GEODÄTISCHES INSTITUT HANNOVER
|
|
|
- Björn Kranz
- vor 6 Jahren
- Abrufe
Transkript

1 Alexander Dorndorf, M.Sc. GEODÄTISCHES INSTITUT HANNOVER Entwicklung eines robusten Bayesschen Ansatzes für klein-redundante Ausgleichungsmodelle

2 Motivation Funktionaler Zusammenhang: h = β 0 + β 1 x + β 2 y 2
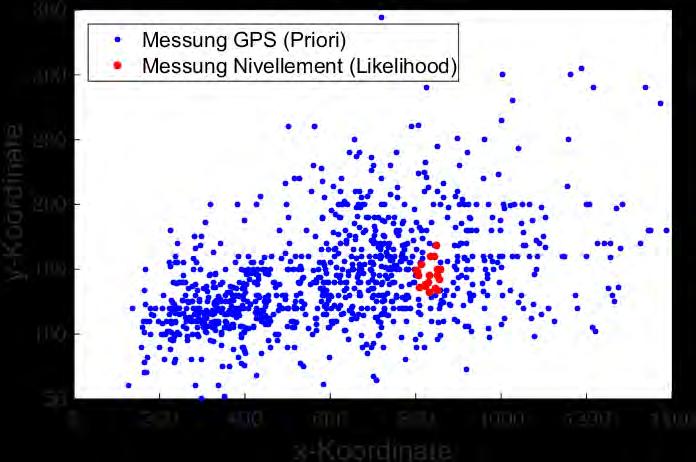

3 Motivation 3
4 Agenda 1. Bayesischer Ansatz 2. Vorstellung eines robusten Bayesschen Ansatzes 3. Validierung des robusten Bayesschen Ansatzes 4. Fazit und Ausblick 4
5 Bayesischer Ansatz Bayesischer Ansatz: P β y P β P y β Kombiniert Prioriwissen und Daten mit Hilfe des Bayes- Theorems auf Basis von Wahrscheinlichkeitsdichten 5
6 Bayesischer Ansatz Bayesischer Ansatz: P β y P β P y β Kombiniert Prioriwissen und Daten mit Hilfe des Bayes- Theorems auf Basis von Wahrscheinlichkeitsdichten Priori-Dichte: P β Ergebnis einer vorherigen Ausgleichung Ergebnis einer Expertenbefragung Herstellerangaben z.b. Fehlerquellen von Messinstrument Vorwissen über die Objektgeometrie oder Messkonfiguration 5
7 Bayesischer Ansatz Bayesischer Ansatz: P β y P β P y β Kombiniert Prioriwissen und Daten mit Hilfe des Bayes- Theorems auf Basis von Wahrscheinlichkeitsdichten Priori-Dichte: P β Ergebnis einer vorherigen Ausgleichung Ergebnis einer Expertenbefragung Herstellerangaben z.b. Fehlerquellen von Messinstrument Vorwissen über die Objektgeometrie oder Messkonfiguration Likelihood-Funktion: P y β Messungen (Beobachtungen) Verteilungsannahmen der zu schätzenden Fehler 5
8 Bayesischer Ansatz Bayesischer Ansatz: P β y P β P y β Verteilung der Beobachtungen 6

9 Bayesischer Ansatz Bayesischer Ansatz: P β y P β P y β Verteilung der Beobachtungen Student-Verteilung unempfindlicher gegenüber Ausreißern 6
10 Robuster Bayesischer Ansatz Ansatz: t-verteilung für Gewichtung der Likelihood-Funktion Likelihood: P y Xβ, var ε ~N Xβ, var ε Priori-Dichte: P β, σ, ω P β P σ P ω und β, σ, ω sind stochastisch unabhängig Posteriori Dichte: β = X T Ω X + σ 2 V 1 1 X T Ω y + σ 2 V 1 β y : Unabhängige Daten (Höhe Nivellement) X : Abhängige Einflussgrößen (Koordinaten) β: Posteriori-Dichte (Regressionskoeffizienten) β : Priori-Wissen über Koeffizienten aus GPS V : VKM der Priori-Koeffizienten aus GPS σ 2 : Priori-Wissen Varianzfaktor. Gewichtung der Priori-Dichte mit der Likelihood Funktion Ω : Priori-Wissen Gewichtsmatrix Likelihood 7
11 Robuster Bayesischer Ansatz Numerische Lösung der Posteriori-Dichte mit Markov-Chain-Monte-Carlo 1. Generierung von Ω j mit σ j 1 und β j 1 3. Generierung von β j mit σ j und Ω j 2. Generierung von σ j mit β j 1 und Ω j Ergebnis: β = mean β j Schematischer Ablauf Gibbs-Sampler 8
12 Robuster Bayesischer Ansatz Numerische Lösung der Posteriori-Dichte mit Markov-Chain-Monte-Carlo 1. Generierung von Ω j mit σ j 1 und β j 1 3. Generierung von β j mit σ j und Ω j 2. Generierung von σ j mit β j 1 und Ω j Ergebnis: β = mean β j Schematischer Ablauf Gibbs-Sampler 8


13 Robuster Bayesischer Ansatz Bestimmung der Gewichte ω mit der t-verteilung: σ 2 ε i 2 +ν ω i β, σ ~χ 2 υ + 1 mit ε i 2 = y i X i β 2 Ω j = 1/ω /ω n 9

14 Robuster Bayesischer Ansatz Iterationen Gibbs-Sampler:
15 Robuster Bayesischer Ansatz Iterationen Gibbs-Sampler:

16 Robuster Bayesischer Ansatz Iterationen Gibbs-Sampler:
17 Robuster Bayesischer Ansatz Iterationen Gibbs-Sampler:
18 Robuster Bayesischer Ansatz In jeder Iteration j werden neue Gewichte gezogen Ausreißeranteil < 50 % Beobachtungen ohne Ausreißer werden öfter zur Berechnung von β verwendet 11
19 Validierung Sensitivitätsanalyse mit Monte-Carlo-Simulation (MCS) Anzahl Priori: 1000 Messungen Anzahl Likelihood: 20 Messungen Messrauschen σ Priori : 15 σ Likelihood Anteil Ausreißer: 20% Verteilung Ausreißer: 12

20 Validierung Sensitivitätsanalyse mit Monte-Carlo-Simulation (MCS) Anzahl Priori: 1000 Messungen Anzahl Likelihood: 20 Messungen Messrauschen σ Priori : 15 σ Likelihood Anteil Ausreißer: 20% Verteilung Ausreißer: nicht normalverteilt Ausreißer < E(h) 12
21 Validierung Ergebnis für eine Iteration der Sensitivitätsanalyse 13
22 Validierung Ergebnis für eine Iteration der Sensitivitätsanalyse Ergebnis der MCS für Iterationen Beobachtung y Regression Klassisch Huber Bayes Robust Nicht Informativ Informativ RMSE zu E y 32,42 16,49 10,25 10,19 3,94 13
23 Fazit und Ausblick Die Priori-Dichte beeinflusst die Posteriori-Dichte stärker bei kleinen n der Likelihood Robustheit hängt vom Freiheitsgrad υ ab Zukünftige Arbeiten: Freiheitsgrad υ mitschätzen Kombinierung verschiedener Priori-Informationen Varianzfaktor für Gewichtung optimieren 14





24 Fazit und Ausblick Die Priori-Dichte beeinflusst die Posteriori-Dichte stärker bei kleinen n der Likelihood Robustheit hängt vom Freiheitsgrad υ ab Zukünftige Arbeiten: Freiheitsgrad υ mitschätzen Kombinierung verschiedener Priori-Informationen Varianzfaktor für Gewichtung optimieren DFG Projekt: & Immobilienbewertung in kaufpreisarmen Lagen durch ein Robustes Bayesisches hedonisches Modell (WE 5631/1-1) 14
25 15
26 Validierung Ergebnis für eine Iteration der Sensitivitätsanalyse Ergebnis der MCS für Iterationen Regression Huber Nicht Informativ Informativ Δ b1 / σ1-14,02 326,53-1,58 259,076-2,13 249,57-0,15 17,92 Δ b2 / σ2 0,0005 0, ,0019 0,3010 0,0040 0,2898-0,0068 0,0162 Δ b3 / σ3-0,0002 0,7208-0,0517 0,5880-0,0597 0,5651 0,0177 0,1286 RMSE von y 16,49 10,25 10,19 3,94 16
κ Κα π Κ α α Κ Α
 κ Κα π Κ α α Κ Α Ζ Μ Κ κ Ε Φ π Α Γ Κ Μ Ν Ξ λ Γ Ξ Ν Μ Ν Ξ Ξ Τ κ ζ Ν Ν ψ Υ α α α Κ α π α ψ Κ α α α α α Α Κ Ε α α α α α α α Α α α α α η Ε α α α Ξ α α Γ Α Κ Κ Κ Ε λ Ε Ν Ε θ Ξ κ Ε Ν Κ Μ Ν Τ μ Υ Γ φ Ε Κ Τ θ
κ Κα π Κ α α Κ Α Ζ Μ Κ κ Ε Φ π Α Γ Κ Μ Ν Ξ λ Γ Ξ Ν Μ Ν Ξ Ξ Τ κ ζ Ν Ν ψ Υ α α α Κ α π α ψ Κ α α α α α Α Κ Ε α α α α α α α Α α α α α η Ε α α α Ξ α α Γ Α Κ Κ Κ Ε λ Ε Ν Ε θ Ξ κ Ε Ν Κ Μ Ν Τ μ Υ Γ φ Ε Κ Τ θ
Simulationsmethoden in der Bayes-Statistik
 Simulationsmethoden in der Bayes-Statistik Hansruedi Künsch Seminar für Statistik, ETH Zürich 6. Juni 2012 Inhalt Warum Simulation? Modellspezifikation Markovketten Monte Carlo Simulation im Raum der Sprungfunktionen
Simulationsmethoden in der Bayes-Statistik Hansruedi Künsch Seminar für Statistik, ETH Zürich 6. Juni 2012 Inhalt Warum Simulation? Modellspezifikation Markovketten Monte Carlo Simulation im Raum der Sprungfunktionen
Problem aller bisheriger Methoden: Ergebnis ist nur so gut wie das Modell selbst.
