Hauptkomponente von ISO beschreibt die Verwendung von Repositories (siehe 4.2), UBL verwendet allerdings kein Repository. Die Verwendungen des Support Package anstatt eines Repository bietet Vor- und Nachteil zugleich. Der Vorteil liegt in der Verfügbarkeit aller nötigen Dateien, wie Schemata, Dokumentation und Codelisten. So ist die Gefahr von fehlenden Dateien nicht existent. Allerdings gibt es dadurch auch keine Möglichkeit, UBL Conformance oder UBL Compatibility zentral zu speichern und auch die Korrektheit überprüfen zulassen. Im Rahmen dieser Arbeit wurde die Erfahrung gemacht, dass UBL in Deutschland noch nicht sehr bekannt ist. Dies wird sich allerdings ändern durch Projekt wie PEPPOL oder grenzüberschreitende Geschäft im Zuge der Globalisierung mit anderen europäischen Ländern, die UBL bereits verwenden. UBL-Dokumente sind durch deren Aufbau einen Schritt von Ontologien entfernt durch die Bildung von Objekten aus Bausteinen. Zwei Merkmale unterscheiden sich allerdings von Ontologien. UBL ist an XML gebunden und es existieren keine Sub-Klassenbeziehungen, siehe dazu Abschnitt Mit diesem Problem kam ich während eines Praktikums bei einer international aufgestellten Bank in Berührung, als ich Anfragen aus dem asiatischen Raum beantwortete.
47 KAPITEL 5 ISO Dieses Kapitel behandelt den Standard ISO und ist in vier Teilen gegliedert. Abschnitt 5.1 stellt das europäische Projekt SEPA vor und den Zusammenhang mit dem Standard ISO Abschnitt 5.2 beleuchtet die technische Seite des Standards. Dabei handelt es sich um den ISO Standard (Unterabschnitt 5.2.1), wichtige Begriffe innerhalb ISO (Unterabschnitt 5.2.2), das ISO Repository (Unterabschnitt 5.2.3), die ISO Geschäftsnachrichten (Unterabschnitt 5.2.4), die Entwicklung von Compliant- Nachrichten (Unterabschnitt 5.2.5) sowie die ISO Codelisten (Unterabschnitt 5.2.6). Abschnitt 5.3 stellt die ISO Administration vor. Abschließend wird in Abschnitt 5.4 der Standard bewertet. 5.1 Einführung: Single Euro Payments Area SEPA (oft auch SCPA) steht für Single Euro Payments Area und ist eine Initiative der Europäisches Union. Die deutschsprachige Bezeichnung lautet der einheitliche Euro Zahlungsverkehrsraum. Dabei handelt es sich um den europäischen Währungsraum, in dem Bürger und Unternehmen sowie sonstige am Wirtschaftsgeschehen beteiligte Akteure innerhalb Europas Euro-Zahlungen veranlassen sowie erhalten können, unabhängig von der Frage, ob die Zahlungen grenzüberschreitend sind. Nationale und internationale Transaktionen werden hierbei gleichgestellt, es gelten dieselben grundlegenden Bedingungen, Rechte und Pflichten 1. Die Idee hinter SEPA wurde im Jahr 2000 im Vertrag von Lissabon festgehalten und von der Europäischen Union nach der Einführung der Euro-Banknoten und -münzen im Jahr 2002 vorangetrieben 2. Es ist die konsequente Weiterführung des Gedankens einer einheitlichen Währung und der daraus folgenden Harmonisierung des europäischen Zahlungsverkehrs. Aktuell nehmen neben den 27 Mitgliedstaaten der EU noch Island, Liechtenstein, Norwegen, Schweiz und Monaco an SEPA teil. Im Januar 2008 wurde SEPA umgesetzt. Ab diesem Zeitpunkt war es möglich, von einem einzigen Konto die verschiedene Zahlungs- 1 vgl. [Cou09] S. 5 2 vgl. [Cou12] P. 1 33
48 34 KAPITEL 5. ISO instrumente (SEPA-Credit Transfer und SEPA-Direct Debit) 3 zu verwenden. Dabei ist zu beachten, dass SEPA nicht nur für internationale Finanztransaktionen verwendet werden soll, sondern auch nationale Verwendung finden soll. Für das Überweisungs- und das Lastschriftverfahren verwendet SEPA die ISO MX-Nachrichten aus den Domänen pain, pacs sowie camt (Siehe Abschnitt 5.2.4), allerdings existieren für Kartenzahlungen keine ISO Varianten. pain-nachrichten umfassen die Nachrichten, die in der Kunde-Bank- Beziehung verwendet werden. pacs-nachrichten beschreiben die Prozesse im Interbanken- Bereich. Die camt-nachrichten werden innerhalb von Bank-Kunde-Beziehungen verwendet. SEPA verfügt über ein Rahmenwerk für die Kartenzahlungen, dem sogenannten SEPA Cards Framwork (SCF). Dieses Rahmenwerk definiert Anforderungen an Zahlungsdienstleister, Kartensysteme und andere Marktteilnehmer 4. Die Abbildung 5.1 gibt eine Übersicht der verschiedenen Nachrichtenstandards, die innerhalb der Finanzdomäne verwendet werden. So ist erkenntbar, dass das (europäische) Bankensystem auch von einer Vielzahl von Nachrichtenstandards betroffen ist. Dabei ist die Abbildung nur ein kurzer Überblick. Es existieren noch ISO 15022, ISO 8583, SWIFT FIN(auch bekannt als MT Nachrichten), proprietäre inländische Standards sowie XBRL 5. Abbildung 5.1: Ein Teil der Nachtichtenstandards innerhalb der Finanzdomäne. - Quelle:[Bob09] F Der Standard Der ISO Standard, gesprochen twenty-o-two-two 6, ist auch bekannt als UNIFI, wobei dies für UNIversal Financial Industry Message Scheme steht und laut [ISO12b] 3 Einheitliche Verfahren zum Tätigen der verschiedenen Instrumente, wird von European Payments Council (EPC) geregelt [Cou09] S. 9 4 vgl. [Cou09] S. 6 5 vgl. [Tea10] S. 9 6 [SWI]
49 5.2. DER STANDARD 35 folgendes bedeutet: ISO Universal financial industry message scheme (which used tobe also called UNIFI ) is the international standard that defines the ISO platform for the development of financial message standards. Its business modelling approach allows users and developers to represent financial business processes and underlying transactions in a formal but syntax-independent notation. Die International Organization for Standardization (ISO) hat UNIFI im Jahr 2004 als Norm ISO spezifiziert. ISO ist eine Methode, welche in der Finanzwirtschaft verwendet wird, um Geschäftsprozesse als konsistente Nachrichten abzubilden. Dies ermöglicht durch Geschäftsmodellierung den Benutzern, ihre Geschäftsprozesse korrekt abzubilden. Wie in der englischsprachigen Definition erwähnt, ist ISO Syntax unabhängig. Allerdings war XML defacto der Syntax-Standard für den elektronischen Nachrichtenaustausch während der ISO Entwicklung. Deshalb entstand die erste Version von IS mit einer XML-basierender Syntax. Genau genommen wird von ISO MX gesprochen, wenn XML-basierende ISO Nachrichten gemeint sind, da ISO bis jetzt nur eine Syntax unterstützt. Als Ausgangspunkt jeder ISO XML-Nachricht steht ein UML-Modell. Diese UML-Modelle ermöglichen theoretisch eine Abbildung der ISO Prozesse auf einer beliebigen Syntax. ISO hat zwei Aufgabe. Zum einem soll es den Nachrichtenaustausch zwischen finanzwirtschaftlichen Institutionen, deren Kunden sowie der in- und ausländischen Infrastruktur ermöglichen. Zum anderen soll es auch neuen Geschäftsfeldern innerhalb der der Finanzwirtschaft ermöglichen, ISO zu verwenden. Dies wird durch ein Repository ermöglicht, welches unter bestimmten Bedingung um neue Nachrichten erweitert werden kann. Der ISO Standard besteht aktuell 7 aus sechs Teilen. Dabei handelt es sich bei drei Teilen um technische Spezifikationen 8 (ISO/TS), Teil Sechs wurde bislang noch nicht implementiert. Im Gegensatz zu UBL ist die Spezifikation der ISO Norm nicht kostenfrei verfügbar, sondern über International Organization for Standardization (ISO) 9 und deren Mitglieder erhältlich. 10 Die Norm besteht aus folgenden Teilen: 1. ISO : Financial services UNIversal Financial Industry message scheme Part 1: Overall methodology and format specifications for inputs to and outputs from the ISO Repository Dieser Teil beinhaltet die allgemeine Beschreibung des Modellierung-Ansatzes, die allgemeine Beschreibung des Repository-Inhalts, eine high-level Beschreibung um das Repository zu modifizieren sowie eine high-level Beschreibung der Ausgabe des Repositorys. 2. ISO : Financial services UNIversal Financial Industry message scheme Part 2: Roles and responsibilities of the registration bodies 7 Mai Technische Spezifikationen (TS) haben innerhalb der ISO eine temporäre Rolle. Sie werden irgendwann zur einer fixen Norm, editiert oder zurückgezogen In Deutschland ist es der Verlag Beuth ( ein Tochterunternehmen des DIN Deutsches Institut für Normung e. V.. Die komplette Auflistung der Anbieter ist hier about/iso_members.htm erhältlich.
50 36 KAPITEL 5. ISO Dieser Teil beschreibt die Verwaltung und Organisation, die hinter ISO steht. 3. ISO/TS : Financial services UNIversal Financial Industry message scheme Part 3: ISO modelling guidelines Dieser Leitfaden gibt vor, wie Geschäftstransaktionen und Nachrichtensätze korrekt generiert werden. 4. ISO/TS : Financial services UNIversal Financial Industry message scheme Part 4: ISO XML design rules Dieser Teil unterstützt den Prozess der Umwandlung von ISO Compliant Messages Defintions in ISO Syntax. 5. ISO/TS : Financial services UNIversal Financial Industry message scheme Part 5: ISO reverse engineering Dieser Teil fungiert als Leitfaden, um relevante Informationen aus existierenden Industrienachrichtensätzen zu extrahieren, damit äquivalente ISO compliant Business Transaction und Nachrichtensätze bei der Registration Authorithy eingereicht werden können. Zu diesem Zweck stellt die Registratoin Authority verschiedene Vorlagen zur Verfügung, die das Einreichen neuen Nachrichten erleichtern sollen. 6. ISO : Financial services UNIversal Financial Industry message scheme Part 6: Message Transport Characteristics Dieser Teil spezifiziert die Charakteristiken eines Nachrichtensystems, welches für den Versand der Business Transaction und Message Definition verwendet wird ISO Folgende Informationen stammen aus der ISO Norm ISO : Der Vorläufer von ISO ist die ISO Dieser Standard entstand durch die Bedürfnisse des Finanzbereichs Secrurities. Diese Bedürfnisse waren beziehungsweise sind noch: 1. Zeitersparnis bei Einführung neuer, standardisierter Nachrichten im existierenden Markt sowie 2. die Verbesserung des STP. Die ISO verfügt über verschiedene Werkzeuge, um den jeweiligen spezifischen Informationsfluss zu ermöglichen. Diese Werkzeuge sind: eine Menge von Syntax- und Nachricht-Designregeln, ein Data Field Dictionary, welches Business Elements und deren technische Repräsentation beinhaltet sowie ein Nachrichtenkatalog, der nach obigen Regeln kreiert worden ist. Das Data Field Dictionary und der Catalogue of Messages bilden zusammen das ISO Repository, welches nicht direkt in der ISO Norm festgehalten wird. Damit ist eine ständige 11 [ISO04a] S. 1ff
51 5.2. DER STANDARD 37 Aktualisierung seitens der Registration Authority möglich, ohne die Norm jedesmal anpassen zu müssen. Dies betrifft auch Codelisten. Die ISO wurde auf weitere Industriebereiche des Bankenwesens ausgeweitet. Diese Ausweitung brachte den ISO Standard hervor. So wurde der Bereich Secrurities um Payments Clearing, Payments Settlement, Cash Managment, Trade Services vergrößert. ISO verwendet eine proprietäre Syntax, die aus einzelnen Blöcken besteht, siehe Listing 5.1. :20:MT101-Test :28D:00001/00001 :30: :21:Start B-Seq :32B:EUR1, :23E:CMTO :50G:/Kontonummer BANKDEM0XXX :59A:/Kontonummer BANKDEM0XXX :71A:SHA Quelle Wikipedia. 12 Listing 5.1: ISO Nachticht. Typ MT 101 Die ISO ist allerdings nicht nur eine Ausweitung des Anwendungsgebietes, sondern auch eine Erweiterung um Ansätze. Diese sind: Modellierungsmethoden (UML), welche Business Areas, Business Processes, Business Transactions, Business Actors, Business Roles, und Business Informations sowie Message Flow Diagramms und Message Definitions erfassen, analysieren und beschreiben. Design Rules, welche modellierte Message Definitions in standardisierten Syntax konvertieren Begriffe innerhalb ISO Dieser Abschnitt erklärt Schlüsselbegriffe, die innerhalb der ISO von Bedeutung sind 13 : Geschäftsakteur (Business Actor) Dies ist eine physische Partei, welche eine oder mehrere Geschäftsrollen in bestimmten Geschäftsprozessen oder Geschäftstransaktionen hat. Sie kann dabei eine natürliche Person, eine Organisation oder sogar eine Infrastruktur sein. Geschäftsakteur ist eine Kategorie von Geschäftskonzepten und im Data Dictionary hinterlegt. Beispiel: Bank, Konzern. Geschäftsdomäne oder Geschäftsfeld (Business Area) Eine Geschäftsdomäne stellt eine Menge von stark korrelierenden Geschäftsaktivitäten dar. Dabei kann sie weitere Geschäftsdomänen enthalten, besteht aber in der niedrigsten Stufe aus einer Menge von vgl.[iso04a] S. 2ff
52 38 KAPITEL 5. ISO Geschäftsprozesse. Sind im Business Process Catalogue hinterlegt. Beispiel: Kontoverwaltung, Zahlungsanweisungen. Geschäftsassoziation (Business Association) Dies ist eine semantische Relation zwischen zwei Geschäftskomponenten und kann nur durch deren Geschäftskomponenten identifiziert werden. Sie wird im Data Dictionary gespeichert inklusive der Verlinkung zu den Geschäftskonzepten. Zwischen den Geschäftskomponenten können mehrere Geschäftsassoziation bestehen. Beispiel: Eine Partei bietet den Services eines Bankkontos an. Geschäftskomponente (Buisness Component) Repräsentation eines Schlüsselgeschäftsbegriffes, charakterisiert von spezifischen Geschäftselementen. Die Geschäftskomponente ist eine Kategorie von Geschäftskonzepten und in Data Dictionary hinterlegt. Beispiel: Konto, Partei. Geschäftskonzept (Business Concept) Data Dictionary-Objekt mit einer Geschäftsbedeutung. Beispiel: Geschäftspartner, Geschäftsrolle, Geschäftskonzept, Geschäftselement. Geschäftselement (Business Element) Dies ist eine Geschäftscharakteristik einer Geschäftskomponente. Sie sind im Data Dictionary hinterlegt. Beispiel: Kontostatus, Ausstellungsdatum. Geschäftinformation (Business Information) Generischer Name für ein Geschäftskonzept, Geschäftselement oder Geschäftsverbindung. Geschäftsprozess (Business Prozess) Haupt-Geschäftsaktivität innerhalb einer Geschäftsdomäne. Kann durch eine hierarische Struktur andere Geschäftsprozesse beinhalten. Beispiel: Orderung von Wertpapieren. Geschäftsrolle (Business Role) Funktionale Rolle eines Geschäftsakteurs in einem bestimmten Geschäftsprozess oder in einer Geschäftstransaktion. Sie ist eine Kategorie von Geschäftskonzepten und ist im Data Dictionary gespeichert. Beispiel: Kontobesitzer, Käufer. Geschäftstransaktion (Business Transaction) Dies ist eine Aktivität der Kommunikation, die in einem Geschäftsprozess und/oder einer Geschäftsdomäne stattfindet. Nachrichtenkomponente (Message Component) Wiederverwendbares Data Dictionary Objekt, welches als Baustein für den Aufbau von Nachrichten dient. Ist im Data Dictionary hinterlegt. Beispiel: Handelspartei. Nachrichtenelement (Message Element) Dies ist eine Charakteristik einer Nachrichtenkomponente und kann nur in Verbindung mit dieser beschrieben werden. Beispiel: Handelstag -und zeit. Der Rechnungsausteller Invoicer ist ein Geschäftsakteur und gleichzeitig eine Geschäftsrolle. TradeParty1 ist eine Nachrichtenkomponente und wird von dem Nachrichtenelementen wie Inovicer verwendet und erhält so eine semantische Bedeutung. Der Name Messeturm eines Gebäudes ist eine Geschäftsinformation und ist der Wert des Geschäftselement BuildingName, welches wiederum in der Geschäftskomponente PostalAddress vorkommt. PostalAddress steht über die Geschäftsassoziation Address in Verbindung mit

53 5.2. DER STANDARD 39 Location, welches wiederum eine Geschäftskomponente ist. Das Ausstellen einer Rechnung ist ein Geschäftsprozess. Das Versenden der Rechnung ist eine Geschäftstransaktion. Um die einzelnen Begriffe zu verstehen, sollte die Suche mittels Dictionary Search und Catalogue Search verwendet werden. Es existieren noch weitere Begriffe, die aber von sekundärer Natur sind und deshalb nicht vorgestellt werden, diese befinden sich in [ISO04a] Das Repository Der zentraler Baustein für den ISO Standard ist das Repository oder auch Financial Repository, welches aus zwei Teilen besteht: Der Business Process Catalog und das Data Dictionary. Beide Komponenten sind über die ISO Seite 14 erreichbar. Abbildung 5.2: Der schematische Aufbau der Financial Repository von ISO Quelle:[ISO12a] Data Dictionary Das Data Dictionary beinhaltet drei Kategorien: Die Geschäftskonzepte, die Nachrichtenkonzepte und die Datentypen. Objekte dieser Kategorien bilden die Grundbausteine für die Nachrichten und werden auch Dictionary Items genannt. Die Dictionary Items sind frei verfügbar und wiederverwendbar, der Zugriff wird über zwei Arten realisiert. Die erste Möglichkeit ist die Verwendung der Quick Search oder Dictionary Search und deren Suchmaske. Die zweite Möglichkeit ist die Verwendung von einem UML 2 Modell, das entweder auf XMI 2 oder Rational Software Modeler basiert. Diese Modelle werden ebenfalls über die Website angeboten. Business Process Catalogue Das Business Process Catalogue ist in Geschäftsdomänen aufgeteilt und besteht aus drei Kategorien: Die Geschäftsdomäne, die Nachrichtendefinition und das dazugehörige XML- Schema. Der Zugriff auf diesen Informationen erfolgt ebenfalls über eine Suche oder über den Cataloque of Messages. Der Catalogue of Messages listet entweder alle oder vereinzelte Geschäftsdomänen mit den dazu gehörigen Objekten auf. 14
54 40 KAPITEL 5. ISO Abbildung 5.3: Die ISO Dictionary Search Suchmaske. Quelle: ISO Website, Aufnahme Catalogue of Messages Der Catalogue of Messages enthält alle aktuell genehmigte 15 sowie obsolete genehmigte 16 Nachrichten (Siehe Abbildung 5.4). Im unteren Drittel der Abbildung 5.4 sind die ersten fünf Business Areas der insgesamt 16 erkenntlich. Diese alphabetisch nach Namen sortierten Business Areas besitzen auch zugleich die zugehörigen Message Definitions. Abbildung 5.5 zeigt die Trade Service Initiation mit den Catalogue Items Message Defintion Report, Message Usage Guide, XML Instanzen, XML Schemata und Vorlagen für mögliche Anmerkungen. Die T or P-Spalte in Abbildung 5.5 gibt Aufschluss über die Integration der Nachrichten. Status T Diese Nachricht wurde getestet. Status P Diese Nachricht wurde bereits in einem laufenden System implementiert. Status - Registration Authority hat keinerlei Information über die Intergration der Nachricht. Wie Abbildung 5.5 zeigt, wurde die für diese Arbeit wichtige Invoice Nachricht nicht von der Registration Authority getestet. Dies mag auch eine Erklärung dafür sein, dass die problemlose Validierung der XML-Instanz mit dem dazugehörigen Schema nicht möglich ist. Dieser Umstand wird in Abschnitt genauer erläutert. Die im Repository befindlichen Inhalte können so in bestehende System migriert werden. Falls diese Modelle nicht ausreichen, können die Inhalte vom Data Dictionary als Bausteine für eigene Business Transactions und Message Defintions verwendet werden oder
55 5.2. DER STANDARD 41 Abbildung 5.4: Der ISO Business Catalogue des ISO Repository. Quelle: ISO Webseite - Stand: Abbildung 5.5: Die Business Transactions und Katalog Items (Quelle: ISO Webseite - Stand: 11. Juni 2011)
56 42 KAPITEL 5. ISO bereits existierende modifiziert werden. Für dieses Vorgehen sollten die Teile drei bis fünf der Norm konsultiert werden, sowie Submission Templates. Die Submission Templates sind Vorlagen, welche dem Interessenten eines neuen/modifizierten Objekt die Einreichung bei der Registration Authority unterstützen. Diese selbsterstellten Objekte tragen die Namen compliant Business Transactions beziehungsweise Compliant Message Sets. Die Registration Authority validiert mit Hilfe der Standard Management Groups die Anfrage. Falls die Anfrage akzeptiert wird, wird das Repository aktualisiert. Tabelle 5.1 zeigt die bisherigen Verantwortlichen für Nachrichten. Organisation Anzahl der Nachrichten ISO TSG 1 CBI 5 CLS 15 Deutsche Bundesbank (on behalf of 4CB) and SWIFT 1 EPASOrg 18 Euroclear 22 GUF 3 ISITC 1 ISTH 6 Omgeo SWIFT 5 SWIFT 222 UN CEFACT TBG5 1 Tabelle 5.1: Die verantwortlichen Verfasser für die ISO Nachrichten und deren Anzahl der akzeptierten Nachrichten - Quelle der Daten: ISO Catalogue of Messages - Stand 11. Dezember Die Geschäftsnachrichten Die Geschäftsnachrichten sind im Catalogue of Messages hinterlegt, dort werden verschiedene zusammenhängende Dateien angeboten (Siehe 5.5). Um die Nachrichtenstruktur der XML Syntax zu reglementieren, verwendet die ISO anstatt Document Type Definition 17 das vom W3C empfohlene XML Schema 18. Laut der ersten Teil der Norm kann die XML-Syntax durch XML-Schema oder DTD strukturiert sein, allerdings bietet die Webseite 19 nur XML-Schemata an. Die Bezeichnung eines ISO Schema für eine Nachricht erfolgt nach dem Muster xxxx.nnn.aaa.bb. Dabei stehen die einzelnen Teile für folgende Definitionen: xxxx Der vierstellige alphabetische Code identifiziert die Geschäftsdomäne. nnn Der dreistellige numerische Code identifiziert die Nachricht. aaa Der dreistellige numerische Code identifiziert die Variante Juni 2012
57 5.2. DER STANDARD 43 acmt Account Management reda Reference Data admi Administration seev Securities Events caaa Acceptor to Acquirer Card semt Securities Management Transactions camt Cash Management sese Securities Settlement catm Terminal Management setr Securities Trade pacs Payments Clearing and Settlement trea Treasury pain Payments Initiation tsin Trade Services Initiation tsmt Trade Services Management Tabelle 5.2: Die 15 Business Areas innerhalb ISO Quelle der Daten: ISO Catalogue of Messages - Stand 11. Dezember 2012 bb Der zweistellige numerische Code identifiziert die Version. SWIFT bietet keine Prüfsumme (z.b. CRC32, MD5 oder SHA-1) oder ähnliche Mechanismen an, um die Integrität der Daten (Schema, Instanz, Codelisten, MUG, MDG) zu überprüfen. Allerdings bietet GEFEG ein Online-Portal 20 für die Validierung von ISO MX-Dateien. ISO spezifiziert jedes Schema mit dem sogenannten MDR (Message Definition Report), jedes Schema hat genau ein MDR. In manchen Fällen existiert laut der ISO-FAQ 21 Seite auch ein MUG (Message Usage Guide). Allerdings gibt es bis dato 22 nur für den Business Application Header einen MUG. Die Nachrichten und deren XML- Präsentationen der Blöcke unterliegen zum Teil einigen Regeln den sogenannter Rules and Guidelines. Diese Regeln geben zum Beispiel den Länder-Code 23 oder auch den Währungs- Code 24 vor. Das Schema der Financial Invoice Nachricht ISO verwendet die Nachricht tsin mit dem offiziellen Namen FinancialInvoiceV01, um die Rechnung abzubilden. Dabei gibt es keine offizielle Definition, sondern nur eine Beschreibung der Verwendung einer Rechnung, welche wie folgt lautet: While the prime function of the FinancialInvoice message is as a request from the seller to the buyer for payment, the FinancialInvoice message can also serve to evidence an invoice in support of a financial service such as invoice factoring, letters of credit, and bank payment obligations, to enable Web based services such as electronic bill payment and presentment, and as the basis to transfer invoice information via third parties such as e-invoicing service providers [ISO12b] P. What s the difference between a MUG (Message Usage Guide) and a MIG (Message Implementation Guide)? Oktober ISO ISO [TBG] S. 7
58 44 KAPITEL 5. ISO Die ISO hat die Nachricht in der Business Area Trade Services Initiation unter der Business Domain Trade Services eingegliedert, diese Business Domain beinhaltet weiterhin noch die Business Area Trade Services Management (tsmt). Der verantwortliche Autor (Submitting Orangisation) der Financial Invoice Message ist die UN/CEFACT TBG Working Group 5 Finance Domain. 26 Das XML Schema der FinancialInvoiceV01- Nachricht ist über die URL schemas/tsin zip 27 erhältlich. Sie wurde Dezember 2010 veröffentlicht und besitzt folgende Charakteristika: Das XML Schema hat die Nachrichten ID tsin , ist als ZIP-Archive Bytes groß, ist unkomprimiert Bytes groß, hat den eindeutigen Namen tsin xsd, hat 1362 Zeilen, verwendet XML in der Version 1.0, kodiert die Informationen mit UTF-8, besitzt 65 simpletype sowie 94 complextype Elemente, wurde nach dem Venetian Blind -Stil 28 entwickelt, besitzt zwei Namespace-Deklarationen (xmlns="urn:iso:std:iso:20022:tech:xsd:tsin " & xmlns:xs=" und besitzt die TargetNamespace-Deklaration (targetnamespace="urn:iso:std:iso:20022:tech:xsd:tsin "). Die IS Invoice-Nachricht besteht aus fünf Blöcken, den sogenannten Message Components, wobei nur vier Blöcke verpflichtende Angaben sind. Diese sind wie folgt: Invoice Header [1..1] Dieser Block beinhaltet generelle Informationen, die für den Hauptteil relevant sind, wie beispielsweise das Ausstellungsdatum, das Identifikationskürzel für die Währung oder auch die Rechnungsnummer. TradeAgreement [1..1] Dieser Block beinhaltet Informationen, wie zum Beispiel teilnehmende Akteure, Dokumente und Geschäftsvereinbarungen. TradeDeliverey [1..] Dieser Block legt die Daten für die Versorgungskette fest. Als Beispiele seien genannt das Lieferdatum oder das Datum des erbrachten beziehungsweise zu erbringenden Services. 26 Diese Organisation hat die Kommunikation zwischen Banken und ihrer Kunden, wie zum Beispiel Konzerne oder stattliche Institutionen als Hauptziel Juni Es wird bei der XML-Schema-Entwicklung zwischen vier verschieden Typen unterschieden, je nachdem wie die Elemente global und lokal definiert wurden. Für Informationen bitte [Gre12]
59 5.2. DER STANDARD 45 TradeSettlement [1..] Dieser Block legt die Zahlungsmodalitäten fest, als Beispiel kann hier die Fälligkeit der Zahlung genannt werden. LineItem [0..*] Dieser Block steht für einen Rechnungsposten und dessen Details, wie zum Beispiel Anzahl, Preis, Verpackung, Versand oder auch Steuer. Abbildung 5.6: Visualisierung des ISO Hauptteile Entwicklung einer Compliant Nachricht Der folgende Abschnitt gibt eine kurze Übersicht über die Entwicklung einer Compliant Business Transaction und eines Compliant Message Sets, der Hauptfokus dieser Arbeit liegt wie bereits erwähnt auf die Transformation eines Standards in ein anderen Standard. Mit ISO/TS :2004, ISO/TS :2004 und ISO/TS :2004 gibt ISO ISO Interessenten eine Methode vor, um Compliant Objekte nach deren Vorgaben zu erstellen. Diese Methodik umfasst fünf Stufen, die hier nur kurz erwähnt werden Die Stufe Business Analysis klärt, um welche Business Areas und Aufgaben es sich handelt. 2. Die Stufe Requirement Analysis erforscht die Anforderung der Kommunikation und Interaktion des Buisness Process in der jeweiligen Business Area. 3. Die Stufe Logical Analysis erarbeitet die Details der Business Transaction und des Message Sets. 4. Das Stufe Logical Desgin formalisiert die Ergebnisse der vorigen Stufe und klärt, welche Messages aus dem Repository wiederverwendet werden können. 5. Die Stufe Technical Design liefert die implementierten Message Definitions und Message Rules in gültiger Syntax. Supplementary Data Die Supplementary Data-Komponente ist eine Erweiterung bestimmter Nachrichten. Diese Erweiterung beziehungsweise das Customizing ist für den Fall vorgesehen, dass eine Nachricht mit zusätzliche Informationen ausgestattet werden kann. Allerdings sind nur einige 29 Für tiefer gehende Informationen Quelle [ISO04b] beachten.
