J. Bortz/N. Döring: Forschungsmethoden und Evaluation (jeweils neueste Auflage) Springer, Berlin S. 463ff
|
|
|
- Bernd Sternberg
- vor 8 Jahren
- Abrufe
Transkript
1 J. Bortz/N. Döring: Forschungsmethoden und Evaluation (jeweils neueste Auflage) Springer, Berlin S. 463ff Signifikanztests Zur Logik des Signifikanztests Tests zur statistischen Überprüfung von Hypothesen heißen Signifikanztests. Der Signifikanztest ermittelt die Wahrscheinlichkeit, mit der das gefundene empirische Ergebnis sowie Ergebnisse, die noch extremer sind als das gefundene Ergebnis, auftreten können, wenn die Populationsverhältnisse der Nullhypothese entsprechen. Ist diese Wahrscheinlichkeit kleiner als α%, bezeichnen wir das Stichprobenergebnis als statistisch signifikant. Für α sind per Konvention die Werte 5% bzw. 1% festgelegt. Stichprobenergebnisse, deren bedingte Wahrscheinlichkeit bei Gültigkeit der H 0 kleiner als 5% ist, sind auf dem 5%-(Signifikanz-)Niveau signifikant (kurz: signifikant) und Stichprobenergebnisse mit Wahrscheinlichkeiten kleiner als 1% sind auf dem 1%-(Signifikanz-) Niveau signifikant (kurz: sehr signifikant). Ein (sehr) signifikantes Ergebnis ist also ein Ergebnis, das sich mit der Nullhypothese praktisch nicht vereinbaren läßt. Man verwirft deshalb die Nullhypothese und akzeptiert die Alternativhypothese. Andernfalls, bei einem nicht-signifikanten Ergebnis, wird die Nullhypothese beibehalten und die Alternativhypothese verworfen. Dies ist die Kurzform des Aufbaus eines Signifikanztests. Seine Vor- und Nachteile werden deutlich, wenn wir die mathematische Struktur eines Signifikanztests etwas genauer betrachten. Stichprobenkennwerteverteilungen In jeder hypothesenprüfenden Untersuchung bestimmen wir einen statistischen Kennwert, der möglichst die gesamte hypothesenrelevante Information einer Untersuchung zusammenfaßt. Hierbei kann es sich - je nach Art der Hypothese und nach Art des Skalenniveaus der Variablen - um Mittelwertsdifferenzen, Häufigkeitsdifferenzen, Korrelationen, Quotienten zweier Varianzen, Differenzen von Rangsummen, Prozentwertdifferenzen o. ä. handeln. Unabhängig von der Art des Kennwertes gilt, daß die in einer Untersuchung ermittelte Größe des Kennwertes von den spezifischen Besonderheiten der zufällig ausgewählten Stichprobe(n) abhängt. Mit hoher Wahrscheinlichkeit wird der untersuchungsrelevante Kennwert bei einer Wiederholung der Untersuchung mit anderen Untersuchungsobjekten nicht exakt mit dem zuerst ermittelten Wert übereinstimmen. Der Kennwert ist stichprobenabhängig und wird damit wie eine Realisierung einer Zufallsvariablen behandelt. Zieht man aus einer Population theoretisch unendlich viele gleich große Stichproben und berechnet für jede Stichprobe einen Kennwert (z. B. den Stichprobenmittelwert), so verteilen sich diese Stichprobenkennwerte in bekannter Weise um den zugehörigen Populationsparameter (z. B. Populationsmittelwert). Eine solche theoretische (d.h. mathematisch ableitbare) Stichprobenkennwerteverteilung aller möglichen Stichprobenergebnisse dient dazu, ein einzelnes empirisches Stichprobenresultat einschätzen zu können. VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 1

2 Die Feststellung, ob es sich bei dem in einer Untersuchung gefundenen Kennwert um einen extremen" oder eher um einen typischen" Kennwert handelt, ist nur möglich, wenn die Dichtefunktion (bei stetig verteilten Kennwerten) bzw. die Wahrscheinlichkeitsfunktion (bei diskret verteilten Kennwerten) der Zufallsvariablen statistischer Kennwert" bekannt ist. Die Verteilung eines statistischen Kennwertes bezeichneten wir als Stichprobenkennwerteverteilung ( Sampling Distribution"). Diese Verteilung ist unbekannt, solange wir die wahren Populationsverhältnisse (z. B. die Differenz zweier Populationsmittelwerte oder die Korrelation zweier Merkmale in der untersuchten Population) nicht kennen. Signifikanztests werden nur eingesetzt, wenn die Ausprägungen der interessierenden Populationsparameter unbekannt sind, denn sonst würde sich ein Signifikanztest erübrigen. Über die wahren" Populationsparameter können wir bestenfalls Vermutungen anstellen (z. B. die Differenz zweier Populationsmittelwerte sei vom Betrage a oder die Populationskorrelation zweier Merkmale sei b). Wir können aber auch behaupten - und dies ist der übliche Fall - die Nullhypothese sei richtig, d. h. es gelten die mit der Nullhypothese festgelegten Populationsverhältnisse. Statistische Tabellen Damit stehen wir vor der Aufgabe, herauszufinden, wie sich ein Stichprobenkennwert (z. B. die Differenz zweier Stichprobenmittelwerte oder die Stichprobenkorrelation verteilen würde, wenn die Populationsverhältnisse durch die H O charakterisiert sind. Dies ist ein mathematisches Problem, das für die gebräuchlichsten statistischen Kennwerte gelöst ist. Sind in Abhängigkeit von der Art des statistischen Kennwertes unterschiedliche Zusatzannahmen erfüllt (diese finden sich in Statistikbüchern als Voraussetzungen der verschiedenen Signifikanztests wieder), lassen sich die Verteilungen von praktisch allen in der empirischen Forschung gebräuchlichen Kennwerten auf einige wenige mathematisch bekannte Verteilungen zurückführen. Werden die statistischen Kennwerte zudem nach mathematisch eindeutigen Vorschriften transformiert (dies sind die Formeln zur Durchführung eines Signifikanztests), resultieren statistische Testwerte (z.b. t-werte, z-werte, χ 2 -Werte, F-Werte etc.), deren Verteilungen (Verteilungsfunktionen) in jedem Statistikbuch in tabellarischer Form aufgeführt sind. Signifikante Ergebnisse Der Signifikanztest reduziert sich damit auf den einfachen Vergleich der Größe des empirisch ermittelten, statistischen Testwertes mit demjenigen Wert, der von der entsprechenden Testwerteverteilung α% (α=1% oder α=5%) abschneidet. Ist der empirische Testwert größer als dieser kritische" Tabellenwert, beträgt dessen Wahrscheinlichkeit sowie die Wahrscheinlichkeit aller extremeren Testwerte unter der Annahme, die Ho sei richtig, weniger als α%. Das Ergebnis ist statistisch signifikant (α.<5%) bzw. sehr signifikant (α<1%). Wir fragen also nach der Wahrscheinlichkeit, mit der Stichprobenergebnisse auftreten können, wenn die Nullhypothese gilt. Wir betrachten nur diejenigen extremen Ergebnisse, die bei Gültigkeit der Nullhypothese höchstens mit einer Wahrscheinlichkeit von 5% (1%) vorkommen. Gehört das gefundene Stichprobenergebnis zu diesen Ergebnissen, ist das Stichprobenergebnis praktisch" nicht mit der Nullhypothese zu vereinbaren. Wir entscheiden uns deshalb dafür, die Nullhypothese abzulehnen und akzeptieren die Alternativhypothese als Erklärung. VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 2

3 Ein signifikantes Ergebnis sagt also nichts über die Wahrscheinlichkeit von Hypothesen aus, sondern nur" etwas über die Wahrscheinlichkeit von statistischen Kennwerten bei Gültigkeit der Nullhypothese. Die Hypothesen (die H 0 oder die H 1 ) sind entweder richtig oder falsch, d.h. auch unsere Entscheidung, bei einem signifikanten Ergebnis die H 0 zu verwerfen, ist entweder richtig oder falsch. Bei dieser Entscheidungsstrategie riskieren wir, daß mit 5% (oder 1%) Irrtumswahrscheinlichkeit eine tatsächlich richtige H 0 fälschlicherweise verworfen wird. Bei einem Signifikanztest geht man zunächst davon aus, die Nullhypothese würde in der Population gelten. Unter dieser Annahme läßt sich für den Populationsparameter, der in der Nullhypothese angesprochen ist, eine Stichprobenkennwerteverteilung konstruieren, die angibt, mit welcher Wahrscheinlichkeit mögliche Stichprobenergebnisse auftreten können. Mit dieser Stichprobenkennwerteverteilung (bzw. Ho-Verteilung, Ho-Modell) wird nun das konkret in der Untersuchung ermittelte Stichprobenresultat verglichen. - Ist das gefundene Stichprobenergebnis ein wahrscheinliches Ergebnis, so steht es in Einklang mit der Ho. - Ist das Stichprobenergebnis ein unwahrscheinliches Ergebnis, das unter Gültigkeit der Ho nur extrem selten auftreten kann, entschließt man sich, die Nullhypothese als unplausibel zu verwerfen. Dies geschieht aber nur, wenn die Wahrscheinlichkeit für das Auftreten des gefundenen oder eines extremeren Ergebnisses unter Gültigkeit der Ho sehr klein, nämlich kleiner als 5% ist. Ein solches, im Sinne der Ho unplausibles Ergebnis wird als signifikantes Ergebnis" bezeichnet. Bei einem signifikanten Ergebnis entscheidet man sich dafür, die Ho abzulehnen und die H 1 anzunehmen. Ein Beispiel: Der t-test Der Gedankengang des Signifikanztests sei wegen seiner Bedeutung nochmals anhand eines Beispiels erläutert. Wir interessieren uns für die psychische Belastbarkeit weiblicher und männlicher Erwachsener und formulieren als Ho: µ 1 = µ 2 und als H 1: µ 1 µ 2 (µ 1 ist der Populationsmittelwert weiblicher Personen und µ 2 ist der Populationsmittelwert männlicher Personen). Psychische Belastbarkeit wird mit einem psychologischen Test gemessen, der bei einer Zufallsstichprobe von n 1 männlichen Personen im Durchschnitt - so unsere operationale Hypothese - anders ausfallen soll als bei einer Zufallsstichprobe von n 2 weiblichen Personen (ungerichtete, unspezifische Hypothese). Der für die Überprüfung von Unterschiedshypothesen bei zwei Stichproben verwendete statistische Kennwert ist die Mittelwertsdifferenz x 1 x 2. Dieser statistische Kennwert wird nach folgender Gleichung in einen statistischen Testwert transformiert: t = x x 1 s x x Den Ausdruck im Nenner bezeichnen wir als (geschätzten) Standardfehler der Mittelwertsdifferenz. Der statistische Testwert t folgt bei Gültigkeit der Ho einer t-verteilung (mit n 1 + n 2 2 Freiheitsgraden), wenn das Merkmal psychische Belastbarkeit" in beiden Populationen normalverteilt und die Merkmalsvarianz σ 2 ( Sigma ) in beiden Populationen gleich ist (bzw. die geschätzten Populationsvarianzen homogen sind). Die t-verteilung geht für n 1 + n 2 > 30 in die Standardnormalverteilung über. VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 3

4 Gerichtete Hypothesen (Die psychische Belastbarkeit männlicher Personen ist größer als die psychische Belastbarkeit weiblicher Personen) werden anhand dieser Verteilung über einseitige und ungerichtete Hypothesen (Die psychische Belastbarkeit männlicher und weiblicher Personen unterscheidet sich) über zweiseitige Tests geprüft. Annahme- und Ablehnungsbereich der Ho bei zweiseitigem Test Bei einem zweiseitigen Test markieren die Werte t (α/2) und -t (α/2) diejenigen t-werte einer t- Verteilung, die von den Extremen der Verteilungsfläche jeweils α/2% abschneiden. Empirische t- Werte, die in diese Extrembereiche fallen, haben damit insgesamt eine Wahrscheinlichkeit von höchstens α%, vorausgesetzt, die Nullhypothese ist richtig. Da derart extreme Ergebnisse nur schlecht mit der Annahme, die Ho sei richtig, zu vereinbaren sind, verwerfen wir die Ho und akzeptieren die H 1: µ 1 µ 2 (Die psychische Belastbarkeit männlicher und weiblicher Personen unterscheidet sich). Befindet sich der empirisch ermittelte t-wert jedoch im Annahmebereich der Ho, dann sind das Stichprobenergebnis und die Nullhypothese besser miteinander zu vereinbaren und wir behalten die Ho: µ 1 = µ 2. Annahme- und Ablehnungsbereich der Ho bei einseitigem Test Die Überprüfung einer gerichteten H 1: µ 1 > µ 2 erfordert einen einseitigen Test. Wir verwerfen die Nullhypothese und akzeptieren die Alternativhypothese, wenn der empirische t-wert größer ist als derjenige t-wert, der von der t-verteilung einseitig" α% abschneidet. Ist der empirische t- Wert jedoch kleiner als der kritische Wert t α, kann die H, nicht angenommen werden (nichtsignifikantes Ergebnis). VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 4