 2.7 Validierung durch Backtesting Problem aller bisheriger Methoden: Ergebnis ist nur so gut wie das Modell selbst. Modell besteht im Wesentlichen aus zwei Faktoren: 1. Einflussgrößen 2. Modellierungsalgorithmus
2.7 Validierung durch Backtesting Problem aller bisheriger Methoden: Ergebnis ist nur so gut wie das Modell selbst. Modell besteht im Wesentlichen aus zwei Faktoren: 1. Einflussgrößen 2. Modellierungsalgorithmus
1. Lösungen zu Kapitel 7
 1. Lösungen zu Kapitel 7 Übungsaufgabe 7.1 Um zu testen ob die Störterme ε i eine konstante Varianz haben, sprich die Homogenitätsannahme erfüllt ist, sind der Breusch-Pagan-Test und der White- Test zwei
1. Lösungen zu Kapitel 7 Übungsaufgabe 7.1 Um zu testen ob die Störterme ε i eine konstante Varianz haben, sprich die Homogenitätsannahme erfüllt ist, sind der Breusch-Pagan-Test und der White- Test zwei
Einführung in die Bayes-Statistik. Helga Wagner. Ludwig-Maximilians-Universität München WS 2010/11. Helga Wagner Bayes Statistik WS 2010/11 1
 Einführung in die Bayes-Statistik Helga Wagner Ludwig-Maximilians-Universität München WS 2010/11 Helga Wagner Bayes Statistik WS 2010/11 1 Organisatorisches Termine: Montag: 16.00-18.00 AU115 Dienstag:
Einführung in die Bayes-Statistik Helga Wagner Ludwig-Maximilians-Universität München WS 2010/11 Helga Wagner Bayes Statistik WS 2010/11 1 Organisatorisches Termine: Montag: 16.00-18.00 AU115 Dienstag:
8. Keine Normalverteilung der Störgrößen (Verletzung der B4-Annahme)
") 8. Keine Normalverteilung der Störgrößen (Verletzung der B4-Annahme) Annahme B4: Die Störgrößen u i sind normalverteilt, d.h. u i N(0, σ 2 ) Beispiel: [I] Neoklassisches Solow-Wachstumsmodell Annahme einer
8. Keine Normalverteilung der Störgrößen (Verletzung der B4-Annahme) Annahme B4: Die Störgrößen u i sind normalverteilt, d.h. u i N(0, σ 2 ) Beispiel: [I] Neoklassisches Solow-Wachstumsmodell Annahme einer
ANalysis Of VAriance (ANOVA) 2/2
 2/2") ANalysis Of VAriance (ANOVA) 2/2 Markus Kalisch 22.10.2014 1 Wdh: ANOVA - Idee ANOVA 1: Zwei Medikamente zur Blutdrucksenkung und Placebo (Faktor X). Gibt es einen sign. Unterschied in der Wirkung (kontinuierlich
ANalysis Of VAriance (ANOVA) 2/2 Markus Kalisch 22.10.2014 1 Wdh: ANOVA - Idee ANOVA 1: Zwei Medikamente zur Blutdrucksenkung und Placebo (Faktor X). Gibt es einen sign. Unterschied in der Wirkung (kontinuierlich
Vorlesung 8a. Kovarianz und Korrelation
 Vorlesung 8a Kovarianz und Korrelation 1 Wir erinnern an die Definition der Kovarianz Für reellwertige Zufallsvariable X, Y mit E[X 2 ] < und E[Y 2 ] < ist Cov[X, Y ] := E [ (X EX)(Y EY ) ] Insbesondere
Vorlesung 8a Kovarianz und Korrelation 1 Wir erinnern an die Definition der Kovarianz Für reellwertige Zufallsvariable X, Y mit E[X 2 ] < und E[Y 2 ] < ist Cov[X, Y ] := E [ (X EX)(Y EY ) ] Insbesondere
Überblick. Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung
 Grundlagen Überblick Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes- Entscheidungsfunktionen
Grundlagen Überblick Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes- Entscheidungsfunktionen
Clusteranalyse: Gauß sche Mischmodelle
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse: Gauß sche Mischmodelle iels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse: Gauß sche Mischmodelle iels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
4. Das multiple lineare Regressionsmodell
 4. Das multiple lineare Regressionsmodell Bisher: 1 endogene Variable y wurde zurückgeführt auf 1 exogene Variable x (einfaches lineares Regressionsmodell) Jetzt: Endogenes y wird regressiert auf mehrere
4. Das multiple lineare Regressionsmodell Bisher: 1 endogene Variable y wurde zurückgeführt auf 1 exogene Variable x (einfaches lineares Regressionsmodell) Jetzt: Endogenes y wird regressiert auf mehrere
Statistics, Data Analysis, and Simulation SS 2015
 Mainz, May 12, 2015 Statistics, Data Analysis, and Simulation SS 2015 08.128.730 Statistik, Datenanalyse und Simulation Dr. Michael O. Distler Dr. Michael O. Distler
Mainz, May 12, 2015 Statistics, Data Analysis, and Simulation SS 2015 08.128.730 Statistik, Datenanalyse und Simulation Dr. Michael O. Distler Dr. Michael O. Distler
1 Gemischte Lineare Modelle
 1 Gemischte Lineare Modelle Wir betrachten zunächst einige allgemeine Aussagen für Gemischte Lineare Modelle, ohne zu tief in die mathematisch-statistische Theorie vorzustoßen. Danach betrachten wir zunächst
1 Gemischte Lineare Modelle Wir betrachten zunächst einige allgemeine Aussagen für Gemischte Lineare Modelle, ohne zu tief in die mathematisch-statistische Theorie vorzustoßen. Danach betrachten wir zunächst
Analyse von Querschnittsdaten. Signifikanztests I Basics
 Analyse von Querschnittsdaten Signifikanztests I Basics Warum geht es in den folgenden Sitzungen? Kontinuierliche Variablen Generalisierung kategoriale Variablen Datum 13.10.2004 20.10.2004 27.10.2004
Analyse von Querschnittsdaten Signifikanztests I Basics Warum geht es in den folgenden Sitzungen? Kontinuierliche Variablen Generalisierung kategoriale Variablen Datum 13.10.2004 20.10.2004 27.10.2004
Simulation von Zufallsvariablen und Punktprozessen
 Simulation von Zufallsvariablen und Punktprozessen 09.11.2009 Inhaltsverzeichnis 1 Einleitung 2 Pseudozufallszahlen 3 Punktprozesse Zufallszahlen Definition (Duden): Eine Zufallszahl ist eine Zahl, die
Simulation von Zufallsvariablen und Punktprozessen 09.11.2009 Inhaltsverzeichnis 1 Einleitung 2 Pseudozufallszahlen 3 Punktprozesse Zufallszahlen Definition (Duden): Eine Zufallszahl ist eine Zahl, die
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 2016
 Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 1 M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Übungsblatt 3 Maschinelles Lernen und Klassifikation Abgabe online
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 1 M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Übungsblatt 3 Maschinelles Lernen und Klassifikation Abgabe online
Prof. Dr. Walter F. Tichy Dr. Matthias Müller Sommersemester 2006
 Empirische Softwaretechnik Prof. Dr. Walter F. Tichy Dr. Matthias Müller Sommersemester 2006 1 Experiment zur Vererbungstiefe Softwaretechnik: die Vererbungstiefe ist kein guter Schätzer für den Wartungsaufwand
