METHODENPRAKTIKUM II Kurs 1. Prof. Dr. Beat Fux SUZ Frühlingssemester 2009
|
|
|
- Claudia Kirchner
- vor 6 Jahren
- Abrufe
Transkript
1 METHODENPRAKTIKUM II Kurs 1 Prof. Dr. Beat Fux SUZ Frühlingssemester 2009

2 Durch SHP Cleaning Missings Imputation Gewichtung ADD FILES AGGREGATE MATCH FILES z.b. Hinzufügen von Daten aus EXCEL Recodierungen Ausreisser Normierung Standardisierung Dummies Interaktionsvariablen Indikatoren/Skalen 2
3 Daten- und Filemanagement
4 Filemanagement Hinzufügen von Beobachtungen ADD FILE Hinzufügen von Variablen (identische Einheiten) MATCH FILES /BY <key> [sortieren!] Hinzufügen von Variablen (unterschiedliche Einheiten, z.b. Individuen und Haushalte Aufblähen des Haushaltfiles Reduzieren des Individualfiles AGGREGATE 4



5 Filemanagement MATCH FILES /BY ID 5
6 Aggregieren 6
7 Cleaning der Daten
8 Verzerrungen 8

9 Datenfehler 9

10 Cleaning Fehlerarten 10
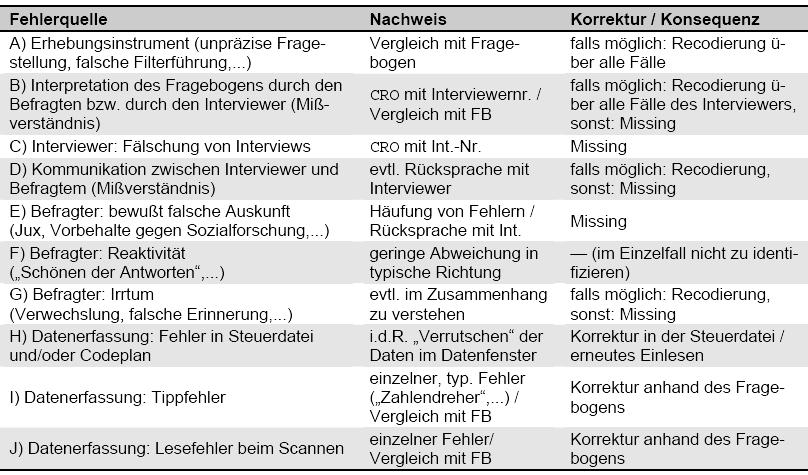
11 Cleaning Fehlerquellen 11
12 Missings, fehlende Werte
13 Fehlende Werte: Erkennung 13
14 Gültige und fehlende Werte Für jede»untersuchungseinheit«sollte bei allen»variablen«jeweils ein Wert vorliegen. In einigen Fällen kann jedoch die entsprechende Angabe fehlen, z.b. dann, wenn bei Befragungsdaten eine Person die Antwort auf eine Frage verweigert hat, keine Antwort wußte oder die Frage für sie nicht zutraf. Ganz allgemein spricht man hier von fehlenden Werten (engl.: missing values), die von den anderen, sogenannten gültigen Werten (engl.: valid values) unterschieden werden müssen. Sie müssen durch geeignete Kodes erkennbar gemacht werden, um sie entweder unter methodischen Gesichtspunkten auswerten zu können (z.b. die Antwortverweigerer) oder um bei in-haltlichen Auswertungen die Untersuchungseinheiten auszuschließen, die keine gültigen Werte aufweisen. Bei multivariaten Auswertungen werden dabei zwei Formen unterschieden: 14
15 Gültige und fehlende Werte (2) fallweiser Ausschluß (engl.: listwise deletion): Eine Untersuchungseinheit wird nicht berücksichtigt, wenn irgendeine der analysierten Variablen bei dieser Untersuchungseinheit einen fehlenden Wert aufweist. paarweiser Ausschluß (engl.: pairwise deletion): Manchmal lassen sich multivariate Auswertungen als eine Serie von bivariaten Analysen darstellen. Bei jeder dieser bivariaten Auswertungen werden jeweils die Untersuchungseinheiten ausgeschlossen, die bei einer der jeweils zwei beteiligten Variablen einen fehlenden Wert aufweisen. 15
16 Gültige und fehlende Werte (3) Fallweiser und paarweiser Ausschluss können bei multivariaten Analysen einen unterschiedlichen Stichprobenumfang ergeben. Bei bivariaten Auswertungen führen fall- und paarweiser Ausschluss zum gleichen Stichprobenumfang. Wenn in diesem Glossar von bestimmten statistischen Operationen für alle Untersuchungseinheiten die Rede ist, dann sind damit die Untersuchungseinheiten gemeint, für die gültige Werte vorliegen 16
17 Imputation
18 Imputation fehlender Werte Wenn man im konkreten Anwendungsfall über detailliertes Wissen (z.b. aus Vergleichsstudien) hat, kann es allenfalls sinnvoll sein, die fehlenden Werte zu ergänzen (Man sollte diese Möglichkeiten jedoch sparsam anwenden). Vorgehen: Aufbrechen der Stichprobe in eine mehrdimensionale Tabelle; Berechnen des Mittelwerts der Zellen. die missings können den jeweiligen Mittelwert erhalten Wenn die Missings normalverteilt sind, lässt sich eine Schätzgleichung rechnen (Regression). Anhand der Schätzwerte lassen sich die Missings ergänzen. Dies wird oft bei der Variable Einkommen gemacht. 18
19 Repräsentativitätsprüfung Nachschichtung, Gewichtung, Hochrechnung
20 Repräsentativität (1) Grundgesamtheit (GG) (Zahl der Elemente N) Menge aller Untersuchungselemente, für die eine Aussage gemacht werden soll (endlich oder unendlich gross) Stichprobe (Zahl der Elemente n) Endliche, möglichst repräsentative Teilmenge von Elementen von der auf die GG geschlossen werden kann Stichprobenumfang Auswahlverfahren 20
21 Validität (engl.: Validity) V. heißt allgemein Gültigkeit. Konkret versteht man darunter im Bereich der empirischen Sozialforschung vor allem zwei Aspekte: (1.) Die V. von Messungen, d.h. die Eigenschaft, das zu messen, was gemessen werden soll; (2.) die V. von Untersuchungen allgemein. Validität von Messungen Die V. von Messungen ist zunächst zu unterscheiden von der Reliabilität oder Zuverlässigkeit. Messinstrumente können sehr exakt immer das Falsche messen; dann sind sie zwar reliabel, aber nicht valide. Die Bestimmung der V. ist nicht einfach, und sie kann fast nie als endgültig betrachtet werden. Dies schon deshalb, weil man streng genommen die V. nur mittels eines anderen Messinstruments prüfen kann, dessen V. bereits bekannt sein müsste, so dass man hier im Prinzip in einen infiniten Regress kommt. Die Bestimmung der V. ähnelt also eher einer Detektivarbeit als einem eindeutigen und klar geregelten Vorgehen mit ebenso eindeutigen und klaren Ergebnissen. Man unterscheidet heute im wesentlichen drei Arten von V.: Die Inhaltsvalidität, die Kriteriumsvalidität und die Konstruktvalidität. (ILMES) 21
22 Reliabilität (Zuverlässigkeit) (engl.: Reliability) Neben der Validität (Gültigkeit) das zweite zentrale Qualitätskriterium bei Messungen. Meint, dass Messinstrumente bei wiederholter Messung unter gleichen Bedingungen auch das gleiche Ergebnis produzieren müssen. Einige wichtige Verfahren zur Bestimmung der R. sind: Test-Retest-Reliabilität: Das Messinstrument wird bei den gleichen Untersuchungspersonen wiederholt eingesetzt. Dieses Verfahren ist dann geeignet, wenn angenommen werden kann, dass die entsprechende Eigenschaft kon-stant bleibt (sonst würden Änderungen der Messergebnisse auftreten, die man als mangelnde R. interpretieren würde) und die Untersuchungspersonen durch die erste Messung nicht "lernen" (denn sonst würde die zweite Messung auch wegen des Lerneffekts mit der ersten übereinstimmen und so die R. überschätzt). Split-Half-Reliabilität: Ein Messinstrument, das aus mehreren Items besteht, kann in zwei Hälften geteilt werden; die Übereinstimmung dieser beiden Hälften kann als R. interpretiert werden. Die interne Konsistenz eines aus mehreren Items bestehenden Messinstruments, (Zusammenhang zwischen den einzelnen Items und der Gesamtheit der übrigen 22 Items). Die interne Konsistenz wird im allg. anhand von Cronbachs Alpha bestimmt.
