Graph Mining. Discovering Frequent Subgraphs Discovering Frequent Geometric Subgraphs Angela Eigenstetter und Christian Wirth
|
|
|
- Gerhard Biermann
- vor 6 Jahren
- Abrufe
Transkript
1 Graph Mining Discovering Frequent Subgraphs Discovering Frequent Geometric Subgraphs Angela Eigenstetter und Christian Wirth Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 1
2 FSG und GFSG Allgemein Apriori Ansatz Candidate Generation, Frequency Counting Über eine Menge von Graphen Support Grenze: min. Anzahl von Graphen die das Pattern beinhalten Isomorphie Test über kanonische Labels (FSG) Geometrische Transformationen (GFSG) Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 2
3 Anwendungen Allgemeiner Ansatz Chemische Verbindungen Knoten = Atom Kante = Verbindung Kantenlabel = Verbindungstyp Häufige Subgraphen dienen der Klassifizierung Andere Anwendungen möglich Athlon MP (1,53Ghz), 2Gb Ram Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 3
4 Frequent Subgraph Discovery Algorithm
5 Übersicht Allgemeine Informationen Candidate Generation Frequency Counting Ergebnisse Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 5
6 Allgemein Generalisiert (3D-) Strukturinformationen als Kantenlabel Datenstrukturbasierte Verbesserungen Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 6
7 Candidate Generation I Zusammenfassen zweier k-subgraphen Jede mögliche Kombination Auch zwei gleiche Subgraphen Gemeinsamer k-1 Kern Isomorph Primärer Subgraph Erzeugt k+1 Subgraph + = Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 7
8 Candidate Generation II Muss nicht eindeutig sein Gleiches Label + = oder Automorphismus + = oder Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 8
9 Frequency Counting Transaction Identifier List Liste je Pattern Beinhaltet alle Graphen die dieses Pattern enthalten Erstellen der k+1 Liste Berechnen der Überschneidungen Liste aller Graphen die in beiden Listen vorkommen Länge < Grenzwert => Prune Berechnen der Isomorphie Canonical Labeling für alle Elemente Neue TID List Länge < Grenzwert => Prune Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 9

10 Canonical Labeling I Allgemein Nutzung der Knoten Invarianten Grad Label Nachbarschaft Erstellung Kanonisches Label Oberes Dreieck der Adjazenzmatrix Labelreihe + Matrixspalten Maximierung des Labels durch Permutation v0 v1 v2 A A A v0 A z x v1 A z y v2 A x y Label: AAA zxy v1 v0 v2 A A A v1 A z y v0 A z x v2 A y x Maximiertes Label: AAA zyx Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 10
11 Canonical Labeling II Problem: Berechnung aller Permutationen O( V!) Bereits bei kleinen Graphen problematisch Lösung: Partitionierung Äquivalenzklassen Knoten Invarianten Erstellung Iterativ Erst Grad & Label Dann Nachbarschaft Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 11
12 Canonical Labeling - Algorithmus 1. Partitionen nach Grad und Label 2. Repartitionierung nach Nachbarschaftsliste 3. Sortieren der Partitionen 4. Maximierung der Labels je Partition 5. Erstellen des Labels Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 12
13 Canonical Labeling Beispiel I Erstellen der Partitionen Eine Partition je Grad und Label 1. Partitionierung 2. Repartitionierung 3. Sortieren 4. Maximierung des Labels 5. Erstellen des Labels Partitionen: p0 : Label = B und Grad = 3 v1, v2, v3, v4 p1 : Label = A und Grad = 1 v0, v Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 13
14 Canonical Labeling Beispiel II Erstellen der Nachbarschaftslisten Partitionsnummer Edgelabel Partitionen: p0 : Label = B und Grad = 3 v1, v2, v3, v4 p1 : Label = A und Grad = 1 v0, v6 1. Partitionierung 2. Repartitionierung 3. Sortierung 4. Maximierung des Labels 5. Erstellen des Labels Nachbarschaften: p0 v1 : (p0,y),(p0,y),(p1,x) v2 : (p0,y),(p0,y),(p0,y) v3 : (p0,y),(p0,y),(p1,z) v4 : (p0,y),(p0,y),(p0,y) p1 v0 : (p0,x) v5 : (p0,z) Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 14

15 Canonical Labeling Beispiel III Repartitionierung Erstellen neuer Partitionen nach Nachbarschaft Kann erneutes Repartitionieren verursachen 1. Partitionierung 2. Repartitionierung 3. Sortieren 4. Maximierung des Labels 5. Erstellen des Labels Partitionen: p0 : Label = B und Grad = 3 v1, v2, v3, v4 p1 : Label = A und Grad = 1 v0, v6 Nachbarschaften: p0 v1 : (p0,y),(p0,y),(p1,x) v2 : (p0,y),(p0,y),(p0,y) v3 : (p0,y),(p0,y),(p1,z) v4 : (p0,y),(p0,y),(p0,y) p1 v0 : (p0,x) v5 : (p0,z) Partitionen: p0 : Label = B, Grad = 3 und Nachbarschaft = (p0,y),(p0,y),(p0,y) v2, v4 p1 : Label = B, Grad = 3 und Nachbarschaft = (p0,y),(p0,y),(p1,x) v1 p2 : Label = B, Grad = 3 und Nachbarschaft = (p0,y),(p0,y),(p1,z) v3 p3 : Label = A und Grad = 1 und Nachbarschaft = (p0,x) v0 p4 : Label = A und Grad = 1 und Nachbarschaft = (p0,z) Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 15
16 Canonical Labeling Beispiel IV Sortierung Isomorphe Graphen haben gleiche Partitionen Reinfolge egal solange Eindeutig Sollte schnelles Pruning ermöglichen Große Variationen am Anfang Sortieren nach Grad 1. Partitionierung 2. Repartitionierung 3. Sortieren 4. Maximierung des Labels 5. Erstellen des Labels Partitionen: p0 : Label = B, Grad = 3 und Nachbarschaft = (p0,y),(p0,y),(p0,y) p1 : Label = B, Grad = 3 und Nachbarschaft = (p0,y),(p0,y),(p1,x) p2 : Label = B, Grad = 3 und Nachbarschaft = (p0,y),(p0,y),(p1,z) p3 : Label = A und Grad = 1 und Nachbarschaft = (p0,x) p4 : Label = A und Grad = 1 und Nachbarschaft = (p0,z) p2 > p0 > p1 > p4 > p Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 16
17 Canonical Labeling Beispiel V Maximierung des Labels Partitionsreinfolge definiert Reinfolge innerhalb der Partition Maximierung Vertauschung 1. Partitionierung 2. Repartitionierung 3. Sortieren 4. Maximierung des Labels 5. Erstellen des Labels v3 v2 v4 v1 v5 v0 B B B B A A v3 B y y z v2 B y y y v4 B y y y v1 B y y x P0 : mögliche Label yyy keine Permutationen möglich v5 A z v0 A x p2 p0 p1 p4 p Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 17
18 Canonical Labeling Beispiel VI Erstellen des Labels Reihe der Labels Spaltenkonkatenation 1. Partitionierung 2. Repartitionierung 3. Sortieren 4. Maximierung des Labels 5. Erstellen des Labels v3 v2 v4 v1 v5 v0 B B B B A A v3 B y y z v2 B y y y v4 B y y y v1 B y y x Label: BBBBAA yyy0yyz000000x0 v5 A z v0 A x p2 p0 p1 p4 p Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 18
19 Zusammenfassung Apriori Generieren der Kandidaten Primäre Subgraphen Mehrere Kandidaten Häufigkeit testen Transaction Identifier Lists Isomorphie über Canonical Labels Canonical Labels Partitionen nach Vertex Invarianten Maximieren des Labels Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 19
20 Verbesserungen Vertex Stabilisation Große Partitionen haben O(k!) Permutationen Kann verkleinert werden Zufälliges Vertex mit neuer Partition Erzeugt ~ (k/2) neue Partitionen Muss für alle k Möglichkeiten berechnet werden O(k(k/2)!) < O(k!) Datenbank Unterteilung Unterteilen der Graphmenge Berechnen der Häufigkeit je Teil Häufigkeiten ergibt Obergrenze => Pruning Speicherersparnis Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 20
21 Ergebnisse Keine Vergleiche mit anderen Algorithmen Evaluation der Eigenschaften Auf natürlichem Datenset Verhältnis Graphen/Laufzeit Verhältnis Support/Laufzeit Speicherbedarf/Datenbank Unterteilungen Auf synthetischem Datenset Verhältnis Anzahl Vertexlabel/Laufzeit Verhältnis Patterngröße/Laufzeit Verhältnis Graphgröße/Laufzeit System: Athlon MP (1,53Ghz), 2Gb Ram Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 21

22 Ergebnisse I Natürliches Datenset Predictive Toxicology Evaluation (PTE) Challenge Developmental Therapeutics Program (DTP) Beides Molekularstrukturen Ergebnis Verhältnis Graphen/Laufzeit: Sehr gut, fast linear Verhältnis Support/Laufzeit: Starke Abhängigkeit, Datenabhängig Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 22

23 Ergebnisse II Datenbank Unterteilungen zur Speicherreduktion Ergebnis Starke Reduktion bis ~ 20 Unterteilungen Geringer Anstieg der Laufzeit Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 23
24 Ergebnisse III Synthetisches Datenset Diverse Kontrollparameter Anzahl Graphen D Durchschnittliche Anzahl Kanten je Graph T Durchschnittliche Anzahl Kanten je FSG I Durchschnittliche Anzahl FSG je Graph S Anzahl der unterschiedlichen Kantenlabels L E Anzahl der unterschiedlichen Knotenlabels L V Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 24
25 Ergebnisse IV Ergebnis Die Laufzeit sinkt mit L V, weniger Automorphismen, weniger Isomorphismen Die Laufzeit steigt mit I, komplexere Patterns Die Laufzeit steigt mit T, mehr Pattern je Graph möglich Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 25
26 Frequent Geometric Subgraph Discovery Algorithm
27 Übersicht Wichtige Begriffe Isomorphismus in geometrischen Graphen Parameter und High Level Struktur des gfsg Algorithmus Candidate Generation Frequency Counting Iterative Shape Adjustment Experimentelle Evaluation Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 27
28 Begriffe I Geometric Graph Ungerichteter Graph Mit Labeln, nicht eindeutig Jeder Knoten hat eine zwei bzw. dreidimensionale Koordinaten Coordinate Matching Tolerance r Y r X Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 28
29 Begriffe II r tolerant frequent Subgraph D Menge von Graphen 0 < σ 1.0 Ein Subgraph ist frequent, wenn er mindestens σ D % aller Graphen gefunden wird (Minimum Support) Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 29