Empirische Softwaretechnik Prof. Dr. Walter F. Tichy Dr. Matthias Müller Sommersemester 2006 1 Experiment zur Vererbungstiefe Softwaretechnik: die Vererbungstiefe ist kein guter Schätzer für den Wartungsaufwand
Empirische Analysen mit dem SOEP
 Empirische Analysen mit dem SOEP Methodisches Lineare Regressionsanalyse & Logit/Probit Modelle Kurs im Wintersemester 2007/08 Dipl.-Volksw. Paul Böhm Dipl.-Volksw. Dominik Hanglberger Dipl.-Volksw. Rafael
Empirische Analysen mit dem SOEP Methodisches Lineare Regressionsanalyse & Logit/Probit Modelle Kurs im Wintersemester 2007/08 Dipl.-Volksw. Paul Böhm Dipl.-Volksw. Dominik Hanglberger Dipl.-Volksw. Rafael
Übung zu Empirische Ökonomie für Fortgeschrittene SS 2009
 Übung zu Empirische Ökonomie für Fortgeschrittene Steen Elstner, Klaus Wohlrabe, Steen Henzel SS 9 1 Wichtige Verteilungen Die Normalverteilung Eine stetige Zufallsvariable mit der Wahrscheinlichkeitsdichte
Übung zu Empirische Ökonomie für Fortgeschrittene Steen Elstner, Klaus Wohlrabe, Steen Henzel SS 9 1 Wichtige Verteilungen Die Normalverteilung Eine stetige Zufallsvariable mit der Wahrscheinlichkeitsdichte
Konfidenzintervalle Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Anteilswert Differenzen von Erwartungswert Anteilswert
 Konfidenzintervalle Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Anteilswert Differenzen von Erwartungswert Anteilswert Beispiel für Konfidenzintervall Im Prinzip haben wir
Konfidenzintervalle Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Anteilswert Differenzen von Erwartungswert Anteilswert Beispiel für Konfidenzintervall Im Prinzip haben wir
Computer Vision: Kalman Filter
 Computer Vision: Kalman Filter D. Schlesinger TUD/INF/KI/IS D. Schlesinger () Computer Vision: Kalman Filter 1 / 8 Bayesscher Filter Ein Objekt kann sich in einem Zustand x X befinden. Zum Zeitpunkt i
Computer Vision: Kalman Filter D. Schlesinger TUD/INF/KI/IS D. Schlesinger () Computer Vision: Kalman Filter 1 / 8 Bayesscher Filter Ein Objekt kann sich in einem Zustand x X befinden. Zum Zeitpunkt i
Kapitel 3. Inferenz bei OLS-Schätzung I (small sample, unter GM1,..., GM6)
") 8 SMALL SAMPLE INFERENZ DER OLS-SCHÄTZUNG Damit wir die Verteilung von t (und anderen Teststatistiken) exakt angeben können, benötigen wir Verteilungsannahmen über die Störterme; Kapitel 3 Inferenz bei
8 SMALL SAMPLE INFERENZ DER OLS-SCHÄTZUNG Damit wir die Verteilung von t (und anderen Teststatistiken) exakt angeben können, benötigen wir Verteilungsannahmen über die Störterme; Kapitel 3 Inferenz bei
Einführung in die Maximum Likelihood Methodik
 in die Maximum Likelihood Methodik Thushyanthan Baskaran thushyanthan.baskaran@awi.uni-heidelberg.de Alfred Weber Institut Ruprecht Karls Universität Heidelberg Gliederung 1 2 3 4 2 / 31 Maximum Likelihood
in die Maximum Likelihood Methodik Thushyanthan Baskaran thushyanthan.baskaran@awi.uni-heidelberg.de Alfred Weber Institut Ruprecht Karls Universität Heidelberg Gliederung 1 2 3 4 2 / 31 Maximum Likelihood
 =!'04 #>4 )-:!- / )) $!# & $ % # %)6 ) + # 6 0 %% )90 % 1% $ 9116 69)" %" :"6. 1-0 &6 -% ' 0' )%1 0(,"'% #6 0 )90 1-11 ) 9 #,0. 1 #% 0 9 & %) ) '' #' ) 0 # %6 ;+'' 0 6%((&0 6?9 ;+'' 0 9)&6? #' 1 0 +& $
=!'04 #>4 )-:!- / )) $!# & $ % # %)6 ) + # 6 0 %% )90 % 1% $ 9116 69)" %" :"6. 1-0 &6 -% ' 0' )%1 0(,"'% #6 0 )90 1-11 ) 9 #,0. 1 #% 0 9 & %) ) '' #' ) 0 # %6 ;+'' 0 6%((&0 6?9 ;+'' 0 9)&6? #' 1 0 +& $
 Bachelor BEE Statistik Übung: Blatt 1 Ostfalia - Hochschule für angewandte Wissenschaften Fakultät Versorgungstechnik Aufgabe (1.1): Gegeben sei die folgende Messreihe: Nr. ph-werte 1-10 6.4 6.3 6.7 6.5
Bachelor BEE Statistik Übung: Blatt 1 Ostfalia - Hochschule für angewandte Wissenschaften Fakultät Versorgungstechnik Aufgabe (1.1): Gegeben sei die folgende Messreihe: Nr. ph-werte 1-10 6.4 6.3 6.7 6.5
Klausur zu Statistik II
 GOETHE-UNIVERSITÄT FRANKFURT FB Wirtschaftswissenschaften Statistik und Methoden der Ökonometrie Prof. Dr. Uwe Hassler Wintersemester 03/04 Klausur zu Statistik II Matrikelnummer: Hinweise Hilfsmittel
GOETHE-UNIVERSITÄT FRANKFURT FB Wirtschaftswissenschaften Statistik und Methoden der Ökonometrie Prof. Dr. Uwe Hassler Wintersemester 03/04 Klausur zu Statistik II Matrikelnummer: Hinweise Hilfsmittel
Einführung: Bayessches Lernen. Dipl.-Inform. Martin Lösch. martin.loesch@kit.edu (0721) 608 45944. Dipl.-Inform. Martin Lösch
 608 45944. Dipl.-Inform. Martin Lösch") Einführung: martin.loesch@kit.edu (0721) 608 45944 Übersicht Motivation & Hintergrund Naiver Bayes-Klassifikator Bayessche Netze EM-Algorithmus 2 Was ist eigentlich? MOTIVATION & HINTERGRUND 3 Warum Lernen
Einführung: martin.loesch@kit.edu (0721) 608 45944 Übersicht Motivation & Hintergrund Naiver Bayes-Klassifikator Bayessche Netze EM-Algorithmus 2 Was ist eigentlich? MOTIVATION & HINTERGRUND 3 Warum Lernen
Kapitel 8. Einfache Regression. Anpassen des linearen Regressionsmodells, OLS. Eigenschaften der Schätzer für das Modell
 Kapitel 8 Einfache Regression Josef Leydold c 2006 Mathematische Methoden VIII Einfache Regression 1 / 21 Lernziele Lineares Regressionsmodell Anpassen des linearen Regressionsmodells, OLS Eigenschaften
Kapitel 8 Einfache Regression Josef Leydold c 2006 Mathematische Methoden VIII Einfache Regression 1 / 21 Lernziele Lineares Regressionsmodell Anpassen des linearen Regressionsmodells, OLS Eigenschaften
3. Kombinatorik und Wahrscheinlichkeit
 3. Kombinatorik und Wahrscheinlichkeit Es geht hier um die Bestimmung der Kardinalität endlicher Mengen. Erinnerung: Seien A, B, A 1,..., A n endliche Mengen. Dann gilt A = B ϕ: A B bijektiv Summenregel:
3. Kombinatorik und Wahrscheinlichkeit Es geht hier um die Bestimmung der Kardinalität endlicher Mengen. Erinnerung: Seien A, B, A 1,..., A n endliche Mengen. Dann gilt A = B ϕ: A B bijektiv Summenregel:
Statistik für Punktprozesse. Seminar Stochastische Geometrie und ihre Anwendungen WS 2009/2010
 Statistik für Punktprozesse Seminar Stochastische Geometrie und ihre Anwendungen WS 009/00 Inhalt I. Fragestellung / Problematik II. Ansätze für a) die Schätzung der Intensität b) ein Testverfahren auf
Statistik für Punktprozesse Seminar Stochastische Geometrie und ihre Anwendungen WS 009/00 Inhalt I. Fragestellung / Problematik II. Ansätze für a) die Schätzung der Intensität b) ein Testverfahren auf
VS PLUS