23 Repräsentativität (2) Stichprobenumfang ( Gesetz der grossen Zahl ) Je grösser die Stichprobe, desto mehr nähern sich die Eigenschaften der Stichprobe denen der GG an. Je stärker die untersuchten Variablen streuen, desto grösser sollte der Umfang sein. Auswahlverfahren Zufällige Stichprobenauswahl (Abschätzung des Fehlers möglich) Bewusste Auswahlverfahren (Fehlerabschätzung nicht möglich) Prüfung der Repräsentativität (Nachschichtung, Gewichtung, Hochrechnung) 23
24 Erwartungswert Ähnlich wie das»arithmetische Mittel«einer empirischen Variablen beschreibt der Erwartungswert (engl.: expected value) das Zentrum der Verteilung einer»zufallsvariablen«. Der Erwartungswert E(x) der Zufallsvariablen X entspricht dem Wert, den man im Durchschnitt erwartet, wenn man alle Ausprägungen der Zufallsvariablen und ihre jeweiligen Auftretenswahrscheinlichkeiten berücksichtigt. Das läßt sich mathematisch noch am einfachsten bei diskreten Zufallsvariablen nachvollziehen: E(x) = x 1 P(X=x 1 ) + x 2 P(X=x 2 ) + + x n P(X=x n ) für alle Ausprägungen (engl.: categories) der Zufallsvariablen. Bei kontinuierlichen Zufallsvariablen ist eine Integration über den Definitionsbereich der Zufallsvariablen notwendig. 24



25 Erwartungswert 25
26 Frauen nach Alter (SHP 2000) Häufigkeit und Erwartungswert Frau (osb.) Frau (exp.) 26
27 Frauen nach Alter (SHP 2000) und BFS- Daten für 2000 Häufigkeit und Erwartungswert Frau (osb.) Frau (exp.) Frau (BFS) 27
28 Frauen nach Alter (SHP 2000) und BFS-Daten für 2000 Häufigkeit und Erwartungswert Überrepräsentierung Unterrepräsentierung Unterrepräsentierung Überrepräsentierung Frau (osb.) Frau (exp.) Frau (BFS) 28
29 Häufigkeiten, Erwartungswerte, Grundgesamtheit, gewichtete Häufigkeiten, gleitende Mittelwerte Überrepräsentierung Unterrepräsentierung Unterrepräsentierung Überrepräsentierung Frau (osb.) Frau (exp.) Frau (BFS) gew MA(3) 29


30 Gewichtung (Vorgehen) 30
31 Anfordern der Häufigkeiten und Erwartungswerte CROSSTABS /TABLES=age00 BY sex00 /FORMAT= AVALUE TABLES /CELLS= COUNT /COUNT ROUND CELL. CROSSTABS /TABLES=age00 BY sex00 /FORMAT= AVALUE TABLES /CELLS= COLUMN /COUNT ROUND CELL. CROSSTABS /TABLES=age00 BY sex00 /FORMAT= AVALUE TABLES /CELLS= EXPECTED /COUNT ROUND CELL. 31
32 Einfügen der Gewichtungsvariable Hinzufügen der Gewichtungsvariable zum Datenfile If (age00 = 1) GEWICHT = If (age00 = 2) GEWICHT = If (age00 = 3) GEWICHT = Verwenden WEIGHT BY GEWICHT. 32
33 Weitergehend zur Gewichtung Das hier vorgestellte Verfahren ist sehr einfach. In der empirischen Praxis lässt es sich leicht auch auf mehrdimensionale Kreuztabellen anwenden. Wenn die Gewichtung (z.b. in makrosoziologischen Studien) an der Grundgesamtheit relativiert wird spricht man in der Regel von einer Hochrechnung Probleme: Gewichtung kann bei stark verzerrten Stichproben oder sehr spezifischen Subsamples leicht auch das Gegenteil bewirken und die Verzerrungen erhöhen. Viele multivariate Verfahren erlauben keine Gewichtung Wenn in einem multivariaten Modell die 33 Variablen, anhand derer gewichtet wurde, kontrolliert sind, erübrigt sich die Gewichtung
34 Ausreisser
35 Ausreisser 35
36 Transformationen von Variablen
37 Wann, wozu Recodieren? Variablen gruppieren Variablen neuordnen (zwecks Optimierung des Zusammenhangs) Optimierung von schiefen Verteilungen 37
")
38 Transformation von Daten (1) 38
39 Transformation von Daten (2) 39
40 Transformation von Daten (3) 40
")
41 Transformation von Daten (4) 41
42 Transformation von Daten (5) 42
")
43 Transformation von Daten (6) 43
")
44 Transformation von Daten (7) 44
45 Transformation von Daten (8) Statistische Kennzahlen, Mittelwerte 45
46 Verteilungen (z-standardisierung), Dummy-Variablen, Interaktionsvariablen
47 z-transformation Messwerte aus unterschiedlichen Verteilungen (bspw. unterschiedliche Statistikklausuren) sollen miteinander verglichen werden Dazu wird zunächst von jedem Messwert der Mittelwert seiner Verteilung abgezogen (Zentrierung), um Niveau-unterschiede auszugleichen Die unterschiedliche Streuung (z.b. durch unterschiedliche Masseinheiten) der Verteilungen wird kompensiert, indem die zentrierten Werte durch die Standardabweichung ihrer Verteilung geteilt werden. 47
48 z-transformation (2) z-werte sind das Ergebnis der z-transformation Repräsentieren die Abweichung des ursprünglichen Messwertes vom Mittelwert seiner Verteilung Diese Abweichung wird in Standardabweichungen der ursprünglichen Verteilung ausgedrückt Damit informieren z-werte skalenunabhängig über die Lage des ursprünglichen Messwertes innerhalb seiner Verteilung z-werte weisen ihrerseits einen Mittelwert von 0 und eine Standardabweichung von 1 auf 48
49 Mittelwerte 49
50 Schiefe und Prüfung auf Normalverteilung Manche statistischen Verfahren für stetige Daten setzen voraus, dass diese Daten zumindest angenähert normalverteilt sind. Ein Kriterium dafür, ob Daten als normalverteilt betrachtet werden dürfen ist die Schiefe (Abweichung von der Symmetrie) der Werteverteilung. Bei linkssteilen Daten sind Extremwerte eher am rechten Rand der Verteilung aufzufinden, bei rechtssteilen Daten eher am linken Rand der Verteilung. Für symmetrische Daten beträgt die Schiefe 0, für linkssteile Daten ist sie positiv, für rechtssteile Daten negativ. Liegt die Schiefe zwischen 1 und + 1, dürfen die Daten als normalverteilt angesehen werden. (Zur statistischen Absicherung der Normalverteilung ist ein t-test erforderlich) 50
51 Schiefe und Prüfung auf Normalverteilung 51
52 Dummy-Variablen In vielen Fällen, z.b. wenn bei einer intervallskalierten Variable die Normalverteilung nicht erfüllt ist, vor allem aber bei ordinalen und nominalen Variablen ist für multivariate Verfahren die Bildung von Dummy-Variablen erforderlich. Es gibt unterschiedliche Verfahren zum Erstellen von Dummies, die häufigsten sind cornered und centered kodierte Dummies. Ich konzentriere mich hier auf cornered-kodierte Dummy Variablen. If (bildung = 1 [tief]) D_Bild_1 = 1. If (bildung = 2 [mittel]) D_Bild_1 = 0. If (bildung = 3 [hoch]) D_Bild_1 = 0. If (bildung = 1 [tief]) D_Bild_2 = 0. If (bildung = 2 [mittel]) D_Bild_2 = 1. If (bildung = 3 [hoch]) D_Bild_2 = 0. Für eine Ordinalvariable mit x Ausprägungen müssen x-1 Dummies 52 gebildet werden.