60 46 KAPITEL 5. ISO Nachricht mit der Möglichkeit der Erweiterung ausgestattet. Die Erweiterungen müssen wie Compliant-Nachrichten entwickelt werden und erfordern die Zustimmung der jeweiligen SEG. Diese Erweiterungen durchlaufen allerdings einen kleineren Prozess als eine Schemamodifizierung und benötigen so weniger Zeit. Die Supplementary Data-Komponente wird mittels eines Elements an die nötige Stelle in der Struktur verankert. Das Supplementary Data-Element wird in ein externes XML- Schema gespeichert und auf der Website veröffentlicht Codelisten Einige Elemente der XML-Instanzen unterliegen Restriktionen durch Codelisten. Allerdings sind diese kein Teil des Standards. Die ISO verwendet dabei zwei unterschiedliche Verfahren - Externe Codeliste sowie interne Codelisten. Externe Codelisten Externe Codelisten sind Codelisten, die nicht im Schema hinterlegt sind oder referenziert werden mittels einer Verknüpfung. Dabei existieren zwei unterschiedliche Formen, die Data Source Scheme sowie die External Code Lists. Data Source Scheme (DSS) Dies sind proprietäre Codelisten aus der Industrie, die weder ISO gehören noch von ISO verwaltet werden. Diese werden auch nicht von ISO verteilt, sondern sind nur über die Verfasser erhältlich. ISO indexiert nur die Listen. Anträge auf Indexierung oder Modifizierung können über (Change) Request-Dokumente gestellt werden. Der Index liegt als ein Microsoft Word-Dokument vor. Abbildung 5.7 zeigt einen Auszug aus dem Index der Data Source Scheme, dabei ist ersichtlich, dass keine Werte angegeben werden, sondern nur die zweistellige ID des Land des Verfassers, die vierstellige ID des Verfassers, der vierstellige Name der Codelist sowie eine Beschreibung. Abbildung 5.7: Auszug des Data Source Scheme-Index von ISO Quelle: ISO Webseite External Code Lists Diese Codelisten unterstehen ISO und werden von ISO verwaltet. Es existieren aktuell 30 drei separate Dateien. Die erste Datei in Form eines Microsoft Excel-Dokumentes beherbergt 33 Listen, wobei 4 Listen leer sind. Die Codelisten decken die drei Geschäftsdomänen Payments, Trade und Securities ab. Neben den Codelisten existieren noch Indexlisten, die eine Übersicht über die Nachrichten und deren verwendeten Codelisten ermöglichen. Des weiteren wird in einem anderen Arbeitsblatt die November 2012

61 5.2. DER STANDARD 47 Revisions-Geschichte sowie Informationen wiedergegeben. Das Excel-Dokument wird in unregelmäßigen Abständen von wenigen Monaten aktualisiert. Abbildung 5.8 zeigt einen Auszug der Codeliste für die Incoterms. Neben dieser Datei existiert noch ein Microsoft Abbildung 5.8: Auszug einer Codelist für Incoterms die im Rechnungs-Dokument verwendet wird, die mittels eines Microsoft Excel-Dokumentes verteilt wird. Quelle: ISO Webseite - Stand: 01. Dezember 2012 Word-Dokument (Abbildung 5.9) sowie ein Microsoft Excel-Dokument (Abbildung 5.10). Das Word-Dokument beherbergt Werte für Banktransaktionen und das Excel-Dokument Werte für Kombinationen von Banktransaktionen. Abbildung 5.9: Auszug einer Codeliste für Issued Credit Transfer, die mittels eines Microsoft Word-Dokumentes verteilt wird. Quelle: ISO20022-Webseite - Stand: 01. Dezember 2012 Abbildung 5.10: Auszug einer Codeliste für mögliche Kombinationen für Bank Transakttions Codes die mittels eines Microsoft Excel-Dokumentes verteilt wird. Quelle: ISO Webseite - Stand: 01. Dezember 2012 Interne Codelisten Interne Codelisten sind im XML-Schema hinterlegt und können direkt validiert werden, in Gegenteil zu den externen Codelisten. Listing 5.2 zeigt die interne Codeliste für den Datentyp AddressType2Code. 1 <xs:simpletype name="addresstype2code">
62 48 KAPITEL 5. ISO <xs:restriction base="xs:string"> 3 <xs:enumeration value="addr"/> 4 <xs:enumeration value="pbox"/> 5 <xs:enumeration value="home"/> 6 <xs:enumeration value="bizz"/> 7 <xs:enumeration value="mlto"/> 8 <xs:enumeration value="dlvy"/> 9 </xs:restriction> 10 </xs:simpletype> Listing 5.2: Auszug aus dem Invoice XML-Schema. Der Datentyp AddressType2Code wird auf sechs mögliche Wert beschränkt. Quelle: ISO Invoice Schema 5.3 Die Organisation Für den ISO20022 Standard sind vier Abteilungen innerhalb der ISO zuständig: Die Registration Management Group (RMG), die Registration Authority (RA),die Standards Evalution Groups (SEGs) sowie die Technical Support Group (TSG). Abbildung 5.11 ist zeigt den Aufbau der ISO Administration. Abbildung 5.11: Der Aufbau der ISO Veraltung Die folgenden Informationen stammen von [ISO12b]: Registration Management Group (RMG) Die Arbeitsgruppe besteht aus verschiedenen Experten aus industriellen Bereichen, Ländern 31 sowie Institutionen und hat die höchste Position innerhalb von ISO und dem dazugehörigen Regiestrieungsprozess 31 Australien, Brasilien, China, Dänemark, Deutschland, Finnland, Frankreich, Großbritannien, Italien, Japan, Kanada, Korea, Luxemburg, Niederlande, Norwegen, Österreich, Russische Föderation, Schweden, Schweiz,
63 5.4. BEURTEILUNG 49 und zählt zum technischen Komitee 68 - Finanz Service (TC68) 32. RMG überwacht den gesamten Registrierungsprozess inklusive die Arbeit der der anderen Registrieungskörper und legt dabei auch die Bereich der jeweiligen SEGs fest. Außerdem agiert sie als Schiedsgericht, falls Differenzen zwischen den anderen Parteien auftreten. Des weiteren prüft sie die Notwendigkeit von neuen Nachrichten oder auch die Modifikation bestehender Nachrichten und leitet diese an den zuständigen SEG weiter und gibt ebenfalls eine Expertise zu Modifizierungen des Standards ab. Geleitet wird die RMG von einem Convenor 33 und einem Vice-Convenor und deren Secretary. Standards Evaluation Groups (SEGs) Die Gruppen bestehen jeweils aus Experten aus den Finanz-Domänen. Sie haben zwei Aufgaben: Die erste Aufgabe besteht darin sicherzustellen, dass die betroffenen Parteien der Industrie über Entwicklungen informiert werden. Die zweite Aufgabe ist die Sicherstellung, dass die Bedürfnisse der Parteien befriedigt werden. Dies beinhaltet auch, dass keine Schranke gebildet werden, die eine zukünftige Teilnahme neuer Parteien verhindern würde. Die RMG hat im Zeitraum von 2005 bis 2008 fünf SEGs und deren Fokus definiert, dies sind Payments, Securities, Trade Services, FX (Foreign Exchanges) und Cards and related retail financial services. Technical Support Group (TSG) Die TSG unterstützt bei technischen Anfrage die ISO Institutionen, die Submitting Organisations und Anwender des Standards. Anfragen an die TSG werden ausschließlich über den Convenor, Vice-Convenor und dem Secretary gestellt. Registration Authority (RA) Die RA administriert das Financial Repository bestehend aus dem Data Dictionary und dem Business Catalogue. Dabei muss sichergestellt werden, dass die entwickelten Nachrichten der technischen Spezifikation unterliegen sowie und die dazugehörigen XML-Schemata. Des weiteren ist sie für die Seite mit Hilfe der ISO verantwortlich. Die RA darf keine eigenständige Entscheidungen treffen ohne vorher die RMG und die SEGs zu konsultieren. ISO übertrug SWIFT die Rolle der RA. 5.4 Beurteilung Die Beurteilung ist subjektiver Natur und basiert auf den gesammelten Erfahrungen dieses Arbeitsprozesses. Wie bereits angedeutet, gibt es eine Komplikation bei der von ISO angeboten Instanz der Invoice-Nachricht. Dies führt dazu, dass keine problemlose Validation möglich ist. Dies liegt am falschen Namensraum. Im XML Schema wird mit targetnamespace="urn:iso:std:iso:20022:tech:xsd:tsin " im Ziel-Instanzdokument der Namespace vorgegeben. Die Beispiel-Instanz verwendet allerdings als Target-Namespace Singapur, Südafrika, USA, Clearstream, Euroclear, Europäischen Zentralbank (EZB), European Payments Council (EPC), Fix Protocol Ltd, IFX Forum, ISDA / FpML, ISITC, SIIA / FISD, SWIFT und Visa. 32 Technical Committee 68 - Financial Services (TC68) 33 Obmann
64 50 KAPITEL 5. ISO urn:swift:xsd:tsin Ist dieser Namespace korrigiert, funktioniert die Validation. Das zeigt die Verletzung der Sorgfaltspflicht bei der Bereitstellung der Daten im Repository. Dies offenbart sich auch an zwei anderen Stellen. Die Suche für den Buisness Process Catalogue ist nicht auf dem neuesten Stand. So sind die Nachrichten der Geschäftsdomäne Trade Services Management nicht indexiert. Die Webseite von ISO verfügt für jede Geschäftsdomäne über ein Dashboard, dieses Dashboard gibt eine Übersicht über die bereits definierten Geschäftsprozesse und Candidate Messages. Das Dashboard für die Geschäftsdomäne Trade Services ist fehlerhaft, dort führen alle Verknüpfungen zu einem 404-Fehler. Trotz Meldung an die Registration Authority besteht der Fehler bis heute 34, es erfolgte auch bis heute keine Reaktion auf den Hinweis. Die Verwendung eines Repository als zentrale Anlaufstelle wird auch von ISO (ebxml) forciert. Ein Vorteil ist, dass Objekte, die nicht der Kontrolle von ISO unterfallen, trotzdem auf der Website indexiert werden, siehe Codeliste. Die ISO bietet nur eine FinalInvoiceV01-Instanz im Repository an. Auch eine Anfrage per Mail an die Registration Authority sowie an die verantwortliche Submission Organistation UN/CEFACT TBG5 ergaben keine weitere Instanz. Beide Organisationen antworteten, dass sie keine weitere Instanzen haben. Dies scheint jedoch fragwürdig, da die Entwicklung eines Schemas nur mit einer Testinstanz nicht sehr sicher ist. Im Laufe dieser Arbeit wurden mehrere Unternehmen kontaktiert, die mit diesem Standard arbeiten. Dabei teilte ein Unternehmen mit, dass SWIFT-Mitglieder Unterstützung von SWIFT erhalten. Eine solche Mitgliedschaft kostet allerdings mehrere tausende Euro, was eine nicht unerhebliche Barriere darstellt und so gerade KMU benachteiligt. Sollte ISO in allen finanztechnischen Bereichen Anwendung finden, wird mindestens eine weitere schlanke Syntax benötigt. Der algorithmische Handel hat im Jahr 2010 geschätzt 70 Prozent des Handelgeschehens ausgemacht 35, im Mittelpunkt dieser Handelsart steht der sogenannte Hochfrequenzhandel. Dieser Hochfrequenzhandel zeichnet sich durch Transaktionen im Millisekundenbereich aus, die eine geringe Marge im Vergleich zu anderen Handelsarten erwirtschaften. Allerdings macht die Menge der Transaktionen den Gewinn aus. Geschwindigkeit ist der zentrale Faktor dieser Handelsart, so hat sich der Begriff Co-Location gebildet. Co-Location beschreibt die Tatsache, dass die agierenden Handelssysteme möglichst nahe an Markt platziert werden, um Geschwindigkeitsvorteile zu erzielen. Wenn solche elementaren Methoden genutzt werden, wird höchst wahrscheinlich auch auf die Syntax der Nachrichten geachtet. XML bringt nicht nur Vorteile. Zu einem ist das Speichern als normales Textdokument speicherintensiv, zum anderem benötigt das Parsen der Tags einen gewissen Aufwand. Dadurch ist XML für diese Art des Handelns nicht geeignet und es werden solche Protokolle wie FIX verwendet. Sollte sich ISO in allen Bereichen zum Standard etablieren, wird eine weitere Syntax für diesen wichtigen Handelszweig benötigt. Ein weiterer Kritikpunkt ist die Handhabung von Codes bzw. Codelisten. Zu einem scheint die Verwendung von Excel-Worksheets sehr fragwürdig. XML ist ebenfalls prädestiniert für die Handhabung der Codes, es ist also die Verwendung eines proprietären Formates nicht nötig. Des weiteren fehlen Hintergrundinformationen zu den jeweiligen November vgl. [PDPG12] S. 37
65 5.4. BEURTEILUNG 51 Codelisten. So ist aus den Werten der INCO-Terms-Liste (ExternalIncoterms1Code) ersichtlich, dass es sich um die Codes der Internationalen Handelskammer handeln in der Version 2010, allerdings ist diese Information nicht hinterlegt. Sollte jemand dies nicht wissen, werden die Codes als ISO Schemacodes interpretiert, was ein potentiellen Konflikt in einer Nachrichten-Transformation darstellt könnte. Die Verwendung von hard wired Codes im XML Schema stellt ebenfalls einen Schwachpunkt dar. Wie bereits erwähnt, wurde das Schema nach dem Venetian Blind-Stil entworfen. Generell empfiehlt ISO in [ISO04c], diese Entwurfsart zu verwenden. Venetian Blind zeichnet sich dadurch aus, dass die Elemente lokal und die Typen global definiert werden. Daher sind die Typen wiederverwendbar und das gesamte Schema hat eine konstante Strukturtiefe 36. Dies hat aber den Nachteil, dass durch die mögliche große Menge an globalen Definitionen das XML- Schemadokument unübersichtlich und zusammenhanglos erscheint im Falle der Verwendung eines normalen Editors wie XMLMind oder auch Notepad++. Allerdings kann man diese Probleme mit aktuellen XML-Tools wie dem kostenlosen Eclipse (mit dem Web Tools Plattform-Plugin) oder dem kommerziellen XMLSpy umgehen. Durch Venetian Blind wäre es auch möglich die Business Components in separaten XML-Schemta zu kapseln und durch Import der einzelnen Schemata wieder zu verwenden, wie es auch UBL macht. Die ISO definiert in jedem Schema die einzelnen Bausteine neu. Zum Beispiel haben die Business Messages Invoice Financing Request und Financial Invoice unter anderem die Geschäftskomponente NamePrefix1Code identisch definiert. Sollte nun eine weiterer Ausprägung von NamePrefix hinzugefügt werden, weil Doktor, Madam, Miss und Mister nicht mehr ausreichen, müssen alle Schemata aktualisiert werden, anstatt nur das eine betroffene Schema, wie es bei UBL mit der UBL-CommonAggregateComponents-2.0.xsd der Fall ist. Es wird also unnötiger Weise hoch versionisiert. Hierbei stellt sich auch die Frage, warum nur vier Werte erlaubt sind, Professor ist zum Beispiel nicht möglich, auch sind die Namens-Prefixe durch den amerikanischen Sprachraum geprägt, was für einen international Standard fragwürdig ist (so ist Sultan nicht möglich, obwohl der arabische Sprachraum einen wichtigen Platz in der Finanzwelt einnimmt). Allerdings sollten der Vorteil bezüglich der Implemenations-Sicht nicht unerwähnt lassen. Durch eine feste Vorgabe der möglichen Werte müssen keine besonderen Vorsichtsmaßnahmen wie im Fall von UBL getroffen werden. Häufig wird in CRM bzw. ERP Software die Prefix-Festlegung durch Dropdown-Auswahl realisiert, wie es der Londoner Stadtbezirk City of Westminter in Abbildung 5.12 verwendet. 37. Auch die Tatsache, dass Codes existieren ist ebenfalls positiv zu bewerten, da es mitunter eine gemeinsame Übereinkunft von Codelisten ersparen kann. Allerdings müssen die Werte aus den Listen nicht immer genommen werden. Die ISO bietet auch die Möglichkeit, eigene Informationsschemata zu verwenden mit Hilfe des GenericOrganisationIdentification1-Elementes. Dieser Block speichert individuelle Werte zu der Identifikation-Nummer, zum Namen sowie zum Besitzer des Schemas. Besonders positiv hervorzuheben ist die Dokumentation der einzelnen Nachrichten. Jedes einzelne Element ist bequem in einem Message Definiton Report nach zuschlagen. UBL hingegen zwingt mehrmals zum Hin-und Herspringen in der Dokumentation. Des weiteren kommt die Frage auf, wieso nur maximal zwei Lieferadressen mittels ShipTo und UltimateShipTo möglich sind. Es ist nicht verständlich, warum bei gleichzeitiger Existenz eines Lieferadressenketten-Konzeptes nur maximal zwei Stationen eingetragen wer- 36 vgl. [Gre12] S
66 52 KAPITEL 5. ISO Abbildung 5.12: Beispiel eines Versuches, alle möglichen Fälle mittels Dropdown abzufangen - Quelle: City of Westminter mywestminster/account/sign-up/step-1/ - Stand 01. Dezember 2012 den können. Es sollte auch angemerkt werden, dass der ISO Standard ebenfalls ein Repository besitzt, welches wie in ISO nur über eine Website realisiert wird. Dies hat den Vorteil, dass die Daten theoretisch von überall aus erreichbar sind. Leider werden diese Ressourcen für eine Absicherung nicht gespiegelt. So scheiterte ein Zugriffsversuch auf das ISO Repository am 04. Juni 2012 an fehlerhaften Verlinkungen, was mit einer 404-Fehlermeldung quittiert wurde. Ein schriftlicher Hinweis an die ISO Registration Authority blieb bis heute unbeantwortet. Allerdings waren die Verlinkungen bei einem erneuten Zugriffsversuch am 11. Juni 2012 wieder funktionsfähig. Dieses Ereignisse wirkt insoweit befremdlich, da laut [Tea10] ca. 7 Millionen ISO Nachrichten tagtäglich weltweit versendet werden. Negativ zu bewerten sind auch die Kosten der ISO Norm. Alle sechs Teile kosten zusammen circa 580 Euro. Die Codelisten werden in unregelmäßigen monatlichen Abständen aktualisiert, was positiv zu bewerten ist. Die ISO orientiert sich nicht an der gängige vcard-format für das Kontaktkonstrukt. So kann nur Telefonnummer, Mobilnummer, Faxnummer, adresse sowie ein sonstiges Textfeld festlegt werden. Andere Kontaktinformationen wie eine Skype-Adresse oder eine weitere Mobilnummer sind nur durch Freitext im Nachrichtenelement Other möglich. Dadurch ist nur bedingt eine automatische Verarbeitung möglich. Der Aufbau der ISO Verwaltung beherbergt die Gefahr, dass der Prozess der Entwicklung schwerfällig werden kann.
67 KAPITEL 6 Vergleich ISO zu UBL Dieses Kapitel vergleicht ISO und UBL anhand gemachter Erfahrungen im Mapping- Prozess. Um Missverständnisse zu vermeiden werden kurz die Identifizierungen der Standards und deren Zusammenhang wiederholt. UNIFI wurde als ISO spezifiziert. ISO ist der Vorgänger von ISO ebxml wurde von der ISO als ISO spezifiziert. ISO und ISO stehen laut einer ISO in keiner Verbindung. 1 Die nachfolgende Liste gibt die Punkte wieder, die in diesem Kapitel behandelt werden. Dabei ist zu beachten, dass dies kein vollständiger Vergleich ist und daher nicht alle Unterschiede abgedeckt werden. Die Punkte der Aufzählung wurden im jeweiligen Textabschnitt dick hervorgehoben. Gemeinsames Datenmodell Unterschiedliche Bezeichnungen Unterschiedliche Pflichtangaben Variation der Bausteine Schema-Entwurf Verteilung der Daten Bibliothek Codelisten vcard-format Syntax-Struktur 1 Antwort von ISO auf die Anfrage, ob die beiden Standards in einer Verbindung stehen. 53
68 54 KAPITEL 6. VERGLEICH ISO ZU UBL Community Customizing Logische Inkonsistenzen Beide Standards verwenden semantische Bausteine für die Konstruktion der Nachrichten. UBL-Dokumente sind E-Business-Dokumente, wobei ISO Dokumente von finanztechnische Bedeutung sind. Ein gemeinsamer Schnittpunkt beider Standards ist die elektronische Rechnung. Die Rechnung von ISO sowie die von UBL basieren auf dem Cross Industry Invoice (CII) Version 2.0 Modell. Diese Modell der UN/CEFACT ermöglicht es, dass der Waren- oder auch Geschäftsfluss mit dem Finanzfluss verbunden werden kann. Durch dieses Modell ist eine gegenseitige Transformation des UBL- und ISO Rechnungsdokumentes bedingt möglich. Dies wird deutlich beim Matching, da ähnliche semantische Objekte mit vergleichbaren Strukturen existieren. Allerdings verwenden beiden Standards verschiedene Bezeichnungen,was das Auffinden der Gemeinsamkeiten erschwert. Dies zeigt sich zum Beispiel in der Definition des Rechnungstellers. In der ISO ist er eindeutig mit dem Begriff Invoicer definiert, in UBL hingegen wird der Begriff AccountingSupplierParty verwendet. Erst die UBL-Spezifikation verrät, dass diese Partei die Rechnung ausstellt, was von Vor- und Nachteil sein kann. Ein Nachteil ist die Verwendung von nicht offensichtlichen Begriffen, dies hat unnötige Recherche zu Folge. Allerdings zwingt die Recherche die korrekte Interpretation und verhindert eine zu voreilig falsch getroffene Verwendung. Abbildung 6.1 stellt die Hauptakteure gegenüber inklusive deren Bezeichnung, deren Kardinalität und deren Definition. Obwohl beide Nachrichten auf CII basieren, haben sie unterschiedliche Pflichtangaben. ISO kennt sechs Hauptakteure, UBL hingegen nur fünf. Dies sind der Rechnungssteller, der Rechnungsempfänger, der Käufer, der Verkäufer, der Zahlungsempfänger sowie nur in ISO existent der Zahlungspflichtige. UBL kennt nur zu einem Teil das semantische Konstrukt des Zahlungspflichtigen, UBL bietet wohl keine eigenständige Einheit an, verwendet allerdings im ABIE PaymentMeans das ASBIE PayerFinancinal- Account. Im Invoice-Dokument von ISO ist der Käufer und der Verkäufer jeweils eine Mindestangabe, in UBL hingegen ist der Rechnungssteller und der Rechnungsempfänger Pflicht. Durch diesen Umstand ist eine Transformation einer ISO Rechnung in die originäre UBL-Rechnung nur möglich, wenn der Rechnungssteller, der Rechnungsempfänger, der Käufer und der Verkäufer angegeben sind. CII hingegen verwendet für keinen dieser Akteure eine Pflichtangabe. So sind alle ISO Rechnungsdokumente, die nur die Mindestangaben erfüllen, nicht in ein originäres UBL-Rechnungsdokument transformierbar. Allerdings kann auch die Möglichkeit bestehen, dass bei Fehlen von Invoicer und Invoicee im ISO Dokument, diese Rollen automatisch von Buyer und Seller übernommen werden. Ist dies der Fall, ist eine Übersetzung diesbezüglich nicht problematisch. Für den Fall des Zahlungspflichtigen wurde eine weitere Hauptperson im Extension Content Type (Extension Element fortan genannt) erstellt. Da das Dokument vergrößert wird, entsteht so ein UBL Compatibility Dokument. Um das UBL-Schema anzupassen, wird das ASBIE PayeeParty kopiert und PayerParty umbenannt und in das UBL Extensions- Element inkludiert, da beide Parteien gleich aufgebaut sind. Beide Standards gehen unterschiedlich mit der Handhabung der semantischen Bausteinen um. UBL definiert für ein semantisches Objekt ein Konstrukt mit allen möglichen Anga-
69 Abbildung 6.1: Die Haupt-Akteure einer Rechnung in der ISO Rechnung und der UBL-Rechnung 55
70 56 KAPITEL 6. VERGLEICH ISO ZU UBL ben. ISO hingegen verwendet Varianten für dieses semantische Objekt. Als Beispiel soll hier die Adresse dargestellt werden: UBL kennt nur das ABIE cac:address für ein Adresse oder auch Anschrift, ISO hingegen kennt für dieses Objekt acht verschiedene Geschäftskomponenten (PostalAddress1-PostalAddress8), wobei diese Varianten sich nur zum Teil in wenigen Elementen unterscheiden. PostalAddress1 und PostalAddress8 sind sogar identisch und daher redundant im Repository. Dabei ist zu beachten, dass die Angaben in den Konstrukten zum Teil optional sind. So wäre es möglich, wie UBL nur eine Ausprägung der PostalAddress mit allen möglichen Elementen zu erstellen. Allerdings ist diese Variation für eine Nachrichtentransformation besser zu bewerkstelligen. Wenn ein Dokument beispielsweise Postaladdress2 verwendet, ist die Transformationenvorbereitung geringer, da die Variante 1 aus acht Nachrichtenkomponenten besteht, Variante 2 hingegen nur aus fünf. Dies macht die zu mappende Menge geringer, da nur eine Teilmenge übersetzt werden muss. Beide Standards verwenden XML als Syntax: ISO verwendet für den Schema- Entwurf den Venetian-Blind-Stil, UBL hingegen verwendet den Garden-of-Eden-Stil. Beide Stile ermöglichen eine Definition der elementaren Bausteine und so eine maximale Wiederverwendung. Der Garden-of-Eden-Stil definiert alle Elemente als global, was eine Vielzahl an validen XML-Dokumenten-Arten ermöglicht. Der Venetian-Blind-Stil hingegen definiert ein globales Element, was dazu führt, dass auch nur eine valide XML-Dokument-Art existiert. Vor- und Nachteile dieser Entwurfs-Schemen werden hier nicht behandelt. ISO und UBL unterscheiden sich auch mit der Verteilung der Daten. Die ISO verwendet eine Repository, UBL hingegen verwendet ein Support Package. Der Vorteil des Support Packages liegt in der Verfügbarkeit aller Nachrichten und optionalen Daten. Dies verhindert ein Übersehen möglicher Daten. Allerdings ist so das Aktualisierungsverhalten in gewissen Maßen träge. Elemente des Repositorys können jederzeit aktualisiert werden, UBL-Erneuerungen werden in einem Update-Paket veröffentlicht. So existieren im Update Paket Delta fünf verschiedene Aktualisierung. Daraus folgt, dass UBL fünf Posten angesammelt hat, anstatt stufenweise zu aktualisieren. Tabelle 6.1 stellt den UBL Schlüsselbegriffe in der englischen Bezeichnung die ISO Pendants gegenüber. Die überstehenden ISO Begriffe werden hier nicht erwähnt. ISO Begriff UBL Begriff Data Type Data Type Document Type Nachrichtendefinition Aggregate Business Information Entity (ABIE) Message Component (M- Component) Association Business Information Entity (ASBIE) Business Association (B- Association) Basic Business Information Entity (BBIE) Message Element (M- Element) Tabelle 6.1: Gegenüberstellung der Begriff der äquivalente Objekte von ISO und UBL ISO definiert alle XML-Typen in den jeweiligen Nachrichten und verwendet kei-
71 57 ne gemeinsame Bibliotheken. Dadurch fällt die Arbeit mit dem Schema leichter als mit UBL, da kein Wechsel zwischen den Dokumenten nötig ist. Beide Standards bieten hinreichende Unterlagen für das Arbeiten mit den Standards, wie Definitionen, Rollenerklärungen und Customization. Allerdings sind die ISO Normen im Gegensatz zu UBL kostenpflichtig. UBL hat die Codelisten in einer externen Codelists vorgeben. Diese haben die Endung.gc oder.xsd, XML als Syntax und ermöglichen so eine leichteres parsen als ISO Die ISO speichert mitunter die möglichen Werte in einer Microsoft Excel-Liste ab. Zum Beispiel ist für das XML-Element TpCd die Codeliste ExternalDocumentType1Code vorgegeben 2. UBL verwendet Genericode 3 Codelisten, was offensichtlich einen Verarbeitungsvorteil bringt beim Parsen. So kann nur UBL die Werte mittels XML-Schema validieren. Allerdings bietet ISO mehr Listen an als UBL. UBL bietet zehn Default Lists mit Inhalt an, ISO hingegen 33 Codelisten. Dabei aktualisiert ISO in kurzen, unregelmäßigen Abständen diese Liste. ISO erlaubt Codes, die in den Codelisten vorkommen, eine maximale Länge von vier Stellen. Nichts desto trotz fehlt eine Brücke zwischen dem Schema und den Codelisten bei ISO 20022, sodass eine manuell erstellte ISO Codeliste nicht zur XML-Validierung beitragen kann. Beide Standards haben sich nicht an das etablierte vcard-format gehalten, was die Situation einer Kontaktaufnahme erschwert. ISO strukturiert die XML-Dokumente unnötigerweise. Diese Strukturierung mag wohl dem menschlichen Betrachter helfen, bringt aber auch mehr Aufwand mit sich. So ist die DOM-API in JAVA relativ langsam und speicherintensiv, da die API den kompletten Baum im Speicher abbildet. Durch unnötige Tiefen wird dadurch der Baum komplizierter und es benötigt mehr Rechenaufwand. Beide Standards bieten einen Service, damit Benutzer sich gegenseitig helfen können. SWIFT verwendet dafür ein Forum, UBL ein Forum sowie eine Mailingliste. Beide Standards kennen das Konzept des Customizing. ISO bietet in einigen Dokumenten die Verwendung von Supplementary Data, was dem Extension Element von UBL ähnelt. In ISO können aber nur einige wenige Dokumente diese zusätzlichen Informationen beherbergen im Gegensatz zu UBL. Des weiteren wird das Supplementary Data von Experten begutachtet, bevor es im Repository indexiert wird und es ist nicht sicher, ob der Nachrichtentyp dann auch offiziell modifiziert wird. In UBL hingegen ist eine vergleichbare Kontrollinstanz nicht existent. Dies kann zu fehlerhaften Ergebnisse führen, ist aber im Gegenzug nicht mit einem administrativen Zeitaufwand verbunden. ISO verwendet das XML-Schema-Element CHOICE, diese Element ermöglicht die Aussage: Entweder-Oder, UBL untersagt dies. Dadurch können logische Inkonsistenzen im UBL-Dokument herrschen (siehe 4.4), bei ISO hingegen nicht. Allerdings existieren auch in ISO logische Inkonsistenzen. ISO ermöglicht in der Regel die Angabe verschiedener Währungsbeträge, allerdings ist es auch möglich, eine Währung mehrmals anzugeben mit unterschiedlichen Beträgen. Dies wird bei der XML- Schemavalidierung nicht erkannt und ist daher sehr problematisch. Beide Standards sind etabliert und haben eine starke Bedeutung. ISO wird für SEPA verwendet und soll den Standard ISO ablösen. UBL hingegen wird europaweit für Initiativen in öffentlichen Sektoren verwendet. Durch diese Ausbreitung und der 2 Siehe Unterabschnitt Siehe Unterabschnitt 4.3.4
72 58 KAPITEL 6. VERGLEICH ISO ZU UBL Tatsache, dass beide auf dem selben Modell basieren, ist ein Zusammentreffen der Nachrichten wahrscheinlich.