30 Begriffe III Geometric Configuration Koordinatensystems ergibt sich aus Kanten des Graphen 2D : Kante des Graphen entspricht X-Achse Y X 3D : zwei Kanten (nicht parallel) mit einem gemeinsamen Knoten als XY-Ebene Z Y => Ermöglicht translations- und rotations-invariante Isomorphismen X Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 30
31 Geometric Configuration Example Skalierung des Graphen eine Kante besitzt Länge eins Erlaubt uns skalen-invariante Isomorphismen zu finden Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 31
32 Geometric Graph Isomorphism Finde geometrische Transformation zwischen g 1 und g 2 Rotation, Skalierung und Translation Nur zwischen den Knoten Überprüfe die Topologie (und Label) jeder Transformation Topologie: Struktur des Graphen Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 32
33 Geometric Graph Isomorphism 1. g 1 und g 2 haben unterschiedliche Anzahl Knoten oder Kanten -> false 2. Zufällige geometrische Konfiguration von g 2 1. Für jede geometrische Konfiguration von g 1 2. Für jeden Knoten v in g 1 1. Finde den nächsten Knoten u in g 2 mit gleichem Label 2. Distanz zwischen den Knoten größer r -> break 3. u wird dem Knoten v zugeordnet 3. Bijektion gefunden 4. Ist Bijektion eine zulässiger topologischer Isomorphismus zwischen g 1 und g 2 -> return true 3. Return false Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 33
34 Parameter von gfsg Eingabe Graphenmenge D Support threshold σ Matching Tolerance r Shape Adjustment Type type Anzahl der Shape Adjustment Iterationen N Ausgabe Alle Subgraphen die den Minimum Support erfüllen Frequent Subraphs (FSG) genannt Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 34
35 GFSG High Level Structure 1.Spezifizieren aller FGS der Größe 1,2 und 3 in D 2.Solange es 2 FGS der Größe k-1 gibt 1. Generiere alle Kandidaten g k der Größe k (Candidate Generation) 2. Für jeden Kandidaten der Größe k 1. Berechne die Menge S der Graphen t є D in denen der Kandidat vorkommt (Frequency Counting) 2. Kommt der Kandidat in keinem der Graphen vor fahre mit nächstem Kandidaten fort 3. Gegebenenfalls wird die geometrische Form des Kandidaten angepasst (Iterative Shape Adjustment) 3. Verwirft Subgraphen g k die den Minimum Support nicht erfüllen Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 35
36 GFSG High Level Structure 1.Spezifizieren aller FGS der Größe 1,2 und 3 in D 2.Solange es 2 FGS der Größe k-1 gibt 1. Generiere alle Kandidaten g k der Größe k (Candidate Generation) 2. Für jeden Kandidaten der Größe k 1. Berechne die Menge S der Graphen t є D in denen der Kandidat vorkommt (Frequency Counting) 2. Kommt der Kandidat in keinem der Graphen vor fahre mit nächstem Kandidaten fort 3. Gegebenenfalls wird die geometrische Form des Kandidaten angepasst (Iterative Shape Adjustment) 3. Verwirft Subgraphen g k die den Minimum Support nicht erfüllen Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 36



37 Candidate Generation Zusammenfügen FGS der Größe k zu einem der Größe k+1 müssen gleichen k-1 Subgraph (Kern) enthalten nicht unbedingt eindeutig Kern hat mehrere Authomorphismen FSG hat mehrere geometrische Kerne + = oder Kern 1 Kern Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 37
38 Candidate Generation Algo 1. Für jedes Paar g i, g j von FSG der Größe k 1. Für jede Kante e des 1. FSG 1. Entferne Kante e aus FSG -> k-1 Subgraph 2. Enthält der 2. FSG g j den k-1 Subgraph -> gleicher Kern 1. Zusammenfügen der beiden FSG g i und g j zu einem neuen Subgraphen der Größe k+1 2. k+1 Subgraph wurde bereits generiert -> continue 3. Subgraph ist neuer Kandidat Größe k Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 38



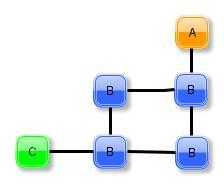

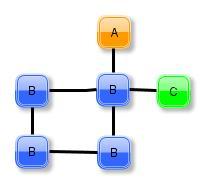
39 Join Beisipiel + = Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 39
40 GFSG High Level Structure 1.Spezifizieren aller FGS der Größe 1,2 und 3 in D 2.Solange es 2 FGS der Größe k-1 gibt 1. Generiere alle Kandidaten g k der Größe k 2. Für jeden Kandidaten der Größe k 1. Berechne die Menge S der Graphen t є D in denen der Kandidat vorkommt 2. Kommt der Kandidat in keinem der Graphen vor fahre mit nächstem Kandidaten fort 3. Gegebenenfalls wird die geometrische Form des Kandidaten angepasst 3. Verwirft Subgraphen g k die den Minimum Support nicht erfüllen Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 40
41 GFSG High Level Structure 1.Spezifizieren aller FGS der Größe 1,2 und 3 in D 2.Solange es 2 FGS der Größe k-1 gibt 1. Generiere alle Kandidaten g k der Größe k 2. Für jeden Kandidaten der Größe k 1. Berechne die Menge S der Graphen t є D in denen der Kandidat vorkommt 2. Kommt der Kandidat in keinem der Graphen vor fahre mit nächstem Kandidaten fort 3. Gegebenenfalls wird die geometrische Form des Kandidaten angepasst 3. Verwirft Subgraphen g k die den Minimum Support nicht erfüllen Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 41
 Teilmenge eal(t) 10.12.2008 Fachbereich 20 Fachgebiet Knowledge Engineering Prof.")
42 Count Frequency (EAL) Edge Angle List (eal) Multimenge von Winkeln zwischen jedem Kantenpaar mit gemeinsamem Knoten θ 2 θ 3 eal(g)= {θ 1,θ 2,θ 3 } θ 1 Winkel sind invariant gegenüber geometrischen Transformationen wenn g isomorph zu einem Subgraphen aus t є D dann eal(g) Teilmenge eal(t) Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 42
43 Count Frequency (TID List) TID List (Transaction ID List) Liste von Graphen (Transactions) in denen ein FSG enthalten Berechnung der Häufigkeit eines Kandidaten der Größe k+1 : 1. Berechne Schnittmenge der TIDs der beiden zugrunde liegenden FSG der Größe k 2. Größe der Schnittmenge kleiner als Minimum Support =>Subgraph der Größe k+1 verworfen 3. Sonst Berechne Häufigkeit mit Subgraph Isomorphismus auf den Graphen die sich in der Schnittmenge befinden Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 43
44 Count Frequency (Hybrid) 1. Finden der frequent edge angles 2. TID list für jeden frequent edge angle der Graphen die eine Instanz des Winkels enthalten tid(θ)={t 1,t 2,...,t n } 3. Kandidat g hat eine eal(g)={θ 1,θ 2,...,θ n } 4. Berechnung der Schnittmenge der TID Listen der verschiedenen edge angles in g l=schnitt i (tid(θ i )) θ i є eal(g) =>Wenn g den Minimum Support erfüllt ist l σ D Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 44
45 Frequency Counting Bewertung der drei Ansätze Edge Angle List Sehr langsam TID List Schnell verbraucht aber sehr viel Speicher Speichere Listen von allen FSG der Größe k Hybrid 5 mal schneller als Edge Angle List 2 mal langsamer als TID List Verbraucht allerdings viel weniger Speicher => Hybrid wurde in allen Experimenten verwendet Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 45
46 GFSG High Level Structure 1.Spezifizieren aller FGS der Größe 1,2 und 3 in D 2.Solange es 2 FGS der Größe k-1 gibt 1. Generiere alle Kandidaten g k der Größe k 2. Für jeden Kandidaten der Größe k 1. Berechne die Menge S der Graphen t є D in denen der Kandidat vorkommt 2. Kommt der Kandidat in keinem der Graphen vor fahre mit nächstem Kandidaten fort 3. Gegebenenfalls wird die geometrische Form des Kandidaten angepasst 3. Verwirft Subgraphen g k die den Minimum Support nicht erfüllen Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 46
47 GFSG High Level Structure 1.Spezifizieren aller FGS der Größe 1,2 und 3 in D 2.Solange es 2 FGS der Größe k-1 gibt 1. Generiere alle Kandidaten g k der Größe k 2. Für jeden Kandidaten der Größe k 1. Berechne die Menge S der Graphen t є D in denen der Kandidat vorkommt 2. Kommt der Kandidat in keinem der Graphen vor fahre mit nächstem Kandidaten fort 3. Gegebenenfalls wird die geometrische Form des Kandidaten angepasst 3. Verwirft Subgraphen g k die den Minimum Support nicht erfüllen Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 47
48 Anpassung der geometrischen Form Geometrische Konfiguration eines Kandidaten nicht unbedingt optimal Problem: Einige vorkommen des Kandidaten können nicht gefunden werden Lösung: Anpassung der From des Kandidaten Führe Frequency Counting für jeden Kandidaten mehrmals durch In jeder Iteration : Berechne Menge der vorkommenden isomorphen Subgraphen Berechne Durchschnitt der Knotenkoordinaten Diese Koordinaten sind die neuen Koordinaten des Kandidaten (Angepasste Form) Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 48
49 Anpassung der geometrischen From Terminierung Simple Adjustment (SA) Terminiert nach N Iterationen (Benutzerspezifiziert) Supporting Transaction Monitoring (STM) Wie Simple Adjustment, aber......frühere Terminierung möglich, wenn die Menge der gefundenen Subgraphen sich in zwei aufeinanderfolgenden Iterationen nicht verändert Downward Closure Check (DWC) Wie Supporting Transaction Monitoring, aber......wenn Veränderungen des Kandidaten zu groß werden kann es passieren, dass die k-1 Subgraphen des Kandidaten nicht mehr den Minimum Support erfüllen => Terminiert Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 49
50 Experimentelle Evaluierung Skalierbarkeit bezüglich der Datenbankgröße D Skalierbarkeit bezüglich der Graphengröße T Effektivität der Formanpassung σ Minimum Support Threshold t Laufzeit in Sekunden l Größe des größten FSG # f Gesamtzahl der gefunden FSG Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 50