53 Dummy-Variablen (2) Ergebnis: Person mit Bildung = 1 (tief) D_Bild_1 = 1. D_Bild_2 = 0. Person mit Bildung = 2 (mittel) D_Bild_1 = 0. D_Bild_2 = 1. Person mit Bildung = 3 (hoch) Referenzkategorie D_Bild_1 = 0. D_Bild_2 = 0. Centered oder Effektkodierte Dummies definieren den Sample-Mittelwert als Referenz. Die Dummies indizieren die jeweilige Abweichung von diesem. 53
54 Dummy-Variablen (3) Dummies sind schwer zu interpretieren, weil sie zwingend untereinander hoch korreliert sind. 54
55 Interaktions-Variablen Vielfach interessiert in einer Analyse, ob die Kombination von zwei Variablen zusammen einen Effekt haben, z.b. junge, bildungsferne Personen sind fremdenfeindlicher als alte bildungsferne Personen Gefordert ist in diesem Fall die Bildung von Interaktionsvariablen. Das ist in jeweils das Produkt der Ausprägungen zwischen den beiden Variablen. Bei vielen Verfahren lassen sich diese innerhalb von SPSS direkt bestimmen (z.b. log.reg.) Interaktionsartige Zusammenhänge sind auch in der explorativen Phase einer Studie zweckmässig. Es bietet sich das folgende einfache Verfahren an: Compute inter_alt_bild = 0. Compute inter_alt_bild = (alt * 10) + bild. Eine Häufigkeitsauszählung für diese Variable zeigt die Struktur der Interaktion direkt. 55
Lage- und Streuungsparameter
 Lage- und Streuungsparameter Beziehen sich auf die Verteilung der Ausprägungen von intervall- und ratio-skalierten Variablen Versuchen, diese Verteilung durch Zahlen zu beschreiben, statt sie graphisch
Lage- und Streuungsparameter Beziehen sich auf die Verteilung der Ausprägungen von intervall- und ratio-skalierten Variablen Versuchen, diese Verteilung durch Zahlen zu beschreiben, statt sie graphisch
Einführung in SPSS. Sitzung 4: Bivariate Zusammenhänge. Knut Wenzig. 27. Januar 2005
 Sitzung 4: Bivariate Zusammenhänge 27. Januar 2005 Inhalt der letzten Sitzung Übung: ein Index Umgang mit missing values Berechnung eines Indexes Inhalt der letzten Sitzung Übung: ein Index Umgang mit
Sitzung 4: Bivariate Zusammenhänge 27. Januar 2005 Inhalt der letzten Sitzung Übung: ein Index Umgang mit missing values Berechnung eines Indexes Inhalt der letzten Sitzung Übung: ein Index Umgang mit
Testtheorie und Gütekriterien von Messinstrumenten. Objektivität Reliabilität Validität
 Testtheorie und Gütekriterien von Messinstrumenten Objektivität Reliabilität Validität Genauigkeit von Messungen Jede Messung zielt darauf ab, möglichst exakte und fehlerfreie Messwerte zu erheben. Dennoch
Testtheorie und Gütekriterien von Messinstrumenten Objektivität Reliabilität Validität Genauigkeit von Messungen Jede Messung zielt darauf ab, möglichst exakte und fehlerfreie Messwerte zu erheben. Dennoch
= = =0,2=20% 25 Plätze Zufallsübereinstimmung: 0.80 x x 0.20 = %
 allgemein Klassifizierung nach Persönlichkeitseigenschaften Messung von Persönlichkeitseigenschaften Zuordnung von Objekten zu Zahlen, so dass die Beziehungen zwischen den Zahlen den Beziehungen zwischen
allgemein Klassifizierung nach Persönlichkeitseigenschaften Messung von Persönlichkeitseigenschaften Zuordnung von Objekten zu Zahlen, so dass die Beziehungen zwischen den Zahlen den Beziehungen zwischen
Stichwortverzeichnis. Symbole
 Stichwortverzeichnis Symbole 50ste Perzentil 119 A Absichern, Ergebnisse 203 Abzählbar unendliche Zufallsvariable 146 Alternativhypothese 237 238 formulieren 248 Anekdote 340 Annäherung 171, 191 Antwortquote
Stichwortverzeichnis Symbole 50ste Perzentil 119 A Absichern, Ergebnisse 203 Abzählbar unendliche Zufallsvariable 146 Alternativhypothese 237 238 formulieren 248 Anekdote 340 Annäherung 171, 191 Antwortquote
Biomathematik für Mediziner, Klausur WS 1999/2000 Seite 1
 Biomathematik für Mediziner, Klausur WS 1999/2000 Seite 1 Aufgabe 1: Wieviele der folgenden Variablen sind quantitativ stetig? Schulnoten, Familienstand, Religion, Steuerklasse, Alter, Reaktionszeit, Fahrzeit,
Biomathematik für Mediziner, Klausur WS 1999/2000 Seite 1 Aufgabe 1: Wieviele der folgenden Variablen sind quantitativ stetig? Schulnoten, Familienstand, Religion, Steuerklasse, Alter, Reaktionszeit, Fahrzeit,
Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1
 LÖSUNG 2C a) Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1 Bei HHEINK handelt es sich um eine metrische Variable. Bei den Analysen sollen Extremwerte ausgeschlossen werden. Man sollte
LÖSUNG 2C a) Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1 Bei HHEINK handelt es sich um eine metrische Variable. Bei den Analysen sollen Extremwerte ausgeschlossen werden. Man sollte
Eigene MC-Fragen SPSS. 1. Zutreffend auf die Datenerfassung und Datenaufbereitung in SPSS ist
 Eigene MC-Fragen SPSS 1. Zutreffend auf die Datenerfassung und Datenaufbereitung in SPSS ist [a] In der Variablenansicht werden für die betrachteten Merkmale SPSS Variablen definiert. [b] Das Daten-Editor-Fenster
Eigene MC-Fragen SPSS 1. Zutreffend auf die Datenerfassung und Datenaufbereitung in SPSS ist [a] In der Variablenansicht werden für die betrachteten Merkmale SPSS Variablen definiert. [b] Das Daten-Editor-Fenster
Klassifikation von Signifikanztests
 Klassifikation von Signifikanztests nach Verteilungsannahmen: verteilungsabhängige = parametrische Tests verteilungsunabhängige = nichtparametrische Tests Bei parametrischen Tests werden im Modell Voraussetzungen
Klassifikation von Signifikanztests nach Verteilungsannahmen: verteilungsabhängige = parametrische Tests verteilungsunabhängige = nichtparametrische Tests Bei parametrischen Tests werden im Modell Voraussetzungen
Statistik. Jan Müller
 Statistik Jan Müller Skalenniveau Nominalskala: Diese Skala basiert auf einem Satz von qualitativen Attributen. Es existiert kein Kriterium, nach dem die Punkte einer nominal skalierten Variablen anzuordnen
Statistik Jan Müller Skalenniveau Nominalskala: Diese Skala basiert auf einem Satz von qualitativen Attributen. Es existiert kein Kriterium, nach dem die Punkte einer nominal skalierten Variablen anzuordnen
Hypothesentests mit SPSS
 Beispiel für einen chi²-test Daten: afrikamie.sav Im Rahmen der Evaluation des Afrikamie-Festivals wurden persönliche Interviews durchgeführt. Hypothese: Es gibt einen Zusammenhang zwischen dem Geschlecht
Beispiel für einen chi²-test Daten: afrikamie.sav Im Rahmen der Evaluation des Afrikamie-Festivals wurden persönliche Interviews durchgeführt. Hypothese: Es gibt einen Zusammenhang zwischen dem Geschlecht
Konkretes Durchführen einer Inferenzstatistik
 Konkretes Durchführen einer Inferenzstatistik Die Frage ist, welche inferenzstatistischen Schlüsse bei einer kontinuierlichen Variablen - Beispiel: Reaktionszeit gemessen in ms - von der Stichprobe auf
Konkretes Durchführen einer Inferenzstatistik Die Frage ist, welche inferenzstatistischen Schlüsse bei einer kontinuierlichen Variablen - Beispiel: Reaktionszeit gemessen in ms - von der Stichprobe auf
1. Datei Informationen
 1. Datei Informationen Datei vorbereiten (Daten, Variablen, Bezeichnungen und Skalentypen) > Datei Dateiinformation anzeigen Arbeitsdatei 2. Häufigkeiten Analysieren Deskriptive Statistik Häufigkeiten
1. Datei Informationen Datei vorbereiten (Daten, Variablen, Bezeichnungen und Skalentypen) > Datei Dateiinformation anzeigen Arbeitsdatei 2. Häufigkeiten Analysieren Deskriptive Statistik Häufigkeiten
Standardisierte Vorgehensweisen und Regeln zur Gewährleistung von: Eindeutigkeit Schlussfolgerungen aus empirischen Befunden sind nur dann zwingend
 Standardisierte Vorgehensweisen und Regeln zur Gewährleistung von: Eindeutigkeit Schlussfolgerungen aus empirischen Befunden sind nur dann zwingend oder eindeutig, wenn keine alternativen Interpretationsmöglichkeiten
Standardisierte Vorgehensweisen und Regeln zur Gewährleistung von: Eindeutigkeit Schlussfolgerungen aus empirischen Befunden sind nur dann zwingend oder eindeutig, wenn keine alternativen Interpretationsmöglichkeiten
Auswertung und Lösung
 Dieses Quiz soll Ihnen helfen, Kapitel 4.6 und 4.7 besser zu verstehen. Auswertung und Lösung Abgaben: 59 / 265 Maximal erreichte Punktzahl: 8 Minimal erreichte Punktzahl: 0 Durchschnitt: 4.78 1 Frage
Dieses Quiz soll Ihnen helfen, Kapitel 4.6 und 4.7 besser zu verstehen. Auswertung und Lösung Abgaben: 59 / 265 Maximal erreichte Punktzahl: 8 Minimal erreichte Punktzahl: 0 Durchschnitt: 4.78 1 Frage
Imputation (Ersetzen fehlender Werte)
") Imputation (Ersetzen fehlender Werte) Gliederung Nonresponse bias Fehlende Werte (missing values): Mechanismen Imputationsverfahren Überblick Mittelwert- / Regressions Hot-Deck-Imputation Row-Column-Imputation
Imputation (Ersetzen fehlender Werte) Gliederung Nonresponse bias Fehlende Werte (missing values): Mechanismen Imputationsverfahren Überblick Mittelwert- / Regressions Hot-Deck-Imputation Row-Column-Imputation
Häufigkeitsauszählungen, zentrale statistische Kennwerte und Mittelwertvergleiche
 Lehrveranstaltung Empirische Forschung und Politikberatung der Universität Bonn, WS 2007/2008 Häufigkeitsauszählungen, zentrale statistische Kennwerte und Mittelwertvergleiche 30. November 2007 Michael
Lehrveranstaltung Empirische Forschung und Politikberatung der Universität Bonn, WS 2007/2008 Häufigkeitsauszählungen, zentrale statistische Kennwerte und Mittelwertvergleiche 30. November 2007 Michael
Kontrolle und Aufbereitung der Daten. Peter Wilhelm Herbstsemester 2014
 Kontrolle und Aufbereitung der Daten Peter Wilhelm Herbstsemester 2014 Übersicht 1.) Kontrolle und Aufbereitung der Daten Fehlerkontrolle Umgang mit Missing 2.) Berechnung von Skalen- und Summenscores
Kontrolle und Aufbereitung der Daten Peter Wilhelm Herbstsemester 2014 Übersicht 1.) Kontrolle und Aufbereitung der Daten Fehlerkontrolle Umgang mit Missing 2.) Berechnung von Skalen- und Summenscores
Datenstrukturen. Querschnitt. Grösche: Empirische Wirtschaftsforschung
 Datenstrukturen Datenstrukturen Querschnitt Panel Zeitreihe 2 Querschnittsdaten Stichprobe von enthält mehreren Individuen (Personen, Haushalte, Firmen, Länder, etc.) einmalig beobachtet zu einem Zeitpunkt
Datenstrukturen Datenstrukturen Querschnitt Panel Zeitreihe 2 Querschnittsdaten Stichprobe von enthält mehreren Individuen (Personen, Haushalte, Firmen, Länder, etc.) einmalig beobachtet zu einem Zeitpunkt
Es können keine oder mehrere Antworten richtig sein. Eine Frage ist NUR dann richtig beantwortet, wenn ALLE richtigen Antworten angekreuzt wurden.
