Umgang mit und Ersetzen von fehlenden Werten bei multivariaten Analysen
|
|
|
- Marie Hoch
- vor 8 Jahren
- Abrufe
Transkript
1 Umgang mit und Ersetzen von fehlenden Werten bei multivariaten Analysen

2 Warum überhaupt Gedanken machen? Was fehlt, ist doch weg, oder? Allgegenwärtiges Problem in psychologischer Forschung Bringt Fehlerquellen in die Studie Verzerrung der Ergebnisse möglich Verringerung der Effizienz von statistischen Verfahren Analyse kann Aufschluss über Verbesserungen der Studie geben Mögliche Verzerrungen können bei der Interpretation berücksichtigt werden

3 Missing Values: : Ursachen (Schnell, 1986) Fehlerhaftes oder mangelhaftes Design (unpräzise Items, nicht kongruente Items, Darbietung, ) Antwortverweigerung bei einer Untersuchung Wissensdefizite beim Befragten Mangelnde Antwortmotivation beim Befragten (Unaufmerksamkeit der Beobachter) (Unvollständigkeit von Sekundärdaten) Codierungs- und Übertragungsfehler
 (Unvollständigkeit von Sekundärdaten) Codierungs- und")
4 Missing Value-Mechanismen Systematisch (NMAR) vs. unsystematisch (MAR) fehlende Werte MAR OAR MCAR Missing at random. Antwortrate ist unabhängig von der Ausprägung des gemessenen Merkmals Observed at random. Antwortrate ist unabhängig von der Ausprägung anderer Merkmale Missing completely at random MAR und OAR treffen zu

5 Diagramm von MCAR-Fehlwerten

6 Diagramm von MAR-Fehlwerten
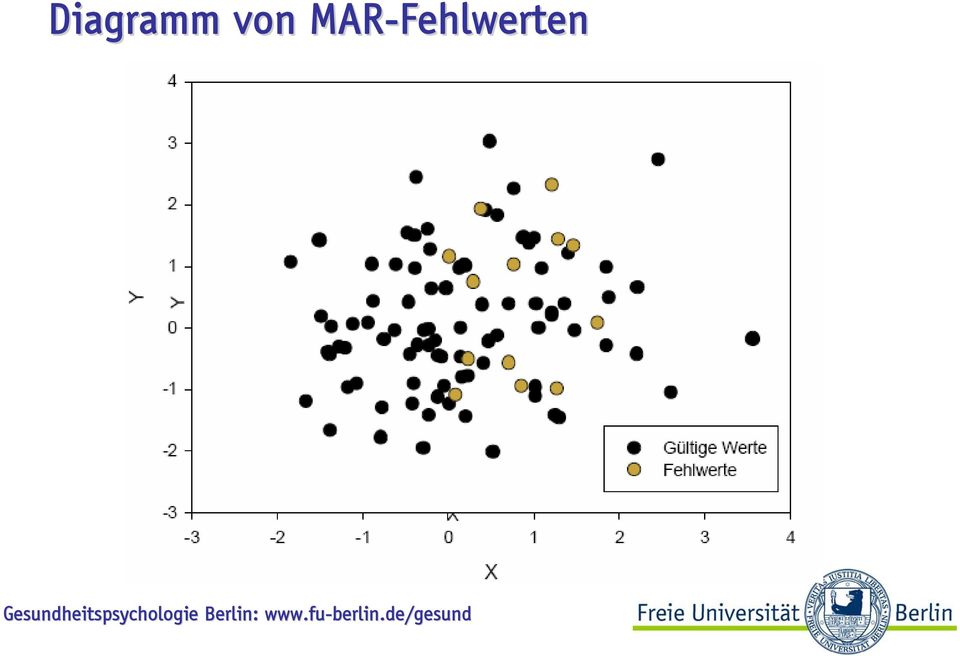
7 Diagramm von NMAR-Fehlwerten

8 Systematisch fehlende Werte (NMAR) Fehlende Werte sind mit gemessener und anderen Variablen assoziiert z.b.: Erfassen von Altern und Einkommen, fehlende Werte bei Einkommen NMAR: Fehlende Werte hängen vom Einkommen in bestimmten Altersgruppen ab MAR: Fehlende Werte unabhängig von Einkommen, aber assoziiert mit Alter MCAR: Fehlende Werte unabhängig von Einkommen und Alter

9 Kann man das überprüfen? Schwer bis überhaupt nicht (Teilnehmer kontaktieren, Antworten erzwingen?) Ausschluss der MAR und MCAR Annahmen über Missing Value Analysis (MVA) möglich As with other statistical assumptions,[..] the missing at random assumption may be a useful approximation even if it is believed to be false. (Allison, 1987)

10 Missing Value Analyis (MVA) SPSS MVA N_1 N_2 N_3 N_4 AGE SEX Descriptives: Univariate Statistiken, Percent Mismatch, t- Test, Crosstabs Patterns: Muster von fehlenden Werten werden angezeigt Univariate Statistics Missing N Mean Std. Deviation Count Percent Low High 9 2, , , ,777778, , , , , , , , ,7273 6,7393 0, ,0 a. Number of cases outside the range (Q1-1.5*IQR, Q *IQR). No. of Extremes a
.")
11 SPSS MVA Tabulated Patterns Number of Cases N_4 Missing Patterns a AGE SEX N_3 N_2 N_1 Complete if... b 8 X 9 X X 10 Patterns with less than 1% cases (0 or fewer) are not displayed. a. Variables are sorted on missing patterns. b. Number of complete cases if variables missing in that pattern (marked with X) are not used.

12 SPSS MVA Missing Patterns (cases with missing values) Case # Missing % Missing Missing and Extreme Value Patterns a N_4 AGE SEX N_3 1 16,7 S N_2 N_1 2 33,3 S S 2 33,3 S S Tukey s Robust Boxplot Criterion (Ansonsten M +/- 2 SD) - indicates an extreme low value, while + indicates an extreme high value. The range used is (Q1-1.5*IQR, Q *IQR). a. Cases and variables are sorted on missing patterns.
. a.")
13 Data Patterns (all cases) SPSS-MVA Case a # Missing % Missing Missing and Extreme Value Patterns N_1 N_2 N_3 N_4 AGE 0,0-4,0000,0000, ,3 S S,, 3,0000 0,0 1,0000,0000 3,0000 0,0 3,0000,0000 1,0000 0,0 2,0000 2,0000 3, ,3 S S,, 3,0000 0,0 1,0000 1,0000 3,0000 0,0-2,0000 1,0000 4,0000 0,0 4,0000,0000 2,0000 0,0 3,0000 2,0000 3, ,7 S 2,0000 1,0000, SEX N_1 Variable Values - indicates an extreme low value, while + indicates an extreme high value. The range used is (Q1-1.5*IQR, Q *IQR). a. Cases are sorted by E_1. N_2 N_3
. a. Cases are sorted by E_1.")
14 SPSS-MVA Percent Mismatch of Indicator Variables ạ,b N_3 N_2 N_1 N_3 N_2 N_1 9,09 27,27 18,18 27,27,00 18,18 The diagonal elements are the percentages missing, and the off-diagonal elements are the mismatch percentages of indicator variables. a. Variables are sorted on missing patterns. b. Indicator variables with less than 5% missing values are not displayed.

15 SPSS-MVA: t-tests N_1 N_2 N_3 t df P(2-tail) # Present # Missing Mean(Present) Mean(Missing) t df P(2-tail) # Present # Missing Mean(Present) Mean(Missing) t df P(2-tail) # Present # Missing Mean(Present) Mean(Missing) Separate Variance t Tests a N_1 N_2,, -1,4 -,6,6,, 7,0 1,4 2,1,,,217,624, ,444444, , , ,2222,, 3, , ,5000,, -1,4 -,6,6,, 7,0 1,4 2,1,,,217,624, ,444444, , , ,2222,, 3, , ,5000,,,,,,,,,,,,,,, ,500000, , , ,0000,,,,, For each quantitative variable, pairs of groups are formed by indicator variables (present, missing). a. Indicator variables with less than 5% missing are not displayed. N_3 N_4 AGE
. a. Indicator variables with less than 5% missing are not displayed.")
16 SPSS-MVA: Crosstabs SEX Total male female N_1 N_2 N_3 Present Missing Present Missing Present Missing Count Percent % SysMis Count Percent % SysMis Count Percent % SysMis ,8 80,0 83,3 18,2 20,0 16, ,8 80,0 83,3 18,2 20,0 16, ,9 100,0 83,3 9,1,0 16,7 Indicator variables with less than 5% missing are not displayed.