51 Skalierbarkeit bezüglich der Datenbankgröße Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 51
52 Skalierbarkeit bezüglich der Graphengröße Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 52
53 Effektivität der Formanpassung + 34 % + 25 % Fachbereich 20 Fachgebiet Knowledge Engineering Prof. Fürnkranz 53
54 Danke für die Aufmerksamkeit Fragen???
Konvexe Hülle. Konvexe Hülle. Mathematik. Konvexe Hülle: Definition. Mathematik. Konvexe Hülle: Eigenschaften. AK der Algorithmik 5, SS 2005 Hu Bin
 Konvexe Hülle Konvexe Hülle AK der Algorithmik 5, SS 2005 Hu Bin Anwendung: Computergraphik Boundary Kalkulationen Geometrische Optimierungsaufgaben Konvexe Hülle: Definition Mathematik Konvex: Linie zwischen
Konvexe Hülle Konvexe Hülle AK der Algorithmik 5, SS 2005 Hu Bin Anwendung: Computergraphik Boundary Kalkulationen Geometrische Optimierungsaufgaben Konvexe Hülle: Definition Mathematik Konvex: Linie zwischen
Häufige Item-Mengen: die Schlüssel-Idee. Vorlesungsplan. Apriori Algorithmus. Methoden zur Verbessung der Effizienz von Apriori
 Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Parallele Algorithmen in der Bildverarbeitung
 Seminar über Algorithmen - SoSe 2009 Parallele Algorithmen in der Bildverarbeitung von Christopher Keiner 1 Allgemeines 1.1 Einleitung Parallele Algorithmen gewinnen immer stärker an Bedeutung. Es existieren
Seminar über Algorithmen - SoSe 2009 Parallele Algorithmen in der Bildverarbeitung von Christopher Keiner 1 Allgemeines 1.1 Einleitung Parallele Algorithmen gewinnen immer stärker an Bedeutung. Es existieren
Kapitel 12: Schnelles Bestimmen der Frequent Itemsets
 Einleitung In welchen Situationen ist Apriori teuer, und warum? Kapitel 12: Schnelles Bestimmen der Frequent Itemsets Data Warehousing und Mining 1 Data Warehousing und Mining 2 Schnelles Identifizieren
Einleitung In welchen Situationen ist Apriori teuer, und warum? Kapitel 12: Schnelles Bestimmen der Frequent Itemsets Data Warehousing und Mining 1 Data Warehousing und Mining 2 Schnelles Identifizieren
Mining über RDBMSe. von. Christian Widmer. Wie gut lässt sich Mining mit SQL realisieren?
 Mining über RDBMSe von Christian Widmer Wie gut lässt sich Mining mit SQL realisieren? Müssen neue Konstrukte zur Verfügung gestellt werden, wenn ja welche? Vortragsüberblick Association Rules Apriori
Mining über RDBMSe von Christian Widmer Wie gut lässt sich Mining mit SQL realisieren? Müssen neue Konstrukte zur Verfügung gestellt werden, wenn ja welche? Vortragsüberblick Association Rules Apriori
Ansätze für das Frequent-Subgraph-Problem als Anwendung für Graph Mining
 Leibniz Universität Hannover Fakultät für Elektrotechnik und Informatik Institut für Theoretische Informatik Ansätze für das Frequent-Subgraph-Problem als Anwendung für Graph Mining Bachelorarbeit im Studiengang
Leibniz Universität Hannover Fakultät für Elektrotechnik und Informatik Institut für Theoretische Informatik Ansätze für das Frequent-Subgraph-Problem als Anwendung für Graph Mining Bachelorarbeit im Studiengang
Heuristische Verfahren
 Heuristische Verfahren Bei heuristischen Verfahren geht es darum in polynomieller Zeit eine Näherungslösung zu bekommen. Diese kann sehr gut oder sogar optimal sein, jedoch gibt es keine Garantie dafür.
Heuristische Verfahren Bei heuristischen Verfahren geht es darum in polynomieller Zeit eine Näherungslösung zu bekommen. Diese kann sehr gut oder sogar optimal sein, jedoch gibt es keine Garantie dafür.
Wissensentdeckung in Datenbanken
 Wissensentdeckung in Datenbanken SQL, Häufige Mengen Nico Piatkowski und Uwe Ligges 11.05.2017 1 von 16 Überblick Was bisher geschah... Modellklassen Verlustfunktionen Numerische Optimierung Regularisierung
Wissensentdeckung in Datenbanken SQL, Häufige Mengen Nico Piatkowski und Uwe Ligges 11.05.2017 1 von 16 Überblick Was bisher geschah... Modellklassen Verlustfunktionen Numerische Optimierung Regularisierung
9 Minimum Spanning Trees
 Im Folgenden wollen wir uns genauer mit dem Minimum Spanning Tree -Problem auseinandersetzen. 9.1 MST-Problem Gegeben ein ungerichteter Graph G = (V,E) und eine Gewichtsfunktion w w : E R Man berechne
Im Folgenden wollen wir uns genauer mit dem Minimum Spanning Tree -Problem auseinandersetzen. 9.1 MST-Problem Gegeben ein ungerichteter Graph G = (V,E) und eine Gewichtsfunktion w w : E R Man berechne
Verteilen von Bällen auf Urnen
 Verteilen von Bällen auf Urnen Szenario: Wir verteilen n Bälle auf m Urnen, d.h. f : B U mit B = {b 1,..., b n } und U = {u 1,..., u m }. Dabei unterscheiden wir alle Kombinationen der folgenden Fälle
Verteilen von Bällen auf Urnen Szenario: Wir verteilen n Bälle auf m Urnen, d.h. f : B U mit B = {b 1,..., b n } und U = {u 1,..., u m }. Dabei unterscheiden wir alle Kombinationen der folgenden Fälle
Datenstrukturen und Algorithmen. Christian Sohler FG Algorithmen & Komplexität
 Datenstrukturen und Algorithmen Christian Sohler FG Algorithmen & Komplexität 1 Clustering: Partitioniere Objektmenge in Gruppen(Cluster), so dass sich Objekte in einer Gruppe ähnlich sind und Objekte
Datenstrukturen und Algorithmen Christian Sohler FG Algorithmen & Komplexität 1 Clustering: Partitioniere Objektmenge in Gruppen(Cluster), so dass sich Objekte in einer Gruppe ähnlich sind und Objekte
Assoziationsregeln & Sequenzielle Muster. A. Hinneburg, Web Data Mining MLU Halle-Wittenberg, SS 2007
 Assoziationsregeln & Sequenzielle Muster 0 Übersicht Grundlagen für Assoziationsregeln Apriori Algorithmus Verschiedene Datenformate Finden von Assoziationsregeln mit mehren unteren Schranken für Unterstützung
Assoziationsregeln & Sequenzielle Muster 0 Übersicht Grundlagen für Assoziationsregeln Apriori Algorithmus Verschiedene Datenformate Finden von Assoziationsregeln mit mehren unteren Schranken für Unterstützung
1 Rotating Calipers. 2 Antipodal und Copodal. 3 Distanzen Rechtecke Eigenschaften
 1 Rotating Calipers 2 3 Rotating Calipers - Algorithmus Konvexes Polygon mit parallelen Stützgeraden Rotating Calipers - Finder Shamos lässt 1978 zwei Stützgeraden um ein Polygon rotieren Zwei Stützgeraden
1 Rotating Calipers 2 3 Rotating Calipers - Algorithmus Konvexes Polygon mit parallelen Stützgeraden Rotating Calipers - Finder Shamos lässt 1978 zwei Stützgeraden um ein Polygon rotieren Zwei Stützgeraden
Distributed Algorithms. Image and Video Processing
 Chapter 6 Optical Character Recognition Distributed Algorithms for Übersicht Motivation Texterkennung in Bildern und Videos 1. Erkennung von Textregionen/Textzeilen 2. Segmentierung einzelner Buchstaben
Chapter 6 Optical Character Recognition Distributed Algorithms for Übersicht Motivation Texterkennung in Bildern und Videos 1. Erkennung von Textregionen/Textzeilen 2. Segmentierung einzelner Buchstaben
Teil III. Komplexitätstheorie
 Teil III Komplexitätstheorie 125 / 160 Übersicht Die Klassen P und NP Die Klasse P Die Klassen NP NP-Vollständigkeit NP-Vollständige Probleme Weitere NP-vollständige Probleme 127 / 160 Die Klasse P Ein
Teil III Komplexitätstheorie 125 / 160 Übersicht Die Klassen P und NP Die Klasse P Die Klassen NP NP-Vollständigkeit NP-Vollständige Probleme Weitere NP-vollständige Probleme 127 / 160 Die Klasse P Ein
Lösungen zur 1. Klausur. Einführung in Berechenbarkeit, formale Sprachen und Komplexitätstheorie
 Hochschuldozent Dr. Christian Schindelhauer Paderborn, den 21. 2. 2006 Lösungen zur 1. Klausur in Einführung in Berechenbarkeit, formale Sprachen und Komplexitätstheorie Name :................................
Hochschuldozent Dr. Christian Schindelhauer Paderborn, den 21. 2. 2006 Lösungen zur 1. Klausur in Einführung in Berechenbarkeit, formale Sprachen und Komplexitätstheorie Name :................................