 Teil III: Statistik Alle Fragen sind zu beantworten. Es können keine oder mehrere Antworten richtig sein. Eine Frage ist NUR dann richtig beantwortet, wenn ALLE richtigen Antworten angekreuzt wurden. Wird
Teil III: Statistik Alle Fragen sind zu beantworten. Es können keine oder mehrere Antworten richtig sein. Eine Frage ist NUR dann richtig beantwortet, wenn ALLE richtigen Antworten angekreuzt wurden. Wird
Modul G.1 WS 07/08: Statistik
 Modul G.1 WS 07/08: Statistik 10.01.2008 1 2 Test Anwendungen Der 2 Test ist eine Klasse von Verfahren für Nominaldaten, wobei die Verteilung der beobachteten Häufigkeiten auf zwei mehrfach gestufte Variablen
Modul G.1 WS 07/08: Statistik 10.01.2008 1 2 Test Anwendungen Der 2 Test ist eine Klasse von Verfahren für Nominaldaten, wobei die Verteilung der beobachteten Häufigkeiten auf zwei mehrfach gestufte Variablen
Trim Size: 176mm x 240mm Lipow ftoc.tex V1 - March 9, :34 P.M. Page 11. Über die Übersetzerin 9. Einleitung 19
 Trim Size: 176mm x 240mm Lipow ftoc.tex V1 - March 9, 2016 6:34 P.M. Page 11 Inhaltsverzeichnis Über die Übersetzerin 9 Einleitung 19 Was Sie hier finden werden 19 Wie dieses Arbeitsbuch aufgebaut ist
Trim Size: 176mm x 240mm Lipow ftoc.tex V1 - March 9, 2016 6:34 P.M. Page 11 Inhaltsverzeichnis Über die Übersetzerin 9 Einleitung 19 Was Sie hier finden werden 19 Wie dieses Arbeitsbuch aufgebaut ist
Eigene MC-Fragen Testgütekriterien (X aus 5) 2. Das Ausmaß der Auswertungsobjektivität lässt sich in welcher statistischen Kennzahl angeben?
 2. Das Ausmaß der Auswertungsobjektivität lässt sich in welcher statistischen Kennzahl angeben?") Eigene MC-Fragen Testgütekriterien (X aus 5) 1. Wenn verschieden Testanwender bei Testpersonen mit demselben Testwert zu denselben Schlussfolgerungen kommen, entspricht dies dem Gütekriterium a) Durchführungsobjektivität
Eigene MC-Fragen Testgütekriterien (X aus 5) 1. Wenn verschieden Testanwender bei Testpersonen mit demselben Testwert zu denselben Schlussfolgerungen kommen, entspricht dies dem Gütekriterium a) Durchführungsobjektivität
Ermitteln Sie auf 2 Dezimalstellen genau die folgenden Kenngrößen der bivariaten Verteilung der Merkmale Weite und Zeit:
 1. Welche der folgenden Kenngrößen, Statistiken bzw. Grafiken sind zur Beschreibung der Werteverteilung des Merkmals Konfessionszugehörigkeit sinnvoll einsetzbar? A. Der Modalwert. B. Der Median. C. Das
1. Welche der folgenden Kenngrößen, Statistiken bzw. Grafiken sind zur Beschreibung der Werteverteilung des Merkmals Konfessionszugehörigkeit sinnvoll einsetzbar? A. Der Modalwert. B. Der Median. C. Das
Parametrische vs. Non-Parametrische Testverfahren
 Parametrische vs. Non-Parametrische Testverfahren Parametrische Verfahren haben die Besonderheit, dass sie auf Annahmen zur Verteilung der Messwerte in der Population beruhen: die Messwerte sollten einer
Parametrische vs. Non-Parametrische Testverfahren Parametrische Verfahren haben die Besonderheit, dass sie auf Annahmen zur Verteilung der Messwerte in der Population beruhen: die Messwerte sollten einer
Dozent: Dawid Bekalarczyk Universität Duisburg-Essen Fachbereich Gesellschaftswissenschaften Institut für Soziologie Lehrstuhl für empirische
 TEIL 3: MESSEN UND SKALIEREN 1 Das Messen eine Umschreibung Feststellung der Merkmalsausprägungen von Untersuchungseinheiten (z.b. Feststellung, wie viel eine Person wiegt oder Feststellung, wie aggressiv
TEIL 3: MESSEN UND SKALIEREN 1 Das Messen eine Umschreibung Feststellung der Merkmalsausprägungen von Untersuchungseinheiten (z.b. Feststellung, wie viel eine Person wiegt oder Feststellung, wie aggressiv
Marcus Hudec. Statistik 2 für SoziologInnen. Normalverteilung. Univ.Prof. Dr. Marcus Hudec. Statistik 2 für SoziologInnen 1 Normalverteilung
 Statistik 2 für SoziologInnen Normalverteilung Univ.Prof. Dr. Marcus Hudec Statistik 2 für SoziologInnen 1 Normalverteilung Inhalte Themen dieses Kapitels sind: Das Konzept stetiger Zufallsvariablen Die
Statistik 2 für SoziologInnen Normalverteilung Univ.Prof. Dr. Marcus Hudec Statistik 2 für SoziologInnen 1 Normalverteilung Inhalte Themen dieses Kapitels sind: Das Konzept stetiger Zufallsvariablen Die
Mathematische und statistische Methoden II
 Methodenlehre e e Prof. Dr. G. Meinhardt 6. Stock, Wallstr. 3 (Raum 06-206) Sprechstunde jederzeit nach Vereinbarung und nach der Vorlesung. Mathematische und statistische Methoden II Dr. Malte Persike
Methodenlehre e e Prof. Dr. G. Meinhardt 6. Stock, Wallstr. 3 (Raum 06-206) Sprechstunde jederzeit nach Vereinbarung und nach der Vorlesung. Mathematische und statistische Methoden II Dr. Malte Persike
Grundlegende Eigenschaften von Punktschätzern
 Grundlegende Eigenschaften von Punktschätzern Worum geht es in diesem Modul? Schätzer als Zufallsvariablen Vorbereitung einer Simulation Verteilung von P-Dach Empirische Lage- und Streuungsparameter zur
Grundlegende Eigenschaften von Punktschätzern Worum geht es in diesem Modul? Schätzer als Zufallsvariablen Vorbereitung einer Simulation Verteilung von P-Dach Empirische Lage- und Streuungsparameter zur
Marcus Hudec. Statistik 2 für SoziologInnen. Normalverteilung. Univ.Prof. Dr. Marcus Hudec. Statistik 2 für SoziologInnen 1 Normalverteilung
 Statistik 2 für SoziologInnen Normalverteilung Univ.Prof. Dr. Marcus Hudec Statistik 2 für SoziologInnen 1 Normalverteilung Stetige Zufalls-Variable Erweitert man den Begriff der diskreten Zufallsvariable
Statistik 2 für SoziologInnen Normalverteilung Univ.Prof. Dr. Marcus Hudec Statistik 2 für SoziologInnen 1 Normalverteilung Stetige Zufalls-Variable Erweitert man den Begriff der diskreten Zufallsvariable
Statistik-Klausur A WS 2009/10
 Statistik-Klausur A WS 2009/10 Name: Vorname: Immatrikulationsnummer: Studiengang: Hiermit erkläre ich meine Prüfungsfähigkeit vor Beginn der Prüfung. Unterschrift: Dauer der Klausur: Erlaubte Hilfsmittel:
Statistik-Klausur A WS 2009/10 Name: Vorname: Immatrikulationsnummer: Studiengang: Hiermit erkläre ich meine Prüfungsfähigkeit vor Beginn der Prüfung. Unterschrift: Dauer der Klausur: Erlaubte Hilfsmittel:
Willkommen zur Vorlesung Statistik (Master)
") Willkommen zur Vorlesung Statistik (Master) Thema dieser Vorlesung: Verteilungen stetiger Zufallsvariablen Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften
Willkommen zur Vorlesung Statistik (Master) Thema dieser Vorlesung: Verteilungen stetiger Zufallsvariablen Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften
Wahrscheinlichkeitsrechnung und schließende Statistik
 Karl Mosler Friedrich Schmid Wahrscheinlichkeitsrechnung und schließende Statistik Vierte, verbesserte Auflage Springer Inhaltsverzeichnis 0 Einführung 1 1 Zufalls Vorgänge und Wahrscheinlichkeiten 5 1.1
Karl Mosler Friedrich Schmid Wahrscheinlichkeitsrechnung und schließende Statistik Vierte, verbesserte Auflage Springer Inhaltsverzeichnis 0 Einführung 1 1 Zufalls Vorgänge und Wahrscheinlichkeiten 5 1.1
Inhaltsverzeichnis. 1 Über dieses Buch Zum Inhalt dieses Buches Danksagung Zur Relevanz der Statistik...