 VS PLUS Zusatzinformationen zu Medien des VS Verlags Statistik II Inferenzstatistik 2010 Übungsaufgaben und Lösungen Inferenzstatistik 2 [Übungsaufgaben und Lösungenn - Inferenzstatistik 2] ÜBUNGSAUFGABEN
VS PLUS Zusatzinformationen zu Medien des VS Verlags Statistik II Inferenzstatistik 2010 Übungsaufgaben und Lösungen Inferenzstatistik 2 [Übungsaufgaben und Lösungenn - Inferenzstatistik 2] ÜBUNGSAUFGABEN
Imputationsverfahren
 Minh Ngoc Nguyen Betreuer: Eva Endres München, 09.01.2015 Einführung 2 / 45 Einführung 3 / 45 Imputation Prinzip: fehlende Werte sollen durch möglichst passenden Werte ersetzt werden Vorteil Erzeugen den
Minh Ngoc Nguyen Betreuer: Eva Endres München, 09.01.2015 Einführung 2 / 45 Einführung 3 / 45 Imputation Prinzip: fehlende Werte sollen durch möglichst passenden Werte ersetzt werden Vorteil Erzeugen den
Finite Elemente Berechnungen verklebter Strukturen
 Finite Elemente Berechnungen verklebter Strukturen Dr. Pierre Jousset, Sika Technology AG 24.4.213 1 Sika Technology AG Agenda Motivation und Ziele Die strukturellen Epoxy Klebstoffe SikaPower Finite Element
Finite Elemente Berechnungen verklebter Strukturen Dr. Pierre Jousset, Sika Technology AG 24.4.213 1 Sika Technology AG Agenda Motivation und Ziele Die strukturellen Epoxy Klebstoffe SikaPower Finite Element
3. Das einfache lineare Regressionsmodell
 3. Das einfache lineare Regressionsmodell Ökonometrie: (I) Anwendung statistischer Methoden in der empirischen Forschung in den Wirtschaftswissenschaften Konfrontation ökonomischer Theorien mit Fakten
3. Das einfache lineare Regressionsmodell Ökonometrie: (I) Anwendung statistischer Methoden in der empirischen Forschung in den Wirtschaftswissenschaften Konfrontation ökonomischer Theorien mit Fakten
Einführung in die Theorie der Markov-Ketten. Jens Schomaker
 Einführung in die Theorie der Markov-Ketten Jens Schomaker Markov-Ketten Zur Motivation der Einführung von Markov-Ketten betrachte folgendes Beispiel: 1.1 Beispiel Wir wollen die folgende Situation mathematisch
Einführung in die Theorie der Markov-Ketten Jens Schomaker Markov-Ketten Zur Motivation der Einführung von Markov-Ketten betrachte folgendes Beispiel: 1.1 Beispiel Wir wollen die folgende Situation mathematisch
Statistische Verfahren in der Künstlichen Intelligenz, Bayesische Netze
 Statistische Verfahren in der Künstlichen Intelligenz, Bayesische Netze Erich Schubert 6. Juli 2003 LMU München, Institut für Informatik, Erich Schubert Zitat von R. P. Feynman Richard P. Feynman (Nobelpreisträger
Statistische Verfahren in der Künstlichen Intelligenz, Bayesische Netze Erich Schubert 6. Juli 2003 LMU München, Institut für Informatik, Erich Schubert Zitat von R. P. Feynman Richard P. Feynman (Nobelpreisträger
Entscheidung zwischen zwei Möglichkeiten auf der Basis unsicherer (zufälliger) Daten
 Daten") Prof. Dr. J. Franke Statistik II für Wirtschaftswissenschaftler 4.1 4. Statistische Entscheidungsverfahren Entscheidung zwischen zwei Möglichkeiten auf der Basis unsicherer (zufälliger) Daten Beispiel:
Prof. Dr. J. Franke Statistik II für Wirtschaftswissenschaftler 4.1 4. Statistische Entscheidungsverfahren Entscheidung zwischen zwei Möglichkeiten auf der Basis unsicherer (zufälliger) Daten Beispiel:
Stochastik I. Vorlesungsmitschrift
 Stochastik I Vorlesungsmitschrift Ulrich Horst Institut für Mathematik Humboldt-Universität zu Berlin Inhaltsverzeichnis 1 Grundbegriffe 1 1.1 Wahrscheinlichkeitsräume..................................
Stochastik I Vorlesungsmitschrift Ulrich Horst Institut für Mathematik Humboldt-Universität zu Berlin Inhaltsverzeichnis 1 Grundbegriffe 1 1.1 Wahrscheinlichkeitsräume..................................
Zweiseitiger Test für den unbekannten Mittelwert µ einer Normalverteilung bei unbekannter Varianz
 Grundlage: Zweiseitiger Test für den unbekannten Mittelwert µ einer Normalverteilung bei unbekannter Varianz Die Testvariable T = X µ 0 S/ n genügt der t-verteilung mit n 1 Freiheitsgraden. Auf der Basis
Grundlage: Zweiseitiger Test für den unbekannten Mittelwert µ einer Normalverteilung bei unbekannter Varianz Die Testvariable T = X µ 0 S/ n genügt der t-verteilung mit n 1 Freiheitsgraden. Auf der Basis
Test auf den Erwartungswert
 Test auf den Erwartungswert Wir interessieren uns für den Erwartungswert µ einer metrischen Zufallsgröße. Beispiele: Alter, Einkommen, Körpergröße, Scorewert... Wir können einseitige oder zweiseitige Hypothesen
Test auf den Erwartungswert Wir interessieren uns für den Erwartungswert µ einer metrischen Zufallsgröße. Beispiele: Alter, Einkommen, Körpergröße, Scorewert... Wir können einseitige oder zweiseitige Hypothesen
Wahrscheinlichkeitsrechnung
 Statistik und Wahrscheinlichkeitsrechnung Prof. Dr. Michael Havbro Faber 28.05.2009 1 Korrektur zur letzten Vorlesung Bsp. Fehlerfortpflanzung in einer Messung c B a 2 2 E c Var c a b A b 2 2 2 n h( x)
Statistik und Wahrscheinlichkeitsrechnung Prof. Dr. Michael Havbro Faber 28.05.2009 1 Korrektur zur letzten Vorlesung Bsp. Fehlerfortpflanzung in einer Messung c B a 2 2 E c Var c a b A b 2 2 2 n h( x)
Einsatz Risikobewertung, Entscheidungsfindung und Simulation
 Einsatz von @Risk: Risikobewertung, Entscheidungsfindung und Simulation Case Study Insolvenzwahrscheinlichkeit eines Unternehmens Risikoregister 1 Case Study: Insolvenzwahrscheinlichkeit eines Unternehmens
Einsatz von @Risk: Risikobewertung, Entscheidungsfindung und Simulation Case Study Insolvenzwahrscheinlichkeit eines Unternehmens Risikoregister 1 Case Study: Insolvenzwahrscheinlichkeit eines Unternehmens
Sprungprozesse in der Finanzmathematik
 Sprungprozesse in der Finanzmathematik Stefan Kassberger Frankfurt School of Finance and Management Antrittsvorlesung am 22.3.2012 1. Empirische Beobachtungen 2. Jump-Prozesse und alternative Verteilungen
Sprungprozesse in der Finanzmathematik Stefan Kassberger Frankfurt School of Finance and Management Antrittsvorlesung am 22.3.2012 1. Empirische Beobachtungen 2. Jump-Prozesse und alternative Verteilungen
Statistische Eigenschaften der OLS-Schätzer, Residuen,
 Statistische Eigenschaften der OLS-Schätzer, Residuen, Bestimmtheitsmaß Stichwörter: Interpretation des OLS-Schätzers Momente des OLS-Schätzers Gauss-Markov Theorem Residuen Schätzung von σ 2 Bestimmtheitsmaß