17 Wie mit Missings umgehen? Ignorieren (Listenweiser/Paarweiser Fallausschluss): Schlecht.

18 Ignorieren (Fallausschluss) z.b. Listenweiser Fallausschluss: Analyse der kompletten Datensätze, Datensätze mit fehlenden Werten fliegen raus Bei sehr wenig fehlenden Werten (MCAR) kein Problem Probleme bei vielen fehlenden Werten Verzerrte Daten bei NMAR Reduktion der Stichprobe bis zur Unbrauchbarkeit

19 Auswirkungen

20 Ignorieren (Mittelwerte einsetzen) Ersetzen der fehlenden Werte durch den Mittelwert der Variable Nur bei der Berechnung von Summen- und Mittelwerten verzerrungsfrei Verzerrung der wahren Verteilung Unterschätzung der wahren Varianz Unterschätzung der wahren Zusammenhänge

21 Auswirkungen
22 Wie mit Missings umgehen? Ignorieren (Listenweiser/Paarweiser Fallausschluss): Schlecht. Besser: Imputieren Faustregel: Bei weniger als 5% fehlender Werte auf einer Variablen gibt es kaum Unterschiede zwischen Imputationsverfahren
23 EM-Imputation (SPSS MVA) E-Schritt (Estimation): Finden der erwarteten Werte für die fehlenden Werte unter Gültigkeit der beobachteten (und momentan geschätzten) Parameter M-Schritt: Maximum Likelihood-Schätzung der fehlenden Werte gegeben die durch den E-Schritt aufgefüllte Verteilung Iteration, bis es passt Besser viele Prädiktoren (default: Alle quantitativen Variablen)
24 FIML (Full Information Maximum Likelihood) Anwendung bei Strukturgleichungsmodellen Default-Einstellung in AMOS zur Schätzung fehlender Werte Maximum-Likelihood-Schätzung der fehlenden Werte aufgrund der Kovarianzmatrizen der beobachteten Werte ML-Schätzung: Suche nach einer Kombination von Parametern, die die Wahrscheinlichkeit der Kovarianzmatrix der beobachteten Werte maximiert
25 Multiple Imputation (MI; viel Arbeit)
26 MI: Wie wird das gemacht? Mehrere Kopien des unvollständigen Datensatzes Mehr: Je mehr Missings, desto mehr Datensätze Faustregel: ca Datensätze Imputation der fehlenden Werte mit randomisierten Variationen (simuliert Zufallsfehler) Bestimmen des Fits der einzelnen Modelle Rekombination der verschiedenen imputierten Datensätze
27 Mehr? Fehlende_Werte.pdf values.pdf SPSS_Missing_Value_Analysis_7.5
Behandlung fehlender Werte
 Halle/Saale, 8.6.2 Behandlung fehlender Werte Dipl.-Psych. Wilmar Igl - Methodenberatung - Rehabilitationswissenschaftlicher Forschungsverbund Bayern Einleitung () Fehlende Werte als allgegenwärtiges Problem
Halle/Saale, 8.6.2 Behandlung fehlender Werte Dipl.-Psych. Wilmar Igl - Methodenberatung - Rehabilitationswissenschaftlicher Forschungsverbund Bayern Einleitung () Fehlende Werte als allgegenwärtiges Problem
Statistische Auswertung:
 Statistische Auswertung: Die erhobenen Daten mittels der selbst erstellten Tests (Surfaufgaben) Statistics Punkte aus dem Punkte aus Surftheorietest Punkte aus dem dem und dem Surftheorietest max.14p.
Statistische Auswertung: Die erhobenen Daten mittels der selbst erstellten Tests (Surfaufgaben) Statistics Punkte aus dem Punkte aus Surftheorietest Punkte aus dem dem und dem Surftheorietest max.14p.
Imputation (Ersetzen fehlender Werte)
") Imputation (Ersetzen fehlender Werte) Gliederung Nonresponse bias Fehlende Werte (missing values): Mechanismen Imputationsverfahren Überblick Mittelwert- / Regressions Hot-Deck-Imputation Row-Column-Imputation
Imputation (Ersetzen fehlender Werte) Gliederung Nonresponse bias Fehlende Werte (missing values): Mechanismen Imputationsverfahren Überblick Mittelwert- / Regressions Hot-Deck-Imputation Row-Column-Imputation
Melanie Kaspar, Prof. Dr. B. Grabowski 1
 7. Hypothesentests Ausgangssituation: Man muss sich zwischen 2 Möglichkeiten (=Hypothesen) entscheiden. Diese Entscheidung soll mit Hilfe von Beobachtungen ( Stichprobe ) getroffen werden. Die Hypothesen
7. Hypothesentests Ausgangssituation: Man muss sich zwischen 2 Möglichkeiten (=Hypothesen) entscheiden. Diese Entscheidung soll mit Hilfe von Beobachtungen ( Stichprobe ) getroffen werden. Die Hypothesen
Würfelt man dabei je genau 10 - mal eine 1, 2, 3, 4, 5 und 6, so beträgt die Anzahl. der verschiedenen Reihenfolgen, in denen man dies tun kann, 60!.
 040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
Güte von Tests. die Wahrscheinlichkeit für den Fehler 2. Art bei der Testentscheidung, nämlich. falsch ist. Darauf haben wir bereits im Kapitel über
 Güte von s Grundlegendes zum Konzept der Güte Ableitung der Gütefunktion des Gauss im Einstichprobenproblem Grafische Darstellung der Gütefunktionen des Gauss im Einstichprobenproblem Ableitung der Gütefunktion
Güte von s Grundlegendes zum Konzept der Güte Ableitung der Gütefunktion des Gauss im Einstichprobenproblem Grafische Darstellung der Gütefunktionen des Gauss im Einstichprobenproblem Ableitung der Gütefunktion
Einfache statistische Auswertungen mit dem Programm SPSS
 Einfache statistische Auswertungen mit dem Programm SPSS Datensatz: fiktive_daten.sav Dipl. Päd. Anne Haßelkus Dr. Dorothea Dette-Hagenmeyer 11/2011 Überblick 1 Deskriptive Statistiken; Mittelwert berechnen...
Einfache statistische Auswertungen mit dem Programm SPSS Datensatz: fiktive_daten.sav Dipl. Päd. Anne Haßelkus Dr. Dorothea Dette-Hagenmeyer 11/2011 Überblick 1 Deskriptive Statistiken; Mittelwert berechnen...
Auswertung mit dem Statistikprogramm SPSS: 30.11.05
 Auswertung mit dem Statistikprogramm SPSS: 30.11.05 Seite 1 Einführung SPSS Was ist eine Fragestellung? Beispiel Welche statistische Prozedur gehört zu welcher Hypothese? Statistische Berechnungen mit
Auswertung mit dem Statistikprogramm SPSS: 30.11.05 Seite 1 Einführung SPSS Was ist eine Fragestellung? Beispiel Welche statistische Prozedur gehört zu welcher Hypothese? Statistische Berechnungen mit
Übungen zur Veranstaltung Statistik 2 mit SPSS
 Raum 22, Tel. 39 4 Aufgabe 5. Wird der neue Film MatchPoint von Woody Allen von weiblichen und männlichen Zuschauern gleich bewertet? Eine Umfrage unter 00 Kinobesuchern ergab folgende Daten: Altersgruppe
Raum 22, Tel. 39 4 Aufgabe 5. Wird der neue Film MatchPoint von Woody Allen von weiblichen und männlichen Zuschauern gleich bewertet? Eine Umfrage unter 00 Kinobesuchern ergab folgende Daten: Altersgruppe
Biostatistik, WS 2015/2016 Der zwei-stichproben-t-test
 1/29 Biostatistik, WS 2015/2016 Der zwei-stichproben-t-test (t-test für ungepaarte Stichproben) Matthias Birkner http://www.staff.uni-mainz.de/birkner/biostatistik1516/ 11.12.2015 2/29 Inhalt 1 t-test
1/29 Biostatistik, WS 2015/2016 Der zwei-stichproben-t-test (t-test für ungepaarte Stichproben) Matthias Birkner http://www.staff.uni-mainz.de/birkner/biostatistik1516/ 11.12.2015 2/29 Inhalt 1 t-test
Analog zu Aufgabe 16.1 werden die Daten durch folgenden Befehl eingelesen: > kredit<-read.table("c:\\compaufg\\kredit.