 Inhaltsverzeichnis 1 Über dieses Buch... 11 1.1 Zum Inhalt dieses Buches... 13 1.2 Danksagung... 15 2 Zur Relevanz der Statistik... 17 2.1 Beispiel 1: Die Wahrscheinlichkeit, krank zu sein, bei einer positiven
Inhaltsverzeichnis 1 Über dieses Buch... 11 1.1 Zum Inhalt dieses Buches... 13 1.2 Danksagung... 15 2 Zur Relevanz der Statistik... 17 2.1 Beispiel 1: Die Wahrscheinlichkeit, krank zu sein, bei einer positiven
fh management, communication & it Constantin von Craushaar fh-management, communication & it Statistik Angewandte Statistik
 fh management, communication & it Folie 1 Überblick Grundlagen (Testvoraussetzungen) Mittelwertvergleiche (t-test,..) Nichtparametrische Tests Korrelationen Regressionsanalyse... Folie 2 Überblick... Varianzanalyse
fh management, communication & it Folie 1 Überblick Grundlagen (Testvoraussetzungen) Mittelwertvergleiche (t-test,..) Nichtparametrische Tests Korrelationen Regressionsanalyse... Folie 2 Überblick... Varianzanalyse
Bivariate Analyseverfahren
 Bivariate Analyseverfahren Bivariate Verfahren beschäftigen sich mit dem Zusammenhang zwischen zwei Variablen Beispiel: Konservatismus/Alter Zusammenhangsmaße beschreiben die Stärke eines Zusammenhangs
Bivariate Analyseverfahren Bivariate Verfahren beschäftigen sich mit dem Zusammenhang zwischen zwei Variablen Beispiel: Konservatismus/Alter Zusammenhangsmaße beschreiben die Stärke eines Zusammenhangs
4.2 Grundlagen der Testtheorie. Wintersemester 2008 / 2009 Hochschule Magdeburg-Stendal (FH) Frau Prof. Dr. Gabriele Helga Franke
 Frau Prof. Dr. Gabriele Helga Franke") 4.2 Grundlagen der Testtheorie Wintersemester 2008 / 2009 Hochschule Magdeburg-Stendal (FH) Frau Prof. Dr. Gabriele Helga Franke GHF im WiSe 2008 / 2009 an der HS MD-SDL(FH) im Studiengang Rehabilitationspsychologie,
4.2 Grundlagen der Testtheorie Wintersemester 2008 / 2009 Hochschule Magdeburg-Stendal (FH) Frau Prof. Dr. Gabriele Helga Franke GHF im WiSe 2008 / 2009 an der HS MD-SDL(FH) im Studiengang Rehabilitationspsychologie,
Lagemaße Übung. Zentrale Methodenlehre, Europa Universität - Flensburg
 Lagemaße Übung M O D U S, M E D I A N, M I T T E L W E R T, M O D A L K L A S S E, M E D I A N, K L A S S E, I N T E R P O L A T I O N D E R M E D I A N, K L A S S E M I T T E Zentrale Methodenlehre, Europa
Lagemaße Übung M O D U S, M E D I A N, M I T T E L W E R T, M O D A L K L A S S E, M E D I A N, K L A S S E, I N T E R P O L A T I O N D E R M E D I A N, K L A S S E M I T T E Zentrale Methodenlehre, Europa
Wahrscheinlichkeitsverteilungen
 Universität Bielefeld 3. Mai 2005 Wahrscheinlichkeitsrechnung Wahrscheinlichkeitsrechnung Das Ziehen einer Stichprobe ist die Realisierung eines Zufallsexperimentes. Die Wahrscheinlichkeitsrechnung betrachtet
Universität Bielefeld 3. Mai 2005 Wahrscheinlichkeitsrechnung Wahrscheinlichkeitsrechnung Das Ziehen einer Stichprobe ist die Realisierung eines Zufallsexperimentes. Die Wahrscheinlichkeitsrechnung betrachtet
Statistik Testverfahren. Heinz Holling Günther Gediga. Bachelorstudium Psychologie. hogrefe.de
 rbu leh ch s plu psych Heinz Holling Günther Gediga hogrefe.de Bachelorstudium Psychologie Statistik Testverfahren 18 Kapitel 2 i.i.d.-annahme dem unabhängig. Es gilt also die i.i.d.-annahme (i.i.d = independent
rbu leh ch s plu psych Heinz Holling Günther Gediga hogrefe.de Bachelorstudium Psychologie Statistik Testverfahren 18 Kapitel 2 i.i.d.-annahme dem unabhängig. Es gilt also die i.i.d.-annahme (i.i.d = independent
Statistik 2 für SoziologInnen. Normalverteilung. Univ.Prof. Dr. Marcus Hudec. Themen dieses Kapitels sind:
 Statistik 2 für SoziologInnen Normalverteilung Univ.Prof. Dr. Marcus Hudec Statistik 2 für SoziologInnen 1 Normalverteilung Inhalte Themen dieses Kapitels sind: Das Konzept stetiger Zufallsvariablen Die
Statistik 2 für SoziologInnen Normalverteilung Univ.Prof. Dr. Marcus Hudec Statistik 2 für SoziologInnen 1 Normalverteilung Inhalte Themen dieses Kapitels sind: Das Konzept stetiger Zufallsvariablen Die
Statistische Grundlagen I
 Statistische Grundlagen I Arten der Statistik Zusammenfassung und Darstellung von Daten Beschäftigt sich mit der Untersuchung u. Beschreibung von Gesamtheiten oder Teilmengen von Gesamtheiten durch z.b.
Statistische Grundlagen I Arten der Statistik Zusammenfassung und Darstellung von Daten Beschäftigt sich mit der Untersuchung u. Beschreibung von Gesamtheiten oder Teilmengen von Gesamtheiten durch z.b.
Einführung in die computergestützte Datenanalyse
 Karlheinz Zwerenz Statistik Einführung in die computergestützte Datenanalyse 6., überarbeitete Auflage DE GRUYTER OLDENBOURG Vorwort Hinweise zu EXCEL und SPSS Hinweise zum Master-Projekt XI XII XII TEIL
Karlheinz Zwerenz Statistik Einführung in die computergestützte Datenanalyse 6., überarbeitete Auflage DE GRUYTER OLDENBOURG Vorwort Hinweise zu EXCEL und SPSS Hinweise zum Master-Projekt XI XII XII TEIL
Übungen mit dem Applet Wahrscheinlichkeitsnetz
 Wahrscheinlichkeitsnetz 1 Übungen mit dem Applet Wahrscheinlichkeitsnetz 1 Statistischer Hintergrund... 1.1 Verteilungen... 1. Darstellung von Daten im Wahrscheinlichkeitsnetz...4 1.3 Kurzbeschreibung
Wahrscheinlichkeitsnetz 1 Übungen mit dem Applet Wahrscheinlichkeitsnetz 1 Statistischer Hintergrund... 1.1 Verteilungen... 1. Darstellung von Daten im Wahrscheinlichkeitsnetz...4 1.3 Kurzbeschreibung
1. Einführung in die induktive Statistik
 Wichtige Begriffe 1. Einführung in die induktive Statistik Grundgesamtheit: Statistische Masse, die zu untersuchen ist, bzw. über die Aussagen getroffen werden soll Stichprobe: Teil einer statistischen
Wichtige Begriffe 1. Einführung in die induktive Statistik Grundgesamtheit: Statistische Masse, die zu untersuchen ist, bzw. über die Aussagen getroffen werden soll Stichprobe: Teil einer statistischen
Empirische Wirtschaftsforschung
 Empirische Wirtschaftsforschung Prof. Dr. Bernd Süßmuth Universität Leipzig Institut für Empirische Wirtschaftsforschung Volkswirtschaftslehre, insbesondere Ökonometrie 1 3. Momentenschätzung auf Stichprobenbasis
Empirische Wirtschaftsforschung Prof. Dr. Bernd Süßmuth Universität Leipzig Institut für Empirische Wirtschaftsforschung Volkswirtschaftslehre, insbesondere Ökonometrie 1 3. Momentenschätzung auf Stichprobenbasis
Statistische Tests für unbekannte Parameter
 Konfidenzintervall Intervall, das den unbekannten Parameter der Verteilung mit vorgegebener Sicherheit überdeckt ('Genauigkeitsaussage' bzw. Zuverlässigkeit einer Punktschätzung) Statistischer Test Ja-Nein-Entscheidung
Konfidenzintervall Intervall, das den unbekannten Parameter der Verteilung mit vorgegebener Sicherheit überdeckt ('Genauigkeitsaussage' bzw. Zuverlässigkeit einer Punktschätzung) Statistischer Test Ja-Nein-Entscheidung
Angewandte Statistik 3. Semester
 Angewandte Statistik 3. Semester Übung 5 Grundlagen der Statistik Übersicht Semester 1 Einführung ins SPSS Auswertung im SPSS anhand eines Beispieles Häufigkeitsauswertungen Grafiken Statistische Grundlagen
Angewandte Statistik 3. Semester Übung 5 Grundlagen der Statistik Übersicht Semester 1 Einführung ins SPSS Auswertung im SPSS anhand eines Beispieles Häufigkeitsauswertungen Grafiken Statistische Grundlagen
B. Heger / R. Prust: Quantitative Methoden der empirischen Sozialforschung (Master Modul 1.3)
") B. Heger / R. Prust: Quantitative Methoden der empirischen Sozialforschung (Master Modul 1.3) Übung 1 (mit SPSS-Ausgabe) 1. Erstellen Sie eine einfache Häufigkeitsauszählung der Variable V175 ( des/der
B. Heger / R. Prust: Quantitative Methoden der empirischen Sozialforschung (Master Modul 1.3) Übung 1 (mit SPSS-Ausgabe) 1. Erstellen Sie eine einfache Häufigkeitsauszählung der Variable V175 ( des/der
1. Maße der zentralen Tendenz Beispiel: Variable Anzahl der Geschwister aus Jugend '92. Valid Cum Value Frequency Percent Percent Percent
 Deskriptive Statistik 1. Verteilungsformen symmetrisch/asymmetrisch unimodal(eingipflig) / bimodal (zweigipflig schmalgipflig / breitgipflig linkssteil / rechtssteil U-förmig / abfallend Statistische Kennwerte
Deskriptive Statistik 1. Verteilungsformen symmetrisch/asymmetrisch unimodal(eingipflig) / bimodal (zweigipflig schmalgipflig / breitgipflig linkssteil / rechtssteil U-förmig / abfallend Statistische Kennwerte
Statistik, Geostatistik
 Geostatistik Statistik, Geostatistik Statistik Zusammenfassung von Methoden (Methodik), die sich mit der wahrscheinlichkeitsbezogenen Auswertung empirischer (d.h. beobachteter, gemessener) Daten befassen.