Apriori-Algorithmus zur Entdeckung von Assoziationsregeln
 Apriori-Algorithmus zur Entdeckung von PG 42 Wissensmanagment Lehrstuhl für Künstliche Intelligenz 22. Oktober 21 Gliederung Motivation Formale Problemdarstellung Apriori-Algorithmus Beispiel Varianten
Apriori-Algorithmus zur Entdeckung von PG 42 Wissensmanagment Lehrstuhl für Künstliche Intelligenz 22. Oktober 21 Gliederung Motivation Formale Problemdarstellung Apriori-Algorithmus Beispiel Varianten
Algorithmen auf Sequenzen Paarweiser Sequenzvergleich: Alignments
 Algorithmen auf Sequenzen Paarweiser Sequenzvergleich: Alignments Sven Rahmann Genominformatik Universitätsklinikum Essen Universität Duisburg-Essen Universitätsallianz Ruhr Einführung Bisher: Berechnung
Algorithmen auf Sequenzen Paarweiser Sequenzvergleich: Alignments Sven Rahmann Genominformatik Universitätsklinikum Essen Universität Duisburg-Essen Universitätsallianz Ruhr Einführung Bisher: Berechnung
Häufige Mengen ohne Kandidatengenerierung. FP-Tree: Transaktionen. Konstruktion eines FP-Trees. FP-Tree: Items
 Häufige Mengen ohne Kandidatengenerierung Jiawei Han, Micheline Kamber 2006 (2nd ed.)! Ziel 1: Kompression der Datenbank in eine Frequent-Pattern Tree Struktur (FP-Tree)! Stark komprimiert, vollständig
Häufige Mengen ohne Kandidatengenerierung Jiawei Han, Micheline Kamber 2006 (2nd ed.)! Ziel 1: Kompression der Datenbank in eine Frequent-Pattern Tree Struktur (FP-Tree)! Stark komprimiert, vollständig
Sokoban. Knowledge Engineering und Lernen in Spielen. Mark Sollweck Fachbereich 20 Seminar Knowledge Engineering Mark Sollweck 1
 Sokoban Knowledge Engineering und Lernen in Spielen Mark Sollweck 29.04.2010 Fachbereich 20 Seminar Knowledge Engineering Mark Sollweck 1 Überblick Sokoban Spielregeln Eigenschaften Lösungsansatz IDA*
Sokoban Knowledge Engineering und Lernen in Spielen Mark Sollweck 29.04.2010 Fachbereich 20 Seminar Knowledge Engineering Mark Sollweck 1 Überblick Sokoban Spielregeln Eigenschaften Lösungsansatz IDA*
Einheit 11 - Graphen
 Einheit - Graphen Bevor wir in medias res (eigentlich heißt es medias in res) gehen, eine Zusammenfassung der wichtigsten Definitionen und Notationen für Graphen. Graphen bestehen aus Knoten (vertex, vertices)
Einheit - Graphen Bevor wir in medias res (eigentlich heißt es medias in res) gehen, eine Zusammenfassung der wichtigsten Definitionen und Notationen für Graphen. Graphen bestehen aus Knoten (vertex, vertices)
Core-Graphen. ein Graphgeneratoren-Praktikum von Thorsten Vogel und Sergej Müller am Lehrstuhl für Algorithmik 13. Februar 2006
 Core-Graphen ein Graphgeneratoren-Praktikum von Thorsten Vogel und Sergej Müller am Lehrstuhl für Algorithmik 13. Februar 2006 Zielsetzung Durch Dekomposition von Graphen, beruhend auf k-cores nach S.
Core-Graphen ein Graphgeneratoren-Praktikum von Thorsten Vogel und Sergej Müller am Lehrstuhl für Algorithmik 13. Februar 2006 Zielsetzung Durch Dekomposition von Graphen, beruhend auf k-cores nach S.
Softwareprojektpraktikum Maschinelle Übersetzung
 Softwareprojektpraktikum Maschinelle Übersetzung Jan-Thorsten Peter, Andreas Guta, Jan Rosendahl max.bleu@i6.informatik.rwth-aachen.de Vorbesprechung 5. Aufgabe 22. Juni 2017 Human Language Technology
Softwareprojektpraktikum Maschinelle Übersetzung Jan-Thorsten Peter, Andreas Guta, Jan Rosendahl max.bleu@i6.informatik.rwth-aachen.de Vorbesprechung 5. Aufgabe 22. Juni 2017 Human Language Technology
Programmiertechnik II
 Graph-Algorithmen Anwendungsgebiete "Verbundene Dinge" oft Teilproblem/Abstraktion einer Aufgabenstellung Karten: Wie ist der kürzeste Weg von Sanssouci nach Kunnersdorf? Hypertext: Welche Seiten sind
Graph-Algorithmen Anwendungsgebiete "Verbundene Dinge" oft Teilproblem/Abstraktion einer Aufgabenstellung Karten: Wie ist der kürzeste Weg von Sanssouci nach Kunnersdorf? Hypertext: Welche Seiten sind
Programmiertechnik II
 Graph-Algorithmen Anwendungsgebiete "Verbundene Dinge" oft Teilproblem/Abstraktion einer Aufgabenstellung Karten: Wie ist der kürzeste Weg von Sanssouci nach Kunnersdorf? Hypertext: Welche Seiten sind
Graph-Algorithmen Anwendungsgebiete "Verbundene Dinge" oft Teilproblem/Abstraktion einer Aufgabenstellung Karten: Wie ist der kürzeste Weg von Sanssouci nach Kunnersdorf? Hypertext: Welche Seiten sind
Lösungen zu Kapitel 5
 Lösungen zu Kapitel 5 Lösung zu Aufgabe : (a) Es gibt derartige Graphen: (b) Offensichtlich besitzen 0 der Graphen einen solchen Teilgraphen. Lösung zu Aufgabe : Es sei G = (V, E) zusammenhängend und V
Lösungen zu Kapitel 5 Lösung zu Aufgabe : (a) Es gibt derartige Graphen: (b) Offensichtlich besitzen 0 der Graphen einen solchen Teilgraphen. Lösung zu Aufgabe : Es sei G = (V, E) zusammenhängend und V
Systems of Distinct Representatives
 Systems of Distinct Representatives Seminar: Extremal Combinatorics Peter Fritz Lehr- und Forschungsgebiet Theoretische Informatik RWTH Aachen Systems of Distinct Representatives p. 1/41 Gliederung Einführung
Systems of Distinct Representatives Seminar: Extremal Combinatorics Peter Fritz Lehr- und Forschungsgebiet Theoretische Informatik RWTH Aachen Systems of Distinct Representatives p. 1/41 Gliederung Einführung
IR Seminar SoSe 2012 Martin Leinberger
 IR Seminar SoSe 2012 Martin Leinberger Suchmaschinen stellen Ergebnisse häppchenweise dar Google: 10 Ergebnisse auf der ersten Seite Mehr Ergebnisse gibt es nur auf Nachfrage Nutzer geht selten auf zweite
IR Seminar SoSe 2012 Martin Leinberger Suchmaschinen stellen Ergebnisse häppchenweise dar Google: 10 Ergebnisse auf der ersten Seite Mehr Ergebnisse gibt es nur auf Nachfrage Nutzer geht selten auf zweite
Relationen und DAGs, starker Zusammenhang
 Relationen und DAGs, starker Zusammenhang Anmerkung: Sei D = (V, E). Dann ist A V V eine Relation auf V. Sei andererseits R S S eine Relation auf S. Dann definiert D = (S, R) einen DAG. D.h. DAGs sind
Relationen und DAGs, starker Zusammenhang Anmerkung: Sei D = (V, E). Dann ist A V V eine Relation auf V. Sei andererseits R S S eine Relation auf S. Dann definiert D = (S, R) einen DAG. D.h. DAGs sind
Fortgeschrittene Computerintensive Methoden: Assoziationsregeln Steffen Unkel Manuel Eugster, Bettina Grün, Friedrich Leisch, Matthias Schmid
 Fortgeschrittene Computerintensive Methoden: Assoziationsregeln Steffen Unkel Manuel Eugster, Bettina Grün, Friedrich Leisch, Matthias Schmid Institut für Statistik LMU München Sommersemester 2013 Zielsetzung
Fortgeschrittene Computerintensive Methoden: Assoziationsregeln Steffen Unkel Manuel Eugster, Bettina Grün, Friedrich Leisch, Matthias Schmid Institut für Statistik LMU München Sommersemester 2013 Zielsetzung
Übungsblatt 6. Vorlesung Theoretische Grundlagen der Informatik im WS 16/17
 Institut für Theoretische Informatik Lehrstuhl Prof. Dr. D. Wagner Übungsblatt 6 Vorlesung Theoretische Grundlagen der Informatik im WS 16/17 Ausgabe 22. Dezember 2016 Abgabe 17. Januar 2017, 11:00 Uhr
Institut für Theoretische Informatik Lehrstuhl Prof. Dr. D. Wagner Übungsblatt 6 Vorlesung Theoretische Grundlagen der Informatik im WS 16/17 Ausgabe 22. Dezember 2016 Abgabe 17. Januar 2017, 11:00 Uhr
Programmierkurs Python II
 Programmierkurs Python II Stefan Thater & Michaela Regneri Universität des Saarlandes FR 4.7 Allgemeine Linguistik (Computerlinguistik) Übersicht Topologische Sortierung (einfach) Kürzeste Wege finden
Programmierkurs Python II Stefan Thater & Michaela Regneri Universität des Saarlandes FR 4.7 Allgemeine Linguistik (Computerlinguistik) Übersicht Topologische Sortierung (einfach) Kürzeste Wege finden
Definition Gerichteter Pfad. gerichteter Pfad, wenn. Ein gerichteter Pfad heißt einfach, falls alle u i paarweise verschieden sind.