 Lösung 16.3 Analog zu Aufgabe 16.1 werden die Daten durch folgenden Befehl eingelesen: > kredit
Lösung 16.3 Analog zu Aufgabe 16.1 werden die Daten durch folgenden Befehl eingelesen: > kredit
QM: Prüfen -1- KN16.08.2010
 QM: Prüfen -1- KN16.08.2010 2.4 Prüfen 2.4.1 Begriffe, Definitionen Ein wesentlicher Bestandteil der Qualitätssicherung ist das Prüfen. Sie wird aber nicht wie früher nach der Fertigung durch einen Prüfer,
QM: Prüfen -1- KN16.08.2010 2.4 Prüfen 2.4.1 Begriffe, Definitionen Ein wesentlicher Bestandteil der Qualitätssicherung ist das Prüfen. Sie wird aber nicht wie früher nach der Fertigung durch einen Prüfer,
Monte-Carlo-Simulationen mit Copulas. Kevin Schellkes und Christian Hendricks 29.08.2011
 Kevin Schellkes und Christian Hendricks 29.08.2011 Inhalt Der herkömmliche Ansatz zur Simulation logarithmischer Renditen Ansatz zur Simulation mit Copulas Test und Vergleich der beiden Verfahren Fazit
Kevin Schellkes und Christian Hendricks 29.08.2011 Inhalt Der herkömmliche Ansatz zur Simulation logarithmischer Renditen Ansatz zur Simulation mit Copulas Test und Vergleich der beiden Verfahren Fazit
Statistik für Studenten der Sportwissenschaften SS 2008
 Statistik für Studenten der Sportwissenschaften SS 008 Aufgabe 1 Man weiß von Rehabilitanden, die sich einer bestimmten Gymnastik unterziehen, dass sie im Mittel µ=54 Jahre (σ=3 Jahre) alt sind. a) Welcher
Statistik für Studenten der Sportwissenschaften SS 008 Aufgabe 1 Man weiß von Rehabilitanden, die sich einer bestimmten Gymnastik unterziehen, dass sie im Mittel µ=54 Jahre (σ=3 Jahre) alt sind. a) Welcher
Forschungsstatistik I
 Prof. Dr. G. Meinhardt. Stock, Nordflügel R. 0-49 (Persike) R. 0- (Meinhardt) Sprechstunde jederzeit nach Vereinbarung Forschungsstatistik I Dr. Malte Persike persike@uni-mainz.de WS 008/009 Fachbereich
Prof. Dr. G. Meinhardt. Stock, Nordflügel R. 0-49 (Persike) R. 0- (Meinhardt) Sprechstunde jederzeit nach Vereinbarung Forschungsstatistik I Dr. Malte Persike persike@uni-mainz.de WS 008/009 Fachbereich
Eine Einführung in R: Statistische Tests
 Eine Einführung in R: Statistische Tests Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.uni-leipzig.de/ zuber/teaching/ws12/r-kurs/
Eine Einführung in R: Statistische Tests Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.uni-leipzig.de/ zuber/teaching/ws12/r-kurs/
Berechnung von Strukturgleichungsmodellen mit Amos. Im folgenden kurze Einführung: Arbeiten mit Amos Graphics
 Oliver Schiling Handout:: Amos 6.0 / Graphics 1 Berechnung von Strukturgleichungsmodellen mit Amos Was kann Amos? Klassische Strukturgleichungsmodelle (Kovarianzstrukturanalysen, Pfadmodelle mit/ohne latente
Oliver Schiling Handout:: Amos 6.0 / Graphics 1 Berechnung von Strukturgleichungsmodellen mit Amos Was kann Amos? Klassische Strukturgleichungsmodelle (Kovarianzstrukturanalysen, Pfadmodelle mit/ohne latente
Imputation von Werten bei fehlenden Angaben zur Mutterschaft und zur Zahl der geborenen Kinder im Mikrozensus 2008
 Statistisches Bundesamt Methodeninformation Imputation von Werten bei fehlenden Angaben zur Mutterschaft und zur Zahl der geborenen Kinder im 2009 Erschienen am 24.07.2009 Ihr Kontakt zu uns: www.destatis.de/kontakt
Statistisches Bundesamt Methodeninformation Imputation von Werten bei fehlenden Angaben zur Mutterschaft und zur Zahl der geborenen Kinder im 2009 Erschienen am 24.07.2009 Ihr Kontakt zu uns: www.destatis.de/kontakt
B. Heger / R. Prust: Quantitative Methoden der empirischen Sozialforschung (Master Modul 1.3)
") B. Heger / R. Prust: Quantitative Methoden der empirischen Sozialforschung (Master Modul 1.3) Übung 1 (mit SPSS-Ausgabe) 1. Erstellen Sie eine einfache Häufigkeitsauszählung der Variable V175 ( des/der
B. Heger / R. Prust: Quantitative Methoden der empirischen Sozialforschung (Master Modul 1.3) Übung 1 (mit SPSS-Ausgabe) 1. Erstellen Sie eine einfache Häufigkeitsauszählung der Variable V175 ( des/der
W-Rechnung und Statistik für Ingenieure Übung 11
 W-Rechnung und Statistik für Ingenieure Übung 11 Christoph Kustosz (kustosz@statistik.tu-dortmund.de) Mathematikgebäude Raum 715 Christoph Kustosz (kustosz@statistik.tu-dortmund.de) W-Rechnung und Statistik
W-Rechnung und Statistik für Ingenieure Übung 11 Christoph Kustosz (kustosz@statistik.tu-dortmund.de) Mathematikgebäude Raum 715 Christoph Kustosz (kustosz@statistik.tu-dortmund.de) W-Rechnung und Statistik
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren
 Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Klausur zu Methoden der Statistik I (mit Kurzlösung) Wintersemester 2007/2008. Aufgabe 1
 Wintersemester 2007/2008. Aufgabe 1") Lehrstuhl für Statistik und Ökonometrie der Otto-Friedrich-Universität Bamberg Prof. Dr. Susanne Rässler Klausur zu Methoden der Statistik I (mit Kurzlösung) Wintersemester 2007/2008 Aufgabe 1 Ihnen liegt
Lehrstuhl für Statistik und Ökonometrie der Otto-Friedrich-Universität Bamberg Prof. Dr. Susanne Rässler Klausur zu Methoden der Statistik I (mit Kurzlösung) Wintersemester 2007/2008 Aufgabe 1 Ihnen liegt
R ist freie Software und kann von der Website. www.r-project.org
 R R ist freie Software und kann von der Website heruntergeladen werden. www.r-project.org Nach dem Herunterladen und der Installation von R kann man R durch Doppelklicken auf das R-Symbol starten. R wird
R R ist freie Software und kann von der Website heruntergeladen werden. www.r-project.org Nach dem Herunterladen und der Installation von R kann man R durch Doppelklicken auf das R-Symbol starten. R wird
Tutorial: Homogenitätstest
 Tutorial: Homogenitätstest Eine Bank möchte die Kreditwürdigkeit potenzieller Kreditnehmer abschätzen. Einerseits lebt die Bank ja von der Vergabe von Krediten, andererseits verursachen Problemkredite
Tutorial: Homogenitätstest Eine Bank möchte die Kreditwürdigkeit potenzieller Kreditnehmer abschätzen. Einerseits lebt die Bank ja von der Vergabe von Krediten, andererseits verursachen Problemkredite
Kosten-Leistungsrechnung Rechenweg Optimales Produktionsprogramm
 Um was geht es? Gegeben sei ein Produktionsprogramm mit beispielsweise 5 Aufträgen, die nacheinander auf vier unterschiedlichen Maschinen durchgeführt werden sollen: Auftrag 1 Auftrag 2 Auftrag 3 Auftrag
Um was geht es? Gegeben sei ein Produktionsprogramm mit beispielsweise 5 Aufträgen, die nacheinander auf vier unterschiedlichen Maschinen durchgeführt werden sollen: Auftrag 1 Auftrag 2 Auftrag 3 Auftrag
Motivation. Wilcoxon-Rangsummentest oder Mann-Whitney U-Test. Wilcoxon Rangsummen-Test Voraussetzungen. Bemerkungen
 Universität Karlsruhe (TH) Forschungsuniversität gegründet 825 Wilcoxon-Rangsummentest oder Mann-Whitney U-Test Motivation In Experimenten ist die Datenmenge oft klein Daten sind nicht normalverteilt Dann
Universität Karlsruhe (TH) Forschungsuniversität gegründet 825 Wilcoxon-Rangsummentest oder Mann-Whitney U-Test Motivation In Experimenten ist die Datenmenge oft klein Daten sind nicht normalverteilt Dann
Erfahrungen mit Hartz IV- Empfängern
 Erfahrungen mit Hartz IV- Empfängern Ausgewählte Ergebnisse einer Befragung von Unternehmen aus den Branchen Gastronomie, Pflege und Handwerk Pressegespräch der Bundesagentur für Arbeit am 12. November
Erfahrungen mit Hartz IV- Empfängern Ausgewählte Ergebnisse einer Befragung von Unternehmen aus den Branchen Gastronomie, Pflege und Handwerk Pressegespräch der Bundesagentur für Arbeit am 12. November
Resultate GfS-Umfrage November 2006. Wie bekannt ist das Phänomen Illettrismus bei der Schweizer Bevölkerung?
