Data-Mining: Ausgewählte Verfahren und Werkzeuge
|
|
|
- Mona Heinrich
- vor 8 Jahren
- Abrufe
Transkript
1 Fakultät Informatik Institut für Angewandte Informatik Lehrstuhl Technische Informationssysteme Data-Mining: Ausgewählte Verfahren und Vortragender: Jia Mu Betreuer: Dipl.-Inf. Denis Stein Dresden, den

2 Gliederung 1. Einordnung der Data-Mining-Verfahren 2. Data-Mining-Verfahren 3. Data-Mining- 4. Zusammenfassung Folie 2 von 29

3 Gliederung 1. Einordnung der Data-Mining-Verfahren 1.1 Verschiedene Einordnungen in der Literatur 1.2 Meine Klassifikation Statistische Verfahren Maschinelles Lernen 2. Data-Mining-Verfahren 3. Data-Mining- 4. Zusammenfassung Folie 3 von 29

4 1. Einordnung der Data-Mining-Verfahren 1.1 Verschiedene Einordnungen in der Literatur a. Nach Otte, Otte und Kaiser DataMining für die industrielle Praxis : Folie 4 von 29

5 1. Einordnung der Data-Mining-Verfahren b. Nach Krahl, Windheuser und Zick Data Mining Einsatz in der Praxis : Folie 5 von 29

6 1. Einordnung der Data-Mining-Verfahren 1.2 Meine Klassifikation: Data- Mining Statistische Verfahren maschinelles Lernen Prüfende Verfahren Entdeckende Verfahren Unüberwachtes Lernen Überwachtes Lernen Regression Korrelationsanal. Entscheidungsbäume Assoziation Diskriminanzanal. Faktoranalyse k-means Clustering k-nächste-nachbarn Varianzanalyse Clusteranalyse usw. usw. Kontingenzanalyse Folie 6 von 29

7 1. Einordnung der Data-Mining-Verfahren Statistische Verfahren: a. Prüfende Analyseverfahren: -Um die genaue Regel herauszufinden -Verfahren für verschiedene Wertebereiche der unabhängigen Variablen: Regressionsanalyse und Diskriminanzanalyse: metrisch (Zahlen, Vergleiche) Varianzanalyse und Kontingenzanalyse : nominal (Aufzählungen) - hier betrachtet: lineare Regressionsanalyse b. Entdeckende Analyseverfahren: -Abhängigkeit testen (Korrelationsanalyse) -Reduzierung von Variablen (Faktoranalyse) -Gruppierung (Clusteranalyse) -hier betrachtet: lineare Korrelationsanalyse Folie 7 von 29

8 1. Einordnung der Data-Mining-Verfahren Maschinelles Lernen a. Überwachtes Lernen z.b.: Klassifikation -basiert auf einem Klassifikator Ein Klassifikator ist ein System, welches Objekte in vorgegebene Kategorie eingeordnet. (Quelle: Krahl, Windheuser und Zick Data Mining Einsatz in der Praxis ) -Verfahren: neuronale Netze, Entscheidungsbäume, Regelinduktion, k nächste Nachbarn usw. -hier betrachtet: k nächste Nachbarn b. Unüberwachtes Lernen -Entdeckung interessanter Strukturen in einem noch unstrukturierten Datenbestand -Verfahren: Assoziationen, neuronale Netze, demographisches Clustern, k-means-clustering usw. -hier betrachtet: k-means-clustering Folie 8 von 29

9 Gliederung 1. Einordnung der Data-Mining-Verfahren 2. Data-Mining-Verfahren 2.1 Korrelationsanalyse 2.2 Regressionsanalyse 2.3 k nächste Nachbarn 2.4 k-means-clustering 2.5 Vergleich 3. Data-Mining- 4. Zusammenfassung Folie 9 von 29

10 2. Data-Mining-Verfahren 2.1 Lineare Korrelationsanalyse: a. Ziel: Untersuchung der Zusammenhänge zwischen Zufallsvariablen anhand einer Stichprobe. b. Korrelationskoeffizient r und Bestimmtheitsmaß r 2 - r und r 2 sind Parameter zum Test der linearen Abhängigkeit. - Für den Korrelationskoeffizient r der Merkmale (Zufallsvariablen) x und y gilt: Wertebreich: Ein Beispiel werde ich nach der Vorstellung der linearen Regressionsanalyse angeben. Folie 10 von 29
 x und y gilt: Wertebreich: Ein Beispiel werde")
11 2. Data-Mining-Verfahren 2.2 Lineare Regressionsanalyse: a. Ziel: Bestimmung eines Modells für die Abhängigkeit zwischen Zufallsvariablen x und y. b. Parameter: y = a + b * x a, b : zu berechnende Parameter x, y : Zufallsvariablen c. Berechnung der Parameter a und b: 1.Testen mit der lin. Korrelationsanalyse, ob x und y linear abhängig sind. 2.Berechnung der Parameter a und b : Folie 11 von 29

12 2. Data-Mining-Verfahren Beispiel für lin. Korrelationsanalyse und lin. Regressionsanalyse: Aufgabe: x y Folie 12 von 29

13 2. Data-Mining-Verfahren Folie 13 von 29
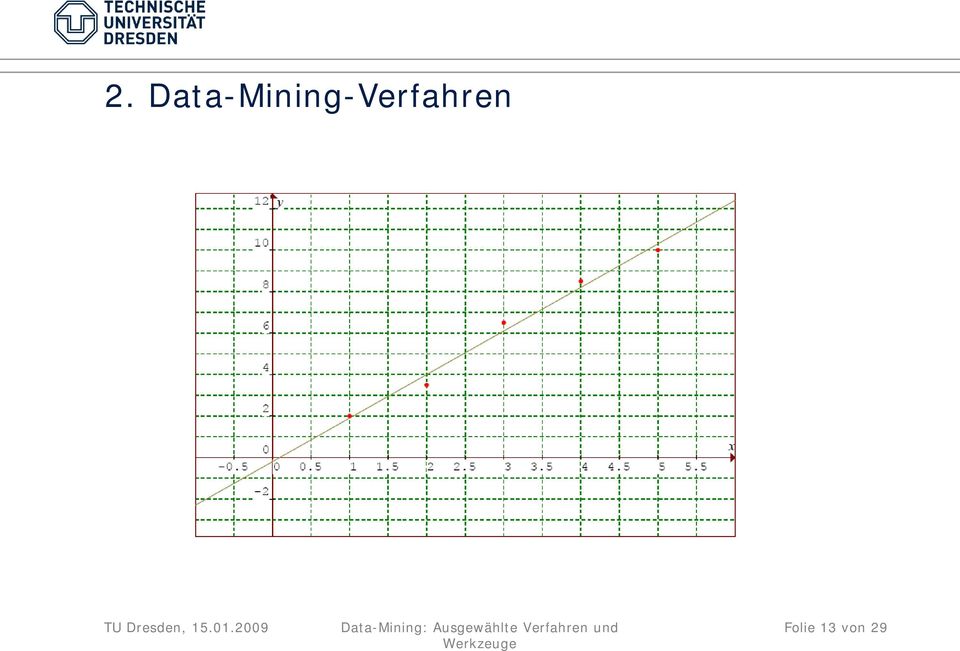
14 2. Data-Mining-Verfahren 2.3 k nächste Nachbarn: a.ziel : Klassifizieren von Daten mit Hilfe eines Modells b. Idee : Zuordnung analog der k nächsten Nachbarn. Quelle: Krahl, Windheuser und Zick Data Mining: Einsatz in der Praxis c.schritte: 1. Bestimmung des Parameters k (Anzahl der zu betrachtenden Nachbarn) 2. Berechnung der Distanz zwi. zu klassifizierendem Objekt und allen Daten. 3. Sortieren dieser Distanzen. 4. Auswahl der ersten k Daten Finden der Gruppe,zu der die meisten Daten gehören. 5. Das zu klassifizierende Objekt gehört zu dieser Gruppe. Folie 14 von 29

15 2. Data-Mining-Verfahren d. Beispiel: (Quelle: Kardi Teknomo KNN Numerical Example ) -Aufgabe: Eine Fabrik produziert Papier. Mittels einer Umfrage hat sie eine Gruppierung der derzeitigen Produkte gemacht. Jetzt produziert sie ein neues Papier und möchte dieses Produkt klassifizieren. -Input: Daten (Gruppierung der alten Produkten): Zu klassifizierendes Objekt (neues Produkt) : X1 = 3, X2 = 7 (3,7) Folie 15 von 29

16 2. Data-Mining-Verfahren -Klassifizierung mit KNN: 1.wähle k = 3 2.Berechnung der Distanz zwi. zu klassifizierendes Objekt und die Daten 3. Sortieren dieser Distanzen und finden 3 nähesten Daten Folie 16 von 29

17 2. Data-Mining-Verfahren 4. Finden der Gruppe, zu der die meisten 3 nähesten Daten gehören. Das zu klassifizierendes Objekt hat 2 Nachbarn, die zu Good Gruppe gehören, und 1 Nachbar, der zu Bad Gruppe gehört. Deswegen gehört das zu klassifizierende Objekt zu der Gruppe Good. - Output: X1=3, X2=7, Y=Good (3,7,Good) Folie 17 von 29