 3.5 Gerichteter Pfad Definition 291 Eine Folge (u 0, u 1,..., u n ) mit u i V für i = 0,..., n heißt gerichteter Pfad, wenn ( i {0,..., n 1} ) [ (u i, u i+1 ) A]. Ein gerichteter Pfad heißt einfach, falls
3.5 Gerichteter Pfad Definition 291 Eine Folge (u 0, u 1,..., u n ) mit u i V für i = 0,..., n heißt gerichteter Pfad, wenn ( i {0,..., n 1} ) [ (u i, u i+1 ) A]. Ein gerichteter Pfad heißt einfach, falls
Algorithms for Pattern Mining AprioriTID. Stefan George, Felix Leupold
 Algorithms for Pattern Mining AprioriTID Stefan George, Felix Leupold Gliederung 2 Einleitung Support / Confidence Apriori ApriorTID Implementierung Performance Erweiterung Zusammenfassung Einleitung 3
Algorithms for Pattern Mining AprioriTID Stefan George, Felix Leupold Gliederung 2 Einleitung Support / Confidence Apriori ApriorTID Implementierung Performance Erweiterung Zusammenfassung Einleitung 3
NP-Vollständigkeit. Krautgartner Martin (9920077) Markgraf Waldomir (9921041) Rattensberger Martin (9921846) Rieder Caroline (0020984)
 Markgraf Waldomir (9921041) Rattensberger Martin (9921846) Rieder Caroline (0020984)") NP-Vollständigkeit Krautgartner Martin (9920077) Markgraf Waldomir (9921041) Rattensberger Martin (9921846) Rieder Caroline (0020984) 0 Übersicht: Einleitung Einteilung in Klassen Die Klassen P und NP
NP-Vollständigkeit Krautgartner Martin (9920077) Markgraf Waldomir (9921041) Rattensberger Martin (9921846) Rieder Caroline (0020984) 0 Übersicht: Einleitung Einteilung in Klassen Die Klassen P und NP
Entscheidungsbäume aus großen Datenbanken: SLIQ
 Entscheidungsbäume aus großen Datenbanken: SLIQ C4.5 iteriert häufig über die Trainingsmenge Wie häufig? Wenn die Trainingsmenge nicht in den Hauptspeicher passt, wird das Swapping unpraktikabel! SLIQ:
Entscheidungsbäume aus großen Datenbanken: SLIQ C4.5 iteriert häufig über die Trainingsmenge Wie häufig? Wenn die Trainingsmenge nicht in den Hauptspeicher passt, wird das Swapping unpraktikabel! SLIQ:
Nash-Gleichgewichte in 2-Spieler Systemen. Katharina Klost Freie Universität Berlin
 Nash-Gleichgewichte in 2-Spieler Systemen Katharina Klost Freie Universität Berlin Seminar über Algorithmen, 29.10.2013 Grundlegende Definitionen A Gewinnmatrix für Spieler 1, B Gewinnmatrix für Spieler
Nash-Gleichgewichte in 2-Spieler Systemen Katharina Klost Freie Universität Berlin Seminar über Algorithmen, 29.10.2013 Grundlegende Definitionen A Gewinnmatrix für Spieler 1, B Gewinnmatrix für Spieler
Einführung in Heuristische Suche
 Einführung in Heuristische Suche Beispiele 2 Überblick Intelligente Suche Rundenbasierte Spiele 3 Grundlagen Es muss ein Rätsel / Puzzle / Problem gelöst werden Wie kann ein Computer diese Aufgabe lösen?
Einführung in Heuristische Suche Beispiele 2 Überblick Intelligente Suche Rundenbasierte Spiele 3 Grundlagen Es muss ein Rätsel / Puzzle / Problem gelöst werden Wie kann ein Computer diese Aufgabe lösen?
Mining top-k frequent itemsets from data streams
 Seminar: Maschinelles Lernen Mining top-k frequent itemsets from data streams R.C.-W. Wong A.W.-C. Fu 1 Gliederung 1. Einleitung 2. Chernoff-basierter Algorithmus 3. top-k lossy counting Algorithmus 4.
Seminar: Maschinelles Lernen Mining top-k frequent itemsets from data streams R.C.-W. Wong A.W.-C. Fu 1 Gliederung 1. Einleitung 2. Chernoff-basierter Algorithmus 3. top-k lossy counting Algorithmus 4.
Maschinelles Lernen: Symbolische Ansätze
 Maschinelles Lernen: Symbolische Ansätze Wintersemester 2009/2010 Musterlösung für das 13. Übungsblatt Aufgabe 1: Apriori Gegeben seien folgende Beobachtungen vom Kaufverhalten von Kunden: beer chips dip
Maschinelles Lernen: Symbolische Ansätze Wintersemester 2009/2010 Musterlösung für das 13. Übungsblatt Aufgabe 1: Apriori Gegeben seien folgende Beobachtungen vom Kaufverhalten von Kunden: beer chips dip
Übungsblatt Nr. 5. Lösungsvorschlag
 Institut für Kryptographie und Sicherheit Prof. Dr. Jörn Müller-Quade Nico Döttling Dirk Achenbach Tobias Nilges Vorlesung Theoretische Grundlagen der Informatik Übungsblatt Nr. 5 svorschlag Aufgabe 1
Institut für Kryptographie und Sicherheit Prof. Dr. Jörn Müller-Quade Nico Döttling Dirk Achenbach Tobias Nilges Vorlesung Theoretische Grundlagen der Informatik Übungsblatt Nr. 5 svorschlag Aufgabe 1
Diskrete Strukturen Kapitel 4: Graphentheorie (Grundlagen)
") WS 2015/16 Diskrete Strukturen Kapitel 4: Graphentheorie (Grundlagen) Hans-Joachim Bungartz Lehrstuhl für wissenschaftliches Rechnen Fakultät für Informatik Technische Universität München http://www5.in.tum.de/wiki/index.php/diskrete_strukturen_-_winter_15
WS 2015/16 Diskrete Strukturen Kapitel 4: Graphentheorie (Grundlagen) Hans-Joachim Bungartz Lehrstuhl für wissenschaftliches Rechnen Fakultät für Informatik Technische Universität München http://www5.in.tum.de/wiki/index.php/diskrete_strukturen_-_winter_15
Data Mining auf Datenströmen Andreas M. Weiner
 Technische Universität Kaiserslautern Fachbereich Informatik Lehrgebiet Datenverwaltungssysteme Integriertes Seminar Datenbanken und Informationssysteme Sommersemester 2005 Thema: Data Streams Andreas
Technische Universität Kaiserslautern Fachbereich Informatik Lehrgebiet Datenverwaltungssysteme Integriertes Seminar Datenbanken und Informationssysteme Sommersemester 2005 Thema: Data Streams Andreas
Flüsse, Schnitte, bipartite Graphen
 Flüsse, chnitte, bipartite Graphen Matthias Hoffmann 5.5.009 Matthias Hoffmann Flüsse, chnitte, bipartite Graphen 5.5.009 / 48 Übersicht Einführung Beispiel Definitionen Ford-Fulkerson-Methode Beispiel
Flüsse, chnitte, bipartite Graphen Matthias Hoffmann 5.5.009 Matthias Hoffmann Flüsse, chnitte, bipartite Graphen 5.5.009 / 48 Übersicht Einführung Beispiel Definitionen Ford-Fulkerson-Methode Beispiel
Domain-independent. independent Duplicate Detection. Vortrag von Marko Pilop & Jens Kleine. SE Data Cleansing
 SE Data Cleansing Domain-independent independent Duplicate Detection Vortrag von Marko Pilop & Jens Kleine http://www.informatik.hu-berlin.de/~pilop/didd.pdf {pilop jkleine}@informatik.hu-berlin.de 1.0
SE Data Cleansing Domain-independent independent Duplicate Detection Vortrag von Marko Pilop & Jens Kleine http://www.informatik.hu-berlin.de/~pilop/didd.pdf {pilop jkleine}@informatik.hu-berlin.de 1.0
Fortgeschrittene Netzwerk- und Graph-Algorithmen
 Fortgeschrittene Netzwerk- und Graph-Algorithmen Dr. Hanjo Täubig Lehrstuhl für Eziente Algorithmen (Prof. Dr. Ernst W. Mayr) Institut für Informatik Technische Universität München Wintersemester 2007/08
Fortgeschrittene Netzwerk- und Graph-Algorithmen Dr. Hanjo Täubig Lehrstuhl für Eziente Algorithmen (Prof. Dr. Ernst W. Mayr) Institut für Informatik Technische Universität München Wintersemester 2007/08
Sachrechnen/Größen WS 14/15-
 Kapitel Daten & Wahrscheinlichkeit 3.1 Kombinatorische Grundlagen 3.2 Kombinatorik & Wahrscheinlichkeit in der Grundschule 3.3 Daten Darstellen 3.1 Kombinatorische Grundlagen Verschiedene Bereiche der
Kapitel Daten & Wahrscheinlichkeit 3.1 Kombinatorische Grundlagen 3.2 Kombinatorik & Wahrscheinlichkeit in der Grundschule 3.3 Daten Darstellen 3.1 Kombinatorische Grundlagen Verschiedene Bereiche der
Kapitel 6: Graphalgorithmen Gliederung
 Gliederung 1. Grundlagen 2. Zahlentheoretische Algorithmen 3. Sortierverfahren 4. Ausgewählte Datenstrukturen 5. Dynamisches Programmieren 6. Graphalgorithmen 7. String-Matching 8. Kombinatorische Algorithmen
Gliederung 1. Grundlagen 2. Zahlentheoretische Algorithmen 3. Sortierverfahren 4. Ausgewählte Datenstrukturen 5. Dynamisches Programmieren 6. Graphalgorithmen 7. String-Matching 8. Kombinatorische Algorithmen
INTELLIGENTE DATENANALYSE IN MATLAB. Unüberwachtes Lernen: Clustern von Attributen
 INTELLIGENTE DATENANALYSE IN MATLAB Unüberwachtes Lernen: Clustern von Attributen Literatur J. Han, M. Kamber: Data Mining Concepts and Techniques. J. Han et. al: Mining Frequent Patterns without Candidate
INTELLIGENTE DATENANALYSE IN MATLAB Unüberwachtes Lernen: Clustern von Attributen Literatur J. Han, M. Kamber: Data Mining Concepts and Techniques. J. Han et. al: Mining Frequent Patterns without Candidate
Effiziente Algorithmen und Datenstrukturen I. Kapitel 9: Minimale Spannbäume
 Effiziente Algorithmen und Datenstrukturen I Kapitel 9: Minimale Spannbäume Christian Scheideler WS 008 19.0.009 Kapitel 9 1 Minimaler Spannbaum Zentrale Frage: Welche Kanten muss ich nehmen, um mit minimalen