73 KAPITEL 7 Ontologien Dies Kapitel stellt das Konzept der Ontologien vor und die Verwendung. Zuerst wird in Abschnitt 7.1 das Konzept der Ontologien vorgestellt. Darauf folgt im Abschnitt 7.2 die Begründung für die Verwendung von Ontologien für die Datenrepräsentation. Abschnitt 7.4 stellt Web Ontology Language (OWL) als Sprache für Ontologien vor. Abschnitt 7.5 erklärt, wie eine Ontologie entwickelt wird, worauf in Abschnitt 7.6 eine Domänenontologie erstellt wird. Als Abschluss des Kapitels wird in Abschnitt 7.7 ein Fazit gezogen. 7.1 Ontologien Eine Ontologie ist eine Wissensrepräsentationssprache, die auch als Datenmodell dienen kann und syntax unabhängig ist. Durch Bildung von Relationen und Eigenschaften innerhalb einer Ontologie sind logische Rückschlüsse sowie Ableitungen möglich. Die bisher behandelten Nachrichtenstandards verfügen alle über die Eigenschaft, dass die Daten in einer Nachricht für datenverarbeitende Systeme keine Semantik besitzen, Informationen haben keine Bedeutung. Für einen menschlichen Betrachter haben Informationen in einem Dokument in der Regel jedoch meistens einen Sinn. So kann ein Betrachter den Sinn hinter dem XML-Tag <Fahrzeug> Automobil </Fahrzeug> ableiten. Er kennt die Bedeutung die hinter beiden Begriffen steht, so weiß er das ein Automobil ein Fahrzeug ist. Ein datenverarbeitendes System kann allerdings nicht auf dieses Wissen zurückgreifen. Für dieses System besitzt der Ausdruck eher folgende Natur: < > </ >. Dabei weiß es nur, dass und in einer Verbindung stehen, mehr nicht. Dem menschlichen Betrachter geht es in diesem Fall ebenfalls so. Eine Ontologie behebt diesen Missstand durch Angaben von Relationen. So würde ein Autor einer Ontologie folgende mögliche Relation festlegen: Automobil ist-eine-unterklasse-von Fahrzeug beziehungsweise ist-eine-unterklasse-von Dadurch weiß das System, dass eine Klassenbeziehung existiert, allerdings auch nicht mehr. Es kennt die Bedeutung eines Autos immer noch nicht. Durch Bildung weiterer Relationen wie Klassenzugehörigkeit und Eigenschaft, kann so ein Objekt logisch konstruiert werden. Ontologien sind also eine Art zusätzliche Informationsschicht bestehend zu Daten. Sie ermöglichen einem System (in der 59
74 60 KAPITEL 7. ONTOLOGIEN Regel Agenten genannt) eine automatische Verarbeitung des Wissens. Ontologien haben Ihren Ursprung in der Philosophie und sind ein Teil der Metaphysik, die sich mit der Lehre des Seins beschäftigen. Dieser Charakter der Realitätsabbildung wurde durch die Informatik übernommen und lässt sich wie folgt beschreiben: Eine Ontologie ist eine formale, explizite Spezifikation einer gemeinsamen Konzeptualisierung 1 [Den11] spezifiziert diesen Begriff weiter, indem er die einzelne Merkmale hervorhebt 2, eine Ontologie ist danach: Die Nutzung gemeinsamer Symbole und Begriffe im Sinne einer Syntax, die gemeinschaftliche Übereinkunft deren Semantik, die Klassifikation der Objekte in Form einer Taxonomie 3, ein Verteilung der Begriffe und deren Relationen bei gleichzeitiger Festlegung der Regeln und Definitionen darüber, welche Relationen sinnvoll und erlaubt sind. Diese Relationen stellen also Metadaten da, dass heißt Daten über Daten. Die Informationen folgender Textpassage stammen aus [Den11] Seite 13f. Grundlagen der Semantik und daraus folgende Ontologien, sind Metadaten. Dies sind Daten über Daten und werden in drei verschiedene Kategorien eingeteilt, die extrinsischen, die intrinsische und die qualitativen Metadaten. Die wahrscheinlich bekanntesten Metadaten sind die extrinsischen, hier wird ein Dokument anhand von zusätzlichen Attributen beschrieben. Als prominentestes Beispiel seien die Dokumente in einer Bibliothek genannt. Hier werden Bücher oder sonstige Dokumente mittels spezieller Charakteristika beschrieben, wie zum Beispiel Autor, Ausgabe, Titel oder Verlag. Bei den intrinsischen Metadaten handelt es sich ein Wörtermenge, die das Dokument repräsentativ beschreibt. Als Beispiel sei die vorliegende Arbeit genannt; diese würde mit den intrinsischen Metadaten beschrieben UBL, ISO 20022, Mapping, Transformation, XML, EDI, Computer, XSD, genial, Ontologie, RDF, XSLT, XML werden. Diese Deskriptoren oder auch Keywords bestehen in der Regel meist aus Nomen, es können aber auch Verben oder Adjektive verwendet werden. Die dritte Kategorien sind qualitativen Metadaten. Diese Daten beschreiben eine andere Ebene der Information. Anstelle des Inhalts des Dokuments wird die Quelle beschrieben. Zum Beispiel wird die Vollständigkeit, die Vertrauenswürdigkeit, die Aktualität und der Wahrheitsgrad der Quelle beschrieben. Auch bei interoperablen Metadaten müssen zuerst Konventionen festgelegt werden, damit die kommunizierenden Partner sich verständigen können. Diese Charakterisierung der Metadaten findet auch in den Ontologien Verwendung 4, so werden die Objekte 5 per Eigenschaften beschrieben. Intrinsische Eigenschaften 1 [Den11], S [Den11], S Eine Taxonomie ist ein Klassifikation verschiedener Objekte anhand spezieller Charakteristika 4 vgl. [Stu11], S. 169f 5 Klassen oder auch Konzepte, es werden im Gebiet der Ontologie verschieden Begriffe für die selben Entitäten verwendet
75 7.2. ONTOLOGIE ALS DATENREPRÄSENTATION 61 sind fest mit einem Objekt verbunden und charakterisieren dieses. Die extrinsische Eigenschaften sind hingegen flexibel und können sich verändern ohne das Objekt grundlegend zu verändern. Allerdings ist die Unterscheidung beider Eigenschaften nicht immer klar, je nach Standpunkt oder Abstraktionsgrad. Ontologien können durch die Abgeschlossenheit ihrer Modelle unterschieden werden. Es existieren dabei zwei gegenteilige Modelle, das sogenannte Closed World-Modell sowie das Open World-Modell 6. Bei dem Closed World-Modell sind alle relevanten Methoden im Modell angegeben. Ist in einer Ontologie angegeben, dass ein Fahrzeug zwei Räder besitzt, können nur Motorräder existieren, Automobile sind nicht mehr möglich. Hingegen geht das Open World-Modell von der Annahme aus, dass ein Modell nicht alle relevanten Informationen besitzt und jederzeit erweitert werden kann. Besitzt die Ontologie die Information, dass ein Fahrzeug zwei Räder hat, bedeutet dies, dass ein Fahrzeug mindestens zwei Räder besitzen muss, Automobile sind daher nicht ausgeschlossen. Allerdings können in Open World auch Aussagen getroffen werden, welche die Eigenschaften festlegen und so explizite Aussagen treffen und ein Modell abschließen. Neben den World-Modellen existieren noch weitere Einstufungen der Ontologien. So wird der Typ der Ontologien durch den Fokus der abgebildeten Welt beschrieben 7. Toplevel-Ontologien 8 beschreiben grundlegende Konzepte der Welt, wo hingegen Domänen- Ontologien nur spezielle Bereiche abbilden Ontologie als Datenrepräsentation Die Verständigung verschiedener Nachrichtenstandards, beziehungsweise die wechselseitige Überführung von Nachrichten benötigt einen gewissen Aufwand, je nach dem wie unterschiedlich die Standards sind. Um diese Heterogenität der einzelnen Standards zu überwinden, ist eine Transformation der Quellnachricht in die Zielnachricht notwendig. Die Abbildung von der Zielnachricht zur Quellnachricht ist bei einer Kommunikation zwischen zwei verschiedenen Teilnehmern mit unterschiedlichen Standards vergleichsweise unproblematisch, da die Pflege dieser Verbindung überschaubar ist. Erweitert sich die Verbindung um weitere Gesprächspartner mit wiederum abweichenden Standards zum einem Netzwerk (Graph), wird die Pflege und Aufrechterhaltung dieses Netzwerkes für alle Teilnehmer kostspielig und ab einer bestimmten Größe schwer skalierbar. Je nach Größe und Aufstellung eines Teilnehmers sind die Faktoren unterschiedlich gewichtet. Das bedeutet, dass ein vollständiges Netzwerk aus n-teilnehmern ( n k) -Verbindungen besitzt und O(n 2 ) Abbildungen benötigt. Abbildung 7.1 ist eine Darstellung der Kommunikationswege der verschiedenen Standards. Dabei ist zu beachten, dass ein Nachrichtenstandard mehrere verschiedene Nachrichten anbietet. Daraus folgend eine Vielzahl von Abbildungen alleine zwischen zwei Standards. Ändert sich nun ein Standard, müssen die Abbildungen aller anderen Standards überarbeitet werden. Ein zentrale Datenrepräsentation welche die Informationen aus der jeweiligen Nachrichtensyntax extrahiert und sich einverleibt, benötigt bei einer Änderung nur die Anpassung zweier Schnittstellen. Die erste Schnittstelle integriert die Daten der Quellnachricht 6 vgl. [Stu11], S. 32f 7 vgl. [Stu11], S Auch bekannt als Upper-Level- oder Foundational-Ontologien. 9 Für weitere Klassifizierungen bitte [Stu11] Seite 54f beachten.
76 62 KAPITEL 7. ONTOLOGIEN Abbildung 7.1: Ein vollständiges Netzwerk bestehend aus verschiedenen Nachrichtenstandards. in die Ontologie, die zweite Schnittstelle exportiert die Daten der Ontologie in die Quellnachricht. Dabei sollte allerdings erwähnt werden, dass die Ontologie notfalls modifiziert werden muss wegen neuen Annahmen (siehe 63 P. Explizite Darstellung von Annahmen ) oder auch wegen Informationen mit neuer semantischer Bedeutung. Abbildung 7.2 zeigt die Verwendung einer Ontologie als universelles Datenmodell. Ontologien zeichnen sich Abbildung 7.2: Ein Netzwerk bestehend aus verschiedenen Nachrichtenstandards, die eine Ontologie als gemeinsames Datenmodell verwenden. nicht nur durch eine mögliche Verwendung als eine Datenmodellierung aus, sondern auch durch das Angebot von Inferenz- und Integritätsregeln. Diese Regeln ermöglichen logische Ableitungen.
77 7.3. EIGENSCHAFTEN EINER ONTOLOGIE ALS GEMEINSAME DATENREPRÄSENTATION Eigenschaften einer Ontologie als gemeinsame Datenrepräsentation Ontologien finden seit den 80er Jahren auch in der Datenintegration Anklang. So werden heterogene Quellen mittels Ontologien zusammengebracht, um strukturelle und semantische Konflikte zu überwinden. Dabei erfüllen Ontologien drei wichtige Zwecke 10 : Neutrale Darstellung von Domänenstrukturen Heterogene Systeme verwenden in der Regel für sich optimierte Strukturen. Diese Strukturen sind nicht ohne weiteres mit anderen Strukturen kompatibel, so sind die Daten und deren Semantik innerhalb des jeweiligen Formates gefangen. UBL 2.0 verwendet eine proprietäre XML-Syntax, genauso wie ISO Ontologien besitzen eine anwendungsunabhängige und neutrale Struktur zur Beschreibung von Informationen und dienen als universelles Datenmodell. So kann eine neutrale Struktur innerhalb der Ontologie erstellt werden, die sich jeweils die Informationen der heterogene Struktur einverleibt. Die Integration einer Nachricht in eine Ontologie löst die Daten mit ihrer Semantik von der Syntax. Explizite Darstellung von Annahmen Heterogene Informationsquelle können mitunter eigene Annahmen beziehungsweise Werte mit eigenen Definitionen beherbergen. Im Gegensatz zu einer einfachen Konvertierung von Werten (wie zum Beispiel Kilometer in Meilen) existieren Annahmen, die durch verschiedene Faktoren bestimmt werden. Beispiel: Zwei Immobilien-Datenbanken sollen in eine gemeinsame Immobilien-Ontologie integriert werden. Dabei verwendet die eine Immobiliendatenbank eine proprietäre Skala (Annahme) für die Bewertung von Wohnlagen. Sehr gut falls eine Schule, ein Supermarkt und ein Arzt in der unmittelbaren Nachbarschaft liegen. Befriedigend wenn es ein reines Wohngebiet ist, Mangelhaft falls es ein Gefängnis als Nachbar existiert. Dieses Bewertungssystem ist für das andere Immobiliensystem unbekannt. Diese Bewertungssystem kann aber durch eine Ontologie bestimmt werden, dadurch erfolgt eine automatische Einteilung der Objekte des anderen Systems. Konsistenzprüfung Eine Komponente der Ontologien ist die Logik. Mit logischen Ableitungen können Fehler in Datenmodellen sichtbar gemacht werden. In Anlehnung an das vorherige Beispiel besitzt das Immobiliensystem nun ein Wohnobjekt, welches mit einem Sehr gut bewertet wurde, allerdings ist ein direkter Nachbar ein Gefängnis. Dies ist ein Widerspruch in der Logik und durch eine Ontologie erkennbar. Im Grunde ist dies vergleichbar mit einer Validierung einer XML-Instanz mit einem XML-Schema, nur auf einer semantisch höheren Ebene. 7.4 OWL als Ontologiesprache In diesem Abschnitt wird die Sprache Web Ontology Language (OWL) sowie deren Versionen kurz vorgestellt 11. OWL wurde vom W3C im Rahmen des Semantic Web entwickelt und wurde im Jahr 2004 als eine Recommendation 12 vorgestellt. Im Jahr 2009 folgte OWL 2, wobei OWL 2 eine Erweiterung von OWL 1 ist. 10 vgl. [Stu11], S. 220f 11 Für tiefergehende Informationen bitte [Deb04] beachten. 12 Diese Empfehlung gleicht einer Norm. Die offizielle Defintion ist wie folgt: A Recommendation reflects consensus within W3C, as represented by the Director s approval. W3C considers that the ideas or technology
78 64 KAPITEL 7. ONTOLOGIEN OWL 1 Der Vorläufer von OWL ist RDF bzw. RDF Schema (RDFS). RDF(S) bietet die Möglichkeit, Taxonomien und einfache Ontologien zu erstellen, allerdings benötigt die Repräsentation komplexerer Zusammenhänge Ontologien, die über der Aussagefähigkeit von RDF(S) liegen. 13. OWL 1 wird in drei verschiedene Arten (OWL Lite, OWL DL und OWL Full) nach Aussagekraft klassifiziert, wobei die Klassifikation die Mächtigkeit charakterisiert. Die Sprachversionen stehen dabei in Teilmengen-Beziehungen, OWL Lite ist eine echte Teilmenge von OWL DL und OWL DL ist eine echte Teilmenge von OWL Full. Folgende Informationen stammen von [Deb04] 14 OWL Lite Diese Sprache eignet sich für einfache Klassifikationshierarchien mit einfachen Beschränkungen. So sind zum Beispiel Kardinalitäten erlaubt, allerdings sind diese auf 0 und 1 beschränkt. Durch solch eine Beschneidung der Mächtigkeit und die daraus resultierende Minderung der Komplexität ist ein positiver Einfluss auf die Effizienz des Reasoners 15 gegeben. Weiterhin soll die Entwicklung für Applikationen erleichtert werden sowie eine vereinfachte Migration von Thesauri und Taxonomien. OWL Lite beinhaltet wiederum nur eine echte Teilmenge von RDF. OWL DL Diese Sprache beinhaltet komplett die OWL Lite. DL steht für Description Logics und ist eine entscheidbare terminologische Logik. Durch diese Logik ist eine stärkere Ausdruckskraft möglich, welche die Entscheidbarkeit und die Verarbeitbarkeit garantiert. Wie OWL Lite-Dokumente sind OWL DL-Dokumente korrekte RDF- Dokument, allerdings herrscht auch hier eine echte Teilmengenbeziehung. OWL Full Dies ist die ausdruckskräftigste Sprache, die allerdings einen hohen Preis hat - sie garantiert weder Entscheidbarkeit noch Vollständigkeit. Neben der maximalen Ausdrucksstärke bietet sie ebenfalls noch die syntaktische Freiheit von RDF. OWL Full ist eine Erweiterung von RDF, ohne das RDF beschnitten wird, wie es bei OWL Lite und OWL Full der Fall ist. Daraus folgt, dass jedes RDF-Dokument eine OWL Full-Dokument ist, aber nicht automatisch eine OWL Lite- oder OWL DL-Dokument. Durch den Makel der Unentscheidbarkeit und Nichtvollständigkeit existieren keine Reasoner, die OWL Full vollständig implemtiert haben. Für OWL Ontologien wird in der Regel XML verwendet, allerdings existiert neben XML auch weitere Syntax-Arten - Functional Syntax, Notation3 (N3) und Turtle und Manchester Syntax. OWL 2 Im Jahr 2009 verabschiedete das W3C die neue OWL-Version - OWL 2. Wobei OWL 2 eine Art Upgrade von OWL 1 ist und neue Features bietet, wobei es vollkommen abwärtskompatibel zu OWL 1 ist. Neben der mächtigeren Ausdrucksstärke, gibt es nun OWL specified by a Recommendation are appropriate for widespread deployment and promote W3C s mission. Every document must clearly indicate its maturity level. 13 [Den11], S. 127 und [HKRS07], S Abschnitt Software, die Schlüsse mit Hilfe von Logik aus Ontologien und deren inkludierten Sachverhalte ziehen kann
79 7.5. DIE ENTWICKLUNG DER ONTOLOGIE ALS KONZEPTUELLES DATENMODELL - THEORIE65 2-Profile 16 sowie eine neue Syntax OWL 2 Manchester Syntax 17. Weiterhin wurden einige Beschränkungen bei OWL DL gelockert. Diese neue Profile sind Sub-Sprachen in der Berechnungslogik und ermöglichen unterschiedliche Komplexitäten. Diese Profile sollen Ontologie-Entwicklern die Arbeit erleichtern, indem sie auf verschiedene Fälle angepasst sind. So ist das OWL 2 EL-Profil hilfreich, wenn Ontologien mit einer großen Anzahl von Eigenschaften und/oder Klassen entwickelt werden sollen, wobei eine polynomielle Laufzeit garantiert ist. Das OWL 2 QL-Profil ist wiederum auf eine große Anzahl von Instanzen angelegt. OWL 2 RL hat die Skalierbarkeit des Reasoning als Ziel, ohne die Ausdrucksstärke zu opfern. Die drei genannten Profile sind keine gegenseitigen Teilmengen von einander wie dies der Fall ist bei OWL Lite, DL und Full. Es gibt noch weitere Profile, zum Beispiel existieren mehrere Varianten von OWL 2 QL. Die Sprachversionen von OWL 1 können ebenfalls als OWL 2-Profile verstanden werden. 7.5 Die Entwicklung der Ontologie als konzeptuelles Datenmodell - Theorie Bevor die theoretische Ontologie-Entwicklung detailliert beschrieben wird, müssen einige Formalismen geklärt werden, die später in diesem Abschnitt genannt werden. Konzepte (Concepts) sind Klassen (Classes), wobei Klassen Mengen von Instanzen (Instances) mit ähnlichen Charaktermerkmalen sind. Slots (Slots) sind Eigenschaften von Konzepten, sie sind auch als Rollen (Role) oder Eigenschaften (Properties) bekannt. Slots werden durch Restriktionen beschränkt, sogenannte Facetten (Facets). Eine Ontologie zusammen mit einer Instanzmenge bildet die Wissensdatenbank (Knowledge Base). Instanzen unterscheiden sich in den Werten für die Slots. Für die Entwicklung einer Ontologie existiert kein gemeingültiges Verfahren wie es aus der Software Technik bekannt ist, allerdings wird oft in der Literatur die Vorgehensweise von Natalya F. Noy und Deborah L. McGuinness und deren Werk Ontology Development 101: A Guide to Creating Your First Ontology [NM01] genannt. Dort wird die Entwicklung als iterativer Prozess charakterisiert, welcher aus sieben Schritten besteht. Stuckenschmidt greift diese Schritte in seinen Werk [Stu11] auf. Explizite Hilfestellungen, wie diese einzelnen Schritte bearbeitet werden können, fehlen zum größten Teil in [NM01]. Die Schritte sind wie folgt: 1. Determine the domain and scope of the ontology In diesem Schritt wird der Anwendungsbereich fokussiert, dies beinhaltet auch die Abgrenzung zu anderen Domänen. Die Fokussierung erfolgt mit Hilfe von zwei Arten von Fragen - den Basic Questions sowie die Competency Questions. Die Basic Questions bestehen wiederum aus vier Fragen: Welche Domäne wird durch die Ontologie abgebildet? Für was wird die Ontologie verwendet? Für welche Arten von Fragen sollte die Ontologie Antworten bereithalten? Wer benutzt und verwaltet die Ontologien?