18 2. Data-Mining-Verfahren 2.4 k-means-clustering: a. Ziel : Klassifizierung der Daten ohne vorhandenes Modell b. Idee : Vergleich des Datenbestandes mit ausgewählten Repräsentanten c. Schritte: 1.Auswahl von k Repräsentanten. Diese Repräsentanten sollten möglichst repräsentativ sein. Iter. 2.Zuordnung der Objekten. Ordnen Objekte mit großer Ähnlichkeit den Repräsentanten zu. 3.Anpassung der Repräsentanten Vergleich der Repräsentanten und Objekte, dann ggf. Auswahl besserer Repräsentanten. Folie 18 von 29

19 2. Data-Mining-Verfahren d.beispiel: Quelle: Krahl, Windheuser und Zick Data Mining: Einsatz in der Praxis Folie 19 von 29

20 2. Data-Mining-Verfahren 2.5 Vergleich: a. lin. Regression und lin. Korrelation: -Häufig benutzt in vielen Bereichen (z.b.: Signalverarbeitung) -Beschränkungen ist auch deutlich (z.b.: die Kurve) -Es gibt noch Multiple Regression. b. k nächste Nachbarn: -Einfach zu implementieren -Aber man muss ein schon klassifiziertes Modell haben. -Bestimmung von k nach Erfahrungen. c. k-means-clustering: -Das am längsten eingesetzte Verfahren zur Segmentierung. (Quelle: Krahl, Windheuser und Zick Data Mining: Einsatz in der Praxis ) -Viele Abwandlungen und Variationen -Problem: die Bestimmung von k ist schwer. -Um optimale k zu bekommen mehrere Durchläufe Folie 20 von 29
 -Viele Abwandlungen und Variationen -Problem: die Bestimmung von k ist schwer.")
21 Gliederung 1. Einordnung der Data-Mining-Verfahren 2. Data-Mining-Verfahren 3. Data-Mining- 3.1 Allgemein 3.2 RapidMiner 3.3 Knime 3.4 Gait-CAD 3.5 Vergleich 4. Zusammenfassung Folie 21 von 29
22 3.Data-Mining- 3.1 Allgemein: -Auswahl kommerzieller Data-Mining- (teilweise nicht weiterentwickelt): Data Cockpit (DeltaMaster) Knowledge Studio NeuroModel Enterprise 6 D-Miner IBM Intelligent Miner Polyanalyst von Metaputer DataEngine von MIT SAS Enterprise Miner SPSS Clementine -Auswahl hier betrachteter freier Data-Mining-: Rapidminer (1. Platz bei KDNuggets) Knime (4. Platz bei KDNuggets) Gait-CAD Folie 22 von 29
23 3.Data-Mining- 3.2 RapidMiner: -Ein Data-Mining-Tool von RAPID-I in Dortmund (vorher YALE genannt, Uni Dortmund) -Java-Applikation (plattformunabhängig), weka-kompatibel weka : Waikato Environment for Knowledge Analysis -Community-Version ist kostenlos -ca. 150 unterstützte Verfahren: Entscheidungsbäume und Regellerner Lazy Learners Bayes'sche Lerner Logistische Lerner Gauss'sche Prozesse Meta Learning Association Rule Mining Clustering und mehr Folie 23 von 29
24 3.Data-Mining- 3.3 KNIME: -Ein Data-Mining-Tool von der Universität Konstanz -Eine Eclipse-RCP-Anwendung, weka-kompatibel weka : Waikato Environment for Knowledge Analysis -Base Version ist kostenlos -ca. 100 bis 150 unterstützte Verfahren für data I/O, preprocessing, cleansing, modelling, analysis und data mining, various interactive views usw. - API, d.h.: Man kann eigene Programm darauf schreiben. Folie 24 von 29
25 3.Data-Mining- 3.4 Gait-CAD: -Ein Data-Mining-Tool vom Forschungszentrum Karlsruhe -Eine MATLAB-TOOLBOX -Kostenlos, open source -ca. 50 Algorithmen zur Lösung von Data-Mining-Problemen: Datentupelselektion, Merkmalsextraktion, Merkmalsbewertung und selektion, Merkmalstransformation, überwachte bzw. unüberwachte Klassifikation, Validierung -Update sehr langsam (letztes Update im Januar 2008) Folie 25 von 29
26 3.Data-Mining- 3.5 Vergleich: -RapidMiner: Die beste Graphendarstellungsfähigkeit. Vorgehensweise ist nicht bequem. Dokumentation für DM-Algorithmen ist nicht gut. Erweiterbarkeit ist gut. (API) -KNIME: Graphendarstellung ist nicht so gut, aber geht. Vorgehensweise ist sehr bequem. Gut dokumentiert. Erweiterbarkeit ist gut. (API) -Gait-CAD: Graphendarstellung ist schlecht. Vorgehensweise ist nicht bequem. weil auf MATLAB basiert, z.b.: für Elektrotechniker sehr gut. Folie 26 von 29
27 Gliederung 1. Einordnung der Data-Mining-Verfahren 2. Data-Mining-Verfahren 3. Data-Mining- 4. Zusammenfassung Folie 27 von 29
28 4.Zusammenfassung - Data-Mining-Klassifikation vorgestellt, um eine Übersicht über alle Data- Mining-Verfahren zu geben. - 4 Verfahren aus verschiedenen Data-Mining-Verfahren beispielhaft erklärt. lin. Regression und Korrelation, k nächste Nachbarn und k-means- Clustering. - 3 kurz gezeigt, um praktische Übersicht zu geben. - 3 verglichen. Folie 28 von 29
29 Literaturverzeichnis [1] Otte, Otte, Kaiser, Data Mining für die industrielle Praxis, ISBN [2] Krahl, Windheuser, Zick, Data Mining Einsatz in der Praxis, ISBN X [3] Teknomo, KNN Numerical Example (hand computation), Stand: [4] Wikipedia, Regressionsanalyse, Stand: Folie 29 von 29
30 FRAGEN? Folie 30 von 29
31 DANKESCHÖN! Folie 31 von 29
32 Berechnung eines Korrelationskoeffizienten r = 0 : kein Zusammenhang -1<- r ->1 : stärkere lineare Abhängigkeit - Häufig wird Bestimmtheitsmaß r 2 statt r benutzt. r 2 = r * r r 2 = 0 : kein Zusammenhang r 2 -> 1 : stark linear abhängig - Berechnung von r x,y : Zufallsvariable n : Anzahl der Stichproben r : Korrelationskoeffizient Folie 32 von 29
33 Berechnung der lin. Regressionsparameter y = a + bx a,b : zu berechnende Parameter x,y : Zufallsvariablen Folie 33 von 29
34 Beispiel für Lin. Korrelation und Regression c. Beispiel für lin. Korrelationsanalyse und lin. Regressionsanalyse: 1. Korrelationsanalyse: 2. Regressionsanalyse: r 2 = 0, Ergebnis: y = -0,2 + 2,1x mit r = 0,99327 oder r 2 = 0,9866 Folie 34 von 29
35 Kurze Erklärung zu Entscheidungsbäumen - Ist eine spezielle Darstellungsform von Entscheidungsregeln - Knoten : Abfrage der Attribute, Treffen der Entscheidung Blatt : Ein Knoten, an dem es keine weitere Verzweigung gibt. - Schritt : 1. An jedem Knoten wird ein Attribut abgefragt 2. Entscheidung 3. Wiederholung dieses Prozess bis dem Erreichen eines Blatt Alter - Beispiel: <35 >35 Gehalt Gehalt <40000 >40000 <50000 >50000 Bezahlung schlecht Bezahlung gut Bezahlung schlecht Bezahlung gut Folie 35 von 29
Würfelt man dabei je genau 10 - mal eine 1, 2, 3, 4, 5 und 6, so beträgt die Anzahl. der verschiedenen Reihenfolgen, in denen man dies tun kann, 60!.
 040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
Tiefgreifende Prozessverbesserung und Wissensmanagement durch Data Mining
 Tiefgreifende Prozessverbesserung und Wissensmanagement durch Data Mining Ausgangssituation Kaizen Data Mining ISO 9001 Wenn andere Methoden an ihre Grenzen stoßen Es gibt unzählige Methoden, die Abläufe
Tiefgreifende Prozessverbesserung und Wissensmanagement durch Data Mining Ausgangssituation Kaizen Data Mining ISO 9001 Wenn andere Methoden an ihre Grenzen stoßen Es gibt unzählige Methoden, die Abläufe
Was meinen die Leute eigentlich mit: Grexit?
 Was meinen die Leute eigentlich mit: Grexit? Grexit sind eigentlich 2 Wörter. 1. Griechenland 2. Exit Exit ist ein englisches Wort. Es bedeutet: Ausgang. Aber was haben diese 2 Sachen mit-einander zu tun?
Was meinen die Leute eigentlich mit: Grexit? Grexit sind eigentlich 2 Wörter. 1. Griechenland 2. Exit Exit ist ein englisches Wort. Es bedeutet: Ausgang. Aber was haben diese 2 Sachen mit-einander zu tun?
Leichte-Sprache-Bilder
 Leichte-Sprache-Bilder Reinhild Kassing Information - So geht es 1. Bilder gucken 2. anmelden für Probe-Bilder 3. Bilder bestellen 4. Rechnung bezahlen 5. Bilder runterladen 6. neue Bilder vorschlagen
Leichte-Sprache-Bilder Reinhild Kassing Information - So geht es 1. Bilder gucken 2. anmelden für Probe-Bilder 3. Bilder bestellen 4. Rechnung bezahlen 5. Bilder runterladen 6. neue Bilder vorschlagen