Effiziente Algorithmen und Datenstrukturen I Kapitel 9: Minimale Spannbäume Christian Scheideler WS 008 19.0.009 Kapitel 9 1 Minimaler Spannbaum Zentrale Frage: Welche Kanten muss ich nehmen, um mit minimalen
Data Mining. Informationssysteme, Sommersemester 2017
 Data Mining Informationssysteme, Sommersemester 2017 Literatur zu Data-Mining Pang-Ning Tan, Michael Steinbach, Vipin Kuma. Introduction to Data Minig. Ein paar relevante Kapitel sind frei verfügbar unter
Data Mining Informationssysteme, Sommersemester 2017 Literatur zu Data-Mining Pang-Ning Tan, Michael Steinbach, Vipin Kuma. Introduction to Data Minig. Ein paar relevante Kapitel sind frei verfügbar unter
Geometrische Algorithmen Einige einfache Definitionen: Ist ein Punkt in einem Polygon? Punkt-in-Polygon-Problem. Das Punkt-in-Polygon-Problem
 Geometrische Algorithmen Einige einfache Definitionen: Punkt: im n-dimensionalen Raum ist ein n-tupel (n Koordinaten) Gerade: definiert durch zwei beliebige Punkte auf ihr Strecke: definiert durch ihre
Geometrische Algorithmen Einige einfache Definitionen: Punkt: im n-dimensionalen Raum ist ein n-tupel (n Koordinaten) Gerade: definiert durch zwei beliebige Punkte auf ihr Strecke: definiert durch ihre
Kapitel 9: Lineare Programmierung Gliederung
 Gliederung 1. Grundlagen 2. Zahlentheoretische Algorithmen 3. Sortierverfahren 4. Ausgewählte Datenstrukturen 5. Dynamisches Programmieren 6. Graphalgorithmen 7. String-Matching 8. Kombinatorische Algorithmen
Gliederung 1. Grundlagen 2. Zahlentheoretische Algorithmen 3. Sortierverfahren 4. Ausgewählte Datenstrukturen 5. Dynamisches Programmieren 6. Graphalgorithmen 7. String-Matching 8. Kombinatorische Algorithmen
Theoretische Grundlagen der Informatik
 Theoretische Grundlagen der Informatik Vorlesung am 5. Dezember 2017 INSTITUT FÜR THEORETISCHE 0 05.12.2017 Dorothea Wagner - Theoretische Grundlagen der Informatik INSTITUT FÜR THEORETISCHE KIT Die Forschungsuniversität
Theoretische Grundlagen der Informatik Vorlesung am 5. Dezember 2017 INSTITUT FÜR THEORETISCHE 0 05.12.2017 Dorothea Wagner - Theoretische Grundlagen der Informatik INSTITUT FÜR THEORETISCHE KIT Die Forschungsuniversität
Erzeugung zufälliger Graphen und Bayes-Netze
 Erzeugung zufälliger Graphen und Bayes-Netze Proseminar Algorithmen auf Graphen Georg Lukas, IF2000 2002-07-09 E-Mail: georg@op-co.de Folien: http://op-co.de/bayes/ Gliederung 1. Einleitung 2. einfache
Erzeugung zufälliger Graphen und Bayes-Netze Proseminar Algorithmen auf Graphen Georg Lukas, IF2000 2002-07-09 E-Mail: georg@op-co.de Folien: http://op-co.de/bayes/ Gliederung 1. Einleitung 2. einfache
Kapitel 6: Dynamic Shortest Path
 Kapitel 6: Dynamic Shortest Path 6.4 Experimentelle Analyse VO Algorithm Engineering Professor Dr. Petra Mutzel Lehrstuhl für Algorithm Engineering, LS11 18. VO 12. Juni 2007 Literatur für diese VO C.
Kapitel 6: Dynamic Shortest Path 6.4 Experimentelle Analyse VO Algorithm Engineering Professor Dr. Petra Mutzel Lehrstuhl für Algorithm Engineering, LS11 18. VO 12. Juni 2007 Literatur für diese VO C.
Algorithmen und Datenstrukturen
 Algorithmen und Datenstrukturen 13. Übung minimale Spannbäume, topologische Sortierung, AVL-Bäume Clemens Lang Übungen zu AuD 4. Februar 2010 Clemens Lang (Übungen zu AuD) Algorithmen und Datenstrukturen
Algorithmen und Datenstrukturen 13. Übung minimale Spannbäume, topologische Sortierung, AVL-Bäume Clemens Lang Übungen zu AuD 4. Februar 2010 Clemens Lang (Übungen zu AuD) Algorithmen und Datenstrukturen
1. Motivation / Grundlagen 2. Sortierverfahren 3. Elementare Datenstrukturen / Anwendungen 4. Bäume / Graphen 5. Hashing 6. Algorithmische Geometrie
 Gliederung 1. Motivation / Grundlagen 2. Sortierverfahren 3. Elementare Datenstrukturen / Anwendungen 4. äume / Graphen 5. Hashing 6. Algorithmische Geometrie 4/5, olie 1 2014 Prof. Steffen Lange - HDa/bI
Gliederung 1. Motivation / Grundlagen 2. Sortierverfahren 3. Elementare Datenstrukturen / Anwendungen 4. äume / Graphen 5. Hashing 6. Algorithmische Geometrie 4/5, olie 1 2014 Prof. Steffen Lange - HDa/bI
Das Heiratsproblem. Definition Matching
 Das Heiratsproblem Szenario: Gegeben: n Frauen und m > n Männer. Bekanntschaftsbeziehungen zwischen allen Männern und Frauen. Fragestellung: Wann gibt es für jede der Frauen einen Heiratspartner? Modellierung
Das Heiratsproblem Szenario: Gegeben: n Frauen und m > n Männer. Bekanntschaftsbeziehungen zwischen allen Männern und Frauen. Fragestellung: Wann gibt es für jede der Frauen einen Heiratspartner? Modellierung
11. Übung zu Algorithmen I 6. Juli 2016
 11. Übung zu Algorithmen I 6. Juli 2016 Lisa Kohl lisa.kohl@kit.edu mit Folien von Lukas Barth Roadmap Ausblick: Was sind schwierige Probleme? Travelling Salesman Problem - Reprise ein ILP ein Algorithmus
11. Übung zu Algorithmen I 6. Juli 2016 Lisa Kohl lisa.kohl@kit.edu mit Folien von Lukas Barth Roadmap Ausblick: Was sind schwierige Probleme? Travelling Salesman Problem - Reprise ein ILP ein Algorithmus
{0,1} rekursive Aufteilung des Datenraums in die Quadranten NW, NE, SW und SE feste Auflösung des Datenraums in 2 p 2 p Gitterzellen
 4.4 MX-Quadtrees (I) MatriX Quadtree Verwaltung 2-dimensionaler Punkte Punkte als 1-Elemente in einer quadratischen Matrix mit Wertebereich {0,1} rekursive Aufteilung des Datenraums in die Quadranten NW,
4.4 MX-Quadtrees (I) MatriX Quadtree Verwaltung 2-dimensionaler Punkte Punkte als 1-Elemente in einer quadratischen Matrix mit Wertebereich {0,1} rekursive Aufteilung des Datenraums in die Quadranten NW,
Mesh-Visualisierung. Von Matthias Kostka. Visualisierung großer Datensätze
 Mesh-Visualisierung Von Matthias Kostka Übersicht Einführung Streaming Meshes Quick-VDR Rendering virtueller Umgebung Rendering mit PC-Clustern Zusammenfassung 2 Mesh Untereinander verbundene Punkte bilden
Mesh-Visualisierung Von Matthias Kostka Übersicht Einführung Streaming Meshes Quick-VDR Rendering virtueller Umgebung Rendering mit PC-Clustern Zusammenfassung 2 Mesh Untereinander verbundene Punkte bilden
Algorithmus zum Graphen-Matching. und. Anwendung zur inhaltsbasierten Bildersuche
 Algorithmus zum Graphen-Matching und Anwendung zur inhaltsbasierten Bildersuche Gliederung 1. Einführung 2. Algorithmus Beschreibung Beispiel Laufzeit 3. Anwendung des Algorithmus Seite 1 von 18 1. Einführung
Algorithmus zum Graphen-Matching und Anwendung zur inhaltsbasierten Bildersuche Gliederung 1. Einführung 2. Algorithmus Beschreibung Beispiel Laufzeit 3. Anwendung des Algorithmus Seite 1 von 18 1. Einführung
4.2 Minimale Spannbäume: Der Algorithmus von Jarník/Prim Definition 4.2.1
 Allgemeines. Minimale Spannbäume: Der Algorithmus von Jarník/Prim Definition.. (a) Ein Graph G =(V, E) heißt kreisfrei, wenn er keinen Kreis besitzt. Beispiel: Ein kreisfreier Graph: FG KTuEA, TU Ilmenau
Allgemeines. Minimale Spannbäume: Der Algorithmus von Jarník/Prim Definition.. (a) Ein Graph G =(V, E) heißt kreisfrei, wenn er keinen Kreis besitzt. Beispiel: Ein kreisfreier Graph: FG KTuEA, TU Ilmenau
Discovering Frequent Substructures in Large Unordered Trees Unot
 Discovering Frequent Substructures in Large Unordered Trees Unot WS08/09 Prof. J. Fürnkranz 1 Inhalt Motivation asic Definitions Canonical Representation lgorithm Unot Overview Enumerating Pattern Compute
Discovering Frequent Substructures in Large Unordered Trees Unot WS08/09 Prof. J. Fürnkranz 1 Inhalt Motivation asic Definitions Canonical Representation lgorithm Unot Overview Enumerating Pattern Compute
Klausur Algorithmen und Datenstrukturen II 29. Juli 2013
 Technische Universität Braunschweig Sommersemester 2013 Institut für Betriebssysteme und Rechnerverbund Abteilung Algorithmik Prof. Dr. Sándor P. Fekete Stephan Friedrichs Klausur Algorithmen und Datenstrukturen
Technische Universität Braunschweig Sommersemester 2013 Institut für Betriebssysteme und Rechnerverbund Abteilung Algorithmik Prof. Dr. Sándor P. Fekete Stephan Friedrichs Klausur Algorithmen und Datenstrukturen
1. Übung Algorithmen I
 Timo Bingmann, Christian Schulz INSTITUT FÜR THEORETISCHE INFORMATIK, PROF. SANDERS 1 KIT Timo Universität Bingmann, des LandesChristian Baden-Württemberg Schulz und nationales Forschungszentrum in der
Timo Bingmann, Christian Schulz INSTITUT FÜR THEORETISCHE INFORMATIK, PROF. SANDERS 1 KIT Timo Universität Bingmann, des LandesChristian Baden-Württemberg Schulz und nationales Forschungszentrum in der
Scheduling und Lineare ProgrammierungNach J. K. Lenstra, D. B. Shmoys und É.