5 Anselm Eder (2003): Statistik für Sozialwissenschaftler, Skriptum, facultas, S. 131 Der t - Test Der Grundgedanke des t-tests ist die Fragestellung, ob zwei Mittelwerte ein- und derselben Variablen, die in zwei Gruppen (etwa: zwei Stichproben) erhoben worden sind, sich voneinander nur zufällig unterscheiden, oder ob diese Unterschiede eher auf etwas systematisches zurückzuführen sind: z.b. darauf, dass es sich eben doch nicht um zwei zufällig gezogene Stichproben handelt, sondern eher um zwei Auswahlverfahren, die systematisch einmal kleinere, und einmal größere Werte der betrachteten Variablen aussuchen. (Anmerkung isa hager: Auswahlverfahren z.b. Geschlecht: durchschnittliches Einkommen von Männern und Frauen) So könnte etwa der Mittelwert der Körpergröße von Soldaten in einer Kaserne 168 cm sein, und der von Soldaten einer anderen Kaserne 172 cm. Die Frage, die man stellen könnte, lautet: wurden die Soldaten in den beiden Kasernen nach Größe rekrutiert, oder handelt es sich dabei einfach um zufällige Unterschiede, die deshalb zustande kamen, weil die beiden Stichproben aus der Grundgesamtheit aller österreichischen Wehrdienstpflichtigen sich eben zufällig um 4cm im Durchschnitt unterschieden haben? Das Instrumentarium, das wir dafür brauchen, unterscheidet sich nicht mehr sehr wesentlich von den Elementen, die wir schon einerseits als Grundelemente jedes Signifikanztests beim Chiquadrat-Test, und andererseits beim Konfidenzintervall kennen gelernt haben. Zunächst müssen wir wieder ein vernünftiges Prüfmaß konstruieren. Dabei wird natürlich der Unterschied zwischen den beiden Mittelwerten eine Rolle spielen. Aus dem Abschnitt über Konfidenzintervalle wissen wir schon, dass die Standardabweichung eines Stichprobenmittelwertes s s x n x = ist. Außerdem wissen wir, dass eine Zufallsvariable, von der wir ihren Erwartungswert abziehen, den Erwartungswert 0 hat; dividieren wir sie noch durch ihre Standardabweichung, dann hat sie die Standardabweichung 1. Gemäß der Nullhypothese sind die Abweichungen der beiden Mittelwerte voneinander zufällig, d.h. die Erwartungswerte für die beiden Mittelwerte (die Mittelwerte der zugehörigen Grundgesamtheiten) sind gleich, oder sogar identisch. Somit ist die Größe t x x 1 2 = normalverteilt s 1, mit dem Erwartungswert 0 und der Standardabweichung 1. x x 1 2 Dass der Erwartungswert 0 ist, ergibt sich unmittelbar aus der Nullhypothese, gemäß der die beiden Mittelwerte x1 und x2 gleich sind. Wenn wir daher unendlich viele Paare von Stichproben ziehen, dann werden die Durchschnitte der Mittelwerte dieser beiden Stichproben gleich sein. 1 Genau genommen ist dieses Prüfmaß ist für größere Stichproben (größer als ca. 50 für beide Stichproben zusammen) annähernd normalverteilt. Für kleinere Stichproben hat GOSSET die zugehörige Verteilung unter dem Namen t-verteilung berechnet. Ähnlich wie die χ 2 -Verteilung ist auch die t-verteilung durch Freiheitsgrade charakterisiert. Die Anzahl der Freiheitsgrade ist n 1 +n 2-2, wobei n 1 und n 2 die Größen der beiden Stichproben sind. VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 5

6 Aus der Vorlesung: Signifikanztests Anwendung Signifikanztests dienen zur statistischen Überprüfung von Hypothesen. Zunächst wird davon ausgegangen, dass die Nullhypothese (H 0 ) in der Grundgesamtheit (Population) gilt. Unter dieser Annahme lässt sich für die Population eine Stichprobenkennwerteverteilung konstruieren, die angibt, mit welcher Wahrscheinlichkeit mögliche Stichprobenergebnisse auftreten können. Mit dieser Stichprobenkennwerteverteilung wird nun das konkret in der Untersuchung ermittelte Stichprobenresultat verglichen. Ist das gefundene Stichprobenergebnis ein wahrscheinliches Ergebnis, so steht es in Einklang mit der H 0. Ist das Stichprobenergebnis ein unwahrscheinliches Ergebnis, das unter Gültigkeit der H 0 nur extrem selten auftreten kann, wird die Nullhypothese als unplausibel verworfen. Ein solches, im Sinne der H 0 unplausibles Ergebnis wird als signifikantes Ergebnis bezeichnet (H 0 wird abgelehnt und H 1 wird angenommen). Signifikanztests sind nur sinnvoll bei Zufallsstichproben. Je nach Signifikanztest können weitere Voraussetzungen erforderlich sein (z.b. metrisches Skalenniveau, Normalverteilung). Vorgehen 1. Formulierung der Nullhypothese (H 0 ) und der Alternativhypothese (H 1 ). 2. Ermittlung einer statistischen Prüfgröße. 3. Festlegung des Signifikanzniveaus (üblicherweise 5%-Niveau) und bestimmen der Wahrscheinlichkeit der Prüfgröße anhand der zugehörigen Wahrscheinlichkeitsverteilung derselben (in Tabellen nachzulesen bzw. macht SPSS automatisch). 4. Annahme der H 1, wenn Irrtumswahrscheinlichkeit kleiner <0,05, ansonsten wird H 0 vorläufig beibehalten. HYPOTHESEN-TESTUNG??? Wozu brauch ich Signifikanztests??? 1. Hypothesen (H 0 und H 1 ) formulieren 2. Prüfgröße berechnen 3. Signifikanzniveau der Prüfgröße festlegen. 4. Je nach Irrtums-WS H 0 beibehalten oder H 1 annehmen. VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 6

7 Fragestellung Zweiseitige Fragestellung: Wenn über die Richtung des vermuteten Zusammenhangs keine sichere Annahme getroffen werden kann (z.b. x x ). 1 2 Einseitige Fragestellung: Wenn die Richtung des vermuteten Zusammenhangs angegeben werden kann (z.b. x < x ). 1 2 Fehlerarten Fehler 1. Art (α): Fehler 2. Art (β): H 0 wird irrtümlich abgelehnt, d.h. eine falsche H 1 wird angenommen. H 0 wird irrtümlich beibehalten, d.h. eine richtige H 1 wird abgelehnt. Fehlerarten Grundgesamtheit/Population H 0 H 1 Stichprobe H 0 H 1 kein Zusammenhang a α - Fehler Zusammenhang falsch β - Fehler Zusammenhang nicht erkannt Zusammenhang a Unterschied zwischen Prüfgröße und Signifikanz Grundsätzlich wird bei jedem statistischen Test zwischen der Prüfgröße (z.b. der Chi-Quadrat- Wert) und der Signifikanz der Prüfgröße unterschieden. Während die Prüfgröße Chi-Quadrat theoretisch Werte bis unendlich annehmen kann, liegt die Signifikanz (=Wahrscheinlichkeit der Prüfgröße bei angenommener Unabhängigkeit) immer zwischen 0 und 1. Signifikanz ein Wert nahe bei 0 bedeutet: der berechnete Wert der Prüfgröße ist bei angenommener Unabhängigkeit sehr unwahrscheinlich ist dieser Wert gleich oder kleiner als das gewählte Signifikanzniveau (üblicherweise 0,05 oder 0,01), dann wird konventionell die H 0 verworfen und die H 1 (Annahme von Abhängigkeit oder Zusammenhang) angenommen; ein Wert nahe bei 1 bedeutet: der berechnete Wert der Prüfgröße ist bei angenommener Unabhängigkeit sehr wahrscheinlich ist dieser Wert größer als das gewählte Signifikanzniveau (üblicherweise 0,05 oder 0,01), dann wird konventionell die H 0 (Annahme von Unabhängigkeit oder keinem Zusammenhang) beibehalten; VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 7

8 Übersicht über die wichtigsten Signifikanztests VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 8

9 VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 9

")
10 Entscheidungsbaum VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 10
")
11 VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 11
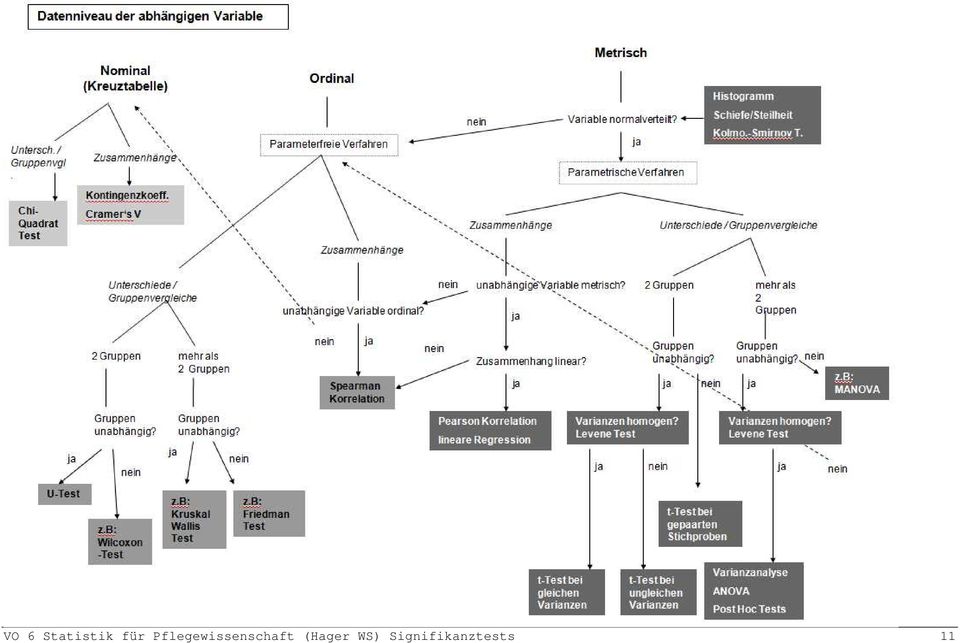
12 Im Folgenden sollen die verschiedenen Testverfahren kurz besprochen werden. Es gibt noch sehr viel mehr Testverfahren, hier werden lediglich die wichtigsten angeführt. χ 2 - Test Test auf Unabhängigkeit zweier Merkmale. Der χ 2 - Test kann bei nominal- und ordinalskalierten Variablen verwendet werden. Der Test wird bei Kreuztabellen in sinnvoller, der Fragestellung entsprechender Kategorisierung angewandt. Logik: tatsächliche und erwartete Zellenhäufigkeiten werden miteinander verglichen, die Prüfgröße Chi-Quadrat misst diese Abweichung zur Unabhängigkeit. Nullhypothese: Die Variablen treten unabhängig voneinander in der Grundgesamtheit auf bzw. es besteht kein Zusammenhang zwischen den beiden Variablen in der Grundgesamtheit. Prüfgröße χ 2 unter der Nullhypothese: k l i= 1 j= 1 ( f o f e f e ) 2... χ 2 ( k 1)( l 1) Kolmogorov-Smirnov-Test (bei einer Stichprobe) Test, ob die Verteilung einer Variablen in der Grundgesamtheit mit einer theoretischen Verteilung übereinstimmt. Es wird in der Praxis Normal- und Gleichverteilung getestet. Das dahinterliegende Verfahren ist wieder die Chi-Quadrat-Logik (Vergleich tatsächlicher mit erwarteten Häufigkeiten). Nullhypothese: Es besteht kein Unterschied zwischen der empirischen und der theoretischen Verteilung. Bei diesem Test besteht der Sonderfall, dass unsere Wunschhypothese die Nullhypothese ist. Prüfgröße unter der Nullhypothese: Kolmogorov Smirnov Z = n D max D max ist die maximale absolute Differenz der kumulierten Häufigkeiten. Weiterführende Literatur: Bortz/Lienert (1998): Kurzgefasste Statistik für die klinische Forschung, Springer, Berlin, S. 67 ff und 203 ff VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 12