Data Mining und maschinelles Lernen
 Data Mining und maschinelles Lernen Einführung und Anwendung mit WEKA Caren Brinckmann 16. August 2000 http://www.coli.uni-sb.de/~cabr/vortraege/ml.pdf http://www.cs.waikato.ac.nz/ml/weka/ Inhalt Einführung:
Data Mining und maschinelles Lernen Einführung und Anwendung mit WEKA Caren Brinckmann 16. August 2000 http://www.coli.uni-sb.de/~cabr/vortraege/ml.pdf http://www.cs.waikato.ac.nz/ml/weka/ Inhalt Einführung:
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren
 Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Binäre Bäume. 1. Allgemeines. 2. Funktionsweise. 2.1 Eintragen
 Binäre Bäume 1. Allgemeines Binäre Bäume werden grundsätzlich verwendet, um Zahlen der Größe nach, oder Wörter dem Alphabet nach zu sortieren. Dem einfacheren Verständnis zu Liebe werde ich mich hier besonders
Binäre Bäume 1. Allgemeines Binäre Bäume werden grundsätzlich verwendet, um Zahlen der Größe nach, oder Wörter dem Alphabet nach zu sortieren. Dem einfacheren Verständnis zu Liebe werde ich mich hier besonders
OECD Programme for International Student Assessment PISA 2000. Lösungen der Beispielaufgaben aus dem Mathematiktest. Deutschland
 OECD Programme for International Student Assessment Deutschland PISA 2000 Lösungen der Beispielaufgaben aus dem Mathematiktest Beispielaufgaben PISA-Hauptstudie 2000 Seite 3 UNIT ÄPFEL Beispielaufgaben
OECD Programme for International Student Assessment Deutschland PISA 2000 Lösungen der Beispielaufgaben aus dem Mathematiktest Beispielaufgaben PISA-Hauptstudie 2000 Seite 3 UNIT ÄPFEL Beispielaufgaben
Catherina Lange, Heimbeiräte und Werkstatträte-Tagung, November 2013 1
 Catherina Lange, Heimbeiräte und Werkstatträte-Tagung, November 2013 1 Darum geht es heute: Was ist das Persönliche Geld? Was kann man damit alles machen? Wie hoch ist es? Wo kann man das Persönliche Geld
Catherina Lange, Heimbeiräte und Werkstatträte-Tagung, November 2013 1 Darum geht es heute: Was ist das Persönliche Geld? Was kann man damit alles machen? Wie hoch ist es? Wo kann man das Persönliche Geld
Fortgeschrittene Statistik Logistische Regression
 Fortgeschrittene Statistik Logistische Regression O D D S, O D D S - R A T I O, L O G I T T R A N S F O R M A T I O N, I N T E R P R E T A T I O N V O N K O E F F I Z I E N T E N, L O G I S T I S C H E
Fortgeschrittene Statistik Logistische Regression O D D S, O D D S - R A T I O, L O G I T T R A N S F O R M A T I O N, I N T E R P R E T A T I O N V O N K O E F F I Z I E N T E N, L O G I S T I S C H E
Korrelation (II) Korrelation und Kausalität
 Korrelation und Kausalität") Korrelation (II) Korrelation und Kausalität Situation: Seien X, Y zwei metrisch skalierte Merkmale mit Ausprägungen (x 1, x 2,..., x n ) bzw. (y 1, y 2,..., y n ). D.h. für jede i = 1, 2,..., n bezeichnen
Korrelation (II) Korrelation und Kausalität Situation: Seien X, Y zwei metrisch skalierte Merkmale mit Ausprägungen (x 1, x 2,..., x n ) bzw. (y 1, y 2,..., y n ). D.h. für jede i = 1, 2,..., n bezeichnen
Profil A 49,3 48,2 50,7 50,9 49,8 48,7 49,6 50,1 Profil B 51,8 49,6 53,2 51,1 51,1 53,4 50,7 50 51,5 51,7 48,8
 1. Aufgabe: Eine Reifenfirma hat für Winterreifen unterschiedliche Profile entwickelt. Bei jeweils gleicher Geschwindigkeit und auch sonst gleichen Bedingungen wurden die Bremswirkungen gemessen. Die gemessenen
1. Aufgabe: Eine Reifenfirma hat für Winterreifen unterschiedliche Profile entwickelt. Bei jeweils gleicher Geschwindigkeit und auch sonst gleichen Bedingungen wurden die Bremswirkungen gemessen. Die gemessenen
Was ich als Bürgermeister für Lübbecke tun möchte
 Wahlprogramm in leichter Sprache Was ich als Bürgermeister für Lübbecke tun möchte Hallo, ich bin Dirk Raddy! Ich bin 47 Jahre alt. Ich wohne in Hüllhorst. Ich mache gerne Sport. Ich fahre gerne Ski. Ich
Wahlprogramm in leichter Sprache Was ich als Bürgermeister für Lübbecke tun möchte Hallo, ich bin Dirk Raddy! Ich bin 47 Jahre alt. Ich wohne in Hüllhorst. Ich mache gerne Sport. Ich fahre gerne Ski. Ich
Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut, keine vorgegebenen Klassen
 7. Clusteranalyse (= Häufungsanalyse; Clustering-Verfahren) wird der multivariaten Statistik zugeordnet Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut,
7. Clusteranalyse (= Häufungsanalyse; Clustering-Verfahren) wird der multivariaten Statistik zugeordnet Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut,
Fachdidaktik der Informatik 18.12.08 Jörg Depner, Kathrin Gaißer
 Fachdidaktik der Informatik 18.12.08 Jörg Depner, Kathrin Gaißer Klassendiagramme Ein Klassendiagramm dient in der objektorientierten Softwareentwicklung zur Darstellung von Klassen und den Beziehungen,
Fachdidaktik der Informatik 18.12.08 Jörg Depner, Kathrin Gaißer Klassendiagramme Ein Klassendiagramm dient in der objektorientierten Softwareentwicklung zur Darstellung von Klassen und den Beziehungen,
Güte von Tests. die Wahrscheinlichkeit für den Fehler 2. Art bei der Testentscheidung, nämlich. falsch ist. Darauf haben wir bereits im Kapitel über
 Güte von s Grundlegendes zum Konzept der Güte Ableitung der Gütefunktion des Gauss im Einstichprobenproblem Grafische Darstellung der Gütefunktionen des Gauss im Einstichprobenproblem Ableitung der Gütefunktion
Güte von s Grundlegendes zum Konzept der Güte Ableitung der Gütefunktion des Gauss im Einstichprobenproblem Grafische Darstellung der Gütefunktionen des Gauss im Einstichprobenproblem Ableitung der Gütefunktion
15.3 Bedingte Wahrscheinlichkeit und Unabhängigkeit
 5.3 Bedingte Wahrscheinlichkeit und Unabhängigkeit Einführendes Beispiel ( Erhöhung der Sicherheit bei Flugreisen ) Die statistische Wahrscheinlichkeit, dass während eines Fluges ein Sprengsatz an Bord
5.3 Bedingte Wahrscheinlichkeit und Unabhängigkeit Einführendes Beispiel ( Erhöhung der Sicherheit bei Flugreisen ) Die statistische Wahrscheinlichkeit, dass während eines Fluges ein Sprengsatz an Bord
ec@ros2-installer ecaros2 Installer procar informatik AG 1 Stand: FS 09/2012 Eschenweg 7 64331 Weiterstadt
 ecaros2 Installer procar informatik AG 1 Stand: FS 09/2012 Inhaltsverzeichnis 1 Download des ecaros2-installer...3 2 Aufruf des ecaros2-installer...3 2.1 Konsolen-Fenster (Windows)...3 2.2 Konsolen-Fenster
ecaros2 Installer procar informatik AG 1 Stand: FS 09/2012 Inhaltsverzeichnis 1 Download des ecaros2-installer...3 2 Aufruf des ecaros2-installer...3 2.1 Konsolen-Fenster (Windows)...3 2.2 Konsolen-Fenster
Diese Ansicht erhalten Sie nach der erfolgreichen Anmeldung bei Wordpress.
 Anmeldung http://www.ihredomain.de/wp-admin Dashboard Diese Ansicht erhalten Sie nach der erfolgreichen Anmeldung bei Wordpress. Das Dashboard gibt Ihnen eine kurze Übersicht, z.b. Anzahl der Beiträge,
Anmeldung http://www.ihredomain.de/wp-admin Dashboard Diese Ansicht erhalten Sie nach der erfolgreichen Anmeldung bei Wordpress. Das Dashboard gibt Ihnen eine kurze Übersicht, z.b. Anzahl der Beiträge,
90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft
 Prof. Dr. Helmut Küchenhoff SS08 90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft am 22.7.2008 Anmerkungen Überprüfen Sie bitte sofort, ob Ihre Angabe vollständig ist. Sie sollte
Prof. Dr. Helmut Küchenhoff SS08 90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft am 22.7.2008 Anmerkungen Überprüfen Sie bitte sofort, ob Ihre Angabe vollständig ist. Sie sollte