Statistische Eigenschaften der OLS-Schätzer, Residuen, Bestimmtheitsmaß Stichwörter: Interpretation des OLS-Schätzers Momente des OLS-Schätzers Gauss-Markov Theorem Residuen Schätzung von σ 2 Bestimmtheitsmaß
Übung zur Empirischen Wirtschaftsforschung V. Das Lineare Regressionsmodell
 Universität Ulm 89069 Ulm Germany Dipl.-WiWi Christian Peukert Institut für Wirtschaftspolitik Fakultät für Mathematik und Wirtschaftswissenschaften Ludwig-Erhard-Stiftungsprofessur Sommersemester 2010
Universität Ulm 89069 Ulm Germany Dipl.-WiWi Christian Peukert Institut für Wirtschaftspolitik Fakultät für Mathematik und Wirtschaftswissenschaften Ludwig-Erhard-Stiftungsprofessur Sommersemester 2010
Kapitel 10 Mittelwert-Tests Einstichproben-Mittelwert-Tests 10.2 Zweistichproben Mittelwert-Tests
 Kapitel 10 Mittelwert-Tests 10.1 Einstichproben-Mittelwert-Tests 10.2 Zweistichproben Mittelwert-Tests 10.1 Einstichproben- Mittelwert-Tests 10.1.1 Einstichproben- Gauß-Test Dichtefunktion der Standard-Normalverteilung
Kapitel 10 Mittelwert-Tests 10.1 Einstichproben-Mittelwert-Tests 10.2 Zweistichproben Mittelwert-Tests 10.1 Einstichproben- Mittelwert-Tests 10.1.1 Einstichproben- Gauß-Test Dichtefunktion der Standard-Normalverteilung
Kapitel 5: Einfaktorielle Varianzanalyse
 Rasch, Friese, Hofmann & Naumann (006). Quantitative Methoden. Band (. Auflage). Heidelberg: Springer. Kapitel 5: Einfaktorielle Varianzanalyse Berechnen der Teststärke a priori bzw. Stichprobenumfangsplanung
Rasch, Friese, Hofmann & Naumann (006). Quantitative Methoden. Band (. Auflage). Heidelberg: Springer. Kapitel 5: Einfaktorielle Varianzanalyse Berechnen der Teststärke a priori bzw. Stichprobenumfangsplanung
Zufallsvariablen [random variable]
![Zufallsvariablen [random variable]](/thumbs/52/29710821.jpg "Zufallsvariablen [random variable]") Zufallsvariablen [random variable] Eine Zufallsvariable (Zufallsgröße) X beschreibt (kodiert) die Versuchsausgänge ω Ω mit Hilfe von Zahlen, d.h. X ist eine Funktion X : Ω R ω X(ω) Zufallsvariablen werden
Zufallsvariablen [random variable] Eine Zufallsvariable (Zufallsgröße) X beschreibt (kodiert) die Versuchsausgänge ω Ω mit Hilfe von Zahlen, d.h. X ist eine Funktion X : Ω R ω X(ω) Zufallsvariablen werden
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Clusteranalyse. Tobias Scheffer Thomas Vanck
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Seminar im Wintersemester 2010/2011: Quantitative und implementierte Methoden der Marktrisikobewertung
 M.Sc. Brice Hakwa hakwa@uni-wuppertal.de Seminar im Wintersemester 2010/2011: Quantitative und implementierte Methoden der Marktrisikobewertung - Zusammenfassung zum Thema: Berechnung von Value-at-Risk
M.Sc. Brice Hakwa hakwa@uni-wuppertal.de Seminar im Wintersemester 2010/2011: Quantitative und implementierte Methoden der Marktrisikobewertung - Zusammenfassung zum Thema: Berechnung von Value-at-Risk
Statistische Tests für unbekannte Parameter
 Konfidenzintervall Intervall, das den unbekannten Parameter der Verteilung mit vorgegebener Sicherheit überdeckt ('Genauigkeitsaussage' bzw. Zuverlässigkeit einer Punktschätzung) Statistischer Test Ja-Nein-Entscheidung
Konfidenzintervall Intervall, das den unbekannten Parameter der Verteilung mit vorgegebener Sicherheit überdeckt ('Genauigkeitsaussage' bzw. Zuverlässigkeit einer Punktschätzung) Statistischer Test Ja-Nein-Entscheidung
Einsatz von Reinforcement Learning in der Modellfahrzeugnavigation
 Einsatz von Reinforcement Learning in der Modellfahrzeugnavigation von Manuel Trittel Informatik HAW Hamburg Vortrag im Rahmen der Veranstaltung AW1 im Masterstudiengang, 02.12.2008 der Anwendung Themeneinordnung
Einsatz von Reinforcement Learning in der Modellfahrzeugnavigation von Manuel Trittel Informatik HAW Hamburg Vortrag im Rahmen der Veranstaltung AW1 im Masterstudiengang, 02.12.2008 der Anwendung Themeneinordnung
Ergänzungsmaterial zur Vorlesung. Statistik 2. Modelldiagnostik, Ausreißer, einflussreiche Beobachtungen
 Institut für Stochastik WS 2007/2008 Universität Karlsruhe JProf. Dr. H. Holzmann Dipl.-Math. oec. D. Engel Ergänzungsmaterial zur Vorlesung Statistik 2 Modelldiagnostik, Ausreißer, einflussreiche Beobachtungen
Institut für Stochastik WS 2007/2008 Universität Karlsruhe JProf. Dr. H. Holzmann Dipl.-Math. oec. D. Engel Ergänzungsmaterial zur Vorlesung Statistik 2 Modelldiagnostik, Ausreißer, einflussreiche Beobachtungen
6.1 Definition der multivariaten Normalverteilung
 Kapitel 6 Die multivariate Normalverteilung Wir hatten die multivariate Normalverteilung bereits in Abschnitt 2.3 kurz eingeführt. Wir werden sie jetzt etwas gründlicher behandeln, da die Schätzung ihrer
Kapitel 6 Die multivariate Normalverteilung Wir hatten die multivariate Normalverteilung bereits in Abschnitt 2.3 kurz eingeführt. Wir werden sie jetzt etwas gründlicher behandeln, da die Schätzung ihrer
Datenanalyse. (PHY231) Herbstsemester Olaf Steinkamp
 Herbstsemester Olaf Steinkamp") Datenanalyse (PHY31) Herbstsemester 015 Olaf Steinkamp 36-J- olafs@physik.uzh.ch 044 63 55763 Einführung, Messunsicherheiten, Darstellung von Messdaten Grundbegriffe der Wahrscheinlichkeitsrechnung und
Datenanalyse (PHY31) Herbstsemester 015 Olaf Steinkamp 36-J- olafs@physik.uzh.ch 044 63 55763 Einführung, Messunsicherheiten, Darstellung von Messdaten Grundbegriffe der Wahrscheinlichkeitsrechnung und
Formelsammlung für das Modul. Statistik 2. Bachelor. Sven Garbade
 Version 2015 Formelsammlung für das Modul Statistik 2 Bachelor Sven Garbade Prof. Dr. phil. Dipl.-Psych. Sven Garbade Fakultät für Angewandte Psychologie SRH Hochschule Heidelberg sven.garbade@hochschule-heidelberg.de
Version 2015 Formelsammlung für das Modul Statistik 2 Bachelor Sven Garbade Prof. Dr. phil. Dipl.-Psych. Sven Garbade Fakultät für Angewandte Psychologie SRH Hochschule Heidelberg sven.garbade@hochschule-heidelberg.de
Berechnung des Häuserpreisindex und aktuelle Ergebnisse
 Berechnung des Häuserpreisindex und aktuelle Ergebnisse Nutzerkonferenz Immobilienpreise Was bietet die amtliche Statistik? am 30. Juni 2016 im Statistischen Bundesamt Eva-Maria Diehl & Timm Behrmann Statistisches
Berechnung des Häuserpreisindex und aktuelle Ergebnisse Nutzerkonferenz Immobilienpreise Was bietet die amtliche Statistik? am 30. Juni 2016 im Statistischen Bundesamt Eva-Maria Diehl & Timm Behrmann Statistisches