13 t-test auf Gleichheit der Mittelwerte von zwei unabhängigen Stichproben Test auf Gleichheit der Mittelwerte. Sollte nur verwendet werden, wenn echte metrische Variablen analysiert werden. Die Variablen sollten zudem normalverteilt sein. Dies kann mit dem Kolmogrov-Smirnov-Test überprüft werden. Diese Überprüfung kann ausbleiben, wenn der Stichprobenumfang der beiden Subgruppen n > 30 ist, weil dann von einer Normalverteilung ausgegangen wird. Nullhypothese: Die Mittelwerte in den zwei Stichproben (Subgruppen der Bevölkerung) sind gleich, d.h. x = x oder x x = Hier gibt es zwei Berechnungsformeln für die Prüfgröße t, einmal wenn die Varianzen der Variable der beiden zu vergleichenden Gruppen/Stichproben gleich/homogen sind, einmal wenn sie ungleich/heterogen sind. Dies ist mit dem F-Test (Leven s-test auf Homogenität der Varianzen) zu überprüfen. Je nach Ergebnis ist eine der beiden Formeln anzuwenden: Prüfgröße t unter der Nullhypothese: falls Varianzen gleich: t = s p x x n n 1 2 sp² = ( n1 1) s1² + ( n2 1) s2² ( n1 1) + ( n2 1) falls Varianzen nicht gleich: 1 2 Im SPSS werden die Testergebnisse beider Formeln ausgewiesen. Anhand des ebenfalls ausgewiesenen Levene s-test ist zu entscheiden, welches Testergebnis interpretiert wird. Varianzanalyse t = x x 1 2 s1² s2² + n n Bei der Varianzanalyse wird ein multipler Mittelwertvergleich durchgeführt. Die Testvariable muss metrisch und normalverteilt sein, die Gruppenvariable ist nominal oder ordinal. Das Testverfahren ist ein F-Test: F = erklärte Varianz / Fehlervarianz ; Erklärte Varianz = Streuung der Gruppenmittelwerte um den Gesamtmittelwert (between groups) Fehlervarianz = Streuung der Einzelwerte um den jeweiligen Gruppenmittelwert (within groups); Je größer die Prüfgröße F, desto größer die erklärte Varianz. Signifikanz wird anhand der F- Verteilung überprüft. Weiterführendes zur Varianzanalyse siehe Eder Statistik für Sozialwissenschaftler S. 134 ff; und: gut beschrieben bei Jürgen Bortz: Statistik für Sozialwissenschaftler, S. 225 ff VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 13
 sind gleich, d.h. x = x oder x x =.")
14 t-test auf Gleichheit der Mittelwerte von zwei abhängigen Stichproben Test auf Gleichheit der Mittelwerte bei abhängigen Stichproben. Beispiele: Befragung von Ehepaaren, Vergleich des sozialen Status zwischen Elternteil-Kind, Vorher-Nacher-Messungen. Wie den t-test bei unabhängigen Stichproben, sollte man auch diesen Test nur verwenden, wenn echte metrische Variablen vorliegen. Nullhypothese: Die mittlere Differenz der Messwerte der Vergleichspaare (= durchschnittliche Abweichung zwischen Ehemann/-frau; Kind/Elternteil, vorher/nachher) ist 0. Prüfgröße t unter der Nullhypothese: D... mittlere Differenz U-Test auf Gleichheit der Verteilung bei zwei unabhängigen Stichproben Mann-Whitney-U-Test auf Gleichheit der Rangsummen bzw. mittleren Ränge. Der U-Test kann ab Daten mit ordinalem Skalenniveau verwendet werden. Wenn metrische Daten vorliegen, die nicht normalverteilt sind bzw. die beiden Gruppen zu kleine Fallzahlen haben, dann ist der U-Test dem t-test vorzuziehen. Nullhypothese: Die Variable hat in beiden Grundgesamtheiten (Gruppen in der Bevölkerung) die gleiche Verteilung. Prüfgrößen unter der Nullhypothese: z = R R 1 2 ( m+ n)²( m+ n+ 1) 12mn m = Fallzahl der einen Gruppe n = Fallzahl der anderen Gruppe R = mittlerer Rang Weitere Tests auf Gleichheit der Verteilung: Wilcoxon-Test bei zwei verbundenen Rängen (zwei gepaarten oder abhängigen Stichproben) Kruskal-Wallis-Test: bei mehreren unabhängigen Stichproben Friedman-Test: bei mehreren abhängigen Stichproben Gute Übersicht bei: Janssen/Laatz: Statistische Datenanalyse mit SPSS und Felix Brosius: SPSS 13 Professionelle Statistik, jeweils neueste Auflage, Kapitel Nicht-parametrische Tests; VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 14
 ist 0.")
15 Aus Materialien von isa hager: Zufall oder Nicht-Zufall? das ist hier die Frage! Der Zweck eines Signifikanztests ist es, Gesetzmäßigkeiten, die wir in Form der Alternativhypothesen formulieren, zu erkennen. Nachdem wir nun einige Signifikanztests und statistische Verfahren kennen-gelernt haben, soll das Prinzip der Signifikanztestung nochmals erläutert werden. Bei jedem statistischen Test erhalten wir ein Prüfmaß, welches sich aus den vorgestellten Formeln ergibt. Das Prüfmaß ist immer ein Maß dafür, wie stark die von uns postulierte Gesetzmäßigkeit zutrifft - also etwa ein Mittelwertunterschied wie beim t-test, der Unterschied zwischen tatsächlichen und erwarteten Häufigkeiten beim Chi 2 -Test, die durchschnittliche Abweichung eines Messwerts bei zwei Messzeitpunkten, der Korrelationskoeffizient von zwei Variablen und so weiter und so fort Zu diesem Prüfmaß erhalten wir weiters die Wahrscheinlichkeit für dessen Zustandekommen, wenn wir in einer Welt des totalen Zufalls leben würden. Oder anders gesagt: Die Signifikanz sagt uns, wie wahrscheinlich es ist, genau dieses Prüfmaß zu erhalten, wenn es keinen Zusammenhang gibt. Die Welt des Zufalls hat einen Vorteil: Der Zufall ist berechenbar, und wir können genau angeben, wie das Prüfmaß aussieht, wenn der Zufall herrscht. Aus dieser Welt des Zufalls stammen die "Zufalls-Verteilungen": Wahrscheinlichkeitsverteilungen wie die Normalverteilung und die Chi 2 -Verteilung (quadrierte Normalverteilung), die wir bereits kennengelernt haben. Weitere sind: Für Prüfmaß t Für Prüfmaß F und viele andere. Für alle gilt: Bei genügend df gehen sie alle in eine Normalverteilung über! (vergleiche auch die wunderschöne χ2-verteilung von Seite 63! = quadrierte Normalverteilung) VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 15

16 Freiheitsgrade (df): Was bedeutet das? Die Freiheitsgrade definieren immer die Fallzahl in der unter-suchten Gruppe oder die Anzahl der untersuchten Gruppen minus 1. Ein Fall wird abgezogen, weil der "letzte" Fall vorherbestimmt werden kann. Überlege: Wenn ich den Notendurchschnitt einer Prüfung und die Noten von 9 Prüflingen weiß, dann ist die Note des 10. Prüflings (Hubsi Huber) durch die anderen festgelegt. Die Note von Hubsi Huber ist demnach nicht mehr frei (vom Zufall) wählbar. The Art of Fehler oder: Die widerspenstige Zähmung des Zufalls: Alpha-Fehler: Die bei einem Test berechnete Signifikanz ist der Alpha-Fehler. Wir testen, wie hoch das Risiko ist, einen falschen Zusammenhang zu behaupten, den es gar nicht gibt. Den Alpha-Fehler können wir berechnen, weil - wie gesagt - der Zufall berechenbar ist, und der Alpha- Fehler angibt, inwieweit das Ergebnis für den Zufall spricht. Wenn die WS für den Zufall kleiner als 5% ist (α), dann gehen wir davon aus, dass nicht der Zufall sondern die Gesetzmäßigkeit "herrscht." Beta-Fehler: Schwieriger ist es beim Beta-Fehler, denn der Beta-Fehler basiert auf der Annahme, dass es einen Zusammenhang in der Grundgesamtheit gibt, und wir aber diesen Zusammenhang in unserer Stichprobe nicht nachweisen konnten. Für den Beta-Fehler brauchen wir also die Wahrscheinlichkeits-verteilung für das exakt geltende Prüfmaß in der Grundgesamtheit, das wir aber nicht wissen! Daher können wir den Beta-Fehler nur schätzen. Standardmäßig wird ein Beta- Fehler von 20% angenommen. Hier die hypothetischen Verteilungen für das Prüfmaß t in der Grundgesamtheit (t GG ): t-verteilung wenn t GG = 0 bei 5%-Grenze t-verteilung wenn t GG = 5 = GESETZ Wenn t Stpr zwischen 1 und 3, aber Gesetz gilt: Wir haben es nicht erkannt (β-fehler) Wenn t Stpr größer als 3 aber Gesetzt gilt nicht: Wir behaupten falsches Gesetz (α-fehler) ZUFALL erkannt! GESETZ erkannt! VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 16

17 Es herrscht die H 0 auch in der Stichprobe Es herrscht die H 0 und ich behaupte einen falschen Zusammenhang!! Das liegt oft daran, dass die Stichprobe zu klein oder verzerrt ist. Es herrscht die H A dies konnte aber nicht in der Stichprobe nachgewiesen werden. Das liegt oft daran, dass die Stichprobe zu klein ist. Es herrscht die H A das zeigt sich auch in der Stichprobe! Die Teststärke eines Tests: Die Teststärke ist die Chance, mit dem jeweiligen Verfahren eine Gesetzmäßigkeit zu erkennen. Dabei ist von entscheidender Bedeutung, stets die jeweils genaueste Information zu verwenden, also: Hierarchie: metrisch geht vor ordinal, ordinal geht vor dichotom. Mit jedem Schritt auf die "tiefere" Skala geht immer Information verloren! (Denken Sie ans Rekodieren!) Wir wenden immer das "höchstmögliche" Testverfahren an, denn je höher die Teststärke, desto höher die Chance, ein signifikantes Ergebnis zu erhalten und damit die Gesetzmäßigkeit zu erkennen! Hierarchie: parametrische Verfahren gehen vor nicht-parametrischen Verfahren, diese wiederum gehen vor Chi-Quadrat-Testung. Einseitige oder Zweiseitige Fragestellung: Bei einer "zweiseitigen" Fragestellung wissen wir nicht, in welche Richtung der Zusammenhang geht, bei einer "einseitigen" Fragestellung schon: Beispiel anhand eines t-tests: Zweiseitig: Das Durchschnittseinkommen unterschiedet sich bei Männern und Frauen. Einseitig: Das Durchschnittseinkommen der Männer ist höher als jener der F rauen. Bei der zweiseitigen Fragestellung schneiden wir auf der t-zufallsverteilung auf jeder Seite 2,5% ab, um 5%-Fehler-WS zu erhalten: auf der negativen und auf der positiven Seite. Bei der einseitigen Fragestellung können wir die eine Seite der Zufallsverteilung vernachlässigen, weil wir ja die (positive oder negative) Richtung des Zusammenhangs kennen, daher können wir die gesamten 5% auf einer Seite abschneiden. Im SPSS wird die zweiseitige Fehler-WS angeben, wenn wir die halbieren, erhalten wir die einseitige Fehler-WS. Denn: Wir betrachten nur eine Seite der Wahrscheinlichkeitsverteilung, das heißt: 50% sind jetzt 100%, also ist der Fehler nur halb so groß! Also: Eine zweiseitige Irrtums-WS von 0,06 wird bei einer einseitigen Fragestellung zu einem halb so großen Fehler, nämlich 0,03. Aber Achtung: Diese Halbierung des p-werts ist nur dann zulässig, wenn es sich um eine abgesicherte Theorie handelt. VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 17