Künstliche Intelligenz Maschinelles Lernen
 Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
Die Post hat eine Umfrage gemacht
 Die Post hat eine Umfrage gemacht Bei der Umfrage ging es um das Thema: Inklusion Die Post hat Menschen mit Behinderung und Menschen ohne Behinderung gefragt: Wie zufrieden sie in dieser Gesellschaft sind.
Die Post hat eine Umfrage gemacht Bei der Umfrage ging es um das Thema: Inklusion Die Post hat Menschen mit Behinderung und Menschen ohne Behinderung gefragt: Wie zufrieden sie in dieser Gesellschaft sind.
Statuten in leichter Sprache
 Statuten in leichter Sprache Zweck vom Verein Artikel 1: Zivil-Gesetz-Buch Es gibt einen Verein der selbstbestimmung.ch heisst. Der Verein ist so aufgebaut, wie es im Zivil-Gesetz-Buch steht. Im Zivil-Gesetz-Buch
Statuten in leichter Sprache Zweck vom Verein Artikel 1: Zivil-Gesetz-Buch Es gibt einen Verein der selbstbestimmung.ch heisst. Der Verein ist so aufgebaut, wie es im Zivil-Gesetz-Buch steht. Im Zivil-Gesetz-Buch
How to do? Projekte - Zeiterfassung
 How to do? Projekte - Zeiterfassung Stand: Version 4.0.1, 18.03.2009 1. EINLEITUNG...3 2. PROJEKTE UND STAMMDATEN...4 2.1 Projekte... 4 2.2 Projektmitarbeiter... 5 2.3 Tätigkeiten... 6 2.4 Unterprojekte...
How to do? Projekte - Zeiterfassung Stand: Version 4.0.1, 18.03.2009 1. EINLEITUNG...3 2. PROJEKTE UND STAMMDATEN...4 2.1 Projekte... 4 2.2 Projektmitarbeiter... 5 2.3 Tätigkeiten... 6 2.4 Unterprojekte...
Tutorial: Homogenitätstest
 Tutorial: Homogenitätstest Eine Bank möchte die Kreditwürdigkeit potenzieller Kreditnehmer abschätzen. Einerseits lebt die Bank ja von der Vergabe von Krediten, andererseits verursachen Problemkredite
Tutorial: Homogenitätstest Eine Bank möchte die Kreditwürdigkeit potenzieller Kreditnehmer abschätzen. Einerseits lebt die Bank ja von der Vergabe von Krediten, andererseits verursachen Problemkredite
Qualität und Verlässlichkeit Das verstehen die Deutschen unter Geschäftsmoral!
 Beitrag: 1:43 Minuten Anmoderationsvorschlag: Unseriöse Internetanbieter, falsch deklarierte Lebensmittel oder die jüngsten ADAC-Skandale. Solche Fälle mit einer doch eher fragwürdigen Geschäftsmoral gibt
Beitrag: 1:43 Minuten Anmoderationsvorschlag: Unseriöse Internetanbieter, falsch deklarierte Lebensmittel oder die jüngsten ADAC-Skandale. Solche Fälle mit einer doch eher fragwürdigen Geschäftsmoral gibt
Tangentengleichung. Wie lautet die Geradengleichung für die Tangente, y T =? Antwort:
 Tangentengleichung Wie Sie wissen, gibt die erste Ableitung einer Funktion deren Steigung an. Betrachtet man eine fest vorgegebene Stelle, gibt f ( ) also die Steigung der Kurve und somit auch die Steigung
Tangentengleichung Wie Sie wissen, gibt die erste Ableitung einer Funktion deren Steigung an. Betrachtet man eine fest vorgegebene Stelle, gibt f ( ) also die Steigung der Kurve und somit auch die Steigung
Kapitel 4 Die Datenbank Kuchenbestellung Seite 1
 Kapitel 4 Die Datenbank Kuchenbestellung Seite 1 4 Die Datenbank Kuchenbestellung In diesem Kapitel werde ich die Theorie aus Kapitel 2 Die Datenbank Buchausleihe an Hand einer weiteren Datenbank Kuchenbestellung
Kapitel 4 Die Datenbank Kuchenbestellung Seite 1 4 Die Datenbank Kuchenbestellung In diesem Kapitel werde ich die Theorie aus Kapitel 2 Die Datenbank Buchausleihe an Hand einer weiteren Datenbank Kuchenbestellung
Das Persönliche Budget in verständlicher Sprache
 Das Persönliche Budget in verständlicher Sprache Das Persönliche Budget mehr Selbstbestimmung, mehr Selbstständigkeit, mehr Selbstbewusstsein! Dieser Text soll den behinderten Menschen in Westfalen-Lippe,
Das Persönliche Budget in verständlicher Sprache Das Persönliche Budget mehr Selbstbestimmung, mehr Selbstständigkeit, mehr Selbstbewusstsein! Dieser Text soll den behinderten Menschen in Westfalen-Lippe,
Was ist Sozial-Raum-Orientierung?
 Was ist Sozial-Raum-Orientierung? Dr. Wolfgang Hinte Universität Duisburg-Essen Institut für Stadt-Entwicklung und Sozial-Raum-Orientierte Arbeit Das ist eine Zusammen-Fassung des Vortrages: Sozialräume
Was ist Sozial-Raum-Orientierung? Dr. Wolfgang Hinte Universität Duisburg-Essen Institut für Stadt-Entwicklung und Sozial-Raum-Orientierte Arbeit Das ist eine Zusammen-Fassung des Vortrages: Sozialräume
Unterrichtsmaterialien in digitaler und in gedruckter Form. Auszug aus: Übungsbuch für den Grundkurs mit Tipps und Lösungen: Analysis
 Unterrichtsmaterialien in digitaler und in gedruckter Form Auszug aus: Übungsbuch für den Grundkurs mit Tipps und Lösungen: Analysis Das komplette Material finden Sie hier: Download bei School-Scout.de
Unterrichtsmaterialien in digitaler und in gedruckter Form Auszug aus: Übungsbuch für den Grundkurs mit Tipps und Lösungen: Analysis Das komplette Material finden Sie hier: Download bei School-Scout.de
Wichtig ist die Originalsatzung. Nur was in der Originalsatzung steht, gilt. Denn nur die Originalsatzung wurde vom Gericht geprüft.
 Das ist ein Text in leichter Sprache. Hier finden Sie die wichtigsten Regeln für den Verein zur Förderung der Autonomie Behinderter e. V.. Das hier ist die Übersetzung der Originalsatzung. Es wurden nur
Das ist ein Text in leichter Sprache. Hier finden Sie die wichtigsten Regeln für den Verein zur Förderung der Autonomie Behinderter e. V.. Das hier ist die Übersetzung der Originalsatzung. Es wurden nur
Anleitung über den Umgang mit Schildern
 Anleitung über den Umgang mit Schildern -Vorwort -Wo bekommt man Schilder? -Wo und wie speichert man die Schilder? -Wie füge ich die Schilder in meinen Track ein? -Welche Bauteile kann man noch für Schilder
Anleitung über den Umgang mit Schildern -Vorwort -Wo bekommt man Schilder? -Wo und wie speichert man die Schilder? -Wie füge ich die Schilder in meinen Track ein? -Welche Bauteile kann man noch für Schilder
WinWerk. Prozess 6a Rabatt gemäss Vorjahresverbrauch. KMU Ratgeber AG. Inhaltsverzeichnis. Im Ifang 16 8307 Effretikon
 WinWerk Prozess 6a Rabatt gemäss Vorjahresverbrauch 8307 Effretikon Telefon: 052-740 11 11 Telefax: 052-740 11 71 E-Mail info@kmuratgeber.ch Internet: www.winwerk.ch Inhaltsverzeichnis 1 Ablauf der Rabattverarbeitung...
WinWerk Prozess 6a Rabatt gemäss Vorjahresverbrauch 8307 Effretikon Telefon: 052-740 11 11 Telefax: 052-740 11 71 E-Mail info@kmuratgeber.ch Internet: www.winwerk.ch Inhaltsverzeichnis 1 Ablauf der Rabattverarbeitung...
1. Weniger Steuern zahlen
 1. Weniger Steuern zahlen Wenn man arbeitet, zahlt man Geld an den Staat. Dieses Geld heißt Steuern. Viele Menschen zahlen zu viel Steuern. Sie haben daher wenig Geld für Wohnung, Gewand oder Essen. Wenn
1. Weniger Steuern zahlen Wenn man arbeitet, zahlt man Geld an den Staat. Dieses Geld heißt Steuern. Viele Menschen zahlen zu viel Steuern. Sie haben daher wenig Geld für Wohnung, Gewand oder Essen. Wenn
Nicht über uns ohne uns
 Nicht über uns ohne uns Das bedeutet: Es soll nichts über Menschen mit Behinderung entschieden werden, wenn sie nicht mit dabei sind. Dieser Text ist in leicht verständlicher Sprache geschrieben. Die Parteien
Nicht über uns ohne uns Das bedeutet: Es soll nichts über Menschen mit Behinderung entschieden werden, wenn sie nicht mit dabei sind. Dieser Text ist in leicht verständlicher Sprache geschrieben. Die Parteien
Was ist PZB? Personen-zentrierte Begleitung in einfacher Sprache erklärt