Geostatistik Statistik, Geostatistik Statistik Zusammenfassung von Methoden (Methodik), die sich mit der wahrscheinlichkeitsbezogenen Auswertung empirischer (d.h. beobachteter, gemessener) Daten befassen.
Willkommen zur Vorlesung Statistik (Master)
") Willkommen zur Vorlesung Statistik (Master) Thema dieser Vorlesung: Punkt- und Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften Prof. Dr.
Willkommen zur Vorlesung Statistik (Master) Thema dieser Vorlesung: Punkt- und Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften Prof. Dr.
Tutorium Testtheorie. Termin 3. Inhalt: WH: Hauptgütekriterien- Reliabilität & Validität. Charlotte Gagern
 Tutorium Testtheorie Termin 3 Charlotte Gagern charlotte.gagern@gmx.de Inhalt: WH: Hauptgütekriterien- Reliabilität & Validität 1 Hauptgütekriterien Objektivität Reliabilität Validität 2 Hauptgütekriterien-Reliabilität
Tutorium Testtheorie Termin 3 Charlotte Gagern charlotte.gagern@gmx.de Inhalt: WH: Hauptgütekriterien- Reliabilität & Validität 1 Hauptgütekriterien Objektivität Reliabilität Validität 2 Hauptgütekriterien-Reliabilität
Statistik Einführung // Stichprobenverteilung 6 p.2/26
 Statistik Einführung Kapitel 6 Statistik WU Wien Gerhard Derflinger Michael Hauser Jörg Lenneis Josef Leydold Günter Tirler Rosmarie Wakolbinger Statistik Einführung // 6 p.0/26 Lernziele 1. Beschreiben
Statistik Einführung Kapitel 6 Statistik WU Wien Gerhard Derflinger Michael Hauser Jörg Lenneis Josef Leydold Günter Tirler Rosmarie Wakolbinger Statistik Einführung // 6 p.0/26 Lernziele 1. Beschreiben
Statistische Tests für unbekannte Parameter
 Konfidenzintervall Intervall, das den unbekannten Parameter der Verteilung mit vorgegebener Sicherheit überdeckt ('Genauigkeitsaussage' bzw. Zuverlässigkeit einer Punktschätzung) Statistischer Test Ja-Nein-Entscheidung
Konfidenzintervall Intervall, das den unbekannten Parameter der Verteilung mit vorgegebener Sicherheit überdeckt ('Genauigkeitsaussage' bzw. Zuverlässigkeit einer Punktschätzung) Statistischer Test Ja-Nein-Entscheidung
Forschungsstatistik I
 Psychologie Prof. Dr. G. Meinhardt 6. Stock, TB II R. 06-206 (Persike) R. 06-321 (Meinhardt) Sprechstunde jederzeit nach Vereinbarung Forschungsstatistik I Dr. Malte Persike persike@uni-mainz.de http://psymet03.sowi.uni-mainz.de/
Psychologie Prof. Dr. G. Meinhardt 6. Stock, TB II R. 06-206 (Persike) R. 06-321 (Meinhardt) Sprechstunde jederzeit nach Vereinbarung Forschungsstatistik I Dr. Malte Persike persike@uni-mainz.de http://psymet03.sowi.uni-mainz.de/
Statistische Messdatenauswertung
 Roland Looser Statistische Messdatenauswertung Praktische Einführung in die Auswertung von Messdaten mit Excel und spezifischer Statistik-Software für naturwissenschaftlich und technisch orientierte Anwender
Roland Looser Statistische Messdatenauswertung Praktische Einführung in die Auswertung von Messdaten mit Excel und spezifischer Statistik-Software für naturwissenschaftlich und technisch orientierte Anwender
Forschungsmethoden in der Sozialen Arbeit
 Forschungsmethoden in der Sozialen Arbeit Fachhochschule für Sozialarbeit und Sozialpädagogik Alice- Salomon Hochschule für Soziale arbeit, Gesundheit, Erziehung und Bildung University of Applied Sciences
Forschungsmethoden in der Sozialen Arbeit Fachhochschule für Sozialarbeit und Sozialpädagogik Alice- Salomon Hochschule für Soziale arbeit, Gesundheit, Erziehung und Bildung University of Applied Sciences
1.1.1 Ergebnismengen Wahrscheinlichkeiten Formale Definition der Wahrscheinlichkeit Laplace-Experimente...
 Inhaltsverzeichnis 0 Einführung 1 1 Zufallsvorgänge und Wahrscheinlichkeiten 5 1.1 Zufallsvorgänge.......................... 5 1.1.1 Ergebnismengen..................... 6 1.1.2 Ereignisse und ihre Verknüpfung............
Inhaltsverzeichnis 0 Einführung 1 1 Zufallsvorgänge und Wahrscheinlichkeiten 5 1.1 Zufallsvorgänge.......................... 5 1.1.1 Ergebnismengen..................... 6 1.1.2 Ereignisse und ihre Verknüpfung............
5. Spezielle stetige Verteilungen
 5. Spezielle stetige Verteilungen 5.1 Stetige Gleichverteilung Eine Zufallsvariable X folgt einer stetigen Gleichverteilung mit den Parametern a und b, wenn für die Dichtefunktion von X gilt: f x = 1 für
5. Spezielle stetige Verteilungen 5.1 Stetige Gleichverteilung Eine Zufallsvariable X folgt einer stetigen Gleichverteilung mit den Parametern a und b, wenn für die Dichtefunktion von X gilt: f x = 1 für
Bestimmte Zufallsvariablen sind von Natur aus normalverteilt. - naturwissenschaftliche Variablen: originär z.b. Intelligenz, Körpergröße, Messfehler
 6.6 Normalverteilung Die Normalverteilung kann als das wichtigste Verteilungsmodell der Statistik angesehen werden. Sie wird nach ihrem Entdecker auch Gaußsche Glockenkurve genannt. Die herausragende Stellung
6.6 Normalverteilung Die Normalverteilung kann als das wichtigste Verteilungsmodell der Statistik angesehen werden. Sie wird nach ihrem Entdecker auch Gaußsche Glockenkurve genannt. Die herausragende Stellung
Statistisches Testen
 Statistisches Testen Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Differenzen Anteilswert Chi-Quadrat Tests Gleichheit von Varianzen Prinzip des Statistischen Tests Konfidenzintervall
Statistisches Testen Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Differenzen Anteilswert Chi-Quadrat Tests Gleichheit von Varianzen Prinzip des Statistischen Tests Konfidenzintervall
Willkommen zur Vorlesung Statistik (Master)
") Willkommen zur Vorlesung Statistik (Master) Thema dieser Vorlesung: Punkt- und Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften Prof. Dr.
Willkommen zur Vorlesung Statistik (Master) Thema dieser Vorlesung: Punkt- und Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften Prof. Dr.