18 Für das Prüfmaß t: α/2= 2,5% auf negativer Seite α = 5 % auf einer Seite α/2 = 2,5% auf positiver Seite Prüfmaß und Signifikanz: Das Prüfmaß misst, wie stark das Stichprobenergebnis vom Zufall abweicht. Das Prüfmaß ist sehr klein, wenn das Testergebnis dem Zufall entspricht. Zufall! Das Prüfmaß ist sehr hoch, wenn das Testergebnis sehr weit vom Zufall entfernt ist. Gesetz! Die Signifikanz misst, wie wahrscheinlich das Prüfmaß ist, wenn es zufallsverteilt wäre. Die Wahrscheinlichkeit ist sehr hoch, wenn das Prüfmaß sehr klein und daher zufällig ist. Zufall! Die Wahrscheinlichkeit ist sehr klein, wenn das Prüfmaß sehr groß und daher nicht zufällig ist! Gesetz! Sie können einfach die Frage stellen: Kann mein Ergebnis Zufall sein? Wenn p >,05 gehen wir davon aus, dass das Ergebnis zufällig zustande gekommen ist. (H 0 ) Wenn p <=,05 gehen wir davon aus, dass das Ergebnis kein Zufall ist, sondern dass die von uns postulierte Gesetzmäßigkeit zutrifft (H A ). hohes Prüfmaß kleines p, kleine Fehler-WS, wenn p <= 0,05 signifikant! Gesetz gilt! kleines Prüfmaß großes p, große Fehler-WS, wenn p > 0,05 nicht signifikant! Zufall regiert! Rückschluss auf die Grundgesamtheit ist der Sinn der Signifikanz-Testung: Wenn sich eine Hypothese als signifikant erwiesen hat, dann behaupten wir, das dieses Ergebnis nicht zufällig ist, dann gehen wir davon aus, dass diese Gesetzmäßigkeit auch in der Grundgesamtheit - aus der wir ja unsere Stichprobe gezogen haben - gilt. Erst wenn sich eine Hypothese als signifikant erwiesen hat, können wir davon ausgehend Rückschlüsse auf die Grundgesamtheit machen. Fallzahl und Signifikanz: Die Signifikanz ist sehr stark abhängig von der Fallzahl der Stichprobe. Eine Stichprobe aus 30 Personen ist viel stärker vom Zufall abhängig als eine Stichprobe von 3000 Personen! Denken Sie an die Korrelation: Nehmen wir an, wir haben eine Stichprobe von 2 Personen und wir korrelieren Alter und Einkommen. Wenn die Personen gleich alt sind und gleich viel verdienen, dann ergibt die Korrelation 0! Wenn die Personen sich aber nur minimal unterscheiden ergibt die Korrelation 1! Bei kleinen Stichproben schwanken demnach die Ergebnisse viel stärker. Denken Sie an das Konfidenzintervall: Bei einer Stichprobe von 10 Personen stellt eine Person bereits 10% dar! Bei einer Stichprobe von 1000 Personen stellt eine Person lediglich 0,1 % dar! Dementsprechend groß ist das Konfidenzintervall bei kleinen Stichproben! VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 18

19 In der empirischen Praxis zeigt sich das so, dass wir bei kleinen Stichproben unter Umständen sehr hohe Korrelationen erreichen können und es besteht die Gefahr, dass diese zufällig zustande gekommen sind. Bei sehr großen Stichproben hingegen sind die Korrelationen selten besonders hoch, dafür sind die Korrelationen wenig zufallsanfällig und daher relativ zuverlässig. Hier eine Übersicht: Neben der Fallzahl der ersten Spalte sind die kleinsten Koeffizienten angeführt, die bei gegebener Fallzahl bereits signifikant sind. Alle Koeffizienten die kleiner sind, sind nicht signifikant. So muss beispielsweise bei einer Fallzahl von 25 Personen die Korrelation zumindest stärker als 0,4 sein, sonst ist sie nicht signifikant. Bei einer Fallzahl von 1000 Personen sind bereits fast alle Korrelationen (alle über 0,06, was sehr nahe bei 0 ist) signifikant, aber deswegen sind sie nicht inhaltlich relevant. Inhaltlich relevant sind bei großen Stichproben erst Korrelationen über etwa 0,3 oder 0,4. Fallzahl n r ab dem die Korrelation signifikant ist 5 0, ,58 "schwacher" Zushg. "mittlerer" Zushg. "starker" Zushg. 25 0,40 0,5 0,6 0,7 50 0,27 0,4 0,5 0, ,20 0,3 0,4 0, ,09 0,2 0,3 0, ,06 0,15 0,25 0, ,04 0,1 0,2 0,3 Interpretation "schwach" "mittelmäßig" "stark" Achtung: Diese Richtwerte sind keine Konvention! Ein signifikantes Ergebnis muss also noch lange nicht inhaltlich bedeutsam sein! Vielmehr gilt: Je größer die Stichprobe, desto kleinere Unterschiede oder Zusammenhänge sind bereits signifikant. Ab einer Fallzahl von etwa 500 sind bereits sehr kleine Unterschiede signifikant. Beispielsweise korreliert die Lebenszufriedenheit (g14) bei 30 Häftlingen mit der Beziehung zu den GefängniswärterInnen (h55) mit rho =,291 und p =,119 ist nicht signifikant. Bei simulierter Verdoppelung der Stichprobe beträgt der Korrelationskoeffizient weiterhin,291 und p =,024. Wenn wir die Stichprobe in der Simulation verdreifachen, dann beträgt der Korrelationskoeffizient weiterhin,291 und die Signifikanz p =,005. So wird jedes Ergebnis bei nur genügend hoher Fallzahl signifikant! ABER: Die Simulation hat auch ihre Grenzen: Unser Chi 2 -Beispiel, ob sich die Trennung der Eltern (b1) auf ein früheres Einstiegsalter mit Heroin (heroin_di) auswirkt, erreicht bei 30 Häftlingen ein = 0,03 und p=,873, also kein Unterschied. Hier bräuchten wir eine Verhundertfünfzigfachung der Stichprobe (n= 4500), um ein signifikantes Ergebnis bei diesem geringen Unterschied zu erreichen. Weil es wichtig ist, dieses Prinzip der Statistik zu verstehen, hier nochmals eine Veranschaulichung: Ein Verein der Bewährungshilfe untersucht, ob sich die Rückfälligkeit (erneute Straffälligkeit nach 2 Jahren) bei ehemaligen Häftlingen im Entlassungsvollzug mit Fußfessel oder mit Freigang unterscheidet. Nehmen wir an, wir hätten es mit einem geringen Zusammenhang (KK=,119) zu tun: Es zeigt sich zwar, dass die Häftlinge mit Fußfessel seltener rückfällig wurden, aber nur schwach: VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 19