 Was ist PZB? Personen-zentrierte Begleitung in einfacher Sprache erklärt Diese Broschüre wurde gemeinsam mit Kundinnen und Kunden von Jugend am Werk Steiermark geschrieben. Vielen Dank an Daniela Bedöcs,
Was ist PZB? Personen-zentrierte Begleitung in einfacher Sprache erklärt Diese Broschüre wurde gemeinsam mit Kundinnen und Kunden von Jugend am Werk Steiermark geschrieben. Vielen Dank an Daniela Bedöcs,
Erstellen von x-y-diagrammen in OpenOffice.calc
 Erstellen von x-y-diagrammen in OpenOffice.calc In dieser kleinen Anleitung geht es nur darum, aus einer bestehenden Tabelle ein x-y-diagramm zu erzeugen. D.h. es müssen in der Tabelle mindestens zwei
Erstellen von x-y-diagrammen in OpenOffice.calc In dieser kleinen Anleitung geht es nur darum, aus einer bestehenden Tabelle ein x-y-diagramm zu erzeugen. D.h. es müssen in der Tabelle mindestens zwei
Professionelle Seminare im Bereich MS-Office
 Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
DISKUSSIONSBEITRÄGE DER FAKULTÄT FÜR BETRIEBSWIRTSCHAFTSLEHRE MERCATOR SCHOOL OF MANAGEMENT UNIVERSITÄT DUISBURG-ESSEN. Nr. 374
 DISKUSSIONSBEITRÄGE DER FAKULTÄT FÜR BETRIEBSWIRTSCHAFTSLEHRE MERCATOR SCHOOL OF MANAGEMENT UNIVERSITÄT DUISBURG-ESSEN Nr. 374 Eignung von Verfahren der Mustererkennung im Process Mining Sabrina Kohne
DISKUSSIONSBEITRÄGE DER FAKULTÄT FÜR BETRIEBSWIRTSCHAFTSLEHRE MERCATOR SCHOOL OF MANAGEMENT UNIVERSITÄT DUISBURG-ESSEN Nr. 374 Eignung von Verfahren der Mustererkennung im Process Mining Sabrina Kohne
HIER GEHT ES UM IHR GUTES GELD ZINSRECHNUNG IM UNTERNEHMEN
 HIER GEHT ES UM IHR GUTES GELD ZINSRECHNUNG IM UNTERNEHMEN Zinsen haben im täglichen Geschäftsleben große Bedeutung und somit auch die eigentliche Zinsrechnung, z.b: - Wenn Sie Ihre Rechnungen zu spät
HIER GEHT ES UM IHR GUTES GELD ZINSRECHNUNG IM UNTERNEHMEN Zinsen haben im täglichen Geschäftsleben große Bedeutung und somit auch die eigentliche Zinsrechnung, z.b: - Wenn Sie Ihre Rechnungen zu spät
Darstellungsformen einer Funktion
 http://www.flickr.com/photos/sigfrid/348144517/ Darstellungsformen einer Funktion 9 Analytische Darstellung: Eplizite Darstellung Funktionen werden nach Möglichkeit eplizit dargestellt, das heißt, die
http://www.flickr.com/photos/sigfrid/348144517/ Darstellungsformen einer Funktion 9 Analytische Darstellung: Eplizite Darstellung Funktionen werden nach Möglichkeit eplizit dargestellt, das heißt, die
Albert HAYR Linux, IT and Open Source Expert and Solution Architect. Open Source professionell einsetzen
 Open Source professionell einsetzen 1 Mein Background Ich bin überzeugt von Open Source. Ich verwende fast nur Open Source privat und beruflich. Ich arbeite seit mehr als 10 Jahren mit Linux und Open Source.
Open Source professionell einsetzen 1 Mein Background Ich bin überzeugt von Open Source. Ich verwende fast nur Open Source privat und beruflich. Ich arbeite seit mehr als 10 Jahren mit Linux und Open Source.
Mining High-Speed Data Streams
 Mining High-Speed Data Streams Pedro Domingos & Geoff Hulten Departement of Computer Science & Engineering University of Washington Datum : 212006 Seminar: Maschinelles Lernen und symbolische Ansätze Vortragender:
Mining High-Speed Data Streams Pedro Domingos & Geoff Hulten Departement of Computer Science & Engineering University of Washington Datum : 212006 Seminar: Maschinelles Lernen und symbolische Ansätze Vortragender:
Anlegen eines DLRG Accounts
 Anlegen eines DLRG Accounts Seite 1 von 6 Auf der Startseite des Internet Service Centers (https:\\dlrg.de) führt der Link DLRG-Account anlegen zu einer Eingabemaske, mit der sich jedes DLRG-Mitglied genau
Anlegen eines DLRG Accounts Seite 1 von 6 Auf der Startseite des Internet Service Centers (https:\\dlrg.de) führt der Link DLRG-Account anlegen zu einer Eingabemaske, mit der sich jedes DLRG-Mitglied genau
Varianzanalyse (ANOVA: analysis of variance)
") Varianzanalyse (AOVA: analysis of variance) Einfaktorielle VA Auf der Basis von zwei Stichproben wird bezüglich der Gleichheit der Mittelwerte getestet. Variablen müssen Variablen nur nominalskaliert sein.
Varianzanalyse (AOVA: analysis of variance) Einfaktorielle VA Auf der Basis von zwei Stichproben wird bezüglich der Gleichheit der Mittelwerte getestet. Variablen müssen Variablen nur nominalskaliert sein.
Informatik-Sommercamp 2012. Mastermind mit dem Android SDK
 Mastermind mit dem Android SDK Übersicht Einführungen Mastermind und Strategien (Stefan) Eclipse und das ADT Plugin (Jan) GUI-Programmierung (Dominik) Mastermind und Strategien - Übersicht Mastermind Spielregeln
Mastermind mit dem Android SDK Übersicht Einführungen Mastermind und Strategien (Stefan) Eclipse und das ADT Plugin (Jan) GUI-Programmierung (Dominik) Mastermind und Strategien - Übersicht Mastermind Spielregeln
L10N-Manager 3. Netzwerktreffen der Hochschulübersetzer/i nnen Mannheim 10. Mai 2016
 L10N-Manager 3. Netzwerktreffen der Hochschulübersetzer/i nnen Mannheim 10. Mai 2016 Referentin: Dr. Kelly Neudorfer Universität Hohenheim Was wir jetzt besprechen werden ist eine Frage, mit denen viele
L10N-Manager 3. Netzwerktreffen der Hochschulübersetzer/i nnen Mannheim 10. Mai 2016 Referentin: Dr. Kelly Neudorfer Universität Hohenheim Was wir jetzt besprechen werden ist eine Frage, mit denen viele
Zeichen bei Zahlen entschlüsseln
 Zeichen bei Zahlen entschlüsseln In diesem Kapitel... Verwendung des Zahlenstrahls Absolut richtige Bestimmung von absoluten Werten Operationen bei Zahlen mit Vorzeichen: Addieren, Subtrahieren, Multiplizieren
Zeichen bei Zahlen entschlüsseln In diesem Kapitel... Verwendung des Zahlenstrahls Absolut richtige Bestimmung von absoluten Werten Operationen bei Zahlen mit Vorzeichen: Addieren, Subtrahieren, Multiplizieren
SCHRITT 1: Öffnen des Bildes und Auswahl der Option»Drucken«im Menü»Datei«...2. SCHRITT 2: Angeben des Papierformat im Dialog»Drucklayout«...
 Drucken - Druckformat Frage Wie passt man Bilder beim Drucken an bestimmte Papierformate an? Antwort Das Drucken von Bildern ist mit der Druckfunktion von Capture NX sehr einfach. Hier erklären wir, wie
Drucken - Druckformat Frage Wie passt man Bilder beim Drucken an bestimmte Papierformate an? Antwort Das Drucken von Bildern ist mit der Druckfunktion von Capture NX sehr einfach. Hier erklären wir, wie
teamsync Kurzanleitung
 1 teamsync Kurzanleitung Version 4.0-19. November 2012 2 1 Einleitung Mit teamsync können Sie die Produkte teamspace und projectfacts mit Microsoft Outlook synchronisieren.laden Sie sich teamsync hier
1 teamsync Kurzanleitung Version 4.0-19. November 2012 2 1 Einleitung Mit teamsync können Sie die Produkte teamspace und projectfacts mit Microsoft Outlook synchronisieren.laden Sie sich teamsync hier
Geld Verdienen im Internet leicht gemacht
 Geld Verdienen im Internet leicht gemacht Hallo, Sie haben sich dieses E-book wahrscheinlich herunter geladen, weil Sie gerne lernen würden wie sie im Internet Geld verdienen können, oder? Denn genau das
Geld Verdienen im Internet leicht gemacht Hallo, Sie haben sich dieses E-book wahrscheinlich herunter geladen, weil Sie gerne lernen würden wie sie im Internet Geld verdienen können, oder? Denn genau das
Informatik 2 Labor 2 Programmieren in MATLAB Georg Richter
 Informatik 2 Labor 2 Programmieren in MATLAB Georg Richter Aufgabe 3: Konto Um Geldbeträge korrekt zu verwalten, sind zwecks Vermeidung von Rundungsfehlern entweder alle Beträge in Cents umzuwandeln und