80 66 KAPITEL 7. ONTOLOGIEN Die Competency Questions sind im Gegensatz zu den Basic Questions nicht fix und müssen selbst erstellt werden. Diese Frage sollten von der Ontologie beantworten werden können und sind im Gegensatz zur dritten Frage der Basic Questions nicht abstrakt. Zu beachten ist, dass die Fragen in jedem iterativen Schritt erweitert, modifiziert und/oder gelöscht werden können. Diese Fragen ermöglichen die Korrektheit sowie die Vollständigkeit der Ontologie. 2. Consider reusing existing ontologies Hier werden bereits existierende Ontologien recherchiert und zum Teil analysiert. Dies vermeidet redundante Ontologien, allerdings hat das Verwenden bereits erstellter Ontologien Vor- und Nachteile 18. Der offensichtlichste Vorteil ist, dass weniger Aufwand von Nöten ist. Neben diesem offensichtlichen Vorteil existiert noch die Reduzierung typischer Fehler, da bereits andere Entwickler womöglich die Fehler bereits begangen und korrigiert haben. Ein weiterer enormer Vorteil, wenn nicht sogar der bedeutenste, ist die Standardisierung. Sprächen alle die selbe Sprache, gibt es keine Kommunikationsprobleme bezogen auf das Nachrichtenformat und diese Arbeit hätte keine Existenzgrundlage. Diesen Vorteilen gegenüber stehen die nicht zu unterschätzenden Nachteile. Es existieren nicht zu jedem Anwendungsgebiet genau passende Ontologien, existierende Ontologien müssen gegebenenfalls analysiert und modifiziert werden. Dieser Prozess kann im schlimmsten Fall aufwendiger sein als die Entwicklung proprietärer Ontologien. Zudem ist die Korrektheit der Ontologien nicht garantiert. Der Vorteil der Standardisierung sollte allerdings alle Nachteile überwiegen. 3. Enumerate important terms in the ontology In diesem Schritt werden so weit wie möglich alle relevanten Begriffe aufgezählt. Diese Begriffe können mit Hilfe von Fragen eruiert werden. Über welche Begriffe reden wir? Welche Eigenschaften haben diese Begriffe? Was können wir über diese Begriffe aussagen? Stuckenschmidt 19 schlägt für die Identifizierung die Konsultation von Experten vor, die Verwendung der Competency Questions, die Analyse bestehender Dokumente sowie den Gebrauch struktureller Daten 20 wie zum Beispiel Datenbanken oder Schema-Dateien. Dabei vertritt er die Meinung, dass Substantive in Dokumente potentielle Konzepte beschreiben, Verben Relationen und Adjektive Werte darstellen. 4. Define the classes and the class hierarchy Wie auch in der Softwaretechnik existieren hier verschiedene klassische Methoden, um die Klassenhierarchie abzubilden. Die Bottom Up-Methode, die Top Down-Methode oder auch die Kombination beider. In diesem Schritt werden die gesammelten Begriffe in formale Modelle überführt und die Konzepte gebildet. Um die Konzepthierarchie zu erstellen, schlägt Stuckenschmidt 21 zwei Fragen vor: 18 [Stu11], Seite 159ff 19 [Stu11], Seite Siehe 5 21 [Stu11], Seite
81 7.5. DIE ENTWICKLUNG DER ONTOLOGIE ALS KONZEPTUELLES DATENMODELL - THEORIE67 1. Welche Terme repräsentieren Klassen von Objekten? 2. Zwischen welchen Klassen besteht eine Subsumtionsbeziehung? Um diese Fragen zu beantworten, können Faustregeln verwendet werden. Für Konzepte können Sätze mit folgendem Muster verwendet werden: Die Menge aller XY. Der Satz Alle XY sind UV beschreibt Subsumtionsbeziehung. Nach Erstellen dieser Aussagen wird der Wahrheitsgehalt ausgewertet. Falls die Aussage korrekt ist, ist die Wahrscheinlichkeit hoch, dass ein Konzept bzw. eine Subsumptionsbeziehung vorliegt. So ist die Aussage Die Menge aller Parteien ein Indiz für ein Konzept und die Aussage Die Menge aller Deutsch (bezogen auf die Sprache) für kein Konzept. Für die Subsumptionsbeziehung ist die Aussage Alle Verkäufer sind Parteien wahr und Alle Verkäufer sind Länder falsch. Es sollte beachtet werden, dass verschiedene Hierarchien möglich sind, es existiert also kein allgemeingültiges Muster. 5. Define the properties of classes slots 22 In diesem Schritt wird die innere Struktur der Konzepte ergründet. Die im dritten Schritt erarbeiteten Begriffe, exklusive der identifizierten Konzepte, sind zum größten Teil nur Properties. Diese Properties müssen zu den dazugehörigen Konzepten zugeordnet werden. Auch hier gibt Stuckenschmidt Fragen vor, welche die Identifizierung der Differentiae 23 unterstützen sollen: Welche Eigenschaften haben alle Objekte einer Klasse gemeinsam? Welche Eigenschaften unterscheiden die Objekte einer Klasse von denen anderer Klassen? Welche Eigenschaften unterscheiden die Objekte einer Klasse? Um Redundanz zu verhindern wird von oben nach unten gearbeitet, es werden also erst die Eigenschaften der Superklassen gebildet, da diese durch Vererbung automatisch weitergegeben werden. Die Eigenschaften werden in drei verschiedene Typen eingeteilt: Intrinsische Eigenschaften Diese Eigenschaften definieren ein Objekt und sind fix. Extrinsische Eigenschaften Diese liegen vor wenn diese ein Objekt nicht im Wesen beeinflussen und sich über die Zeit ändern können. Teil Eigenschaften Diese Eigenschaft existiert nur in Verbindung mit einem anderen Objekt. 6. Define the facets of the slots In diesem Schritt werden die Facetten der Slots in drei Dimensionen eingeteilt - die Kardinalität, den Datentyp sowie die Domain- und Range- Einschränkung. So kann der Datentyp von der Art eine Zeichenkette, eine Nummer, ein Boolescher Wert, eine Liste oder eine Instanz sein. Für die Domain und Range- Identifizierung sollte auch die höchste sinnvolle Superklasse gewählt werden. Allerdings darf dies nicht zu generell sein, da sich die Instanzen wie am Anfang erwähnt durch Slots unterscheiden. 22 Slot ist ein anderer Terminus für Rolle oder Eigenschaft 23 Merkmale die Objekte unterscheidbar machen
82 68 KAPITEL 7. ONTOLOGIEN 7. Create instances Dieser optionale Schritt ist in gewisser Art ein Proof-of-Concept und dient als Validierung der bisherigen Ontologie-Entwicklung. Die Vorgehensweise ist recht einfach. Zuerst wird eine Klasse ausgewählt, für die Instanzen gebildet und Slots gefüllt werden. Bei Auftreten von Fehlern sollte die Ontologie überarbeitet werden. 7.6 Die Entwicklung der Ontologie als konzeptuelles Datenmodell - Praxis In diesem Abschnitt wird eine Domänen-Ontologie erstellt, die die Rechnung abdeckt. Dabei orientiert sie sich stark an dem Aufbau von UBL, da UBL semantische Bausteine von Haus aus verwendet. Allerdings ist eine 1-zu-1 Ableitung nicht möglich, da die ISO Rechnung Informationen besitzt, die in UBL unbekannt sind. Zu beachten ist, dass die Domänen-Ontologie nur eine Partei abbildet, für den Fall UBL ist es ABIE Accounting- SupplierParty und für ISO das Message Component TraderParty1. Begründet wird die Komplexität und der daraus resultierende Umfang der Ontologie. So hat alleine die im Zusammenhang mit dieser Arbeit erstellte Teil-Domänen-Ontologie 85 Klassen, 274 Restriktionen und 128 Eigenschaften. Dabei erfolgte eine Entscheidung für die Partei, da sie auch ein wichtiger Baustein in anderen Dokumenten ist. Weiterhin besitzen die Parteien in den Standards einen ähnlichen Inhalt, allerdings mit unterschiedlichen Eigenschaften und einer unterschiedlichen Struktur. Für die Erstellung der Ontologie wurde Protégé verwendet. 1. Determine the domain and scope of the ontology Für diese Arbeit wird eine Domänen- Ontologie benötigt, die Informationen einer elektronischen Rechnung beherbergt. Frage: Welche Domäne wird durch die Ontologie abgebildet? Antwort: Die elektronische Rechnung. Für was wird die Ontologie verwendet? Antwort: Als Datenmodell und daraus folgend als eine Komponente zur Transformation von Nachrichten. Für welche Arten von Fragen sollte die Ontologie Antworten bereit halten? Antwort: Inferenz-Regeln sind nicht Teil dieser Arbeit. Wer benutzt und verwaltet die Ontologien? Antwort: Der Autor dieser Arbeit. Die Erstellung von Competency Questions sind nicht nötig, da eine genaue semantische Definition per UBL-Spezifikation vorliegt. So ist jedes Objekt und jede Rolle ersichtlich. 2. Consider reusing existing ontologies Es existieren einige Ontologien, die die Domäne Rechnungen abdecken können, allerdings entsprach keine den Anforderungen reines Datenmodell und UBL ähnliche Struktur. So existiert eine Ontologie mit dem Namen UBL Ontology von Michael Daconta als Protégé-Frames-Ontologie. Diese Ontologie 24 basiert auf SUMO und bildet mehrere Prozesse ab. Diese Ontologie hat 24
83 7.6. DIE ENTWICKLUNG DER ONTOLOGIE ALS KONZEPTUELLES DATENMODELL - PRAXIS69 allerdings einen anderen Aufbau als die UBL XML-Schemata und deckt auch Geschäftsprozesse ab, die in dieser Arbeit keine Rolle spielen. Sie wurde laut Informationen des Dateisystems zuletzt 2003 geändert und ist damit älter als UBL 1.0. Dies hat eine Disqualifikation zur Folge. Weiterhin existiert eine Invoice-Ontologie 25 von Aldo Gangemi und Jose Manuel Gomez. Diese konnte jedoch nicht geöffnet werden, weder mit Protége noch Protégé Einige referenzierte Rechnungs- Ontologien sind nicht auffindbar, wie die Aggregated Invoice Ontology von isoco oder die Ontologie Invoicing Backbone Ontology. Daher folgte der Entschluss zur Entwicklung einer eigenen Ontologie auf Basis von OWL, die auf keiner anderen Ontologie aufbaut. 3. Enumerate important terms in the ontology Auch hier sind keine Fragen nötig, da die UBL- und ISO Dokumentation alle Objekte und Rollen aufschlüsselt und definiert. 4. Define the classes and the class hierarchy 5. Define the properties of classes slots - 6. Define the facets of the slots Diese drei Schritte können in einem Vorgang abgearbeitet werden, da die UBL-Dokumentation alle nötigen Informationen beherbergt. Dabei gelten folgende Faustregeln: ABIE ist eine OWL Class. ASBIE ist ein OWL Object Property zu anderen Class. BBIE ist ein OWL Object Property die zu einer grundlegenden Class verweist, die wiederum Data Properties besitzen. Grundlegende Classes sind Bausteine die sich an die unqualified Datatypes orientieren. Kardinalitäten sind Facetes. Als Beispiel gilt Abbildung 7.3, dies ist ein Teilauszug der UBL-Definition des ABIE Party. Abbildung 7.3: Auszug der Party-Definiton aus der UBL Dokumentation Das ABIE Party ist eine Class. 25
84 70 KAPITEL 7. ONTOLOGIEN Das ASBIE PostalAddress ist ein Object Property zu dem ABIE Address, welches wiederum eine Class ist. Das BBIE WebsiteURI ist ein Object Property zu der grundlegenden Class IdentifierType. IdentifierType besitzt acht verschiedene Data Properties. Siehe Abbildung 7.4, wobei udt_hasidentifiertype den Wert des BBIE darstellt, die anderen Data Properties sind dabei Informationen zum möglichen Schema des Wertes. Der Wert des XML-Elements steht hier auf einer Stufe mit den Attributen des Wertes. Jeder Datentyp der unqualified Datatypes stellt eine eigene Class da. Abbildung 7.4: Die acht verschiedenen Data Properties der OWL Klasse IdentifierType und deren Zuordnung zu den XML-Werte und den Attributen des IdentifierType des XML-Schemas für die unqualified Datatypes. Die Kardinalität 0..1 und 0..n bilden die Faceten. So darf die Klasse Party nur maximal eine WebsiteURI haben. Allerdings gelten die ersten beiden Faustregeln nicht, wenn es um Subklassen-Beziehung geht. Abbildung 7.5 zeigt diesen Fall. Abbildung 7.5: Auszug aus der UBL Dokumentation zum ABIE CustomerParty Würde der ersten Faustregel (ABIE sind OWL Classes) gefolgt werden, so würde das ABIE CustomerParty eine Object Property zu ABIE Party darstellen. Allerdings ist
85 7.7. FAZIT 71 das ABIE CustomerParty eine Spezialisierung vom ABIE Party und steht so in einer Subklassenbeziehung. CustomerParty ist also eine Subklasse von Party. Eine Subklassenbeziehung zu den anderen ASBIEs ergibt keinen semantischen Sinn. Während des Festlegens der Relationen wurden Instanzen angelegt, um die Korrektheit zu testen. Durch die Abbildung der UBL-Struktur auf die Ontologie ist der Prozess der Ontologie- Entwicklung noch nicht abgeschlossen. Die Ontologie soll als gemeinsames Datenmodell von UBL und ISO dienen, wobei ISO einige Informationen besitzt, die UBL unbekannt sind. Weiterhin besitzt ISO auch abweichende Kardinalitäten. Das Kardinalitäten- Problem ist von geringer Natur. Für die ISO Integration in die Ontologie müssen nur die Facetes angepasst werden. Für die neuen Informationen wird eine Klasse gebildet. TradeParty1 besitzt größtenteils die gleichen semantischen Informationen, was eine Ausweitung der Ontologie in Grenzen hält. 7.7 Fazit ISO und UBL verwenden jeweils semantische Bausteine für den Aufbau der Nachrichten. Die Tatsache und die Existenz der jeweiligen Spezifikation oder Definition begünstigen in diesem Fall die Ontologie-Entwicklung enorm. Beide Standards sind einen Schritt von einer Ontologie entfernt. Allerdings besitzt meiner Meinung nach UBL einen logischeren Aufbau als ISO bedingt durch unnötige Struktur in einzelnen Konstrukten. Inferenzregeln sind kein Teil dieser Arbeit, stellen aber einen wichtigen Teil der Ontologien da. Spezielle (Domänen)Ontologien könnten mit passenden Anfragen entwickelt werden, die wichtige Fragen beantworten. So wäre zum Beispiel die Bildungen von Annahmen, welche steuerrechtliche Tatsachen ermitteln, nützlich für Steuererklärungen. Allerdings wäre eine Domänenontologie nicht ausreichend für solch eine Verwendung, da der Fokus erweitert werden müsste um Klassen und Prozesse. So müssten zum Beispiel Gegenstände erfasst und definiert werden, um eine steuerliche Bewertung zu ermöglichen. Dies würde ein Ausufern der Ontologien mit sich bringen. Durch Aufkommen von XML sowie die dazugehörigen Techniken wurde das Problem der verschiedenen Syntaxen behoben, es wurde in der Regel XML gesprochen. Ontologien besitzen die Möglichkeit, den nächsten Schritt in der Wissensrepräsentation darzustellen. Die Daten und deren Semantik werden von der Syntax getrennt und existieren durch ihre Relationen und Ausprägungen, dadurch bereichern sie die Daten noch mit logischen Ableitungen. Allerdings stehen Ontologien vor den selben Problemen wie syntaxbasierenden Nachrichten (XML, EDIFACT, JSON) zur der Zeit ihrer Einführung und Etablierung. Es existiert kein einheitliches Rahmenwerk wie ebxml, das eine standardisierte Entwicklung ermöglicht oder eine Anleitung für die Entwicklung einer Domänenontologie. Dies hat zur Folge, dass interoperable Ontologien entwickelt werden, die sich vom Aufbau und sogar von der Art unterscheiden wie zum Beispiel F-Logic und OWL. Dies führt dazu, dass die Probleme der Heterogenität der sytaxbasierenden Nachrichten auf eine höhere Ebene verschoben werden. Um dies zu verhindern, müsste schnellstmöglich ein gemeinsames Rahmenwerk spezifiziert werden. Nichts desto sind Ontologien eine mächtige und hilfreiche Technik, um Daten zu transformieren.
86 72 KAPITEL 7. ONTOLOGIEN
87 Teil II Das Schemamanagment 73
88
89 KAPITEL 8 Die Transformation und deren Herausforderung Das Kapitel behandelt die Transformation und die daraus folgenden Probleme. In Abschnitt 8.1 werden die Begriffe Matching sowie Mapping erläutert. Gefolgt von Abschnitt 8.2, welcher die Probleme, die bei einer Transformation überwunden werden müssen, definiert. Abschließend wird in Abschnitt 8.3 die Erstellung der Wertkorrespondenzen vorgestellt. 8.1 Die Transformation Grundlage für die direkte Transformation sowie die Transformation mittels einer Ontologie ist das Mapping. Das Mapping ist das Ergebnis des Matching-Prozesses. Im Matching-Prozess werden die passenden Elemente identifiziert und im anschließenden Mapping-Prozess zueinander verknüpft 1. Diese Verknüpfungen werden auch Wertkorrespondenzen (WK) genannt, diese Wertkorrespondenzen werden zu Schemakorrespondenzen zusammengefasst, aus diesen leiten sich die Datentransformationsregeln ab. Eine Wertkorrespondenz ist also eine Funktionen, die einen Wert des Zielschemas in das Quellschema abbildet, dabei kann ihre Ausprägung von einfacher Natur sein wie zum Beispiel eine Namensabbildung (siehe Abbildung 8.1) oder auch von komplexerer Art wie eine Datumskonvertierung (siehe Abbildung 8.2). 2 Neben diesen beiden Korrespondenzen existieren ebenfalls die soge- Abbildung 8.1: Einfache WK von ISO zu UBL via Altova MapForce 2013 nannten höherstufigen Wertkorrespondenzen 3. Dies ist der Fall, wenn nicht nur die Wer- 1 vgl. [Köh10], S vgl. [LN06], S vgl. [LN06], S

90 76 KAPITEL 8. DIE TRANSFORMATION UND DEREN HERAUSFORDERUNG Abbildung 8.2: Komplexe WK von ISO zu UBL via Altova MapForce 2013 te von Attributen die Ausprägung definieren, sondern auch die Existenz des wertebesitzenden Elementes. Als Beispiel sei die Korrespondenz zwischen dem ISO Type OrganisationIdentification6 und dem UBL BBIE PartyIdentificationType (siehe Abbildung 8.3) genannt. ISO kennt vom Haus aus die Identifikationsart BIC 4, UBL im Gegenteil nicht. Wird also ein BIC-Code in ISO verwendet, muss UBL neben dem Wert auch die Information hinzugefügt werden, dass sich es um ein BIC Code handelt. Abbildung 8.3: Höherstufige WK von ISO zu UBL via Altova MapForce Heterogenität der Nachrichtenstandards Die Ziel der Transformation ist die Kommunikation verschiedener Standards durch Behebung der Heterogenität 5. Das Hauptproblem der Transformation ist die Heterogenität der Daten 6. Es existieren sechs verschiedene Arten der Heterogenität 7. Die Technische Heterogenität bezeichnet die Probleme von unterschiedlichen technischen Systemen und deren Kommunikation. Die Syntaktische Heterogenität schließt alle Probleme ein, die Konflikte bei der Darstellung von Informationen verursachen. Bei der Datenmodellheterogenität existieren unterschiedliche Datenmodelle, die zur Repräsentation verwendet werden. Die Strukturelle Heterogenität umfasst die Differenzen bei verschiedenen strukturellen Repräsentationen bei gleichem semantischen Sinn. Die Datenmodellheterogenität und Struk- 4 International gültige Bankleitzahl unter Kontrolle von S.W.I.F.T. 5 Daten werden durch ihre Struktur in drei verschiedene Klassen eingeteilt. Strukturierte Daten sind solche, die durch ein Schema bestimmt werden, wie eine Datenbank oder eine XML und XSD-Paar. Semistrukturierte Daten sind ebenfalls nach einem Schema strukturiert, allerdings können sie von dem Schema abweichen. Die dritte Klasse sind die unstrukturierten Daten, wie natürlichsprachliche Texte. vgl. [LN06], S vgl. [LN06], S Die nachfolgenden Informationen stammen aus [LN06], S.60 ff
91 8.3. MAPPING 77 turelle Heterogenität bilden zusammen die Modellierungsheterogenität. Die Schematische Heterogenität ist die Spezialisierung der strukturellen Heterogenität und beschreibt die Probleme bei unterschiedlichen Datenmodellelementen. Bei der Semantische Heterogenität handelt es sich um die Probleme der Bedeutung der Begriffe und Konzepte. Die Arten der Heterogenität sind nicht ohne weiteres trennbar und fließen ineinander. Die Technische Heterogenität wird in dieser Arbeit außer Acht gelassen, da nur der jeweilige technisch Verantwortliche diese Probleme lösen kann. Die Syntaktische Heterogenität spielte ebenfalls keine Rolle, da die zu verarbeitenden Daten XML-Dateien sind. Das Invoice-Dokument von UBL und ISO basieren auf dem selben Modell, dem Cross Industry Invoice (CII) Version 2.0-Modell, deswegen unterscheidet sich die Datenmodellheterogenität von UBL und ISO nicht signifikant. ISO hat seinen Syntax sehr an die finanztechnischen Bedürfnisse angepasst, UBL hingegen verwendet eine allgemeineren Aufbau der Syntax. Dadurch ist die Strukturellen Heterogenität gegeben. Da der Fokus beider Nachrichten auf der Rechnung liegt, ist die semantische Heterogenität nicht sehr ausgeprägt. Schematische Konflikte erscheinen bei Namen und Konzepten und betreffen meistens Synonyme und Homonyme. Synonyme beschrieben die selben Objekte, haben aber unterschiedliche Namen. Homonyme tragen die identische Namen, drücken aber unterschiedliche Sachverhalte aus 8. Diese Art der Heterogenität taucht zum Beispiel bei Codelisten und Abkürzungen auf. Zum Beispiel kann der Titel in ISO nur vier Werte annehmen (DOCT, MADM, MISS und MIST) im Gegensatz zu UBL. Dort ist er frei wählbar, dies führt zu Problemen bei der Überführung von UBL zu ISO Es wird daher eine explizite Fallunterscheidung benötigt, wie zum Beispiel bei dem Wert Sir. Leider sind semantische Konflikte nicht immer auflösbar, da zum Beispiel nicht der gesamte Kontext bekannt ist oder die Dokumentation fehler- und/oder lückenhaft ist. 8.3 Mapping Das Mapping ist die Grundlage beider Transformationen. Bei der direkten Transformation (Abbildung 8.4) wird im Matching-Prozess die WKs ermittelt, welche die ISO XML-Elemente in die UBL XML-Elemente übersetzen. Bei der Transformation mittels einer Ontologie (Abbildung 8.5) sind zwei Mappings notwendig, das erste Mapping bildet die Werte der ISO XML-Elemente auf die Ontologie ab, das zweite Mapping bildet die Daten der Ontologie auf die UBL XML-Elemente. Da die Struktur der Ontologie UBL ähnelt, sind die Mappings annähernd identisch. ISO XML UBL XML Abbildung 8.4: Transformation 1: Visualisierung der direkten Methode Durch diese Ähnlichkeit gelten die Wertkorrespondenzen in Kapitel 9 Die direkte Transformation auch für das Kapitel 10 Die ontologie-basierende Transformation. Daher werden sie dort nicht wiederholt. Mit dem Prozess des Mappings geht auch die Erzeugung ein UBL Compatibility-Dokumentes mit ein. Würde nur das originäre Invoice-Dokument verwendet werden, würde dies einen Informationsverlust bedeuten. 8 vgl. [LN06], S. 76
92 78 KAPITEL 8. DIE TRANSFORMATION UND DEREN HERAUSFORDERUNG Die Erstellung der Wertkorrespondenzen sind auf zwei verschiedenen Wegen möglich: Der erste Weg ist die Programmierung, der zweite Weg ist das Verwenden eines Mapping- Tools. Die Programmierung ist der flexibelste Weg, es wird für jedes XML-Element eine Wertkorrespondenz manuell geschrieben und hängt so nicht von einer vorgefertigten und fixen Funktionsbibliothek ab. Diese Programmierung kann mittels Java, C#, XSLT oder sonstigen Programmiersprachen geschehen. Dies erfordert allerdings ein Beherrschen der jeweiligen Sprache. Im Gegenteil zum elementaren Weg, verwendet ein Mapping-Tool in der Regel eine GUI, in der Pfeile vom Quellelement zum Zielelement gezogen werden. Diese Pfeile werden dann vom Mappingtool als Programme oder Skript realisiert, je nach Mächtigkeit des Programms Die Programmierung Die Programmierung ist im Grunde wie folgt: Das Quelldokument wird geöffnet, jedes einzelne Element wird wenn möglich übersetzt, anschließend wird überprüft, ob dieses Element Bedingungen des Quellschemas verletzt. ISt dies nicht der Fall, wird das transformierte Element in das Zieldokument einsortiert. Abbildung 8.6 zeigt den Arbeitsfluss der Programmierung. Bei der Identifizierung des Quellelements existieren wiederum zwei unterschiedliche Methoden. Die erste Methode verwendet Typendefinitionen mittels eines Schemas, die zweite Identifizierung wird mittels der Position des Elementes innerhalb des Dokuments vollzogen. Die erste Methode benötigt daher ein XML-Schema, welches nicht immer verfügbar ist oder existieren kann, da es ein XML-fremde Syntax ist. Die zweite Methode hingegen ist mit jeder Syntax möglich Die Mapping-Tools Für dieses Anwendungsgebiet existiert keine nennenswerte freie Mapping-Software, beziehungsweise ist eine solche nicht bekannt. Es existieren allerdings einige kommerzielle Programme: MapForce von Altova; Clio von IBM BizTalk-Mapper von Microsoft Stylus Studio von Progress Software Corporation GEFEG.FX von GEFEG Bis auf GEFEG.FX werden in allen Programmen die Wertkorrespondenzen durch Verbindungeslinien erzeugt. Das heißt, dass das Quellelement per Drag-and-Drop markiert und mit dem Zielelement verbunden wird. Je nach Komplexität der Wertkorrespondenz können Funktionen zwischengeschaltet werden. Bei GEFEG.FX hingegen werden beide Elemente markiert und mittels eines Buttons erzeugt. Sind diese Wertkorrespondenzen erzeugt worden, können diese als Java, XSLT, C# oder ähnliche Programm umgesetzt werden, je nach Programm. BizTalk-Mapper und Clio unterstützen zudem die automatische Erzeugung der
93 8.3. MAPPING 79 ISO XML Ontologie OWL UBL XML Abbildung 8.5: Transformation 2: Visualisierung der ontologie-basierenden Methode Abbildung 8.6: Workflow einer Transformation-Anwendung
94 80 KAPITEL 8. DIE TRANSFORMATION UND DEREN HERAUSFORDERUNG Wertkorrespondenzen mit Hilfe von Algorithmen. Allerdings sind diese Ergebnis zumindestens bei BizTalk nicht sehr hilfreich, CLIO konnte nicht getestet werden. Da neben GE- FEG.FX lediglich MapForce zur Verfügung stand, wurde das Mapping mit letzterem realisiert. Im Zuge dieser Arbeit werden keine Bewertungen oder Vorstellungen der Programme vorgenommen.
95 KAPITEL 9 Die direkte Transformation Dieses Kapitel behandelt die direkte Transformation sowie das Matching, welches auch die Grundlage für Kapitel 10 ist. In Abschnitt 9.1 werden die Anforderung an eine Transformation aufgestellt, welche ebenfalls für die ontologie-basierenden Methode gelten. Abschnitt 9.2 ist die Aufstellung der Anforderung an die direkte Transformation. Abschnitt 9.3 definiert die Wertkorrespondenzen, dabei werden stets Beispiel aus der direkten Transformation vorgebracht. Abschnitt 9.4 analysiert das Mapping. 9.1 Anforderungen der Transformation Die direkte Transformation kann auf verschiedene Wege erfolgen. Die erste Methode ist die direkte Umwandlung einer Nachricht mit Hilfe eines Skriptes oder einem Programm, es ist also eine Übersetzung eines jeden Elements des Quellschemas in das Zielschema, diese Verfahren wird auch als Datentransformation 1 genannt. Die meisten High-Level-Programmiersprachen bieten mehrere unterschiedliche Bibliotheken bzw. APIs für das Arbeiten mit XML. Bei Java ist es unter anderem die JAXP-API oder auch die Open-Source Bibliothek JDOM, C++ kann ebenfalls auf verschiedene Bibliotheken zugreifen wie libxml++ oder auch Xerces, Python hat ebenfalls die Auswahlmöglichkeit wie zum Beispiel lxml oder Amara. Dies sind nur wenige Beispiele, die Liste ist um ein vielfaches länger. Die zweite Methode, die Anfrageplanung 2, ist eine Anpassung der Anfrage. Es werden individuelle Anfragen das Dokument gestellt um ein globales Schema zu füllen, dies geschieht mit Hilfe eines Thesaurus oder auch einer erweiterten Look-up-Tabelle. Für das direkte Mapping bzw. die Transformation findet die erste Methode Anwendung. Mit XML verabschiedete das W3C auch verschiedene Sprachen, wie zum Beispiel XPath, XQuery, XSL-FO oder auch XSLT. Wobei XSLT für Extensible Stylesheet Language Transformation steht und verwendet wird, um XML Dokumente in anderen Dokumente zu transformieren. Ein gravierender Vorteil der XSLT-Stylesheets ist, dass diese nicht nur plattformunabhängig sind, 1 [LN06], S [LN06], S

96 82 KAPITEL 9. DIE DIREKTE TRANSFORMATION sondern auch in gewisser Art programmunabhängig. Dies wird durch XLST-Prozessoren ermöglicht, die in verschiedenen Programmen auffindbar sind. Es wurde XSLT für die Entwicklung der direkte Transformation gewählt, da XSLT eine sehr bekannte und verbreitete Sprache ist, sie ist lizenzfrei und die Stylesheet sind mit jedem Textverarbeitungsprogramm editierbar. Zudem ist die Plattformunabhängigkeit ein enormer Vorteil der Entwicklung. Allerdings wird MapForce von Altova verwendet für die Erstellung des Mappings. Laut Batini 3 sollte die Integration mehrerer Schemata in ein neues Schema drei Ziele verfolgen. Dies Ziele lassen sich ebenfalls beim Mapping als Ergebnis des Matching übertragen. Dies sind: Vollständigkeit und Korrektheit Alle Konzepte der zu transformierende Schemata müssen verlustfrei und korrekt übersetzt werden, es dürfen dabei keine Widersprüche entstehen. Minimalität Gleiche Konzepte sollten nur einmal repräsentiert werden, um so eine Redundanz zu vermeiden. Verständlichkeit Das Ergebnis muss für die Anwender und Entwickler verständlich sein. Dabei ist zu beachten, dass das Kriterium Vollständigkeit in der Regel nur erfüllbar ist, wenn das Zielschema modifizierbar ist. Da dies nicht immer der Fall ist, geht daher auch ein Informationsverlust mit ein. Anstatt einer bidirektionalen Transformation, wird eine direktionale Transformation erstellt. Begründet wird es damit, dass nur die Methoden und Techniken vorgestellt werden sollen und eine komplette bidirektionale Transformation zu zeitaufwendig ist. Hinzu kommt, dass UBL mächtiger in seiner Informationsvielfalt ist als ISO Dadurch ist eine Einigung nötig, welche Informationen inklusive deren Informationsschemata beschränkt. Die Abbildung 9.1 stellt die Mächtigkeit beider Rechnungen gegenüber. Abbildung 9.1: Informationsmächtigkeit der UBL- sowie der ISO Rechnung. Der rote Kreis symbolisiert die ISO Rechnung, der blaue Kreis die UBL-Rechnung. a ist die Informationsmenge, die UBL unbekannt ist. b ist die Schnittmenge beider Rechnungen, c ist die Informationsmenge, die ISO unbekannt ist und d ist das Extension Element von UBL, welches die Daten von a erfassen kann. Kardinalitäten werden nicht berücksichtigt. Nachfolgend werden die Phasen des durchgeführten Mapping-Prozesses dargestellt. Dabei ist dieser Mapping-Prozess in drei Phasen unterteilt: 3 vgl. [BLN86], S. 337
97 9.2. PHASE 1 - ANFORDERUNGSERHEBUNG Phase 1 - Anforderungserhebung Der erste Schritt des Prozesses ist die Gewinnung aller nötigen Daten. Dies sind die jeweiligen Schemata und zugehörige Beispiel-Instanzen, sowie deren Dokumentation. UBL und ISO veröffentlichen alles über deren Website, im Fall von ISO über ein Repository und im Fall für UBL über ein Support-Package. Bei ISO gibt es noch optional die Normen, diese sind aber für den Prozess nicht nötig, sind allerdings hilfreich um die Methodik, die sich hinter ISO befindet, zu verstehen. Für beide Standards ist der Zugang frei, es wird keine Mitgliedschaft für den Zugriff auf die erforderlichen Dateien benötigt. Des weiteren inkludiert die Anforderungserhebung ebenfalls die Wahl eines Mapping Tools. Eine manuelle Erstellung eines XSLT-Stylesheet wäre zu komplex, die Wahl fiel auf Map- Force 2012 sowie später Altova MapForce Nach Beschaffung aller nötigen Daten und Installation der Mapping-Applikation wurde das ISO XSD-Schema modifiziert, jedes einzelne XSD-Element erhielt ein zusätzliches <annotation>-tag-element. Dieser Tag umschließt die zugehörigen Definitionen aus der Dokumentation. Dieser Schritt ermöglicht eine semi-automatische Dokumentation der Transformation. Die Bedeutung dieser Phase darf nicht unterschätzt werden. Wird der Aufbau der Nachricht nicht berücksichtigt, erfolgt dadurch ein erhöhter Mehraufwand, dazu mehr in Phase Phase 2 - Das Matching In der zweiten Phase wurden die Schemata und die Instanzen in das Mapping-Tool importiert. Anschließend wurden mit Hilfe der Dokumentationen die Wertkorrespondenzen erstellt und soweit erforderlich für jedes unbekannte ISO Element ein Pendant in UBL gebildet. Semantische Bausteine Beide Standards verwenden Bausteine und versehen diese mit Semantik. Dadurch sollten soweit wie wie möglich Teil-Schemakorrespondenzen für die Bausteine mit ähnlichen semantischen Sinn erstellt werden, diese sind wiederverwendbar und reduzieren dadurch die Kosten des Mappings-Prozesses. Dabei ist zu beachten, dass diese Bausteine ebenfalls aus anderen Bausteine bestehen können, auch für diese Bausteine sollten wieder Teil-Schemakorrespondenzen erstellt werden. Dies ermöglicht eine Verwendung einer Bibliothek von Korrespondenzen. Dabei ist aber zu beachten, dass die Bausteine ohne semantischen Rolle transformiert werden sollen, um eine maximale Wiederverwendbarkeit zu ermöglichen. So ist zum Beispiel der Rechnungssteller Invoicer in ISO eine Ausprägung der XML-Elementtyp-Definition TradeParty1 und in UBL ist der AccountingSupplierParty eine Ausprägung der XML-Elementtyp-Definition SupplierParty. Wird nun ein Mapping für die beiden Akteure erstellt, gibt es zwei Möglichkeiten: 1. Es wird eine direkte Verbindung von Invoicer zu AccountingSupplierParty erstellt. Dieses Mapping ist nur für diese Parteien gültig und hat zur Folge, dass diese Konstellation in dem Mapping nur einmal Verwendung findet. Allerdings könnten andere Nachrichten diese Konstellation verwenden. 2. Es wird eine direkte Verbindung von TradeParty1 zu SupplierParty erstellt. Diese Verbindung kommt im Mapping zwei Mal vor, so ist dieses Mapping auch für die Verbindung zwischen Payee (ISO 20022) und SellerSupplierParty (UBL) gültig.