20 Nämlich: In der Gruppe mit Fußfessel wurden 44% rückfällig, in der Gruppe mit Freigang wurden 56% rückfällig: Dieser Zusammenhang mit unterschiedlicher Stichprobengröße zeigt: Kleine Stichprobe (n = 100): Diesen - nicht besonders deutlichen - Zusammenhang weisen wir zuerst bei n= 100 Häftlingen nach. Die absolute Abweichung zum Zufall beträgt 3 Personen, das Ergebnis ist mit einer Fehler-WS von 23% bei dieser Fallzahl nicht signifikant. Mittlere Stichprobe (n = 200): Wir erheben weiter, bis wir die doppelte Stichprobengröße haben: Wir haben weiterhin denselben Zusammenhang, aber nun eine Absolutabweichung zum Zufall von 6 Personen. Das Ergebnis ist mit 9% Alpha-Fehler noch immer nicht signifikant. Größere Stichprobe (n = 400): Wir erheben weiter und verdoppeln die Stichprobe nochmals. Der Zusammenhang ist gleich geblieben, wir haben nun 12 Personen Abweichung zu den erwarteten Häufigkeiten, und jetzt (mit n=400) ist unser Ergebnis schließlich signifikant mit unter 2% Fehler-WS. n = 100 Res = 3 P. = 1,44 KK =,119 p =,230 α-fehler = 23% n = 200 Res = 6 P. = 2,88 KK =,119 p =, 089 α-fehler = 9% n = 400 Res = 12 P. = 5,76 KK =,119 p =, 016 α-fehler = 1,6% Fazit: Die Signifikanztestung ist besonders bei Studien mit kleinerer Fallzahl von Bedeutung. Bei großen Stichproben sind bereits kleine Unterschiede signifikant. Denn: Die Signifikanz gibt Auskunft darüber, wie aussagekräftig das Stichprobenergebnis ist, wenn beim beobachteten Ergebnis die Zufallsanfälligkeit der jeweiligen Fallzahl berücksichtigt wird. Wäre der gemessene Unterschied stärker, also etwa 60% zu 40% (statt 56% zu 44%), dann wäre dieses Ergebnis schon mit viel geringerer Fallzahl signifikant. Probieren Sie es aus! VO 6 Statistik für Pflegewissenschaft (Hager WS) Signifikanztests 20
: Wir erheben weiter, bis wir die doppelte Stichprobengröße haben: Wir haben weiterhin denselben Zusammenhang, aber nun eine Absolutabweichung zum Zufall von 6 Personen.")
J. Bortz/N. Döring: Forschungsmethoden und Evaluation (jeweils neueste Auflage) Springer, Berlin S. 463ff
 Springer, Berlin S. 463ff") J. Bortz/N. Döring: Forschungsmethoden und Evaluation (jeweils neueste Auflage) Springer, Berlin S. 463ff Signifikanztests Zur Logik des Signifikanztests Tests zur statistischen Überprüfung von Hypothesen
J. Bortz/N. Döring: Forschungsmethoden und Evaluation (jeweils neueste Auflage) Springer, Berlin S. 463ff Signifikanztests Zur Logik des Signifikanztests Tests zur statistischen Überprüfung von Hypothesen
Grundlagen der Inferenzstatistik
 Grundlagen der Inferenzstatistik (Induktive Statistik oder schließende Statistik) Dr. Winfried Zinn 1 Deskriptive Statistik versus Inferenzstatistik Die Deskriptive Statistik stellt Kenngrößen zur Verfügung,
Grundlagen der Inferenzstatistik (Induktive Statistik oder schließende Statistik) Dr. Winfried Zinn 1 Deskriptive Statistik versus Inferenzstatistik Die Deskriptive Statistik stellt Kenngrößen zur Verfügung,
Business Value Launch 2006
 Quantitative Methoden Inferenzstatistik alea iacta est 11.04.2008 Prof. Dr. Walter Hussy und David Tobinski UDE.EDUcation College im Rahmen des dokforums Universität Duisburg-Essen Inferenzstatistik Erläuterung
Quantitative Methoden Inferenzstatistik alea iacta est 11.04.2008 Prof. Dr. Walter Hussy und David Tobinski UDE.EDUcation College im Rahmen des dokforums Universität Duisburg-Essen Inferenzstatistik Erläuterung
Überblick über die Verfahren für Ordinaldaten
 Verfahren zur Analyse ordinalskalierten Daten 1 Überblick über die Verfahren für Ordinaldaten Unterschiede bei unabhängigen Stichproben Test U Test nach Mann & Whitney H Test nach Kruskal & Wallis parametrische
Verfahren zur Analyse ordinalskalierten Daten 1 Überblick über die Verfahren für Ordinaldaten Unterschiede bei unabhängigen Stichproben Test U Test nach Mann & Whitney H Test nach Kruskal & Wallis parametrische
METHODENLEHRE I WS 2013/14 THOMAS SCHÄFER
 METHODENLEHRE I WS 2013/14 THOMAS SCHÄFER DAS THEMA: INFERENZSTATISTIK IV INFERENZSTATISTISCHE AUSSAGEN FÜR ZUSAMMENHÄNGE UND UNTERSCHIEDE Inferenzstatistik für Zusammenhänge Inferenzstatistik für Unterschiede
METHODENLEHRE I WS 2013/14 THOMAS SCHÄFER DAS THEMA: INFERENZSTATISTIK IV INFERENZSTATISTISCHE AUSSAGEN FÜR ZUSAMMENHÄNGE UND UNTERSCHIEDE Inferenzstatistik für Zusammenhänge Inferenzstatistik für Unterschiede
9. Schätzen und Testen bei unbekannter Varianz
 9. Schätzen und Testen bei unbekannter Varianz Dr. Antje Kiesel Institut für Angewandte Mathematik WS 2011/2012 Schätzen und Testen bei unbekannter Varianz Wenn wir die Standardabweichung σ nicht kennen,
9. Schätzen und Testen bei unbekannter Varianz Dr. Antje Kiesel Institut für Angewandte Mathematik WS 2011/2012 Schätzen und Testen bei unbekannter Varianz Wenn wir die Standardabweichung σ nicht kennen,
Willkommen zur Vorlesung Statistik
 Willkommen zur Vorlesung Statistik Thema dieser Vorlesung: Varianzanalyse Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften Prof. Dr. Wolfgang
Willkommen zur Vorlesung Statistik Thema dieser Vorlesung: Varianzanalyse Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften Prof. Dr. Wolfgang
Güte von Tests. die Wahrscheinlichkeit für den Fehler 2. Art bei der Testentscheidung, nämlich. falsch ist. Darauf haben wir bereits im Kapitel über
 Güte von s Grundlegendes zum Konzept der Güte Ableitung der Gütefunktion des Gauss im Einstichprobenproblem Grafische Darstellung der Gütefunktionen des Gauss im Einstichprobenproblem Ableitung der Gütefunktion
Güte von s Grundlegendes zum Konzept der Güte Ableitung der Gütefunktion des Gauss im Einstichprobenproblem Grafische Darstellung der Gütefunktionen des Gauss im Einstichprobenproblem Ableitung der Gütefunktion
Einfache statistische Auswertungen mit dem Programm SPSS
 Einfache statistische Auswertungen mit dem Programm SPSS Datensatz: fiktive_daten.sav Dipl. Päd. Anne Haßelkus Dr. Dorothea Dette-Hagenmeyer 11/2011 Überblick 1 Deskriptive Statistiken; Mittelwert berechnen...
Einfache statistische Auswertungen mit dem Programm SPSS Datensatz: fiktive_daten.sav Dipl. Päd. Anne Haßelkus Dr. Dorothea Dette-Hagenmeyer 11/2011 Überblick 1 Deskriptive Statistiken; Mittelwert berechnen...
Ein möglicher Unterrichtsgang
 Ein möglicher Unterrichtsgang. Wiederholung: Bernoulli Experiment und Binomialverteilung Da der sichere Umgang mit der Binomialverteilung, auch der Umgang mit dem GTR und den Diagrammen, eine notwendige
Ein möglicher Unterrichtsgang. Wiederholung: Bernoulli Experiment und Binomialverteilung Da der sichere Umgang mit der Binomialverteilung, auch der Umgang mit dem GTR und den Diagrammen, eine notwendige
Einfache Varianzanalyse für abhängige
 Einfache Varianzanalyse für abhängige Stichproben Wie beim t-test gibt es auch bei der VA eine Alternative für abhängige Stichproben. Anmerkung: Was man unter abhängigen Stichproben versteht und wie diese
Einfache Varianzanalyse für abhängige Stichproben Wie beim t-test gibt es auch bei der VA eine Alternative für abhängige Stichproben. Anmerkung: Was man unter abhängigen Stichproben versteht und wie diese
Statistik II für Betriebswirte Vorlesung 2
 PD Dr. Frank Heyde TU Bergakademie Freiberg Institut für Stochastik Statistik II für Betriebswirte Vorlesung 2 21. Oktober 2014 Verbundene Stichproben Liegen zwei Stichproben vor, deren Werte einander
PD Dr. Frank Heyde TU Bergakademie Freiberg Institut für Stochastik Statistik II für Betriebswirte Vorlesung 2 21. Oktober 2014 Verbundene Stichproben Liegen zwei Stichproben vor, deren Werte einander
Profil A 49,3 48,2 50,7 50,9 49,8 48,7 49,6 50,1 Profil B 51,8 49,6 53,2 51,1 51,1 53,4 50,7 50 51,5 51,7 48,8
 1. Aufgabe: Eine Reifenfirma hat für Winterreifen unterschiedliche Profile entwickelt. Bei jeweils gleicher Geschwindigkeit und auch sonst gleichen Bedingungen wurden die Bremswirkungen gemessen. Die gemessenen
1. Aufgabe: Eine Reifenfirma hat für Winterreifen unterschiedliche Profile entwickelt. Bei jeweils gleicher Geschwindigkeit und auch sonst gleichen Bedingungen wurden die Bremswirkungen gemessen. Die gemessenen
Franz Kronthaler. Statistik angewandt. Datenanalyse ist (k)eine Kunst. Excel Edition. ^ Springer Spektrum
eine Kunst. Excel Edition. ^ Springer Spektrum") Franz Kronthaler Statistik angewandt Datenanalyse ist (k)eine Kunst Excel Edition ^ Springer Spektrum Inhaltsverzeichnis Teil I Basiswissen und Werkzeuge, um Statistik anzuwenden 1 Statistik ist Spaß 3
Franz Kronthaler Statistik angewandt Datenanalyse ist (k)eine Kunst Excel Edition ^ Springer Spektrum Inhaltsverzeichnis Teil I Basiswissen und Werkzeuge, um Statistik anzuwenden 1 Statistik ist Spaß 3
geben. Die Wahrscheinlichkeit von 100% ist hier demnach nur der Gehen wir einmal davon aus, dass die von uns angenommenen
 geben. Die Wahrscheinlichkeit von 100% ist hier demnach nur der Vollständigkeit halber aufgeführt. Gehen wir einmal davon aus, dass die von uns angenommenen 70% im Beispiel exakt berechnet sind. Was würde
geben. Die Wahrscheinlichkeit von 100% ist hier demnach nur der Vollständigkeit halber aufgeführt. Gehen wir einmal davon aus, dass die von uns angenommenen 70% im Beispiel exakt berechnet sind. Was würde
90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft
 Prof. Dr. Helmut Küchenhoff SS08 90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft am 22.7.2008 Anmerkungen Überprüfen Sie bitte sofort, ob Ihre Angabe vollständig ist. Sie sollte
Prof. Dr. Helmut Küchenhoff SS08 90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft am 22.7.2008 Anmerkungen Überprüfen Sie bitte sofort, ob Ihre Angabe vollständig ist. Sie sollte
Statistische Auswertung:
 Statistische Auswertung: Die erhobenen Daten mittels der selbst erstellten Tests (Surfaufgaben) Statistics Punkte aus dem Punkte aus Surftheorietest Punkte aus dem dem und dem Surftheorietest max.14p.
Statistische Auswertung: Die erhobenen Daten mittels der selbst erstellten Tests (Surfaufgaben) Statistics Punkte aus dem Punkte aus Surftheorietest Punkte aus dem dem und dem Surftheorietest max.14p.
Grundlagen quantitativer Sozialforschung Interferenzstatistische Datenanalyse in MS Excel
 Grundlagen quantitativer Sozialforschung Interferenzstatistische Datenanalyse in MS Excel 16.11.01 MP1 - Grundlagen quantitativer Sozialforschung - (4) Datenanalyse 1 Gliederung Datenanalyse (inferenzstatistisch)
Grundlagen quantitativer Sozialforschung Interferenzstatistische Datenanalyse in MS Excel 16.11.01 MP1 - Grundlagen quantitativer Sozialforschung - (4) Datenanalyse 1 Gliederung Datenanalyse (inferenzstatistisch)
Tutorial: Homogenitätstest
 Tutorial: Homogenitätstest Eine Bank möchte die Kreditwürdigkeit potenzieller Kreditnehmer abschätzen. Einerseits lebt die Bank ja von der Vergabe von Krediten, andererseits verursachen Problemkredite
Tutorial: Homogenitätstest Eine Bank möchte die Kreditwürdigkeit potenzieller Kreditnehmer abschätzen. Einerseits lebt die Bank ja von der Vergabe von Krediten, andererseits verursachen Problemkredite
Melanie Kaspar, Prof. Dr. B. Grabowski 1
 7. Hypothesentests Ausgangssituation: Man muss sich zwischen 2 Möglichkeiten (=Hypothesen) entscheiden. Diese Entscheidung soll mit Hilfe von Beobachtungen ( Stichprobe ) getroffen werden. Die Hypothesen
7. Hypothesentests Ausgangssituation: Man muss sich zwischen 2 Möglichkeiten (=Hypothesen) entscheiden. Diese Entscheidung soll mit Hilfe von Beobachtungen ( Stichprobe ) getroffen werden. Die Hypothesen