 Resultate GfS-Umfrage November 2006 Wie bekannt ist das Phänomen Illettrismus bei der Schweizer Bevölkerung? Frage 1: Kennen Sie das Phänomen, dass Erwachsene fast nicht lesen und schreiben können, obwohl
Resultate GfS-Umfrage November 2006 Wie bekannt ist das Phänomen Illettrismus bei der Schweizer Bevölkerung? Frage 1: Kennen Sie das Phänomen, dass Erwachsene fast nicht lesen und schreiben können, obwohl
Studiendesign/ Evaluierungsdesign
 Jennifer Ziegert Studiendesign/ Evaluierungsdesign Praxisprojekt: Nutzerorientierte Evaluierung von Visualisierungen in Daffodil mittels Eyetracker Warum Studien /Evaluierungsdesign Das Design einer Untersuchung
Jennifer Ziegert Studiendesign/ Evaluierungsdesign Praxisprojekt: Nutzerorientierte Evaluierung von Visualisierungen in Daffodil mittels Eyetracker Warum Studien /Evaluierungsdesign Das Design einer Untersuchung
Repräsentative Umfrage zur Beratungsqualität im deutschen Einzelhandel (Auszug)
") Porsche Consulting Exzellent handeln Repräsentative Umfrage zur Beratungsqualität im deutschen Einzelhandel (Auszug) Oktober 2013 Inhalt Randdaten der Studie Untersuchungsziel der Studie Ergebnisse der
Porsche Consulting Exzellent handeln Repräsentative Umfrage zur Beratungsqualität im deutschen Einzelhandel (Auszug) Oktober 2013 Inhalt Randdaten der Studie Untersuchungsziel der Studie Ergebnisse der
Varianzanalyse ANOVA
 Varianzanalyse ANOVA Johannes Hain Lehrstuhl für Mathematik VIII Statistik 1/23 Einfaktorielle Varianzanalyse (ANOVA) Bisher war man lediglich in der Lage, mit dem t-test einen Mittelwertsvergleich für
Varianzanalyse ANOVA Johannes Hain Lehrstuhl für Mathematik VIII Statistik 1/23 Einfaktorielle Varianzanalyse (ANOVA) Bisher war man lediglich in der Lage, mit dem t-test einen Mittelwertsvergleich für
Evaluation der Normalverteilungsannahme
 Evaluation der Normalverteilungsannahme. Überprüfung der Normalverteilungsannahme im SPSS P. Wilhelm; HS SPSS bietet verschiedene Möglichkeiten, um Verteilungsannahmen zu überprüfen. Angefordert werden
Evaluation der Normalverteilungsannahme. Überprüfung der Normalverteilungsannahme im SPSS P. Wilhelm; HS SPSS bietet verschiedene Möglichkeiten, um Verteilungsannahmen zu überprüfen. Angefordert werden
Informationsblatt Induktionsbeweis
 Sommer 015 Informationsblatt Induktionsbeweis 31. März 015 Motivation Die vollständige Induktion ist ein wichtiges Beweisverfahren in der Informatik. Sie wird häufig dazu gebraucht, um mathematische Formeln
Sommer 015 Informationsblatt Induktionsbeweis 31. März 015 Motivation Die vollständige Induktion ist ein wichtiges Beweisverfahren in der Informatik. Sie wird häufig dazu gebraucht, um mathematische Formeln
Auswertung und Darstellung wissenschaftlicher Daten (1)
") Auswertung und Darstellung wissenschaftlicher Daten () Mag. Dr. Andrea Payrhuber Zwei Schritte der Auswertung. Deskriptive Darstellung aller Daten 2. analytische Darstellung (Gruppenvergleiche) SPSS-Andrea
Auswertung und Darstellung wissenschaftlicher Daten () Mag. Dr. Andrea Payrhuber Zwei Schritte der Auswertung. Deskriptive Darstellung aller Daten 2. analytische Darstellung (Gruppenvergleiche) SPSS-Andrea
Hauptseminar am Fachgebiet für Quantitative Methoden der Wirtschaftswissenschaften
 Hauptseminar am Fachgebiet für Quantitative Methoden der Wirtschaftswissenschaften Fehlende Daten in der Multivariaten Statistik SS 2011 Allgemeines Das Seminar richtet sich in erster Linie an Studierende
Hauptseminar am Fachgebiet für Quantitative Methoden der Wirtschaftswissenschaften Fehlende Daten in der Multivariaten Statistik SS 2011 Allgemeines Das Seminar richtet sich in erster Linie an Studierende
Einfache Varianzanalyse für abhängige
 Einfache Varianzanalyse für abhängige Stichproben Wie beim t-test gibt es auch bei der VA eine Alternative für abhängige Stichproben. Anmerkung: Was man unter abhängigen Stichproben versteht und wie diese
Einfache Varianzanalyse für abhängige Stichproben Wie beim t-test gibt es auch bei der VA eine Alternative für abhängige Stichproben. Anmerkung: Was man unter abhängigen Stichproben versteht und wie diese
sondern alle Werte gleich behandelt. Wir dürfen aber nicht vergessen, dass Ergebnisse, je länger sie in der Vergangenheit
 sondern alle Werte gleich behandelt. Wir dürfen aber nicht vergessen, dass Ergebnisse, je länger sie in der Vergangenheit liegen, an Bedeutung verlieren. Die Mannschaften haben sich verändert. Spieler
sondern alle Werte gleich behandelt. Wir dürfen aber nicht vergessen, dass Ergebnisse, je länger sie in der Vergangenheit liegen, an Bedeutung verlieren. Die Mannschaften haben sich verändert. Spieler
Etwas positive Tendenz ist beim Wechsel der Temperatur von 120 auf 170 zu erkennen.
 Explorative Datenanalyse Erstmal die Grafiken: Aufreisskraft und Temperatur 3 1-1 N = 1 15 17 Temperatur Diagramm 3 1 95% CI -1 N = 1 15 17 Temperatur Etwas positive Tendenz ist beim Wechsel der Temperatur
Explorative Datenanalyse Erstmal die Grafiken: Aufreisskraft und Temperatur 3 1-1 N = 1 15 17 Temperatur Diagramm 3 1 95% CI -1 N = 1 15 17 Temperatur Etwas positive Tendenz ist beim Wechsel der Temperatur
Mehr Geld verdienen! Lesen Sie... Peter von Karst. Ihre Leseprobe. der schlüssel zum leben. So gehen Sie konkret vor!