98 84 KAPITEL 9. DIE DIREKTE TRANSFORMATION Die zweite Möglichkeit reduziert den Mapping-Prozess um eine Abbildung. Allerdings kann die Wiederverwendbarkeit erhöht werden, wenn beide Konstrukte SupplierParty und CustomerParty in UBL näher beleuchtet werden in Verbindung mit dem TradeParty1 von ISO CustomerParty und SupplierParty sind beide eine Erweiterung der Party. Allerdings werden diese zusätzlichen Angaben nicht von ISO verwendet. So kann ein direktes Mapping von TradeParty1 (ISO 20022) auf Party (UBL)erfolgen. Dieses Mapping reduziert den Aufwand um zwölf weitere Wertkorrespondenzen zwischen semantischen Bausteinen bei den Invoice-Dokumenten. Die Menge dieser Teil-Schemakorrespondenzen stellt eine Mapping-Bibliothek dar. Schema-Matching-Methoden Im Matching-Prozess existieren zwei Verfahren, um ein Schemakorrespondenz zu erstellen 4. Das schemabasierte Verfahren ermittelt Korrespondenzen anhand des Schemas, wobei das instanzbasierte Verfahren Korrespondenzen anhand von Instanzen ermittelt. Das zweite Verfahren erfordert, das genügend Instanzen für ein Vergleich vorliegen. Dies ist in dieser Arbeit nicht der Fall. Beide Verfahren können unterschiedliche Methoden für das Matching verwenden, indem unterschiedliche Metadaten 5 untersucht werden. Die linguistische Methode untersucht den Namen sowie die Definition des Schema-Elementes (schemabasiert) beziehungsweise die Datenwerte des Schema- Elementes (instanzbasiert). Der linguistischen Methode steht die constrainbasierte Methode gegenüber. Bei dieser werden zusätzliche Metadaten wie Datentypen (schemabasiert) oder Wertebereiche (instanzbasiert) untersucht. Abbildung 9.2 zeigt die unterschiedlichen Verfahren. Alle Ansätze können miteinander kombiniert werden, was allerdings den Auf- Abbildung 9.2: Klassifikation von Schema-Matching-Ansätzen. Mit Anlehnung an [LN06] S.146 wand des Matching-Prozess ansteigen lässt. Für den Matching-Prozess werden primär die linguistische schemabasierte Methode sowie in einzelnen Fällen die linguistische instanzbasierte Methode verwendet. Wertkorrespondenzen Die Wertkorrespondenzen werden in sechs verschiedene Arten 6 klassifiziert: 4 vgl. [LN06] S vgl. [LN06] S Mit Anlehnung an [LN06] S. 127f
99 9.3. PHASE 2 - DAS MATCHING 85 1:1-Wertkorrespondenzen: Diese Verbindung ist die simpelste Art der Zuordnung. Eine 1:1-Verbindung liegt vor, wenn im Quell-Schema ein Wert genau nur einmal vorkommen kann, genau so wie im Ziel-Schema. Die ist der Fall bei der Korrespondenz zwischen der Rechnungsnummer, siehe Abbildung 9.3 Abbildung 9.3: 1:1-Wertkorrespondenzen der UBL Rechnungs-ID zur ISO Rechnungs-ID n:1-wertkorrespondenzen: Diese Art der Wertkorrespondenzen liegt vor, wenn im Quellschema das Element eine maximale Kardinalität von n hat, aber das Ziel-Schema nicht. So besitzt TradeParty1 (ISO 20022) das Konstrukt Contacts3 für die Angabe einer Kontaktperson mit einer maximalen Kardinalität von n. PartyType (UBL) hingegen kann nur eine Kontaktperson ContactType angeben. UBL unterstützt von Haus aus das Customizing (Siehe 4.3.3), so werden für die überstehenden Kontaktpersonen im Extension Element ein Äquvivalent kreiert. Hierbei muss die Wertkorrespondenz mit einer Funktion erweitert werden, die die n-1- Kontaktpersonen ausfiltert. Listing 9.1 zeigt die XML-Definition des UBL Compatibility- Konstrukts. 1 <xsd:complextype name="partyadditionalinformation"> 2 <xsd:sequence> 3 <xsd:element ref="cac:contact" minoccurs="0" maxoccurs= "unbounded"/> 4 </xsd:sequence> 5 </xsd:complextype> Listing 9.1: UBL Compatibilty XML-Element für das Abfangen aller n-1- Kontaktpersonen. Dokumentationselemente wurden zum der Übersicht weggelassen. Die Wertkorrespondenz wurde nun so gestaltet, das nur die erste Kontaktperson in das originäre UBL-Dokument gespeichert wird, alle weiteren Kontaktpersonen werden in das Extensionelement gespeichert. Die Wertkorrespondenz wird mit einem Konstrukt aus einer Nodeposition-Abfrage mit Verbindung einer IF-Abfrage erweitert. Algorithmus 1 (Pseudocode) Sollte allerdings ein Ziel-Standard genommen werden, der diese Erweiterbarkeit nicht unterstützt, gibt es nur zwei Lösungen, die beide nicht befriedigend sind. Die Erste ist das Wegfallen der unbekannten Daten 7, die zweite 7 Dieses Verfahren erlebte ich in einem Praktikum bei einer Bank, so wurden bei der Datenintegration nicht alle Daten übermittelt. Es wurde nur der Endbetrag gemappt, nicht die Berechnungen, die zu diesem Endbetrag führten. Das hatte die Folge, dass eine Korrektur eines Wertes in einer Zwischenberechnung kein konsistentes Ergebnis liefert, der Endbetrag wurde mittels eines Standard-Rechnung neu berechnet. Allerdings waren einige Werte nicht mit der Standard-Berechnung erzeugt, da die teilnehmenden Partei sich auf andere Gewinnbeteiligungen einigten.
100 konkateniere verteile 86 KAPITEL 9. DIE DIREKTE TRANSFORMATION 1 Data : ISO20022.CONTACT Result : Transformierte ISO Kontaktperson in UBL import WKLibrary.transform(); while CONTACT.next()!= null do if CONTACT.position() == 1 then UBL.CONTACT := transform(iso20022.contact); else UBL.EXTENSION.CONTACT := transform(iso20022.contact); end CONTACT := CONTACT.next(); end Algorithmus 1: Filter für die Wertkorrespondenz der ISO Kontaktperson. Speichert in das originäre UBL Element ab oder in das UBL Extension Element Lösung ist die Verwendung eines Kommentar-Feldes als universellen Speicher, wobei neben dem Wert auch die dazugehörigen Metadaten gespeichert werden müssen. Dies ist für ein einzelnes XML-Element akzeptabel, aber für ein ganzes Konstrukt ungeeignet. Eine Variante dieses Falles ist die Existenz von zwei semantisch ähnlichen Konstrukten. ISO kennt für die Postanschrift die Informationen Department sowie Subdepartment, UBL hingegen kennt nur Department. Hier wird nun ein UBL Customizing vollzogen. Allerdings kann in diesem Fall auch eine andere Möglichkeit verfolgt werden. Beide Informationen werden konkateniert und zu dem entsprechenden UBL- Element verbunden. So gibt es zwei Kategorien von Wertzuweisungen von n:1-wertkorrespondenzen: Quellschema Zielschema Quellschema Zielschema Element A Element A Element A... Element A Element A Element A Element A Element A... Element A Element A Element A (Alternative) Kategorie 1 Kategorie 2 Abbildung 9.4: Arten der [n:1]-wertkorrespondenzen 1:n-Wertkorrespondenzen: Diese Art ist der konträre Fall zum [n:1]-fall. Es wird ein Element im Quellschema auf der n-elemente des Zielschemas verbunden. In Fall gibt es mehrere Möglichkeit für den Aufbau der Wertkorrespondenz: Clonen Das Element des Quellschemas wird auf alle n-elemente des Zielschemas verteilt. Verarbeiten Der Wert wird mittels einer Funktion verteilt, so dass unterschiedliche Werte für die n-elemente erzeugt werden.
101 9.3. PHASE 2 - DAS MATCHING 87 Dummy-Werte Das Element des Quellschemas wird auf ein Elemente des Zielschemas verteilt, die anderen n-1-elemente werden anschließend mit Dummy- Werten gefüllt. n:0-wertkorrespondenzen: Aus logischer Sicht kann diese Korrespondenz nicht existieren, da eine Verbindung zwei Eckpunkte besitzen muss. Allerdings soll dieser Name den Fall näher bringen, dass ein Wert im Quellschema keine Pendant im Zielschema hat. ISO hat zum Beispiel das Element Nm im InvcHdr, dieses Element wird benutzt um der Rechnung einen Namen zugeben, in UBL ist dies unbekannt. Da nicht das Risiko des Verlustes eines Wertes eingegangen werden soll, wird dieser Name im UBL-Extension Element hinterlegt, diese Methode wurde bereits im [n:1]-fall verwendet. Es wird also in diesem Schema ein Element kreiert, anschließend werden die Elemente mit einer WK verbunden. 0:n-Wertkorrespondenzen: Auch dieser Fall ist aus logischer Sicht nicht möglich, was aber auch wie im vorherigen Fall nicht außer acht gelassen wird. Dieser Fall liegt vor, wenn das Zielschema ein Wert kennt, dieser Wert aber im Quellschema unbekannt ist. Hier gibt es zwei verschiedene Lösungen, die sich in der Interaktion unterscheiden. Die interaktionslose Methode gibt in diesem Fall ein Wert per Konstante vor, dies kann (muss aber nicht im Falle eines Dummywertes wie NULL) aus logisch Sicht korrekt sein, wenn zum Beispiel in UBL die cbc:ubl-versionid mit dem Wert 2.0 gefüllt wird. Die interaktive Methode benötigt bei der Transformation Eingaben eines Benutzers, was allerdings den STP massiv beeinträchtigt. m:n-wertkorrespondenzen: Dies ist im Grunde der komplexe Fall der [n:1]-verbindung. Daher wird auf diesem Fall nicht weiter ausgeführt. Neben der Brücke zwischen den Schemata (also die Wertkorrespondenz) müssen auch die transportierten Werte berücksichtigt werden. Dabei kann die Sicht auf drei verschiedene Bereiche gelegt werden: Datentyp: Die Problematik der verschiedenen Datentypen ist aus dem Spielfeld der Programmierung bekannt und liefern deshalb bekannte Lösungen wie das Casting. Allerdings ist dies in diesem Mapping nur von geringer Relevanz. Die Werte sind meistens vom Datentyp String bei Text und Integer bei Zahlen, daher ist dies kein Problem. Datentyp : Die Länge des Datentypes hat eine Problematik von nicht geringer Relevanz wie im Fall des Datentypes. UBL gibt keine Begrenzung eines Wertes vor, ISO hingegen schon, hier existieren zum Beispiel Stings in verschiedene Längen, beispielsweise Max35Text oder auch Max140Text. Für die Wertkorrespondenz in Richtung ISO UBL ist dies unproblematisch, für die entgegengesetzte Richtung ist dies nicht so. Hier könnte auf eine externen Thesaurus-Datei bzw. Hash-Tabelle ausgewichen werden. Existieren zu lange Werte, werden diese extern gespeichert und mit einem Key versehen. Anstatt des korrekten Wertes wird nun der reguläre Key verwendet. Allerdings benötigt diese Vorgehensweise eine Anpassung der Middleware sowie die Miteinbeziehung der gesamten am Prozess beteiligten Systeme. Dies kann jedoch eine Lawine lostreten, da nach und nach die Konsistenz verletzt wird. Deshalb benötigt dieser Fall eine genauere Untersuchung der Standards und kann nicht universell gelöst werden.
102 88 KAPITEL 9. DIE DIREKTE TRANSFORMATION Range bzw. Codelisten: Der vorgegebene Wertebereich 8, beschränkt die erlaubten Werte. Dies kann intern oder extern geschehen. Im internen Fall sind die Werte im XML- Schema vorgegeben, im externen Fall sind diese durch Codelisten geregelt. Hier existieren wieder unterschiedliche Vorgehensweisen. Die erste Methode übersetzt die Codes in aussagekräftige Werte, zum Beispiel wird MIST (ISO 20022) zu Mister übersetzt. Die andere Methode transformiert keine Werte, sondern gibt Informationen über die Codeliste mit, wie im Fall des BIC-Codes (siehe Beispiel 7)) oder bei den Incoterms (siehe Beispiel 11). Dabei sollte die letzte Variante nur verwendet werden, wenn das Endsystem Zugriff auf die einzelnen Codelists-Schemata hat. Die bob-bibliothek Altova MapForce bietet Bibliotheken an. Diese Bibliotheken beherbergen Funktionen, die als Bausteine für die Wertkorrespondenzen dienen. Die hier erstellte Bibliothek trägt den Namen bob. Die Aufzählung der einzelnen Funktionen und deren Definition sind im Anhang Abschnitt 11. Fallbeispiele Die Reihenfolge der Zuordnungen ähnelt der FIFO-Queue, allerdings mit der Modifizierung, dass die komplexeren Zuordnungen von den offensichtlichen leichteren Nachfolgern überholt werden. Die Elemente werden in der Reihenfolge eingelesen und verarbeitet wie es das Schema der ISO Invoice-Nachricht vor gibt. Es werden nun erwähnenswerte Fälle für Wertkorrespondenzen (WK) aufgezählt, wobei die Vorgehensweisen auch auf andere Elemente anwendbar sind. Der hervorgehobene Text gibt dabei die aktuelle Problematik an: 1. [1:1]-WK. Die erste WK ist die Verbindung der XML-Wurzel, hierfür verwendet ISO Document [1..1]9 und UBL Invoice [1..1]. 2. [1:1]-WK, Datentyp. Die erst echte WK, d.h. ein Wert wird übergeben anstatt nur eine Node zu erstellen, ist die Verbindung zwischen ISO 20022: Id [1..1] und UBL: cbc:id [1..1]. Hierbei muss keine besondere Vorkehrung getroffen werden. ISO erlaubt nur einen String mit maximal 35 Stellen. UBL handelt ähnlich, allerdings ohne Beschränkung der Stellenanzahl. Dieser Umstand ist für die Transformationsrichtung ISO UBL kein Problem, kann allerdings für die konträre Richtung UBL ISO problematisch sein. Dies tritt ein, wenn ein UBL Instanz einen String für cbc:id verwendet, der mehr als 35 Stellen hat. Hier muss interveniert werden. Eine Möglichkeit wäre den String ab der 35ten Stelle einfach abzuschneiden. Dies dürfte aber problematisch sein, wenn zwei verschiedene Rechnungen sich erst ab der 35ten Stelle unterscheiden. Die erfolgversprechende Methode wäre die Verwendung eines zusätzlichen Thesaurus, dieser Thesaurus würde für jeden problematischen Fall (z.b. zu langer Wert, falscher Datentyp) eine regulären Wert zuordnen. So würde der wahre Wert mitgegeben, aber trotzdem ein regulärer Wert verwendet werden. Allerdings muss hier wieder die Middelware angepasst und auch entschieden werden, wie beide Werte sinnvoll genutzt werden, was Zeit und Geld kostet und nicht im Sinn des STP ist. Die eben besprochene Lösung wäre auch mit XSLT realisierbar, indem Funktionen wie Modulo, IF-Abfragen und Addition 10 verwendet werden, um 8 In Ontologien ist es der Range 9 Der Exponent am XML-Element gibt die Kardinalität an 10 Stichwort: Hashing bei Datenbanken
103 9.3. PHASE 2 - DAS MATCHING 89 einen eindeutigen Schüssel (regulärer Wert) zu erzeugen. Dieser Fall kommt öfters beim Matching vor und wird ebenfalls nicht mehr erwähnt. 3. [1:1]-WK, Codeliste. Die nächste erwähnenswerte WK ist die Verbindung zwischen ISO 20022: TpCd und UBL: InoviceTypeCode. ISO gibt hierfür eine externe Codeliste vor, die insgesamt 17 verschiedene Werte ermöglicht - so steht zum Beispiel HIRI für HireInvoice, INVS für InvoiceSigned oder PUOR für PurchaseOrder. Für diesen Fall wurde eine Werteliste bzw. ein Thesaurus erstellt (XSL realisiert dies durch das xsl:choose-konstrukt). Jeder vierstellige Code bekam seinen aussagekräftigen Namen zugewiesen. Zusätzlich wurden den Attributen des Elementes noch weitere Konstanten vom Typ String zugewieses, diese Informationen definieren die verwendete Codeliste (siehe 9.5). Abbildung 9.5: Abbildung der ersten 3 WK (MapForce 2012) Die Richtung UBL ISO benötigt eine andere Vorgehensweise, da UBL keine Werte vorgibt, sondern nur eine Platzhalter-Codelist. Jede customized-codeliste 11 benötigt eine Übersetzung zu einem regulären ISO Wert. 4. [1:0]-WK. Die nächste zu erwähnende WK ist die Verbindung zwischen ISO 20022: Nm [0.. ] und UBL: bob:invoicename [0.. ]. ISO verwendet dieses Element, um der Rechnung einen Namen zu geben, UBL bietet dies nicht an. Deshalb wurde ein Pendant im UBL Extension Element kreiert. Sobald UBL keinen passende Äquivalenz bietet, wird das fehlende Pendant kreiert und anschließend gemappt. Dies sichert ab, dass kein Wert verloren geht, falls das Zielsystem dies doch benötigt. Diese Methode wird ebenfalls oft verwendet und wird nicht mehr erwähnt. Da UBL im originären Schema diese Information nicht besitzt, wird eine Lösung für die gegen gesetzte Richtung nicht benötigt. 5. [1:n]-WK Als nächstes wird die passende WK für ISO 20022: IsseDtTm 1 kreiert. Dieses ISO Element enthält das Ausstellungsdatum sowie die Uhrzeit in ISO 8601 Zeitangabe. Dieser Standard ermöglicht drei verschiedene Formate: UTC Zeit, 11 Dies sind selbstdefinierte Codelisten
104 90 KAPITEL 9. DIE DIREKTE TRANSFORMATION lokale UTC Zeit sowie lokale Zeit. Diese drei Zeitangaben unterscheiden sich nur durch ein zusätzliches Suffix 12. UBL verwendet hierfür zwei verschiedene Elemente: cbc:issuedate [1..1] und cbc:issuetime [1..1], diese Elemente besitzen aber kein vorgegebenes Format. Da UBL allerdings für das BBIE DurationMeasure ebenfalls ISO 8601 verwendet, wird die Information nur gesplittet ohne eine weiter Formatveränderung zu erfahren. Aus diesem Grund werden die Daten in der entgegengesetzte Richtung auch nur konkateniert. 6. [n:1]-wk. Nun folgt eine WK für Anmerkungen in ISO Der ISO InclNote [0.. ] -Block ist auf zwei Kinder aufgeteilt: InfTp [1..1] und InfVal [1..1]. UBL besitzt nur ein Element cbc:note [0.. ]. Deshalb werden beide ISO Elemente konkateniert inklusive des jeweiligen Pfades und einem Trennzeichen. Die entgegengesetzte Richtung ist ebenfalls simpel: Hier wird ISO mitgeteilt, dass dies ein Anmerkung bzw. Notiz mit dem in UBL definierten Notiz Schema ist. 7. [n:1]-wk Nun folgt der ISO Invcr [0..1] -Block. Dieser Block besteht aus dem semantischen Element TradeParty1, der noch häufiger Verwendung findet und definiert damit den Rechnungssteller. Im Gegensatz zu UBL ist der Aussteller in ISO keine Pflichtangabe. Der Invcr-Block besteht wiederum aus drei Blöcken. Der erste Block definiert die Hauptcharakteristika, wie Name, ID oder Adresse. Der zweite Block ist eine optionale Angabe eines Namens, der durch eine Organisation ausgestellt wurde. Der dritte Block gibt Steuer-Informationen zu dem Aussteller wider. ISO unterscheidet bei dem Aussteller entweder zwischen einer Organisation oder einer natürlichen Person, wobei eine Auswahl getätigt werden muss. Allerdings haben die Kinder der jeweiligen Blöcke keine Existenz-Pflicht, es kann also ein leerer OrgId oder PrvtId konstruiert werden. ISO ermöglicht, dass eine Partei mehrere Identifikationen hat. Sie kann eine BIC-ID besitzen und/oder eine weitere definierbare ID im Fall einer Organisation oder im Fall einer natürlichen Personen Merkmal über die Geburt oder auch eine definierbare ID. UBL verwendet für die Identifizierung mittels ID das ABIE cac:partyidendification [0.. ], dies ermöglicht WK für alle IDs. Ein vorgegebenes ID-Schema ist das BIC, diese Schema benötigt für die Zuweisung zu UBL mehrere Konstante. Allerdings dürfen diese Konstante nur in UBL kreiert werden, falls die BIC-ID auch Verwendung findet. Dies wird durch die exists und if-else-abfragen sowie drei WK zu BIC. Die erste WK kreiert für sich einen eigenen PartyIdentification-Block, damit die verschiedenen ID-Schemen nicht fälschlicherweise gemischt werden. Die zweite WK überträgt den BIC-Wert und die dritte WK ist eine indirekte Zuweisung, diese fragt nur die Existenz der BIC-Node ab, um die Konstanten zuweisen zu können (Abbildung 9.6). Die definierbaren IDs benötigen das eben verwendete Konstrukt nicht, da die Informationen in der Nachricht definiert werden und nicht per Konstanten erzeugt werden müssen. Die entgegengesetzte Richtung benötigt diesmal keine andere Vorgehensweise, es wird allerdings eine kleine Inkonsistenz hervorgerufen, falls in UBL nicht hinterlegt wird, ob es eine natürlich oder juristische Person ist. 8. [n:0]-wk. Nun folgt die Zuweisung des DtAndPlcOfBirth [0..1] -Blocks. Diese se- 12 (YYYY-MMDDThh: mm:ss.sssz), (YYYY-MM-DDThh:mm:ss.sss+/-hh:mm), (YYYY-MM- DDThh:mm:ss.sss).
105 9.3. PHASE 2 - DAS MATCHING 91 mantische Informationseinheit ist in UBL unbekannt, anstatt es zu archivieren wird diese Information in eine ID umgewandelt, indem die Daten konkateniert werden und die Schema-Definition mit gegeben wird. Eine Betrachtung der entgegengesetzten Richtung ist nicht nötig, da dies zum zuvor behandelten Fall gehört. Es wurden also für alle vier verschiedenen IDs in ISO immer das identische UBL-Konstrukt verwendet. Abbildung 9.6: Wertzuweisung der BIC-ID (MapForce 2012) 9. [n:1]-wk (komplexe Art). Nun folgt die Abbildung der Konaktdetails für den zuständigen Ansprechpartner des Rechnugsstellers. ISO verwendet dafür CtcDtls, welches auf dem semantischen Block Contacts3. UBL bietet ebenfalls ein solches sematisches Konstrukt mit dem Namen cac:contact vom ABIE Type cac:contacttype (Abbildung 9.7. Hierbei fällt auf, dass das ISO Konstrukt mehr Informationen speichern kann, aber durch die Festlegung sehr beschränkt ist. Es bietet nur ein modifizierbares Element an (Othr), mit der Kardinalität [0..1], allerdings hat das semantische Konstrukt eine maximale Kardinalität von. UBL verfährt hier konträr, cac:contact hat eine maximale Kardinalität von 1 und eine Kardinalität bei cac:othercommunication. Dies bringt Probleme für beide Mapping-Richtungen. Für die Richtung ISO UBL ist es problematisch, da theoretisch unendlich viele Ansprechpartner in ISO existieren können, in UBL hingegen nur maximal eine Person. Deshalb wurde für die n-1 Kontaktpersonen ein Auffangbecken im Extension Elemente kreiert. Dies geschieht mit der XSLT position-abfrage sowie der XLST if-else-anweisung. Falls das zu transformierende Element schon vorkam dann muss dieses Element im Extension Element archiviert werden. Dieses Vorgehen löst allerdings nur das erste Teilproblem. Wie schon erwähnt hat ISO 20022: CtcDtls mehrere Elemente, die in UBL nicht vorkommen. Falls es sich bei dem Element um Informationen über eine Kommunikationsart handelt, wird diese auf das ASBIE cac:othercommuncation gemappt. Handelt es sich um andere Funktionen wie Titel oder Abteilung, kommt dieses in das BBIE cbc:note [0..1]. Allerdings müssen alle Informationen konkateniert werden, da die maximale Kardinalität auf 1 beschränkt ist. Dabei werden die Namen des Nodes, Trennzeichen sowie deren Werte verbunden (NameOfNode::Value$#$). Die andere Richtung UBL ISO ist durch die maximale Kardinalität von 1 einfacher. Hier werden die nicht deckungsgleichen Elemente ebenfalls konkateniert mit
106 92 KAPITEL 9. DIE DIREKTE TRANSFORMATION anschließender Erstellung der WK. Abbildung 9.7: Gegenüberstellung der beiden semantisch vergleichbaren Konstrukte 10. [1:1]-WK, Codeliste. Die letzte erwähnenswerte WK im InvcHdr ist die Zuweisung von ISO 20022: Strd zu UBL: cac:exemptionreasoncode. Beide Elemente geben im aktuell betrachteten Kontext eine Ausnahmeregelung für die Steuerpflicht an. ISO verwendet für diese Werte eine im Schema festgelegte Codeliste, also eine interne Codeliste. UBL hingegen bietet wieder eine Platzhalter in Form einer Dummieliste an. Diesmal werden die Codes jedoch nicht per Wertzuweisung übersetzt, UBL bekommt stattdessen eine Definition des verwendeten ISO Werte-Schemas, da ie Übersetzungen, also die Namen, wenig aussagekräftig sind. So trägt zum Beispiel der Wert 457x den Namen FourHundredFiftySeven, allerdings dürfte dies für einen Domänenfachmann nicht gelten. Für die entgegengesetzte Richtung muss wieder die in UBL verwendete Codeliste betrachtet werden. Falls dort für ISO unbekannte Steuerarten stehen, müssen diese auf ISO OTHR gemappt werden. 11. [1:1]-WK, Codeliste. Eine weitere Codelisten-Betrachtung folgt im Fall der Incoterms 13. ISO verwendet hierfür die aktuelle Version (2010) mit 11 Codes 14, UBL kann diese auch verwenden, präferiert laut der UBL-Spezifikation allerdings die veraltete Version (2000) mit 13 Codes. Für die Richtung ISO UBL ist dies kein Problem. Die entgegengesetzte Richtung benötigt hingegen bei der Version eine Wertzuweisung, diese wird durch die Organistation ICC ermöglicht. Dazu benennt die Organisation den Code innerhalb der 2000-Version, der die Codes aus der 2010-Version ersetzt. Generell kann gesagt werden, dass, obwohl ISO und UBL auf dem CII-Modell basieren, in vielen Fällen das Abfangen der n:1-wertkorrespondenzen-problematik von Relevanz ist. Dies ist bedingt durch die Verwendung unterschiedlicher Kardinalitäten. 13 Diese regeln, wer für die Transportkosten inklusive Versicherung aufkommen muss. Verantwortlich für diesen Standard ist der ICC. ( icc-incotermsr.html) 14 Dies ist eine Vermutung, da weder in der Spezifikation noch in der externen Codeliste Information zum Schema stehen. Die Codes sind deckungsgleich mit der 2010-Version, daher dieses Annahme.