Universität Bonn 28. Juli 2010 Fachbereich Rechts- und Wirtschaftswissenschaften Statistische Abteilung Prof. Dr. A. Kneip. KLAUSUR Statistik B
 Universität Bonn 28. Juli 2010 Fachbereich Rechts- und Wirtschaftswissenschaften Statistische Abteilung Prof. Dr. A. Kneip Sommersemester 2010 KLAUSUR Statistik B Hinweise zur Bearbeitung: Bei allen Teilaufgaben
Universität Bonn 28. Juli 2010 Fachbereich Rechts- und Wirtschaftswissenschaften Statistische Abteilung Prof. Dr. A. Kneip Sommersemester 2010 KLAUSUR Statistik B Hinweise zur Bearbeitung: Bei allen Teilaufgaben
Willkommen zur Vorlesung Statistik (Master)
") Willkommen zur Vorlesung Statistik (Master) Thema dieser Vorlesung: Verteilungsfreie Verfahren Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften
Willkommen zur Vorlesung Statistik (Master) Thema dieser Vorlesung: Verteilungsfreie Verfahren Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften
Bachelorabschlussseminar Dipl.-Kfm. Daniel Cracau
 1 Einführung in die statistische Datenanalyse Bachelorabschlussseminar Dipl.-Kfm. Daniel Cracau 2 Gliederung 1.Grundlagen 2.Nicht-parametrische Tests a. Mann-Whitney-Wilcoxon-U Test b. Wilcoxon-Signed-Rank
1 Einführung in die statistische Datenanalyse Bachelorabschlussseminar Dipl.-Kfm. Daniel Cracau 2 Gliederung 1.Grundlagen 2.Nicht-parametrische Tests a. Mann-Whitney-Wilcoxon-U Test b. Wilcoxon-Signed-Rank
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren
 Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Gibt es einen Geschmacksunterschied zwischen Coca Cola und Cola Zero?
 Gibt es einen Geschmacksunterschied zwischen Coca Cola und Cola Zero? Manche sagen: Ja, manche sagen: Nein Wie soll man das objektiv feststellen? Kann man Geschmack objektiv messen? - Geschmack ist subjektiv
Gibt es einen Geschmacksunterschied zwischen Coca Cola und Cola Zero? Manche sagen: Ja, manche sagen: Nein Wie soll man das objektiv feststellen? Kann man Geschmack objektiv messen? - Geschmack ist subjektiv
Zeichen bei Zahlen entschlüsseln
 Zeichen bei Zahlen entschlüsseln In diesem Kapitel... Verwendung des Zahlenstrahls Absolut richtige Bestimmung von absoluten Werten Operationen bei Zahlen mit Vorzeichen: Addieren, Subtrahieren, Multiplizieren
Zeichen bei Zahlen entschlüsseln In diesem Kapitel... Verwendung des Zahlenstrahls Absolut richtige Bestimmung von absoluten Werten Operationen bei Zahlen mit Vorzeichen: Addieren, Subtrahieren, Multiplizieren
Motivation. Wilcoxon-Rangsummentest oder Mann-Whitney U-Test. Wilcoxon Rangsummen-Test Voraussetzungen. Bemerkungen
 Universität Karlsruhe (TH) Forschungsuniversität gegründet 825 Wilcoxon-Rangsummentest oder Mann-Whitney U-Test Motivation In Experimenten ist die Datenmenge oft klein Daten sind nicht normalverteilt Dann
Universität Karlsruhe (TH) Forschungsuniversität gegründet 825 Wilcoxon-Rangsummentest oder Mann-Whitney U-Test Motivation In Experimenten ist die Datenmenge oft klein Daten sind nicht normalverteilt Dann
J. Bortz/N. Döring: Forschungsmethoden und Evaluation (1995 bzw. neueste Auflage) Springer, Berlin S. 463ff
 Springer, Berlin S. 463ff") J. Bortz/N. Döring: Forschungsmethoden und Evaluation (1995 bzw. neueste Auflage) Springer, Berlin S. 463ff Signifikanztests Zur Logik des Signifikanztests Tests zur statistischen Überprüfung von Hypothesen
J. Bortz/N. Döring: Forschungsmethoden und Evaluation (1995 bzw. neueste Auflage) Springer, Berlin S. 463ff Signifikanztests Zur Logik des Signifikanztests Tests zur statistischen Überprüfung von Hypothesen
3. Der t-test. Der t-test
 Der t-test 3 3. Der t-test Dieses Kapitel beschäftigt sich mit einem grundlegenden statistischen Verfahren zur Auswertung erhobener Daten: dem t-test. Der t-test untersucht, ob sich zwei empirisch gefundene
Der t-test 3 3. Der t-test Dieses Kapitel beschäftigt sich mit einem grundlegenden statistischen Verfahren zur Auswertung erhobener Daten: dem t-test. Der t-test untersucht, ob sich zwei empirisch gefundene
9. StatistischeTests. 9.1 Konzeption
 9. StatistischeTests 9.1 Konzeption Statistische Tests dienen zur Überprüfung von Hypothesen über einen Parameter der Grundgesamtheit (bei einem Ein-Stichproben-Test) oder über die Verteilung einer Zufallsvariablen
9. StatistischeTests 9.1 Konzeption Statistische Tests dienen zur Überprüfung von Hypothesen über einen Parameter der Grundgesamtheit (bei einem Ein-Stichproben-Test) oder über die Verteilung einer Zufallsvariablen
Primzahlen und RSA-Verschlüsselung
 Primzahlen und RSA-Verschlüsselung Michael Fütterer und Jonathan Zachhuber 1 Einiges zu Primzahlen Ein paar Definitionen: Wir bezeichnen mit Z die Menge der positiven und negativen ganzen Zahlen, also
Primzahlen und RSA-Verschlüsselung Michael Fütterer und Jonathan Zachhuber 1 Einiges zu Primzahlen Ein paar Definitionen: Wir bezeichnen mit Z die Menge der positiven und negativen ganzen Zahlen, also
Biostatistik, WS 2015/2016 Der zwei-stichproben-t-test
 1/29 Biostatistik, WS 2015/2016 Der zwei-stichproben-t-test (t-test für ungepaarte Stichproben) Matthias Birkner http://www.staff.uni-mainz.de/birkner/biostatistik1516/ 11.12.2015 2/29 Inhalt 1 t-test
1/29 Biostatistik, WS 2015/2016 Der zwei-stichproben-t-test (t-test für ungepaarte Stichproben) Matthias Birkner http://www.staff.uni-mainz.de/birkner/biostatistik1516/ 11.12.2015 2/29 Inhalt 1 t-test
Prüfung eines Datenbestandes
 Prüfung eines Datenbestandes auf Abweichungen einzelner Zahlen vom erwarteten mathematisch-statistischen Verhalten, die nicht mit einem Zufall erklärbar sind (Prüfung auf Manipulationen des Datenbestandes)
Prüfung eines Datenbestandes auf Abweichungen einzelner Zahlen vom erwarteten mathematisch-statistischen Verhalten, die nicht mit einem Zufall erklärbar sind (Prüfung auf Manipulationen des Datenbestandes)
Von der Untersuchungsfrage zu statistischen Hypothesen, und wie war das nochmal mit dem α- und
 Von der Untersuchungsfrage zu statistischen Hypothesen, und wie war das nochmal mit dem α- und β-fehler? Sven Garbade Fakultät für Angewandte Psychologie SRH Hochschule Heidelberg sven.garbade@hochschule-heidelberg.de
Von der Untersuchungsfrage zu statistischen Hypothesen, und wie war das nochmal mit dem α- und β-fehler? Sven Garbade Fakultät für Angewandte Psychologie SRH Hochschule Heidelberg sven.garbade@hochschule-heidelberg.de
Webergänzung zu Kapitel 10
 Webergänzung zu Kapitel 10 10.1.4 Varianzanalyse (ANOVA: analysis of variance) Im Kapitel 10 haben wir uns hauptsächlich mit Forschungsbeispielen beschäftigt, die nur zwei Ergebnissätze hatten (entweder
Webergänzung zu Kapitel 10 10.1.4 Varianzanalyse (ANOVA: analysis of variance) Im Kapitel 10 haben wir uns hauptsächlich mit Forschungsbeispielen beschäftigt, die nur zwei Ergebnissätze hatten (entweder
Stichprobenauslegung. für stetige und binäre Datentypen
 Stichprobenauslegung für stetige und binäre Datentypen Roadmap zu Stichproben Hypothese über das interessierende Merkmal aufstellen Stichprobe entnehmen Beobachtete Messwerte abbilden Schluss von der Beobachtung
Stichprobenauslegung für stetige und binäre Datentypen Roadmap zu Stichproben Hypothese über das interessierende Merkmal aufstellen Stichprobe entnehmen Beobachtete Messwerte abbilden Schluss von der Beobachtung
Grundlagen der Inferenzstatistik: Was Ihnen nicht erspart bleibt!
 Grundlagen der Inferenzstatistik: Was Ihnen nicht erspart bleibt! 1 Einführung 2 Wahrscheinlichkeiten kurz gefasst 3 Zufallsvariablen und Verteilungen 4 Theoretische Verteilungen (Wahrscheinlichkeitsfunktion)
Grundlagen der Inferenzstatistik: Was Ihnen nicht erspart bleibt! 1 Einführung 2 Wahrscheinlichkeiten kurz gefasst 3 Zufallsvariablen und Verteilungen 4 Theoretische Verteilungen (Wahrscheinlichkeitsfunktion)
Auswertung mit dem Statistikprogramm SPSS: 30.11.05
 Auswertung mit dem Statistikprogramm SPSS: 30.11.05 Seite 1 Einführung SPSS Was ist eine Fragestellung? Beispiel Welche statistische Prozedur gehört zu welcher Hypothese? Statistische Berechnungen mit
Auswertung mit dem Statistikprogramm SPSS: 30.11.05 Seite 1 Einführung SPSS Was ist eine Fragestellung? Beispiel Welche statistische Prozedur gehört zu welcher Hypothese? Statistische Berechnungen mit
Eine Einführung in R: Statistische Tests
 Eine Einführung in R: Statistische Tests Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.uni-leipzig.de/ zuber/teaching/ws12/r-kurs/
Eine Einführung in R: Statistische Tests Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.uni-leipzig.de/ zuber/teaching/ws12/r-kurs/
Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005
 Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005 Aufgabe 1: Grundzüge der Wahrscheinlichkeitsrechnung 19 P. Als Manager eines großen
Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005 Aufgabe 1: Grundzüge der Wahrscheinlichkeitsrechnung 19 P. Als Manager eines großen
14.01.14 DAS THEMA: INFERENZSTATISTIK II. Standardfehler Konfidenzintervalle Signifikanztests. Standardfehler
 DAS THEMA: INFERENZSTATISTIK II INFERENZSTATISTISCHE AUSSAGEN Standardfehler Konfidenzintervalle Signifikanztests Standardfehler der Standardfehler Interpretation Verwendung 1 ZUR WIEDERHOLUNG... Ausgangspunkt:
DAS THEMA: INFERENZSTATISTIK II INFERENZSTATISTISCHE AUSSAGEN Standardfehler Konfidenzintervalle Signifikanztests Standardfehler der Standardfehler Interpretation Verwendung 1 ZUR WIEDERHOLUNG... Ausgangspunkt:
1.3 Die Beurteilung von Testleistungen
 1.3 Die Beurteilung von Testleistungen Um das Testergebnis einer Vp zu interpretieren und daraus diagnostische Urteile ableiten zu können, benötigen wir einen Vergleichsmaßstab. Im Falle des klassischen
1.3 Die Beurteilung von Testleistungen Um das Testergebnis einer Vp zu interpretieren und daraus diagnostische Urteile ableiten zu können, benötigen wir einen Vergleichsmaßstab. Im Falle des klassischen
Statistik im Versicherungs- und Finanzwesen
 Springer Gabler PLUS Zusatzinformationen zu Medien von Springer Gabler Grimmer Statistik im Versicherungs- und Finanzwesen Eine anwendungsorientierte Einführung 2014 1. Auflage Übungsaufgaben zu Kapitel
Springer Gabler PLUS Zusatzinformationen zu Medien von Springer Gabler Grimmer Statistik im Versicherungs- und Finanzwesen Eine anwendungsorientierte Einführung 2014 1. Auflage Übungsaufgaben zu Kapitel
Statistik für Studenten der Sportwissenschaften SS 2008
 Statistik für Studenten der Sportwissenschaften SS 008 Aufgabe 1 Man weiß von Rehabilitanden, die sich einer bestimmten Gymnastik unterziehen, dass sie im Mittel µ=54 Jahre (σ=3 Jahre) alt sind. a) Welcher
Statistik für Studenten der Sportwissenschaften SS 008 Aufgabe 1 Man weiß von Rehabilitanden, die sich einer bestimmten Gymnastik unterziehen, dass sie im Mittel µ=54 Jahre (σ=3 Jahre) alt sind. a) Welcher
Das große ElterngeldPlus 1x1. Alles über das ElterngeldPlus. Wer kann ElterngeldPlus beantragen? ElterngeldPlus verstehen ein paar einleitende Fakten
 Das große x -4 Alles über das Wer kann beantragen? Generell kann jeder beantragen! Eltern (Mütter UND Väter), die schon während ihrer Elternzeit wieder in Teilzeit arbeiten möchten. Eltern, die während
Das große x -4 Alles über das Wer kann beantragen? Generell kann jeder beantragen! Eltern (Mütter UND Väter), die schon während ihrer Elternzeit wieder in Teilzeit arbeiten möchten. Eltern, die während
3. Der t-test. Der t-test