 Peter von Karst Mehr Geld verdienen! So gehen Sie konkret vor! Ihre Leseprobe Lesen Sie...... wie Sie mit wenigen, aber effektiven Schritten Ihre gesteckten Ziele erreichen.... wie Sie die richtigen Entscheidungen
Peter von Karst Mehr Geld verdienen! So gehen Sie konkret vor! Ihre Leseprobe Lesen Sie...... wie Sie mit wenigen, aber effektiven Schritten Ihre gesteckten Ziele erreichen.... wie Sie die richtigen Entscheidungen
Ergebnisbericht Die Akzeptanz der elektronischen Gesundheitskarte
 Ergebnisbericht Die Akzeptanz der elektronischen Gesundheitskarte Thomas Gorniok, Diplom Wirtschaftsinformatiker (FH) Prof. Dr. Dieter Litzinger, Professur für Wirtschaftsinformatik an der FOM 1 Einleitung
Ergebnisbericht Die Akzeptanz der elektronischen Gesundheitskarte Thomas Gorniok, Diplom Wirtschaftsinformatiker (FH) Prof. Dr. Dieter Litzinger, Professur für Wirtschaftsinformatik an der FOM 1 Einleitung
August 2009. Umfrage zum Verbraucherschutz im Auftrag des Verbraucherzentrale Bundesverbandes e.v. Untersuchungsanlage
 Umfrage zum Verbraucherschutz im Auftrag des Verbraucherzentrale Bundesverbandes e.v. Untersuchungsanlage Grundgesamtheit: Stichprobe: Erhebungsverfahren: Fallzahl: Wahlberechtigte Bevölkerung in Deutschland
Umfrage zum Verbraucherschutz im Auftrag des Verbraucherzentrale Bundesverbandes e.v. Untersuchungsanlage Grundgesamtheit: Stichprobe: Erhebungsverfahren: Fallzahl: Wahlberechtigte Bevölkerung in Deutschland
Mean Time Between Failures (MTBF)
") Mean Time Between Failures (MTBF) Hintergrundinformation zur MTBF Was steht hier? Die Mean Time Between Failure (MTBF) ist ein statistischer Mittelwert für den störungsfreien Betrieb eines elektronischen
Mean Time Between Failures (MTBF) Hintergrundinformation zur MTBF Was steht hier? Die Mean Time Between Failure (MTBF) ist ein statistischer Mittelwert für den störungsfreien Betrieb eines elektronischen
Elektromobilität. Eine quantitative Untersuchung für ElectroDrive Salzburg
 Elektromobilität Eine quantitative Untersuchung für ElectroDrive Salzburg Untersuchungsdesign Aufgabenstellung Die Wahrnehmung von Elektromobilität in der Bevölkerung präsentiert im Vergleich zu. Methode
Elektromobilität Eine quantitative Untersuchung für ElectroDrive Salzburg Untersuchungsdesign Aufgabenstellung Die Wahrnehmung von Elektromobilität in der Bevölkerung präsentiert im Vergleich zu. Methode
Hauptprüfung Fachhochschulreife 2015. Baden-Württemberg
 Baden-Württemberg: Fachhochschulreie 2015 www.mathe-augaben.com Hauptprüung Fachhochschulreie 2015 Baden-Württemberg Augabe 1 Analysis Hilsmittel: graikähiger Taschenrechner Beruskolleg Alexander Schwarz
Baden-Württemberg: Fachhochschulreie 2015 www.mathe-augaben.com Hauptprüung Fachhochschulreie 2015 Baden-Württemberg Augabe 1 Analysis Hilsmittel: graikähiger Taschenrechner Beruskolleg Alexander Schwarz
STATISTIK. Erinnere dich
 Thema Nr.20 STATISTIK Erinnere dich Die Stichprobe Drei Schüler haben folgende Noten geschrieben : Johann : 4 6 18 7 17 12 12 18 Barbara : 13 13 12 10 12 3 14 12 14 15 Julia : 15 9 14 13 10 12 12 11 10
Thema Nr.20 STATISTIK Erinnere dich Die Stichprobe Drei Schüler haben folgende Noten geschrieben : Johann : 4 6 18 7 17 12 12 18 Barbara : 13 13 12 10 12 3 14 12 14 15 Julia : 15 9 14 13 10 12 12 11 10
Korrelation (II) Korrelation und Kausalität
 Korrelation und Kausalität") Korrelation (II) Korrelation und Kausalität Situation: Seien X, Y zwei metrisch skalierte Merkmale mit Ausprägungen (x 1, x 2,..., x n ) bzw. (y 1, y 2,..., y n ). D.h. für jede i = 1, 2,..., n bezeichnen
Korrelation (II) Korrelation und Kausalität Situation: Seien X, Y zwei metrisch skalierte Merkmale mit Ausprägungen (x 1, x 2,..., x n ) bzw. (y 1, y 2,..., y n ). D.h. für jede i = 1, 2,..., n bezeichnen
METHODENLEHRE I WS 2013/14 THOMAS SCHÄFER
 METHODENLEHRE I WS 2013/14 THOMAS SCHÄFER DAS THEMA: INFERENZSTATISTIK IV INFERENZSTATISTISCHE AUSSAGEN FÜR ZUSAMMENHÄNGE UND UNTERSCHIEDE Inferenzstatistik für Zusammenhänge Inferenzstatistik für Unterschiede
METHODENLEHRE I WS 2013/14 THOMAS SCHÄFER DAS THEMA: INFERENZSTATISTIK IV INFERENZSTATISTISCHE AUSSAGEN FÜR ZUSAMMENHÄNGE UND UNTERSCHIEDE Inferenzstatistik für Zusammenhänge Inferenzstatistik für Unterschiede
Messung von Veränderungen. Dr. Julia Kneer Universität des Saarlandes
 von Veränderungen Dr. Julia Kneer Universität des Saarlandes Veränderungsmessung Veränderungsmessung kennzeichnet ein Teilgebiet der Methodenlehre, das direkt mit grundlegenden Fragestellungen der Psychologie
von Veränderungen Dr. Julia Kneer Universität des Saarlandes Veränderungsmessung Veränderungsmessung kennzeichnet ein Teilgebiet der Methodenlehre, das direkt mit grundlegenden Fragestellungen der Psychologie
Interne und externe Modellvalidität
 Interne und externe Modellvalidität Interne Modellvalidität ist gegeben, o wenn statistische Inferenz bzgl. der untersuchten Grundgesamtheit zulässig ist o KQ-Schätzer der Modellparameter u. Varianzschätzer
Interne und externe Modellvalidität Interne Modellvalidität ist gegeben, o wenn statistische Inferenz bzgl. der untersuchten Grundgesamtheit zulässig ist o KQ-Schätzer der Modellparameter u. Varianzschätzer
Politikverständnis und Wahlalter. Ergebnisse einer Studie mit Schülern und Studienanfängern
 Politikverständnis und Wahlalter Ergebnisse einer Studie mit Schülern und Studienanfängern Frage: Lässt sich eine Herabsetzung des Wahlalters in Deutschland durch Ergebnisse zum Politikverständnis bei
Politikverständnis und Wahlalter Ergebnisse einer Studie mit Schülern und Studienanfängern Frage: Lässt sich eine Herabsetzung des Wahlalters in Deutschland durch Ergebnisse zum Politikverständnis bei
Wahrnehmung der Internetnutzung in Deutschland
 Eine Umfrage der Initiative Internet erfahren, durchgeführt von TNS Infratest Inhaltsverzeichnis Studiensteckbrief Zentrale Ergebnisse Vergleich tatsächliche und geschätzte Internetnutzung Wahrgenommene
Eine Umfrage der Initiative Internet erfahren, durchgeführt von TNS Infratest Inhaltsverzeichnis Studiensteckbrief Zentrale Ergebnisse Vergleich tatsächliche und geschätzte Internetnutzung Wahrgenommene
B. Heger / R. Prust: Quantitative Methoden der empirischen Sozialforschung (Master Modul 1.3) GET FILE ='Z:\ALLBUS_2007_neu.sav'.
 GET FILE ='Z:\ALLBUS_2007_neu.sav'.") B. Heger / R. Prust: Quantitative Methoden der empirischen Sozialforschung (Master Modul 1.3) Übung 1 (mit SPSS-Ausgabe) 1. Öffnen Sie den Datensatz ALLBUS_2007_neu! GET FILE ='Z:\ALLBUS_2007_neu.sav'.
B. Heger / R. Prust: Quantitative Methoden der empirischen Sozialforschung (Master Modul 1.3) Übung 1 (mit SPSS-Ausgabe) 1. Öffnen Sie den Datensatz ALLBUS_2007_neu! GET FILE ='Z:\ALLBUS_2007_neu.sav'.