MATLAB im Studium. Analyse niederfrequenter Magnetfeldsignale in eingebetteten Algorithmen. Claudia Beyß. Datum:
 MATLAB im Studium Analyse niederfrequenter Magnetfeldsignale in eingebetteten Algorithmen Datum: 16.10.2014 Claudia Beyß MATLAB in Höhere Regelungstechnik MATLAB in Sensortechnik & Datenverarbeitung MATLAB
MATLAB im Studium Analyse niederfrequenter Magnetfeldsignale in eingebetteten Algorithmen Datum: 16.10.2014 Claudia Beyß MATLAB in Höhere Regelungstechnik MATLAB in Sensortechnik & Datenverarbeitung MATLAB
Vermessungskunde für Bauingenieure und Geodäten
 Vermessungskunde für Bauingenieure und Geodäten Übung 6: statistische Auswertung ungleichgenauer Messungen Milo Hirsch Hendrik Hellmers Florian Schill Institut für Geodäsie Fachbereich 13 Inhaltsverzeichnis
Vermessungskunde für Bauingenieure und Geodäten Übung 6: statistische Auswertung ungleichgenauer Messungen Milo Hirsch Hendrik Hellmers Florian Schill Institut für Geodäsie Fachbereich 13 Inhaltsverzeichnis
Vorbereitung auf 3. Übungsblatt (Präsenzübungen) - Lösungen
 - Lösungen") Prof Dr Rainer Dahlhaus Statistik 1 Wintersemester 2016/2017 Vorbereitung auf Übungsblatt (Präsenzübungen) - Lösungen Aufgabe P9 (Prognosen und Konfidenzellipsoide in der linearen Regression) Wir rekapitulieren
Prof Dr Rainer Dahlhaus Statistik 1 Wintersemester 2016/2017 Vorbereitung auf Übungsblatt (Präsenzübungen) - Lösungen Aufgabe P9 (Prognosen und Konfidenzellipsoide in der linearen Regression) Wir rekapitulieren
Bivariate Kreuztabellen
 Bivariate Kreuztabellen Kühnel, Krebs 2001 S. 307-342 Gabriele Doblhammer: Empirische Sozialforschung Teil II, SS 2004 1/33 Häufigkeit in Zelle y 1 x 1 Kreuztabellen Randverteilung x 1... x j... x J Σ
Bivariate Kreuztabellen Kühnel, Krebs 2001 S. 307-342 Gabriele Doblhammer: Empirische Sozialforschung Teil II, SS 2004 1/33 Häufigkeit in Zelle y 1 x 1 Kreuztabellen Randverteilung x 1... x j... x J Σ
Quantilsregression. Martin Gubisch. 13. April Universität Konstanz
 Universität Konstanz 13. April 2011 Warum ein Berufspraktikum? Warum ein Berufspraktikum? Ein paar Bemerkungen zur Firma Einige Unterschiede zum akademischen Arbeiten Aufgabenfeld und Tätigkeiten Berufliche
Universität Konstanz 13. April 2011 Warum ein Berufspraktikum? Warum ein Berufspraktikum? Ein paar Bemerkungen zur Firma Einige Unterschiede zum akademischen Arbeiten Aufgabenfeld und Tätigkeiten Berufliche
Rabea Haas, Kai Born DACH September 2010
 Rabea Haas, Kai Born rhaas@meteo.uni-koeln.de DACH2010 21. September 2010 Motivation Niederschlagsdaten aus dem Gebiet des Hohen Atlas in Marokko Starke Gradienten des Niederschlags und der Höhe Komplexe
Rabea Haas, Kai Born rhaas@meteo.uni-koeln.de DACH2010 21. September 2010 Motivation Niederschlagsdaten aus dem Gebiet des Hohen Atlas in Marokko Starke Gradienten des Niederschlags und der Höhe Komplexe
Lügen für Fortgeschrittene Bayesianische Statistik in der Ökonom(etr)ie
ie") Lügen für Fortgeschrittene Bayesianische Statistik in der Ökonom(etr)ie Mathias Moser Forschungsinstitut Verteilungsfragen Research Institute Economics of Inequality WU Wien AG-Tagung Mathematik St. Pölten,
Lügen für Fortgeschrittene Bayesianische Statistik in der Ökonom(etr)ie Mathias Moser Forschungsinstitut Verteilungsfragen Research Institute Economics of Inequality WU Wien AG-Tagung Mathematik St. Pölten,
Chi-Quadrat-Verteilung
 Chi-Quadrat-Verteilung Die Verteilung einer Summe X +X +...+X n, wobei X,..., X n unabhängige standardnormalverteilte Zufallsvariablen sind, heißt χ -Verteilung mit n Freiheitsgraden. Eine N(, )-verteilte
Chi-Quadrat-Verteilung Die Verteilung einer Summe X +X +...+X n, wobei X,..., X n unabhängige standardnormalverteilte Zufallsvariablen sind, heißt χ -Verteilung mit n Freiheitsgraden. Eine N(, )-verteilte
Analyse von Querschnittsdaten. Spezifikation der unabhängigen Variablen
 Analyse von Querschnittsdaten Spezifikation der unabhängigen Variablen Warum geht es in den folgenden Sitzungen? Kontinuierliche Variablen Annahmen gegeben? kategoriale Variablen Datum 3.0.004 0.0.004
Analyse von Querschnittsdaten Spezifikation der unabhängigen Variablen Warum geht es in den folgenden Sitzungen? Kontinuierliche Variablen Annahmen gegeben? kategoriale Variablen Datum 3.0.004 0.0.004
Friedrich-Alexander-Universität Professur für Computerlinguistik. Nguyen Ai Huong
 Part-of-Speech Tagging Friedrich-Alexander-Universität Professur für Computerlinguistik Nguyen Ai Huong 15.12.2011 Part-of-speech tagging Bestimmung von Wortform (part of speech) für jedes Wort in einem
Part-of-Speech Tagging Friedrich-Alexander-Universität Professur für Computerlinguistik Nguyen Ai Huong 15.12.2011 Part-of-speech tagging Bestimmung von Wortform (part of speech) für jedes Wort in einem
Gemischte Modelle zur Schätzung geoadditiver Regressionsmodelle
 Gemischte Modelle zur Schätzung geoadditiver Regressionsmodelle Thomas Kneib & Ludwig Fahrmeir Institut für Statistik, Ludwig-Maximilians-Universität München 1. Regressionsmodelle für geoadditive Daten
Gemischte Modelle zur Schätzung geoadditiver Regressionsmodelle Thomas Kneib & Ludwig Fahrmeir Institut für Statistik, Ludwig-Maximilians-Universität München 1. Regressionsmodelle für geoadditive Daten
Schätzverfahren ML vs. REML & Modellbeurteilung mittels Devianz, AIC und BIC. Referenten: Linda Gräfe & Konstantin Falk
 Schätzverfahren ML vs. REML & Modellbeurteilung mittels Devianz, AIC und BIC Referenten: Linda Gräfe & Konstantin Falk 1 Agenda Schätzverfahren ML REML Beispiel in SPSS Modellbeurteilung Devianz AIC BIC
Schätzverfahren ML vs. REML & Modellbeurteilung mittels Devianz, AIC und BIC Referenten: Linda Gräfe & Konstantin Falk 1 Agenda Schätzverfahren ML REML Beispiel in SPSS Modellbeurteilung Devianz AIC BIC
1.1.1 Ergebnismengen Wahrscheinlichkeiten Formale Definition der Wahrscheinlichkeit Laplace-Experimente...
 Inhaltsverzeichnis 0 Einführung 1 1 Zufallsvorgänge und Wahrscheinlichkeiten 5 1.1 Zufallsvorgänge.......................... 5 1.1.1 Ergebnismengen..................... 6 1.1.2 Ereignisse und ihre Verknüpfung............
Inhaltsverzeichnis 0 Einführung 1 1 Zufallsvorgänge und Wahrscheinlichkeiten 5 1.1 Zufallsvorgänge.......................... 5 1.1.1 Ergebnismengen..................... 6 1.1.2 Ereignisse und ihre Verknüpfung............