Informatik 2 Labor 2 Programmieren in MATLAB Georg Richter Aufgabe 3: Konto Um Geldbeträge korrekt zu verwalten, sind zwecks Vermeidung von Rundungsfehlern entweder alle Beträge in Cents umzuwandeln und
5 Zusammenhangsmaße, Korrelation und Regression
 5 Zusammenhangsmaße, Korrelation und Regression 5.1 Zusammenhangsmaße und Korrelation Aufgabe 5.1 In einem Hauptstudiumsseminar des Lehrstuhls für Wirtschafts- und Sozialstatistik machten die Teilnehmer
5 Zusammenhangsmaße, Korrelation und Regression 5.1 Zusammenhangsmaße und Korrelation Aufgabe 5.1 In einem Hauptstudiumsseminar des Lehrstuhls für Wirtschafts- und Sozialstatistik machten die Teilnehmer
Papierverbrauch im Jahr 2000
 Hier findest du Forschertipps. Du kannst sie allein oder in der kleinen Gruppe mit anderen Kindern bearbeiten! Gestaltet ein leeres Blatt, schreibt Berichte oder entwerft ein Plakat. Sprecht euch in der
Hier findest du Forschertipps. Du kannst sie allein oder in der kleinen Gruppe mit anderen Kindern bearbeiten! Gestaltet ein leeres Blatt, schreibt Berichte oder entwerft ein Plakat. Sprecht euch in der
Grundbegriffe der Informatik
 Grundbegriffe der Informatik Einheit 15: Reguläre Ausdrücke und rechtslineare Grammatiken Thomas Worsch Universität Karlsruhe, Fakultät für Informatik Wintersemester 2008/2009 1/25 Was kann man mit endlichen
Grundbegriffe der Informatik Einheit 15: Reguläre Ausdrücke und rechtslineare Grammatiken Thomas Worsch Universität Karlsruhe, Fakultät für Informatik Wintersemester 2008/2009 1/25 Was kann man mit endlichen
Das Leitbild vom Verein WIR
 Das Leitbild vom Verein WIR Dieses Zeichen ist ein Gütesiegel. Texte mit diesem Gütesiegel sind leicht verständlich. Leicht Lesen gibt es in drei Stufen. B1: leicht verständlich A2: noch leichter verständlich
Das Leitbild vom Verein WIR Dieses Zeichen ist ein Gütesiegel. Texte mit diesem Gütesiegel sind leicht verständlich. Leicht Lesen gibt es in drei Stufen. B1: leicht verständlich A2: noch leichter verständlich
Formelsammlung zur Kreisgleichung
 zur Kreisgleichung Julia Wolters 6. Oktober 2008 Inhaltsverzeichnis 1 Allgemeine Kreisgleichung 2 1.1 Berechnung des Mittelpunktes und Radius am Beispiel..... 3 2 Kreis und Gerade 4 2.1 Sekanten, Tangenten,
zur Kreisgleichung Julia Wolters 6. Oktober 2008 Inhaltsverzeichnis 1 Allgemeine Kreisgleichung 2 1.1 Berechnung des Mittelpunktes und Radius am Beispiel..... 3 2 Kreis und Gerade 4 2.1 Sekanten, Tangenten,
Abituraufgabe zur Stochastik, Hessen 2009, Grundkurs (TR)
") Abituraufgabe zur Stochastik, Hessen 2009, Grundkurs (TR) Eine Firma stellt USB-Sticks her. Sie werden in der Fabrik ungeprüft in Packungen zu je 20 Stück verpackt und an Händler ausgeliefert. 1 Ein Händler
Abituraufgabe zur Stochastik, Hessen 2009, Grundkurs (TR) Eine Firma stellt USB-Sticks her. Sie werden in der Fabrik ungeprüft in Packungen zu je 20 Stück verpackt und an Händler ausgeliefert. 1 Ein Händler
Simulation LIF5000. Abbildung 1
 Simulation LIF5000 Abbildung 1 Zur Simulation von analogen Schaltungen verwende ich Ltspice/SwitcherCAD III. Dieses Programm ist sehr leistungsfähig und wenn man weis wie, dann kann man damit fast alles
Simulation LIF5000 Abbildung 1 Zur Simulation von analogen Schaltungen verwende ich Ltspice/SwitcherCAD III. Dieses Programm ist sehr leistungsfähig und wenn man weis wie, dann kann man damit fast alles
Elternzeit Was ist das?
 Elternzeit Was ist das? Wenn Eltern sich nach der Geburt ihres Kindes ausschließlich um ihr Kind kümmern möchten, können sie bei ihrem Arbeitgeber Elternzeit beantragen. Während der Elternzeit ruht das
Elternzeit Was ist das? Wenn Eltern sich nach der Geburt ihres Kindes ausschließlich um ihr Kind kümmern möchten, können sie bei ihrem Arbeitgeber Elternzeit beantragen. Während der Elternzeit ruht das
Quantitative Methoden der Bildungsforschung
 Glieung Wieholung Korrelationen Grundlagen lineare Regression Lineare Regression in SPSS Übung Wieholung Korrelationen Standardisiertes Zusammenhangsmaß (unstandardisiert: Kovarianz) linearer Zusammenhang
Glieung Wieholung Korrelationen Grundlagen lineare Regression Lineare Regression in SPSS Übung Wieholung Korrelationen Standardisiertes Zusammenhangsmaß (unstandardisiert: Kovarianz) linearer Zusammenhang
1 Darstellen von Daten
 1 Darstellen von Daten BesucherInnenzahlen der Bühnen Graz in der Spielzeit 2010/11 1 Opernhaus 156283 Hauptbühne 65055 Probebühne 7063 Ebene 3 2422 Next Liberty 26800 Säulen- bzw. Balkendiagramm erstellen
1 Darstellen von Daten BesucherInnenzahlen der Bühnen Graz in der Spielzeit 2010/11 1 Opernhaus 156283 Hauptbühne 65055 Probebühne 7063 Ebene 3 2422 Next Liberty 26800 Säulen- bzw. Balkendiagramm erstellen
Künstliches binäres Neuron
 Künstliches binäres Neuron G.Döben-Henisch Fachbereich Informatik und Ingenieurwissenschaften FH Frankfurt am Main University of Applied Sciences D-60318 Frankfurt am Main Germany Email: doeben at fb2.fh-frankfurt.de
Künstliches binäres Neuron G.Döben-Henisch Fachbereich Informatik und Ingenieurwissenschaften FH Frankfurt am Main University of Applied Sciences D-60318 Frankfurt am Main Germany Email: doeben at fb2.fh-frankfurt.de
Erfahrungen mit Hartz IV- Empfängern
 Erfahrungen mit Hartz IV- Empfängern Ausgewählte Ergebnisse einer Befragung von Unternehmen aus den Branchen Gastronomie, Pflege und Handwerk Pressegespräch der Bundesagentur für Arbeit am 12. November
Erfahrungen mit Hartz IV- Empfängern Ausgewählte Ergebnisse einer Befragung von Unternehmen aus den Branchen Gastronomie, Pflege und Handwerk Pressegespräch der Bundesagentur für Arbeit am 12. November
Data Mining für die industrielle Praxis
 Data Mining für die industrielle Praxis von Ralf Otte, Viktor Otte, Volker Kaiser 1. Auflage Hanser München 2004 Verlag C.H. Beck im Internet: www.beck.de ISBN 978 3 446 22465 0 Zu Leseprobe schnell und
Data Mining für die industrielle Praxis von Ralf Otte, Viktor Otte, Volker Kaiser 1. Auflage Hanser München 2004 Verlag C.H. Beck im Internet: www.beck.de ISBN 978 3 446 22465 0 Zu Leseprobe schnell und
1 Einleitung. Lernziele. Symbolleiste für den Schnellzugriff anpassen. Notizenseiten drucken. eine Präsentation abwärtskompatibel speichern
 1 Einleitung Lernziele Symbolleiste für den Schnellzugriff anpassen Notizenseiten drucken eine Präsentation abwärtskompatibel speichern eine Präsentation auf CD oder USB-Stick speichern Lerndauer 4 Minuten
1 Einleitung Lernziele Symbolleiste für den Schnellzugriff anpassen Notizenseiten drucken eine Präsentation abwärtskompatibel speichern eine Präsentation auf CD oder USB-Stick speichern Lerndauer 4 Minuten
Platinen mit dem HP CLJ 1600 direkt bedrucken ohne Tonertransferverfahren
 Platinen mit dem HP CLJ 1600 direkt bedrucken ohne Tonertransferverfahren Um die Platinen zu bedrucken, muß der Drucker als allererstes ein wenig zerlegt werden. Obere und seitliche Abdeckungen entfernen:
Platinen mit dem HP CLJ 1600 direkt bedrucken ohne Tonertransferverfahren Um die Platinen zu bedrucken, muß der Drucker als allererstes ein wenig zerlegt werden. Obere und seitliche Abdeckungen entfernen:
Welche Bereiche gibt es auf der Internetseite vom Bundes-Aufsichtsamt für Flugsicherung?
 Welche Bereiche gibt es auf der Internetseite vom Bundes-Aufsichtsamt für Flugsicherung? BAF ist die Abkürzung von Bundes-Aufsichtsamt für Flugsicherung. Auf der Internetseite gibt es 4 Haupt-Bereiche:
Welche Bereiche gibt es auf der Internetseite vom Bundes-Aufsichtsamt für Flugsicherung? BAF ist die Abkürzung von Bundes-Aufsichtsamt für Flugsicherung. Auf der Internetseite gibt es 4 Haupt-Bereiche:
Dow Jones am 13.06.08 im 1-min Chat
 Dow Jones am 13.06.08 im 1-min Chat Dieser Ausschnitt ist eine Formation: Wechselstäbe am unteren Bollinger Band mit Punkt d über dem 20-er GD nach 3 tieferen Hoch s. Wenn ich einen Ausbruch aus Wechselstäben
Dow Jones am 13.06.08 im 1-min Chat Dieser Ausschnitt ist eine Formation: Wechselstäbe am unteren Bollinger Band mit Punkt d über dem 20-er GD nach 3 tieferen Hoch s. Wenn ich einen Ausbruch aus Wechselstäben
Wie man Registrationen und Styles von Style/Registration Floppy Disketten auf die TYROS-Festplatte kopieren kann.
 Wie man Registrationen und Styles von Style/Registration Floppy Disketten auf die TYROS-Festplatte kopieren kann. Einleitung Es kommt vor, dass im Handel Disketten angeboten werden, die Styles und Registrationen
Wie man Registrationen und Styles von Style/Registration Floppy Disketten auf die TYROS-Festplatte kopieren kann. Einleitung Es kommt vor, dass im Handel Disketten angeboten werden, die Styles und Registrationen
Vorgestellt von Hans-Dieter Stubben
 Neue Lösungen in der GGf-Versorgung Vorgestellt von Hans-Dieter Stubben Geschäftsführer der Bundes-Versorgungs-Werk BVW GmbH Verbesserungen in der bav In 2007 ist eine wichtige Entscheidung für die betriebliche
Neue Lösungen in der GGf-Versorgung Vorgestellt von Hans-Dieter Stubben Geschäftsführer der Bundes-Versorgungs-Werk BVW GmbH Verbesserungen in der bav In 2007 ist eine wichtige Entscheidung für die betriebliche
Eva Douma: Die Vorteile und Nachteile der Ökonomisierung in der Sozialen Arbeit
 Eva Douma: Die Vorteile und Nachteile der Ökonomisierung in der Sozialen Arbeit Frau Dr. Eva Douma ist Organisations-Beraterin in Frankfurt am Main Das ist eine Zusammen-Fassung des Vortrages: Busines
Eva Douma: Die Vorteile und Nachteile der Ökonomisierung in der Sozialen Arbeit Frau Dr. Eva Douma ist Organisations-Beraterin in Frankfurt am Main Das ist eine Zusammen-Fassung des Vortrages: Busines
Verwendung von LS-OPT zur Generierung von Materialkarten am Beispiel von Schaumwerkstoffen
 Verwendung von LS-OPT zur Generierung von Materialkarten am Beispiel von Schaumwerkstoffen Katharina Witowski (DYNAmore GmbH) Peter Reithofer (4a engineering GmbH) Übersicht Problemstellung Parameteridentifikation
Verwendung von LS-OPT zur Generierung von Materialkarten am Beispiel von Schaumwerkstoffen Katharina Witowski (DYNAmore GmbH) Peter Reithofer (4a engineering GmbH) Übersicht Problemstellung Parameteridentifikation
UNIVERSITÄT LEIPZIG WIRTSCHAFTSWISSENSCHAFTLICHE FAKULTÄT DIPLOM-PRÜFUNG
 UNIVERSITÄT LEIPZIG WIRTSCHAFTSWISSENSCHAFTLICHE FAKULTÄT DIPLOM-PRÜFUNG DATUM: 13. Juli 2009 FACH: TEILGEBIET: KLAUSURDAUER: Allgemeine Betriebswirtschaftslehre SL-Schein Marketing II 60 Minuten PRÜFER:
UNIVERSITÄT LEIPZIG WIRTSCHAFTSWISSENSCHAFTLICHE FAKULTÄT DIPLOM-PRÜFUNG DATUM: 13. Juli 2009 FACH: TEILGEBIET: KLAUSURDAUER: Allgemeine Betriebswirtschaftslehre SL-Schein Marketing II 60 Minuten PRÜFER:
Tipps für die praktische Durchführung von Referaten Prof. Dr. Ellen Aschermann
 UNIVERSITÄT ZU KÖLN Erziehungswissenschaftliche Fakultät Institut für Psychologie Tipps für die praktische Durchführung von Referaten Prof. Dr. Ellen Aschermann Ablauf eines Referates Einleitung Gliederung
UNIVERSITÄT ZU KÖLN Erziehungswissenschaftliche Fakultät Institut für Psychologie Tipps für die praktische Durchführung von Referaten Prof. Dr. Ellen Aschermann Ablauf eines Referates Einleitung Gliederung
14. Minimale Schichtdicken von PEEK und PPS im Schlauchreckprozeß und im Rheotensversuch
 14. Minimale Schichtdicken von PEEK und PPS im Schlauchreckprozeß und im Rheotensversuch Analog zu den Untersuchungen an LDPE in Kap. 6 war zu untersuchen, ob auch für die Hochtemperatur-Thermoplaste aus
14. Minimale Schichtdicken von PEEK und PPS im Schlauchreckprozeß und im Rheotensversuch Analog zu den Untersuchungen an LDPE in Kap. 6 war zu untersuchen, ob auch für die Hochtemperatur-Thermoplaste aus
MORE Profile. Pass- und Lizenzverwaltungssystem. Stand: 19.02.2014 MORE Projects GmbH
 MORE Profile Pass- und Lizenzverwaltungssystem erstellt von: Thorsten Schumann erreichbar unter: thorsten.schumann@more-projects.de Stand: MORE Projects GmbH Einführung Die in More Profile integrierte
MORE Profile Pass- und Lizenzverwaltungssystem erstellt von: Thorsten Schumann erreichbar unter: thorsten.schumann@more-projects.de Stand: MORE Projects GmbH Einführung Die in More Profile integrierte
Korrelation - Regression. Berghold, IMI
 Korrelation - Regression Zusammenhang zwischen Variablen Bivariate Datenanalyse - Zusammenhang zwischen 2 stetigen Variablen Korrelation Einfaches lineares Regressionsmodell 1. Schritt: Erstellung eines
Korrelation - Regression Zusammenhang zwischen Variablen Bivariate Datenanalyse - Zusammenhang zwischen 2 stetigen Variablen Korrelation Einfaches lineares Regressionsmodell 1. Schritt: Erstellung eines
In diesem Tutorial lernen Sie, wie Sie einen Termin erfassen und verschiedene Einstellungen zu einem Termin vornehmen können.
 Tutorial: Wie erfasse ich einen Termin? In diesem Tutorial lernen Sie, wie Sie einen Termin erfassen und verschiedene Einstellungen zu einem Termin vornehmen können. Neben den allgemeinen Angaben zu einem
Tutorial: Wie erfasse ich einen Termin? In diesem Tutorial lernen Sie, wie Sie einen Termin erfassen und verschiedene Einstellungen zu einem Termin vornehmen können. Neben den allgemeinen Angaben zu einem
macs Support Ticket System
 macs Support Ticket System macs Software GmbH Raiffeisenstrasse 8 78658 Zimmern ob Rottweil Tel. (0741)9422880 1 ALLGEMEIN... 3 2 ABLAUF TICKET-SYSTEM... 4 2.1 Ticket Erstellung... 4 2.2 Ablauf... 4 2.3
macs Support Ticket System macs Software GmbH Raiffeisenstrasse 8 78658 Zimmern ob Rottweil Tel. (0741)9422880 1 ALLGEMEIN... 3 2 ABLAUF TICKET-SYSTEM... 4 2.1 Ticket Erstellung... 4 2.2 Ablauf... 4 2.3
PTV VISWALK TIPPS UND TRICKS PTV VISWALK TIPPS UND TRICKS: VERWENDUNG DICHTEBASIERTER TEILROUTEN
 PTV VISWALK TIPPS UND TRICKS PTV VISWALK TIPPS UND TRICKS: VERWENDUNG DICHTEBASIERTER TEILROUTEN Karlsruhe, April 2015 Verwendung dichte-basierter Teilrouten Stellen Sie sich vor, in einem belebten Gebäude,
PTV VISWALK TIPPS UND TRICKS PTV VISWALK TIPPS UND TRICKS: VERWENDUNG DICHTEBASIERTER TEILROUTEN Karlsruhe, April 2015 Verwendung dichte-basierter Teilrouten Stellen Sie sich vor, in einem belebten Gebäude,
Pädagogik. Melanie Schewtschenko. Eingewöhnung und Übergang in die Kinderkrippe. Warum ist die Beteiligung der Eltern so wichtig?
 Pädagogik Melanie Schewtschenko Eingewöhnung und Übergang in die Kinderkrippe Warum ist die Beteiligung der Eltern so wichtig? Studienarbeit Inhaltsverzeichnis 1. Einleitung.2 2. Warum ist Eingewöhnung
Pädagogik Melanie Schewtschenko Eingewöhnung und Übergang in die Kinderkrippe Warum ist die Beteiligung der Eltern so wichtig? Studienarbeit Inhaltsverzeichnis 1. Einleitung.2 2. Warum ist Eingewöhnung
Prozentrechnung. Wir können nun eine Formel für die Berechnung des Prozentwertes aufstellen:
 Prozentrechnung Wir beginnen mit einem Beisiel: Nehmen wir mal an, ein Handy kostet 200 und es gibt 5% Rabatt (Preisnachlass), wie groß ist dann der Rabatt in Euro und wie viel kostet dann das Handy? Wenn