 Scheduling und Lineare ProgrammierungNach J. K. Lenstra, D. B. Shmoys und É. Tardos Janick Martinez Esturo jmartine@techfak.uni-bielefeld.de xx.08.2007 Sommerakademie Görlitz Arbeitsgruppe 5 Gliederung
Scheduling und Lineare ProgrammierungNach J. K. Lenstra, D. B. Shmoys und É. Tardos Janick Martinez Esturo jmartine@techfak.uni-bielefeld.de xx.08.2007 Sommerakademie Görlitz Arbeitsgruppe 5 Gliederung
Tree-Mining. Warum Tree-Mining? Baumtypen. Anwendungsgebiete. Philipp Große
 Tree Mining 2 Warum Tree-Mining? Tree-Mining Philipp Große Theoretische Probleme des Graphminings: Kein effektiver Algorithmus zur systematischen Nummerierung von Subgraphen bekannt Kein effizienter Algorithmus
Tree Mining 2 Warum Tree-Mining? Tree-Mining Philipp Große Theoretische Probleme des Graphminings: Kein effektiver Algorithmus zur systematischen Nummerierung von Subgraphen bekannt Kein effizienter Algorithmus
Graphdurchmusterung, Breiten- und Tiefensuche
 Prof. Thomas Richter 18. Mai 2017 Institut für Analysis und Numerik Otto-von-Guericke-Universität Magdeburg thomas.richter@ovgu.de Material zur Vorlesung Algorithmische Mathematik II am 18.05.2017 Graphdurchmusterung,
Prof. Thomas Richter 18. Mai 2017 Institut für Analysis und Numerik Otto-von-Guericke-Universität Magdeburg thomas.richter@ovgu.de Material zur Vorlesung Algorithmische Mathematik II am 18.05.2017 Graphdurchmusterung,
= n (n 1) 2 dies beruht auf der Auswahl einer zweielementigen Teilmenge aus V = n. Als Folge ergibt sich, dass ein einfacher Graph maximal ( n E = 2
 2 dies beruht auf der Auswahl einer zweielementigen Teilmenge aus V = n. Als Folge ergibt sich, dass ein einfacher Graph maximal ( n E = 2") 1 Graphen Definition: Ein Graph G = (V,E) setzt sich aus einer Knotenmenge V und einer (Multi)Menge E V V, die als Kantenmenge bezeichnet wird, zusammen. Falls E symmetrisch ist, d.h.( u,v V)[(u,v) E (v,u)
1 Graphen Definition: Ein Graph G = (V,E) setzt sich aus einer Knotenmenge V und einer (Multi)Menge E V V, die als Kantenmenge bezeichnet wird, zusammen. Falls E symmetrisch ist, d.h.( u,v V)[(u,v) E (v,u)
Einführung in die Informatik 1
 Einführung in die Informatik 1 Algorithmen und algorithmische Sprachkonzepte Sven Kosub AG Algorithmik/Theorie komplexer Systeme Universität Konstanz E 202 Sven.Kosub@uni-konstanz.de Sprechstunde: Freitag,
Einführung in die Informatik 1 Algorithmen und algorithmische Sprachkonzepte Sven Kosub AG Algorithmik/Theorie komplexer Systeme Universität Konstanz E 202 Sven.Kosub@uni-konstanz.de Sprechstunde: Freitag,
Hidden Markov Model ein Beispiel
 Hidden Markov Model ein Beispiel Gegeben: Folge von Beobachtungen O = o 1,..., o n = nass, nass, trocken, nass, trocken Menge möglicher Systemzustände: Z = {Sonne, Regen} Beobachtungswahrscheinlichkeiten:
Hidden Markov Model ein Beispiel Gegeben: Folge von Beobachtungen O = o 1,..., o n = nass, nass, trocken, nass, trocken Menge möglicher Systemzustände: Z = {Sonne, Regen} Beobachtungswahrscheinlichkeiten:
Musterlösung Datenstrukturen und Algorithmen
 Eidgenössische Technische Hochschule Zürich Ecole polytechnique fédérale de Zurich Politecnico federale di Zurigo Federal Institute of Technology at Zurich Institut für Theoretische Informatik Peter Widmayer
Eidgenössische Technische Hochschule Zürich Ecole polytechnique fédérale de Zurich Politecnico federale di Zurigo Federal Institute of Technology at Zurich Institut für Theoretische Informatik Peter Widmayer
6.6 Vorlesung: Von OLAP zu Mining
 6.6 Vorlesung: Von OLAP zu Mining Definition des Begriffs Data Mining. Wichtige Data Mining-Problemstellungen, Zusammenhang zu Data Warehousing,. OHO - 1 Definition Data Mining Menge von Techniken zum
6.6 Vorlesung: Von OLAP zu Mining Definition des Begriffs Data Mining. Wichtige Data Mining-Problemstellungen, Zusammenhang zu Data Warehousing,. OHO - 1 Definition Data Mining Menge von Techniken zum
Vorlesung 7 GRAPHBASIERTE BILDSEGMENTIERUNG
 Vorlesung 7 GRAPHBASIERTE BILDSEGMENTIERUNG 195 Bildsegmentierung! Aufgabe: Bestimme inhaltlich zusammenhängende, homogene Bereiche eines Bildes! Weit verbreitetes Problem in der Bildverarbeitung! Viele
Vorlesung 7 GRAPHBASIERTE BILDSEGMENTIERUNG 195 Bildsegmentierung! Aufgabe: Bestimme inhaltlich zusammenhängende, homogene Bereiche eines Bildes! Weit verbreitetes Problem in der Bildverarbeitung! Viele
Theoretische Informatik 1
 Theoretische Informatik 1 Approximierbarkeit David Kappel Institut für Grundlagen der Informationsverarbeitung Technische Universität Graz 10.06.2016 Übersicht Das Problem des Handelsreisenden TSP EUCLIDEAN-TSP
Theoretische Informatik 1 Approximierbarkeit David Kappel Institut für Grundlagen der Informationsverarbeitung Technische Universität Graz 10.06.2016 Übersicht Das Problem des Handelsreisenden TSP EUCLIDEAN-TSP
Programmierkurs Python
 Programmierkurs Python Stefan Thater Michaela Regneri 2010-0-29 Heute Ein wenig Graph-Theorie (in aller Kürze) Datenstrukturen für Graphen Tiefen- und Breitensuche Nächste Woche: mehr Algorithmen 2 Was
Programmierkurs Python Stefan Thater Michaela Regneri 2010-0-29 Heute Ein wenig Graph-Theorie (in aller Kürze) Datenstrukturen für Graphen Tiefen- und Breitensuche Nächste Woche: mehr Algorithmen 2 Was
Programmierkurs Python II
 Programmierkurs Python II Stefan Thater & Michaela Regneri FR.7 Allgemeine Linguistik (Computerlinguistik) Universität des Saarlandes Sommersemester 011 Heute Ein wenig Graph-Theorie (in aller Kürze) Datenstrukturen
Programmierkurs Python II Stefan Thater & Michaela Regneri FR.7 Allgemeine Linguistik (Computerlinguistik) Universität des Saarlandes Sommersemester 011 Heute Ein wenig Graph-Theorie (in aller Kürze) Datenstrukturen
Vorlesungsplan. Von Naïve Bayes zu Bayesischen Netzwerk- Klassifikatoren. Naïve Bayes. Bayesische Netzwerke
 Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Algo&Komp. - Wichtige Begriffe Mattia Bergomi Woche 6 7
 1 Kürzeste Pfade Woche 6 7 Hier arbeiten wir mit gewichteten Graphen, d.h. Graphen, deren Kanten mit einer Zahl gewichtet werden. Wir bezeichnen die Gewichtsfunktion mit l : E R. Wir wollen einen kürzesten
1 Kürzeste Pfade Woche 6 7 Hier arbeiten wir mit gewichteten Graphen, d.h. Graphen, deren Kanten mit einer Zahl gewichtet werden. Wir bezeichnen die Gewichtsfunktion mit l : E R. Wir wollen einen kürzesten
Cognitive Interaction Technology Center of Excellence
 Kanonische Abdeckung Motivation: eine Instanz einer Datenbank muss nun alle funktionalen Abhängigkeiten in F + erfüllen. Das muss natürlich immer überprüft werden (z.b. bei jedem update). Es reicht natürlich
Kanonische Abdeckung Motivation: eine Instanz einer Datenbank muss nun alle funktionalen Abhängigkeiten in F + erfüllen. Das muss natürlich immer überprüft werden (z.b. bei jedem update). Es reicht natürlich
8. A & D - Heapsort. Werden sehen, wie wir durch geschicktes Organsieren von Daten effiziente Algorithmen entwerfen können.