Wiederholung Qualitätssicherung Drittvariablen. Regression II. Statistik I. Sommersemester Statistik I Regression II (1/33) Wiederholung
 Wiederholung") Regression II Statistik I Sommersemester 2009 Statistik I Regression II (1/33) R 2 Root Mean Squared Error Statistik I Regression II (2/33) Zum Nachlesen Agresti: 9.1-9.4 Gehring/Weins: 8 Schumann: 8.1-8.2
Regression II Statistik I Sommersemester 2009 Statistik I Regression II (1/33) R 2 Root Mean Squared Error Statistik I Regression II (2/33) Zum Nachlesen Agresti: 9.1-9.4 Gehring/Weins: 8 Schumann: 8.1-8.2
in die Immobilienbewertung (Teil 1)
") Alkhatib/Weitkamp, Bayesischer Ansatz zur Integration von Expertenwissen Teil 1) Fachbeitrag HamzaBayesischer Alkhatib und Ansatz Alexandra zur Integration Weitkamp von Bayesischer Expertenwissen Ansatz
Alkhatib/Weitkamp, Bayesischer Ansatz zur Integration von Expertenwissen Teil 1) Fachbeitrag HamzaBayesischer Alkhatib und Ansatz Alexandra zur Integration Weitkamp von Bayesischer Expertenwissen Ansatz
Reinforcement Learning
 Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Zeitreihenökonometrie
 Zeitreihenökonometrie Kapitel 8 Impuls-Antwort-Funktionen Interpretation eines VAR-Prozesses 2 Fall eines bivariaten Var(p)-Prozess mit 2 Variablen und ohne Konstante 1 1 p p 1,t α11 α 12 1,t-1 α11 α 12
Zeitreihenökonometrie Kapitel 8 Impuls-Antwort-Funktionen Interpretation eines VAR-Prozesses 2 Fall eines bivariaten Var(p)-Prozess mit 2 Variablen und ohne Konstante 1 1 p p 1,t α11 α 12 1,t-1 α11 α 12
Mikro-Ökonometrie: Small Sample Inferenz mit OLS
 Mikro-Ökonometrie: Small Sample Inferenz mit OLS 1. November 014 Mikro-Ökonometrie: Small Sample Inferenz mit OLS Folie Zusammenfassung wichtiger Ergebnisse des letzten Kapitels (I) Unter den ersten vier
Mikro-Ökonometrie: Small Sample Inferenz mit OLS 1. November 014 Mikro-Ökonometrie: Small Sample Inferenz mit OLS Folie Zusammenfassung wichtiger Ergebnisse des letzten Kapitels (I) Unter den ersten vier
Seminar zur Energiewirtschaft:
 Seminar zur Energiewirtschaft: Ermittlung der Zahlungsbereitschaft für erneuerbare Energien bzw. bessere Umwelt Vladimir Udalov 1 Modelle mit diskreten abhängigen Variablen 2 - Ausgangssituation Eine Dummy-Variable
Seminar zur Energiewirtschaft: Ermittlung der Zahlungsbereitschaft für erneuerbare Energien bzw. bessere Umwelt Vladimir Udalov 1 Modelle mit diskreten abhängigen Variablen 2 - Ausgangssituation Eine Dummy-Variable
Bayes sches Lernen: Übersicht
 Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 5: Naive Bayes + IBL (V.
Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 5: Naive Bayes + IBL (V.
Angewandte Ökonometrie Übung. Endogenität, VAR, Stationarität und Fehlerkorrekturmodell
 Angewandte Ökonometrie Übung 3 Endogenität, VAR, Stationarität und Fehlerkorrekturmodell Zeitreihenmodelle Zeitreihenmodelle Endogenität Instrumentvariablenschätzung Schätzung eines VARs Tests auf Anzahl
Angewandte Ökonometrie Übung 3 Endogenität, VAR, Stationarität und Fehlerkorrekturmodell Zeitreihenmodelle Zeitreihenmodelle Endogenität Instrumentvariablenschätzung Schätzung eines VARs Tests auf Anzahl
PROC MEANS. zum Berechnen statistischer Maßzahlen (für quantitative Merkmale)
") PROC MEAS zum Berechnen statistischer Maßzahlen (für quantitative Merkmale) Allgemeine Form: PROC MEAS DATA=name Optionen ; VAR variablenliste ; CLASS vergleichsvariable ; Beispiel und Beschreibung der
PROC MEAS zum Berechnen statistischer Maßzahlen (für quantitative Merkmale) Allgemeine Form: PROC MEAS DATA=name Optionen ; VAR variablenliste ; CLASS vergleichsvariable ; Beispiel und Beschreibung der
Kapitel 2.1: Die stochastische Sicht auf Signale Georg Dorffner 67
 Kapitel 2.1: Die stochastische Sicht auf Signale 215 Georg Dorffner 67 Stochastische Prozesse Stochastische Prozesse sind von Zufall geprägte Zeitreihen x n f x, n 1 xn2,... n vorhersagbarer Teil, Signal
Kapitel 2.1: Die stochastische Sicht auf Signale 215 Georg Dorffner 67 Stochastische Prozesse Stochastische Prozesse sind von Zufall geprägte Zeitreihen x n f x, n 1 xn2,... n vorhersagbarer Teil, Signal
Lösungen zur Klausur GRUNDLAGEN DER WAHRSCHEINLICHKEITSTHEORIE UND STATISTIK
 Institut für Stochastik Dr. Steffen Winter Lösungen zur Klausur GRUNDLAGEN DER WAHRSCHEINLICHKEITSTHEORIE UND STATISTIK für Studierende der INFORMATIK vom 17. Juli 01 (Dauer: 90 Minuten) Übersicht über
Institut für Stochastik Dr. Steffen Winter Lösungen zur Klausur GRUNDLAGEN DER WAHRSCHEINLICHKEITSTHEORIE UND STATISTIK für Studierende der INFORMATIK vom 17. Juli 01 (Dauer: 90 Minuten) Übersicht über
Einführung in die (induktive) Statistik
 Statistik") Einführung in die (induktive) Statistik Typische Fragestellung der Statistik: Auf Grund einer Problemmodellierung sind wir interessiert an: Zufallsexperiment beschrieben durch ZV X. Problem: Verteilung
Einführung in die (induktive) Statistik Typische Fragestellung der Statistik: Auf Grund einer Problemmodellierung sind wir interessiert an: Zufallsexperiment beschrieben durch ZV X. Problem: Verteilung
Statistik IV für Studenten mit dem Nebenfach Statistik Lösungen zu Blatt 9 Gerhard Tutz, Jan Ulbricht SS 07
 Statistik IV für Studenten mit dem Nebenfach Statistik Lösungen zu Blatt 9 Gerhard Tutz, Jan Ulbricht SS 07 Ziel der Clusteranalyse: Bilde Gruppen (cluster) aus einer Menge multivariater Datenobjekte (stat
Statistik IV für Studenten mit dem Nebenfach Statistik Lösungen zu Blatt 9 Gerhard Tutz, Jan Ulbricht SS 07 Ziel der Clusteranalyse: Bilde Gruppen (cluster) aus einer Menge multivariater Datenobjekte (stat
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Clusteranalyse. Christoph Sawade/Niels Landwehr/Tobias Scheffer
 Universität Potsdam Institut für Informati Lehrstuhl Maschinelles Lernen Clusteranalyse Christoph Sawade/iels Landwehr/Tobias Scheffer Überblic Problemstellung/Motivation Deterministischer Ansatz: K-Means
Universität Potsdam Institut für Informati Lehrstuhl Maschinelles Lernen Clusteranalyse Christoph Sawade/iels Landwehr/Tobias Scheffer Überblic Problemstellung/Motivation Deterministischer Ansatz: K-Means
2.1 Importance sampling: Metropolis-Algorithmus
 Kapitel 2 Simulationstechniken 2.1 Importance sampling: Metropolis-Algorithmus Eine zentrale Fragestellung in der statistischen Physik ist die Bestimmung von Erwartungswerten einer Observablen O in einem
Kapitel 2 Simulationstechniken 2.1 Importance sampling: Metropolis-Algorithmus Eine zentrale Fragestellung in der statistischen Physik ist die Bestimmung von Erwartungswerten einer Observablen O in einem
Grundbegriffe der Wahrscheinlichkeitstheorie. Karin Haenelt
 Grundbegriffe der Wahrscheinlichkeitstheorie Karin Haenelt 1 Inhalt Wahrscheinlichkeitsraum Bedingte Wahrscheinlichkeit Abhängige und unabhängige Ereignisse Stochastischer Prozess Markow-Kette 2 Wahrscheinlichkeitsraum
Grundbegriffe der Wahrscheinlichkeitstheorie Karin Haenelt 1 Inhalt Wahrscheinlichkeitsraum Bedingte Wahrscheinlichkeit Abhängige und unabhängige Ereignisse Stochastischer Prozess Markow-Kette 2 Wahrscheinlichkeitsraum
Methoden der Werkstoffprüfung Kapitel II Statistische Verfahren I. WS 2009/2010 Kapitel 2.0
 Methoden der Werkstoffprüfung Kapitel II Statistische Verfahren I WS 009/010 Kapitel.0 Schritt 1: Bestimmen der relevanten Kenngrößen Kennwerte Einflussgrößen Typ A/Typ B einzeln im ersten Schritt werden
Methoden der Werkstoffprüfung Kapitel II Statistische Verfahren I WS 009/010 Kapitel.0 Schritt 1: Bestimmen der relevanten Kenngrößen Kennwerte Einflussgrößen Typ A/Typ B einzeln im ersten Schritt werden
Decoupling in der Sozialpolitik
 Research Programme SocialWorld World Society, Global Social Policy and New Welfare States University of Bielefeld, Germany Institute for World Society Studies Julia Hansmeyer Decoupling in der Sozialpolitik
Research Programme SocialWorld World Society, Global Social Policy and New Welfare States University of Bielefeld, Germany Institute for World Society Studies Julia Hansmeyer Decoupling in der Sozialpolitik
Methodenlehre. Vorlesung 10. Prof. Dr. Björn Rasch, Cognitive Biopsychology and Methods University of Fribourg
 Methodenlehre Vorlesung 10 Prof. Dr., Cognitive Biopsychology and Methods University of Fribourg 1 Methodenlehre II Woche Datum Thema 1 FQ Einführung, Verteilung der Termine 1 18.2.15 Psychologie als Wissenschaft
Methodenlehre Vorlesung 10 Prof. Dr., Cognitive Biopsychology and Methods University of Fribourg 1 Methodenlehre II Woche Datum Thema 1 FQ Einführung, Verteilung der Termine 1 18.2.15 Psychologie als Wissenschaft
Prof. Dr. Walter F. Tichy Dr. Matthias Müller Sommersemester 2006
 Empirische Softwaretechnik Prof. Dr. Walter F. Tichy Dr. Matthias Müller Sommersemester 2006 Hypothesentesten, Fehlerarten und Güte 2 Literatur Kreyszig: Statistische Methoden und ihre Anwendungen, 7.