107 9.4. PHASE 3 - ANALYSE DES MAPPINGS Phase 3 - Analyse des Mappings In der dritten Phase wird das Mapping als Ergebnis von Phase zwei in eine Transformationsregel übersetzt. MapForce generiert aus diesen WK ein XSLT 2.0 Skript. Das erzeugte XSLT-Stylesheet wird nun auf verschiedene Instanzen getestet, darauf folgt eine UBL XML-Schemavalidierung. Da kein Zugriff auf weitere Instanzen vorhanden ist, werden einige Instanzen manuellsowie generisch über Altova XMLSpy 2013 erstellt. Die Validierung des Mappings geschieht auf zwei Ebenen: XML-Schema-Validierung Das transformierte Dokument wird mittels des Ziel-XML-Schemas auf Fehler überprüft. Domänenexperte Das Mapping wird von einem oder mehreren Domänenexperten begutachtet. Das Mapping liegt in Form einer Altova MapForce 2013-Mapping-Datei vor. Für alle Element des Ziel-XML-Schemas werden Wertkorrespondenzen erstellt. Falls das originäre UBL-Dokument kein Pendant für ISO aufweist, wird dieses erweitert und anschließend der jeweilige Wert zugewiesen. Im Anhang befindet sich eine Auflistung aller Mapping-Funktionen, diese sind wieder verwendbar. Dabei ist zu beachten, dass Anweisungen zwar kreiert worden sind allerdings, wurden sie nicht von einem Domänenexperte begutachtet. Domänenexperten haben in der Regel eine mehrjährige Ausbildung und entsprechende Erfahrung. Ein solcher Domänenexperten stand jedoch weder zur Verfügung, noch ist adäquates Wissen in ausreichender Form vorhanden. Es ist daher trotz intensiven Befassens mit den Definitionen beider Nachrichten eine Korrektheit nicht garantiert und auch sehr unwahrscheinlich. Zudem existiert das Problem von Pflichtangaben in UBL. UBL besitzt einige Pflichtangaben, die allerdings für ISO unbekannt sind. Das führt dazu, dass ein UBL Konstrukt, welches durch ein ISO Konstrukt entstanden ist, Pflichtangaben besitzt, die nicht existent sind. Da das Domänenwissen fehlt, ist es nicht möglich, semantisch korrekte Dummy-Werte zu erstellen. Dadurch wird das entstehende Zieldokument in der Regel nicht valide sein. Die Rechnungsdokumente von UBL und ISO sind beide inhaltsmächtige Dokumente. Durch die Möglichkeit von UBL, die Dokumente zu erweitern ist ein Informationsverlust vermeidbar, allerdings sind diese neuen UBL-Dokumente am Anfang fremd. ISO unterstützt auch eine Erweiterung mittels Supplementary Data, diese unterliegen allerdings einem Review der ISO Administration. Für ein verlustfreies Mapping mit dem Verzicht auf Erweiterungen beider Nachrichten ist es notwendig beide Dokumente auf bestimmte Elemente zu beschränken. Es ist daher eine Übereinkunft nötig, die besagt, dass nur ein Subset der ISO Rechnung sowie ein Subset der UBL-Rechnung ausgetauscht werden darf. Diese Subsets werden mittels einer Gap-Analyse 15 definiert. Die erstellten Wertkorrespondenzen, die auf den semantischen Bausteinen basieren, können als mögliche Grundlage für eine Mapping-Datenbank dienen, da diese Funktionen in der Regel auf den XML-Type-Deklarationen basieren. So wäre eine Datenbank möglich, die die Wertkorrespondenzen aller semantisch ähnlichen Elemente von ISO zu UBL beherbergt. Allerdings sollte hierfür ein quelloffener und lizenzfrei Mapping-Standard verwendet werden, anstatt einer proprietären MapForce-Mapping-Bibliothek. 15 Lückenanalyse
108 94 KAPITEL 9. DIE DIREKTE TRANSFORMATION Durch die Komplexität der Rechnung bedingt, sind die Funktionen nicht auf den ersten Blick ersichtlich. Leider unterstützt MapForce die Dokumentation nur als Label an den Wertkorrespondenzen-Pfeilen. Ein freischwebendes Annotation-Feld, welches einen Text beherbergt, um so die einzelnen Stufen zu dokumentieren ist nicht möglich. Durch die Komplexität der Dokumente ist zudem Unübersichtlichkeit gegeben. Obwohl das Mapping nicht im produktiven Gebrauch verwendbar ist, ist es hilfreich, um die Methoden zu verstehen, die die Probleme der verschiedenen Heterogenität-Arten überwinden. Daher hat das Mapping den Charakter einer Anleitung. Außerdem sollte beachtet werden, dass die MapForce-Mapping-Datei das Ergebnis ist und nicht das Skript, da nur die MapForce-Datei die Handhabung mit verschiedenen WK-Lösungen aufzeigen kann.
109 KAPITEL 10 Die ontologie-basierenden Transformation Dieses Kapitel befasst sich mit der ontologie-basierenden Transformation. In Abschnitt 10.1 wird der Fokus der Applikation definiert und begründet. Abschnitt 10.2 stellt eine Anforderungsanalyse an die Applikation vor. Abschnitt 10.3 begründet die Wahl der Programmiersprache Java. Abschnitt 10.4 stellt die im Zuge dieser Arbeit entwickelte Applikation ISUT vor. Abschließend wird in Abschnitt 10.5 die Methoden verglichen Entwicklung der ontologie-basierenden Transformation Die ontologie-basierende Transformation (nachfolgend ISUT 1 genannt) integriert ein XML- Dokument des Quellschemas in eine Domänenontologie, anschließend wird der Inhalt dieser Ontologie wieder in ein XML-Dokument des Zielschemas überführt. In der direkten Transformation wird das Quell-Schema mit Hilfe eines XSLT-Skriptes in das Ziel-Schema umgewandelt. Ein Nachteil der direkten Methode ist die Gebundenheit an XML. Es wird eine auf XML-basierende Nachricht eingelesen, transformiert und eine auf XML-basierende Nachricht ausgegeben. Sollte eine andere Syntax verwendet werden, ist eine neue Zuordnung nötig. Bei der ontologie-basierenden Transformation ist das Herzstück die Ontologie. Es wird eine auf XML-basierende Nachricht eingelesen, auf die Ontologie gemappt und anschließend diese Ontologie auf den Syntax des Ausgabe-Formates gemappt. Im Gegensatz zur ersten Methode wird der Inhalt der Nachricht komplett von der Syntax gelöst. Dieses Vorgehen ist um einiges aufwendiger, hat aber neben dem dargestellten Vorteil der Syntaxbefreiung noch weitere Vorteile (siehe Kapitel 7). Die Struktur der erstellten Domänen-Ontologie orientiert sich stark an der Struktur des Rechnungs-XML-Schemas von UBL. Dadurch sind erstellte Wertkorrespondenzen in der direkten Transformation mit einigen vereinzelten Ausnahmen auch hier gültig. Durch die Komplexität der direkten Transformation und den daraus resultierenden Umfang, wird ISUT nur die ISO Geschäftskomponente Invoicer in das UBL ABIE Accounting- SupplierParty transformieren. Dies geschieht aus folgenden Gründen: 1 ISO2022 UBL-Transformator 95
110 96 KAPITEL 10. DIE ONTOLOGIE-BASIERENDEN TRANSFORMATION Invoicer beziehungsweise AccountingSupplierParty besitzt eine komplexe Struktur, erfordert deswegen komplexe Wertkorrespondenzen und eignet sich hervorragend für Fallbeispiele. Beide Komponenten sind Hauptakteure und lassen sich mit einigen wenigen Modifikationen auf alle Akteure erweitern. Das Mapping in der direkte Transformation hat mehrere Wochen gedauert. Dies würde auch für die Applikation gelten und den zeitlichen Rahmen sprengen Anforderungsanalyse Für die Entwicklung der Applikation wird eine Anforderungsanalyse benötigt, die Anforderungen und Rahmenbedingungen benennt. Das Referenz-System für quantitative Aussagen ist ein Intel Core 2 Quad CPU mit 2,5 GHz und 8 GB RAM. Das System hat einen Windows- Leistungsindex von 5,9. Dabei sind der Prozessor sowie der Arbeitsspeicher mit 7,2 und die primäre Festplatte mit 5,9 bewertet. Die drei Hauptaufgaben der Applikation sind: Ontologie Modifizierung Die Applikation muss Ontologien lesen sowie speichern können. Dabei ist zu beachten, dass das Lesen auch das Laden einer bestehenden Domänen- Ontologie beinhaltet. XML Modifizierung Die Applikation muss lokale XML-Instanzen lesen sowie speichern können. Dabei ist zu beachten, dass die Applikation das Speichern verschiedener Syntaxarten unterstützen kann. Anwendung von Mappings Die Applikation muss die jeweiligen XML-Instanzen mittels Mapping-Anweisungen in die lokale Ontologie-Domäne integrieren, die entgegengesetzte Richtung ist ebenfalls. Das Erstellen eines Mappings ist kein Teil der Aufgabe. Neben diesen drei Hauptaufgaben gibt es noch weitere Anforderungen von sekundärer Natur: Effizienz Die Applikation muss in angemessener Zeit ausführbar sein und die Gefahr eines endlosen Prozesses unterbinden. Die quantitative obere Grenze liegt bei 10 Sekunden für den gesamten Prozess, exklusive Anwenderinteraktionen. Zudem darf sie nicht speicherintensiv sein, eine manuelle Veränderung der Java Heap-Größe sollte nicht erforderlich sein. Benutzbarkeit Die Applikation muss mittels einer Maus und Tastatur bedienbar sein. Sie sollte so einfach wie möglich gehalten werden. Erweiterbarkeit Die Applikation muss mit neuen Mapping-Anweisungen per Programmcode erweiterbar sein. Verhalten Die Applikation muss bei n-maligen ausführen mit den jeweils identischen Eingaben immer dasselbe Ergebnis liefern. Kleine Abweichungen bedingt durch zufällige Erstellung von Werten sind akzeptabel. Plattformunabhängig Die Applikation sollte auf jeder Plattform lauffähig sein.
111 10.3. XSLT ODER JAVA ALS TECHNOLOGIE 97 Rechtlich Die Applikation darf nur Komponenten verwenden, die öffentlich zugänglich sind XSLT oder Java als Technologie Die direkte Transformation verwendet als Technologie XSLT. XSLT eignet sich nicht für die ontologie-basierte Methode, da XSLT nur in Verbindung mit XML funktioniert und OWL, falls es auf XML basiert, auf einem anderen logischen Konstrukt basiert. Die Fixierung auf XML verhindert andere Syntax-Arten als Quell- und Zielnachrichten, zudem sind Ontologien, die auf einer anderen Syntax basieren nicht verwendbar für die Domänen-Ontologie. XML verwendet als logischen Aufbau eine Baumstruktur, OWL hingegen basiert auf einem Graph. Diese beiden Tatsachen verhindern die Verwendung von XSLT. Es wurde daher für die die Entwicklung die Programmiersprache Java gewählt, da Java plattformunabhängig ist, weitverbreitet ist, verschieden XML-APIs besitzt sowie eine OWL-API Die ontologie-basierende Applikation ISUT Die Technologien ISUT 2 verwendet zwei elementare APIs, die die Interaktionen mit XML und OWL ermöglichen: OWL API (for OWL 2.0) Diese Java API der University of Manchester ermöglicht die Manipulation von OWL Ontologien sowie Anfragen mittels Reasoners. Sie unterstützt das Schreiben und Lesen von Dokumenten mit folgender Syntax: RDF/XML, OWL/XML, OWL Functional Syntax und Turtle. Des weiteren kann sie auch KRSS und OBO Flat File Format lesen, allerdings nicht speichern. Die API basiert auf OWL 2.0 im Gegensatz zum Vorgänger. Diese API wird auch in Protégé 4.x verwendet und löste die Jena OWL API ab. JDOM Diese Java API ermöglicht das Manipulieren von XML-Dateien. Dabei arbeitet diese mit DOM sowie SAX und wurde so entwickelt, dass sie für JAVA optimiert wurde. Beispielsweise verwendet sie die Collection-API zur Speicherung. Zudem werden XML-Knoten nicht als abstrakte Nodes realisiert, sondern als Java-Klassen. Diese Vorteile ermöglichen ein schnelles und effizientes Arbeiten. 2 ISO20022-UBL-Transformator. Danke an Dr. K. Toll für den Namen.

112 98 KAPITEL 10. DIE ONTOLOGIE-BASIERENDEN TRANSFORMATION Die OWL-API verwendet OWL 2 als Ontologie-Sprache, OWL 1 Ontologien sind durch die Rückwärtskompatibilität von OWL 2 ebenfalls auch OWL 2 Ontologien (Siehe 7.4. Allerdings verändert die OWL-API bei der Manipulation der Ontologie die Struktur, darausfolgend sind die Ontologien nicht mehr mit Protégé 3.x kompatibel, obwohl diese originär mit Protégé 3.x erstellt wurden. Das führt dazu, dass die manipulierten Ontologien nur mit Protégé 4.x kompatibel sind. Dies ist zwar nicht sehr problematisch, zwingt aber zur Umgewöhnung. Die Wahl fiel vorliegend auf JDOM anstatt die Java-integrierte DOM-API, da JDOM laut einigen Java-Foren schneller ist, als die anderen APIs, des weiteren soll das Arbeiten einfacher sein. Neben diesen APIs werden noch Bibliotheken und andere Komponenten verwendet, diese sind aber von rein sekundärer Natur und nicht zwingend notwendig für die Applikation, daher werden diese nicht behandelt. So zum Beispiel der Java GUI-Designer WindowBuilder Pro von Google Das Interface Das Interface von ISUT ist sehr simple gehalten und auf ein Fenster beschränkt, siehe Abbildung Dabei verfolgt das Fenster eine Interaktionsrichtung, die nach unten gerichtet ist. Dies äußert dadurch, dass erst wenn Button 2 und Button 4 mit einem positiven Ergebnis getätigt worden sind, wird Button 5 aktiviert. Nach positivem Ergebnis wird Button 7 aktiviert. Abbildung 10.1: Interface des ontologie-basierenden Transformation 1 - Informationsfeld Eingabe Dieses Feld stellt die Metadaten des Eingabe-Dokumentes dar. Es ist auf die Analyse von ISO 20022, UBL und EDIFACT beschränkt. Informationen werden nach erfolgreichem Ausführen von Button 2 ausgegeben. 2 - Button Datei laden Dieser Button öffnet ein Auswahlfenster für die zu übersetzende XML-Instanz. Nach Ausführung wird dies Button 5 mitgeteilt.
113 10.4. DIE ONTOLOGIE-BASIERENDE APPLIKATION ISUT Informationsfeld Ontologie Dieses Feld stellt die Metadaten der Ontologie (OWL Domänen- Ontologie) dar. Informationen werden nach erfolgreichem Ausführen von Button 4 ausgegeben. 4 - Button Datei laden Dieser Button öffnet ein Auswahlfenster für die Domänenontologie, wobei ein Filter OWL-Dateien auf die Ansicht gelegt wurde. Nach Ausführung wird dies Button 5 mitgeteilt. 5 - Button Integriere XML-Instanz in die Ontologie und speichere sie unter... Dieser Button wird erst nach Ausführung von Button 2 und Button 4 aktiviert. Bei Aktivierung des Buttons wird der Inhalt des Eingabe-Dokumentes (nur ISO und UBL XML-Instanzen) in die Ontologie integriert. Anschließend wird diese Ontologie mittels eines Speicher-Dialoges gespeichert und Button 7 aktiviert. 6 - Informationsfeld Ausgabe In diesem Feld wird das Ausgabe-Format festgelegt. Es ist nur UBL als Ausgabe-Dokument implementiert. 7 - Button Datei speichern Dieser Button übersetzt die Ontologie in das Ausgabe-Dokument und speichert das Dokument mittels eines Speicher-Dialoges. 8 - Informationsfeld In diesem Feld werden Rückmeldungen der einzelnen Prozesse wiedergegeben Klassenaufbau von ISUT ISUT besteht im Wesentlichen aus zwei Komponenten, welche wiederum aus einer Menge von Klassen bestehen. Die hier erfolgten Aussagen müssen in dem Kontext betrachtet werden, dass die Eingabe eine XML-Instanz ist. Dabei verfahren die Komponenten wie folgt: Die erste Komponente öffnet die XML-Instanz sowie die Domänen-Ontologie. Anschließend wird das Eingabe-Dokument geparst und für jedes Element sowie deren Attribute wird ein eindeutiger XPath-ähnlicher Ausdruck erzeugt. Diese Pfade dienen gleichzeitig als Namen der OWL Objekte, daher müssen sich diese unterscheiden, falls ein Objekte mehrmals vorkommt. Die Abgrenzung der identischen Objekte wurde mittels einer Nummerierung realisiert. Eine andere denkbare Methode wäre die Identifizierung mittels der Typdefinitionen in den Schemata. Zum einem basiert die direkte Transformation auf diesem Verfahren und wurde deshalb schon angewendet. Zu anderem ist das Einbinden mit eines Schemas rechenintensiver. Weiterhin sollte eine Möglichkeit realisieren werden, die funktioniert, falls kein XML-Schema zur Verfügung steht. Die XPath-Ausdrücke werden mit Separatoren versehen. Dies ermöglicht eine Identifizierung des Pfades, des Elementes sowie der Attribute. Da OWL und Java spezielle Zeichen nicht zulassen, erfolgte eine Entscheindung für Buchstaben als Basis der Separatoren. Diese werden mittels einer Zufallsfunktion sowie mit einer Zeichenbasis erstellt, mit der anschließenden überprüft werden muss, ob die Separatoren im Dokument vorkommen. Ist dies der Fall, werden Separatoren erzeugt. Dabei wird darauf geachtet, dass die fünf Separatoren keine gemeinsame Buchstabenbasis haben, um
114 100 KAPITEL 10. DIE ONTOLOGIE-BASIERENDEN TRANSFORMATION ein fehlerhaftes Verhalten vorzubeugen. Für jeden dieser Pfade, allerdings ohne Separator und Nummerierung, wird eine Anweisung erstellt. Die erzeugten Pfade werden anschließend einzeln überprüft und, falls ein Mapping-Anweisung vorliegt, in ein OWL-Objekt (Individual, Object Property oder Data Property) erzeugt. Wenn jedes Element untersucht worden ist, wird die Ontologie gespeichert. Die zweite Komponente öffnet die erzeugte Domänenontologie der ersten Komponente und erstellt für jede Instanz, wenn Mapping vorhanden, die XML-Ausgabe. Da Ontologien keine feste Reihenfolge in ihrer Struktur aufweisen, werden die Elemente in der Reihenfolge des Zielschemas erstellt. Die Separatoren werden wieder ausgefiltert, sodass die original Werte in den XML-Elementen und deren Attribute stehen. Da die OWL-API größtenteils mit Mengen arbeitet, kann die Reihenfolge der XML-Attribute bei jeder Ausführung unterschiedlich sein Die Mapping-Anweisung XML zu OWL Die Mapping-Anweisungen werden mittels Java-Quellcode erstellt. Dabei ist die Klasse in zwei Komponenten aufgeteilt. Die erste Komponente ist eine Fallunterscheidung für die Pfade aus Abschnitt Dabei steht für jeden Pfad in der Regel eine Methode, die Methode wird mit zusätzlichen Parametern aufgerufen. Die zweite Komponente ist die Menge der Methoden, die in der ersten Komponente aufgerufen werden. Diese sind durch Parameter wiederverwendbar und dienen als universelle Methode. XML zu OWL Die Extraktion der Invoice-Instanz in der Domänenontologie wird auf andere Weise realisiert. Die Ontologie wird durch ein Gerüst, welches dem XML-Schema ähnelt, geleitet. Dabei testet jedes Element, ob eine Instanz von sich vorliegt. Wenn dies der Fall ist, wird das Element mit dem Wert erzeugt. Dabei wird auch die Kardinalität beachten inklusive der Verschiebung ins Extension Element, falls die Kardinalität dazu zwingt. Da nur das Invoicer-Objekt beziehungsweise das AccountingSupplierParty-Objekt transformiert wird, ist die Kontaktperson von der Verteilung betroffen. Anmerkung zu ISUT Die Probleme des Mappings sind identisch mit den Problemen der direkten Transformationen. Daher werden sie hier nicht wiederholt. Die Mapping-Anweisung wurden schriftlich erstellt. Da da ISUT als Proof-of-Concept gilt, wurden für dieses Programm nur wenige Mapping-Anweisungen erstellt. Zudem ist das Mapping ohne eine GUI aufwendiger und unübersichtlicher. Die Mappping-Anweisungen von ISUT sind wie auch bei der direkten Methode wiederverwendbar. Das komplette Mapping benötigt in der Regel nur zwei bis drei Sekunden mit Ausnahme der Interaktionszeit Vergleich zu der direkten Transformation Grundlage beider Transformationsarten ist das Matching sowie das resultierende Mapping. Für den Fall, dass nur zwei Schemata transformiert werden, benötigt die direkte Transformation nur eine Schemakorrespondenz. Die ontologie-basierende Methode hingegen benötigt zwei Schemakorrespondenzen (Schema-Ontologie & Ontologie-Schema) sowie eine
115 10.5. VERGLEICH ZU DER DIREKTEN TRANSFORMATION 101 Ontologie als Repräsentation der Daten. Da sich der Aufbau der Ontologie an UBL orientiert, ist die Schemakorrespondenz von ISO auf UBL nahezu identisch zu der direkten Transformation. Die OWL XML-Transformation ist daher auch von sehr geringer Problematik. Eine Transformation nur zwischen zwei Nachrichten mittels der direkten Art ist völlig ausreichend. Ist aber absehbar, dass eitere Nachrichtenstandards hinzukommen, lohnt sich eine Kosten- und Nutzenanalyse beider Transformationen. Ein Vorteil der Ontologie ist die Erweiterbarkeit der Repräsentation der Daten. So ist es möglich, die Domänenontologie so zu erweitern dass nicht nur die Rechnung abgedeckt ist, sonder auch zum Beispiel die Bestellung. Allerdings sollte auch beachtet werden, dass die Entwicklung einer Ontologie ein Prozess ist, welcher nur abgeschlossen ist, wenn kein weiterer Standard mehr hinzugefügt wird. Wird ein Standard hinzugefügt der Informationen beherbergt, die die Ontologie nicht abdeckt, muss diese erweitert werden. Im schlimmsten Fall muss die Ontologie in der Struktur angepasst werden, da sonst eine Inkonsistenz in der Logik existiert. Ist dies der Fall, müssen auch alle Wertkorrespondenzen angepasst werden. Allerdings ist kein Beispiel für diese Situation bekannt, die Situation sollte allerdings bedacht werden. Ein Vorteil der direkten Transformation ist die Übersicht der Schemata beziehungsweise die Struktur der Daten bedingt durch die Existenz von Mapping-Tools, da keine produktive Mapping-Anwendung für Ontologien existiert. Allerdings existiert eine Gebundenheit an die Mächtigkeit der proprietären Programme. Die Programmiersprache stattdessen ist die mächtigste Variante. Nichtsdestotrotz wäre ein Mapping-Tool, das ontologie-kompatibel ist, wünschenswert. Die ontologie-basierenden Methode benötigt zusätzlich zum Wissen über die Nachrichten auch das Wissen über Ontologien, so ist die Entwicklung am Anfang kostspieliger und aufwendiger. Es kann aber der Schluss gezogen werden, dass beide Varianten eingesetzt werden können um Nachrichten zu transformieren.
116 102 KAPITEL 10. DIE ONTOLOGIE-BASIERENDEN TRANSFORMATION
117 KAPITEL 11 Ausblick Um unnötige Wiederholungen zu vermeiden, werden auf die Fazit-Ausführungen sowie auf die Beurteilungen innerhalb den jeweiligen Kapitel verwiesen. Diese sollen jedoch abschließend um nachfolgende Ausführungen ergänzt werden. Durch Initiativen wie PEPPOL oder SEPA ist ein kurz- oder mittelfristig Verschwinden von UBL oder ISO nicht wahrscheinlich. Es ist vielmehr davon auszugegehen dass sich beides Standards ausbreiten werden, wobei die Ausbreitung abhängig ist von der Akzeptanz durch Unternehmen und den öffentlichen Sektor. Beides Standards gehen in die Richtung der Ontologien, durch ihre semantischen Bausteine und den zugehörigen Relationen. Der nächste Schritt in der Entwicklung der Nachrichten ist die Verwendung von Ontologien. Um die Fehler zu verhindern, die aus den syntax-basierenden 1 Nachrichten bekannt sind, also die Überwindung der Heterogenitäten, ist die Entwicklung eines Rahmenwerkes wie ebxml für Ontologien notwendig. Nachrichten können ohne weiteres mittels Ontologien transportiert werden, im Gegensatz zu syntax-basierenden Nachrichten können sie auch Ableitungsregeln beinhalten. 1 Wie JSON, XML oder EDIFACT 103
118 104 KAPITEL 11. AUSBLICK
119 Anhang Die bob-bibliothek In diesem werden die Funktionen vorgestellt, die sich in der bob-bibliothek befinden. Es werden nur vereinzelt Funktion mittels eines Bildes präsentiert, diese stammen wenn nicht anders erwähnt von Altova MapForce AddressConverter Diese Funktion konvertiert PostalAddress6 (ISO 20022) in cac:- PostalAddress (UBL). Diese Funktion verwendet die Funktion DepartmentConcater. Die Wertkorrespondenzen sind alle von einfacher Natur, weiteren Funktionen benötigt werden. Siehe Abbildung 1 Abbildung 1: Abbildung des Address_Convert-Funktion der bob-bibliothek Amount_Converter Diese Funktion filtert Beträge mit der Hauptwährung aus. BIC_Converter Diese Funktion transformiert den BIC-Code in eine UBL ID. CashAccount_Converter Diese Funktion transformiert Kontoinformationen. 105

120 106 KAPITEL 11. AUSBLICK Characteristics_Converter Diese Funktion transformiert die ISO Nachrichtenkomponente ProductCharacteristic2 in das UBL Pendant ABIE PhysicalAttribute. Contact3_Converter Diese Funktion transformiert die Kontakt-Angabe von ISO zu der Kontakt-Angabe von UBL. Contact3_Switcher Diese Funktion fungiert als eine Weich für die n möglichen Kontakte, dabei wird die erste Kontakt-Angabe ausgefiltert von den restlichen n-1-kontakten. Die ausgefilterten Kontakte werden im Extension Element gespeichert. CurrencyAndAmount_Filter Diese Funktion filtert den Betrag in der Hauptwährung aus. ISO ermöglicht in der Regel den Betrag in mehreren Währungen anzugeben, UBL hingegen verwendet nur einen Betrag. Die Hauptwährung wird in Dokument angegeben. Falls keine Hauptwährung angegeben ist, wird der erste Betrag verwendet. Siehe Abbildung 1. Abbildung 2: Abbildung der CurrencyAndAmount_Filter-Funktion der bob-bibliothek Die IF-ELSE-Anweisungen im blauen Bereich filtern in Verbindung mit den Anweisungen im rotem Bereich den ersten Betrag aus. Die IF-ELSE-Anweisungen im grünen Rechteck filtern die Hauptwährung aus. Falls die Hauptwährung nicht angegeben ist, wird die erste Währung verwendet. DateDormat4Choice_Converter Diese Funktion verteilt die Zeitangaben im ISO DateFormat4Choice. Department_Concater Diese Funktion konkateniert das Departemnt und Subdepartment Elemte von ISO zu einem UBL Element. DiscountOrChargeType1Choice_Converter Diese Funktion transformiert die Nachrichtenkomponente DiscountOrChargeType1Choice von ISO in das UBL BBIE AllowanceChargeReasonCodeType DtAndPlcOfBirth_Converter Diese Funktion wandelt die Nachrichtenkomponente Dt- AndPlcOfBirth in das UBL BBIE ID. ISO Verwendet dieses Konstrukt als eine Identifizierung für eine Person. Die Werte werden hier konkateniert und übersetzt. Ein andere Möglichkeit ist das kreieren des Konstrukts im UBL Extension Element. Ich habe die Konkatenation gewählt, da diese Konstrukt eine Identifizierung sein. Siehe Abbildung
Der Vertrag und die Rechnung
 Der Vertrag und die Rechnung Butter bei die Fische Hamburg Kreativgesellschaft HAW 26.05.2014 Dr. Gero Brugmann, LL.M. (UNSW) Der Vertrag und die Rechnung Verträge schließen und Rechnungen schreiben sind
Der Vertrag und die Rechnung Butter bei die Fische Hamburg Kreativgesellschaft HAW 26.05.2014 Dr. Gero Brugmann, LL.M. (UNSW) Der Vertrag und die Rechnung Verträge schließen und Rechnungen schreiben sind
ISO 20022 im Überblick
 Inhaltsverzeichnis Was ist ISO 20022? 2 Wo sind die ISO-20022-Nachrichten veröffentlicht? 2 Welche Bereiche umfasst ISO 20022? 2 Welche Bedeutung hat ISO 20022 für die Standardisierung? 3 Welche Bedeutung
Inhaltsverzeichnis Was ist ISO 20022? 2 Wo sind die ISO-20022-Nachrichten veröffentlicht? 2 Welche Bereiche umfasst ISO 20022? 2 Welche Bedeutung hat ISO 20022 für die Standardisierung? 3 Welche Bedeutung
Workshop 3. Excel, EDIFACT, ebxml- Was ist state. of the art und wo liegt die Zukunft. 16. September 2002
 Workshop 3 Excel, EDIFACT, ebxml- Was ist state of the art und wo liegt die Zukunft 16. September 2002 Dipl. Kfm. power2e energy solutions GmbH Wendenstraße 4 20097 Hamburg Telefon (040) 80.80.65.9 0 info@power2e.de
Workshop 3 Excel, EDIFACT, ebxml- Was ist state of the art und wo liegt die Zukunft 16. September 2002 Dipl. Kfm. power2e energy solutions GmbH Wendenstraße 4 20097 Hamburg Telefon (040) 80.80.65.9 0 info@power2e.de
Ordnungsgemäße Rechnung gem. 14 Abs. 4 UStG. Rechtsstand: April 2013
 Ordnungsgemäße Rechnung gem. 14 Abs. 4 UStG Rechtsstand: April 2013 Inhalt I. Muster (Brutto-Rechnungsbetrag über 150 )... 2 II. Erleichterungen für Rechnungen von weniger als 150,- brutto (sog. Kleinstbetragsrechnungen)
Ordnungsgemäße Rechnung gem. 14 Abs. 4 UStG Rechtsstand: April 2013 Inhalt I. Muster (Brutto-Rechnungsbetrag über 150 )... 2 II. Erleichterungen für Rechnungen von weniger als 150,- brutto (sog. Kleinstbetragsrechnungen)
Das kleine (oder auch große) Rechnungs-Einmaleins
 Rechnungs-Einmaleins") HLB Ratgeber II/2014 Das kleine (oder auch große) Rechnungs-Einmaleins Steuertipps rund um die Rechnung und die elektronische Rechnung Dem Finanzamt genügt oft schon ein kleiner formaler Fehler um den
HLB Ratgeber II/2014 Das kleine (oder auch große) Rechnungs-Einmaleins Steuertipps rund um die Rechnung und die elektronische Rechnung Dem Finanzamt genügt oft schon ein kleiner formaler Fehler um den
Wie stelle ich eine korrekte Rechnung?