Wearables und Gesundheits-Apps
 Wearables und Gesundheits-Apps Verbraucherbefragung im Auftrag des Bundesministeriums der Justiz und für Verbraucherschutz Berlin, den 09.0.06 Methodik / Eckdaten Die Umfrage basiert auf Online-Interviews
Wearables und Gesundheits-Apps Verbraucherbefragung im Auftrag des Bundesministeriums der Justiz und für Verbraucherschutz Berlin, den 09.0.06 Methodik / Eckdaten Die Umfrage basiert auf Online-Interviews
Professionelle Seminare im Bereich MS-Office
 Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
mehrmals mehrmals mehrmals alle seltener nie mindestens **) in der im Monat im Jahr 1 bis 2 alle 1 bis 2 Woche Jahre Jahre % % % % % % %
 in der im Monat im Jahr 1 bis 2 alle 1 bis 2 Woche Jahre Jahre % % % % % % %") Nicht überraschend, aber auch nicht gravierend, sind die altersspezifischen Unterschiede hinsichtlich der Häufigkeit des Apothekenbesuchs: 24 Prozent suchen mindestens mehrmals im Monat eine Apotheke auf,
Nicht überraschend, aber auch nicht gravierend, sind die altersspezifischen Unterschiede hinsichtlich der Häufigkeit des Apothekenbesuchs: 24 Prozent suchen mindestens mehrmals im Monat eine Apotheke auf,
Gemischte Modelle. Fabian Scheipl, Sonja Greven. SoSe 2011. Institut für Statistik Ludwig-Maximilians-Universität München
 Gemischte Modelle Fabian Scheipl, Sonja Greven Institut für Statistik Ludwig-Maximilians-Universität München SoSe 2011 Inhalt Amsterdam-Daten: LMM Amsterdam-Daten: GLMM Blutdruck-Daten Amsterdam-Daten:
Gemischte Modelle Fabian Scheipl, Sonja Greven Institut für Statistik Ludwig-Maximilians-Universität München SoSe 2011 Inhalt Amsterdam-Daten: LMM Amsterdam-Daten: GLMM Blutdruck-Daten Amsterdam-Daten:
Erweiterung der Aufgabe. Die Notenberechnung soll nicht nur für einen Schüler, sondern für bis zu 35 Schüler gehen:
 VBA Programmierung mit Excel Schleifen 1/6 Erweiterung der Aufgabe Die Notenberechnung soll nicht nur für einen Schüler, sondern für bis zu 35 Schüler gehen: Es müssen also 11 (B L) x 35 = 385 Zellen berücksichtigt
VBA Programmierung mit Excel Schleifen 1/6 Erweiterung der Aufgabe Die Notenberechnung soll nicht nur für einen Schüler, sondern für bis zu 35 Schüler gehen: Es müssen also 11 (B L) x 35 = 385 Zellen berücksichtigt
90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft
 Prof. Dr. Helmut Küchenhoff SS08 90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft am 22.7.2008 Anmerkungen Überprüfen Sie bitte sofort, ob Ihre Angabe vollständig ist. Sie sollte
Prof. Dr. Helmut Küchenhoff SS08 90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft am 22.7.2008 Anmerkungen Überprüfen Sie bitte sofort, ob Ihre Angabe vollständig ist. Sie sollte
WSI/PARGEMA Betriebsrätebefragung tebefragung 2008/09 zu Arbeitsbedingungen und Gesundheit im Betrieb. Zentrale Ergebnisse
 WSI/PARGEMA Betriebsrätebefragung tebefragung 2008/09 zu Arbeitsbedingungen und Gesundheit im Betrieb Zentrale Ergebnisse Dipl.Soz.wiss.. Elke Ahlers WSI/PARGEMA-Befragung 2008/09: 1. Zweck und Methodik
WSI/PARGEMA Betriebsrätebefragung tebefragung 2008/09 zu Arbeitsbedingungen und Gesundheit im Betrieb Zentrale Ergebnisse Dipl.Soz.wiss.. Elke Ahlers WSI/PARGEMA-Befragung 2008/09: 1. Zweck und Methodik
Die Pareto Verteilung wird benutzt, um Einkommensverteilungen zu modellieren. Die Verteilungsfunktion ist
 Frage Die Pareto Verteilung wird benutzt, um Einkommensverteilungen zu modellieren. Die Verteilungsfunktion ist k a F (x) =1 k>0,x k x Finden Sie den Erwartungswert und den Median der Dichte für a>1. (Bei
Frage Die Pareto Verteilung wird benutzt, um Einkommensverteilungen zu modellieren. Die Verteilungsfunktion ist k a F (x) =1 k>0,x k x Finden Sie den Erwartungswert und den Median der Dichte für a>1. (Bei
Zm Eingewöhnen Aufgabe 1 Schreiben Sie ein Programm, daß Ihren Namen in einem Fenster ausgibt.
 Zm Eingewöhnen Aufgabe 1 Schreiben Sie ein Programm, daß Ihren Namen in einem Fenster ausgibt. Aufgabe 2 Das nächste Programm soll 2 Zahlen einlesen und die zweite von der ersten abziehen! Das Ergebnis
Zm Eingewöhnen Aufgabe 1 Schreiben Sie ein Programm, daß Ihren Namen in einem Fenster ausgibt. Aufgabe 2 Das nächste Programm soll 2 Zahlen einlesen und die zweite von der ersten abziehen! Das Ergebnis
Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005
 Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005 Aufgabe 1: Grundzüge der Wahrscheinlichkeitsrechnung 19 P. Als Manager eines großen
Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005 Aufgabe 1: Grundzüge der Wahrscheinlichkeitsrechnung 19 P. Als Manager eines großen
Versuchsplanung. Inhalt. Grundlagen. Faktor-Effekt. Allgemeine faktorielle Versuchspläne. Zweiwertige faktorielle Versuchspläne
 Inhalt Versuchsplanung Faktorielle Versuchspläne Dr. Tobias Kiesling Allgemeine faktorielle Versuchspläne Faktorielle Versuchspläne mit zwei Faktoren Erweiterungen Zweiwertige
Inhalt Versuchsplanung Faktorielle Versuchspläne Dr. Tobias Kiesling Allgemeine faktorielle Versuchspläne Faktorielle Versuchspläne mit zwei Faktoren Erweiterungen Zweiwertige
Leitfaden E-Books Apple. CORA E-Books im ibook Store kaufen. Liebe Leserinnen und Leser, vielen Dank für Ihr Interesse an unseren CORA E-Books.
 CORA E-Books im ibook Store kaufen Liebe Leserinnen und Leser, vielen Dank für Ihr Interesse an unseren CORA E-Books. Wir sind sehr daran interessiert, dass Sie die CORA E-Books auf Ihre gewünschten Lesegeräte
CORA E-Books im ibook Store kaufen Liebe Leserinnen und Leser, vielen Dank für Ihr Interesse an unseren CORA E-Books. Wir sind sehr daran interessiert, dass Sie die CORA E-Books auf Ihre gewünschten Lesegeräte
Wenn Russland kein Gas mehr liefert
 Ergänzen Sie die fehlenden Begriffe aus der Liste. abhängig Abhängigkeit bekommen betroffen bezahlen Gasspeicher Gasverbrauch gering hätte helfen importieren liefert 0:02 Pläne politischen Projekte Prozent
Ergänzen Sie die fehlenden Begriffe aus der Liste. abhängig Abhängigkeit bekommen betroffen bezahlen Gasspeicher Gasverbrauch gering hätte helfen importieren liefert 0:02 Pläne politischen Projekte Prozent
Primzahlen und RSA-Verschlüsselung
 Primzahlen und RSA-Verschlüsselung Michael Fütterer und Jonathan Zachhuber 1 Einiges zu Primzahlen Ein paar Definitionen: Wir bezeichnen mit Z die Menge der positiven und negativen ganzen Zahlen, also
Primzahlen und RSA-Verschlüsselung Michael Fütterer und Jonathan Zachhuber 1 Einiges zu Primzahlen Ein paar Definitionen: Wir bezeichnen mit Z die Menge der positiven und negativen ganzen Zahlen, also
Statistik mit Excel. für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE. Markt+Technik
 Statistik mit Excel für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE Markt+Technik Vorwort Schreiben Sie uns! 13 15 Statistische Untersuchungen 17 Wozu Statistik? 18 Wirtschaftliche
Statistik mit Excel für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE Markt+Technik Vorwort Schreiben Sie uns! 13 15 Statistische Untersuchungen 17 Wozu Statistik? 18 Wirtschaftliche
Hauptabteilung Politische Bildung