Prozentrechnung Wir beginnen mit einem Beisiel: Nehmen wir mal an, ein Handy kostet 200 und es gibt 5% Rabatt (Preisnachlass), wie groß ist dann der Rabatt in Euro und wie viel kostet dann das Handy? Wenn
Predictive Modeling Markup Language. Thomas Morandell
 Predictive Modeling Markup Language Thomas Morandell Index Einführung PMML als Standard für den Austausch von Data Mining Ergebnissen/Prozessen Allgemeine Struktur eines PMML Dokuments Beispiel von PMML
Predictive Modeling Markup Language Thomas Morandell Index Einführung PMML als Standard für den Austausch von Data Mining Ergebnissen/Prozessen Allgemeine Struktur eines PMML Dokuments Beispiel von PMML
Binär Codierte Dezimalzahlen (BCD-Code)
") http://www.reiner-tolksdorf.de/tab/bcd_code.html Hier geht es zur Startseite der Homepage Binär Codierte Dezimalzahlen (BCD-) zum 8-4-2-1- zum Aiken- zum Exeß-3- zum Gray- zum 2-4-2-1- 57 zum 2-4-2-1-
http://www.reiner-tolksdorf.de/tab/bcd_code.html Hier geht es zur Startseite der Homepage Binär Codierte Dezimalzahlen (BCD-) zum 8-4-2-1- zum Aiken- zum Exeß-3- zum Gray- zum 2-4-2-1- 57 zum 2-4-2-1-
Vorlesungsplan. Von Naïve Bayes zu Bayesischen Netzwerk- Klassifikatoren. Naïve Bayes. Bayesische Netzwerke
 Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
1. Motivation / Grundlagen 2. Sortierverfahren 3. Elementare Datenstrukturen / Anwendungen 4. Bäume / Graphen 5. Hashing 6. Algorithmische Geometrie
 Gliederung 1. Motivation / Grundlagen 2. Sortierverfahren 3. Elementare Datenstrukturen / Anwendungen 4. äume / Graphen 5. Hashing 6. Algorithmische Geometrie 4/5, olie 1 2014 Prof. Steffen Lange - HDa/bI
Gliederung 1. Motivation / Grundlagen 2. Sortierverfahren 3. Elementare Datenstrukturen / Anwendungen 4. äume / Graphen 5. Hashing 6. Algorithmische Geometrie 4/5, olie 1 2014 Prof. Steffen Lange - HDa/bI
Vertrauen in Medien und politische Kommunikation die Meinung der Bürger
 Vortrag Vertrauen in Medien und politische Kommunikation die Meinung der Bürger Christian Spahr, Leiter Medienprogramm Südosteuropa Sehr geehrte Damen und Herren, liebe Kolleginnen und Kollegen, herzlich
Vortrag Vertrauen in Medien und politische Kommunikation die Meinung der Bürger Christian Spahr, Leiter Medienprogramm Südosteuropa Sehr geehrte Damen und Herren, liebe Kolleginnen und Kollegen, herzlich
Name (in Druckbuchstaben): Matrikelnummer: Unterschrift:
: Matrikelnummer: Unterschrift:") 20-minütige Klausur zur Vorlesung Lineare Modelle im Sommersemester 20 PD Dr. Christian Heumann Ludwig-Maximilians-Universität München, Institut für Statistik 2. Oktober 20, 4:5 6:5 Uhr Überprüfen Sie
20-minütige Klausur zur Vorlesung Lineare Modelle im Sommersemester 20 PD Dr. Christian Heumann Ludwig-Maximilians-Universität München, Institut für Statistik 2. Oktober 20, 4:5 6:5 Uhr Überprüfen Sie
1.3 Die Beurteilung von Testleistungen
 1.3 Die Beurteilung von Testleistungen Um das Testergebnis einer Vp zu interpretieren und daraus diagnostische Urteile ableiten zu können, benötigen wir einen Vergleichsmaßstab. Im Falle des klassischen
1.3 Die Beurteilung von Testleistungen Um das Testergebnis einer Vp zu interpretieren und daraus diagnostische Urteile ableiten zu können, benötigen wir einen Vergleichsmaßstab. Im Falle des klassischen
Übungsaufgaben Tilgungsrechnung
 1 Zusatzmaterialien zu Finanz- und Wirtschaftsmathematik im Unterricht, Band 1 Übungsaufgaben Tilgungsrechnung Überarbeitungsstand: 1.März 2016 Die grundlegenden Ideen der folgenden Aufgaben beruhen auf
1 Zusatzmaterialien zu Finanz- und Wirtschaftsmathematik im Unterricht, Band 1 Übungsaufgaben Tilgungsrechnung Überarbeitungsstand: 1.März 2016 Die grundlegenden Ideen der folgenden Aufgaben beruhen auf
Welche Gedanken wir uns für die Erstellung einer Präsentation machen, sollen Ihnen die folgende Folien zeigen.
 Wir wollen mit Ihnen Ihren Auftritt gestalten Steil-Vorlage ist ein österreichisches Start-up mit mehr als zehn Jahren Erfahrung in IT und Kommunikation. Unser Ziel ist, dass jede einzelne Mitarbeiterin
Wir wollen mit Ihnen Ihren Auftritt gestalten Steil-Vorlage ist ein österreichisches Start-up mit mehr als zehn Jahren Erfahrung in IT und Kommunikation. Unser Ziel ist, dass jede einzelne Mitarbeiterin
Versetzungsgefahr als ultimative Chance. ein vortrag für versetzungsgefährdete
 Versetzungsgefahr als ultimative Chance ein vortrag für versetzungsgefährdete Versetzungsgefährdete haben zum Großteil einige Fallen, die ihnen das normale Lernen schwer machen und mit der Zeit ins Hintertreffen
Versetzungsgefahr als ultimative Chance ein vortrag für versetzungsgefährdete Versetzungsgefährdete haben zum Großteil einige Fallen, die ihnen das normale Lernen schwer machen und mit der Zeit ins Hintertreffen
Willkommen zur Vorlesung Statistik
 Willkommen zur Vorlesung Statistik Thema dieser Vorlesung: Varianzanalyse Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften Prof. Dr. Wolfgang
Willkommen zur Vorlesung Statistik Thema dieser Vorlesung: Varianzanalyse Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften Prof. Dr. Wolfgang
ONLINE-AKADEMIE. "Diplomierter NLP Anwender für Schule und Unterricht" Ziele
 ONLINE-AKADEMIE Ziele Wenn man von Menschen hört, die etwas Großartiges in ihrem Leben geleistet haben, erfahren wir oft, dass diese ihr Ziel über Jahre verfolgt haben oder diesen Wunsch schon bereits
ONLINE-AKADEMIE Ziele Wenn man von Menschen hört, die etwas Großartiges in ihrem Leben geleistet haben, erfahren wir oft, dass diese ihr Ziel über Jahre verfolgt haben oder diesen Wunsch schon bereits
P = U eff I eff. I eff = = 1 kw 120 V = 1000 W
 Sie haben für diesen 50 Minuten Zeit. Die zu vergebenen Punkte sind an den Aufgaben angemerkt. Die Gesamtzahl beträgt 20 P + 1 Formpunkt. Bei einer Rechnung wird auf die korrekte Verwendung der Einheiten
Sie haben für diesen 50 Minuten Zeit. Die zu vergebenen Punkte sind an den Aufgaben angemerkt. Die Gesamtzahl beträgt 20 P + 1 Formpunkt. Bei einer Rechnung wird auf die korrekte Verwendung der Einheiten
Dokumentation. estat Version 2.0
 Dokumentation estat Version 2.0 Installation Die Datei estat.xla in beliebiges Verzeichnis speichern. Im Menü Extras AddIns... Durchsuchen die Datei estat.xla auswählen. Danach das Auswahlhäkchen beim
Dokumentation estat Version 2.0 Installation Die Datei estat.xla in beliebiges Verzeichnis speichern. Im Menü Extras AddIns... Durchsuchen die Datei estat.xla auswählen. Danach das Auswahlhäkchen beim
Informationen zum Ambulant Betreuten Wohnen in leichter Sprache
 Informationen zum Ambulant Betreuten Wohnen in leichter Sprache Arbeiterwohlfahrt Kreisverband Siegen - Wittgenstein/ Olpe 1 Diese Information hat geschrieben: Arbeiterwohlfahrt Stephanie Schür Koblenzer
Informationen zum Ambulant Betreuten Wohnen in leichter Sprache Arbeiterwohlfahrt Kreisverband Siegen - Wittgenstein/ Olpe 1 Diese Information hat geschrieben: Arbeiterwohlfahrt Stephanie Schür Koblenzer
Meet the Germans. Lerntipp zur Schulung der Fertigkeit des Sprechens. Lerntipp und Redemittel zur Präsentation oder einen Vortrag halten
 Meet the Germans Lerntipp zur Schulung der Fertigkeit des Sprechens Lerntipp und Redemittel zur Präsentation oder einen Vortrag halten Handreichungen für die Kursleitung Seite 2, Meet the Germans 2. Lerntipp
Meet the Germans Lerntipp zur Schulung der Fertigkeit des Sprechens Lerntipp und Redemittel zur Präsentation oder einen Vortrag halten Handreichungen für die Kursleitung Seite 2, Meet the Germans 2. Lerntipp