Übung 1: Wiederholung Wahrscheinlichkeitstheorie
 Übung 1: Wiederholung Wahrscheinlichkeitstheorie Ü1.1 Zufallsvariablen Eine Zufallsvariable ist eine Variable, deren numerischer Wert solange unbekannt ist, bis er beobachtet wird. Der Wert einer Zufallsvariable
Übung 1: Wiederholung Wahrscheinlichkeitstheorie Ü1.1 Zufallsvariablen Eine Zufallsvariable ist eine Variable, deren numerischer Wert solange unbekannt ist, bis er beobachtet wird. Der Wert einer Zufallsvariable
Softwaretechnik. Prof. Dr. Rainer Koschke. Fachbereich Mathematik und Informatik Arbeitsgruppe Softwaretechnik Universität Bremen
 Softwaretechnik Prof. Dr. Rainer Koschke Fachbereich Mathematik und Informatik Arbeitsgruppe Softwaretechnik Universität Bremen Wintersemester 2010/11 Überblick I Statistik bei kontrollierten Experimenten
Softwaretechnik Prof. Dr. Rainer Koschke Fachbereich Mathematik und Informatik Arbeitsgruppe Softwaretechnik Universität Bremen Wintersemester 2010/11 Überblick I Statistik bei kontrollierten Experimenten
Auswahl von Schätzfunktionen
 Auswahl von Schätzfunktionen Worum geht es in diesem Modul? Überblick zur Punktschätzung Vorüberlegung zur Effizienz Vergleich unserer Schätzer für My unter Normalverteilung Relative Effizienz Einführung
Auswahl von Schätzfunktionen Worum geht es in diesem Modul? Überblick zur Punktschätzung Vorüberlegung zur Effizienz Vergleich unserer Schätzer für My unter Normalverteilung Relative Effizienz Einführung
Einfaktorielle Varianzanalyse
 Kapitel 16 Einfaktorielle Varianzanalyse Im Zweistichprobenproblem vergleichen wir zwei Verfahren miteinander. Nun wollen wir mehr als zwei Verfahren betrachten, wobei wir unverbunden vorgehen. Beispiel
Kapitel 16 Einfaktorielle Varianzanalyse Im Zweistichprobenproblem vergleichen wir zwei Verfahren miteinander. Nun wollen wir mehr als zwei Verfahren betrachten, wobei wir unverbunden vorgehen. Beispiel
Konfidenzintervalle Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Anteilswert Differenzen von Erwartungswert Anteilswert
 Konfidenzintervalle Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Anteilswert Differenzen von Erwartungswert Anteilswert Beispiel für Konfidenzintervall Im Prinzip haben wir
Konfidenzintervalle Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Anteilswert Differenzen von Erwartungswert Anteilswert Beispiel für Konfidenzintervall Im Prinzip haben wir
Inhaltsverzeichnis. Über die Autoren Einleitung... 21
 Inhaltsverzeichnis Über die Autoren.... 7 Einleitung... 21 Über dieses Buch... 21 Was Sie nicht lesen müssen... 22 Törichte Annahmen über den Leser... 22 Wie dieses Buch aufgebaut ist... 23 Symbole, die
Inhaltsverzeichnis Über die Autoren.... 7 Einleitung... 21 Über dieses Buch... 21 Was Sie nicht lesen müssen... 22 Törichte Annahmen über den Leser... 22 Wie dieses Buch aufgebaut ist... 23 Symbole, die
Inhaltsverzeichnis. Inhalt Teil I: Beschreibende (Deskriptive) Statistik Seite. 1.0 Erste Begriffsbildungen Merkmale und Skalen 5
 Statistik Seite. 1.0 Erste Begriffsbildungen Merkmale und Skalen 5") Inhaltsverzeichnis Inhalt Teil I: Beschreibende (Deskriptive) Statistik Seite 1.0 Erste Begriffsbildungen 1 1.1 Merkmale und Skalen 5 1.2 Von der Urliste zu Häufigkeitsverteilungen 9 1.2.0 Erste Ordnung
Inhaltsverzeichnis Inhalt Teil I: Beschreibende (Deskriptive) Statistik Seite 1.0 Erste Begriffsbildungen 1 1.1 Merkmale und Skalen 5 1.2 Von der Urliste zu Häufigkeitsverteilungen 9 1.2.0 Erste Ordnung
Missing Data. VL Forschungsmethoden
 Missing Data VL Forschungsmethoden Missing Data VL Forschungsmethoden VL Forschungsmethoden Missing Data (0/27) Übersicht Missing Data: Typen Vor- und Nachteile : Ansatz Implementation VL Forschungsmethoden
Missing Data VL Forschungsmethoden Missing Data VL Forschungsmethoden VL Forschungsmethoden Missing Data (0/27) Übersicht Missing Data: Typen Vor- und Nachteile : Ansatz Implementation VL Forschungsmethoden
Standardnormalverteilung
 Standardnormalverteilung 1720 erstmals von Abraham de Moivre beschrieben 1809 und 1816 grundlegende Arbeiten von Carl Friedrich Gauß 1870 von Adolphe Quetelet als "ideales" Histogramm verwendet alternative
Standardnormalverteilung 1720 erstmals von Abraham de Moivre beschrieben 1809 und 1816 grundlegende Arbeiten von Carl Friedrich Gauß 1870 von Adolphe Quetelet als "ideales" Histogramm verwendet alternative
Mehrdimensionale Zufallsvariablen
 Mehrdimensionale Zufallsvariablen Im Folgenden Beschränkung auf den diskreten Fall und zweidimensionale Zufallsvariablen. Vorstellung: Auswerten eines mehrdimensionalen Merkmals ( ) X Ỹ also z.b. ω Ω,
Mehrdimensionale Zufallsvariablen Im Folgenden Beschränkung auf den diskreten Fall und zweidimensionale Zufallsvariablen. Vorstellung: Auswerten eines mehrdimensionalen Merkmals ( ) X Ỹ also z.b. ω Ω,
Statistische Methoden in den Umweltwissenschaften
 Statistische Methoden in den Umweltwissenschaften Stetige und diskrete Wahrscheinlichkeitsverteilungen Lageparameter Streuungsparameter Diskrete und stetige Zufallsvariablen Eine Variable (oder Merkmal
Statistische Methoden in den Umweltwissenschaften Stetige und diskrete Wahrscheinlichkeitsverteilungen Lageparameter Streuungsparameter Diskrete und stetige Zufallsvariablen Eine Variable (oder Merkmal
5. Lektion: Einfache Signifikanztests
 Seite 1 von 7 5. Lektion: Einfache Signifikanztests Ziel dieser Lektion: Du ordnest Deinen Fragestellungen und Hypothesen die passenden einfachen Signifikanztests zu. Inhalt: 5.1 Zwei kategoriale Variablen
Seite 1 von 7 5. Lektion: Einfache Signifikanztests Ziel dieser Lektion: Du ordnest Deinen Fragestellungen und Hypothesen die passenden einfachen Signifikanztests zu. Inhalt: 5.1 Zwei kategoriale Variablen
1 Univariate Statistiken
 1 Univariate Statistiken Im ersten Kapitel berechnen wir zunächst Kenngrößen einer einzelnen Stichprobe bzw. so genannte empirische Kenngrößen, wie beispielsweise den Mittelwert. Diese können, unter gewissen
1 Univariate Statistiken Im ersten Kapitel berechnen wir zunächst Kenngrößen einer einzelnen Stichprobe bzw. so genannte empirische Kenngrößen, wie beispielsweise den Mittelwert. Diese können, unter gewissen
3. Lektion: Deskriptive Statistik
 Seite 1 von 5 3. Lektion: Deskriptive Statistik Ziel dieser Lektion: Du kennst die verschiedenen Methoden der deskriptiven Statistik und weißt, welche davon für Deine Daten passen. Inhalt: 3.1 Deskriptive
Seite 1 von 5 3. Lektion: Deskriptive Statistik Ziel dieser Lektion: Du kennst die verschiedenen Methoden der deskriptiven Statistik und weißt, welche davon für Deine Daten passen. Inhalt: 3.1 Deskriptive
Schätzverfahren, Annahmen und ihre Verletzungen, Standardfehler. Oder: was schiefgehen kann, geht schief. Statistik II
 Schätzverfahren, Annahmen und ihre Verletzungen, Standardfehler. Oder: was schiefgehen kann, geht schief Statistik II Wiederholung Literatur Kategoriale Unabhängige, Interaktion, nicht-lineare Effekte
Schätzverfahren, Annahmen und ihre Verletzungen, Standardfehler. Oder: was schiefgehen kann, geht schief Statistik II Wiederholung Literatur Kategoriale Unabhängige, Interaktion, nicht-lineare Effekte
Übungen mit dem Applet Vergleich von zwei Mittelwerten
 Vergleich von zwei Mittelwerten 1 Übungen mit dem Applet Vergleich von zwei Mittelwerten 1 Statistischer Hintergrund... 2 1.1 Typische Fragestellungen...2 1.2 Fehler 1. und 2. Art...2 1.3 Kurzbeschreibung
Vergleich von zwei Mittelwerten 1 Übungen mit dem Applet Vergleich von zwei Mittelwerten 1 Statistischer Hintergrund... 2 1.1 Typische Fragestellungen...2 1.2 Fehler 1. und 2. Art...2 1.3 Kurzbeschreibung
SozialwissenschaftlerInnen II
 Statistik für SozialwissenschaftlerInnen II Henning Best best@wiso.uni-koeln.de Universität zu Köln Forschungsinstitut für Soziologie Statistik für SozialwissenschaftlerInnen II p.1 Wahrscheinlichkeitsfunktionen
Statistik für SozialwissenschaftlerInnen II Henning Best best@wiso.uni-koeln.de Universität zu Köln Forschungsinstitut für Soziologie Statistik für SozialwissenschaftlerInnen II p.1 Wahrscheinlichkeitsfunktionen
Missing Data. Missing Data. VL Forschungsmethoden. VL Forschungsmethoden. Missing Data: Typen Strategien Fazit
 Missing Data VL Forschungsmethoden Missing Data VL Forschungsmethoden VL Forschungsmethoden Missing Data (0/27) Übersicht 1 2 Vor- und Nachteile : Ansatz Implementation 3 VL Forschungsmethoden Missing
Missing Data VL Forschungsmethoden Missing Data VL Forschungsmethoden VL Forschungsmethoden Missing Data (0/27) Übersicht 1 2 Vor- und Nachteile : Ansatz Implementation 3 VL Forschungsmethoden Missing
2. Deskriptive Statistik