 Hauptabteilung Politische Bildung Digitale Kultur und politische Bildung - Ergebnisse einer repräsentativen Umfrage - Die Auswertung beruht auf einer Umfrage in der zweiten Oktoberhälfte 2011. Insgesamt
Hauptabteilung Politische Bildung Digitale Kultur und politische Bildung - Ergebnisse einer repräsentativen Umfrage - Die Auswertung beruht auf einer Umfrage in der zweiten Oktoberhälfte 2011. Insgesamt
Bachelorabschlussseminar Dipl.-Kfm. Daniel Cracau
 1 Einführung in die statistische Datenanalyse Bachelorabschlussseminar Dipl.-Kfm. Daniel Cracau 2 Gliederung 1.Grundlagen 2.Nicht-parametrische Tests a. Mann-Whitney-Wilcoxon-U Test b. Wilcoxon-Signed-Rank
1 Einführung in die statistische Datenanalyse Bachelorabschlussseminar Dipl.-Kfm. Daniel Cracau 2 Gliederung 1.Grundlagen 2.Nicht-parametrische Tests a. Mann-Whitney-Wilcoxon-U Test b. Wilcoxon-Signed-Rank
Erwin Grüner 09.02.2006
 FB Psychologie Uni Marburg 09.02.2006 Themenübersicht Folgende Befehle stehen in R zur Verfügung: {}: Anweisungsblock if: Bedingte Anweisung switch: Fallunterscheidung repeat-schleife while-schleife for-schleife
FB Psychologie Uni Marburg 09.02.2006 Themenübersicht Folgende Befehle stehen in R zur Verfügung: {}: Anweisungsblock if: Bedingte Anweisung switch: Fallunterscheidung repeat-schleife while-schleife for-schleife
Statistik mit Excel. für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE
 Statistik mit Excel für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE INHALTS- VERZEICHNIS Vorwort 13 Schreiben Sie uns! 15 1 Statistische Untersuchungen 17 Wozu Statistik? 18
Statistik mit Excel für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE INHALTS- VERZEICHNIS Vorwort 13 Schreiben Sie uns! 15 1 Statistische Untersuchungen 17 Wozu Statistik? 18
4. Erstellen von Klassen
 Statistik mit Tabellenkalkulation 4. Erstellen von Klassen Mit einem einfachen Befehl lässt sich eine Liste von Zahlen auf die Häufigkeit der einzelnen Werte untersuchen. Verwenden Sie dazu den Befehl
Statistik mit Tabellenkalkulation 4. Erstellen von Klassen Mit einem einfachen Befehl lässt sich eine Liste von Zahlen auf die Häufigkeit der einzelnen Werte untersuchen. Verwenden Sie dazu den Befehl
Diana Lange. GENERATIVE GESTALTUNG Arten des Zufalls
 Diana Lange GENERATIVE GESTALTUNG Arten des Zufalls RANDOM int index = 0; while (index < 200) { float x = random(0, width); float y = random(0, height); float d = random(40, 100); ellipse(x, y, d, d);
Diana Lange GENERATIVE GESTALTUNG Arten des Zufalls RANDOM int index = 0; while (index < 200) { float x = random(0, width); float y = random(0, height); float d = random(40, 100); ellipse(x, y, d, d);
Überblick über die Tests
 Anhang A Überblick über die Tests A.1 Ein-Stichproben-Tests A.1.1 Tests auf Verteilungsannahmen ˆ Shapiro-Wilk-Test Situation: Test auf Normalverteilung H 0 : X N(µ, σ 2 ) H 1 : X nicht normalverteilt
Anhang A Überblick über die Tests A.1 Ein-Stichproben-Tests A.1.1 Tests auf Verteilungsannahmen ˆ Shapiro-Wilk-Test Situation: Test auf Normalverteilung H 0 : X N(µ, σ 2 ) H 1 : X nicht normalverteilt
Verband der TÜV e. V. STUDIE ZUM IMAGE DER MPU
 Verband der TÜV e. V. STUDIE ZUM IMAGE DER MPU 2 DIE MEDIZINISCH-PSYCHOLOGISCHE UNTERSUCHUNG (MPU) IST HOCH ANGESEHEN Das Image der Medizinisch-Psychologischen Untersuchung (MPU) ist zwiespältig: Das ist
Verband der TÜV e. V. STUDIE ZUM IMAGE DER MPU 2 DIE MEDIZINISCH-PSYCHOLOGISCHE UNTERSUCHUNG (MPU) IST HOCH ANGESEHEN Das Image der Medizinisch-Psychologischen Untersuchung (MPU) ist zwiespältig: Das ist
Das Dilemma des Einbrechers Wer die Wahl hat, hat die Qual!
 Das Dilemma des Einbrechers Wer die Wahl hat, hat die Qual! 0kg 4000 Euro Luster 5,5 kg, 430.- Laptop 2,0 kg, 000.- Schatulle 3,2 kg, 800.- Uhr 3,5 kg, 70.- Schwert,5 kg, 850.- Bild 3,4 kg, 680.- Besteck
Das Dilemma des Einbrechers Wer die Wahl hat, hat die Qual! 0kg 4000 Euro Luster 5,5 kg, 430.- Laptop 2,0 kg, 000.- Schatulle 3,2 kg, 800.- Uhr 3,5 kg, 70.- Schwert,5 kg, 850.- Bild 3,4 kg, 680.- Besteck
Bürger legen Wert auf selbstbestimmtes Leben
 PRESSEINFORMATION Umfrage Patientenverfügung Bürger legen Wert auf selbstbestimmtes Leben Ergebnisse der forsa-umfrage zur Patientenverfügung im Auftrag von VorsorgeAnwalt e.v. Der Verband VorsorgeAnwalt
PRESSEINFORMATION Umfrage Patientenverfügung Bürger legen Wert auf selbstbestimmtes Leben Ergebnisse der forsa-umfrage zur Patientenverfügung im Auftrag von VorsorgeAnwalt e.v. Der Verband VorsorgeAnwalt
Aber zuerst: Was versteht man unter Stromverbrauch im Standby-Modus (Leerlaufverlust)?
?") Ich habe eine Umfrage durchgeführt zum Thema Stromverbrauch im Standby Modus! Ich habe 50 Personen befragt und allen 4 Fragen gestellt. Ich werde diese hier, anhand von Grafiken auswerten! Aber zuerst:
Ich habe eine Umfrage durchgeführt zum Thema Stromverbrauch im Standby Modus! Ich habe 50 Personen befragt und allen 4 Fragen gestellt. Ich werde diese hier, anhand von Grafiken auswerten! Aber zuerst:
Institut für Marketing und Handel Prof. Dr. W. Toporowski. SPSS Übung 5. Heutige Themen: Faktorenanalyse. Einführung in Amos
 SPSS Übung 5 Heutige Themen: Faktorenanalyse Einführung in Amos 1 Faktorenanalyse Datei Öffnen V:/Lehre/Handelswissenschaft/Daten_Übung3/Preisimage_F_und_C.sav 2 Datensatz (I) v1 Wenn Produkte zu Sonderpreisen
SPSS Übung 5 Heutige Themen: Faktorenanalyse Einführung in Amos 1 Faktorenanalyse Datei Öffnen V:/Lehre/Handelswissenschaft/Daten_Übung3/Preisimage_F_und_C.sav 2 Datensatz (I) v1 Wenn Produkte zu Sonderpreisen
MSXFORUM - Exchange Server 2003 > SMTP Konfiguration von Exchange 2003
 Page 1 of 8 SMTP Konfiguration von Exchange 2003 Kategorie : Exchange Server 2003 Veröffentlicht von webmaster am 25.02.2005 SMTP steht für Simple Mail Transport Protocol, welches ein Protokoll ist, womit
Page 1 of 8 SMTP Konfiguration von Exchange 2003 Kategorie : Exchange Server 2003 Veröffentlicht von webmaster am 25.02.2005 SMTP steht für Simple Mail Transport Protocol, welches ein Protokoll ist, womit
Investition und Risiko. Finanzwirtschaft I 5. Semester
 Investition und Risiko Finanzwirtschaft I 5. Semester 1 Gliederung Ziel Korrekturverfahren: Einfache Verfahren der Risikoberücksichtigung Sensitivitätsanalyse Monte Carlo Analyse Investitionsentscheidung
Investition und Risiko Finanzwirtschaft I 5. Semester 1 Gliederung Ziel Korrekturverfahren: Einfache Verfahren der Risikoberücksichtigung Sensitivitätsanalyse Monte Carlo Analyse Investitionsentscheidung
Statistische Analyse von Ereigniszeiten
 Statistische Analyse von Survival Analysis VO Biostatistik im WS 2006/2007 1 2 3 : Leukemiedaten (unzensiert) 33 Patienten mit Leukemie; Zielvariable Überlebenszeit. Alle Patienten verstorben und Überlebenszeit
Statistische Analyse von Survival Analysis VO Biostatistik im WS 2006/2007 1 2 3 : Leukemiedaten (unzensiert) 33 Patienten mit Leukemie; Zielvariable Überlebenszeit. Alle Patienten verstorben und Überlebenszeit
Wie ist das Wissen von Jugendlichen über Verhütungsmethoden?
 Forschungsfragen zu Verhütung 1 Forschungsfragen zu Verhütung Wie ist das Wissen von Jugendlichen über Verhütungsmethoden? Wie viel Information über Verhütung ist enthalten? Wie wird das Thema erklärt?