 3 3. Der t-test Dieses Kapitel beschäftigt sich mit einem grundlegenden statistischen Verfahren zur Auswertung erhobener Daten: dem t-test. Der t-test untersucht, ob sich zwei empirisch gefundene Mittelwerte
3 3. Der t-test Dieses Kapitel beschäftigt sich mit einem grundlegenden statistischen Verfahren zur Auswertung erhobener Daten: dem t-test. Der t-test untersucht, ob sich zwei empirisch gefundene Mittelwerte
1. Man schreibe die folgenden Aussagen jeweils in einen normalen Satz um. Zum Beispiel kann man die Aussage:
 Zählen und Zahlbereiche Übungsblatt 1 1. Man schreibe die folgenden Aussagen jeweils in einen normalen Satz um. Zum Beispiel kann man die Aussage: Für alle m, n N gilt m + n = n + m. in den Satz umschreiben:
Zählen und Zahlbereiche Übungsblatt 1 1. Man schreibe die folgenden Aussagen jeweils in einen normalen Satz um. Zum Beispiel kann man die Aussage: Für alle m, n N gilt m + n = n + m. in den Satz umschreiben:
B 2. " Zeigen Sie, dass die Wahrscheinlichkeit, dass eine Leiterplatte akzeptiert wird, 0,93 beträgt. (genauerer Wert: 0,933).!:!!
.!:!!") Das folgende System besteht aus 4 Schraubenfedern. Die Federn A ; B funktionieren unabhängig von einander. Die Ausfallzeit T (in Monaten) der Federn sei eine weibullverteilte Zufallsvariable mit den folgenden
Das folgende System besteht aus 4 Schraubenfedern. Die Federn A ; B funktionieren unabhängig von einander. Die Ausfallzeit T (in Monaten) der Federn sei eine weibullverteilte Zufallsvariable mit den folgenden
Einige Statistische Tests für den Ein- Zwei- und k-stichprobenfall (Nach Sachs, Stat. Meth.)
") ue biostatistik: nichtparametrische testverfahren / ergänzung 1/6 h. Lettner / physik Statistische Testverfahren Einige Statistische Tests für den Ein- Zwei- und k-stichprobenfall (Nach Sachs, Stat. Meth.)
ue biostatistik: nichtparametrische testverfahren / ergänzung 1/6 h. Lettner / physik Statistische Testverfahren Einige Statistische Tests für den Ein- Zwei- und k-stichprobenfall (Nach Sachs, Stat. Meth.)
Dieses erste Kreisdiagramm, bezieht sich auf das gesamte Testergebnis der kompletten 182 getesteten Personen. Ergebnis
 Datenanalyse Auswertung Der Kern unseres Projektes liegt ganz klar bei der Fragestellung, ob es möglich ist, Biere von und geschmacklich auseinander halten zu können. Anhand der folgenden Grafiken, sollte
Datenanalyse Auswertung Der Kern unseres Projektes liegt ganz klar bei der Fragestellung, ob es möglich ist, Biere von und geschmacklich auseinander halten zu können. Anhand der folgenden Grafiken, sollte
 Name:... Matrikel-Nr.:... 3 Aufgabe Handyklingeln in der Vorlesung (9 Punkte) Angenommen, ein Student führt ein Handy mit sich, das mit einer Wahrscheinlichkeit von p während einer Vorlesung zumindest
Name:... Matrikel-Nr.:... 3 Aufgabe Handyklingeln in der Vorlesung (9 Punkte) Angenommen, ein Student führt ein Handy mit sich, das mit einer Wahrscheinlichkeit von p während einer Vorlesung zumindest
Nichtparametrische statistische Verfahren
 Nichtparametrische statistische Verfahren (im Wesentlichen Analyse von Abhängigkeiten) Kategorien von nichtparametrischen Methoden Beispiel für Rangsummentests: Wilcoxon-Test / U-Test Varianzanalysen 1-faktorielle
Nichtparametrische statistische Verfahren (im Wesentlichen Analyse von Abhängigkeiten) Kategorien von nichtparametrischen Methoden Beispiel für Rangsummentests: Wilcoxon-Test / U-Test Varianzanalysen 1-faktorielle
QM: Prüfen -1- KN16.08.2010
 QM: Prüfen -1- KN16.08.2010 2.4 Prüfen 2.4.1 Begriffe, Definitionen Ein wesentlicher Bestandteil der Qualitätssicherung ist das Prüfen. Sie wird aber nicht wie früher nach der Fertigung durch einen Prüfer,
QM: Prüfen -1- KN16.08.2010 2.4 Prüfen 2.4.1 Begriffe, Definitionen Ein wesentlicher Bestandteil der Qualitätssicherung ist das Prüfen. Sie wird aber nicht wie früher nach der Fertigung durch einen Prüfer,
12.1 Wie funktioniert ein Signifikanztest?
 Sedlmeier & Renkewitz Kapitel 12 Signifikanztests 12.1 Wie funktioniert ein Signifikanztest? Zentrales Ergebnis eine Signifikanztests: Wie wahrscheinlich war es unter der Bedingung dass H0 gilt, diesen
Sedlmeier & Renkewitz Kapitel 12 Signifikanztests 12.1 Wie funktioniert ein Signifikanztest? Zentrales Ergebnis eine Signifikanztests: Wie wahrscheinlich war es unter der Bedingung dass H0 gilt, diesen
Fortgeschrittene Statistik Logistische Regression
 Fortgeschrittene Statistik Logistische Regression O D D S, O D D S - R A T I O, L O G I T T R A N S F O R M A T I O N, I N T E R P R E T A T I O N V O N K O E F F I Z I E N T E N, L O G I S T I S C H E
Fortgeschrittene Statistik Logistische Regression O D D S, O D D S - R A T I O, L O G I T T R A N S F O R M A T I O N, I N T E R P R E T A T I O N V O N K O E F F I Z I E N T E N, L O G I S T I S C H E
Statistische Thermodynamik I Lösungen zur Serie 1
 Statistische Thermodynamik I Lösungen zur Serie Zufallsvariablen, Wahrscheinlichkeitsverteilungen 4. März 2. Zwei Lektoren lesen ein Buch. Lektor A findet 2 Druckfehler, Lektor B nur 5. Von den gefundenen
Statistische Thermodynamik I Lösungen zur Serie Zufallsvariablen, Wahrscheinlichkeitsverteilungen 4. März 2. Zwei Lektoren lesen ein Buch. Lektor A findet 2 Druckfehler, Lektor B nur 5. Von den gefundenen
Repetitionsaufgaben Wurzelgleichungen
 Repetitionsaufgaben Wurzelgleichungen Inhaltsverzeichnis A) Vorbemerkungen B) Lernziele C) Theorie mit Aufgaben D) Aufgaben mit Musterlösungen 4 A) Vorbemerkungen Bitte beachten Sie: Bei Wurzelgleichungen
Repetitionsaufgaben Wurzelgleichungen Inhaltsverzeichnis A) Vorbemerkungen B) Lernziele C) Theorie mit Aufgaben D) Aufgaben mit Musterlösungen 4 A) Vorbemerkungen Bitte beachten Sie: Bei Wurzelgleichungen
Skriptum zur Veranstaltung. Quantitative Methoden (Mathematik/Statistik) Teil Induktive Statistik. 1. Version (mehr Draft als Skriptum)
 Teil Induktive Statistik. 1. Version (mehr Draft als Skriptum)") Skriptum zur Veranstaltung Quantitative Methoden (Mathematik/Statistik) Teil Induktive Statistik 1. Version (mehr Draft als Skriptum) Anmerkungen, Aufzeigen von Tippfehlern und konstruktive Kritik erwünscht!!!
Skriptum zur Veranstaltung Quantitative Methoden (Mathematik/Statistik) Teil Induktive Statistik 1. Version (mehr Draft als Skriptum) Anmerkungen, Aufzeigen von Tippfehlern und konstruktive Kritik erwünscht!!!
Klausur zu Methoden der Statistik I (mit Kurzlösung) Wintersemester 2007/2008. Aufgabe 1
 Wintersemester 2007/2008. Aufgabe 1") Lehrstuhl für Statistik und Ökonometrie der Otto-Friedrich-Universität Bamberg Prof. Dr. Susanne Rässler Klausur zu Methoden der Statistik I (mit Kurzlösung) Wintersemester 2007/2008 Aufgabe 1 Ihnen liegt
Lehrstuhl für Statistik und Ökonometrie der Otto-Friedrich-Universität Bamberg Prof. Dr. Susanne Rässler Klausur zu Methoden der Statistik I (mit Kurzlösung) Wintersemester 2007/2008 Aufgabe 1 Ihnen liegt
q = 1 p = 0.8 0.2 k 0.8 10 k k = 0, 1,..., 10 1 1 0.8 2 + 10 0.2 0.8 + 10 9 1 2 0.22 1 = 0.8 8 [0.64 + 1.6 + 1.8] = 0.678
![q = 1 p = 0.8 0.2 k 0.8 10 k k = 0, 1,..., 10 1 1 0.8 2 + 10 0.2 0.8 + 10 9 1 2 0.22 1 = 0.8 8 [0.64 + 1.6 + 1.8] = 0.678](/thumbs/26/7581163.jpg "q = 1 p = 0.8 0.2 k 0.8 10 k k = 0, 1,..., 10 1 1 0.8 2 + 10 0.2 0.8 + 10 9 1 2 0.22 1 = 0.8 8 [0.64 + 1.6 + 1.8] = 0.678") Lösungsvorschläge zu Blatt 8 X binomialverteilt mit p = 0. und n = 10: a PX = = 10 q = 1 p = 0.8 0. 0.8 10 = 0, 1,..., 10 PX = PX = 0 + PX = 1 + PX = 10 10 = 0. 0 0.8 10 + 0. 1 0.8 9 + 0 1 10 = 0.8 8 [
Lösungsvorschläge zu Blatt 8 X binomialverteilt mit p = 0. und n = 10: a PX = = 10 q = 1 p = 0.8 0. 0.8 10 = 0, 1,..., 10 PX = PX = 0 + PX = 1 + PX = 10 10 = 0. 0 0.8 10 + 0. 1 0.8 9 + 0 1 10 = 0.8 8 [
Messung von Veränderungen. Dr. Julia Kneer Universität des Saarlandes
 von Veränderungen Dr. Julia Kneer Universität des Saarlandes Veränderungsmessung Veränderungsmessung kennzeichnet ein Teilgebiet der Methodenlehre, das direkt mit grundlegenden Fragestellungen der Psychologie
von Veränderungen Dr. Julia Kneer Universität des Saarlandes Veränderungsmessung Veränderungsmessung kennzeichnet ein Teilgebiet der Methodenlehre, das direkt mit grundlegenden Fragestellungen der Psychologie
Die Optimalität von Randomisationstests
 Die Optimalität von Randomisationstests Diplomarbeit Elena Regourd Mathematisches Institut der Heinrich-Heine-Universität Düsseldorf Düsseldorf im Dezember 2001 Betreuung: Prof. Dr. A. Janssen Inhaltsverzeichnis
Die Optimalität von Randomisationstests Diplomarbeit Elena Regourd Mathematisches Institut der Heinrich-Heine-Universität Düsseldorf Düsseldorf im Dezember 2001 Betreuung: Prof. Dr. A. Janssen Inhaltsverzeichnis
R ist freie Software und kann von der Website. www.r-project.org
 R R ist freie Software und kann von der Website heruntergeladen werden. www.r-project.org Nach dem Herunterladen und der Installation von R kann man R durch Doppelklicken auf das R-Symbol starten. R wird
R R ist freie Software und kann von der Website heruntergeladen werden. www.r-project.org Nach dem Herunterladen und der Installation von R kann man R durch Doppelklicken auf das R-Symbol starten. R wird
Der Provider möchte möglichst vermeiden, dass die Werbekampagne auf Grund des Testergebnisses irrtümlich unterlassen wird.
 Hypothesentest ================================================================== 1. Ein Internetprovider möchte im Fichtelgebirge eine Werbekampagne durchführen, da er vermutet, dass dort höchstens 40%
Hypothesentest ================================================================== 1. Ein Internetprovider möchte im Fichtelgebirge eine Werbekampagne durchführen, da er vermutet, dass dort höchstens 40%
Beurteilung der biometrischen Verhältnisse in einem Bestand. Dr. Richard Herrmann, Köln
 Beurteilung der biometrischen Verhältnisse in einem Bestand Dr. Richard Herrmann, Köln Beurteilung der biometrischen Verhältnisse in einem Bestand 1 Fragestellung Methoden.1 Vergleich der Anzahlen. Vergleich
Beurteilung der biometrischen Verhältnisse in einem Bestand Dr. Richard Herrmann, Köln Beurteilung der biometrischen Verhältnisse in einem Bestand 1 Fragestellung Methoden.1 Vergleich der Anzahlen. Vergleich
Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1
 LÖSUNG 3A Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1 Mit den Berechnungsfunktionen LG10(?) und SQRT(?) in "Transformieren", "Berechnen" können logarithmierte Werte sowie die Quadratwurzel
LÖSUNG 3A Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1 Mit den Berechnungsfunktionen LG10(?) und SQRT(?) in "Transformieren", "Berechnen" können logarithmierte Werte sowie die Quadratwurzel
Korrelation. Übungsbeispiel 1. Übungsbeispiel 4. Übungsbeispiel 2. Übungsbeispiel 3. Korrel.dtp Seite 1
 Korrelation Die Korrelationsanalyse zeigt Zusammenhänge auf und macht Vorhersagen möglich Was ist Korrelation? Was sagt die Korrelationszahl aus? Wie geht man vor? Korrelation ist eine eindeutige Beziehung
Korrelation Die Korrelationsanalyse zeigt Zusammenhänge auf und macht Vorhersagen möglich Was ist Korrelation? Was sagt die Korrelationszahl aus? Wie geht man vor? Korrelation ist eine eindeutige Beziehung
a n + 2 1 auf Konvergenz. Berechnen der ersten paar Folgenglieder liefert:
 Beispiel: Wir untersuchen die rekursiv definierte Folge a 0 + auf Konvergenz. Berechnen der ersten paar Folgenglieder liefert: ( ) (,, 7, 5,...) Wir können also vermuten, dass die Folge monoton fallend