 Philipps-Universitat Marburg 2.1 Stichproben und Datentypen Untersuchungseinheiten: mogliche, statistisch zu erfassende Einheiten je Untersuchungseinheit: ein oder mehrere Merkmale oder Variablen beobachten
Philipps-Universitat Marburg 2.1 Stichproben und Datentypen Untersuchungseinheiten: mogliche, statistisch zu erfassende Einheiten je Untersuchungseinheit: ein oder mehrere Merkmale oder Variablen beobachten
Prüfung aus Statistik 1 für SoziologInnen
 Prüfung aus Statistik 1 für SoziologInnen 1) Wissenstest (maximal 20 Punkte) Prüfungsdauer: 120 Minuten netto Kreuzen ( ) Sie die jeweils richtige Antwort an. Jede richtige Antwort gibt 2 Punkte. Pro falsche
Prüfung aus Statistik 1 für SoziologInnen 1) Wissenstest (maximal 20 Punkte) Prüfungsdauer: 120 Minuten netto Kreuzen ( ) Sie die jeweils richtige Antwort an. Jede richtige Antwort gibt 2 Punkte. Pro falsche
Grundlagen sportwissenschaftlicher Forschung Inferenzstatistik 2
 Grundlagen sportwissenschaftlicher Forschung Inferenzstatistik 2 Dr. Jan-Peter Brückner jpbrueckner@email.uni-kiel.de R.216 Tel. 880 4717 Statistischer Schluss Voraussetzungen z.b. bzgl. Skalenniveau und
Grundlagen sportwissenschaftlicher Forschung Inferenzstatistik 2 Dr. Jan-Peter Brückner jpbrueckner@email.uni-kiel.de R.216 Tel. 880 4717 Statistischer Schluss Voraussetzungen z.b. bzgl. Skalenniveau und
GLIEDERUNG Das Messen eine Umschreibung Skalenniveaus von Variablen Drei Gütekriterien von Messungen Konstruierte Skalen in den Sozialwissenschaften
 TEIL 3: MESSEN UND SKALIEREN GLIEDERUNG Das Messen eine Umschreibung Skalenniveaus von Variablen Drei Gütekriterien von Messungen Objektivität Reliabilität Validität Konstruierte Skalen in den Sozialwissenschaften
TEIL 3: MESSEN UND SKALIEREN GLIEDERUNG Das Messen eine Umschreibung Skalenniveaus von Variablen Drei Gütekriterien von Messungen Objektivität Reliabilität Validität Konstruierte Skalen in den Sozialwissenschaften
Kapitel 2. Mittelwerte
 Kapitel 2. Mittelwerte Im Zusammenhang mit dem Begriff der Verteilung, der im ersten Kapitel eingeführt wurde, taucht häufig die Frage auf, wie man die vorliegenden Daten durch eine geeignete Größe repräsentieren
Kapitel 2. Mittelwerte Im Zusammenhang mit dem Begriff der Verteilung, der im ersten Kapitel eingeführt wurde, taucht häufig die Frage auf, wie man die vorliegenden Daten durch eine geeignete Größe repräsentieren
Statistik II. Statistische Tests. Statistik II
 Statistik II Statistische Tests Statistik II - 12.5.2006 1 Test auf Anteilswert: Binomialtest Sei eine Stichprobe unabhängig, identisch verteilter ZV (i.i.d.). Teile diese Stichprobe in zwei Teilmengen
Statistik II Statistische Tests Statistik II - 12.5.2006 1 Test auf Anteilswert: Binomialtest Sei eine Stichprobe unabhängig, identisch verteilter ZV (i.i.d.). Teile diese Stichprobe in zwei Teilmengen
Statistik. Datenanalyse mit EXCEL und SPSS. R.01denbourg Verlag München Wien. Von Prof. Dr. Karlheinz Zwerenz. 3., überarbeitete Auflage
 Statistik Datenanalyse mit EXCEL und SPSS Von Prof. Dr. Karlheinz Zwerenz 3., überarbeitete Auflage R.01denbourg Verlag München Wien Inhalt Vorwort Hinweise zu EXCEL und SPSS Hinweise zum Master-Projekt
Statistik Datenanalyse mit EXCEL und SPSS Von Prof. Dr. Karlheinz Zwerenz 3., überarbeitete Auflage R.01denbourg Verlag München Wien Inhalt Vorwort Hinweise zu EXCEL und SPSS Hinweise zum Master-Projekt
Statistik II: Grundlagen und Definitionen der Statistik
 Medien Institut : Grundlagen und Definitionen der Statistik Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Hintergrund: Entstehung der Statistik 2. Grundlagen
Medien Institut : Grundlagen und Definitionen der Statistik Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Hintergrund: Entstehung der Statistik 2. Grundlagen
Wichtige Definitionen und Aussagen
 Wichtige Definitionen und Aussagen Zufallsexperiment, Ergebnis, Ereignis: Unter einem Zufallsexperiment verstehen wir einen Vorgang, dessen Ausgänge sich nicht vorhersagen lassen Die möglichen Ausgänge
Wichtige Definitionen und Aussagen Zufallsexperiment, Ergebnis, Ereignis: Unter einem Zufallsexperiment verstehen wir einen Vorgang, dessen Ausgänge sich nicht vorhersagen lassen Die möglichen Ausgänge
1 x 1 y 1 2 x 2 y 2 3 x 3 y 3... n x n y n
 3.2. Bivariate Verteilungen zwei Variablen X, Y werden gemeinsam betrachtet (an jedem Objekt werden gleichzeitig zwei Merkmale beobachtet) Beobachtungswerte sind Paare von Merkmalsausprägungen (x, y) Beispiele:
3.2. Bivariate Verteilungen zwei Variablen X, Y werden gemeinsam betrachtet (an jedem Objekt werden gleichzeitig zwei Merkmale beobachtet) Beobachtungswerte sind Paare von Merkmalsausprägungen (x, y) Beispiele:
Zufallsvariablen [random variable]
![Zufallsvariablen [random variable]](/thumbs/52/29710821.jpg "Zufallsvariablen [random variable]") Zufallsvariablen [random variable] Eine Zufallsvariable (Zufallsgröße) X beschreibt (kodiert) die Versuchsausgänge ω Ω mit Hilfe von Zahlen, d.h. X ist eine Funktion X : Ω R ω X(ω) Zufallsvariablen werden
Zufallsvariablen [random variable] Eine Zufallsvariable (Zufallsgröße) X beschreibt (kodiert) die Versuchsausgänge ω Ω mit Hilfe von Zahlen, d.h. X ist eine Funktion X : Ω R ω X(ω) Zufallsvariablen werden
Statistik. Einführung in die com putergestützte Daten an alyse. Oldenbourg Verlag München B , überarbeitete Auflage
 Statistik Einführung in die com putergestützte Daten an alyse von Prof. Dr. Karlheinz Zwerenz 4., überarbeitete Auflage B 366740 Oldenbourg Verlag München Inhalt Vorwort XI Hinweise zu EXCEL und SPSS XII
Statistik Einführung in die com putergestützte Daten an alyse von Prof. Dr. Karlheinz Zwerenz 4., überarbeitete Auflage B 366740 Oldenbourg Verlag München Inhalt Vorwort XI Hinweise zu EXCEL und SPSS XII
Klausurvorbereitung - Statistik
 Aufgabe 1 Klausurvorbereitung - Statistik Studenten der Politikwissenschaft der Johannes Gutenberg-Universität wurden befragt, seit wie vielen Semestern sie eingeschrieben sind. Berechnen Sie für die folgenden
Aufgabe 1 Klausurvorbereitung - Statistik Studenten der Politikwissenschaft der Johannes Gutenberg-Universität wurden befragt, seit wie vielen Semestern sie eingeschrieben sind. Berechnen Sie für die folgenden
4.1. Nullhypothese, Gegenhypothese und Entscheidung
 rof. Dr. Roland Füss Statistik II SS 8 4. Testtheorie 4.. Nullhypothese, Gegenhypothese und Entscheidung ypothesen Annahmen über die Verteilung oder über einzelne arameter der Verteilung eines Merkmals
rof. Dr. Roland Füss Statistik II SS 8 4. Testtheorie 4.. Nullhypothese, Gegenhypothese und Entscheidung ypothesen Annahmen über die Verteilung oder über einzelne arameter der Verteilung eines Merkmals
3.2 Streuungsmaße. 3 Lage- und Streuungsmaße 133. mittlere Variabilität. geringe Variabilität. große Variabilität 0.0 0.1 0.2 0.3 0.4 0.
 Eine Verteilung ist durch die Angabe von einem oder mehreren Mittelwerten nur unzureichend beschrieben. Beispiel: Häufigkeitsverteilungen mit gleicher zentraler Tendenz: geringe Variabilität mittlere Variabilität
Eine Verteilung ist durch die Angabe von einem oder mehreren Mittelwerten nur unzureichend beschrieben. Beispiel: Häufigkeitsverteilungen mit gleicher zentraler Tendenz: geringe Variabilität mittlere Variabilität
Institut für Soziologie Werner Fröhlich. Methoden 2. Kontingenztabellen Chi-Quadrat-Unabhängigkeitstest
 Institut für Soziologie Methoden 2 Kontingenztabellen Chi-Quadrat-Unabhängigkeitstest Aufbau der Sitzung Was sind Kontingenztabellen? Wofür werden Kontingenztabellen verwendet? Aufbau und Interpretation
Institut für Soziologie Methoden 2 Kontingenztabellen Chi-Quadrat-Unabhängigkeitstest Aufbau der Sitzung Was sind Kontingenztabellen? Wofür werden Kontingenztabellen verwendet? Aufbau und Interpretation
4.1 Stichproben, Verteilungen und Schätzwerte. N(t) = N 0 e λt, (4.1)
 = N 0 e λt, (4.1)") Kapitel 4 Stichproben und Schätzungen 4.1 Stichproben, Verteilungen und Schätzwerte Eine physikalische Messung ist eine endliche Stichprobe aus einer Grundgesamtheit, die endlich oder unendlich sein kann.
Kapitel 4 Stichproben und Schätzungen 4.1 Stichproben, Verteilungen und Schätzwerte Eine physikalische Messung ist eine endliche Stichprobe aus einer Grundgesamtheit, die endlich oder unendlich sein kann.
Wiederholung der Hauptklausur STATISTIK
 Name, Vorname: Matrikel-Nr. Die Klausur enthält zwei Typen von Aufgaben: Teil A besteht aus Fragen mit mehreren vorgegebenen Antwortvorschlägen, von denen mindestens eine Antwort richtig ist und von denen
Name, Vorname: Matrikel-Nr. Die Klausur enthält zwei Typen von Aufgaben: Teil A besteht aus Fragen mit mehreren vorgegebenen Antwortvorschlägen, von denen mindestens eine Antwort richtig ist und von denen