 Rechnungsstellung Wie stelle ich eine korrekte Rechnung?... denn DAMIT fängt das Geldverdienen an! Rechnungsstellung Was ist eine Rechnung? Grundsätzlich jedes Dokument, mit dem eine Leistung abgerechnet
Rechnungsstellung Wie stelle ich eine korrekte Rechnung?... denn DAMIT fängt das Geldverdienen an! Rechnungsstellung Was ist eine Rechnung? Grundsätzlich jedes Dokument, mit dem eine Leistung abgerechnet
Elektronische Rechnungen. Endlich einfach?
 Elektronische Rechnungen Endlich einfach? Informationstag für Unternehmen in Zittau 13.06.2012 Angela Looke Niederlassungsleiterin Löbau Steuerberaterin Diplom-Kauffrau angela.looke@connex-stb.de +49 (0)
Elektronische Rechnungen Endlich einfach? Informationstag für Unternehmen in Zittau 13.06.2012 Angela Looke Niederlassungsleiterin Löbau Steuerberaterin Diplom-Kauffrau angela.looke@connex-stb.de +49 (0)
Digitales Rechnungsmanagement as a Service Lösungen für ALLE TEXTILER (Handel und Industrie)
") Digitales Rechnungsmanagement as a Service Lösungen für ALLE TEXTILER (Handel und Industrie) Folie: 1 Hohe Erwartungen an die E-Rechnung Folie: 3 Definition e-invoicing Papierlos von A-Z Gesetzeskonforme
Digitales Rechnungsmanagement as a Service Lösungen für ALLE TEXTILER (Handel und Industrie) Folie: 1 Hohe Erwartungen an die E-Rechnung Folie: 3 Definition e-invoicing Papierlos von A-Z Gesetzeskonforme
Pflichtangaben einer ordnungsgemäßen Rechnung
 Pflichtangaben einer ordnungsgemäßen Rechnung Wir machen aus Zahlen Werte Wie der Gesetzgeber die Rechnung definiert Eine Rechnung ist jedes Dokument (bzw. eine Mehrzahl von Dokumenten), mit dem über eine
Pflichtangaben einer ordnungsgemäßen Rechnung Wir machen aus Zahlen Werte Wie der Gesetzgeber die Rechnung definiert Eine Rechnung ist jedes Dokument (bzw. eine Mehrzahl von Dokumenten), mit dem über eine
Spezial. Das System für alle Kostenträger! Elektronischer Kostenvoranschlag. Schnell zu Ihrem Geld: Sofortauszahlung mit egeko cash!
 Spezial Elektronischer Kostenvoranschlag Das System für alle Kostenträger! Das kann nur egeko: ekv mit allen Kostenträgern egeko: Mehr als nur ekv Schnell zu Ihrem Geld: Sofortauszahlung mit egeko cash!
Spezial Elektronischer Kostenvoranschlag Das System für alle Kostenträger! Das kann nur egeko: ekv mit allen Kostenträgern egeko: Mehr als nur ekv Schnell zu Ihrem Geld: Sofortauszahlung mit egeko cash!
Weniger Kosten, mehr Möglichkeiten. Electronic Data Interchange (EDI): Optimierung von Geschäftsprozessen durch beleglosen Datenaustausch
: Optimierung von Geschäftsprozessen durch beleglosen Datenaustausch") Weniger Kosten, mehr Möglichkeiten Electronic Data Interchange (EDI): Optimierung von Geschäftsprozessen durch beleglosen Datenaustausch Schneller, transparenter, kostengünstiger EDI Was ist EDI und was
Weniger Kosten, mehr Möglichkeiten Electronic Data Interchange (EDI): Optimierung von Geschäftsprozessen durch beleglosen Datenaustausch Schneller, transparenter, kostengünstiger EDI Was ist EDI und was
AGROPLUS Buchhaltung. Daten-Server und Sicherheitskopie. Version vom 21.10.2013b
 AGROPLUS Buchhaltung Daten-Server und Sicherheitskopie Version vom 21.10.2013b 3a) Der Daten-Server Modus und der Tresor Der Daten-Server ist eine Betriebsart welche dem Nutzer eine grosse Flexibilität
AGROPLUS Buchhaltung Daten-Server und Sicherheitskopie Version vom 21.10.2013b 3a) Der Daten-Server Modus und der Tresor Der Daten-Server ist eine Betriebsart welche dem Nutzer eine grosse Flexibilität
Wie stelle ich eine korrekte Rechnung?
 Steuerberater I Rechtsanwalt Wie stelle ich eine korrekte Rechnung?... denn DAMIT fängt das Geldverdienen an! Rechnungsstellung Was ist eine Rechnung? Grundsätzlich jedes Dokument, mit dem eine Leistung
Steuerberater I Rechtsanwalt Wie stelle ich eine korrekte Rechnung?... denn DAMIT fängt das Geldverdienen an! Rechnungsstellung Was ist eine Rechnung? Grundsätzlich jedes Dokument, mit dem eine Leistung
Containerformat Spezifikation
 Containerformat Spezifikation Version 1.0-09.05.2011 Inhaltsverzeichnis 0 Einführung... 4 0.1 Referenzierte Dokumente... 4 0.2 Abkürzungen... 4 1 Containerformat... 5 1.1 Aufbau des Container-Headers...
Containerformat Spezifikation Version 1.0-09.05.2011 Inhaltsverzeichnis 0 Einführung... 4 0.1 Referenzierte Dokumente... 4 0.2 Abkürzungen... 4 1 Containerformat... 5 1.1 Aufbau des Container-Headers...
Kapitel 4 Die Datenbank Kuchenbestellung Seite 1
 Kapitel 4 Die Datenbank Kuchenbestellung Seite 1 4 Die Datenbank Kuchenbestellung In diesem Kapitel werde ich die Theorie aus Kapitel 2 Die Datenbank Buchausleihe an Hand einer weiteren Datenbank Kuchenbestellung
Kapitel 4 Die Datenbank Kuchenbestellung Seite 1 4 Die Datenbank Kuchenbestellung In diesem Kapitel werde ich die Theorie aus Kapitel 2 Die Datenbank Buchausleihe an Hand einer weiteren Datenbank Kuchenbestellung
Das große ElterngeldPlus 1x1. Alles über das ElterngeldPlus. Wer kann ElterngeldPlus beantragen? ElterngeldPlus verstehen ein paar einleitende Fakten
 Das große x -4 Alles über das Wer kann beantragen? Generell kann jeder beantragen! Eltern (Mütter UND Väter), die schon während ihrer Elternzeit wieder in Teilzeit arbeiten möchten. Eltern, die während
Das große x -4 Alles über das Wer kann beantragen? Generell kann jeder beantragen! Eltern (Mütter UND Väter), die schon während ihrer Elternzeit wieder in Teilzeit arbeiten möchten. Eltern, die während
Systemen im Wandel. Autor: Dr. Gerd Frenzen Coromell GmbH Seite 1 von 5
 Das Management von Informations- Systemen im Wandel Die Informations-Technologie (IT) war lange Zeit ausschließlich ein Hilfsmittel, um Arbeitsabläufe zu vereinfachen und Personal einzusparen. Sie hat
Das Management von Informations- Systemen im Wandel Die Informations-Technologie (IT) war lange Zeit ausschließlich ein Hilfsmittel, um Arbeitsabläufe zu vereinfachen und Personal einzusparen. Sie hat
Das unternehmerische 1x1 Steuern und Buchführung für Gründer
 Handelsrecht Buchführungspflicht für alle Kaufleute nach 238 (1) HGB Führung der Handelsbücher ( 239 HGB) Inventar (Vermögensaufstellung) ( 240, 241 HGB) Entlastung von der Buchführungspflicht 241 a HGB
Handelsrecht Buchführungspflicht für alle Kaufleute nach 238 (1) HGB Führung der Handelsbücher ( 239 HGB) Inventar (Vermögensaufstellung) ( 240, 241 HGB) Entlastung von der Buchführungspflicht 241 a HGB
.. für Ihre Business-Lösung
 .. für Ihre Business-Lösung Ist Ihre Informatik fit für die Zukunft? Flexibilität Das wirtschaftliche Umfeld ist stärker den je im Umbruch (z.b. Stichwort: Globalisierung). Daraus resultierenden Anforderungen,
.. für Ihre Business-Lösung Ist Ihre Informatik fit für die Zukunft? Flexibilität Das wirtschaftliche Umfeld ist stärker den je im Umbruch (z.b. Stichwort: Globalisierung). Daraus resultierenden Anforderungen,
ebinterface 4.0 AK Meeting 29. Jänner 2013
 ebinterface 4.0 AK Meeting 29. Jänner 2013 Philipp Liegl Marco Zapletal Agenda ebinterface Umfrage für weitere Dokumenttypen Anpassung des Standards Input BMD Abbildung von GLNs in ebinterface 3.x Diskussion:
ebinterface 4.0 AK Meeting 29. Jänner 2013 Philipp Liegl Marco Zapletal Agenda ebinterface Umfrage für weitere Dokumenttypen Anpassung des Standards Input BMD Abbildung von GLNs in ebinterface 3.x Diskussion:
Prozessbewertung und -verbesserung nach ITIL im Kontext des betrieblichen Informationsmanagements. von Stephanie Wilke am 14.08.08
 Prozessbewertung und -verbesserung nach ITIL im Kontext des betrieblichen Informationsmanagements von Stephanie Wilke am 14.08.08 Überblick Einleitung Was ist ITIL? Gegenüberstellung der Prozesse Neuer
Prozessbewertung und -verbesserung nach ITIL im Kontext des betrieblichen Informationsmanagements von Stephanie Wilke am 14.08.08 Überblick Einleitung Was ist ITIL? Gegenüberstellung der Prozesse Neuer
Vorgaben und Erläuterungen zu den XML-Schemata im Bahnstromnetz
 Anwendungshandbuch Vorgaben und Erläuterungen zu den XML-Schemata im Bahnstromnetz Version: 1.0 Herausgabedatum: 31.07.2015 Ausgabedatum: 01.11.2015 Autor: DB Energie http://www.dbenergie.de Seite: 1 1.
Anwendungshandbuch Vorgaben und Erläuterungen zu den XML-Schemata im Bahnstromnetz Version: 1.0 Herausgabedatum: 31.07.2015 Ausgabedatum: 01.11.2015 Autor: DB Energie http://www.dbenergie.de Seite: 1 1.
Your EDI Competence Center
 Your Mit EDI (Electronic Data Interchange) bieten wir Ihnen einen speziellen Service rund um die Datenübertragung in Ihrem Umfeld. Mit Hilfe festgelegter Nachrichtenstandards ermöglichen wir Ihnen die
Your Mit EDI (Electronic Data Interchange) bieten wir Ihnen einen speziellen Service rund um die Datenübertragung in Ihrem Umfeld. Mit Hilfe festgelegter Nachrichtenstandards ermöglichen wir Ihnen die
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren
 Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
In S-Firm wird nur angeboten die Datei auf Diskette zu exportieren; die Einstellung für HBCI ist ausgegraut.
 S-Firm/StarMoney/StarMoney Business mehrere Stapel über HBCI Problembeschreibung: Die oben genannten Produkte der Star Finanz GmbH, Hamburg nachfolgend Banking Software genannt, erlauben in der aktuellen
S-Firm/StarMoney/StarMoney Business mehrere Stapel über HBCI Problembeschreibung: Die oben genannten Produkte der Star Finanz GmbH, Hamburg nachfolgend Banking Software genannt, erlauben in der aktuellen
Containerformat Spezifikation
 Containerformat Spezifikation Version 1.1-21.02.2014 Inhaltsverzeichnis 0 Einführung... 4 0.1 Referenzierte Dokumente... 4 0.2 Abkürzungen... 4 1 Containerformat... 5 1.1 Aufbau des Container-Headers...
Containerformat Spezifikation Version 1.1-21.02.2014 Inhaltsverzeichnis 0 Einführung... 4 0.1 Referenzierte Dokumente... 4 0.2 Abkürzungen... 4 1 Containerformat... 5 1.1 Aufbau des Container-Headers...
Elektronische Rechnung Was ist zu beachten?
 Elektronische Rechnung Was ist zu beachten? Mandantenveranstaltung 05. September 2012 Hotel Weißenburg Gliederung ü Ausgangslage ü Erleichterungen ab dem 01.07.2011 ü Definition elektronische Rechnung
Elektronische Rechnung Was ist zu beachten? Mandantenveranstaltung 05. September 2012 Hotel Weißenburg Gliederung ü Ausgangslage ü Erleichterungen ab dem 01.07.2011 ü Definition elektronische Rechnung
Web Services stellen eine Integrationsarchitektur dar, die die Kommunikation zwischen verschiedenen Anwendungen
 9 3 Web Services 3.1 Überblick Web Services stellen eine Integrationsarchitektur dar, die die Kommunikation zwischen verschiedenen Anwendungen mit Hilfe von XML über das Internet ermöglicht (siehe Abb.
9 3 Web Services 3.1 Überblick Web Services stellen eine Integrationsarchitektur dar, die die Kommunikation zwischen verschiedenen Anwendungen mit Hilfe von XML über das Internet ermöglicht (siehe Abb.
Task: Nmap Skripte ausführen
 Task: Nmap Skripte ausführen Inhalt Einfache Netzwerkscans mit NSE Ausführen des Scans Anpassung der Parameter Einleitung Copyright 2009-2015 Greenbone Networks GmbH Herkunft und aktuellste Version dieses
Task: Nmap Skripte ausführen Inhalt Einfache Netzwerkscans mit NSE Ausführen des Scans Anpassung der Parameter Einleitung Copyright 2009-2015 Greenbone Networks GmbH Herkunft und aktuellste Version dieses
EDI Datenaustausch und Konvertierung Funktionsumfang & Services
 cleardax EDI Datenaustausch und Konvertierung Funktionsumfang & Services Einleitung Hauptfunktionen Datenaustausch (Anbindungsmöglichkeiten) Konvertierung Mappings Zusatzleistungen und Funktionen cleardax
cleardax EDI Datenaustausch und Konvertierung Funktionsumfang & Services Einleitung Hauptfunktionen Datenaustausch (Anbindungsmöglichkeiten) Konvertierung Mappings Zusatzleistungen und Funktionen cleardax
Merkblatt Nr. 3: Umsatzsteuer - Versteuerung von Anzahlungen, Abschlagsrechnungen Stand: Februar 2009
 Merkblatt Nr. 3: Umsatzsteuer - Versteuerung von Anzahlungen, Abschlagsrechnungen Stand: Februar 2009 I. Versteuerung von Anzahlungen 1. Was sind Anzahlungen? Anzahlungen (auch: Abschlagzahlungen, Vorauszahlungen)
Merkblatt Nr. 3: Umsatzsteuer - Versteuerung von Anzahlungen, Abschlagsrechnungen Stand: Februar 2009 I. Versteuerung von Anzahlungen 1. Was sind Anzahlungen? Anzahlungen (auch: Abschlagzahlungen, Vorauszahlungen)
Workflow, Business Process Management, 4.Teil
 Workflow, Business Process Management, 4.Teil 24. Januar 2004 Der vorliegende Text darf für Zwecke der Vorlesung Workflow, Business Process Management des Autors vervielfältigt werden. Eine weitere Nutzung
Workflow, Business Process Management, 4.Teil 24. Januar 2004 Der vorliegende Text darf für Zwecke der Vorlesung Workflow, Business Process Management des Autors vervielfältigt werden. Eine weitere Nutzung
EDI/XML Datentransaktionen über System- und Unternehmensgrenzen. Referent: Jan Freitag
 EDI/XML Datentransaktionen über System- und Unternehmensgrenzen Referent: Jan Freitag Warum EDI? Internet bedeutender Wirtschaftsfaktor Nur wenige Unternehmen steuern Geschäftsprozesse über das Internet
EDI/XML Datentransaktionen über System- und Unternehmensgrenzen Referent: Jan Freitag Warum EDI? Internet bedeutender Wirtschaftsfaktor Nur wenige Unternehmen steuern Geschäftsprozesse über das Internet
Kostensenkungspotenzial erechnungen. Die elektronische Rechnung (erechnung) Anforderungen für den Einsatz im Handwerksunternehmen
 Anforderungen für den Einsatz im Handwerksunternehmen") Kostensenkungspotenzial erechnungen Die elektronische Rechnung (erechnung) Anforderungen für den Einsatz im Handwerksunternehmen Elektronischer Rechnungsverkehr Ein Trend elektronischer Rechnungsverkehr
Kostensenkungspotenzial erechnungen Die elektronische Rechnung (erechnung) Anforderungen für den Einsatz im Handwerksunternehmen Elektronischer Rechnungsverkehr Ein Trend elektronischer Rechnungsverkehr
Skript Pilotphase em@w für Arbeitsgelegenheiten
 Die Pilotphase erstreckte sich über sechs Meilensteine im Zeitraum August 2011 bis zur EMAW- Folgeversion 2.06 im August 2013. Zunächst einmal musste ein grundsätzliches Verständnis für das Verfahren geschaffen
Die Pilotphase erstreckte sich über sechs Meilensteine im Zeitraum August 2011 bis zur EMAW- Folgeversion 2.06 im August 2013. Zunächst einmal musste ein grundsätzliches Verständnis für das Verfahren geschaffen
Vereinbarung über den elektronischen Datenaustausch (EDI)
") Vereinbarung über den elektronischen Datenaustausch (EDI) RECHTLICHE BESTIMMUNGEN Die Vereinbarung über den elektronischen Datenaustausch (EDI) wird getroffen von und zwischen: Stadtwerke Mengen Mittlere
Vereinbarung über den elektronischen Datenaustausch (EDI) RECHTLICHE BESTIMMUNGEN Die Vereinbarung über den elektronischen Datenaustausch (EDI) wird getroffen von und zwischen: Stadtwerke Mengen Mittlere
Digitalisierung im Mittelstand. (Steuer-)Rechtliche Rahmenbedingungen für den elektronischen Geschäftsverkehr
Rechtliche Rahmenbedingungen für den elektronischen Geschäftsverkehr") Digitalisierung im Mittelstand (Steuer-)Rechtliche Rahmenbedingungen für den elektronischen Geschäftsverkehr (Steuer-)Rechtliche Rahmenbedingungen für den elektronischen Geschäftsverkehr Referent: Dipl.
Digitalisierung im Mittelstand (Steuer-)Rechtliche Rahmenbedingungen für den elektronischen Geschäftsverkehr (Steuer-)Rechtliche Rahmenbedingungen für den elektronischen Geschäftsverkehr Referent: Dipl.
SIRIUS virtual engineering GmbH
 SIRIUS virtual engineering GmbH EDI Optimierungspotential und Outsourcing für mittelständische SAP Anwender. Eingangsrechnungsprozesse in SAP automatisieren. DMS - Workflow - BPM EDI. Wenn es um Geschäftsprozesse
SIRIUS virtual engineering GmbH EDI Optimierungspotential und Outsourcing für mittelständische SAP Anwender. Eingangsrechnungsprozesse in SAP automatisieren. DMS - Workflow - BPM EDI. Wenn es um Geschäftsprozesse
Informationsaustausch mit StratOz ZUGVoGEL. Formatunabhängig, modular, clever.
 Informationsaustausch mit StratOz ZUGVoGEL Formatunabhängig, modular, clever. 1 Was ist der StratOz ZUGVoGEL? ZUGVoGEL ist die Lösung von StratOz, mit der unterschiedliche Belege, wie z. B. Papier- und
Informationsaustausch mit StratOz ZUGVoGEL Formatunabhängig, modular, clever. 1 Was ist der StratOz ZUGVoGEL? ZUGVoGEL ist die Lösung von StratOz, mit der unterschiedliche Belege, wie z. B. Papier- und
GDI-Business-Line 3.x Ticketverwaltung
 Ticketverwaltung Seite 1/6 GDI-Business-Line 3.x Ticketverwaltung Kurzdokumentation Stand: 04. Januar 2012 3.2.0.200 Ticketverwaltung Seite 2/6 Einführung...3 Lizenz...3 Funktionsweise...3 Vergabe der
Ticketverwaltung Seite 1/6 GDI-Business-Line 3.x Ticketverwaltung Kurzdokumentation Stand: 04. Januar 2012 3.2.0.200 Ticketverwaltung Seite 2/6 Einführung...3 Lizenz...3 Funktionsweise...3 Vergabe der
Dieser Ablauf soll eine Hilfe für die tägliche Arbeit mit der SMS Bestätigung im Millennium darstellen.
 Millennium SMS Service Schnellübersicht Seite 1 von 6 1. Tägliche Arbeiten mit der SMS Bestätigung Dieser Ablauf soll eine Hilfe für die tägliche Arbeit mit der SMS Bestätigung im Millennium darstellen.
Millennium SMS Service Schnellübersicht Seite 1 von 6 1. Tägliche Arbeiten mit der SMS Bestätigung Dieser Ablauf soll eine Hilfe für die tägliche Arbeit mit der SMS Bestätigung im Millennium darstellen.
Was sind Jahres- und Zielvereinbarungsgespräche?
 6 Was sind Jahres- und Zielvereinbarungsgespräche? Mit dem Jahresgespräch und der Zielvereinbarung stehen Ihnen zwei sehr wirkungsvolle Instrumente zur Verfügung, um Ihre Mitarbeiter zu führen und zu motivieren
6 Was sind Jahres- und Zielvereinbarungsgespräche? Mit dem Jahresgespräch und der Zielvereinbarung stehen Ihnen zwei sehr wirkungsvolle Instrumente zur Verfügung, um Ihre Mitarbeiter zu führen und zu motivieren
1. Einführung 2. 2. Erstellung einer Teillieferung 2. 3. Erstellung einer Teilrechnung 6
 Inhalt 1. Einführung 2 2. Erstellung einer Teillieferung 2 3. Erstellung einer Teilrechnung 6 4. Erstellung einer Sammellieferung/ Mehrere Aufträge zu einem Lieferschein zusammenfassen 11 5. Besonderheiten
Inhalt 1. Einführung 2 2. Erstellung einer Teillieferung 2 3. Erstellung einer Teilrechnung 6 4. Erstellung einer Sammellieferung/ Mehrere Aufträge zu einem Lieferschein zusammenfassen 11 5. Besonderheiten
Leitfaden zur Anlage einer Nachforderung. Nachforderung. 04.04.2013 Seite 1 von 11 RWE IT GmbH
 Leitfaden zur Anlage einer 04.04.2013 Seite 1 von 11 Inhaltsverzeichnis 1 Aufruf des RWE smanagements...3 2 Eingabe der Benutzerdaten...4 3 Erfassen der...5 4 Neue...6 4.1 Allgemeine Daten...7 4.2 Beschreibung...7
Leitfaden zur Anlage einer 04.04.2013 Seite 1 von 11 Inhaltsverzeichnis 1 Aufruf des RWE smanagements...3 2 Eingabe der Benutzerdaten...4 3 Erfassen der...5 4 Neue...6 4.1 Allgemeine Daten...7 4.2 Beschreibung...7
D i e n s t e D r i t t e r a u f We b s i t e s
 M erkblatt D i e n s t e D r i t t e r a u f We b s i t e s 1 Einleitung Öffentliche Organe integrieren oftmals im Internet angebotene Dienste und Anwendungen in ihre eigenen Websites. Beispiele: Eine
M erkblatt D i e n s t e D r i t t e r a u f We b s i t e s 1 Einleitung Öffentliche Organe integrieren oftmals im Internet angebotene Dienste und Anwendungen in ihre eigenen Websites. Beispiele: Eine
Autorisierung. Sicherheit und Zugriffskontrolle & Erstellen einer Berechtigungskomponente
 Autorisierung Sicherheit und Zugriffskontrolle & Erstellen einer Berechtigungskomponente Dokumentation zum Referat von Matthias Warnicke und Joachim Schröder Modul: Komponenten basierte Softwareentwickelung
Autorisierung Sicherheit und Zugriffskontrolle & Erstellen einer Berechtigungskomponente Dokumentation zum Referat von Matthias Warnicke und Joachim Schröder Modul: Komponenten basierte Softwareentwickelung
E-Invoicing auf internationaler Ebene
 E-Invoicing auf internationaler Ebene SEEBURGER E-Invoicing-Tage 25./26. März in Frankfurt Flughafen-Hotel Bruno Koch Marktgröße und Status global Seite 2 "Ich stehe Statistiken etwas skeptisch gegenüber.
E-Invoicing auf internationaler Ebene SEEBURGER E-Invoicing-Tage 25./26. März in Frankfurt Flughafen-Hotel Bruno Koch Marktgröße und Status global Seite 2 "Ich stehe Statistiken etwas skeptisch gegenüber.