Beispiel: Wir untersuchen die rekursiv definierte Folge a 0 + auf Konvergenz. Berechnen der ersten paar Folgenglieder liefert: ( ) (,, 7, 5,...) Wir können also vermuten, dass die Folge monoton fallend
Auswerten mit Excel. Viele Video-Tutorials auf Youtube z.b. http://www.youtube.com/watch?v=vuuky6xxjro
 Auswerten mit Excel Viele Video-Tutorials auf Youtube z.b. http://www.youtube.com/watch?v=vuuky6xxjro 1. Pivot-Tabellen erstellen: In der Datenmaske in eine beliebige Zelle klicken Registerkarte Einfügen
Auswerten mit Excel Viele Video-Tutorials auf Youtube z.b. http://www.youtube.com/watch?v=vuuky6xxjro 1. Pivot-Tabellen erstellen: In der Datenmaske in eine beliebige Zelle klicken Registerkarte Einfügen
Leseprobe. Wilhelm Kleppmann. Versuchsplanung. Produkte und Prozesse optimieren ISBN: 978-3-446-42033-5. Weitere Informationen oder Bestellungen unter
 Leseprobe Wilhelm Kleppmann Versuchsplanung Produkte und Prozesse optimieren ISBN: -3-44-4033-5 Weitere Informationen oder Bestellungen unter http://www.hanser.de/-3-44-4033-5 sowie im Buchhandel. Carl
Leseprobe Wilhelm Kleppmann Versuchsplanung Produkte und Prozesse optimieren ISBN: -3-44-4033-5 Weitere Informationen oder Bestellungen unter http://www.hanser.de/-3-44-4033-5 sowie im Buchhandel. Carl
Varianzanalyse (ANOVA: analysis of variance)
") Varianzanalyse (AOVA: analysis of variance) Einfaktorielle VA Auf der Basis von zwei Stichproben wird bezüglich der Gleichheit der Mittelwerte getestet. Variablen müssen Variablen nur nominalskaliert sein.
Varianzanalyse (AOVA: analysis of variance) Einfaktorielle VA Auf der Basis von zwei Stichproben wird bezüglich der Gleichheit der Mittelwerte getestet. Variablen müssen Variablen nur nominalskaliert sein.
Einfache statistische Testverfahren
 Einfache statistische Testverfahren Johannes Hain Lehrstuhl für Mathematik VIII (Statistik) 1/29 Hypothesentesten: Allgemeine Situation Im Folgenden wird die statistische Vorgehensweise zur Durchführung
Einfache statistische Testverfahren Johannes Hain Lehrstuhl für Mathematik VIII (Statistik) 1/29 Hypothesentesten: Allgemeine Situation Im Folgenden wird die statistische Vorgehensweise zur Durchführung
Klausur Nr. 1. Wahrscheinlichkeitsrechnung. Keine Hilfsmittel gestattet, bitte alle Lösungen auf dieses Blatt.
 Klausur Nr. 1 2014-02-06 Wahrscheinlichkeitsrechnung Pflichtteil Keine Hilfsmittel gestattet, bitte alle Lösungen auf dieses Blatt. Name: 0. Für Pflicht- und Wahlteil gilt: saubere und übersichtliche Darstellung,
Klausur Nr. 1 2014-02-06 Wahrscheinlichkeitsrechnung Pflichtteil Keine Hilfsmittel gestattet, bitte alle Lösungen auf dieses Blatt. Name: 0. Für Pflicht- und Wahlteil gilt: saubere und übersichtliche Darstellung,
Varianzanalyse ANOVA
 Varianzanalyse ANOVA Johannes Hain Lehrstuhl für Mathematik VIII Statistik 1/23 Einfaktorielle Varianzanalyse (ANOVA) Bisher war man lediglich in der Lage, mit dem t-test einen Mittelwertsvergleich für
Varianzanalyse ANOVA Johannes Hain Lehrstuhl für Mathematik VIII Statistik 1/23 Einfaktorielle Varianzanalyse (ANOVA) Bisher war man lediglich in der Lage, mit dem t-test einen Mittelwertsvergleich für
Forschungsstatistik I
 Prof. Dr. G. Meinhardt. Stock, Nordflügel R. 0-49 (Persike) R. 0- (Meinhardt) Sprechstunde jederzeit nach Vereinbarung Forschungsstatistik I Dr. Malte Persike persike@uni-mainz.de WS 008/009 Fachbereich
Prof. Dr. G. Meinhardt. Stock, Nordflügel R. 0-49 (Persike) R. 0- (Meinhardt) Sprechstunde jederzeit nach Vereinbarung Forschungsstatistik I Dr. Malte Persike persike@uni-mainz.de WS 008/009 Fachbereich
Professionelle Seminare im Bereich MS-Office
 Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Name (in Druckbuchstaben): Matrikelnummer: Unterschrift:
: Matrikelnummer: Unterschrift:") 20-minütige Klausur zur Vorlesung Lineare Modelle im Sommersemester 20 PD Dr. Christian Heumann Ludwig-Maximilians-Universität München, Institut für Statistik 2. Oktober 20, 4:5 6:5 Uhr Überprüfen Sie
20-minütige Klausur zur Vorlesung Lineare Modelle im Sommersemester 20 PD Dr. Christian Heumann Ludwig-Maximilians-Universität München, Institut für Statistik 2. Oktober 20, 4:5 6:5 Uhr Überprüfen Sie
Füllmenge. Füllmenge. Füllmenge. Füllmenge. Mean = 500,0029 Std. Dev. = 3,96016 N = 10.000. 485,00 490,00 495,00 500,00 505,00 510,00 515,00 Füllmenge
 2.4 Stetige Zufallsvariable Beispiel. Abfüllung von 500 Gramm Packungen einer bestimmten Ware auf einer automatischen Abfüllanlage. Die Zufallsvariable X beschreibe die Füllmenge einer zufällig ausgewählten
2.4 Stetige Zufallsvariable Beispiel. Abfüllung von 500 Gramm Packungen einer bestimmten Ware auf einer automatischen Abfüllanlage. Die Zufallsvariable X beschreibe die Füllmenge einer zufällig ausgewählten
Stellen Sie bitte den Cursor in die Spalte B2 und rufen die Funktion Sverweis auf. Es öffnet sich folgendes Dialogfenster
 Es gibt in Excel unter anderem die so genannten Suchfunktionen / Matrixfunktionen Damit können Sie Werte innerhalb eines bestimmten Bereichs suchen. Als Beispiel möchte ich die Funktion Sverweis zeigen.
Es gibt in Excel unter anderem die so genannten Suchfunktionen / Matrixfunktionen Damit können Sie Werte innerhalb eines bestimmten Bereichs suchen. Als Beispiel möchte ich die Funktion Sverweis zeigen.
Prüfen von Mittelwertsunterschieden: t-test
 Prüfen von Mittelwertsunterschieden: t-test Sven Garbade Fakultät für Angewandte Psychologie SRH Hochschule Heidelberg sven.garbade@hochschule-heidelberg.de Statistik 1 S. Garbade (SRH Heidelberg) t-test
Prüfen von Mittelwertsunterschieden: t-test Sven Garbade Fakultät für Angewandte Psychologie SRH Hochschule Heidelberg sven.garbade@hochschule-heidelberg.de Statistik 1 S. Garbade (SRH Heidelberg) t-test
Informationsblatt Induktionsbeweis
 Sommer 015 Informationsblatt Induktionsbeweis 31. März 015 Motivation Die vollständige Induktion ist ein wichtiges Beweisverfahren in der Informatik. Sie wird häufig dazu gebraucht, um mathematische Formeln
Sommer 015 Informationsblatt Induktionsbeweis 31. März 015 Motivation Die vollständige Induktion ist ein wichtiges Beweisverfahren in der Informatik. Sie wird häufig dazu gebraucht, um mathematische Formeln
Kontingenzkoeffizient (nach Pearson)
") Assoziationsmaß für zwei nominale Merkmale misst die Unabhängigkeit zweier Merkmale gibt keine Richtung eines Zusammenhanges an 46 o jl beobachtete Häufigkeiten der Kombination von Merkmalsausprägungen
Assoziationsmaß für zwei nominale Merkmale misst die Unabhängigkeit zweier Merkmale gibt keine Richtung eines Zusammenhanges an 46 o jl beobachtete Häufigkeiten der Kombination von Merkmalsausprägungen
Univariates Chi-Quadrat-Verfahren für ein dichotomes Merkmal und eine Messwiederholung: Test nach McNemar
 Univariates Chi-Quadrat-Verfahren für ein dichotomes Merkmal und eine Messwiederholung: Test nach McNemar Inhaltsverzeichnis Univariates Chi-Quadrat-Verfahren für ein dichotomes Merkmal und eine Messwiederholung:
Univariates Chi-Quadrat-Verfahren für ein dichotomes Merkmal und eine Messwiederholung: Test nach McNemar Inhaltsverzeichnis Univariates Chi-Quadrat-Verfahren für ein dichotomes Merkmal und eine Messwiederholung:
1 Mathematische Grundlagen
 Mathematische Grundlagen - 1-1 Mathematische Grundlagen Der Begriff der Menge ist einer der grundlegenden Begriffe in der Mathematik. Mengen dienen dazu, Dinge oder Objekte zu einer Einheit zusammenzufassen.
Mathematische Grundlagen - 1-1 Mathematische Grundlagen Der Begriff der Menge ist einer der grundlegenden Begriffe in der Mathematik. Mengen dienen dazu, Dinge oder Objekte zu einer Einheit zusammenzufassen.
Statistik II für Betriebswirte Vorlesung 3
 PD Dr. Frank Heyde TU Bergakademie Freiberg Institut für Stochastik Statistik II für Betriebswirte Vorlesung 3 5. November 2013 Beispiel: Aktiensplit (Aczel & Sounderpandan, Aufg. 14-28) Ein Börsenanalyst
PD Dr. Frank Heyde TU Bergakademie Freiberg Institut für Stochastik Statistik II für Betriebswirte Vorlesung 3 5. November 2013 Beispiel: Aktiensplit (Aczel & Sounderpandan, Aufg. 14-28) Ein Börsenanalyst
Anhand des bereits hergeleiteten Models erstellen wir nun mit der Formel
 Ausarbeitung zum Proseminar Finanzmathematische Modelle und Simulationen bei Raphael Kruse und Prof. Dr. Wolf-Jürgen Beyn zum Thema Simulation des Anlagenpreismodels von Simon Uphus im WS 09/10 Zusammenfassung
Ausarbeitung zum Proseminar Finanzmathematische Modelle und Simulationen bei Raphael Kruse und Prof. Dr. Wolf-Jürgen Beyn zum Thema Simulation des Anlagenpreismodels von Simon Uphus im WS 09/10 Zusammenfassung
Würfelt man dabei je genau 10 - mal eine 1, 2, 3, 4, 5 und 6, so beträgt die Anzahl. der verschiedenen Reihenfolgen, in denen man dies tun kann, 60!.
 040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
Beispiel 48. 4.3.2 Zusammengesetzte Zufallsvariablen
 4.3.2 Zusammengesetzte Zufallsvariablen Beispiel 48 Ein Würfel werde zweimal geworfen. X bzw. Y bezeichne die Augenzahl im ersten bzw. zweiten Wurf. Sei Z := X + Y die Summe der gewürfelten Augenzahlen.
4.3.2 Zusammengesetzte Zufallsvariablen Beispiel 48 Ein Würfel werde zweimal geworfen. X bzw. Y bezeichne die Augenzahl im ersten bzw. zweiten Wurf. Sei Z := X + Y die Summe der gewürfelten Augenzahlen.
infach Geld FBV Ihr Weg zum finanzellen Erfolg Florian Mock
 infach Ihr Weg zum finanzellen Erfolg Geld Florian Mock FBV Die Grundlagen für finanziellen Erfolg Denn Sie müssten anschließend wieder vom Gehaltskonto Rückzahlungen in Höhe der Entnahmen vornehmen, um
infach Ihr Weg zum finanzellen Erfolg Geld Florian Mock FBV Die Grundlagen für finanziellen Erfolg Denn Sie müssten anschließend wieder vom Gehaltskonto Rückzahlungen in Höhe der Entnahmen vornehmen, um
4. Versicherungsangebot
 4. Versicherungsangebot Georg Nöldeke Wirtschaftswissenschaftliche Fakultät, Universität Basel Versicherungsökonomie (FS 11) Versicherungsangebot 1 / 13 1. Einleitung 1.1 Hintergrund In einem grossen Teil
4. Versicherungsangebot Georg Nöldeke Wirtschaftswissenschaftliche Fakultät, Universität Basel Versicherungsökonomie (FS 11) Versicherungsangebot 1 / 13 1. Einleitung 1.1 Hintergrund In einem grossen Teil
Box-and-Whisker Plot -0,2 0,8 1,8 2,8 3,8 4,8
 . Aufgabe: Für zwei verschiedene Aktien wurde der relative Kurszuwachs (in % beobachtet. Aus den jeweils 20 Quartaldaten ergaben sich die folgenden Box-Plots. Box-and-Whisker Plot Aktie Aktie 2-0,2 0,8,8
. Aufgabe: Für zwei verschiedene Aktien wurde der relative Kurszuwachs (in % beobachtet. Aus den jeweils 20 Quartaldaten ergaben sich die folgenden Box-Plots. Box-and-Whisker Plot Aktie Aktie 2-0,2 0,8,8
Lineare Gleichungssysteme
 Brückenkurs Mathematik TU Dresden 2015 Lineare Gleichungssysteme Schwerpunkte: Modellbildung geometrische Interpretation Lösungsmethoden Prof. Dr. F. Schuricht TU Dresden, Fachbereich Mathematik auf der
Brückenkurs Mathematik TU Dresden 2015 Lineare Gleichungssysteme Schwerpunkte: Modellbildung geometrische Interpretation Lösungsmethoden Prof. Dr. F. Schuricht TU Dresden, Fachbereich Mathematik auf der
Das RSA-Verschlüsselungsverfahren 1 Christian Vollmer
 Das RSA-Verschlüsselungsverfahren 1 Christian Vollmer Allgemein: Das RSA-Verschlüsselungsverfahren ist ein häufig benutztes Verschlüsselungsverfahren, weil es sehr sicher ist. Es gehört zu der Klasse der
Das RSA-Verschlüsselungsverfahren 1 Christian Vollmer Allgemein: Das RSA-Verschlüsselungsverfahren ist ein häufig benutztes Verschlüsselungsverfahren, weil es sehr sicher ist. Es gehört zu der Klasse der