Empirische Softwaretechnik Prof. Dr. Walter F. Tichy Dr. Matthias Müller Sommersemester 2006 Hypothesentesten, Fehlerarten und Güte 2 Literatur Kreyszig: Statistische Methoden und ihre Anwendungen, 7.
0 + #! % ( ) % )1, !,
 % )1, !,") ! #! % ( ) % +!,../ 0 + #! % ( ) % )1,233 3 4!, 5 2 6 7 2 6 ( (% 6 2 58.9../ : 2../ ! # % & # ( ) + +, % ( ( + +., / (! & 0 + 1 2 3 4! 5! 6! ( 7 ) + 8 9! + : +, 5 & ; + 9 0 < 5 3 & 9 ; + 9 0 < 5 3 %!
! #! % ( ) % +!,../ 0 + #! % ( ) % )1,233 3 4!, 5 2 6 7 2 6 ( (% 6 2 58.9../ : 2../ ! # % & # ( ) + +, % ( ( + +., / (! & 0 + 1 2 3 4! 5! 6! ( 7 ) + 8 9! + : +, 5 & ; + 9 0 < 5 3 & 9 ; + 9 0 < 5 3 %!
Signalverarbeitung 2. Volker Stahl - 1 -
 - 1 - Hidden Markov Modelle - 2 - Idee Zu klassifizierende Merkmalvektorfolge wurde von einem (unbekannten) System erzeugt. Nutze Referenzmerkmalvektorfolgen um ein Modell Des erzeugenden Systems zu bauen
- 1 - Hidden Markov Modelle - 2 - Idee Zu klassifizierende Merkmalvektorfolge wurde von einem (unbekannten) System erzeugt. Nutze Referenzmerkmalvektorfolgen um ein Modell Des erzeugenden Systems zu bauen
Zusammenfassung Mathe II. Themenschwerpunkt 2: Stochastik (ean) 1. Ein- und mehrstufige Zufallsexperimente; Ergebnismengen
 1. Ein- und mehrstufige Zufallsexperimente; Ergebnismengen") Zusammenfassung Mathe II Themenschwerpunkt 2: Stochastik (ean) 1. Ein- und mehrstufige Zufallsexperimente; Ergebnismengen Zufallsexperiment: Ein Vorgang, bei dem mindestens zwei Ereignisse möglich sind
Zusammenfassung Mathe II Themenschwerpunkt 2: Stochastik (ean) 1. Ein- und mehrstufige Zufallsexperimente; Ergebnismengen Zufallsexperiment: Ein Vorgang, bei dem mindestens zwei Ereignisse möglich sind
Laborchemische Referenzwerte in der klinischen Versorgung
 Laborchemische Referenzwerte in der klinischen Versorgung Dr. Robin Haring Institut für Klinische Chemie und Laboratoriumsmedizin Universitätsmedizin Greifswald Wozu Referenzwerte? Vor allem in der Laboratoriumsmedizin
Laborchemische Referenzwerte in der klinischen Versorgung Dr. Robin Haring Institut für Klinische Chemie und Laboratoriumsmedizin Universitätsmedizin Greifswald Wozu Referenzwerte? Vor allem in der Laboratoriumsmedizin
1. Lösungen zu Kapitel 8
 1. Lösungen zu Kapitel 8 Übungsaufgabe 8.1 a) Falsch! Die Nichtberücksichtigung von unwichtigen Variablen für die Identifikation kausaler Effekte stellt kein Problem dar, sofern diese Variablen keinen
1. Lösungen zu Kapitel 8 Übungsaufgabe 8.1 a) Falsch! Die Nichtberücksichtigung von unwichtigen Variablen für die Identifikation kausaler Effekte stellt kein Problem dar, sofern diese Variablen keinen
Biomathematik für Mediziner, Klausur SS 2001 Seite 1
 Biomathematik für Mediziner, Klausur SS 2001 Seite 1 Aufgabe 1: Von den Patienten einer Klinik geben 70% an, Masern gehabt zu haben, und 60% erinnerten sich an eine Windpockeninfektion. An mindestens einer
Biomathematik für Mediziner, Klausur SS 2001 Seite 1 Aufgabe 1: Von den Patienten einer Klinik geben 70% an, Masern gehabt zu haben, und 60% erinnerten sich an eine Windpockeninfektion. An mindestens einer
Lineare Regression II
 Lineare Regression II Varianzanalyse als multiple Regession auf Designvariablen Das lineare Regressionsmodell setzt implizit voraus, dass nicht nur die abhängige, sondern auch die erklärenden Variablen
Lineare Regression II Varianzanalyse als multiple Regession auf Designvariablen Das lineare Regressionsmodell setzt implizit voraus, dass nicht nur die abhängige, sondern auch die erklärenden Variablen
Statistik. R. Frühwirth Teil 1: Deskriptive Statistik. Statistik. Einleitung Grundbegriffe Merkmal- und Skalentypen Aussagen und
 Übersicht über die Vorlesung Teil 1: Deskriptive fru@hephy.oeaw.ac.at VO 142.090 http://tinyurl.com/tu142090 Teil 2: Wahrscheinlichkeitsrechnung Teil 3: Zufallsvariable und Verteilungen Februar 2010 Teil
Übersicht über die Vorlesung Teil 1: Deskriptive fru@hephy.oeaw.ac.at VO 142.090 http://tinyurl.com/tu142090 Teil 2: Wahrscheinlichkeitsrechnung Teil 3: Zufallsvariable und Verteilungen Februar 2010 Teil
Entwicklung und Erprobung eines digitalen Zenitkamerasystems für die hochpräzise Lotabweichungsbestimmung
 WISSENSCHAFTLICHE ARBEITEN DER FACHRICHTUNG VERMESSUNGSWESEN DER UNIVERSITÄT HANNOVER ISSN 0174-1454 Nr. 253 Entwicklung und Erprobung eines digitalen Zenitkamerasystems für die hochpräzise Lotabweichungsbestimmung
WISSENSCHAFTLICHE ARBEITEN DER FACHRICHTUNG VERMESSUNGSWESEN DER UNIVERSITÄT HANNOVER ISSN 0174-1454 Nr. 253 Entwicklung und Erprobung eines digitalen Zenitkamerasystems für die hochpräzise Lotabweichungsbestimmung
Doz. Dr. H.P. Scheffler Sommer 2000 Klausur zur Vorlesung Stochastik I
 Doz. Dr. H.P. Scheffler Sommer 2000 Klausur zur Vorlesung Stochastik I Wählen Sie aus den folgenden sechs Aufgaben fünf Aufgaben aus. Die maximal erreichbare Punktezahl finden Sie neben jeder Aufgabe.
Doz. Dr. H.P. Scheffler Sommer 2000 Klausur zur Vorlesung Stochastik I Wählen Sie aus den folgenden sechs Aufgaben fünf Aufgaben aus. Die maximal erreichbare Punktezahl finden Sie neben jeder Aufgabe.