Outlook. sysplus.ch outlook - mail-grundlagen Seite 1/8. Mail-Grundlagen. Posteingang
 sysplus.ch outlook - mail-grundlagen Seite 1/8 Outlook Mail-Grundlagen Posteingang Es gibt verschiedene Möglichkeiten, um zum Posteingang zu gelangen. Man kann links im Outlook-Fenster auf die Schaltfläche
sysplus.ch outlook - mail-grundlagen Seite 1/8 Outlook Mail-Grundlagen Posteingang Es gibt verschiedene Möglichkeiten, um zum Posteingang zu gelangen. Man kann links im Outlook-Fenster auf die Schaltfläche
optivo listexpress Die schlagkräftige Dienstleistung für absatzfördernde E-Mail-Kampagnen
 Die schlagkräftige Dienstleistung für absatzfördernde E-Mail-Kampagnen Einführung In Kontakt mit Millionen Interessenten Sie haben keinen eigenen Newsletter, möchten aber dennoch die Vorteile von E-Mail-Marketing
Die schlagkräftige Dienstleistung für absatzfördernde E-Mail-Kampagnen Einführung In Kontakt mit Millionen Interessenten Sie haben keinen eigenen Newsletter, möchten aber dennoch die Vorteile von E-Mail-Marketing
Robot Karol für Delphi
 Robot Karol für Delphi Reinhard Nitzsche, OSZ Handel I Version 0.1 vom 24. Januar 2003 Zusammenfassung Nach der Einführung in die (variablenfreie) Programmierung mit Robot Karol von Freiberger und Krško
Robot Karol für Delphi Reinhard Nitzsche, OSZ Handel I Version 0.1 vom 24. Januar 2003 Zusammenfassung Nach der Einführung in die (variablenfreie) Programmierung mit Robot Karol von Freiberger und Krško
360 - Der Weg zum gläsernen Unternehmen mit QlikView am Beispiel Einkauf
 360 - Der Weg zum gläsernen Unternehmen mit QlikView am Beispiel Einkauf Von der Entstehung bis heute 1996 als EDV Beratung Saller gegründet, seit 2010 BI4U GmbH Firmensitz ist Unterschleißheim (bei München)
360 - Der Weg zum gläsernen Unternehmen mit QlikView am Beispiel Einkauf Von der Entstehung bis heute 1996 als EDV Beratung Saller gegründet, seit 2010 BI4U GmbH Firmensitz ist Unterschleißheim (bei München)
Gesetzliche Aufbewahrungspflicht für E-Mails
 Gesetzliche Aufbewahrungspflicht für E-Mails sind Sie vorbereitet? Vortragsveranstaltung TOP AKTUELL Meins und Vogel GmbH, Plochingen Dipl.-Inf. Klaus Meins Dipl.-Inf. Oliver Vogel Meins & Vogel GmbH,
Gesetzliche Aufbewahrungspflicht für E-Mails sind Sie vorbereitet? Vortragsveranstaltung TOP AKTUELL Meins und Vogel GmbH, Plochingen Dipl.-Inf. Klaus Meins Dipl.-Inf. Oliver Vogel Meins & Vogel GmbH,
Fragen und Antworten zu Secure E-Mail
 Fragen und Antworten zu Secure E-Mail Inhalt Secure E-Mail Sinn und Zweck Was ist Secure E-Mail? Warum führt die Suva Secure E-Mail ein? Welche E-Mails sollten verschlüsselt gesendet werden? Wie grenzt
Fragen und Antworten zu Secure E-Mail Inhalt Secure E-Mail Sinn und Zweck Was ist Secure E-Mail? Warum führt die Suva Secure E-Mail ein? Welche E-Mails sollten verschlüsselt gesendet werden? Wie grenzt
BUSINESS SOFTWARE. www. sage.at
 Unbegrenzt tiefe Explosionszeichnungen Internationale Features ITc Shop Der neue Webshop mit brillanter Anbindung an die Sage Office Line und enormem Leistungsumfang. Integriertes CMS Online-Payment Schnittstellen
Unbegrenzt tiefe Explosionszeichnungen Internationale Features ITc Shop Der neue Webshop mit brillanter Anbindung an die Sage Office Line und enormem Leistungsumfang. Integriertes CMS Online-Payment Schnittstellen
visionapp Base Installation Packages (vbip) Update
 Update") visionapp Base Installation Packages (vbip) Update Juli 2005 Beschreibung der Installationspakete und Installationspaketschablonen Copyright visionapp GmbH, 2005. Alle Rechte vorbehalten. Die in diesem
visionapp Base Installation Packages (vbip) Update Juli 2005 Beschreibung der Installationspakete und Installationspaketschablonen Copyright visionapp GmbH, 2005. Alle Rechte vorbehalten. Die in diesem
Steuern I News I Recht
 Steuern I News I Recht Merkblatt Rechnung und Vorsteuerabzug Sehr geehrte Mandantin, sehr geehrter Mandant, in dieser Information möchten wir Sie auf die wichtigsten Punkte bei der Rechnungsstellung hinweisen.
Steuern I News I Recht Merkblatt Rechnung und Vorsteuerabzug Sehr geehrte Mandantin, sehr geehrter Mandant, in dieser Information möchten wir Sie auf die wichtigsten Punkte bei der Rechnungsstellung hinweisen.
Informationssicherheit als Outsourcing Kandidat
 Informationssicherheit als Outsourcing Kandidat aus Kundenprojekten Frankfurt 16.06.2015 Thomas Freund Senior Security Consultant / ISO 27001 Lead Auditor Agenda Informationssicherheit Outsourcing Kandidat
Informationssicherheit als Outsourcing Kandidat aus Kundenprojekten Frankfurt 16.06.2015 Thomas Freund Senior Security Consultant / ISO 27001 Lead Auditor Agenda Informationssicherheit Outsourcing Kandidat
4 Aufzählungen und Listen erstellen
 4 4 Aufzählungen und Listen erstellen Beim Strukturieren von Dokumenten und Inhalten stellen Listen und Aufzählungen wichtige Werkzeuge dar. Mit ihnen lässt sich so ziemlich alles sortieren, was auf einer
4 4 Aufzählungen und Listen erstellen Beim Strukturieren von Dokumenten und Inhalten stellen Listen und Aufzählungen wichtige Werkzeuge dar. Mit ihnen lässt sich so ziemlich alles sortieren, was auf einer
DAS NEUE GESETZ ÜBER FACTORING ( Amtsblatt der RS, Nr.62/2013)
") DAS NEUE GESETZ ÜBER FACTORING ( Amtsblatt der RS, Nr.62/2013) I Einleitung Das Parlament der Republik Serbien hat das Gesetz über Factoring verabschiedet, welches am 24. Juli 2013 in Kraft getreten ist.
DAS NEUE GESETZ ÜBER FACTORING ( Amtsblatt der RS, Nr.62/2013) I Einleitung Das Parlament der Republik Serbien hat das Gesetz über Factoring verabschiedet, welches am 24. Juli 2013 in Kraft getreten ist.
Elektronischer Rechnungsaustausch im Kontext von Umsatzsteuer, GoBD & Compliance
 Elektronischer Rechnungsaustausch im Kontext von Umsatzsteuer, GoBD & Compliance Stefan Groß Steuerberater CISA (Certified Information Systems Auditor) E-Rechnung, Umsatzsteuer, GoBD & Compliance 2 Die
Elektronischer Rechnungsaustausch im Kontext von Umsatzsteuer, GoBD & Compliance Stefan Groß Steuerberater CISA (Certified Information Systems Auditor) E-Rechnung, Umsatzsteuer, GoBD & Compliance 2 Die
Handbuch ECDL 2003 Basic Modul 5: Datenbank Grundlagen von relationalen Datenbanken
 Handbuch ECDL 2003 Basic Modul 5: Datenbank Grundlagen von relationalen Datenbanken Dateiname: ecdl5_01_00_documentation_standard.doc Speicherdatum: 14.02.2005 ECDL 2003 Basic Modul 5 Datenbank - Grundlagen
Handbuch ECDL 2003 Basic Modul 5: Datenbank Grundlagen von relationalen Datenbanken Dateiname: ecdl5_01_00_documentation_standard.doc Speicherdatum: 14.02.2005 ECDL 2003 Basic Modul 5 Datenbank - Grundlagen
Anbindung an easybill.de
 Anbindung an easybill.de Stand: 14. Dezember 2011 2011 Virthos Systems GmbH www.pixtacy.de Einleitung Pixtacy verfügt ab Version 2.3 über eine Schnittstelle zu dem Online-Fakturierungsprogramm easybill.de.
Anbindung an easybill.de Stand: 14. Dezember 2011 2011 Virthos Systems GmbH www.pixtacy.de Einleitung Pixtacy verfügt ab Version 2.3 über eine Schnittstelle zu dem Online-Fakturierungsprogramm easybill.de.
Änderung der Bedingungen für den Handel an der Eurex Deutschland und der Eurex Zürich
 eurex Bekanntmachung Änderung der Eurex Deutschland und der Eurex Zürich Der Börsenrat der Eurex Deutschland hat am 30. Juni 2011, der Verwaltungsrat der Eurex Zürich hat am 22. Juni 2011 die nachfolgende
eurex Bekanntmachung Änderung der Eurex Deutschland und der Eurex Zürich Der Börsenrat der Eurex Deutschland hat am 30. Juni 2011, der Verwaltungsrat der Eurex Zürich hat am 22. Juni 2011 die nachfolgende
Kurzskript Literaturverzeichnis Microsoft Office Word 2010
 Training & S upport Kurzskript Literaturverzeichnis Microsoft Office Word 2010 PC & EDV Support - Köln, Februar 2011 Training & S upport Inhalt ZITATE VERWALTEN MIT WORD... 1 Quellen-Manager... 1 Quellen
Training & S upport Kurzskript Literaturverzeichnis Microsoft Office Word 2010 PC & EDV Support - Köln, Februar 2011 Training & S upport Inhalt ZITATE VERWALTEN MIT WORD... 1 Quellen-Manager... 1 Quellen
Änderung des IFRS 2 Anteilsbasierte Vergütung
 Änderung IFRS 2 Änderung des IFRS 2 Anteilsbasierte Vergütung Anwendungsbereich Paragraph 2 wird geändert, Paragraph 3 gestrichen und Paragraph 3A angefügt. 2 Dieser IFRS ist bei der Bilanzierung aller
Änderung IFRS 2 Änderung des IFRS 2 Anteilsbasierte Vergütung Anwendungsbereich Paragraph 2 wird geändert, Paragraph 3 gestrichen und Paragraph 3A angefügt. 2 Dieser IFRS ist bei der Bilanzierung aller
Prozessualer Nutzen der globalen Standards für die Logistik
 Prozessualer Nutzen der globalen Standards für die Logistik Roadshow: 03.06.2014 Wolfsburg, 05.06.2014 Ingolstadt Matthias Lühr (LLX/B) Die Informationslogistik als Erfolgsfaktor in der logistischen Lieferkette
Prozessualer Nutzen der globalen Standards für die Logistik Roadshow: 03.06.2014 Wolfsburg, 05.06.2014 Ingolstadt Matthias Lühr (LLX/B) Die Informationslogistik als Erfolgsfaktor in der logistischen Lieferkette
Bedienungsanleitung. Matthias Haasler. Version 0.4. für die Arbeit mit der Gemeinde-Homepage der Paulus-Kirchengemeinde Tempelhof
 Bedienungsanleitung für die Arbeit mit der Gemeinde-Homepage der Paulus-Kirchengemeinde Tempelhof Matthias Haasler Version 0.4 Webadministrator, email: webadmin@rundkirche.de Inhaltsverzeichnis 1 Einführung
Bedienungsanleitung für die Arbeit mit der Gemeinde-Homepage der Paulus-Kirchengemeinde Tempelhof Matthias Haasler Version 0.4 Webadministrator, email: webadmin@rundkirche.de Inhaltsverzeichnis 1 Einführung
Primzahlen und RSA-Verschlüsselung
 Primzahlen und RSA-Verschlüsselung Michael Fütterer und Jonathan Zachhuber 1 Einiges zu Primzahlen Ein paar Definitionen: Wir bezeichnen mit Z die Menge der positiven und negativen ganzen Zahlen, also
Primzahlen und RSA-Verschlüsselung Michael Fütterer und Jonathan Zachhuber 1 Einiges zu Primzahlen Ein paar Definitionen: Wir bezeichnen mit Z die Menge der positiven und negativen ganzen Zahlen, also
Universität Passau. Betriebswirtschaftslehre mit Schwerpunkt Internationales Management Prof. Dr. Carola Jungwirth. Seminararbeit
 Universität Passau Betriebswirtschaftslehre mit Schwerpunkt Internationales Management Prof. Dr. Carola Jungwirth Seminararbeit "E-Recruiting und die Nutzung von Social Media zur Rekrutierung von externen
Universität Passau Betriebswirtschaftslehre mit Schwerpunkt Internationales Management Prof. Dr. Carola Jungwirth Seminararbeit "E-Recruiting und die Nutzung von Social Media zur Rekrutierung von externen
Leitfaden Online Shopping 1. Gastgeberinnen-Portal und Online-Einladungen 2. Online Plus 3. Klassisches Online Shopping (Einzelbestellung)
") Leitfaden Online Shopping 1. Gastgeberinnen-Portal und Online-Einladungen 2. Online Plus 3. Klassisches Online Shopping (Einzelbestellung) 1. Gastgeberinnen Portal und Online-Einladungen Sie als Gastgeberin
Leitfaden Online Shopping 1. Gastgeberinnen-Portal und Online-Einladungen 2. Online Plus 3. Klassisches Online Shopping (Einzelbestellung) 1. Gastgeberinnen Portal und Online-Einladungen Sie als Gastgeberin
Wholesale und FTTH. Handbuch Abrechnung 1/5. Ausgabedatum 01.05.2015 Ersetzt Version 2-0. Swisscom (Schweiz) AG CH-3050 Bern
 AG CH-3050 Bern") Ausgabedatum 005.2015 Ersetzt Version 2-0 Gültig ab 005.2015 Gültig ab 005.2015 1/5 Inhaltsverzeichnis 1 Einleitung... 3 2 Rechnungsstellung... 3 3 Rechnungen... 3 4 Zahlungen... 4 5 Widerspruch gegen
Ausgabedatum 005.2015 Ersetzt Version 2-0 Gültig ab 005.2015 Gültig ab 005.2015 1/5 Inhaltsverzeichnis 1 Einleitung... 3 2 Rechnungsstellung... 3 3 Rechnungen... 3 4 Zahlungen... 4 5 Widerspruch gegen
Vortrag. Elektronische Rechnungslegung
 Vortrag 29. November 2007 ecomm Berlin Dag Klimas Ihr Vortragender Jahrgang 1961 Werdegang Ausbildung Bankkaufmann Weiterbildung Bankfachwirt Ausbildereignung Kommunikationstrainer und Berater... Basisinformationen
Vortrag 29. November 2007 ecomm Berlin Dag Klimas Ihr Vortragender Jahrgang 1961 Werdegang Ausbildung Bankkaufmann Weiterbildung Bankfachwirt Ausbildereignung Kommunikationstrainer und Berater... Basisinformationen
Erstellen einer E-Mail in OWA (Outlook Web App)
") Erstellen einer E-Mail in OWA (Outlook Web App) Partner: 2/12 Versionshistorie: Datum Version Name Status 13.09.2011 1.1 J. Bodeit Punkte 7 hinzugefügt, alle Mailempfänger unkenntlich gemacht 09.09.2011
Erstellen einer E-Mail in OWA (Outlook Web App) Partner: 2/12 Versionshistorie: Datum Version Name Status 13.09.2011 1.1 J. Bodeit Punkte 7 hinzugefügt, alle Mailempfänger unkenntlich gemacht 09.09.2011
Das neue Widerrufsrecht
 Das neue Widerrufsrecht Gestaltungshinweise für die Widerrufsbelehrung für den Verkauf von Dienstleistungen nach dem Gesetz zur Umsetzung der Verbraucherrechterichtlinie und zur Änderung des Gesetzes zur
Das neue Widerrufsrecht Gestaltungshinweise für die Widerrufsbelehrung für den Verkauf von Dienstleistungen nach dem Gesetz zur Umsetzung der Verbraucherrechterichtlinie und zur Änderung des Gesetzes zur
Die Lernumgebung des Projekts Informationskompetenz
 Beitrag für Bibliothek aktuell Die Lernumgebung des Projekts Informationskompetenz Von Sandra Merten Im Rahmen des Projekts Informationskompetenz wurde ein Musterkurs entwickelt, der den Lehrenden als
Beitrag für Bibliothek aktuell Die Lernumgebung des Projekts Informationskompetenz Von Sandra Merten Im Rahmen des Projekts Informationskompetenz wurde ein Musterkurs entwickelt, der den Lehrenden als
Du hast hier die Möglichkeit Adressen zu erfassen, Lieferscheine & Rechnungen zu drucken und Deine Artikel zu verwalten.
 Bedienungsanleitung Professionell aussehende Rechnungen machen einen guten Eindruck vor allem wenn du gerade am Beginn deiner Unternehmung bist. Diese Vorlage ist für den Beginn und für wenige Rechnungen
Bedienungsanleitung Professionell aussehende Rechnungen machen einen guten Eindruck vor allem wenn du gerade am Beginn deiner Unternehmung bist. Diese Vorlage ist für den Beginn und für wenige Rechnungen
1 Mathematische Grundlagen
 Mathematische Grundlagen - 1-1 Mathematische Grundlagen Der Begriff der Menge ist einer der grundlegenden Begriffe in der Mathematik. Mengen dienen dazu, Dinge oder Objekte zu einer Einheit zusammenzufassen.
Mathematische Grundlagen - 1-1 Mathematische Grundlagen Der Begriff der Menge ist einer der grundlegenden Begriffe in der Mathematik. Mengen dienen dazu, Dinge oder Objekte zu einer Einheit zusammenzufassen.
Widerrufrecht bei außerhalb von Geschäftsräumen geschlossenen Verträgen
 Widerrufrecht bei außerhalb von Geschäftsräumen geschlossenen Verträgen Häufig werden Handwerker von Verbrauchern nach Hause bestellt, um vor Ort die Leistungen zu besprechen. Unterbreitet der Handwerker
Widerrufrecht bei außerhalb von Geschäftsräumen geschlossenen Verträgen Häufig werden Handwerker von Verbrauchern nach Hause bestellt, um vor Ort die Leistungen zu besprechen. Unterbreitet der Handwerker
Rechnungen richtig erstellen und Vorsteuerabzug sichern
 Rechnungen richtig erstellen und Vorsteuerabzug sichern Die Umsetzung der Mehrwertsteuer- Systemrichtlinie, der EU-Rechnungsrichtlinie als auch aktuell die neue obligatorische Gelangensbestätigungen (eingeführt
Rechnungen richtig erstellen und Vorsteuerabzug sichern Die Umsetzung der Mehrwertsteuer- Systemrichtlinie, der EU-Rechnungsrichtlinie als auch aktuell die neue obligatorische Gelangensbestätigungen (eingeführt
IT-Governance und Social, Mobile und Cloud Computing: Ein Management Framework... Bachelorarbeit
 IT-Governance und Social, Mobile und Cloud Computing: Ein Management Framework... Bachelorarbeit zur Erlangung des akademischen Grades Bachelor of Science (B.Sc.) im Studiengang Wirtschaftswissenschaft
IT-Governance und Social, Mobile und Cloud Computing: Ein Management Framework... Bachelorarbeit zur Erlangung des akademischen Grades Bachelor of Science (B.Sc.) im Studiengang Wirtschaftswissenschaft
Definition der Schnittstelle zur Übertragung der. gemäß Deponieselbstüberwachungsverordnung NRW
 Jahresberichte gemäß Deponieselbstüberwachungsverordnung NRW Inhaltsverzeichnis... 1 Historie der Änderungen... 2 Einleitung... 2 Rückblick... 2 Auswirkungen der neuen Verordnung... 2 Auslieferung... 2
Jahresberichte gemäß Deponieselbstüberwachungsverordnung NRW Inhaltsverzeichnis... 1 Historie der Änderungen... 2 Einleitung... 2 Rückblick... 2 Auswirkungen der neuen Verordnung... 2 Auslieferung... 2
Form- und Inhaltsvorschriften für Rechnungen
 Form- und Inhaltsvorschriften für Rechnungen Inhalt 1. Definition... 2 2. Pflicht zur Rechnungsstellung... 2 3. Allgemeine Formvorschriften... 2 4. Notwendige Angaben auf einer Rechnung... 2 5. Rechnungen
Form- und Inhaltsvorschriften für Rechnungen Inhalt 1. Definition... 2 2. Pflicht zur Rechnungsstellung... 2 3. Allgemeine Formvorschriften... 2 4. Notwendige Angaben auf einer Rechnung... 2 5. Rechnungen
L10N-Manager 3. Netzwerktreffen der Hochschulübersetzer/i nnen Mannheim 10. Mai 2016
 L10N-Manager 3. Netzwerktreffen der Hochschulübersetzer/i nnen Mannheim 10. Mai 2016 Referentin: Dr. Kelly Neudorfer Universität Hohenheim Was wir jetzt besprechen werden ist eine Frage, mit denen viele
L10N-Manager 3. Netzwerktreffen der Hochschulübersetzer/i nnen Mannheim 10. Mai 2016 Referentin: Dr. Kelly Neudorfer Universität Hohenheim Was wir jetzt besprechen werden ist eine Frage, mit denen viele
Schulungsunterlagen zur Version 3.3
 Schulungsunterlagen zur Version 3.3 Versenden und Empfangen von Veranstaltungen im CMS-System Jürgen Eckert Domplatz 3 96049 Bamberg Tel (09 51) 5 02 2 75 Fax (09 51) 5 02 2 71 Mobil (01 79) 3 22 09 33
Schulungsunterlagen zur Version 3.3 Versenden und Empfangen von Veranstaltungen im CMS-System Jürgen Eckert Domplatz 3 96049 Bamberg Tel (09 51) 5 02 2 75 Fax (09 51) 5 02 2 71 Mobil (01 79) 3 22 09 33
Softwareentwicklungspraktikum Sommersemester 2007. Feinentwurf
 Softwareentwicklungspraktikum Sommersemester 2007 Feinentwurf Auftraggeber Technische Universität Braunschweig
Softwareentwicklungspraktikum Sommersemester 2007 Feinentwurf Auftraggeber Technische Universität Braunschweig
etutor Benutzerhandbuch XQuery Benutzerhandbuch Georg Nitsche
 etutor Benutzerhandbuch Benutzerhandbuch XQuery Georg Nitsche Version 1.0 Stand März 2006 Versionsverlauf: Version Autor Datum Änderungen 1.0 gn 06.03.2006 Fertigstellung der ersten Version Inhaltsverzeichnis:
etutor Benutzerhandbuch Benutzerhandbuch XQuery Georg Nitsche Version 1.0 Stand März 2006 Versionsverlauf: Version Autor Datum Änderungen 1.0 gn 06.03.2006 Fertigstellung der ersten Version Inhaltsverzeichnis:
Speicher in der Cloud
 Speicher in der Cloud Kostenbremse, Sicherheitsrisiko oder Basis für die unternehmensweite Kollaboration? von Cornelius Höchel-Winter 2013 ComConsult Research GmbH, Aachen 3 SYNCHRONISATION TEUFELSZEUG
Speicher in der Cloud Kostenbremse, Sicherheitsrisiko oder Basis für die unternehmensweite Kollaboration? von Cornelius Höchel-Winter 2013 ComConsult Research GmbH, Aachen 3 SYNCHRONISATION TEUFELSZEUG
Fachbericht zum Thema: Anforderungen an ein Datenbanksystem
 Fachbericht zum Thema: Anforderungen an ein Datenbanksystem von André Franken 1 Inhaltsverzeichnis 1 Inhaltsverzeichnis 1 2 Einführung 2 2.1 Gründe für den Einsatz von DB-Systemen 2 2.2 Definition: Datenbank
Fachbericht zum Thema: Anforderungen an ein Datenbanksystem von André Franken 1 Inhaltsverzeichnis 1 Inhaltsverzeichnis 1 2 Einführung 2 2.1 Gründe für den Einsatz von DB-Systemen 2 2.2 Definition: Datenbank
Volksbank Oelde-Ennigerloh-Neubeckum eg
 Volksbank Oelde-Ennigerloh-Neubeckum eg Willkommen im elektronischen Postkorb in Ihrer Online-Filiale! Die gute Adresse für Vertrauliches von Ihrer Bank Wünschen Sie den persönlichen Kontakt zu unserer
Volksbank Oelde-Ennigerloh-Neubeckum eg Willkommen im elektronischen Postkorb in Ihrer Online-Filiale! Die gute Adresse für Vertrauliches von Ihrer Bank Wünschen Sie den persönlichen Kontakt zu unserer
Konfiguration eines DNS-Servers
 DNS-Server Grundlagen des Themas DNS sind im Kapitel Protokolle und Dienste in meinem Buch (LINUX erschienen im bhv-verlag) beschrieben. Als Beispiel dient ein Intranet mit mehreren Webservern auf verschiedenen
DNS-Server Grundlagen des Themas DNS sind im Kapitel Protokolle und Dienste in meinem Buch (LINUX erschienen im bhv-verlag) beschrieben. Als Beispiel dient ein Intranet mit mehreren Webservern auf verschiedenen
PowerPoint 2010 Mit Folienmastern arbeiten
 PP.002, Version 1.1 07.04.2015 Kurzanleitung PowerPoint 2010 Mit Folienmastern arbeiten Der Folienmaster ist die Vorlage für sämtliche Folien einer Präsentation. Er bestimmt das Design, die Farben, die
PP.002, Version 1.1 07.04.2015 Kurzanleitung PowerPoint 2010 Mit Folienmastern arbeiten Der Folienmaster ist die Vorlage für sämtliche Folien einer Präsentation. Er bestimmt das Design, die Farben, die
Sie haben das Recht, binnen vierzehn Tagen ohne Angabe von Gründen diesen Vertrag zu widerrufen.
 Widerrufsbelehrung Nutzt der Kunde die Leistungen als Verbraucher und hat seinen Auftrag unter Nutzung von sog. Fernkommunikationsmitteln (z. B. Telefon, Telefax, E-Mail, Online-Web-Formular) übermittelt,
Widerrufsbelehrung Nutzt der Kunde die Leistungen als Verbraucher und hat seinen Auftrag unter Nutzung von sog. Fernkommunikationsmitteln (z. B. Telefon, Telefax, E-Mail, Online-Web-Formular) übermittelt,
Umsatzsteuer Wichtige Neuerungen: Wer schuldet die Steuer bei Bauleistungen?
 WIRTSCHAFT UND RECHT W 041/2014 vom 10.04.2014 Umsatzsteuer Wichtige Neuerungen: Wer schuldet die Steuer bei Bauleistungen? Bitte beachten Sie, dass die neuen Grundsätze des BMF-Schreibens (Anlage 1) ohne
WIRTSCHAFT UND RECHT W 041/2014 vom 10.04.2014 Umsatzsteuer Wichtige Neuerungen: Wer schuldet die Steuer bei Bauleistungen? Bitte beachten Sie, dass die neuen Grundsätze des BMF-Schreibens (Anlage 1) ohne
Pädagogik. Melanie Schewtschenko. Eingewöhnung und Übergang in die Kinderkrippe. Warum ist die Beteiligung der Eltern so wichtig?
 Pädagogik Melanie Schewtschenko Eingewöhnung und Übergang in die Kinderkrippe Warum ist die Beteiligung der Eltern so wichtig? Studienarbeit Inhaltsverzeichnis 1. Einleitung.2 2. Warum ist Eingewöhnung
Pädagogik Melanie Schewtschenko Eingewöhnung und Übergang in die Kinderkrippe Warum ist die Beteiligung der Eltern so wichtig? Studienarbeit Inhaltsverzeichnis 1. Einleitung.2 2. Warum ist Eingewöhnung
Widerrufsbelehrung der Free-Linked GmbH. Stand: Juni 2014
 Widerrufsbelehrung der Stand: Juni 2014 www.free-linked.de www.buddy-watcher.de Inhaltsverzeichnis Widerrufsbelehrung Verträge für die Lieferung von Waren... 3 Muster-Widerrufsformular... 5 2 Widerrufsbelehrung
Widerrufsbelehrung der Stand: Juni 2014 www.free-linked.de www.buddy-watcher.de Inhaltsverzeichnis Widerrufsbelehrung Verträge für die Lieferung von Waren... 3 Muster-Widerrufsformular... 5 2 Widerrufsbelehrung
SCHRITT FÜR SCHRITT ZU IHRER VERSCHLÜSSELTEN E-MAIL
 SCHRITT FÜR SCHRITT ZU IHRER VERSCHLÜSSELTEN E-MAIL www.klinik-schindlbeck.de info@klinik-schindlbeck.de Bitte beachten Sie, dass wir nicht für die Sicherheit auf Ihrem Endgerät verantwortlich sein können.
SCHRITT FÜR SCHRITT ZU IHRER VERSCHLÜSSELTEN E-MAIL www.klinik-schindlbeck.de info@klinik-schindlbeck.de Bitte beachten Sie, dass wir nicht für die Sicherheit auf Ihrem Endgerät verantwortlich sein können.
Urlaubsregel in David
 Urlaubsregel in David Inhaltsverzeichnis KlickDown Beitrag von Tobit...3 Präambel...3 Benachrichtigung externer Absender...3 Erstellen oder Anpassen des Anworttextes...3 Erstellen oder Anpassen der Auto-Reply-Regel...5
Urlaubsregel in David Inhaltsverzeichnis KlickDown Beitrag von Tobit...3 Präambel...3 Benachrichtigung externer Absender...3 Erstellen oder Anpassen des Anworttextes...3 Erstellen oder Anpassen der Auto-Reply-Regel...5
IRF2000 Application Note Lösung von IP-Adresskonflikten bei zwei identischen Netzwerken
 Version 2.0 1 Original-Application Note ads-tec GmbH IRF2000 Application Note Lösung von IP-Adresskonflikten bei zwei identischen Netzwerken Stand: 27.10.2014 ads-tec GmbH 2014 IRF2000 2 Inhaltsverzeichnis
Version 2.0 1 Original-Application Note ads-tec GmbH IRF2000 Application Note Lösung von IP-Adresskonflikten bei zwei identischen Netzwerken Stand: 27.10.2014 ads-tec GmbH 2014 IRF2000 2 Inhaltsverzeichnis
Welche Unterschiede gibt es zwischen einem CAPAund einem Audiometrie- Test?
 Welche Unterschiede gibt es zwischen einem CAPAund einem Audiometrie- Test? Auch wenn die Messungsmethoden ähnlich sind, ist das Ziel beider Systeme jedoch ein anderes. Gwenolé NEXER g.nexer@hearin gp
Welche Unterschiede gibt es zwischen einem CAPAund einem Audiometrie- Test? Auch wenn die Messungsmethoden ähnlich sind, ist das Ziel beider Systeme jedoch ein anderes. Gwenolé NEXER g.nexer@hearin gp