Forschungsfragen zu Verhütung 1 Forschungsfragen zu Verhütung Wie ist das Wissen von Jugendlichen über Verhütungsmethoden? Wie viel Information über Verhütung ist enthalten? Wie wird das Thema erklärt?
Klausur Nr. 1. Wahrscheinlichkeitsrechnung. Keine Hilfsmittel gestattet, bitte alle Lösungen auf dieses Blatt.
 Klausur Nr. 1 2014-02-06 Wahrscheinlichkeitsrechnung Pflichtteil Keine Hilfsmittel gestattet, bitte alle Lösungen auf dieses Blatt. Name: 0. Für Pflicht- und Wahlteil gilt: saubere und übersichtliche Darstellung,
Klausur Nr. 1 2014-02-06 Wahrscheinlichkeitsrechnung Pflichtteil Keine Hilfsmittel gestattet, bitte alle Lösungen auf dieses Blatt. Name: 0. Für Pflicht- und Wahlteil gilt: saubere und übersichtliche Darstellung,
Risikoeinstellungen empirisch
 Risikoeinstellungen empirisch Risk attitude and Investment Decisions across European Countries Are women more conservative investors than men? Oleg Badunenko, Nataliya Barasinska, Dorothea Schäfer http://www.diw.de/deutsch/soep/uebersicht_ueber_das_soep/27180.html#79569
Risikoeinstellungen empirisch Risk attitude and Investment Decisions across European Countries Are women more conservative investors than men? Oleg Badunenko, Nataliya Barasinska, Dorothea Schäfer http://www.diw.de/deutsch/soep/uebersicht_ueber_das_soep/27180.html#79569
Private Altersvorsorge
 Private Altersvorsorge Datenbasis: 1.003 Befragte im Alter von 18 bis 65 Jahren, bundesweit Erhebungszeitraum: 10. bis 16. November 2009 Statistische Fehlertoleranz: +/- 3 Prozentpunkte Auftraggeber: HanseMerkur,
Private Altersvorsorge Datenbasis: 1.003 Befragte im Alter von 18 bis 65 Jahren, bundesweit Erhebungszeitraum: 10. bis 16. November 2009 Statistische Fehlertoleranz: +/- 3 Prozentpunkte Auftraggeber: HanseMerkur,
2 Evaluierung von Retrievalsystemen
 2. Evaluierung von Retrievalsystemen Relevanz 2 Evaluierung von Retrievalsystemen Die Evaluierung von Verfahren und Systemen spielt im IR eine wichtige Rolle. Gemäß der Richtlinien für IR der GI gilt es,...
2. Evaluierung von Retrievalsystemen Relevanz 2 Evaluierung von Retrievalsystemen Die Evaluierung von Verfahren und Systemen spielt im IR eine wichtige Rolle. Gemäß der Richtlinien für IR der GI gilt es,...
Fortgeschrittene Statistik Logistische Regression
 Fortgeschrittene Statistik Logistische Regression O D D S, O D D S - R A T I O, L O G I T T R A N S F O R M A T I O N, I N T E R P R E T A T I O N V O N K O E F F I Z I E N T E N, L O G I S T I S C H E
Fortgeschrittene Statistik Logistische Regression O D D S, O D D S - R A T I O, L O G I T T R A N S F O R M A T I O N, I N T E R P R E T A T I O N V O N K O E F F I Z I E N T E N, L O G I S T I S C H E
Willkommen zur Vorlesung Statistik
 Willkommen zur Vorlesung Statistik Thema dieser Vorlesung: Varianzanalyse Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften Prof. Dr. Wolfgang
Willkommen zur Vorlesung Statistik Thema dieser Vorlesung: Varianzanalyse Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften Prof. Dr. Wolfgang
Musterlösung zu Serie 14
 Dr. Lukas Meier Statistik und Wahrscheinlichkeitsrechnung FS 21 Musterlösung zu Serie 14 1. Der Datensatz von Forbes zeigt Messungen von Siedepunkt (in F) und Luftdruck (in inches of mercury) an verschiedenen
Dr. Lukas Meier Statistik und Wahrscheinlichkeitsrechnung FS 21 Musterlösung zu Serie 14 1. Der Datensatz von Forbes zeigt Messungen von Siedepunkt (in F) und Luftdruck (in inches of mercury) an verschiedenen
Univariates Chi-Quadrat-Verfahren für ein dichotomes Merkmal und eine Messwiederholung: Test nach McNemar
 Univariates Chi-Quadrat-Verfahren für ein dichotomes Merkmal und eine Messwiederholung: Test nach McNemar Inhaltsverzeichnis Univariates Chi-Quadrat-Verfahren für ein dichotomes Merkmal und eine Messwiederholung:
Univariates Chi-Quadrat-Verfahren für ein dichotomes Merkmal und eine Messwiederholung: Test nach McNemar Inhaltsverzeichnis Univariates Chi-Quadrat-Verfahren für ein dichotomes Merkmal und eine Messwiederholung:
Bernadette Büsgen HR-Consulting www.buesgen-consult.de
 Reiss Profile Es ist besser mit dem Wind zu segeln, als gegen ihn! Möchten Sie anhand Ihres Reiss Rofiles erkennen, woher Ihr Wind weht? Sie haben verschiedene Möglichkeiten, Ihr Leben aktiv zu gestalten.
Reiss Profile Es ist besser mit dem Wind zu segeln, als gegen ihn! Möchten Sie anhand Ihres Reiss Rofiles erkennen, woher Ihr Wind weht? Sie haben verschiedene Möglichkeiten, Ihr Leben aktiv zu gestalten.
Scrum. Übung 3. Grundlagen des Software Engineerings. Asim Abdulkhaleq 20 November 2014
 Grundlagen des Software Engineerings Übung 3 Scrum Asim Abdulkhaleq 20 November 2014 http://www.apartmedia.de 1 Inhalte Scrum Wiederholung Was ist Scrum? Übung: Scrum Workshop (Bank Accounts Management
Grundlagen des Software Engineerings Übung 3 Scrum Asim Abdulkhaleq 20 November 2014 http://www.apartmedia.de 1 Inhalte Scrum Wiederholung Was ist Scrum? Übung: Scrum Workshop (Bank Accounts Management
Glaube an die Existenz von Regeln für Vergleiche und Kenntnis der Regeln
 Glaube an die Existenz von Regeln für Vergleiche und Kenntnis der Regeln Regeln ja Regeln nein Kenntnis Regeln ja Kenntnis Regeln nein 0 % 10 % 20 % 30 % 40 % 50 % 60 % 70 % 80 % 90 % Glauben Sie, dass
Glaube an die Existenz von Regeln für Vergleiche und Kenntnis der Regeln Regeln ja Regeln nein Kenntnis Regeln ja Kenntnis Regeln nein 0 % 10 % 20 % 30 % 40 % 50 % 60 % 70 % 80 % 90 % Glauben Sie, dass
Häufigkeitstabellen. Balken- oder Kreisdiagramme. kritischer Wert für χ2-test. Kontingenztafeln
 Häufigkeitstabellen Menüpunkt Data PivotTable Report (bzw. entsprechendes Icon): wähle Data Range (Zellen, die die Daten enthalten + Zelle mit Variablenname) wähle kategoriale Variable für Spalten- oder
Häufigkeitstabellen Menüpunkt Data PivotTable Report (bzw. entsprechendes Icon): wähle Data Range (Zellen, die die Daten enthalten + Zelle mit Variablenname) wähle kategoriale Variable für Spalten- oder
Statuten in leichter Sprache
 Statuten in leichter Sprache Zweck vom Verein Artikel 1: Zivil-Gesetz-Buch Es gibt einen Verein der selbstbestimmung.ch heisst. Der Verein ist so aufgebaut, wie es im Zivil-Gesetz-Buch steht. Im Zivil-Gesetz-Buch
Statuten in leichter Sprache Zweck vom Verein Artikel 1: Zivil-Gesetz-Buch Es gibt einen Verein der selbstbestimmung.ch heisst. Der Verein ist so aufgebaut, wie es im Zivil-Gesetz-Buch steht. Im Zivil-Gesetz-Buch
Warum Sie dieses Buch lesen sollten
 Warum Sie dieses Buch lesen sollten zont nicht schaden können. Sie haben die Krise ausgesessen und können sich seit 2006 auch wieder über ordentliche Renditen freuen. Ähnliches gilt für die Immobilienblase,
Warum Sie dieses Buch lesen sollten zont nicht schaden können. Sie haben die Krise ausgesessen und können sich seit 2006 auch wieder über ordentliche Renditen freuen. Ähnliches gilt für die Immobilienblase,