 8. A & D - Heapsort Werden sehen, wie wir durch geschicktes Organsieren von Daten effiziente Algorithmen entwerfen können. Genauer werden wir immer wieder benötigte Operationen durch Datenstrukturen unterstützen.
8. A & D - Heapsort Werden sehen, wie wir durch geschicktes Organsieren von Daten effiziente Algorithmen entwerfen können. Genauer werden wir immer wieder benötigte Operationen durch Datenstrukturen unterstützen.
Algorithmen für Routenplanung Vorlesung 3
 Algorithmen für Routenplanung Vorlesung 3 Daniel Delling 1/ 45 Letztes Mal bidirektionale Suche A Suche A mit Landmarken bidirektionale A Suche 2/ 45 Themen Heute Geometrische Container Arc-Flags s t 3/
Algorithmen für Routenplanung Vorlesung 3 Daniel Delling 1/ 45 Letztes Mal bidirektionale Suche A Suche A mit Landmarken bidirektionale A Suche 2/ 45 Themen Heute Geometrische Container Arc-Flags s t 3/
Einführung in die Graphentheorie. Monika König
 Einführung in die Graphentheorie Monika König 8. 11. 2011 1 Vorwort Diese Seminararbeit basiert auf den Unterkapiteln 1.1-1.3 des Buches Algebraic Graph Theory von Chris Godsil und Gordon Royle (siehe
Einführung in die Graphentheorie Monika König 8. 11. 2011 1 Vorwort Diese Seminararbeit basiert auf den Unterkapiteln 1.1-1.3 des Buches Algebraic Graph Theory von Chris Godsil und Gordon Royle (siehe
7. Sortieren Lernziele. 7. Sortieren
 7. Sortieren Lernziele 7. Sortieren Lernziele: Die wichtigsten Sortierverfahren kennen und einsetzen können, Aufwand und weitere Eigenschaften der Sortierverfahren kennen, das Problemlösungsparadigma Teile-und-herrsche
7. Sortieren Lernziele 7. Sortieren Lernziele: Die wichtigsten Sortierverfahren kennen und einsetzen können, Aufwand und weitere Eigenschaften der Sortierverfahren kennen, das Problemlösungsparadigma Teile-und-herrsche
Datenstrukturen & Algorithmen
 Datenstrukturen & Algorithmen Matthias Zwicker Universität Bern Frühling 2010 Übersicht Dynamische Programmierung Einführung Ablaufkoordination von Montagebändern Längste gemeinsame Teilsequenz Optimale
Datenstrukturen & Algorithmen Matthias Zwicker Universität Bern Frühling 2010 Übersicht Dynamische Programmierung Einführung Ablaufkoordination von Montagebändern Längste gemeinsame Teilsequenz Optimale
Query Translation from XPath to SQL in the Presence of Recursive DTDs
 Humboldt Universität zu Berlin Institut für Informatik Query Translation from XPath to SQL in the Presence of Recursive DTDs VL XML, XPath, XQuery: Neue Konzepte für Datenbanken Jörg Pohle, pohle@informatik.hu-berlin.de
Humboldt Universität zu Berlin Institut für Informatik Query Translation from XPath to SQL in the Presence of Recursive DTDs VL XML, XPath, XQuery: Neue Konzepte für Datenbanken Jörg Pohle, pohle@informatik.hu-berlin.de
Grundlagen der Informatik Kapitel 20. Harald Krottmaier Sven Havemann
 Grundlagen der Informatik Kapitel 20 Harald Krottmaier Sven Havemann Agenda Klassen von Problemen Einige Probleme... Approximationsalgorithmen WS2007 2 Klassen P NP NP-vollständig WS2007 3 Klasse P praktisch
Grundlagen der Informatik Kapitel 20 Harald Krottmaier Sven Havemann Agenda Klassen von Problemen Einige Probleme... Approximationsalgorithmen WS2007 2 Klassen P NP NP-vollständig WS2007 3 Klasse P praktisch
Algorithmen und Datenstrukturen II
 Algorithmen und Datenstrukturen II Algorithmen zur Textverarbeitung III: D. Rösner Institut für Wissens- und Sprachverarbeitung Fakultät für Informatik Otto-von-Guericke Universität Magdeburg Sommer 2009,
Algorithmen und Datenstrukturen II Algorithmen zur Textverarbeitung III: D. Rösner Institut für Wissens- und Sprachverarbeitung Fakultät für Informatik Otto-von-Guericke Universität Magdeburg Sommer 2009,
Algorithmen für schwierige Probleme
 Algorithmen für schwierige Probleme Britta Dorn Wintersemester 2011/12 30. November 2011 Wiederholung Baumzerlegung G = (V, E) Eine Baumzerlegung von G ist ein Paar {X i i V T }, T, wobei T Baum mit Knotenmenge
Algorithmen für schwierige Probleme Britta Dorn Wintersemester 2011/12 30. November 2011 Wiederholung Baumzerlegung G = (V, E) Eine Baumzerlegung von G ist ein Paar {X i i V T }, T, wobei T Baum mit Knotenmenge
Maschinelles Lernen: Symbolische Ansätze
 Maschinelles Lernen: Symbolische Ansätze Musterlösung für das 7. Übungsblatt Aufgabe 1 Gegeben sei folgende Beispielmenge: Day Outlook Temperature Humidity Wind PlayTennis D1? Hot High Weak No D2 Sunny
Maschinelles Lernen: Symbolische Ansätze Musterlösung für das 7. Übungsblatt Aufgabe 1 Gegeben sei folgende Beispielmenge: Day Outlook Temperature Humidity Wind PlayTennis D1? Hot High Weak No D2 Sunny
Quicksort ist ein Divide-and-Conquer-Verfahren.
 . Quicksort Wie bei vielen anderen Sortierverfahren (Bubblesort, Mergesort, usw.) ist auch bei Quicksort die Aufgabe, die Elemente eines Array a[..n] zu sortieren. Quicksort ist ein Divide-and-Conquer-Verfahren.
. Quicksort Wie bei vielen anderen Sortierverfahren (Bubblesort, Mergesort, usw.) ist auch bei Quicksort die Aufgabe, die Elemente eines Array a[..n] zu sortieren. Quicksort ist ein Divide-and-Conquer-Verfahren.
Algorithmen & Datenstrukturen Midterm Test 2
 Algorithmen & Datenstrukturen Midterm Test 2 Martin Avanzini Thomas Bauereiß Herbert Jordan René Thiemann
Algorithmen & Datenstrukturen Midterm Test 2 Martin Avanzini Thomas Bauereiß Herbert Jordan René Thiemann
Flüsse, Schnitte, Bipartite Graphen II
 Flüsse, Schnitte, Bipartite Graphen II Jonathan Hacker 06.06.2016 Jonathan Hacker Flüsse, Schnitte, Bipartite Graphen II 06.06.2016 1 / 42 Gliederung Einführung Jonathan Hacker Flüsse, Schnitte, Bipartite
Flüsse, Schnitte, Bipartite Graphen II Jonathan Hacker 06.06.2016 Jonathan Hacker Flüsse, Schnitte, Bipartite Graphen II 06.06.2016 1 / 42 Gliederung Einführung Jonathan Hacker Flüsse, Schnitte, Bipartite
Vollständiger Graph. Definition 1.5. Sei G =(V,E) ein Graph. Gilt {v, w} E für alle v, w V,v w, dann heißt G vollständig (complete).
 ein Graph. Gilt {v, w} E für alle v, w V,v w, dann heißt G vollständig (complete).") Vollständiger Graph Definition 1.5. Sei G =(V,E) ein Graph. Gilt {v, w} E für alle v, w V,v w, dann heißt G vollständig (complete). Mit K n wird der vollständige Graph mit n Knoten bezeichnet. Bemerkung
Vollständiger Graph Definition 1.5. Sei G =(V,E) ein Graph. Gilt {v, w} E für alle v, w V,v w, dann heißt G vollständig (complete). Mit K n wird der vollständige Graph mit n Knoten bezeichnet. Bemerkung
Triangulierung von einfachen Polygonen
 Triangulierung von einfachen Polygonen - Seminarvortrag von Tobias Kyrion - Inhalt: 1.1 Die Problemstellung Quellenangabe 1.1 Die Problemstellung Definition Polygon: endlich viele paarweise verschiedene
Triangulierung von einfachen Polygonen - Seminarvortrag von Tobias Kyrion - Inhalt: 1.1 Die Problemstellung Quellenangabe 1.1 Die Problemstellung Definition Polygon: endlich viele paarweise verschiedene
Lösungen zur Vorlesung Berechenbarkeit und Komplexität
 Lehrstuhl für Informatik 1 WS 009/10 Prof. Dr. Berthold Vöcking 0.0.010 Alexander Skopalik Thomas Kesselheim Lösungen zur Vorlesung Berechenbarkeit und Komplexität. Zulassungsklausur Aufgabe 1: (a) Worin
Lehrstuhl für Informatik 1 WS 009/10 Prof. Dr. Berthold Vöcking 0.0.010 Alexander Skopalik Thomas Kesselheim Lösungen zur Vorlesung Berechenbarkeit und Komplexität. Zulassungsklausur Aufgabe 1: (a) Worin
Algorithmen und Datenstrukturen
 Algorithmen und Datenstrukturen Graphen 9/1 Begriffsdefinitionen Ein Graph besteht aus Knoten und Kanten. Ein Knoten(Ecke) ist ein benanntes Objekt. Eine Kante verbindet zwei Knoten. Kanten haben ein Gewicht
Algorithmen und Datenstrukturen Graphen 9/1 Begriffsdefinitionen Ein Graph besteht aus Knoten und Kanten. Ein Knoten(Ecke) ist ein benanntes Objekt. Eine Kante verbindet zwei Knoten. Kanten haben ein Gewicht